






一.理论
logistic回归又称logistic回归分析,是一种广义的线性回归分析模型,常用于数据挖掘,疾病自动诊断,经济预测等领域。 逻辑回归根据给定的自变量数据集来估计事件的发生概率,由于结果是一个概率,因此因变量的范围在 0 和 1 之间。 [3]例如,探讨引发疾病的危险因素,并根据危险因素预测疾病发生的概率等。以胃癌病情分析为例,选择两组人群,一组是胃癌组,一组是非胃癌组,两组人群必定具有不同的体征与生活方式等。因此因变量就为是否胃癌,值为“是”或“否”,自变量就可以包括很多了,如年龄、性别、饮食习惯、幽门螺杆菌感染等。自变量既可以是连续的,也可以是分类的。然后通过logistic回归分析,可以得到自变量的权重,从而可以大致了解到底哪些因素是胃癌的危险因素。同时根据该权值可以根据危险因素预测一个人患癌症的可能性。
二.代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
# 获取用户输入的特征值
def get_user_input():
feature1 = float(input("Enter value for Feature 1: "))
feature2 = float(input("Enter value for Feature 2: "))
return np.array([[feature1, feature2]])
# 创建并训练逻辑回归模型
def train_logistic_regression(X_train, y_train):
model = LogisticRegression()
model.fit(X_train, y_train)
return model
# 获取用户输入的特征值并进行预测
def predict_with_model(model):
user_input = get_user_input()
prediction = model.predict(user_input)
return prediction
if __name__ == "__main__":
# 使用已有的虚拟数据集
X_train = np.array([[1, 2], [2, 3], [3, 4], [4, 5]])
y_train = np.array([0, 0, 1, 1]) # 0和1代表两个类别
# 创建并训练逻辑回归模型
model = train_logistic_regression(X_train, y_train)
# 获取用户输入并进行预测
user_prediction = predict_with_model(model)
print("Prediction:", user_prediction)
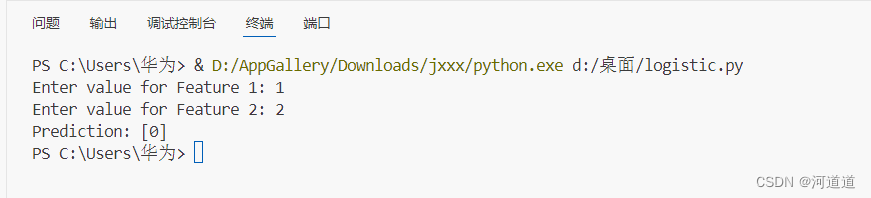
三.结果
四.总结
优点:
- 实现简单:逻辑回归是一种简单且高效的分类算法,易于理解和实现。
- 计算速度快:逻辑回归的计算复杂度低,训练速度快。
- 输出结果概率化:逻辑回归可以输出样本属于不同类别的概率,而不仅仅是分类结果。
- 容易解释:模型的结果具有很好的可解释性,可以清晰地理解每个特征对分类的影响程度。
缺点:
- 对特征空间的线性可分性要求高:逻辑回归假设数据是线性可分的,对于非线性数据的分类效果不佳。
- 对异常值敏感:逻辑回归对异常值比较敏感,可能会影响模型的性能。
- 只能处理两分类问题:逻辑回归只能处理二分类问题,在多分类问题上需要进行修改或组合。
- 特征相关性:当特征之间存在相关性时,逻辑回归的表现可能不稳定,容易受到多重共线性的影响。















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









