







作者:老余捞鱼
原创不易,转载请标明出处及原作者。

写在前面的话:
本文介绍了利用深度强化学习(DRL)创建自动股票交易系统的研究与实现过程。文中详细阐述了如何利用 Python 库获取数据,增强技术指标,用不同 DRL 算法训练多个代理,设计集合代理提高性能,定义回调函数监控训练,评估代理表现确定最佳策略,本文还展示如何用模型提供交易建议。
一、参考资料
- Yang,Hongyang,et al. "Deep reinforcement learning for automated stock trading: An ensemble strategy"。首届 ACM 金融人工智能国际会议论文集。2020.
- GitHub - theanh97/Deep-Reinforcement-Learning-with-Stock-Trading: This project uses Deep Reinforcement Learning (DRL) to develop and evaluate stock trading strategies. By implementing agents like PPO, A2C, DDPG, SAC, and TD3 in a realistic trading environment with transaction costs, it aims to optimize trading decisions based on return, volatility, and Sharpe ratio.
- https://medium.com/@pta.forwork/deep-reinforcement-learning-for-automated-stock-trading-9d47457707fa
本文受上述 "参考资料 1 "研究论文的启发。它还受到 "参考资料 2 和 3 "的影响,将它们作为技术基准,并对其中介绍的工作添加了一些修正和改进。
二、概述
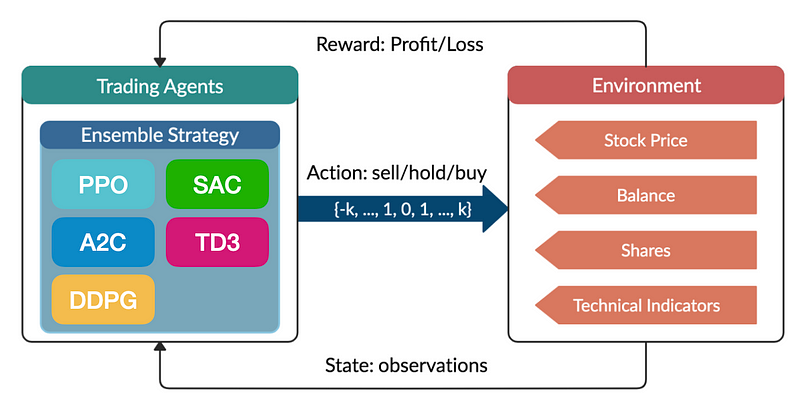
本文旨在说明如何利用深度强化学习(DRL)创建一个自动股票交易系统。通过应用先进的机器学习技术,该系统将被训练成能在股市中做出有利可图的交易决策。该项目包括下载历史股票数据,用技术指标对其进行增强,开发模拟交易环境,以及训练多个 DRL 代理,如 PPO、A2C、DDPG、SAC、TD3 和一个集合代理。将使用各种金融指标对这些代理的性能进行评估和比较。
三、深度强化学习(DRL)
强化学习背景下的深度学习涉及一个代理与环境交互,通过试错学习最佳行为。该领域的主要术语和概念对于理解这些系统如何运行至关重要:
- 环境:与代理互动的外部系统。它提供了一个可以采取行动并获得响应(以观察和奖励的形式)的环境。例如,游戏世界、机器人系统或任何进行学习的模拟场景。
- 状态:当前情况或环境配置的表征。状态包含决策所需的所有必要信息。在游戏中,状态可以包括所有角色和物体的位置。
- 观测数据:代理从环境中感知到的数据。观测数据可以是状态的部分或完整表述。在许多情况下,代理无法获得完整的状态,必须依靠观察结果来推断。
- 行动:代理针对当前状态或观察结果做出的决定或行动。行动会改变环境的状态。代理可以采取的所有可能行动的集合称为行动空间。
- 步骤:代理与环境交互循环中的一次迭代。在一个步骤中,代理根据其当前策略采取一项行动,从环境中接收观察结果和奖励,并过渡到一个新的状态。
- 策略:一种策略,由代理根据状态或观察结果决定采取何种行动。策略可以是确定性的(对给定状态总是采取相同的行动),也可以是随机性的(根据概率分布选择行动)。
- 奖励:代理在采取某项行动后收到的标量反馈信号。奖励量化了行动带来的直接收益,用于强化理想行为。代理的目标是在一段时间内使累积奖励最大化。
- 集: 从初始状态到终端状态的一系列步骤。当达到预定条件(如达到目标或时间耗尽)时,一集结束。
在强化学习中,代理的目标是通过反复与环境互动、采取行动,并根据所获奖励调整其策略,从而学习一种能使累积奖励最大化的策略。这些要素的结合使代理能够发展出复杂的行为,并通过经验提高其性能。
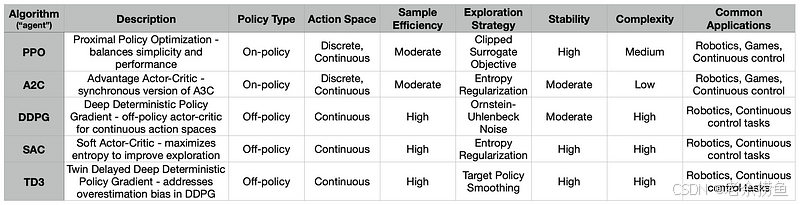
下面简要介绍常见的强化学习算法 PPO、A2C、DDPG、SAC 和 TD3(又称 "DRL 代理"):
四、代码实施
4.1 数据收集与整理
要开始深度强化学习自动股票交易之旅,我们首先需要收集必要的数据。第一步是加载历史股票数据,作为我们交易模型的基础。
在本项目中,我们使用 numpy、pandas 和 yfinance 等 Python 库来获取和处理股票市场数据。具体来说,我们重点关注道琼斯 30 指数,这是一份由 30 只著名股票组成的列表。我们利用雅虎财经下载这些股票的历史数据,时间跨度为 2009 年 1 月 1 日至 2020 年 5 月 8 日。这些数据对于训练和测试我们的强化学习模型至关重要。通过创建字典来存储这些数据,我们可以确保在整个项目中高效、有序地访问这些数据。通过这种设置,我们可以在将股票数据输入我们的交易算法之前对其进行分析和预处理。
import numpy as np
import pandas as pd
import yfinance as yf
import gymnasium as gym
from gymnasium import spaces
import matplotlib.pyplot as plt
from stable_baselines3 import PPO, A2C, DDPG, SAC, TD3
from stable_baselines3.common.vec_env import DummyVecEnv
from stable_baselines3.common.callbacks import BaseCallback
# List of stocks in the Dow Jones 30
tickers = [
'MMM', 'AXP', 'AAPL', 'BA', 'CAT', 'CVX', 'CSCO', 'KO', 'DIS', 'DOW',
'GS', 'HD', 'IBM', 'INTC', 'JNJ', 'JPM', 'MCD', 'MRK', 'MSFT', 'NKE',
'PFE', 'PG', 'TRV', 'UNH', 'UTX', 'VZ', 'V', 'WBA', 'WMT', 'XOM'
]
tickers.remove('DOW')
tickers.remove('UTX')
# Get historical data from Yahoo Finance and save it to dictionary
def fetch_stock_data(tickers, start_date, end_date):
stock_data = {}
for ticker in tickers:
stock_data[ticker] = yf.download(ticker, start=start_date, end=end_date)
return stock_data
# Call the function to get data
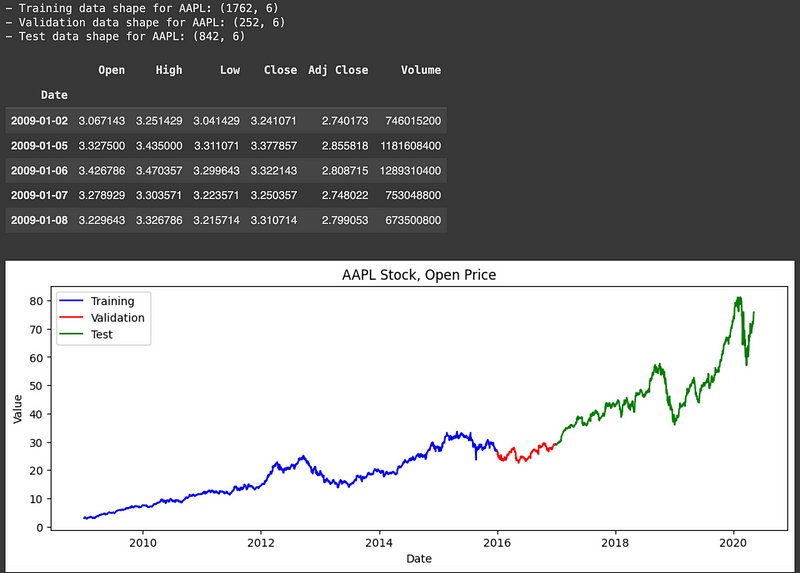
stock_data = fetch_stock_data(tickers, '2009-01-01', '2020-05-08')为确保模型的稳健性和通用性,我们将历史股票数据分为三个不同的数据集:训练数据集、验证数据集和测试数据集。这样,我们就可以在一组数据上训练模型,在第二组数据上验证其性能,最后在第三组数据上测试其有效性,确保我们的模型在未见数据上表现良好。
在本项目中,我们指定 2009 年 1 月 1 日至 2015 年 12 月 31 日为训练数据集。这是最大的数据集,用于训练我们的强化学习模型。验证数据集的时间跨度为 2016 年 1 月 1 日至 2016 年 12 月 31 日,用于微调模型和防止过拟合。最后,从 2017 年 1 月 1 日到 2020 年 5 月 8 日的测试数据集用于评估模型在实际场景中的性能。
我们将道琼斯 30 指数中每只股票的数据进行相应的拆分。通过绘制苹果公司 (AAPL) 在这三个时段的开盘价,我们可以直观地看到数据分布,并确保正确实施分割。这种细致的分割对于开发可靠的自动交易系统至关重要。
# split the data into training, validation and test sets
training_data_time_range = ('2009-01-01', '2015-12-31')
validation_data_time_range = ('2016-01-01', '2016-12-31')
test_data_time_range = ('2017-01-01', '2020-05-08')
# split the data into training, validation and test sets
training_data = {}
validation_data = {}
test_data = {}
for ticker, df in stock_data.items():
training_data[ticker] = df.loc[training_data_time_range[0]:training_data_time_range[1]]
validation_data[ticker] = df.loc[validation_data_time_range[0]:validation_data_time_range[1]]
test_data[ticker] = df.loc[test_data_time_range[0]:test_data_time_range[1]]
# print shape of training, validation and test data
ticker = 'AAPL'
print(f'- Training data shape for {ticker}: {training_data[ticker].shape}')
print(f'- Validation data shape for {ticker}: {validation_data[ticker].shape}')
print(f'- Test data shape for {ticker}: {test_data[ticker].shape}\n')
# Display the first 5 rows of the data
display(stock_data['AAPL'].head())
print('\n')
# Plot:
plt.figure(figsize=(12, 4))
plt.plot(training_data[ticker].index, training_data[ticker]['Open'], label='Training', color='blue')
plt.plot(validation_data[ticker].index, validation_data[ticker]['Open'], label='Validation', color='red')
plt.plot(test_data[ticker].index, test_data[ticker]['Open'], label='Test', color='green')
plt.xlabel('Date')
plt.ylabel('Value')
plt.title(f'{ticker} Stock, Open Price')
plt.legend()
plt.show()相应的结果如下:
4.2 开发策略
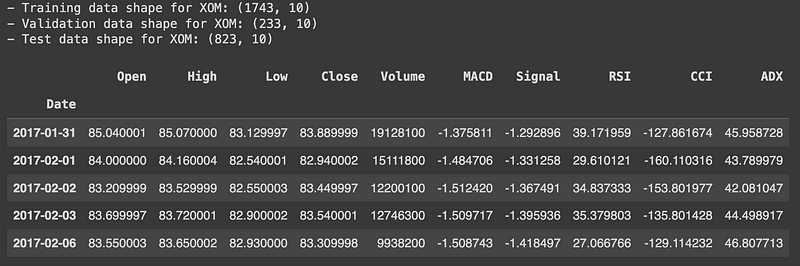
接下来,我们用对交易策略开发至关重要的各种技术指标来丰富我们的数据集。我们计算了几个关键指标:
- MACD(移动平均收敛背离):该指标通过计算 12 天和 26 天指数移动平均线 (EMA) 来确定 MACD 线,然后将 9 天 EMA 应用于 MACD 线以生成信号线。MACD 线和信号线有助于根据其交叉情况确定潜在的买入或卖出信号。
- RSI(相对强弱指数):我们以 14 天为窗口计算 RSI,以衡量价格变动的势头。该指标通过衡量价格变动的速度和变化,帮助识别超买或超卖情况。
- CCI(商品通道指数):该指标评估价格与其平均值的偏差,有助于识别新趋势或极端情况。我们使用 20 天窗口来计算 CCI。
- ADX(平均方向指数):为了衡量趋势的强度,我们使用 14 天窗口计算 ADX。这包括计算方向运动(DM)指标和平均真实范围(ATR),以确定 ADX 值。
通过添加这些指标,我们将原始股票价格数据转化为一个特征丰富的数据集,从而更好地捕捉市场趋势和价格动态。然后,这个增强型数据集将用于训练和评估我们的强化学习模型。
def add_technical_indicators(df):
df = df.copy()
# Calculate EMA 12 and 26 for MACD
df.loc[:, 'EMA12'] = df['Close'].ewm(span=12, adjust=False).mean()
df.loc[:, 'EMA26'] = df['Close'].ewm(span=26, adjust=False).mean()
df.loc[:, 'MACD'] = df['EMA12'] - df['EMA26']
df.loc[:, 'Signal'] = df['MACD'].ewm(span=9, adjust=False).mean()
# Calculate RSI 14
rsi_14_mode = True
delta = df['Close'].diff()
if rsi_14_mode:
gain = (delta.where(delta > 0, 0)).rolling(window=14).mean()
loss = (-delta.where(delta < 0, 0)).rolling(window=14).mean()
rs = gain / loss
else:
up = delta.where(delta > 0, 0)
down = -delta.where(delta < 0, 0)
rs = up.rolling(window=14).mean() / down.rolling(window=14).mean()
df.loc[:, 'RSI'] = 100 - (100 / (1 + rs))
# Calculate CCI 20
tp = (df['High'] + df['Low'] + df['Close']) / 3
sma_tp = tp.rolling(window=20).mean()
mean_dev = tp.rolling(window=20).apply(lambda x: np.mean(np.abs(x - x.mean())))
df.loc[:, 'CCI'] = (tp - sma_tp) / (0.015 * mean_dev)
# Calculate ADX 14
high_diff = df['High'].diff()
low_diff = df['Low'].diff()
df.loc[:, '+DM'] = np.where((high_diff > low_diff) & (high_diff > 0), high_diff, 0)
df.loc[:, '-DM'] = np.where((low_diff > high_diff) & (low_diff > 0), low_diff, 0)
tr = pd.concat([df['High'] - df['Low'], np.abs(df['High'] - df['Close'].shift(1)), np.abs(df['Low'] - df['Close'].shift(1))], axis=1).max(axis=1)
atr = tr.ewm(span=14, adjust=False).mean()
df.loc[:, '+DI'] = 100 * (df['+DM'].ewm(span=14, adjust=False).mean() / atr)
df.loc[:, '-DI'] = 100 * (df['-DM'].ewm(span=14, adjust=False).mean() / atr)
dx = 100 * np.abs(df['+DI'] - df['-DI']) / (df['+DI'] + df['-DI'])
df.loc[:, 'ADX'] = dx.ewm(span=14, adjust=False).mean()
# Drop NaN values
df.dropna(inplace=True)
# Keep only the required columns
df = df[['Open', 'High', 'Low', 'Close', 'Volume', 'MACD', 'Signal', 'RSI', 'CCI', 'ADX']]
return df
# -----------------------------------------------------------------------------
# add technical indicators to the training data for each stock
for ticker, df in training_data.items():
training_data[ticker] = add_technical_indicators(df)
# add technical indicators to the validation data for each stock
for ticker, df in validation_data.items():
validation_data[ticker] = add_technical_indicators(df)
# add technical indicators to the test data for each stock
for ticker, df in test_data.items():
test_data[ticker] = add_technical_indicators(df)
# print the first 5 rows of the data
print(f'- Training data shape for {ticker}: {training_data[ticker].shape}')
print(f'- Validation data shape for {ticker}: {validation_data[ticker].shape}')
print(f'- Test data shape for {ticker}: {test_data[ticker].shape}\n')
display(test_data[ticker].head())相应的结果如下:
4.3 自定义交易环境
在这里,我们将使用 OpenAI Gym 框架为强化学习模型定义一个自定义交易环境。该环境模拟股票交易,允许代理通过购买、出售或持有股票等操作与市场互动。
环境的主要特征:
- 初始化:使用历史股票数据对环境进行初始化,并设置各种参数,包括行动空间和观察空间、交易成本以及账户变量(如余额、净资产和所持股票)。
- 观察空间:在每个步骤中,环境都会提供一个综合状态,其中包括当前股票价格、账户余额、所持股票、净资产和其他相关指标。这个观察空间对于代理做出明智决策至关重要。
- 行动空间:行动空间被定义为一个连续的空间,在这个空间中,代理可以决定买入或卖出每只股票在投资组合中所占的比例。正值代表买入行动,负值代表卖出行动。
- 步骤函数:分步函数执行代理的行动,更新账户余额和持有的股票,计算新的净值,并确定奖励。它还负责管理交易成本,并检查是否应根据最大步数或净值低于零时结束本集。
- 渲染:渲染功能可提供当前状态的人工可读输出,包括步数、余额、所持股份、净值和利润。
- 重置:重置功能可为新的事件重新初始化环境,确保代理以初始条件和数据启动。
这种定制环境旨在密切模拟真实世界的交易场景,为强化学习代理提供学习和优化交易策略的必要工具。
class StockTradingEnv(gym.Env):
metadata = {'render_modes': ['human']}
# - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
def __init__(self, stock_data, transaction_cost_percent=0.005):
super(StockTradingEnv, self).__init__()
"""
This function initializes the environment with stock data and sets up necessary variables:
- Action and Observation Space: Defines the action space (buy/sell/hold) and
observation space (stock prices, balance, shares held, net worth, etc.).
- Account Variables: Initializes balance, net worth, shares held, and transaction costs.
"""
# Remove any empty DataFrames
self.stock_data = {ticker: df for ticker, df in stock_data.items() if not df.empty}
self.tickers = list(self.stock_data.keys())
if not self.tickers:
raise ValueError("All provided stock data is empty")
# Calculate the size of one stock's data
sample_df = next(iter(self.stock_data.values()))
self.n_features = len(sample_df.columns)
# Define action and observation space
self.action_space = spaces.Box(low=-1, high=1, shape=(len(self.tickers),), dtype=np.float32)
# Observation space: price data for each stock + balance + shares held + net worth + max net worth + current step
self.obs_shape = self.n_features * len(self.tickers) + 2 + len(self.tickers) + 2
self.observation_space = spaces.Box(low=-np.inf, high=np.inf, shape=(self.obs_shape,), dtype=np.float32)
# Initialize account balance
self.initial_balance = 1000
self.balance = self.initial_balance
self.net_worth = self.initial_balance
self.max_net_worth = self.initial_balance
self.shares_held = {ticker: 0 for ticker in self.tickers}
self.total_shares_sold = {ticker: 0 for ticker in self.tickers}
self.total_sales_value = {ticker: 0 for ticker in self.tickers}
# Set the current step
self.current_step = 0
# Calculate the minimum length of data across all stocks
self.max_steps = max(0, min(len(df) for df in self.stock_data.values()) - 1)
# Transaction cost
self.transaction_cost_percent = transaction_cost_percent
# - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
def reset(self, seed=None, options=None):
super().reset(seed=seed)
""" Resets the environment to its initial state for a new episode. """
# Reset the account balance
self.balance = self.initial_balance
self.net_worth = self.initial_balance
self.max_net_worth = self.initial_balance
self.shares_held = {ticker: 0 for ticker in self.tickers}
self.total_shares_sold = {ticker: 0 for ticker in self.tickers}
self.total_sales_value = {ticker: 0 for ticker in self.tickers}
self.current_step = 0
return self._next_observation(), {}
# - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
def _next_observation(self):
""" Returns the current state of the environment, including stock prices, balance, shares held, net worth, etc. """
# initialize the frame
frame = np.zeros(self.obs_shape)
# Add stock data for each ticker
idx = 0
# Loop through each ticker
for ticker in self.tickers:
# Get the DataFrame for the current ticker
df = self.stock_data[ticker]
# If the current step is less than the length of the DataFrame, add the price data for the current step
if self.current_step < len(df):
frame[idx:idx+self.n_features] = df.iloc[self.current_step].values
# Otherwise, add the last price data available
elif len(df) > 0:
frame[idx:idx+self.n_features] = df.iloc[-1].values
# Move the index to the next ticker
idx += self.n_features
# Add balance, shares held, net worth, max net worth, and current step
frame[-4-len(self.tickers)] = self.balance # Balance
frame[-3-len(self.tickers):-3] = [self.shares_held[ticker] for ticker in self.tickers] # Shares held
frame[-3] = self.net_worth # Net worth
frame[-2] = self.max_net_worth # Max net worth
frame[-1] = self.current_step # Current step
return frame
# - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
def step(self, actions):
""" Executes an action in the environment, updates the state, calculates rewards, and checks if the episode is done. """
# update the current step
self.current_step += 1
# check if we have reached the maximum number of steps
if self.current_step > self.max_steps:
return self._next_observation(), 0, True, False, {}
current_prices = {}
# Loop through each ticker and perform the action
for i, ticker in enumerate(self.tickers):
# Get the current price of the stock
current_prices[ticker] = self.stock_data[ticker].iloc[self.current_step]['Close']
# get the action for the current ticker
action = actions[i]
if action > 0: # Buy
# Calculate the number of shares to buy
shares_to_buy = int(self.balance * action / current_prices[ticker])
# Calculate the cost of the shares
cost = shares_to_buy * current_prices[ticker]
# Transaction cost
transaction_cost = cost * self.transaction_cost_percent
# Update the balance and shares held
self.balance -= (cost + transaction_cost)
# Update the total shares sold
self.shares_held[ticker] += shares_to_buy
elif action < 0: # Sell
# Calculate the number of shares to sell
shares_to_sell = int(self.shares_held[ticker] * abs(action))
# Calculate the sale value
sale = shares_to_sell * current_prices[ticker]
# Transaction cost
transaction_cost = sale * self.transaction_cost_percent
# Update the balance and shares held
self.balance += (sale - transaction_cost)
# Update the total shares sold
self.shares_held[ticker] -= shares_to_sell
# Update the shares sold
self.total_shares_sold[ticker] += shares_to_sell
# Update the total sales value
self.total_sales_value[ticker] += sale
# Calculate the net worth
self.net_worth = self.balance + sum(self.shares_held[ticker] * current_prices[ticker] for ticker in self.tickers)
# Update the max net worth
self.max_net_worth = max(self.net_worth, self.max_net_worth)
# Calculate the reward
reward = self.net_worth - self.initial_balance
# Check if the episode is done
done = self.net_worth <= 0 or self.current_step >= self.max_steps
obs = self._next_observation()
return obs, reward, done, False, {}
# - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
def render(self, mode='human'):
""" Displays the current state of the environment in a human-readable format. """
# Print the current step, balance, shares held, net worth, and profit
profit = self.net_worth - self.initial_balance
print(f'Step: {self.current_step}')
print(f'Balance: {self.balance:.2f}')
for ticker in self.tickers:
print(f'{ticker} Shares held: {self.shares_held[ticker]}')
print(f'Net worth: {self.net_worth:.2f}')
print(f'Profit: {profit:.2f}')
def close(self):
""" Placeholder for any cleanup operations """
pass4.4 建立强化学习代理
接下来,我们建立了各种强化学习代理,与前面定义的交易环境进行互动。每个代理都基于不同的强化学习算法,而集合代理则综合了这些单个模型的优势。
4.4.1 PolicyGradientLossCallback Class
- Purpose: 此自定义回调记录培训期间的策略梯度损失,以便进行性能监控。
- Functionality:
_on_step: 从模型的日志记录器中捕捉并附加策略梯度损失。_on_training_end: 绘制训练后的策略梯度损失图,以直观显示损失随时间的变化。
4.4.2 Individual Trading Agents
PPOAgent (近端策略优化)
- Initialization: 用指定的时间步数和行动决策阈值设置 PPO 模型。
- Methods:
predict: 返回 PPO 模型针对给定观测数据所决定的行动。- action_to_recommendation(行动建议):根据阈值将模型的操作转换为交易建议(买入/卖出/持有)。
validate: 通过在环境中运行代理并计算总奖励来评估代理的性能。
4.4.3 Other agents
- A2CAgent (Advantage Actor-Critic)
- DDPGAgent (Deep Deterministic Policy Gradient)
- SACAgent (Soft Actor-Critic)
- TD3Agent (Twin Delayed Deep Deterministic Policy Gradient)
- Initialization:初始化继承自 PPOAgent,但分别使用 A2C、DDPG、SAC 和 TD3 算法。它们还包括 PolicyGradientLossCallback,用于在训练过程中跟踪损失。
4.3.4 EnsembleAgent
- Purpose: 综合多个单独模型(PPO、A2C、DDPG、SAC 和 TD3)的预测结果,做出最终决定。这种集合方法旨在充分利用每种算法的优势。
- Methods:
predict: 平均每个单独模型预测的行动,以确定集合行动。action_to_recommendation: 根据阈值将集合行动转化为买入/卖出/持有建议。validate: 测试集合代理在环境中的表现,并计算总奖励。
这些代理被设计用于处理环境中的交易决策,并经过验证,以确保它们在最大限度地提高回报和做出明智的交易选择方面的有效性。
4.5 用于训练和评估交易代理的辅助功能
class PolicyGradientLossCallback(BaseCallback):
"""
A custom callback class that logs the policy_gradient_loss during training.
This class extends BaseCallback and used to capture and store the metrics we want.
"""
def __init__(self, verbose=0):
super(PolicyGradientLossCallback, self).__init__(verbose)
self.losses = []
def _on_step(self) -> bool:
if hasattr(self.model, 'logger'):
logs = self.model.logger.name_to_value
if 'train/policy_gradient_loss' in logs:
loss = logs['train/policy_gradient_loss']
self.losses.append(loss)
return True
def _on_training_end(self):
""" Plot the loss after training ends """
name = self.model.__class__.__name__
plt.figure(figsize=(12, 4))
plt.plot(self.losses, label='Policy Gradient Loss')
plt.title(f'{name} - Policy Gradient Loss During Training')
plt.xlabel('Training Steps')
plt.ylabel('Loss')
plt.legend()
plt.show()# Define PPO Agent
class PPOAgent:
def __init__(self, env, total_timesteps, threshold):
self.model = PPO("MlpPolicy", env, verbose=1)
self.callback = PolicyGradientLossCallback()
self.model.learn(total_timesteps=total_timesteps, callback=self.callback)
self.threshold = threshold
# - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
def predict(self, obs):
action, _ = self.model.predict(obs, deterministic=True)
return action
# - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
def action_to_recommendation(self, action):
recommendations = []
for a in action:
if a > self.threshold:
recommendations.append('buy')
elif a < -self.threshold:
recommendations.append('sell')
else:
recommendations.append('hold')
return recommendations
# - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
def validate(self, env):
obs = env.reset()
total_rewards = 0
for _ in range(1000): # Adjust based on needs
action, _ = self.model.predict(obs)
obs, reward, done, _ = env.step(action)
total_rewards += reward
if done:
obs = env.reset()
print(f'Agent Validation Reward: {total_rewards}')
# -----------------------------------------------------------------------------
# Define A2C Agent
class A2CAgent(PPOAgent):
def __init__(self, env, total_timesteps, threshold):
super().__init__(env, total_timesteps, threshold)
self.model = A2C("MlpPolicy", env, verbose=1)
self.callback = PolicyGradientLossCallback()
self.model.learn(total_timesteps=total_timesteps, callback=self.callback)
# -----------------------------------------------------------------------------
# Define DDPG Agent
class DDPGAgent(PPOAgent):
def __init__(self, env, total_timesteps, threshold):
super().__init__(env, total_timesteps, threshold)
self.model = DDPG("MlpPolicy", env, verbose=1)
self.callback = PolicyGradientLossCallback()
self.model.learn(total_timesteps=total_timesteps, callback=self.callback)
# -----------------------------------------------------------------------------
# Define SAC Agent
class SACAgent(PPOAgent):
def __init__(self, env, total_timesteps, threshold):
super().__init__(env, total_timesteps, threshold)
self.model = SAC("MlpPolicy", env, verbose=1)
self.callback = PolicyGradientLossCallback()
self.model.learn(total_timesteps=total_timesteps, callback=self.callback)
# -----------------------------------------------------------------------------
# Define TD3 Agent
class TD3Agent(PPOAgent):
def __init__(self, env, total_timesteps, threshold):
super().__init__(env, total_timesteps, threshold)
self.model = TD3("MlpPolicy", env, verbose=1)
self.callback = PolicyGradientLossCallback()
self.model.learn(total_timesteps=total_timesteps, callback=self.callback)
# -----------------------------------------------------------------------------
# Define Ensemble Agent
class EnsembleAgent:
def __init__(self, ppo_model, a2c_model, ddpg_model, sac_model, td3_model, threshold):
self.ppo_model = ppo_model
self.a2c_model = a2c_model
self.ddpg_model = ddpg_model
self.sac_model = sac_model
self.td3_model = td3_model
self.threshold = threshold
# - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
def predict(self, obs):
ppo_action, _ = self.ppo_model.predict(obs, deterministic=True)
a2c_action, _ = self.a2c_model.predict(obs, deterministic=True)
ddpg_action, _ = self.ddpg_model.predict(obs, deterministic=True)
sac_action, _ = self.sac_model.predict(obs, deterministic=True)
td3_action, _ = self.td3_model.predict(obs, deterministic=True)
# Average the actions
ensemble_action = np.mean([ppo_action, a2c_action, ddpg_action, sac_action, td3_action], axis=0)
return ensemble_action
# - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
def action_to_recommendation(self, action):
recommendations = []
for a in action:
if a > self.threshold:
recommendations.append('buy')
elif a < -self.threshold:
recommendations.append('sell')
else:
recommendations.append('hold')
return recommendations
# - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
def validate(self, env):
obs = env.reset()
total_rewards = 0
for _ in range(1000): # Adjust based on needs
action = self.predict(obs)
obs, reward, done, _ = env.step(action)
total_rewards += reward
if done:
obs = env.reset()
print(f'Agent Validation Reward: {total_rewards}')以下是用于训练和评估交易代理的辅助功能的详细概述:
4.5.1 创造环境和培训代理的功能
create_env_and_train_agents (创建环境和培训代理)
- Purpose:初始化交易环境并培训各种交易代理。
- Functionality(功能性):
- Environments:使用 StockTradingEnv 类创建训练 (train_env) 和验证 (val_env) 环境。
- Agents: 使用各自的类别和验证数据对每个代理(PPO、A2C、DDPG、SAC、TD3)进行培训和验证。
- Ensemble: 训练并验证一个集合代理,该代理综合了所有单个模型的预测结果。
- Returns: 提供初始化环境和训练有素的代理,供进一步分析。
4.5.2 可视化功能
visualize_portfolio (可视化组合)
- Purpose: 显示余额、净值和所持股票的时间变化。
- Parameters(参数):
steps:时间步骤列表。balances,net_worths,shares_held: 长期跟踪的指标。tickers: 股票代码列表。show_balance,show_net_worth,show_shares_held:显示平衡(show_balance)、显示净值(show_net_worth)、显示所持股票(show_shares_held):用于控制显示哪些图表的标志。
- Functionality: 功能为余额、净值和所持股票创建多面板图,可直观查看投资组合的长期表现。
visualize_portfolio_net_worth (可视化投资组合净值)
- Purpose: 绘制一段时间内的净资产图。
- Parameters(参数):
steps: 时间步骤列表。net_worths: 长期跟踪的净资产。
- Functionality:创建单一的净值图,提供投资组合价值增长的清晰视图。
visualize_multiple_portfolio_net_worth (多个可视化投资组合净值)
- Purpose: 在同一图表上比较多个投资组合的净值。
- Parameters(参数):
steps: 时间步骤列表。net_worths_list: 不同代理商的净资产系列列表。labels:每个代理商净资产系列的标签。
- Functionality: 将多个代理的净资产绘制在一张图表上,便于直接比较。
4.5.3 测试功能
test_agent(测试代理)
- Purpose: 测试单个代理在环境中的性能并跟踪关键指标。
- Parameters(参数):
env:测试代理的环境。agent: 待测代理。stock_data: 用于指标跟踪的股票相关数据。n_tests: 测试迭代次数。visualize: 可视化:标志,用于控制测试期间的环境渲染。
- Functionality: 在环境中运行代理,收集指标(余额、净值、所持股票),并可选择将环境可视化。
test_and_visualize_agents (测试和可视化代理)
- Purpose: 测试多个代理并可视化其性能。
- Parameters(参数):
env: 测试代理的环境。agents: 待测制剂词典。data: 用于指标跟踪的库存数据。n_tests: 测试迭代次数。
- Functionality: 测试每个代理,收集性能指标,并生成净值随时间变化的可视化对比图。
4.5.4 性能比较功能
compare_and_plot_agents(比较和绘图代理)
- Purpose: 根据代理的收益、标准差和夏普比率对其进行比较。
- Parameters(参数):
agents_metrics: 从测试代理收集的指标。labels: 每个代理的标签。risk_free_rate:用于计算夏普比率的无风险利率。
- Functionality(功能性):
- Comparison: 计算每个代理的收益、标准差和夏普比率。
- Visualization: 显示分类数据框和条形图,比较代理的夏普比率,突出显示哪个代理在风险调整后收益方面表现最佳。
这些功能为培训、测试和评估交易代理提供了全面的工具包,可对不同的模型进行深入分析和比较。
# Function to create the environment and train the agents
def create_env_and_train_agents(train_data, val_data, total_timesteps, threshold):
# Create environments for training and validation
train_env = DummyVecEnv([lambda: StockTradingEnv(train_data)])
val_env = DummyVecEnv([lambda: StockTradingEnv(val_data)])
# Train and Validate PPO Agent
ppo_agent = PPOAgent(train_env, total_timesteps, threshold)
ppo_agent.validate(val_env)
# Train and Validate A2C Agent
a2c_agent = A2CAgent(train_env, total_timesteps, threshold)
a2c_agent.validate(val_env)
# Train and Validate DDPG Agent
ddpg_agent = DDPGAgent(train_env, total_timesteps, threshold)
ddpg_agent.validate(val_env)
# Train and Validate SAC Agent
sac_agent = SACAgent(train_env, total_timesteps, threshold)
sac_agent.validate(val_env)
# Train and Validate TD3 Agent
td3_agent = TD3Agent(train_env, total_timesteps, threshold)
td3_agent.validate(val_env)
# Train and Validate the ensemble agent
ensemble_agent = EnsembleAgent(ppo_agent.model, a2c_agent.model, ddpg_agent.model,
sac_agent.model, td3_agent.model, threshold)
ensemble_agent.validate(val_env)
return train_env, val_env, ppo_agent, a2c_agent, ddpg_agent, sac_agent, td3_agent, ensemble_agent
# -----------------------------------------------------------------------------
# Function to visualize portfolio changes
def visualize_portfolio(steps, balances, net_worths, shares_held, tickers,
show_balance=True, show_net_worth=True, show_shares_held=True):
fig, axs = plt.subplots(3, figsize=(12, 18))
# Plot the balance
if show_balance:
axs[0].plot(steps, balances, label='Balance')
axs[0].set_title('Balance Over Time')
axs[0].set_xlabel('Steps')
axs[0].set_ylabel('Balance')
axs[0].legend()
# Plot the net worth
if show_net_worth:
axs[1].plot(steps, net_worths, label='Net Worth', color='orange')
axs[1].set_title('Net Worth Over Time')
axs[1].set_xlabel('Steps')
axs[1].set_ylabel('Net Worth')
axs[1].legend()
# Plot the shares held
if show_shares_held:
for ticker in tickers:
axs[2].plot(steps, shares_held[ticker], label=f'Shares Held: {ticker}')
axs[2].set_title('Shares Held Over Time')
axs[2].set_xlabel('Steps')
axs[2].set_ylabel('Shares Held')
axs[2].legend()
plt.tight_layout()
plt.show()
# -----------------------------------------------------------------------------
# function to visualize the portfolio net worth
def visualize_portfolio_net_worth(steps, net_worths):
plt.figure(figsize=(12, 6))
plt.plot(steps, net_worths, label='Net Worth', color='orange')
plt.title('Net Worth Over Time')
plt.xlabel('Steps')
plt.ylabel('Net Worth')
plt.legend()
plt.show()
# -----------------------------------------------------------------------------
# function to visualize the multiple portfolio net worths ( same chart )
def visualize_multiple_portfolio_net_worth(steps, net_worths_list, labels):
plt.figure(figsize=(12, 6))
for i, net_worths in enumerate(net_worths_list):
plt.plot(steps, net_worths, label=labels[i])
plt.title('Net Worth Over Time')
plt.xlabel('Steps')
plt.ylabel('Net Worth')
plt.legend()
plt.show()
# -----------------------------------------------------------------------------
def test_agent(env, agent, stock_data, n_tests=1000, visualize=False):
""" Test a single agent and track performance metrics, with an option to visualize the results """
# Initialize metrics tracking
metrics = {
'steps': [],
'balances': [],
'net_worths': [],
'shares_held': {ticker: [] for ticker in stock_data.keys()}
}
# Reset the environment before starting the tests
obs = env.reset()
for i in range(n_tests):
metrics['steps'].append(i)
action = agent.predict(obs)
obs, rewards, dones, infos = env.step(action)
if visualize:
env.render()
# Track metrics
metrics['balances'].append(env.get_attr('balance')[0])
metrics['net_worths'].append(env.get_attr('net_worth')[0])
env_shares_held = env.get_attr('shares_held')[0]
# Update shares held for each ticker
for ticker in stock_data.keys():
if ticker in env_shares_held:
metrics['shares_held'][ticker].append(env_shares_held[ticker])
else:
metrics['shares_held'][ticker].append(0) # Append 0 if ticker is not found
if dones:
obs = env.reset()
return metrics
# -----------------------------------------------------------------------------
def test_and_visualize_agents(env, agents, data, n_tests=1000):
metrics = {}
for agent_name, agent in agents.items():
print(f"Testing {agent_name}...")
metrics[agent_name] = test_agent(env, agent, data, n_tests=n_tests, visualize=True)
# Extract net worths for visualization
net_worths = [metrics[agent_name]['net_worths'] for agent_name in agents.keys()]
steps = next(iter(metrics.values()))['steps'] # Assuming all agents have the same step count for simplicity
# Visualize the performance metrics of multiple agents
visualize_multiple_portfolio_net_worth(steps, net_worths, list(agents.keys()))
# -----------------------------------------------------------------------------
def compare_and_plot_agents(agents_metrics, labels, risk_free_rate=0.0):
# Function to compare returns, standard deviation, and sharpe ratio of agents
def compare_agents(agents_metrics, labels):
returns = []
stds = []
sharpe_ratios = []
for metrics in agents_metrics:
net_worths = metrics['net_worths']
# Calculate daily returns
daily_returns = np.diff(net_worths) / net_worths[:-1]
avg_return = np.mean(daily_returns)
std_return = np.std(daily_returns)
sharpe_ratio = ((avg_return - risk_free_rate) / std_return) if std_return != 0 else 'Inf'
returns.append(avg_return)
stds.append(std_return)
sharpe_ratios.append(sharpe_ratio)
df = pd.DataFrame({
'Agent': labels,
'Return': returns,
'Standard Deviation': stds,
'Sharpe Ratio': sharpe_ratios
})
return df
# Compare agents
df = compare_agents(agents_metrics, labels)
# Sort the dataframe by sharpe ratio
df_sorted = df.sort_values(by='Sharpe Ratio', ascending=False)
# Display the dataframe
display(df_sorted)
# Plot bar chart for sharpe ratio
plt.figure(figsize=(12, 6))
plt.bar(df_sorted['Agent'], df_sorted['Sharpe Ratio'])
plt.title('Sharpe Ratio Comparison')
plt.xlabel('Agent')
plt.ylabel('Sharpe Ratio')
plt.show()4.6 训练交易代理
4.6.1 训练参数设置
- Threshold: 阈值决定触发买入或卖出决策的最小动作幅度。在本例中,阈值设置为 0.1。
- Total Timesteps: 该参数指定了训练代理的总时间步数。这里设置为 10,000 个时间步。
4.6.2 环境创建和代理培训
- Environment Creation: 该步骤使用
StockTradingEnv类初始化训练和验证环境,并根据提供的股票数据进行调整。 - Agent Training:
create_env_and_train_agents函数使用训练环境训练各种强化学习代理(PPO、A2C、DDPG、SAC、TD3)。每个代理的训练时间为指定的时间步数。 - Ensemble Agent:还可以训练一个集合代理,它综合了所有单个模型的预测结果。这种方法旨在充分利用每个模型的优势,并有可能提高整体性能。
返回的对象包括经过训练的环境和代理,这些环境和代理可用于进一步的评估和性能分析。
# Create the environment and train the agents
threshold = 0.1
total_timesteps = 10000
train_env, val_env, ppo_agent, a2c_agent, ddpg_agent, sac_agent, td3_agent, ensemble_agent = \
create_env_and_train_agents(training_data, validation_data, total_timesteps, threshold)我们还可以对代理进行测试和可视化:
n_tests = 1000
agents = {
'PPO Agent': ppo_agent,
'A2C Agent': a2c_agent,
'DDPG Agent': ddpg_agent,
'SAC Agent': sac_agent,
'TD3 Agent': td3_agent,
'Ensemble Agent': ensemble_agent
}
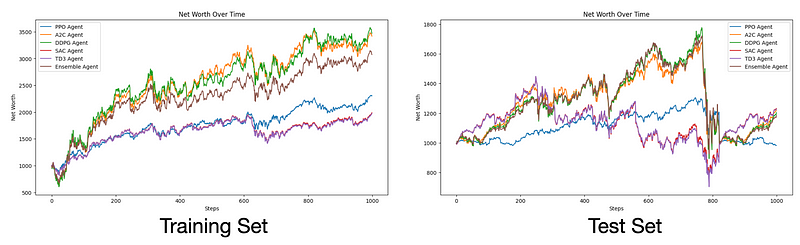
test_and_visualize_agents(train_env, agents, training_data, n_tests=n_tests)
test_env = DummyVecEnv([lambda: StockTradingEnv(test_data)])
test_and_visualize_agents(test_env, agents, test_data, n_tests=n_tests)相应的结果如下:
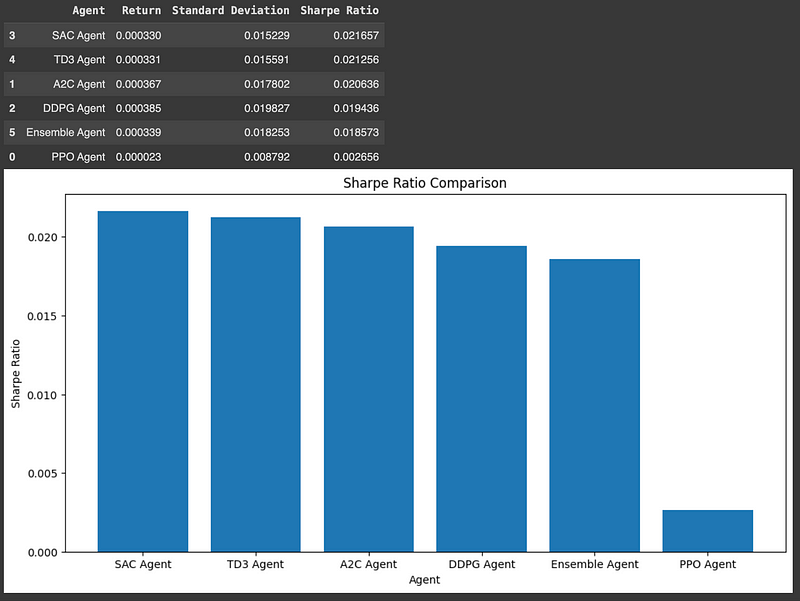
我们还比较了代理在测试数据上的表现(收益、标准偏差和锐利比率)。
代理的夏普比率越高,其收益相对于所承担的投资风险而言就越好。因此,我们要选择能够最大化收益的交易代理,以适应不断增加的风险。
test_agents_metrics = [test_agent(test_env, agent, test_data, n_tests=n_tests, visualize=False) for agent in agents.values()]
compare_and_plot_agents(test_agents_metrics, list(agents.keys()))相应的结果如下:
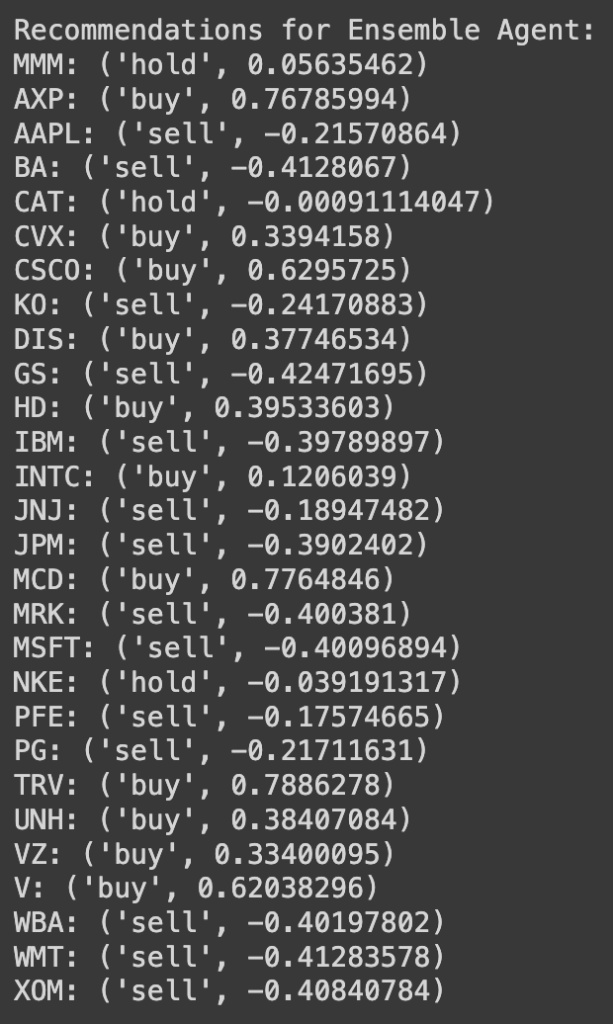
最后,我们还可以利用该模型提出次日建议:
def prepare_next_day_data(stock_data):
""" Prepares the observation for the next trading day """
# Initialize the environment with the current stock data
env = StockTradingEnv(stock_data)
env.reset()
# Prepare the next day's observation
next_day_observations = env._next_observation()
return next_day_observations
# -----------------------------------------------------------------------------
def generate_next_day_recommendations(agents, next_day_observation):
""" Generate recommendations for the next trading day using the trained agents """
recommendations = {agent_name: [] for agent_name in agents.keys()}
for agent_name, agent in agents.items():
action = agent.predict(next_day_observation)
recs = agent.action_to_recommendation(action)
recommendations[agent_name] = zip(recs, action)
return recommendations
# -----------------------------------------------------------------------------
# Prepare next day's observation
next_day_observation = prepare_next_day_data(test_data)
# Generate recommendations for the next trading day
recommendations = generate_next_day_recommendations(agents, next_day_observation)
# Print or display recommendations
for agent_name, recs in recommendations.items():
if agent_name == 'Ensemble Agent':
print(f'\nRecommendations for {agent_name}:')
for ticker, recommendation in zip(tickers, recs):
print(f"{ticker}: {recommendation}")相应的结果如下:
五、观点回顾
我们利用定制的交易环境,完成了为股票交易设置和训练强化学习代理的复杂过程。我们首先设计了一个全面的环境,以捕捉股票交易的细微差别,包括交易成本、状态观察和奖励计算。有了这个环境,我们训练了各种强化学习代理--PPO、A2C、DDPG、SAC 和 TD3--每个代理都为交易策略贡献了自己的独特优势。我们还实施了一个集合代理,将所有单个模型的预测结合在一起,旨在最大限度地提高性能和稳健性。
我们的探索展示了如何将这些先进算法应用于现实世界的交易场景,突出了它们根据市场数据进行调整并做出明智决策的潜力。从这一实践中获得的启示不仅展示了强化学习在金融领域的威力,还强调了严格评估和可视化在评估代理性能方面的重要性。通过不断完善我们的模型并分析其结果,我们可以努力制定更有效的交易策略,并加深对市场动态的理解。
深度强化学习在自动股票交易系统中的应用可以通过学习和优化交易策略来提高交易收益。通过结合技术指标和DRL算法,可以开发出能够适应市场变化并做出明智交易决策的智能交易系统。此外,通过使用集合方法和严格的评估标准(如夏普比率),可以进一步提高交易策略的鲁棒性和性能。网页强调了在实际交易中对模型性能进行详细分析和可视化的重要性,以及持续优化模型以适应市场动态的必要性。
感谢您阅读到最后。如果对文中的内容有任何疑问,请给我留言,必复。
本文内容仅仅是技术探讨和学习,并不构成任何投资建议。
转发请注明原作者和出处。



















 774
774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











