







课程概要:
1.朴素贝叶斯多项式事件模型
2.神经网络
3.支持向量机
一、朴素贝叶斯多项式事件模型
在上一篇中提到过的朴素贝叶斯中,主要是二元值,即以0,1标示邮件中的词是否在词典中出现。这个最基本的NB模型也被称为多元伯努利事件模型(NB-MBEN),而这一篇要讲的为多项式事件模型(NB-MEN)。
NB-MBEN与NB-MEN的区别
首先,NB-MEM 改变了特征向量的表示方法。在 NB-MBEM 中,特征向量的每个分量代表词典中该 index 上的词语是否在文本中出现过,
其取值范围为{0,1},特征向量的长度为词典的大小。
而在 NB-MEM 中,特征向量中的每个分量的值是文本中处于该分量的位置的词语在词典中的索引,其取值范围是{1,2,…,|V|},|V|是词典的大小,
特征向量的长度为相应样例文本中词语的数目。
举例来说,在NB-MBEM 中,一篇文档的特征向量可能如下所示:

其在 NB-MEM 中的向量表示则如下所示:

在 NB-MEM 中,假设文本的生成过程如下:
确定文本的类别,比如是否为垃圾文本、是财经类还是教育类等;
遍历文本的各个位置,以相同的多项式分布生成各个词语,生成词语时相互独立。
由上面的生成过程可知,NB-MEM 假设文本类别服从多项式分布或伯努利
布,而词典中所有的词语服从多项式分布。生成过程还可如下解释,即先在类
所服从的多项式分布中选取类别,然后遍历整个文本,在词语所服从的多项式
布中选取词语,放到文本中相应的位置上。
于是,NB-MEM 的参数如下所示:
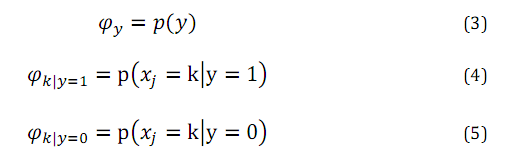
上述式子含义分别为垃圾邮件频率,当为垃圾邮件时在词典中k位置的词出现频率,和当为非垃圾邮件时在词典中k位置的词出现频率。(而在NB-MBEN中标示的是当为垃圾邮件或非垃圾邮件时词典中某词是否出现的频率)
所以参数在训练集上的极大似然估计为:

极大化该函数,得到各参数的极大似然估计:
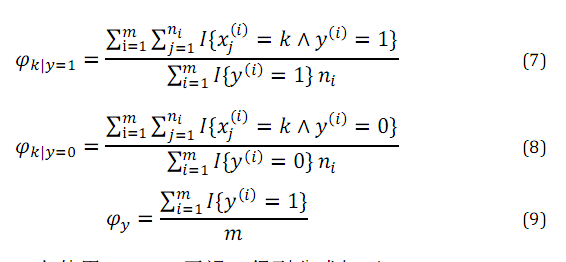
上面第一个式子,分子的意思是,对所有标签为1的邮件求和,之后对垃圾邮件中的词k(词典中第k个位置的词)求和,所以分子实际上就是训练集中所有垃圾邮件中词k出现的次数。分母是训练集中所有垃圾邮件的长度。比值的含义就是所有垃圾邮件中,词
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 694
694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









