









这篇将前面的内容写成.py文件,对各个机器学习算法的正确率进行评估,然后选择具有较高正确率的算法生成模型。
这篇只是作者对sklearn库学习过后的简单的应用,之后会更深入的去学习。
第一个代码主要是将数据进行整理,变成前文说的形式。
titanic1.py
import pandas as pd
import numpy as np
import re
def get_title(name):
title_search = re.search(' ([A-Za-z]+)\.', name)
if title_search:
return title_search.group(1)
return ""
def data_cleaning():
train = pd.read_csv('train.csv', header=0, dtype={'Age': np.float64})
test = pd.read_csv('test.csv', header=0, dtype={'Age': np.float64})
full_data = [train, test]
title_mapping = {"Mr": 3, "Miss": 2, "Mrs": 4, "Master": 1, "Rare": 5}
for dataset in full_data:
dataset['FamilySize'] = dataset['SibSp'] + dataset['Parch'] + 1
dataset['IsAlone'] = 0
dataset.loc[dataset['FamilySize'] == 1, 'IsAlone'] = 1
dataset['Embarked'] = dataset['Embarked'].fillna('S')
dataset['Title'] = dataset['Name'].apply(get_title)
dataset['Title'] = dataset['Title'].replace(['Lady', 'Countess', 'Capt', 'Col', \
'Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')
dataset['Title'] = dataset['Title'].replace('Mlle', 'Miss')
dataset['Title'] = dataset['Title'].replace('Ms', 'Miss')
dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs')
dataset['Title'] = dataset['Title'].map(title_mapping)
dataset['Title'] = dataset['Title'].fillna(0)
for dataset in full_data:
age_avg = dataset.groupby('Title').Age.mean()
age_std = dataset.groupby('Title').Age.std()
for i in range(1, 6):
dataset.loc[(dataset.Age.isnull()) & (dataset.Title == i), 'Age'] = np.random.randint(
age_avg[i] - age_std[i], age_avg[i] + age_std[i])
fare_avg = dataset.Fare.mean()
dataset.loc[(dataset.Fare.isnull()), 'Fare'] = fare_avg
dataset['Age'] = dataset['Age'].astype(int)
dataset['Fare'] = dataset['Fare'].astype(int)
for dataset in full_data:
dataset.loc[dataset['Age'] <= 16, 'Age'] = 0
dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 32), 'Age'] = 1
dataset.loc[(dataset['Age'] > 32) & (dataset['Age'] <= 48), 'Age'] = 2
dataset.loc[(dataset['Age'] > 48) & (dataset['Age'] <= 64), 'Age'] = 3
dataset.loc[dataset['Age'] > 64, 'Age'] = 4
dataset.loc[dataset['Fare'] <= 7.91, 'Fare'] = 0
dataset.loc[(dataset['Fare'] > 7.91) & (dataset['Fare'] <= 14.454), 'Fare'] = 1
dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] <= 31), 'Fare'] = 2
dataset.loc[dataset['Fare'] > 31, 'Fare'] = 3
train = train.drop(['Name', 'Ticket', 'Cabin', 'SibSp', 'FamilySize', 'Parch', 'PassengerId'], axis=1)
train = pd.get_dummies(train, columns=["Embarked", "Sex"])
test = test.drop(['Name', 'Ticket', 'Cabin', 'SibSp', 'FamilySize', 'Parch'], axis=1)
test = pd.get_dummies(test, columns=["Embarked", "Sex"])
return train, test
train, test = data_cleaning()
if __name__ == "__main__":
print(train.head())
print(test.head())
下面是对各个机器学习算法的效果的评估,代码来自Kaggle
titanic2.py
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.metrics import accuracy_score
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier, GradientBoostingClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis, QuadraticDiscriminantAnalysis
from sklearn.linear_model import LogisticRegression
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from titanic1 import train
import warnings
warnings.filterwarnings("ignore")
classifiers = [
KNeighborsClassifier(3),
SVC(probability=True),
DecisionTreeClassifier(),
RandomForestClassifier(),
AdaBoostClassifier(),
GradientBoostingClassifier(),
GaussianNB(),
LinearDiscriminantAnalysis(),
QuadraticDiscriminantAnalysis(),
LogisticRegression()]
log_cols = ["Classifier", "Accuracy"]
log = pd.DataFrame(columns=log_cols)
sss = StratifiedShuffleSplit(n_splits=10, test_size=0.1, random_state=0)
train = train.values
X = train[0::, 1::]
y = train[0::, 0]
acc_dict = {}
for train_index, test_index in sss.split(X, y):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
for clf in classifiers:
name = clf.__class__.__name__
clf.fit(X_train, y_train)
train_predictions = clf.predict(X_test)
acc = accuracy_score(y_test, train_predictions)
if name in acc_dict:
acc_dict[name] += acc
else:
acc_dict[name] = acc
for clf in acc_dict:
acc_dict[clf] = acc_dict[clf] / 10.0
log_entry = pd.DataFrame([[clf, acc_dict[clf]]], columns=log_cols)
log = log.append(log_entry)
if __name__ == "__main__":
plt.figure()
plt.xlabel('Accuracy')
plt.title('Classifier Accuracy')
sns.set_color_codes("muted")
sns.barplot(x='Accuracy', y='Classifier', data=log, color="b")
plt.show()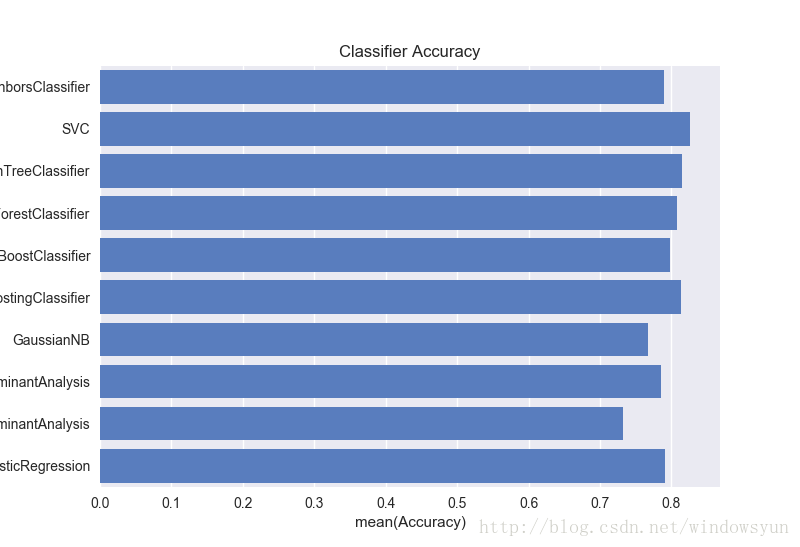
SVC的准确率较高,就它了。
titanic3.py
import numpy as np
import pandas as pd
from titanic1 import train, test
from sklearn.svm import SVC
train = train.values
X = train[0::, 1::]
y = train[0::, 0]
test = test.values
real_test = test[0::, 1::]
clf = SVC(probability=True)
clf.fit(X, y)
predictions = clf.predict(real_test)
result = pd.DataFrame({'PassengerId': test[0::, 0], 'Survived': predictions.astype(np.int32)})
result.to_csv("predictions.csv", index=False)
将生成的csv文件提交就可以看到成绩了。这里只用了sklearn的SVC,并没有做更进一步的优化,我第一次提交排在2000多名,所以,努力学习,再接再厉。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









