




 本文介绍了人工神经网络如何通过训练学习输入与输出的映射关系,特别是BP神经网络的正向传播和反向传播机制。通过实例展示了如何使用MLPClassifier进行分类和MLPRegressor进行回归,以及如何设置参数进行训练和预测。
本文介绍了人工神经网络如何通过训练学习输入与输出的映射关系,特别是BP神经网络的正向传播和反向传播机制。通过实例展示了如何使用MLPClassifier进行分类和MLPRegressor进行回归,以及如何设置参数进行训练和预测。
人工神经网络无需事先确定输入输出之间映射关系的数学方程,仅通过自身的训练,学习某种规则,在给定输入值时得到最接近期望输出值的结果。
BP神经网络的计算过程由正向计算过程和反向计算过程组成。正向传播过程,输入模式从输入层经隐单元层逐层处理,并转向输出层,每一层神经元的状态只影响下一层神经元的状态。如果在输出层不能得到期望的输出,则转入反向传播,将误差信号沿原来的连接通路返回,通过修改各神经元的权值,使得误差信号最小。
【例题1】

 【代码】
【代码】
'''神经网络编程步骤
(1)寻找对结果产生影响的各种指标,假设有m个
(2)寻找样本n个,构造矩阵m*n,其对应的标准输出是n*1
(3)将上述m*n与n*1分别带入网络中训练
(4)输入新的数据进行仿真'''
#Multi-layer Perceptron classifier optimizes the log-loss function using LBFGS or stochastic gradient descent.
from sklearn.neural_network import MLPClassifier
from numpy import array, r_, ones,zeros
#训练数据
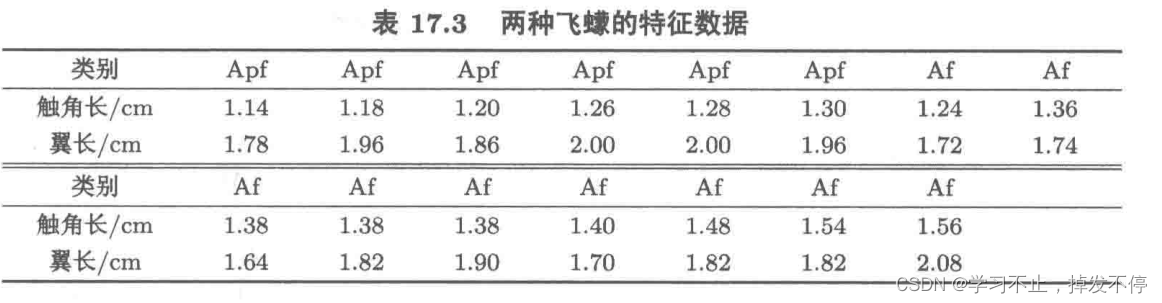
x0=array([[1.14,1.18,1.20,1.26,1.28,1.30,1.24,1.36,1.38,1.38,1.38,1.40,1.48,1.54,1.56],
[1.78,1.96,1.86,2.00,2.00,1.96,1.72,1.74,1.64,1.82,1.90,1.70,1.82,1.82,2.08]]).T
#目标标签
y0=r_[ones(6),zeros(9)]
#‘lbfgs’ is an optimizer in the family of quasi-Newton methods.一般就选择lbfgs
md = MLPClassifier(solver='lbfgs', alpha=1e-5,
hidden_layer_sizes=15)
#使用训练好的 md 模型对 x 中的样本进行预测,并将预测结果存储在 pred 变量中
md.fit(x0, y0);
#待预测数据集
x=array([[1.24, 1.80], [1.28, 1.84], [1.40, 2.04]])
pred=md.predict(x)
#输出训练集上的准确率,即模型在训练数据上表现的好坏
print(md.score(x0,y0))
#输出模型的权重矩阵
print(md.coefs_)
#输出待预测样本点属于各个类别的概率分布
print("属于各类的概率为:",md.predict_proba(x))
print("三个待判样本点的类别为:",pred);hidden_layer_sizes=15:这个参数指定了隐藏层神经元的数量或结构。在这个例子中,设置为15意味着有一个隐藏层,并且该层包含15个神经元。
如果需要多个隐藏层或者每个隐藏层有不同的神经元数量,可以传入一个列表,例如 [15, 10] 表示两个隐藏层,第一个隐藏层有15个神经元,第二个隐藏层有10个神经元。在这里只有一层隐藏层且固定了神经元数量为15。
【结果】

将问题视为系统,飞蠓的数据作为输入,类型作为输出,建立只有一个隐层,神经元数为15的BP神经网络,求得三只待判断蠓虫分别属于Apf、Af、Apf类别。
【例题2】

【代码】
以求解客运量为例:
from sklearn.neural_network import MLPClassifier
from numpy import array, r_
from numpy import array, loadtxt
from pylab import subplot, plot, show, xticks,rc,legend
a=loadtxt("D:\桌面的文件\Pdata17_5.txt")
#客运量训练集
x0=a[:,:3]
#客运量训练标签
y1=a[:,3]
md1=MLPRegressor(solver='lbfgs', alpha=1e-5,hidden_layer_sizes=10,max_iter=500)
md1.fit(x0,y1)
#待测数据
x=array([[73.39,3.9635,0.988],[75.55,4.0975,1.0268]])
pred1=md1.predict(x)
print(pred1)
print(md1.score(x0,y1))
yr=range(1990,2010)
plot(yr,y0,'o')
plot(yr,md1.predict(x0),'-*')
xticks(yr,rotation=55);
legend(("original data","amount of passenger traffic"))
show()【结果】
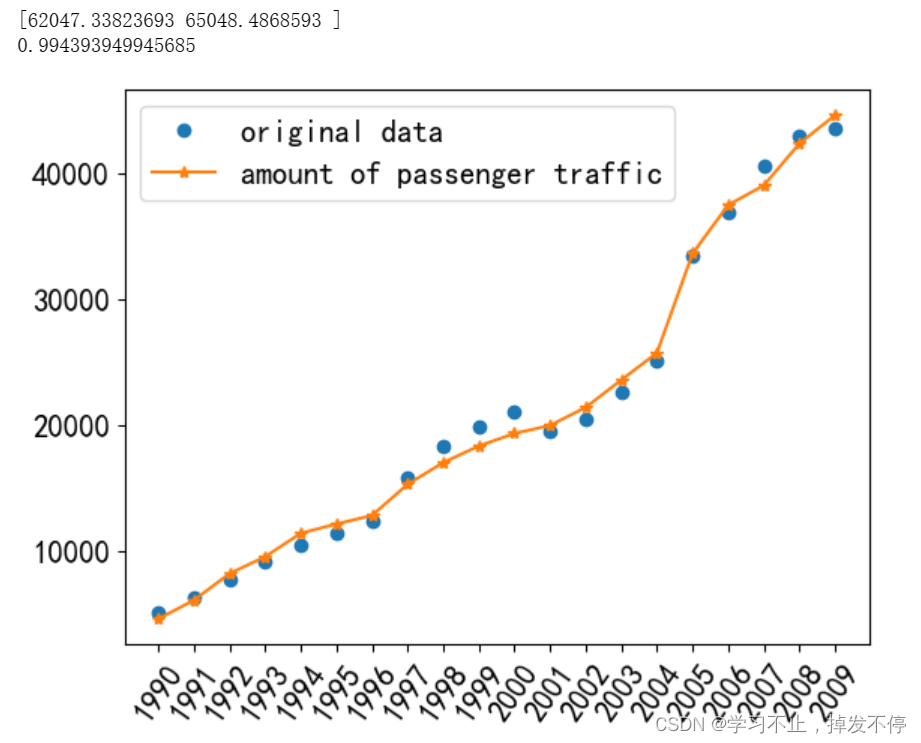
图片显示的是原始数据与网络输出值的对比
【例题3】
【代码】
from sklearn.neural_network import MLPClassifier
from numpy import array, r_
from numpy import array, loadtxt
from pylab import subplot, plot, show, xticks,rc,legend
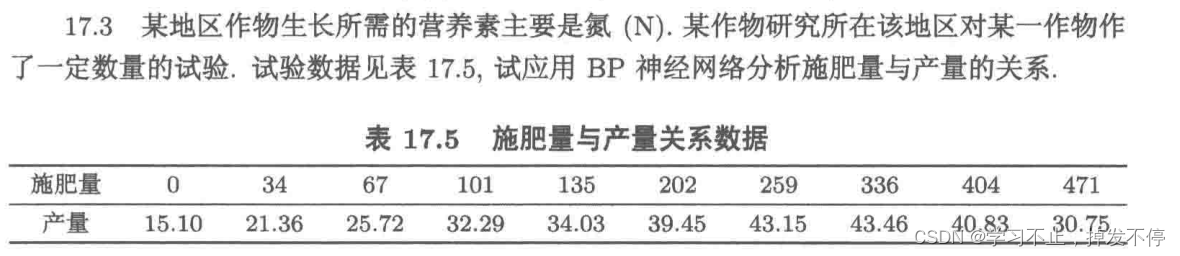
x=array([0,34,67,101,135,202,259,336,404,471]).reshape(-1, 1)
y=array([15.10,21.36,25.72,32.29,34.03,39.45,43.15,43.46,40.83,30.75])
md=MLPRegressor(solver='lbfgs', alpha=1e-5,hidden_layer_sizes=10)
md.fit(x,y)
plot(x,y,'o')
plot(x,md.predict(x),'-*')
legend(("rate of fertilisation","Yield"))
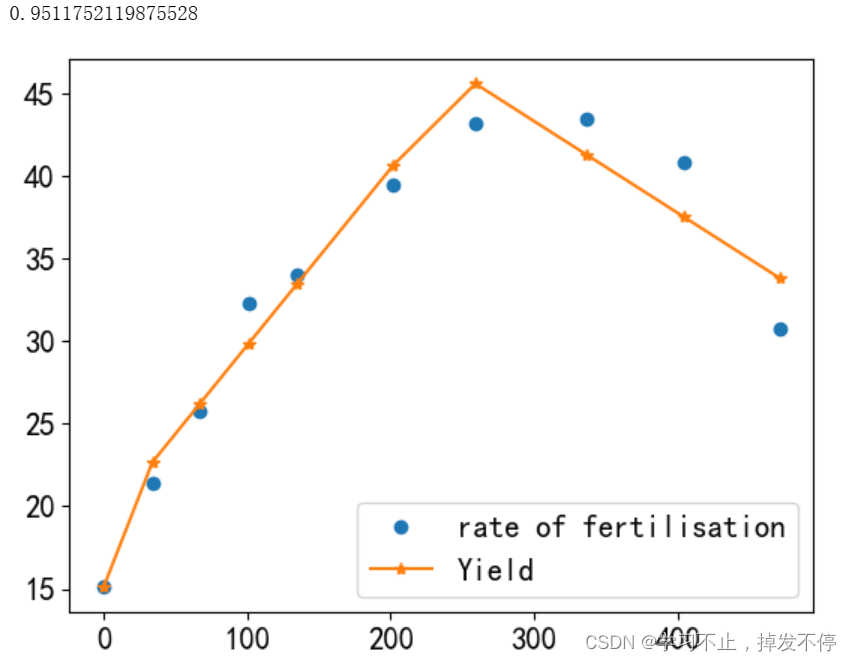
print(md.score(x,y))
show()【结果】
【总结】
MLPRegressor 和 MLPClassifier 都是来自 scikit-learn 库中的多层感知器(Multilayer Perceptron, MLP)模型,它们都属于神经网络家族的一部分。然而,它们在功能和目标上有所区别:
-
MLPRegressor:
- 是一个用于回归任务的神经网络模型。它的目的是预测连续变量的值,即输出是一个实数。
- 在训练过程中,它最小化的是均方误差(Mean Squared Error, MSE)或类似的回归损失函数。
-
MLPClassifier:
- 是一个用于分类任务的神经网络模型。它的目标是预测离散类标签,即输出是一个类别或者说是有限个离散值之一。
- 在训练过程中,它通常使用交叉熵损失函数(对于多类别问题)或二元交叉熵损失函数(对于二分类问题),以及其他可能的分类损失函数。
总结来说,如果你的任务是要预测一个数值结果,比如房价、销售额等连续变量,则应使用 MLPRegressor;而如果你的任务是要对数据进行分类,如判断邮件是否为垃圾邮件、图像识别等,则应使用 MLPClassifier

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









