










提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
自注意力机制的原理相当于一个词在其上下文中的联系,即将这一个词赋予这一句话中将每个词乘以不同的权重,即是这一个词对上下文的关系程度。
I am a student将本句话中的a对上下文的关系程度即为,将上下的词分别乘以不同的权重赋予到a词中,这就是a对上下问的关系程度。
接下来详细介绍自注意力机制如何计算?
一、总述
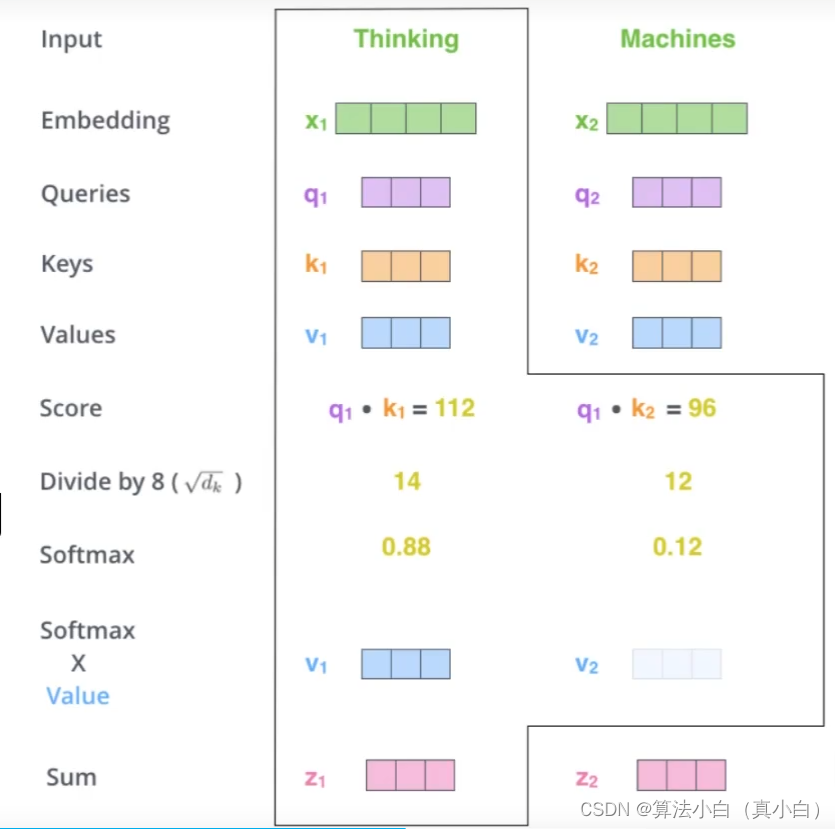
- input输入thinking和machines两个词作为样例
- 先对输入经过Embedding编码得到词向量
- 想得到当前词语上下文的关系,可以当作是加权
- 最后构建三个矩阵分别来查询当前词跟其他词的关系,以及特征向量的表达。
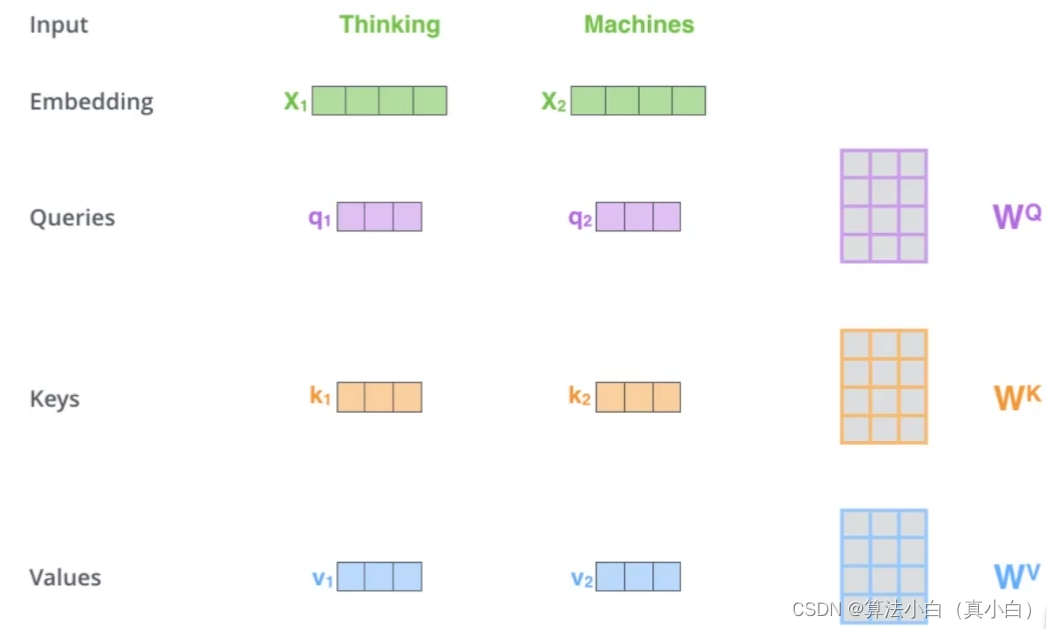
二、如何计算self-attention
- 三个需要训练的矩阵
- Q:query,要去查询的
- K:key,等着被查的
- V:value,实际的特征信息
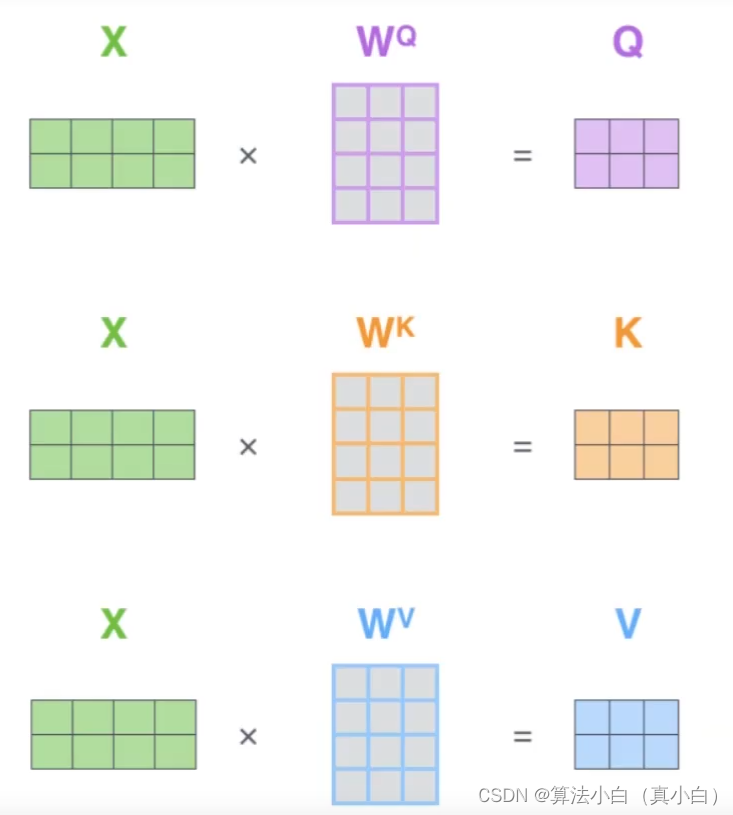
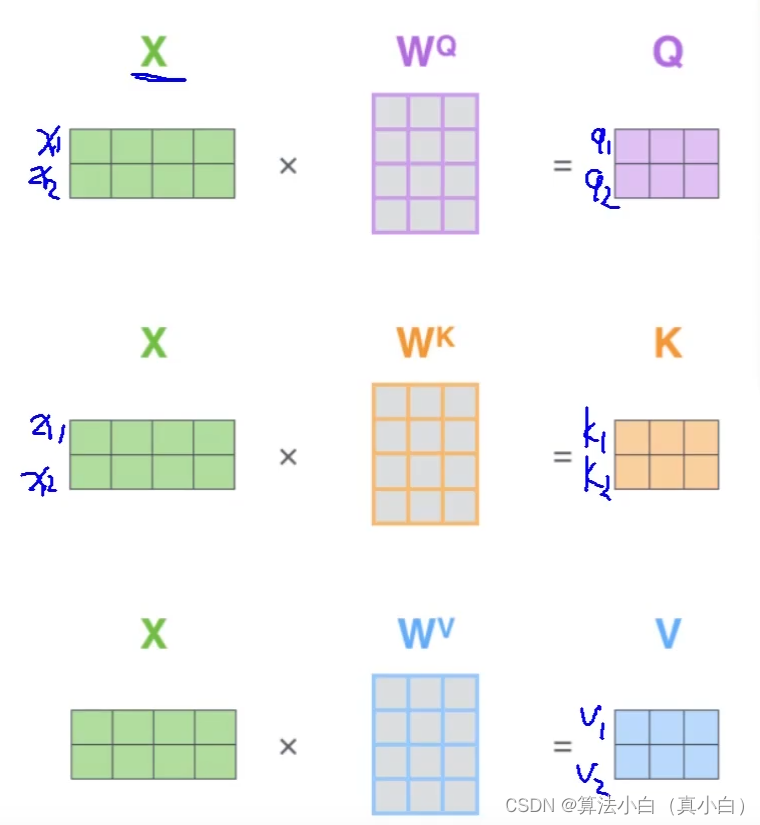
即设X矩阵有x1和x2两个向量,经过各自的权重矩阵相乘后得到各自的特征矩阵。
- q与k的内积表示有多少匹配度
- 输入两个向量得到一个分值
- K:key,等着被查的
- V:value,实际的特征信息
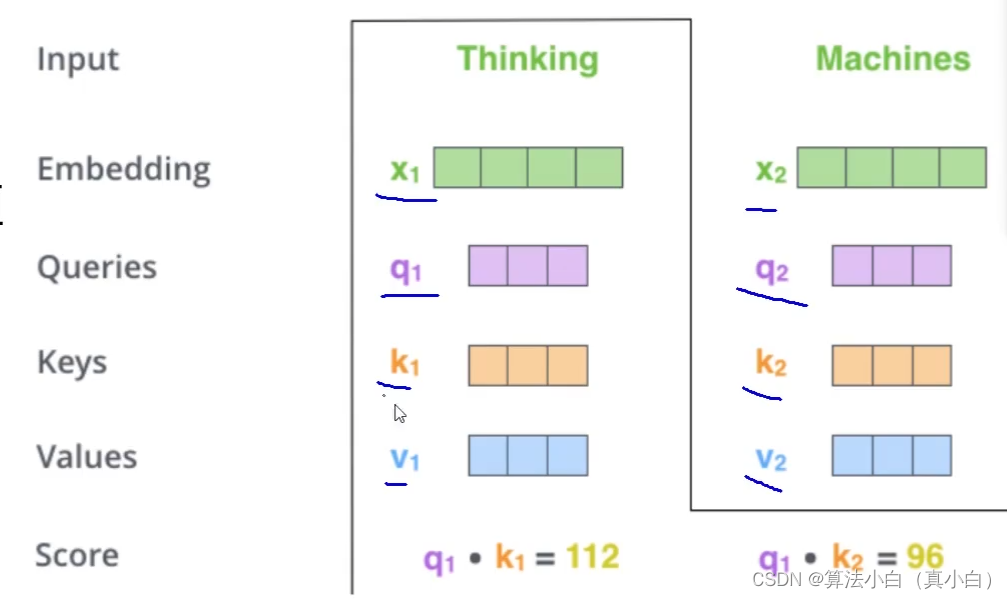
- 其中上述的q1 × \times ×k1和q1 × \times ×k2内积的结果分别为第一个词和第一个词的匹配程度和第一个词与第二个词的匹配程度,这两个都是对第一个词的计算不是第二个的。
三、softmax归一处理
- softmax函数是一种将多分类问题转化为每一类是多少概率的函数,范围在 0 − 1 0-1 0−1。
- 首先回忆一下以前的softmax。softmax又称归一化指数函数。它是二分类函数sigmoid在多分类上的推广,目的是将多分类的结果以概率的形式展现出来。它将多个神经元的输出,映射到(0,1)区间内,可以看成概率来理解,从而来进行多分类!假设我们有一个数组,V,Vi表示V中的第i个元素,那么这个元素的softmax值就是
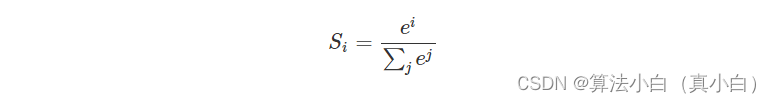
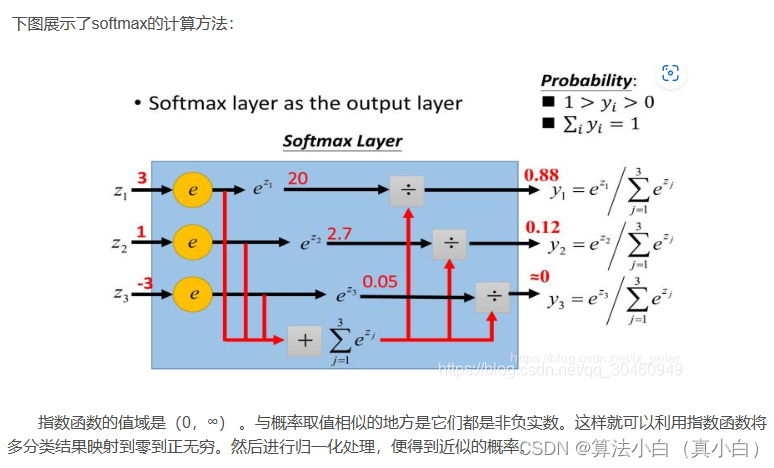
那么在本文中softmax的计算和作用如下: - 将第二步的最终得分经过softmax就是最终上下文结果
- Scaled Dot-Product Attention 不能让分值随着向量维度的增加而增大
- 本文的计算公式如下:
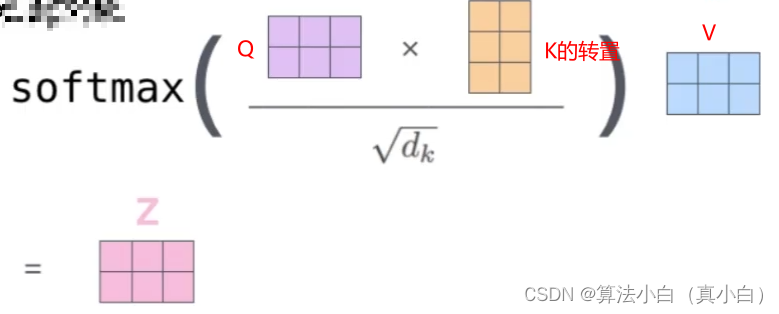
- 最后输出结果如下图:
计算一句话中一个词与本句话中所有词的关系程度也就是内积然后进行softmax归一化,将得到的这个词对每个词的关系概率乘以各自的V向量最终输出本词的Attention Value。
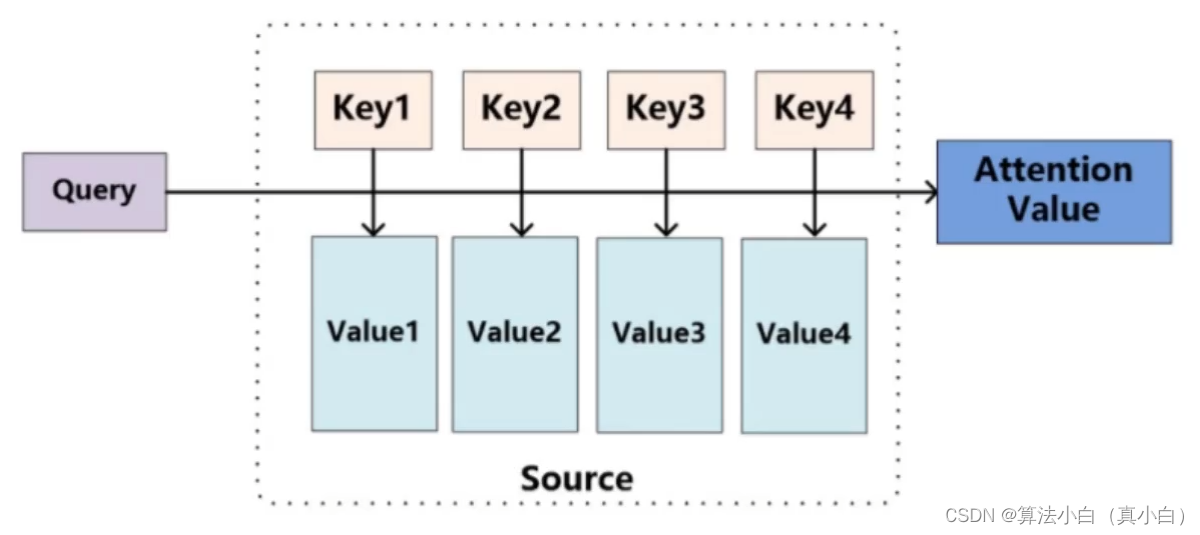
Attention整体计算流程
- Attention计算流程
- 每个词的Q都会跟每一个K计算得分
- Softmax后得到整个的加权结果(假设下面的词的维度为64维)
- 此时每个词看的不只是它前面的序列而是整个输入序列
- 同以时间计算出所有词的表示结果


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











