







之前看了很多人介绍网络的优化器optimizer,无奈很多都把简单的东西讲的复杂化了,不容易让人懂,恰好之前看过吴恩达老师的最新的课程,这里结合老师讲的和个人想法写一下,方便别人同时也为自己以后回顾吧。
深度学习的优化算法主要有GD,SGD,Momentum,RMSProp和Adam算法吧,还有诸如Adagrad算法,不过大同小异,理解了前面几个,后面的也就引刃而解了。GD算法,SGD算法以及mini-batch SGD算法基本大家都能理解,这里就一笔带过了。下面重点讲一下Momentum算法,RMSProp算法和Adam算法。
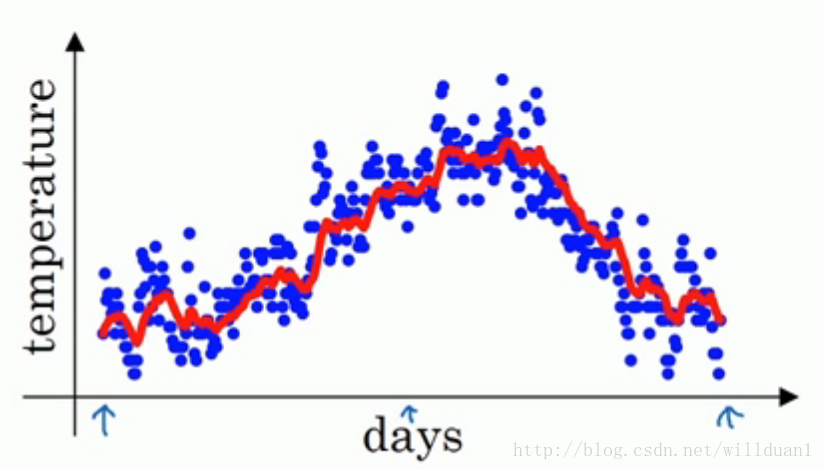
在讲这个算法之前说一下移动指数加权平均。移动指数加权平均法加权就是根据同一个移动段内不同时间的数据对预测值的影响程度,分别给予不同的权数,然后再进行平均移动以预测未来值。假定给定一系列数据值 x1 , x2 , x3 ,…… xn 。那么,我们根据这些数据来拟合一条曲线,所得的值 v1 , v2 …..就是如下的公式:
v1=βv0+(1−β)x1
v2=βv1+(1−β)x2
.............
其中,在上面的公式中, β 等于历史值的加权率。如果把公式详细的展开,就会得到一个指数形式的公式,这里就不详细讲了。根据这个公式我们可以根据给定的数据,拟合出下图类似的一条比较平滑的曲线。
1. Momentum
通常情况我们在训练深度神经网络的时候把数据拆解成一小批一小批地进行训练,这就是我们常用的mini-batch SGD训练算法,然而虽然这种算法能够带来很好的训练速度,但是在到达最优点的时候并不能够总是真正到达最优点,而是在最优点附近徘徊。另一个缺点就是这种算法需要我们挑选一个合适的学习率,当我们采用小的学习率的时候,会导致网络在训练的时候收敛太慢;当我们采用大的学习率的时候,会导致在训练过程中优化的幅度跳过函数的范围,也就是可能跳过最优点。我们所希望的仅仅是网络在优化的时候网络的损失函数有一个很好的收敛速度同时又不至于摆动幅度太大。
所以Momentum优化器刚好可以解决我们所面临的问题,它主要是基于梯度的移动指数加权平均。假设在当前的迭代步骤第 t 步中,那么基于Momentum优化算法可以写成下面的公式:
vdb=βvdb+(1−β
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 64
64

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









