






目录
1、 ID3(Iterative Dichotomiser 3)。
一、介绍
机器学习是人工智能的一个分支,它使计算机系统能够从数据中学习并做出决策或预测,而不是依赖于严格的编程指令。机器学习算法可以从数据中识别模式和关系,并用这些信息来做出预测或执行任务。决策树是一种常用的机器学习算法,它是一种监督学习算法,可以用于分类和回归任务。决策树模型表示一系列的决策规则,这些规则将输入特征映射到输出标签。
二、决策树的基本概念
1、决策树
决策树是一种树形结构,其中每个内部节点代表一个特征,每个分支代表一个特征值的选择,每个叶节点代表一个输出标签。从根节点开始,决策树通过一系列的决策来分割数据集,直到达到叶节点,从而做出预测。
2、主要组成:
根节点:决策树的起始点,包含整个数据集。
内部节点:代表一个特征,节点包含一个判断条件,用于分割数据集。
分支:连接内部节点和子节点,代表特征的某个值。
叶节:也称为终端节点,每个叶节点都有一个类标签,用于做出预测。
三、决策树的构造算法
1、 ID3(Iterative Dichotomiser 3)。
ID3算法采用信息增益(Information Gain)作为特征选择的标准。信息增益是基于信息论的概念,表示使用特征A对样本集合进行划分所获得的信息增益。信息增益越大,表示特征A对分类的能力越强。
信息增益的计算基于信息熵(Entropy)的概念,信息熵定义为信息的期望值,信息熵越大,则表明数据集的混乱程度越大。
数据集D的信息熵用如下公式表示:

在给定特征 ( A ) 的条件下,数据集 ( D ) 的信息熵为: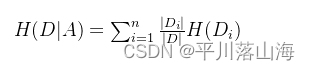
信息增益公式为:
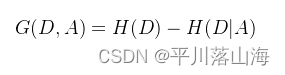
2、 C4.5。
C4.5算法是ID3算法的改进版本,它在信息增益的基础上引入了信息增益比(Gain Ratio)来解决ID3算法对取值较多特征的偏向性问题。
下面是C4.5算法中使用的公式,前面的公式和ID3一样,最后多加了两个公式
分裂信息(Split Information):
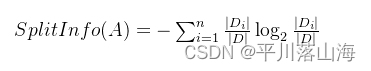
信息增益比(Gain Ratio):
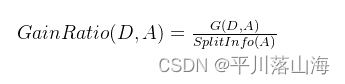
3、基尼指数(CART)。
决策树中的基尼指数是用来衡量节点的纯度或不纯度的指标之一。在构建决策树时,基尼指数通常用于选择最佳的划分特征,以便将数据集划分为纯度更高的子集。
基尼指数计算公式: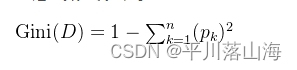
基尼指数的取值范围在0到1之间,数值越低表示节点的纯度越高,即样本的类别分布越趋于一致;而数值越高则表示节点的不纯度越高,即样本的类别分布越杂乱。
在构建决策树时,基尼指数通常与信息增益或信息增益比等指标一起使用,以帮助选择最佳的划分特征。通过选择基尼指数最小的划分点,可以使得子节点的纯度更高,从而提高了决策树的分类性能。
四、代码实现
#数据加载
def loadData( ):
data = pd.read_csv("titanic.csv")
data["Age"] = data["Age"].fillna(data["Age"].mean()) #针对Age字段,采用均值进行填充
data = data.dropna()
data.isna().sum()
dataset = data.values.tolist()
#四个属性
labels=['Pclass','Age','Sex','Survived']
return dataset,labels#计算给定数据的香农熵
def calShannonEnt(dataset):
numEntries = len(dataset) #获得数据集函数
labelCounts={} #用于保存每个标签出现的次数
for data in dataset:
#提取标签信息
classlabel = data[-1]
if(classlabel not in labelCounts.keys()): #如果标签未放入统计次数的字典,则添加进去
labelCounts[classlabel]=0
labelCounts[classlabel]+=1 #标签计数
shannonEnt=0.0 #熵初始化
for key in labelCounts:
p = float(labelCounts[key])/numEntries #选择该标签的概率
shannonEnt-= p*np.log2(p)
return shannonEnt #返回经验熵
#根据某一特征划分数据集
def splitDataset(dataset,axis,value):
# dataset 待划分的数据集 axis 划分数据集的特征 value 返回数据属性值为value
retDataSet = [] #创建新的list对象
for featVec in dataset: #遍历元素
if featVec[axis]==value: #符合条件的抽取出来
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
# 统计出现次数最多的元素(类标签)
def majorityCnt(classList):
classCount={} #统计classList中每个类标签出现的次数
for vote in classList:
if vote not in classCount.keys():
classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True) #根据字典的值降序排列
return sortedClassCount[0][0] #返回出现次数最多的类标签
def createTree(dataset,labels):#数据集和标签列表
classList =[example[-1] for example in dataset]#数据所属类得值
if classList.count(classList[0])==len(classList):#条件1:classList只剩下一种值
return classList[0]
if len(dataset[0])==1:#条件2:数据dataset中属性已使用完毕,但没有分配完毕
return majorityCnt(classList)#取数量多的作为分类
bestFeat = chooseBestFeatureToSplit(dataset)#选择最好的分类点,即香农熵值最小的
labels2 = labels.copy()#复制一分labels值,防止原数据被修改。
bestFeatLabel = labels2[bestFeat]
myTree = {bestFeatLabel:{}}#选取获取的最好的属性作为
del(labels2[bestFeat])
featValues = [example[bestFeat] for example in dataset]#获取该属性下的几类值
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels2[:]#剩余属性列表
myTree[bestFeatLabel][value] = createTree(splitDataset(dataset,bestFeat,value),subLabels)
return myTree
if __name__ == '__main__':
dataSet, labels = loadData( )
print("数据集信息熵:"+str(calShannonEnt(dataSet)))
mytree = createTree(dataSet,labels)
print(mytree)import numpy as np
import pandas as pd
from sklearn import tree
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import export_graphviz
import matplotlib.pyplot as plt
# 加载数据
data = pd.read_csv('titanic.csv')
# print(data.head())
# print(data.shape) # (891, 12)
# 获取数据
x = data[['Pclass','Age','Sex']]
y = data['Survived']
# print(x.head())
# print(y.head())
# 缺失值处理
x['Age'].fillna(x['Age'].mean(),inplace=True)
# 特征处理
x['Sex'] = np.array([0 if i == 'male' else 1 for i in x['Sex']]).T
# 打印查看是否替换成功
# print(x.head())
# 划分数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2,random_state=22)
# 创建模型
model = DecisionTreeClassifier(criterion='entropy',max_depth=3)
# 3 准确率: 0.7653631284916201
# 4 准确率: 0.7653631284916201
# 5 准确率: 0.7430167597765364
# 6 准确率: 0.7486033519553073
# 8 准确率: 0.7541899441340782
# 12 准确率: 0.770949720670391
model.fit(x_train,y_train)
# 评估
score = model.score(x_test,y_test)
pred = model.predict(x_test)
print('准确率:',score)
print('预测值:',pred)
# 可视化方法一:
# export_graphviz(model, out_file="tree.dot", feature_names=['pclass','age','sex'])
# 更简单的方法:
plt.figure(figsize=(20,20))
feature_name = ['pclass','age','sex']
class_name = ['survived','death']
tree.plot_tree(model,feature_names=feature_name,class_names=class_name)
plt.savefig('tree.png')
五、决策树的优缺点
1、ID3决策树的优点:
简单性:ID3算法简单易懂,易于实现。它基于简单的数学原理,不需要复杂的数学模型或大量的参数调整。
高效性:在处理大规模数据时,ID3算法表现出较高的效率。它的时间复杂度较低,可以在短时间内完成分类任务。
健壮性:ID3算法对噪声数据具有较强的鲁棒性。即使是在数据集存在一定程度的噪声或不完整的情况下,ID3也能够较好地捕捉到数据的本质特征,从而做出准确的分类。
可扩展性:ID3算法具有良好的可扩展性。当需要处理更多特征的数据时,ID3可以轻松地添加新的分支,而不会导致性能下降。
易于理解:ID3算法的决策过程清晰可见,易于理解和解释。用户可以根据树的结构直观地了解分类器的逻辑推理过程。
适用于多种数据类型:ID3算法可以处理数值型和离散型数据。对于连续型的数据,它可以将其转化为离散型数据来进行处理。
快速学习:ID3算法的学习速度较快,能够在较短的时间内完成模型构建。
2、ID3决策树的缺点:
过度拟合:ID3算法可能会产生过度的树形结构,导致模型在训练数据上表现良好,但在测试数据上表现不佳。这是因为ID3在选择分裂属性时倾向于选择那些在训练集中区分能力强的属性,而这些属性可能并不总是适用于测试集。
忽略相关性:ID3算法没有考虑属性的相关性,可能导致某些属性被过度重视,而其他更有意义的属性却被忽视。
无法处理缺失数据:当数据集中存在大量缺失值时,ID3算法可能会遇到困难。因为它依赖于完整的数据集来构建决策树,缺失的数据会导致树的结构不完整或不准确。
空间复杂度高:随着树深度的增加,ID3算法的空间复杂度也会增加。这可能会导致内存消耗过大,尤其是在处理大型数据集时。
不适合处理连续数据:虽然ID3可以处理部分连续数据,但它更适合处理离散数据。对于连续数据,需要进行预处理,将其转换为适合ID3处理的离散形式。
总的来说,ID3决策树在许多实际应用中是一种有效的分类方法,但其性能受到数据质量和算法参数的影响。在使用ID3时,应充分考虑其优缺点,并根据具体情况进行调整和改进















 1690
1690

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









