






在整个过程中,非常感谢这位大佬乱觉先森的不吝分享,让我能够快速实现火焰图像分类功能,在这里我做个记录。

EfficientNet论文链接 EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
pytorch版本的代码地址 EfficientNet-Pytorch
主要使用的是该代码中EfficientNet-Pytorch文件夹下的这三个文件:__init-_.py,model.py,utils.py,存放在自己的工程中的efficientnet目录下
我自己的工程目录结构如图所示,感兴趣的小伙伴阔以照猫画老鼠整起来
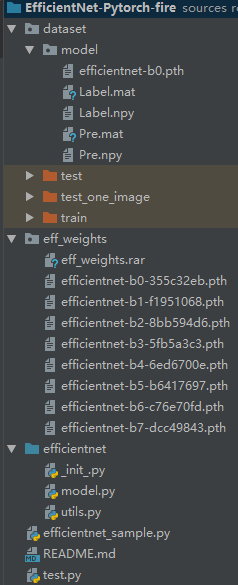

1.数据集
包含本人收集到的3300张含有火焰的图片与3300张没有火焰的图片,data目录为:
dataset/train/fire # 用于训练的含有火焰的图片2500张
dataset/train/nonfire # 用于训练的不含有火焰的图片800张
dataset/test/fire # 用于测试的含有火焰的图片2500张
dataset/test/nonfire # 用于测试的不含有火焰的图片800张
dataset/model # 用来存放训练生成的模型
2.下载权重文件
手动下载权重文件efficientnet-b0-355c32eb.pth后存入eff_weights目录下,方便起见,下载链接双手奉上点我,代码中手动载入模型的程序如下:
net_name = 'efficientnet-b0'
model_ft = EfficientNet.from_name(net_name)
net_weight = 'eff_weights/' + 'efficientnet-b0-355c32eb.pth'
state_dict = torch.load(net_weight)
model_ft.load_state_dict(state_dict)
3.完整训练代码
这部分代码存放在工程中的 efficientnet_sample.py中。
from __future__ import print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
from torchvision import datasets, models, transforms
import time
import os
from efficientnet.model import EfficientNet
# some parameters
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "1" # 使用的服务器上的编号为“1”的gpu
use_gpu = torch.cuda.is_available()
data_dir = 'dataset'
batch_size = 16
lr = 0.01
momentum = 0.9
num_epochs = 15
input_size = 300
class_num = 2 # 我的是二分类问题,有火/没火
net_name = 'efficientnet-b0' # 使用的efficientnet-b0权重
def loaddata(data_dir, batch_size, set_name, shuffle):
data_transforms = {
'train': transforms.Compose([
transforms.Resize(input_size),
transforms.CenterCrop(input_size),
transforms.RandomAffine(degrees=0, translate=(0.05, 0.05)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'test': transforms.Compose([
transforms.Resize(input_size),
transforms.CenterCrop(input_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in [set_name]}
# num_workers=0 if CPU else =1
dataset_loaders = {x: torch.utils.data.DataLoader(image_datasets[x],
batch_size=batch_size,
shuffle=shuffle, num_workers=1) for x in [set_name]}
data_set_sizes = len(image_datasets[set_name])
return dataset_loaders, data_set_sizes
def train_model(model_ft, criterion, optimizer, lr_scheduler, num_epochs=50):
train_loss = []
since = time.time()
best_model_wts = model_ft.state_dict()
best_acc = 0.0
model_ft.train(True)
for epoch in range(num_epochs):
dset_loaders, dset_sizes = loaddata(data_dir=data_dir, batch_size=batch_size, set_name='train', shuffle=True)
print('Data Size', dset_sizes)
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
optimizer = lr_scheduler(optimizer, epoch)
running_loss = 0.0
running_corrects = 0
count = 0
for data in dset_loaders['train']:
inputs, labels = data
labels = torch.squeeze(labels.type(torch.LongTensor))
if use_gpu:
inputs, labels = Variable(inputs.cuda()), Variable(labels.cuda())
else:
inputs, labels = Variable(inputs), Variable(labels)
outputs = model_ft(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs.data, 1)
optimizer.zero_grad()
loss.backward()
optimizer.step()
count += 1
if count % 30 == 0 or outputs.size()[0] < batch_size:
print('Epoch:{}: loss:{:.7f}'.format(epoch, loss.item()))
train_loss.append(loss.item())
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / dset_sizes
epoch_acc = running_corrects.double() / dset_sizes
print('Loss: {:.7f} Acc: {:.5f}'.format(epoch_loss, epoch_acc))
if epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = model_ft.state_dict()
if epoch_acc > 0.999:
break
# save best model
save_dir = '/media/fang/DATA/luozhiwei/EfficientNet-pytorch-fire/' + data_dir + '/model'
model_ft.load_state_dict(best_model_wts)
model_out_path = save_dir + "/" + net_name + '.pth'
torch.save(model_ft, model_out_path)
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
return train_loss, best_model_wts
def test_model(model, criterion):
model.eval()
running_loss = 0.0
running_corrects = 0
cont = 0
outPre = []
outLabel = []
dset_loaders, dset_sizes = loaddata(data_dir=data_dir, batch_size=16, set_name='test', shuffle=False)
for data in dset_loaders['test']:
inputs, labels = data
labels = torch.squeeze(labels.type(torch.LongTensor))
inputs, labels = Variable(inputs.cuda()), Variable(labels.cuda())
outputs = model(inputs)
_, preds = torch.max(outputs.data, 1)
loss = criterion(outputs, labels)
if cont == 0:
outPre = outputs.data.cpu()
outLabel = labels.data.cpu()
else:
outPre = torch.cat((outPre, outputs.data.cpu()), 0)
outLabel = torch.cat((outLabel, labels.data.cpu()), 0)
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
cont += 1
print('Loss: {:.4f} Acc: {:.4f}'.format(running_loss / dset_sizes,
running_corrects.double() / dset_sizes))
def exp_lr_scheduler(optimizer, epoch, init_lr=0.01, lr_decay_epoch=10):
"""Decay learning rate by a f#model_out_path ="./model/W_epoch_{}.pth".format(epoch)
# torch.save(model_W, model_out_path) actor of 0.1 every lr_decay_epoch epochs."""
lr = init_lr * (0.8**(epoch // lr_decay_epoch))
print('LR is set to {}'.format(lr))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
return optimizer
# train
pth_map = {
'efficientnet-b0': 'efficientnet-b0-355c32eb.pth',
'efficientnet-b1': 'efficientnet-b1-f1951068.pth',
'efficientnet-b2': 'efficientnet-b2-8bb594d6.pth',
'efficientnet-b3': 'efficientnet-b3-5fb5a3c3.pth',
'efficientnet-b4': 'efficientnet-b4-6ed6700e.pth',
'efficientnet-b5': 'efficientnet-b5-b6417697.pth',
'efficientnet-b6': 'efficientnet-b6-c76e70fd.pth',
'efficientnet-b7': 'efficientnet-b7-dcc49843.pth',
}
# 自动下载到本地预训练
# model_ft = EfficientNet.from_pretrained('efficientnet-b0')
# 离线加载预训练,需要事先下载好
model_ft = EfficientNet.from_name(net_name)
net_weight = 'eff_weights/' + pth_map[net_name]
state_dict = torch.load(net_weight)
model_ft.load_state_dict(state_dict)
# 修改全连接层
num_ftrs = model_ft._fc.in_features
model_ft._fc = nn.Linear(num_ftrs, class_num)
criterion = nn.CrossEntropyLoss()
if use_gpu:
model_ft = model_ft.cuda()
criterion = criterion.cuda()
optimizer = optim.SGD((model_ft.parameters()), lr=lr, momentum=momentum, weight_decay=0.0004)
train_loss, best_model_wts = train_model(model_ft, criterion, optimizer, exp_lr_scheduler, num_epochs=num_epochs)
# test
print('-' * 10)
print('Test Accuracy:')
model_ft.load_state_dict(best_model_wts)
criterion = nn.CrossEntropyLoss().cuda()
test_model(model_ft, criterion)
4.测试结果

我的epoch数设置的是15,但是程序运行到12个epoch的时候准确率已经达到0.9975了,程序就自动停止了,我也不清楚是什么原因,可能是准确率足够高了没有继续训练的必要了?若有经验丰富的朋友不吝赐教,吾将不胜感激。


















 8529
8529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











