







目录
一、数据通路的概念和功能
计算机中,将各个功能部件连接起来、可以进行数据传送的路径称为 数据通路。
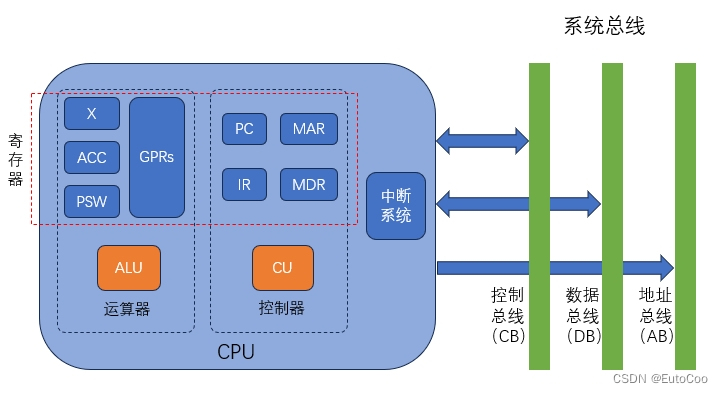
数据通路的主要功能,就是实现计算机中不同部件间的信息传送和数据交换。在这里我们主要讨论 CPU 内部的数据通路,它描述了信息在 CPU 内各部件之间传递的路径,也包括了路径上流经的部件,比如 ALU、寄存器、中断系统等。
二、指令周期中的数据流
CPU 的指令周期可以分为取指、间址、执行和中断四个阶段,在不同的阶段,控制器应该产生不同的控制信号。我们可以先来分析一下每个阶段中数据的流动方向,这就是指令周期中的 数据流。
1.取指周期
这里我们只讨论 CPU 中最重要的 4 个寄存器 PC、IR、MAR 和 MDR。MAR 与地址总线相连,存放要访问的存储单元地址;MDR 与数据总线相连,存放从主存中读出的或者要写入主存的数据;PC 存放要执行的指令地址,有 “自动加 1” 的计数功能;IR 存放正在执行的指令。
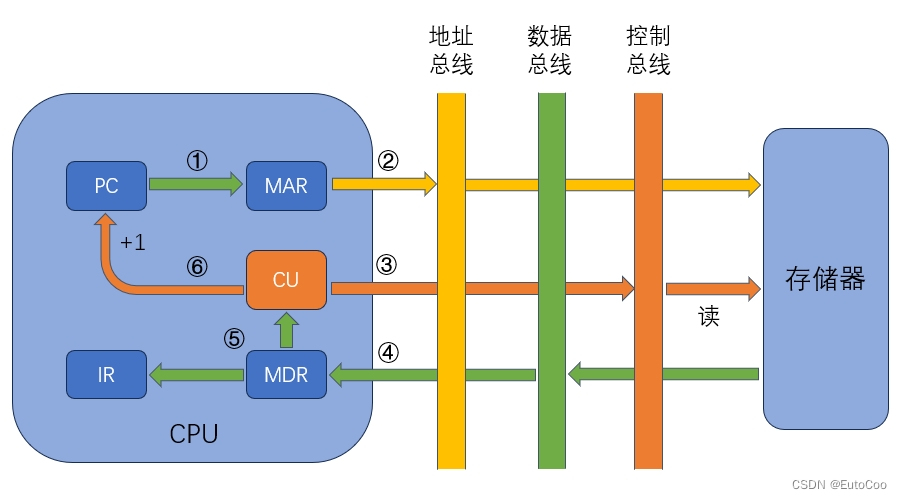
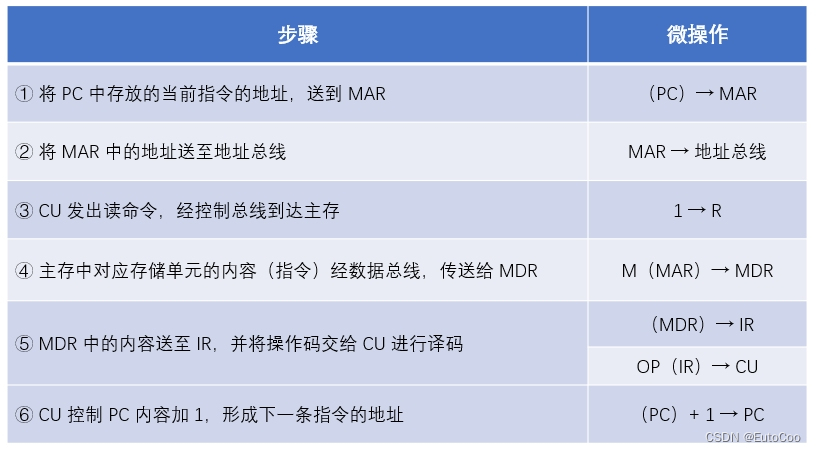
① 将 PC 中存放的当前指令的地址,送到 MAR;
② 将 MAR 中的地址送至地址总线;
③ CU 发出读命令,经控制总线到达主存;
④ 主存中对应存储单元的内容(指令)经数据总线,传送给 MDR;
⑤ MDR 中的内容送至 IR,并将操作码交给 CU 进行译码;
⑥ CU 控制 PC 内容加 1,形成下一条指令的地址。
2.间址周期
取指周期结束后,CU 就会检查 IR 中的内容,判断寻址方式;如果有间接寻址,就执行间址周期中的操作。
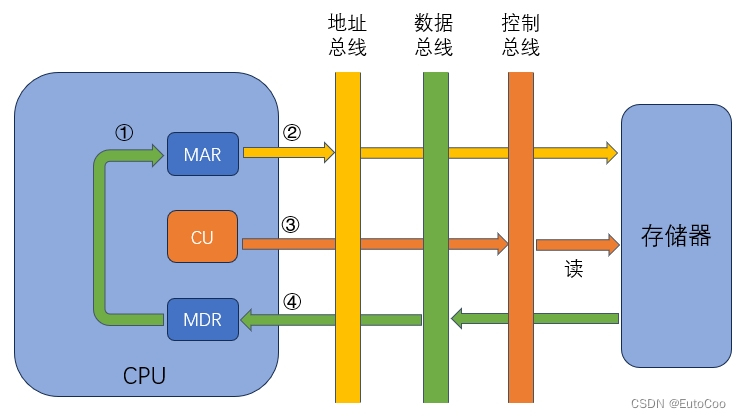
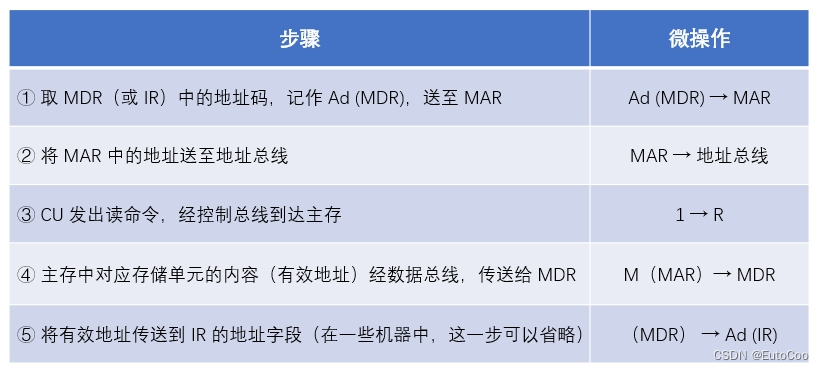
① 取 MDR(或 IR)中的地址码,记作 Ad (MDR),送至 MAR;
② 将 MAR 中的地址送至地址总线;
③ CU 发出读命令,经控制总线到达主存;
④ 主存中对应存储单元的内容(地址)经数据总线,传送给 MDR;
⑤ 将有效地址传送到 IR 的地址字段(在一些机器中,这一步可以省略)。
3.执行周期
在执行周期,可能会涉及到对 ALU 的操作、寄存器之间的数据传递,以及对主存的读写操作。因为不同的指令在执行周期会有不同的操作,对应的数据流也会有所不同,所以不能用同一的数据流图来表示。
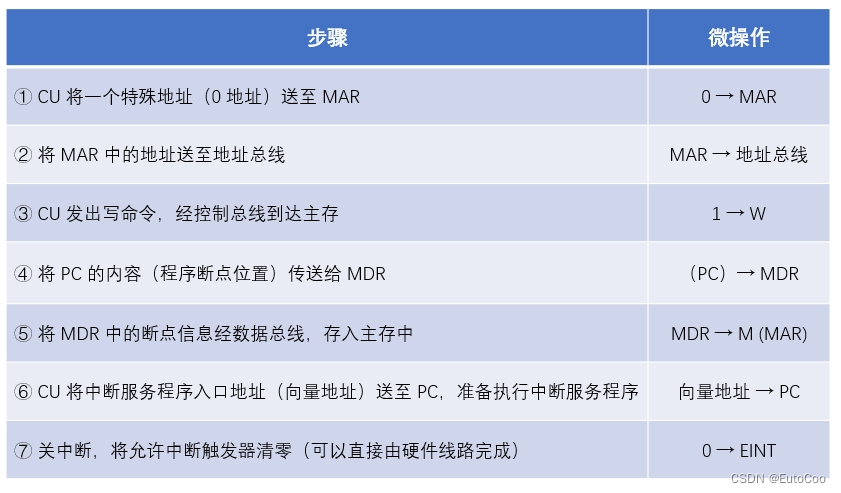
4.中断周期
CPU 进入中断周期后,会进行一系列的操作;核心部分就是要将当前程序执行的状态保存下来,等到中断服务程序执行完毕后再返回继续执行。
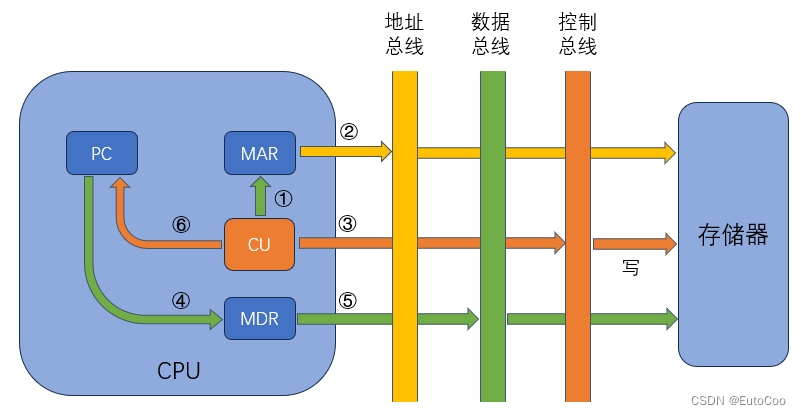
① CU 将一个特殊地址(比如 0 地址)送至 MAR,这个地址对应的存储单元保存程序的断点信息,主要就是 PC 的值;
② 将 MAR 中的地址送至地址总线;
③ CU 发出写命令,经控制总线到达主存;
④ 将 PC 的内容(程序断点位置)传送给 MDR;
⑤ 将 MDR 中的断点信息经数据总线,存入主存中;
⑥ CU 将中断服务程序的入口地址送至 PC,准备执行中断服务程序。
三、指令周期的微操作
数据通路上的每条线路,都会有一个允许数据进出的 “门”,可以控制当前线路是否开启数据的传送;一般可以用三态门来实现。
上面的三态门可以等效地看成:
在不同的时钟周期,给出不同的三态门控制端 EN 信号,就可以精确地控制每条线路依次导通。
CPU 的控制器可以根据每条指令的具体操作,生成一系列的控制信号,控制数据通路上每个三态门在不同时钟周期的 “开” 和 “关”,从而起到控制指令执行的过程。这样的控制信号,就被称为 “微操作” 或者 “微指令”。
下面我们依然根据指令周期的 4 个阶段,分别分析对应的微操作命令。
1.取指周期
对应上一小节分析的取指令过程,可以归纳为以下几个微操作:
2.间址周期
3.执行周期
在执行周期,不同指令的微操作是不同的。这里我们将指令按照功能分为非访存指令、访存指令和转移指令来进行分析。
(1)非访存指令
这类指令一般只是执行一步简单的操作,在执行周期不访问主存。
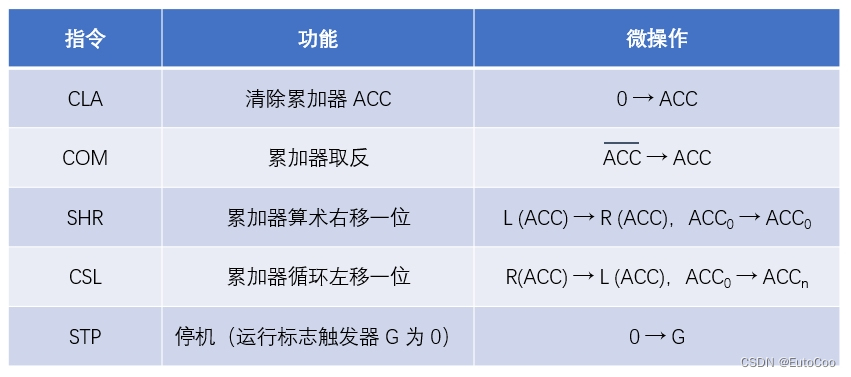
(2)访存指令
这类指令在执行阶段需要访问存储器,例如一个操作数在主存中的加法指令,以及从主存中存取数据的指令。简单起见,我们这里只讨论直接寻址的情况。
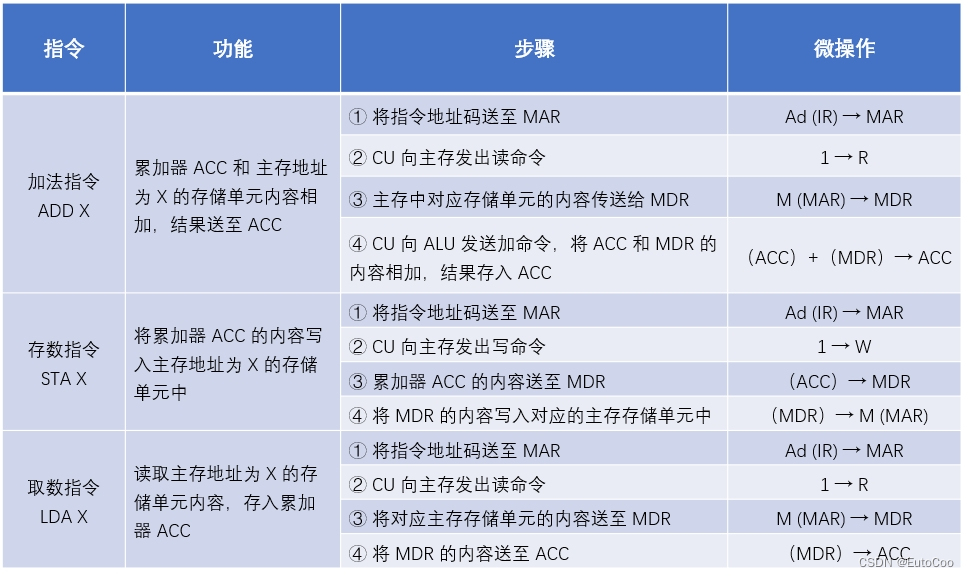
(3)转移指令
转移指令只是通过对 PC 的更改,实现指令执行的跳转,因此执行阶段也不需要访问主存。

4.中断周期
四、数据通路的基本结构和控制信号
CPU 外部和主存、I/O 设备的连接,一般采用总线方式。而 CPU 内部数据通路的结构,其实就是 CPU 内部的连线方式。根据 CPU 内是否采用总线方式进行连接,数据通路可以分为两种结构。
1. 不采用 CPU 内部总线
如果不采用 CPU 内部总线的方式,就需要将 CPU 内的所有需要进行数据传递的部件单独连接起来,相当于为两者之间搭建了一条 “专线”,所以这种方式也叫做 专用数据通路 方式。
这种专用数据通路中所有的路径都是 “专线专用”,不存在冲突,因此性能更好;但所有部件之间都需要进行线路连接,布线比较复杂,硬件成本较高,可扩展性比较差。
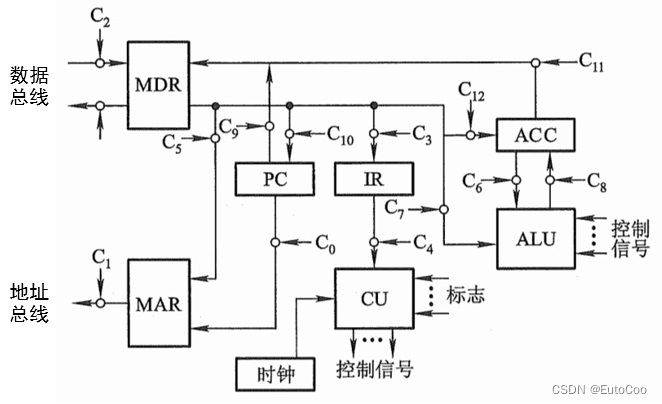
上图就是未采用总线方式时的数据通路和控制信号。为了简便这里没有画出每个部件输入输出通路的控制门,只用一个小圆圈代替,上面用箭头标出了每个门电路的控制信号 Ci 。
接下来以一条采用了间接寻址的加法指令为例 :
ADD @ X这条指令中 @ 是间接寻址标志,X 是存放操作数地址的存储单元地址。需要间接寻址取出操作数,与寄存器 ACC 的值相加,得到的结果再写回 ACC 中。我们依然按照指令周期的不同阶段来进行分析:
(1)取值周期
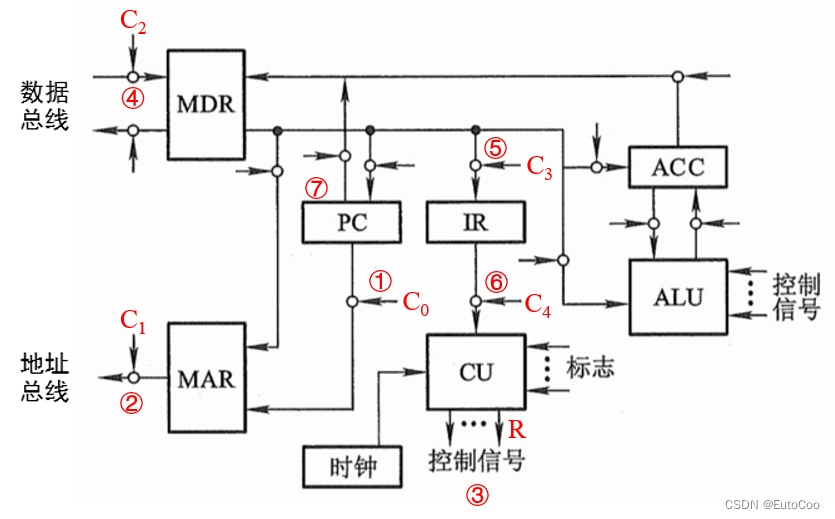
① 控制信号 C0 有效,打开 PC 送往 MAR 的控制门:(PC)→ MAR;
② C1 有效,打开 MAR 送往地址总线(AB)的输出门:(MAR)→ M(主存);
③ CU 通过控制总线(CB)向主存发出读命令(R):1 → R;
④ C2 有效,打开数据总线(DB)送至 MDR 的输入门:M (MAR) → DB → MDR;
⑤ C3 有效,打开 MDR 和 IR 之间的控制门,将指令传送至 IR:(MDR)→ IR;
⑥ C4 有效,打开指令的操作码送往 CU 的输出门:OP(IR) → CU;
CU 在指令操作码和时钟信号的控制下,就可以进一步产生各种控制信号了。
⑦ PC 内容加 1: (PC)+ 1 → PC
(2)间址周期
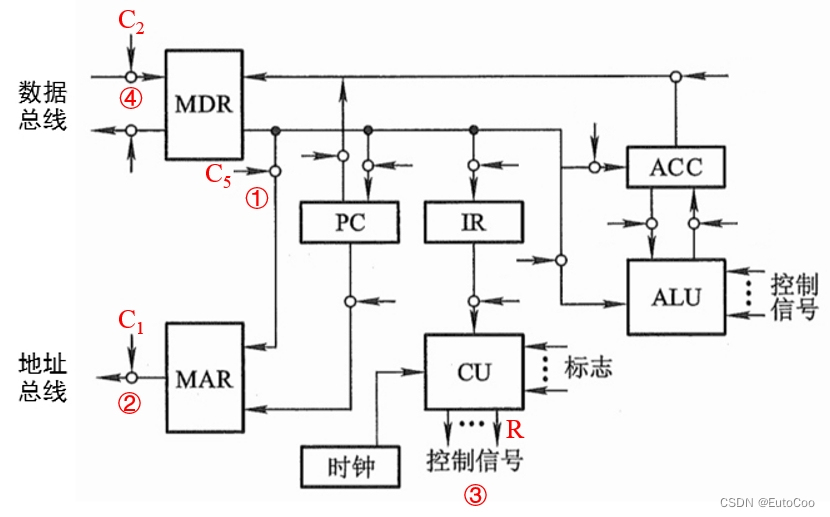
① C5 有效,打开 MDR 和 MAR 之间的控制门,将指令中的形式地址送至 MAR:Ad (MDR) → MAR;
② C1有效,打开 MAR 送往地址总线(AB)的输出门:(MAR)→ AB → M(主存);
③ CU 通过控制总线(CB)向主存发出读命令(R):1 → R;
④ C2 有效,打开数据总线(DB)送至 MDR 的输入门,将有效地址写入 MDR:M (MAR) → DB → MDR
至此,就获取到了指令操作数的有效地址。
(3)执行周期
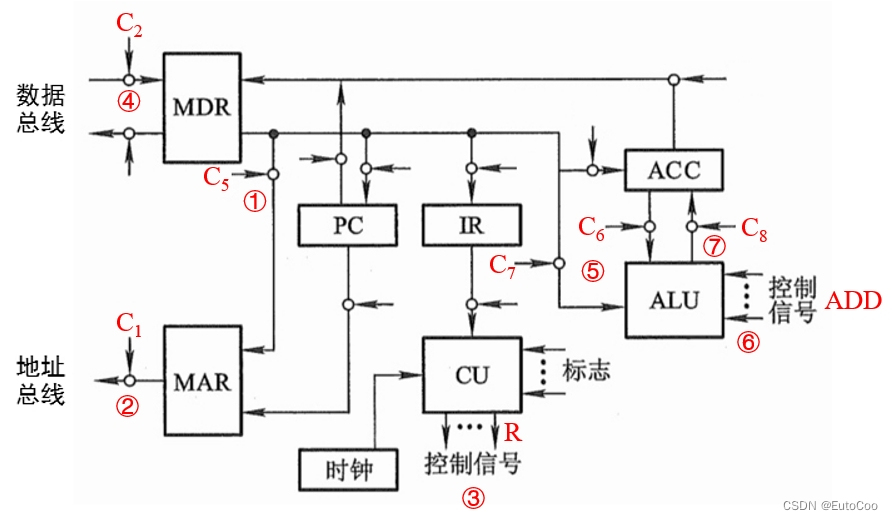
① C5 有效,打开 MDR 和 MAR 之间的控制门,将有效地址送至 MAR: (MDR) → MAR;
② C1 有效,打开 MAR 送往地址总线(AB)的输出门:(MAR)→ AB → M(主存);
③ CU 通过控制总线(CB)向主存发出读命令(R):1 → R;
④ C2 有效,打开数据总线(DB)送至 MDR 的输入门,将操作数存入 MDR:M (MAR) → DB → MDR
至此,就获取到了指令需要的操作数。
⑤ C6、C7 同时有效,打开寄存器 ACC 和 MDR 连接 ALU 的控制门;
⑥ 通过 CPU 内部控制线对 ALU 发出 “ADD” 加法指令的控制信号,完成 ACC 和 MDR 内容的相加;
⑦ C8 有效,打开 ALU 通往 ACC 的控制门,将计算结果存入 ACC:(ACC)+(MDR)→ (ACC)
至此,就完成了加法运算的执行过程。
还有一些控制信号这条指令没有涉及到:C9 和 C10 分别是控制 PC 的输出和输入的控制信号;C11 和 C12 分别是控制 ACC 的输出和输入的控制信号。
2. 采用 CPU 内部总线
类似于系统总线,CPU 内部也可以采用总线方式连接,这种总线也叫做 片内总线。片内总线就是 CPU 内部所有部件的公共数据通路,寄存器之间、寄存器与 ALU 之间都由片内总线连接。
如果只有一条片内总线,这样的结构称为 CPU 内部单总线。这种结构比较简单,硬件容易实现和进行扩展,但存在数据冲突的情况,性能较差。
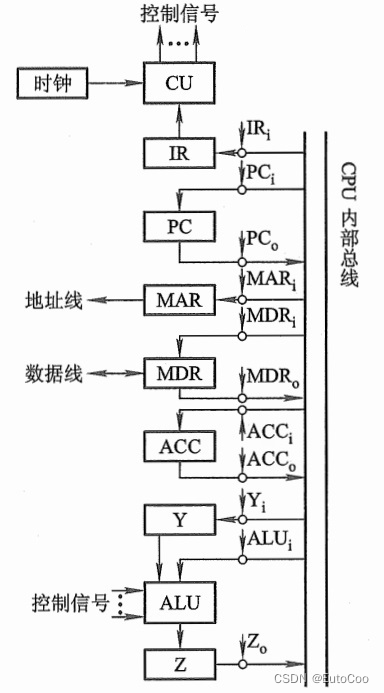
上图中就是采用了 CPU 内部总线方式(单总线)的数据通路和控制信号。每个寄存器都与总线直接相连,这里同样省略了控制门的符号,用一个小圆圈代替,上面用箭头标出了对应的控制信号。控制信号的下标为 i 表示这是输入端的控制,下标为 o 表示输出端的控制。
这里的 ALU 增加了两个寄存器 Y 和 Z,主要是因为 ALU 是组合逻辑电路,本身没有存储数据的功能,运算时必须要求两个输入端同时有效;而单总线上同一时刻(一个时钟周期)只能传送一个数据。因此我们可以设置一个输入寄存器 Y 保存其中一个操作数,让它保持不变,另一个操作数则从总线上获得。同样道理,ALU 的输出也不能直接连接总线输出,否则会影响总线上的输入数据,只能先在输出寄存器 Z 中暂存,等到下个时钟周期再输出。
接下来我们依然以加法指令 “ADD @ X” 为例,按指令周期的不同阶段来分析 CU 发出的控制信号。
(1)取指周期
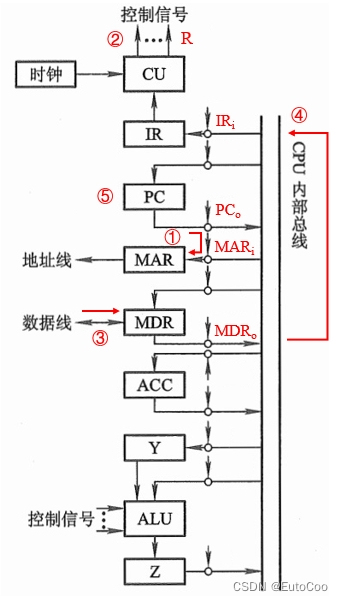
① PCo 和 MARi 有效,PC 中的内容经内部总线送往 MAR:(PC)→ MAR;
② CU 通过控制总线向主存发出读命令(R):1 → R;
③ 主存通过数据总线,将 MAR 中地址所对应存储单元的内容(指令)送至 MDR:M (MAR) → MDR;
④ MDRo 和 IRi 有效,将 MDR 的内容送至 IR:(MDR)→ IR;
至此,指令送至 IR,操作码字段交给 CU,就可以进一步产生各种控制信号了。
⑤ PC 内容加 1: (PC)+ 1 → PC
(2)间址周期
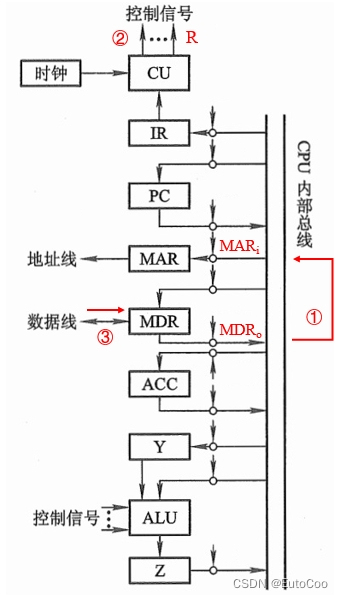
① MDRo 和 MARi 有效,将指令的形式地址经内部总线送至 MAR:Ad (MDR) → MAR;
② CU 通过控制总线向主存发出读命令(R):1 → R;
③ 主存通过数据总线,将 MAR 中地址所对应存储单元的内容(有效地址)送至 MDR:M (MAR) → MDR;
至此,就获取到了指令操作数的有效地址。
(3)执行周期
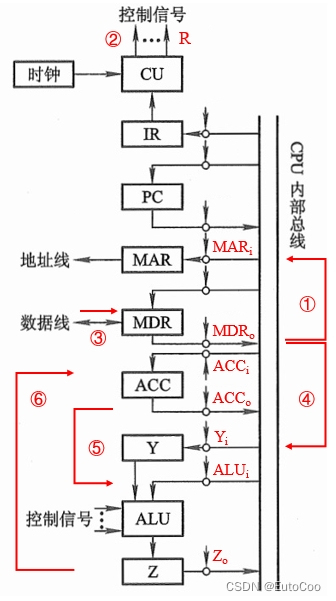
① MDRo 和 MARi 有效,将有效地址经内部总线送至 MAR:(MDR)→ MAR;
② CU 通过控制总线向主存发出读命令(R):1 → R;
③ 主存通过数据总线,将 MAR 中地址所对应存储单元的内容(数据)送至 MDR:M (MAR) → MDR;
至此,就获取到了操作数。
④ MDRo 和 Yi 有效,将操作数送至寄存器 Y,直接作为 ALU 的一个输入:(MDR)→ Y;
⑤ ACCo 和 ALUi 有效,同时 CU 向 ALU 发出 “ADD” 加法指令的控制信号,完成 ACC 和 MDR 内容的相加;得到的结果直接送往寄存器 Z:(ACC)+(Y)→ Z;
⑥ Zo 和 ACCi 有效,将运算结果写入 ACC:(Z)→ ACC
至此,就完成了加法运算的执行过程。
现代计算机的 CPU 都集成在一个芯片内,所以采用片内总线的方式可以极大地节省连线,使芯片密度更高、布局更为合理,也更加容易扩展。
而为了提升性能,解决单总线结构的数据冲突问题,可以增加总线的数量,这就是 CPU 内部多总线方式。这种结构的 CPU 内部有多条公共通路;相比单总线一个时钟内只允许传送一个数据,多总线可以同时传送多个数据,效率更高。

















 1407
1407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









