







Wan2.1-VACE 模型的核心优势
Wan2.1-VACE 模型集成了六大核心功能,包括文生视频、图生视频、视频重绘、局部编辑、背景扩展和时长延展。用户可以通过单一架构实现多任务的灵活组合,例如将竖版《蒙娜丽莎》静态图扩展为横版动态视频,并为其添加眼镜,同时完成画幅扩展、时长延展和图像参考三项任务。

多任务自由组合
用户无需串联多个模型,即可灵活组合基础功能。通过指定视频的局部区域,可以实现视频元素的替换、增加和删除等操作。生成主体加背景参考即可一键生成视频,极大地简化了视频创作流程。



轻量级与高性能并存
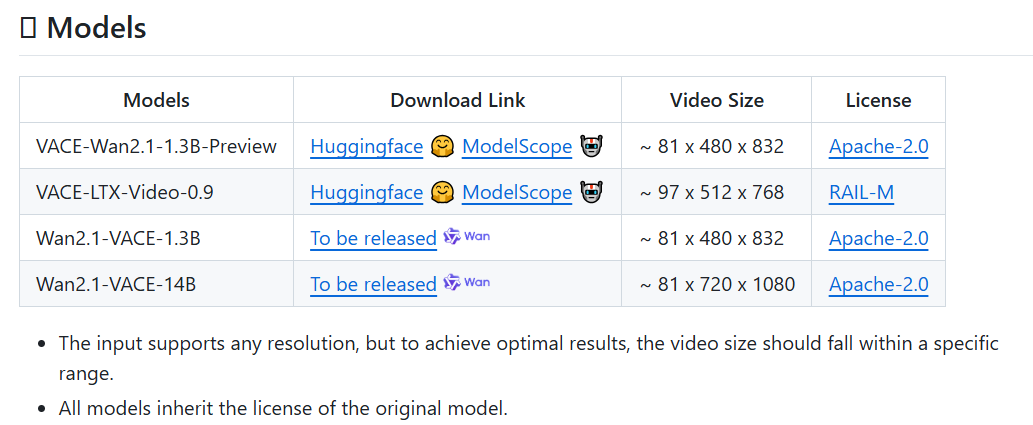
Wan2.1-VACE 模型提供1.3B(轻量级)和14B(满血版)两种版本。1.3B版本支持消费级显卡运行,输出480P视频;14B版本则支持720P高清画面,满足专业级需求。
技术创新:VCU架构
Wan2.1-VACE 的核心突破在于视频条件单元(VCU)的设计。VCU将文本、图像、视频、Mask等输入统一转化为文本、帧序列和Mask序列,解决了多模态输入的兼容性问题。通过分离可变与不可变帧序列的编码方式,模型能高效处理复杂时空信息,实现更精准的控制。

应用场景
艺术创作:在2025年央视春晚中,Wan2.1-VACE 助力《笔走龙蛇》节目生成“子弹时间”特效,并参与《难忘今宵》的舞美设计,将城市地标转化为动态花灯。

影视与广告:支持高清视频生成与局部编辑,例如替换广告中的商品、扩展电影场景背景,显著降低电影制作成本。

教育领域:教师将复杂知识点转化为动画视频,例如通过图像参考生成功能,将静态电路图扩展为动态演示。
个人创作:爱好者可通过手机端接入 API,将旅行照片转化为短视频,或为宠物视频添加趣味特效。
开源与未来展望
通义万相VACE的开源,标志着视频生成技术从单任务迈向多任务组合的新阶段。为AI在影视、广告、文化传承等领域的落地提供了无限可能。正如团队所言:“AI不是替代创作者,而是让创意更自由。”
GitHub地址:https://github.com/ali-vilab/VACE



















 1058
1058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











