






KNN算法简介
1.KNN思想:KNN的思想主要对于任意n维输入向量,分别对应于特征空间中的一个点,输出为该特征向量所对应的类别标签或预测值。
2.KNN近邻算法:KNN近邻算法如名,我们可以将其分成四个部分。一个是你要判断的个体,你要将其分到合适的类别之中。第二个那就是类别,这个是根据你所有的种类,是你最后可以把个体判断出来的。第三个便是邻居,也就是其他个体。第四个便是你要根据几个邻居来推断要判断的个体。
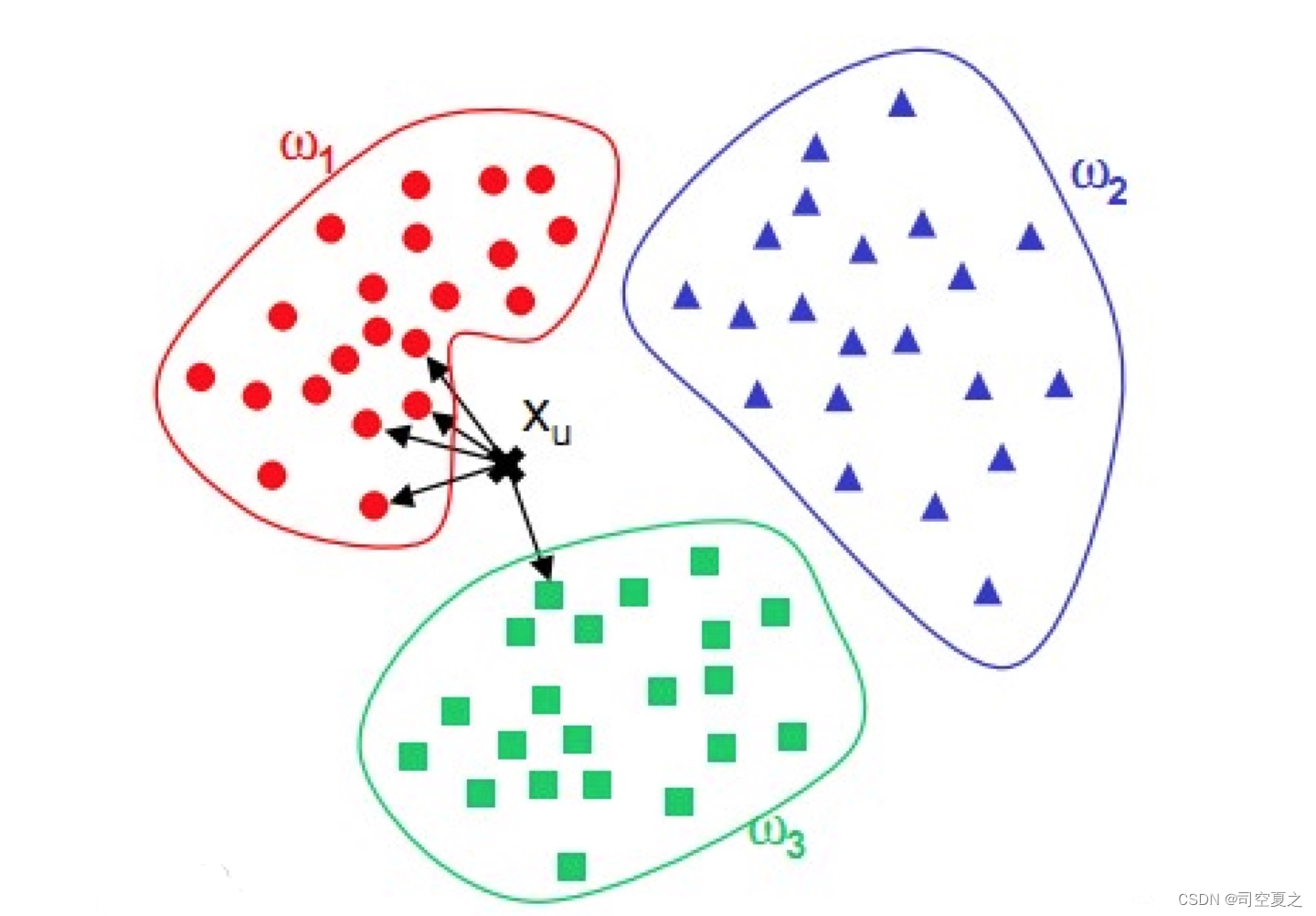
3.KNN近邻算法的计算: KNN的计算是比较简单的,我们将由上述的四个部分来讲解。以平面为例,我们先定好需要几个邻居,基本不会太多(在python中默认为五),然后计算最近的那几个邻居,哪一个类别的比较多就归类于那个类别。后文中我将用代码来解释。

KNN主要解决的问题
KNN主要解决分类问题和回归问题 。
分类问题:
1.计算未知样本到每一个训练样本的距离。
2.将训练样本根据距离大小升序排列。
3.取出距离最近的K个训练样本。
4.进行多数表决,统计K个样本中哪个类别的样本个数最多。
5.将未知的样本归属到出现次数最多的类别。
回归问题
1.计算未知样本到每一个训练样本的距离。
2.将训练样本根据距离大小升序排列。
3.取出距离最近的K个训练样本.
4.把这个K个样本的目标值计算其平均值。
5.作为将未知的样本预测的值。
K值的选择(上文四个部分的第四)
1.过大:用较大邻域中的训练实例进行预测受到样本均衡的问题且K值的增大就意味着 整体的模型变得简单,欠拟合。
2.过小:容易受到异常点的影响K值的减小就意味着整体模型变得复杂,容易发生过拟 合
KNN简单的环境配置
算法的最终还是要用代码来实现。我所用的是pychram,所配置的环境用的为Anaconda。
第一步先下环境:conda create -n 名字 python==3.9(python版本,看自身需求)
第二步进入环境:conda activate 名字

第三步下所需要的库(本次用要安装的库为scikit): pip install scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simple
第二张图中中间部分,这后半部分为清华园网址,加上会更快下载
简单的代码实现
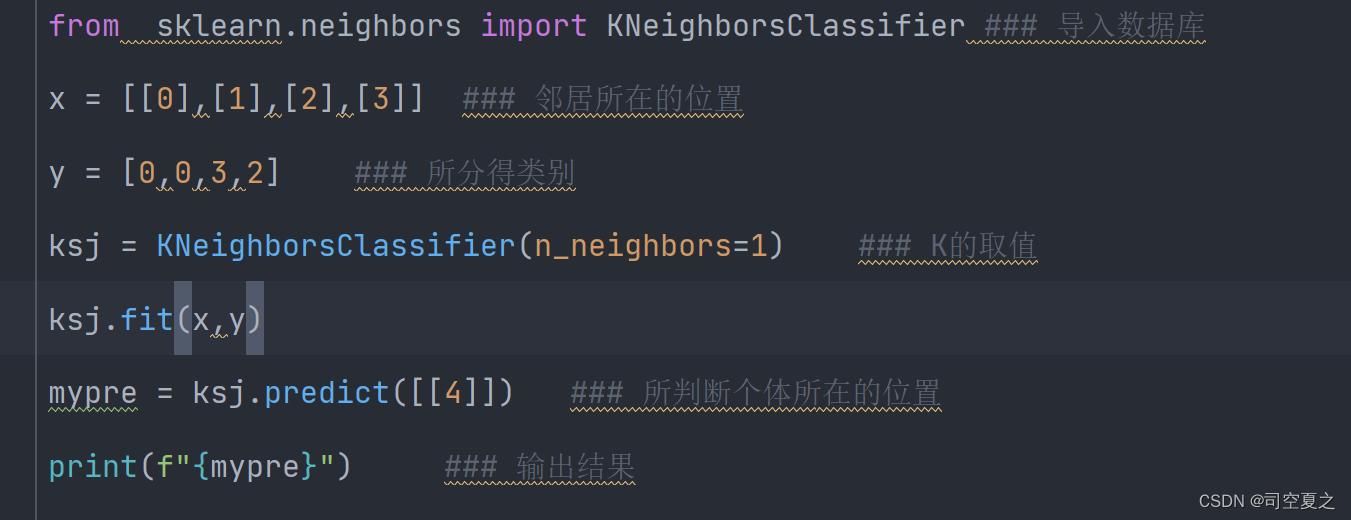
最终的结果会是几呢,各位请看:

我来说以下可能有的误区,其中X与Y是相对映的,我取的K值为1,个体所在的位置为4,上面邻居最近的是3,而三对应的类别为2。及最终结果为2。如果所以值不变,将K变为2,最终结果会是什么呢?
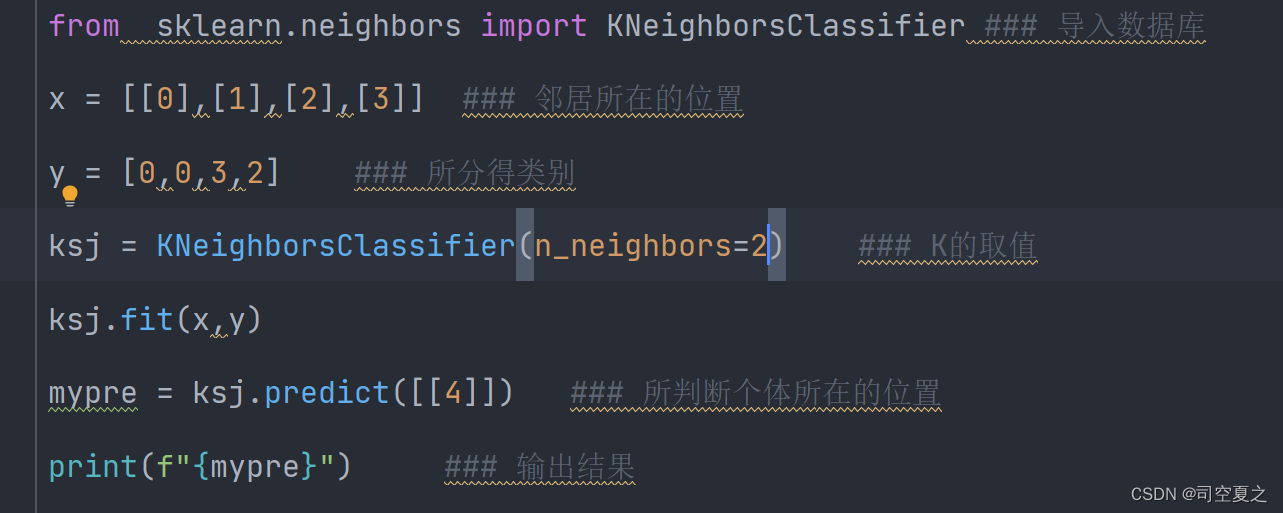

结果还是2,来我们看,当K为2时,最近为2和3,其对应的分别为3和2,它之所以取2是当数量相同时,相y取小。当然,X也可取二维三维,那时个体也要改变。各位可自行尝试。 之后的下次再发。















 632
632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









