






转眼9月了,秋招不知道条有没有过半,只是大致投了几家感兴趣的。(当舔狗是没有好下场的!)。
浅浅罗列了些最近秋招被问到的好问题(个人感觉),受限于知识面浅薄,有些问题当时直接干晕了(红温了属于是),但问题是不错的,所以抛砖引玉,看看有没有大佬给出更好的回答呢,如果能帮上大家就更好啦。

Triton (openai 版)
今年确实挺火的,肉眼可见zhihu上多了很多相关的优秀博客,互联网大厂想用它写算子,比cuda迭代周期更短;硬件厂想用它的DSL来推广自己的软件栈和生态。
浅浅推荐一些:
- 杨军老师的 谈谈对OpenAI Triton的一些理解,帮助大家建立一个宏观印象
- 董鑫大佬的 如何入门 OpenAI Triton 编程?,帮助了解更多关于语法上的信息
- BobHuang大佬的 浅析 Triton 执行流程,帮助初学者大致明白一段 python 程序如何进入 triton pipeline,然后跑起来。
挖坑:有一些基础的认识后,大家就可以在 Triton 中各取所需了。作为一个 MLIR Programer,我还希望了解每个 transform pass 和 每一步 conversion 是怎么做的、作用等,抽空好好读读源码。
1. 你是怎么做triton kernel优化的
不管啥 kernel,到我手上都是经过“两步走”来优化:
浅层优化:通过替换算子、(用atomic op)合并kernel、拆循环、调config等方式实现初步优化。
深层优化:分析下降所得IR,使用perf工具,对照算子库实现等方式,优化kernel的下降行为。

大部分情况下,“第一步”走完性能就接近算子库了,还是大哥们后续codegen的pass太顶级了,我成为了无情的config添加器。
关于这部分更详细的可以看看鄙人的记录,这里详细一些rtfff:[Triton] Kernel Optim
当“第一步”走完性能还是和算子库有距离,那就继续“第二步”,上perf!看ir!看看访存是否连续,得到的汇编是否符合预期等。(自己总有看不懂的时候,直接叫大哥)
分解出优化点,在ir下降过程加点美味的pattern,大部分情况还是得看看算子库的大哥们是咋写的kernel,然后(抄一下)启发一下编译器的 lowering过程。如果还是打不过怎么办,这时候就真得看看IO这些是否打得比较足了,或者换过服务器多跑几次(别试,一般没用)。
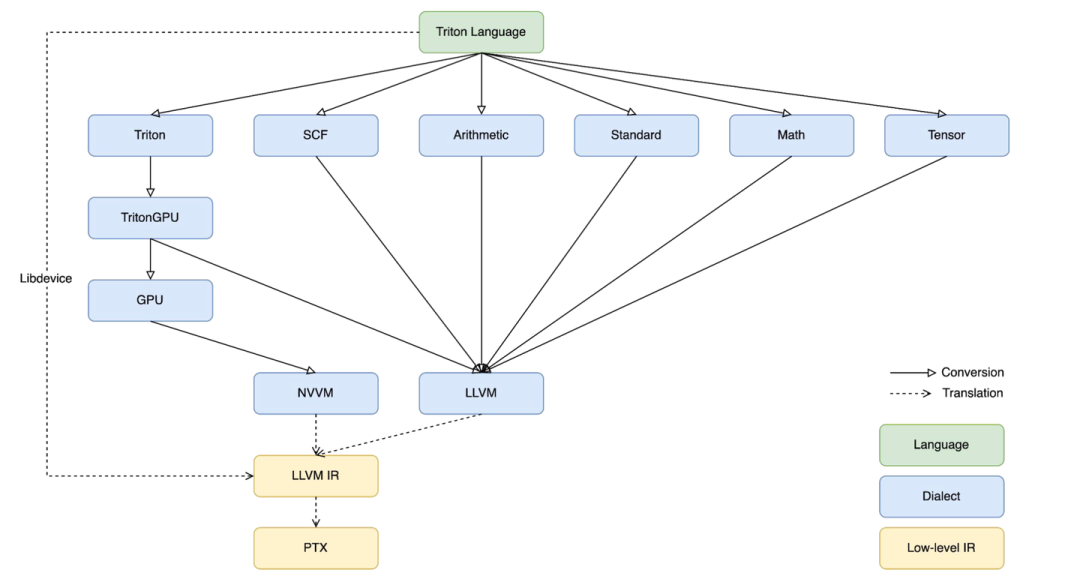
2.triton的下降流程,讲讲你对triton中layout的理解:
官方:triton-lang -> triton ir -> triton gpu dialect ->llvmir -> ptx
其中 llvm ir 更标准地说法应该是 nvvm ir,相比官方的 llvm ir要额外扩展了一些 hardware intrinsic 和 conversion。想了解可以看llvm project中的 llvm/include/llvm/IR/IntrinsicsNVVM.td 和 llvm/lib/Target/NVPTX/。
ptx后序会根据硬件信息转为sass。
我忘了图源哪里了
triton 中的 layout 在 triton gpu dialect 才第一次出现,作为attr辅助op的conversion和transform,主要分为两种:distributed layout 和 shared layout。
distributed layout:描述tensor应该如何被thread访问,又分为 block layout、mma layout 和 dotoperand layout
block layout:使用 AxisInfoAnalysis 获得 load 和 store 等指针操作 op 具体的操作 tensor(shape、layout信息等)以及连续性信息,这个信息后序会用来在 memory-coalesce (访存合并)。
mma layout 和 dotoperand layout:我理解都是描述了特定 op 的 operand 的数据布局,以指导后序 op 的 lowering。
shared layout:shared layout 描述了 share mem 中可能被同时访问的处于同一个bank的数据。share mem中的每个bank会会单独相应内存访问请求,所以同一时间内,若多个 thread 访问的数据处于同一个 bank 就会产出 bank conflict ,导致吞吐异常。所以根据 shared layout 进行 layout-swizzling,调整相关的数据布局。
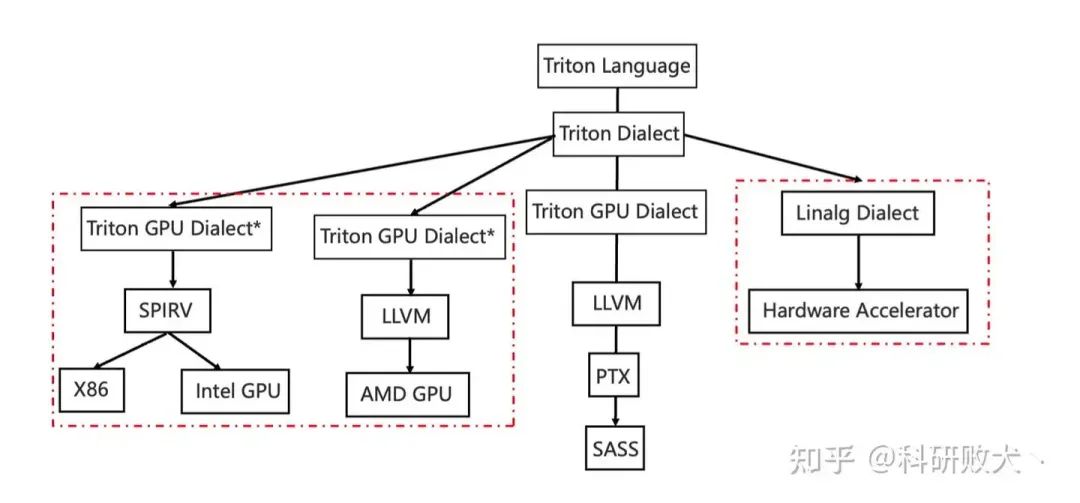
关注开源社区的朋友们可能了解到前段时间寒武纪开源了 triton-linalg 这为其他 DSA(ASIC) 接入 triton 提供了一条不错的道路。
我了解到这条路:triton-lang -> triton ir -> linalg dialect -> hardware dialect -> llvm ir -> … ->hardware assembly
和硬件无关的dialect比官方的更多,优化可以在 ttir、linalg-on-tensor,linalg-on-memref,hardware dialect 做,arch 和 non-arch 的抽象隔离地比较好。但路铺得长工程量也就大。
图源见水印
3.支持triton的好处,和官网的triton有何不同
支持triton,一是可以用户也方便自己定义kernel,迁移成本低。二是开发人员也可以写算子库或者特定的加速库,现在很多框架中都带上了triton的kernel实现。
和官方的不同在于,(个人理解)从ttir开始分叉开,用不上官方的ttgir往后的优化pass,本质上更贴近SPMD的编程范式,某些原语有自己的映射。在优化ir上,某些也是根据硬件特性来的。
MLIR
1. mlir codegen 这条路更适合处理哪类任务 ?
当时比较蒙,后面面试官大哥说“更适合访存密集型任务”,后来想来,或许是codegen这条路更好调整数据的memory层次,比较好优化不同memory-space之间的data flow?(不知道有没有其他大哥解答下)
- 对 SIMD 硬件的优化 和 SIMT 硬件的优化(or codegen) 有什么异同
当时只想到了SIMD希望访存更加连续,SIMT希望吞吐更大。今天回顾了一下 棍哥的 文章,
有了琦琦的棍子:漫谈高性能计算与性能优化:访存
突然感觉能串起来一些了。
SIMD
核心优化 latency,越快完成越好 -> 保证访存连续性,用连续指令(非strided,非scalar)
其他常见优化:
tile(+fuse) 到不同 core 上并行执行,core之间利用smem交换数据 -> 减少 data move
在core内循环展开(最内维)做软流水;core之间async -> 减少访存 latency
SIMT
核心优化 throughtput ,吞吐越大越好 -> 用好 DMA 和 TMA,打满 tensorcore其他常见优化:
离散访存优化 smem 中 memory-coalesce、layout-swizzling -> 减少访存 latency
异步调度 warp,通过warp切换来掩盖访存延迟(其实相当于软流水) -> 减少访存 latency
关于 memory-coalesce、layout-swizzling 再补充一点个人的看法,如有不对,烦请指正~
memory-coalesce:warp中的threads在访问地址时都会发送内存访问请求到LSU,如果这些请求是想访问一片连续的空间,那么这些请求会被合并成一个或者少数几个。
layout-swizzling:smem中的数据是以bank组织的,每个bank可以独立地处理一个内存访问请求,如果多个请求指向同一个bank,就会产生 bank-conflict。该pass就会调整数据的排布来避免 bank-conflit,至于怎么调整,是由硬件shuffle还是软件更改地址映射关系,我真不知道,求大佬们解答。
3. 算子融合先tile再fuse还是先fuse再tile
做算子融合的时候,从写算子的角度上,惯性是想先确定能够fuse到一起的op,再把这个序列一起tile。fuse起来的形式一般是固定的pattern或者像xla那类,或者是贪心的。这样tile时就能获得一个片上一定能放得下且性能不错的 tile_size。
我熟悉的一条路是先tile再fuse,找到一个锚点op,确定好tile策略后再将producer和consumer给贪心的fuse进去,后续hardware dialect再做 mlu+add -> fma 这样的融合行为。今天听大哥讲,可以从 tvm ansor 的那种行为去理解,应用模版后就只需要去寻找其中的 tile_size 就好了,贪心fuse不进去就算了,但后续这条路应该还是会优化的,毕竟我想基于这相关的做做毕设(在大哥的花上雕shit)。
4. mlir codegen 这条路针对推理和训练有什么不同么
好些次听到这个问题了,每次我都是回答会有一些不一样吧,毕竟推理优化和训练优化是有区别的,训练需要关心梯度传播的过程,导致算子融合的行为不能激进,且要保存很多中间结果,而且推理比较好专项根据场景优化。
面试完跟leader聊了下,果然是我too yound too simple了,他说对于codegen这条路并不关心上层是在训练还是推理,来一个task(或者说一段计算图)正常lower + codegen就好了。
5.软流水展开的循环一般是哪一级
软流水是大哥们做的,pass太大了,还没细看,但我直接蒙是最内层展开,确实是这样,但是所以然呢?
大哥简单说了下,最内层展开后再排开,出现的依赖关系好分析一些,排成不同的pipeline stage就好了。有时候我们比算子库的性能好,是因为他们是用高级语言写出的手动排流水,而我们排流水时操作的都是很贴近硬件汇编的dialect了,所以更精细,理论的上限是要比算子库好。
那为什么现在挺多还是差点呢,算子库还是太懂硬件的脾气了!!
6.mlir中tensor和memref抽象设计理念和异同
这个问题并不是我被问到的,而是 睿博哥提及的,感谢!
这个问题我在写代码时也思考过一些,现在总结下来,以我的理解大体如下:
mlir 的框架中主要有两种数据抽象, tensor 和 memref(aka. buffer),这两者分别对应着 ML 编译器中的高层抽象(torch.tensor)和传统低级编译器的低层抽象 memory buffer。tensor 通过 bufferization 转为 memref 表示,一些 dialect 中 operand 可以是 tensor 也可以是 memref,例如 linalg(tensor + linalg-on-tensor --bufferization–> memref + linalg-on-memref)。
相同点:都可以用来表示算子的operand
不同点:tensor 语义上只能被定值一次,即声明的那一次,和 SSA 的定义有点相似。(SSA IR 要求每个变量只能有一次值域,且使用前需要先定义)
``我们从下面的 ir 的 a、b、c 三个点去获得 `extract` 的值,都是相同的,都是源自于 `%1 = tensor.empty` 创建时获得的随机值。 %1 = tensor.empty %extract = tensor.extract %1 // a 点 %fill = linalg.fill outs(%1) %extract = tensor.extract %1 // b 点 %map = linalg.map outs(%1) %extract = tensor.extract %1 // c 点``
memref 是可变的,可以被多次 def,并且许多 memref 是可能存在 alias 关系,所以在 data flow analysis 中需要考虑 alias analysis。
tensor 上的 rewrite 更简单,因为 tensor 操作都没有 side-effect,而 memref 操作大概率有。
memref 中 ir 的顺序很重要,移动 ir 很可能导致程序语义改变,所以 clone 行为要注意。而 tensor 中的 clone 行为一般没问题。简而言之ir-on-tensor 中的 clone 行为即使改变了 ir 的次序,一般也不会影响程序语意。而 ir-on-memref就不行了,memref 上的 ir 要避免改变 ir 次序,否则可能发生下面的情况。
`若把 %load clone 到 它的 user 前(scf.forall) 内,这样程序的语意就被改变了,因为中间有对 %alloc 的 def %load = memref.load %alloc def %alloc scf.forall use %load`
7. linalg dialect的设计理念
听到这个问题的我,流下了平时不好好看文档的泪水 。
按我的理解,linalg包含 linalg-on-tensor 和 linalg-on-memref,做了一个很强的中间胶水层,向上承接程序的计算描述,向下准备下降到 hardware dialect,更贴近目标硬件。后面看了看 linalg 的官方文档
上面赫然写着: Linalg is designed to solve the High-level Hierarchical Optimization
Linalg IR 也提供了许多好用的 transfroms:
- Progressive Buffer Allocation
- Parametric Tiling
- Promotion to Temporary Buffer in Fast Memory(摆数行为)
- Tiled Producer-Consumer Fusion with Parametric Tile-And-Fuse
- Map to Parallel and Reduction Loops and Hardware(方便区分tile parallel 和 reduction)
简而言之,Linalg Dialect 是很重要的一个层级,在这之前的 dialect 更多得是对计算的描述,表达原有的 ML 程序。而从 Linalg 开始,就会经过一系列变换(tile, fuse, promotion, bufferize)贴近目标硬件。
8. mlir中一些概念
Smallvector 和 std::vector 的异同
SmallVector会现在栈上分配一定的预留空间,当压入的元素所占空间超过其预留空间时就会退化到和std::vector差不多的行为(在堆上分配空间)。这样避免了小规模数据空间的申请和释放开销,而且std::vector在空间增长时采用的是倍增策略。
栈上的空间是由编译器自动分配释放,一般存放函数参数和局部变量啥的。
程序员申请的空间一般在堆上,需要手动申请和释放。
StringRef 和 std::string 的异同
StringRef是个轻量化的字符串引用类,指向现有的字符串数据,而不管理这片数据的地址(没有这片数据的所有权)。想要存储一个 StringRef 往往是不安全的。(因为data的真实memory可能随时被修改)
llvm/include/llvm/ADT/StringRef.h 中写到:This class does not own the string data。
const char *Data = nullptr; // 不能改变指针指向区域的值,但是可以改变指针指向的区域
const char * _,_指针可以改,指针指向的值不能改
char * const,指针不能改,指针指向的值可以改
std::string 完全管理自己的内存。
SmallVector可以使用什么替换(ArrayRef、SmallVectorImpl 的使用场景)ArrayRef 表示对一个array的const引用,和 StringRef 一样,也没有真实数据的所有权。当传入函数的对象(Smallvector)不需要被修改时,用ArrayRef就可以避免不必要的拷贝。
const SmallVector & <–> ArrayRef (better)
SmallVectorImpl 在构造时不需要“预留元素个数”这个参数,所以函数可能传入的SmallVector实例大小不一时,常用SmallVectorImpl,这样避免依赖或硬编码任何具体的容量信息,减少参数的拷贝。
如果数据很多,且每次增长(push进)的量很大,或许也可以采用std::vector,这样能减少调整空间的次数。
8. 写一个图的****拓扑排序
代码题乱入!这道题因为当时太紧张,都忘了图节点的关系应该用二维数组或者二维链表来定义了,所以就没写出来。面试官说其实是想考如何分析def-use链。这不巧了,我刚好写过很依赖def-use分析的pass。
其实greedily fuse produer and consumer 的行为也是在对op间的关系进行一个拓扑排序,最终获得的 fuse序列应该保证原来的ir执行顺序的。我们以一个简单的序列为例,a -> b 表示 a 是 b 的 producer,b 是 a 的consumer。使用一个 set 类型的数据结构作为 visited 记录,选择 vector 类型的数据结构来记录结果的拓扑序。
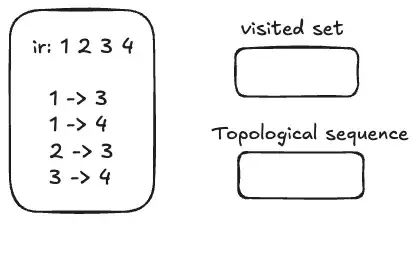
(1)先找到当前无依赖(无前驱/无produer)的节点作为起点,这里选1,作为当前的candidantOp
(2)对于candidantOp,首先看 visited 中是否已经处理过 visited.insert(candidantOp).second,如果没有处理过,如果visited中没有则进入下一步,反正当前对该
(3)遍历candidantOp的producer,若存在 producer ,则递归先把 producer 当作新的 candidantOp 去处理;若没有 producer 则把该 candidantOp 压入 topological seq vector。
(4)然后遍历candidantOp的consumer,若consumer存在 ,则继续把 consumer 当作新的 candidantOp 去处理。
直到所有op都处理完,(2)(3)(4)步会多次处理。
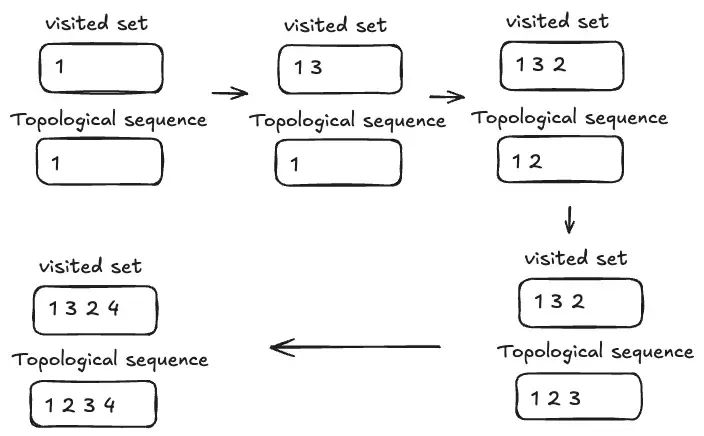
结合上面的例子和算法,那么我们访问的顺序是:
遇见1,1没访问过,1插入visited;1无produer,1入topological seq vector。访问1的consumer,首先是3。3没访问过,3插入visited;3的producer还没处理,则当前去处理2。2没有被访问过,则开始处理2。2无producer,2入topological seq vector。访问2的consumer,2的consumer只有3,且3在visited中,2的处理结束。返回3的处理,现在3的producer已在topological seq vector中,3无其他依赖,将3加入topological seq vector。访问3的consumer,4没访问过,4插入visited。4的producer是1和3,1和3都已经被visited,所以将4加入topological seq vector。4没有consumer。继续访问1的consumer,当前是4,但是4已经被visited,所以结束。最终获得序列 1->2->3->4。
LLM
1.请简单讲讲你了解的推理中常见的优化技术
KV Cache:以空间换时间,将单点attention的计算从 GEMM 降级到 GEMV。
MQA、GQA:减少kv cache的使用(Q之间共享同一组kv cache)。还有一个MLA,避免了QK的点积计算。
window-attention:kv cache只保留一个 window 的大小。这种kv cache使用前需要旋转一下。
flash-attention:一步完成attention的计算,适合计算瓶颈的任务,一般在 prefill的时候用。prefill过程需要生成 Prompt token 时的 KV Cache + 生成首个 token,Q K V 序列长度相同,一般是 计算密集型(计算瓶颈)。
page-attention:用页表的形式管理kv cache,适合访存瓶颈的任务,一般在 decode 时用。decode过程需要逐渐生成token,Q 一般远小于 K 和 V,是 访存密集型(访存瓶颈),每次生成 token 都要去读已经存储的 KV Cache
连续批处理:动态调整批次的触发时机和大小,将请求拼接起来,实现 低延迟与高吞吐量的平衡。属于动态批次调整,适合在线推理,满足实时性和高并发。
量化:牺牲少量精度换执行速度
就只知道这些常见的了,更高级的还是没多关注下,之前看到Mamba,最近看到了一个 linear-attention, 但都还没来得及看看是怎么回事。
2.attention相关问题
QK计算相似度的点积为什么不除以模长:向量长度也是向量之间相似度的重要衡量物,如果处理模长了就变成余弦相似度了,越大的点积能在后序的softmax计算越突出(代表越大的权重)。并且在MHA和self-attention中Q和K都是变换来的,保留模长的信息保证了在训练中可以改变变换Q和K的变换参数。
那为什么又需要除以 作为缩放因子,既保证了点积的值不会太大(极端值会影响softmax后的结果分布),也保证了softmax中有一定区分度。
为什么选用softmax作为激活函数:softmax后结果为在(0, 1),且加起来为1,是天然的概率分布,直接反应了每个Key对Query的作用。虽然其他激活函数通过一定变换也可能完成这样的行为,但是也会增加计算量,并且softmax反向计算简单。
为什么需要mask:decode的过程是逐token生成,所以当要生成token(i+1)时,只在乎前i个token,而关心其后的token,所以通过mask去避免后序元素的引入。
Arch
1.讲讲gpu的SM
每个 SM 都有独立的 smem, constant cache, register mem,SM之间共享 L2 Cache 和 gdram。一个SM包含多个SP(即cuda core)和 tensor core。
一个SM 可以处理多个thread block (或者说CTA),当其中有block 的所有thread 都处理完后,他就会再去找其他还没处理的block 来处理。
自从Volta架构后,smem和L1 Cache就合成一块memory unit了,程序员可以根据任务场景自己配置对应的大小。
例如,在放存密集且连续的场景下(例如matmul),smem大一些性能更好。但是 smem 和 L1 Cache的总大小是一定的。
L1 Cache保留的原因:L1在某些场景下也是必要的,例如以 sparse computing 中;smem是很快会用到的,L1是从dram上取来的,cache是防止低速访存必要的,smem能防止污染cache。
关于smem和L1 cache合并起来我一直稀里糊涂的,在想程序猿咋能将cache和smem统一编程呢,cache咋看得到的。稀里糊涂下,私下请教了下问 @Antinomi,清晰了许多。
对arch的知识还是太薄弱了!
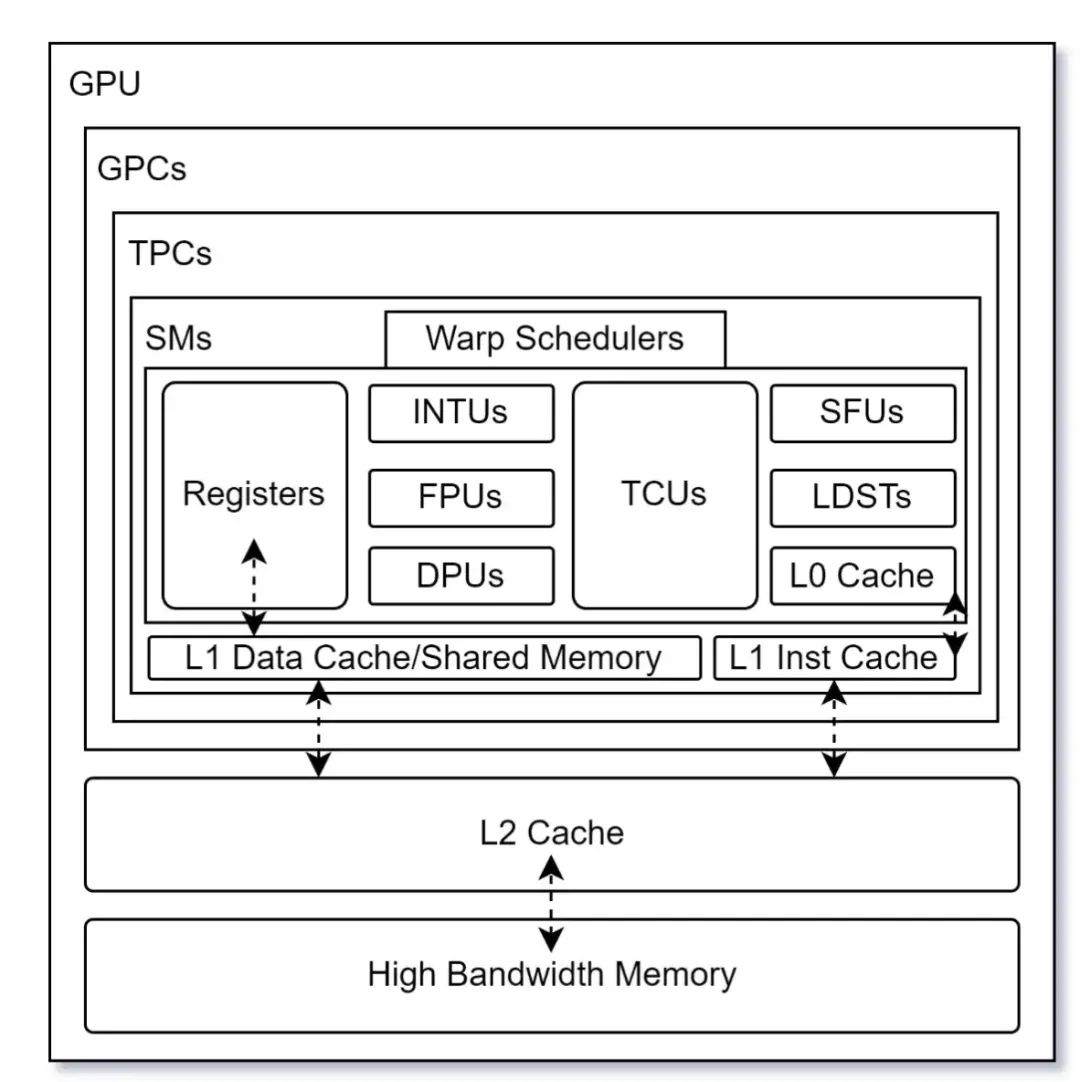
网络图图
C++
还没人问我八股其实。。。但问到我也大概率不咋记得,平时用的多的就继承、虚函数、智能指针、constexpr、override等一些概念,其他用得少记忆模糊.jpg
希望接下来的面试官轻点敲打
Coding
考一次被代码手撕一次,肥肠残忍,这就是我这个饭桶的短板了。每次想到要刷题世界就美好起来了,读源码都十分有意思。
我甚至把刷题的时间用来好好整理了一下以前的博客,弄了个个人主页,嘿嘿。
希望接下来的面试官轻点敲打
总结
虽然到现在还没拿下健身房的健身教练offer和大厂食堂部门的offer很让人痛苦,但是知道不去实习拿到梦厂的offer概率比较难更让舔狗落泪。继续跟着大哥们学习吧,祝大家万事胜意~















 1118
1118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









