






“A Deep Reinforcement Learning Approach to Automated Stock Trading, using xLSTM Networks”

摘要
传统长短期记忆网络(LSTM)在处理时间序列数据时面临梯度消失及长期依赖难以捕捉的挑战,这限制了其在动态市场环境(如股票交易)中的应用效果。本研究创新性地提出将扩展长短期记忆网络(xLSTM)与深度强化学习(DRL)相结合的混合方法,用于自动化证券交易系统构建。具体而言,xLSTM网络被整合至DRL的决策与评估模块中,以更有效地处理金融时间序列的时序特征与市场动态变化特性,同时采用近端策略优化(PPO)算法进行策略优化,实现探索与利用的平衡。
实验验证表明,基于xLSTM的模型在累积收益、单笔交易平均利润、最大收益、最大回撤及夏普比率等核心交易评估指标上,显著优于传统LSTM基线模型。该研究结果验证了xLSTM在提升基于深度强化学习的股票交易系统性能方面的有效性,为金融智能决策提供了新的技术路径。
01
简介
投资者试图通过预测市场走向来提升收益,但金融市场的复杂性与波动性使得人工分析存在显著局限。自动化交易系统的研究焦点已转向深度强化学习(DRL),因其相较监督学习方法具备动态适应市场状态的特性。在策略优化算法中,深度Q学习(DQL)因稳定性不足而逐渐被更先进的近端策略优化(PPO)等算法取代,后者在策略迭代中展现出更高的效率与鲁棒性。
现有研究尝试将模仿学习与DRL结合构建代理驱动模型,以应对金融数据中的噪声干扰。部分工作通过级联LSTM网络与DRL框架的融合,在策略学习中引入PPO算法与LSTM架构。近期研究进一步整合了DQN与DDPG算法,并结合卷积神经网络(CNN)、门控循环单元(GRU)以及注意力机制,以突破传统RNN的局限性。
本研究关注的扩展LSTM(xLSTM)架构在金融交易领域的应用尚未被充分探索。相较于传统LSTM,xLSTM通过指数门控机制和新型内存架构有效缓解了梯度消失问题,并在部分基准测试中超越了参数量更高的Transformer模型。本工作中,我们首次将xLSTM与DRL结合,用于股票价格预测任务,其中xLSTM被嵌入强化学习框架中,专门负责历史市场数据的特征提取。
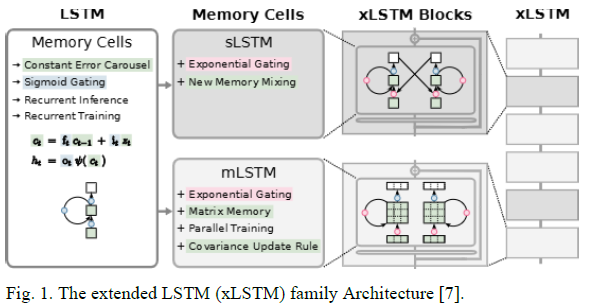
传统循环神经网络(如LSTM)在自然语言处理领域表现突出,但其在长序列建模时仍面临梯度消失或爆炸的挑战。Transformer架构通过并行计算与自注意力机制解决了RNN的短期依赖局限,但其参数规模限制了实际应用。xLSTM则在LSTM基础上进行创新性改进,核心设计包含两个关键模块:sLSTM负责标量记忆单元的更新与状态传递,而mLSTM通过全并行化设计提升计算效率,二者协同优化了模型对长期依赖关系的捕捉能力。
02
方法
模型架构
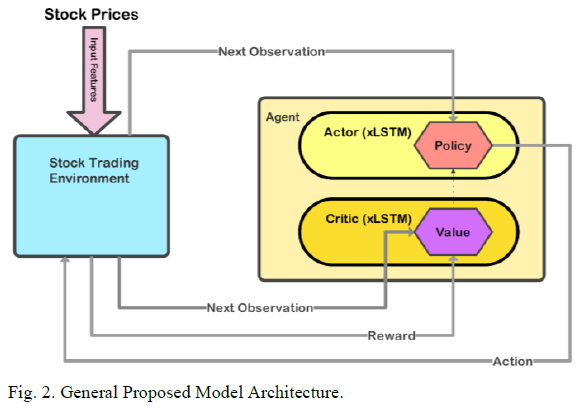
本研究构建了以近端策略优化(PPO)算法为核心的强化学习框架,基于Stable Baselines3工具包中的递归PPO模块实现递归策略支持。通过开发定制化的RecurrentActorCriticPolicy策略类,命名为xLSTMPolicy,并将其与PPO算法模块进行耦合,最终构建出深度强化学习交易模型。该策略类通过集成官方xLSTM库实现的递归神经网络结构,完成对历史市场数据的时序特征提取与策略决策。
循环近端策略优化(PPO)
近端策略优化(PPO)是一种在探索与开发间取得平衡的强化学习算法,旨在优化策略选择。Stable Baselines3库中提供的递归PPO模块可与循环神经网络(如LSTM)结合,形成高效的序列决策模型。本研究采用xLSTM架构替换传统LSTM组件,验证其在金融时间序列分析及股票交易任务中的表现。
具体而言,算法初始化两个独立的xLSTM子网络:决策网络(Actor)负责生成交易动作,价值网络(Critic)用于评估当前市场状态的价值。智能体通过与金融交易环境的持续交互进行训练:首先观测市场状态(如价格序列、成交量等),依据当前策略制定交易动作(买入/卖出/持有),随后根据获得的收益反馈逐步优化策略参数。xLSTM的递归结构使其能够有效捕捉历史状态信息,解析复杂的金融时间序列模式,并支持智能体制定连续的投资决策流程。

xLSTM网络
本方案采用双xLSTM网络结构,其中策略网络负责动作决策,价值网络专注状态评估,两者采用统一的参数配置及网络结构设计。网络中激活函数选用Gaussian Error Linear Unit(GeLU),嵌入维度设定为128。通过策略与价值网络的协同配合,系统在每个时间步中实现最优动作的选择。
股票交易环境
股票交易环境执行由策略决定的操作后,返回新的市场状态与即时奖励值,初始资金设定为100万美元。奖励机制通过监测市场波动指标来规避高风险场景:在高波动状态下执行交易将触发-1的惩罚项。当市场处于平稳状态时,奖励值通过计算投资组合净值变动扣除交易手续费后得出,并进行标准化处理以消除量纲影响。

03
实验
数据集
基于Yahoo Finance的历史市场数据,本研究选取了五家科技行业领军企业:NVIDIA、Apple、Microsoft、Google、Amazon作为分析对象。训练数据覆盖2009年1月至2022年1月,测试数据选取2022年1月至2022年12月期间。特征变量包含每日最低价、最高价、开盘价、收盘价、调整后的收盘价及成交量。为规避极端市场波动下的交易风险,研究中引入了市场波动指数作为约束条件。
评估指标
累计收益(CR)

MER(最大收益率)
![]()
最大利润下降百分比(MPB)
![]()
平均每笔交易盈利(APPT)
![]()
夏普比率(SR)
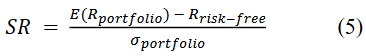
结果
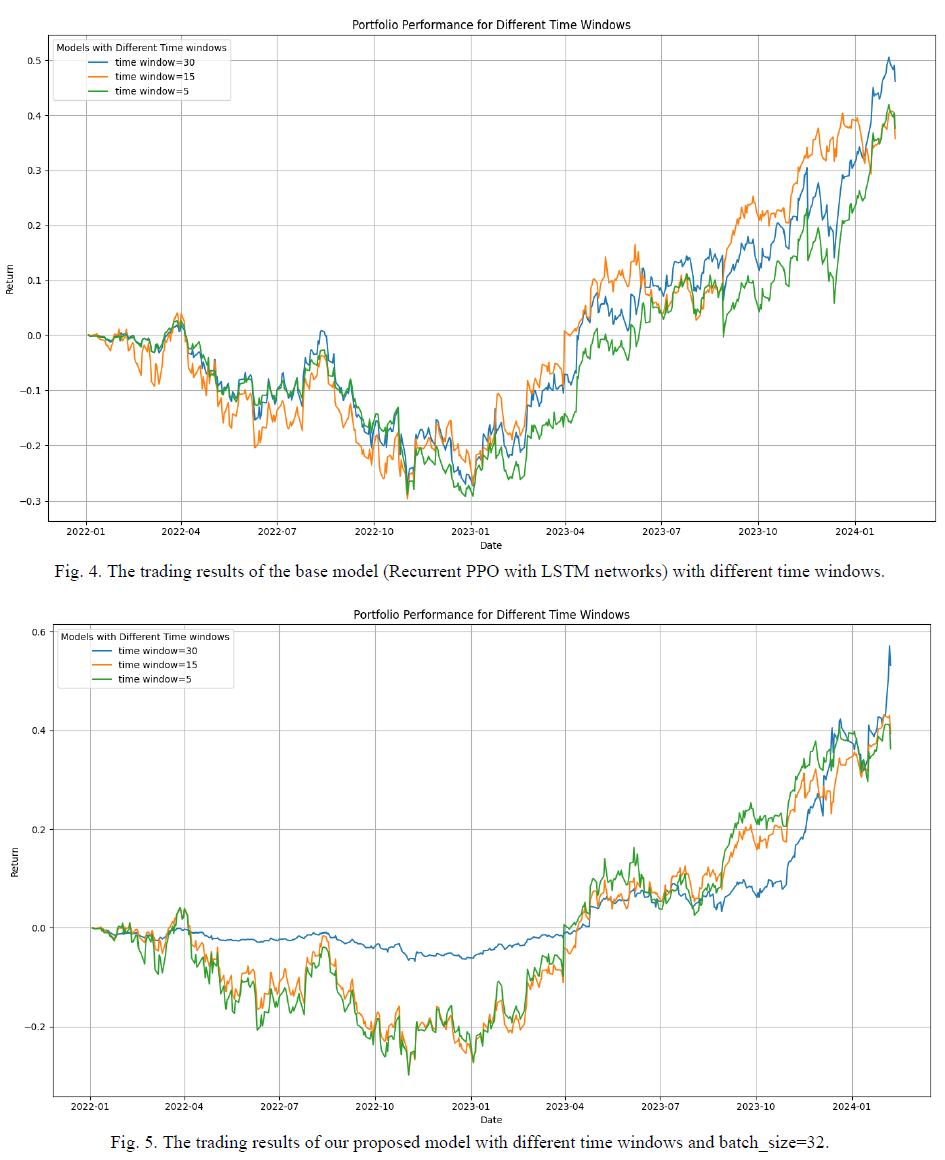
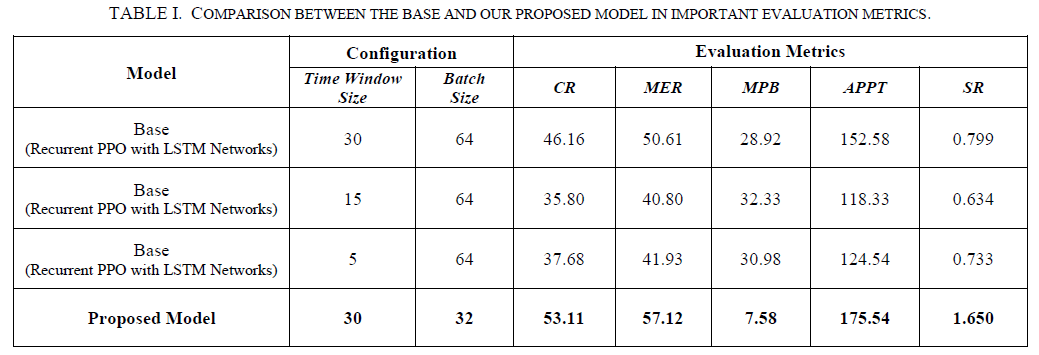
本研究采用Recurrent PPO算法与MLPPolicy构建基准模型,通过对比实验验证xLSTM与传统LSTM的性能差异,测试采用了30、15、5三种时间窗口设置。在超参数调优阶段,以3步时间窗口为基准调整批量大小,发现批量32的模型在回报率上表现最佳,但小窗口配置导致结果波动性较高。进一步扩展时间窗口至30步训练的模型,在测试阶段展现出最优性能,其回报曲线平稳且极少出现负收益,表明策略具备盈利能力和较低风险暴露。
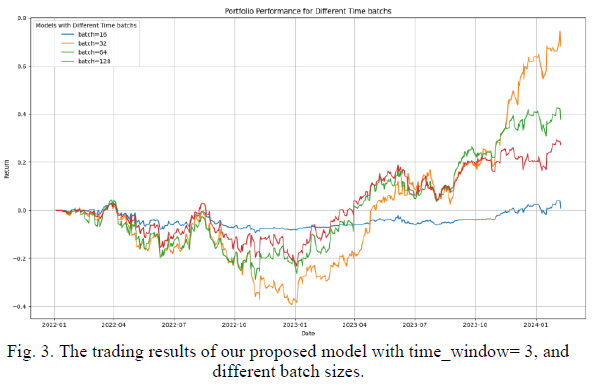
实验结果表明,xLSTM在策略网络和价值网络中的应用在所有评估指标上均显著优于传统LSTM,验证了其在自动化交易系统中的应用潜力。

04
总结
本研究验证了扩展长短期记忆网络(xLSTM)与深度强化学习(DRL)融合在自动化股票交易场景中的应用潜力。实验表明,相较于传统LSTM架构,xLSTM在性能表现上实现了显著提升,有效克服了原始LSTM的局限性。然而,xLSTM的训练过程对计算资源需求较高,限制了其在大规模问题中的扩展性。研究初期通过选取五支科技企业股票价格数据及精简特征集,结合PPO算法框架完成了xLSTM的可行性验证。
未来研究方向将聚焦于:1)通过强化特征工程优化模型输入维度,进一步提升策略性能;2)探索集成学习方法在xLSTM架构中的应用,例如将多模型集成应用于策略网络或价值网络模块,以增强决策鲁棒性。

















 359
359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









