







 本文介绍了大数据时代的特点及分析工具,重点阐述了Spark。大数据具有大量、高速、多样、低价值密度和真实性等特点,需分布式处理。Spark是专为大规模数据处理设计的计算引擎,具有速度快、易用、通用等特点。还介绍了Spark的核心概念、部署模式、基本操作、API及安装配置过程。
本文介绍了大数据时代的特点及分析工具,重点阐述了Spark。大数据具有大量、高速、多样、低价值密度和真实性等特点,需分布式处理。Spark是专为大规模数据处理设计的计算引擎,具有速度快、易用、通用等特点。还介绍了Spark的核心概念、部署模式、基本操作、API及安装配置过程。
PySpark
1.大数据时代
1.1 什么是大数据
根据百度百科显示,最早提出大数据时代到来的是全球知名咨询公司麦肯锡,麦肯锡称:“数据,已经渗透到当今每一个行业和业务职能领域,成为重要的生产因素。人们对于海量数据的挖掘和运用,预示着新一波生产率增长和消费者盈余浪潮的到来。
”大数据(BigData),是一个IT行业术语,是指无法在一定时间范围内用单机软件工具进行捕捉、管理和处理的数据集合,它需要使用分布式模式才能处理,其数据具有数量大、来源广、价值密度低等特征。
至于什么数据量算得上大数据,这个也没有一定的标准,一般来说,单机难以处理的数据量,就可以称得上大数据。大数据和人工智能往往关系密切,人工智能算法必须依据数据才能构建合适的模型,以便用于预测和智能决策。当前,大数据技术已经在医药、电信、金融、安全监管、环保等领域广泛使用。
大数据时代,分布式的数据存储和查询模式可以对全量数据进行处理。举例来说,以前DNA 和指纹数据库的建立,由于信息技术水平的限制,只能重点采集并存储部分人口的DNA和指纹数据,这种限制对于很多案件的侦破是非常不利的。
而当我们步入大数据时代后,从理论上来讲,采集并存储全球人口的DNA和指纹信息是可行的。因此,建立全量的 DNA 和指纹数据库,这对DNA 和指纹数据的比对工作来说,具有非常大的价值。以前我们研究问题,主要研究几个要素之间的因果关系,例如通过经验、观察实验和数学等理论推导出一些公式,用于指导生产和生活。而在大数据时代,更多的是对几个要素之间相关性进行分析。例如,通过对电商平台上的购买行为进行分析,可以对用户进行画像,并根据用户的历史购买记录,来智能推荐他可能感兴趣的商品,这种分析对提升成单率来说至关重要。
基于大数据的推荐系统,可能比你自己都要了解你自己。这也是在大数据时代人类越来越关心个人隐私信息的安全问题的原因。
相关性分析是寻找因果关系的利器。可以说,相关分析和因果分析是互相促进的。如果多个因素之间有明显的相关性,那么就可以进一步研究其因果关系。大数据的价值就在于从海量数据中,通过机器学习算法自动搜寻多个因素之间的相关性,这些相关性可以大大减少人工搜寻的时间。换句话说,人工从海量数据中往往很难发现多个因素之间的相关性,而这恰恰是机器学习比较擅长的领域。
1.1.1 大数据的特点
一般来说,大数据具有如下几个特点,
1.Volume(大量)
大数据场景下,对数据的采集、计算和存储所涉及的数量是非常庞大的,数据量往往多到单台计算机无法处理和存储,必须借助多台计算机构建的集群来分布式处理和存储。
分布式存储要保证数据存储的安全性。如果某一个节点上的数据损坏,那么必须从其他节点上对损坏节点上的数据进行自动修复,这个过程中就需要数据的副本,同一份数据会复制多份,并分布式存储到不同的节点上。
如果不借助大数据工具,自己实现一个分布式文件系统,那么其工作量非常大。因此,对于大数据的处理和存储来说,更好的方案就是选择一款开源的分布式文件系统。
2.Velocity(高速)
以前由于数据采集手段落后、数据存储空间横向扩展困难,不能存储海量的数据,因此只会采集一些重要的数据,如财务数据、生产数据等。这就导致了高层管理人员在决策时,缺乏完整、统一的宏观数据作为数据支撑。
在大数据时代,由于数据采集手段多样、数据可以分布式存储,因此当前很多企业都会尽可能地存储数据,其中不少企业中都有传感器或者视频探头,它们会产生大量的数据,形成一个数据流,这些数据流的产生都是非常迅速的,因此分析这些数据的软件系统必须做到高效地采集、处理和存储这些高速生成的数据。
一般来说,大数据系统可以借助分布式集群构建的强大计算力,对海量数据进行快速处理。若处理数据的响应时间能到秒级,甚至毫秒级,那么其价值将非常大。实时大数据的处理,这也是目前众多大数据工具追求的一个重要能力。
3.Variety(多样)
生物具有多样性,动物有哺乳动物、鸟类和冷血动物等,植物有苔植物、类植物和种子植物等。多样的生物只有和谐相处,才是可持续发展之道。
同样地,数据的载体也是多种多样,一般来说,可以分为结构化数据、非结构化数据和半结构化数据。其中很多业务数据都属于结构化数据,而是视频、音频和图像等都可划分为非结构化数据。在大数据时代下,非结构化数据从数量上来说占了大部分。因此,对视频、音频、图像和自然语言等非结构化数据的处理,也是当前大数据工具要攻克的重点。
4.Value(低价值密度)
大数据首先是数据量庞大,一般来说,都是PB级别的。但在特定场景下,真正有用的数据可能较少,即数据价值密度相对较低。从大数据中挖掘出有用的价值,如大海针一般。举例来说,交通部门为了更好地对道路交通安全进行监管,在重点的路口都设有违法抓拍系统,会对每辆车进行拍照,这个数据量非常巨大,其中有交通违法行为的车辆照片并不多,可以说是万里挑一。因此这个价值密度相对低,但是存储这些数据非常重要,其中某一些图片资料对于协助破案来说会起到至关重要的作用。
5.Veracity(真实性)
大数据场景下,由于数据来源的多样性,互相可以验证,因此数据的真实性往往比较高。这里说的真实性,是指数据的准确性和及时性。数据的真实性也是大数据可以形成数据资产的一个重要前提,只有真实、可信的数据才能挖掘出有用的价值。
大数据由于具有如上的特点,这就对大数据的信息化软件提出了非常高的要求。一般的软件系统是无法很好的处理大数据的。从技术上看,大数据与云计算密不可分。大数据无法用单台计算机进行存储和处理,而必须采用分布式架构,即必须依托云计算提供的分布式存储和计算能力。
1.2大数据下的分析工具
大数据技术首先需要解决的问题是如何高效、安全地存储;其次是如何高效、及时地处理海量的数据,并返回有价值的信息:最后是如何通过机器学习算法,从海量数据中挖掘出在的价值,并构建模型,以用于预测预警。可以说,当今大数据的基石,来源于谷歌公司的三篇论文,这三篇论文主要阐述了谷歌公司对于大数据问题的解决方案。这三篇论文分别是:
Google File System
Google MapReduce
Google BigTable
其中,Google File System 主要解决大数据分布式存储的问题,Google MapReduce 主要解决大数据分布式计算的问题,Google Bigtable主要解决大数据分布式查询的问题。当前大数据工具的蓬勃发展,或多或少都受到上述论文的启发,不少社区根据论文的相关原理,实现了最早一批的开源大数据工具,如Hadoop 和HBase。但值得注意的是,当前每个大数据工具都专注于解决大数据领域的特定问题,很少有一种大数据工具可以一站式解决所有的大数据问题。因此,一般来说,大数据应用需要多种大数据工具相互配合,才能解决大数据相关的业务问题。
大数据工具非常多,据不完全统计,大约有一百多种,但常用的只有10多种,这些大数据工具重点解决的大数据领域各不相同,现列举如下:
分布式存储:主要包含Hadoop HDFS和Kafka等。
分布式计算:包括批处理和流计算,主要包含Hadoop MapReduce、Spark和Flink等。分布式查询:主要包括Hive、HBase、Kylin、Impala等。
分布式挖掘:主要包括Spark ML和Alink等。
据中国信通院企业采购大数据软件调研报告来看,86.6%的企业选择基于开源软件构建自己的大数据处理业务,因此学习和掌握几种常用的开源大数据工具,对于大数据开发人员来说至关重要。下面重点介绍大数据常用的几种分析工具。
1.2.1 Spark
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。它是加州大学伯克利分校的 AMP实验室开源的通用并行框架。它不同于Hadoop MapReduce,计算任务中间输出结果可以保存在内存中,而不再需要读写HDFS,因此Spark计算速度更快,也能更好地适用于机器学习等需要迭代的算法。Apache Spark是由Scala语言开发的,可以与Java程序一起使用。它能够像操作本地集合对象一样轻松地操作分布式数据集。它具有运行速度快、易用性好、通用性强和随处运行等特点。
Apache Spark 提供了Java、Scala、Python 以及R语言的 API。还支持更高级的工具,如Spark SOL、Spark Streaming、Spark MLlib 和 Spark GraphX等。Apache Spark主要有如下几个特点:
非常快的计算速度:它主要在内存中计算,因此在需要反复选代的算法上,优势非常明显,比 Hadoop快100倍。
易用性:它大概提供了80多个高级运算符,包括各种转换、聚合等操作。这相对于Hadoop组件中提供的map和reduce两大类操作来说,丰富了很多,因此可以更好地适应复杂数据的逻辑处理。
通用性:它除了自身不带数据存储外,其他大数据常见的业务需求,比如批处理、流计算、图计算和机器学习等都有对应的组件。
因此,开发者通过Spark提供的各类组件,如Spark SQL、Spark Streaming、Spark MLlib和Spark GraphX等,可以在同一个应用程序中无缝组合使用这些库。
支持多种资源管理器:它支持Hadoop YARN、Apache Mesos,以及Spark自带的Standalone集群管理器。
2.Spark核心概念
2.1Spark软件栈

Spark Core:核心组件,分布式计算引擎;包含了Spark的基本功能,包含任务调度、内存管理和容错机制,内部定义了RDD(弹性分布式数据集),提供了很多的API来创建和操作这些RDD
Spark SQL:高性能的基于Hadoop的SQL解决方案,可以处理结构化数据的查询分析
Spark Streaming:可以实现高吞吐量、具备容错机制的准实时流处理系统,一般需要配合消息队列kafka,来接收数据做实时统计分析
Spark Graphx:分布式图处理框架
Spark MLlib:构建在Spark上的分布式机器学习库
2.2Spark运行架构
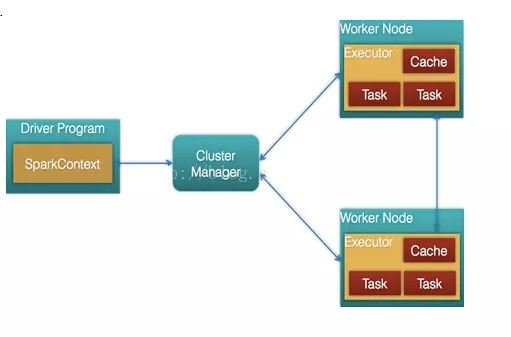
Spark中的重要概念如下:
Application:提交一个作业就是一个Application,一个Application只有一个SparkContext。由群集上的驱动程序和执行程序组成。
Driver程序:一个Spark作业运行时会启动一个Driver进程,也是作业的主进程,负责作业的解析、生成Stage和调度Task到Executor上执行。Driver程序运行应用程序的main函数,并创建SparkContext进程。
Cluster Manager:Cluster Manager是用于获取集群资源的外部服务(如StandaloneYARN或Mesos),在Standalone模式中即为Master(主节点)。Master是集群的领导者,负责管理集群的资源,接收Client提交上来的作业,以及向Worker节点发送命令。在YARN模式中为资源管理器。
Worker:Worker节点是集群中的Worker,执行Master发送来的命令来具体分配资源,并在这些资源上执行任务Task。在YARN模式中为NodeManager,负责计算节点的控制。
Executor:Executor是真正执行作业Task的地方。Executor分布在集群的Worker节点上,每个Executor接收Driver命令来加载和运行Task。一个Executor可以执行一个到多个Task。多个Task之间可以互相通信。SparkContext:SparkContext是程序运行调度的核心,由调度器DAGScheduler划分程序的各个阶段,调度器TaskScheduler划分每个阶段的具体任务。SchedulerBankend管理整个集群中为正在运行的程序分配计算资源的Executor。SparkContext是Spark程序入口。
DAGScheduler:负责高层调度,划分Stage,并生成程序运行的有向无环图。
TaskScheduler:负责具体Stage内部的底层调度、具体Task的调度和容错等。Job:Job是工作单元,每个Action算子都会触发一次Job,一个Job可能包含一个或多个Stage。
Stage:Stage用来计算中间结果的Tasksets。Tasksets中的Task逻辑对于同一RDD内的不同Partition都一样。Stage在Shufe的时候产生,如果下一个Stage要用到上一个Stage的全部数据,则要等上一个Stage全部执行完才能开始。Stage有两种:ShufleMapStage和ResultStage。除了最后一个Stage是ResultStage外,其他的Stage都是ShuffeMapStage。ShuffleManStage会产生中间结果,以文件的方式保存在集群里,Stage经常被不同的Job共享,前提是这些Job重用了同一个RDD。
Task:Task是任务执行的工作单位,每个Task会被发送到一个Worker节点上,每个Task对应RDD的一个Partition。Taskset:划分的Stage会转换成一组相关联的任务集。RDD:RDD指弹性分布数据集,它是不可变的、Lazy级别的、粗粒度的数据集合,包含一个或多个数据分片,即Partition。
DAG:DAG(Directed Acyclic Graph)指有向无环图。Spark实现了DAG计算模型,DAG计算模型是指将一个计算任务按照计算规则分解为若干子任务,这些子任务之间根据逻辑关系构建成有向无环图。
算子:Spark中两种算子:Transformation和Action。Transformation算子会由DAGScheduler划分到pipeline中,是Lazy级别的,它不会触发任务的执行。而Action算子会触发Job来执行pipeline中的运算。
窄依赖:窄依赖(Narrow Dependency)指父RDD的分区只对应一个子RDD的分区。如果子RDD只有部分分区数据损坏或者丢失,只需要从对应的父RDD重新计算即可恢复。
宽依赖:宽依赖(Shuffle Dependency)指子RDD分区依赖父RDD的所有分区。如果子RDD部分分区甚至全部分区数据损坏或丢失,则需要从所有父RDD上重新进行计算。相对窄依赖而言,数据处理的成本更高,所以应尽量避免宽依赖的使用。
Lineage:每个RDD都会记录自己依赖的父RDD信息,一旦出现数据损坏或者丢失,将从父RDD迅速重新恢复。
2.3Spark部署模式
Spark有多种部署方式,包含了:Local模式、Spark on YARN 模式、Standalone模式。
Local模式:本地采用多线程的方式执行,主要用于开发测试;
Spark on YARN模式:每个Spark Excutor作为一个YARN Container在执行。它有两种模式:yarn-client、yarn-cluster,yarn-client模式下,Driver运行在Client端,会和请求的YARN Container通信来调度它们工作,也就是说Client在计算期间不能关闭,计算结果会返回到Client,适合交互式的。而yarn-cluster中Driver是运行在Application Master中的,提交作业后即可关闭,适合非交互式的。
Standalone模式:和Local很相似,但是Standalone的分布式调度器是Spark提供的,运行时,必须启动Spark集群。
2.4Spark基本操作
Spark及内存数据的抽象,即为RDD,RDD是一种分布式、多分区、只读的数组,Spark相关操作都是基于RDD进行的。

在PySpark中,首先利用Python创建Spark Context对象,然后用Socket与JVM上的Spark Context通信,这个过程需要借助Py4j。JVM上的Spark Context负责与集群上的Spark Work进行交互。
在PySpark中,对RDD提供了Transformation和Action两种操作类型。Transformation操作非常丰富,采用延迟方式,在逻辑上定义了RDD的依赖关系和计算逻辑,但并不会真正触发执行操作。只有等到Action操作才会真正触发执行操作。Action操作常用于最终结果的输出。
2.5Spark的部署
2.5.1 python安装
1.安装响应的编译工具

2.下载python3.7的包
wget https://www.python.org/ftp/python/3.7.7/python-3.7.7.tgz
3.解压python3.7压缩包
tar -zxvf python-3.7.7.tgz
4.编译安装(进入python3.7.7目录下)
# prefix:指定安装目录;enable-optimizations:开启优化选项,提高运行速度;with-ssl:支持pip安装软件需要用到ssl
./configure --prefix=/usr/local/python3 --enable-optimizations --with-ssl
5.安装
make && make install
6.创建软连接
ln -s /usr/local/python3/bin/python3 /usr/local/bin/python3
ln -s /usr/local/python3/bin/pip3 /usr/local/bin/pip3
7.验证安装
python3

8.将python3进行分发
[root@hadoop141 ~]# scp -r /usr/local/python3/ root@hadoop142:/usr/local/python3
[root@hadoop141 ~]# scp -r /usr/local/python3/ root@hadoop143:/usr/local/python3
2.5.2 Spark安装
1.下载Spark安装包到Linux中

2.解压缩Spark
tar -zxvf spark-3.5.0-bin-hadoop3.tgz
3.验证spark
解压缩完成后,基本上Spark就可以使用了,首先进入到/home/hadoop/spark-3.5.0/bin目录下,使用spark-submit提交任务:
./spark-submit ../examples/src/main/python/pi.py

此案例为计算Pi的值,运行结果为3.13。此处的结果为很多的日志,我们可以通过修改配置文件来设置输出的日志格式:
4.设置日志格式
首先进入到/home/hadoop/spark-3.5.0/conf目录下,将目录下的log4j2.properties.template进行重命名为log4j2.properties:
[root@hadoop141 conf]# mv log4j2.properties.template log4j2.properties
打开log4j2.properties进行设置:
[root@hadoop141 conf]# vi log4j2.properties

再执行前面的操作,就会看到简单的结果:

5.启动PySpark交互界面
[root@hadoop141 bin]# ./pyspark
6.切换python版本为3.7
首先进入到/home/hadoop/spark-3.5.0/conf目录下,找到spark-env.sh添加如下内容
# 进入到spark-env.sh中编辑
[root@hadoop141 conf]# vi spark-env.sh
# 添加如下内容
PYSPARK_PYTHON=/usr/local/python3/bin/python3
2.5.3 安装与配置Spark集群
1.修改Spark-env.sh文件,添加如下内容
# 进入到spark-env.sh中编辑
[root@hadoop141 conf]# vi spark-env.sh
# 添加如下内容
export JAVA_HOME=/home/hadoop/jdk1.8.0_271
SPARK_MASTER_HOST=hadoop141
SPARK_MASTER_PORT=7077
SPARK_MASTER_WEBUI_PORT=8989
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hadoop141,hadoop142,hadoop143
-Dspark.deploy.zookeeper.dir=/spark"
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=8080
-Dspark.history.logDirectory=hdfs://hadoop141:9000/directory
-Dspark.history.retainedApplications=30"
export SCALA_HOME=/home/hadoop/scala-2.13.12
export SPARK_WORKER_MEMORY=1024m
export HADOOP_HOME=/home/hadoop/hadoop-3.3.0
export HADOOP_CONF_DIR=/home/hadoop/hadoop-3.3.0/etc/hadoop
SPARK_LOCAL_DIRS=/home/hadoop/spark-3.5.0
PYSPARK_PYTHON=/usr/local/python3/bin/python3
2.修改workers文件
[root@hadoop141 conf]# vi workers
# 添加如下内容
hadoop141
hadoop142
hadoop143
3.将Spark进行分发
[root@hadoop141 hadoop]# scp -r spark-3.5.0 root@hadoop142:/home/hadoop/
[root@hadoop141 hadoop]# scp -r spark-3.5.0 root@hadoop143:/home/hadoop/
4.启动Spark集群
[root@hadoop141 spark-3.5.0]# ./sbin/start-all.sh
5.验证集群
[root@hadoop141 spark-3.5.0]# jps

出现worker的进程代表集群已经启动,可以通过访问http://hadoop141:8989/来查看界面

可以通过Standalone模式提交任务:
[root@hadoop141 spark-3.5.0]# ./bin/spark-submit --master=spark://hadoop141:7077 ./examples/src/main/python/pi.py
可以得到对应的结果:

通过可以查看网页端会出现一个已经完成的任务:

还可以通过yarn的模式提交:
[root@hadoop141 spark-3.5.0]# ./bin/spark-submit --master yarn --deploy-mode client ./examples/src/main/python/pi.py
可以得到结果:

在执行的过程中可以通过http://hadoop141:8088/cluster来查看任务的进程:

上面是一个yarn的client模式,还有一个cluster模式,结果不会显示到客户端,而是在服务器中显示:
[root@hadoop141 spark-3.5.0]# ./bin/spark-submit --master yarn --deploy-mode cluster ./examples/src/main/python/pi.py
可以通过网页查看:

2.5.4 Anaconda安装以及Jupyter安装
1.选择下载位置,下载Anaconda
[root@hadoop141 ~]# wget https://repo.continuum.io/archive/Anaconda3-5.0.1-Linux-x86_64.sh

2.进入下载的目录安装anaconda
[root@hadoop141 ~]# cd /home/hadoop/
[root@hadoop141 hadoop]# bash Anaconda3-5.0.1-Linux-x86_64.sh
一直按回车,然后输入yes即可
3.配置anaconda的路径
[root@hadoop141 hadoop]# vi /etc/profile
#保存退出 esc shift+: 输入wq

4.验证anaconda
[root@hadoop141 hadoop]# conda --version
conda 4.10.3
5.安装Jupyter
一般anaconda中已经自带了Jupyter,所以可以直接使用
[root@hadoop141 hadoop]# jupyter notebook --generate-config --allow-root
然后切换路径到anaconda的安装目录下,执行./python
[root@hadoop141 anaconda3]# cd /root/anaconda3
[root@hadoop141 anaconda3]# ./bin/python
Python 3.6.10 |Anaconda, Inc.| (default, Mar 25 2020, 23:51:54)
[GCC 7.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
在上述python中输入:
>>>from notebook.auth import passwd
>>>passwd()
然后输入自己的密码,输入完成后会出现一个sha1字符串,将字符串复制备用
自己创建一个存放Jupyter的目录,随后在终端中输入
[root@hadoop141 anaconda3]# vi ~/.jupyter/jupyter_notebook_config.py
# 随后按shift+g快速定位到文件末尾
# 添加如下内容
# 就是设置所有ip皆可访问
c.NotebookApp.ip='*'
# 上面复制的那个sha密文'
c.NotebookApp.password = 'sha1:0b1651c4d744:b5057f9d7941e761ea0e2f8889521c190ccc9487'
# 禁止自动打开浏览器
c.NotebookApp.open_browser = False
# 端口
c.NotebookApp.port =8888
#设置Notebook启动进入的目录(自己创建的存放Jupyter的目录)
c.NotebookApp.notebook_dir = '/root/jupyternotebook'
随后按gg快捷键到达文件头部,按下键找到图片中的位置,将#去掉,换成True

保存退出,运行Jupyter
[root@hadoop141 anaconda3]# jupyter notebook

在浏览器中访问http://hadoop141:8888/,随后输入密码即可


2.6Spark的API
SparkSession
可以通过SparkSession的驱动器来控制Spark应用程序,需要创建一个SparkSession实例来在集群中执行用户定义的操作,每一个Spark应用程序都需要一个SparkSession与之对应。当启动控制台后,可以看到一个SparkSession就被实例化为一个Spark对象。
scala:

python:

案例:
创建一组固定范围的数字,就像一个电子表格的一个命名列一样:
scala:

python:

此时,已经创建一个DataFrame,其中一列包含1000行,值为0~999.这些数字即为一个分布式集合,在集群上运行命令时,这个集合的每一部分都会被分配到不同的执行器上。这个集合就是一个Spark DataFrame。
DataFrame
DataFrame是常见的结构化API,简单地说,他是包含行和列的数据表,说明这些列和列类型的一些规则被称为模式(schema)。
和电子表格的不同:

数据分区
为了让多个执行器并行地工作,Spark将数据分解成多个数据块,每个数据块叫做一个分区。分区是位于集群中的一台物理机上的多行数据的集合,DataFrame的分区也说明了在执行过程中数据在集群中的物理分布。如果只有一个分区,即使拥有数千个执行器,Spark也只有一个执行器在处理数据。类似地,如果有多个分区,但只有一个执行器,那么Spark仍然只有一个执行器在处理数据,就是因为只有一个计算资源单位。
值得注意的是,当使用DataFrame时,(大部分时候)你不需要手动操作分区,只需指定数据的高级转换操作,然后Spark决定此工作如何在集群上执行。
转换操作
案例:
查找当前DataFrame中的所有的偶数:
scala:

python:

这些转换并没有实际的输出,是因为仅指定了一个抽象转换。在调用一个动作操作之前,Spark不会真正的执行转换操作。转换操作是使用Spark表达业务逻辑的核心。有两类转换操作:窄依赖关系的转换操作和宽依赖关系的转换操作。
窄依赖关系的转换操作:每个输入分区仅决定一个输出分区的转换,在代码中where指定了一个窄依赖关系,其中一个分区最多只会对一个输出分区有影响。
宽依赖关系的转换操作:每个输入分区决定了多个输出分区。这种宽依赖关系的转换经常被称为洗牌(shuffle)操作,它会在整个集群中执行互相交换分区数据的功能。
动作操作
转换操作能够建立逻辑转换计划。为了触发计算,需要运行一个动作操作(action)。一个动作指示Spark在一系列转换操作后计算一个结果。最简单的操作是count,是计算一个DataFrame中的记录总数:
scala:

python:

上述的count并不是唯一的动作,有三类动作:
1.在控制台中查看数据的动作
2.在某个语言中将数据汇集为原生对象的动作
3.写入输出数据源的动作
一个完整的例子
首先创建一个csv文件,在csv文件中保存如下数据(航班数据):

DEST_COUNTRY_NAME,ORIGIN_COUNTRY_NAME,count
United States,Romania,15
United States,Croatia,1
United States,Ireland,344
Spark可以从大量数据源中读取数据或写入数据,为了读取数据,需要用到和创价的呢SparkSession所关联的DataFrameReader,还需要执行文件格式及设置其他选项:
scala:

# 创建一个SparkSession对象
scala> val flightData = spark
flightData: org.apache.spark.sql.SparkSession = org.apache.spark.sql.SparkSession@cf97391
# 通过read来读取
scala> .read
res0: org.apache.spark.sql.DataFrameReader = org.apache.spark.sql.DataFrameReader@3e908a0b
# 设置模式为模式推理,让Spark猜测DataFrame的模式
scala> .option("inferSchema","true")
res1: org.apache.spark.sql.DataFrameReader = org.apache.spark.sql.DataFrameReader@3e908a0b
# 指定文件的第一行为文件头
scala> .option("header","true")
res2: org.apache.spark.sql.DataFrameReader = org.apache.spark.sql.DataFrameReader@3e908a0b
scala> .csv("file:/home/hadoop/summary.csv")
res3: org.apache.spark.sql.DataFrame = [DEST_COUNTRY_NAME: string, ORIGIN_COUNTRY_NAME: string ... 1 more field]
python:

>>> flightData = spark.read.option("inferSchema","true").option("head","true").csv("file:/home/hadoop/summary.csv")
>>> flightData
DataFrame[_c0: string, _c1: string, _c2: string]
如果在DataFrame中执行take操作:
scala:

python:

上述操作工程中,csv文件被读取到一个DataFrame里后,又被转换为了一个本地数组或者行列表,转换完成后可以根据count列的值(整数类型)排序:
scala:

在执行sort的时候没有任何变化,是因为sort只是一个转换操作,但是可以通过调用explain函数观察Spark正在创建一个执行计划:

现在就需要一个动作来执行或者触发这个计划,在执行之前,先完成一个配置,默认情况下,shuffle操作会输出200个分区,我们将此值设置为5,以减少shuffle输出的分区数量:


python:



















 1438
1438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









