







 本文深入探讨了存算一体技术的发展背景、核心技术、产业现状和应用前景,揭示了该技术如何应对冯·诺依曼瓶颈,满足日益增长的高算力需求。通过对浮栅器件、相变存储器、阻变存储器和自旋转移矩磁存储器等存储器件的分析,指出存算一体在内存计算、逻辑计算、模拟计算和搜索计算等方面的优势。尽管面临器件特性、阵列问题、设计挑战等难题,但随着科研巨头和初创企业的积极布局,存算一体技术有望在AI训练和推理、AIoT、感存算一体等领域发挥重要作用,为解决存储墙和功耗墙问题提供解决方案。
本文深入探讨了存算一体技术的发展背景、核心技术、产业现状和应用前景,揭示了该技术如何应对冯·诺依曼瓶颈,满足日益增长的高算力需求。通过对浮栅器件、相变存储器、阻变存储器和自旋转移矩磁存储器等存储器件的分析,指出存算一体在内存计算、逻辑计算、模拟计算和搜索计算等方面的优势。尽管面临器件特性、阵列问题、设计挑战等难题,但随着科研巨头和初创企业的积极布局,存算一体技术有望在AI训练和推理、AIoT、感存算一体等领域发挥重要作用,为解决存储墙和功耗墙问题提供解决方案。
目录
2.1.2 浮栅器件/闪存:工艺成熟,率先应用于存算一体芯片
3.1.2 初创企业涌现,投融资进入活跃期,迎来产业化转折点
摘要
基于存算一体技术产业发展实际情况,结合人工智能算力快速发展的背景,从基础硬件、计算架构、技术挑战等维度分析存算一体技术发展现状和趋势,研究存算一体产业结构、主要应用、产业发展面临的机遇和挑战,最后根据我国算力技术产业发展实际情况,提出存算一体发展策略。
关键词: 内存计算; 存算一体; 非易失性存储器件; 人工智能
0 引言
随着人工智能技术产业的演进和向云端、边缘侧的深入,多种依托人工智能算力的新应用、新业态不断涌现。其中,以ChatGPT等大模型训练推理为代表的一系列高算力人工智能应用掀起了算力竞赛浪潮,使得突破经典冯·诺依曼架构,探索新算力再次成为计算技术突破的重大议题。存算一体技术具备高能效比、可快速进行矩阵运算等特点,是实现人工智能算力提升的重要候选架构。笔者重点对存算一体技术的产生背景、发展历程、核心技术发展态势、产业和应用发展态势等方面进行分析和研究,以期为我国存算一体技术产业发展提出建设性意见。
1 存算一体技术背景及发展历程
1.1 存算一体技术背景
1.1.1 “冯·诺依曼瓶颈”问题
在冯·诺依曼架构中,数据从存储单元外的存储器获取,处理完毕后再写回存储器,计算核心与存储器之间有限的总带宽直接限制了交换数据的速度,计算核心处理速度和访问存储器速度的差异进一步减缓处理速度,即“冯·诺依曼瓶颈”[1-2]。
一方面,处理器和存储器二者的需求、工艺不同,性能差距也就越来越大。存储器数据访问速度远低于中央处理器(Central Processing Unit,CPU)的数据处理速度,即“存储墙”问题。另一方面,数据搬运的能耗比浮点计算高1~2个数量级[3]。芯片内一级缓存功耗达25 pJ/bit,动态随机存取内存(Dynamic Random Access Memory,DRAM)访问功耗达1.3~2.6 nJ/bit[4],是芯片内缓存功耗的50~100倍,进一步增加了数据访问能耗。数据访问和存储已成为算力使用的最大能耗,即“功耗墙”问题。
此外,摩尔定律放缓,工艺尺寸微缩变得越来越困难,甚至趋近极限;传统架构提升使得性能增长速度也在变缓,人们试图寻找一种新的计算范式来取代现有计算范式以跳出冯·诺依曼架构和摩尔定律的围墙,并进行多种路径尝试。
1.1.2 高算力需求的挑战
当前,算力需求快速增长与算力提升放缓形成尖锐矛盾。以人工智能为例,从1960年到2010年算力需求每两年提升一倍,而从2012年Alexnet使用图形处理器(Graphics Processing Unit,GPU)进行训练开始,算力每3~4个月提升一倍[5]。谷歌AlphaGo在与李世石对弈中仅需要使用1 920个CPU和280个GPU[6];而谷歌GPT-3开源人工智能模型有1 746亿个参数,按照训练10天估算,需要3 000~5 000块英伟达A100 GPU;GPT-3.5训练显卡数量进一步增至2万块;预计GPT-4训练参数在万亿的数量级[7],是GPT-3的6倍以上,运行成本和算力需求将大幅高于GPT-3.5。
1.2 存算一体技术解决方案
1.2.1 高带宽数据通信
高带宽数据通信主要包括光互联技术和2.5D/3D堆叠技术。其中光互联技术具有高带宽、长距离、低损耗、无串扰和电磁兼容等优势,但是光互联器件难以在芯片内布设,且光交换重新连接开销和延迟较大,实用化成本较高,难以大规模应用。
2.5 D/3D堆叠技术通过增大并行带宽或利用串行传输提升存储带宽,简化系统存储控制设计难度,具有高集成度、高带宽、高能效等性能优势。但是目前2.5D/3D堆叠技术仅对分立器件或芯片内部进行优化设计,“存”和“算”从本质上依然是分离的,难以弥合“存—算”之间的鸿沟。
1.2.2 缓解访存延迟和功耗的内存计算
为了逾越“存—算”之间的巨大鸿沟,内存计算的概念应运而生。内存计算有两种技术类型,一种是横向扩展(Scale-out),主要是分布式内存计算,典型代表有Spark架构,是一种软件的方案;另一种是纵向扩展(Scale-up),又分为两种,一种是近数据端处理(Near Data Processing,NDP),包括近存储计算和近内存计算,另一种是存算一体,依赖经典存储器件或新型的存算器件,如图1所示。
图1
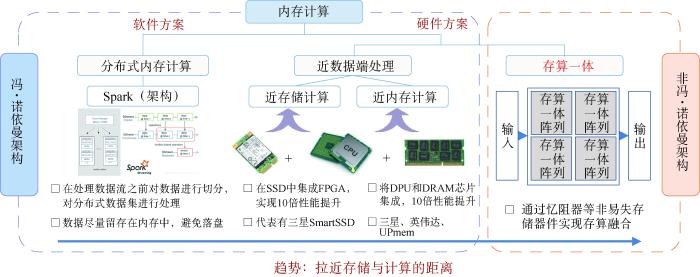
图1 内存计算体系
分布式内存计算是较早前诞生的基于软件的内存计算方案。2003年谷歌公司提出的MapReduce计算框架,能够处理TB级数据量,是一种“分而治之再规约”的计算模型,用多个计算节点来计算。但缺点是在反复迭代计算过程中,数据要落盘,从而影响数据计算速度。2010年,美国加州大学伯克利分校AMP实验室提出的分布式计算框架Spark,能够充分利用内存高速的数据传输速率,同时某些数据集已经能全部放在内存中进行计算,数据尽量留存在内存中,从而避免落盘,随着内存容量持续增长,Spark依然活跃在工业界。
近数据端处理又分为两种,一种是近存储计算(In-Storage Computing,ISC),即在非易失存储模块中(固态硬盘等)加入现场可编程逻辑门阵列(Field Programmable Gate Array,FPGA)、ARM处理器核等计算单元。三星在2019年展示产品Smart SSD(PM1725),集成了数字数据处理器(Numeric Data Processor,NDP),可以通过一些编程模型、库和编译器进行程序编译后在硬盘内计算。近数据端计算的另一种方式是近内存计算(In-Memory Computing,IMC),数据直接在内存中计算后返回,通过将存储层和逻辑层堆叠实现大通道计算,目前业界有三星、英伟达、UPMem等企业跟进。
以上基于软件的分布式内存计算和拉近存储与计算距离的近数据端处理,依然保留了经典冯·诺依曼架构的数据处理特点,而基于器件层面实现的存算一体是真正打破了存算分离架构壁垒的非冯·诺依曼架构。一方面,存算一体将计算和访存融合,在存储单元内实现计算,从体系结构上消除了访存操作,从而避免了访存延迟和访存功耗,解决了“冯·诺依曼瓶颈”。另一方面,存算一体恰好能满足人工智能算法的访存密集、规则运算、低精度特性。因此,存算一体是解决“存储墙”“功耗墙”问题的有效方案之一。
2 存算一体核心技术发展态势
存算一体技术体系包含基础理论、基础硬件、计算架构、软件算法和应用五部分。其中基础理论包含近存储计算、计算型存储、欧姆定律、基尔霍夫定律等;基础硬件又包含非易失性存储和易失性存储两大类,非易失性存储又包含基于传统浮栅器件/闪存的存算一体和基于新型非易失性存储器件
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











