







Actor-Critic(AC)
Policy-Based和Value-Based的结合
Policy Gradient(Actor)和Function Approximation(Critic)
-
提出原因:Policy Gradient的回合更新使学习效率较低,所以结合Value-Based,将单步更新的思想引入Policy Gradient
-
Actor
充当Policy Gradient
- Actor根据Critic给出的“评分”来判断当前行为的好坏
-
Critic
充当Value-Based
- 根据当前所处的状态、行为或其他因素来判断好坏,并将值传给Actor
-
在初始版本的AC方法中,由于Critic仅用一个神经网络进行预测输出,造成神经网络相关性较大,再加之训练时各状态之间的强相关性,导致网络很难收敛
DPG
Paper : Deterministic Policy Gradient Algorithms
Deterministic Policy Gradient
- Deterministic:普通的PG方法输出的是动作的概率,而且筛选的时候是根据动作分布进行随机筛选。Deterministic直接输出特定动作
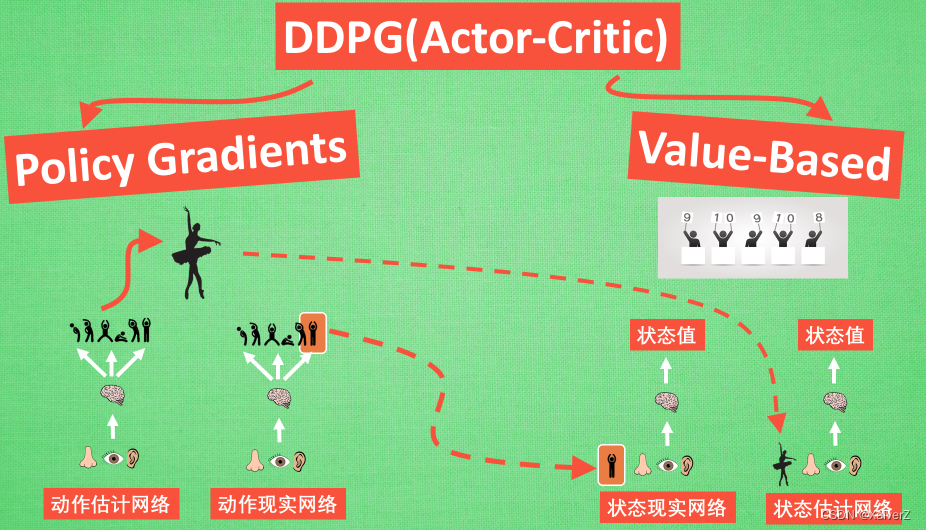
DDPG
Paper : Continuous control with deep reinforcement learning
Deep Deterministic Policy Gradient
Actor-Critic + DQN
Off-Policy
适用于动作连续的环境

-
Actor
-
Actor采用Target和Evaluation两个网络
-
Forward & Loss
- 将State输入Actor Evaluation,输出行为Action;将State和输出的Action输入Critic Evaluation得到对当前State-Action的评价值Q,为了使Q最大化,将-Q作为Loss进行反向传播
∇ θ μ J ≈ 1 N ∑ i ∇ a Q ( s , a ∣ θ Q ) ∣ s = s i , a = μ ( s i ) ∇ θ μ μ ( s ∣ θ μ ) ∣ s i \left.\left.\nabla_{\theta^{\mu}} J \approx \frac{1}{N} \sum_{i} \nabla_{a} Q\left(s, a \mid \theta^{Q}\right)\right|_{s=s_{i}, a=\mu\left(s_{i}\right)} \nabla_{\theta^{\mu}} \mu\left(s \mid \theta^{\mu}\right)\right|_{s_{i}} ∇θμJ≈N1i∑∇aQ(s,a∣θQ) s=si,a=μ(si)∇θμμ(s∣θμ) si
-
-
Critic
-
Critic采用Target和Evaluation两个网络
-
Forward & Loss
- Critic Loss采用 T D − E r r o r = Q T a r g e t − Q E v a l u a t i o n TD-Error = Q_{Target} - Q_{Evaluation} TD−Error=QTarget−QEvaluation。 Q T a r g e t = R w a r d + γ ∗ Q N e x t Q_{Target} = Rward + γ * Q_{Next} QTarget=Rward+γ∗QNext, Q N e x t Q_{Next} QNext通过对Critic Target输入下一State以及下一State对应的Action(这部分Action由Actor Target输入下一State生成)得到。 Q E v a l u a t i o n Q_{Evaluation} QEvaluation通过对Critic Evaluation输入当前State以及经验池样本中的Action得到。
y i = r i + γ Q ′ ( s i + 1 , μ ′ ( s i + 1 ∣ θ μ ′ ) ∣ θ Q ′ ) y_{i}=r_{i}+\gamma Q^{\prime}\left(s_{i+1}, \mu^{\prime}\left(s_{i+1} \mid \theta^{\mu^{\prime}}\right) \mid \theta^{Q^{\prime}}\right) yi=ri+γQ′(si+1,μ′(si+1∣θμ′)∣θQ′)
L = 1 N ∑ i ( y i − Q ( s i , a i ∣ θ Q ) ) 2 L=\frac{1}{N} \sum_{i}\left(y_{i}-Q\left(s_{i}, a_{i} \mid \theta^{Q}\right)\right)^{2} L=N1i∑(yi−Q(si,ai∣θQ))2
-
-
Experience Replay Memory
-
普通的Actor-Critic实时与环境交互并根据实时的样本进行训练,导致样本之间具有较强的时间相关性
-
DDPG模仿DQN中的经验池,在经验池装满样本之后随机采样mini-batch进行训练,切断样本时间相关行,提升训练效果
-
-
Soft Update
-
在DQN中,Target Network和Evaluation Network之间参数的复制使用的是“Hard Update”,即每隔一段时间将Evaluation Network的参数完全复制给Target Network
-
在DDPG中,使用的是“Soft Update”,即每次Evaluation Network参数更新时,都会同时按如下方式更新Target Network
θ Q ′ ← τ θ Q + ( 1 − τ ) θ Q ′ θ μ ′ ← τ θ μ + ( 1 − τ ) θ μ ′ \begin{aligned} \theta^{Q^{\prime}} & \leftarrow \tau \theta^{Q}+(1-\tau) \theta^{Q^{\prime}} \\ \theta^{\mu^{\prime}} & \leftarrow \tau \theta^{\mu}+(1-\tau) \theta^{\mu^{\prime}} \end{aligned} θQ′θμ′←τθQ+(1−τ)θQ′←τθμ+(1−τ)θμ′
-
-
Explore Effectively
-
Off-Policy
- Behaviour Policy和Evaluation不同可增加探索性
-
Exploration Noise
- DDPG在输出的Action上增加一定的噪声,增强探索性
-
A2C
Advantage Actor-Critic
ACER
Paper : Sample Efficient Actor-Critic with Experience Replay
Actor-Critic with Experience Replay
ACKTR
Actor Critic using Kronecker-Factored Trust Region
A3C
Paper : Asynchronous Methods for Deep Reinforcement Learning
Asynchronous Advantage Actor-Critic
-
异步训练
-
设置一个Global Net作为主模型,另设n个结构相同的Local Net作为多线程模型
-
各个Local Net分别跑在不同的线程上,每隔一段时间(比如5个step)将Local Net的的梯度传给Global Net,由Global Net进行参数更新后再将参数复制给Local Net
-
Local Net进行与环境交互、计算损失等,Global Net本身不与环境直接交互,而是接收Local Net传来的梯度并进行更新。Local Net不根据计算出的梯度进行参数更新,而是将梯度给Global Net,由Global Net更新参数以后,将Global Net的参数复制给Local Net
-
异步训练使得不同线程同时运行着多个网络,且线程之间是异步进行,因此可认为各线程之间时间相关性较弱,因此无需经验池。
-
-
网络结构
-
A3C将Actor和Critic合并成在一个网络里,但实际上在网络内部Actor和Critic是分开计算的
-
输入State,返回Action和Value
-
-
损失函数
-
Actor
- log π ( s , a ) ∗ A ( s , t ) \log{\pi{(s, a)}}*A(s, t) logπ(s,a)∗A(s,t)
-
Critic
- TD-Error
-
Entropy
- 为了增强探索性,A3C在损失函数中加入了“熵”的概念,旨在增加“混乱度”,增强探索性。
− 1 2 ( log ( 2 π σ 2 ) + 1 ) -\frac{1}{2}\left(\log \left(2 \pi \sigma^{2}\right)+1\right) −21(log(2πσ2)+1)
-
PPO & PPO2
Paper : Proximal Policy Optimization Algorithms
Proximal Policy Optimization
On-Policy
DPPO
Distributed Proximal Policy Optimization
SAC
Soft Actor-Critic
TD3
Paper : Addressing Function Approximation Error in Actor-Critic Methods
Twin Delayed Deep Deterministic Policy Gradient Algorithm














 627
627











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









