







MobileV1网络结构理解与网络结构代码实现
1、博客说明以及论文链接
小编最近要进行开题了,我所做的研究需要用到MobileNet系列的神经网络,所以趁这次机会,再好好看看MobileNet的论文,并进行总结。本来来说我要用到的是V3版本的,但是又觉得跳过V1和V2版本直接讲V3版本的MobileNet会有点突兀,索性从V1版本开始讲起,便于我在开题中多写一些内容以及方便我毕业答辩的时候进行知识回顾。注:本博文的一些图片来源于博客“炮哥带你学”的博文或这他的课程,以及该篇博文博文链接。
这里放上论文的获取链接:MobileNetV1
2、MobileNetV1
2.1 简介
MobileNetV1是在2017年由谷歌(Google)研发的一种轻量级神经网络架构,专门设计用于移动设备和嵌入式系统。
该模型主要是用了叫做“深度可分离卷积(Depthwise Separable Convolutions)”的结构去大大减少网络所需要的计算量以及网络模型的大小,并保证较高的准确率。“深度可分离卷积”的提出对后续的一些轻量化网络的出现有着深远的影响,许多后面提出的轻量化结构都多多少少的沿用或者借鉴了“深度可分离卷积”。
另外还提出了两个超参数,分别是宽度乘数(Width multiplier)和分辨率乘数(Resolution multiplier)这两个超参数主要的用途是将模型进一步缩小,以便于嵌入到不同的计算能力的移动设备和边缘设备中。其实可以理解为,你有台相机,可以拍出10寸大小的高清照片,但是你目前只有7寸的相框,那你就可以设置一下长宽比和分辨率让相机拍出7寸的高清照片,这样相框就可以放进相片了。小编没接触过相机,不知道这样解释合不合适,但我相信你是能够理解的。那么这里使用超参数进行模型的进一步缩小是以网络的精度为代价的,缩小的越厉害,精度会越来越低,甚至断崖式降低。
2.2 卷积(Convolutions)
在正式介绍深度可分离卷积之前,我需要先介绍一下什么是卷积,卷积在神经网络中的作用是什么,并借介绍卷积的机会,说一说什么是超参数、通道、卷积核、特征图等概念。这些概念在我初入神经网络这一领域时就非常的困扰我。
2.2.1 超参数的含义
在模型训练前,我们人为输入的能够决定神经网络运行的参数就是超参数。
2.2.2 通道(Channels)的含义
这里的通道我们是指的输入数据的通道数。在我们图像处理中,通道的数量是取决于你图片的颜色模式,我们通常看见的图片都是彩色的,也就是RGB颜色模式的图片。

上面的小猫图片就是RGB颜色模式的图片,这张图片中每一个像素的颜色都是由RGB三种颜色组成的,所以这里就可以说,我们输入的小猫这张图片数据的通道数为3.
那我们能否说我们只要输入的数据是图片数据,通道数就为3呢?答案是不可以的,因为在上面我说了,通道的数量是取决于你图片的颜色模式。通道数为3,是意味着你输入的图片的颜色模式为RGB,图片的像素颜色是由RGB这三种颜色决定的,所以通道数为3.其实我们的图片颜色模式还有灰度图像,其每个像素的颜色是由灰度这一种颜色的程度所决定的,所以灰度图像的通道就为1.另外我们图片的颜色模式还有RGBA,其实就是在RGB模式上多加了一个透明度,也就是说该模式下的图片中的每一个像素颜色是由RGB+透明度所决定的,所以这种图片的通道数就是4.
2.2.3 卷积核(Core)的含义
对于我们神经网络,直接用输入的整张图像进行判断和输出是不可行的。
就好比你站在一张非常巨大的世界地图上去找有湖泊的地方,但却放你不能做任何思考,只看一眼就说出湖泊以及湖泊存在的位置。这样是不现实的,因为这张巨大的世界地图对于你来说,有太多没用的细节会干扰你的判断。那么如果真让你要说出这张世界地图上的所有湖泊,你该怎么做,是不是缩小你注意的范围,然后从左到右,从上到下的扫描,只提取能判断出是湖泊的细节。
那么这个例子中,你眼睛所缩小的关注范围其实就是我们神经网络中的卷积核,你所要注意的细节,就是我们神经网络中称之为的特征。所以到这里你应该理解什么是卷积核了,卷积核实际上就是一个过滤器,神经网络借助这个过滤器来提取我们有用的特征。
卷积核的高度宽度:是指我们观察的范围,通常的1x1、3x3以及5x5大小的卷积核,都是说的这个范围的大小,例如3x3就是每次看3个像素x3个像素大小的区域。

卷积核的输入通道数:一个卷积核的输入通道数是取决于你上一层的卷积核的个数(即输出通道数)的。如果是第一层卷积,其个数就取决你输入的图片的通道数。还是拿上面那张小猫图为例,图片是RGB颜色格式,则图片的通道数是3,所以第一层卷积层中的每一个卷积核的通道数为3。
卷积核的输出通道数:卷积核的输出通道数其实就是该层卷积操作的卷积核的个数,它决定了下一层卷积操作或者是其他操作的输入通道数。
我们可以看下面这副图片进一步理解卷积核的这几个参数。小猫图片是三种颜色通道,所以第一层卷积层中的每个卷积核里面的通道就为3,第一层卷积层的卷积核个数为4,所以对应着第二层卷积层中每一个卷积核的通道都为4.
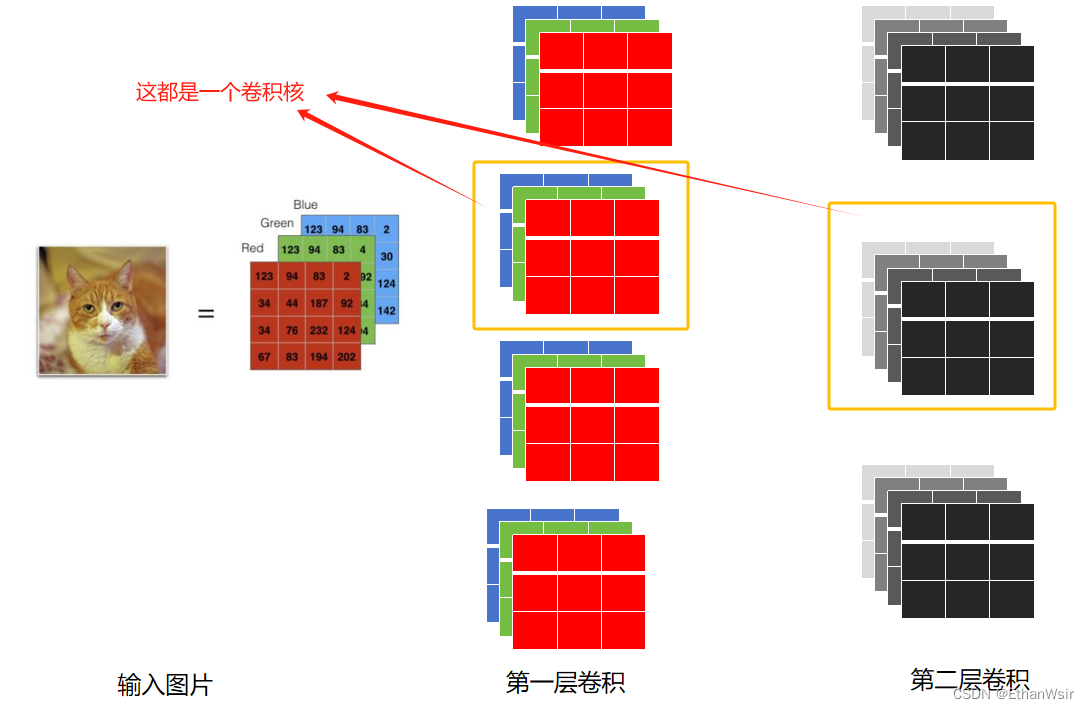
2.2.4 卷积操作
卷积操作可以由下面的张图片表示。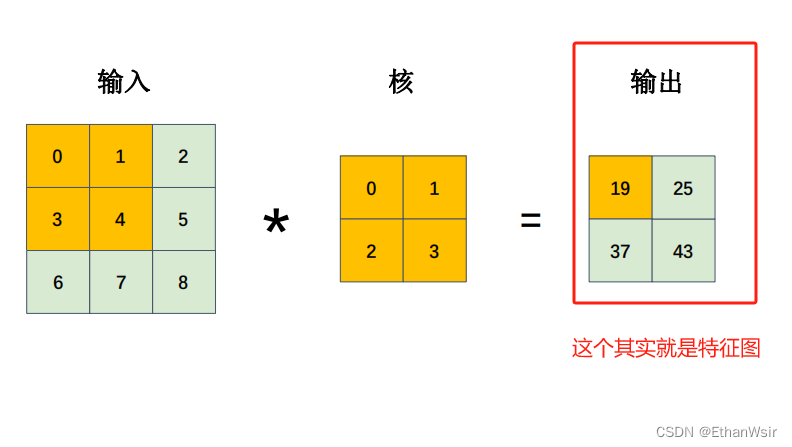
下面的图片是完整的运算过程。

2.2.5 特征图
经过卷积运算后的图片就是特征图了。
2.3 深度可分离卷积
2.3.1 简介
深度可分离卷积就是将标准卷积分解成了一个深度卷积(Depthwise convolution)一个1x1卷积大小的逐点卷积(Pointwise convolution)。原本标准卷积运算只有一步,深度分离卷积分成了两步,第一步用深度卷积进行过滤(Filtering)特征,第二部用逐点卷积组合过(Combining)滤的特征。所以叫做深度可分离卷积。
2.3.2 深度可分离卷积能够减少计算量的原因分析
深度可分离卷积的计算量减小是比较标准卷积的计算量所得出来的结果,所以我们有必要先来讲讲标准卷积的计算量。
2.3.2.1 标准卷积的计算量(输入特征图进行了填充,论文里面分析时进行了填充工作)
填充的意思其实就是在你输入的图像周围补了一圈像素,值一般填入的0。意思是,你输入3x3大小的图像,填充后就变成了5x5大小的图像。
小编在看这一节的时候是很迷糊的,因为我不明白为什么他对输入图像进行填充后,步长设置为1,卷积后的特征图大小与输入图像大小一致。然后又得出了下面要描述出来的标准卷积的计算量公式。最后分析许久才弄清楚,这是3x3卷积核的特性。也就是说只要你对图像进行填充,卷积核大小设置为3x3,步长设置为1,那么图像进行卷积操作之后输出的特征图大小与输入图像大小一样,并且符合下面计算量的公式。如果换成其他大小的卷积核就不适用了。所以下面的DK你就可以认为是3。通过这个你还可以知道,论文中给出的网络结构中最后一个深度可分离卷积的步长写错了,应该是1才对。
我们假设我们输入的图片宽和高都为DF,通道数为M,我们的卷积的宽高为DK,卷积核的个数为N,因为进行过填充,所以经过步长为1(也就是卷积核每次只挪动1个像素)的卷积操作后,得到的特征图其实的宽和高也是DF。
一层标准卷积层如下所示,卷积运算只有一步

标准卷积的运算的示意图如下
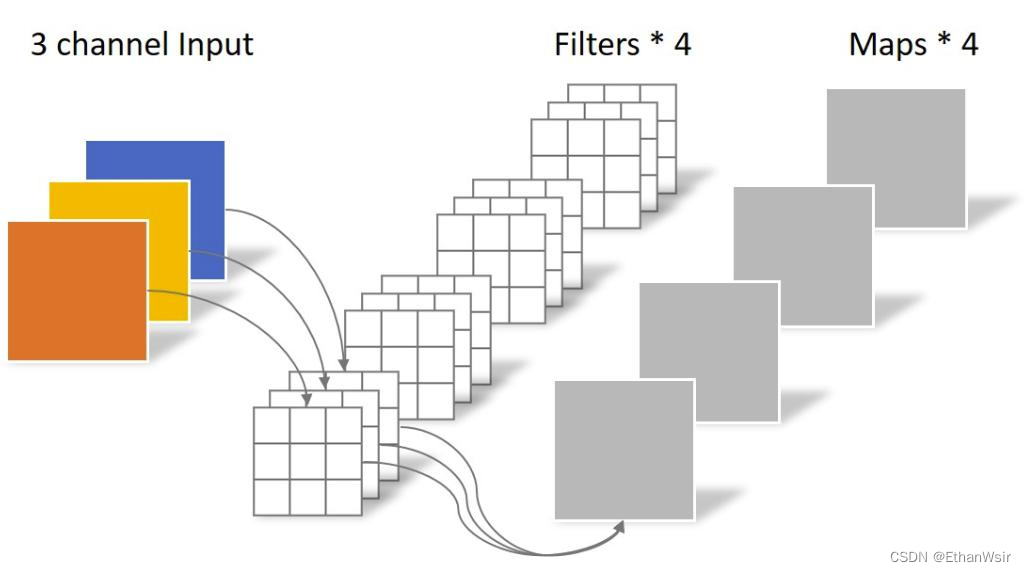
所以我们可以计算出标准卷积这一层进行了多少次乘法,也就是所谓的计算量。注意:不包含加法运算。

2.3.2.2 深度可分离卷积的计算量
深度可分离卷积时将标准卷积分成了两部分,相当于原来标准卷积的一层拆成了两层来做运算。这两层中第一层的深度卷积用来过滤特征,第二层的逐点卷积用来融合特征。
2.3.2.2.1 深度卷积
深度卷积卷积核的输入通道数和输出通道数一致,仅仅用于对特征图的特征进行提取。其实这里就相当于标准卷积计算中卷积核的个数为1的情况,但是输出仍然时与输入通道一一对应的特征图。所以深度卷积的运算量为

下面是深度卷积的示意图
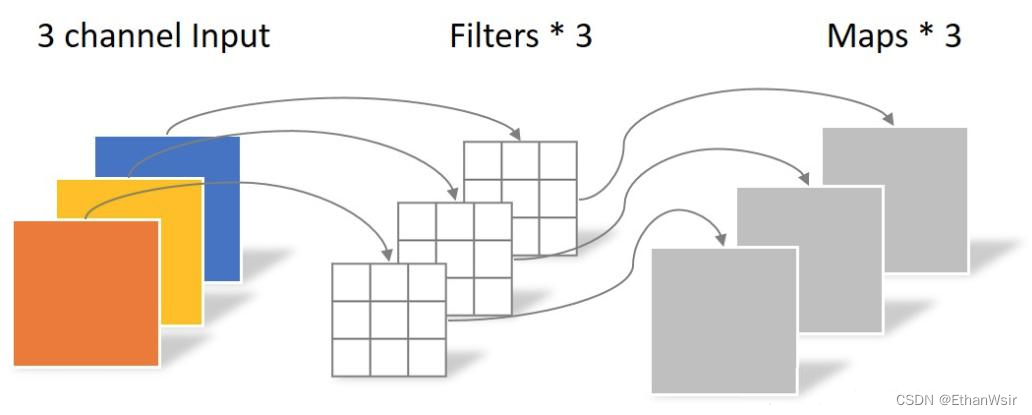
2.3.2.2.2 逐点卷积卷积
逐点卷积是为了将深度卷积输出的特征进行融合,你可以把这一步完全当作标准卷积来看,唯一特俗的时逐点卷积的卷积核高和宽是1x1大小,则DK就等于1,输入通道与深度卷积的通道数M一致,输出通道数为我们自己设置的N。将其带入标准卷积计算量的计算公式中就可以得出逐点卷积的计算量:

下面是逐点卷积的示意图
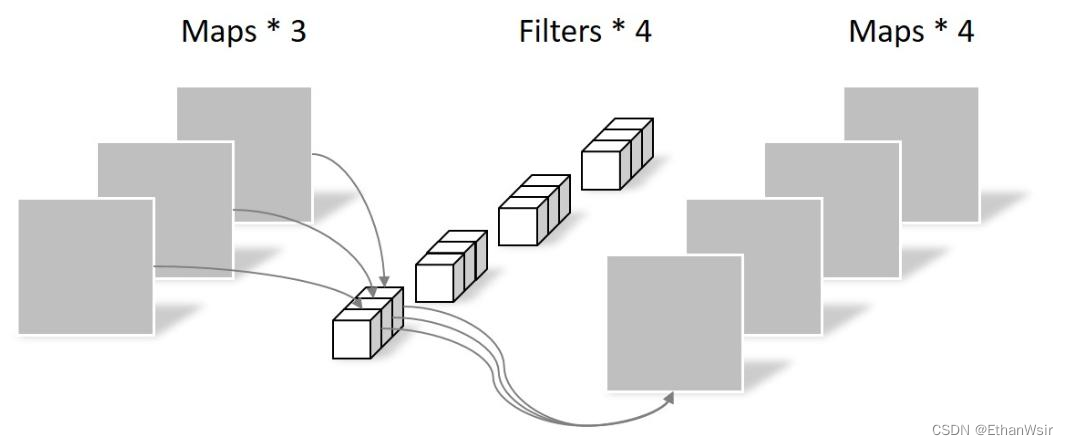
2.3.2.2.3 总结
综上两小节所述,我们就可以得到深度可分离卷积的总体计算量=深度卷积计算量+逐点卷积的计算量,即:
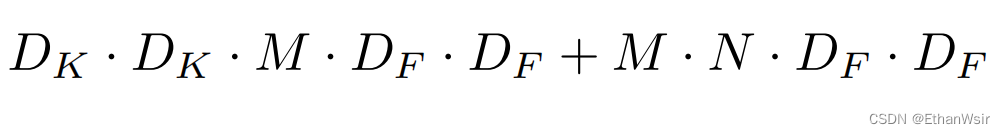
为了更好的理解,我在下方又把标准卷积和深度可分离卷积的示意图放出来了,第一张是标准卷积,第二张是深度可分离卷积。
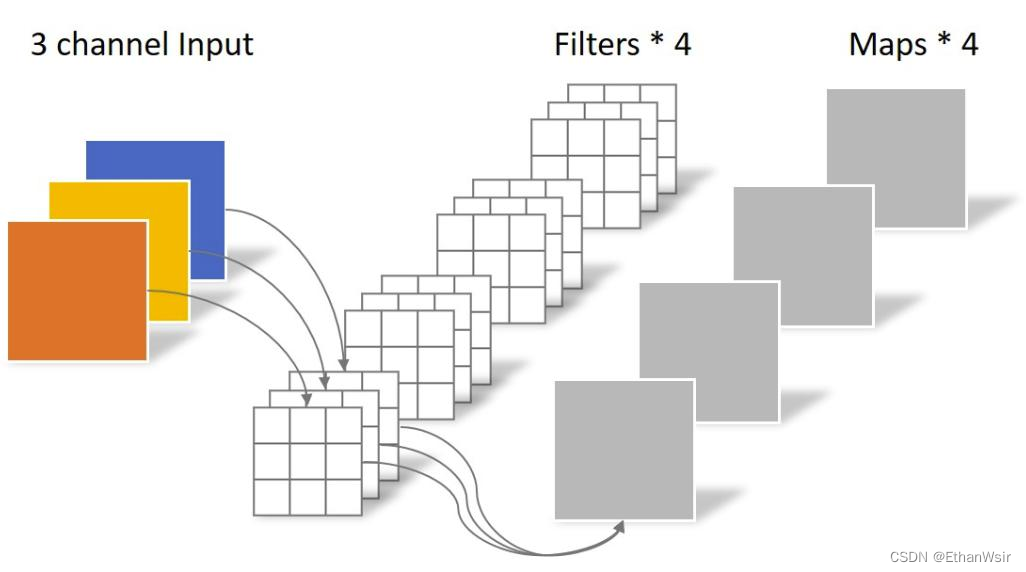

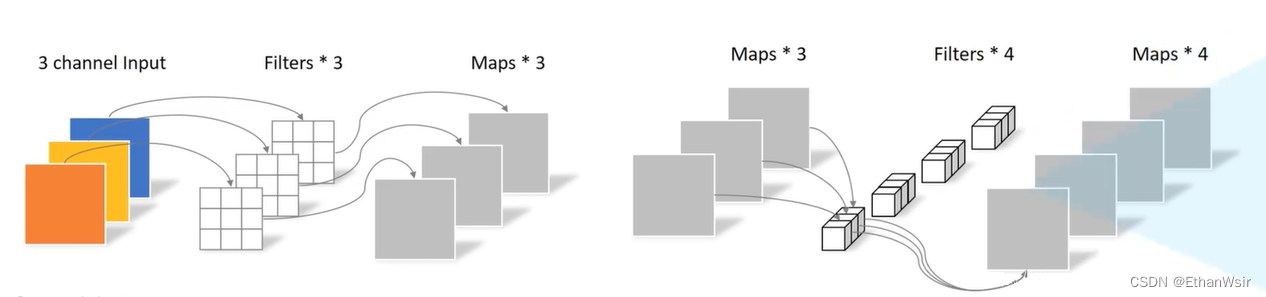
2.3.2.3 标准卷积与深度可分离卷积计算量对比
用深度可分离卷积的计算量除以标准卷积的计算量可得:

由上面的结果可以知道,只要你的输出通道数大于1,并且提取特征的卷积核高度宽度大于1,深度可以分离卷积就能有效的减少计算量。
2.4 两个超参数
2.4.1 宽度乘数(α)
宽度乘数作用在通道上,也就是通过这个超参数该表通道的数量。这里的通道就是指M和N。所以加上宽度乘数之后,深度可分离卷积的总体计算量就变成了:
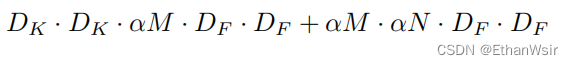
2.4.2 分辨率乘数(ρ)
分辨率,分辨率,通过这个词你就知道了,这个分辨率乘数肯定是作用在图片上的,那么对应到神经网络里面就是作用到特征图上面,想想,深度可分离卷积里面那些参数是相关于特征图的?? 其实就是DF。所以加上分辨率乘数之后,深度可分离卷积的计算量就为:

3、网络结构代码的实现
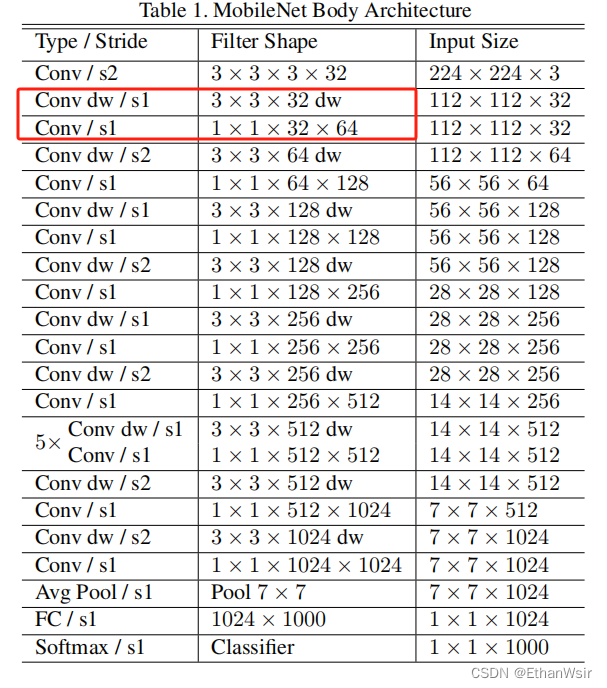
3.1 原文中网络结构图
从下面的网络结构图就可以看出来,MobileNetV1网络结构一共有28层,在其中我们可以看见论文中的网络结构,他将深度可分离卷积分开列出来了,除了第一层的标准卷积和最后一层的全连接层,其他两两结合为深度可分离卷积。(网络结构有多少层,数Type为“Conv”或者“FC”就可以了)。
3.2 代码开写
3.2.1 定义深度可分离卷积类
在深度可分离卷积这个类中,我们除了定义输入输出通道数这两个形参外,还需要定义步长这个形参,因为看上面的MobileNetV1的网络结构图,深度可分离卷积的步长并不是一致的,深度可分离卷积的结构图和代码如下。

# 定义一个深度可分离卷积类
class ConvDSC(nn.Module):
def __init__(self, input_channels, output_channels, strides): # 将我们的形参设计好,输入通道数,输出通道数以及步长
super(ConvDSC, self).__init__()
# 定义第一个部分,深度卷积,特点是输入通道数与输出通道数一致,需要进行分组卷积,卷积核大小为3x3,步长有给定的参数决定,有填充
self.dw = nn.Sequential(
nn.conv2d(in_channels=input_channels, out_channels=input_channels, group=input_channels, lernel_size=3, stride=strides, padding=1),
nn.BatchNorm2d(input_channels), # 对卷积后的数据进行量化,方便计算机计算
nn.ReLU6() # 添加激活函数,这里我就用Relu6
)
# 定义第二给部分,逐点卷积,最大的特点就是,卷积核大小为1x1,无填充,步长为1
self.pw = nn.Sequential(
nn.Conv2d(in_channels=input_channels, out_channels=output_channels, kernel_size=1, stride=1),
nn.BatchNorm2d(output_channels),
nn.ReLU6()
)
# 定义前向传播过程,其实就是怎么用我们上面定义的东西,按要求顺序排列就可以了
def forward(self, x):
x = self.dw(x) # 第一步进行深度卷积
x = self.pw(x) # 第二部进行逐点卷积
return x # 返回我们处理好后的数据
3.2.2 定义MobileNet主体结构类
再将网络结构看简单点,其实就是三部分,第一部分就是第一层的标准卷积;第二部分就是深度可分离卷积,一共13个;第三部分是全连接层。
# 定义我们MobileNetV1主干网络结构的类
class MobileNetV1(nn.Module):
def __init__(self, ConvDSC, width_multiplier, classes_number):
super(MobileNetV1, self).__init__()
# 定义宽度乘数
alpha = width_multiplier
# 定义第一部分,1给标准卷积
self.part1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(32), # 对卷积后的数据进行量化,方便计算机计算
nn.ReLU6() # 添加激活函数,这里我就用Relu6
)# 第一部分卷积结束后的张量大小为# torch.Size([1, 32, 112, 112])
# 定义第二部分,13个深度可分离卷积
self.part2 = nn.Sequential(
ConvDSC(int(alpha * 32), int(alpha * 64), strides=1), # torch.Size([1, 64, 112, 112]), stride=1
ConvDSC(int(alpha * 64), int(alpha * 128), strides=2), # torch.Size([1, 128, 56, 56]), stride=2
ConvDSC(int(alpha * 128), int(alpha * 128), strides=1), # torch.Size([1, 128, 56, 56]), stride=1
ConvDSC(int(alpha * 128), int(alpha * 256), strides=2), # torch.Size([1, 256, 28, 28]), stride=2
ConvDSC(int(alpha * 256), int(alpha * 256), strides=1), # torch.Size([1, 256, 28, 28]), stride=1
ConvDSC(int(alpha * 256), int(alpha * 512), strides=2), # torch.Size([1, 512, 14, 14]), stride=2
ConvDSC(int(alpha * 512), int(alpha * 512), strides=1), # torch.Size([1, 512, 14, 14]), stride=1
ConvDSC(int(alpha * 512), int(alpha * 512), strides=1), # torch.Size([1, 512, 14, 14]), stride=1
ConvDSC(int(alpha * 512), int(alpha * 512), strides=1), # torch.Size([1, 512, 14, 14]), stride=1
ConvDSC(int(alpha * 512), int(alpha * 512), strides=1), # torch.Size([1, 512, 14, 14]), stride=1
ConvDSC(int(alpha * 512), int(alpha * 512), strides=1), # torch.Size([1, 512, 14, 14]), stride=1
ConvDSC(int(alpha * 512), int(alpha * 1024), strides=2), # torch.Size([1, 1024, 7, 7]), stride=2
ConvDSC(int(alpha * 1024), int(alpha * 1024), strides=1) # torch.Size([1, 1024, 7, 7]), stride=1
)
# 定义第三部分,平均池化+展开+全连接层
self.part3 = nn.Sequential(
nn.AvgPool2d(kernel_size=7, stride=1), # torch.Size([1, 1024, 1, 1]), stride=1
nn.Flatten(),
nn.Linear(int(alpha * 1024), classes_number) # torch.Size([1, classes_number])
)
# 定义前向传播函数
def forward(self, x):
x = self.part1(x)
x = self.part2(x)
x = self.part3(x)
return x
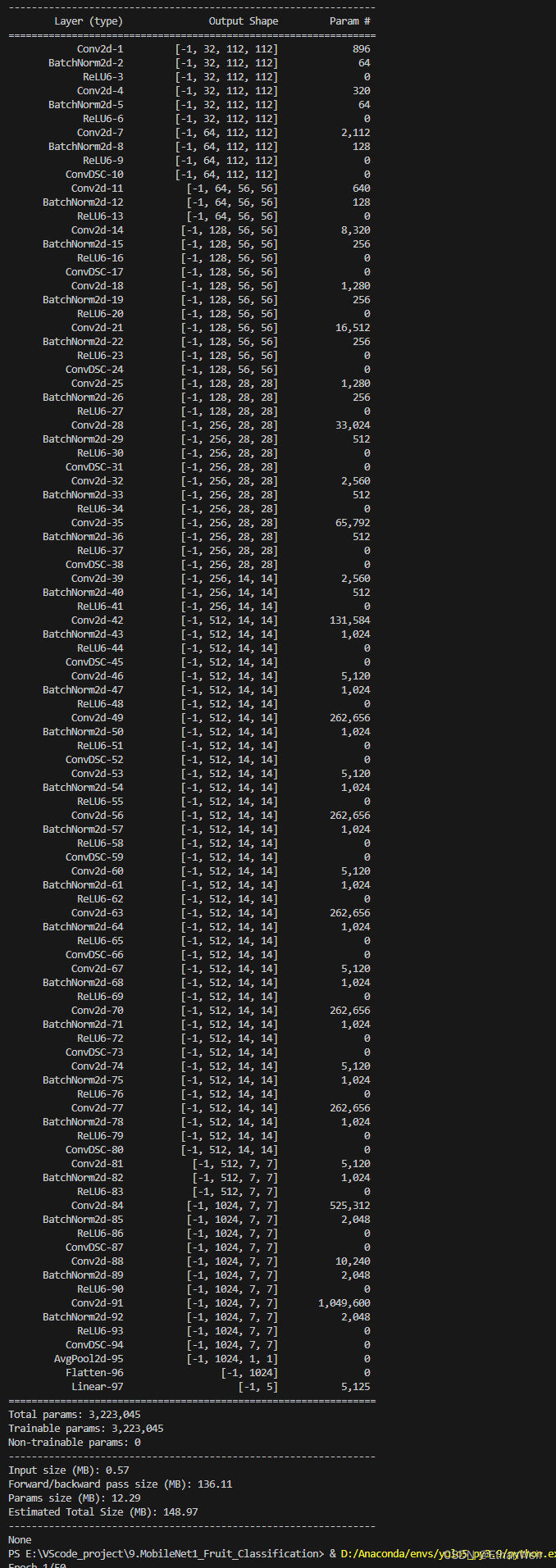
3.2.3 mobile.py文件完整代码,以及该文件运行效果图
import torch
import torch.nn as nn
from torch.autograd import Variable
from torch.utils.data import DataLoader # 添加的导入语句
from torchvision.transforms import transforms # 添加的导入语句
from torchsummary import summary
# 定义一个深度可分离卷积类
class ConvDSC(nn.Module):
def __init__(self, input_channels, output_channels, strides): # 将我们的形参设计好,输入通道数,输出通道数以及步长
super(ConvDSC, self).__init__()
# 定义第一个部分,深度卷积,特点是输入通道数与输出通道数一致,需要进行分组卷积,卷积核大小为3x3,步长有给定的参数决定,有填充
self.dw = nn.Sequential(
nn.Conv2d(in_channels=input_channels, out_channels=input_channels, groups=input_channels, kernel_size=3, stride=strides, padding=1),
nn.BatchNorm2d(input_channels), # 对卷积后的数据进行量化,方便计算机计算
nn.ReLU6() # 添加激活函数,这里我就用Relu6
)
# 定义第二给部分,逐点卷积,最大的特点就是,卷积核大小为1x1,无填充,步长为1
self.pw = nn.Sequential(
nn.Conv2d(in_channels=input_channels, out_channels=output_channels, kernel_size=1, stride=1),
nn.BatchNorm2d(output_channels),
nn.ReLU6()
)
# 定义前向传播过程,其实就是怎么用我们上面定义的东西,按要求顺序排列就可以了
def forward(self, x):
x = self.dw(x) # 第一步进行深度卷积
x = self.pw(x) # 第二部进行逐点卷积
return x # 返回我们处理好后的数据
# 定义我们MobileNetV1主干网络结构的类
class MobileNetV1(nn.Module):
def __init__(self, ConvDSC, width_multiplier, classes_number):
super(MobileNetV1, self).__init__()
# 定义宽度乘数
alpha = width_multiplier
# 定义第一部分,1给标准卷积
self.part1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(32), # 对卷积后的数据进行量化,方便计算机计算
nn.ReLU6() # 添加激活函数,这里我就用Relu6
)# 第一部分卷积结束后的张量大小为# torch.Size([1, 32, 112, 112])
# 定义第二部分,13个深度可分离卷积
self.part2 = nn.Sequential(
ConvDSC(int(alpha * 32), int(alpha * 64), strides=1), # torch.Size([1, 64, 112, 112]), stride=1
ConvDSC(int(alpha * 64), int(alpha * 128), strides=2), # torch.Size([1, 128, 56, 56]), stride=2
ConvDSC(int(alpha * 128), int(alpha * 128), strides=1), # torch.Size([1, 128, 56, 56]), stride=1
ConvDSC(int(alpha * 128), int(alpha * 256), strides=2), # torch.Size([1, 256, 28, 28]), stride=2
ConvDSC(int(alpha * 256), int(alpha * 256), strides=1), # torch.Size([1, 256, 28, 28]), stride=1
ConvDSC(int(alpha * 256), int(alpha * 512), strides=2), # torch.Size([1, 512, 14, 14]), stride=2
ConvDSC(int(alpha * 512), int(alpha * 512), strides=1), # torch.Size([1, 512, 14, 14]), stride=1
ConvDSC(int(alpha * 512), int(alpha * 512), strides=1), # torch.Size([1, 512, 14, 14]), stride=1
ConvDSC(int(alpha * 512), int(alpha * 512), strides=1), # torch.Size([1, 512, 14, 14]), stride=1
ConvDSC(int(alpha * 512), int(alpha * 512), strides=1), # torch.Size([1, 512, 14, 14]), stride=1
ConvDSC(int(alpha * 512), int(alpha * 512), strides=1), # torch.Size([1, 512, 14, 14]), stride=1
ConvDSC(int(alpha * 512), int(alpha * 1024), strides=2), # torch.Size([1, 1024, 7, 7]), stride=2
ConvDSC(int(alpha * 1024), int(alpha * 1024), strides=1) # torch.Size([1, 1024, 7, 7]), stride=1
)
# 定义第三部分,平均池化+展开+全连接层
self.part3 = nn.Sequential(
nn.AvgPool2d(kernel_size=7, stride=1), # torch.Size([1, 1024, 1, 1]), stride=1
nn.Flatten(),
nn.Linear(int(alpha * 1024), classes_number) # torch.Size([1, classes_number])
)
# 定义前向传播函数
def forward(self, x):
x = self.part1(x)
x = self.part2(x)
x = self.part3(x)
return x
if __name__ == "__main__":
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = MobileNetV1(ConvDSC, 1, 5).to(device)
print(summary(model, (3, 224, 224)))
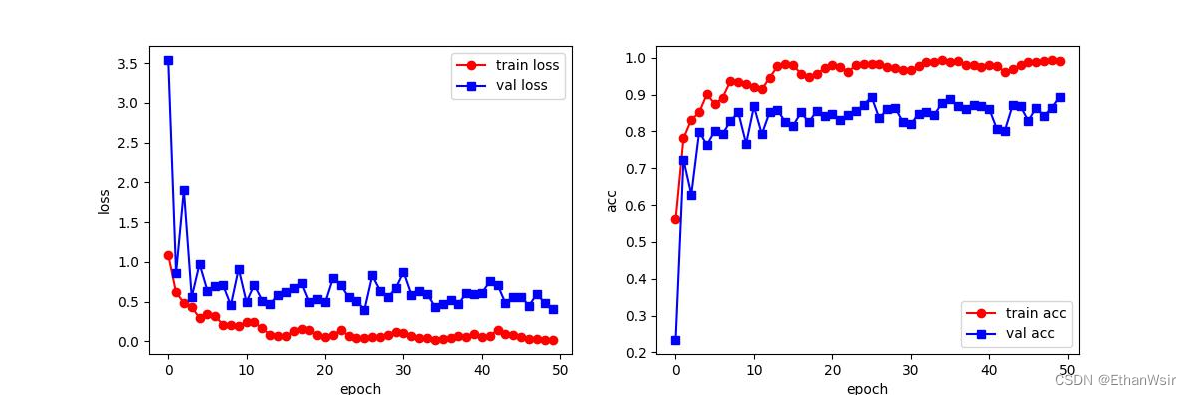
4、简简单单跑一个水果分类试一试效果
这个水果分类跑了50轮,验证集准确率大概在89.5%。由loss曲线图可以看出,稍微有点过拟合。

5、结合到YoloV5中跑一个安全帽目标检测试一试效果
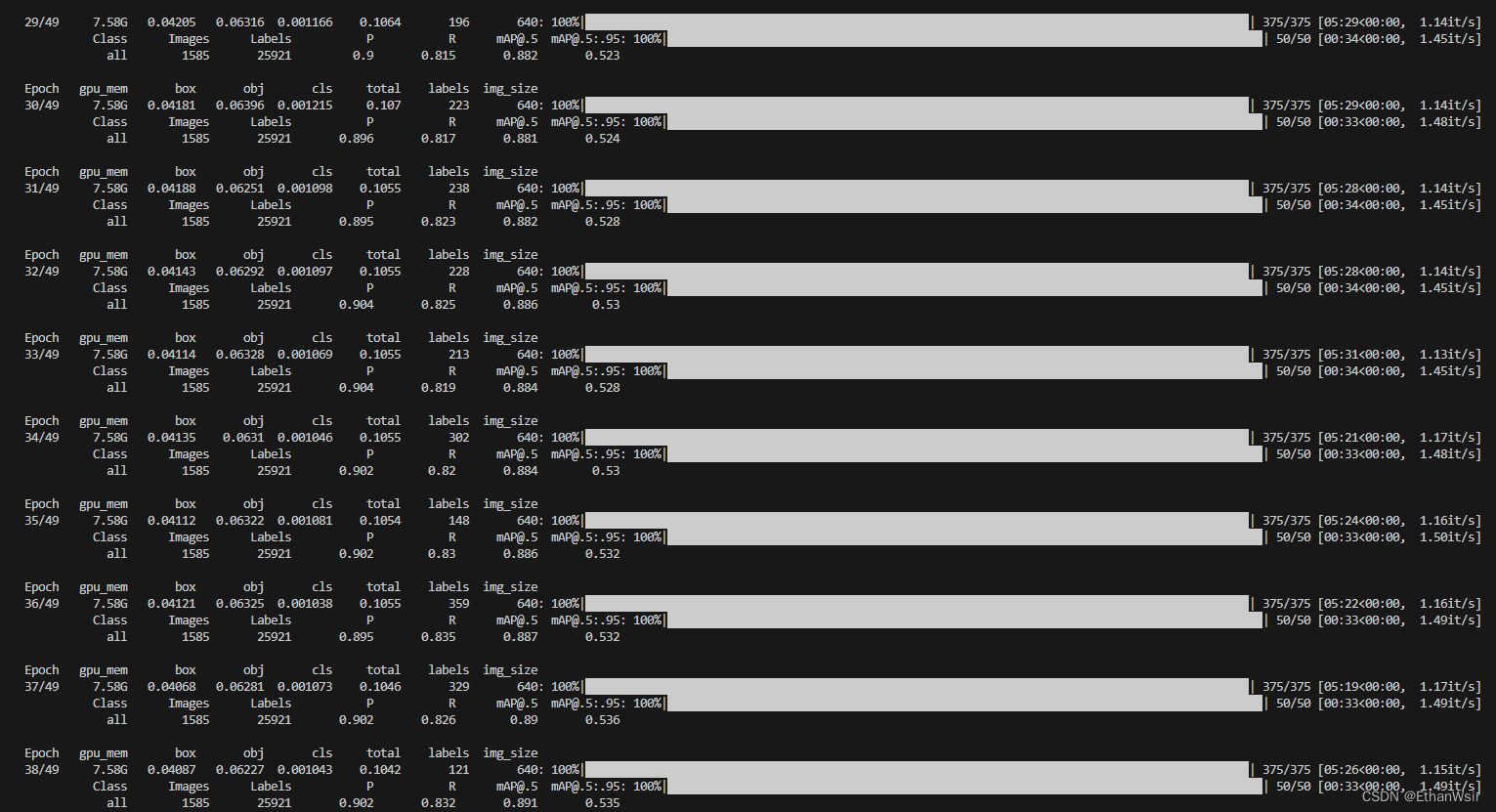
将mobileNet替换为yolo5的网络骨干后,对“炮哥带你学”博客中的安全帽数据集进行训练,预训练参数选择的是yolov5s。如果想要数据集可以看我另外一篇博文:复现炮哥带你学—Yolo5训练安全帽(vscode + pytorch)报错总结,数据库链接+权重文件链接。
跑出来的效果如下:可以看到,大概训练到30几轮,已经差不多拟合,准确率大概在90%,MAP最高时0.895.

6、总结
写这边博文的原因其实是小编要开题汇报了,可能需要用到mobileNet系列的网络结构,为了以后方便写什么东西水水字数,决定写博文记录一下,顺便也看看自己到底对mobileNet掌握多少。本人也是一名深度学习的小白,如果文章中有上面很明显的错误,请留言共同学习。同时希望这篇博文能帮助到你。

















 1714
1714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









