







摘要:
1.基于ORB-SLAM2框架,采用轻量级语义分割网络FcHarDNet提取语义信息
2.采用区域增长算法优化语义分割边界
3.将语义信息与多视图几何相结合,进一步提高定位精度
4.结合语义信息和深度信息,构造静态场景的密集点云图
系统描述
1 系统框架
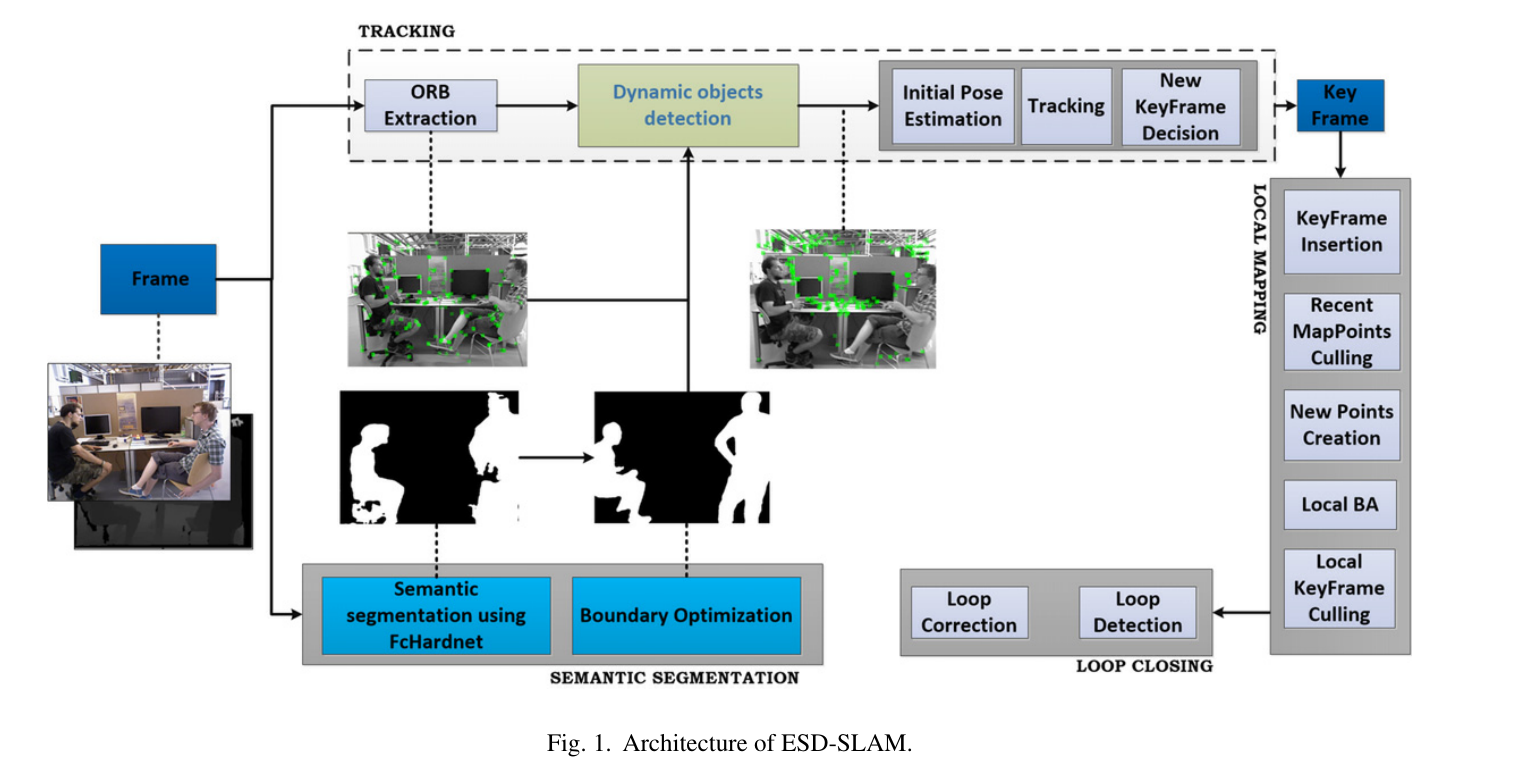
基于ORB-SLAM2的RGB-D模式,在Tracking、local mapping和loop closing线程的基础上增加语义分割线程。
RGB- d摄像机拍摄的RGB图像分别被送入跟踪线程和语义分割线程。在语义分割线程中,使用FcHarDNet对RGB图像进行像素级分割,得到每个像素的语义标签。根据语义标签,所有对象可以分为三类:静态对象、动态对象和潜在动态对象。其中,潜在动态对象是那些通常是静态的,但在其他对象(如椅子和人)的影响下可能成为动态的对象。然后,利用区域增长算法对语义分割结果的边界进行优化,并将优化后的结果输入到跟踪线程中,对三个类别的特征点进行无差别提取。基于语义信息提取潜在的动态特征点。利用语义信息和多视图几何剔除动态特征点,保留静态特征点参与姿态估计。
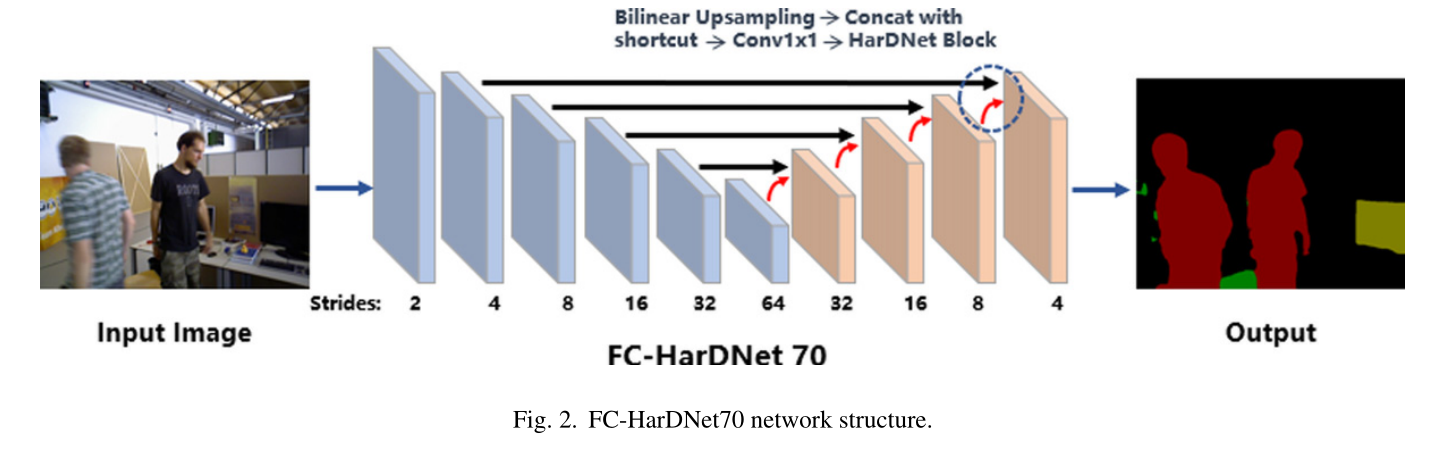
2 FcHarDNet
本文使用的是FC-HarDNet70,FcHarDNet以密集连接网络为基础,使用稀疏连接,形成了一组称为谐波密集块(HDB)的层。该模型包含分布在 10 个 HDB 中的 70 个卷积层。
该网络基于 Pytorch 实现,使用 PASCAL VOC 2012 数据集 [26] 进行训练。
对象可以分为 21 类,包括背景。
3 区域增长算法优化语义分割边界
原理建议看这篇https://blog.csdn.net/sinat_31608641/article/details/103228291
本文中人体掩码内的生长种子点为
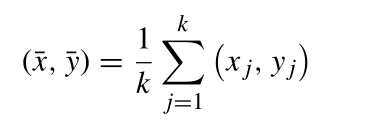
生长阈值为
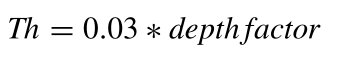
本文的算法:

输入:深度图像、种子像素位置Pt、深度阈值Th和每个像素的状态变量
输出:一块像素区域
先将Pt加入V集合,进入循环:当V集合不为空时,检查与Pt相邻的且状态不是used的像素点Qt,如果Qt点的深度值-Pt点的深度值小于Th,将Qt像素值置为255并且加入集合,将Qt的状态置为used,将Pt点移出V集合,将Qt点加入V集合
4.多视图几何
由于语义分割只能消除动态物体,本文引入了多视图几何方法来检测潜在的动态物体。
选择了与当前帧重合度最高的五个关键帧作为参考帧,其中重合度vs的计算方式为:
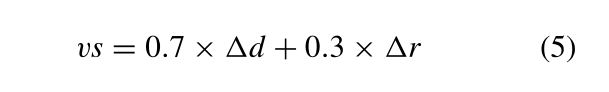
d和r分别表示位置和姿态的变化增量,这部分主要是利用对极几何来判断动态点
5.实验结果
5.1比较特征点提取

ESD-SLAM算法有效去除了属于动态行人的特征点
5.2姿态估计的定性评估
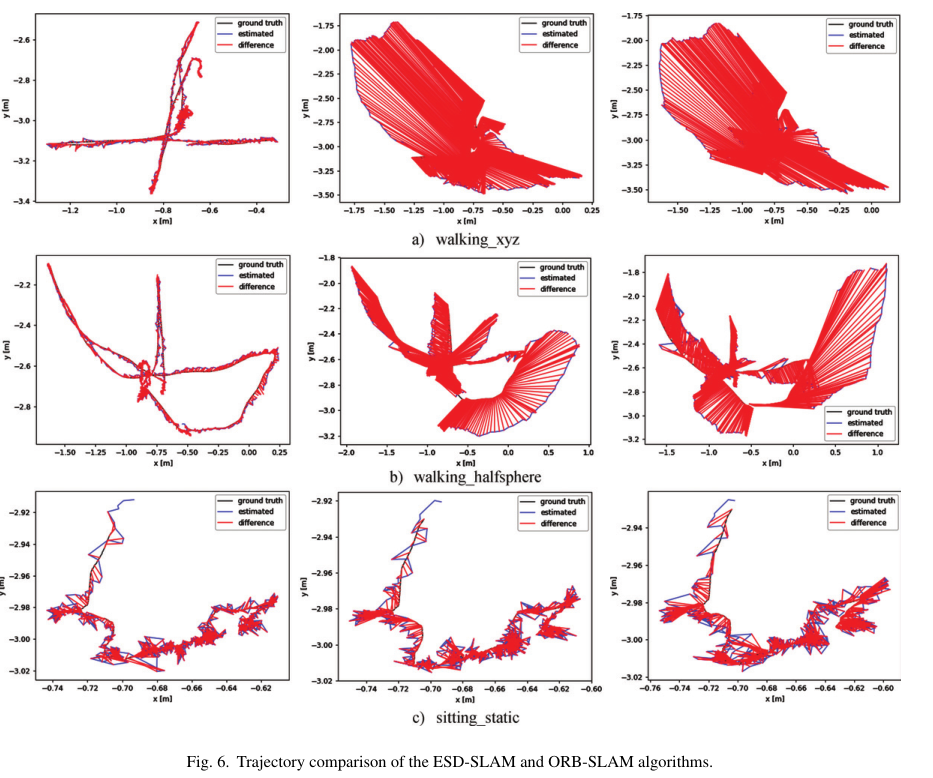
ESD-SLAM是左边一栏,明显比ORB-SLAM2和ORB-SLAM3效果好
5.3姿态估计的定量评估
5.4运行时间
5.5稠密点云地图

本文通过ESD-SLAM对环境中的动态物体进行过滤剔除,最终生成不含动态物体的静态密集点云图
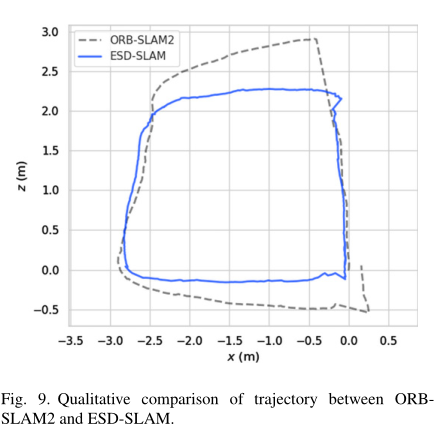
5.6实际运用测评
















 8510
8510











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









