






一.概念
主成分分析,即Principle Component Analysis (PCA),是一种传统的统计学方法,被机器学习领域引入后,通常被认为是一种特殊的非监督学习算法,其可以对复杂或多变量的数据做预处理,以减少次要变量,便于进一步使用精简后的主要变量进行数学建模和统计学模型的训练,所以PCA又被称为主变量分析。
二.原理
PCA的原理及运行过程如下:
-
标准化数据:对于给定的数据集,首先需要对每个特征进行标准化处理,使其均值为0,方差为1。这是为了确保每个特征在计算中具有相同的权重。
-
计算协方差矩阵:对标准化后的数据集计算协方差矩阵。协方差矩阵反映了不同特征之间的线性关系。协方差矩阵的元素表示了相应特征之间的协方差,可以通过以下公式计算:
 其中,N是样本数量,xi是第i个样本的特征向量,x̄是所有样本特征的均值向量,T表示转置。
其中,N是样本数量,xi是第i个样本的特征向量,x̄是所有样本特征的均值向量,T表示转置。 -
特征值分解:对协方差矩阵进行特征值分解,得到特征值和对应的特征向量。特征值代表了这些特征向量所表示的新坐标轴上的方差,而特征向量则表示了新坐标轴的方向。
-
选择主成分:按特征值的大小从大到小排序,选取前k个最大的特征值对应的特征向量作为主成分。这些主成分构成了一个变换矩阵,其中每一列都是一个特征向量。
-
转换数据:将原始数据通过变换矩阵进行线性变换,将数据投影到新的低维空间中。投影后的数据就是降维后的数据,每个样本都由k个主成分组成。
PCA的运行过程可以简化为以下几步:
- 对数据进行标准化处理。
- 计算协方差矩阵。
- 进行特征值分解,得到特征值和特征向量。
- 选择主成分(前k个最大特征值对应的特征向量)。
- 将数据投影到主成分上,得到降维后的数据。
通过PCA,我们可以有效地减少数据的维度,捕捉数据中的主要特征,从而实现降维、特征提取和数据可视化等目标。
三.代码
import matplotlib.pyplot as plt
import numpy as np
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
# 加载鸢尾花数据集
def load_dataset():
iris = load_iris()
X = iris.data
y = iris.target
feature_names = iris.feature_names
target_names = iris.target_names
return X, y, feature_names, target_names
# 交互式选择特征数量
def select_feature_num(feature_names):
while True:
print("Available features:")
for i, feature in enumerate(feature_names):
print(f"{i+1}. {feature}")
try:
choice = int(input("Enter the number of features to use for PCA (1 or 2): "))
if choice < 1 or choice > 2:
print("Invalid choice. Please enter 1 or 2.")
else:
return choice
except ValueError:
print("Invalid input. Please enter a valid number.")
# 可视化降维后的数据
def visualize_pca(X_pca, y, target_names):
if X_pca.shape[1] == 1:
plt.figure(figsize=(8, 6))
scatter = plt.scatter(X_pca[:, 0], np.zeros_like(X_pca[:, 0]), c=y, cmap='viridis', edgecolor='k')
plt.xlabel('Principal Component 1')
plt.title('PCA of Iris Dataset (1D)')
plt.yticks([]) # Hide y-axis
plt.colorbar(scatter, label='Classes')
plt.show()
elif X_pca.shape[1] == 2:
plt.figure(figsize=(8, 6))
scatter = plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y, cmap='viridis', edgecolor='k')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('PCA of Iris Dataset (2D)')
plt.colorbar(scatter, label='Classes')
plt.show()
# 主程序
def main():
X, y, feature_names, target_names = load_dataset()
print("Loaded Iris dataset")
print(f"Number of samples: {X.shape[0]}, Number of features: {X.shape[1]}")
num_features = select_feature_num(feature_names)
pca = PCA(n_components=num_features)
X_pca = pca.fit_transform(X)
print(f"Transformed shape: {X_pca.shape}")
print("Variance explained by each component:", pca.explained_variance_ratio_)
visualize_pca(X_pca, y, target_names)
if __name__ == "__main__":
main()
四.结果

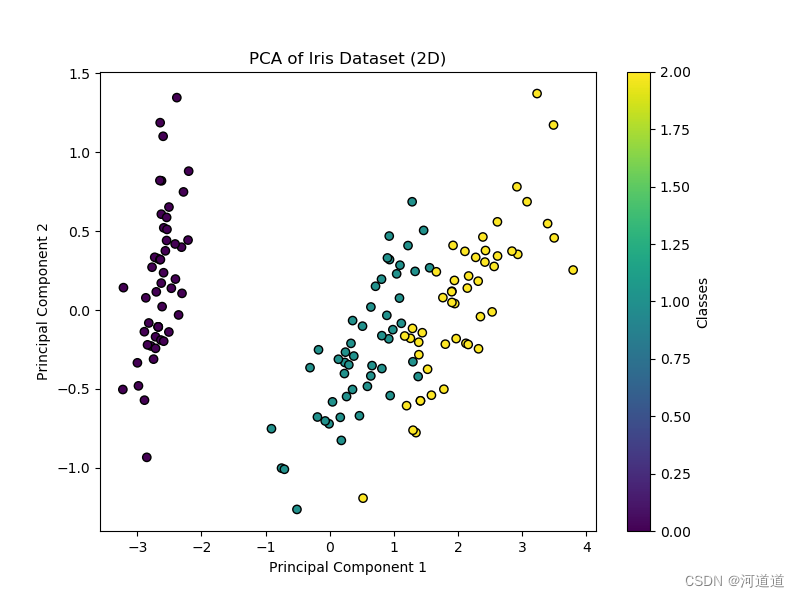
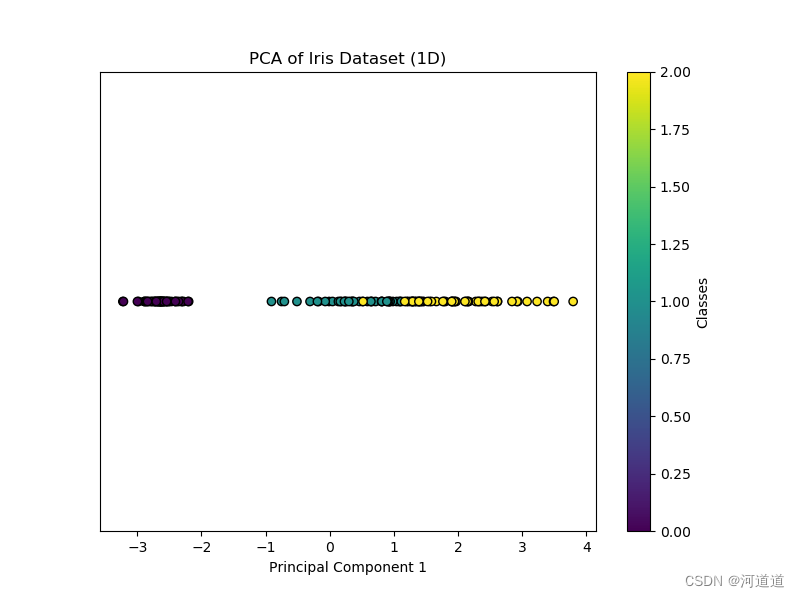
五.结果
- 灵活性:代码允许用户选择降维的维度(1维或2维),并自动调整可视化方法。
- 输入验证:确保用户输入有效的特征数量(1或2),避免错误操作。
- 清晰的结构:加载数据、选择特征数量、PCA降维和可视化的步骤明确且分离,易于维护和扩展。
- 适应性:处理一维和二维数据的可视化需求,提供了不同的可视化方法,以便更好地展示数据的内部结构。















 1894
1894

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









