






写在前面:
本篇文章记录了整个复现过程遇到的报错等问题,如果大家也遇到报错了不妨从文章中找一找,也许就能找到对应的解决办法。
一、数据预处理
需要准备好semantic_kitti完整的数据集,将数据集中每个场景按下图进行布置。


可以直接利用官网下载下来的数据集中data_odometry_labels这个文件夹,直接将其中的数据复制成一个新的文件夹即可。
阅读,data_prepare_semantickitti.py脚本,更改对应的数据集路径、输出数据集路径
运行,win系统一般会报错:

原因是在utils/cpp_wrappers/cpp_subsampling/grid_subsampling.cpp文件中的compute()函数没有被找到。由于是win系统,因此需要对C++模块进行编译,从而确保代码中的某些模块可以正确编译并链接到C++代码中,形成动态链接库(DLL)。
具体实施方法:打开终端进入到utils/cpp_wrappers/cpp_subsampling目录下,运行:
python setup.py build_ext --inplace 对文件进行编译
如果编译成功,将会在cpp_subsampling目录下生成一个grid_subsampling.pyd的文件,确保该文件在整个项目中后,运行脚本,即可进行数据处理。如下图,数据正在处理中.....

*遇到问题:

这里的原因是因为,classes的形状不对,要求classes参数的形状是(N,)或(N,d),因此回到原代码中:

检查labels输出的形状后,发现在02场景报错,根本不会输出标签形状,因此怀疑是原点云数据存在问题,及时更换velodyne中数据后,报错解决,继续数据转换.....
数据转换完成后每个场景下的文件是这样的:
二、训练
在semkitti_trainset.py程序中更改预处理后的数据集路径
运行train_SemanticKITTI.py
报错:

编译,cd utils/nearest_neighbors/,输入python setup.py build_ext --inplace进行编译,观察是否成功?
并没有成功

提示要更换系统
(原文用Ubuntu系统实现)
三、ubuntu系统复现过程
使用环境为cuda11.3 pytorch 1.10.1 python 3.8
更换系统后仍然需要编译C++文件
遇到问题:
- TypeError: confusion_matrix() takes 2 positional arguments but 3 were given
最开始理解报错认为confusion_matrix()需要两个参数,但我传入了三个参数,因此我只传入两个参数:labels_vaild和pred_vaild,我删除了一个参数label(label是用来包含所有类别的列表或数组的)也就有下面一系列报错
2.随后报错:self.gt_classes += np.sum(conf_matrix, axis=1) ValueErro:operands could not be broadcast together with shapes(19)(10).
表明labels和pred的形状不同,于是想把二者形状转换成一样的:
labels_vaild=np.zeros((19,))
pred_valid=np.zeros((19))
再将二者传入conf_matrix中,仍然报错形状不同后在再次报错TypeError: confusion_matrix() takes 2 positional arguments but 3 were given时,仔细翻译了一遍英文,发现是缺少一个参数,原来是原代码中缺少了一个给定参数名,而直接给了这个参数的值np.arange(0, self.cfg.num_classes, 1),因此
conf_matrix = confusion_matrix(labels_valid, pred_valid,labels=np.arange(0, self.cfg.num_classes, 1))给矩阵传入三个参数。label主要是这段代码是创建一个从0到self.cfg.num_classes的数组,步长为1,这个数组包含了所有可能的类别。
代码调试trick:当调训练代码时,不知道是否调通,可以先把加载训练的数据和验证数据选择点数少的场景,从而减少调试时间,效率更高。
更高。
将项目放到服务器上训练:
RandLa-Net服务器训练步骤:
1.将预处理数据集、项目文件、自己的环境分别打包压缩好后,分批次传入服务器中,防止中途网络卡顿导致传输失败
2.遇到问题:自己的环境传入服务器后显示:
可能原因是自己的环境没有上传好。选择使用服务器中备用环境。
3.在新环境中下载各种需要的包(根据报错进行)
4.打开项目文件,重新编译C++文件:
(1)/home/dell/workbench/lys/1/utils/cpp_wrappers/cpp_subsampling目录下,执行python setup.py build_ext –inplace 编译出以下文件:

(2)/home/dell/workbench/lys/1/utils/nearest_neighbors目录下,执行python setup.py install --home="."和python setup.py build_ext –inplace 编译出以下文件:

5.根据报错,再做相应调试即可挂起训练。
训练结果:

原pytorch代码设置参数:
train_bs=16,val_bs=30,num_points=4096,max_epoch=300
训练中发现前70轮最高miou为23%,但原pytorch代码给出的测试结果是52.9%,发现差异太大停止训练。
修改参数为原TensorFlow代码设置参数:
train_bs=6,val_ba=20, num_points=4096*11,max_epoch=100
经过调参,按源码参数更改为:
train_bs=6,val_bs=20, num_points=4096*11,max_epoch=100,训练至33轮mIou达到28.3%左右,继续训练至87轮,mIou为29.4%,不再明显增长,选择停止训练。

分析:
相较于之前num_points=4096在76轮左右mIou为19.7%,提升点数后在76轮mIou达到29.1%,可见增加输入点数对mIou有所提升。于是回看原论文,寻找论文中是如何定义输入点数等其他超参数的。

使用Adam优化器,初始学习速率为0.01,每轮降5%,k_n=16,输入点大约10万个点。怀疑是miou计算有问题,回看代码,iou计算没问题。
训练部分:
继上次实验基础上,选择num_points=45056(每次输入网络采样点数),继续采用指数衰减的方式将原每训练一步降5%更改为降1%。
实验发现模型前几轮学习效率有所提高,比调参前达到最优值稍快,但最后天蚕前后变化基本趋于一致。调参后77轮内最优miou=0.286;调参前77轮内最优miou=0.291。
测试部分:
- 关于通过C++代码编译出的文件识别不出来的问题。可检查如下几项是否完成:
(1)cpp_subsampling文件中是否存在.pyd/.so文件,且.cpxx属于你自己的Python版本
(2)

按上图所示检查nearest_neighbors中对应文件夹是否存在.so/.pyd文件(有时编译出的文件在nearest_neighbors文件夹中,要手动移动到python文件夹下)
2.之前使用的pytoch版本测试代码始终调不通,于是重新寻找代码,在github上找到一个部署到robot上的对应代码,该代码只提取每个场景中的第一个值(注释掉原循环测试部分),于是将这部分注释掉,调试了两天后,大概能将程序跑通,于是生成出11-21场景的预测标签。(需要注意的是,在进行标签生成时,原点云文件可能会被代码删除掉,可以在代码中将remove(xyz_file)注释掉或对点云文件进行备份,以防数据丢失)

使用公司/学校账户邮箱注册codalab比赛账户,选择对应窗口进行提交测试。

需要等待一段时间才能上传结果
官方同意后会给你发送邮件,此时出现上传文件窗口
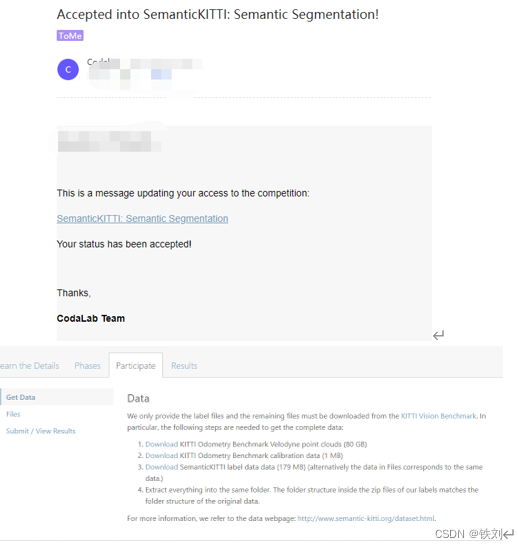

检查需要上传的zip文件是否符合格式要求:
打开semantickitti官方提供的源码validate_submission.py,指定形参:
--zipfile G:/LYSprediction.zip --dataset G:/Data --task segmentation
分别表示压缩文件路径;点云文件路径;所做的任务类型
1.运行过程中报错:“sequences/11\predictions\000000.label
原因是反斜杠的问题即路径错误,要确保路径中使用正斜杠(/)而不是反斜杠(\)
解决方法:将所有的\替换为/。可以在代码中的路径加上‘r’,也可以添加一行代码:
label_files = [file.replace('\\', '/') for file in label_files]即可替换掉所有不符合规范的字符
2.又报错:

初步怀疑是对应的12场景中点云文件有问题,后更换点云文件,仍然报错
于是重新对12场景标签进行预测
▪Semantickitti数据集设置固定类别问题
关于类别和标签映射的相关处理在semantic_kitti.yaml文件中,该文件定义了每个类别对应的序号、颜色信息,标签映射及反映射。(有注释的yaml文件在C:\Users\lys\Desktop\1文件中)
例如,原始数据集中有标签bus,但是semantickitti数据集中,这个类别被映射到了other-vehicel类别中,这是因为bus这个类别很难与其他类别区分,或者在原始数据集中的标注有一些不一致,因此将其与最接近的类别进行合并映射。反向映射则是将新的标签映射回原始数据集中的标签。
除此之外,还有learning_ignore部分,这部分主要定义在学习时是否忽略该类别,因此将不需要的类别设置为True即可。

选择其中比较重要的三类,road、person、car。这几类也是semantickitti数据集检测效果较好的几类。修改完成后,需要对原始数据重新处理以生成新的预处理文件,在传到服务器上训练,需要耗费比较长的时间
(我的数据处理文件在F:\study\Ladir detection\RandLA-Net-pytorch-main),原始数据的存放按照下图布置:

在data_prepare_semantickitti.py中更改原始数据位置及输出文件位置,此时报错:
主要原因是在Python读取文件时遇到的问题:编码错误,原文档用gbk编码,在打开时无法解码,因此将原来的 DATA=yaml.safe_load(open(data_config,’r’))更换为:
即可解决问题。 开始生成新yaml文件对应下的预处理文件.....
开始生成新yaml文件对应下的预处理文件.....
四、数据集:semantic 3D
1.下载代码(源码/pytorch)
2.终端运行requirments.txt文件,命令:pip install -r requirments.txt
3.cd ../utils,运行下载数据集文件,命令:./download_semantic3d.sh(整个下载过程比较慢,耐心等待);注意:在download_semantic3d.sh文件中第一行设置下载文件路径,以便在下载之后寻找数据集![]()
代码会自动生成文件夹,不许其他设置,此过程显示下载文件,后是解压文件,全部解压完成后删除压缩文件即可
4.编译C++文件,即运行(compile_op.sh和compile_wrappers.sh)具体实施和复现semantic_kitti数据集一样
(utils/cpp_wrappers/cpp_subsampling目录下,执行python setup.py build_ext –inplace 编译出以下文件:
utils/nearest_neighbors目录下,执行python setup.py install --home="."和python setup.py build_ext –inplace 编译出以下文件:

5.进行数据预处理
终端运行:Python data_prepare_semantic3d.py(当电脑内内存不足时,数据处理生成的文件会缺少,因此选择放到服务器进行训练)
(当运行TensorFlow版本(源码)时,会报错:
RuntimeError: module compiled against API version Oxe but this version of numpy is 0xd
AttributeError: module 'numpy' has no attribute 'objectl
这个问题是numpy版本不合适,属于低版本。尝试很多更新numpy版本,直接更新numpy版本会更新到1.24.x,但需要更新代码中numpy代码,最终选择numpy==1.23.4版本,问题解决)
后续训练按正常步骤进行即可....
本篇博客是作者很长一段时间之后总结的,当时复现遇到了很多问题,希望这篇文章可以帮助到以后复现模型的友友们,也希望大家看到不对的地方及时提出来,我会更正,也希望大家踊跃在评论区讨论!














 161
161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









