







一、简介
机器学习分预测型和决策型。
决策型就是强化学习。特点是,决策能影响环境,引起环境的改变。
特点:转变到新的状态,获得即时奖励,随着时间的推移最大化积累奖励。
概念:
状态是用于确定接下来会发生事情(行动,观察,奖励),状态是关于历史的函数: St=f(Ht)
策略是状态到行动的映射,分为确定性的和随机的。

奖励(reward):定义强化学习目标的标量。让policy立即感知到什么好的。
价值(value)函数:状态价值是一个标量,定义对于长期来说什么是好的。
价值函数,是未对未来的累积奖励的一种预测。如下是在当前s状态下,在使用给定策略pi下未来积累奖励的期望。
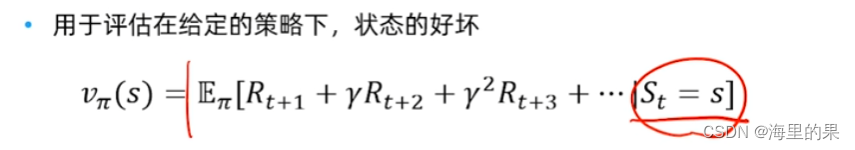
模型(model):
环境的模型用于模拟环境的行为。环境模型有两个必须得函数:1,预测下一个状态,st, at 下预测下一个 st+1 ,状态可能是确定性的(如走迷宫类游戏),也可能是不确定性的。2.预测下一个奖励st, at 下预测下一个 Rt+1
强化学习分类:
基于模型的强化学习:
有环境模型,如迷宫类型的游戏,动态规划就能得到比较好的解。
基于无关的强化学习:
无环境模型,模型是黑箱,比较难。
基于价值的强化学习:
着眼于状态价值的估计,没有策略,或者说是隐含的,最优策略就是去价值函数最大的状态。
基于策略的强化学习:
直接得到一个策略,就能根据于环境的交互,隐式的学习得到状态下的价值,直接优化该策略
Actor-Critic:
策略+价值函数结合
二、探索和利用
序列决策任务的基本问题就是探索与利用。

朴素方法,增加策略噪声,有一定概率随机选择当前未经探索的动作。如衰减谈心策略。
积极初始化,初始化高,没有探索的动作价值高,随着游戏进行,该部分权重下降。
基于不确定性的度量。如UCB 上置信界算法。
概率匹配,基于每个动作给我们的回报,选择一个回报最高的动作,如汤普森采样算法,估计的每个老虎机的收益的期望。
状态搜索,如alpha Go。
多臂老虎机是最典型的无状态强化学习。
如何选取策略?

估计下界,这部分的工作内容是说,随着T到无穷大时,与最优期望的差值存在一个下界O(logT)。它是理论上的渐进最优。

三、马尔科夫决策过程
强化学习研究的是序贯决策问题(Sequential Decision),该问题下的 Agent 状态会随时间变化而转移。其涵盖的主要问题均具有马尔科夫性,即给定现在及所有过去状态下,Agent 未来状态的条件概率分布只依赖于当前状态。

强化学习环境:
*环境完全可观测
*当前状态完全可表征过程(马尔可夫性质)
马尔可夫性质:当前状态已知时,可以抛开历史不管,当前状态是未来的充分统计量
MDP五元组
·MDP可以由一个五元组表示(S,A,{Psa},γ,R),其中:
S是状态的集合
A是动作的集合
Psa是状态转移概率(对每个状态s∈S和动作a∈A,Psa是下一个状态在S中的概率分布)
γ∈[0,1]是对未来奖励的折扣因子
R:S×A–>R是奖励函数,而大部分情况下,奖励只和位置有关,如迷宫中奖励只和位置有关,围棋中奖励只基于最终围地大小有关
四、基于动态规划的强化学习
MDP 目标:选择能够最大化累积奖励期望的动作。
定义价值函数:

上面式子可以转化为Bellman等式,R(s)代表立即奖励,P代码状态转移概率,s’代表下一个状态,贝尔曼等式让我们可以以迭代的方式计算价值函数:
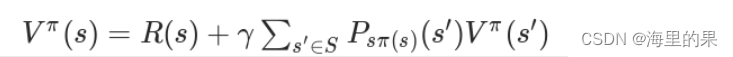
几个重要概念:

因此价值函数是和策略息息相关的, 如下图。
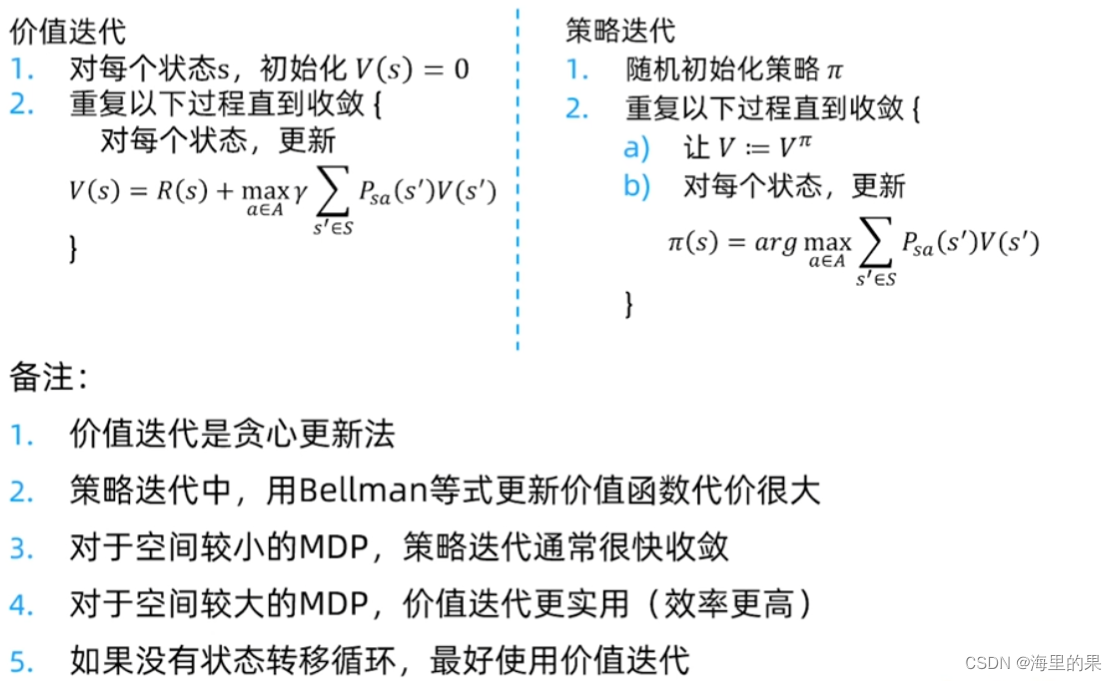
第一个式子:可以利用reward,和当前的V函数,进行迭代。
第二个式子,当V迭代好了时候,就能用这个式子,得到当前状态下最优的策略pi

按照上面两个公式以哪个为主进行迭代过程,分为价值迭代和策略迭代。















 5504
5504











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









