






1、类sql基本查询
use day07; -- 创建演示的表 CREATE TABLE day07.orders ( orderId bigint COMMENT '订单id', orderNo string COMMENT '订单编号', shopId bigint COMMENT '门店id', userId bigint COMMENT '用户id', orderStatus tinyint COMMENT '订单状态 -3:用户拒收 -2:未付款的订单 -1:用户取消 0:待发货 1:配送中 2:用户确认收货', goodsMoney double COMMENT '商品金额', deliverMoney double COMMENT '运费', totalMoney double COMMENT '订单金额(包括运费)', realTotalMoney double COMMENT '实际订单金额(折扣后金额)', payType tinyint COMMENT '支付方式,0:未知;1:支付宝,2:微信;3、现金;4、其他', isPay tinyint COMMENT '是否支付 0:未支付 1:已支付', userName string COMMENT '收件人姓名', userAddress string COMMENT '收件人地址', userPhone string COMMENT '收件人电话', createTime timestamp COMMENT '下单时间', payTime timestamp COMMENT '支付时间', totalPayFee int COMMENT '总支付金额' ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; -- load加载数据到表中 load data inpath '/dir/itheima_orders.txt' into table orders; -- 基础查询语句 select * from orders; select count(*) as cnt from orders; -- 查询具体的字段。工作中推荐这样写,可以提升SQL运行效率,列裁剪 select orderId,orderNo from orders; -- 取别名。as关键字可以省略,一般推荐加上 -- 字段取别名 -- 使用场景:1- 原始字段名称比较长的时候;2- 当多个表同时查询的时候,可能会出现重名 select orderId as oid,orderNo ono from orders; -- 表取别名 select orderId as oid,orderNo ono from orders as o; select o.orderId as oid,o.orderNo ono from orders as o; -- distinct去重 select distinct shopId from orders; -- 演示where语句 /* 比较运算符:> < >= <= != <>不等于 逻辑运算符:and并且 or或者 not取反/非 模糊查询:%匹配0到多个内容,_匹配仅且一个 空判断:为空 is null;不为空is not null 范围查询: between 开始 and 结束 in (x,y,z) */ -- 比较运算符 select * from orders where orderId>=1 and orderId<10; select * from orders where orderId<>1; -- 逻辑运算符 select * from orders where orderId<1 and orderId>10; select * from orders where orderId<1 or orderId>10 order by orderId; select * from orders where not orderId<1; -- 模糊查询 select * from orders where orderNo like '1%'; -- % 匹配的个数 >=0 select * from orders where userId like '__'; -- _ 匹配的个数 ==1 -- 空判断 select * from orders where userId is null; select * from orders where userId is not null; -- 范围查询 select * from orders where userId between 2 and 3; -- 左右都是闭区间 [2,3]。小的放前面,大的放后面 select * from orders where userId between 3 and 2; select * from orders where userId in (2,4); -- 通用函数使用 -- 注意:在使用聚合函数的时候,需要把字段(维度字段)放到group by的语句 -- 维度是X轴,指标是Y轴 select userId,max(totalPayFee) as max_value from orders group by userId; -- having:跟在group by的后面,对分组后的数据进行过滤 select userId,max(totalPayFee) as max_value from orders group by userId having userId=2; -- 分页 -- limit x,y:注意x和y都是整数。x是从0开始,表示当页的第一条数据的索引;y每页的数据条数 select * from orders order by userId asc limit 0,2;
使用聚合函数的时候容易犯的错误:
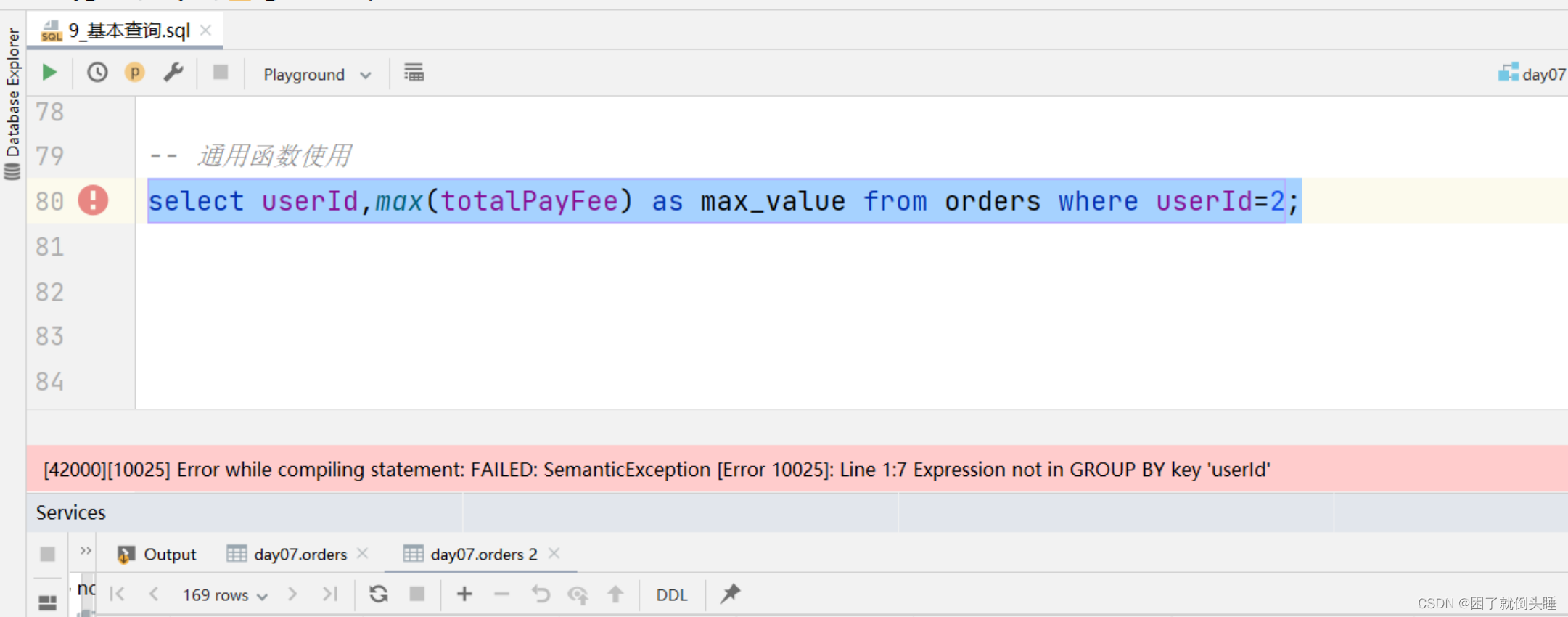
原因: 没有把字段(维度字段)放到group by的语句
2、类sql多表查询
use day07; CREATE TABLE day07.users ( userId int, loginName string, loginSecret int, loginPwd string, userSex tinyint, userName string, trueName string, brithday date, userPhoto string, userQQ string, userPhone string, userScore int, userTotalScore int, userFrom tinyint, userMoney double, lockMoney double, createTime timestamp, payPwd string, rechargeMoney double ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; -- load导入数据 load data inpath '/dir/itheima_users.txt' into table users; -- 数据验证 select * from users; -- cross join:交叉查询,会产生笛卡尔积。在工作中,要尽可能避免产生笛卡尔积 select * from users cross join orders; select count(*) as cnt from users cross join orders; -- inner join:内连接本质是取两个表的交集 select * from users as u inner join orders as o on u.userId=o.userId; -- left outer join:左外关联。以左边的表为主表,取匹配上的数据。差集 select * from users as u left outer join orders as o on u.userId=o.userId; -- right outer join:右外关联。以右边的表为主表,取匹配上的数据。差集 select * from orders as o right outer join users as u on u.userId=o.userId; -- 子查询 -- 获得最高订单金额的用户ID -- 1- 获得最高的订单金额;2- 拿着最高金额,作为数据过滤条件,去找到对应的用户 select max(totalMoney) as max_money from orders; select userId from orders where totalmoney=(select max(totalMoney) as max_money from orders);
3、hive整体语句格式
SELECT [ALL | DISTINCT]字段名称1,字段名称2, ... FROM 表名称 [WHERE 数据过滤条件] [GROUP BY 分组字段名称1,分组字段名称2...] [HAVING 分组之后的数据过滤条件] [ORDER BY 排序字段名称1,排序字段名称2...] [CLUSTER BY 分桶排序的字段名1,分桶排序的字段名2... | [DISTRIBUTE BY 分桶字段名1,分桶字段名2...] [SORT BY 排序的字段名1,排序的字段名2...]] [LIMIT 分页配置]
















 2001
2001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











