






第一步: 安装OpenAI、GPT Index、PyPDF2和Gradio库
pip install openaipip install gpt_indexpip install PyPDF2pip install gradio第二步:用VScode代码编辑器写app.py代码
记得替换api密钥
from llama_index import SimpleDirectoryReader, GPTListIndex, GPTVectorStoreIndex, LLMPredictor, PromptHelper
from langchain import OpenAI
import gradio as gr
import sys
import os
os.environ["OPENAI_API_KEY"] = 'Your API Key'
def construct_index(directory_path):
max_input_size = 4096
num_outputs = 512
max_chunk_overlap = 20
chunk_size_limit = 600
prompt_helper = PromptHelper(max_input_size, num_outputs, max_chunk_overlap, chunk_size_limit=chunk_size_limit)
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0.7, model_name="text-davinci-003", max_tokens=num_outputs))
documents = SimpleDirectoryReader(directory_path).load_data()
index = GPTVectorStoreIndex(documents, llm_predictor=llm_predictor, prompt_helper=prompt_helper)
index.save_to_disk('index.json')
return index
def chatbot(input_text):
index = GPTVectorStoreIndex.load_from_disk('index.json')
response = index.query(input_text, response_mode="compact")
return response.response
iface = gr.Interface(fn=chatbot,
inputs=gr.inputs.Textbox(lines=7, label="Enter your text"),
outputs="text",
title="Custom-trained AI Chatbot")
index = construct_index("docs")
iface.launch(share=True)第三步:免费获取OpenAI的API密钥
目前,OpenAI正在向新用户提供免费的API密钥,前三个月有价值5美元的免费信用。如果你早些时候创建了你的OpenAI账户,你的账户中可能有18美元的免费信用。免费信用额度用完后,你将不得不为API访问付费。但就目前而言,所有用户都可以免费使用。
1、前往 platform.openai.com/signup 并创建一个免费账户。如果你已经有一个OpenAI账户,只需登录。注:建议直接使用Google或者微软账号注册登录,注册需要使用到已支持国家或者地区的手机验证码,可以sms-activate.org(不要选印度或者印尼,泰国是可以收到验证码的)。
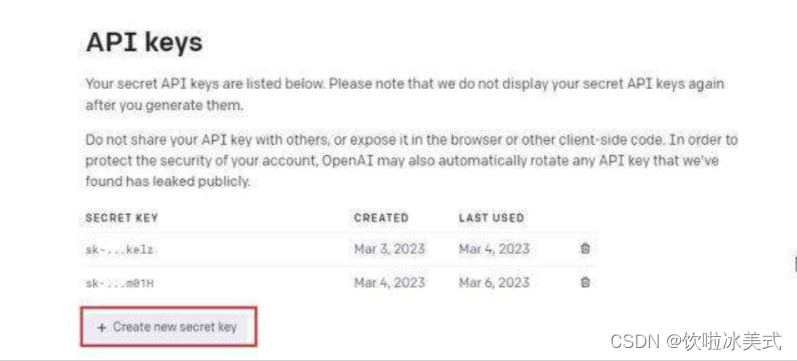
2. 接下来,在右上角点击你的个人资料,从下拉菜单中选择 “View API keys“。

3. 在这里,点击 “Create new secret key” 并复制API密钥。请注意,你以后不能复制或查看整个API密钥。因此,强烈建议立即复制和粘贴API密钥到一个记事本文件。
第四步:使用自定义知识库训练并创建一个人工智能聊天机器人
现在我们已经建立了软件环境并从OpenAI获得了API密钥,让我们来训练人工智能聊天机器人。在这里,我们将使用 “text-davinci-003” 模型,而不是最新的 “gpt-3.5-turbo” 模型,因为Davinci在文本完成方面效果更好。如果你愿意,你完全可以把模型改为Turbo,以减少成本。说完这些,让我们跳到说明上。
添加你的文件来训练人工智能聊天机器人
1. 首先,在一个可访问的位置(如桌面)创建一个名为 docs 的新文件夹。你也可以根据自己的喜好选择其他位置。然而,保持文件夹的名称为 docs。

2. 接下来,将你希望用于训练AI的文件移到 “docs” 文件夹内。你可以添加多个文本或PDF文件(甚至是扫描的文件)。如果你在Excel中有一个大表,你可以把它作为CSV或PDF文件导入,然后把它添加到 “docs” 文件夹中。你甚至可以添加SQL数据库文件,正如这条Langchain AI的推文所解释的。除了提到的那些,我还没有尝试过很多文件格式,但你可以自己添加和检查。对于这篇文章,我正在添加我的一篇关于NFT的PDF格式的文章。
注意:如果你有一个大文件,它将需要更长的时间来处理数据,这取决于你的CPU和GPU。此外,它将很快使用你的免费OpenAI tokens。因此,在开始时,从一个小文件(30-50页或<100MB的文件)开始,以了解这个过程。

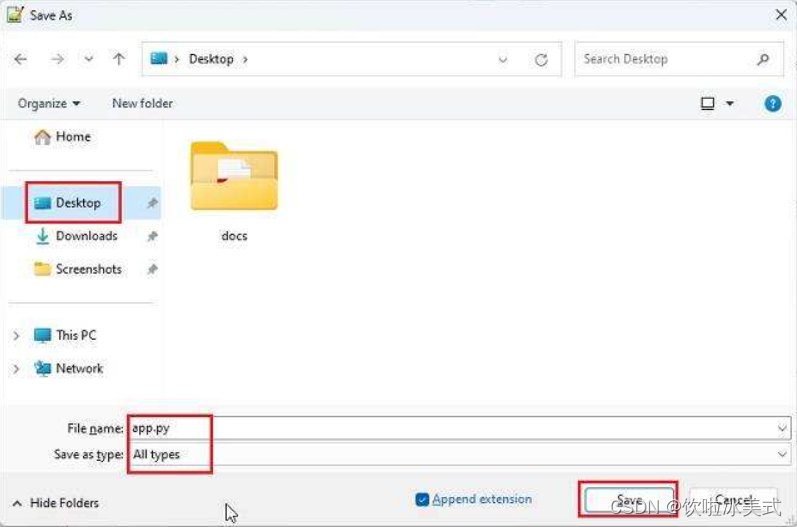
3. 之后,将 app.py保存到你创建 “docs” 文件夹的位置(在我的例子中,是桌面)。你可以根据自己的喜好改变名称,但要确保是 .py 文件后缀。
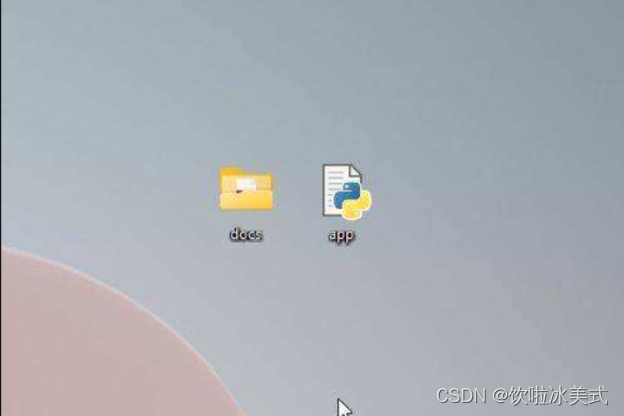
4. 确保 “docs” 文件夹和 “app.py” 在同一个位置,如下面的截图所示。”app.py” 文件将在 “docs” 文件夹的外面,而不是里面。
第五步:正式训练,用自定义知识库创建ChatGPT人工智能机器人
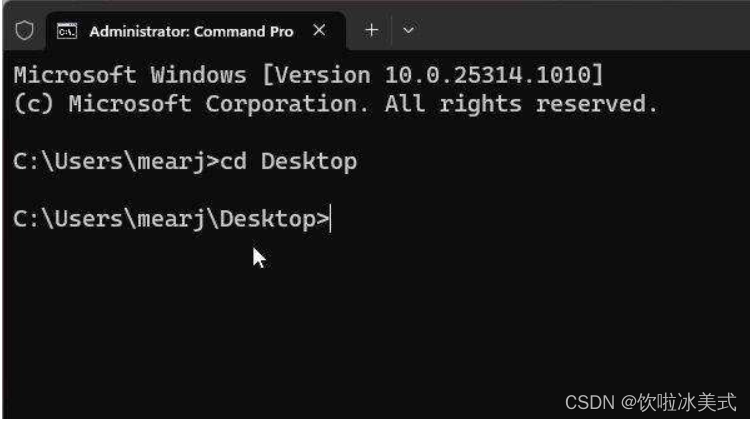
1. 首先,打开终端,运行下面的命令,移动到桌面。这是我保存 “docs” 文件夹和 “app.py” 文件的地方。如果你把这两个项目保存在其他位置,通过终端移动到那个位置。
cd Desktop
2. 现在,运行下面的命令。Linux和macOS用户可能要使用 python3。
python app.py
3. 现在,它将开始使用OpenAI LLM模型分析该文件,并开始为信息编制索引。根据文件的大小和你的计算机的能力,它将需要一些时间来处理该文件。一旦完成,将在桌面上创建一个 “index.json” 文件。如果终端没有显示任何输出,不要担心,它可能仍在处理数据。供你参考,处理一个30MB的文件大约需要10秒钟。

4. 一旦LLM处理了数据,你会得到一些警告,这些警告可以被安全地忽略。最后,在底部,你会发现一个本地URL。复制它。

5. 现在,将复制的URL粘贴到网络浏览器中,你就可以了。您的定制训练的ChatGPT-powered人工智能聊天机器人已经准备就绪。。
6、如果你想用新的数据训练人工智能聊天机器人,请删除 “docs” 文件夹内的文件并添加新文件。你也可以添加多个文件,但要提供同一主题的信息,否则你可能得到不连贯的回应。
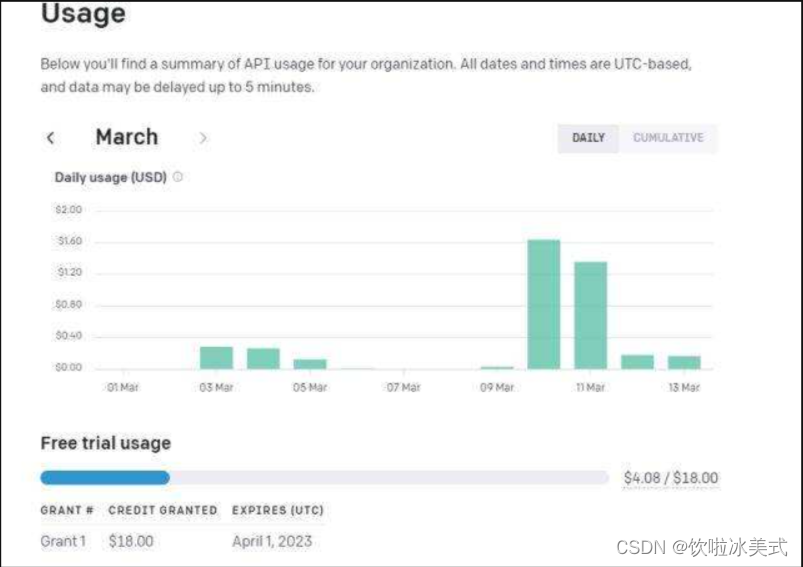
7. 要跟踪你的tokens,可前往OpenAI的在线仪表盘,查看还剩下多少免费额度。
小结
在医学书籍、文章、数据表和旧档案中的报告上训练人工智能效果完美无缺














 951
951











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









