






文章目录
提示:以下是本篇文章正文内容,下面案例可供参考
一、案例引入
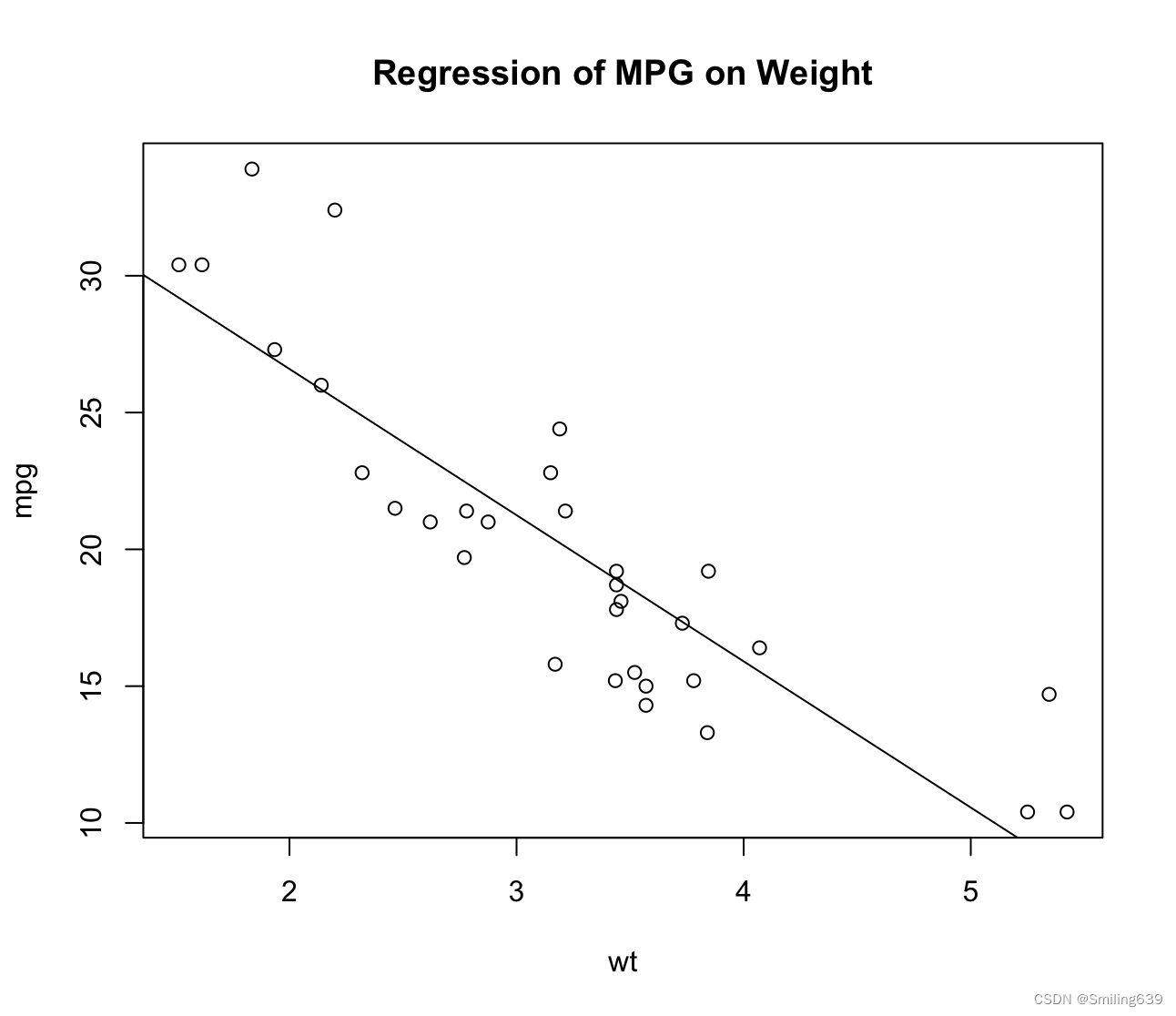
1.根据散点绘制线性回归图
attach(mtcars)
plot(wt, mpg)
abline(lm(mpg~wt))
title("Regression of MPG on Weight")
detach(mtcars)
- attach(mtcars): 将数据框 mtcars 附加到搜索路径中。
- plot(wt, mpg): 绘制散点图,其中 x 轴是汽车重量(wt),y 轴是每加仑英里数(mpg),即汽车的燃油效率。
- abline(lm(mpg~wt)): 添加一个线性回归线到散点图上。lm(mpg~wt) 计算了 mpg 对 wt 的线性回归模型,abline() 函数用于在图上绘制回归线。
- title(“Regression of MPG on Weight”): 添加标题 “Regression of MPG on Weight” 到图形上,用于描述图中所显示的内容。
- detach(mtcars): 这一行代码将数据框 mtcars 从搜索路径中分离出来,这意味着它不再被当前环境所引用。这是一种良好的做法,以防止数据框的变量名称与其他对象发生冲突。
2.对上述图形的改进
attach(mtcars)
plot(wt, mpg, pch=20, col=4, xlab="Weight", ylab="MPG")
abline(lm(mpg~wt), lty=1, col=2)
title("Regression of MPG on Weight")
legend("topright", c("Real Points","Fitting"), pch=c(20,NA),
lty=c(NA,1), col=c(4,2))
detach(mtcars)
这段代码相比上面的代码进行了如下改进:
- plot() 函数调用中增加了参数 pch、col、xlab 和 ylab。这些参数分别用于指定绘制的点的形状、颜色以及 x 轴和 y 轴的标签。这使得图形更具可读性和美观性。
- abline() 函数调用中增加了参数 lty 和 col,用于指定回归线的线型和颜色。这使得回归线更易于辨认。
- legend() 函数的调用中增加了参数 pch、lty 和 col,用于在图形中添加图例。这使得图形更具说明性,使得读者可以理解图中不同元素的含义。
- 给图形添加了 x 轴和 y 轴的标签,以及标题,增强了图形的可读性。

二、保存图形
1.菜单中选择
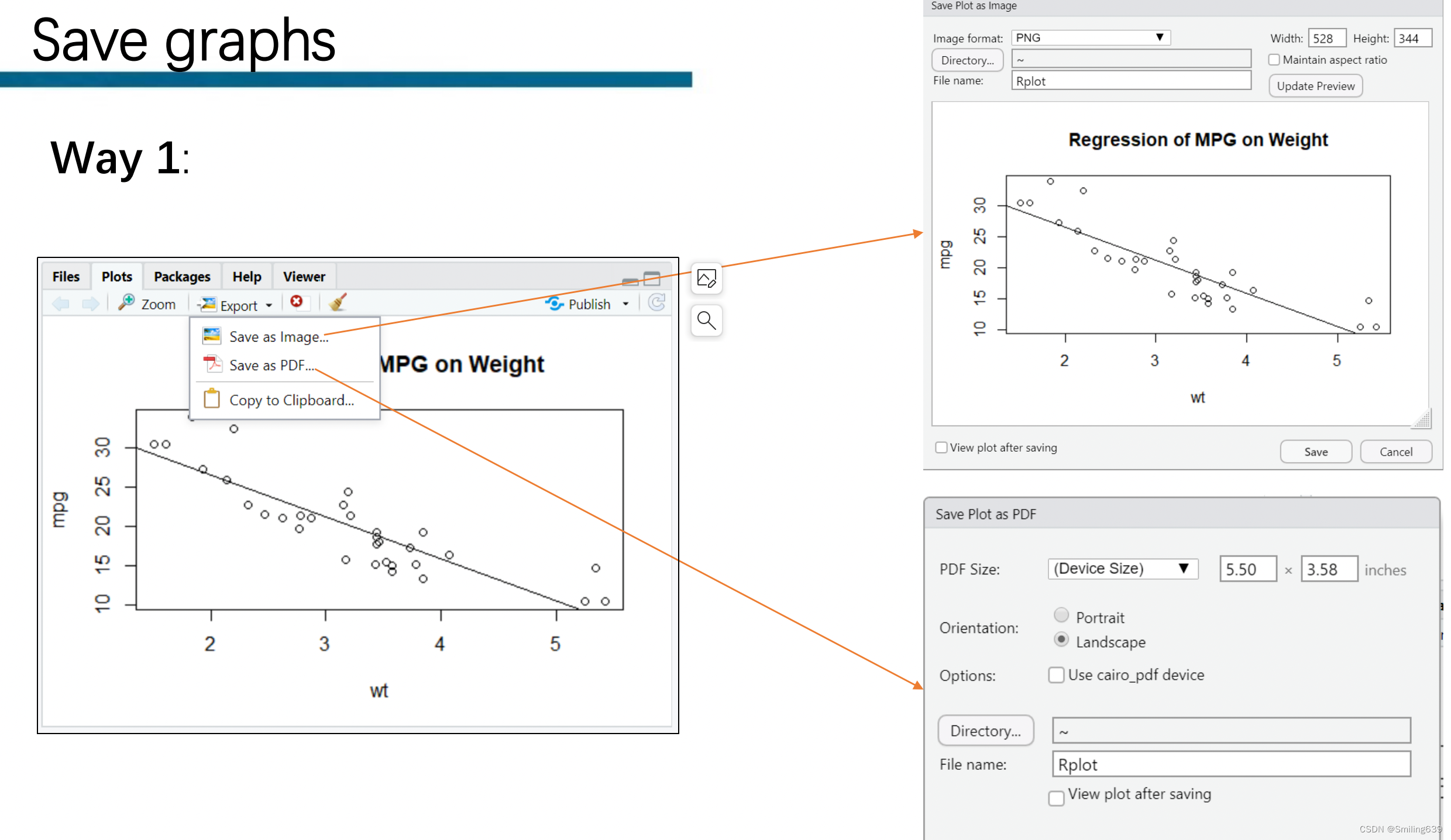
可以定义图片的格式、名称、尺寸和保存路径。
2.使用保存函数
pdf("mygraph.pdf")
attach(mtcars)
plot(wt, mpg)
abline(lm(mpg~wt))
title("Regression of MPG on Weight")
detach(mtcars)
dev.off()
pdf(“mygraph.pdf”): 这一行代码指定了要生成的 PDF 文件的名称为 “mygraph.pdf”,并将之后的图形输出保存到这个文件中。这意味着所有绘图命令生成的图形将被保存到这个 PDF 文件中,而不是直接显示在屏幕上。
dev.off(): 这一行代码关闭了 PDF 设备,结束了图形的绘制。这之后的绘图命令将不再输出到 “mygraph.pdf” 文件中。
三、图形参数
1.绘图函数直接指定
plot(x, y, type="b", lty=2, pch=17)
这个例子是绘制散点图,其中 x 是 x 轴上的数据,y 是 y 轴上的数据。在这个示例中,我们通过提供选项名=值对来设置了图形参数:
type=“b”:指定绘图类型为 “b”,即同时绘制线条和点。
lty=2:指定线条的类型为 2,即虚线。
pch=17:指定点的形状为 17,即实心菱形。
2.par()函数
par() 函数是 R 语言中用于设置图形参数的函数。它可以控制绘图的各种方面,如图形的大小、颜色、线型、点型等等。
opar <- par(no.readonly=TRUE)
par(lty=2, pch=17)
plot(x, y, type="b")
par(opar)
- opar <- par(no.readonly=TRUE): 首先保存当前的图形参数设置到一个对象 opar 中。par(no.readonly=TRUE) 指定了 par() 函数不返回只读的参数列表,这样我们就可以修改这些参数。
- par(lty=2, pch=17): 这个例子设置了新的图形参数。具体地,lty=2 指定了线条的类型为虚线,pch=17 指定了点的形状为实心菱形。
- plot(x, y, type=“b”): 在这个设置下,绘制了一个散点图,其中的线条和点的类型由之前的 par() 设置决定。
- par(opar): 最后,通过 par(opar) 将图形参数恢复为之前保存的状态。这个操作可以在绘图之后恢复到之前的默认参数设置,以避免影响其他绘图。
散点符号类型
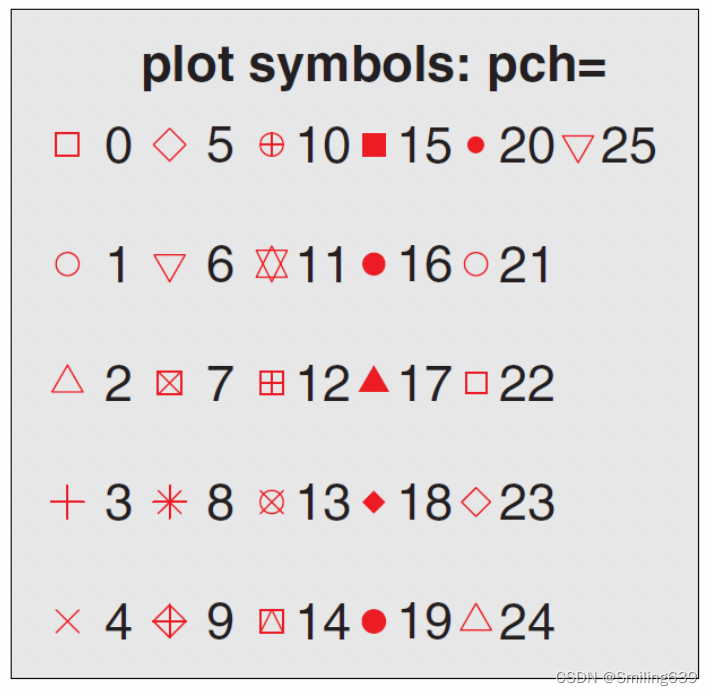
对21~25号可以修改其边框和填充颜色。
符号大小用cex设置
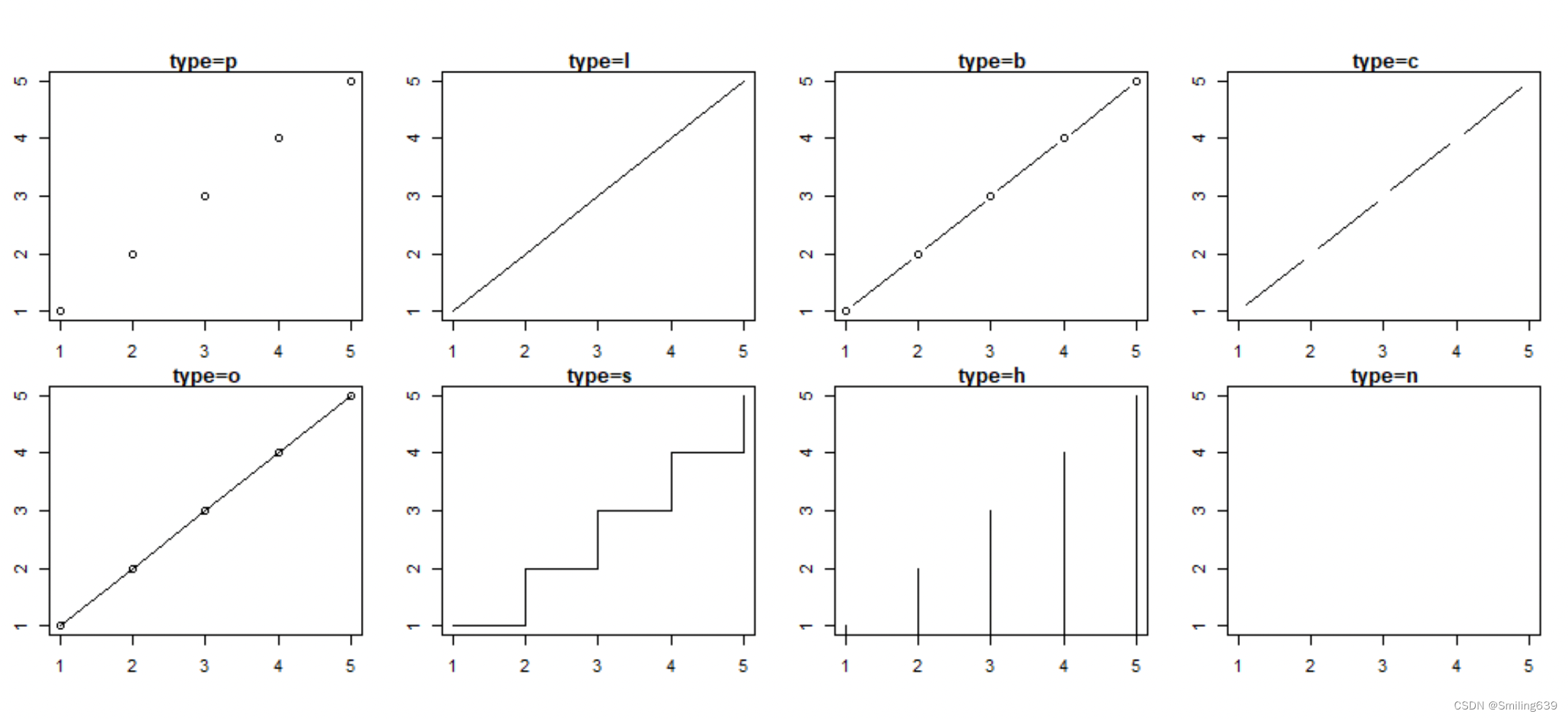
线条类型

点线结合:用type选择
“p”:绘制数据点,不连接它们。
“l”:绘制数据点,并用线段连接它们。
“b”:绘制数据点,并用线段连接它们,同时在每个数据点处绘制一个大点。
“o”:绘制数据点,并用线段连接它们,同时在每个数据点处绘制一个小点。
“h”:绘制一条水平线段,与 y 值有关,数据点位于线段的顶部。
“s”:绘制一条阶梯线,与 x 轴平行,垂直于 y 轴。
3.颜色设置

opar <- par(no.readonly=TRUE)
par(mfrow = c(4,1), mar=c(2,1,1.3,1))
x <- 1:5
y <- 1:5
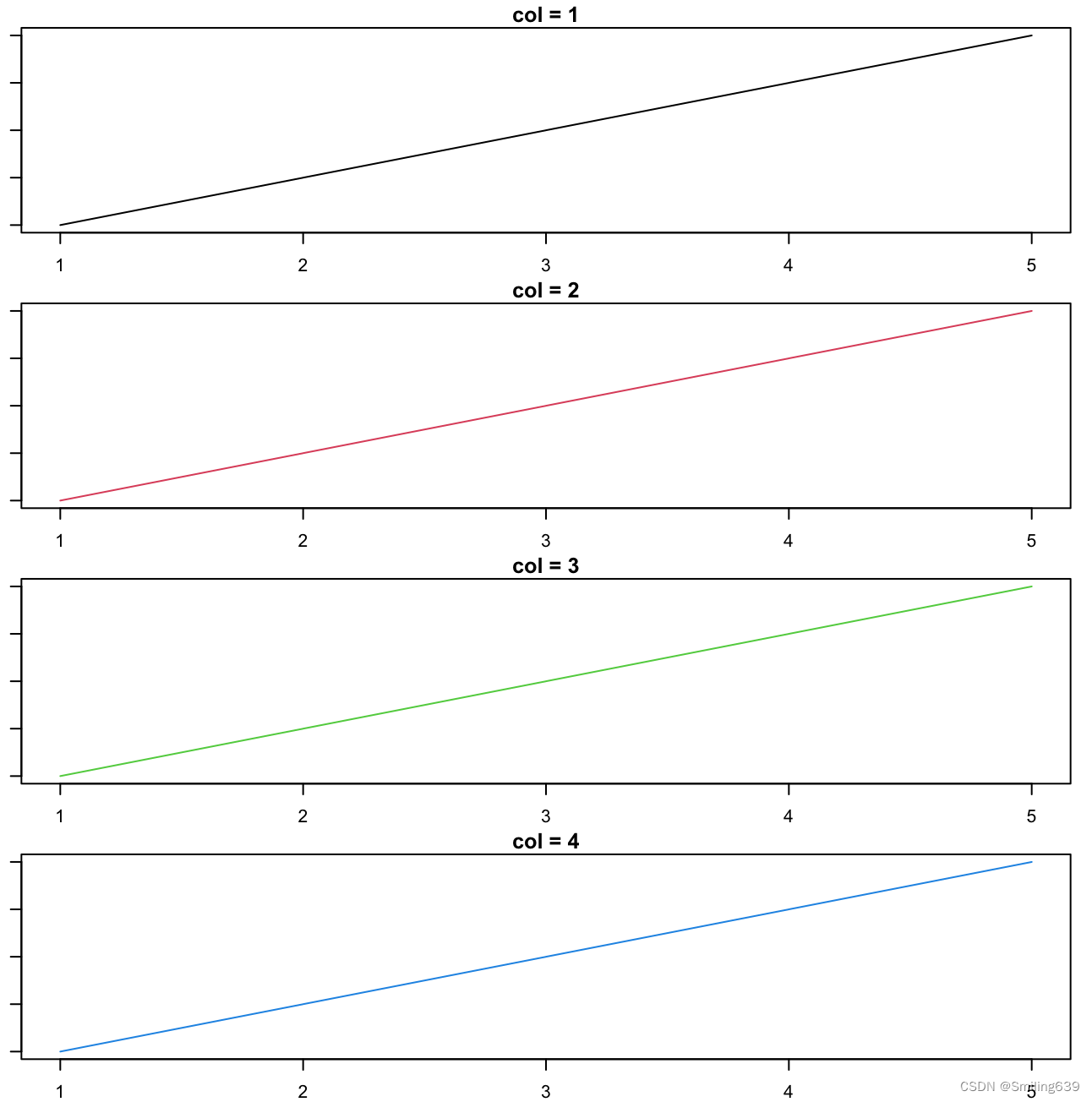
plot(x, y, col = 1, main = "col = 1", type = "l")
plot(x, y, col = 2, main = "col = 2", type = "l")
plot(x, y, col = 3, main = "col = 3", type = "l")
plot(x, y, col = 4, main = "col = 4", type = "l")
par(opar)
- par(mfrow = c(4,1), mar=c(2,1,1.3,1)): 这一行代码设置了图形参数,将图形分割为 4 行 1 列的布局,即绘制四个子图。mfrow 参数指定了图形行列布局(4行1列),mar 参数指定了边距的大小,分别为下、左、上、右。
- 下面四行plot代码分别绘制了四个子图,每个子图中的折线的颜色依次为 1、2、3 和 4(分别代表黑、红、绿、蓝)。
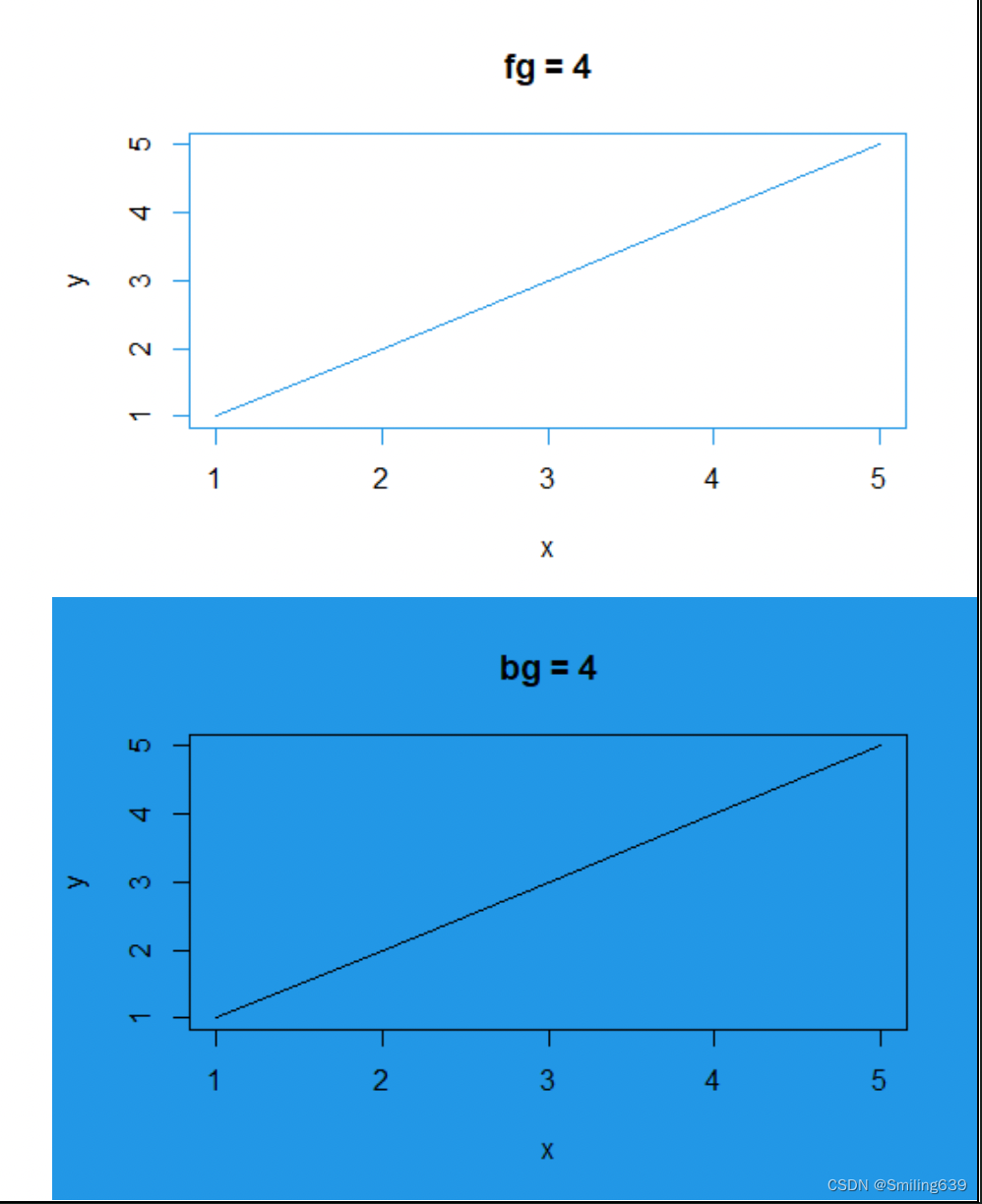
fg和bg的区别:
fg为前景色,bg为背景色,如下图所示:
4.文本设置
文本大小设置:cex

例:修改标签大小
opar <- par(no.readonly=TRUE)
par(mfrow = c(1,2))
x <- 1:5
y <- 1:5
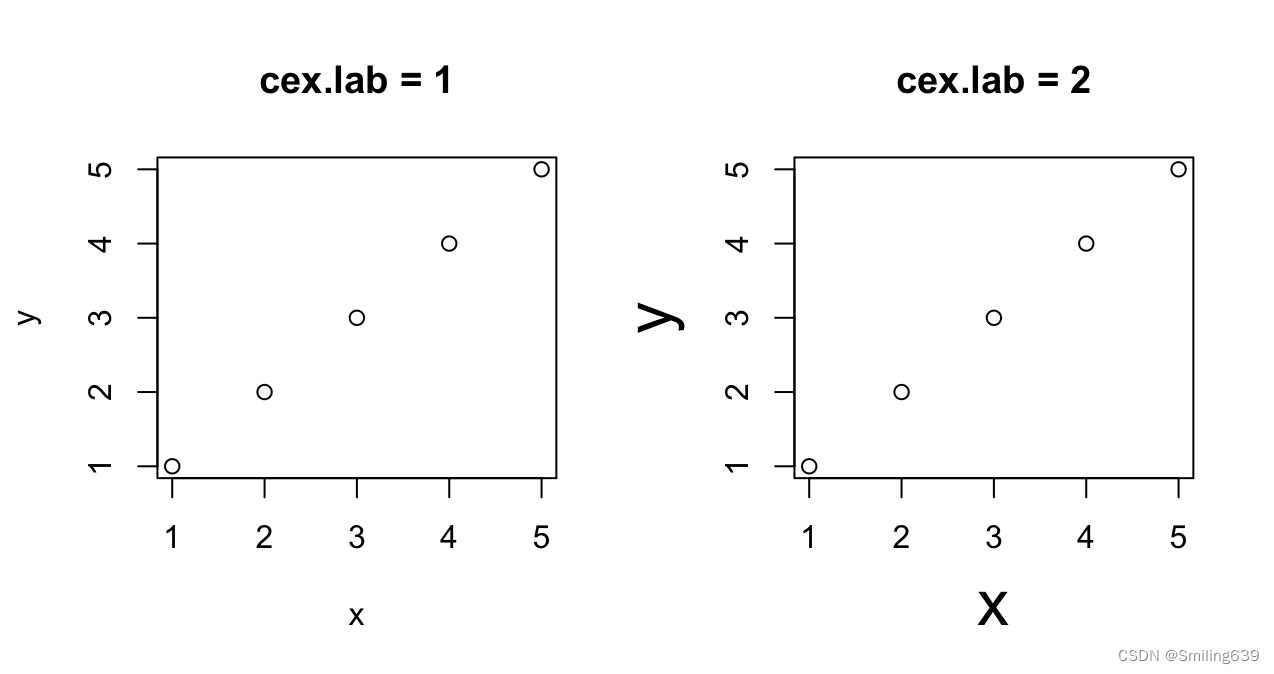
plot(x, y, cex.lab = 1, main = "cex.lab = 1")
plot(x, y, cex.lab = 2, main = "cex.lab = 2")
par(opar)
par(mfrow = c(1,2)): 这一行代码设置了图形布局,将图形分为一行两列,即创建一个具有两个子图的布局。因此,后续的绘图命令将会在这个布局中的两个子图中显示。
cex.lab表示标签大小(x和y的大小)
绘制出的图片:
文字格式设置:字体font、大小ps

font常用取值:
“plain”:普通字体样式;
“bold”:粗体样式;
“italic”:斜体样式;
“bold.italic”:粗斜体样式。
ps默认值为12,表示12磅大小的文本。
5.图形布局

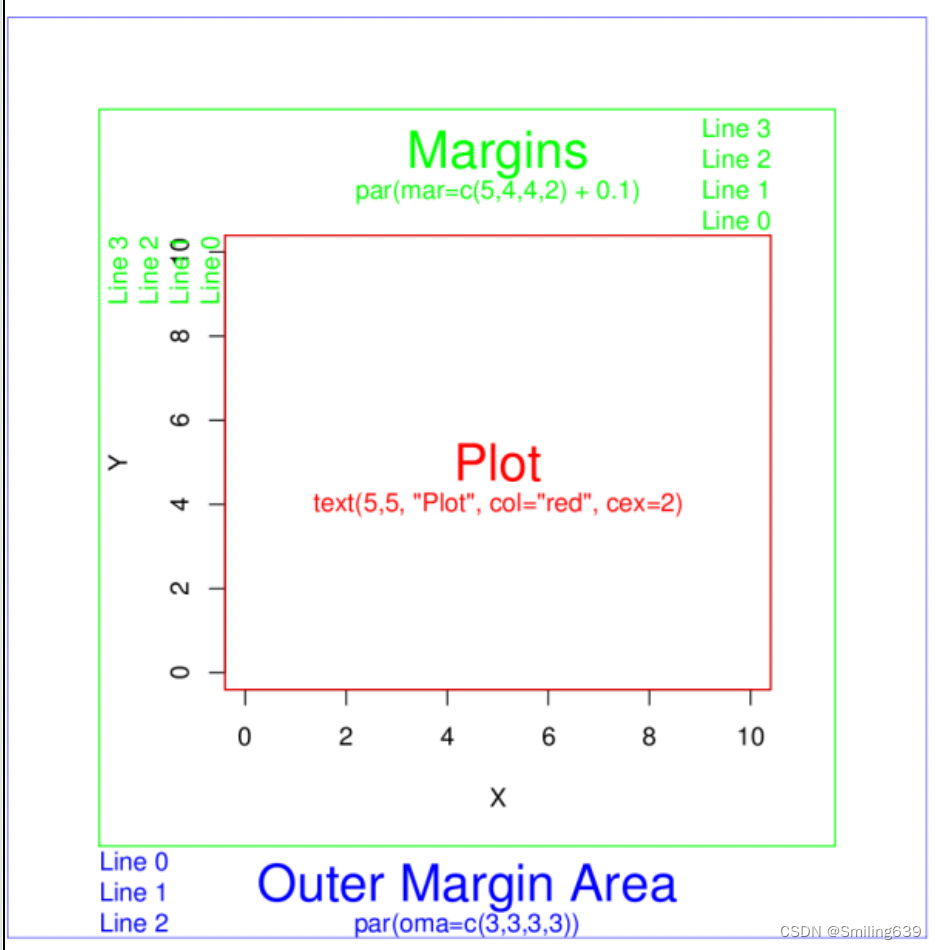
- pin:是图形设备的绘图区域的尺寸,以英寸为单位。pin 是一个长度为 2 的数值向量,包含了绘图区域的宽度和高度。默认情况下,pin 的值是 (7, 7),表示绘图区域的宽度和高度均为 7 英寸。
- mai:是绘图区域的边距参数,用于控制绘图区域内部的空白区域。mai 是一个长度为 4 的数值向量,包含了绘图区域的下、左、上和右边距。默认情况下,mai 的值是 (1, 1, 1, 1),表示绘图区域的四个边距均为 1。
- mar:是图形设备的边距(margin)参数,用于控制整个图形的边距。mar 是一个长度为 4 的数值向量,包含了整个图形的下、左、上和右边距。默认情况下,mar 的值是 (5.1, 4.1, 4.1, 2.1),表示整个图形的四个边距分别为 5.1、4.1、4.1 和 2.1。
四、图形属性
1. 标题
title(main =, sub =, xlab =, ylab =, line =, outer =, …)
- main:主标题的各个属性
par(c(“font.main”, “cex.main”, “col.main”)) - sub:副标题的各个属性
par(c(“font.sub”, “cex.sub”, “col.sub”)) - xlab和ylab:x轴和y轴的各个属性
par(c(“font.lab”, “cex.lab”, “col.lab”)) - line: line 参数的值会覆盖标签的默认放置位置,使标签从图的边缘向外移动指定数量的行。
- outer:指示标题应放置在图形的外边缘上,如果 outer 参数为 TRUE,则标题将放置在整个图形的外边缘上,而不是在内部区域。(默认情况下,outer 参数是 FALSE,意味着标题将放置在图形内部区域的顶部。)
2. 坐标轴
axis(side, at =, labels =, pos =, lty =, col =, las =, tck =, …)
- side:在图形的哪一侧
1 = bottom, 2 = left, 3 = top,and 4 = right - at:用数值向量表示要绘制刻度标记的位置
- labels:用字符向量表示要放置在刻度标记处的标签(默认为at值)
- pos:表示绘制坐标轴线的坐标位置,即与另一个轴交叉的值(原点)。
- lty:线条类型
- col:线条和刻度的颜色
- las:绘制标签的方向(与轴平行(= 0),垂直于轴(= 2))
- tck:每个刻度标记的长度,作为绘图区域的比例(负数表示在图形外部,正数表示在内部,0 不做刻度标记,1 创建网格线),默认值是 -0.01
3.示例
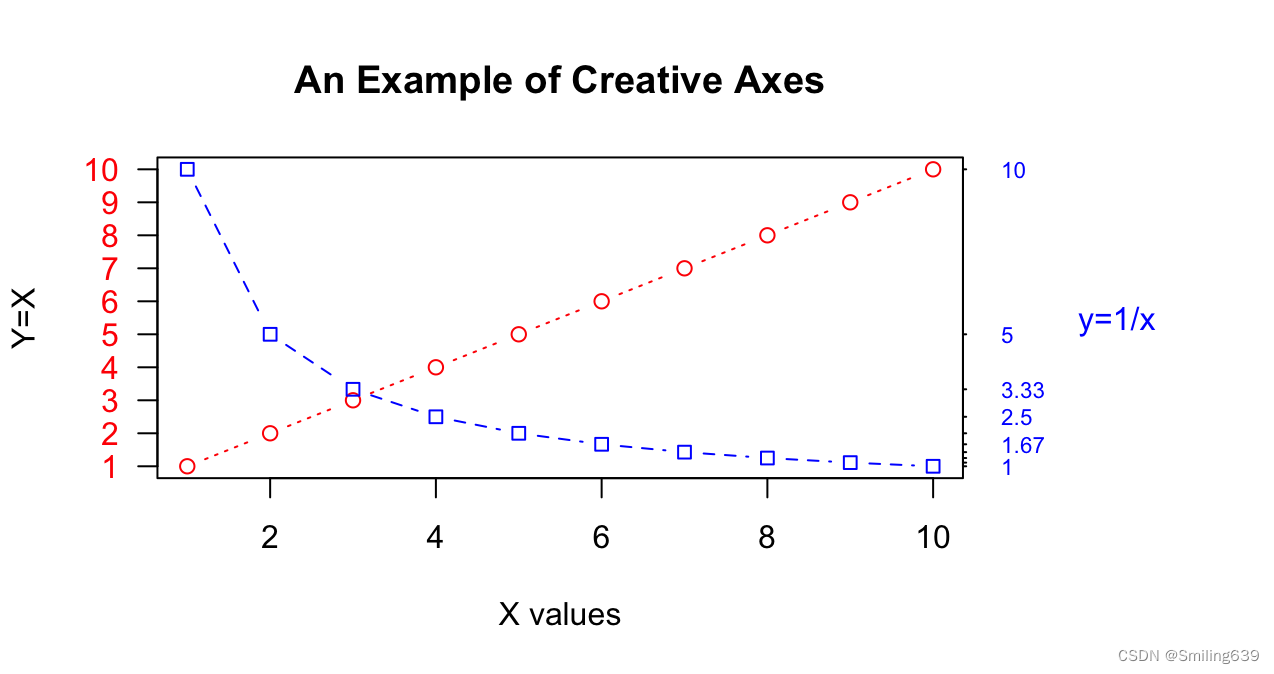
x <- c(1:10)
y <- x
z <- 10/x
opar <- par(no.readonly=TRUE)
par(mar=c(5, 4, 4, 8) + 0.1)
plot(x, y, type="b", pch=21, col="red",yaxt="n", lty=3, ann=FALSE)
lines(x, z, type="b", pch=22, col="blue", lty=2)
axis(2, at=x, labels=x, col.axis="red", las=2)
axis(4, at=z, labels=round(z, digits=2),
col.axis="blue", las=2, cex.axis=0.7, tck=-.01)
mtext("y=1/x", side=4, line=3, cex=1, las=2, col="blue")
title("An Example of Creative Axes", xlab="X values", ylab="Y=X")
par(opar)
- par(mar=c(5, 4, 4, 8) + 0.1): 设置绘图区域的边距,使得右边距稍微大一些。
- plot(x, y, type=“b”, pch=21, col=“red”, yaxt=“n”, lty=3, ann=FALSE): 绘制以 (x, y) 为坐标的散点图,点形状为方块(pch:point character=21),线型为虚线(type),颜色为红色(col),同时禁止绘制 y 轴刻度标签和注释(yaxt=“n”)。
- lines(x, z, type=“b”, pch=22, col=“blue”, lty=2): 绘制以 (x, z) 为坐标的线图,点形状为圆圈(pch=22),线型为虚线(type),颜色为蓝色。(lines用于在已有的图形上添加新的线条)
- axis(2, at=x, labels=x, col.axis=“red”, las=2): 在左侧添加 y 轴,刻度标签和刻度线与 y 轴平行,刻度标签为 x 向量的值,颜色为红色。
- mtext(“y=1/x”, side=4, line=3, cex=1, las=2, col=“blue”): 在右边的 y 轴上添加文字 “y=1/x”,并设置字体大小为原来的 1 倍,颜色为蓝色。
- title(“An Example of Creative Axes”, xlab=“X values”, ylab=“Y=X”): 添加图形的标题和轴标签。
4.参考线
abline(a =, b =, h =, v =, reg =, coef =, untf =, …)
- a, b:截距和斜率,通常用于绘制一条直线。它们是单个数值。
- untf:一个逻辑值,用于指定是否对直线进行反变换。如果设置为 TRUE,则对直线进行反变换;如果设置为 FALSE(默认值),则不进行反变换。
- h:一组 y 值,用于绘制水平线(horizontal)。这些 y 值确定了水平线的位置。
- v:一组 x 值,用于绘制垂直线(vertical)。这些 x 值确定了垂直线的位置。
- coef:一个长度为两的向量,包含直线的截距和斜率。
- reg:一个具有 coef 方法的对象,通常是一个线性回归模型的结果对象。
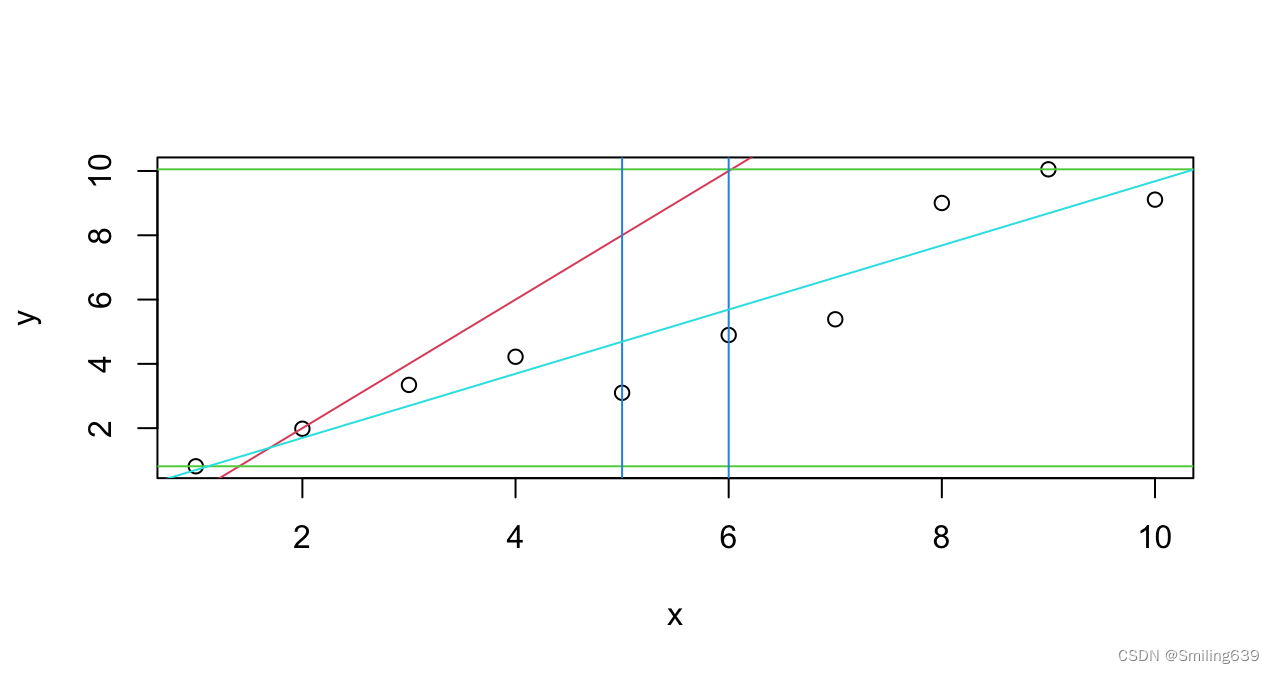
例:
x <- 1:10
y <- x+rnorm(10,0,1)
plot(x, y) //绘制点图
abline(a=-2, b=2, col=2)
abline(h=c(min(y),max(y)), col=3)
abline(v=c(5,6), col=4)
abline(lm(y~x), col=5)
- abline(a=-2, b=2, col=2):绘制一条具有截距 -2 和斜率 2 的直线,颜色为红色(col=2)。
- abline(h=c(min(y),max(y)), col=3):绘制两条水平线,分别位于 y 值的最小值和最大值处,颜色为绿色(col=3)。
- abline(v=c(5,6), col=4):绘制两条垂直线,分别位于 x 值为 5 和 6 处,颜色为蓝色(col=4)。
- abline(lm(y~x), col=5):根据拟合的线性模型绘制一条直线,这条直线是通过拟合散点图中的数据得到的。
5.图例
legend(location, title, legend, …)
- location:指定图例的放置位置,可以是一个包含 x 和 y 坐标的向量,或者是一个字符串,表示图例的位置,如 “bottom”、“bottomleft”、“left”、“topleft”、“top” 、“right”、“toplight”。
- title:图例的标题。
- legend:一个字符向量,包含要在图例中显示的文本标签。
- 其他参数:用于设置图例的外观,例如 col、lty、pch 等。
6. 文本注释
text() 函数用于在图形内部放置文本,而 mtext() 函数用于在图形的四个边缘之一放置文本。
text(location, “text to place”, pos, cex, col, font, …):
- location:指定要放置文本的位置,可以是一个包含 x 和 y 坐标的向量。
- “text to place”:要放置的文本内容。
- pos:指定文本相对于位置的放置方式,可选值有 “outer”、“inner”、“middle” 和 “center” 等。1 = below, 2 = left, 3 = above, 4 = right(1234下左上右)
- cex:指定文本的缩放比例。
- col:指定文本的颜色。
- font:指定文本的字体。
mtext(“text to place”, side, line=n, pos, cex, col, font, …):
- “text to place”:要放置的文本内容。
- side:指定文本要放置在哪个边缘,可选值有 “bottom”、“left”、“top” 和 “right”。1 = bottom, 2 = left, 3 = top, 4 = right(1234下左上右)
- line:指定文本相对于边缘的距离,单位为行数。
- pos:指定文本相对于边缘的放置方式,可选值有 “outer”、“inner” 和 “middle”。
- cex:指定文本的缩放比例。
- col:指定文本的颜色。
- font:指定文本的字体。
例:
plot(mtcars$wt, mtcars$mpg,main="Mileage vs. Car Weight",xlab="Weight",ylab="Mileage",pch=18, col="blue")
text(mtcars$wt, mtcars$mpg,row.names(mtcars),cex=0.6, pos=4, col="red")
text() 函数用于在每个数据点旁边添加汽车的名称。wt 和mpg 分别表示汽车的重量和油耗,此处表示location(一个x坐标,一个y坐标),在点旁边加注释,row.names(mtcars) 返回一个字符向量:汽车的名称。cex=0.6 指定文本的缩放比例为 0.6,pos=4 指定文本相对于数据点的位置,col=“red” 指定文本的颜色为红色。
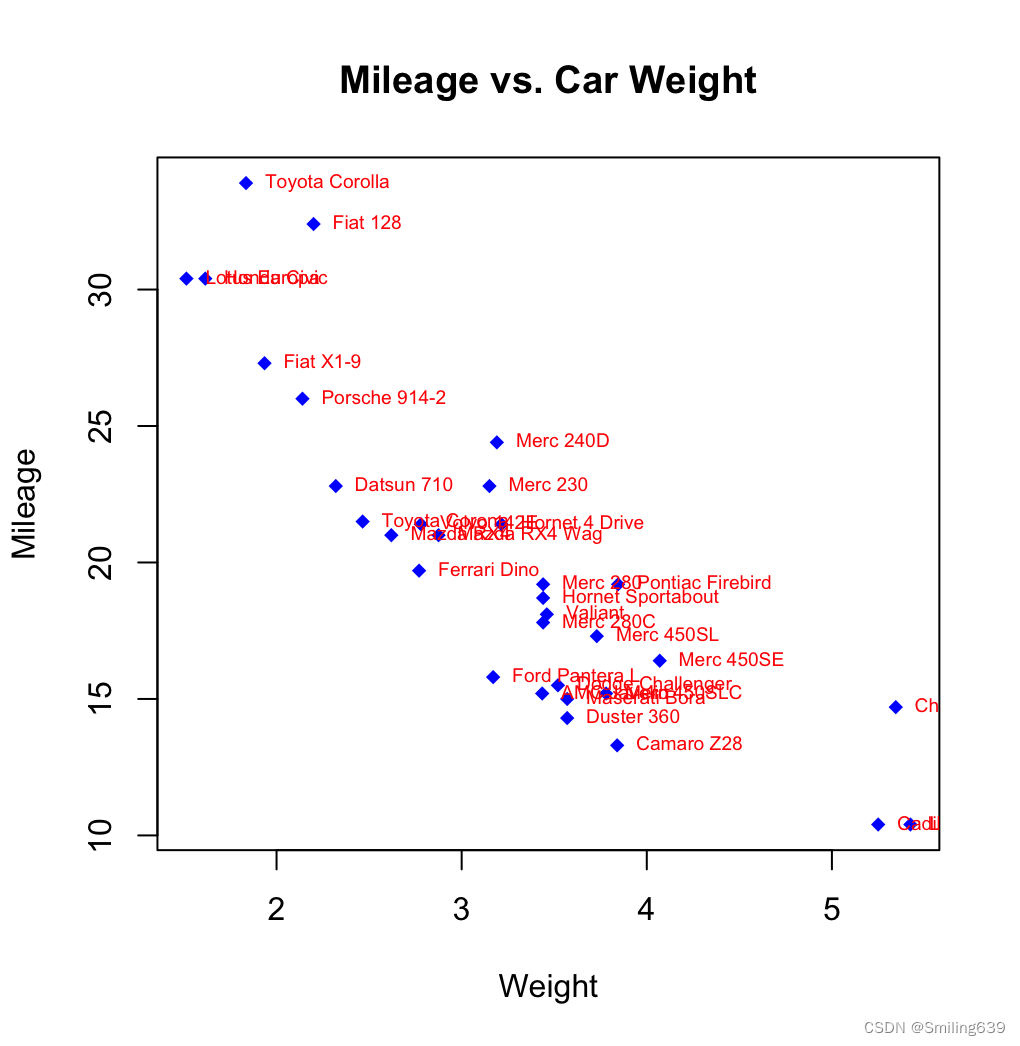
可见上图的文本注释有重合,如何优化该图?
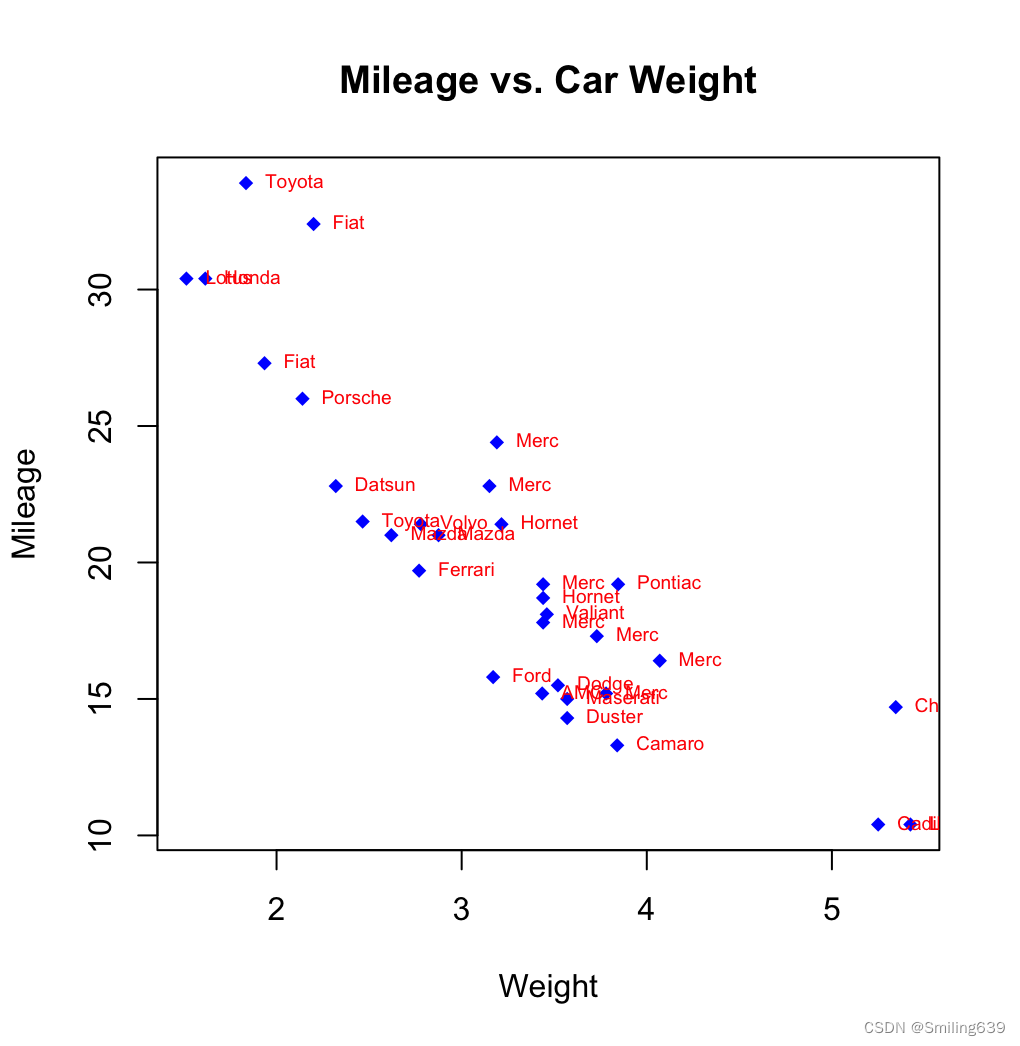
plot(mtcars$wt, mtcars$mpg, main="Mileage vs. Car Weight", xlab="Weight",ylab="Mileage", pch=18, col="blue")
carlabs <- sapply(strsplit(row.names(mtcars)," "), function(x) x[[1]])
text(mtcars$wt, mtcars$mpg, carlabs, cex=0.6, pos=4, col="red")
加入了
rsapply(strsplit(row.names(mtcars)," "), function(x) x[[1]])这一行代码:
- strsplit(row.names(mtcars)," ") 将每个汽车名称按照空格进行分割,返回一个列表,列表中的每个元素是一个字符向量,包含了汽车名称中的每个单词。
- sapply() 函数对这个列表进行处理,对列表中的每个元素(即每个汽车名称)应用匿名函数 function(x) x[[1]],这个函数返回汽车名称的第一个单词,从而使图形更为简洁。
五、其他功能
1.图形组合
par函数:控制绘图时的各种参数,包括在单个绘图设备上排列多个图形的方式。
- mfrow=c(nrows, ncols):这个参数指定了绘图布局的行数和列数。图形会按行填充。
- mfcol=c(nrows, ncols):这个参数也指定了绘图布局的行数和列数。不同的是,图形会按列填充
layout函数:layout() 函数将绘图设备划分为与矩阵 mat 中的行数和列数相同的行和列,其中列宽和行高由相应的参数指定。
layout(mat, widths = rep.int(1, ncol(mat)), heights = rep.int(1, nrow(mat)), respect = FALSE)
- mat:一个矩阵对象,用于指定输出N个图形的位置。
- widths:一个向量,用于指定设备上列的宽度值。可以使用数值指定相对宽度,也可以使用 lcm() 函数指定绝对宽度(以厘米为单位)。
- heights:一个向量,用于指定设备上行的高度值。
- respect:一个逻辑值,指定是否应该保持与 mat 矩阵相同的比例来设置图形的尺寸,默认为FALSE。
例:
def.par<-par(no.readonly = TRUE)
layout(matrix(c(1,1,0,2),2,2,byrow = TRUE))
layout.show(2)
这段代码使用了layout()函数,它指定了一个包含四个图形的绘图布局,其中两个图形占据了第一行的两个位置,另外两个图形占据了第二行的两个位置。通过layout.show(2)函数,我们可以看到这个布局的具体样式。

nf<-layout(matrix(c(1,1,0,2),2,2,byrow=TRUE),respect = TRUE)
layout.show(nf)
respect=TRUE表明输出为正方形

例:
x<- pmin(3, pmax(-3, stats::rnorm(50)))
y<- pmin(3, pmax(-3, stats::rnorm(50)))
xhist <- hist(x, breaks = seq(-3,3,0.5), plot = FALSE)
yhist <- hist(y, breaks = seq(-3,3,0.5), plot = FALSE)
top<- max(c(xhist$counts, yhist$counts))
xrange <-c(-3,3)
yrange <-c(-3,3)
nf <- layout (matrix(c(2, 0,1,3),2,2,byrow= TRUE),c(3,1),c(1,3),TRUE)
layout.show(nf)
这段代码创建了两个随机变量 x 和 y,然后绘制了它们的直方图。
- x <- pmin(3, pmax(-3, stats::rnorm(50))):生成了一个长度为 50 的随机变量 x,其值范围被限制在 [-3, 3] 之间。
- y <- pmin(3, pmax(-3, stats::rnorm(50))):生成了另一个长度为 50 的随机变量 y,其值范围同样被限制在 [-3, 3] 之间。
- xhist <- hist(x, breaks = seq(-3,3,0.5), plot = FALSE):计算了 x 的直方图,将其存储在 xhist 中,但不进行绘制。
- yhist <- hist(y, breaks = seq(-3,3,0.5), plot = FALSE):计算了 y 的直方图,将其存储在 yhist 中,但不进行绘制。
- top <- max(c(xhist c o u n t s , y h i s t counts, yhist counts,yhistcounts)):找到了两个直方图中的最大计数,用于确定直方图的高度范围。
- xrange <- c(-3,3) 和 yrange <- c(-3,3):指定了 x 和 y 轴的范围。
- 最后,通过 layout() 函数创建了一个包含四个区域的 2x2 布局。在这个布局中,直方图被放置在左上角和右下角的位置,而 x 和 y 轴的标签则位于布局的顶部和右侧。layout.show(nf) 函数展示了这个布局。
例:
par(mar = c(3,3,1,1))
plot (x, y, xlim = xrange, ylim= yrange, xlab="",ylab="")
par(mar = e(0,3,1,1))
barplot(xhist$counts, axes =FALSE, ylim = e(0, top), space = 0)
par (mar = c(3,0,1,1))
barplot (yhist$counts, axes =FALSE, xlim = c(0, top), space = 0, horiz = TRUE)
这段代码使用了 barplot() 函数绘制了两个直方图,同时通过 plot() 函数绘制了散点图。这里是代码的解释:
- par(mar = c(3,3,1,1)):设置绘图边距,这里是上、右、下、左边距的值。
- plot(x, y, xlim = xrange, ylim = yrange, xlab = “”, ylab = “”):绘制了散点图,其中 x 和 y 分别表示横纵坐标的值,xlim 和 ylim 参数指定了坐标轴的范围,xlab 和 ylab 参数指定了坐标轴的标签。
- par(mar = c(0,3,1,1)):设置了新的绘图边距。
- barplot(xhist$counts, axes = FALSE, ylim = c(0, top), space = 0):绘制了 xhist 的直方图,axes = FALSE 参数表示不绘制坐标轴,ylim 参数指定了 y 轴的范围,space = 0 参数表示直方图之间没有间隔。
- par(mar = c(3,0,1,1)):设置了另一个新的绘图边距。
- barplot(yhist$counts, axes = FALSE, xlim = c(0, top), space = 0, horiz = TRUE):绘制了 yhist 的直方图,horiz = TRUE 参数表示绘制水平直方图,xlim 参数指定了 x 轴的范围,space = 0 参数表示直方图之间没有间隔。
2.在图形上添加点
points(x =, y =, type =, …)
注意:必须在已有图形的基础上加点。
例:
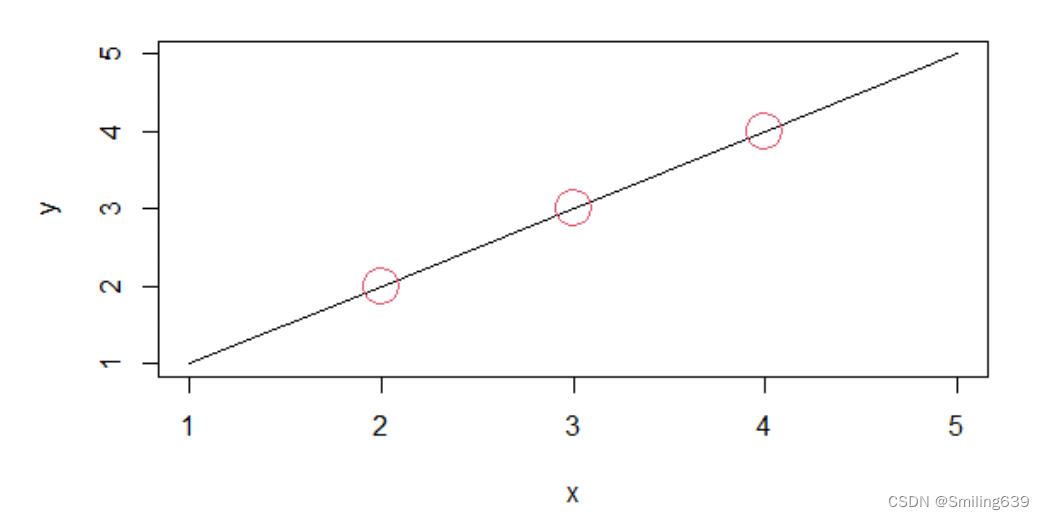
x <- 1:5
y <- 1:5
plot(x, y, type = "l")
points(c(2,3,4), c(2,3,4), cex=3, col=2)
3.绘制特定的图形类型
3.1 条形图
例:
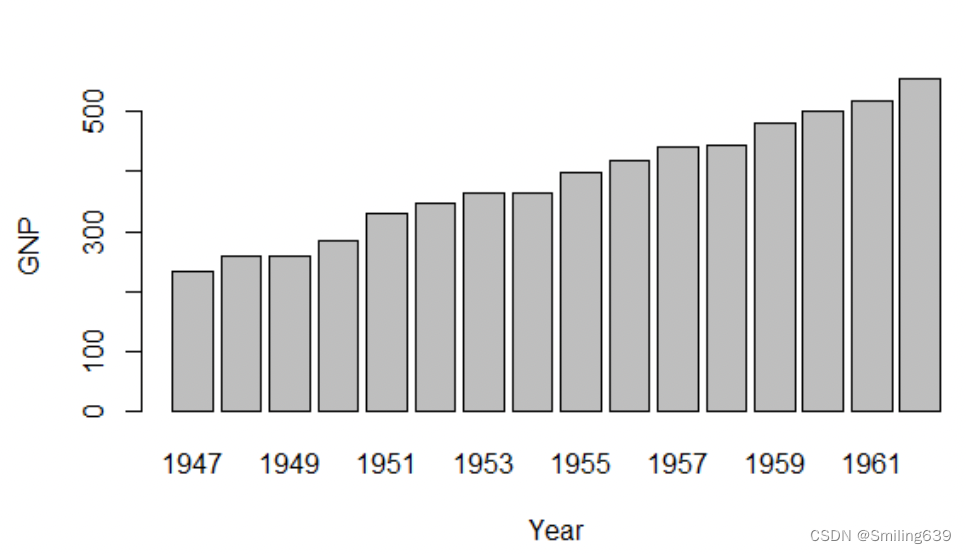
barplot(GNP ~ Year, data = longley)
- GNP是要绘制的数值变量,而Year是用于分组的类别变量,两者用~连接。
- data指定了数据来源,即longley数据集。
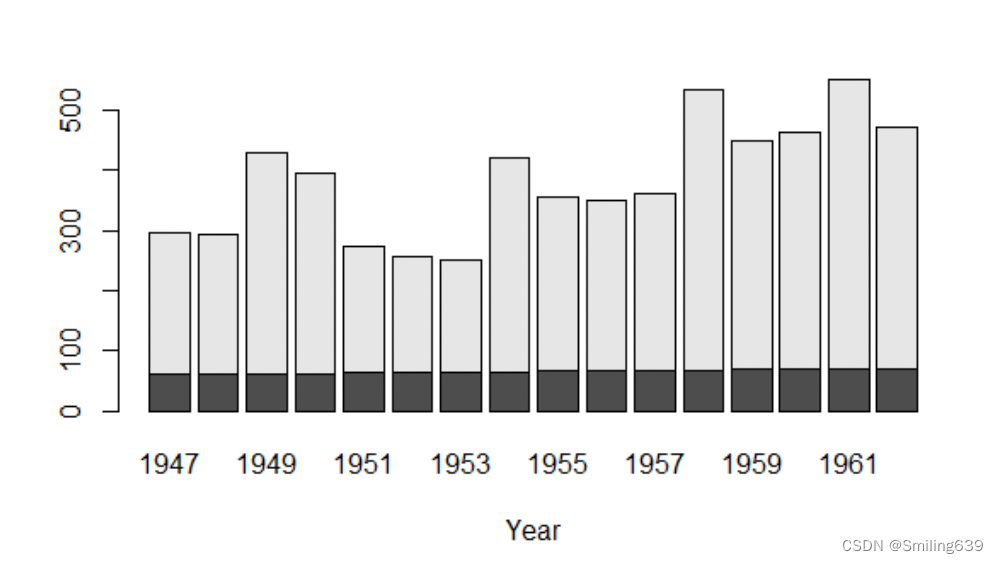
barplot(cbind(Employed, Unemployed) ~ Year, data = longley)
这里使用cbind()函数将就业人数(Employed)和失业人数(Unemployed)合并成一个矩阵,并使用~ Year指定时间(Year)作为分组变量。
对于barplot的更详细的解释:
barplot(height, width = 1, space = NULL,
names.arg = NULL, legend.text = NULL, beside = FALSE,
horiz = FALSE, density = NULL, angle = 45,
col = NULL, border = par("fg"),
main = NULL, sub = NULL, xlab = NULL, ylab = NULL,
xlim = NULL, ylim = NULL, xpd = TRUE, log = "",
axes = TRUE, axisnames = TRUE,
cex.axis = par("cex.axis"), cex.names = par("cex.axis"),
inside = TRUE, plot = TRUE, axis.lty = 0, offset = 0,
add = FALSE, ann = !add && par("ann"), args.legend = NULL, ...)
以下是这些参数的含义:
height: 一个向量,指定了每个条形的高度。width: 一个数值,指定了每个条形的宽度。space: 一个数值或者向量,指定了条形之间的间隔。如果设置为NULL,则由函数自动计算。names.arg: 一个向量,指定了每个条形的标签名称。legend.text: 一个字符向量,指定了图例中每个条形的标签文本。beside: 一个逻辑值,指定了是否将条形图并列显示,默认为FALSE,表示条形将堆叠显示。horiz: 一个逻辑值,指定了是否绘制水平条形图,默认为FALSE,表示绘制垂直条形图。density: 一个数值或者向量,指定了每个条形的阴影线填充密度。如果为NULL,则条形将不填充。angle: 一个数值,指定了条形的阴影线填充角度。col: 一个颜色向量,指定了条形的填充颜色。rainbow(1:10):可以把十个柱子填充成10种颜色。border: 一个颜色向量,指定了条形的边框颜色,为NA则无边框。main: 一个字符值,指定了图形的主标题。sub: 一个字符值,指定了图形的副标题。xlab: 一个字符值,指定了X轴的标签。ylab: 一个字符值,指定了Y轴的标签。xlim: 一个长度为2的数值向量,指定了X轴的范围。ylim: 一个长度为2的数值向量,指定了Y轴的范围。xpd: 一个逻辑值,指定了是否允许绘制超出绘图区域的部分,默认为TRUE。log: 一个字符值,指定了轴上的对数刻度。axes: 一个逻辑值,指定了是否绘制坐标轴。axisnames: 一个逻辑值,指定了是否绘制坐标轴标签。cex.axis: 一个数值,指定了坐标轴标签的大小。cex.names: 一个数值,指定了条形标签的大小。inside: 一个逻辑值,指定了是否将标签绘制在条形内部。plot: 一个逻辑值,指定了是否绘制图形。axis.lty: 一个数值,指定了坐标轴的线条类型。offset: 一个数值,指定了条形的偏移量。add: 一个逻辑值,指定了是否将条形图添加到已有的绘图中。ann: 一个逻辑值,指定了是否绘制标题、轴标签和图例。args.legend: 一个列表,包含了用于绘制图例的其他参数。...: 其他参数,用于传递给legend()函数。
这些参数提供了广泛的选项,允许你自定义条形图的外观和布局。
使用实例:用柱状图生成色卡
pdf("colors-bar.pdf", height=120)
par(mar=c(0,10,3,0)+0.1, yaxs="i")
barplot(rep(length(colors()), length(colors())), col=rev(colors()), names.arg=rev(colors()), horiz=T, las=1, xaxt="n", main=expression("Bar of colors in"~italic(colors())))
dev.off()
pdf("colors-bar.pdf", height=120): 这行代码创建了一个名为"colors-bar.pdf"的PDF文件,并指定了文件的高度为120英寸。pdf()函数会开始记录所有后续的绘图操作,并将它们保存到指定的PDF文件中。par(mar=c(0,10,3,0)+0.1, yaxs="i"): 这行代码设置了图形的绘图参数。mar参数控制了图形的边距,它的值是一个长度为4的数值向量,分别代表了上、右、下、左四个边距的大小。yaxs参数设置了Y轴的扩展方式,"i"表示使用内部扩展。barplot(……): 这行代码创建了一个水平条形图。rep(length(colors()), length(colors()))生成了一个长度等于颜色数量的向量,用于指定每个条形的高度(=颜色个数)。col=rev(colors())设置了条形的填充颜色,使用了颜色向量的倒序。names.arg=rev(colors())设置了每个条形的标签名称,也使用了颜色向量的倒序。horiz=T指定了绘制水平条形图。las=1设置了标签文本的方向为水平。xaxt="n"禁止了X轴的绘制。main=expression("Bar of colors in"~italic(colors()))设置了图形的标题(italic用于设置为斜体)。dev.off(): 这行代码结束了PDF文件的绘制过程,并将其关闭。此时,之前绘制的内容会被保存到"colors-bar.pdf"文件中。
生成的色卡部分:
3.2 饼图
pie(x, labels):
x是非负数值型向量,代表面积;
label代表每个扇形的标签字符。
x和label一一对应。
例:
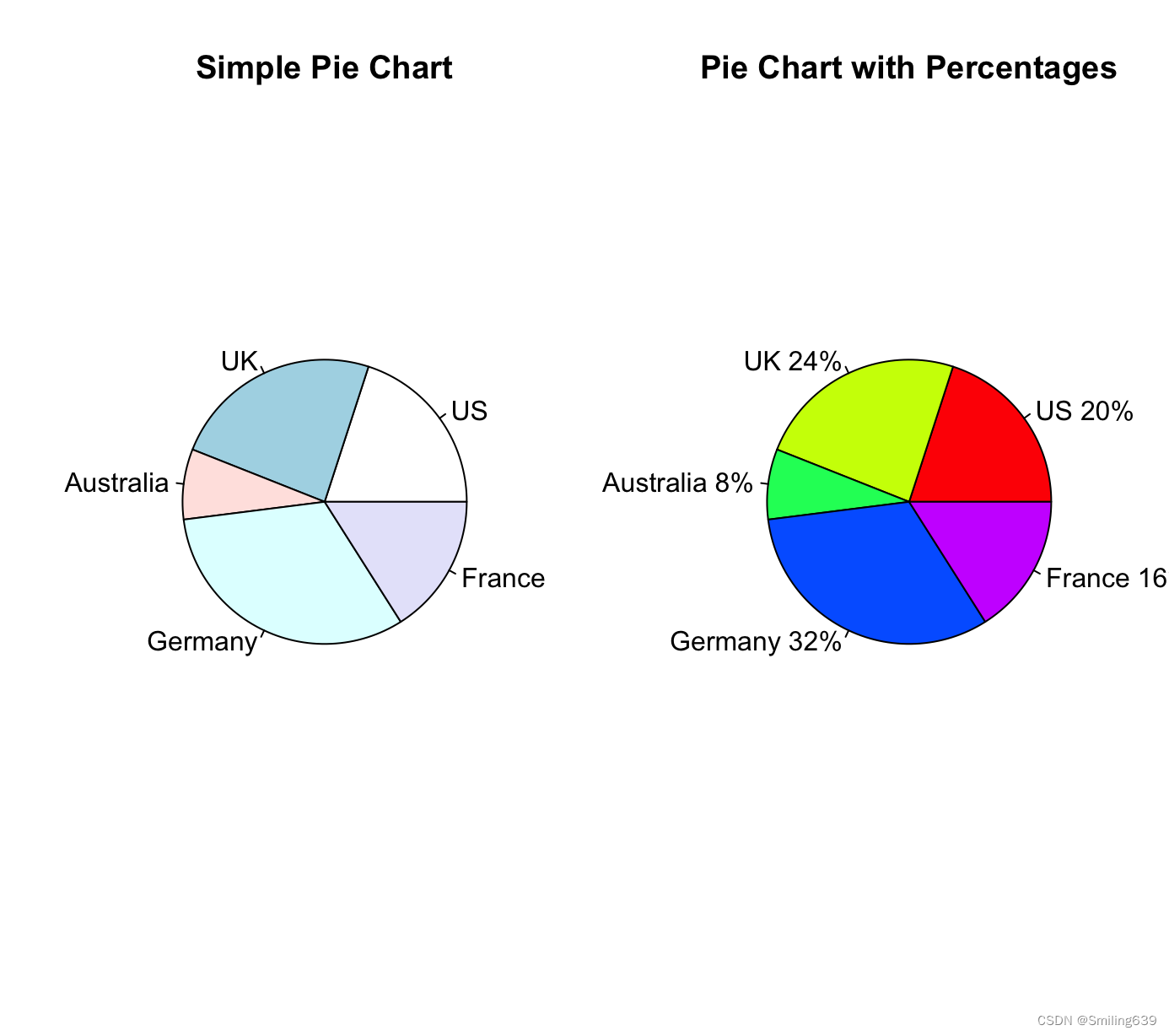
opar <- par(no.readonly=TRUE)
par(mfrow=c(1, 2))
#第一张图
slices <- c(10, 12, 4, 16, 8)
lbls <- c("US", "UK", "Australia", "Germany", "France")
pie(slices, labels = lbls, main="Simple Pie Chart")
#第二张图
pct <- round(slices/sum(slices)*100)
lbls2 <- paste(lbls, " ", pct, "%", sep="")
pie(slices, labels=lbls2, col=rainbow(length(lbls2)), main="Pie Chart with Percentages")
par(opar)
在第二张图中,使用round()函数(取整)计算了每个扇形的百分比,并用paste函数将其合并成一个新的字符串lbls2作为扇形标签。col=rainbow(length(lbls2))用彩虹色系为每个扇形着色。
3.3 直方图
hist(x)函数用于创建直方图,以下是一些常用参数:
- breaks:指定区间的数目或边界。可以是一个整数,表示区间的数量,也可以是一个表示边界值的向量。
- main:指定主标题。
- xlab:指定 x 轴标签。
- ylab:指定 y 轴标签。
- xlim:指定 x 轴的范围。
- ylim:指定 y 轴的范围。
- col:指定直方图的颜色。
- border:指定直方图的边界颜色。
例:
#图1
opar <- par(no.readonly=TRUE)
par(mfrow=c(2,2))
hist(mtcars$mpg)
#图2
hist(mtcars$mpg, breaks=12, col="red",
xlab="Miles Per Gallon",
main="Colored histogram with 12 bins")
#图3
hist(mtcars$mpg, freq=FALSE, breaks=12, col="red",
xlab="Miles Per Gallon",
main="Histogram, rug plot, density curve")
rug(jitter(mtcars$mpg))
lines(density(mtcars$mpg), col="blue", lwd=2)
#图4
x <- mtcars$mpg
h<-hist(x, breaks=12, col="red", xlab="Miles Per Gallon",
main="Histogram with normal curve and box")
xfit<-seq(min(x), max(x), length=40)
yfit<-dnorm(xfit, mean=mean(x), sd=sd(x))
yfit <- yfit*diff(h$mids[1:2])*length(x)
lines(xfit, yfit, col="blue", lwd=2)
box()
par(opar)
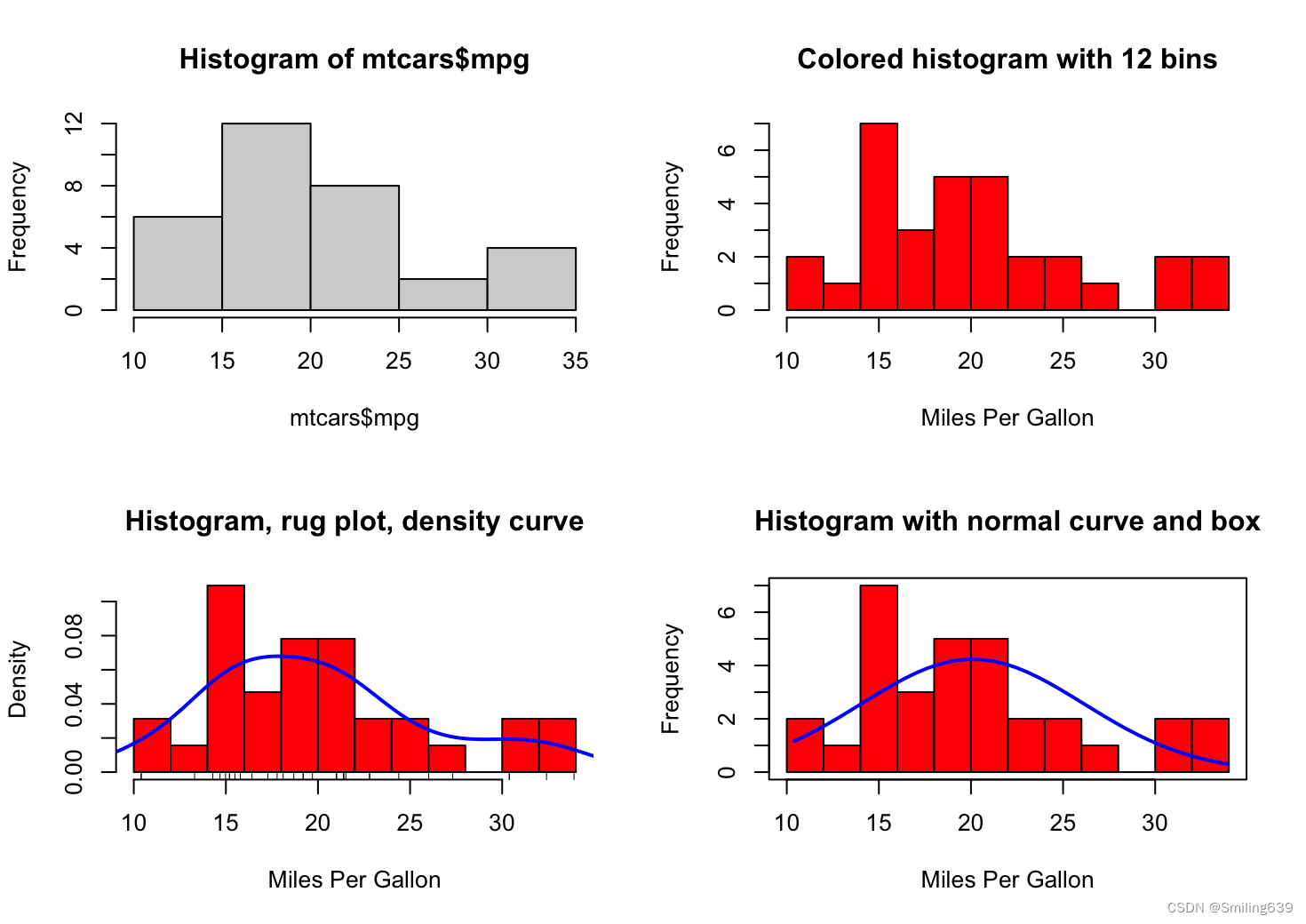
图3中,
freq=FALSE表示绘制的是密度而不是频数,rug(jitter(mtcars$mpg))表示添加rug plot。jitter()函数对数据进行抖动处理,避免数据点之间的重叠,然后rug()函数将抖动后的数据点绘制在x轴上,以表示数据的分布情况。
lines(density(mtcars$mpg), col="blue", lwd=2):添加密度曲线。density()函数用于计算数据的密度估计,然后lines()函数将密度曲线添加到图形中,col="blue"指定了曲线的颜色为蓝色,lwd=2指定了曲线的线宽为2。
图4中,
xfit<-seq(min(x), max(x), length=40):生成40个均匀间隔的值,用于在直方图范围内创建正态分布曲线。
yfit<-dnorm(xfit, mean=mean(x), sd=sd(x)):使用dnorm()函数计算了在给定数据集的均值和标准差下,每个xfit值对应的正态分布的概率密度值。
yfit <- yfit*diff(h$mids[1:2])*length(x):对计算出的正态分布曲线进行调整,以便与直方图的频率分布匹配。频数=频率 * 样本总数=频率 / 组距 * 组距 * 样本总数 ~ 密度 * 组距 * 样本总数。
lines(xfit, yfit, col="blue", lwd=2):使用lines()函数将计算出的正态分布曲线添加到图形中。
box():在图形周围绘制一个边界框。
补充:直方图和条形图的区别
- 用途:
直方图通常用于显示连续变量的分布情况,例如测量数据或观测值。
条形图通常用于比较不同类别或组之间的数据,例如不同产品的销售量或不同月份的收入。 - 数据类型:
直方图的横轴通常表示连续的数据范围,例如时间、长度或温度等。
条形图的横轴通常表示不同的类别或组,例如产品名称、月份或地区等。 - 柱子的形状:
直方图中的柱子通常是相邻的,表示连续的数据范围,柱子之间没有间隔。
条形图中的柱子通常是分开的,每个柱子表示一个类别或组,柱子之间有间隔。 - 数据表示:
直方图的纵轴表示每个区间或范围内的数据频数或密度。
条形图的纵轴表示每个类别或组的数据值,通常是计数或其他汇总统计量。 - 解释:
直方图可以帮助分析数据的分布形状,例如是否对称、是否存在峰值或尾部等特征。
条形图可以帮助比较不同类别或组之间的差异,并快速识别最大值或最小值所在的类别。
3.4 密度图
使用density()函数创建密度图:
- plot(density(x)):创建一个新的图形,并在图形中绘制x向量的密度曲线。
- lines(density(x)):将密度曲线添加到已经存在的图形中。
例:
opar <- par(no.readonly=TRUE)
par(mfrow=c(2,1))
plot(density(mtcars$mpg))
plot(density(mtcars$mpg),
main="Kernel Density of Miles Per Gallon")
polygon(density(mtcars$mpg), col="red", border="blue")
rug(mtcars$mpg, col="brown")
par(opar)
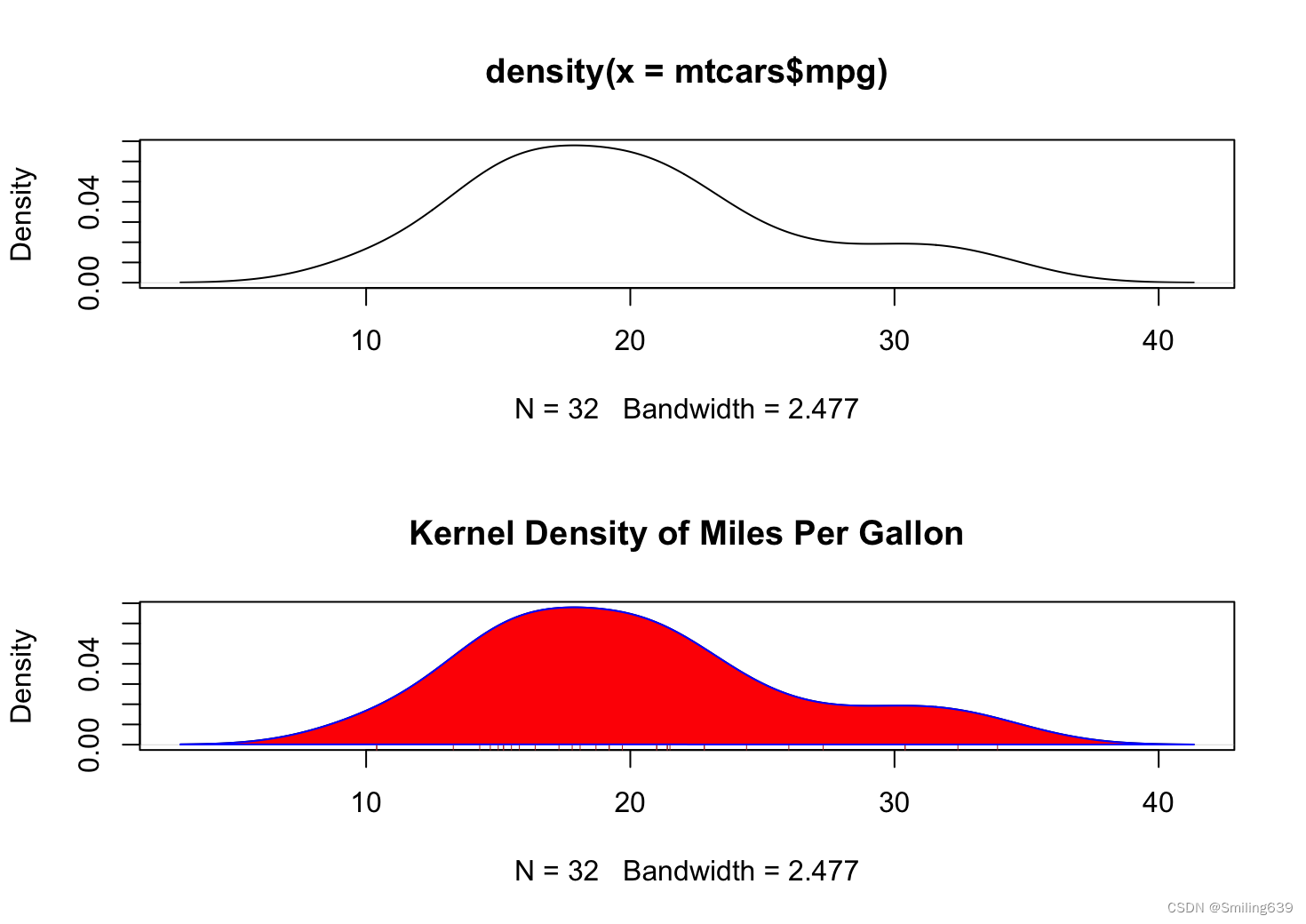
上例绘制了 mtcars 数据集中里程每加仑的密度图,第二张图中,
polygon(density(mtcars$mpg), col="red", border="blue"):在第二个图形中添加了一个多边形,填充颜色为红色,边框颜色为蓝色。这个多边形会覆盖密度曲线的区域。
rug(mtcars$mpg, col="brown"):在第二个图形中添加了地毯图,以棕色表示。地毯图显示了每个观测值的位置。
3.5 箱线图
箱线图描述了连续变量的分布情况,通过绘制其五数概括来实现:最小值(Q0 或第0百分位数)、下四分位数(Q1 或第25百分位数)、中位数(Q2 或第50百分位数)、上四分位数(Q3 或第75百分位数)和最大值(Q4 或第100百分位数)。
箱线图可以显示可能为异常值的观测值(值在±1.5*IQR范围之外,其中IQR定义为上四分位数Q3减去下四分位数 Q1)。
例:
x<-c(1:100,-100,200)
boxplot(x)
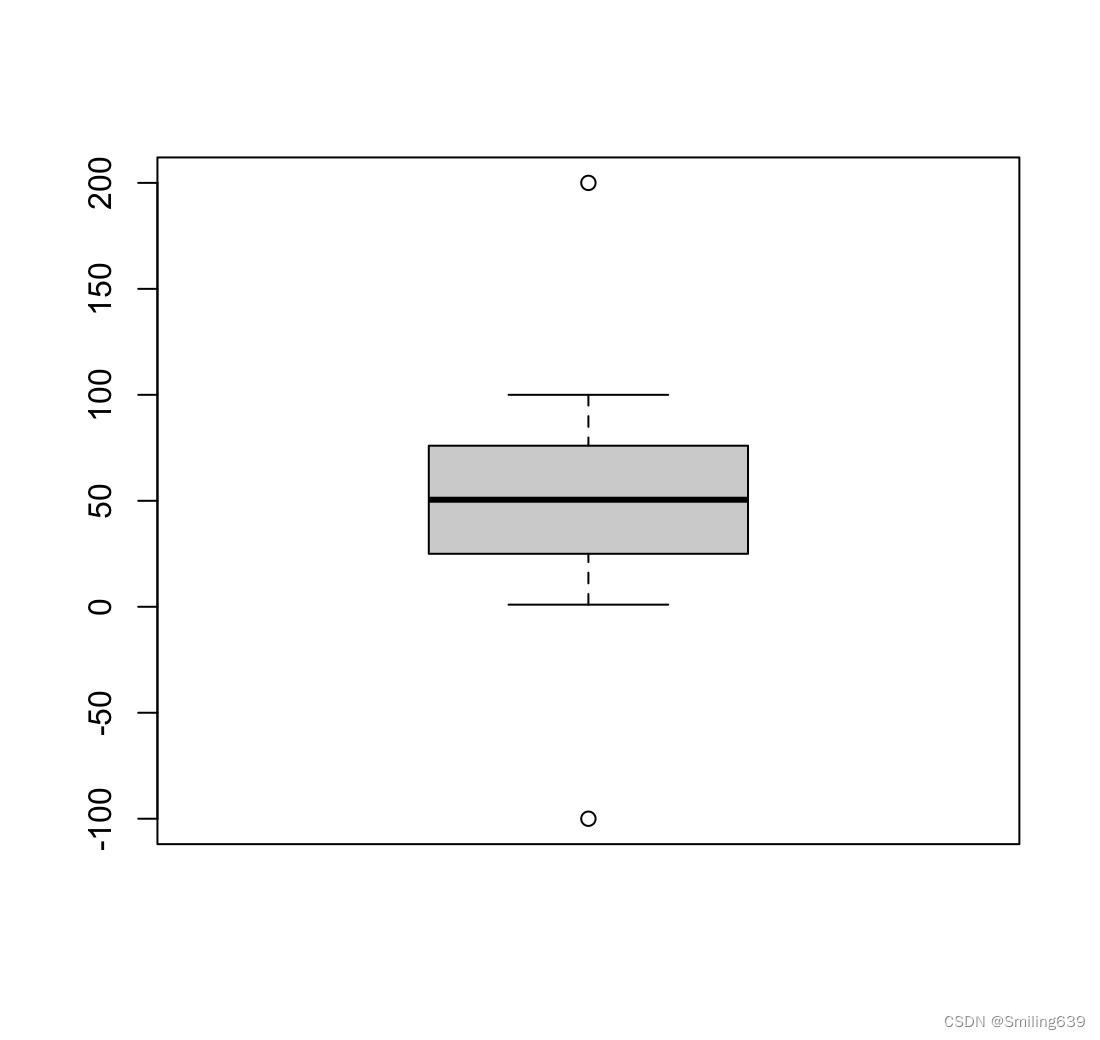
默认情况下,每根箱线的延伸范围为最极端的数据点,其距离箱子的距离不超过箱线图的1.5倍四分位距。超出此范围的值会以点的形式表示。上例中两个异常点-100和200就是这种情况。
箱线图可以针对单个变量或按组变量创建。其格式为:
boxplot(formula, data=dataframe)
公式 y ~ A 会为分类变量 A 的每个值生成一个独立的数值变量 y 的箱线图。
公式 y ~ A*B 会为分类变量 A 和 B 的每个水平组合生成一个数值变量 y 的箱线图。
dataframe 表示提供数据的数据框(或列表)。
添加varwidth=TRUE 使箱线图的宽度与其样本量的平方根成比例。
添加 horizontal=TRUE 以反转轴方向。
例1:
boxplot(mpg ~ cyl, data=mtcars,
main="Car Mileage Data",
xlab="Number of Cylinders",
ylab="Miles Per Gallon")
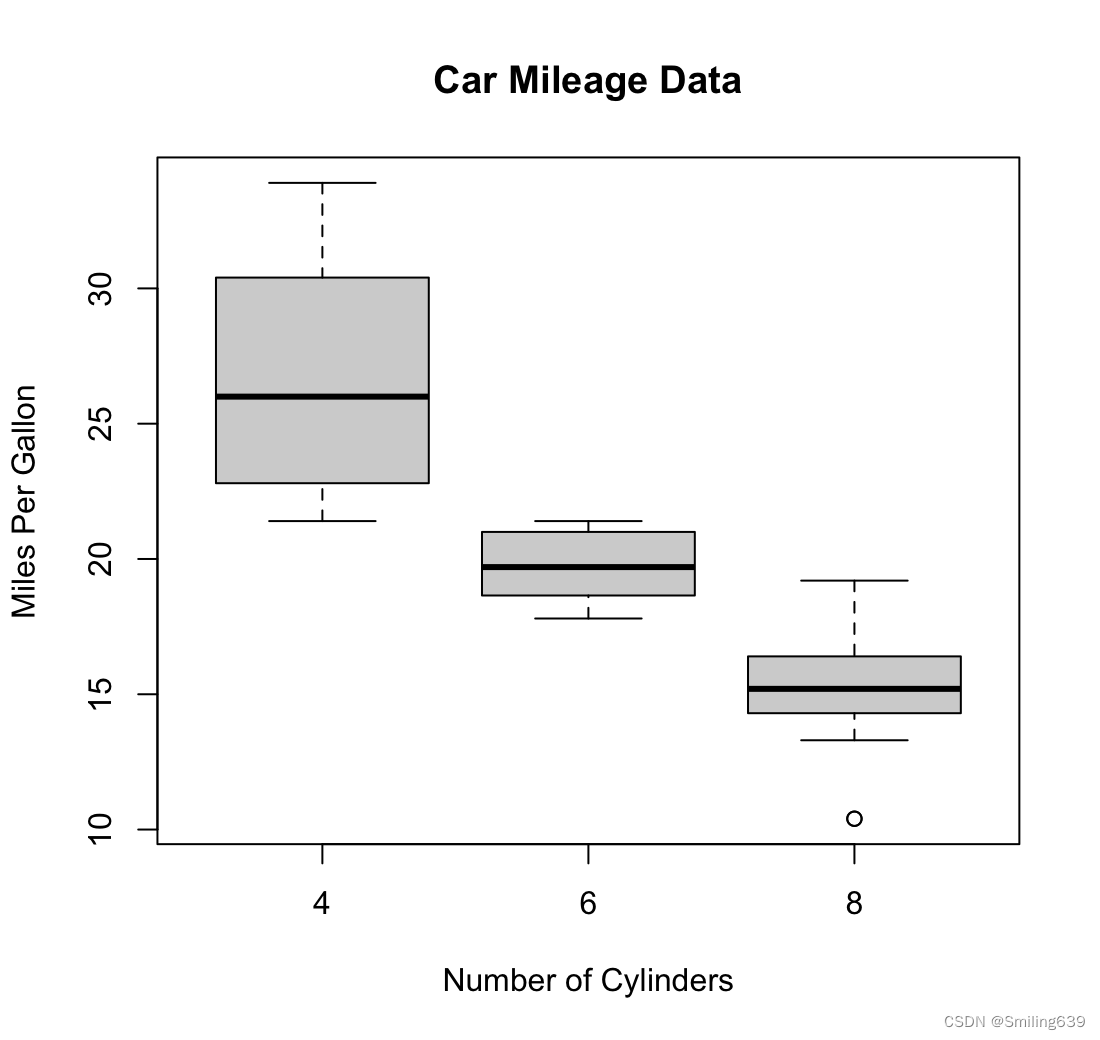
cyl有3种可能:4,6,8,因此绘制出了三个箱子。
例2:
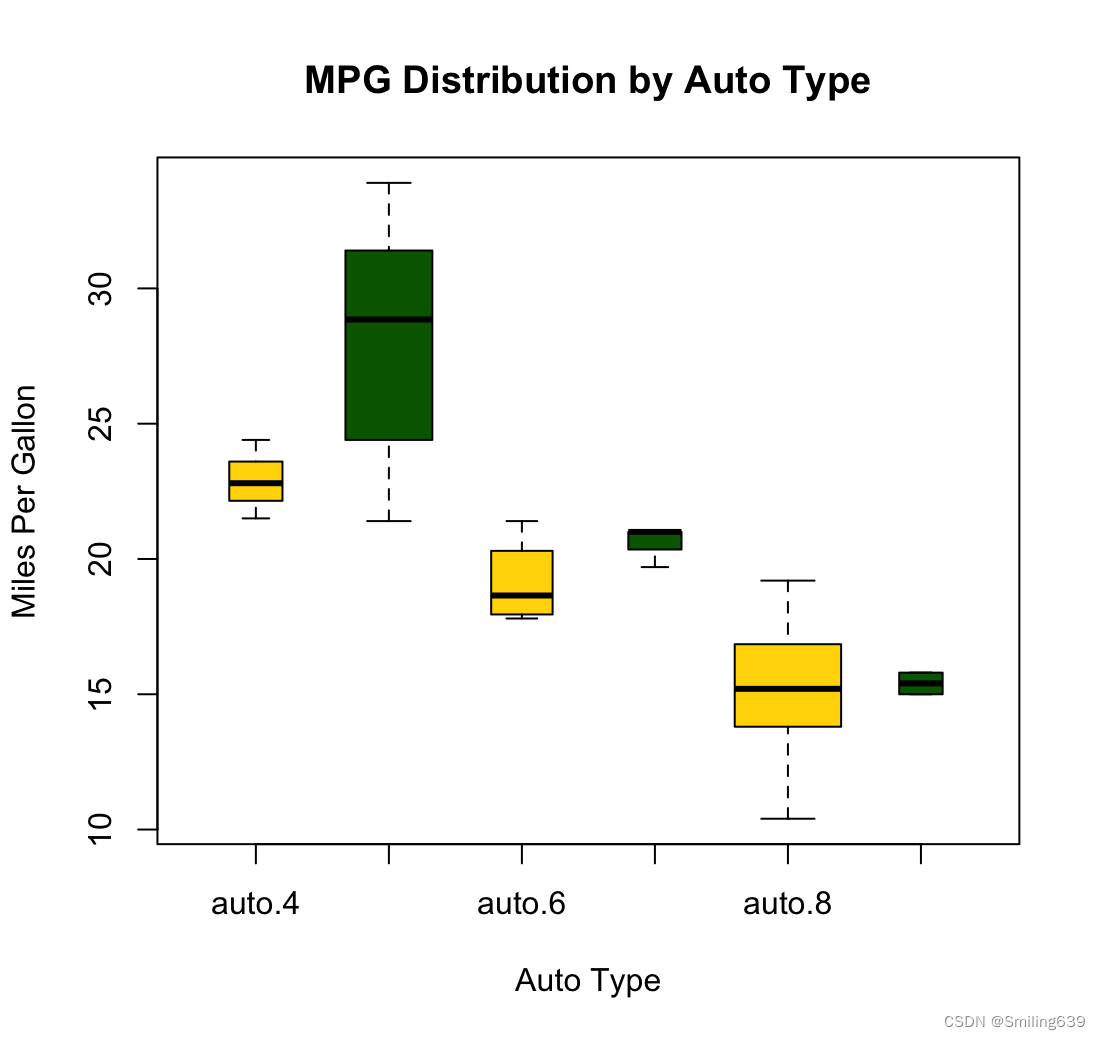
mtcars$cyl.f <- factor(mtcars$cyl,
levels=c(4,6,8),
labels=c("4","6","8"))
mtcars$am.f <- factor(mtcars$am,
levels=c(0,1),
labels=c("auto", "standard"))
boxplot(mpg ~ am.f *cyl.f,
data=mtcars,
varwidth=TRUE,
col=c("gold","darkgreen"),
main="MPG Distribution by Auto Type",
xlab="Auto Type", ylab="Miles Per Gallon")
3.6 点图
用于显示分类变量的频数或水平。
dotchart(x, labels = NULL, groups = NULL, gcolor = par("fg"), color = par("fg"), cex = 1, pt.cex = cex, pch = 1, gpch = par("pch"), bg = par("bg"), lcolor = par("fg"), xlim = NULL, main = NULL, xlab = NULL, ylab = NULL, ...)
其中:
x:数值向量,表示每个点的位置。
labels:标签向量,用于指定每个点的标签。
groups:数值或因子向量,用于指定每个点的分组。
gcolor:分组的颜色。
color:点的颜色。
cex:标签的大小。
pt.cex:点的大小。
pch:点的形状。
gpch:分组标记的形状。
bg:点的背景颜色。
lcolor:线条颜色。
xlim:x轴的限制。
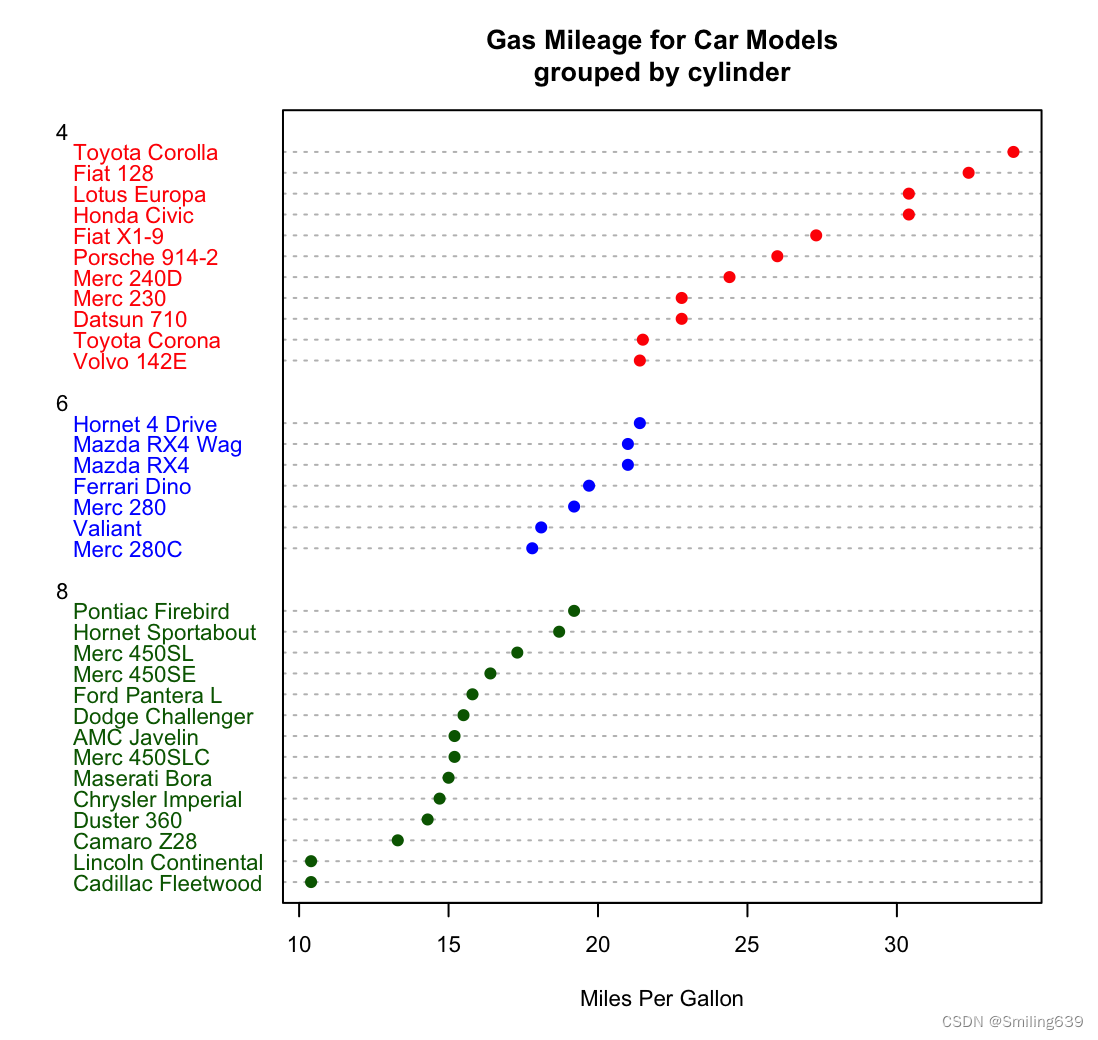
例1:
x <- mtcars[order(mtcars$mpg),]
x$cyl <- factor(x$cyl)
x$color[x$cyl==4] <- "red"
x$color[x$cyl==6] <- "blue"
x$color[x$cyl==8] <- "darkgreen"
dotchart(x$mpg,
labels = row.names(x),
cex=.7,
groups = x$cyl,
gcolor = "black",
color = x$color,
pch=19,
main = "Gas Mileage for Car Models\ngrouped by cylinder",
xlab = "Miles Per Gallon")
x <- mtcars[order(mtcars$mpg),]:首先按照汽车的油耗(mpg)对数据集进行排序。
x$cyl <- factor(x$cyl):将汽缸数量转换为因子变量,不同的气缸数就是不同的因子水平,以便后面对其进行不同颜色的涂色。
groups = x$cyl:根据汽缸数量进行分组。
4.绘图综合练习
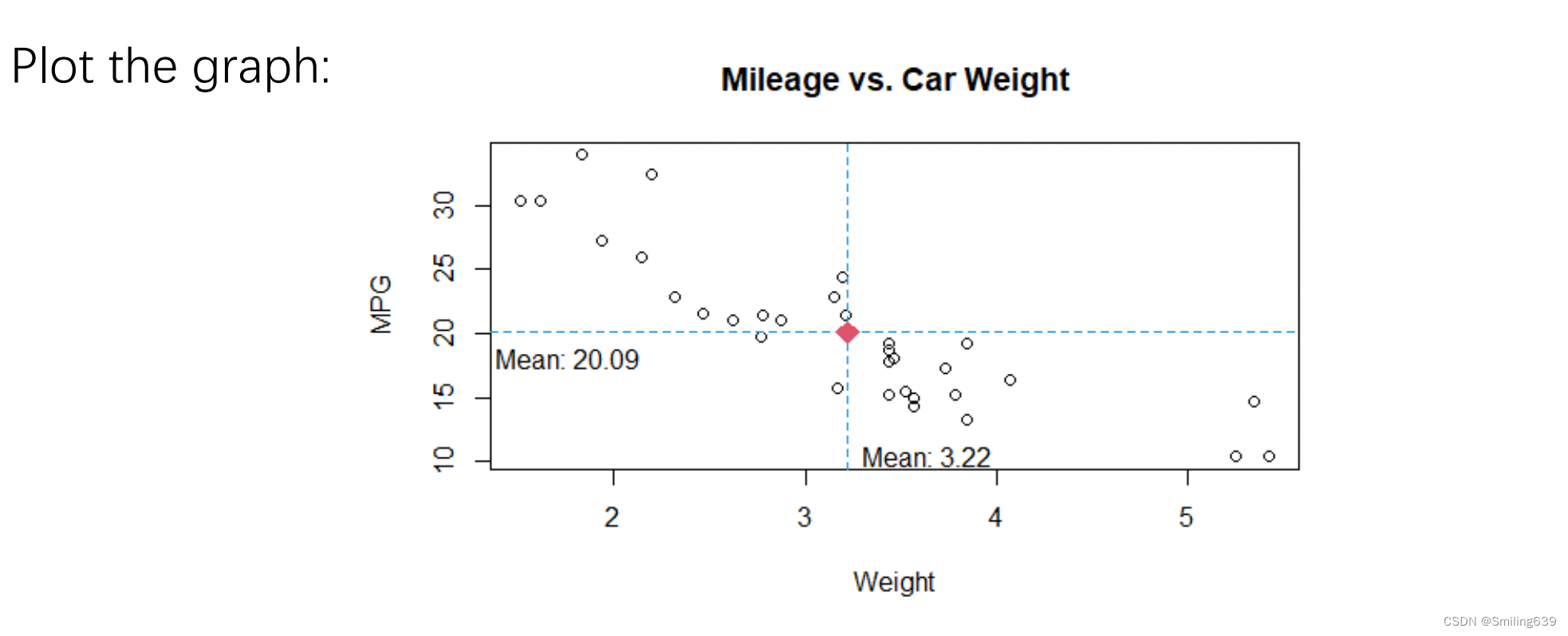
例1
答案:
opar <- par(no.readonly=TRUE)
plot(mtcars$wt, mtcars$mpg,main="Mileage vs. Car Weight",xlab="Weight",ylab="MPG",pch=1, col="black")
abline(h=mean(mtcars$mpg),v=mean(mtcars$wt),col="blue",lty=2)
points(mean(mtcars$wt),mean(mtcars$mpg),pch=23,cex=1.5,col="red",bg="red")
text(min(mtcars$wt)+0.25,mean(mtcars$mpg),paste("Mean:",round(mean(mtcars$mpg),2)),pos=1)
text(mean(mtcars$wt),min(mtcars$mpg),paste("Mean:",round(mean(mtcars$wt),2)),pos=4)#下左上右1234
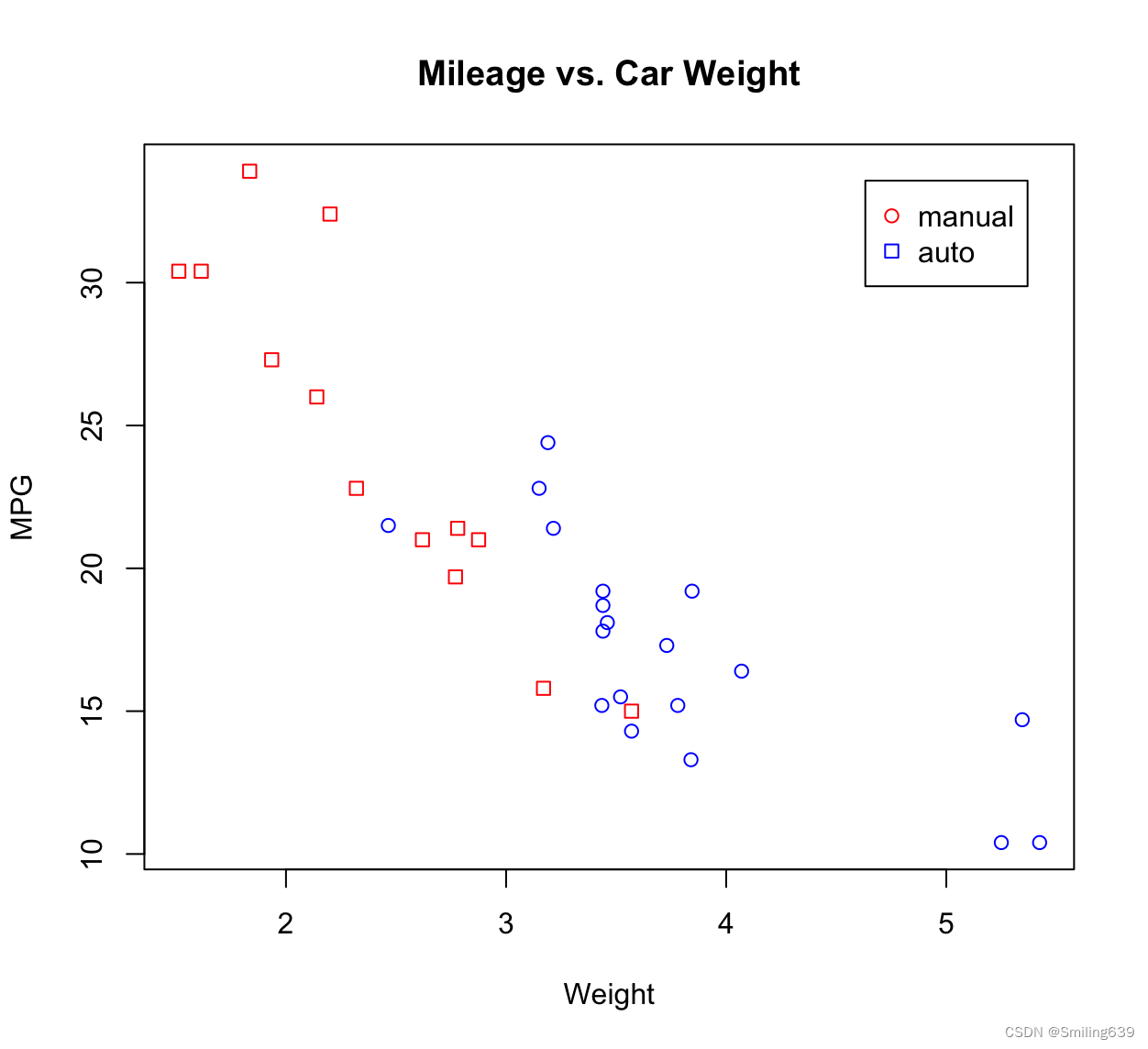
例2
答案:
plot(mtcars$wt, mtcars$mpg, main="Mileage vs. Car Weight", xlab="Weight", ylab="MPG",col=ifelse(mtcars$am==0,"blue","red"),pch=ifelse(mtcars$am==0,1,0))
legend("topright",inset=0.05,"Transmission",legend=c("manual","auto"),col=c("red","blue"),pch=c(1,0))















 9004
9004











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









