







array
arry不过是个数组罢了,那我们已经有了vector 和自定义的普通数组那为什么还要弄出来一个array数组呢,这么做当然有道理,使用vector是在堆上开辟的空间,而对堆的操作比对栈的操作要慢得多,但是它的优点是提供了很多的外部接口让我们使用很方便,
而对于传统数组,虽然是在栈上操作,但是除了这些数据是顺序相连之外好像其他的工作比如排序,去大小,插入元素…都需要我们自己去做
为了综合vector 和 传统数组的优点,所以array就应运而生了,
它既是在栈上操作提高了效率,又提供了一些常用的外部接口
template <class Ty, std::size_t N>
class array;
描述了一个对象,此对象控制类型 Ty 的元素的长度序列 N。 此序列存储为 Ty 的数组,包含在 array<Ty, N> 对象中。
Ty 元素的类型。
N 元素数量。
成员属性:
- const_iterator 受控序列的常量迭代器的类型。
- const_pointer 元素的常量指针的类型。
- const_reference 元素的常量引用的类型。
- const_reverse_iterator 受控序列的常量反向迭代器的类型。
- difference_type 头尾迭代器之间的距离
- iterator 受控序列的迭代器的类型。
- pointer 指向元素的指针的类型。
- reference 元素的引用的类型。
- reverse_iterator 受控序列的反向迭代器的类型。
- size_type 两个元素间的无符号距离的类型。
- value_type 元素的类型。
成员函数:
-
array<type,n> 构造一个数组对象。type 为元素类型 n为元素个数
//也可以用已存在数组拷贝构造 array<type,n>a(b); -
assign (已过时,使用 fill。)替换所有元素。
-
at 访问指定位置处的元素。//稳定性高 而使用[]访问效率高
-
back 访问最后一个元素。
-
begin 指定受控序列的开头。
-
cbegin 返回一个随机访问常量迭代器,它指向数组中的第一个元素。
-
cend 返回一个随机访问常量迭代器,它指向刚超过数组末尾的位置。
-
crbegin 返回一个指向反向数据中第一个元素的常量迭代器。
-
crend 返回一个指向反向数组末尾的常量迭代器。
-
data 获取第一个元素的地址。
-
empty 测试元素是否存在。
-
end 指定受控序列的末尾。//指向最后一个元素的后面一个位置
-
fill 将所有元素替换为指定值。
-
front 访问第一个元素。
-
max_size 对元素数进行计数。//这个不是你插入的元素个数而是构造容量的大小即最多放多少个元素
-
rbegin 指定反向受控序列的开头。//指向最后一个元素
-
rend 指定反向受控序列的末尾。//**指向第一个元素的前一个位置 注意为了顺应逆向的思维,对
-
rbegin 和rend的运算操作被重载了 例如 --rend()才是指向第一个元素 而–end()就是指向最后一个元素
-
size 对元素数进行计数。
-
swap 交换两个容器的内容。
-
array::operator= 替换受控序列。
-
array::operator[] 访问指定位置处的元素。
测试程序:
#include<iostream>
#include<array>
using namespace std;
array<int, 10>b;
void print(array<int, 10>& b)
{
for (auto x : b)
cout << x << " ";
cout << endl;
}
void test1(array<int,10>& t)
{
for (int i = 0; i < 10; i++)
t[i] = i + 1;
cout << "成员属性测试:" << endl;
cout << "difference_type:" << typeid(array<int, 10>::difference_type).name() << endl;
cout << "iterator:" << typeid(t.begin()).name() << endl;
cout << "pointer:" << typeid(array<int, 10>::pointer).name() << endl;
cout<<"reference:"<< typeid(array<int, 10>::reference).name()<< endl;
cout << "reserve_iterator:" << typeid(array<int, 10>::reference).name() << endl;
cout << "sizetype:" << typeid(array<int, 10>::size_type).name() << endl;
cout << "value_type:" << typeid(array<int, 10>::value_type).name() << endl;
cout << "成员函数测试:" << endl;
cout << "遍历数组array:" << endl;
print(t);
array<int, 10>a(t);
cout << "遍历利用拷贝构造的array数组:" << endl;
print(a);
cout << "利用at 访问指定位置处元素:" << endl;
cout << t.at(3) << endl;
cout << "利用front() begin() 和 back()访问开头和结尾的元素:" << endl;
cout <<t.front()<< *t.begin() << " " << t.back() << endl;
cout << "利用data()访问第一个元素的地址:" << endl;
cout << t.data() << endl;
cout << "使用max_size() size()对元素数计数:" << endl;
cout << t.max_size() << endl;
cout << t.size()<< endl;
cout << "使用rbegin()访问最后一个元素:" << endl;
cout << *t.rbegin() << endl;
cout << "使用--rend()访问第一个元素:" << endl;
cout << *(--t.rend())<< endl;
cout << "使用fill()替换array中的所有元素:" << endl;
t.fill(2);
cout << "遍历替换后的数组:" << endl;
print(t);
cout << "使用sawp()替换数组:" << endl;
t.swap(a);
cout << "遍历替换后的数组:" << endl;
print(t);
cout << "使用重载= 替换数组:" << endl;
t = a;
cout << "遍历替换后的数组:" << endl;
print(t);
}
int main()
{
test1(t);
return 0;
}
测试结果:

tuple
元组Tuple,可以将任意种类型建立闭包,和pair类似,但pair只能两个类型。
之前我们用的容器vector deque set 都只能储存同一类型的数据 就算是map
class tuple { tuple(); explicit tuple(P1, P2, ..., PN); // 0 < N tuple(const tuple&); template <class U1, class U2, ..., class UN>
tuple(const tuple<U1, U2, ..., UN>&); t
emplate <class U1, class U2>
tuple(const pair<U1, U2>&); // N == 2
void swap(tuple& right);
tuple& operator=(const tuple&);
template <class U1, class U2, ..., class UN>
tuple& operator=(const tuple<U1, U2, ..., UN>&);
template <class U1, class U2>
tuple& operator=(const pair<U1, U2>&); // N == 2
};
这个类模板描述了一个对象,该对象分别存储 T1、T2、…、TN 类型的 N 个对象,
tuple<T1, T2, …, TN> 的范围是其模板参数的数目,模板参数 Ti 的索引及该类型的相应存储值的索引是 i - 1。
成员函数:
- 默认构造函数
constexpr tuple(); - 拷贝构造函数
tuple (const tuple& tpl); - 移动构造函数
tuple (tuple&& tpl); - 隐式类型转换构造函数
template <class… UTypes>
tuple (const tuple<UTypes…>& tpl); //左值方式
template <class… UTypes>
tuple (tuple<UTypes…>&& tpl); //右值方式 - 支持初始化列表的构造函数
explicit tuple (const Types&… elems); //左值方式
template <class… UTypes>
explicit tuple (UTypes&&… elems); //右值方式 - 将pair对象转换为tuple对象
template <class U1, class U2>
tuple (const pair<U1,U2>& pr); //左值方式
template <class U1, class U2>
tuple (pair<U1,U2>&& pr); //右值方式
获取tuple长度的函数 tuple_size(<tuple&>::value();
获取tuple元素的函数 get<size_t index>(tuple&);//获取指定位置的元素 但是这里的index不能为变量 但是实际中我们往往要用到变量索引,比如循环遍历的时候的变量索引,为了解决这一问题,我在下面提供了一种解决方法
get<value_type>(tuple&);//获取指定类型的元素
测试程序:
#include<iostream>
using namespace std;
#include<tuple>
#include<string>
#include <utility> //index_sequence
string str = "c++天下第一";
int in = 13;
double dou = 1.032;
char ch = 'o';
tuple<string, int, double, char>a1(str, in, dou, ch);//左值形式的初始化列表形式初始化tuple容器
tuple<string, int, double, char>a("123", 1, 1.20, 'n');//右值形式的初始化列表形式初始化tuple容器
template<typename Visit>
void VisitTuple(size_t index, std::tuple<>& t, Visit v) {
}
template<typename T, typename ... Ts, typename Visit>
void VisitTuple(size_t index, std::tuple<T, Ts...>& t, Visit v) {
if (index >= (1 + sizeof...(Ts))) {
throw std::invalid_argument("bad index");
}
if (index > 0) {
VisitTuple(index - 1, reinterpret_cast<std::tuple<Ts...>&>(t), v); 键点
}
else {
v(std::get<0>(t));
}
}
class Vistor {
public:
template<typename Arg>
void operator()(Arg&& arg) {
std::clog << arg << std::endl;
}
};
//上面就是实现通过变量索引访问tuple元素的方法 由于篇幅过长,我在另一篇文章再做详细解释
void test()
{
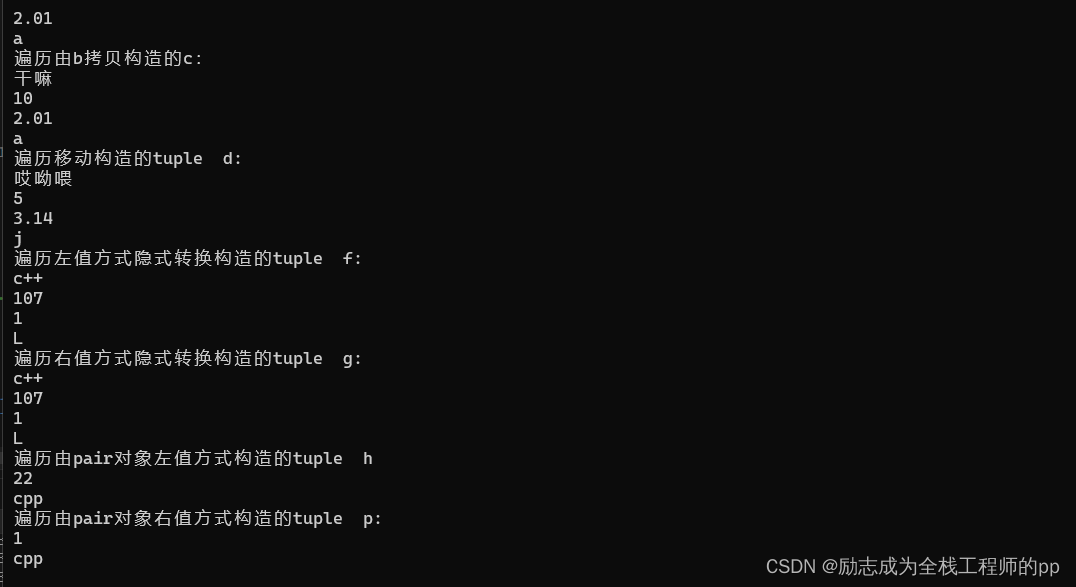
tuple<string, int, double, char>b;
b= { "干嘛",10,2.01,'a' };//定义后以赋值形式初始化容器
cout << "遍历tuple b:" << endl;
size_t len = tuple_size<decltype(b)>::value;
for (size_t i = 0; i < len; i++)
VisitTuple(i, b,Vistor());
tuple<string,int, double, char>c(b);//拷贝构造
cout << "遍历由b拷贝构造的c:" << endl;
for (size_t i = 0; i < len; i++)
VisitTuple(i, c, Vistor());
tuple<string, int, double, char>d(tuple<string, int, double, char>("哎呦喂", 5, 3.14, 'j'));//移动构造
cout << "遍历移动构造的tuple d:" << endl;
for (size_t i = 0; i < 4; i++)
VisitTuple(i, d, Vistor());
tuple<string, char, float, int>e("c++", 'k', 1.0, 76);
tuple<string, int, double, char>f(e);//隐式类型转换构造 左值方式
cout << "遍历左值方式隐式转换构造的tuple f:" << endl;
for (size_t i = 0; i < 4; i++)
VisitTuple(i, f, Vistor());
tuple<string, int, double, char>g(tuple<string, char, float, int>("c++", 'k', 1.0, 76));//隐式类型转化 右值形式
cout << "遍历右值方式隐式转换构造的tuple g:" << endl;
for (size_t i = 0; i < len; i++)
VisitTuple(i, g, Vistor());
pair<int, string>pa(22, "cpp");
tuple<int,string>h(pa);//左值形式将pair对象转为tuple对象
cout << "遍历由pair对象左值方式构造的tuple h" << endl;
for (size_t i = 0; i < 2; i++)
VisitTuple(i, h, Vistor());
tuple<int, string>p(pair<int,string>(1, "cpp"));//右值形式将pair对象转为tuple对象
cout << "遍历由pair对象右值方式构造的tuple p:" << endl;
for (size_t i = 0; i < 2; i++)
VisitTuple(i, p, Vistor());
};
int main()
{
test();
return 0;
}
测试结果:
forward_list
c++11之前在STL中已经有了List 不过是双向链表
而forward_list就是与之对立的单向链表 适用于不需要前向操作的场景 空间利用效率更高
成员属性:
- allocator_type 一种类型,用于表示转发列表对象的分配器类。
- const_iterator 一种类型,用于为转发列表提供常量迭代器。
- const_pointer 一种类型,用于提供指向转发列表中的 const 元素的指针。
- const_reference 一种类型,用于提供对转发列表中元素的常量引用。
- difference_type 一种有符号整数类型,可用于表示转发列表中某个范围类迭代器所指向元素之间的元素数目。
- Iterator 一种类型,用于为转发列表提供迭代器。
- pointer 一种类型,用于提供指向转发列表中元素的指针。
- reference 一种类型,用于提供对转发列表中元素的引用。
- size_type 一种类型,用于表示两个元素之间的无符号距离。
- value_type 一种类型,用于表示转发列表中存储的元素的类型。
成员函数: - assign 清除的元素,并将一组新的元素复制到目标列表。
- before_begin 返回第一个元素之前的位置的迭代器。
- begin 返回第一个元素的迭代器。
- cbefore_begin 返回第一个元素之前的位置的常量迭代器。
- cbegin 返回第一个元素的常量迭代器。
- cend 返回中最后一个元素之后的位置的常量迭代器。
- clear 清除中的所有元素。
- emplace_after 在指定位置之后移动构造新元素。
- emplace_front 在列表的起始位置添加一个就地构造的元素。
- empty 测试转发列表是否为空。
- end 返回最后一个元素之后的位置的迭代器。
- erase_after 删除指定位置之后的元素。
- front 返回第一个元素的引用。
- get_allocator 返回用于构造的分配器对象的一个副本。
- insert_after 在指定位置之后添加元素。
- max_size 返回最大长度,这个时forward_list最多可以容纳的元素个数 并不是当前forword_list中的元素个数
- merge 将元素删除,将它们插入本链表并且按指定的排序方式排序,将新的组合元素集以升序或其他指定顺序排序。(注意:这个函数在执行前必须保证对两个链表已经按照同一种排序方式排好序了,否则直接合并会报错,这和它内置的算法有关)
- pop_front 删除链表起始处的一个元素。
- push_front 在链表起始处添加一个元素。
- remove(const Type& val)删除 清除链表中与指定值匹配的元素。
- remove_if 将满足指定谓词的元素从链表中清除。//这里的参数是一个一元谓词 或者是一个返回值为bool类型的Lambda表达式 如果返回的true就删除
- resize 为链表指定新的大小。
void resize(size_type _Newsize);
void resize(size_type _Newsize, const
Type& val);
注意:如果调整的大小比原来的大小小的话那么从前面删除多的元素
如果调整的大小比原来的大小大的话就从前将你指定的数据填充
- reverse 颠倒链表中元素的顺序。
- sort 按升序或按谓词指定的顺序排列元素。 mo’r
- splice_after 重新联结节点间的链接。
// 插入整个链表
splice_after(const_iterator Where, forward_list& Source); void
splice_after(const_iterator Where, forward_list&& Source);
// 插入链表中的某一个元素
splice_after(const_iterator Where, forward_list& Source,
const_iterator Iter); void splice_after(const_iterator Where,
forward_list&& Source, const_iterator Iter);
// 插入链表中的一部分
splice_after(
const_iterator Where,
forward_list& Source,
const_iterator First,
const_iterator Last);
------------------------------
void splice_after(
const_iterator Where,
forward_list&& Source,
const_iterator First,
const_iterator Last);
- swap 交换两个转发列表的元素。
- unique //保留每个唯一元素的第一个元素,并删除其余元素。 元素必须进行排序,以使具有相等值的元素在列表中相邻。比如 1 1 1 2 2 3 3 只保留第一个1 2 3那么处理之后的元素还剩1 2 3
void unique();
template
void unique(BinaryPredicate comp);
//comp用于比较连续元素的二元谓词。
注意:froward_list中的正向迭代器没有重载-- 运算符,只能++
很简单,因为是单向的只能从前往后,正向迭代器自然也只能往后走
测试程序:
#include<iostream>
using namespace std;
#include<forward_list>
template<class T>
typename forward_list< T>::iterator print( forward_list<T>&b ,int i)
{
if (i<=0||i>b.max_size())
{
return b.begin();
}
else
{
auto x = b.begin();
for (int j = 0; j < i-1;j++)
{
x++;
}
return x;
}
}
void test3()
{
forward_list<int>a;
for (int i = 1; i <=10; i++)
a.push_front(i);
forward_list<int>b;
for (int i = 20; i <=25; i++)
b.push_front(i);
cout << "属性测试:" << endl;
cout << "allocator_type:" << typeid(a.get_allocator()).name();
cout << "diffrence_type:" << typeid(forward_list<int>::difference_type).name() << endl;
cout << "iterator:" << typeid(a.begin()).name() << endl;
cout << "pointer:" << typeid(forward_list<int>::pointer).name() << endl;
cout << "reference:" << typeid(forward_list<int>::reference).name() << endl;
cout << "size_type" << typeid(forward_list<int>::size_type).name() << endl;
cout << "value_type:" << typeid(forward_list<int>::value_type).name() << endl;
cout << "成员函数测试:" << endl;
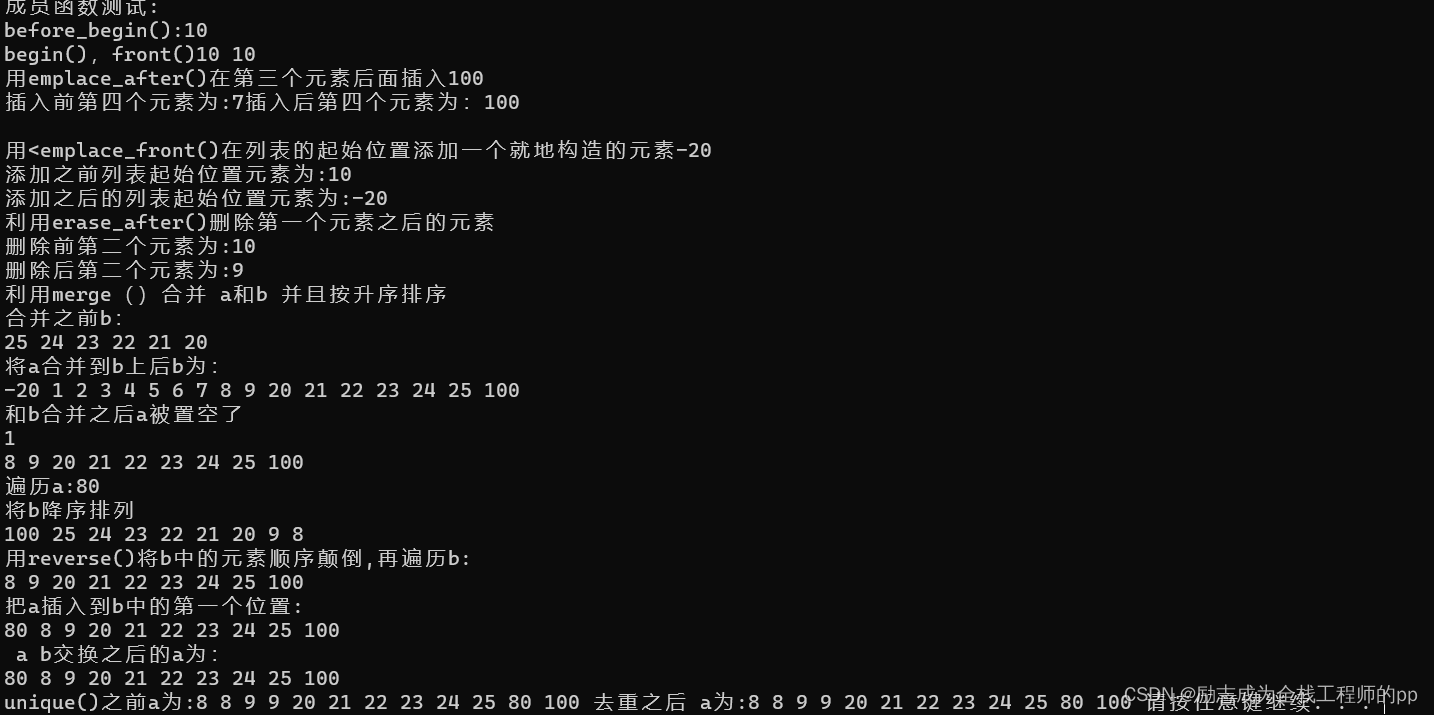
cout << "before_begin():" << *(++a.before_begin()) << endl;
cout << "begin(),front()" << *a.begin()<< " " << a.front() << endl;
cout << "用emplace_after()在第三个元素后面插入100" << endl;
cout << "插入前第四个元素为:"<<*print(a,4);
a.emplace_after(print(a,3), 100);
cout << "插入后第四个元素为:";
cout << *print(a, 4) << endl;
cout << endl << "用<emplace_front()在列表的起始位置添加一个就地构造的元素-20" << endl;
cout << "添加之前列表起始位置元素为:" << a.front() << endl;
a.emplace_front(-20);
cout << "添加之后的列表起始位置元素为:" << a.front() << endl;
cout << "利用erase_after()删除第一个元素之后的元素" << endl;
cout << "删除前第二个元素为:" << *print(a,2) << endl;
a.erase_after(a.begin());
cout << "删除后第二个元素为:" << *print(a,2)<<endl;
cout << "利用merge()合并 a和b 并且按升序排序" << endl;
cout << "合并之前b:" << endl;
for (int i =1;print(b,i)!=b.end(); ++i)
{
cout << *print(b,i) << " ";
}
a.sort();//将 a按升序排序
b.sort();//将 b按升序排序
cout << endl << "将a合并到b上后b为:" << endl;
b.merge(a);
for (int i =1;print(b,i)!=b.end(); i++)
{
cout << *print(b, i) << " ";
}
cout << endl;
if (a.empty())
cout << "和b合并之后a被置空了" << endl;
b.remove(-20);//删除b中的-20
cout << b.front() << endl;
b.remove_if([](const int& a)mutable ->bool {return a < 8; });//删除b中小于8的元素
for (int i = 1; print(b, i) != b.end(); i++)
{
cout << *print(b, i) << " ";
}
cout << endl;
a.push_front(78);
a.push_front(80);
a.resize(1);
cout << "遍历a:";
for (int i = 1; print(a, i) != a.end(); i++)
{
cout << *print(a, i) << " ";
}
cout << endl;
cout << "将b降序排列" << endl;
b.sort([](const int& m, const int& n)mutable ->bool {return m > n; });
for (int i = 1; print(b, i) != b.end(); i++)
{
cout << *print(b, i) << " ";
}
cout << endl;
cout << "用reverse()将b中的元素顺序颠倒,再遍历b:" << endl;
b.reverse();
for (int i = 1; print(b, i) != b.end(); i++)
{
cout << *print(b, i) << " ";
}
cout << endl;
b.splice_after(b.before_begin(), a);//把a插入到b中的第一个位置
cout << "把a插入到b中的第一个位置:" << endl;
for (int i = 1; print(b, i) != b.end(); i++)
{
cout << *print(b, i) << " ";
}
cout << endl;
b.swap(a);//a b交换
cout << " a b交换之后的a为:" << endl;
for (int i = 1; print(a, i) != a.end(); i++)
{
cout << *print(a, i) << " ";
}
cout << endl;
a.push_front(8);
a.push_front(9);
cout << "unique()之前a为:";
a.sort();
for (int i = 1; print(a, i) != a.end(); i++)
{
cout << *print(a, i) << " ";
}
cout << "去重之后 a为:";
for (int i = 1; print(a, i) != a.end(); i++)
{
cout << *print(a, i) << " ";
}
}
int main()
{
test3();
system("pause");
return 0;
}
测试结果:
unordered_map,unorder_multimap
底层是使用哈希表实现的
template <class Key,//键类型
class Ty,//映射类型(值类型)
class Hash = std::hash<Key>,//哈希函数对象
class Pred = std::equal_to<Key>,//相等比较函数类型
class Alloc = std::allocator<std::pair<const Key, Ty>>>//分配器类型
class unordered_map;
此类模板描述用于控制 std::pair<const Key, Ty> 类型的变长元素序列的对象。
序列由哈希函数弱排序,哈希函数将此序列分区到称为存储桶的有序序列集中。 在每个存储桶中,比较函数将确定任一元素对是否具有等效顺序。
每个元素存储两个对象,包括一个排序键和一个值。
序列以允许查找、插入和移除任意元素的方式表示,并包含与序列中的元素数量无关的操作(常量时间),至少在所有存储桶长度大致相等时如此。
在最坏情况下,当所有元素位于一个存储桶中时,操作数量与序列中的元素数量成比例(线性时间)。
此外,插入元素不会使迭代器失效,移除元素仅会使指向已移除元素的迭代器失效。
成员属性:
- allocator_type 用于管理存储的分配器的类型。
- const_iterator 受控序列的常量迭代器的类型。
- const_local_iterator 受控序列的常量存储桶迭代器的类型。
- const_pointer 元素的常量指针的类型。
- const_reference 元素的常量引用的类型。
- difference_type 两个元素间的带符号距离的类型。
- hasher 哈希函数的类型。
- iterator 受控序列的迭代器的类型。
- key_equal 比较函数的类型。
- key_type 排序键的类型。
- local_iterator 受控序列的存储桶迭代器的类型。
- mapped_type 与每个键关联的映射值的类型。
- pointer 指向元素的指针的类型。
- reference 元素的引用的类型。
- size_type 两个元素间的无符号距离的类型。
- value_type 元素的类型。
成员函数:
- at 查找具有指定键的元素。//at(key)
- begin 指定受控序列的开头。
- bucket 获取键值的存储桶编号。//bucket(key)
- bucket_count 获取存储桶数。
- bucket_size 获取存储桶的大小。//size_type bucket_size(储存桶编号) const;
- cbegin 指定受控序列的开头。
- cend 指定受控序列的末尾。
- clear 删除所有元素。
- count 查找与指定键匹配的元素数。containsC++20 检查 unordered_map 中是否包含具有指定键
- 的元素。
- emplace 添加就地构造的元素。
- emplace_hint 添加就地构造的元素,附带提示。
- empty 测试元素是否存在。
- end 指定受控序列的末尾。
- equal_range 查找与指定键匹配的范围。
- erase 移除指定位置处的元素。
- find 查找与指定键匹配的元素。
- get_allocator 获取存储的分配器对象。
- hash_function 获取存储的哈希函数对象。
- insert 添加元素。
- key_eq 获取存储的比较函数对象。
- load_factor 对每个存储桶的平均元素数进行计数。
- max_bucket_count 获取最大的存储桶数。
- max_load_factor 获取或设置每个存储桶的最多元素数。
- max_size 获取受控序列的最大大小。
- rehash 重新生成哈希表。
- size 对元素数进行计数。
- swap 交换两个容器的内容。
- unordered_map 构造容器对象。
- unordered_map::operator[] 查找或插入具有指定键的元素。
- unordered_map::operator= 复制哈希表。
注意:用迭代器访问元素的时候 iterator it; 键:it->first;值:it->second;
unordered_multimap 除了键值可以重复,其他基本和unordered_map一样
测试程序:
#include<iostream>
using namespace std;
#include<unordered_map>
#include<string>
void test4()
{
unordered_map<int, string>a;
a.insert(make_pair(1, "c++真有趣"));
a.insert(make_pair(2, "我爱c++"));
a.insert(make_pair(3, "c++好难"));
a.insert(make_pair(4, "c++语法复杂"));
a.insert(make_pair(5, "c++是个大杂烩"));
a.insert(make_pair(6, "c++爱我"));
a.insert(make_pair(7, "c++性能高"));
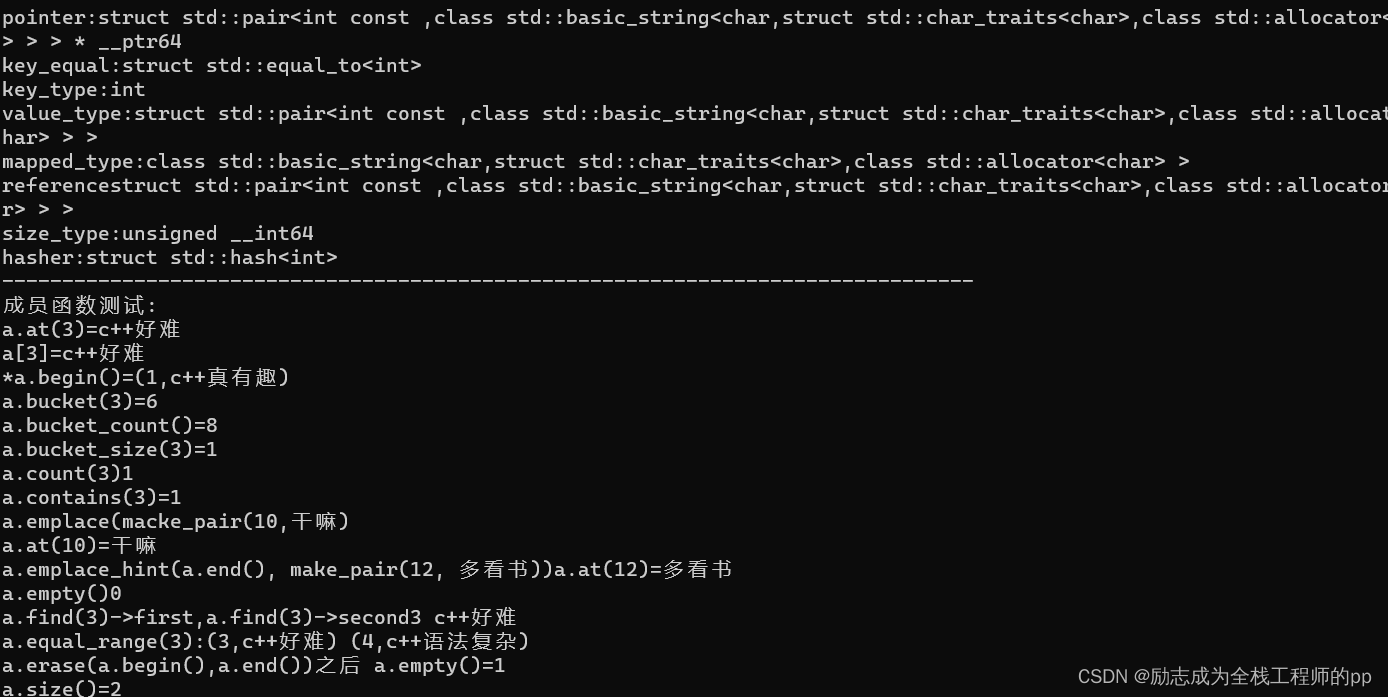
cout << "成员属性测试:" << endl;
cout << "allocator_type:" << typeid(unordered_map<int, string>::allocator_type).name() << endl;
cout << "difference_type:" << typeid(unordered_map<int, string>::difference_type).name() << endl;
cout << "iterator:" << typeid(unordered_map<int, string>::iterator).name() << endl;
cout << "pointer:" << typeid(unordered_map<int, string>::pointer).name() << endl;
cout << "key_equal:" << typeid(unordered_map<int, string>::key_equal).name() << endl;
cout << "key_type:" << typeid(unordered_map<int, string>::key_type).name() << endl;
cout << "value_type:" << typeid(unordered_map<int, string>::value_type).name() << endl;
cout << "mapped_type:" << typeid(unordered_map<int, string>::mapped_type).name() << endl;
cout << "reference" << typeid(unordered_map<int, string>::reference).name() << endl;
cout << "size_type:" << typeid(unordered_map<int, string>::size_type).name() << endl;
cout << "hasher:" << typeid(unordered_map<int, string>::hasher).name() << endl;
cout << "---------------------------------------------------------------------------------" << endl;
cout << "成员函数测试:" << endl;
cout << "a.at(3)=" << a.at(3) << endl;
cout << "a[3]=" << a[3] << endl;
cout << "*a.begin()=" << "(" << a.begin()->first << "," << a.begin()->second << ")" << endl;
cout << "a.bucket(3)=" << a.bucket(3) << endl;
cout << "a.bucket_count()=" << a.bucket_count() << endl;
cout << "a.bucket_size(3)=" << a.bucket_size(3) << endl;
cout << "a.count(3)" << a.count(3) << endl;
cout << "a.contains(3)=" << a.contains(3) << endl;//注意这个时c++20 里新增的如果报错需要将项目属性的c++标准改为c++20
cout << "a.emplace(macke_pair(10,""干嘛"")" << endl;
a.emplace(make_pair(10, "干嘛"));
cout << "a.at(10)=" << a.at(10) << endl;
cout << "a.emplace_hint(a.end(), make_pair(12, ""多看书""))";
a.emplace_hint(a.end(), make_pair(12, "多看书"));
cout << "a.at(12)=" << a.at(12) << endl;
cout << "a.empty()" << a.empty() << endl;
cout << "a.find(3)->first,a.find(3)->second" << a.find(3)->first << " " << a.find(3)->second << endl;
cout << "a.equal_range(3):" << "(" << a.equal_range(3).first->first << "," << a.equal_range(3).first->second << ")" << " (" << a.equal_range(3).second->first << ","<<a.equal_range(3).second->second << ")" << endl;
unordered_map<int, string>b = a;
a.erase(a.begin(),a.end());
cout << "a.erase(a.begin(),a.end())之后 a.empty()=" << a.empty() << endl;
a.insert(make_pair(1, "酷酷酷"));
a.insert(make_pair(2, "啦啦啦啦"));
cout << "a.size()=" << a.size() << endl;
}
int main()
{
test4();
return 0;
}
测试结果:
unorderd_set,unorderd_multiset
和unordered_map的区别就是 键和值一样
其他的没有什么区别,底层也是用哈希表实现的
这个类模板描述用于控制 const Key 类型的变长元素序列的对象。
序列由哈希函数弱排序,哈希函数将此序列分区到称为存储桶的有序序列集中。 在每个存储桶中,比较函数将确定任一元素对是否具有等效顺序。
每个元素同时用作排序键和值。
序列以允许查找、插入和移除任意元素的方式表示,并包含与序列中的元素数量无关的多个操作(常量时间),至少在所有存储桶长度大致相等时如此。
在最坏情况下,当所有元素位于一个存储桶中时,操作数量与序列中的元素数量成比例(线性时间)。
插入元素不会使迭代器失效,移除元素仅会使指向已移除元素的迭代器失效。
cpptemplate <
class Key,
class Hash = std::hash<Key>,
class Pred = std::equal_to<Key>,
class Alloc = std::allocator<Key>>
class unordered_set;
成员属性:

成员函数:

成员属性和成员函数基本一样,所以这里就不再赘述。















 164
164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











