






一.概念
支持向量机(Support Vector Machine,SVM)是一种常用的机器学习算法,用于分类和回归分析。支持向量指的是在特征空间中起决定性作用的训练样本点,即离分隔超平面最近的样本点。而支持向量机的核心思想是找到一个最优的超平面,将不同类别的样本点分隔开来,并且使得间隔(Margin)最大化,从而提高分类的准确性。
支持向量机中的“向量积”通常是指在特征空间中两个向量之间的内积运算,也可以称为向量点积。在支持向量机中,通过计算特征空间中的向量之间的内积来确定分类超平面的位置。这个内积运算在核函数的作用下可以高效地进行,将数据映射到高维空间,从而更好地解决非线性分类问题。
支持向量机是一种强大的算法,在许多领域都得到了广泛应用,包括文本分类、图像识别、生物信息学等。它的优点包括可以处理高维数据、泛化能力强、在处理小样本数据上表现良好等。
二.原理
当使用线性核的支持向量机时,决策函数可以表示为:
[
]
其中,( w ) 是权重向量,( b ) 是偏置项。
支持向量机的优化目标是找到使得间隔最大化的超平面,这可以通过以下凸优化问题来实现:
[
]
同时满足以下约束条件:
[
\text{对于所有} , i = 1, 2, ..., N ]
其中,( (x_i, y_i) ) 是训练数据集中的样本,( y_i ) 是样本的类别标签,( N ) 是训练样本的数量。这个优化问题可以使用拉格朗日乘子法进行求解,得到的最优解即为支持向量机的模型参数。
对于非线性核,例如多项式核或径向基函数(RBF)核,决策函数的形式为:

其中,( \alpha_i ) 是支持向量的拉格朗日乘子,( K(x, x_i) ) 是核函数,( b ) 是偏置项。
支持向量机的预测规则是根据决策函数的值来进行分类:
- 如果 ( f(x) \geq 0 ),则预测样本 ( x ) 属于正类别;
- 如果 ( f(x) < 0 ),则预测样本 ( x ) 属于负类别。
1. 支持向量机的原理:
1.1 最大间隔分类:
支持向量机的目标是找到一个超平面,可以将不同类别的数据点分隔开,并且使得两个类别之间的间隔尽可能大。这个超平面被称为最大间隔超平面。
1.2 支持向量:
在最大间隔分类过程中,支持向量是距离超平面最近的数据点,它们决定了超平面的位置和方向。
1.3 核函数:
当数据不是线性可分的时候,支持向量机可以通过使用核函数将数据映射到高维空间中,从而使得数据在高维空间中变得线性可分。常用的核函数包括线性核、多项式核、径向基函数(RBF)核等。
1.4 正则化:
支持向量机通常使用正则化来防止过拟合。正则化项会惩罚模型复杂度,防止模型在训练集上过度拟合。
2. 支持向量机的运行过程:
2.1 数据准备:
首先,将数据进行预处理,包括特征提取、特征标准化等步骤。
2.2 模型训练:
支持向量机的训练过程就是寻找最大间隔超平面的过程。这个过程可以通过求解一个优化问题来实现,通常使用凸优化算法进行求解。
2.3 边界确定:
支持向量机确定的超平面将数据点分成两类,并确定了决策边界。超平面的位置和方向由支持向量决定。
2.4 预测:
在预测阶段,新的数据点被映射到超平面上,并根据其位置来确定其类别。如果数据点位于超平面的一侧,它将被分类为一个类别;如果位于另一侧,则被分类为另一个类别。
三.代码
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import classification_report, accuracy_score
# 示例数据(特征)
X = [
[35, 50000, 2000, 60000], # 客户1
[40, 60000, 0, 100000], # 客户2
[25, 20000, 8000, 20000], # 客户3
[30, 30000, 3000, 40000], # 客户4
[45, 70000, 5000, 150000] # 客户5
]
# 示例数据(标签)
y = ['B', 'A', 'C', 'B', 'A'] # 信用等级
# 特征标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 将数据集分割为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 创建SVM分类器
svm_classifier = SVC(kernel='linear', random_state=42)
# 在训练集上训练模型
svm_classifier.fit(X_train, y_train)
# 用户输入功能
print("请输入客户信息以预测信用等级:")
age = float(input("年龄:"))
income = float(input("年收入:"))
debt = float(input("债务:"))
assets = float(input("资产:"))
# 对用户输入的数据进行预处理
user_data = [[age, income, debt, assets]]
user_data_scaled = scaler.transform(user_data)
# 进行信用等级预测
user_credit_rating = svm_classifier.predict(user_data_scaled)
print("预测的信用等级为:", user_credit_rating[0])
四.结果
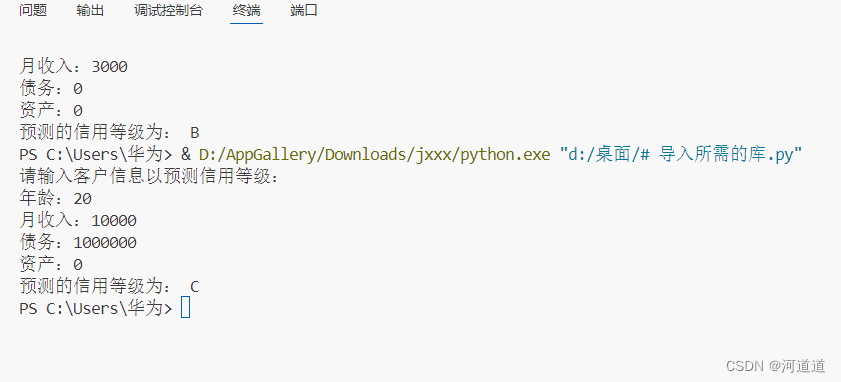
五.总结和分析
重点:
- 数据预处理:包括特征提取、特征标准化以及数据集的分割。
- 使用支持向量机进行分类:支持向量机是一种强大的分类算法,可以用于解决各种类型的分类问题。
- 用户输入功能:通过与用户交互,实现了从用户处获取数据并进行预测的功能。
难点:
- 数据预处理:确保数据的质量和一致性,以及选择合适的特征标准化方法。
- 模型训练:调整支持向量机的参数以获得最佳性能。
- 用户输入:需要处理用户可能输入的各种类型和范围的数据,并进行适当的预处理。
支持向量机的优点包括:
- 适用于高维空间:支持向量机在高维空间中表现出色,适用于处理特征维度较高的数据集。
- 泛化能力强:支持向量机具有很强的泛化能力,对于小样本数据表现良好。
- 可解释性强:支持向量机的决策边界由支持向量决定,因此可以提供较好的可解释性。
支持向量机的缺点包括:
- 对大规模数据集的处理能力有限:在处理大规模数据集时,支持向量机的计算复杂度较高,需要较长的训练时间和大量的内存。
- 对参数和核函数的选择敏感:支持向量机的性能受参数和核函数选择的影响较大,需要进行反复调优。
- 不适用于非线性可分的数据集:对于非线性可分的数据集,需要使用核技巧将数据映射到高维空间中,这可能会增加计算复杂度。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









