







github地址:https://github.com/ShichenLiu/CondenseNet
本文提出了学习组卷积(learned group convolution),大大减少了对冗余特征的利用。首先看提出的模块:
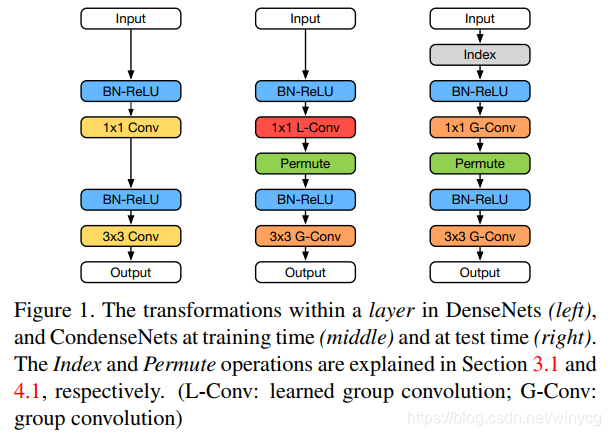
中间是训练阶段的condense块,右边是测试阶段的。训练阶段,作者对于输入到1x1学习组卷积的特征图进行学习稀疏连接。
filter分组
由于是1x1卷积,4D的张量变为
O
×
R
O\times R
O×R矩阵
F
F
F,分别代表输出channel和输入channel。将filter进行分组,每个组的数量相同。每个组
F
g
F^{g}
Fg的规模为
O
G
×
R
\frac{O}{G}\times R
GO×R.
group-lasso学习特征重要性
对于每个组,通过使用group-lasso来正则化来学习特征图通道重要性。
∑
g
=
1
G
∑
j
=
1
R
∑
i
=
1
O
/
G
(
F
i
,
j
g
)
2
\sum_{g=1}^{G}\sum_{j=1}^{R}\sqrt{\sum_{i=1}^{O/G}(F_{i,j}^{g})^{2}}
g=1∑Gj=1∑Ri=1∑O/G(Fi,jg)2
上述的正则化可以使得以组为单位进行正则,判断哪些通道对整组filter是重要的,从而该组filter只对重要的特征进行稀疏连接。通过group-lasso可以将
F
g
F^{g}
Fg中的列趋向于0.
condensation factor
C
C
C
可以通过设置C来调控每组处理的特征通道数量为
⌊
R
C
⌋
\left \lfloor \frac{R}{C} \right \rfloor
⌊CR⌋。
凝聚过程
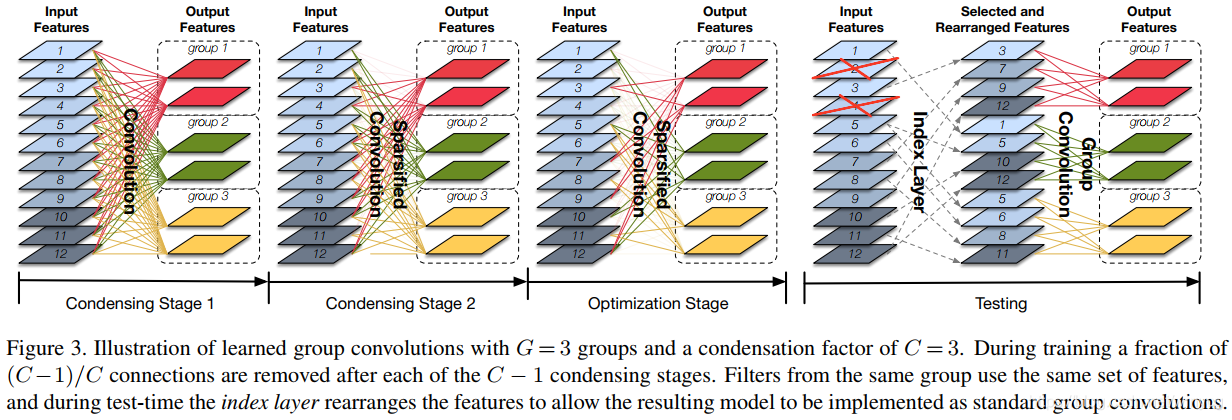
首先要经过
C
−
1
C-1
C−1个condensing stage,图中
C
=
3
C=3
C=3。每个阶段减去
1
C
\frac{1}{C}
C1的filter权重,即减少了
1
C
\frac{1}{C}
C1对特征的连接数量。因此,经过
C
−
1
C-1
C−1个condensing stage之后,
C
−
1
C
\frac{C-1}{C}
CC−1个连接被剪枝。
M
M
M表示总和训练epoch轮数,那么每个condensing stages训练的轮数为
M
2
(
C
−
1
)
\frac{M}{2(C-1)}
2(C−1)M。可以认为是前半部分的epoch数(
M
2
\frac{M}{2}
2M)用来训练condensing,后半部分的epoch数(
M
2
\frac{M}{2}
2M)用来训练稀疏网络,也称为优化阶段。
Note:在实现阶段,作者并没有真正去删除权重,而是采用mask掩码的01张量与filter的权重进行元素级的相乘。
学习率
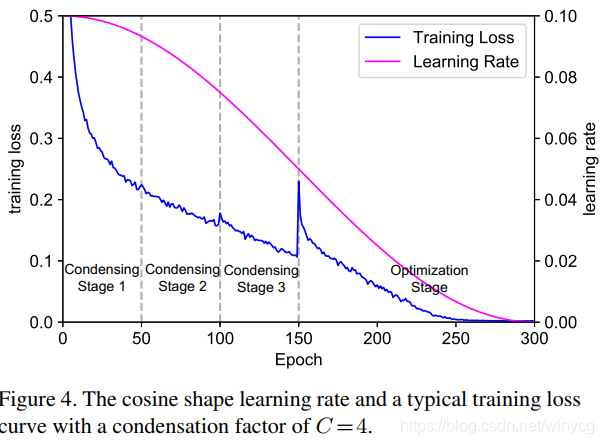
紫红色的为余弦学习率。150epoch之后loss突然地增加,因为删了剩余一般的权重。前面的condensing stage结束后,虽然loss也降了,但是随着往后,剪掉的权重越来越重要,所以loss提升也多。随着训练,精度会逐渐恢复。
index layer(索引层)
使用index layer对特征进行选择和重排。
结构设计
对DenseNet基础上进行如下的修改:
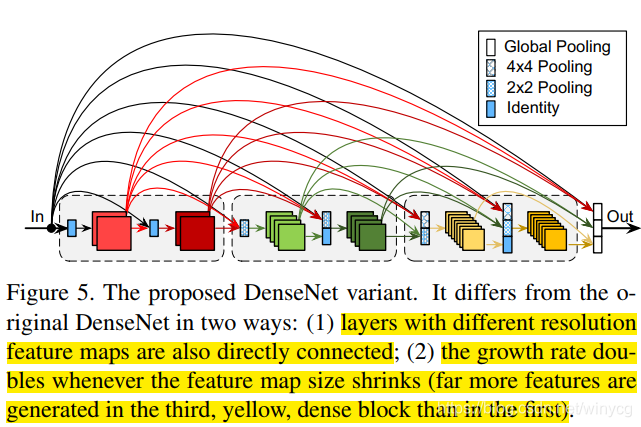
(1)指数级增加growth rate。 更深度的层在densenet中倾向于使用高水平的特征,这促使了进行强化更短的局部连接。可以通过后期特征所占比例逐渐增多的方式。For simplicity,设置growth rate
k
=
2
m
−
1
k
0
k=2^{m-1}k_{0}
k=2m−1k0,
m
m
m是dense块的下标。
(2)对不同分辨率(通过)的特征图也进行直接的连接。
Pytorch实现CondenseNet
参考链接:https://github.com/ShichenLiu/CondenseNet
实现condenseNet组件:–layers.py
导入:
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.nn.functional as F
学习组卷积(Learned group convolution)
class LearnedGroupConv(nn.Module):
# progress代表全局的epoch进度,=cur_epoch/num_epoch
global_progress = 0.0
def __init__(self, in_channels, out_channels,
kernel_size, stride=1,
padding=0, dilation=1, groups=1,
condense_factor=None, dropout_rate=0.):
super(LearnedGroupConv, self).__init__()
self.norm = nn.BatchNorm2d(in_channels)
self.relu = nn.ReLU(inplace=True)
self.dropout_rate = dropout_rate
if self.dropout_rate > 0:
self.drop = nn.Dropout(dropout_rate, inplace=False)
# 在这使用nn.Conv2d来定义一个卷积权重和超参数,
# 卷积权重可以进行梯度更新,但实质上并没有用到里面的卷积函数
self.conv = nn.Conv2d(in_channels, out_channels,
kernel_size, stride,
padding, dilation, groups=1, bias=False)
self.in_channels = in_channels
self.out_channels = out_channels
self.groups = groups
self.condense_factor = condense_factor
if self.condense_factor is None:
self.condense_factor = self.groups
### Parameters that should be carefully used
self.register_buffer('_count', torch.zeros(1))
self.register_buffer('_stage', torch.zeros(1))
self.register_buffer('_mask', torch.ones(self.conv.weight.size()))
### Check if arguments are valid
assert self.in_channels % self.groups == 0, \
"group number can not be divided by input channels"
assert self.in_channels % self.condense_factor == 0, \
"condensation factor can not be divided by input channels"
assert self.out_channels % self.groups == 0, \
"group number can not be divided by output channels"
def forward(self, x):
self._check_drop()
x = self.norm(x)
x = self.relu(x)
if self.dropout_rate > 0:
x = self.drop(x)
### Masked output
weight = self.conv.weight * self.mask
return F.conv2d(x, weight, None, self.conv.stride,
self.conv.padding, self.conv.dilation, 1)
# 检查是否要进行进行新一轮stage的剪枝
def _check_drop(self):
progress = LearnedGroupConv.global_progress
delta = 0
### Get current stage
# 前半部分总epoch数的1/2用来C-1个condensing stage
for i in range(self.condense_factor - 1):
if progress * 2 < (i + 1) / (self.condense_factor - 1):
stage = i
break
# stage的状态从0开始计数,所以condense_factor-1就是optim stage
else:
stage = self.condense_factor - 1
### Check for dropping
if not self._reach_stage(stage):
self.stage = stage # 复值给self.stage当前的stage,
delta = self.in_channels // self.condense_factor
# 之后,如果没有发生self.stage的变化,delta就是0,不会发生剪枝
if delta > 0:
self._dropping(delta)
return
# delta=R/C
# 生成mask向量
def _dropping(self, delta):
weight = self.conv.weight * self.mask
### Sum up all kernels
### Assume only apply to 1x1 conv to speed up
assert weight.size()[-1] == 1
# OxRx1x1→OxR
weight = weight.abs().squeeze()
assert weight.size()[0] == self.out_channels
assert weight.size()[1] == self.in_channels
d_out = self.out_channels // self.groups
### Shuffle weight
weight = weight.view(d_out, self.groups, self.in_channels)
# 交换0和1的维度,
weight = weight.transpose(0, 1).contiguous()
# 变为OxR
weight = weight.view(self.out_channels, self.in_channels)
### Sort and drop
for i in range(self.groups):
# 一组这一段的filter weights
wi = weight[i * d_out:(i + 1) * d_out, :]
### Take corresponding delta index
# 通过L1_norm来选择重要的特征
# self.count之前那是被mask掉的,所以最小的从self.count开始
# [1]是获取sort()函数返回的下标
di = wi.sum(0).sort()[1][self.count:self.count + delta]
for d in di.data:
# 以i为起点,self.groups为步长,mask掉shuffle之前的卷积weights
self._mask[i::self.groups, d, :, :].fill_(0)
self.count = self.count + delta
@property
def count(self):
return int(self._count[0])
@count.setter
def count(self, val):
self._count.fill_(val)
@property
def stage(self):
return int(self._stage[0])
@stage.setter
def stage(self, val):
self._stage.fill_(val)
@property
def mask(self):
return Variable(self._mask)
def _reach_stage(self, stage):
# 返回1或0,表示是否全部>=
return (self._stage >= stage).all()
@property
def lasso_loss(self):
if self._reach_stage(self.groups - 1):
return 0
weight = self.conv.weight * self.mask
### Assume only apply to 1x1 conv to speed up
assert weight.size()[-1] == 1
weight = weight.squeeze().pow(2)
d_out = self.out_channels // self.groups
### Shuffle weight
weight = weight.view(d_out, self.groups, self.in_channels)
# 对应论文里的每组内,每列的和组成的新的weight
weight = weight.sum(0).clamp(min=1e-6).sqrt()
return weight.sum()
对feature-map进行打乱函数
def ShuffleLayer(x, groups):
batchsize, num_channels, height, width = x.data.size()
channels_per_group = num_channels // groups
### reshape
x = x.view(batchsize, groups,
channels_per_group, height, width)
### transpose
x = torch.transpose(x, 1, 2).contiguous()
### flatten
x = x.view(batchsize, -1, height, width)
return x
全连接层的index layer
# 选取重要性较大的列向量,即减掉drop_rate部分的特征
# 将重要性大的特征下标保存在self.index中
# Note:pytorch中的FC层的权重维度为[out_f,in_f]
class CondensingLinear(nn.Module):
# 传入nn.Linear
def __init__(self, model, drop_rate=0.5):
super(CondensingLinear, self).__init__()
self.in_features = int(model.in_features * drop_rate)
self.out_features = model.out_features
self.linear = nn.Linear(self.in_features,
self.out_features)
self.register_buffer('index',
torch.LongTensor(self.in_features))
_, index = model.weight.abs().sum(0).sort()
index = index[model.in_features - self.in_features:]
self.linear.bias.data = model.bias.data.clone()
for i in range(self.in_features):
self.index[i] = index[i]
self.linear.weight.data[:, i] = \
model.weight.data[:, index[i]]
def forward(self, x):
x = torch.index_select(x, 1, self.index)
x = self.linear(x)
return x
组卷积层的index layer
class CondensingConv(nn.Module):
# 传入Learned Group Conv module,用于获取稀疏连接的卷积并构造标准卷积
def __init__(self, model):
super(CondensingConv, self).__init__()
self.in_channels = model.conv.in_channels \
* model.groups // model.condense_factor
self.out_channels = model.conv.out_channels
self.groups = model.groups
self.condense_factor = model.condense_factor
self.norm = nn.BatchNorm2d(self.in_channels)
self.relu = nn.ReLU(inplace=True)
self.conv = nn.Conv2d(self.in_channels, self.out_channels,
kernel_size=model.conv.kernel_size,
padding=model.conv.padding,
groups=self.groups,
bias=False,
stride=model.conv.stride)
# self.index就是论文中的index layer层,存储着原特征的序号
self.register_buffer('index', torch.LongTensor(self.in_channels))
# 表示确定相连的特征图数量,也表示索引特征图的下标0,1,2...
# 每组卷积相连的特征图数量为in_channels/groups
index = 0
mask = model._mask.mean(-1).mean(-1)
for i in range(self.groups):
for j in range(model.conv.in_channels):
if index < (self.in_channels // self.groups) * (i + 1) \
and mask[i, j] == 1:
# 此时表明第j个特征被第i个group相连,遍历每一个filter
for k in range(self.out_channels // self.groups):
# id_x是新权重维度中的filter序号,id_j是顺着的:0,1,...
idx_i = int(k + i * (self.out_channels // self.groups))
idx_j = index % (self.in_channels // self.groups)
# 完整的卷积处理既包括卷积层weight,也包括norm层参数
self.conv.weight[idx_i, idx_j, :, :] = \
model.conv.weight[int(i + k * self.groups), j, :, :]
self.norm.weight[index] = model.norm.weight[j]
self.norm.bias[index] = model.norm.bias[j]
self.norm.running_mean[index] = \
model.norm.running_mean[j]
self.norm.running_var[index] = \
model.norm.running_var[j]
self.index[index] = j
index += 1
def forward(self, x):
x = torch.index_select(x, 1, self.index)
x = self.norm(x)
x = self.relu(x)
x = self.conv(x)
x = ShuffleLayer(x, self.groups)
return x
converted后的全连接层
会发现和上面的FC index layer代码一样,除了计算index的部分。这部分就是转换后的模型,只需要传入self.index,用于构成inference部分。
class CondenseLinear(nn.Module):
def __init__(self, in_features, out_features, drop_rate=0.5):
super(CondenseLinear, self).__init__()
self.in_features = int(in_features * drop_rate)
self.out_features = out_features
self.linear = nn.Linear(self.in_features, self.out_features)
self.register_buffer('index', torch.LongTensor(self.in_features))
def forward(self, x):
x = torch.index_select(x, 1, Variable(self.index))
x = self.linear(x)
return x
converted后的组卷积层
同理,这是由学习组卷积转换后的组卷积。
class CondenseConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size,
stride=1, padding=0, groups=1):
super(CondenseConv, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.groups = groups
self.norm = nn.BatchNorm2d(self.in_channels)
self.relu = nn.ReLU(inplace=True)
self.conv = nn.Conv2d(self.in_channels, self.out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=self.groups,
bias=False)
self.register_buffer('index', torch.LongTensor(self.in_channels))
self.index.fill_(0)
构造普通的卷积块
class Conv(nn.Sequential):
def __init__(self, in_channels, out_channels, kernel_size,
stride=1, padding=0, groups=1):
super(Conv, self).__init__()
self.add_module('norm', nn.BatchNorm2d(in_channels))
self.add_module('relu', nn.ReLU(inplace=True))
self.add_module('conv', nn.Conv2d(in_channels, out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding, bias=False,
groups=groups))
网络结构
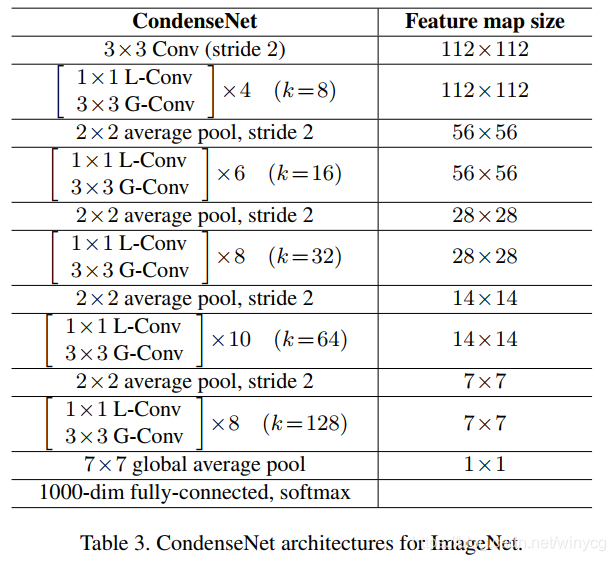
虽然这是ImageNet的结构,CIFAR里的结构是一样的,只是层数少。
CondenseNet总结构设计,
from __future__ import absolute_import
from __future__ import unicode_literals
from __future__ import print_function
from __future__ import division
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
from layers import Conv, LearnedGroupConv
__all__ = ['_DenseLayer']
class _DenseLayer(nn.Module):
def __init__(self, in_channels, growth_rate, args):
super(_DenseLayer, self).__init__()
self.group_1x1 = args.group_1x1
self.group_3x3 = args.group_3x3
### 1x1 conv i --> b*k
self.conv_1 = LearnedGroupConv(in_channels,
args.bottleneck * growth_rate,
kernel_size=1,
groups=self.group_1x1,
condense_factor=args.condense_factor,
dropout_rate=args.dropout_rate)
### 3x3 conv b*k --> k
self.conv_2 = Conv(args.bottleneck * growth_rate, growth_rate,
kernel_size=3, padding=1, groups=self.group_3x3)
def forward(self, x):
x_ = x
x = self.conv_1(x)
x = self.conv_2(x)
return torch.cat([x_, x], 1)
class _DenseBlock(nn.Sequential):
def __init__(self, num_layers, in_channels, growth_rate, args):
super(_DenseBlock, self).__init__()
for i in range(num_layers):
layer = _DenseLayer\
(in_channels + i * growth_rate, growth_rate, args)
self.add_module('denselayer_%d' % (i + 1), layer)
class _Transition(nn.Module):
def __init__(self, in_channels, args):
super(_Transition, self).__init__()
self.pool = nn.AvgPool2d(kernel_size=2, stride=2)
def forward(self, x):
x = self.pool(x)
return x
class CondenseNet(nn.Module):
def __init__(self, args):
super(CondenseNet, self).__init__()
# 列表,表示每个stage有多少个dense块
self.stages = args.stages
self.growth = args.growth
assert len(self.stages) == len(self.growth)
self.args = args
self.progress = 0.0
if args.data in ['cifar10', 'cifar100']:
self.init_stride = 1
self.pool_size = 8
else:
self.init_stride = 2
self.pool_size = 7
self.features = nn.Sequential()
### Initial nChannels should be 3
self.num_features = 2 * self.growth[0]
### Dense-block 1 (224x224)
self.features.add_module('init_conv',
nn.Conv2d(3, self.num_features,
kernel_size=3,
stride=self.init_stride,
padding=1,
bias=False))
for i in range(len(self.stages)):
### Dense-block i
self.add_block(i)
### Linear layer
self.classifier = nn.Linear(self.num_features,
args.num_classes)
### initialize
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * \
m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.bias.data.zero_()
return
def add_block(self, i):
### Check if ith is the last one
last = (i == len(self.stages) - 1)
block = _DenseBlock(
num_layers=self.stages[i],
in_channels=self.num_features,
growth_rate=self.growth[i],
args=self.args,
)
self.features.add_module('denseblock_%d' % (i + 1), block)
self.num_features += self.stages[i] * self.growth[i]
if not last:
trans = _Transition(in_channels=self.num_features,
args=self.args)
self.features.add_module('transition_%d' % (i + 1), trans)
else:
self.features.add_module('norm_last',
nn.BatchNorm2d(self.num_features))
self.features.add_module('relu_last',
nn.ReLU(inplace=True))
self.features.add_module('pool_last',
nn.AvgPool2d(self.pool_size))
def forward(self, x, progress=None):
# 更新LearnedGroupConv类的进度
if progress:
LearnedGroupConv.global_progress = progress
features = self.features(x)
out = features.view(features.size(0), -1)
out = self.classifier(out)
return out
util.py
里面实现了一些功能函数,计算flops,参数量,以及convert 学习组卷积变为普通组卷积。
import torch
import torch.nn as nn
from torch.autograd import Variable
from functools import reduce
import operator
from layers import LearnedGroupConv, CondensingLinear, CondensingConv, Conv
count_ops = 0
count_params = 0
'''
def is_pruned(layer):
try:
layer.mask
return True
except AttributeError:
return False
'''
def is_pruned(layer):
if hasattr(layer, 'mask'):
return True
return False
# 是否为叶子节点
def is_leaf(model):
return sum(1 for x in model.children()) == 0
# 递归替换FC和LGC层
def convert_model(model, args):
# 返回一个OrderedDict,和model.children()内容相同,形式不同
for m in model._modules:
child = model._modules[m]
if is_leaf(child):
if isinstance(child, nn.Linear):
model._modules[m] = CondensingLinear(child, 0.5)
del(child)
elif is_pruned(child):
model._modules[m] = CondensingConv(child)
del(child)
else:
convert_model(child, args)
def get_layer_info(layer):
layer_str = str(layer)
type_name = layer_str[:layer_str.find('(')].strip()
return type_name
# 计算参数量
def get_layer_param(model):
return sum([reduce(operator.mul, i.size(), 1) for i in model.parameters()])
# 计算每层的时间复杂度和参数量
### The input batch size should be 1 to call this function
def measure_layer(layer, x):
global count_ops, count_params
delta_ops = 0
delta_params = 0
multi_add = 1
type_name = get_layer_info(layer)
### ops_conv
if type_name in ['Conv2d']:
out_h = int((x.size()[2] + 2 * layer.padding[0] - layer.kernel_size[0]) /
layer.stride[0] + 1)
out_w = int((x.size()[3] + 2 * layer.padding[1] - layer.kernel_size[1]) /
layer.stride[1] + 1)
delta_ops = layer.in_channels * layer.out_channels * layer.kernel_size[0] * \
layer.kernel_size[1] * out_h * out_w / layer.groups * multi_add
delta_params = get_layer_param(layer)
### ops_learned_conv
elif type_name in ['LearnedGroupConv']:
measure_layer(layer.relu, x)
measure_layer(layer.norm, x)
conv = layer.conv
out_h = int((x.size()[2] + 2 * conv.padding[0] - conv.kernel_size[0]) /
conv.stride[0] + 1)
out_w = int((x.size()[3] + 2 * conv.padding[1] - conv.kernel_size[1]) /
conv.stride[1] + 1)
delta_ops = conv.in_channels * conv.out_channels * \
conv.kernel_size[0] * conv.kernel_size[1] \
* out_h * out_w / layer.condense_factor * multi_add
delta_params = get_layer_param(conv) / layer.condense_factor
### ops_nonlinearity
elif type_name in ['ReLU']:
delta_ops = x.numel()
delta_params = get_layer_param(layer)
### ops_pooling
elif type_name in ['AvgPool2d']:
in_w = x.size()[2]
kernel_ops = layer.kernel_size * layer.kernel_size
out_w = int((in_w + 2 * layer.padding - layer.kernel_size)
/ layer.stride + 1)
out_h = int((in_w + 2 * layer.padding - layer.kernel_size)
/ layer.stride + 1)
delta_ops = x.size()[0] * x.size()[1] \
* out_w * out_h * kernel_ops
delta_params = get_layer_param(layer)
elif type_name in ['AdaptiveAvgPool2d']:
delta_ops = x.size()[0] * x.size()[1] * x.size()[2] * x.size()[3]
delta_params = get_layer_param(layer)
### ops_linear
elif type_name in ['Linear']:
weight_ops = layer.weight.numel() * multi_add
bias_ops = layer.bias.numel()
delta_ops = x.size()[0] * (weight_ops + bias_ops)
delta_params = get_layer_param(layer)
### ops_nothing
elif type_name in ['BatchNorm2d', 'Dropout2d', 'DropChannel', 'Dropout']:
delta_params = get_layer_param(layer)
### unknown layer type
else:
raise TypeError('unknown layer type: %s' % type_name)
count_ops += delta_ops
count_params += delta_params
return
# 计算模型的FLOPS和参数量
def measure_model(model, H, W):
global count_ops, count_params
count_ops = 0
count_params = 0
data = Variable(torch.zeros(1, 3, H, W))
def should_measure(x):
return is_leaf(x) or is_pruned(x)
def modify_forward(model):
for child in model.children():
if should_measure(child):
def new_forward(m):
def lambda_forward(x):
measure_layer(m, x)
# ???还是返回old_forward
return m.old_forward(x)
return lambda_forward
# 新增函数属性.old_forward存储原始的forward
child.old_forward = child.forward
child.forward = new_forward(child)
else:
modify_forward(child)
def restore_forward(model):
for child in model.children():
# leaf node
if is_leaf(child) and hasattr(child, 'old_forward'):
child.forward = child.old_forward
child.old_forward = None
else:
restore_forward(child)
modify_forward(model)
model.forward(data)
restore_forward(model)
return count_ops, count_params

















 276
276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









