







作者:老余捞鱼
原创不易,转载请标明出处及原作者。

写在前面的话:作为一名智慧金融从业者,我一直在寻找用工具预测市场波动的有效方法。最近我提炼出几个高效的波动率模型,通过Python的帮助,它们不仅能帮你从复杂的市场动态中理清思路,还能在混沌中发现潜在的盈利机会。接下来跟随我的脚步,让数据分析成为你投资决策中的强大工具。
一、波动与风险
知名投资人、橡树资本管理公司联合创始人霍华德-马克斯(Howard Marks)曾说:
Volatility is not the same as risk. Volatility is what happens on the way to where you’re going.(波动与风险不同。波动是在通往目的地的途中发生的事情)
上面这句话深刻揭示了波动性与风险之间的关键区别。虽然它们表面相似,但本质截然不同。事实上,波动往往可以被视为一种机遇。
波动是指资产价格在短期内的起伏变化。它让市场显得混乱无序,价格因外部事件、市场情绪或投机行为而频繁波动,甚至可能出现剧烈震荡。尽管这种不确定性让人不安,但波动其实是市场的常态,甚至是其固有特征。
而风险则不同,它意味着资本可能遭受永久损失,或者投资无法达到预期目标的可能性。无论是由于投资决策失误,还是因为不可预见的灾难性事件,你的财务计划都有可能偏离正轨。波动是市场的表象,而风险则是隐藏在背后的真正威胁。
波动率分析对多种金融应用至关重要,例如:
- 投资组合优化
- 风险管理
- 衍生产品定价
- 资产配置策略
二、波动率模型(Volatility Models)
波动率模型是理解和预测金融市场波动的重要工具。通过不同类型的模型,投资者和金融机构能够更好地评估风险、制定投资策略,并在复杂的市场环境中做出明智的决策。随着金融市场的不断发展,波动率模型也在不断演进,以适应新的挑战和机遇。
有几种方法可用于模拟和预测金融市场的波动。主要方法包括:
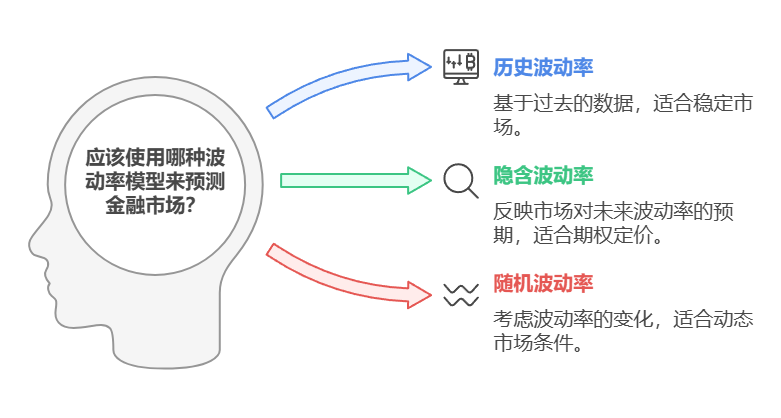
- 历史波动率模型:这种方法根据过去的价格走势计算波动率。简单来说,它是资产回报率在规定时间内的标准差。
- 隐含波动率模型:这是从期权价格中推导出来的,反映了市场对未来波动率的预期。通常使用 Black-Scholes 模型或其他期权定价模型计算。
- 随机波动模型:这些模型假设波动率本身遵循一个随机过程,如使用 GARCH(广义自回归条件异方差)的SV(模型和状态空间模型)。
这些模式各有优缺点,模式的选择取决于具体的财务背景和可用数据。
三、用于波动率分析的Python工具
Python 拥有丰富的库生态系统,是波动性分析的绝佳工具。NumPy、Pandas、Matplotlib 等库以及 QuantLib、Arch 和 yfinance 等专业金融库是定量金融不可或缺的工具。比如:
pip install arch QuantLibimport yfinance as yf
import pandas as pd
import numpy as np
from arch import arch_model
import QuantLib as ql接下来就让我们来探讨如何使用 Python 建立预测和管理市场波动的模型。
3.1 数据收集和准备
任何波动率分析的第一步都是收集历史数据。Python 的 yfinance 库可以直接从雅虎财经轻松访问金融数据。
# Download historical data for a stock (e.g., S&P 500)
ticker = "SPY"
data = yf.download(ticker, start="2010-01-01", end="2024-01-01")一旦收集到数据,对其进行预处理是至关重要的一步。在波动率分析中,我们通常关注的是资产的收益率,也就是价格变化的百分比。这一步不仅能帮助我们更好地理解市场行为,还能为后续的模型构建打下坚实基础。
# Calculate daily returns
data['Returns'] = data['Adj Close'].pct_change()
# Drop missing values
data.dropna(inplace=True)
data_clean = data.copy()
data_clean.columns = ['Date','Close','High','Low','Open','Volume','Returns']
data = data_clean.copy()3.2 历史波动率计算
衡量波动率的一种常见方法是计算一个移动窗口的收益标准差。
# Calculate rolling 30-day volatility
data['Historical Volatility'] = data['Returns'].rolling(window=30).std() * np.sqrt(252) # Annualize volatility假设一年有252个交易日,我们可以通过将标准差乘以252的平方根来计算年度波动率。这种方法能够将日波动率转化为年度波动率,帮助我们更好地评估资产的长期风险。
四、用于波动率预测的 GARCH 模型
对于更复杂的波动率模型,我们可以采用GARCH模型。GARCH模型能够捕捉波动率的集群效应,也就是说,高波动率时期往往会紧随更多的高波动率,而低波动率时期则倾向于延续低波动率。这种模型能够更准确地反映市场的动态变化,帮助我们更好地预测未来的波动性。
4.1 GARCH模型的关键概念
1.波动性聚类:
- 金融时间序列经常出现先高波动后高波动,先低波动后低波动的情况。
- GARCH 模型将当前的波动率模拟为过去波动率和过去预测误差的函数,从而捕捉到这种 "聚类 "效应。
2.条件异方差:
- 收益的方差(波动率)并不是恒定不变的,而是随着时间的推移而变化,这取决于过去的数据。
- "有条件 "意味着模型假定回报的方差以过去的价值为条件。
3.自回归和移动平均方差:
- 自回归 (AR) 部分(GARCH 项)模拟过去的方差如何影响当前的方差。
- 移动平均(MA)成分(ARCH 项)模拟了过去的预测误差(意外冲击)对当前方差的影响。
4.2 GARCH模型的Python实现
Python 的 arch 库是处理 GARCH 模型的强大工具。
# Fit a GARCH(1,1) model to the returns
model = arch_model(data['Returns'] * 100, vol='Garch', p=1, q=1)
garch_fit = model.fit()
# Display the results
garch_fit.summary()GARCH 模型提供了条件方差的估计值,可将其解释为对未来波动率的预测。
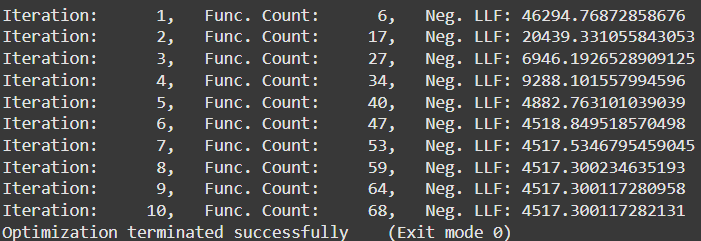
输出结果是使用最大似然估计 (MLE) 对回报数据拟合 GARCH(1,1) 模型的结果。
4.3 迭代细节
每次迭代都显示了用于拟合模型的优化算法的进展情况:
- 迭代次数:优化过程的当前步骤。
- Func.计数:优化过程中执行的函数评估次数。它跟踪计算目标函数(负对数似然)的次数。
- Neg.LLF(负对数似然函数):该值代表最小化的成本函数。该值越小,模型越适合数据。
要点说明:
- 最初,Neg.LLF 非常高(如 46294),表明拟合效果不佳。
- 每次迭代,优化器都会调整模型参数,减少 Neg。LLF 以提高拟合度。
- 优化在迭代 10 时成功结束,最终 Neg.LLF 约为 4517.3。
优化终止:
- 退出模式 0:表示优化算法成功收敛。
- 当前函数值:最终的 Neg.最小化的 LLF 值。
- 迭代次数:收敛所需的迭代总数 (10)。
- 函数评估:计算似然函数的次数(68)。
- 梯度评估:计算似然函数梯度的次数 (10)。
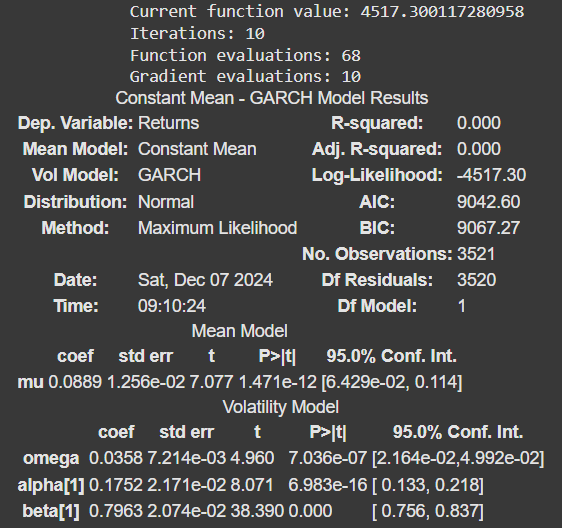
4.4 模型结论
1. 平均模型(Mean Model):
- 均值模型:收益率模型采用恒定均值(mu)。
- coef (mu):常数均值的估计值,即 0.0889。
- std err:估计值的标准误差 (0.01256),表示精确度。
- t:t:检验系数是否与零有显著差异的 t 统计量。
- P>|t|:检验的 p 值。小的 p 值(< 0.05)表明该系数具有统计意义。
- 95% Conf.置信区间:收益平均值的置信区间。
2. 波动模型(Volatility Model):
GARCH模型用于描述波动性:
- ω:GARCH 方程中的常数项,代表波动率的基本水平(0.0358)。
- alpha:滞后平方残差项系数,表示过去的冲击(新闻)对当前波动率的影响(0.1752)。
- beta:滞后条件方差项系数,代表波动率随时间变化的持续性(0.7963)。
3. 要点:
- 阿尔法[1]和贝塔[1]之和接近 1(0.1752 + 0.7963 ≈ 0.97),表明波动持续性很高。
- 所有系数都非常显著(p 值≈0)。
4. 模型统计:
- Dep. 变量:建模变量(收益率)。
- R 平方:表示模型能解释多少收益率方差。对 GARCH 而言接近 0,因为它侧重于波动性建模,而不是收益率建模。
- 对数似然:拟合模型的最终似然值(-4517.30)。
- AIC(阿凯克信息标准):评估模型拟合度的指标(越低越好)。这里,AIC = 9042.60。
- BIC(贝叶斯信息标准):另一种对模型复杂性进行惩罚的拟合度量。这里,BIC = 9067.27。
为了更直观地显示波动率,我们可以用下面的代码绘制波动率曲线:
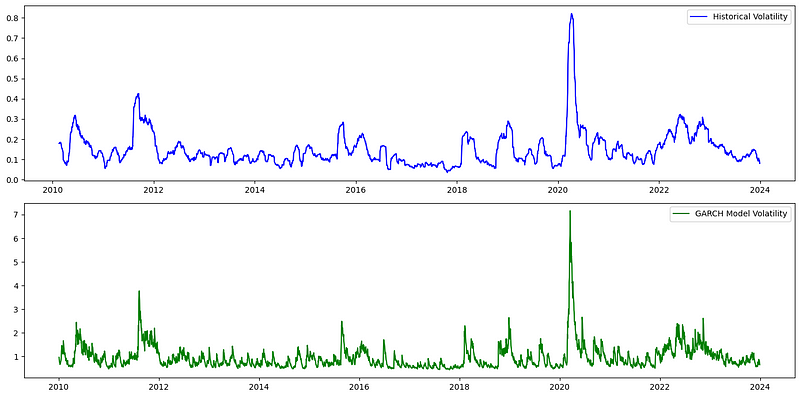
实现代码如下:
# Plot the results
plt.figure(figsize=(14, 7))
# Plot Historical Volatility
plt.subplot(2, 1, 1)
plt.plot(data['Historical Volatility'], label="Historical Volatility", color='blue')
plt.legend()
# Plot GARCH Model Volatility (using the model's estimated volatility)
plt.subplot(2, 1, 2)
plt.plot(garch_fit.conditional_volatility, label="GARCH Model Volatility", color='green')
plt.legend()
plt.tight_layout()
plt.show()五、预测波动率
一旦拟合出 GARCH 模型,我们就可以用它来预测未来的波动率。
# Forecast the next 10 days of volatility forecast = garch_fit.forecast(horizon=10) forecasted_volatility = forecast.variance[-1:] # Display the forecasted volatility forecasted_volatility
输出结果将给出未来 10 天的预测波动率。这有助于预测市场风险并相应调整投资组合。

列标题(h.01 至 h.10):
- 它们代表不同时间跨度(如第 1 天至第 10 天)的预测波动率。
- 这些数值表示每个时期的预期波动水平。
波动率:
- 这些是预测的波动率(例如,第 1 天为 0.403643,第 2 天为 0.427922,等等)。
- 数值越高,表明市场的不确定性或风险越大。
六、建模限制条件
根据经验,即使模型在大多数情况下能够做出准确的预测,但当突发事件发生时——比如COVID-19疫情或9/11事件导致全球股市在一天内暴跌——无论我们准备得多么充分,仍然很难预测这类极端事件。这些黑天鹅事件提醒我们,市场的复杂性和不确定性远超模型的预测能力。
6.1 静态假设
- GARCH 模型假定基础回报是静态的。在实际市场中,回报可能会出现结构性中断或制度变化(如经济危机导致的转变)。
- 考虑因素:确保在应用模型前进行去趋势或静态测试等预处理步骤。
6.2 正态分布假设
- 该模型假设残差服从正态分布。然而,金融回报通常会出现肥尾或过度峰度。
- 结果背景:在结果中,分布是正态分布,可能无法完全反映极端市场行为。
- 缓解措施:在 GARCH 模型中使用其他分布(如学生 t 分布)。
63 过度拟合风险
- GARCH(1,1) 模型兼顾了简单性和准确性,因此很受欢迎,但高阶模型(如 GARCH(2,1))可能会过度拟合历史数据。
- 结果背景:您的模型使用的是 GARCH(1,1),这在大多数应用中都是合理的。
七、观点总结
波动性分析是定量金融领域中风险管理和预测的核心。从简单的历史波动率计算到复杂的GARCH模型,Python为波动性建模和预测提供了强大的工具。无论是初学者还是专业人士,都可以利用Python灵活地构建和分析模型,从而更好地理解市场动态并管理风险。
- 波动与风险虽然相关,但是本质上是不同的。波动是市场的正常特征,而风险则是指可能的负面结果。
- 波动率模型在金融分析中扮演着至关重要的角色,它们不仅有助于理解市场动态,还能用于各种金融应用。
- GARCH模型是一种强大的工具来预测和管理市场波动率,它能够捕捉到波动性聚类和条件异方差的现象。
- Python提供了一套丰富的库生态系统,使得在金融领域进行波动性分析和建模变得更加容易和高效。
- 在应用GARCH模型时,需要注意模型的假设和限制,以及如何通过使用不同的分布或调整模型复杂度来改进模型的预测能力。
- 模型预测的准确性可能受到突发事件的影响,这种不确定性是金融市场分析中需要特别注意的因素。
- 波动性分析的未来发展将越来越依赖于强大的数据分析工具和模型,Python等技术将继续在金融领域发挥重要作用。
感谢您阅读到最后,希望这篇文章为您带来了新的启发和实用的知识!如果觉得有帮助,请不吝点赞和分享,您的支持是我持续创作的动力。祝您投资顺利,收益长虹!如果对文中内容有任何疑问,欢迎留言,我会尽快回复!
本文内容仅限技术探讨和学习,不构成任何投资建议。



















 552
552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











