






Vol.1
引入
在介绍今天的正主“Mokken模型”之前,我希望可以先向大家说明一下为什么要使用这个模型。那么就得从经典测量理论(classical test theory,CTT)的缺点开始说起。
1.1 经典测量理论及其缺陷
经典测量理论以随机抽样理论为基础,建立了简单的数学模型,然而在理论假设和实际应用方面,经典测量理论存在一些固有缺点:
1)真分数与观测分数间存在线性关系的假定与事实相违背;
2)误差与真分数独立的假设难以满足;
3)信度是针对被试全体的,只代表平均测量精度;
4)对于测验等值、适应性测验、标准参照性测验的编制等问题无法给出完善的解决方案。
这上面的每一点若进行展开,都能单独写成一段,这就会使得原本篇幅已经很长的文章变得篇幅更长,所以就不再此展开。不过这些经典测量理论的缺陷基本上是做项目反应理论或者认知诊断理论的研究者的共识,所以大家也可以抓取野生的研究者(ChatGPT?)细细询问,直到明白为止。
1.2 项目反应理论(item response theory,IRT)
既然CTT存在这么多问题,那正义的研究者不能坐视不理,所以他们就在此基础上提出了项目反应理论(item response theory,IRT)。IRT的理论基础是潜在特质理论,其基本思路是确定考生的心理特质值和他们对于项目的反应之间的关系,这种关系的数学形式就是“项目反应模型”。
项目反应理论拥有不少优点,如:
1)采用非线性模型,建立了被试对项目的反应与其潜在特质之间的非线性关系,这一点更符合实际情况;
2)IRT将被试能力和试题难度放在同一量尺上进行估计,不同的测验结果可直接比较;
3)用测验信息函数的概念代替了信度理论,用测验对能力估计所提供的信息量的多少来表示测量的精度,从而避免了平行测验假设,并能给出不同能力被试的测量精度;
4)对于测验等值、适应性测验、标准参照性测验的编制等问题给出了合理的解决办法。
大家如果仔细看这些优点,可以发现基本上就是对CTT缺点的补足。也正因如此,大家现在很喜欢用IRT写文章,我以item response theory为关键词在web of science上进行搜索,并只选取发表的文章,一共有14803个结果(截至2024年4月4日):
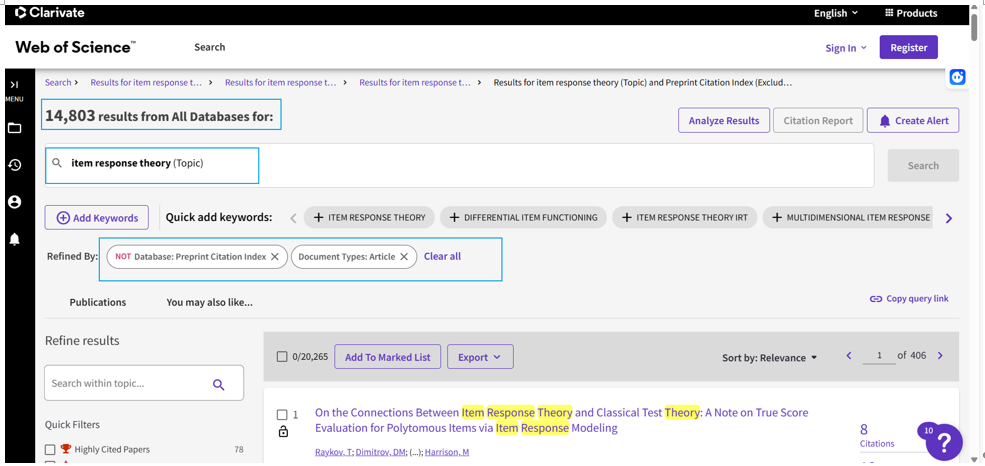
图1 WOS搜索结果
(当然,这结果中不可避免地会存在理论性的文章,不过即使去掉这些理论性的文章,实证类的文章依然非常多)
在IRT的理论体系中,概念和理论推导更加严谨,但IRT也不是完美无缺的,常见的问题如下:
1)IRT建立在复杂的数学模型基础之上,依赖更强的假设,计算过程繁琐,不易掌握;
2)IRT对测验条件要求较严格,样本容量要大,被试的能力分布范围要广,题目数量要多,这些条件不满足就会影响其精确性。
如果对统计分析方法稍微了解的友友,应该都知道统计分析方法对于不同的数据分布形态,有相应的处理方法,其中最为典型的就是参数检验与非参数检验,以最简单的独立样本t检验为例,它对应的非参数检验就是Mann-Whitney U检验。同样地,庞杂的IRT也可以分为参数型和非参数型,在此之前我们可以先将IRT划分为单维和多维,虽然理论上单维只可以检验单维度的量表,但在实际应用中,也可以见到很多将单维IRT应用于多维量表中的文章。本篇文章只讨论单维项目反应理论模型,我们可以将其分为参数型(Parameter item Response Theory,PIRT)与非参数型(Nonparameter Item Response Theory,NIRT)两种。
PIRT模型使用难度、区分度、猜测度等若干项目参数刻画项目特征曲线,描写项目的测量特性;而NIRT模型不要求数据符合某种特定函数形态,比前者限制要少,只使用量表适宜性系数H(scalability coefficients)衡量项目测量被试的适宜性。
Junker and Sijtsma (2001)对非参数项目反应理论的使用提出三条理由:
(1)为参数项目反应模型提供一种更深的理解。在实际的测量中并不是所有的题目都能够拟合项目反应理论中的各个参数,但是这些题目却在测量中同样起十分重要的作用,非参数项目反应理论就很好地解决了这一问题。
(2)为参数项目反应模型的局限性提出更适应更有弹性的框架。IRT的基本假设难以满足,IRT理论基于能力的单维性、局部独立性和单调性这三条强假设。当所选择的参数模型支持这些假设时,所拟合的模型能够提供大量关于项目和被试的信息。而在实际应用中,所收集的数据往往难以满足IRT的基本假设。因NIRT对数据的要求更宽松而NIRT应用的范围更广。同时,NIRT不像PIRT那样通过对项目参数的估计,以期获得更为精确的测量结果,而是通过对样本数据的估计来获得一个从高到低或从低到高的排序,不仅简化了复杂而繁琐的参数估计的运算过程,而且也为广大的测量人员提供了方便,比较简便容易操作,实用性更强。
(3)为短量表和小样本提供比大样本测验更容易更准确的方法,相比参数项目反应理论需要大量项目和被试才能准确确定被试的潜在特质和量表的信度,非参数项目反应理论更适用于项目量小、被试数量小的情况。
在了解完以上知识后,我们终于可以进入今天要介绍的主题了:非参数项目反应理论模型之Mokken 模型。
Vol.2
Mokken模型简介
在上一部分的最后有说“非参数项目反应理论模型之Mokken模型”,那敏锐的友友可能就会意识到NIRT还存在其它模型。确实如此,除了Mokken模型外还存在其它的NIRT模型,不过那些模型都不太出名,只有Mokken模型最为出名(当然即使是Mokken模型在项目反应理论的各类模型中,都不能算是很有名的)。
与PIRT模型不同,Mokken模型不定义被试应答模式与潜在特质之间的函数关系。也就是说,当数据与Mokken模型拟合时,只能得到被试潜在特质在此特质量尺上的位置信息,而不能得到被试潜在特质与项目参数的点估计值。
Mokken模型是单维顺序测量模型,即测量单一维度并且按照一定顺序排序,如项目作答正确率、总分高低等。
Mokken模型有四个基本假设:
第一,数据具有单维性 (unidimensional,UD),即所要测量的变量是单一维度的;
第二,被试作答反应具有局部独立性(local independence,LI),即作答后一项题目的倾向不受前一道题目的影响;
第三,单调递增性(monotonely nondecreasing),项目反应过程为单侧优势反应,假如某被试a的能力为:
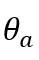
被试b的能力为:
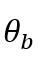
且某被试a的能力小于b被试的能力,那么被试a在某一道题作答正确的概率为:
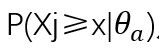
应该小于等于被试b的概率:
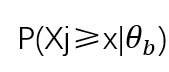
第四,不同项目的项目特征曲线(item characteristic curve,ICC)不相交(Non-Intersection,NI),假设某被试A的能力为:
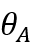
则他在i题与j题上作答概率是:
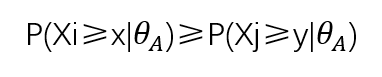
那么其他被试在i题与j题上的作答概率就成立,为:
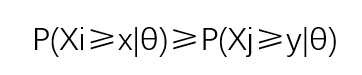
其中i≠j。
如果某测验数据满足前三条假设,构成单调同质模型(monotonely homogeneous model,MHM);如果某测验数据满足全部四条假设,则构成双重单调模型(doubly monotone model,DMM),不仅单个项目单调,项目之间也单调且不相交。DMM模型比MHM模型的条件更为严格,所以只要符合DMM模型的数据一定符合MHM模型,反之则不一定(袁淑莉 & 何壮, 2020)。
MHM模型是指模型有单侧优势反应,那么不同题目的项目特征曲线可能会相交,如图2所示。
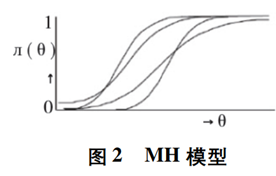
DMM是指模型不仅有单侧优势反应,且不同项目的ICC不相交,如图3所示。
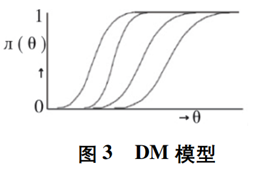
从假设要求来看,NIRT模型比PIRT模型更自由,其对被试潜在能力与项目反应之间关系的理解更宽泛,所以若某数据拟合PIRT模型,那它必然亦拟合NIRT模型。
Vol.3
Mokken scale analysis(MSA)常见指标
在具体介绍如何用R实现Mokken scale analysis(MSA)之前,先向各位友友介绍一下MSA的常见指标,在一篇使用Mokken模型进行分析的文章中,不一定会全部使用这些指标,大家可以重点关注自己想投的期刊上发表的文章中使用了哪些指标。
3.1哥特曼错误(Guttman error)
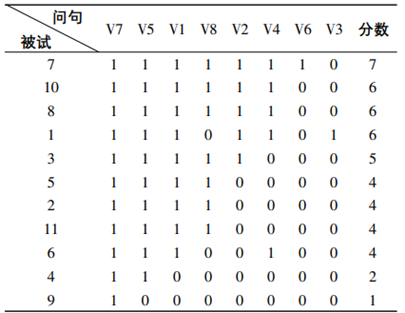
即容易的项目没有答对,难的项目却答对了。下表中,第6个被试在V4项目上做了肯定回答,但在前面两道项目上做了否定回答,这就犯了哥特曼错误,且犯错误的次数为2次,V8和V4记为一次哥特曼错误,V2和V4记为另一次哥特曼错误。再举个例子说明,一套问卷有5道项目MNOPQ(难度从左到右依次增高,M最简单,Q最难),被试1的回答模式是10101,这就有3个哥特曼错误NO、NQ、PQ;被试2的回答模式是00111,这就有6个哥特曼错误MO、MP、MQ、NO、NP、NQ。
3.2单维性检验
这个是为了符合模型的单维性假设所做的测验,可以分为两类,一般进行MSA的文章只会选择一类进行使用,大家可以根据自身情况进行使用。
1)早期在采用探索性因素分析时,研究者都采用了一个经验标准,即分析最大特征值与次大特征值之比的方法,一般认为,只要第一特征值与第二特征值的比值大于3,则可认为该测验是一个单维性测验(Slocum, 2005)。(若碎石图第一因子拐点明显更好)
2)Hemker et al. (1995)认为在测试量表单维性时,可以利用自动项目选择算法(Automated Item Selection Procedure,AISP)检验量表单维性,AISP实施时,以c=0为初始值,0.55为终点值,0.05为步长。随着c值的增加:
· 如果是单维测验,可能出现以下三个阶段:绝大部分或全部项目归为一个量表;形成一个较小的量表;形成一个或几个小量表,同时许多项目被剔除。
· 如果是多维测验,则可能会出现:绝大部分或全部项目归为一个量表;形成两个或多个量表;形成两个或更多的小量表,同时剔除许多项目。
· 关于阶段的划分,有研究者提出,当c<0.3时,为第一阶段;当0.3≤c<0.5时,为第二阶段;当c≥0.5时,为第三阶段(张军, 2010)。
3.3单调性假设检验
想要检验某个项目的单调性就是检验它的正向应答概率是否为潜在特质水平的非递减函数。单调性将最小紊乱系数(vi/ac)、显著性(zsig)和Crit的数值作为评价标准,当以上三个指标等于0时,说明符合单调性假设。但在实际应用中,最小紊乱系数小于0.3可接受(Sijtsma et al., 2011),显著性小于1.96可接受(彭旺, 2020)。若Crit值超过80,则不满足单调性;若Crit值在40和80之间,应根据项目内容和量表目的考虑是否保留;若Crit值小于40,则认为它基本满足单调性,个别的违背单调性情况可视为被试抽样误差。
表1 Crit数值含义

3.4模型拟合指标单维性检验
Mokken模型将被试的得分进行排序,再依据同质性系数(homogeneity coefficients)查看量表设计是否合适。
同质性系数具体分为三种:Hij、Hi、H。
·Hij是题目i与题目j之间的同质性系数;
· Hi是题目i与剩余其他项目的同质性系数;
· H是全部项目的同质性系数。
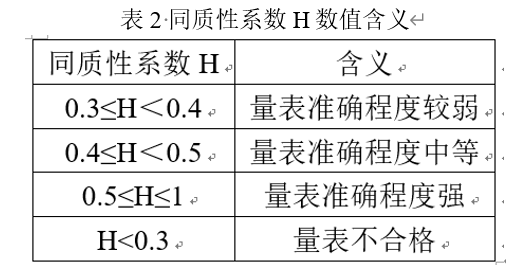
同质性系数在构建Mokken量表中有很重要的作用。H值越高,测验总分对被试潜在特质的排序越准确,Mokken依据他的经验,提出Hij应大于0,Hi和H至少为0.3,当同质性系数为0.3≤H<0.4时,量表的准确程度较弱;当同质性系数为0.4≤H<0.5时,是准确程度中等的量表;当同质性系数为0.5≤H≤1时,是准确程度强的量表;测验整体同质性系数H小于0.3为量表不合格,换言之,如果H处于0到0.3之间,我们就不能相信项目组有足够共同的东西能将被试在一有意义的潜在特质上排序。
同质性系数不但是数据与模型拟合的指标,Hi也可作为项目i的区分度指标。
3.5局部独立性检验
如果大家还有印象的话,应该还记得在Mokken模型的四个假设中,第二个假设是局部独立性假设,但是为什么在前面我都没提呢?因为这个假设真的挺严格的,很少有文章会进行相应的分析。
局部独立性检验利用条件关联程序完成,由三个条件关联指数W(1)、W(2)、W(3)检验,被标记的项目要逐一删除,删除的原则是:具有最多 W 标志的项目被删除,直到只剩下没有标志的项目。如果项目具有相同数量的标志,则同质性系数Hi更小的项目将被删除(Straat et al., 2016)。这里还有一个值得注意的地方,局部独立性检验的程序量表所需条目数不能低于4,否则无法运行相应程序。
3.6信度指标
Mokken模型常报告的信度指标有四个:Molenaar-Sijtsma信度(MS Rho)(Sijtsma & Molenaar, 1987)、内部一致性信度(Cronbach, 1951)、Guttman信度(lambda.2)(Cronbach, 1951)、潜在类别信度系数(Latent Class Reliability Coefficient, LCRC)(van der Ark et al., 2011)。信度指标若均>0.7表明可接受。
当各位看到MSA中居然搞出来四种信度指标,肯定内心非常疑惑:为什么要用四种信度指标呢?直接用Cronbach’α不行吗?很好的问题,我也很好奇问题的答案是什么。
3.7删改项目的要点
对所有项目进行Mokken模型分析后可以将不符合理论假设的项目删除或修改,以提高量表的质量。对于整套量表来说,删改不好项目的最好办法是一次只删改一个项目,查看某一处理对剩余项目Hij和总测验H的影响。
Vol.4
R实现
MSA有对应的R包mokken帮助我们实现,其中也给了一些示例数据集,今天我们使用的数据集是acl,这是433个学生对荷兰版形容词清单的218个条目进行的作答,每个问题是一个形容词,有五个有序的答案类别(0=完全不同意,1=不同意,2=既不同意也不反对,3=同意,4=完全同意)。这218个条目共分为22个子量表。消极措辞的条目在名称中用星号表示,它们的得分被反向计分。

没有安装mokken包的小伙伴需要先安装这个包,然后将这个包导入到目前的工作环境中。
>>> install.packages("mokken") #安装mokken包
>>> library(mokken) #导入mokken包
>>> data(acl) #这一步是导入mokken中自带的acl数据集
>>> head(acl) #简单看一下acl数据集长什么样子
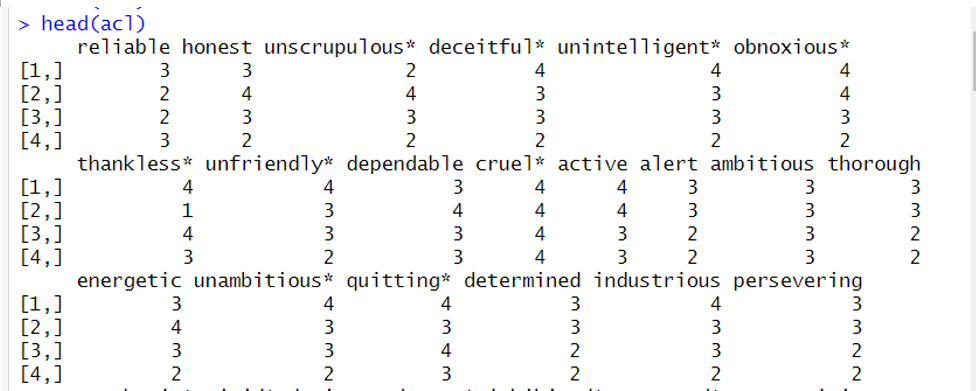
在初步了解数据之后,我们就可以按照单维性检验、同质性系数、局部独立性检验、单调性检验以及信度检验的顺序,依次进行分析了。不过这个数据集有这么多个分量表,分析起来很麻烦,所以我们可以选取第一个分量表作为我们分析的数据。
>>>Communality <- acl[,1:10]# 将acl的前10列所构成的维度Communality作为分析的数据。
在进行单维性检验的时候,有两个选择,第一是直接默认c=0.3进行分析,第二是以c=0为初始值,0.55为终点值,0.05为步长,看c的变化。
首先我们按默认分析的代码来运行:
>>>scale <- aisp(Communality)
>>>View(scale)
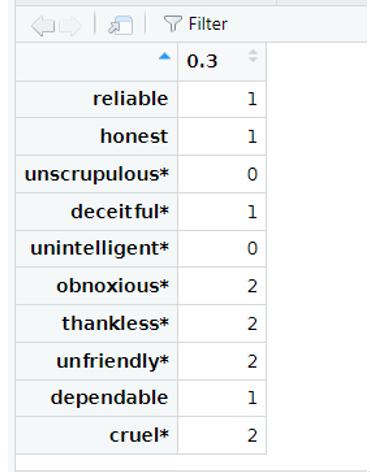
可以看到如果c=0.3的话,Communality的10个条目,有的会被划分到子维度1,有的会被划分到子维度2,还有的会被划分到子维度0。
>>>coefH(Communality[,scale==1], se = FALSE)#计算scale数值为1的各个条目的同质性系数,不显示标准差,如果se=TRUE则显示标准差,可根据自己需要进行选择
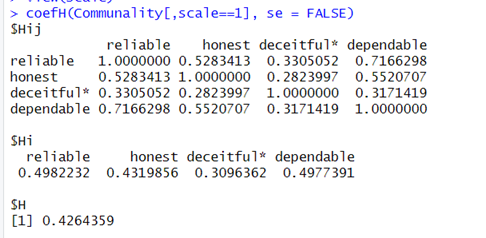
可以看到前文所述的标准,这个结果很不错。
接着我们可以按照c值不断增大的顺序来看结果:
>>>scales <- aisp(Communality, lowerbound = seq(0, .55, .05))
>>>scales

我们可以看到随着c值不断增大,原本这些条目共同属于1个维度,后来逐渐变成更多维度。
在进行单维性检验和同质性系数分析后,我们接着可以进行局部独立性检验,
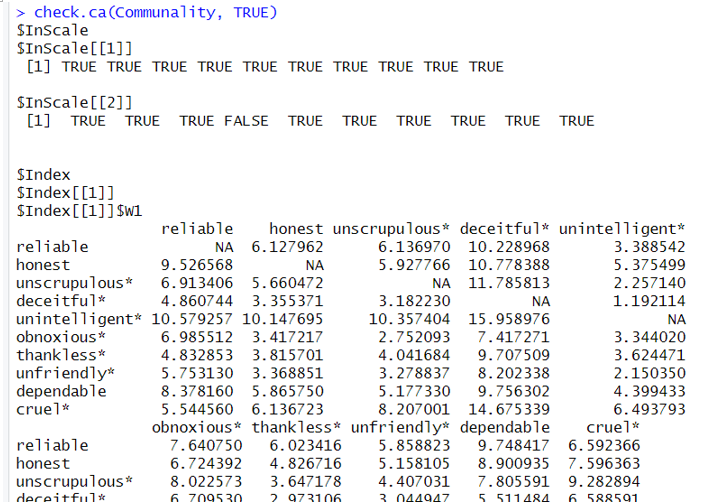
>>>check.ca(Communality, TRUE)
局部独立性检验的结果众多,因版面有限,无法全部显示。不过好在我们可以只看结果的前几行就知道哪个条目需要被剔除了,我们可以看到$InScale[[1]]下的10个条目全部显示TRUE,但在$InScale[[2]]中,第4个条目显示FALSE,这就提示我们应当将第4个条目剔除。(不过剩下的没有显示的结果也能给我们提供其它信息,如果有机会会录制一个视频来讲解剩下的结果。)
按照局部独立性检验的结果,我们应该将条目(deceitful)删除后再进行单调性检验,但本教程只为教会大家各个检验方法的代码,而不是真实操作,所以就不进行剔除了(不然在进行单维性检验时,就发现只能保留4个条目,按照4个条目的结果进行分析的话,后面的分析都会显得很单薄)。
接下来是单调性检验:
>>>monotonicity <- check.monotonicity(Communality) #计算单调性指标
>>>summary(monotonicity) # 展示单调性指标
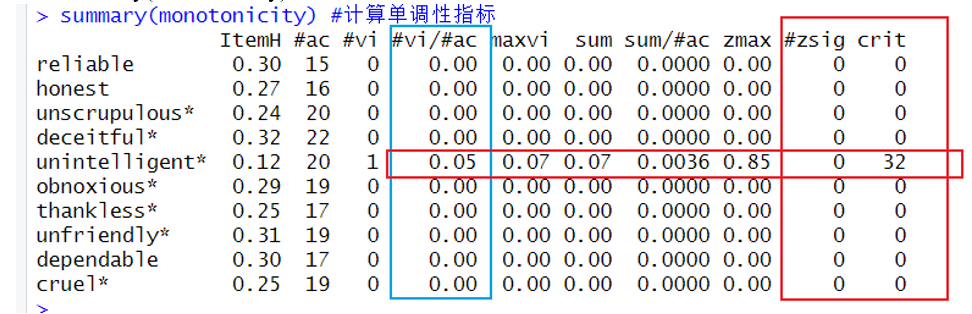
我们可以看到unintelligent虽然有些许违反单调性检验,但各指标都处于可接受的范围,因此不将其剔除。
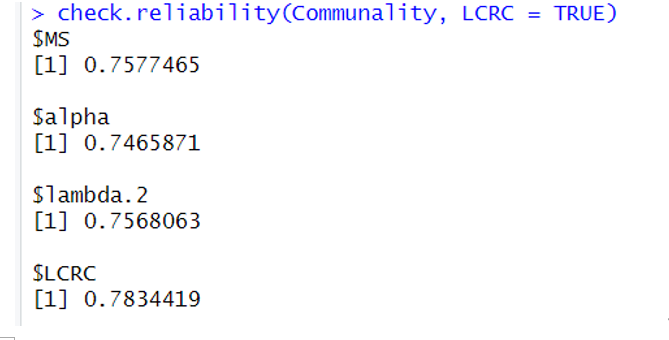
最后计算相应的信度指标:
>>> check.reliability(Communality, LCRC = TRUE)
可以看到4种信度的结果都是可接受的。
在介绍完以上内容后,可能有友友发出疑问:在理论介绍的时候不是有介绍单调同质模型和双调同质模型吗?为什么不检验一下呢?实际上这涉及到排序不变性,很少有完美数据集可以符合条目不变性排序,以2017年的一篇经典教程(Sijtsma & van der Ark, 2017)为例:

因此在这也就不跟各位过多介绍了。并且在这篇文章中,作者也说明在某些情况可以跳过这一步:

Vol.5
方法示例文章介绍
今天向各位友友介绍了这个方法,那大家肯定也想看到具体文章是如何使用这个方法的,那么最后一个部分,我将以一篇发表在《中国全科医学》上的文章为例(孙小楠 et al.)进行讲解。

我们来看一下这篇文章使用到Mokken模型的数据分析部分:



我们可以看到数据分析部分基本上就是教程中的内容,除了在局部独立性检验中因为结果过多,所以我没细致展示,直接说明了怎么识别应该剔除的条目。
然后我们还可以看一下数据分析对应的结果:

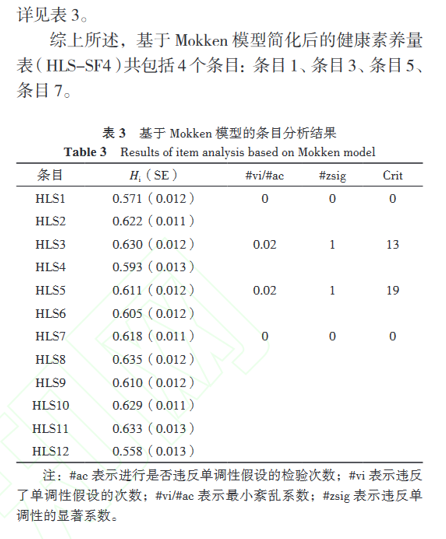
# 留在最后
以上就是MSA应用在实证文章的一个例子了,谢谢大家的阅读~
大家有什么不懂的可以在评论区留言或者向私信噢,如果文中有错误也欢迎指出~
关注我们

参考文献:
Cronbach, L. J. (1951). Coefficient alpha and the internal structure of tests. psychometrika, 16(3), 297-334.
Hemker, B. T., Sijtsma, K., & Molenaar, I. W. (1995). Selection of unidimensional scales from a multidimensional item bank in the polytomous Mokken I RT model. Applied Psychological Measurement, 19(4), 337-352.
Junker, B. W., & Sijtsma, K. (2001). Nonparametric item response theory in action: An overview of the special issue. Applied Psychological Measurement, 25(3), 211-220.
Sijtsma, K., Meijer, R. R., & van der Ark, L. A. (2011). Mokken scale analysis as time goes by: An update for scaling practitioners. Personality and Individual Differences, 50(1), 31-37.
Sijtsma, K., & Molenaar, I. W. (1987). Reliability of test scores in nonparametric item response theory. Psychometrika, 52, 79-97.
Sijtsma, K., & van der Ark, L. A. (2017). A tutorial on how to do a Mokken scale analysis on your test and questionnaire data. British Journal of Mathematical and Statistical Psychology, 70(1), 137-158. https://doi.org/https://doi.org/10.1111/bmsp.12078
Slocum, S. L. (2005). Assessing unidimensionality of psychological scales: Using individual and integrative criteria from factor analysis [University of British Columbia].
Straat, J. H., van der Ark, L. A., & Sijtsma, K. (2016). Using conditional association to identify locally independent item sets. Methodology.
van der Ark, L. A., van der Palm, D. W., & Sijtsma, K. (2011). A latent class approach to estimating test-score reliability. Applied Psychological Measurement, 35(5), 380-392.
彭旺. (2020). 高职生自我批评反刍的测量、现状及其与拖延的关系研究 [硕士],
孙小楠, 陈珂, 武运筹, 汤靖琪, 王飞, 孙昕霙, . . . 吴一波. 简版健康素养量表的开发:基于经典测量理论和项目反应理论. 中国全科医学, 1-10. https://link.cnki.net/urlid/13.1222.R.20230801.1612.004
袁淑莉, & 何壮. (2020). 非参数项目反应理论模型——Mokken模型. 贵阳学院学报(自然科学版), 15(04), 101-106. https://doi.org/10.16856/j.cnki.52-1142/n.2020.04.024
张军. (2010). 非参数项目反应理论在维度分析中的运用及评价. 心理学探新, 30(03), 80-83.
文稿:久久
排版:Peruere
责编:Wink
审核:摘星
本文由“Psych统计自习室”课题组原创。如需转载请联系后台,征得作者同意后方可转载。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









