







NXP出了IMX6系列芯片(现在应该是9系列最新了),性能相当于我们嵌入式行业,已经非常优秀(可以做很多事情)
同时,IMX6DL IMX6Q 自带vpu硬编解码,用来处理下视频也是非常不错的,对于我们来说的确非常合适
众所周知,mxc_vpu_test.out 是官方提供的测试程序,用于测试各种功能,源码也提供,
但是系统里面源码是跟其他测试程序整合在一起的,往往我们想要在此基础上改改弄弄,然后重新编译是件困难的事情(大神除外)
当然,也可以从网上下载 mxc_vpu_test.out 的源码,貌似也有(csdn就有),但可能跟你板子的库文件版本不一致,会导致各种问题
总之这是一个绕不过去的坑(编译过不算,正常运行编解码才算)
以上问题,困扰很久,后来版本搞对了,才算顺利过去。 ---- 记一下,如果用测试程序 编译没有问题,但测试解码时候,出现段错误,往往是你所用h文件跟板子so库用的h文件版本不一样,也就是某些结构体size不一样。
另外一个问题:
假设在同一块板子上,先采集USB摄像头的数据,然后vpu编码产生h264流,然后通过“管道”发送给解码线程,解码线程收到h264流,然后调用vpu的解码,然后再显示。当然这个步骤是异步的,两个线程(进程),中间涉及到数据交互的。
源代码是参考 mxc_vpu_test.out 的源码
ps: 说到这里,可能有些人会说,既然是一块板子,那么直接显示USB摄像头上的数据,不是更好的?嗯,我举的例子,的确这样做更好,但不要忘记现实的项目可能是这样的需求:在本终端上显示的画面是其他终端传过来的h264数据,而本终端需要将自己的视频流传输给对方(就好比视频对讲),这样就需要一台板子上同时编解码(当然此时用的通道肯定是两个)
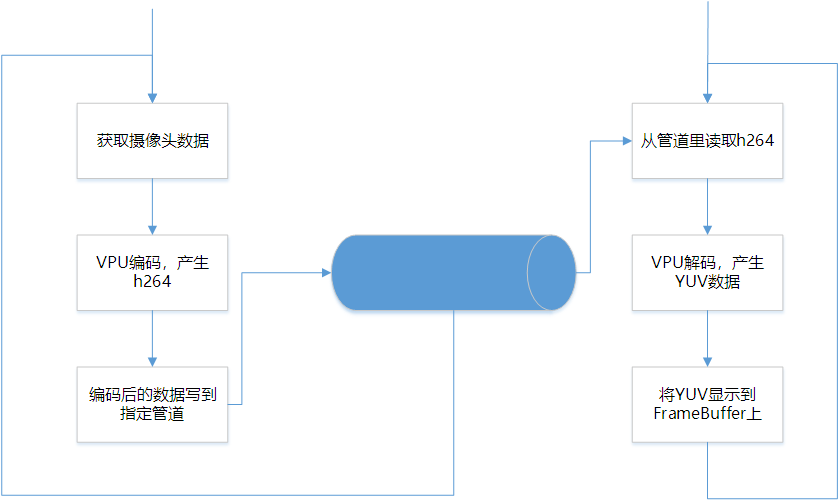
貌似应该没有问题,也说得通,只要编解码本身没有问题,那么问题就没有。但现实往往是骨感的,的确是碰到问题
一开始怀疑管道写错了,但管道的确没有问题
通过步骤printf 的方式,发现卡在:
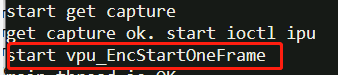
也就是说 开始编码的时候,就不再返回。
分析了dec.c 的源码:
dec这边最后一步是出现这里:
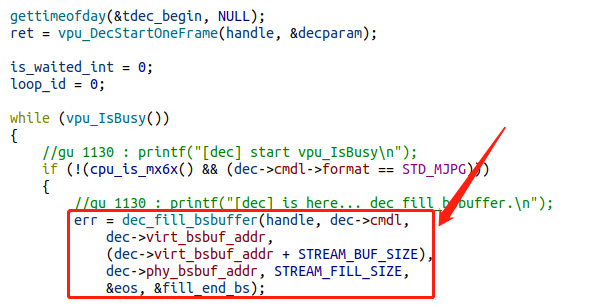
dec_fill_bsbuffer 实际上是去读取管道数据(由于是阻塞式管道,不阻塞不行,不阻塞的话,这里返回是0,那么dec这边会认为“没有数据” 自然退出)。此时卡住了。
原因:
解码这边,在读取管道数据之前,先调用 vpu_DecStartOneFrame ,这个函数会占据vpu资源,
导致解码那边调用 vpu_EncStartOneFrame 函数卡死(因为获取不到vpu资源,从而也没有往下走)
这样就形成了“死锁”,编码这边等待vpu资源释放(才能有数据往管道里放),解码这边等待管道里有数据(才能完成解码,从而才能释放vpu资源)
也许,把 vpu_DecStartOneFrame 放在 dec_fill_bsbuffer 之后,是否可行?也不行,只是概率问题。
从现象来看,我们也知道同一块板子如果同时 vpu_DecStartOneFrame vpu_EncStartOneFrame是不行的
当然唯一的办法就是错时。
我的办法也很简单,利用一个缓冲,错时,如果缓冲里没有数据,解码这边就不调用 vpu_DecStartOneFrame,线程等待就好了。
当然这个缓冲也有点小复杂,不是简简单单加个锁就行了,还是要考虑到各种情况的。
下面亮出我的代码:
1 static char *m_pPipeBuf = NULL;
2 static int m_nNowPos = 0;
3 static int m_nGetPos = 0;
4 static pthread_mutex_t m_lock;
5
6 //建立缓存区
7 void Safe_InitBuff()
8 {
9 if(m_pPipeBuf != NULL)
10 Safe_UnInitBuff();
11
12 pthread_mutex_init(&m_lock,NULL);
13 m_pPipeBuf = (char*)malloc(PIPE_LENTH + 1024);
14 m_nNowPos = 0;
15 m_nGetPos = 0;
16 }
17
18 void Safe_UnInitBuff()
19 {
20 if(m_pPipeBuf != NULL)
21 {
22 free(m_pPipeBuf);
23 m_pPipeBuf = NULL;
24
25 pthread_mutex_destroy(&m_lock);
26 m_nNowPos = 0;
27 m_nGetPos = 0;
28 }
29 }
30
31 //剩余可以存放 多少空间
32 static int GetLastTemp()
33 {
34 int nLast = 0;
35
36 if(m_nNowPos >= m_nGetPos)
37 {
38 nLast = PIPE_LENTH - (m_nNowPos - m_nGetPos);
39 }
40 else
41 {
42
43 }
44 return nLast;
45 }
46
47 static int AddToPipeBuf(void *pBuf,int nLen)
48 {
49 int nRes = -1;
50 if(m_pPipeBuf != NULL)
51 {
52 int nPos = m_nNowPos % PIPE_LENTH;
53 if ((nPos + nLen) > PIPE_LENTH)
54 {
55 int nCpLen = (PIPE_LENTH - nPos);
56 memcpy(&m_pPipeBuf[nPos],pBuf,nCpLen);
57
58 nPos = 0;
59 memcpy(&m_pPipeBuf[0],&pBuf[nCpLen],nLen - nCpLen);
60 }
61 else
62 {
63 memcpy(&m_pPipeBuf[nPos],pBuf,nLen);
64 }
65
66 m_nNowPos = m_nNowPos + nLen;
67 nRes = nLen;
68 }
69
70 return nRes;
71 }
72
73 static int GetSavedLen()
74 {
75 int nLen = 0;
76 if (m_nNowPos == m_nGetPos)
77 {
78 nLen = 0;
79 }
80 else if(m_nNowPos > m_nGetPos)
81 {
82 nLen = m_nNowPos - m_nGetPos;
83 }
84 else
85 {
86 //异常,不存在
87 }
88
89 return nLen;
90 }
91
92 static int GetFromPipeBuf(void *pBuf,int nLen)
93 {
94 int nPos = (m_nGetPos % PIPE_LENTH);
95 int nRes = -1;
96
97 if (nLen > 0)
98 {
99 if ((nPos + nLen) > PIPE_LENTH)
100 {
101 int nCpLen = PIPE_LENTH - nPos;
102 //先拷贝末尾
103 memcpy(pBuf,&m_pPipeBuf[nPos],nCpLen);
104 nPos = 0;
105 memcpy(&pBuf[nCpLen], &m_pPipeBuf[0], nLen - nCpLen);
106 }
107 else
108 {
109 memcpy(pBuf,&m_pPipeBuf[nPos],nLen);
110 }
111
112 nRes = nLen;
113 m_nGetPos = m_nGetPos + nLen;
114 }
115
116 return nRes;
117 }
118
119 //添加数据(如果数据已满,等待)
120 int Safe_AddBuf(char *pBuf,int nLen)
121 {
122 int nRes = -1;
123 if(((nLen + 4) > PIPE_LENTH) || (m_pPipeBuf == NULL))
124 {
125 return nRes;
126 }
127
128 int bIsSaved = 0;
129 while (bIsSaved == 0)
130 {
131 pthread_mutex_lock(&m_lock);
132 int nLast = GetLastTemp();
133
134 if(nLast >= (nLen + 4))
135 {
136 char strNUM[5];
137 memcpy(strNUM, &nLen, 4);
138 AddToPipeBuf(strNUM, 4);
139
140 nRes = AddToPipeBuf(pBuf, nLen);
141 bIsSaved = 1;
142 }
143
144 pthread_mutex_unlock(&m_lock);
145
146 if(bIsSaved == 0)
147 {
148 //< delay 10ms .continue waited
149 printf("Safe_SaveBuf: delay 10ms .continue waited\n");
150 usleep(10000);
151 }
152 }
153
154 return nRes;
155 }
156
157 //提取数据(如果没有数据,等待)
158 int Safe_GetBuf(char *pBuf,int nLen)
159 {
160 static int lastReadAll = 1; ///< 取完
161 static int nLastRead = 0; ///< 还有多少个没读完
162
163 int nRes = -1;
164 if((nLen <= 0) || (m_pPipeBuf == NULL))
165 {
166 return 0;
167 }
168
169 int bIsGet = 0;
170 while (bIsGet == 0)
171 {
172 pthread_mutex_lock(&m_lock);
173 int nSaved = GetSavedLen();
174 int nframe_length = 0;
175
176 if(nSaved > 0)
177 {
178 if(lastReadAll == 1)
179 {
180 if(nSaved > 4)
181 {
182 GetFromPipeBuf(&nframe_length,4);
183
184 if(nframe_length > nLen)
185 {
186 lastReadAll = 0;
187
188 nLastRead = nframe_length - nLen;
189 nframe_length = nLen;
190 //外部存储 不够(先不管,除非长度写错了)
191 }
192 else
193 {
194 //取走这帧
195 lastReadAll = 1;
196 nLastRead = 0;
197 }
198 }
199 else
200 {
201 //错误---
202 }
203 }
204 else
205 {
206 //继续-
207 if(nLen >= nLastRead)
208 {
209 //这次空间够了
210 if(nSaved >= nLastRead)
211 {
212 //把上次未取走的 全部取走
213 nframe_length = nLastRead;
214 nLastRead = 0;
215 lastReadAll = 1;
216 }
217 else
218 {
219 nframe_length = nSaved;
220 nLastRead = nLastRead - nSaved;
221 lastReadAll = 0;
222 }
223 }
224 else
225 {
226 //空间不够 nLastRead
227 if(nSaved >= nLen)
228 {
229 nframe_length = nLen;
230 nLastRead = nLastRead - nLen;
231 lastReadAll = 0;
232 }
233 else
234 {
235 nframe_length = nSaved;
236 nLastRead = nLastRead - nSaved;
237 lastReadAll = 0;
238 }
239 }
240 }
241
242 if(nframe_length > 0)
243 {
244 nRes = GetFromPipeBuf(pBuf, nframe_length);
245 bIsGet = 1;
246 }
247 }
248
249 pthread_mutex_unlock(&m_lock);
250
251 if(bIsGet == 0)
252 {
253 //< delay 100ms .continue waited
254 printf("Safe_GetBuf: delay 10ms .continue waited\n");
255 usleep(10000);
256 }
257 }
258 return nRes;
259 }
260
261 int Safe_IsHaveData()
262 {
263 int nSaved = 0;
264 pthread_mutex_lock(&m_lock);
265 nSaved = GetSavedLen();
266 pthread_mutex_unlock(&m_lock);
267 return nSaved;
268 }
题外话,问题也解决了,效率非常高,cpu仅占3%~5%左右,性能上也很强劲,这款cpu不错
很流畅,延时很少(100ms~200ms左右,感觉!)















 846
846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









