







Generalized Linear Models ( 广义线性模型 )
以下是一组用于回归的方法,他们的目标值是输入变量的线性组合。假设数学符号  表示预测值。
表示预测值。

指定coef_ 代表向量 , intercept_ 代表
, intercept_ 代表 。
。
要使用广义线性回归进行分类,请参阅 Logistic 回归。
Ordinary Least Squares ( 普通最小二乘法 )
最小化观测点和线性近似点的差的平方: 

 的列近似的线性相关时,设计矩阵便接近于一个奇异矩阵,因此最小二乘估计对观测点中的随机误差变得高度敏感,产生大的方差。例如,当没有试验设计的收集数据时,可能会出现这种多重共线性(multicollinearity )的情况。
该方法通过对X进行 singular value decomposition ( 奇异值分解 ) 来计算最小二乘法的解。如果 X 是大小为(n, p) 的矩阵,则该方法的复杂度为
的列近似的线性相关时,设计矩阵便接近于一个奇异矩阵,因此最小二乘估计对观测点中的随机误差变得高度敏感,产生大的方差。例如,当没有试验设计的收集数据时,可能会出现这种多重共线性(multicollinearity )的情况。
该方法通过对X进行 singular value decomposition ( 奇异值分解 ) 来计算最小二乘法的解。如果 X 是大小为(n, p) 的矩阵,则该方法的复杂度为  ,假设
,假设  。
。
>>> from sklearn import linear_model
>>> reg = linear_model.LinearRegression()
>>> reg.fit ([[0, 0], [1, 1], [2, 2]], [0, 1, 2])LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
>>> reg.coef_array([ 0.5, 0.5])
Ridge Regression ( 岭回归 )
岭回归通过对系数的大小施加惩罚来解决 普通最小二乘的一些问题。 ridge coefficients ( 岭系数 ) 最小化一个带罚项的残差平方和, 这里,
这里,  是控制缩减量的复杂度参数:
是控制缩减量的复杂度参数:  值越大,缩减量越大,因此系数变得对共线性变得更加鲁棒。
值越大,缩减量越大,因此系数变得对共线性变得更加鲁棒。
复杂度和最小二乘相同。
>>> from sklearn import linear_model
>>> reg = linear_model.Ridge (alpha = .5)
>>> reg.fit ([[0, 0], [0, 0], [1, 1]], [0, .1, 1])
Ridge(alpha=0.5, copy_X=True, fit_intercept=True, max_iter=None,
normalize=False, random_state=None, solver='auto', tol=0.001)
>>> reg.coef_
array([ 0.34545455, 0.34545455])
>>> reg.intercept_
0.13636...>>> from sklearn import linear_model
>>> reg = linear_model.RidgeCV(alphas=[0.1, 1.0, 10.0])
>>> reg.fit([[0, 0], [0, 0], [1, 1]], [0, .1, 1])
RidgeCV(alphas=[0.1, 1.0, 10.0], cv=None, fit_intercept=True, scoring=None,
normalize=False)
>>> reg.alpha_
0.11. LinearRegression
损失函数:
LinearRegression类就是我们平时说的最常见普通的线性回归,它的损失函数也是最简单的。
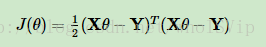
损失函数的优化方法:
一般有梯度下降法和最小二乘法两种极小化损失函数的优化方法,而scikit中的LinearRegression类用的是最小二乘法。求出系数thta为:
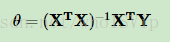
验证方法:
LinearRegression类并没有用到交叉验证之类的验证方法,需要我们自己把数据集分成训练集和测试集,然后训练优化。
使用场景:
一般来说,只要我们觉得数据有线性关系,LinearRegression类是我们的首先。如果发现拟合或者预测的不好,再考虑用其他的线性回归库。LinearRegression没有考虑过拟合的问题,有可能泛化能力较差。
2. Ridge
损失函数:
为了防止过拟合和泛化能力差,这时损失函数可以加入正则化项,如果加入的是L2范数的正则化项,这就是Ridge回归。损失函数如下:
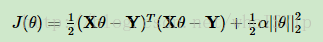
其中α为常数系数,需要进行调优。后面的式子为L2范数。
Ridge回归在不抛弃任何一个特征的情况下,缩小了回归系数,使得模型相对而言比较的稳定,不至于过拟合。
损失函数的优化方法:
对于这个损失函数,一般有梯度下降法和最小二乘法两种极小化损失函数的优化方法,而scikit中的Ridge类用的是最小二乘法。通过最小二乘法,可以解出线性回归系数θ为:
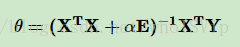
其中E为单位矩阵。
验证方法:
Ridge类并没有用到交叉验证之类的验证方法,需要我们自己把数据集分成训练集和测试集,需要自己设置好超参数α。然后训练优化。
使用场景:
一般来说,只要我们觉得数据有线性关系,用LinearRegression类拟合的不是特别好,需要正则化,可以考虑用Ridge类。但是这个类最大的缺点是每次我们要自己指定一个超参数α,然后自己评估α的好坏,比较麻烦,一般我都用下一节讲到的RidgeCV类来跑Ridge回归。
3. RidgeCV
RidgeCV类的损失函数和损失函数的优化方法完全与Ridge类相同,区别在于验证方法。
验证方法:
RidgeCV类对超参数αα使用了交叉验证,来帮忙我们选择一个合适的α。在初始化RidgeCV类时候,我们可以传一组备选的α值,10个,100个都可以。RidgeCV类会帮我们选择一个合适的αα。免去了我们自己去一轮轮筛选αα的苦恼。
使用场景:
一般来说,只要我们觉得数据有线性关系,用LinearRegression类拟合的不是特别好,需要正则化,可以考虑用RidgeCV类。不是为了学习的话就不用Ridge类。为什么这里只是考虑用RidgeCV类呢?因为线性回归正则化有很多的变种,Ridge只是其中的一种。所以可能需要比选。如果输入特征的维度很高,而且是稀疏线性关系的话,RidgeCV类就不合适了。这时应该主要考虑下面几节要讲到的Lasso回归类家族。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









