







摘要
推理作为解决复杂问题的必备能力,可以为各种现实应用提供后端支持,例如医疗诊断、谈判等。本文全面综述了语言模型推理的前沿研究提示。我们通过比较和总结来介绍研究工作,并提供系统资源来帮助初学者。我们还讨论了出现这种推理能力的潜在原因,并强调了未来的研究方向
给定推理问题 Q、提示 T 和参数化概率模型
P
L
M
P_{LM}
PLM,我们的目标是最大化答案 A 的可能性:
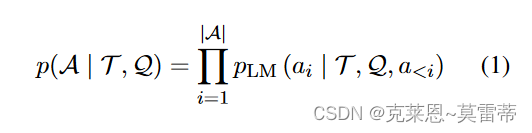
其中
a
i
a_i
ai 和
∣
A
∣
|A|
∣A∣分别表示第 i 个标记和最终答案的长度。
对于few-shot来说

对于COT思维链来说
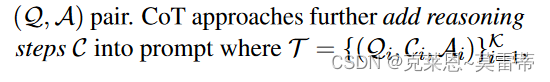
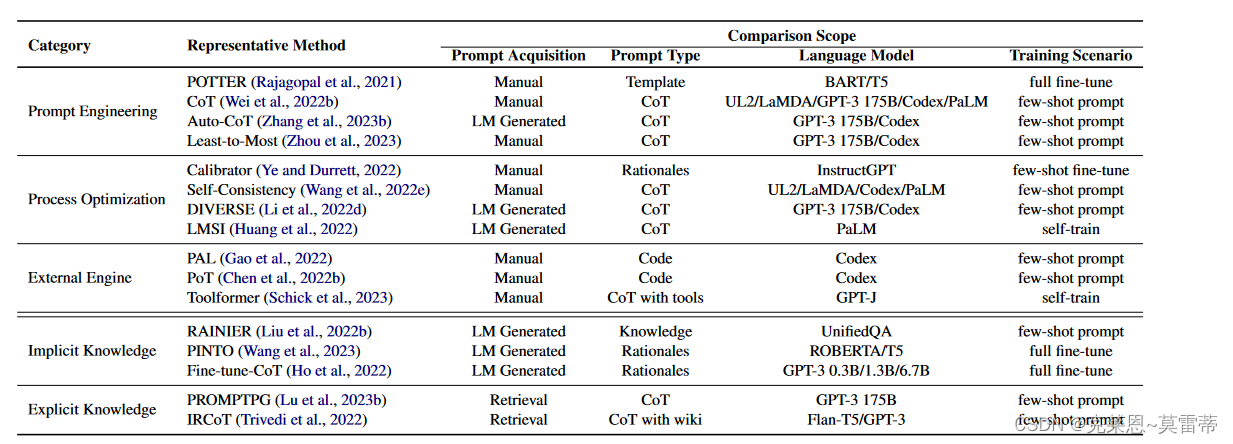
按照分类法分类
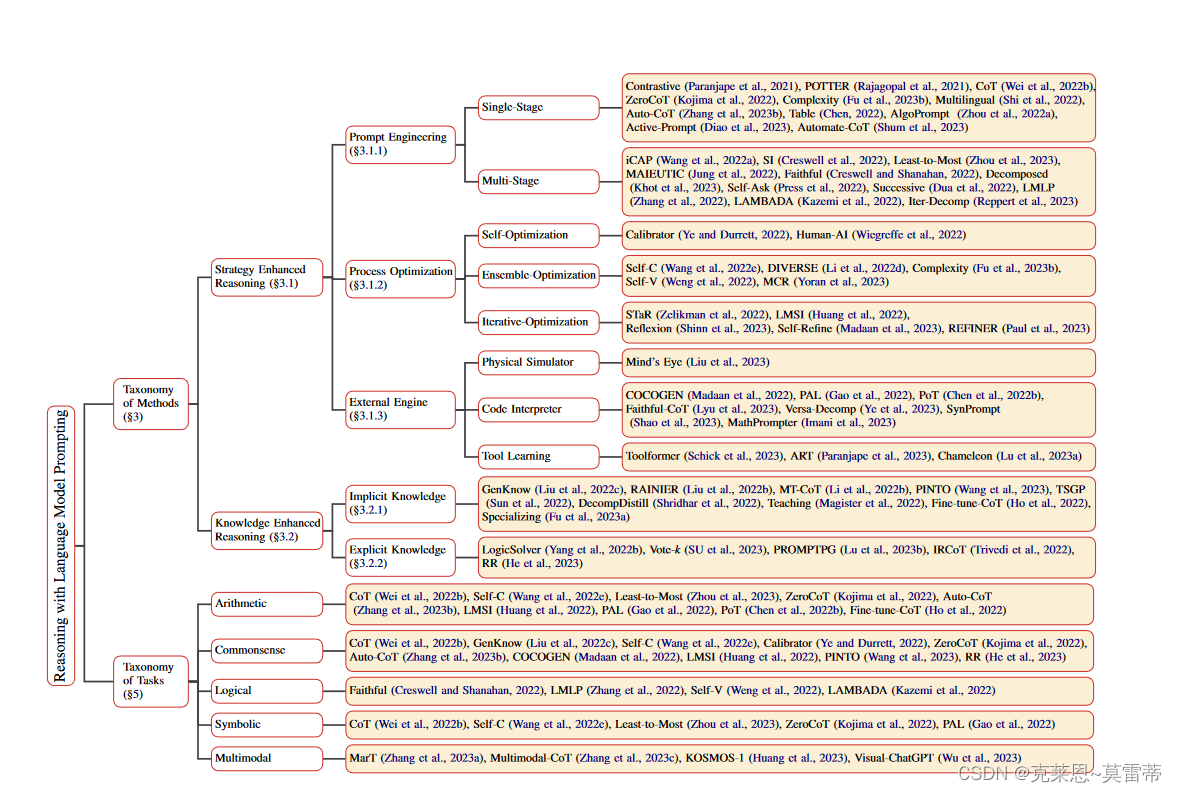
增强推理能力的方法
-
optimizing the reasoning strategy with prompting
- prompt engineering
- single-stage methods(一次性优化提示的质量)
- multi-stage methods.(分多步骤进行提示)
- process optimization
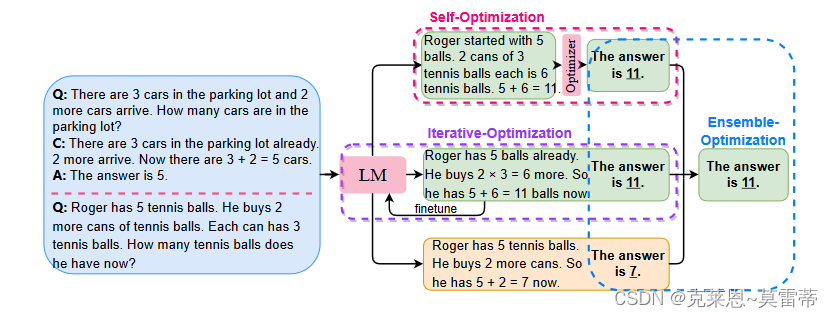
- self-optimization methods 方法是在生成 回答 时引入参数为 θ 的优化器来校准 C
- ensemble-optimization methods 获得多个进程来获得最终的答案。(集成)
- 以上两种方法不仅仅可以调整prompt还可以边调整prompt边微调模型
- external engine
- 用外部api 直接执行C或者通过在C中植入工具API调用进行推理。
- prompt engineering
-
knowledge enhancement with prompting(通过提示增强知识)
- Note that rich implicit “modeledge” (Han et al., 2021) in LMs can generate knowledge or rationales as knowledgeinformed prompt T
- explicit knowledge in external resources can also be leveraged and retrieved as knowledgeable prompts to enhance reasoning
-
optimizing the reasoning strategy with prompting
-
prompt engineering
-
-
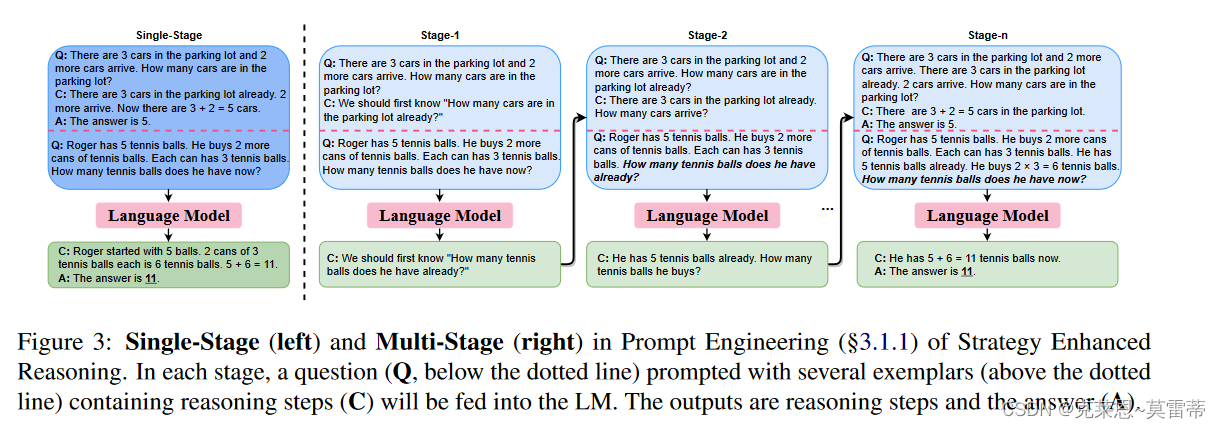
single-stage methods(一次性优化提示的质量)
- 利用基于模板的提示 (Paranjape et al., 2021; Rajagopal et al., 2021)
- COT (Brown et al., 2020), Wei et al. (2022b)
- 上下文学习对样本的选择非常敏感,即使是微小的变化也可能导致模型性能大幅下降 (Lu et al., 2022c; Min et al., 2022; Webson and Pavlick, 2022).
- 用更多的推理步骤生成推理复杂度较高的提示 Fu et al. (2023b)
- 探讨示例多样性对提示的影响 Zhang et al. (2023b)
- 周等人。 (2022a) 缓解了 LM 在面临 (OOD) 算法问题时的模糊性。
- zero-shot 不用额外的样本提示
-
multi-stage methods.(分多步骤进行提示)
- 将每个阶段的输出视为一个单独的新问题
- 将每个阶段输出附加到整个上下文以提示 LM。
- Natural language rationales2 (Ling et al., 2017a), also called reasoning processes in CoT, play a vital role in CoT prompting
- 推理过程的一致性
- 推理步骤之间的连续性
-
-
process optimization
- self-optimization methods 方法是在生成 回答 时引入参数为 θ 的优化器来校准 C
- ensemble-optimization methods 获得多个进程来获得最终的答案。(集成)
- 以上两种方法不仅仅可以调整prompt还可以边调整prompt边微调模型
-
external engine

- 用外部api 直接执行C或者通过在C中植入工具API调用进行推理。
- 物理模拟器。考虑到物理推理问题,Liu 等人。 (2023)利用计算物理引擎(Todorov 等人,2012)来模拟物理过程。模拟结果被视为帮助LM推理的提示,弥补了LM物理知识的缺乏。
- 代码解释器。
- Tool Learning
-
-
knowledge enhancement with prompting(通过提示增强知识)
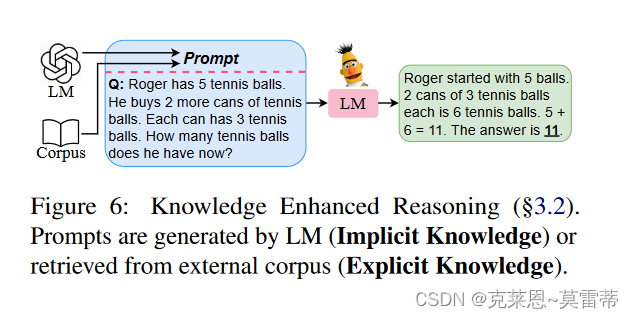
- Note that rich implicit “modeledge” (Han et al., 2021) in LMs can generate knowledge or rationales as knowledgeinformed prompt T
- explicit knowledge in external resources can also be leveraged and retrieved as knowledgeable prompts to enhance reasoning
语言模型比较
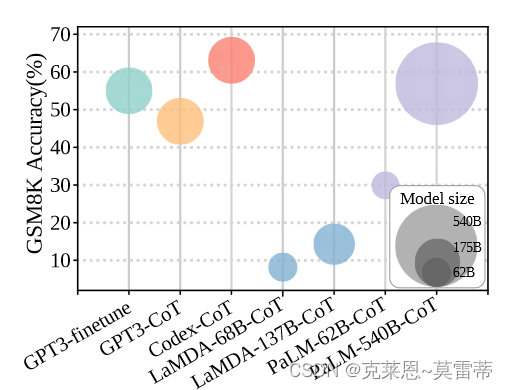
随着模型规模的增加,少样本提示在几乎所有任务中都表现得更好,这可以通过以下事实来解释:模型规模较大的 LM 包含更多用于推理的隐式知识。然而,当模型规模下降到小于 100B 时,CoT 提示将不会带来任何性能提升,甚至可能是有害的。
一种可能是,当存储的知识达到一定水平时,LM的推理能力从量变发生质变,导致涌现能力的出现。这种突现能力不仅由模型参数规模决定,还与预训练数据的质量有关
pre-training on code branch not only enables the ability of code generation/understanding but may also trigger the reasoning ability with CoT.
提示的类型
- Manual construction
- LM Generated
- Retrieval-based prompt
benchmark直接看图















 531
531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









