






特征编码是一种将原始数据转换为模型可以理解的数值形式的过程。其核心思想是将类别型、文本型或其他非数值特征转换为适合机器学习模型处理的数值表示,使模型能够更好地理解和学习数据中的特征。
为什么要进行特征编码?
1、数值化非数值数据:许多机器学习模型(如线性回归、支持向量机等)要求输入数据为数值型。特征编码将类别或文本数据转换为数值,使模型能够处理这些特征。例如,将类别变量(如“红色”,“蓝色”,“绿色”)转换为数值变量(如 0、1、2)。
2、减少计算复杂度、提高模型训练的速度
3、避免模型偏差:有些编码方式可以帮助减少模型对类别变量的偏见。例如,通过独热编码可以避免模型将类别变量误解为有顺序或大小的关系。
常用编码方式
(一)标签编码
原理:标签编码是将类别变量转换为整数,给每个类别分配一个唯一的整数值,例如
A -> 0, B -> 1, C -> 2。这种方法特别适合类别具有自然顺序的数据。优点:简单易用,占用内存较少。
缺点:会引入类别之间的顺序关系,这种顺序可能并不存在,从而误导模型。
适用场景:适用于具有自然顺序的类别数据,例如评分(差、一般、好)。
import pandas as pd
from sklearn.preprocessing import LabelEncoder
# 创建示例DataFrame
data = {
'编号': ['A01', 'B01', 'C01', 'D01', 'E01'],
'评价': ['差', '好', '差', '中等', '好']
}
df = pd.DataFrame(data)
# 对"评价"列进行标签编码
enc = LabelEncoder()
df['encoded'] = enc.fit_transform(df['评价'])
print(df) 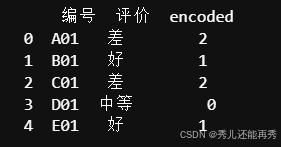
(二)独热编码(One-Hot Encoding)
原理:将每个类别转换为二进制向量,每个类别对应一个新的二进制特征(每个类别都作为一个新特征列),属于该类别时设为1,其他类别设为0。如颜色特征有蓝绿红三个类别,独热编码将蓝绿红各起一个新特征列,且取值只有0或1。
优点:消除了类别之间的顺序关系,适合无序类别。
缺点:当类别数量较多时,特征维度爆炸增加,导致内存消耗和计算开销。
适用场景:适用于无序类别数据,例如颜色、地理位置等。
import pandas as pd
# 创建示例DataFrame
data = {
'编号': ['A01', 'B01', 'C01', 'D01', 'E01'],
'颜色': ['红色', '蓝色', '绿色', '蓝色', '红色']
}
df = pd.DataFrame(data)
# 对"颜色"列进行独热编码
df = pd.get_dummies(df, columns=['颜色'], prefix='颜色', dtype=int) # prefix定义列名前缀
print(df) 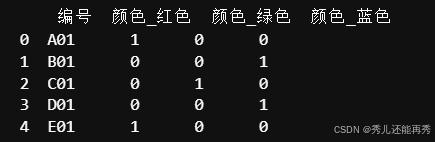
(三)频率编码
原理:将类别值替换为类别在数据集中出现的频率或计数。对于类别
A在数据中出现3次,占比为30%,则用0.3或3表示A。、优点:不增加特征数量,对高基数特征(类别很多)非常有效。
缺点:引入了类别频率信息,在类别频率变化较大时可能会导致偏差。
适用场景:适合处理高基数类别特征(例如,用户ID、产品ID)。
import pandas as pd
# 创建示例DataFrame
data = {
'编号': ['A01', 'B01', 'C01', 'D01', 'E01'],
'颜色': ['红色', '蓝色', '红色', '绿色', '蓝色']
}
df = pd.DataFrame(data)
# 计算颜色频率
color_counts = df['颜色'].value_counts()
# 对“颜色”列进行频率编码
df['颜色_频率编码'] = df['颜色'].map(color_counts)
print(df)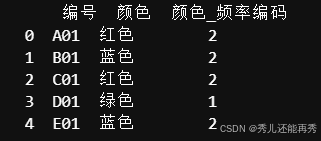
(四)目标编码
原理:根据类别变量在目标变量上的表现,将类别值替换为类别的目标变量的均值或其他统计值。例如,将类别
A替换为类别A在目标变量上的均值。优点:保留了类别和目标之间的关系,适合高基数类别。
缺点:容易引入信息泄露,导致过拟合,尤其在类别较少时。
适用场景:适合用于回归或分类任务,特别是高基数类别数据(例如,用户、产品类别),但需在交叉验证或折叠编码中小心使用,避免过拟合。
import pandas as pd
# 示例数据
data = {
'编号': ['A01', 'B01', 'C01', 'D01', 'E01'],
'颜色': ['红色', '蓝色', '红色', '绿色', '蓝色'],
'销售': [100, 200, 150, 300, 250]
}
df = pd.DataFrame(data)
# 计算每个颜色对应的销售均值
col_mean = df.groupby("颜色")["销售"].mean()
# 使用目标均值进行编码
df["col_encoded"] = df["颜色"].map(col_mean)
print(df) 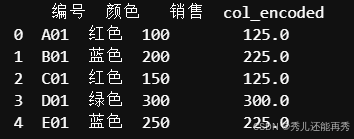
特征编码的局限性
1、可能导致维度爆炸(特别是独热编码)
2、类别顺序信息丢失:标签编码虽然保持了类别的顺序,但对于没有明显顺序的类别变量,标签编码会给模型一种虚假的顺序信息,从而导致误差。例如,"苹果"和"香蕉"是两个无序类别,但标签编码可能会让模型误认为这两者有大小关系。
3、类别关系表达有限:独热编码无法表达类别之间的相似度或距离关系,所有类别被看作独立的,没有考虑到类别之间的潜在关系。例如,“猫”和“狗”在语义上更接近,但在独热编码中,它们完全没有联系。
4、数据稀疏性:对于某些稀疏数据,特征编码会导致模型输入的矩阵变得非常稀疏,尤其是对于类别数量非常大的特征(如邮政编码、产品ID等)。这类高稀疏性数据会增加模型训练难度,并影响模型性能。
5、泛化性差(可能无法处理没出现过的类别):直接的数值编码方法(如标签编码)可能对模型的泛化能力不利。如果模型在训练中没有遇到某些类别,预测时出现新的类别会导致无法处理的情况,或者模型表现较差。
6、无法满足对特征组合的需求
总结


















 397
397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









