







 文章介绍了MultiPath论文,这是Waymo在2019年提出的一种处理轨迹预测不确定性的方法。它将不确定性分为意图和控制两部分,并使用轨迹锚点和高斯分布来建模。模型通过K-means学习锚轨迹,并以每个时间步的高斯分布输出预测。训练目标是最大概率化真值轨迹的对数似然。实验表明,MultiPath在回归位置和不确定性方面表现优越,特别是与Min-Of-K和线性模型相比。
文章介绍了MultiPath论文,这是Waymo在2019年提出的一种处理轨迹预测不确定性的方法。它将不确定性分为意图和控制两部分,并使用轨迹锚点和高斯分布来建模。模型通过K-means学习锚轨迹,并以每个时间步的高斯分布输出预测。训练目标是最大概率化真值轨迹的对数似然。实验表明,MultiPath在回归位置和不确定性方面表现优越,特别是与Min-Of-K和线性模型相比。
前言
文章地址:MultiPath
2019年的一篇论文,也比较久远了,来自waymo,也是这个领域的一篇经典论文。这篇论文当时看的时候自己其实没有完全理解,似懂非懂,现在再回来回顾一下。其做法现在来看非常容易理解,文章认为轨迹的多模,或者说不确定新,来源于两部分,意图的不确定性和控制的不确定性。意图的不确定性,这部分,用trajectory anchor 解决, 在给定一个意图后,控制也会对未来的预测带来不确定性,这种不确定性认为在每个时刻都是服从正态分布的,这种不确定性就用参数化的与锚轨迹之间的offset来表示。
框架
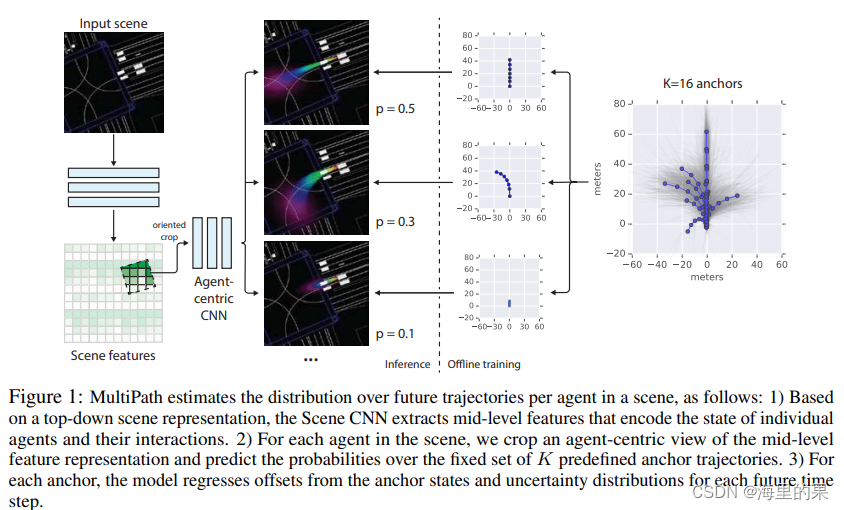
multipath 也是处理bev图,与上一篇covernet不同的是,它输入的是整帧的大图。全过程分为两个阶段,stage1是从大图中提取体征,用到了depth-wise减少参数量。stage2针对每一个待预测的agent,它会crop下来一个特征小图(文中提到是11*11大小),这个是以agent为中心的,agent在特征小图上方向向上,然后基于该agent 级别的特征,在预测每个锚轨迹的概率,以及每个锚轨迹每个预测点的高斯分布。
锚轨迹是对训练集进行无监督的学习得到的。模型最终输出的是每个时间点的高斯混合模型(GMM)。下面来看看一些具体实现的细节。
Method

锚轨迹时基于K-means 算法得到的,轨迹之间的距离定义为每个点距离的平方之和。设当前的状态是x,对K个锚轨迹进行打分,经过softmax就能得到当前对于锚轨迹的概率。
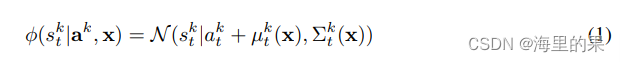
在给定当前状态x和一个锚轨迹的a_k状态下,假定预测轨迹满足1式的分布,其实就是一个多维高斯分布(就是xy两个维度)。其中高斯分布的参数,u 和 Σ 就是模型要预测输出变量,函数的自变量是x,也就是当前的状态。上面式子,还暗含了一个假设,就是不同时间步骤之间的分布是互相独立的,这个假设其实在TNT轨迹回归时也提到了。这个假设能简化问题,让我们得以一次性输出未来数个时间点的预测。基于该假设,最终的轨迹输出以下面的形式表达:
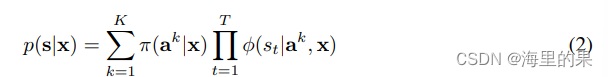
learning
训练时候,其实就是最大化真值轨迹的的对数似然,loss定义如下:
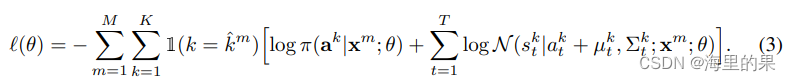
1(·) 的意思是说,推理出的K组轨迹中,只有最接近真值轨迹的那个锚轨迹及其对应的预测轨迹,会产生Loss。剩下的就是2式子中的概率取对数取负值。式子中的,π(ak|x), µ(x)kt, Σ(x)kt 三项,都是神经网络的输出,这样,给定一个真值轨迹,就能计算出相应的loss了。训练的过程其实就是迭代优化参数thata的过程。这么做也避免了GMM算法中直接进行棘手的拟合,用EM算法的计算过程。最终正向推理时候,就能直接得到每个点的标准差和均值了。
by the way, 提到这,就回顾一下自己脑海里的最大似然法。它的思想是说,随机变量的分布满足预设的某个参数化的分布(也就是预先存在着一个概率模型),同时我们又有采样出来的样本值x1 x2 …xn,那参数应该取什么呢? 应该取使得使得 出现采样出 x1 x2 …xn概率最大的参数。最经典的一个例子就是已知随机变量X满足正态分布,但是均值和标准差未知,现在X1,X2…,Xn是来自总体X的样本,那么我们通过似然函数,对均值和标准差求导就会得出,如果取 X1,X2…,Xn的均值和标准差作为对参数均值和标准差的估计,X1,X2…,Xn的概率就是最大的,这种估计也是非常符合我们的common sense的。
Neural network details

前面已经提到了一些网络实现的细节,其他的随手直接截图了,如上。
实验
文章做了几组对比实验,MultiPath µ [, Σ] 是说固定标准差,直接是最大化的似然loss降级成了回归offset。注意公式3中,log π 实际有点代表了分类的loss,后面其实代表的是对offset的回归。 Regression µ [, Σ] 是说只有公式中的后半部分输出计算loss,直接输出每个点的位置和对应的标准差,该方式只输出top1的轨迹。Min-of-K 其实就是cover net 里面所对比的MTP,直接预测K条轨迹,手动设计方法把K条中的某一个与真值计算产生loss,这种方法容易模式坍塌。CVAE,标准的生成式方法,把该网络放在第二阶段的网络后面。Linear模型则是对过去的位置直接做拟合,参数为t,拟合之后就可以外推出未来的轨迹。
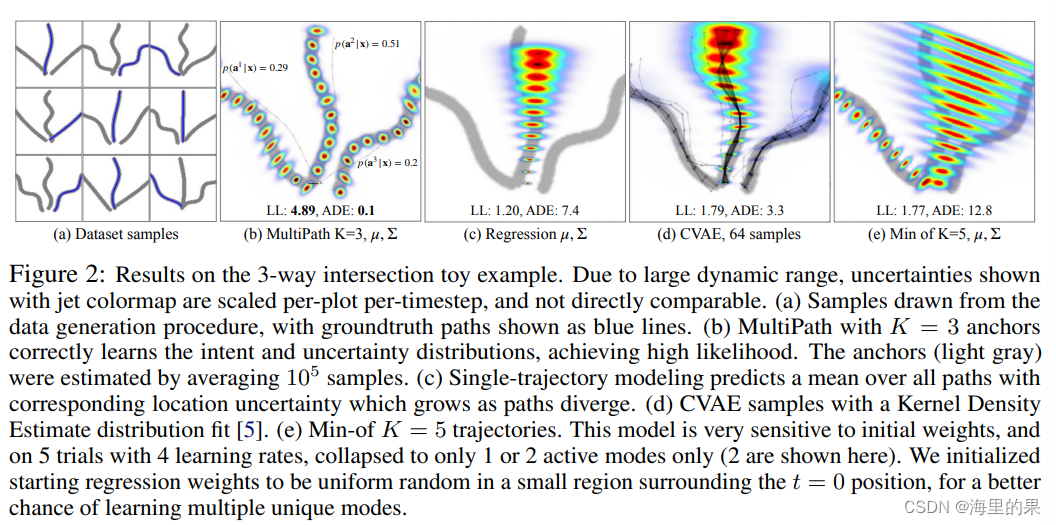
文中做了一个小实验,自己生成一些samples,选择左中右比例是3:5:2,可以看出其他的方法表现都不好。
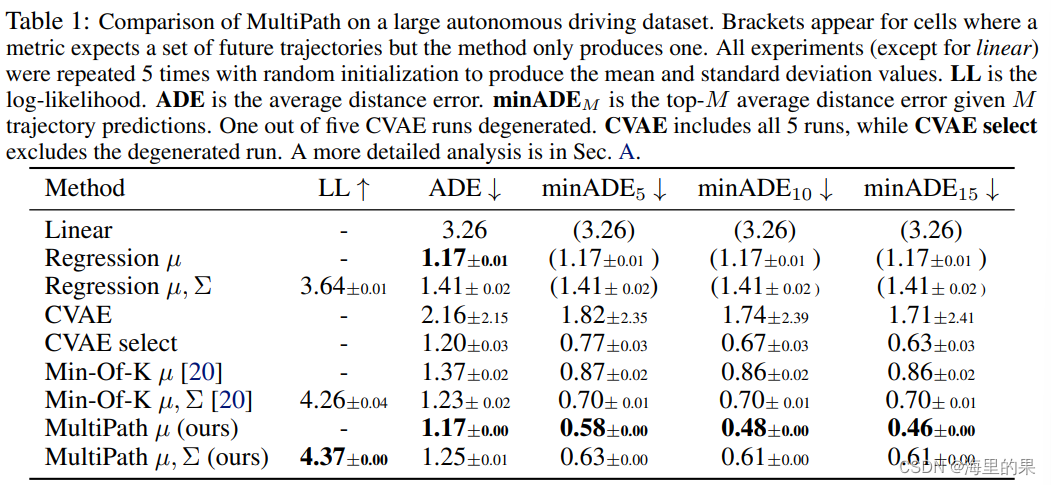
可以看出,mutipath 只回归位置,ADE是最好的,是明显优于Min-Of-K的,加入对不确定性的回归后,ADE等指标有所下降。
mutipath 整体上就是两步走的一个思路,利用似然函数,把标准差纳入其中计算loss,训练走的是所谓模仿学习的思路,实际感觉也没必要直接回归出来方差,直接输出均值就可以了。其实后面比赛中,更多的还是看ADE, ADE5的指标,所以后面像TNT论文,就直接用一分类二回归的方式去做了,而不是这样的loss设计。

















 5118
5118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









