






写在前面
潜在类别模型(latent class model,LCM)是通过间断的潜变量即潜在类别变量来解释外显指标间的关联,使外显指标间的关联通过潜在类别变量来估计,进而维持其局部独立性的统计方法。
上一期,自习室为大家介绍了有调节的中介模型的基本内容,今天小室将向大家介绍潜在类别模型!
Vol.1 潜变量的概念
首先,我们要先明确什么是潜变量?
潜变量是指无法直接观测或测量的变量,但可以通过观测到的指标间接地加以测量或推断。潜变量在统计建模和分析中起着重要作用,尤其是在因果关系的研究和概念化较为模糊的情况下。常见的例子包括心理学中的心理特质(如幸福感、焦虑程度)、教育领域中的学习能力、经济学中的财富水平等。
潜变量通常通过测量一组相关的指标来间接地进行推断或估计。这些指标通常被称为观测变量或指标变量。通过统计方法,可以利用观测变量的数据来估计或推断潜变量的存在和性质,从而更好地理解和解释现象之间的关系。常用的方法包括因子分析、结构方程模型等。
举个例子:

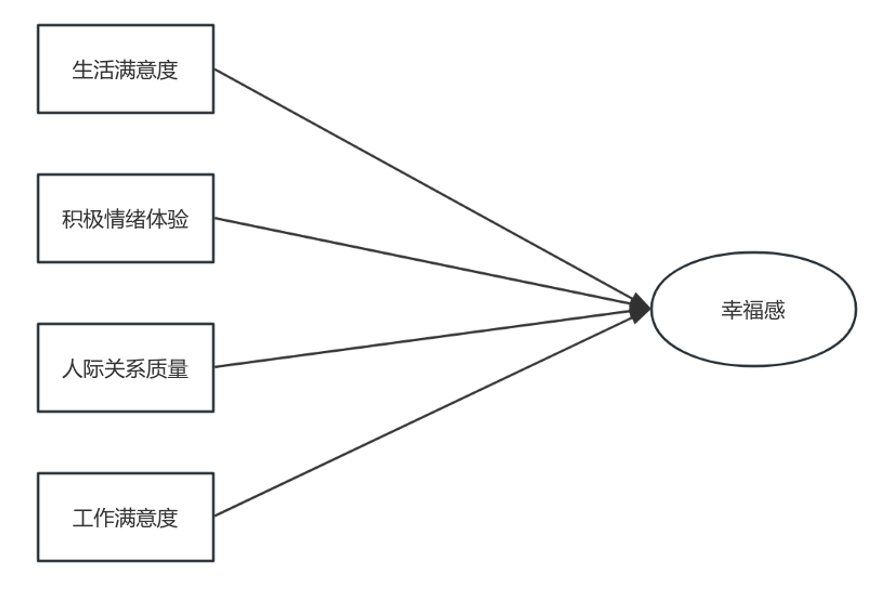
当我们谈论心理学中的幸福感时,幸福感本身是一个潜变量,因为它无法直接观测或测量。然而,我们可以通过一系列相关的指标来间接地推断一个人的幸福感水平。这些指标可以包括生活满意度、积极情绪体验、人际关系质量、工作满意度等。通过对这些指标进行观测和量化,我们可以使用统计方法来估计或推断一个人的幸福感水平,即潜在的幸福感潜变量。而这些可以观测的变量(生活满意度、工作满意度等)被成为外显变量。
Vol.2 潜类别模型
了解了什么是潜变量,我们再来看潜类别模型:
潜变量模型是一种用于建模无法直接观测到的概念或构念的统计模型,它们可以被隐含在观测变量背后,用于解释观测变量之间的关系。主要的潜变量模型包括:
1 结构方程模型
结构方程模型(Structural Equation Modeling,SEM):SEM是一种广泛用于研究潜变量之间关系的统计方法。它将潜在的概念性变量与观测到的变量之间的关系建模为一个方程系统,并且可以同时估计观测变量之间的关系和潜变量之间的关系。
2 因子分析
因子分析(Factor Analysis,FA):FA用于探索和解释观测数据背后的潜在结构。它假设观测变量由一组潜在的因子共同决定,并且通过估计因子之间的相关性来解释观测变量之间的共性和差异性。
3潜类别分析
潜类别分析(Latent Class Analysis,LCA)会在下面详细讲述。

4 混合效应模型
混合效应模型(Mixture Effects Models):这是一类结合了潜在变量和混合模型的方法,用于描述一个或多个潜在变量对观测数据的影响,并且假设这些潜在变量的分布是混合的。
5 半参数模型
半参数模型(Semi-Parametric Models):这类模型将观测数据建模为潜变量和其他参数之间的关系,但不对潜变量的分布进行具体的假设,允许数据的分布更加灵活地适应实际情况。
Vol.3 潜在类别分析
这里我们重点讲一下潜在类别分析(Latent Class Analysis,LCA),LCA主要用于发现样本中的潜在亚群,并将个体分配到不同的类别中。它假设观测到的变量由一个离散的潜在类别变量决定,并且通过估计类别之间的概率分布来识别潜在的群体结构。有关LCA的数学原理我们在这里不多赘述了,感兴趣的同学可以参考《潜变量建模与Mplus应用:进阶篇》,这里我们主要讲临床应用及使用方法。

临床应用上,最初在心理学的探索中最为常用,往往用于区分某一疾病患者不同的心理特征亚群。随方法的不断扩展,研究者也将此方法用于其他的疾病中,用过探索患者的不同临床特征类型,例如有研究者利用心衰严重程度、躯体和心理症状负担、功能状态和合并症数量这几个变量来探究心衰晚期患者的负担类型,已针对不用负担类型的患者给予相应给干预措施。
那么,同样是探索亚组,LCA和我们常用的聚类分析又有什么不同呢?

LCA与聚类分析都是将研究对象根据他们的特征分成不同的互斥小组,他们的差异主要在于以下几个方面:
1理论基础
👉 LCA通常基于潜在变量的概念,假设观测到的变量是由潜在类别决定的。它通常关注群体之间的隐含差异,即潜在类别之间的不同特征。
👉 聚类分析通常不涉及潜在变量的假设,只是根据观测到的变量之间的相似性或距离进行样本分组。它更侧重于个体之间的相似性,即观测值在空间中的聚类结构。
简单来说,聚类分析相当于将小朋友根据相似的身高、体型、性别等特征分成不同的方队,每个方队里的小朋友看起来都是差不多的,而LCA是小朋友们根据不同的兴趣爱好,性格特点、家庭环境选择相互合适的人成为朋友。
2数据类型
LCA通常用于分析离散型数据,如二元型或多元型数据。
聚类分析可以用于分析各种类型的数据,包括连续型、离散型和混合型数据。
3模型复杂性
LCA通常基于概率模型,需要对类别之间的关系进行参数化,并对模型进行拟合。
聚类分析通常更简单直接,只需要定义相似性度量或距离函数,并使用聚类算法来划分样本。
理解了什么LCA我们开始实践。

首先,建立假设,选择你要探究的潜变量以及相应的观察变量,注意观察变量的选择通常需要有参考依据。
第一,选择合适的模型,根据变量的特征,对于分类变量的亚组分析我们通常选择潜在类别分析,而连续变量的亚组分析则使用潜在剖面分析。在 没有确定的亚组数量时,我们通常会选择探索性的LCA来确定样本的亚组数量。
第二,模型拟合:使用适当的统计软件(如Mplus、R中的poLCA包等),对指定的潜在类别模型进行拟合。拟合过程中,通常采用最大似然估计或贝叶斯估计等方法来估计模型参数。
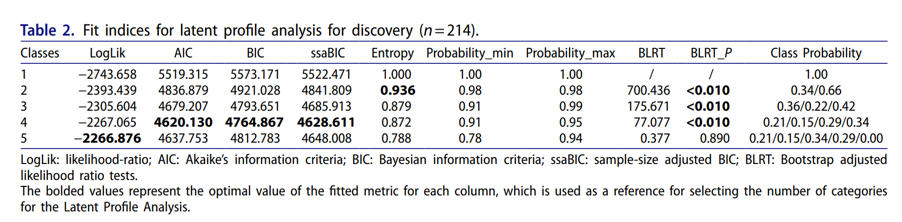
第三,评估模型拟合度:拟合完成后,需要对模型的拟合度进行评估,以确定模型与数据的拟合程度。常用的评估指标包括似然比检验、AIC(赤池信息准则)、BIC(贝叶斯信息准则)等。
(1)贝叶斯信息准则(BIC):BIC是一种惯用的模型选择准则,它考虑了模型的对数似然值和模型参数的数量。BIC值越低,表示模型对数据的拟合效果越好,但不过度拟合。因此,通过比较不同模型的BIC值,可以确定最适合数据的模型。。
(2)赤池信息准则(AIC):AIC与BIC类似,也用于平衡模型的拟合优度和复杂度。AIC值越小表示模型对数据的拟合效果越好,但与BIC相比,AIC倾向于选择更复杂的模型。因此,AIC常用于在简单性和拟合优度之间做出权衡。
(3)最大似然比检验(LRT):最大似然比检验用于比较两个或多个不同数量类别的LCA模型之间的拟合优度。如果在增加类别数量后,模型的拟合优度得到显著提高,那么就说明增加了类别数量是合理的。
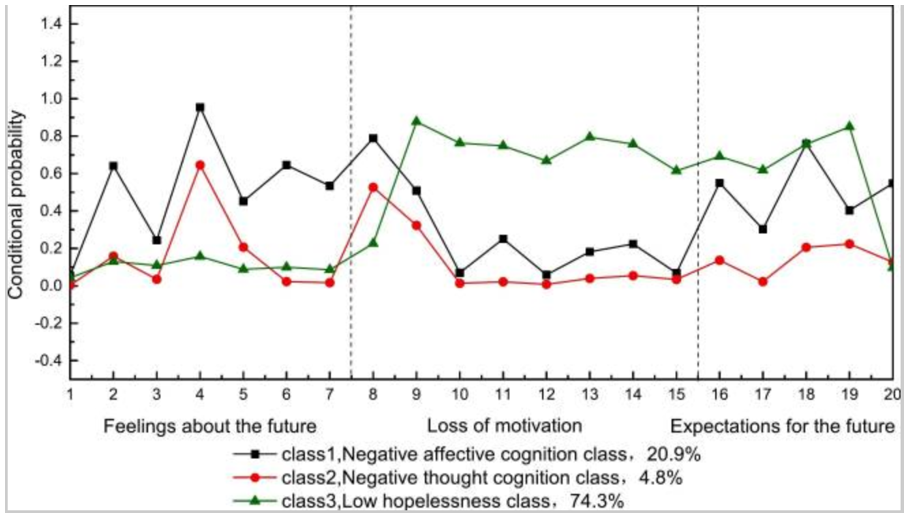
(4)基于Bootstrap的似然比检验(BLRT):BLRT是当前研究中较为常见选择指标。BLRT 使用 Bootstrap 抽样估计两个嵌套模型问的对数似然比差异分布。BLRT 主要比较k-1个和k个类別模型问的拟合差异。例如,对于一个有4个类别的 LCA 模型,BLRT 的p值比较3个类别和4 个类别模型间拟合的差异。显著的 BLRT p值表示4个类别的模型比了个类别的模型拟合显著改善。不显著的 BLRT 的p值则表明4个类别的模型并未比三个类别模型显著改善拟合。
(5)Entropy(熵):Entropy衡量了模型对个体分类的准确程度,值介于0和1之间。Entropy越接近1表示模型对个体的分类越准确。
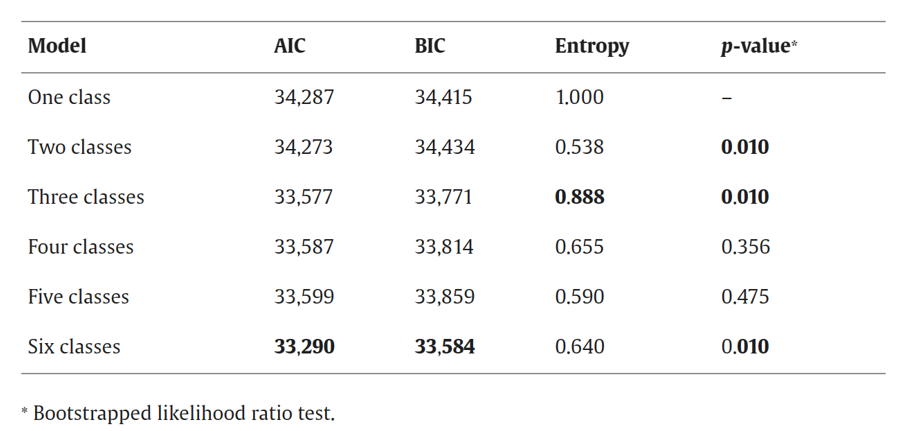

在临床计算当中经常会出现戏剧性的一幕,如下图,不同模型评价指标可能会在不同类别表现出最优解。这时研究者一般会根据临床意义及类别分布选择一个更容易解释的类别数量。通常我们不会选择类别分布中差异较大或某一组的样本量小于总样本的5% 的类别。
根据拟合的潜在类别模型,分析并解释每个潜在类别的特征和差异,探索不同类别之间的异同,以及潜在类别与观测变量之间的关系。
最后,严谨起见可以对模型进行验证,使用验证数据集验证拟合的模型在新数据上的表现,以确保模型的稳健性和泛化能力。

Subscribe
以上就是本期的分享啦,感谢大家的阅读~
同时也欢迎大家在评论区或公众号后台留言,提出自己的建议或问题~
参考文献:
[1] 王孟成、毕向阳《潜变量建模与Mplus应用:进阶篇》
[2] Blum, M., McKendrick, K., Gelfman, L. P., Pinney, S. P., & Goldstein, N. E. (2023). Using Latent Class Analysis to Identify Different Clinical Profiles Among Patients With Advanced Heart Failure. Journal of pain and symptom management, 65(2), 111–119. https://doi.org/10.1016/j.jpainsymman.2022.10.011IF: 4.7 Q1
[3] Wang, J., Xu, M., Li, X., & Ni, Y. (2023). A latent class analysis of hopelessness in relation to depression and trauma during the COVID-19 pandemic in China. Journal of affective disorders, 329, 81–87. https://doi.org/10.1016/j.jad.2023.02.077IF: 6.6 Q1
[4] Wang, X., Meng, X., Yu, Z., Zhang, Y., Li, Y., Xi, Y., He, J., Zhang, J., & Wang, L. (2023). Pulmonary rehabilitation assessment in COPD based on the ICF brief core set: a latent profile analysis. Annals of medicine, 55(1), 2231843. https://doi.org/10.1080/07853890.2023.2231843
[5] van Eijk, N. L., Wetherall, K., Ferguson, E., O'Connor, D. B., & O'Connor, R. C. (2023). A latent class analysis using the integrated motivational-volitional model of suicidal behaviour: Understanding suicide risk over 36 months. Journal of affective disorders, 336, 9–14. https://doi.org/10.1016/j.jad.2023.05.028
更多资讯
关注我们

文稿:梦游小狗
排版:Peruere
责编:Wink
审核:摘星
本文由“Psych统计自习室”课题组原创,欢迎转发。如需转载请联系后台,征得作者同意后方可转载。















 9322
9322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









