






归一化,标椎化
1.归一化: 通过对原始数据进行变换把数据映射到【mi,mx】(默认为【0,1】)之间。
(1)均值方差归一化:均值方差归一化:把所有数据归一到均值为0方差为1的分布中
适用于数据分布没有明显的边界,有可能存在极端数据值。
(2)最值归一化 :把所有数据映射到0-1之间适用于分布有明显边界的情况;受 outlier影响较大。
代码展示:
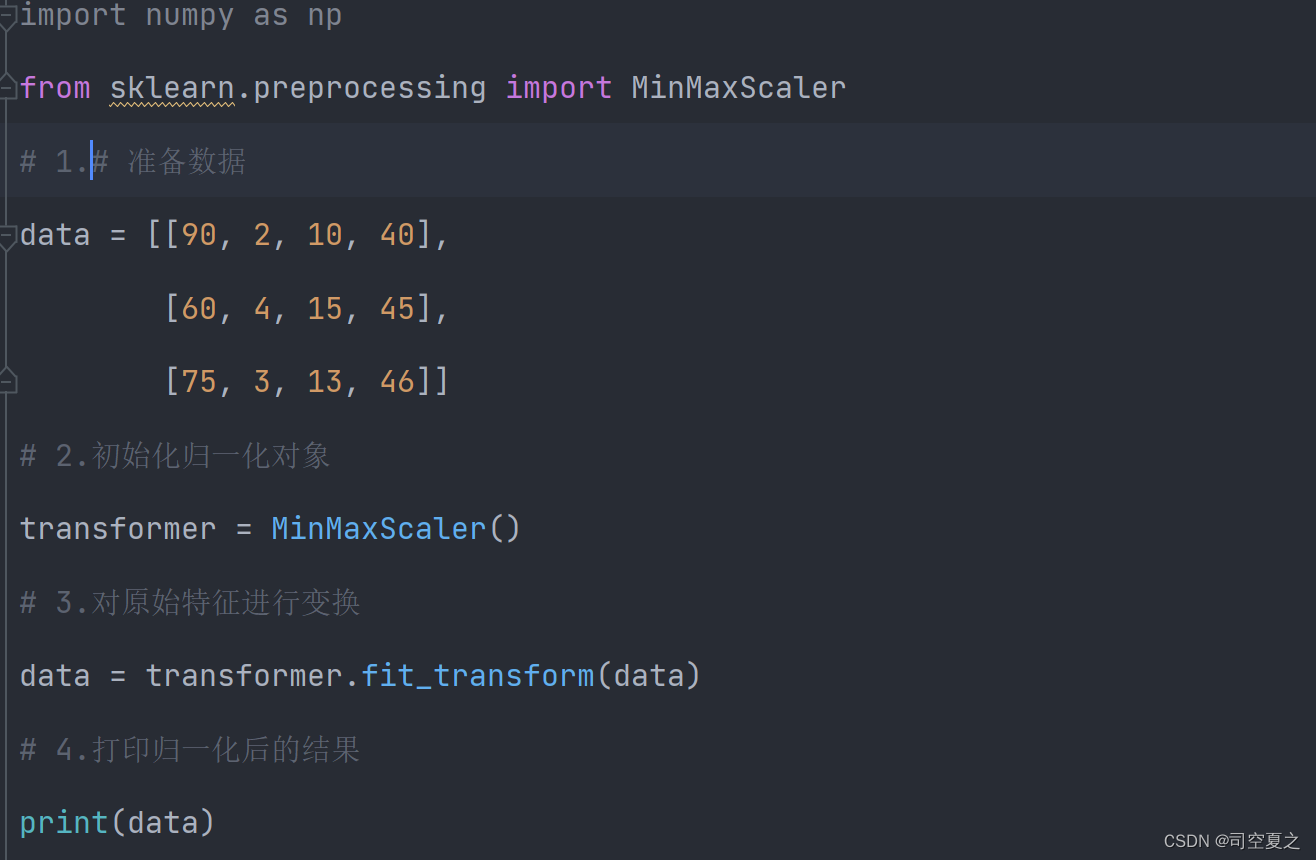
结果: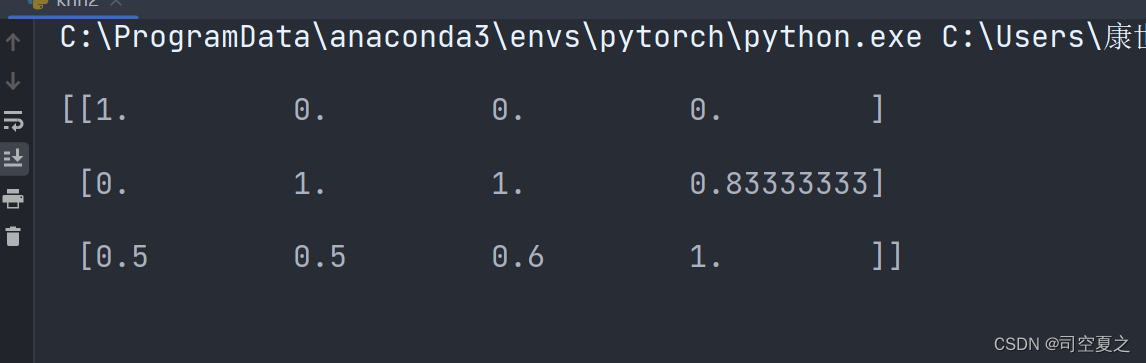
如果出现异常点,影响了最大值和最小值,那么结果显然会发生改变
应用场景:最大值与最小值非常容易受异常点影响,鲁棒性较差,只适合传统精确小数据场景。
2.标椎化:如果数据中的异常点比较多,例如特征2中突然有个数据是100,这明显比其他数据大很多,那么归一化时就会对结果产生很大影响。因为归一化会受到最大和最小值影响,因此归一化的鲁棒性(稳定性)比较差,只适合传统精确的小数据场景。
标准化定义:通过对原始数据进⾏变换把数据变换到平均值为0,标准差为1范围内。对于标准化来说,如果出现异常点,由于具有⼀定数据量,少量的异常点对于平均值的影响并不⼤,从⽽⽅差改变较⼩。 更适合现代嘈杂大数据场景,因此常用的是标准化。
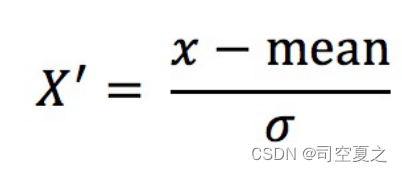
代码演示

结果:
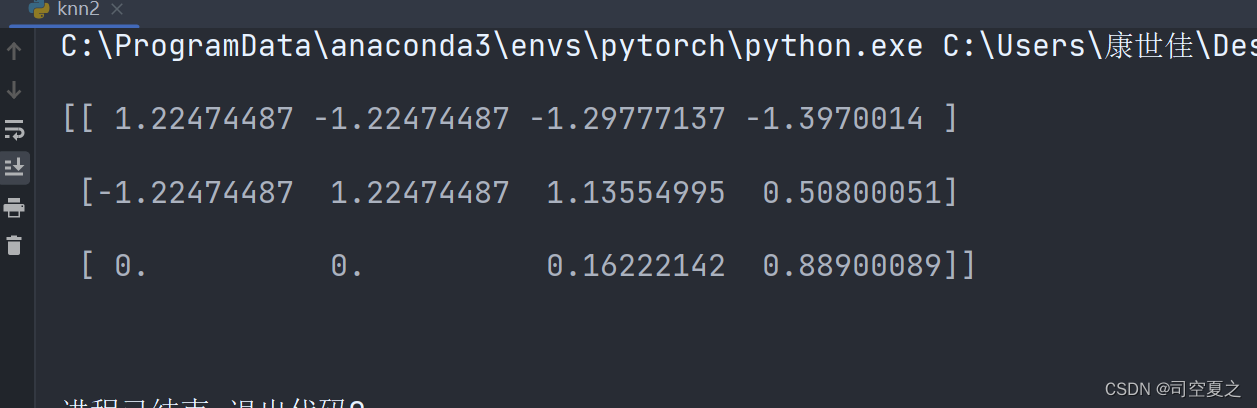
如果出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大
应用场景:适合现代嘈杂大数据场景。
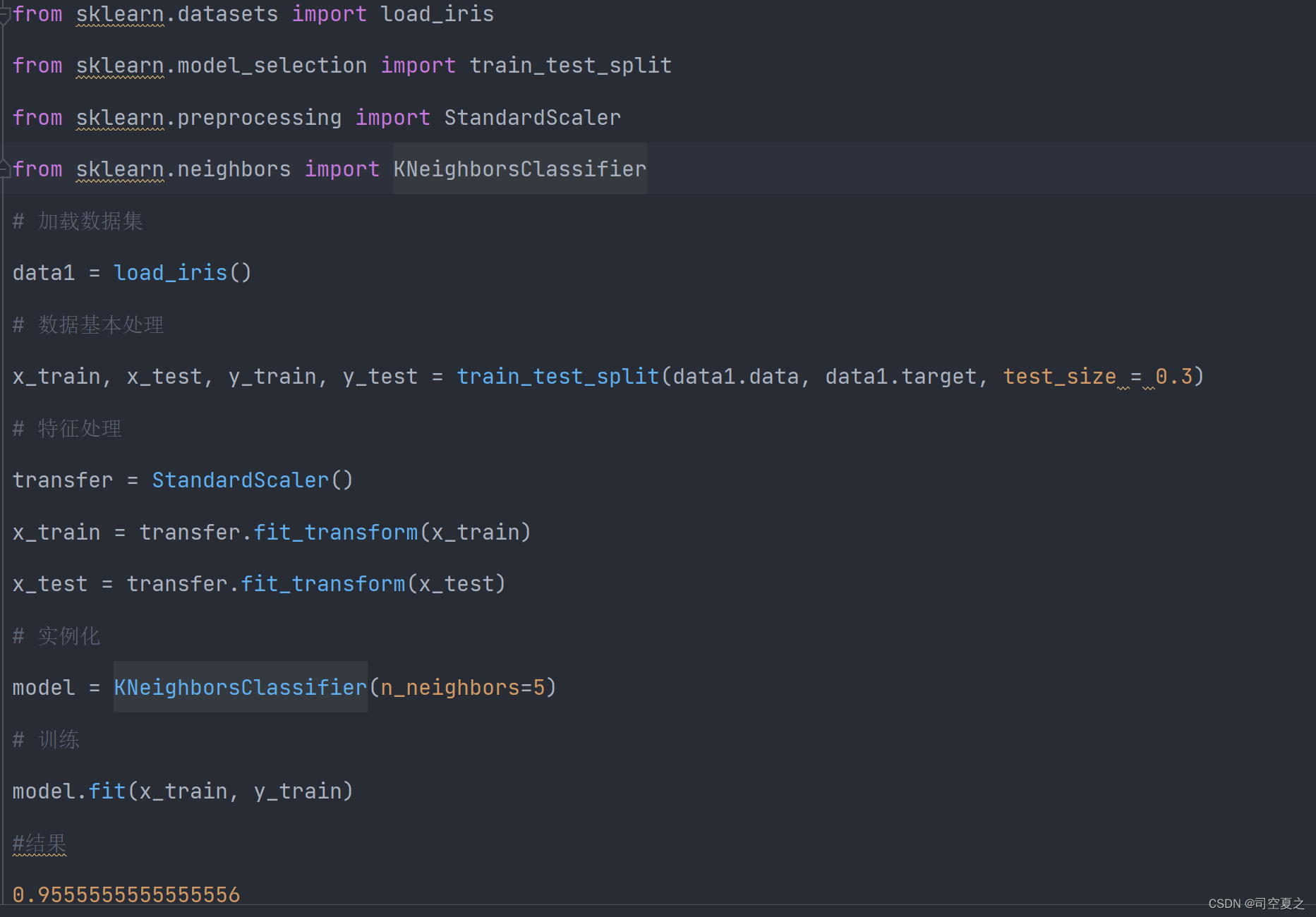
利用KNN算法对鸢尾花分类
兄弟们我直接上代码:
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# 加载数据集
data1 = load_iris()
# print(f"数据集-->{data1.feature_names}\n{data1.data[:10]}")
print(f"目标值\n{data1.target_names}\n{data1.target}")
# 数据展示
data2 = pd.DataFrame(data1["data"], columns=data1.feature_names)
data2["target"] = data1.target
print(data2)
feature_names = list(data1.feature_names)
for i in range(len(feature_names)):
for j in range(i+1, len(feature_names)):
col1 = feature_names[i]
col2 = feature_names[j]
sns.lmplot(x=col1, y=col2,hue='target',data=data2,fit_reg=False)
plt.xlabel(col1)
plt.ylabel(col2)
plt.title(f'{col1} vs {col2}')
plt.show()
结果:
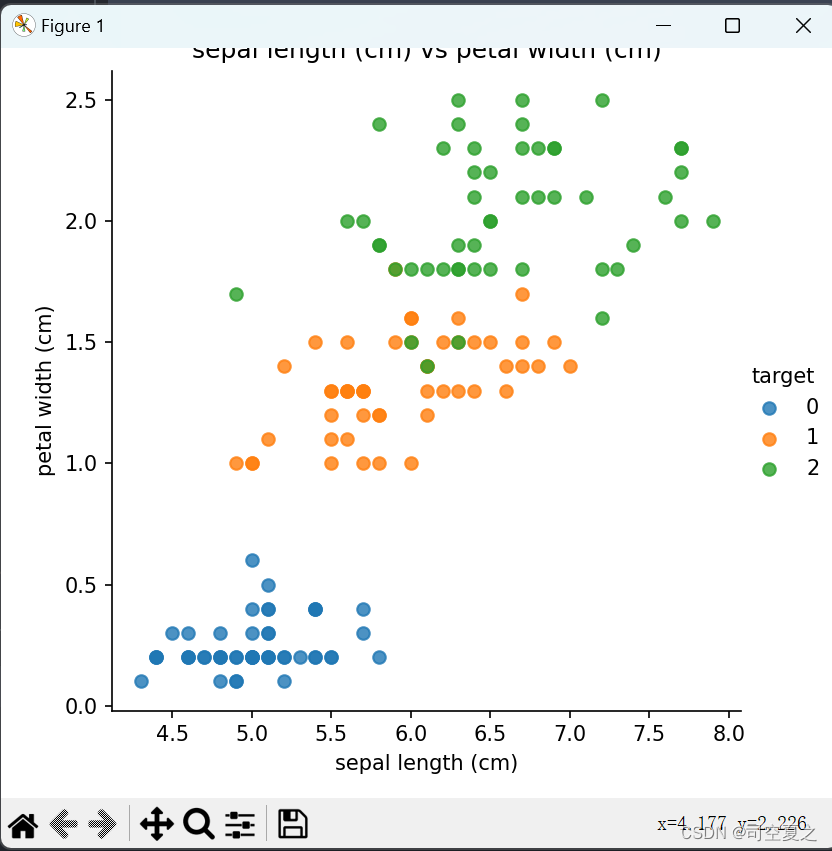
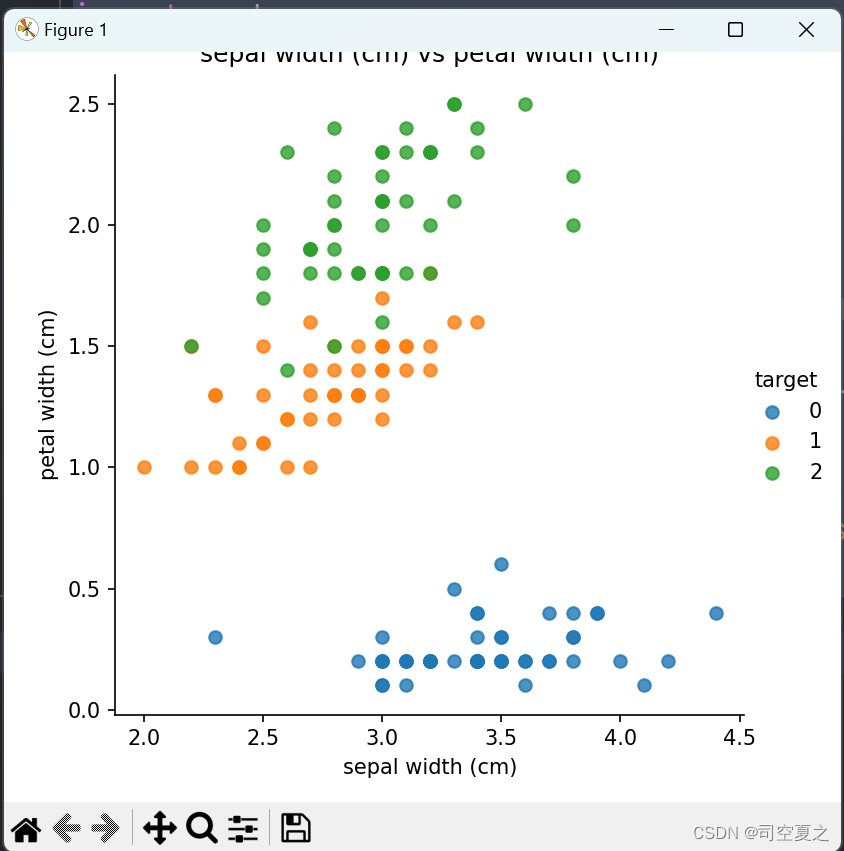
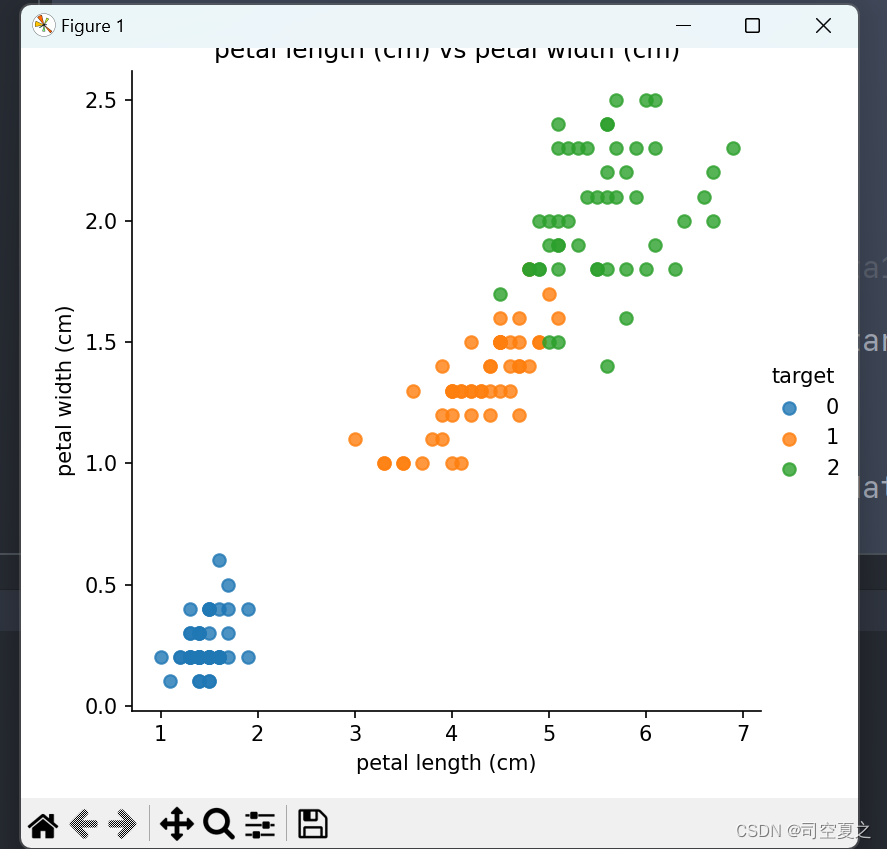
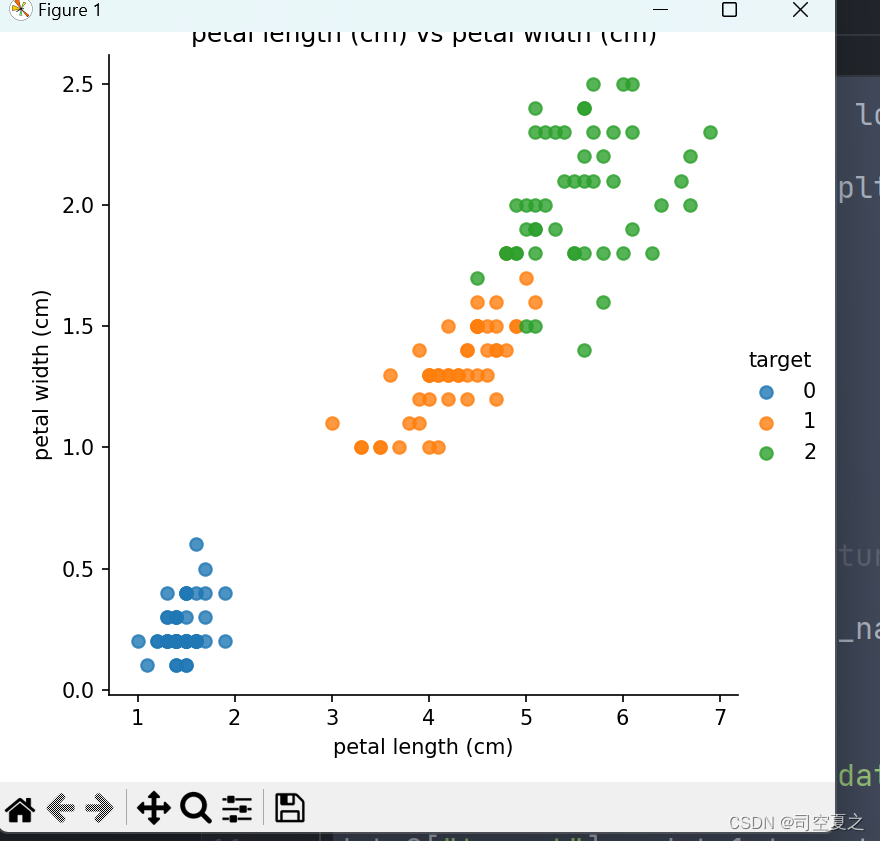
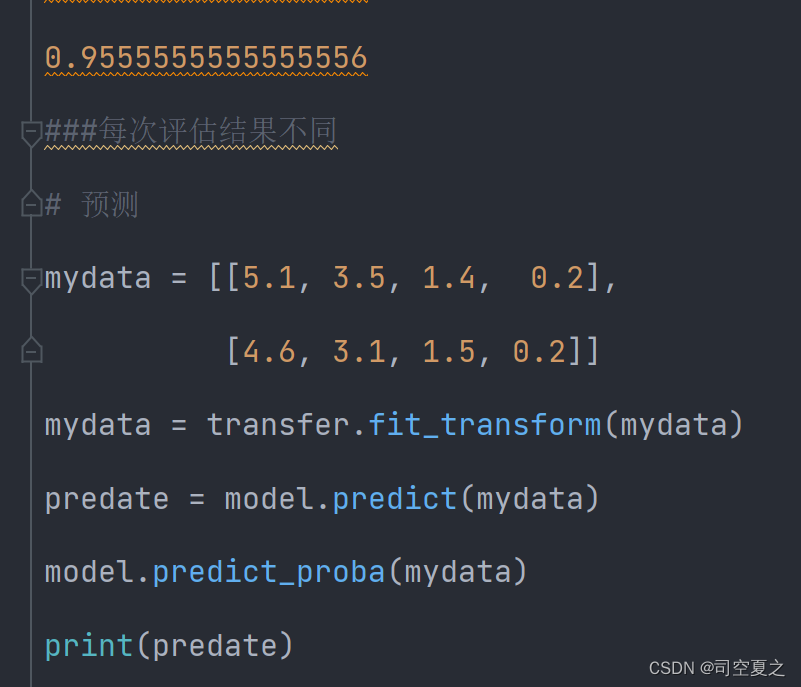
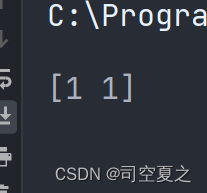
选取较好的模型进行使用:















 2752
2752











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









