







在进入具体的优化算法后,我们首先讲了基于梯度的,比如梯度下降(GD)、次梯度下降(SD);然后又讲了近似点算子,之后讲了基于近似点算子的方法,比如近似点梯度下降(PG)、对偶问题的近似点梯度下降(DPG)、加速近似点梯度下降(APG)。而这一节讲的,还是基于近似点的!他叫近似点方法(Proximal Point Algorithm, PPA),除此之外还会介绍增广拉格朗日方法(Augmentted Larangian Method, ALM)。我们就开始吧!
1. 近似点方法
近似点方法跟近似点梯度下降很像,在此之外我们先简单回顾一下 PG 方法。对优化问题
minimize
f
(
x
)
=
g
(
x
)
+
h
(
x
)
\text{minimize } f(x)=g(x)+h(x)
minimize f(x)=g(x)+h(x)
其中
g
g
g 为光滑凸函数,而且为了保证收敛性需要满足 Lipschitz 光滑性质,
h
h
h 为非光滑函数,只要
h
h
h 为闭凸函数,对于近似点算子
prox
h
(
x
)
\text{prox}_{h}(x)
proxh(x) 自然满足 firmly nonexpansive(co-coercivite) 性质,这个也等价于 Lipschitz continuous 性质
(
prox
h
(
x
)
−
prox
h
(
y
)
)
T
(
x
−
y
)
≥
∥
prox
h
(
x
)
−
prox
h
(
y
)
∥
2
2
\left(\operatorname{prox}_{h}(x)-\operatorname{prox}_{h}(y)\right)^{T}(x-y) \geq\left\|\operatorname{prox}_{h}(x)-\operatorname{prox}_{h}(y)\right\|_{2}^{2}
(proxh(x)−proxh(y))T(x−y)≥∥proxh(x)−proxh(y)∥22
迭代格式为
x
k
+
1
=
prox
t
h
(
x
k
−
t
k
∇
g
(
x
k
)
)
x_{k+1}=\text{prox}_{th}(x_k-t_k\nabla g(x_k))
xk+1=proxth(xk−tk∇g(xk))
这个表达式实际上可以等价表示为
x
+
=
x
−
t
G
t
(
x
)
,
G
t
(
x
)
:
=
x
−
x
+
t
∈
∂
h
(
x
+
)
+
∇
g
(
x
)
x^+ = x-tG_t(x), \qquad G_t(x):=\frac{x-x^+}{t}\in \partial h(x^+)+\nabla g(x)
x+=x−tGt(x),Gt(x):=tx−x+∈∂h(x+)+∇g(x)
然后我们再回顾一下 APG 方法,实际上就是在 PG 的基础上引入了一个外差,直观理解就是加入了动量
x
k
+
1
=
prox
t
h
(
y
k
−
t
k
∇
g
(
y
k
)
)
y
k
=
x
k
+
w
k
(
x
k
−
x
k
−
1
)
\begin{aligned} x_{k+1} &= \text{prox}_{th}(y_k-t_k\nabla g(y_k)) \\ y_k &= x_k + w_k(x_k-x_{k-1}) \end{aligned}
xk+1yk=proxth(yk−tk∇g(yk))=xk+wk(xk−xk−1)
好了复习结束!那么近似点方法 PPA 针对的优化问题是
min
f
\min f
minf,其中
f
f
f 为闭凸函数
迭代格式为
x k + 1 = prox t k f ( x k ) = arg min u ( f ( u ) + 1 2 t k ∥ u − x k ∥ 2 2 ) \begin{aligned} x_{k+1} &= \text{prox}_{t_k f}(x_k) \\ &= \arg\min_u \left( f(u)+\frac{1}{2t_k}\Vert u-x_k\Vert_2^2 \right) \end{aligned} xk+1=proxtkf(xk)=argumin(f(u)+2tk1∥u−xk∥22)
这实际上可以看作是 PG 方法中取函数
g
=
0
g=0
g=0,因此所有适用于 PG 的收敛性分析也都适用于 PPA 方法,而且由于
g
=
0
g=0
g=0,因此也不需要对
f
f
f 做 Lipschitz 光滑的假设,因此步长
t
k
t_k
tk 可以是任意正实数,而不需要
0
<
t
k
<
1
/
L
0< t_k < 1/L
0<tk<1/L。类比 PG 中的收敛性分析可以得到
t
i
(
f
(
x
i
+
1
)
−
f
⋆
)
≤
1
2
(
∥
x
i
−
x
⋆
∥
2
2
−
∥
x
i
+
1
−
x
⋆
∥
2
2
)
⟹
f
(
x
k
)
−
f
⋆
≤
∥
x
0
−
x
⋆
∥
2
2
2
∑
i
=
0
k
−
1
t
i
for
k
≥
1
t_{i}\left(f\left(x_{i+1}\right)-f^{\star}\right) \leq \frac{1}{2}\left(\left\|x_{i}-x^{\star}\right\|_{2}^{2}-\left\|x_{i+1}-x^{\star}\right\|_{2}^{2}\right) \\ \Longrightarrow f\left(x_{k}\right)-f^{\star} \leq \frac{\left\|x_{0}-x^{\star}\right\|_{2}^{2}}{2 \sum_{i=0}^{k-1} t_{i}} \quad \text { for } k \geq 1
ti(f(xi+1)−f⋆)≤21(∥xi−x⋆∥22−∥xi+1−x⋆∥22)⟹f(xk)−f⋆≤2∑i=0k−1ti∥x0−x⋆∥22 for k≥1
同样得,我们也可以引入外差进行加速
x
k
+
1
=
prox
t
k
f
(
x
k
+
θ
k
(
1
θ
k
−
1
−
1
)
(
x
k
−
x
k
−
1
)
)
for
k
≥
1
x_{k+1}=\operatorname{prox}_{t_{k} f}\left(x_{k}+\theta_{k}\left(\frac{1}{\theta_{k-1}}-1\right)\left(x_{k}-x_{k-1}\right)\right) \quad \text { for } k \geq 1
xk+1=proxtkf(xk+θk(θk−11−1)(xk−xk−1)) for k≥1
其中可以是任意
t
k
>
0
t_k> 0
tk>0,
θ
k
\theta_k
θk 由以下方程解得
θ
k
2
t
k
=
(
1
−
θ
k
)
θ
k
−
1
2
t
k
−
1
\frac{\theta_{k}^{2}}{t_{k}}=\left(1-\theta_{k}\right) \frac{\theta_{k-1}^{2}}{t_{k-1}}
tkθk2=(1−θk)tk−1θk−12
并且可以证明加速后的方法收敛速度可以达到
O
(
1
/
k
2
)
O(1/k^2)
O(1/k2)。
PPA 的基本原理就没有了,这里简单总结一下, 实际上核心的地方只有一个迭代格式
x
k
+
1
=
prox
t
k
f
(
x
k
)
x_{k+1} = \text{prox}_{t_k f}(x_k)
xk+1=proxtkf(xk)
其他的收敛性分析以及加速算法都可以类比 PG 得到。
2. 增广拉格朗日方法
增广拉格朗日方法(也叫乘子法)一般是为了解决有约束优化问题,并且我们通常考虑等式约束,对于非等式约束可以通过引入松弛变量将其转化为等式约束。这里我们首先介绍一下基本的 ALM 形式。对于优化问题
min
f
(
x
)
s.t.
C
(
x
)
=
0
\begin{aligned} \min\quad& f(x) \\ \text{s.t.}\quad& C(x)=0 \end{aligned}
mins.t.f(x)C(x)=0
增广拉格朗日函数(重要) 为
L
σ
(
x
,
ν
)
=
f
(
x
)
+
ν
T
C
(
x
)
+
σ
2
∥
C
(
x
)
∥
2
2
,
σ
>
0
L_\sigma(x,\nu) = f(x)+\nu^TC(x) + \frac{\sigma}{2}\Vert C(x)\Vert_2^2,\quad \sigma>0
Lσ(x,ν)=f(x)+νTC(x)+2σ∥C(x)∥22,σ>0
就是在初始的拉格朗日函数后面加了一个等式约束的二次正则项
ALM 的迭代格式则为
x k + 1 = arg min x L σ ( x , ν k ) ν k + 1 = ν k + σ C ( x k + 1 ) \begin{aligned} x^{k+1} &= \arg\min_{x} L_\sigma(x,\nu^k) \\ \nu^{k+1} &= \nu^k + \sigma C(x^{k+1}) \end{aligned} xk+1νk+1=argxminLσ(x,νk)=νk+σC(xk+1)
一般会将增广拉格朗日函数化简成另一种形式(重要)
L
σ
(
x
,
ν
)
=
f
(
x
)
+
σ
2
∥
C
(
x
)
+
ν
σ
∥
2
2
L_\sigma(x,\nu) = f(x) + \frac{\sigma}{2}\Vert C(x)+\frac{\nu}{\sigma}\Vert_2^2
Lσ(x,ν)=f(x)+2σ∥C(x)+σν∥22
就是做了一个配方,但化简前后的两个函数并不完全等价,因为丢掉了
ν
\nu
ν 的二次项,不过对于迭代算法没有影响,因为迭代的第一步仅仅是针对
x
x
x 求最小。
如果是不等式约束呢?比如优化问题
min
x
f
(
x
)
s.t.
C
(
x
)
≥
0
⟺
min
x
,
s
f
(
x
)
s.t.
C
(
x
)
−
s
=
0
,
s
≥
0
\begin{aligned} \min_x\quad& f(x) \\ \text{s.t.}\quad& C(x)\ge0 \end{aligned} \iff \begin{aligned} \min_{x,s}\quad& f(x) \\ \text{s.t.}\quad& C(x)-s=0,\quad s\ge0 \end{aligned}
xmins.t.f(x)C(x)≥0⟺x,smins.t.f(x)C(x)−s=0,s≥0
此时增广拉格朗日函数为
L
σ
(
x
,
s
,
ν
)
=
f
(
x
)
−
ν
T
(
C
(
x
)
−
s
)
+
σ
2
∥
C
(
x
)
−
s
∥
2
,
s
≥
0
L_\sigma(x,s,\nu) = f(x)-\nu^T(C(x)-s)+\frac{\sigma}{2}\Vert C(x)-s\Vert^2,\quad s\ge0
Lσ(x,s,ν)=f(x)−νT(C(x)−s)+2σ∥C(x)−s∥2,s≥0
迭代方程为
(
x
k
+
1
,
s
k
+
1
)
=
arg
min
x
,
s
≥
0
L
σ
(
x
,
s
,
ν
k
)
ν
k
+
1
=
ν
k
−
σ
(
C
(
x
k
+
1
)
−
s
k
+
1
)
\begin{aligned} (x^{k+1},s^{k+1}) &= \arg\min_{x,s\ge0} L_\sigma(x,s,\nu^k) \\ \nu^{k+1} &= \nu^k - \sigma (C(x^{k+1})-s^{k+1}) \end{aligned}
(xk+1,sk+1)νk+1=argx,s≥0minLσ(x,s,νk)=νk−σ(C(xk+1)−sk+1)
第一步求极小要怎么计算呢?先把增广拉格朗日函数化为
min
x
{
f
(
x
)
+
min
s
≥
0
σ
2
∥
C
(
x
)
−
s
−
ν
σ
∥
2
}
=
min
x
{
f
(
x
)
+
σ
2
∥
C
(
x
)
−
ν
σ
−
Π
+
(
C
(
x
)
−
ν
σ
)
∥
2
}
\min_x\left\{f(x)+\min_{s\ge0}\frac{\sigma}{2}\left\Vert C(x)-s-\frac{\nu}{\sigma}\right\Vert^2 \right\} \\ = \min_x\left\{f(x)+\frac{\sigma}{2}\left\Vert C(x)-\frac{\nu}{\sigma}-\Pi_+(C(x)-\frac{\nu}{\sigma})\right\Vert^2 \right\}
xmin{f(x)+s≥0min2σ∥∥∥C(x)−s−σν∥∥∥2}=xmin{f(x)+2σ∥∥∥C(x)−σν−Π+(C(x)−σν)∥∥∥2}
其中
Π
+
\Pi_+
Π+ 表示向
R
+
n
R_+^n
R+n 空间的投影。
例子:这是一个应用 ALM 的例子,考虑优化问题
min
f
(
x
)
,
s.t.
A
x
∈
C
\min f(x),\text{ s.t. }Ax\in C
minf(x), s.t. Ax∈C,用 ALM 的迭代步骤为
x
^
=
arg
min
x
f
(
x
)
+
t
2
d
(
A
x
+
z
/
t
)
2
z
:
=
z
+
t
(
A
x
^
−
P
C
(
A
x
^
+
z
/
t
)
)
\begin{aligned} \hat{x} &= \arg\min_{x} f(x)+\frac{t}{2}d( Ax+z/t)^2 \\ z :&= z + t(A\hat{x}-P_C(A\hat{x}+z/t)) \end{aligned}
x^z:=argxminf(x)+2td(Ax+z/t)2=z+t(Ax^−PC(Ax^+z/t))
其中
P
C
P_C
PC 是向集合
C
C
C 的投影,
d
(
u
)
d(u)
d(u) 是
u
u
u 到集合
C
C
C 的欧氏距离。
3. PPA 与 ALM 的关系
这里先给出一个结论:对原始问题应用 ALM 等价于对对偶问题应用 PPA。
下面看分析,考虑优化问题
(
P
)
minimize
f
(
x
)
+
g
(
A
x
)
(
D
)
maximize
−
g
⋆
(
z
)
−
f
⋆
(
−
A
T
z
)
\begin{aligned} (P)\text { minimize }\quad& f(x)+g(A x)\\ (D)\text { maximize } \quad& -g^{\star}(z)-f^{\star}\left(-A^{T} z\right) \end{aligned}
(P) minimize (D) maximize f(x)+g(Ax)−g⋆(z)−f⋆(−ATz)
我们就先来看看原始问题应用 ALM 会得到什么。原始问题等价于
min
f
(
x
)
+
g
(
y
)
s.t.
A
x
=
y
\begin{aligned} \min\quad& f(x)+g(y) \\ \text{s.t.}\quad& Ax=y \end{aligned}
mins.t.f(x)+g(y)Ax=y
拉格朗日函数为
L
t
(
x
,
y
,
z
)
=
f
(
x
)
+
g
(
y
)
+
z
T
(
A
x
−
y
)
+
t
2
∥
A
x
−
y
∥
2
L_t(x,y,z) = f(x)+g(y)+z^T(Ax-y)+\frac{t}{2}\Vert Ax-y\Vert^2
Lt(x,y,z)=f(x)+g(y)+zT(Ax−y)+2t∥Ax−y∥2
ALM 迭代方程为
(
x
k
+
1
,
y
k
+
1
)
=
arg
min
x
,
y
L
t
(
x
,
y
,
z
k
)
z
k
+
1
=
z
k
+
t
(
A
x
k
+
1
−
y
k
+
1
)
\begin{aligned} (x^{k+1},y^{k+1}) &= \arg\min_{x,y} L_t(x,y,z^k) \\ z^{k+1} &= z^k + t(Ax^{k+1}-y^{k+1}) \end{aligned}
(xk+1,yk+1)zk+1=argx,yminLt(x,y,zk)=zk+t(Axk+1−yk+1)
对偶问题应用 PPA 的迭代方程是什么呢?首先我们令
h
(
z
)
=
g
⋆
(
z
)
+
f
⋆
(
−
A
T
z
)
h(z)=g^{\star}(z)+f^{\star}\left(-A^{T} z\right)
h(z)=g⋆(z)+f⋆(−ATz),那么就需要求解
z
+
=
prox
t
h
(
z
)
=
argmin
u
(
f
⋆
(
−
A
T
u
)
+
g
⋆
(
u
)
+
1
2
t
∥
u
−
z
∥
2
2
)
⟺
z
−
z
+
∈
t
∂
h
(
z
+
)
=
t
(
−
A
∂
f
⋆
(
−
A
T
z
+
)
+
∂
g
⋆
(
z
+
)
z^{+} = \text{prox}_{th}(z) = \underset{u}{\operatorname{argmin}}\left(f^{\star}\left(-A^{T} u\right)+g^{\star}(u)+\frac{1}{2 t}\|u-z\|_{2}^{2}\right) \\ \iff z-z^+ \in t\partial h(z^+)=t\left(-A\partial f^\star(-A^Tz^+)+\partial g^\star(z^+\right)
z+=proxth(z)=uargmin(f⋆(−ATu)+g⋆(u)+2t1∥u−z∥22)⟺z−z+∈t∂h(z+)=t(−A∂f⋆(−ATz+)+∂g⋆(z+)
这个
z
+
z^+
z+ 乍一看跟 ALM 的
z
k
+
1
z^{k+1}
zk+1 没有一点关系啊,为什么说他们俩等价呢?这就要引出下面一个等式了(先打个预防针,这个等式以及他的推导很不直观,我也没有想到一个很好的解释,但是这个等式以及推导又很重要!在后面章节中也会用到)
很重要的式子:
z + = prox t h ( z ) = z + t ( A x ^ − y ^ ) z^+=\text{prox}_{th}(z) = z+t(A\hat{x}-\hat{y}) z+=proxth(z)=z+t(Ax^−y^)
其中 x ^ , y ^ \hat{x},\hat{y} x^,y^ 为
( x ^ , y ^ ) = argmin x , y ( f ( x ) + g ( y ) + z T ( A x − y ) + t 2 ∥ A x − y ∥ 2 2 ) (\hat{x}, \hat{y})=\underset{x, y}{\operatorname{argmin}}\left(f(x)+g(y)+z^{T}(A x-y)+\frac{t}{2}\|A x-y\|_{2}^{2}\right) (x^,y^)=x,yargmin(f(x)+g(y)+zT(Ax−y)+2t∥Ax−y∥22)
先不管推导,这样看来对偶问题的 PPA 是不是就跟原始问题的 ALM 完全等价了呢?!然后我们来看一下证明(更多的是验证上面这两个等式成立,至于怎么推导出来我也不知道…)
增广拉格朗日函数可以转化为
(
x
^
,
y
^
)
=
argmin
x
,
y
(
f
(
x
)
+
g
(
y
)
+
t
2
∥
A
x
−
y
+
z
/
t
∥
2
2
)
(\hat{x},\hat{y}) = \underset{x, y}{\operatorname{argmin}}\left(f(x)+g(y)+\frac{t}{2}\|A x-y+z/t\|_{2}^{2}\right)
(x^,y^)=x,yargmin(f(x)+g(y)+2t∥Ax−y+z/t∥22)
我们把它表示成一个优化问题,并且引入等式约束
minimize
x
,
y
,
w
f
(
x
)
+
g
(
y
)
+
t
2
∥
w
∥
2
2
subject to
A
x
−
y
+
z
/
t
=
w
\begin{aligned} \text{minimize}_{x, y, w} \quad& f(x)+g(y)+\frac{t}{2}\|w\|_{2}^{2} \\ \text{subject to}\quad& A x-y+z / t=w \end{aligned}
minimizex,y,wsubject tof(x)+g(y)+2t∥w∥22Ax−y+z/t=w
他的 KKT 条件就是
A
x
−
y
+
1
t
z
=
w
,
−
A
T
u
∈
∂
f
(
x
)
,
u
∈
∂
g
(
y
)
,
t
w
=
u
A x-y+\frac{1}{t} z=w, \quad-A^{T} u \in \partial f(x), \quad u \in \partial g(y), \quad t w=u
Ax−y+t1z=w,−ATu∈∂f(x),u∈∂g(y),tw=u
我们把
x
,
y
,
w
x,y,w
x,y,w 消掉就得到了
u
=
z
+
t
(
A
x
−
y
)
u = z+t(Ax-y)
u=z+t(Ax−y),并且有
0
∈
−
A
∂
f
∗
(
−
A
T
u
)
+
∂
g
∗
(
u
)
+
1
t
(
u
−
z
)
0 \in-A \partial f^{*}\left(-A^{T} u\right)+\partial g^{*}(u)+\frac{1}{t}(u-z)
0∈−A∂f∗(−ATu)+∂g∗(u)+t1(u−z)
上面这个式子就等价于
u
=
prox
t
h
(
z
)
u=\text{prox}_{th}(z)
u=proxth(z)。因此就有
prox
t
h
(
z
)
=
z
+
t
(
A
x
^
−
y
^
)
\text{prox}_{th}(z) = z+t(A\hat{x}-\hat{y})
proxth(z)=z+t(Ax^−y^)。
4. Moreau–Yosida smoothing
这一部分是从另一个角度看待 PPA 算法。我们知道如果
f
f
f 是光滑函数就可以直接用梯度下降了,如果是非光滑函数则可以用次梯度或者近似点算法,前面复习 PG 方法的时候提到了 PG 也可以看成是一种梯度下降,梯度为
G
t
(
x
)
G_t(x)
Gt(x)
x
k
+
1
=
prox
t
h
(
x
k
−
t
k
∇
g
(
x
k
)
)
⟺
x
+
=
x
−
t
G
t
(
x
)
x_{k+1}=\text{prox}_{th}(x_k-t_k\nabla g(x_k)) \iff x^+ = x-tG_t(x)
xk+1=proxth(xk−tk∇g(xk))⟺x+=x−tGt(x)
这一部分要讲的就是从梯度下降的角度认识 PPA 方法。
这里再次先抛出结论:PPA 实际上就是对 f f f 的某个光滑近似函数 f ~ \tilde{f} f~ 做梯度下降。
这个光滑近似函数是什么呢?对于闭凸函数
f
f
f,我们定义
f
(
t
)
(
x
)
=
inf
u
(
f
(
u
)
+
1
2
t
∥
u
−
x
∥
2
2
)
(
with
t
>
0
)
=
f
(
prox
t
f
(
x
)
)
+
1
2
t
∥
prox
t
f
(
x
)
−
x
∥
2
2
\begin{aligned} f_{(t)}(x) &=\inf _{u}\left(f(u)+\frac{1}{2 t}\|u-x\|_{2}^{2}\right) \quad(\text { with } t>0) \\ &=f\left(\operatorname{prox}_{t f}(x)\right)+\frac{1}{2 t}\left\|\operatorname{prox}_{t f}(x)-x\right\|_{2}^{2} \end{aligned}
f(t)(x)=uinf(f(u)+2t1∥u−x∥22)( with t>0)=f(proxtf(x))+2t1∥∥proxtf(x)−x∥∥22
为函数
f
f
f 的 Moreau Envelop 。这里是将
prox
t
f
(
x
)
\text{prox}_{tf}(x)
proxtf(x) 代回到了原函数中。在此之前我们需要首先研究一下这个函数的性质。
- f ( t ) f_{(t)} f(t) 为凸函数。取 G ( x , u ) = f ( u ) + 1 2 t ∥ u − x ∥ 2 2 G(x,u) = f(u)+\frac{1}{2t}\Vert u-x\Vert^2_2 G(x,u)=f(u)+2t1∥u−x∥22 是关于 ( x , u ) (x,u) (x,u) 的联合凸函数,因此 f ( t ) ( x ) = inf u G ( x , u ) f_{(t)}(x)=\inf_u G(x,u) f(t)(x)=infuG(x,u) 是凸的;
- dom f ( t ) = R n \text{dom}f_{(t)}=R^n domf(t)=Rn。这是因为 prox t f ( x ) \text{prox}_{tf}(x) proxtf(x) 对任意的 x x x 都有唯一的定义;
- f ( t ) ∈ C 1 f_{(t)}\in C^1 f(t)∈C1 连续;
另外可以验证共轭函数为
(
f
(
t
)
)
⋆
(
y
)
=
f
⋆
(
y
)
+
t
2
∥
y
∥
2
2
\left(f_{(t)}\right)^{\star}(y)=f^{\star}(y)+\frac{t}{2}\|y\|_{2}^{2}
(f(t))⋆(y)=f⋆(y)+2t∥y∥22
因此还有性质
- ( f ( t ) ) ∗ ( y ) \left(f_{(t)}\right)^{*}(y) (f(t))∗(y) 为 t-强凸函数,等价的有 f ( t ) ( x ) f_{(t)}(x) f(t)(x) 为 1/t-smooth;
既然这个
f
(
t
)
f_{(t)}
f(t) 为
C
1
C^1
C1 连续的,那么他的梯度是什么呢?
f
(
t
)
(
x
)
=
(
f
(
t
)
(
x
)
)
⋆
⋆
=
sup
y
(
x
T
y
−
f
⋆
(
y
)
−
t
2
∥
y
∥
2
2
)
f_{(t)}(x) = \left(f_{(t)}(x)\right)^{\star\star}=\sup _{y}\left(x^{T} y-f^{\star}(y)-\frac{t}{2}\|y\|_{2}^{2}\right)
f(t)(x)=(f(t)(x))⋆⋆=ysup(xTy−f⋆(y)−2t∥y∥22)
根据 Legendre transform 有
y
⋆
∈
∂
f
(
t
)
(
x
)
y^\star\in\partial f_{(t)}(x)
y⋆∈∂f(t)(x),令上面式子关于
y
y
y 的次梯度等于 0 可以得到
x
−
t
y
⋆
∈
∂
f
⋆
(
y
⋆
)
⟺
y
⋆
∈
∂
f
(
x
−
t
y
⋆
)
⟹
x
−
t
y
⋆
=
prox
t
f
(
x
)
x-ty^\star \in \partial f^\star(y^\star) \iff y^\star\in\partial f(x-ty^\star) \\ \Longrightarrow x-ty^\star=\text{prox}_{tf}(x)
x−ty⋆∈∂f⋆(y⋆)⟺y⋆∈∂f(x−ty⋆)⟹x−ty⋆=proxtf(x)
因此我们就有(重要)
y
⋆
=
∇
f
(
t
)
(
x
)
=
1
t
(
x
−
prox
t
f
(
x
)
)
y^\star=\nabla f_{(t)}(x) = \frac{1}{t}\left(x-\text{prox}_{tf}(x)\right)
y⋆=∇f(t)(x)=t1(x−proxtf(x))
变换一下就是
prox
t
f
(
x
)
=
x
−
t
∇
f
(
t
)
(
x
)
\text{prox}_{tf}(x) = x-t\nabla f_{(t)}(x)
proxtf(x)=x−t∇f(t)(x),注意这个式子左边就是 PPA 的迭代方程,右边就是光滑函数函数
f
(
t
)
(
x
)
f_{(t)}(x)
f(t)(x) 应用梯度下降法的迭代方程,并且由于这个函数是
L
=
1
/
t
L=1/t
L=1/t-smooth 的,因此我们取的步长为
t
t
t 满足要求
0
<
t
≤
1
/
L
0<t\le 1/L
0<t≤1/L。也就是我们这一小节刚开始说的,PPA 等价于对一个光滑近似函数
f
(
t
)
(
x
)
f_{(t)}(x)
f(t)(x) 的梯度下降方法。
例子 1:举个例子算一下 Moreau Envelop,假如函数 f ( x ) = δ C ( x ) f(x)=\delta_C(x) f(x)=δC(x),则 f ( t ) ( x ) = 1 2 t d ( x ) 2 f_{(t)}(x)=\frac{1}{2t}d(x)^2 f(t)(x)=2t1d(x)2,这里 d ( x ) d(x) d(x) 是 x x x 到集合 C C C 的欧氏距离。
例子 2:若
f
(
x
)
=
∥
x
∥
1
f(x)=\Vert x\Vert_1
f(x)=∥x∥1,函数
f
(
t
)
(
x
)
=
∑
k
ϕ
t
(
x
k
)
f_{(t)}(x)=\sum_k \phi_t(x_k)
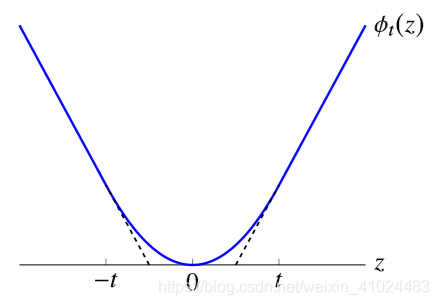
f(t)(x)=∑kϕt(xk) 被称为 Huber penalty,其中
ϕ
t
(
z
)
=
{
z
2
/
(
2
t
)
∣
z
∣
≤
t
∣
z
∣
−
t
/
2
∣
z
∣
≥
t
\phi_{t}(z)=\left\{\begin{array}{ll} z^{2} /(2 t) & |z| \leq t \\ |z|-t / 2 & |z| \geq t \end{array}\right.
ϕt(z)={z2/(2t)∣z∣−t/2∣z∣≤t∣z∣≥t
最后给我的博客打个广告,欢迎光临
https://glooow1024.github.io/
https://glooow.gitee.io/
前面的一些博客链接如下
凸优化专栏
凸优化学习笔记 1:Convex Sets
凸优化学习笔记 2:超平面分离定理
凸优化学习笔记 3:广义不等式
凸优化学习笔记 4:Convex Function
凸优化学习笔记 5:保凸变换
凸优化学习笔记 6:共轭函数
凸优化学习笔记 7:拟凸函数 Quasiconvex Function
凸优化学习笔记 8:对数凸函数
凸优化学习笔记 9:广义凸函数
凸优化学习笔记 10:凸优化问题
凸优化学习笔记 11:对偶原理
凸优化学习笔记 12:KKT条件
凸优化学习笔记 13:KKT条件 & 互补性条件 & 强对偶性
凸优化学习笔记 14:SDP Representablity
最优化方法 15:梯度方法
最优化方法 16:次梯度
最优化方法 17:次梯度下降法
最优化方法 18:近似点算子 Proximal Mapping
最优化方法 19:近似梯度下降
最优化方法 20:对偶近似点梯度下降法
最优化方法 21:加速近似梯度下降方法
最优化方法 22:近似点算法 PPA
最优化方法 23:算子分裂法 & ADMM
最优化方法 24:ADMM

















 3140
3140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









