







Leveldb和lmdb简单介绍
Caffe生成的数据分为2种格式:Lmdb和Leveldb。它们都是键/值对(Key/Value Pair)嵌入式数据库管理系统编程库。
虽然lmdb的内存消耗是leveldb的1.1倍,但是lmdb的速度比leveldb快10%至15%,更重要的是lmdb允许多种训练模型同时读取同一组数据集。
因此lmdb取代了leveldb成为Caffe默认的数据集生成格式(http://blog.csdn.net/ycheng_sjtu/article/details/40361947)
LevelDb有如下一些特点:
首先,LevelDb是一个持久化存储的KV系统,和Redis这种内存型的KV系统不同,LevelDb不会像Redis一样狂吃内存,而是将大部分数据存储到磁盘上。
其次,LevleDb在存储数据时,是根据记录的key值有序存储的,就是说相邻的key值在存储文件中是依次顺序存储的,而应用可以自定义key大小比较函数,LevleDb会按照用户定义的比较函数依序存储这些记录。
再次,像大多数KV系统一样,LevelDb的操作接口很简单,基本操作包括写记录,读记录以及删除记录。也支持针对多条操作的原子批量操作。
另外,LevelDb支持数据快照(snapshot)功能,使得读取操作不受写操作影响,可以在读操作过程中始终看到一致的数据。
除此外,LevelDb还支持数据压缩等操作,这对于减小存储空间以及增快IO效率都有直接的帮助。LevelDb性能非常突出,官方网站报道其随机写性能达到40万条记录每秒,而随机读性能达到6万条记录每秒。总体来说,LevelDb的写操作要大大快于读操作,而顺序读写操作则大大快于随机读写操作。至于为何是这样,看了我们后续推出的LevelDb日知录,估计您会了解其内在原因。(http://www.cnblogs.com/haippy/archive/2011/12/04/2276064.html)
一:程序开始
在Create.sh文件通过convert_mnist_data.bin来转换数据
EXAMPLE=examples/mnist
DATA=data/mnist
BUILD=build/examples/mnist
……
$BUILD/convert_mnist_data.bin $DATA/train-images-idx3-ubyte\
$DATA/train-labels-idx1-ubyte$EXAMPLE/mnist_train_${BACKEND} --backend=${BACKEND}通过命令行解析(gflags)解析后,以上可以理解为在编译平台上(gcc等)运行convert_mnist_data.bin程序,程序需要4个参数:
3个mian函数参数:1训练数据位置,2标签数据位置,3 lmdb数据存储位置。
1个程序中通过gflags宏定义的参数:转换的数据类型lmdb or leveldb。
convert_mnist_data.bin是由convert_mnist_data.cpp编译的可执行文件。
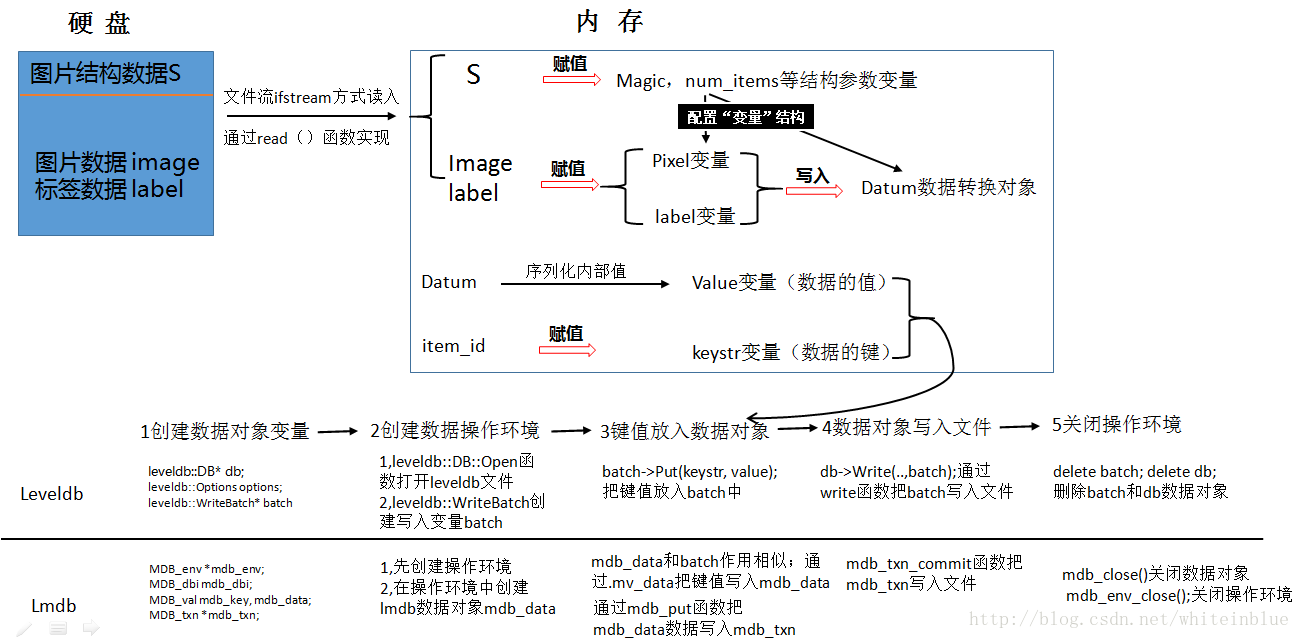
二:数据转换流程图
存放在硬盘中的mnist数据分为4个文件,训练和测试数据集,训练和测试标签集;其中数据集中存放了两类数据:图片结构数据和图片数据
三:convert_mnist_data.cpp函数分析
1.引入必要的头文件和命名空间
#include <gflags/gflags.h>//gflags命令行参数解析的头文件
#include <glog/logging.h>//记录程序日志的glog头文件
#include <google/protobuf/text_format.h>//解析proto类型文件中,解析prototxt类型的头文件
#include <leveldb/db.h>//引入leveldb类型数据头文件
#include <leveldb/write_batch.h>//引入leveldb类型数据写入头文件
#include <lmdb.h>
#include <stdint.h>
#include <sys/stat.h>
#include <fstream> // NOLINT(readability/streams)
#include <string>
#include "caffe/proto/caffe.pb.h"//解析caffe中proto类型文件的头文件
using namespace caffe; // NOLINT(build/namespaces)
using std::string;
2.定义程序变量backend
通过宏定义字符串类型变量DEFINE_stringbackend(这个是通过gflags来定义的变量,在程序调用时,通过--backend=${BACKEND}来给变量命名)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4055
4055

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









