







 本文总结了基于深度学习的六种视觉跟踪算法,包括压缩跟踪(CT)、ECO、TCNN、Staple、MDNet和GOTURN。文章探讨了这些算法的核心思想,如模型降维、特征融合、在线学习策略等,旨在解决模型大小、训练集管理和模型更新等问题,以实现高效实时的跟踪效果。同时,文章指出目标跟踪领域目前面临的挑战,如遮挡和形变处理,并展望了可能的发展趋势,如GAN和3D视觉在目标跟踪中的应用。
本文总结了基于深度学习的六种视觉跟踪算法,包括压缩跟踪(CT)、ECO、TCNN、Staple、MDNet和GOTURN。文章探讨了这些算法的核心思想,如模型降维、特征融合、在线学习策略等,旨在解决模型大小、训练集管理和模型更新等问题,以实现高效实时的跟踪效果。同时,文章指出目标跟踪领域目前面临的挑战,如遮挡和形变处理,并展望了可能的发展趋势,如GAN和3D视觉在目标跟踪中的应用。
本文是博主对最近看的相关跟踪算法的总结,其中的算法有一些不是基于深度学习的。另外本文只是对各篇论文的核心亮点简单描述,同时加上博主自己的一些看法。本文仅作为学习笔记,供学习交流,如果有什么错误或疑问,欢迎留言。
知乎:王弗兰克
https://www.zhihu.com/people/xue-sheng-er-yi/activities
这里提供两个链接,供大家学习参考。
目标跟踪专栏(目前在更新):https://zhuanlan.zhihu.com/visual-tracking
”小白在闭关“个人博客:http://wh1te.me/index.php/tag/tracking/
一、压缩跟踪(compressive tracking)
简称CT,发表于ECCV2012,升级版发表于PAMI2014,简称FCT。
本文的核心在于使用压缩感知的方法来进行特征表示,实现了降维,同时得到的低维信号可以保持高维信号的特性。
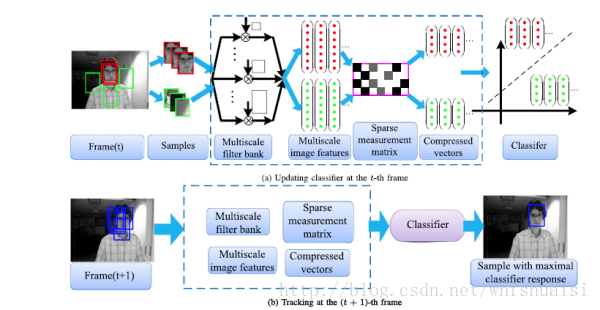
压缩感知请参考:
http://blog.csdn.net/zhang11wu4/article/details/19699763
二、ECO( Efficient Convolution Operators for Tracking)
论文链接:
http://link.zhihu.com/?target=https%3A//arxiv.org/pdf/1611.09224.pdf
本文主要解决三个问题:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7033
7033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









