







原文:
zh.annas-archive.org/md5/ea99677736c22d68b5818a18b5a9213a译者:飞龙
第十一章:生成深度学习
这一章涵盖了
-
生成深度学习是什么,它的应用以及它与我们迄今看到的深度学习任务有何不同
-
如何使用 RNN 生成文本
-
什么是潜在空间以及它如何成为生成新图像的基础,通过变分自编码器示例
-
生成对抗网络的基础知识
深度神经网络展示了生成看起来或听起来真实的图像、声音和文本的一些令人印象深刻的任务。如今,深度神经网络能够创建高度真实的人脸图像,([1])合成自然音质的语音,([2])以及组织连贯有力的文本,([3])这仅仅是一些成就的名单。这种*生成*模型在许多方面都很有用,包括辅助艺术创作,有条件地修改现有内容,以及增强现有数据集以支持其他深度学习任务。([4])
¹
Tero Karras, Samuli Laine 和 Timo Aila, “一种基于风格的生成对抗网络,” 提交日期:2018 年 12 月 12 日,
arxiv.org/abs/1812.04948. 在thispersondoesnotexist.com/查看演示。²
Aäron van den Oord 和 Sander Dieleman, “WaveNet: 一种用于原始音频的生成模型,” 博客, 2016 年 9 月 8 日,
mng.bz/MOrn.³
“更好的语言模型及其影响”,OpenAI, 2019,
openai.com/blog/better-language-models/.⁴
Antreas Antoniou, Amos Storkey 和 Harrison Edwards, “数据增强生成对抗网络,” 提交日期:2017 年 11 月 12 日,
arxiv.org/abs/1711.04340.
除了在潜在顾客的自拍照上化妆等实际应用外,生成模型还值得从理论上研究。生成模型和判别模型是机器学习中两种根本不同类型的模型。到目前为止,我们在本书中研究的所有模型都是判别模型。这些模型旨在将输入映射到离散或连续的值,而不关心生成输入的过程。回想一下,我们构建的网络针对钓鱼网站、鸢尾花、MNIST 数字和音频声音的分类器,以及对房价进行回归的模型。相比之下,生成模型旨在数学地模拟不同类别示例生成的过程。但是一旦生成模型学习到这种生成性知识,它也可以执行判别性任务。因此,与判别模型相比,可以说生成模型“更好地理解”数据。
本节介绍了文本和图像的深度生成模型的基础知识。在本章结束时,您应该熟悉基于 RNN 的语言模型、面向图像的自编码器和生成对抗网络的思想。您还应该熟悉这些模型在 TensorFlow.js 中的实现方式,并能够将这些模型应用到您自己的数据集上。
10.1. 使用 LSTM 生成文本
让我们从文本生成开始。为此,我们将使用我们在前一章中介绍的 RNN。虽然您将在这里看到的技术生成文本,但它并不局限于这个特定的输出领域。该技术可以适应生成其他类型的序列,比如音乐——只要能够以合适的方式表示音符,并找到一个足够的训练数据集。[5]类似的思想可以应用于生成素描中的笔画,以便生成漂亮的素描[6],甚至是看起来逼真的汉字[7]。
⁵
例如,请参阅 Google 的 Magenta 项目中的 Performance-RNN:
magenta.tensorflow.org/performance-rnn。⁶
例如,请参阅 David Ha 和 Douglas Eck 的 Sketch-RNN:
mng.bz/omyv。⁷
David Ha,“Recurrent Net Dreams Up Fake Chinese Characters in Vector Format with TensorFlow”,博客,2015 年 12 月 28 日,
mng.bz/nvX4。
10.1.1. 下一个字符预测器:生成文本的简单方法
首先,让我们定义文本生成任务。假设我们有一个相当大的文本数据语料库(至少几兆字节)作为训练输入,比如莎士比亚的全部作品(一个非常长的字符串)。我们想要训练一个模型,尽可能地生成看起来像训练数据的新文本。这里的关键词当然是“看起来”。现在,让我们满足于不精确地定义“看起来”的含义。在展示方法和结果之后,这个意义将变得更加清晰。
让我们思考如何在深度学习范式中制定这个任务。在前一章节涉及的日期转换示例中,我们看到一个精确格式化的输出序列可以从一个随意格式化的输入序列中生成。那个文本到文本的转换任务有一个明确定义的答案:ISO-8601 格式中的正确日期字符串。然而,这里的文本生成任务似乎不适合这一要求。没有明确的输入序列,并且“正确”的输出并没有明确定义;我们只想生成一些“看起来真实的东西”。我们能做什么呢?
一个解决方案是构建一个模型,预测在一系列字符之后会出现什么字符。这被称为 下一个字符预测。例如,对于在莎士比亚数据集上训练良好的模型,当给定字符串“Love looks not with the eyes, b”作为输入时,应该以高概率预测字符“u”。然而,这只生成一个字符。我们如何使用模型生成一系列字符?为了做到这一点,我们简单地形成一个与之前相同长度的新输入序列,方法是将前一个输入向左移动一个字符,丢弃第一个字符,并将新生成的字符(“u”)粘贴到末尾。在这种情况下,我们的下一个字符预测器的新输入就是“ove looks not with the eyes, bu”。给定这个新的输入序列,模型应该以高概率预测字符“t”。这个过程,如图 10.1 所示,可以重复多次,直到生成所需长度的序列。当然,我们需要一个初始的文本片段作为起点。为此,我们可以从文本语料库中随机抽样。
图 10.1. 用基于 RNN 的下一个字符预测器生成文本序列的示意图,以初始输入文本片段作为种子。在每个步骤中,RNN 使用输入文本预测下一个字符。然后,将输入文本与预测的下一个字符连接起来,丢弃第一个字符。结果形成下一个步骤的输入。在每个步骤中,RNN 输出字符集中所有可能字符的概率分数。为了确定实际的下一个字符,进行随机抽样。

这种表述将序列生成任务转化为基于序列的分类问题。这个问题类似于我们在第九章中看到的 IMDb 情感分析问题,其中从固定长度的输入中预测二进制类别。文本生成模型基本上做了同样的事情,尽管它是一个多类别分类问题,涉及到 N 个可能的类别,其中 N 是字符集的大小——即文本数据集中所有唯一字符的数量。
这种下一个字符预测的表述在自然语言处理和计算机科学中有着悠久的历史。信息论先驱克劳德·香农进行了一项实验,在实验中,被要求的人类参与者在看到一小段英文文本后猜测下一个字母。[8] 通过这个实验,他能够估计出在给定上下文的情况下,典型英文文本中每个字母的平均不确定性。这种不确定性约为 1.3 位的熵,告诉我们每个英文字母所携带的平均信息量。
⁸
1951 年的原始论文可在
mng.bz/5AzB中获取。
当字母以完全随机的方式出现时,1.3 位的结果比如果 26 个字母完全随机出现所需的位数要少,该数值为 log2 = 4.7 位数。这符合我们的直觉,因为我们知道英语字母并不是随机出现的,而是具有某些模式。在更低的层次上,只有某些字母序列是有效的英语单词。在更高的层次上,只有某些单词的排序满足英语语法。在更高的层次上,只有某些语法上有效的句子实际上是有意义的。
如果你考虑一下,这正是我们的文本生成任务的基础所在:学习所有这些层面的模式。注意,我们的模型基本上是被训练来做 Shannon 实验中的那个志愿者所做的事情——也就是猜测下一个字符。现在,让我们来看一下示例代码以及它是如何工作的。请记住 Shannon 的 1.3 位结果,因为我们稍后会回到它。
10.1.2《LSTM-text-generation》示例
在 tfjs-examples 仓库中的 lstm-text-generation 示例中,我们训练了一个基于 LSTM 的下一个字符预测器,并利用它生成了新的文本。训练和生成都在 JavaScript 中使用 TensorFlow.js 完成。你可以在浏览器中或者使用 Node.js 运行示例。前者提供了更加图形化和交互式的界面,但后者具有更快的训练速度。
要在浏览器中查看此示例的运行情况,请使用以下命令:
git clone https://github.com/tensorflow/tfjs-examples.git
cd tfjs-examples/lstm-text-generation
yarn && yarn watch
在弹出的页面中,你可以选择并加载四个提供的文本数据集中的一个来训练模型。在下面的讨论中,我们将使用莎士比亚的数据集。一旦数据加载完成,你可以点击“创建模型”按钮为它创建一个模型。一个文本框允许你调整创建的 LSTM 将具有的单元数。它默认设置为 128。但你也可以尝试其他值,例如 64。如果你输入由逗号分隔的多个数字(例如 128,128),则创建的模型将包含多个叠放在一起的 LSTM 层。
若要使用 tfjs-node 或 tfjs-node-gpu 在后端执行训练,请使用 yarn train 命令而不是 yarn watch:
yarn train shakespeare \
--lstmLayerSize 128,128 \
--epochs 120 \
--savePath ./my-shakespeare-model
如果你已经正确地设置了 CUDA-enabled GPU,可以在命令中添加 --gpu 标志,让训练过程在 GPU 上运行,这将进一步加快训练速度。--lstmLayerSize 标志在浏览器版本的示例中起到了 LSTM-size 文本框的作用。前面的命令将创建并训练一个由两个 LSTM 层组成的模型,每个 LSTM 层都有 128 个单元,叠放在一起。
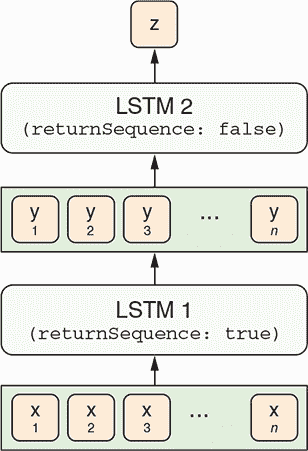
此处正在训练的模型具有堆叠 LSTM 架构。堆叠 LSTM 层是什么意思?在概念上类似于在 MLP 中堆叠多个密集层,这增加了 MLP 的容量。类似地,堆叠多个 LSTM 允许输入序列在被最终 LSTM 层转换为最终回归或分类输出之前经历多个 seq2seq 表示转换阶段。图 10.2 给出了这种架构的图解。一个重要的事情要注意的是,第一个 LSTM 的returnSequence属性被设置为true,因此生成包括输入序列的每个单个项目的输出序列。这使得可以将第一个 LSTM 的输出馈送到第二个 LSTM 中,因为 LSTM 层期望顺序输入而不是单个项目输入。
图 10.2. 在模型中如何堆叠多个 LSTM 层。在这种情况下,两个 LSTM 层被堆叠在一起。第一个 LSTM 的returnSequence属性被设置为true,因此输出一个项目序列。第一个 LSTM 的序列输出被传递给第二个 LSTM 作为其输入。第二个 LSTM 输出一个单独的项目而不是项目序列。单个项目可以是回归预测或 softmax 概率数组,它形成模型的最终输出。
清单 10.1 包含构建下一个字符预测模型的代码,其架构如图 10.2 所示(摘自 lstm-text-generation/model.js)。请注意,与图表不同,代码包括一个稠密层作为模型的最终输出。密集层具有 softmax 激活。回想一下,softmax 激活将输出归一化,使其值介于 0 和 1 之间,并总和为 1,就像概率分布一样。因此,最终的密集层输出表示唯一字符的预测概率。
createModel() 函数的 lstmLayerSize 参数控制 LSTM 层的数量和每个层的大小。第一个 LSTM 层的输入形状根据 sampleLen(模型一次接收多少个字符)和 charSetSize(文本数据中有多少个唯一字符)进行配置。对于基于浏览器的示例,sampleLen 是硬编码为 40 的;对于基于 Node.js 的训练脚本,可以通过 --sampleLen 标志进行调整。对于莎士比亚数据集,charSetSize 的值为 71。字符集包括大写和小写英文字母、标点符号、空格、换行符和几个其他特殊字符。给定这些参数,清单 10.1 中的函数创建的模型具有输入形状 [40, 71](忽略批处理维度)。该形状对应于 40 个 one-hot 编码字符。模型的输出形状是 [71](同样忽略批处理维度),这是下一个字符的 71 种可能选择的 softmax 概率值。
清单 10.1. 构建一个用于下一个字符预测的多层 LSTM 模型
export function createModel(sampleLen, ***1***
charSetSize, ***2***
lstmLayerSizes) { ***3***
if (!Array.isArray(lstmLayerSizes)) {
lstmLayerSizes = [lstmLayerSizes];
}
const model = tf.sequential();
for (let i = 0; i < lstmLayerSizes.length; ++i) {
const lstmLayerSize = lstmLayerSizes[i];
model.add(tf.layers.lstm({ ***4***
units: lstmLayerSize,
returnSequences: i < lstmLayerSizes.length - 1, ***5***
inputShape: i === 0 ?
[sampleLen, charSetSize] : undefined ***6***
}));
}
model.add(
tf.layers.dense({
units: charSetSize,
activation: 'softmax'
})); ***7***
return model;
}
-
1 模型输入序列的长度
-
2 所有可能的唯一字符的数量
-
3 模型的 LSTM 层的大小,可以是单个数字或数字数组
-
4 模型以一堆 LSTM 层开始。
-
5 设置
returnSequences为true以便可以堆叠多个 LSTM 层 -
6 第一个 LSTM 层是特殊的,因为它需要指定其输入形状。
-
7 模型以一个密集层结束,其上有一个 softmax 激活函数,适用于所有可能的字符,反映了下一个字符预测问题的分类特性。
为了准备模型进行训练,我们使用分类交叉熵损失对其进行编译,因为该模型本质上是一个 71 路分类器。对于优化器,我们使用 RMSProp,这是递归模型的常用选择:
const optimizer = tf.train.rmsprop(learningRate);
model.compile({optimizer: optimizer, loss: 'categoricalCrossentropy'});
输入模型训练的数据包括输入文本片段和每个片段后面的字符的对,所有这些都编码为 one-hot 向量(参见图 10.1)。在 lstm-text-generation/data.js 中定义的 TextData 类包含从训练文本语料库生成此类张量数据的逻辑。那里的代码有点乏味,但思想很简单:随机从我们的文本语料库中的非常长的字符串中抽取固定长度的片段,并将它们转换为 one-hot 张量表示。
如果您正在使用基于 Web 的演示,页面的“模型训练”部分允许您调整超参数,例如训练时期的数量、每个时期进入的示例数量、学习率等等。单击“训练模型”按钮启动模型训练过程。对于基于 Node.js 的训练,这些超参数可以通过命令行标志进行调整。有关详细信息,您可以通过输入 yarn train --help 命令获取帮助消息。
根据您指定的训练周期数和模型大小,训练时间可能会在几分钟到几个小时之间不等。基于 Node.js 的训练作业在每个训练周期结束后会自动打印模型生成的一些示例文本片段(见 表格 10.1)。随着训练的进行,您应该看到损失值从初始值约为 3.2 不断降低,并在 1.4–1.5 的范围内收敛。大约经过 120 个周期后,损失减小后,生成的文本质量应该会提高,以至于在训练结束时,文本应该看起来有些像莎士比亚的作品,而验证损失应该接近 1.5 左右——并不远离香农实验中的每字符信息不确定性 1.3 比特。但请注意,考虑到我们的训练范式和模型容量,生成的文本永远不会像实际的莎士比亚的写作。
表格 10.1. 基于 LSTM 的下一字符预测模型生成的文本样本。生成基于种子文本。初始种子文本:" “在每小时的关于你的特定繁荣的议会中,和 lo”。^([a]) 根据种子文本后续的实际文本(用于比较):“爱你不会比你的老父亲梅奈尼乌斯对你更差!…”。
^a
摘自 莎士比亚的《科里奥兰纳斯》,第 5 幕,第 2 场。请注意,示例中包括换行和单词中间的停顿(love)。
| 训练周期 | 验证损失 | T = 0 | T = 0.25 | T = 0.5 | T = 0.75 |
|---|---|---|---|---|---|
| 5 | 2.44 | "rle the the the the the the the the the the the the the the the the the the the the the the the the the the the the the " | “te ans and and and and and warl torle an at an yawl and tand and an an ind an an in thall ang ind an tord and and and wa” | “te toll nlatese ant ann, tomdenl, teurteeinlndting fall ald antetetell linde ing thathere taod winld mlinl theens tord y” | "p, af ane me pfleh; fove this? Iretltard efidestind ants anl het insethou loellr ard, |
| 25 | 1.96 | "ve tray the stanter an truent to the stanter to the stanter to the stanter to the stanter to the stanter to the stanter " | “ve to the enter an truint to the surt an truin to me truent me the will tray mane but a bean to the stanter an trust tra” | “ve of marter at it not me shank to an him truece preater the beaty atweath and that marient shall me the manst on hath s” | “rd; not an an beilloters An bentest the like have bencest on it love gray to dreath avalace the lien I am sach me, m” |
| 50 | 1.67 | “世界的世界的世界的世界的世界的世界的世界的世界的世界的世界的世界” | “他们是他们的英语是世界的世界的立场的证明了他们的弦应该世界我” | “他们的愤怒的苦恼的,因为你对于你的设备的现在的将会” | “是我的光,我将做 vall twell。斯伯” |
| 100 | 1.61 | “越多的人越多,越奇怪的是,越奇怪的是,越多的人越多” | “越多的人越多越多” | “越多的人越多。为了这样一个内容,” | “和他们的 consent,你将会变成三个。长的和一个心脏和不奇怪的。一位 G” |
| 120 | 1.49 | “打击的打击的打击的打击的打击的打击和打击的打击的打击” | “亲爱的打击我的排序的打击,打击打击,亲爱的打击和” | “为他的兄弟成为这样的嘲笑。一个模仿的” | “这是我的灵魂。Monty 诽谤他你的矫正。这是为了他的兄弟,这是愚蠢的” |
表格 10.1 展示了在四个不同 温度值 下采样的一些文本,这是一个控制生成文本随机性的参数。在生成文本的样本中,您可能已经注意到,较低的温度值与更多重复和机械化的文本相关联,而较高的值与不可预测的文本相关联。由 Node.js 的训练脚本演示的最高温度值默认为 0.75,有时会导致看起来像英语但实际上不是英语单词的字符序列(例如表格中的“stratter”和“poins”)。在接下来的部分中,我们将探讨温度是如何工作的,以及为什么它被称为温度。
10.1.3. 温度:生成文本中的可调随机性
列表 10.2 中的函数 sample() 负责根据模型在文本生成过程的每一步的输出概率来确定选择哪个字符。正如您所见,该算法有些复杂:它涉及到三个低级 TensorFlow.js 操作的调用:tf.div()、tf.log() 和 tf.multinomial()。为什么我们使用这种复杂的算法而不是简单地选择具有最高概率得分的选项,这将需要一个单独的 argMax() 调用呢?
如果我们这样做,文本生成过程的输出将是确定性的。也就是说,如果你多次运行它,它将给出完全相同的输出。到目前为止,我们所见到的深度神经网络都是确定性的,也就是说,给定一个输入张量,输出张量完全由网络的拓扑结构和其权重值决定。如果需要的话,你可以编写一个单元测试来断言其输出值(见第十二章讨论机器学习算法的测试)。对于我们的文本生成任务来说,这种确定性并不理想。毕竟,写作是一个创造性的过程。即使给出相同的种子文本,生成的文本也更有趣些带有一些随机性。这就是tf.multinomial()操作和温度参数有用的地方。tf.multinomial()是随机性的来源,而温度控制着随机性的程度。
列表 10.2。带有温度参数的随机抽样函数
export function sample(probs, temperature) {
return tf.tidy(() => {
const logPreds = tf.div(
tf.log(probs), ***1***
Math.max(temperature, 1e-6)); ***2***
const isNormalized = false;
return tf.multinomial(logPreds, 1, null, isNormalized).dataSync()[0]; ***3***
});
}
-
1 模型的密集层输出归一化的概率分数;我们使用 log()将它们转换为未归一化的 logits,然后再除以温度。
-
2 我们用一个小的正数来防止除以零的错误。除法的结果是调整了不确定性的 logits。
-
3
tf.multinomial()是一个随机抽样函数。它就像一个多面的骰子,每个面的概率不相等,由 logPreds——经过温度缩放的 logits 来确定。
在列表 10.2 的sample()函数中最重要的部分是以下行:
const logPreds = tf.div(tf.log(probs),
Math.max(temperature, 1e-6));
它获取了probs(模型的概率输出)并将它们转换为logPreds,概率的对数乘以一个因子。对数运算(tf.log())和缩放(tf.div())做了什么?我们将通过一个例子来解释。为了简单起见,假设只有三个选择(字符集中的三个字符)。假设我们的下一个字符预测器在给定某个输入序列时产生了以下三个概率分数:
[0.1, 0.7, 0.2]
让我们看看两个不同的温度值如何改变这些概率。首先,让我们看一个相对较低的温度:0.25。缩放后的 logits 是
log([0.1, 0.7, 0.2]) / 0.25 = [-9.2103, -1.4267, -6.4378]
要理解 logits 的含义,我们通过使用 softmax 方程将它们转换回实际的概率分数,这涉及将 logits 的指数和归一化:
exp([-9.2103, -1.4267, -6.4378]) / sum(exp([-9.2103, -1.4267, -6.4378]))
= [0.0004, 0.9930, 0.0066]
正如你所看到的,当温度为 0.25 时,我们的 logits 对应一个高度集中的概率分布,在这个分布中,第二个选择的概率远高于其他两个选择(见图 10.3 的第二面板)。
图 10.3. 不同温度(T)值缩放后的概率得分。较低的 T 值导致分布更集中(更少随机);较高的 T 值导致分布在类别之间更均等(更多随机)。T 值为 1 对应于原始概率(无变化)。请注意,无论 T 的值如何,三个选择的相对排名始终保持不变。

如果我们使用更高的温度,比如说 0.75,通过重复相同的计算,我们得到
log([0.1, 0.7, 0.2]) / 0.75 = [-3.0701, -0.4756, -2.1459]
exp([-3.0701, -0.4756, -2.1459]) / sum([-3.0701, -0.4756, -2.1459])
= [0.0591, 0.7919 0.1490]
与之前的情况相比,这是一个峰值较低的分布,当温度为 0.25 时(请参阅图 10.3 的第四面板)。但是与原始分布相比,它仍然更尖峭。你可能已经意识到,温度为 1 时,你将得到与原始概率完全相同的结果(图 10.3,第五面板)。大于 1 的温度值会导致选择之间的概率分布更“均等”(图 10.3,第六面板),而选择之间的排名始终保持不变。
这些转换后的概率(或者说它们的对数)然后被馈送到 tf.multinomial() 函数中,该函数的作用类似于一个多面骰子,其面的不等概率由输入参数控制。这给我们了下一个字符的最终选择。
所以,这就是温度参数如何控制生成文本的随机性。术语 temperature 源自热力学,我们知道,温度较高的系统内部混乱程度较高。这个类比在这里是合适的,因为当我们在代码中增加温度值时,生成的文本看起来更加混乱。温度值有一个“甜蜜的中间值”。在此之下,生成的文本看起来太重复和机械化;在此之上,文本看起来太不可预测和古怪。
这结束了我们对文本生成 LSTM 的介绍。请注意,这种方法非常通用,可以应用于许多其他序列,只需进行适当的修改即可。例如,如果在足够大的音乐分数数据集上进行训练,LSTM 可以通过逐步从之前的音符中预测下一个音符来作曲。^([9])
⁹
Allen Huang 和 Raymond Wu,“Deep Learning for Music”,2016 年 6 月 15 日提交,
arxiv.org/abs/1606.04930。
10.2. 变分自动编码器:找到图像的高效和结构化的向量表示
前面的部分为您介绍了如何使用深度学习来生成文本等连续数据。在本章的剩余部分,我们将讨论如何构建神经网络来生成图像。我们将研究两种类型的模型:变分自编码器(VAE)和生成对抗网络(GAN)。与 GAN 相比,VAE 的历史更悠久,结构更简单。因此,它为您进入基于深度学习的图像生成的快速领域提供了很好的入口。
10.2.1. 传统自编码器和 VAE: 基本概念
图 10.4 以示意方式显示了自编码器的整体架构。乍一看,自编码器是一个有趣的模型,因为它的输入和输出模型的图像大小是相同的。在最基本的层面上,自编码器的损失函数是输入和输出之间的均方误差(MSE)。这意味着,如果经过适当训练,自编码器将接受一个图像,并输出一个几乎相同的图像。这种模型到底有什么用呢?
图 10.4. 传统自编码器的架构
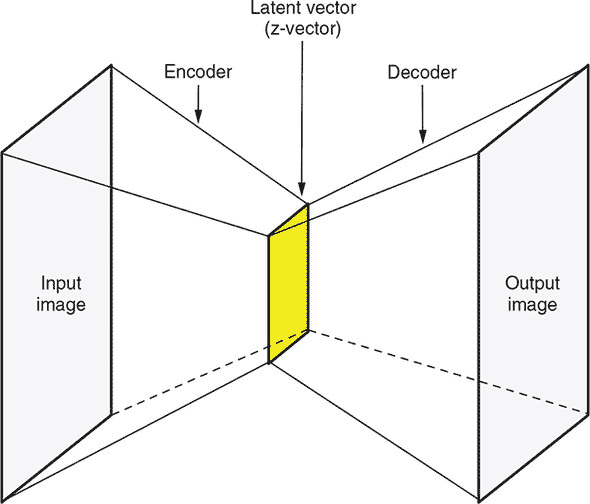
实际上,自编码器是一种重要的生成模型,而且绝不是无用的。对于前面的问题答案在于小时钟形状的架构(图 10.4)。自编码器的最细部分是一个与输入和输出图像相比具有更少元素的向量。因此,由自编码器执行的图像转换是非平凡的:它首先将输入图像转变为高压缩形式的表示,然后在不使用任何额外信息的情况下从该表示中重新构建图像。中间的有效表示称为潜在向量,或者z-向量。我们将这两个术语互换使用。这些向量所在的向量空间称为潜在空间,或者z-空间。将输入图像转换为潜在向量的自编码器部分称为编码器;将潜在向量转换回图像的后面部分称为解码器。
和图像本身相比,潜在向量可以小几百倍,我们很快会通过一个具体的例子进行展示。因此,经过训练的自编码器的编码器部分是一个非常高效的维度约简器。它对输入图像的总结非常简洁,但包含足够重要的信息,以使得解码器可以忠实地复制输入图像,而不需要使用额外的信息。解码器能够做到这一点,这也是非常了不起的。
我们还可以从信息理论的角度来看待自编码器。假设输入和输出图像各包含N比特的信息。从表面上看,N是每个像素的位深度乘以像素数量。相比之下,自编码器中间的潜在向量由于其小的大小(假设为m比特),只能保存极少量的信息。如果m小于N,那么从潜在向量重构出图像就在理论上不可能。然而,图像中的像素不是完全随机的(完全由随机像素组成的图像看起来像静态噪音)。相反,像素遵循某些模式,比如颜色连续性和所描绘的现实世界对象的特征。这导致N的值比基于像素数量和深度的表面计算要小得多。自编码器的任务是学习这种模式;这也是自编码器能够工作的原因。
在自编码器训练完成后,其解码器部分可以单独使用,给定任何潜在向量,它都可以生成符合训练图像的模式和风格的图像。这很好地符合了生成模型的描述。此外,潜在空间将有望包含一些良好的可解释结构。具体而言,潜在空间的每个维度可能与图像的某个有意义的方面相关联。例如,假设我们在人脸图像上训练了一个自编码器,也许潜在空间的某个维度将与微笑程度相关。当你固定潜在向量中所有其他维度的值,仅变化“微笑维度”的值时,解码器产生的图像将是同一张脸,但微笑程度不同(例如,参见图 10.5)。这将使得有趣的应用成为可能,例如在保持所有其他方面不变的情况下,改变输入人脸图像的微笑程度。可以通过以下步骤来完成此操作。首先,通过应用编码器获取输入的潜在向量。然后,仅修改向量的“微笑维度”即可;最后,通过解码器运行修改后的潜在向量。
图 10.5. “微笑维度”。自编码器所学习的潜在空间中期望的结构的示例。

不幸的是,图 10.4 中所示的 经典自编码器 并不能产生特别有用和良好结构的潜变量空间。它们在压缩方面也不太出色。因此,到 2013 年,它们在很大程度上已经不再流行了。VAE(Variational Autoencoder)则在 2013 年 12 月由 Diederik Kingma 和 Max Welling 几乎同时发现^([10]),而在 2014 年 1 月由 Danilo Rezende、Shakir Mohamed 和 Daan Wiestra 发现^([11]),通过一点统计魔法增加了自编码器的能力,强制模型学习连续且高度结构化的潜变量空间。VAE 已经证明是一种强大的生成式图像模型。
¹⁰
Diederik P. Kingma 和 Max Welling,“Auto-Encoding Variational Bayes”,2013 年 12 月 20 日提交,
arxiv.org/abs/1312.6114。¹¹
Danilo Jimenez Rezende,Shakir Mohamed 和 Daan Wierstra,“Stochastic Backpropagation and Approximate Inference in Deep Generative Models”,2014 年 1 月 16 日提交,
arxiv.org/abs/1401.4082。
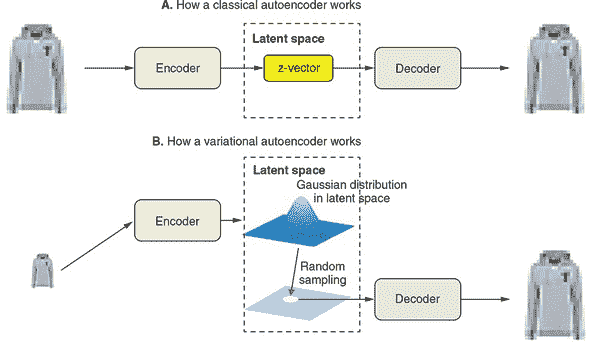
VAE 不是将输入图像压缩为潜变量空间中的固定向量,而是将图像转化为统计分布的参数——具体来说是高斯分布的参数。高斯分布有两个参数:均值和方差(或者等效地,标准差)。VAE 将每个输入图像映射到一个均值上。唯一的额外复杂性在于,如果潜变量空间超过 1D,则均值和方差可以是高于一维的,正如我们将在下面的例子中看到的那样。本质上,我们假设图像是通过随机过程生成的,并且在编码和解码过程中应该考虑到这个过程的随机性。然后,VAE 使用均值和方差参数从分布中随机采样一个向量,并使用该随机向量将其解码回原始输入的大小(参见图 10.6)。这种随机性是 VAE 改善鲁棒性、强迫潜变量空间在每个位置都编码有意义表示的关键方式之一:在解码器解码时,潜变量空间中采样的每个点应该是一个有效的图像输出。
图 10.6. 比较经典自编码器(面板 A)和 VAE(面板 B)的工作原理。经典自编码器将输入图像映射到一个固定的潜变量向量上,并使用该向量进行解码。相比之下,VAE 将输入图像映射到一个由均值和方差描述的分布上,从该分布中随机采样一个潜变量向量,并使用该随机向量生成解码后的图像。这个 T 恤图案是来自 Fashion-MNIST 数据集的一个例子。
接下来,我们将通过使用 Fashion-MNIST 数据集展示 VAE 的工作原理。正如其名称所示,Fashion-MNIST^([12]) 受到了 MNIST 手写数字数据集的启发,但包含了服装和时尚物品的图像。与 MNIST 图像一样,Fashion-MNIST 图像是 28 × 28 的灰度图像。有着确切的 10 个服装和时尚物品类别(如 T 恤、套头衫、鞋子和包袋;请参见 图 10.6 作为示例)。然而,与 MNIST 数据集相比,Fashion-MNIST 数据集对机器学习算法来说略微“更难”,当前最先进的测试集准确率约为 96.5%,远低于 MNIST 数据集的 99.75% 最先进准确率。^([13]) 我们将使用 TensorFlow.js 构建一个 VAE 并在 Fashion-MNIST 数据集上对其进行训练。然后,我们将使用 VAE 的解码器从 2D 潜在空间中对样本进行采样,并观察该空间内部的结构。
¹²
Han Xiao、Kashif Rasul 和 Roland Vollgraf,“Fashion-MNIST: 用于机器学习算法基准测试的新型图像数据集”,提交于 2017 年 8 月 25 日,
arxiv.org/abs/1708.07747。¹³
来源:“所有机器学习问题的最新技术结果”,GitHub,2019 年,
mng.bz/6w0o。
10.2.2. VAE 的详细示例:Fashion-MNIST 示例
要查看 fashion-mnist-vae 示例,请使用以下命令:
git clone https://github.com/tensorflow/tfjs-examples.git
cd tfjs-examples/fashion-mnist-vae
yarn
yarn download-data
这个例子由两部分组成:在 Node.js 中训练 VAE 和使用 VAE 解码器在浏览器中生成图像。要开始训练部分,请使用以下命令
yarn train
如果您正确设置了 CUDA 启用的 GPU,则可以使用 --gpu 标志来加速训练:
yarn train --gpu
训练在配备有 CUDA GPU 的合理更新的台式机上大约需要五分钟,没有 GPU 的情况下则需要不到一个小时。训练完成后,使用以下命令构建并启动浏览器前端:
yarn watch
前端将加载 VAE 的解码器,通过使用正则化的 2D 网格的潜在向量生成多个图像,并在页面上显示这些图像。这将让您欣赏到潜在空间的结构。
从技术角度来看,这就是 VAE 的工作原理:
-
编码器将输入样本转换为潜在空间中的两个参数:
zMean和zLogVar,分别是均值和方差的对数(对数方差)。这两个向量的长度与潜在空间的维度相同。例如,我们的潜在空间将是 2D,因此zMean和zLogVar将分别是长度为 2 的向量。为什么我们使用对数方差(zLogVar)而不是方差本身?因为方差必须是非负的,但没有简单的方法来强制该层输出的符号要求。相比之下,对数方差允许具有任何符号。通过使用对数,我们不必担心层输出的符号。对数方差可以通过简单的指数运算(tf.exp())操作轻松地转换为相应的方差。¹⁴
严格来说,长度为 N 的潜在向量的协方差矩阵是一个 N × N 矩阵。然而,
zLogVar是一个长度为 N 的向量,因为我们将协方差矩阵约束为对角线矩阵——即,潜在向量的两个不同元素之间没有相关性。 -
VAE 算法通过使用一个称为
epsilon的向量——与zMean和zLogVar的长度相同的随机向量——从潜在正态分布中随机抽样一个潜在向量。在简单的数学方程中,这一步骤在文献中被称为重参数化,看起来像是z = zMean + exp(zLogVar * 0.5) * epsilon乘以 0.5 将方差转换为标准差,这基于标准差是方差的平方根的事实。等效的 JavaScript 代码是
z = zMean.add(zLogVar.mul(0.5).exp().mul(epsilon));(见 listing 10.3。) 然后,
z将被馈送到 VAE 的解码器部分,以便生成输出图像。
在我们的 VAE 实现中,潜在向量抽样步骤是由一个名为 ZLayer 的自定义层执行的(见 listing 10.3)。我们在 第九章 中简要介绍了一个自定义 TensorFlow.js 层(我们在基于注意力的日期转换器中使用的 GetLastTimestepLayer 层)。我们 VAE 使用的自定义层略微复杂,值得解释一下。
ZLayer 类有两个关键方法:computeOutputShape() 和 call()。computeOutputShape() 被 TensorFlow.js 用来推断给定输入形状的 Layer 实例的输出形状。call() 方法包含了实际的数学计算。它包含了先前介绍的方程行。下面的代码摘自 fashion-mnist-vae/model.js。
listing 10.3 抽样潜在空间(z 空间)的代码示例
class ZLayer extends tf.layers.Layer {
constructor(config) {
super(config);
}
computeOutputShape(inputShape) {
tf.util.assert(inputShape.length === 2 && Array.isArray(inputShape[0]),
() => `Expected exactly 2 input shapes. ` +
`But got: ${inputShape}`); ***1***
return inputShape[0]; ***2***
}
call(inputs, kwargs) {
const [zMean, zLogVar] = inputs;
const batch = zMean.shape[0];
const dim = zMean.shape[1];
const mean = 0;
const std = 1.0;
const epsilon = tf.randomNormal( ***3***
[batch, dim], mean, std); ***3***
return zMean.add( ***4***
zLogVar.mul(0.5).exp().mul(epsilon)); ***4***
}
static get ClassName() { ***5***
return 'ZLayer';
}
}
tf.serialization.registerClass(ZLayer); ***6***
-
1 检查确保我们只有两个输入:zMean 和 zLogVar
-
2 输出(z)的形状将与 zMean 的形状相同。
-
3 从单位高斯分布中获取一个随机批次的 epsilon
-
4 这是 z 向量抽样发生的地方:zMean + standardDeviation * epsilon。
-
5 如果要对该层进行序列化,则设置静态的 className 属性。
-
6 注册类以支持反序列化
如清单 10.4 所示,ZLayer被实例化并被用作编码器的一部分。编码器被编写为一个功能型模型,而不是更简单的顺序模型,因为它具有非线性的内部结构,并且产生三个输出:zMean、zLogVar和z(参见图 10.7 中的示意图)。编码器输出z是因为它将被解码器使用,但为什么编码器包括zMean和zLogVar在输出中?这是因为它们将用于计算 VAE 的损失函数,很快你就会看到。
图 10.7。TensorFlow.js 实现 VAE 的示意图,包括编码器和解码器部分的内部细节以及支持 VAE 训练的自定义损失函数和优化器。
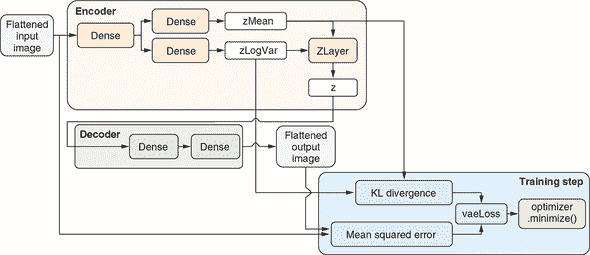
除了ZLayer,编码器还包括两个单隐藏层的 MLP。它们用于将扁平化的输入 Fashion-MNIST 图像转换为zMean和zLogVar向量,分别。这两个 MLP 共享相同的隐藏层,但使用单独的输出层。这种分支模型拓扑结构也是由于编码器是一个功能型模型。
清单 10.4。我们 VAE 的编码器部分(摘自 fashion-mnist-vae/model.js)
function encoder(opts) {
const {originalDim, intermediateDim, latentDim} = opts;
const inputs = tf.input({shape: [originalDim], name: 'encoder_input'});
const x = tf.layers.dense({units: intermediateDim, activation: 'relu'})
.apply(inputs); ***1***
const zMean = tf.layers.dense({units: latentDim, name: 'z_mean'}).apply(x);***2***
const zLogVar = tf.layers.dense({ ***2***
units: latentDim, ***2***
name: 'z_log_var' ***2***
}).apply(x); ***2*** ***3***
const z = ***3***
new ZLayer({name: 'z', outputShape: [latentDim]}).apply([zMean, ***3***
zLogVar]); ***3***
const enc = tf.model({
inputs: inputs,
outputs: [zMean, zLogVar, z],
name: 'encoder',
})
return enc;
}
-
1 编码器底部是一个简单的 MLP,有一个隐藏层。
-
2 与普通的 MLP 不同,我们在隐藏的密集层之后放置了两个层,分别用于预测 zMean 和 zLogVar。这也是我们使用功能型模型而不是更简单的顺序模型类型的原因。
-
3 实例化我们自定义的 ZLayer,并使用它来生成遵循由 zMean 和 zLogVar 指定的分布的随机样本
清单 10.5 中的代码构建了解码器。与编码器相比,解码器的拓扑结构更简单。它使用一个 MLP 将输入的 z 向量(即潜在向量)转换为与编码器输入相同形状的图像。请注意,我们的 VAE 处理图像的方式有些简单和不寻常,因为它将图像扁平化为 1D 向量,因此丢弃了空间信息。面向图像的 VAE 通常使用卷积和池化层,但由于我们图像的简单性(其尺寸较小且仅有一个颜色通道),扁平化方法足够简单地处理此示例的目的。
清单 10.5。我们 VAE 的解码器部分(摘自 fashion-mnist-vae/model.js)
function decoder(opts) {
const {originalDim, intermediateDim, latentDim} = opts;
const dec = tf.sequential({name: 'decoder'}); ***1***
dec.add(tf.layers.dense({
units: intermediateDim,
activation: 'relu',
inputShape: [latentDim]
}));
dec.add(tf.layers.dense({
units: originalDim,
activation: 'sigmoid' ***2***
}));
return dec;
}
-
1 解码器是一个简单的 MLP,将潜在(z)向量转换为(扁平化的)图像。
-
2 Sigmoid 激活是输出层的一个好选择,因为它确保输出图像的像素值被限制在 0 和 1 之间。
将编码器和解码器合并成一个名为 VAE 的单个tf.LayerModel对象时,列表 10.6 中的代码会提取编码器的第三个输出(z 向量)并将其通过解码器运行。然后,组合模型会将解码图像暴露为其输出,同时还有其他三个输出:zMean、zLogVar和 z 向量。这完成了 VAE 模型拓扑结构的定义。为了训练模型,我们需要两个东西:损失函数和优化器。以下列表中的代码摘自 fashion-mnist-vae/model.js。
将编码器和解码器放在一起组成 VAE 时,列表 10.6 中完成。
function vae(encoder, decoder) {
const inputs = encoder.inputs; ***1***
const encoderOutputs = encoder.apply(inputs);
const encoded = encoderOutputs[2]; ***2***
const decoderOutput = decoder.apply(encoded);
const v = tf.model({ ***3***
inputs: inputs,
outputs: [decoderOutput, ...encoderOutputs], ***4***
name: 'vae_mlp',
})
return v;
}
-
1 VAE 的输入与编码器的输入相同:原始输入图像。
-
2 在编码器的所有三个输出中,只有最后一个(z)进入解码器。
-
3 由于模型的非线性拓扑结构,我们使用功能模型 API。
-
4 VAE 模型对象的输出除了 zMean、zLogVar 和z之外还包括解码图像。
当我们访问第五章中的 simple-object-detection 模型时,我们描述了如何在 TensorFlow.js 中定义自定义损失函数的方式。在这里,需要自定义损失函数来训练 VAE。这是因为损失函数将是两个项的总和:一个量化输入和输出之间的差异,另一个量化潜在空间的统计属性。这让人想起了 simple-object-detection 模型的自定义损失函数,其中一个项用于对象分类,另一个项用于对象定位。
如您从列表 10.7 中的代码中所见(摘自 fashion-mnist-vae/model.js),定义输入输出差异项是直接的。我们简单地计算原始输入和解码器输出之间的均方误差(MSE)。然而,统计项,称为Kullbach-Liebler(KL)散度,数学上更加复杂。我们会免去详细的数学[¹⁵],但从直觉上讲,KL 散度项(代码中的 klLoss)鼓励不同输入图像的分布更均匀地分布在潜在空间的中心周围,这使得解码器更容易在图像之间进行插值。因此,klLoss项可以被视为 VAE 的主要输入输出差异项之上添加的正则化项。
¹⁵
Irhum Shafkat 的这篇博文包含了对 KL 散度背后数学的更深入讨论:
mng.bz/vlvr。
第 10.7 节列出了 VAE 的损失函数。
function vaeLoss(inputs, outputs) {
const originalDim = inputs.shape[1];
const decoderOutput = outputs[0];
const zMean = outputs[1];
const zLogVar = outputs[2];
const reconstructionLoss = ***1***
tf.losses.meanSquaredError(inputs, decoderOutput).mul(originalDim); ***1***
let klLoss = zLogVar.add(1).sub(zMean.square()).sub(zLogVar.exp());
klLoss = klLoss.sum(-1).mul(-0.5); ***2***
return reconstructionLoss.add(klLoss).mean(); ***3***
}
-
1 计算“重构损失”项。最小化此项的目标是使模型输出与输入数据匹配。
-
2 计算 zLogVar 和 zMean 之间的 KL 散度。最小化此项旨在使潜变量的分布更接近于潜在空间的中心处正态分布。
-
3 将图像重建损失和 KL-散度损失汇总到最终的 VAE 损失中
我们 VAE 训练的另一个缺失部分是优化器及其使用的训练步骤。优化器的类型是流行的 ADAM 优化器(tf.train .adam())。VAE 的训练步骤与本书中所有其他模型不同,因为它不使用模型对象的fit()或fitDataset()方法。相反,它调用优化器的minimize()方法(列表 10.8)。这是因为自定义损失函数的 KL-散度项使用模型的四个输出中的两个,但在 TensorFlow.js 中,只有在模型的每个输出都具有不依赖于任何其他输出的损失函数时,fit()和fitDataset()方法才能正常工作。
如列表 10.8 所示,minimize()函数以箭头函数作为唯一参数进行调用。这个箭头函数返回当前批次的扁平化图像的损失(代码中的reshaped),这个损失被函数闭包。minimize()计算损失相对于 VAE 的所有可训练权重的梯度(包括编码器和解码器),根据 ADAM 算法调整它们,然后根据调整后的梯度在权重的相反方向应用更新。这完成了一次训练步骤。这一步骤重复进行,遍历 Fashion-MNIST 数据集中的所有图像,并构成一个训练时期。yarn train 命令执行多个训练周期(默认:5 个周期),在此之后损失值收敛,并且 VAE 的解码器部分被保存到磁盘上。编码器部分不保存的原因是它不会在接下来的基于浏览器的演示步骤中使用。
列表 10.8. VAE 的训练循环(摘自 fashion-mnist-vae/train.js)
for (let i = 0; i < epochs; i++) {
console.log(`\nEpoch #${i} of ${epochs}\n`)
for (let j = 0; j < batches.length; j++) {
const currentBatchSize = batches[j].length
const batchedImages = batchImages(batches[j]); ***1***
const reshaped =
batchedImages.reshape([currentBatchSize, vaeOpts.originalDim]);
optimizer.minimize(() => { ***2***
const outputs = vaeModel.apply(reshaped);
const loss = vaeLoss(reshaped, outputs, vaeOpts);
process.stdout.write('.'); ***3***
if (j % 50 === 0) {
console.log('\nLoss:', loss.dataSync()[0]);
}
return loss;
});
tf.dispose([batchedImages, reshaped]);
}
console.log('');
await generate(decoderModel, vaeOpts.latentDim); ***4***
}
-
1 获取一批(扁平化的)Fashion-MNIST 图像
-
2 VAE 训练的单个步骤:使用 VAE 进行预测,并计算损失,以便 optimizer.minimize 可以调整模型的所有可训练权重
-
3 由于我们不使用默认的
fit()方法,因此不能使用内置的进度条,必须自己打印控制台上的状态更新。 -
4 在每个训练周期结束时,使用解码器生成一幅图像,并将其打印到控制台以进行预览
yarn watch 命令打开的网页将加载保存的解码器,并使用它生成类似于图 10.8 所示的图像网格。这些图像是从二维潜在空间中的正则网格的潜在向量获得的。每个潜在维度上的上限和下限可以在 UI 中进行调整。
图 10.8. 在训练后对 VAE 的潜在空间进行采样。该图显示了一个 20 × 20 的解码器输出网格。该网格对应于一个 20 × 20 的二维潜在向量的正则间隔网格,其中每个维度位于[-4, 4]的区间内。

图像网格显示了来自 Fashion-MNIST 数据集的完全连续的不同类型的服装,一种服装类型在潜在空间中沿着连续路径逐渐变形为另一种类型(例如,套头衫变成 T 恤,T 恤变成裤子,靴子变成鞋子)。潜在空间的特定方向在潜在空间的子域内具有一定的意义。例如,在潜在空间的顶部区域附近,水平维度似乎代表“靴子特性与鞋子特性;”在潜在空间的右下角附近,水平维度似乎代表“T 恤特性与裤子特性”,依此类推。
在接下来的章节中,我们将介绍另一种生成图像的主要模型类型:GANs。
10.3. 使用 GANs 进行图像生成
自从 Ian Goodfellow 和他的同事在 2014 年引入了 GANs^([16]) 这项技术以来,它的兴趣和复杂程度迅速增长。如今,GANs 已经成为生成图像和其他数据模态的强大工具。它们能够输出高分辨率图像,有些情况下,这些图像在人类眼中几乎无法与真实图像区分开来。查看 NVIDIA 的 StyleGANs 生成的人脸图像,如 图 10.9^([17]) 所示。如果不是人脸上偶尔出现的瑕疵点和背景中不自然的场景,人类观察者几乎无法将这些生成的图像与真实图像区分开来。
¹⁶
Ian Goodfellow 等人,“生成对抗网络”,NIPS 会议论文集,2014 年,
mng.bz/4ePv。¹⁷
thispersondoesnotexist.com的网站。有关学术论文,请参阅 Tero Karras,Samuli Laine 和 Timo Aila,“用于生成对抗网络的基于样式的生成器架构”,于 2018 年 12 月 12 日提交,arxiv.org/abs/1812.04948。
图 10.9. NVIDIA 的 StyleGAN 生成的示例人脸图像,从 thispersondoesnotexist.com 中采样于 2019 年 4 月

除了“从蓝天中生成引人注目的图像”之外,GAN 生成的图像还可以根据某些输入数据或参数进行条件约束,这带来了更多的特定任务和有用的应用。例如,GAN 可以用于从低分辨率输入(图像超分辨率)生成更高分辨率的图像,填补图像的缺失部分(图像修复),将黑白图像转换为彩色图像(图像着色),根据文本描述生成图像以及根据输入图像中同一人采取的姿势生成该人的图像。此外,已经开发了新类型的 GAN 用于生成非图像输出,例如音乐。^([18]) 除了在艺术、音乐制作和游戏设计等领域中生成无限量的逼真材料的明显价值之外,GAN 还有其他应用,例如通过在获取此类样本代价高昂的情况下生成训练示例来辅助深度学习。例如,GAN 正被用于为训练自动驾驶神经网络生成逼真的街景图像。^([19])
¹⁸
请参阅 Hao-Wen Dong 等人的 MuseGAN 项目:
salu133445.github.io/musegan/。¹⁹
James Vincent,《NVIDIA 使用 AI 让永远阳光的街道下雪》,The Verge,2017 年 12 月 5 日,
mng.bz/Q0oQ。
虽然 VAE 和 GAN 都是生成模型,但它们基于不同的思想。VAE 通过使用原始输入和解码器输出之间的均方误差损失来确保生成的示例的质量,而 GAN 则通过使用鉴别器来确保其输出逼真,我们很快就会解释。此外,GAN 的许多变体允许输入不仅包含潜空间向量,还包括条件输入,例如所需的图像类别。我们将要探索的 ACGAN 就是这方面的一个很好的例子。在这种具有混合输入的 GAN 类型中,潜空间不再与网络输入具有连续性。
在这个部分,我们将深入研究一种相对简单的 GAN 类型。具体而言,我们将在熟悉的 MNIST 手写数字数据集上训练一个辅助分类器 GAN (ACGAN)^([20])。这将给我们一个能够生成与真实 MNIST 数字完全相似的数字图像的模型。同时,由于 ACGAN 的“辅助分类器”部分,我们将能够控制每个生成图像所属的数字类别(0 到 9)。为了理解 ACGAN 的工作原理,让我们一步一步来。首先,我们将解释 ACGAN 的基本“GAN”部分如何工作。然后,我们将描述 ACGAN 通过额外的机制如何使类别标识具有可控性。
²⁰
Augustus Odena、Christopher Olah 和 Jonathon Shlens,“带辅助分类器 GAN 的条件图像合成”,2016 年 10 月 30 日提交,
arxiv.org/abs/1610.09585。
10.3.1. GANs 背后的基本思想
生成对抗网络(GAN)是如何学习生成逼真图片的?它通过其包含的两个子部分之间的相互作用来实现这一点:一个生成器和一个鉴别器。把生成器想象成一个伪造者,其目标是创建高质量的假毕加索画作;而鉴别器则像是一位艺术品经销商,其工作是将假的毕加索画作与真实的区分开来。伪造者(生成器)努力创建越来越好的假画作以欺骗艺术品经销商(鉴别器),而艺术品经销商的工作是成为对画作的评判者越来越好,从而不被伪造者欺骗。我们两个角色之间的这种对抗是“GAN”名称中“对抗性”部分的原因。有趣的是,伪造者和艺术品经销商最终互相帮助变得更好,尽管表面上是对手。
起初,伪造者(生成器)在创建逼真的毕加索画作方面表现糟糕,因为其权重是随机初始化的。结果,艺术品经销商(鉴别器)很快就学会了区分真假毕加索画作。这里是所有这些工作的重要部分:每次伪造者给艺术品经销商带来一幅新画作时,他们都会得到详细的反馈(来自艺术品经销商),指出画作的哪些部分看起来不对劲,以及如何改变画作使其看起来更真实。伪造者学习并记住这一点,以便下次他们来到艺术品经销商那里时,他们的画作看起来会稍微好一些。这个过程重复多次。结果发现,如果所有参数都设置正确,我们最终会得到一个技艺精湛的伪造者(生成器)。当然,我们也会得到一个技艺精湛的鉴别器(艺术品经销商),但通常在 GAN 训练完成后我们只需要生成器。
图 10.10 更详细地描述了如何训练通用 GAN 模型的判别器部分。为了训练判别器,我们需要一批生成的图像和一批真实图像。生成的图像由生成器生成。但生成器无法从空气中制作图像。相反,它需要作为输入的随机向量。潜在向量在概念上类似于我们在第 10.2 节中用于 VAE 的向量。对于生成器生成的每个图像,潜在向量是形状为[latentSize]的一维张量。但像本书中大多数训练过程一样,我们一次对一批图像执行步骤。因此,潜在向量的形状为[batchSize, latentSize]。真实图像直接从实际 MNIST 数据集中提取。为了对称起见,我们在每个训练步骤中绘制与生成的图像完全相同数量的batchSize真实图像。
图 10.10. 示出 GAN 判别器部分训练算法的示意图。请注意,为简单起见,该图省略了 ACGAN 的数字类部分。有关 ACGAN 生成器训练的完整图表,请参见图 10.13。
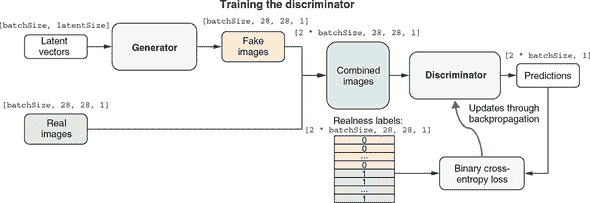
生成的图像和真实图像随后被连接成一批图像,表示为形状为[2 * batchSize, 28, 28, 1]的张量。判别器在这批合并图像上执行,输出每个图像是真实的预测概率分数。这些概率分数可以轻松地通过二元交叉熵损失函数与基准真值进行测试(我们知道哪些是真实的,哪些是生成的!)。然后,熟悉的反向传播算法发挥作用,借助优化器(图中未显示)更新判别器的权重参数。这一步使判别器略微朝着正确的预测方向推进。请注意,生成器仅通过提供生成的样本参与此训练步骤,但它不会通过反向传播过程进行更新。下一步训练将更新生成器(图 10.11)。
图 10.11. 示出 GAN 生成器部分训练算法的示意图。请注意,为简单起见,该图省略了 ACGAN 的数字类部分。有关 ACGAN 生成器训练过程的完整图表,请参见图 10.14。
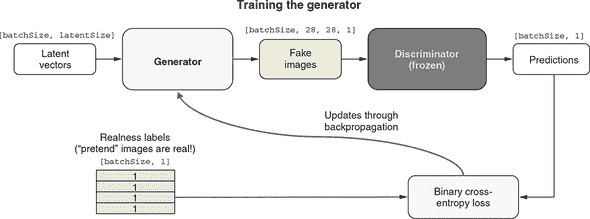
图 10.11 说明了生成器的训练步骤。我们让生成器生成另一批生成图像。但与鉴别器的训练步骤不同,我们不需要任何真实的 MNIST 图像。鉴别器被赋予了这批生成图像以及一批二进制真实性标签。我们假装这些生成图像都是真实的,将真实性标签设置为全部为 1。静下心来思考一下:这是 GAN 训练中最重要的技巧。当然,这些图像都是生成的(并非真实的),但我们让真实性标签表明它们是真实的。鉴别器可能(正确地)对一些或所有的输入图像分配较低的真实性概率。但是如果这样做,由于虚假的真实性标签,二进制交叉熵损失将得到较大的值。这将导致反向传播更新生成器,以使鉴别器的真实性得分稍微增加。请注意,反向传播只更新生成器,不对鉴别器进行任何更改。这是另一个重要的技巧:它确保生成器最终产生的图像看起来更真实一些,而不是降低鉴别器对真实性的要求。这是通过冻结模型的鉴别器部分实现的,这是我们在第五章中用于迁移学习的一种操作。
总结生成器训练步骤:冻结鉴别器并向其提供全是 1 的真实性标签,尽管它得到的是由生成器生成的生成图像。由于这样,对生成器的权重更新将导致其生成的图像在鉴别器中看起来稍微更真实。只有当鉴别器相当擅长区分真实和生成的图像时,这种训练生成器的方式才会奏效。我们如何确保这一点?答案是我们已经讨论过的鉴别器训练步骤。因此,你可以看到这两个训练步骤形成了一种复杂的阴阳动态,其中 GAN 的两个部分相互抵触并互相帮助。
这就是对通用 GAN 训练的高级概览。在下一节中,我们将介绍鉴别器和生成器的内部架构以及它们如何融入有关图像类别的信息。
10.3.2. ACGAN 的构建模块
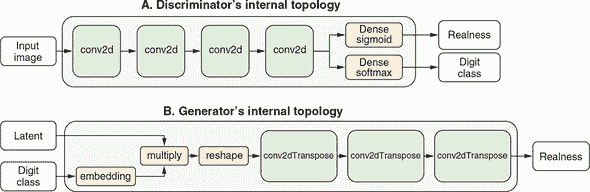
清单 10.9 显示了创建 MNIST ACGAN 判别器部分的 TensorFlow.js 代码(摘自 mnist-acgan/gan.js)。在判别器的核心是一种类似于我们在第四章中看到的深度卷积网络。其输入具有 MNIST 图像的经典形状,即 [28, 28, 1]。输入图像通过四个 2D 的卷积(conv2d)层,然后被展平并经过两个全连接层处理。其中一个全连接层为输入图像的真实性二进制预测输出,另一个输出 10 个数字类别的 softmax 概率。判别器是一个有两个全连接层输出的函数模型。图 10.12 的面板 A 提供了判别器的一个输入-两个输出拓扑结构的示意图。
图 10.12。ACGAN 的判别器(面板 A)和生成器(面板 B)部分的内部拓扑示意图。为简洁起见,省略了某些细节(例如判别器中的 dropout 层)。有关详细的代码,请参见清单 10.9 和 10.10。
清单 10.9。创建 ACGAN 的判别器部分。
function buildDiscriminator() {
const cnn = tf.sequential();
cnn.add(tf.layers.conv2d({
filters: 32,
kernelSize: 3,
padding: 'same',
strides: 2,
inputShape: [IMAGE_SIZE, IMAGE_SIZE, 1] ***1***
}));
cnn.add(tf.layers.leakyReLU({alpha: 0.2}));
cnn.add(tf.layers.dropout({rate: 0.3})); ***2***
cnn.add(tf.layers.conv2d(
{filters: 64, kernelSize: 3, padding: 'same', strides: 1}));
cnn.add(tf.layers.leakyReLU({alpha: 0.2}));
cnn.add(tf.layers.dropout({rate: 0.3}));
cnn.add(tf.layers.conv2d(
{filters: 128, kernelSize: 3, padding: 'same', strides: 2}));
cnn.add(tf.layers.leakyReLU({alpha: 0.2}));
cnn.add(tf.layers.dropout({rate: 0.3}));
cnn.add(tf.layers.conv2d(
{filters: 256, kernelSize: 3, padding: 'same', strides: 1}));
cnn.add(tf.layers.leakyReLU({alpha: 0.2}));
cnn.add(tf.layers.dropout({rate: 0.3}));
cnn.add(tf.layers.flatten());
const image = tf.input({shape: [IMAGE_SIZE, IMAGE_SIZE, 1]});
const features = cnn.apply(image);
const realnessScore = ***3***
tf.layers.dense({units: 1, activation: 'sigmoid'}).apply(features); ***3***
const aux = tf.layers.dense({units: NUM_CLASSES, activation: 'softmax'}) ***4***
.apply(features); ***4***
return tf.model({inputs: image, outputs: [realnessScore, aux]});
}
-
1 判别器只接受 MNIST 格式的图像作为输入。
-
2 使用 Dropout 层来对抗过拟合。
-
3 判别器的两个输出之一是二进制真实性分类的概率分数。
-
4 第二个输出是 10 个 MNIST 数字类别的 softmax 概率。
清单 10.10 中的代码负责创建 ACGAN 生成器。正如我们之前暗示的那样,生成器的生成过程需要一个叫做潜在向量(代码中称为 latent)的输入。这体现在其第一个全连接层的 inputShape 参数中。然而,如果你仔细检查代码,就会发现生成器实际上接受两个输入。这在 图 10.12 的面板 B 中有描述。除了潜在向量外,也就是一个形状为 [latentSize] 的一维张量,生成器需要一个额外的输入,名为 imageClass,形状简单,为 [1]。这是告诉模型要生成哪个 MNIST 数字(0 到 9)的方式。例如,如果我们想要模型生成数字 8 的图像,我们应该将形状为 tf.tensor2d([[8]]) 的张量值输入到第二个输入(请记住,即使只有一个示例,模型也始终期望批量张量)。同样,如果我们想要模型生成两个图像,一个是数字 8,另一个是数字 9,则馈送的张量应为 tf.tensor2d([[8], [9]])。
一旦 imageClass 输入进入生成器,嵌入层将其转换为与 latent 相同形状的张量 ([latentSize])。这一步在数学上类似于我们在 第九章 中用于情感分析和日期转换模型的嵌入查找过程。期望的数字类别是一个整数量,类似于情感分析数据中的单词索引和日期转换数据中的字符索引。它被转换为与单词和字符索引转换为 1D 向量的方式相同的 1D 向量。然而,我们在这里对 imageClass 使用嵌入查找是为了不同的目的:将其与 latent 向量合并并形成一个单一的组合向量(在 清单 10.10 中命名为 h)。这个合并是通过一个 multiply 层完成的,该层在两个相同形状的向量之间执行逐元素相乘。结果张量的形状与输入相同 ([latentSize]),并传入生成器的后续部分。
生成器立即在合并的潜在向量 (h) 上应用一个密集层,并将其重塑为 3D 形状 [3, 3, 384]。这种重塑产生了一个类似图像的张量,随后可以由生成器的后续部分转换为具有标准 MNIST 形状 ([28, 28, 1]) 的图像。
生成器不使用熟悉的 conv2d 层来转换输入,而是使用 conv2dTranspose 层来转换其图像张量。粗略地说,conv2dTranspose 执行与 conv2d 的逆操作(有时称为反卷积)。conv2d 层的输出通常比其输入具有更小的高度和宽度(除了 kernelSize 为 1 的情况之外),如您在 第四章 中的 convnets 中所见。然而,conv2dTranspose 层的输出通常比其输入具有更大的高度和宽度。换句话说,虽然 conv2d 层通常缩小其输入的维度,但典型的 conv2dTranspose 层扩展它们。这就是为什么在生成器中,第一个 conv2dTranspose 层接受高度为 3 和宽度为 3 的输入,但最后一个 conv2dTranspose 层输出高度为 28 和宽度为 28 的原因。这就是生成器将输入潜在向量和数字索引转换为标准 MNIST 图像尺寸的图像的方式。以下清单中的代码摘录自 mnist-acgan/gan.js; 为了清晰起见,删除了一些错误检查代码。
清单 10.10. 创建 ACGAN 的生成器部分
function buildGenerator(latentSize) {
const cnn = tf.sequential();
cnn.add(tf.layers.dense({
units: 3 * 3 * 384, ***1***
inputShape: [latentSize],
activation: 'relu'
}));
cnn.add(tf.layers.reshape({targetShape: [3, 3, 384]}));
cnn.add(tf.layers.conv2dTranspose({ ***2***
filters: 192,
kernelSize: 5,
strides: 1,
padding: 'valid',
activation: 'relu',
kernelInitializer: 'glorotNormal'
}));
cnn.add(tf.layers.batchNormalization());
cnn.add(tf.layers.conv2dTranspose({ ***3***
filters: 96,
kernelSize: 5,
strides: 2,
padding: 'same',
activation: 'relu',
kernelInitializer: 'glorotNormal'
}));
cnn.add(tf.layers.batchNormalization());
cnn.add(tf.layers.conv2dTranspose({ ***4***
filters: 1,
kernelSize: 5,
strides: 2,
padding: 'same',
activation: 'tanh',
kernelInitializer: 'glorotNormal'
}));
const latent = tf.input({shape: [latentSize]}); ***5***
const imageClass = tf.input({shape: [1]}); ***6***
const classEmbedding = tf.layers.embedding({ ***7***
inputDim: NUM_CLASSES,
outputDim: latentSize,
embeddingsInitializer: 'glorotNormal'
}).apply(imageClass);
const h = tf.layers.multiply().apply( ***8***
[latent, classEmbedding]); ***8***
const fakeImage = cnn.apply(h);
return tf.model({ ***9***
inputs: [latent, imageClass], ***9***
outputs: fakeImage ***9***
}); ***9***
}
-
1 单元的数量被选择为当输出被重塑并通过后续的 conv2dTranspose 层时,最终输出的张量的形状与 MNIST 图像完全匹配 ([28, 28, 1])。
-
2 从 [3, 3, …] 上采样至 [7, 7, …]
-
3 上采样至 [14, 14, …]
-
4 上采样至 [28, 28, …]
-
5 这是生成器的两个输入之一:作为伪图像生成的“种子”的潜在(z-空间)向量。
-
6 生成器的第二个输入:控制生成的图像属于哪个 MNIST 数字类别的类标签
-
7 通过嵌入查找将期望标签转换为长度为 latentSize 的向量
-
8 通过乘法将潜在向量和类别条件嵌入组合起来
-
9 最终创建模型,以顺序卷积网络为核心。
10.3.3. 更深入地了解 ACGAN 的训练
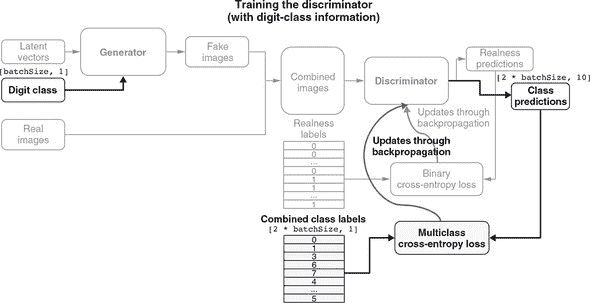
最后一节应该让你更好地理解了 ACGAN 的鉴别器和生成器的内部结构,以及它们如何整合数字类别信息(ACGAN 名字中的“AC”部分)。有了这些知识,我们就可以扩展 figures 10.10 和 10.11,以全面了解 ACGAN 的训练方式。
Figure 10.13 是 figure 10.10 的扩展版本。它展示了 ACGAN 的鉴别器部分的训练。与之前相比,这一训练步骤不仅提高了鉴别器区分真实和生成(伪造)图像的能力,还磨练了其确定给定图像(包括真实和生成的图像)属于哪个数字类别的能力。为了更容易与之前的简单图表进行比较,我们将已在 figure 10.10 中看到的部分灰暗显示,并突出显示新的部分。首先,注意到生成器现在有了一个额外的输入(数字类别),这使得指定生成器应该生成什么数字成为可能。此外,鉴别器不仅输出真实性预测,还输出数字类别预测。因此,鉴别器的两个输出头都需要进行训练。对于真实性预测的训练与之前相同(figure 10.10);类别预测部分的训练依赖于我们知道生成和真实图像属于哪些数字类别。模型的两个头部编译了不同的损失函数,反映了两种预测的不同性质。对于真实性预测,我们使用二元交叉熵损失,但对于数字类别预测,我们使用了稀疏分类交叉熵损失。你可以在 mnist-acgan/gan.js 的下一行中看到这一点:
discriminator.compile({
optimizer: tf.train.adam(args.learningRate, args.adamBeta1),
loss: ['binaryCrossentropy', 'sparseCategoricalCrossentropy']
});
图 10.13. 说明 ACGAN 的鉴别器部分是如何训练的示意图。这个图表在 figure 10.10 的基础上添加了与数字类别相关的部分。图表的其余部分已经在 figure 10.10 中出现,并且被灰暗显示。
如 图 10.13 中的两条弯曲箭头所示,当更新鉴别器的权重时,通过反向传播的梯度会相互叠加。图 10.14 是 图 10.11 的扩展版本,提供了 ACGAN 生成器部分训练的详细示意图。该图显示了生成器学习如何根据指定的数字类别生成正确的图像,以及学习如何生成真实的图像。与 图 10.13 类似,新添加的部分被突出显示,而已经存在于 图 10.11 的部分则被隐藏。从突出显示的部分中,可以看到我们在训练步骤中输入的标签现在不仅包括真实性标签,还包括数字类别标签。与以前一样,真实性标签都是故意虚假的。但是新添加的数字类别标签更加真实,因为我们确实将这些类别标签给了生成器。
图 10.14. 示意图,说明 ACGAN 的生成器部分是如何训练的。这个图是 图 10.11 的扩展,显示了与数字类别相关的部分。图的其余部分已经在图 10.11 中出现,已被隐藏。
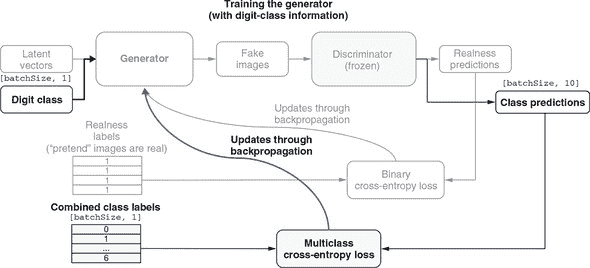
先前,我们看到虚假真实标签与鉴别器的真实概率输出之间的任何差异会被用来更新 ACGAN 的生成器,使其在“欺骗”鉴别器方面更加优秀。在这里,鉴别器的数字分类预测发挥了类似的作用。例如,如果我们告诉生成器生成一个数字 8 的图像,但是鉴别器将图像分类为 9,则稀疏分类交叉熵的值将较高,并且与之关联的梯度将有较大的幅度。因此,生成器权重的更新将导致生成器生成一个更像数字 8 的图像(根据鉴别器的判断)。显然,只有当鉴别器在将图像分类为 10 个 MNIST 数字类别方面足够好时,这种训练生成器的方法才会起作用。这就是前一个鉴别器训练步骤所帮助确保的。再次强调,在 ACGAN 的训练过程中,我们看到了鉴别器和生成器部分之间的阴阳动力学。
GAN 训练:一大堆诡计
训练和调整 GAN 的过程众所周知地困难。您在 mnist-acgan 示例中看到的训练脚本是研究人员大量试错的结晶。像深度学习中的大多数事物一样,这更像是一种艺术而不是精确科学:这些技巧是启发式的,没有系统理论的支持。它们得到了对手头现象的直觉理解,并且在经验上被证明效果良好,尽管不一定在每种情况下都有效。
以下是本节中 ACGAN 中使用的一些值得注意的技巧列表:
-
我们在生成器的最后一个 conv2dTranspose 层中使用 tanh 作为激活函数。在其他类型的模型中,tanh 激活函数出现得较少。
-
随机性有助于诱导鲁棒性。因为 GAN 的训练可能导致动态平衡,所以 GAN 很容易陷入各种各样的困境中。在训练过程中引入随机性有助于防止这种情况发生。我们通过两种方式引入随机性:在鉴别器中使用 dropout,以及为鉴别器的真实标签使用“soft one”值(0.95)。
-
稀疏梯度(许多值为零的梯度)可能会妨碍 GAN 的训练。在其他类型的深度学习中,稀疏性通常是一种理想的特性,但在 GAN 中不是这样。梯度中的稀疏性可能由两个因素引起:最大池化操作和 relu 激活函数。建议使用步幅卷积进行下采样,而不是最大池化,这正是生成器创建代码中所示的内容。建议使用 leakyReLU 激活函数,其中负部分具有小的负值,而不是严格的零。这也在清单 10.10 中显示。
10.3.4. 查看 MNIST ACGAN 训练和生成
mnist-acgan 示例可以通过以下命令检出和准备:
git clone https://github.com/tensorflow/tfjs-examples.git
cd tfjs-examples/mnist-acganyarn
运行示例涉及两个阶段:在 Node.js 中进行训练,然后在浏览器中进行生成。要启动训练过程,只需使用以下命令:
yarn train
训练默认使用 tfjs-node。然而,像我们之前见过的涉及卷积神经网络的示例一样,使用 tfjs-node-gpu 可以显著提高训练速度。如果您的计算机上正确设置了支持 CUDA 的 GPU,您可以在yarn train命令中追加--gpu标志来实现。训练 ACGAN 至少需要几个小时。对于这个长时间运行的训练任务,您可以使用--logDir标志通过 TensorBoard 监控进度:
yarn train --logDir /tmp/mnist-acgan-logs
一旦在单独的终端中使用以下命令启动了 TensorBoard 进程,
tensorboard --logdir /tmp/mnist-acgan-logs
您可以在浏览器中导航到 TensorBoard URL(由 TensorBoard 服务器进程打印)以查看损失曲线。图 10.15 显示了训练过程中的一些示例损失曲线。GAN 训练的损失曲线的一个显著特征是,它们并不总是像大多数其他类型的神经网络的损失曲线那样趋向于下降。相反,判别器的损失(图中的 dLoss)和生成器的损失(图中的 gLoss)都以非单调方式变化,并相互交织形成复杂的舞蹈。
图 10.15. ACGAN 训练作业中的样本损失曲线。dLoss 是判别器训练步骤的损失。具体来说,它是真实性预测的二元交叉熵和数字类别预测的稀疏分类交叉熵的总和。gLoss 是生成器训练步骤的损失。与 dLoss 类似,gLoss 是来自二元真实性分类和多类数字分类的损失的总和。
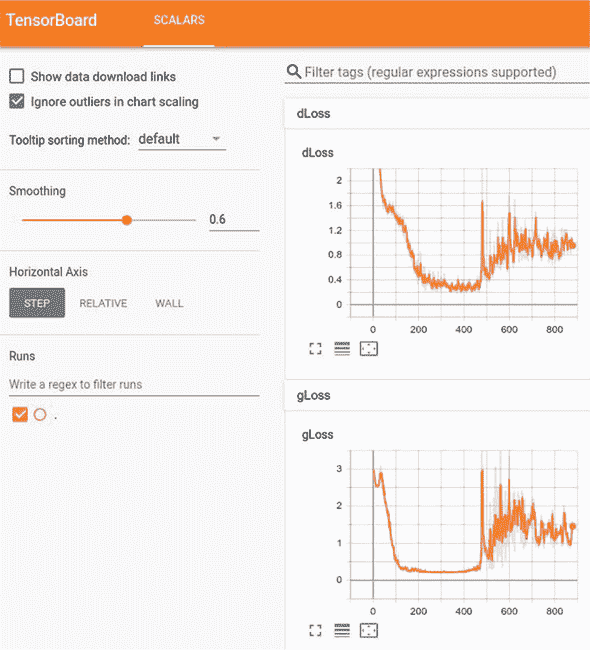
在训练接近结束时,两者的损失都不会接近零。相反,它们只是趋于平稳(收敛)。此时,训练过程结束并将模型的生成器部分保存到磁盘上,以便在浏览器内生成步骤中进行服务:
await generator.save(saveURL);
要运行浏览器内生成演示,请使用命令 yarn watch。它将编译 mnist-acgan/index.js 和相关的 HTML 和 CSS 资源,然后会在您的浏览器中打开一个标签页并显示演示页面。^([21])
²¹
您还可以完全跳过训练和构建步骤,直接导航到托管的演示页面,网址为
mng.bz/4eGw。
演示页面加载了从前一阶段保存的训练好的 ACGAN 生成器。由于判别器在此演示阶段并不真正有用,因此它既不保存也不加载。有了生成器加载后,我们可以构建一批潜在向量,以及一批期望的数字类别索引,并调用生成器的 predict()。执行此操作的代码位于 mnist-acgan/index.js 中:
const latentVectors = getLatentVectors(10);
const sampledLabels = tf.tensor2d(
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9], [10, 1]);
const generatedImages =
generator.predict([latentVectors, sampledLabels]).add(1).div(2);
我们的数字类别标签批次始终是一个有序的 10 元素向量,从 0 到 9。这就是为什么生成的图像批次总是一个从 0 到 9 的有序图像数组。这些图像使用 tf.concat() 函数拼接在一起,并在页面上的 div 元素中呈现(参见图 10.16 中的顶部图像)。与随机抽样的真实 MNIST 图像(参见图 10.16 中的底部图像)相比,这些 ACGAN 生成的图像看起来就像真实的一样。此外,它们的数字类别身份看起来是正确的。这表明我们的 ACGAN 训练是成功的。如果您想查看 ACGAN 生成器的更多输出,请点击页面上的 Generator 按钮。每次点击按钮,都会生成并显示页面上的新批次包含 10 张假图像。您可以玩一下,直观地感受图像生成的质量。
图 10.16. ACGAN 训练模型的生成器部分生成的样本图片(顶部的 10 x 1 面板)。底部的面板展示了一个 10 x 10 的真实 MNIST 图像网格,以进行比较。点击“显示 Z-向量滑块”按钮,您可以打开一个填满了 100 个滑块的区域。这些滑块允许您改变潜在向量(z-向量)的元素,并观察其对生成的 MNIST 图像的影响。请注意,如果您逐个更改滑块,大多数滑块对图像的影响都很微小且不易察觉。但偶尔,您会发现一个具有更大且更明显影响的滑块。

进一步阅读材料
-
Ian Goodfellow、Yoshua Bengio 和 Aaron Courville,“深度生成模型”,深度学习,第二十章,麻省理工学院出版社,2017 年。
-
Jakub Langr 和 Vladimir Bok,《GAN 行动中:生成对抗网络的深度学习》,Manning 出版社,2019 年。
-
Andrej Karpathy,“循环神经网络的不合理有效性”,博客,2015 年 5 月 21 日,
karpathy.github.io/2015/05/21/rnn-effectiveness/。 -
Jonathan Hui,“GAN—什么是生成对抗网络 GAN?” Medium,2018 年 6 月 19 日,
mng.bz/Q0N6。 -
GAN 实验室,一个用 TensorFlow.js 构建的交互式网络环境,用于理解和探索 GAN 的工作原理:Minsuk Kahng 等人,
poloclub.github.io/ganlab/。
练习
-
除了莎士比亚文本语料库外,lstm-text-generation 示例还配置了其他几个文本数据集,并准备好供您探索。运行它们的训练,并观察其效果。例如,使用未压缩的 TensorFlow.js 代码作为训练数据集。在模型训练期间和之后,观察生成的文本是否表现出以下 JavaScript 源代码的模式以及温度参数如何影响这些模式:
-
较短程模式,例如关键字(例如,“for”和“function”)
-
中程模式,例如代码的逐行组织
-
较长程模式,例如括号和方括号的配对,以及每个“function”关键字后必须跟着一对括号和一对花括号
-
-
在 fashion-mnist-vae 示例中,如果您将 VAE 的自定义损失中的 KL 散度项删除会发生什么?通过修改 fashion-mnist-vae/model.js 中的
vaeLoss()函数(清单 10.7)来测试。从潜在空间采样的图像是否仍然看起来像 Fashion-MNIST 图像?空间是否仍然展现出可解释的模式? -
在 mnist-acgan 示例中,尝试将 10 个数字类别合并为 5 个(0 和 1 将成为第一类,2 和 3 将成为第二类,依此类推),并观察在训练后这如何改变 ACGAN 的输出。当您指定第一类时,您期望看到生成的图像是什么?例如,当您指定第一类时,您期望 ACGAN 生成什么?提示:要进行此更改,您需要修改 mnist-acgan/data.js 中的
loadLabels()函数。需要相应修改 gan.js 中的常量NUM_CLASSES。此外,generateAnd-VisualizeImages()函数(位于 index.js 中)中的sampledLabels变量也需要修改。
总结
-
生成模型与我们在本书早期章节中学习的判别模型不同,因为它们旨在模拟训练数据集的生成过程,以及它们的统计分布。由于这种设计,它们能够生成符合分布并且看起来类似于真实训练数据的新样本。
-
我们介绍了一种模拟文本数据集结构的方法:下一个字符预测。LSTM 可以用来以迭代方式执行此任务,以生成任意长度的文本。温度参数控制生成文本的随机性(多么随机和不可预测)。
-
自动编码器是一种由编码器和解码器组成的生成模型。首先,编码器将输入数据压缩为称为潜在向量或 z-向量的简明表示。然后,解码器尝试仅使用潜在向量来重构输入数据。通过训练过程,编码器变成了一个高效的数据摘要生成器,解码器则具有对示例的统计分布的知识。VAE 对潜在向量添加了一些额外的统计约束,使得在 VAE 训练后组成这些向量的潜在空间显示出连续变化和可解释的结构。
-
GAN 基于鉴别器和生成器之间的竞争和合作的想法。鉴别器试图区分真实数据示例和生成的数据示例,而生成器旨在生成“欺骗”鉴别器的虚假示例。通过联合训练,生成器部分最终将能够生成逼真的示例。ACGAN 在基本 GAN 架构中添加了类信息,以便指定要生成的示例的类别。
第十一章:深度强化学习的基础知识
本章内容
-
强化学习与前面几章讨论的监督学习有什么不同
-
强化学习的基本范例:智能体、环境、行动和奖励以及它们之间的交互
-
解决强化学习问题的两种主要方法背后的一般思想:基于策略和基于值的方法
到目前为止,在本书中,我们主要关注一种叫做监督学习的机器学习方法。在监督学习中,我们通过给出一个输入来训练模型给我们正确的答案。无论是给输入图像赋予一个类别标签(第四章)还是根据过去的天气数据预测未来温度(第八章和第九章),这种模式都是一样的:将静态输入映射到静态输出。在我们访问的第九章和第十章中生成序列的模型要稍微复杂一些,因为输出是一系列项而不是单个项。但是通过将序列拆分成步骤,这些问题仍然可以归结为一对一的输入输出映射。
在本章中,我们将介绍一种非常不同的机器学习类型,称为强化学习(RL)。在强化学习中,我们的主要关注点不是静态输出;相反,我们训练一个模型(或者在强化学习术语中称为智能体)在一个环境中采取行动,目的是最大化称为奖励的成功指标。例如,RL 可以用于训练一个机器人在建筑物内航行并收集垃圾。实际上,环境不一定是物理环境;它可以是任何一个智能体采取行动的真实或虚拟空间。国际象棋棋盘是训练智能体下棋的环境;股票市场是训练智能体交易股票的环境。强化学习范式的普遍性使其适用于广泛的实际问题(图 11.1)。另外,深度学习革命中一些最为引人瞩目的进展涉及将深度学习的能力与强化学习相结合。这包括可以以超人的技巧打败 Atari 游戏的机器人和可以在围棋和国际象棋游戏中击败世界冠军的算法^([1])。
¹
David Silver 等人,“通过自我对弈用通用强化学
图 11.1。强化学习的实际应用示例。左上:解决象棋和围棋等棋类游戏。右上:进行算法交易。左下:数据中心的自动资源管理。右下:机器人的控制和行动规划。所有图像均为免费许可证,并从www.pexels.com下载。
引人入胜的强化学习话题在一些基本方式上与我们在前几章中看到的监督学习问题有所不同。与监督学习中学习输入-输出映射不同,强化学习是通过与环境交互来发现最优决策过程。在强化学习中,我们没有给定标记的训练数据集;相反,我们被提供了不同类型的环境来探索。此外,时间是强化学习问题中不可或缺且基础性的维度,与许多监督学习问题不同,后者要么缺乏时间维度,要么将时间更多地视为空间维度。由于强化学习的独特特征,本章将涉及一种与前几章非常不同的词汇和思维方式。但不要担心。我们将使用简单而具体的例子来说明基本概念和方法。此外,我们的老朋友,深度神经网络及其在 TensorFlow.js 中的实现,将仍然与我们同在。它们将构成本章中我们将遇到的强化学习算法的重要支柱(尽管不是唯一的!)。
在本章结束时,您应该熟悉强化学习问题的基本公式化,理解强化学习中两种常用神经网络(策略网络和 Q 网络)背后的基本思想,并知道如何使用 TensorFlow.js 的 API 对这些网络进行训练。
11.1. 强化学习问题的制定
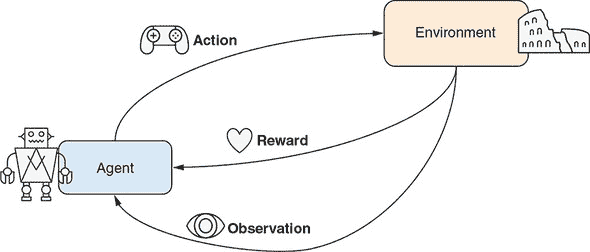
图 11.2 描绘了强化学习问题的主要组成部分。代理是我们(强化学习从业者)直接控制的对象。代理(例如在建筑物中收集垃圾的机器人)以三种方式与环境交互:
-
在每一步中,代理程序采取一种 行动,这改变了环境的状态。例如,在我们的垃圾收集机器人的背景下,可供选择的行动集可能是
{前进,后退,左转,右转,抓取垃圾,将垃圾倒入容器}。 -
偶尔,环境会向代理程序提供一个 奖励,在人性化的术语中,可以理解为即时愉悦或满足的衡量。但更抽象地说,奖励(或者,如我们稍后将看到的,一段时间内的奖励总和)是一个代理试图最大化的数字。它是一个重要的数值,以类似于损失值引导监督学习算法的方式引导强化学习算法。奖励可以是正的或负的。在我们的垃圾收集机器人的例子中,当一袋垃圾成功倒入机器人的垃圾容器时,可以给予正奖励。此外,当机器人撞倒垃圾桶,撞到人或家具,或者在容器外倒垃圾时,应给予负奖励。
-
除了奖励外,代理还可以通过另一个渠道观察环境的状态,即观察。这可以是环境的完整状态,也可以只是代理可见的部分,可能通过某个不完美的渠道而失真。对于我们的垃圾收集机器人来说,观察包括来自其身体上的相机和各种传感器的图像和信号流。
图 11.2:强化学习问题的基本公式的示意图。在每个时间步,代理从可能的行动集合中选择一个行动,从而导致环境状态的变化。环境根据其当前状态和选择的行动向代理提供奖励。代理可以部分或完全观察到环境的状态,并将使用该状态来决定未来的行动。
刚定义的公式有些抽象。让我们看看一些具体的强化学习问题,并了解公式所涵盖的可能范围。在此过程中,我们还将浏览所有强化学习问题的分类。首先让我们考虑一下行动。代理可以选择的行动空间可以是离散的,也可以是连续的。例如,玩棋盘游戏的强化学习代理通常有离散的行动空间,因为在这种问题中,只有有限的移动选择。然而,一个涉及控制虚拟类人机器人的强化学习问题需要在双足行走时使用连续的行动空间,因为关节上的扭矩是连续变化的。在本章中,我们将介绍关于离散行动空间的示例问题。请注意,在某些强化学习问题中,可以通过离散化将连续的行动空间转化为离散的。例如,DeepMind 的《星际争霸 II》游戏代理将高分辨率的 2D 屏幕划分成较粗的矩形,以确定将单位移动到哪里或在哪里发起攻击。
²
查看 OpenAI Gym 中的 Humanoid 环境:
gym.openai.com/envs/Humanoid-v2/。³
Oriol Vinyals 等,“星际争霸 II:强化学习的新挑战”,提交日期:2017 年 8 月 16 日,
arxiv.org/abs/1708.04782。
奖励在强化学习问题中起着核心作用,但也呈现出多样性。首先,有些强化学习问题仅涉及正奖励。例如,正如我们稍后将看到的,一个强化学习代理的目标是使一个杆保持在移动的推车上,则它只会获得正奖励。每次它保持杆竖立时,它都会获得少量正奖励。然而,许多强化学习问题涉及正负奖励的混合。负奖励可以被看作是“惩罚”或“处罚”。例如,一个学习向篮筐投篮的代理应该因进球而获得正奖励,而因投篮失误而获得负奖励。
奖励的发生频率也可能不同。一些强化学习问题涉及连续的奖励流。比如前文提到的倒立摆问题:只要杆子还没倒下,智能体每一个时间步长都会获得(正面的)奖励。而对于下棋的强化学习智能体,则只有在游戏结束(胜利、失败或平局)时才会获得奖励。两种极端之间还有其他强化学习问题。例如,我们的垃圾收集机器人在两次成功垃圾转移之间可能完全没有任何奖励——也就是在从 A 点到 B 点的移动过程中。此外,训练打 Atari 游戏 Pong 的强化学习智能体也不会在电子游戏的每一步(帧)都获得奖励;相反,在球拍成功击中乒乓球并将其反弹到对手处时,才会每隔几步(帧)获得正面的奖励。本章我们将介绍一些奖励频率高低不同的强化学习问题。
观察是强化学习问题中的另一个重要因素。它是一个窗口,通过它智能体可以看到环境的状态,并且基于这个状态做出决策,而不仅仅是依据任何奖励。像动作一样,观察可以是离散的(例如在棋盘游戏或者扑克游戏中),也可以是连续的(例如在物理环境中)。你可能会问:为什么我们的强化学习公式将观察和奖励分开,即使它们都可以被看作是环境向智能体提供反馈的形式?答案是为了概念上的清晰和简单易懂。尽管奖励可以被视为观察,但它是智能体最终“关心”的。而观察可以包含相关和无关的信息,智能体需要学会过滤并巧妙地使用。
一些强化学习问题通过观察向智能体揭示环境的整个状态,而另一些问题则仅向智能体提供部分状态信息。第一类问题的例子包括棋类游戏(如棋类和围棋)。对于后一类问题,德州扑克等纸牌游戏是一个很好的例子,在这种游戏中你无法看到对手的手牌,而股票交易也是其中的一个例子。股票价格受许多因素的影响,例如公司的内部运营和市场上其他股票交易者的想法。但是,智能体只能观察到股票价格的逐时历史记录,可能还加上公开的信息,如财经新闻。
这个讨论建立了强化学习发生的平台。关于这个表述值得指出的一个有趣的事情是,代理与环境之间的信息流是双向的:代理对环境进行操作;环境反过来提供给代理奖励和状态信息。这使得强化学习与监督学习有所不同,监督学习中信息流主要是单向的:输入包含足够的信息,使得算法能够预测输出,但输出并不会以任何重要的方式影响输入。
强化学习问题的另一个有趣而独特的事实是,它们必须沿着时间维度发生,以便代理-环境交互由多个轮次或步骤组成。时间可以是离散的或连续的。例如,解决棋盘游戏的 RL 代理通常在离散的时间轴上操作,因为这类游戏是在离散的回合中进行的。视频游戏也是如此。然而,控制物理机器人手臂操纵物体的 RL 代理面临着连续的时间轴,即使它仍然可以选择在离散的时间点采取行动。在本章中,我们将专注于离散时间 RL 问题。
这个关于强化学习的理论讨论暂时就够了。在下一节中,我们将开始亲手探索一些实际的强化学习问题和算法。
11.2. 策略网络和策略梯度:车杆示例
我们将解决的第一个强化学习问题是模拟一个物理系统,在该系统中,一个装有杆的小车在一维轨道上移动。这个问题被恰如其名地称为车杆问题,它是由安德鲁·巴托(Andrew Barto)、理查德·萨顿(Richard Sutton)和查尔斯·安德森(Charles Anderson)在 1983 年首次提出的。自那时以来,它已经成为控制系统工程的基准问题(在某种程度上类似于 MNIST 数字识别问题用于监督学习),因为它的简单性和良好构建的物理学和数学,以及解决它并非完全微不足道。在这个问题中,代理的目标是通过施加左右方向的力来控制小车的运动,以尽可能长时间地保持杆的平衡。
⁴
安德鲁·G·巴托(Andrew G. Barto)、理查德·S·萨顿(Richard S. Sutton)和查尔斯·W·安德森(Charles W. Anderson),“可以解决困难学习控制问题的类神经自适应元件”,IEEE 系统、人类和控制论交易,1983 年 9 月/10 月,页码 834–846,
mng.bz/Q0rG。
11.2.1. 作为强化学习问题的车杆
在进一步探讨之前,你应该通过玩车杆示例来直观地理解这个问题。车杆问题简单轻便,我们完全可以在浏览器中进行模拟和训练。图 11.3 提供了车杆问题的可视化描述,你可以在通过yarn watch命令打开的页面中找到。要查看和运行示例,请使用
git clone https://github.com/tensorflow/tfjs-examples.git
cd tfjs-examples/cart-pole
yarn && yarn watch
图 11.3. 小车杆问题的视觉渲染。A 面板:四个物理量(小车位置x,小车速度x′,杆倾角 θ 和杆角速度 θ’)构成环境状态和观察。在每个时间步长,代理可以选择向左施加力或向右施加力的行动,这将相应地改变环境状态。B 和 C 面板:导致游戏结束的两个条件——要么小车向左或向右移动太多(B),要么杆从垂直位置倾斜太多(C)。
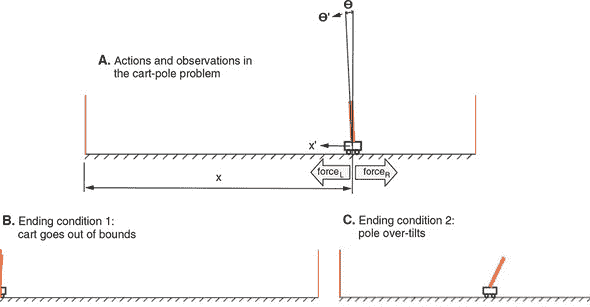
点击“创建模型”按钮,然后再点击“训练”按钮。然后您应该在页面底部看到一个动画,显示一个未经训练的代理执行车杆任务。由于代理模型的权重被初始化为随机值(关于模型的更多信息稍后再说),它的表现会非常糟糕。从游戏开始到结束的所有时间步有时在 RL 术语中称为一个episode。我们在这里将术语game和episode互换使用。
正如图 11.3 中的 A 面板所示,任何时间步中小车沿轨道的位置由称为x的变量捕获。它的瞬时速度表示为x’。此外,杆的倾斜角由另一个称为 θ 的变量捕获。杆的角速度(θ 变化的速度和方向)表示为 θ’。因此,这四个物理量(x,x’,θ 和 θ’)每一步都由代理完全观察到,并构成此 RL 问题的观察部分。
模拟在满足以下任一条件时结束:
-
x 的值超出预先指定的边界,或者从物理角度来说,小车撞到轨道两端的墙壁之一(图 11.3 的 B 面板)。
-
当 θ 的绝对值超过一定阈值时,或者从物理角度来说,杆过于倾斜,偏离了垂直位置(图 11.3 的 C 面板)。
环境还在第 500 个模拟步骤后终止一个 episode。这样可以防止游戏持续时间过长(一旦代理通过学习变得非常擅长游戏,这种情况可能会发生)。步数的上限在用户界面中是可以调整的。直到游戏结束,代理在模拟的每一步都获得一个单位的奖励(1)。因此,为了获得更高的累积奖励,代理需要找到一种方法来保持杆站立。但是代理如何控制小车杆系统呢?这就引出了这个 RL 问题的行动部分。
如图 11.3 A 面板中的力箭头所示,智能体在每一步只能执行两种可能的动作:在小车上施加向左或向右的力。智能体必须选择其中一种力的方向。力的大小是固定的。一旦施加了力,模拟将执行一组数学方程来计算环境的下一个状态(x、x’、θ 和 θ’ 的新值)。详细内容涉及熟悉的牛顿力学。我们不会详细介绍这些方程,因为在这里理解它们并不重要,但是如果您感兴趣,可以在 cart-pole 目录下的 cart-pole/cart_pole.js 文件中找到它们。
类似地,渲染小车摆杆系统的 HTML 画布的代码可以在 cart-pole/ui.js 中找到。这段代码突显了使用 JavaScript(特别是 TensorFlow.js)编写 RL 算法的优势:UI 和学习算法可以方便地用同一种语言编写,并且彼此紧密集成。这有助于可视化和直观理解问题,并加速开发过程。为了总结小车摆杆问题,我们可以用经典强化学习框架来描述它(参见 table 11.1)。
表 11.1. 在经典强化学习框架中描述了小车摆杆问题
| 抽象 RL 概念 | 在小车摆杆问题中的实现 |
|---|---|
| 环境 | 一个运载杆子并在一维轨道上移动的小车。 |
| 动作 | (离散)在每一步中,在左侧施加力和右侧施加力之间进行二进制选择。力的大小是固定的。 |
| 奖励 | (频繁且仅为正值)对于游戏每一步,智能体会收到固定的奖励(1)。当小车撞到轨道一端的墙壁,或者杆子从直立位置倾斜得太厉害时,该情节就会结束。 |
| 观测 | (完整状态,连续)每一步,智能体可以访问小车摆杆系统的完整状态,包括小车位置(x)和速度(x’),以及杆倾斜角(θ)和角速度(θ’)。 |
11.2.2. 策略网络
现在小车摆杆强化学习问题已经描述完毕,让我们看看如何解决它。从历史上看,控制理论家们曾经为这个问题设计过巧妙的解决方案。他们的解决方案基于这个系统的基本物理原理。[5] 但是在本书的背景下,我们不会这样来解决这个问题。在本书的背景下,这样做有点类似于编写启发式算法来解析 MNIST 图像中的边缘和角落,以便对数字进行分类。相反,我们将忽略系统的物理特性,让我们的智能体通过反复试错来学习。这符合本书其余部分的精神:我们不是在硬编码算法,也不是根据人类知识手动设计特征,而是设计了一种允许模型自主学习的算法。
⁵
如果您对传统的、非 RL 方法解决小车-杆问题感兴趣,并且不怕数学,可以阅读麻省理工学院 Russ Tedrake 的控制理论课程的开放课程 Ware:
mng.bz/j5lp。
我们如何让代理在每一步决定动作(向左还是向右的力)?鉴于代理可用的观察和代理每一步需要做出的决定,这个问题可以被重新制定为一个简单的输入输出映射问题,就像在监督学习中那样。一个自然的解决方案是构建一个神经网络,根据观察来选择一个动作。这是策略网络背后的基本思想。
这个神经网络将一个长度为 4 的观察向量(x,x’,θ和θ’)作为输入,并输出一个可以转化为左右决定的数字。该网络架构类似于我们在第三章中为仿冒网站构建的二元分类器。抽象地说,每一步,我们将查看环境,并使用我们的网络决定采取哪些行动。通过让我们的网络玩一些回合,我们将收集一些数据来评价那些决定。然后,我们将发明一种方法来给这些决定分配质量,以便我们可以调整我们的网络的权重,使其在将来做出更像“好”的决定,而不像“坏”的决定。
该系统的细节与我们之前的分类器工作在以下方面有所不同:
-
模型在游戏过程中多次被调用(在每个时间步长)。
-
模型的输出(图 11.4 中的策略网络框中的输出)是对数而不是概率分数。通过 S 形函数将对数值转换为概率分数。我们之所以不直接在策略网络的最后(输出)层中包含 S 形非线性,是因为我们需要对数值进行训练,我们很快就会看到原因。
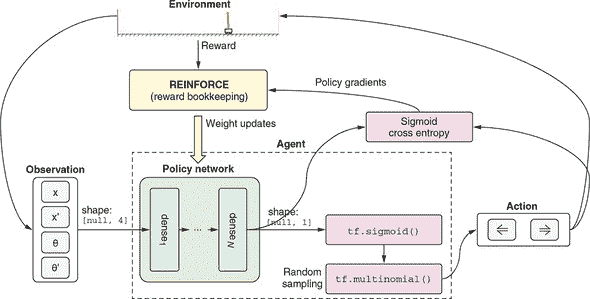
图 11.4。策略网络如何融入我们解决小车-杆问题的解决方案。策略网络是一个 TensorFlow.js 模型,通过使用观察向量(x,x’,θ和θ’)作为输入,输出左向力动作的概率。通过随机抽样将概率转换为实际行动。
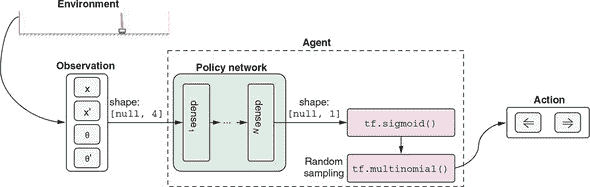
-
由 S 形函数输出的概率必须转换为具体的动作(向左还是向右)。这是通过随机抽样
tf.multinomial()函数调用完成的。回想一下,在 lstm-text-generation example 中,我们使用tf.multinomial()来对字母表上的 softmax 概率进行抽样以抽取下一个字符。在这里的情况稍微简单一些,因为只有两个选择。
最后一点有着更深层次的含义。考虑到我们可以直接将 tf.sigmoid() 函数的输出通过应用阈值(例如,当网络的输出大于 0.5 时选择左侧动作,否则选择右侧动作)转换为一个动作。为什么我们更倾向于使用 tf.multinomial() 的更复杂的随机抽样方法,而不是这种更简单的方法?答案是我们希望tf.multinomial() 带来的随机性。在训练的早期阶段,策略网络对于如何选择力的方向一无所知,因为其权重是随机初始化的。通过使用随机抽样,我们鼓励它尝试随机动作并查看哪些效果更好。一些随机试验将会失败,而另一些则会获得良好的结果。我们的算法会记住这些良好的选择,并在将来进行更多这样的选择。但是除非允许代理随机尝试,否则这些良好的选择将无法实现。如果我们选择了确定性的阈值方法,模型将被困在其初始选择中。
这将我们带入了强化学习中一个经典而重要的主题,即探索与利用。探索指的是随机尝试;这是 RL 代理发现良好行动的基础。利用意味着利用代理已学到的最优解以最大化奖励。这两者是相互不兼容的。在设计工作 RL 算法时,找到它们之间的良好平衡非常关键。起初,我们想要探索各种可能的策略,但随着我们逐渐收敛于更好的策略,我们希望对这些策略进行微调。因此,在许多算法中,训练过程中的探索通常会逐渐减少。在 cart-pole 问题中,这种减少是隐含在 tf.multinomial() 抽样函数中的,因为当模型的置信水平随着训练增加时,它会给出越来越确定的结果。
清单 11.1(摘自 cart-pole/index.js)展示了创建策略网络的 TensorFlow.js 调用。清单 11.2 中的代码(同样摘自 cart-pole/index.js)将策略网络的输出转换为代理的动作,并返回用于训练目的的对数概率。与我们在前几章遇到的监督学习模型相比,这里的模型相关代码并没有太大不同。
然而,这里根本不同的是,我们没有一组可以用来教模型哪些动作选择是好的,哪些是坏的标记数据集。如果我们有这样的数据集,我们可以简单地在策略网络上调用 fit() 或 fitDataset() 来解决问题,就像我们在前几章中对模型所做的那样。但事实是我们没有,所以智能体必须通过玩游戏并观察到的奖励来弄清楚哪些动作是好的。换句话说,它必须“通过游泳学会游泳”,这是 RL 问题的一个关键特征。接下来,我们将详细看一下如何做到这一点。
策略网络 MLP:基于观察选择动作
createModel(hiddenLayerSizes) { ***1***
if (!Array.isArray(hiddenLayerSizes)) {
hiddenLayerSizes = [hiddenLayerSizes];
}
this.model = tf.sequential();
hiddenLayerSizes.forEach((hiddenLayerSize, i) => {
this.model.add(tf.layers.dense({
units: hiddenLayerSize,
activation: 'elu',
inputShape: i === 0 ? [4] : undefined ***2***
}));
});
this.model.add(tf.layers.dense({units: 1})); ***3***
}
}
-
hiddenLayerSize 控制策略网络除最后一层(输出层)之外的所有层的大小。
-
inputShape 仅在第一层需要。
-
最后一层被硬编码为一个单元。单个输出数字将被转换为选择左向力动作的概率。
从策略网络输出获取 logit 和动作的方法示例
getLogitsAndActions(inputs) {
return tf.tidy(() => {
const logits = this.policyNet.predict(inputs);
const leftProb = tf.sigmoid(logits); ***1***
const leftRightProbs = tf.concat( ***2***
[leftProb, tf.sub(1, leftProb)], 1); ***2***
const actions = tf.multinomial( ***3***
leftRightProbs, 1, null, true); ***3***
return [logits, actions];
});
}
-
将 logit 转换为左向动作的概率值
-
计算两个动作的概率值,因为 tf.multinomial() 需要它们。
-
根据概率值随机抽样动作。四个参数分别是概率值、抽样数量、随机种子(未使用),以及一个指示概率值是否归一化的标志。
训练策略网络:REINFORCE 算法
现在关键问题是如何计算哪些动作是好的,哪些是坏的。如果我们能回答这个问题,我们就能够更新策略网络的权重,使其在未来更有可能选择好的动作,这与监督学习类似。很快能想到的是我们可以使用奖励来衡量动作的好坏。但是车杆问题涉及奖励:1)总是有一个固定值(1);2)只要剧集没有结束,就会在每一步发生。所以,我们不能简单地使用逐步奖励作为度量标准,否则所有动作都会被标记为同样好。我们需要考虑每个剧集持续的时间。
一个简单的方法是在一个剧集中求所有奖励的总和,这给了我们剧集的长度。但是总和能否成为对动作的良好评估?很容易意识到这是不行的。原因在于剧集末尾的步骤。假设在一个长剧集中,智能体一直很好地平衡车杆系统,直到接近结束时做了一些不好的选择,导致剧集最终结束。简单的总和方法会将最后的不良动作和之前的良好动作平等评估。相反,我们希望将更高的分数分配给剧集早期和中间部分的动作,并将较低的分配给靠近结尾的动作。
这引出了 奖励折扣 的概念,一个简单但在 RL 中非常重要的概念:某一步的价值应等于即时奖励加上预期未来奖励。未来奖励可能与即时奖励同等重要,也可能不那么重要。可以通过折扣系数 γ 来量化相对平衡。γ 通常设置为接近但略小于 1 的值,如 0.95 或 0.99。我们可以用公式表示:
公式 11.1。
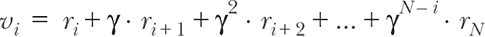
在 公式 11.1 中,v[i] 表示第 i 步状态的总折扣奖励,可以理解为该特定状态的价值。它等于在该步骤给予智能体的即时奖励 (r[i]),加上下一步奖励 (r[i][+1]) 乘以折扣系数 γ,再加上再后两步的折扣奖励,以此类推,直到该事件结束(第 N 步)。
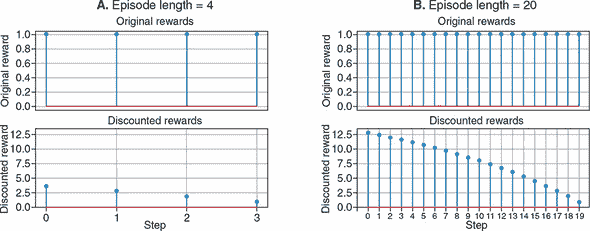
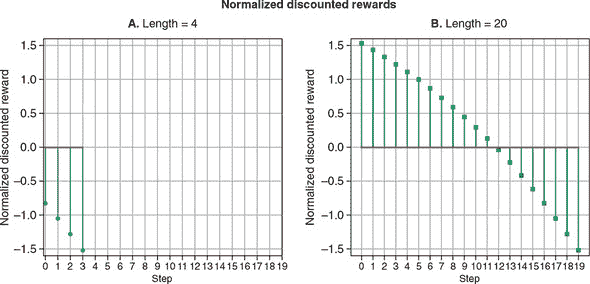
为了说明奖励折扣,我们展示了这个公式如何将原始奖励转换为更有用的价值度量方式,如 图 11.5 所示。面板 A 的顶部图显示了来自一段短情节的所有四步原始奖励。底部图显示了根据 公式 11.1 计算的折扣奖励。为了比较,面板 B 显示了来自长度为 20 的更长情节的原始和折扣总奖励。从两个面板可以看出,折扣总奖励值在开头较高,在结尾较低,这是有意义的,因为我们要为一个游戏结束的动作分配较低的值。此外,长情节的开头和中段的值(面板 B)高于短情节的开头(面板 A)。这也是有意义的,因为我们要为导致更长情节的动作分配更高的值。
图 11.5。面板 A:对四步情节的奖励进行奖励折扣(公式 11.1)。面板 B:与面板 A 相同,但来自一个包含 20 步的情节(即比面板 A 的情节长五倍)。由于折扣,与靠近结尾的动作相比,为每个情节的开始动作分配更高的值。
奖励折扣公式为我们提供了一组比单纯地求和更有意义的值。但我们仍然面临着如何使用这些折扣奖励价值来训练策略网络的问题。为此,我们将使用一种名为 REINFORCE 的算法,该算法由罗纳德·威廉姆斯在 1992 年发明。^([6]) REINFORCE 的基本思想是调整策略网络的权重,使其更有可能做出良好的选择(选择分配更高的折扣奖励)并减少做出不良选择(分配更低的折扣奖励)。
⁶
Ronald J. Williams,“Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning,” Machine Learning, vol. 8, nos. 3–4, pp. 229–256,
mng.bz/WOyw.
为了达到此目的,我们需要计算改变参数的方向,以使给定观察输入更有可能进行动作。这是通过 代码清单 11.3(摘自 cart-pole/index.js)实现的。函数 getGradientsAndSaveActions() 在游戏的每个步骤中被调用。它比较逻辑回归(未归一化的概率得分)和该步骤选择的实际动作,并返回相对于策略网络权重的两者不一致性的梯度。这可能听起来很复杂,但直观上是相当简单的。返回的梯度告诉策略网络如何更改其权重,以使选择更类似于实际选择。这些梯度与训练集的奖励一起构成了我们强化学习方法的基础。这就是为什么该方法属于被称为 策略梯度 的强化学习算法家族的原因。
代码清单 11.3 通过比较逻辑回归和实际动作来获取权重的梯度。
getGradientsAndSaveActions(inputTensor) {
const f = () => tf.tidy(() => {
const [logits, actions] =
this.getLogitsAndActions(inputTensor); ***1***
this.currentActions_ = actions.dataSync();
const labels =
tf.sub(1, tf.tensor2d(this.currentActions_, actions.shape));
return tf.losses.sigmoidCrossEntropy( ***2***
labels, logits).asScalar(); ***2***
});
return tf.variableGrads(f); ***3***
}
-
1
getLogitsAndActions()在 代码清单 11.2 中定义。 -
2 sigmoid 交叉熵损失量化其在游戏中实际执行的动作与策略网络输出的逻辑回归之间的差异。
-
3 计算损失相对于策略网络权重的梯度。
在训练期间,我们让代理对象玩一些游戏(比如 N 个游戏),并根据 方程式 11.1 收集所有折扣奖励以及所有步骤中的梯度。然后,我们通过将梯度与折扣奖励的归一化版本相乘来结合折扣奖励和梯度。奖励归一化在这里是一个重要的步骤。它线性地转移和缩放了 N 个游戏中所有折扣奖励,使得它们的总体均值为 0 和总体标准偏差为 1。图 11.6 显示了在折扣奖励上应用此归一化的示例。它说明了短剧集(长度为 4)和较长剧集(长度为 20)的归一化、折扣奖励。从这张图中可以明确 REINFORCE 算法所偏向的步骤是什么:它们是较长剧集的早期和中间部分的动作。相比之下,所有来自较短(长度为 4)剧集的步骤都被赋予 负 值。负的归一化奖励意味着什么?这意味着当它用于稍后更新策略网络的权重时,它将使网络远离未来给定相似状态输入时进行类似动作的选择。这与正的归一化奖励相反,后者将使策略网络向未来在类似的输入条件下做出相似的动作方向
图 11.6. 对两个长度为 4(面板 A)和 20(面板 B)的情节中的折现奖励进行归一化。我们可以看到,归一化的折现奖励在长度为 20 的情节开始部分具有最高值。策略梯度方法将使用这些折现奖励值来更新策略网络的权重,这将使网络更不可能选择导致第一个情节(长度 = 4)中不良奖励的动作选择,并且更有可能选择导致第二个情节开始部分(长度 = 20)中良好奖励的选择(在相同的状态输入下,即)。
对折现奖励进行归一化,并使用它来缩放梯度的代码有些冗长但不复杂。它在 cart-pole/index.js 中的 scaleAndAverageGradients() 函数中,由于篇幅限制这里不列出。缩放后的梯度用于更新策略网络的权重。随着权重的更新,策略网络将对从分配了更高折现奖励的步骤中的动作输出更高的 logits,并对从分配了较低折现奖励的步骤中的动作输出较低的 logits。
这基本上就是 REINFORCE 算法的工作原理。基于 REINFORCE 的 cart-pole 示例的核心训练逻辑显示在 列表 11.4 中。它是前面描述的步骤的重述:
-
调用策略网络以基于当前代理观察获得 logits。
-
基于 logits 随机采样一个动作。
-
使用采样的动作更新环境。
-
记住以下内容以备后续更新权重(步骤 7):logits 和所选动作,以及损失函数相对于策略网络权重的梯度。这些梯度被称为 策略梯度。
-
从环境中接收奖励,并将其记住以备后用(步骤 7)。
-
重复步骤 1–5 直到完成
numGames情节。 -
一旦所有
numGames情节结束,对奖励进行折扣和归一化,并使用结果来缩放步骤 4 中的梯度。然后使用缩放后的梯度来更新策略网络的权重。(这是策略网络的权重被更新的地方。) -
(未在 列表 11.4 中显示)重复步骤 1–7
numIterations次。
将这些步骤与代码中的步骤进行比较(从 cart-pole/index.js 中摘录),以确保您能够看到对应关系并按照逻辑进行。
列表 11.4. Cart-pole 示例中实现 REINFORCE 算法的训练循环
async train(
cartPoleSystem, optimizer, discountRate, numGames, maxStepsPerGame) {
const allGradients = [];
const allRewards = [];
const gameSteps = [];
onGameEnd(0, numGames);
for (let i = 0; i < numGames; ++i) { ***1***
cartPoleSystem.setRandomState(); ***2***
const gameRewards = [];
const gameGradients = [];
for (let j = 0; j < maxStepsPerGame; ++j) { ***3***
const gradients = tf.tidy(() => {
const inputTensor = cartPoleSystem.getStateTensor();
return this.getGradientsAndSaveActions( ***4***
inputTensor).grads; ***4***
});
this.pushGradients(gameGradients, gradients);
const action = this.currentActions_[0];
const isDone = cartPoleSystem.update(action); ***5***
await maybeRenderDuringTraining(cartPoleSystem);
if (isDone) {
gameRewards.push(0);
break;
} else {
gameRewards.push(1); ***6***
}
}
onGameEnd(i + 1, numGames);
gameSteps.push(gameRewards.length);
this.pushGradients(allGradients, gameGradients);
allRewards.push(gameRewards);
await tf.nextFrame();
}
tf.tidy(() => {
const normalizedRewards = ***7***
discountAndNormalizeRewards(allRewards, discountRate); ***7***
optimizer.applyGradients( ***8***
scaleAndAverageGradients(allGradients, normalizedRewards)); ***8***
});
tf.dispose(allGradients);
return gameSteps;
}
-
1 循环指定次数的情节
-
2 随机初始化一个游戏情节
-
3 循环游戏的步骤
-
4 跟踪每步的梯度以备后续 REINFORCE 训练
-
5 代理在环境中采取一个动作。
-
6 只要游戏尚未结束,代理每步都会获得一个单位奖励。
-
7 对奖励进行折扣和归一化(REINFORCE 的关键步骤)
-
8 使用来自所有步骤的缩放梯度更新策略网络的权重
要看到 REINFORCE 算法的运行情况,请在演示页面上指定 25 个时期,并单击“训练”按钮。默认情况下,训练期间实时显示环境的状态,以便您可以看到学习代理的重复尝试。要加快训练速度,请取消选中“训练期间渲染”复选框。在合理更新的笔记本电脑上,25 个时期的训练需要几分钟,并且应足以达到天花板性能(默认设置下游戏每轮 500 步)。图 11.7 显示了典型的训练曲线,该曲线将平均每轮长度作为训练迭代的函数绘制出来。请注意,训练进度显示出一些戏剧性的波动,平均步数随着迭代次数以非单调和高度嘈杂的方式变化。这种波动在强化学习训练工作中并不罕见。
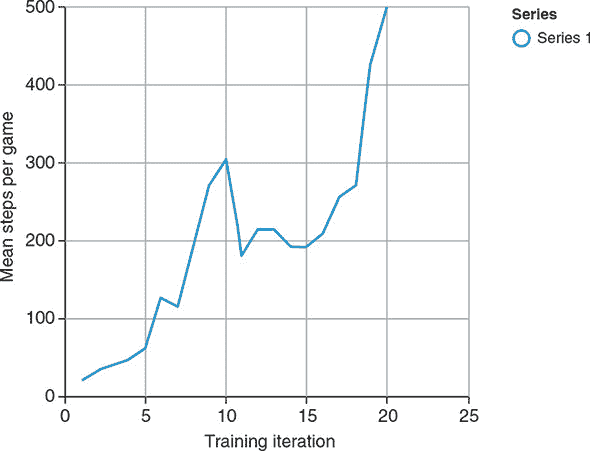
图 11.7. 一条曲线显示了智能体在车杆问题的每个训练迭代中生存的平均步数与训练迭代次数的关系。在约第 20 次迭代时达到完美分数(在本例中为 500 步)。这个结果是在隐藏层大小为 128 的情况下获得的。曲线的高度非单调和波动形状在强化学习问题中并不罕见。
训练完成后,单击“测试”按钮,您应该会看到代理在许多步骤上很好地保持车杆系统平衡的表现。由于测试阶段不涉及最大步数(默认为 500 步),因此代理可以保持游戏进行超过 1,000 步。如果持续时间过长,您可以单击“停止”按钮终止模拟。
总结这一节,图 11.8 概括了问题的表述以及 REINFORCE 策略梯度算法的作用。这张图展示了解决方案的所有主要部分。在每个步骤中,代理使用一个名为策略网络的神经网络来估计向左行动(或等效地,向右行动)是更好的选择的可能性。这种可能性通过一个随机抽样过程转换为实际行动,该过程鼓励代理早期探索并在后期遵守估计的确定性。行动驱动环境中的车杆系统,该系统反过来为代理提供奖励,直到本集的结束。这个过程重复了多个集,期间 REINFORCE 算法记住了每一步的奖励、行动和策略网络的估计。当 REINFORCE 需要更新策略网络时,它通过奖励折现和归一化区分网络中的好估计和坏估计,然后使用结果来推动网络的权重朝着未来做出更好的估计。这个过程迭代了多次,直到训练结束(例如,当代理达到阈值性能时)。
图 11.8. 展示了基于 REINFORCE 算法的解决方案对车杆问题的示意图。该图是图 11.4 中图示的扩展视图。
抛开所有优雅的技术细节,让我们退后一步,看一看这个例子中体现的 RL 的大局。基于 RL 的方法相对于非机器学习方法(如传统控制理论)具有明显的优势:普适性和人力成本的经济性。在系统具有复杂或未知特性的情况下,RL 方法可能是唯一可行的解决方案。如果系统的特性随时间变化,我们不必从头开始推导新的数学解:我们只需重新运行 RL 算法,让代理适应新情况。
RL 方法的劣势,这仍然是 RL 研究领域中一个未解决的问题,是它需要在环境中进行许多次重复试验。在车杆示例中,大约需要 400 个游戏回合才能达到目标水平的熟练程度。一些传统的、非 RL 方法可能根本不需要试验。实施基于控制理论的算法,代理应该能够从第 1 个回合就平衡杆子。对于像车杆这样的问题,RL 对于重复试验的渴望并不是一个主要问题,因为计算机对环境的模拟是简单、快速和廉价的。然而,在更现实的问题中,比如自动驾驶汽车和物体操纵机器臂,RL 的这个问题就变得更加尖锐和紧迫。没有人能承担在训练代理时多次撞车或者摧毁机器臂的成本,更不用说在这样的现实问题中运行 RL 训练算法将需要多么长的时间。
这就结束了我们的第一个 RL 示例。车杆问题具有一些特殊的特征,在其他 RL 问题中不适用。例如,许多 RL 环境并不会在每一步向代理提供正面奖励。在某些情况下,代理可能需要做出几十个甚至更多的决策,才能获得积极的奖励。在正面奖励之间的空隙中,可能没有奖励,或者只有负面奖励(可以说很多现实生活中的努力,比如学习、锻炼和投资,都是如此!)。此外,车杆系统在“无记忆”方面是“无记忆”的,即系统的动态不取决于代理过去的行为。许多 RL 问题比这更复杂,因为代理的行为改变了环境的某些方面。我们将在下一节中研究的 RL 问题将展示稀疏的正面奖励和一个随着行动历史而变化的环境。为了解决这个问题,我们将介绍另一个有用且流行的 RL 算法,称为 deep Q-learning。
11.3. 价值网络和 Q 学习:蛇游戏示例
我们将使用经典的动作游戏 snake 作为我们深度 Q 学习的示例问题。就像我们在上一节中所做的那样,我们将首先描述 RL 问题及其带来的挑战。在这样做的过程中,我们还将讨论为什么策略梯度和 REINFORCE 对这个问题不会非常有效。
11.3.1. 蛇作为一个强化学习问题
蛇游戏首次出现在 1970 年代的街机游戏中,已经成为一个广为人知的视频游戏类型。tfjs-examples 中的 snake-dqn 目录包含一个简单变体的 JavaScript 实现。您可以通过以下代码查看:
git clone https://github.com/tensorflow/tfjs-examples.git
cd tfjs-examples/snake-dqn
yarn
yarn watch
在由yarn watch命令打开的网页中,你可以看到贪吃蛇游戏的棋盘。你可以加载一个预先训练并托管的深度 Q 网络(DQN)模型,并观察它玩游戏。稍后,我们将讨论如何从头开始训练这样的模型。现在,通过观察,你应该能直观地感受到这款游戏是如何运行的。如果你还不熟悉贪吃蛇游戏,它的设置和规则可以总结如下。
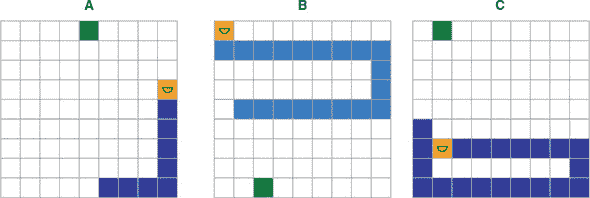
首先,所有动作发生在一个 9×9 的网格世界中(参见图 11.9 的例子)。世界(或棋盘)可以设得更大,但在我们的例子中,9×9 是默认大小。棋盘上有三种类型的方块:蛇、果子和空白。蛇由蓝色方块表示, 只有头部是橙色的,并带有半圆形代表蛇的嘴巴。果子由内部有圆圈的绿色方块表示。空白方块是白色的。游戏按步骤进行,或者按视频游戏术语来说是帧。在每一帧中,代理必须从三个可能的动作中为蛇选择:直行、左转或右转(原地不动不是选项)。当蛇的头部与果子方块接触时,代理被奖励呈积极反应,这种情况下果子方块将消失(被蛇“吃掉”),蛇的长度会在尾部增加一个。一个新的果子将出现在空白方块中。如果代理在某一步没有吃到果子,它将受到负奖励。游戏终止(蛇“死亡”)是指当蛇的头部离开边界(如图 11.9 的面板 B)或撞到自己的身体时。
图 11.9. 贪吃蛇游戏:一个网格世界, 玩家控制蛇吃果子。蛇的“目标”是通过有效的移动模式尽可能多地吃果子(面板 A)。每次吃一个果子蛇的长度增加 1。游戏结束(蛇“死掉”)是当蛇离开边界(面板 B)或撞到自己的身体(面板 C)时。注意,在面板 B 中,蛇的头部到达边缘位置,然后发生了向上的运动(直行动作),导致游戏终止。简单到达边缘方块并不会导致终止。吃掉每个果子会导致一个很大的正奖励。在没有吃果子的情况下移动一个方块会导致一个较小幅度的负奖励。游戏终止(蛇死亡)也会导致一个负奖励。
蛇游戏中的一个关键挑战是蛇的增长。如果没有这个规则,游戏会简单得多。只需一遍又一遍地将蛇导航到水果,智能体可以获得无限的奖励。然而,有了长度增长规则,智能体必须学会避免撞到自己的身体,随着蛇吃更多的水果和变得更长,这变得更加困难。这是蛇 RL 问题的非静态方面,推车杆环境所缺乏的,正如我们在上一节末尾提到的。
表 11.2 在经典 RL 表述中描述了蛇问题。与推车杆问题的表述(表 11.1)相比,最大的区别在于奖励结构。在蛇问题中,正奖励(每吃一颗水果+10)出现不频繁——也就是说,只有在蛇移动到达水果后,经历了一系列负奖励后才会出现。考虑到棋盘的大小,即使蛇以最有效的方式移动,两个正奖励之间的间隔也可能长达 17 步。小的负奖励是一个惩罚,鼓励蛇走更直接的路径。没有这个惩罚,蛇可以以蜿蜒的间接方式移动,并且仍然获得相同的奖励,这将使游戏和训练过程不必要地变长。这种稀疏而复杂的奖励结构也是为什么策略梯度和 REINFORCE 方法在这个问题上效果不佳的主要原因。策略梯度方法在奖励频繁且简单时效果更好,就像推车杆问题一样。
表 11.2. 在经典 RL 表述中描述蛇游戏问题
| 抽象 RL 概念 | 在蛇问题中的实现 |
|---|---|
| 环境 | 一个包含移动蛇和自我补充水果的网格世界。 |
| 动作 | (离散) 三元选择:直行,左转,或右转。 |
| 奖励 | (频繁,混合正负奖励)
-
吃水果——大正奖励 (+10)
-
移动而不吃水果——小负奖励 (–0.2)
-
死亡——大负奖励 (–10)
|
| 观测 | (完整状态,离散) 每一步,智能体可以访问游戏的完整状态:即棋盘上每个方块的内容。 |
|---|
蛇的 JavaScript API
我们的 JavaScript 实现可以在文件 snake-dqn/snake_ game.js 中找到。我们只会描述SnakeGame类的 API,并略过实现细节,如果你感兴趣,可以自行学习。SnakeGame类的构造函数具有以下语法:
const game = new SnakeGame({height, width, numFruits, initLen});
这里,棋盘的大小参数,height和width,默认值为 9。numFruits是棋盘上任意给定时间存在的水果数量,默认值为 1。initLen,蛇的初始长度,默认值为 2。
game对象暴露的step()方法允许调用者在游戏中执行一步:
const {state, reward, done, fruitEaten} = game.step(action);
step() 方法的参数表示动作:0 表示直行,1 表示向左转,2 表示向右转。step() 方法的返回值具有以下字段:
-
state—动作后立即棋盘的新状态,表示为具有两个字段的普通 JavaScript 对象:-
s—蛇占据的方块,以[x, y]坐标数组形式表示。此数组的元素按照头部对应第一个元素,尾部对应最后一个元素的顺序排列。 -
f—水果占据的方块的[x, y]坐标。请注意,此游戏状态的表示设计为高效,这是由 Q 学习算法存储大量(例如,成千上万)这样的状态对象所必需的,正如我们很快将看到的。另一种方法是使用数组或嵌套数组来记录棋盘上每个方块的状态,包括空的方块。这将是远不及空间高效的方法。
-
-
reward—蛇在步骤中立即执行动作后获得的奖励。这是一个单一数字。 -
done—一个布尔标志,指示游戏在动作发生后是否立即结束。 -
fruitEaten—一个布尔标志,指示蛇在动作中是否吃到了水果。请注意,这个字段部分冗余于reward字段,因为我们可以从reward推断出是否吃到了水果。它包含在内是为了简单起见,并将奖励的确切值(可能是可调节的超参数)与水果被吃与未被吃的二进制事件解耦。
正如我们将在稍后看到的,前三个字段(state、reward 和 done)在 Q 学习算法中将发挥重要作用,而最后一个字段(fruitEaten)主要用于监视。
11.3.2. 马尔可夫决策过程和 Q 值
要解释我们将应用于蛇问题的深度 Q 学习算法,首先需要有点抽象。特别是,我们将以基本水平介绍马尔可夫决策过程(MDP)及其基本数学。别担心:我们将使用简单具体的示例,并将概念与我们手头的蛇问题联系起来。
从 MDP 的视角看,RL 环境的历史是通过有限数量的离散状态的一系列转换。此外,状态之间的转换遵循一种特定类型的规则:
下一步环境的状态完全由代理在当前步骤采取的状态和动作决定。
关键是下一个状态仅取决于两件事:当前状态和采取的动作,而不是其他。换句话说,MDP 假设你的历史(你如何到达当前状态)与决定下一步该做什么无关。这是一个强大的简化,使问题更易处理。什么是 非马尔可夫决策过程?这将是一种情况,即下一个状态不仅取决于当前状态和当前动作,还取决于先前步骤的状态或动作,可能一直追溯到情节开始。在非马尔可夫情况下,数学会变得更加复杂,解决数学问题需要更多的计算资源。
对于许多强化学习问题来说,马尔可夫决策过程的要求是直观的。象棋游戏是一个很好的例子。在游戏的任何一步中,棋盘配置(以及轮到哪个玩家)完全描述了游戏状态,并为玩家提供了计算下一步移动所需的所有信息。换句话说,可以从棋盘配置恢复棋局而不知道先前的移动。 (顺便说一句,这就是为什么报纸可以以非常节省空间的方式发布国际象棋谜题的原因。)像贪吃蛇这样的视频游戏也符合马尔可夫决策过程的公式化。蛇和食物在棋盘上的位置完全描述了游戏状态,这就足以从那一点恢复游戏或代理决定下一步行动。
尽管诸如国际象棋和贪吃蛇等问题与马尔可夫决策过程完全兼容,但它们都涉及天文数字级别的可能状态。为了以直观和视觉的方式呈现马尔可夫决策过程,我们需要一个更简单的例子。在 图 11.10 中,我们展示了一个非常简单的马尔可夫决策过程问题,其中只有七种可能的状态和两种可能的代理动作。状态之间的转换受以下规则管理:
-
初始状态始终为 s[1]。
-
从状态 s[1] 开始,如果代理采取动作 a[1],环境将进入状态 s[2]。如果代理采取动作 a[2],环境将进入状态 s[3]。
-
从每个状态 s[2] 和 s[3],进入下一个状态的转换遵循一组类似的分叉规则。
-
状态 s[4]、s[5]、s[6] 和 s[7] 是终止状态:如果达到任何一个状态,那么该情节结束。
图 11.10. 马尔可夫决策过程(MDP)的一个非常简单具体的例子。状态表示为标有 s[n] 的灰色圆圈,而动作表示为标有 a[m] 的灰色圆圈。由动作引起的每个状态转换的奖励标有 r = x。
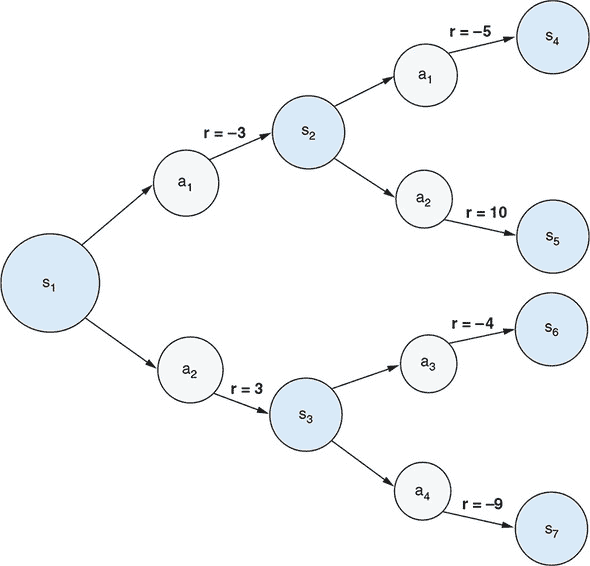
因此,在这个强化学习问题中,每个阶段都恰好持续三个步骤。在这个强化学习问题中,代理应该如何决定在第一步和第二步采取什么行动?考虑到我们正在处理一个强化学习问题,只有在考虑奖励时,这个问题才有意义。在马尔可夫决策过程中,每个动作不仅引起状态转移,而且还导致奖励。在 图 11.10 中,奖励被描述为将动作与下一个状态连接的箭头,标记为 r = <reward_value>。代理的目标当然是最大化总奖励(按比例折现)。现在想象一下我们是第一步的代理。让我们通过思考过程来确定我们将选择 a[1] 还是 a[2] 更好的选择。假设奖励折现因子(γ)的值为 0.9。
思考过程如下。如果我们选择动作 a[1],我们将获得–3 的即时奖励并转移到状态 s[2]。如果我们选择动作 a[2],我们将获得 3 的即时奖励并转移到状态 s[3]。这是否意味着 a[2] 是更好的选择,因为 3 大于 –3?答案是否定的,因为 3 和 –3 只是即时奖励,并且我们还没有考虑以下步骤的奖励。我们应该看看每个 s[2] 和 s[3] 的最佳可能结果是什么。从 s[2] 得到的最佳结果是通过采取动作 a[2] 而产生的结果,该动作获得了 11 的奖励。这导致我们从状态 s[1] 采取动作 a[1] 可以期望的最佳折现奖励:
| 当从状态 s[1] 采取动作 a[1] 时的最佳奖励 = 即时奖励 + 折现未来奖励 |
|---|
同样,从状态 s[3] 得到的最佳结果是我们采取动作 a[1],这给我们带来了–4 的奖励。因此,如果我们从状态 s[1] 采取动作 a[2],我们可以得到的最佳折现奖励是
| 当从状态 s[1] 采取动作 a[2] 时的最佳奖励 = 即时奖励 + 折现未来奖励 |
|---|
我们在这里计算的折现奖励是我们所说的 Q-values 的示例。 Q-value 是给定状态的动作的预期总累积奖励(按比例折现)。从这些 Q-values 中,很明显 a[1] 是在状态 s[1] 下更好的选择——这与仅考虑第一个动作造成的即时奖励的结论不同。本章末尾的练习 3 将指导您完成涉及随机性的更现实的 MDP 情景的 Q-value 计算。
描述的示例思考过程可能看起来微不足道。但它引导我们得到一个在 Q 学习中起着核心作用的抽象。Q 值,表示为 Q(s, a),是当前状态 (s) 和动作 (a) 的函数。换句话说,Q(s, a) 是一个将状态-动作对映射到在特定状态采取特定动作的估计值的函数。这个值是长远眼光的,因为它考虑了最佳未来奖励,在所有未来步骤中都选择最优动作的假设下。
由于它的长远眼光,Q(s, a) 是我们在任何给定状态决定最佳动作的全部内容。特别是,鉴于我们知道 *Q*(*s*, *a*) 是什么,最佳动作是在所有可能动作中给出最高 Q 值的动作:
方程 11.2.
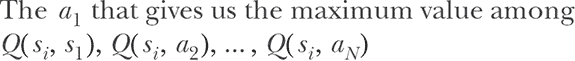
其中 N 是所有可能动作的数量。如果我们对 Q(s, a) 有一个很好的估计,我们只需在每一步简单地遵循这个决策过程,我们就能保证获得最高可能的累积奖励。因此,找到最佳决策过程的强化学习问题被简化为学习函数 Q(s, a)。这就是为什么这个学习算法被称为 Q 学习的原因。
让我们停下来,看看 Q 学习与我们在小车杆问题中看到的策略梯度方法有何不同。策略梯度是关于预测最佳动作的;Q 学习是关于预测所有可能动作的值(Q 值)。虽然策略梯度直接告诉我们选择哪个动作,但 Q 学习需要额外的“选择最大值”的步骤,因此稍微间接一些。这种间接性带来的好处是,它使得在涉及稀疏正奖励(如蛇)的问题中更容易形成奖励和连续步骤值之间的连接,从而促进学习。
奖励与连续步骤的值之间有什么联系?当我们解决简单的 MDP 问题时,我们已经窥见了这一点,见图 11.10。这种连接可以用数学方式表示为:
方程 11.3.
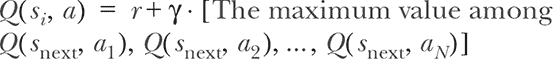
s[next] 是我们在状态 s[i] 中选择动作 a 后到达的状态。这个方程被称为贝尔曼方程,是我们在简单的早期示例中得到数字 6 和 -0.6 的抽象。简单来说,这个方程表示:
⁷
归因于美国应用数学家理查德·E·贝尔曼(1920–1984)。参见他的书 Dynamic Programming,普林斯顿大学出版社,1957 年。
在状态 s[i] 采取动作 a 的 Q 值是两个术语的总和:
- 由于 a 而产生的即时奖励,以及
- 从下一个状态中获得的最佳 Q 值乘以一个折扣因子(“最佳”是指在下一个状态选择最优动作的意义上)
贝尔曼方程是使 Q 学习成为可能的因素,因此很重要理解。你作为程序员会立即注意到贝尔曼方程(方程 11.3)是递归的:方程右侧的所有 Q 值都可以使用方程本身进一步展开。我们在图 11.10 中解释的示例在两步之后结束,而真实的 MDP 问题通常涉及更多步骤和状态,甚至可能包含状态-动作-转换图中的循环。但贝尔曼方程的美丽和力量在于,它允许我们将 Q 学习问题转化为一个监督学习问题,即使对于大状态空间也是如此。我们将在下一节解释为什么会这样。
11.3.3。深度 Q 网络
手工制作函数Q(s, a)可能很困难,因此我们将让函数成为一个深度神经网络(在本节中之前提到的 DQN),并训练其参数。这个 DQN 接收一个表示环境完整状态的输入张量——也就是蛇板配置,这个张量作为观察结果提供给智能体。正如图 11.11 所示,该张量的形状为[9, 9, 2](不包括批次维度)。前两个维度对应于游戏板的高度和宽度。因此,张量可以被视为游戏板上所有方块的位图表示。最后一个维度(2)是代表蛇和水果的两个通道。特别地,蛇被编码在第一个通道中,头部标记为 2,身体标记为 1。水果被编码在第二个通道中,值为 1。在两个通道中,空方块用 0 表示。请注意,这些像素值和通道数目是或多或少任意的。其他值排列(例如,蛇头为 100,蛇身为 50,或者将蛇头和蛇身分成两个通道)也可能有效,只要它们保持三种实体(蛇头、蛇身和水果)是不同的。
图 11.11。蛇游戏的板状态如何表示为形状为[9, 9, 2]的三维张量
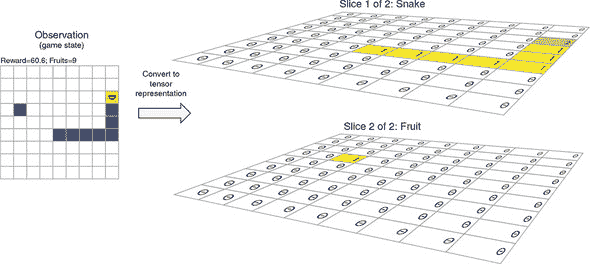
请注意,这种游戏状态的张量表示比我们在上一节中描述的由字段s和f组成的 JSON 表示要不太空间有效,因为它总是包含板上的所有方块,无论蛇有多长。这种低效的表示仅在我们使用反向传播来更新 DQN 的权重时使用。此外,在任何给定时间,由于我们即将访问的基于批次的训练范式,这种方式下只存在一小部分(batchSize)游戏状态。
将有效表示的棋盘状态转换为图 11.11 中所示张量的代码可以在 snake-dqn/snake_game.js 的getStateTensor()函数中找到。这个函数在 DQN 的训练过程中会被频繁使用,但我们这里忽略其细节,因为它只是根据蛇和水果的位置机械地为张量缓冲区的元素赋值。
你可能已经注意到这种[height, width, channel]的输入格式恰好是卷积神经网络设计来处理的。我们使用的 DQN 是熟悉的卷积神经网络架构。定义 DQN 拓扑的代码可以在列表 11.5 中找到(从 snake-dqn/dqn.js 中摘录,为了清晰起见删除了一些错误检查代码)。正如代码和图 11.12 中的图示所示,网络由一组 conv2d 层后跟一个 MLP 组成。额外的层包括 batchNormalization 和 dropout 被插入以增加 DQN 的泛化能力。DQN 的输出形状为[3](排除批次维度)。输出的三个元素是对应动作(向左转,直行和向右转)的预测 Q 值。因此,我们对Q(s, a)的模型是一个神经网络,它以状态作为输入,并输出给定该状态的所有可能动作的 Q 值。
图 11.12 作为蛇问题中Q(s, a)函数的近似所使用的 DQN 的图示示意图。在“Online DQN”框中,“BN”代表 BatchNormalization。
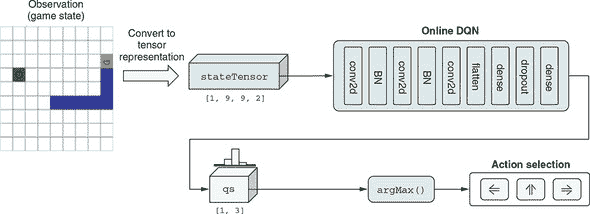
列表 11.5 创建蛇问题的 DQN
export function createDeepQNetwork(h, w, numActions) {
const model = tf.sequential();
model.add(tf.layers.conv2d({ ***1***
filters: 128,
kernelSize: 3,
strides: 1,
activation: 'relu',
inputShape: [h, w, 2] ***2***
}));
model.add(tf.layers.batchNormalization()); ***3***
model.add(tf.layers.conv2d({
filters: 256,
kernelSize: 3,
strides: 1,
activation: 'relu'
}));
model.add(tf.layers.batchNormalization());
model.add(tf.layers.conv2d({
filters: 256,
kernelSize: 3,
strides: 1,
activation: 'relu'
}));
model.add(tf.layers.flatten()); ***4***
model.add(tf.layers.dense({units: 100, activation: 'relu'}));
model.add(tf.layers.dropout({rate: 0.25})); ***5***
model.add(tf.layers.dense({units: numActions}));
return model;
}
-
1 DQN 具有典型的卷积神经网络架构:它始于一组 conv2d 层。
-
2 输入形状与代理观察的张量表示相匹配,如图 11.11 所示。
-
3 batchNormalization 层被添加以防止过拟合并提高泛化能力
-
4 DQN 的 MLP 部分以一个 flatten 层开始。
-
5 与 batchNormalization 类似,dropout 层被添加以防止过拟合。
让我们停下来思考一下为什么在这个问题中使用神经网络作为函数Q(s, a)是有意义的。蛇游戏具有离散状态空间,不像连续状态空间的车杆问题,后者由四个浮点数组成。因此,Q(s, a)函数原则上可以实现为查找表,即将每个可能的棋盘配置和动作组合映射为Q的值。那么为什么我们更喜欢 DQN 而不是这样的查找表呢?原因在于,即使是相对较小的棋盘尺寸(9×9),可能的棋盘配置也太多了,导致了查找表方法的两个主要缺点。首先,系统 RAM 无法容纳如此庞大的查找表。其次,即使我们设法构建了具有足够 RAM 的系统,代理在 RL 期间访问所有状态也需要耗费非常长的时间。DQN 通过其适度大小(约 100 万参数)解决了第一个(内存空间)问题。它通过神经网络的泛化能力解决了第二个(状态访问时间)问题。正如我们在前面章节中已经看到的大量证据所示,神经网络不需要看到所有可能的输入;它通过泛化学习来插值训练示例。因此,通过使用 DQN,我们一举解决了两个问题。
⁸
一个粗略的估算表明,即使我们将蛇的长度限制为 20,可能的棋盘配置数量也至少达到 10¹⁵数量级。例如,考虑蛇长度为 20 的特定情况。首先,为蛇头选择一个位置,共有 81 种可能性(9 * 9 = 81)。然后第一段身体有四个可能的位置,接着第二段有三个可能的位置,依此类推。当然,在一些身体姿势的配置中,可能的位置会少于三个,但这不应显著改变数量级。因此,我们可以估算出长度为 20 的蛇可能的身体配置数量约为 81 * 4 * 3¹⁸ ≈ 10¹²。考虑到每种身体配置有 61 种可能的水果位置,关节蛇-水果配置的估算增加到了 10¹⁴。类似的估算可以应用于更短的蛇长度,从 2 到 19。将从长度 2 到 20 的估算数字求和得到了 10¹⁵数量级。与我们的蛇棋盘上的方块数量相比,视频游戏如 Atari 2600 游戏涉及更多的像素,因此更不适合查找表方法。这就是为什么 DQNs 是解决这类视频游戏使用 RL 的适当技术之一,正如 DeepMind 的 Volodymyr Mnih 及其同事在 2015 年的里程碑式论文中所示的那样。
11.3.4. 训练深度 Q 网络
现在,我们有了一个 DQN,可以在蛇游戏的每一步估计出三个可能行动的 Q 值。为了实现尽可能大的累积奖励,我们只需要在每一步运行 DQN,并选择具有最高 Q 值的动作即可。我们完成了吗?并没有,因为 DQN 还没有经过训练!没有适当的训练,DQN 只会包含随机初始化的权重,它给出的动作不会比随机猜测更好。现在,蛇的强化学习问题已经被减少为如何训练 DQN 的问题,这是我们在本节中要讨论的主题。这个过程有些复杂。但别担心:我们将使用大量的图表以及代码摘录,逐步详细说明训练算法。
深度 Q 网络训练的直觉
我们将通过迫使 DQN 与贝尔曼方程相匹配来训练我们的 DQN。如果一切顺利,这意味着我们的 DQN 将同时反映即时奖励和最优折现未来奖励。
我们该如何做到这一点呢?我们需要的是许多输入-输出对的样本,其中输入是实际采取的状态和动作,而输出是 Q 的“正确”(目标)值。计算输入样本需要当前状态 s[i] 和我们在该状态下采取的动作 a[j],这两者都可以直接从游戏历史中获取。计算目标 Q 值需要即时奖励 r[i] 和下一个状态 s[i][+1],这两者也可以从游戏历史中获取。我们可以使用 r[i] 和 s[i][+1],通过应用贝尔曼方程来计算目标 Q 值,其细节将很快涉及到。然后,我们将计算由 DQN 预测的 Q 值与贝尔曼方程中的目标 Q 值之间的差异,并将其称为我们的损失。我们将使用标准的反向传播和梯度下降来减少损失(以最小二乘的方式)。使这成为可能和高效的机制有些复杂,但基本的直觉却相当简单。我们想要一个 Q 函数的估计值,以便能做出良好的决策。我们知道我们对 Q 的估计必须与环境奖励和贝尔曼方程相匹配,因此我们将使用梯度下降来实现。简单!
回放内存:用于 DQN 训练的滚动数据集
我们的 DQN 是一个熟悉的卷积网络,在 TensorFlow.js 中作为 tf.LayersModel 的一个实例实现。关于如何训练它,首先想到的是调用其 fit() 或 fitDataset() 方法。然而,我们在这里不能使用常规方法,因为我们没有一个包含观察到的状态和相应 Q 值的标记数据集。考虑这样一个问题:在 DQN 训练之前,没有办法知道 Q 值。如果我们有一个给出真实 Q 值的方法,我们就会在马尔科夫决策过程中使用它并完成。因此,如果我们局限于传统的监督学习方法,我们将面临一个先有鸡还是先有蛋的问题:没有训练好的 DQN,我们无法估计 Q 值;没有良好的 Q 值估计,我们无法训练 DQN。我们即将介绍的强化学习算法将帮助我们解决这个先有鸡还是先有蛋的问题。
具体来说,我们的方法是让代理者随机玩游戏(至少最初是如此),并记住游戏的每一步发生了什么。随机游戏部分很容易通过随机数生成器实现。记忆部分则通过一种称为重放内存的数据结构实现。图 11.13 展示了重放内存的工作原理。它为游戏的每一步存储五个项目:
-
s[i],第 i 步的当前状态观察(棋盘配置)。
-
a[i],当前步骤实际执行的动作(可以是 DQN 选择的,如图 11.12,也可以是随机选择)。
-
r[i],在此步骤接收到的即时奖励。
-
d[i],一个布尔标志,指示游戏在当前步骤后立即结束。由此可见,重放内存不仅仅是为了一个游戏回合。相反,它将来自多个游戏回合的结果连接在一起。一旦前一场游戏结束,训练算法就会简单地开始新的游戏,并将新记录追加到重放内存中。
-
s[i][+1],如果 d[i] 为假,则是下一步的观察。(如果 d[i] 为真,则存储 null 作为占位符。)
图 11.13. 在 DQN 训练过程中使用的重放内存。每一步都将五条数据推到重放内存的末尾。在 DQN 的训练过程中对这些数据进行抽样。
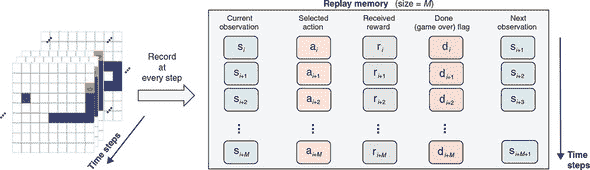
这些数据片段将用于 DQN 的基于反向传播的训练。回放记忆可以被视为 DQN 训练的“数据集”。然而,它不同于监督学习中的数据集,因为它会随着训练的进行而不断更新。回放记忆有一个固定长度M(在示例代码中默认为 10,000)。当一个记录(s[i], a[i], r[i], d[i], s[i][+1])被推到其末尾时,一个旧的记录会从其开始弹出,这保持了一个固定的回放记忆长度。这确保了回放记忆跟踪了训练中最近M步的发生情况,除了避免内存不足的问题。始终使用最新的游戏记录训练 DQN 是有益的。为什么?考虑以下情况:一旦 DQN 训练了一段时间并开始“熟悉”游戏,我们将不希望使用旧的游戏记录来教导它,比如训练开始时的记录,因为这些记录可能包含不再相关或有利于进一步网络训练的幼稚移动。
实现回放记忆的代码非常简单,可以在文件 snake-dqn/replay_memory.js 中找到。我们不会描述代码的详细信息,除了它的两个公共方法,append()和sample():
-
append()允许调用者将新记录推送到回放记忆的末尾。 -
sample(batchSize)从回放记忆中随机选择batchSize个记录。这些记录完全均匀地抽样,并且通常包括来自多个不同情节的记录。sample()方法将用于在计算损失函数和随后的反向传播期间提取训练批次,我们很快就会看到。
epsilon-greedy 算法:平衡探索和利用
一个不断尝试随机事物的智能体将凭借纯运气偶然发现一些好的动作(在贪吃蛇游戏中吃几个水果)。这对于启动智能体的早期学习过程是有用的。事实上,这是唯一的方法,因为智能体从未被告知游戏的规则。但是,如果智能体一直随机行为,它在学习过程中将无法走得很远,因为随机选择会导致意外死亡,而且一些高级状态只能通过一连串良好的动作达到。
这就是蛇游戏中探索与开发的两难境地的体现。我们在平衡摇摆杆的示例中看到了这个两难境地,其中的策略梯度方法通过逐渐增加训练过程中的多项式采样的确定性来解决这个问题。在蛇游戏中,我们没有这个便利,因为我们的动作选择不是基于 tf.multinomial(),而是选择具有最大 Q 值的动作。我们解决这个问题的方式是通过参数化动作选择过程的随机性,并逐渐减小随机性参数。特别地,我们使用所谓的epsilon-greedy 策略。该策略可以用伪代码表示为`
x = Sample a random number uniformly between 0 and 1.
if x < epsilon:
Choose an action randomly
else:
qValues = DQN.predict(observation)
Choose the action that corresponds to the maximum element of qValues
这个逻辑在训练的每一步都会应用。epsilon 的值越大(接近 1),选择动作的随机性越高。相反,epsilon 的值越小(接近 0),基于 DQN 预测的 Q 值选择动作的概率越高。随机选择动作可以看作是对环境的探索(“epsilon” 代表 “exploration”),而选择最大 Q 值的动作被称为贪心。现在你明白了 “epsilon-greedy” 这个名字的来历。
如 代码清单 11.6 所示,实现蛇 DQN 示例中 epsilon-greedy 算法的实际 TensorFlow.js 代码与之前的伪代码具有密切的一对一对应关系。该代码摘自 snake-dqn/agent.js。
代码清单 11.6。实现 epsilon-greedy 算法的部分蛇 DQN 代码
let action;
const state = this.game.getState();
if (Math.random() < this.epsilon) {
action = getRandomAction(); ***1***
} else {
tf.tidy(() => { ***2***
const stateTensor = ***2***
getStateTensor(state, ***2***
this.game.height, ***2***
this.game.width); ***2***
action = ALL_ACTIONS[
this.onlineNetwork.predict( ***3***
stateTensor).argMax(-1).dataSync()[0]]; ***3***
});
}
-
1 探索:随机选择动作
-
2 将游戏状态表示为张量
-
3 贪心策略:从 DQN 获取预测的 Q 值,并找到对应于最高 Q 值的动作的索引
epsilon-greedy 策略在早期需要探索和后期需要稳定行为之间保持平衡。它通过逐渐减小 epsilon 的值,从一个相对较大的值逐渐减小到接近(但不完全等于)零。在我们的蛇 DQN 示例中,epsilon 在训练的前 1 × 105 步中以线性方式逐渐减小从 0.5 到 0.01。请注意,我们没有将 epsilon 减小到零,因为在智能体的训练的高级阶段,我们仍然需要适度的探索程度来帮助智能体发现新的智能举动。在基于 epsilon-greedy 策略的 RL 问题中,epsilon 的初始值和最终值都是可调节的超参数,epsilon 的降低时间也是如此。
在 epsilon-greedy 策略设定下的深度 Q 学习算法背景下,接下来让我们详细了解 DQN 的训练细节。
提取预测的 Q 值
尽管我们正在使用一种新方法来解决 RL 问题,但我们仍然希望将我们的算法塑造成监督学习,因为这样可以让我们使用熟悉的反向传播方法来更新 DQN 的权重。这样的制定需要三个要素:
-
预测的 Q 值。
-
“真实”的 Q 值。请注意,在这里,“真实”一词带有引号,因为实际上并没有办法获得 Q 值的基本真实值。这些值只是我们在训练算法的给定阶段能够得到的Q(s, a)的最佳估计值。因此,我们将其称为目标 Q 值。
-
一个损失函数,它以预测和目标 Q 值作为输入,并输出一个量化两者之间不匹配的数字。
在这个小节中,我们将看看如何从回放记忆中获取预测的 Q 值。接下来的两个小节将讨论如何获取目标 Q 值和损失函数。一旦我们有了这三个要素,我们的蛇 RL 问题基本上就变成了一个简单的反向传播问题。
图 11.14 说明了如何从回放记忆中提取预测的 Q 值的 DQN 训练步骤。应该将这个图表与实现代码清单 11.7 一起查看,以便更好地理解。
图 11.14. 如何从回放记忆和在线 DQN 中获取预测的 Q 值。这是 DQN 训练算法中监督学习部分的两个部分中的第一个部分。这个工作流的结果,即 DQN 预测的 Q 值actionQs,是将与targetQs一起用于计算 MSE 损失的两个参数之一。查看图 11.15 以了解计算targetQs的工作流程。
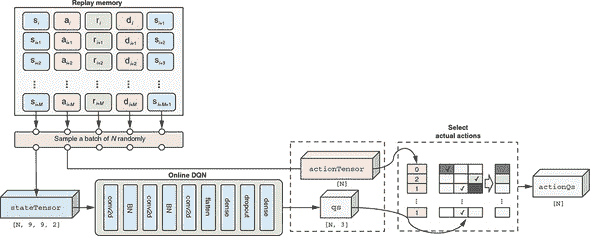
特别地,我们从回放记忆中随机抽取batchSize(默认为N = 128)条记录。正如之前所描述的,每条记录都有五个项目。为了获得预测的 Q 值,我们只需要前两个。第一个项目,包括N个状态观察,一起转换成一个张量。这个批处理的观察张量由在线 DQN 处理,它给出了预测的 Q 值(在图表和代码中都是qs)。然而,qs包含的 Q 值不仅包括实际选择的动作,还包括未选择的动作。对于我们的训练,我们希望忽略未选择动作的 Q 值,因为没有办法知道它们的目标 Q 值。这就是第二个回放记忆项发挥作用的地方。
第二项包含实际选择的动作。它们被格式化成张量表示(图和代码中的 actionTensor)。然后使用 actionTensor 选择我们想要的 qs 元素。这一步骤在图中标记为选择实际动作的框中完成,使用了三个 TensorFlow.js 函数:tf.oneHot()、mul() 和 sum()(参见清单 11.7 中的最后一行)。这比切片张量稍微复杂一些,因为在不同的游戏步骤可以选择不同的动作。清单 11.7 中的代码摘自 snake-dqn/agent.js 中的 SnakeGameAgent.trainOnReplayBatch() 方法,为了清晰起见进行了些许省略。
清单 11.7. 从回放内存中提取一批预测的 Q 值
const batch = this.replayMemory.sample(batchSize); ***1***
const stateTensor = getStateTensor(
batch.map(example => example[0]), ***2***
this.game.height, this.game.width);
const actionTensor = tf.tensor1d(
batch.map(example => example[1]), ***3***
'int32');
const qs = this.onlineNetwork.apply( ***4***
stateTensor, {training: true}) ***4***
.mul(tf.oneHot(actionTensor, NUM_ACTIONS)).sum(-1); ***5***
-
1 从回放内存中随机选择一批大小为 batchSize 的游戏记录
-
2 每个游戏记录的第一个元素是代理的状态观察(参见图 11.13)。它由 getStateTensor() 函数(参见图 11.11)将其从 JSON 对象转换为张量。
-
3 游戏记录的第二个元素是实际选择的动作。它也被表示为张量。
-
4 apply() 方法与 predict() 方法类似,但显式指定了“training: true”标志以启用反向传播。
-
5 我们使用 tf.oneHot()、mul() 和 sum() 来隔离仅针对实际选择的动作的 Q 值,并丢弃未选择的动作的 Q 值。
这些操作给了我们一个名为 actionQs 的张量,其形状为 [N],其中 N 是批次大小。这就是我们寻找的预测的 Q 值,即我们所处的状态 s 和我们实际采取的动作 a 的预测 Q(s, a)。接下来,我们将探讨如何获取目标 Q 值。
提取目标 Q 值:使用贝尔曼方程
获取目标 Q 值比获取预测值稍微复杂一些。这是理论上的贝尔曼方程将被实际应用的地方。回想一下,贝尔曼方程用两个因素描述了状态-动作对的 Q 值:1) 即时奖励和 2) 下一步状态可用的最大 Q 值(通过一个因子折现)。前者很容易获得。它直接作为回放内存的第三项可得到。图 11.15 中的 rewardTensor 用示意图的方式说明了这一点。
图 11.15. 如何从重播记忆和目标 DQN 获取目标 Q 值(targetQs)。此图与图 11.14 共享重播记忆和批量采样部分。应该与列表 11.8 中的代码一起检查。这是进入 DQN 训练算法的监督学习部分的两个部分之一。targetQs在计算中起着类似于前几章中监督学习问题中的真实标签的作用(例如,MNIST 示例中的已知真实标签或 Jena-weather 示例中的已知真实未来温度值)。贝尔曼方程在计算targetQs中起着关键作用。与目标 DQN 一起,该方程允许我们通过形成当前步骤的 Q 值和随后步骤的 Q 值之间的连接来计算targetQs的值。
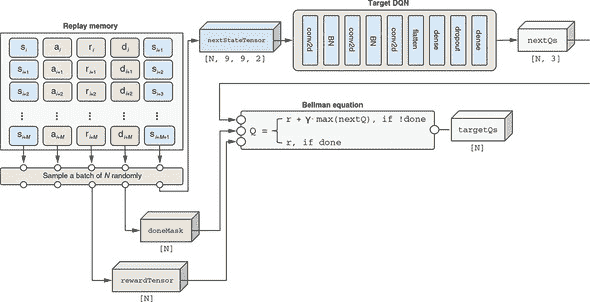
要计算后者(最大的下一步 Q 值),我们需要来自下一步的状态观察。幸运的是,下一步观察被存储在重播记忆中的第五项。我们取随机抽样批次的下一步观察,将其转换为张量,并通过名为目标 DQN的 DQN 的副本运行它(见图 11.15)。这给了我们下一步状态的估计 Q 值。一旦我们有了这些值,我们沿着最后(动作)维度进行max()调用,这导致从下一步状态中获得的最大 Q 值(在列表 11.8 中表示为nextMaxQTensor)。遵循贝尔曼方程,这个最大值乘以折扣因子(图 11.15 中的γ和列表 11.8 中的gamma)并与即时奖励相结合,产生目标 Q 值(在图和代码中均为targetQs)。
注意,只有当当前步骤不是游戏剧集的最后一步时(即,它不会导致蛇死亡),下一步 Q 值才存在。如果是,那么贝尔曼方程的右侧将仅包括即时奖励项,如图 11.15 所示。这对应于列表 11.8 中的doneMask张量。此列表中的代码摘自 snake-dqn/agent.js 中的SnakeGameAgent.trainOnReplayBatch()方法,为了清晰起见做了一些小的省略。
图 11.8. 从重播记忆中提取一批目标(“真实”)Q 值
const rewardTensor = tf.tensor1d(
batch.map(example => example[2])); ***1***
const nextStateTensor = getStateTensor(
batch.map(example => example[4]), ***2***
this.game.height, this.game.width);
const nextMaxQTensor =
this.targetNetwork.predict(nextStateTensor) ***3***
.max(-1); ***4***
const doneMask = tf.scalar(1).sub(
tf.tensor1d(batch.map(example => example[3]))
.asType('float32')); ***5***
const targetQs = ***6***
rewardTensor.add(nextMaxQTensor.mul( ***6***
doneMask).mul(gamma)); ***6***
-
1 重播记录的第三项包含即时奖励值。
-
2 记录的第五项包含下一状态观察。它被转换为张量表示。
-
3 目标 DQN 用于下一个状态张量,它产生下一步所有动作的 Q 值。
-
4 使用
max()函数提取下一步可能的最高奖励。这在贝尔曼方程的右侧。 -
5 doneMask 在终止游戏的步骤上具有值 0,并在其他步骤上具有值 1。
-
6 使用贝尔曼方程来计算目标 Q 值。
正如你可能已经注意到的,在深度 Q 学习算法中的一个重要技巧是使用两个 DQN 实例。它们分别被称为 在线 DQN 和 目标 DQN。在线 DQN 负责计算预测的 Q 值(参见上一小节的 图 11.14)。它也是我们在 epsilon-greedy 算法决定采用贪婪(无探索)方法时选择蛇行动的 DQN。这就是为什么它被称为“在线”网络。相比之下,目标 DQN 仅用于计算目标 Q 值,就像我们刚刚看到的那样。这就是为什么它被称为“目标”DQN。为什么我们使用两个 DQN 而不是一个?为了打破不良反馈循环,这可能会导致训练过程中的不稳定性。
在线 DQN 和目标 DQN 是由相同的 createDeepQNetwork() 函数创建的(清单 11.5)。它们是两个具有相同拓扑结构的深度卷积网络。因此,它们具有完全相同的层和权重集。权重值周期性地从在线 DQN 复制到目标 DQN(在默认设置的 snake-dqn 中每 1,000 步)。这使目标 DQN 与在线 DQN 保持同步。没有这种同步,目标 DQN 将过时,并通过产生贝尔曼方程中最佳下一步 Q 值的劣质估计来阻碍训练过程。
Q 值预测和反向传播的损失函数
有了预测和目标 Q 值,我们使用熟悉的 meanSquaredError 损失函数来计算两者之间的差异(图 11.16)。在这一点上,我们已经成功将我们的 DQN 训练过程转化为一个回归问题,类似于以前的例子,如波士顿房屋和耶拿天气。来自 meanSquaredError 损失的误差信号驱动反向传播;由此产生的权重更新用于更新在线 DQN。
图 11.16. 将 actionQs 和 targetQs 结合在一起,以计算在线 DQN 的 meanSquaredError 预测误差,从而使用反向传播来更新其权重。这张图的大部分部分已经在 图 11.12 和 11.13 中展示过。新添加的部分是 meanSquaredError 损失函数和基于它的反向传播步骤,位于图的右下部分。
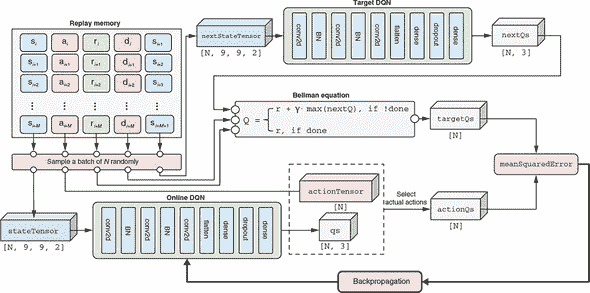
图 11.16 中的示意图包括我们已经在 图 11.12 和 11.13 中展示过的部分。它将这些部分放在一起,并添加了新的框和箭头,用于 meanSquaredError 损失和基于它的反向传播(见图的右下部分)。这完成了我们用来训练蛇游戏代理的深度 Q 学习算法的完整图景。
代码清单 11.9 中的代码与图 11.16 中的图表紧密对应。这是在蛇 DQN / agent.js 中的 SnakeGameAgent 类的 trainOnReplayBatch()方法,它在我们的强化学习算法中发挥着核心作用。该方法定义了一个损失函数,该函数计算预测 Q 值和目标 Q 值之间的 meanSquaredError。然后,它使用tf.variableGrads()函数(附录 B,第 B.4 节包含了有关 TensorFlow.js 的梯度计算函数(如tf.variableGrads())的详细讨论)计算在线 DQN 权重相对于 meanSquaredError 的梯度。通过优化器使用计算出的梯度来更新 DQN 的权重。这将促使在线 DQN 朝着更准确的 Q 值估计方向移动。重复数百万次后,这将导致 DQN 能够引导蛇达到不错的性能。对于下面的列表,已经展示了负责计算目标 Q 值(targetQs)的代码部分(参见代码清单 11.8)。
代码清单 11.9。训练 DQN 的核心函数
trainOnReplayBatch(batchSize, gamma, optimizer) {
const batch = this.replayMemory.sample(batchSize); ***1***
const lossFunction = () => tf.tidy(() => { ***2***
const stateTensor = getStateTensor(
batch.map(example => example[0]),
this.game.height,
this.game.width);
const actionTensor = tf.tensor1d(
batch.map(example => example[1]), 'int32');
const qs = this.onlineNetwork ***3***
.apply(stateTensor, {training: true})
.mul(tf.oneHot(actionTensor, NUM_ACTIONS)).sum(-1);
const rewardTensor = tf.tensor1d(batch.map(example => example[2]));
const nextStateTensor = getStateTensor(
batch.map(example => example[4]),
this.game.height, this.game.width);
const nextMaxQTensor =
this.targetNetwork.predict(nextStateTensor).max(-1);
const doneMask = tf.scalar(1).sub(
tf.tensor1d(batch.map(example => example[3])).asType('float32'));
const targetQs = ***4***
rewardTensor.add(nextMaxQTensor.mul(doneMask).mul(gamma));
return tf.losses.meanSquaredError(targetQs, qs); ***5***
});
const grads = tf.variableGrads( ***6***
lossFunction, this.onlineNetwork.getWeights());
optimizer.applyGradients(grads.grads); ***7***
tf.dispose(grads);
}
-
1 从重播缓冲区中获取一组随机示例
-
2 lossFunction 返回标量,将用于反向传播。
-
3 预测的 Q 值
-
4 通过应用贝尔曼方程计算的目标 Q 值
-
5 使用均方误差(MSE)作为预测和目标 Q 值之间差距的度量
-
6 计算损失函数相对于在线 DQN 权重的梯度
-
7 通过优化器使用梯度更新权重
至此,深度 Q 学习算法的内部细节就介绍完了。在 Node.js 环境中,可以使用以下命令开始基于这个算法的训练:
yarn train --logDir /tmp/snake_logs
如果您有支持 CUDA 的 GPU,请将--gpu标志添加到命令中,以加快训练速度。此--logDir标志让该命令在训练过程中将以下指标记录到 TensorBoard 日志目录中:1)最近 100 个游戏周期内累计奖励的运行平均值(cumulativeReward100);2)最近 100 个周期内食用水果数量的运行平均值(eaten100);3)探索参数的值(epsilon);4)每秒钟处理的步数(framesPerSecond)的训练速度。这些日志可以通过使用以下命令启动 TensorBoard 并导航到 TensorBoard 前端的 HTTP URL(默认为:http://localhost:6006)进行查看:
pip install tensorboard tensorboard --logdir /tmp/snake_logs
图 11.17 展示了一组训练过程中典型的对数曲线。在强化学习中,cumulativeReward100 和 eaten100 曲线都经常展现出波动。经过几个小时的训练,模型可以达到 cumulativeReward100 的最佳成绩为 70-80,eaten100 的最佳成绩约为 12。
图 11.17:tfjs-node 中蛇的强化学习训练过程的示例日志。面板显示:1)cumulativeReward100,最近 100 场游戏的累积奖励的移动平均;2)eaten100,最近 100 场游戏中水果被吃的移动平均;3)epsilon,epsilon 的值,您可以从中看到 epsilon-greedy 策略的时间进程;以及 4)framesPerSecond,训练速度的度量。

训练脚本还会在每次达到新的最佳 cumulativeReward100 值时,将模型保存到相对路径./models/dqn。在调用 yarn watch 命令时,从 web 前端加载保存的模型。前端会在游戏的每一步显示 DQN 预测的 Q 值(参见图 11.18)。在训练期间使用的 epsilon-greedy 策略在训练后的游戏中被“始终贪婪”的策略所取代。蛇的动作总是选择对应于最高 Q 值的动作(例如,在图 11.18 中,直行的 Q 值为 33.9)。这可以直观地了解训练后的 DQN 如何玩游戏。
图 11.18:经过训练的 DQN 估计的 Q 值以数字形式显示,并以不同的绿色叠加在游戏的前端。
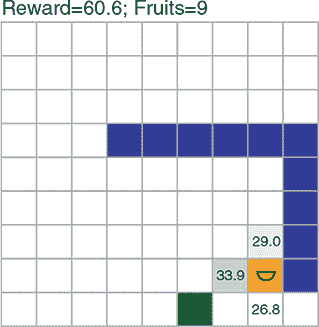
从蛇的行为中有几个有趣的观察。首先,在前端演示中,蛇实际吃到的水果数量(约为 18)平均要大于训练日志中的 eaten100 曲线(约为 12)。这是因为 epsilon-greedy 策略的移除,这消除了游戏过程中的随机动作。请记住,epsilon 在 DQN 训练的后期维持为一个小但非零的值(参见图 11.17 的第三个面板)。由此引起的随机动作偶尔会导致蛇的提前死亡,这就是探索性行为的代价。其次,蛇在靠近水果之前会经过棋盘的边缘和角落,即使水果位于棋盘的中心附近。这种策略对于帮助蛇在长度适中(例如,10-18)时减少碰到自己的可能性是有效的。这并不是坏事,但也不是完美的,因为蛇尚未形成更聪明的策略。例如,蛇在长度超过 20 时经常陷入一个循环。这就是蛇的强化学习算法能够带给我们的。为了进一步改进蛇的智能体,我们需要调整 epsilon-greedy 算法,以鼓励蛇在长度较长时探索更好的移动方式。[9] 在当前的算法中,一旦蛇的长度需要在其自身周围熟练操纵时,探索的程度太低。
⁹
这就是我们对 DQN 技术的介绍结束了。我们的算法是基于 2015 年的论文“通过深度强化学习实现人类水平的控制”,[10],在该论文中,DeepMind 的研究人员首次证明,结合深度神经网络和强化学习的力量使得机器能够解决许多类似 Atari 2600 的视频游戏。我们展示的 snake-dqn 解决方案是 DeepMind 算法的简化版本。例如,我们的 DQN 仅查看当前步骤的观察,而 DeepMind 的算法将当前观察与前几个步骤的观察结合起来作为 DQN 的输入。但我们的示例捕捉到了这一划时代技术的本质——即使用深度卷积网络作为强大的函数逼近器来估计动作的状态相关值,并使用 MDP 和贝尔曼方程进行训练。强化学习研究人员的后续成就,如征服围棋和国际象棋等游戏,都基于类似的深度神经网络和传统非深度学习强化学习方法的结合。
¹⁰
Volodymyr Mnih 等人,《深度强化学习实现人类水平的控制》,自然, vol. 518, 2015, pp. 529–533,www.nature.com/articles/nature14236/。
进一步阅读材料
-
Richard S. Sutton 和 Andrew G. Barto,《强化学习导论》,A Bradford 书籍,2018。
-
David Silver 在伦敦大学学院的强化学习讲座笔记:
www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching.html。 -
Alexander Zai 和 Brandon Brown,《深度强化学习实战》,Manning 出版社,即将出版,www.manning.com/books/deep-reinforcement-learning-in-action。
-
Maxim Laplan,《深度强化学习实战:应用现代强化学习方法,包括深度 Q 网络,值迭代,策略梯度,TRPO,AlphaGo Zero 等》,Packt 出版社,2018。
练习
-
在小车摆杆示例中,我们使用了一个策略网络,其中包含一个带有 128 个单元的隐藏密集层,因为这是默认设置。这个超参数如何影响基于策略梯度的训练?尝试将其更改为小值,如 4 或 8,并将结果的学习曲线(每游戏平均步数与迭代曲线)与默认隐藏层大小的曲线进行比较。这对模型容量和其估计最佳动作的有效性之间的关系告诉了你什么?
-
我们提到使用机器学习解决类似倒立摆的问题的一个优点是人力经济性。具体来说,如果环境意外改变,我们不需要弄清楚它是如何真正改变的并重新确定物理方程,而是可以让代理人自行重新学习问题。通过以下步骤向自己证明这一点。首先,确保倒立摆示例是从源代码而不是托管的网页启动的。使用常规方法训练一个有效的倒立摆策略网络。其次,编辑 cart-pole/cart_pole.js 中的
this.gravity的值,并将其更改为一个新值(例如,如果您要假装我们将倒立摆的配置移到一个比地球更高重力的外行星上,可以将其改为 12)。再次启动页面,加载您在第一步训练的策略网络,并对其进行测试。你能确认它因为重力的改变而表现明显更差吗?最后,再多训练几次策略网络。你能看到策略又逐渐适应新环境而在游戏中表现越来越好吗? -
(有关 MDP 和贝尔曼方程的练习)我们在 第 11.3.2 节 和 图 11.10 中提供的 MDP 示例在一定程度上是简单的,因为状态转移和相关奖励没有随机性。但是,许多现实世界的问题更适合描述为随机 MDP。在随机 MDP 中,代理人在采取行动后将进入的状态和获得的奖励遵循概率分布。例如,如 图 11.19 所示,如果代理人在状态S[1]采取行动A[1],它将以 0.5 的概率进入状态S[2],以 0.5 的概率进入状态S[3]。与这两个状态转换关联的奖励是不同的。在这种随机 MDP 中,代理人必须计算预期未来奖励,以考虑随机性。预期未来奖励是所有可能奖励的加权平均值,权重为概率。你能应用这种概率方法并在图中估计s[1]的a[1]和a[2]的 Q 值吗?根据答案,在状态s[1]时,a[1]和a[2]哪个是更好的行动?
图 11.19. 练习 3 第一部分的 MDP 图表
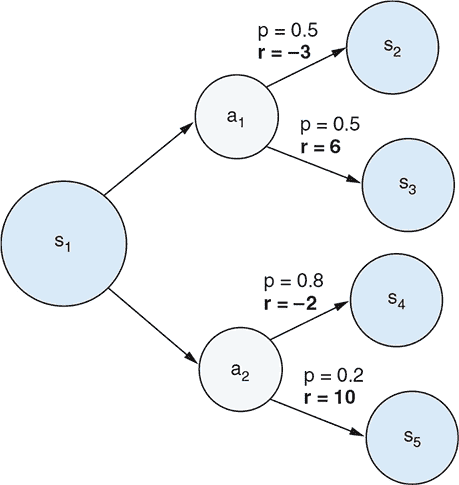
现在让我们看一个稍微复杂一点的随机 MDP,其中涉及多个步骤(参见 图 11.20)。在这种稍微复杂的情况下,您需要应用递归的贝尔曼方程,以考虑第一步之后的可能的最佳未来奖励,这些奖励本身也是随机的。请注意,有时在第一步之后,该情节结束,而有时它将持续进行另一步。你能决定在s[1]时哪个行动更好吗?对于这个问题,您可以使用奖励折扣因子 0.9。
图 11.20。练习 3 第二部分中 MDP 的图表
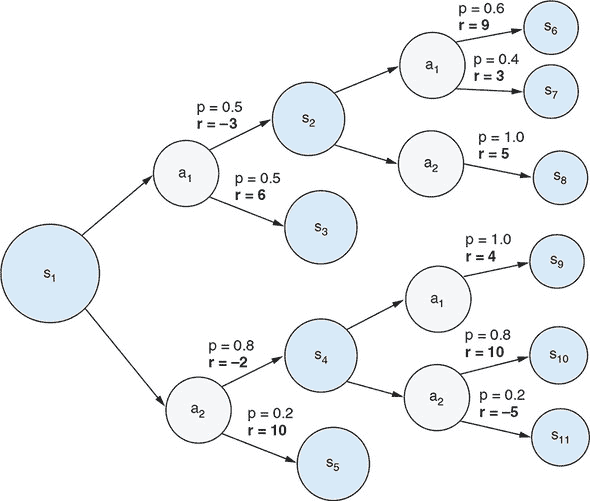
-
在贪吃蛇-dqn 示例中,我们使用ε-贪心策略来平衡探索和利用的需求。默认设置将ε从初始值 0.5 减小到最终值 0.01,并将其保持在那里。尝试将最终ε值更改为较大的值(例如 0.1)或较小的值(例如 0),并观察蛇代理学习效果的影响。您能解释ε扮演的角色造成的差异吗?
摘要
-
作为一种机器学习类型,强化学习是关于学习如何做出最优决策。在强化学习问题中,代理学习在环境中选择行动以最大化称为累积奖励的指标。
-
与监督学习不同,RL 中没有标记的训练数据集。相反,代理必须通过尝试随机动作来学习在不同情况下哪些动作是好的。
-
我们探讨了两种常用的强化学习算法类型:基于策略的方法(以倒立摆为例)和基于 Q 值的方法(以贪吃蛇为例)。
-
策略是一种算法,代理根据当前状态观察选择动作。策略可以封装在一个神经网络中,该网络将状态观察作为输入并产生动作选择作为输出。这样的神经网络称为策略网络。在倒立摆问题中,我们使用策略梯度和 REINFORCEMENT 方法来更新和训练策略网络。
-
与基于策略的方法不同,Q 学习使用一种称为Q 网络的模型来估算在给定观察状态下行动的值。在贪吃蛇-dqn 示例中,我们演示了深度卷积网络如何作为 Q 网络以及如何通过使用 MDP 假设、贝尔曼方程和一种称为回放 记忆的结构来训练它。
第四部分:总结和结束语。
本书的最后一部分包括两个章节。第十二章解决了 TensorFlow.js 用户在部署模型到生产环境时可能遇到的问题。本章讨论了帮助开发人员更有信心地确保模型正确性的最佳实践,使模型体积更小且运行更高效的技术,以及 TensorFlow.js 模型支持的部署环境的范围。第十三章是对整本书的总结,回顾了关键概念、工作流程和技术。
第十二章:测试、优化和部署模型
—有贡献者:Yannick Assogba,Ping Yu 和 Nick Kreeger
本章内容包括
-
机器学习代码测试和监控的重要性和实用指南
-
如何优化在 TensorFlow.js 中训练或转换的模型,以实现更快的加载和推理
-
如何将 TensorFlow.js 模型部署到各种平台和环境中,从浏览器扩展到移动应用,从桌面应用到单板计算机
正如我们在第一章中提到的,机器学习不同于传统软件工程,因为它自动发现规则和启发式方法。本书的前几章应该已经让你对这个机器学习的独特性有了扎实的理解。但是,机器学习模型及其周围的代码仍然是代码;他们作为整体软件系统的一部分运行。为了确保机器学习模型可靠高效地运行,从业者需要像管理非机器学习代码时那样采取相应的预防措施。
本章重点介绍如何在软件堆栈中使用 TensorFlow.js 进行机器学习的实践应用。第一部分探讨了机器学习代码和模型的测试和监控这一至关重要但经常被忽视的话题。第二部分介绍了帮助你优化训练模型、减小计算量和模型大小,从而加快下载和执行速度的工具和技巧。这对于客户端和服务器端模型部署来说是一个至关重要的考虑因素。在最后一部分,我们将为您介绍 TensorFlow.js 创作的模型可以部署到的各种环境。在此过程中,我们将讨论每个部署选项所涉及的独特优势、限制和策略。
本章结束时,你将熟悉关于在 TensorFlow.js 中深度学习模型的测试、优化和部署的最佳实践。
12.1. 测试 TensorFlow.js 模型
到目前为止,我们已经讨论了如何设计、构建和训练机器学习模型。现在,我们将深入探讨一些在部署训练好的模型时会出现的话题,首先是测试 - 包括机器学习代码和相关的非机器学习代码。当你试图在你的模型和其训练过程周围设置测试时,你面临的一些关键挑战包括模型的大小、训练所需的时间以及训练过程中发生的非确定性行为(例如权重初始化和某些神经网络操作(如 dropout)中的随机性)。当我们从一个单独的模型扩展到一个完整的应用程序时,你还会遇到各种类型的偏差或漂移,包括训练和推断代码路径之间的偏差,模型版本问题以及数据中的人口变化。你会发现,为了实现你对整个机器学习系统的可靠性和信心,测试需要配合强大的监控解决方案。
一个关键考虑因素是,“你的模型版本是如何受控制的?”在大多数情况下,模型被调整和训练直到达到满意的评估精度,然后模型就不需要进一步调整了。模型不会作为正常构建过程的一部分进行重建或重新训练。相反,模型拓扑结构和训练权重应该被检入你的版本控制系统中,更类似于二进制大对象(BLOB)而不是文本/代码工件。改变周围的代码不应该导致你的模型版本号更新。同样,重新训练模型并检入它不应该需要改变非模型源代码。
机器学习系统的哪些方面应该被测试?在我们看来,答案是“每个部分”。图 12.1 解释了这个答案。一个从原始输入数据到准备部署的训练好的模型的典型系统包含多个关键组件。其中一些看起来类似于非机器学习代码,并且适合于传统的单元测试覆盖,而其他一些则显示出更多的机器学习特性,因此需要专门定制的测试或监控处理。但这里的重要信息是永远不要忽视或低估测试的重要性,仅仅因为你正在处理一个机器学习系统。相反,我们会认为,单元测试对于机器学习代码来说更加重要,也许甚至比传统软件开发的测试更加重要,因为机器学习算法通常比非机器学习算法更加难以理解。它们在面对不良输入时可能会悄无声息地失败,导致很难察觉和调试的问题,而针对这些问题的防御措施是测试和监控。在接下来的小节中,我们将扩展图 12.1 的各个部分。
图 12.1. 生产就绪的机器学习系统的测试和监控覆盖范围。图的上半部分包括典型机器学习模型创建和训练管道的关键组件。下半部分显示可以应用于每个组件的测试实践。某些组件适合传统的单元测试实践:创建和训练代码以及执行模型输入数据和输出结果的预处理和后处理代码。其他组件需要更多的机器学习特定的测试和监控实践。这些包括用于数据质量的示例验证、监控经过训练的模型的字节大小和推断速度,以及对训练模型所做预测的细粒度验证和评估。
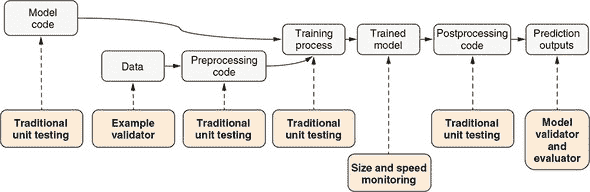
12.1.1. 传统单元测试
就像非机器学习项目一样,可靠且轻量级的单元测试应该构成测试套件的基础。然而,需要特殊考虑来设置围绕机器学习模型的单元测试。正如您在之前的章节中所见,诸如在评估数据集上的准确率之类的度量通常用于量化在成功超参数调整和训练后模型的最终质量。这些评估指标对于人工工程师的监控很重要,但不适合自动化测试。添加一个测试来断言某个评估指标优于某个阈值(例如,二分类任务的 AUC 大于 0.95,或回归任务的 MSE 小于 0.2)是很诱人的。然而,这些基于阈值的断言应该谨慎使用,如果不完全避免的话,因为它们往往很脆弱。模型的训练过程包含多个随机性来源,包括权重的初始化和训练示例的洗牌。这导致模型训练的结果在不同运行中略有不同。如果您的数据集发生变化(例如,由于定期添加新数据),这将形成额外的变异源。因此,选择阈值是一项困难的任务。太宽容的阈值在发生真正问题时无法捕捉到。太严格的阈值将导致一个不稳定的测试,即经常失败而没有真正的潜在问题。
TensorFlow.js 程序中的随机性通常可以通过在创建和运行模型之前调用 Math.seedrandom() 函数来禁用。例如,以下代码将以确定的种子来设置权重初始化器、数据混洗器和退出层的随机状态,以便随后的模型训练产生确定性结果:
Math.seedrandom(42); ***1***
- 1 42 只是一个任意选择的、固定的随机种子。
如果您需要编写对损失或度量值进行断言的测试,这是一个有用的技巧。
然而,即使确定性种子,仅仅测试 model.fit() 之类的调用还不足以对您的机器学习代码进行良好的覆盖。像其他难以进行单元测试的代码部分一样,您应该努力对易于单元测试的周围代码进行全面的单元测试,并探索模型部分的替代解决方案。您用于数据加载、数据预处理、模型输出的后处理以及其他实用方法的代码应该符合正常的测试实践。此外,还可以对模型本身进行一些非严格的测试,比如测试其输入和输出形状,以及“确保模型在训练一步时不会抛出异常”的风格的测试,可以提供最基本的模型测试环境,以在重构过程中保持信心。(正如您在上一章的示例代码中所注意到的,我们在 tfjs-examples 中使用了 Jasmine 测试框架进行测试,但您可以随意使用您和您的团队偏好的任何单元测试框架和运行器。)
作为实践示例,我们可以看一下我们在 第九章 中探索过的情感分析示例的测试。当您查看代码时,您应该会看到 data_test.js、embedding_test.js、sequence_utils_test.js 和 train_test.js 这四个文件。这三个文件覆盖了非模型代码,它们看起来就像普通的单元测试一样。它们的存在使我们对训练和推理过程中进入模型的数据的源格式有了更高的信心,并且我们对它的处理是有效的。
列表中的最后一个文件与机器学习模型有关,值得我们更加关注。下面的代码片段是其中的一部分。
列表 12.1. 模型 API 的单元测试——其输入输出形状和可训练性
describe('buildModel', () => {
it('flatten training and inference', async () => {
const maxLen = 5;
const vocabSize = 3;
const embeddingSize = 8;
const model = buildModel('flatten', maxLen, vocabSize, embeddingSize);
expect(model.inputs.length).toEqual(1); ***1***
expect(model.inputs[0].shape).toEqual([null, maxLen]); ***1***
expect(model.outputs.length).toEqual(1); ***1***
expect(model.outputs[0].shape).toEqual([null, 1]); ***1***
model.compile({
loss: 'binaryCrossentropy',
optimizer: 'rmsprop',
metrics: ['acc']
});
const xs = tf.ones([2, maxLen])
const ys = tf.ones([2, 1]);
const history = await model.fit(xs, ys, { ***2***
epochs: 2, ***2***
batchSize: 2 ***2***
}); ***2***
expect(history.history.loss.length).toEqual(2); ***2******3***
expect(history.history.acc.length).toEqual(2); ***2***
const predictOuts = model.predict(xs); ***4***
expect(predictOuts.shape).toEqual([2, 1]); ***4***
const values = predictOuts.arraySync(); ***4******5***
expect(values[0][0]).toBeGreaterThanOrEqual(0); ***4******5***
expect(values[0][0]).toBeLessThanOrEqual(1); ***4******5***
expect(values[1][0]).toBeGreaterThanOrEqual(0); ***4******5***
expect(values[1][0]).toBeLessThanOrEqual(1); ***4******5***
}); ***5***
});
-
1 确保模型的输入和输出具有预期的形状
-
2 对模型进行非常简短的训练;这个过程应该很快,但不一定准确。
-
3 检查训练是否报告了每次训练步骤的指标,作为训练是否发生的信号
-
4 对模型进行预测以验证 API 是否符合预期
-
5 确保预测值在可能答案的范围内;我们不想检查实际值,因为训练时间非常短可能会不稳定。
这个测试覆盖了很多方面,所以让我们稍微细分一下。我们首先使用一个辅助函数来构建一个模型。在这个测试中,我们并不关心模型的结构,并将其视为一个黑盒子。然后我们对输入和输出的形状进行断言:
expect(model.inputs.length).toEqual(1);
expect(model.inputs[0].shape).toEqual([null, maxLen]);
expect(model.outputs.length).toEqual(1);
expect(model.outputs[0].shape).toEqual([null, 1]);
这些测试可以检测到错误的批次维度(回归或分类)、输出形状等问题。之后,我们在很少的步骤中编译和训练模型。我们的目标仅是确保模型可以被训练,此时我们不担心准确性、稳定性或收敛性:
const history = await model.fit(xs, ys, {epochs: 2, batchSize: 2})
expect(history.history.loss.length).toEqual(2);
expect(history.history.acc.length).toEqual(2);
此代码片段还检查训练是否报告了所需的分析指标:如果我们进行了实际训练,我们能否检查训练的进度和生成模型的准确性?最后,我们尝试一个简单的:
const predictOuts = model.predict(xs);
expect(predictOuts.shape).toEqual([2, 1]);
const values = predictOuts.arraySync();
expect(values[0][0]).toBeGreaterThanOrEqual(0);
expect(values[0][0]).toBeLessThanOrEqual(1);
expect(values[1][0]).toBeGreaterThanOrEqual(0);
expect(values[1][0]).toBeLessThanOrEqual(1);
我们不检查任何特定的预测结果,因为这可能会因权重值的随机初始化或可能的模型架构未来修订而发生变化。我们所检查的是我们获得了预测并且预测在预期范围内,在这种情况下是 0 到 1。
这里最重要的教训是注意到无论我们如何更改模型架构的内部,只要我们不改变其输入或输出 API,这个测试应该始终通过。如果测试失败了,那么我们的模型就有问题。这些测试仍然是轻量级且快速的,提供了强大的 API 正确性,并适合包含在您使用的常见测试挂钩中。
12.1.2. 使用黄金值进行测试
在前一节中,我们讨论了在不断言阈值指标值或不要求稳定或收敛训练的情况下可进行的单元测试。现在让我们探讨人们通常希望在完全训练后的模型上运行的测试类型,从检查特定数据点的预测开始。也许有一些“明显”的示例需要测试。例如,对于一个物体检测器,具有可识别猫咪的输入图像应被标记为识别了猫咪;对于一个情感分析器,明显是负面的客户评论的文本片段应被分类为负面。这些针对给定模型输入的正确答案是我们所谓的“黄金值”。如果盲目地遵循传统单元测试的思路,很容易陷入使用“黄金值”测试训练后的机器学习模型的误区。毕竟,我们希望一个训练良好的物体检测器总是能够在图像中的猫咪上打上“猫”的标记,对吗?并不完全是这样。基于“黄金值”的测试在机器学习设置中可能会存在问题,因为我们篡改了训练、验证和评估数据分割。
假设你的验证集和测试集有代表性的样本,并且你设置了一个合适的目标指标(准确率、召回率等),为什么要求任何一个例子比另一个例子更准确?机器学习模型的训练关注的是整个验证集和测试集的准确率。对于单个样本的预测可能会随着超参数和初始权重值的选择而变化。如果有些例子必须被正确分类并且很容易识别,为什么不在要求机器学习模型对它们进行分类之前检测它们,而是使用非机器学习代码来处理它们呢?在自然语言处理系统中偶尔会使用这样的例子,其中查询输入的子集(如经常遇到且易于识别的输入)会自动路由到非机器学习模块进行处理,而其余的查询会由机器学习模型处理。你会节省计算时间,并且该部分代码更容易通过传统的单元测试进行测试。虽然在机器学习预测器之前(或之后)添加业务逻辑层似乎多此一举,但它为你提供了控制预测覆盖的钩子。这也是你可以添加监控或日志记录的地方,当你的工具变得更广泛使用时,你可能会需要。有了这个前提,让我们分别探讨三种常见的对金标值的需求。
这种类型的金标值测试的一个常见动机是为了进行完整的端到端测试——给定一个未经处理的用户输入,系统会输出什么?机器学习系统经过训练,通过正常的端用户代码流程请求预测,然后将答案返回给用户。这类似于我们在列表 12.1 中的单元测试,但机器学习系统是在应用程序的其余部分的上下文中。我们可以编写一个类似于列表 12.1 的测试,它不关心预测的实际值,实际上,这将是一个更稳定的测试。但是,当开发人员重新访问测试时,将其与一个有意义且容易理解的示例/预测对结合起来是非常诱人的。
这就是问题出现的时候——我们需要一个其预测已知且保证正确的示例,否则端到端测试将失败。因此,我们添加了一个较小规模的测试,通过端到端测试涵盖的管道的子集来测试该预测。现在,如果端到端测试失败,而较小的测试通过,则我们已将错误隔离到核心机器学习模型与管道的其他部分之间的交互(例如数据摄取或后处理)。如果两者同时失败,我们知道我们的示例/预测不变式被打破了。在这种情况下,它更像是一种诊断工具,但配对失败的可能结果是选择一个新的示例进行编码,而不是重新训练模型。
下一个最常见的来源是某种业务需求。某些可识别的示例集必须比其他示例更准确。如前所述,这是添加一个用于处理这些预测的模型前后业务逻辑层的完美设置。但是,您可以尝试示例加权,其中一些示例在计算整体质量指标时占比更多。这不会保证正确性,但它会使模型倾向于获得这些正确。如果由于无法轻松预先识别触发特殊情况的输入属性而导致业务逻辑层困难,则可能需要探索第二个模型——一个纯粹用于确定是否需要覆盖的模型。在这种情况下,您正在使用模型的集成,并且您的业务逻辑是将两个层的预测组合起来执行正确的操作。
这里的最后一种情况是当你有一个带有用户提供示例的错误报告,该示例产生了错误的结果。如果出于业务原因错误,我们回到了刚才讨论的情况。如果出错只是因为它落入模型性能曲线的失败百分比中,那我们应该做的事情就不多了。这在经过训练的算法的可接受性能范围内;所有模型都有可能出错。您可以将示例/正确预测对添加到适当的训练/测试/评估集中,以便希望在未来生成更好的模型,但不适合使用黄金值进行单元测试。
一个例外是如果您保持模型恒定——您已将模型权重和架构检入版本控制,并且在测试中不重新生成它们。那么使用黄金值来测试将使用模型作为其核心的推理系统的输出可能是适当的,因为模型和示例都不会发生变化。这样的推理系统包含除模型之外的其他部分,例如预处理输入数据并将其馈送到模型的部分以及获取模型输出并将其转换为更适合下游系统使用的形式的部分。这样的单元测试确保了这种预处理和后处理逻辑的正确性。
另一个合理使用黄金值的场景是在单元测试之外:随着模型的演化监控模型的质量(但不作为单元测试)。我们将在下一节讨论模型验证器和评估器时进行详细展开。
12.1.3. 关于持续训练的考虑
在许多机器学习系统中,您会定期获得新的训练数据(每周或每天)。也许你能够使用前一天的日志生成新的、更及时的训练数据。在这种系统中,模型需要经常重新训练,使用最新可用的数据。在这些情况下,人们相信模型的年龄或陈旧程度会影响其能力。随着时间的推移,模型的输入会漂移到与其训练不同的分布,因此质量特征会变差。例如,你可能有一个服装推荐工具,在冬天训练过,但在夏天做出预测。
在你开始探索需要连续训练的系统时,根据这个基本思想,你将拥有多种额外组件来创建你的流水线。关于这些组件的全面讨论超出了本书的范围,但 TensorFlow Extended(TFX)^([1])是一个值得一看的基础设施,可以提供更多的想法。在测试领域中,它列出的最相关的流水线组件是示例验证器,模型验证器和模型评估器。图 12.1 中的图表包含与这些组件对应的框。
¹
Denis Baylor 等人,“TFX:基于 TensorFlow 的生产规模机器学习平台”,KDD 2017,www.kdd.org/kdd2017/papers/view/tfx-a-tensorflow-based-production-scale-machine-learning-platform。
示例验证器是关于测试数据的,这是测试机器学习系统时容易忽视的一个方面。在机器学习实践者中有一句著名的话:“垃圾进,垃圾出。”训练好的机器学习模型的质量受到输入数据质量的限制。具有无效特征值或不正确标签的示例在部署使用时(即使模型训练任务由于坏示例而失败!)可能会影响训练模型的准确性。示例验证器用于确保进入模型训练和评估的数据的属性始终满足某些要求:你有足够的数据,其分布看起来有效,并且没有任何奇怪的离群值。例如,如果你有一组医疗数据,身高(以厘米为单位)应该是一个不大于 280 的正数;患者年龄应该是 0 到 130 之间的正数;口腔温度(以摄氏度为单位)应该是大约在 30 到 45 之间的正数,等等。如果某些数据示例包含超出这些范围的特征或具有“None”或 NaN 等占位符值,我们就知道这些示例有问题,它们应该相应地处理——在大多数情况下,排除在训练和评估之外。通常,这里的错误表明数据收集过程失败,或者当构建系统时持有的假设与“世界变化”的方式不兼容。通常,这更类似于监视和警报,而不是集成测试。
像示例验证器这样的组件还对检测训练服务偏差有用,这是机器学习系统中可能出现的一种特别严重的错误。两个主要原因是 1)属于不同分布的训练和服务数据,以及 2)数据预处理涉及在训练和服务期间行为不同的代码路径。部署到训练和服务环境的示例验证器有潜力捕获通过任一路径引入的错误。
模型验证器扮演着构建模型的人在决定模型是否“足够好”以用于服务的角色。你可以根据自己关心的质量指标对其进行配置,然后它要么“祝福”该模型,要么拒绝它。再次强调,就像示例验证器一样,这更像是一种监视和警报式的交互。你还通常会想要随时间记录和绘制你的质量指标(准确度等),以便查看是否存在可能不会单独触发警报但可能仍然有用于诊断长期趋势并隔离其原因的小规模系统性恶化。
模型评估器是对模型质量统计的更深入的探究,沿着用户定义的轴切割和分析质量。通常,这用于探测模型是否对不同的用户群体——年龄段、教育水平、地理位置等——表现公平。一个简单的例子是查看我们在第 3.3 节中使用的鸢尾花示例,并检查我们的分类准确率在三种鸢尾花物种之间是否大致相似。如果我们的测试或评估集对其中一种人口有异常偏向,那么可能我们总是在最小的人口上出错,但这并没有显示为一个最高级别的准确性问题。与模型验证器一样,随时间变化的趋势通常与个别时点的测量一样有用。
12.2. 模型优化
一旦您费尽心思地创建、训练和测试了您的模型,就该是将其投入使用的时候了。这个过程被称为模型部署,它与模型开发的前几个步骤同样重要。无论模型是要在客户端进行推理还是在后端进行服务,我们总是希望模型能够快速高效。具体而言,我们希望模型能够
-
体积小,因此在网络上或从磁盘加载时速度快
-
当调用其
predict()方法时,尽可能少地消耗时间、计算和内存。
本节描述了 TensorFlow.js 中用于优化训练模型大小和推理速度的技术,然后它们才会发布部署。
优化一词的含义是多重的。在本节的语境中,优化指的是包括模型大小减小和计算加速在内的改进。这不应与权重参数优化技术混淆,比如模型训练和优化器中的梯度下降。这种区别有时被称为模型质量与模型性能。性能指的是模型完成任务所消耗的时间和资源。质量指的是结果与理想结果的接近程度。
12.2.1. 通过后训练权重量化实现模型大小优化
互联网上快速加载小文件的需求对于网页开发者来说应该是非常明确的。如果您的网站目标是非常庞大的用户群或者拥有较慢的互联网连接的用户,这一点尤为重要。^([2])此外,如果您的模型存储在移动设备上(请参阅 12.3.4 节 对使用 TensorFlow.js 进行移动部署的讨论),则模型的大小通常受到有限的存储空间的限制。作为模型部署的挑战,神经网络是庞大的,并且仍在不断增大。深度神经网络的容量(即,预测能力)往往是以增加层数和更大的层尺寸为代价的。在撰写本文时,最先进的图像识别、([3])语音识别、([4])自然语言处理、([5])以及生成模型([6])往往超过 1 GB 的权重大小。由于模型需要同时小巧和强大之间的紧张关系,深度学习中一个极其活跃的研究领域是模型大小优化,即如何设计一个尽可能小但仍能以接近较大神经网络的准确度执行任务的神经网络。有两种一般方法可供选择。在第一种方法中,研究人员设计一个神经网络,旨在从一开始就将模型大小最小化。其次,还有通过这些方法将现有神经网络缩小至更小尺寸的技术。
²
2019 年 3 月,Google 推出了一个涉及使用神经网络以约翰·塞巴斯蒂安·巴赫风格创作音乐的涂鸦(
mng.bz/MOQW)。这个神经网络在浏览器中运行,由 TensorFlow.js 提供动力。该模型以本节描述的方法量化为 8 位整数,将模型的传输大小减少了数倍,降至约 380 KB。如果没有这种量化,将无法将模型提供给谷歌首页(Google 涂鸦出现的地方)等如此广泛的观众。³
Kaiming He 等人,“深度残差学习用于图像识别”,于 2015 年 12 月 10 日提交,
arxiv.org/abs/1512.03385。⁴
Johan Schalkwyk,“一种全神经元设备上的语音识别器”,Google AI 博客,于 2019 年 3 月 12 日,
mng.bz/ad67。⁵
Jacob Devlin 等人,“BERT: 深度双向转换器的预训练用于语言理解”,于 2018 年 10 月 11 日提交,
arxiv.org/abs/1810.04805。⁶
Tero Karras,Samuli Laine 和 Timo Aila,“用于生成对抗网络的基于风格的生成器架构”,于 2018 年 12 月 12 日提交,
arxiv.org/abs/1812.04948。
我们在卷积神经网络章节中介绍过的 MobileNetV2 是第一行研究的产物。[7] 它是一种适用于资源受限环境(如 Web 浏览器和移动设备)部署的小型、轻量级图像模型。与在相同任务上训练的更大的图像模型(如 ResNet50)相比,MobileNetV2 的准确度略差一些。但是它的尺寸(14 MB)比较小(ResNet50 的尺寸约为 100 MB),这使得准确度的轻微降低是值得的。
⁷
Mark Sandler 等人,“MobileNetV2: 反向残差和线性瓶颈”,IEEE 计算机视觉与模式识别会议(CVPR),2018 年,pp. 4510–4520,
mng.bz/NeP7.
即使内置了尺寸压缩功能,MobileNetV2 对于大多数 JavaScript 应用程序来说仍然稍大。考虑到其大小(14 MB)约为平均网页大小的八倍。[8] MobileNetV2 提供了一个宽度参数,如果将其设置为小于 1 的值,则可以减小所有卷积层的尺寸,从而进一步减小尺寸(以及进一步降低准确度)。例如,将宽度设置为 0.25 的 MobileNetV2 版本大约是完整模型大小的四分之一(3.5 MB)。但即便如此,对于对页面权重和加载时间的增加敏感的高流量网站来说,这可能仍然无法接受。
⁸
根据 HTTP Archive,截至 2019 年 5 月,桌面端平均页面权重(HTML、CSS、JavaScript、图像和其他静态文件的总传输大小)约为 1,828 KB,移动端约为 1,682 KB:
httparchive.org/reports/page-weight.
是否有办法进一步减小这种模型的尺寸?幸运的是,答案是肯定的。这将我们带到了提到的第二种方法,即模型无关的尺寸优化。这类技术更加通用,因为它们不需要对模型体系结构本身进行更改,因此应该适用于各种现有的深度神经网络。我们将在这里专门关注的技术称为训练后权重量化。其思想很简单:在模型训练完成后,以更低的数值精度存储其权重参数。 信息框 12.1 描述了对于对底层数学感兴趣的读者如何实现这一点。
基于训练后权重量化的数学原理
神经网络的权重参数在训练过程中以 32 位浮点(float32)数表示。这不仅适用于 TensorFlow.js,还适用于其他深度学习框架,如 TensorFlow 和 PyTorch。尽管这种相对昂贵的表示通常在训练模型时没有问题(例如,配备了充足内存、快速 CPU 和 CUDA GPU 的工作站后端环境),但经验研究表明,对于许多推理用例,我们可以降低权重的精度而不会导致精度大幅度下降。为了降低表示精度,我们将每个 float32 值映射到一个 8 位或 16 位整数值,该值表示该权重中所有值范围内的离散位置。这个过程就是我们所说的量化。
在 TensorFlow.js 中,权重量化是逐个权重进行的。例如,如果神经网络由四个权重变量组成(例如两个密集层的权重和偏置),则每个权重将作为整体进行量化。控制权重量化的方程式如下:
方程 12.1。
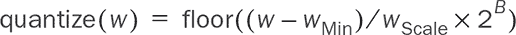
在此方程中,B是量化结果将存储的位数。它可以是 8 位或 16 位,如 TensorFlow.js 目前支持的。w[Min]是权重参数的最小值。wScale 是参数的范围(最大值与最小值之间的差异)。当然,只有在wScale 非零时,方程才有效。在wScale 为零的特殊情况下,即当权重的所有参数具有相同值时,quantize(w)将为所有w返回 0。
两个辅助值w[Min]和wScale 与量化后的权重值一起保存,以支持在模型加载期间恢复权重(我们称之为去量化)的过程。控制去量化的方程式如下:
方程 12.2。
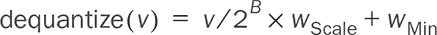
无论wScale 是否为零,此方程式都有效。
后训练量化可以大大减小模型大小:16 位量化将模型大小减少约 50%,8 位量化则减少约 75%。这些百分比是近似值,有两个原因。首先,模型大小的一部分用于模型的拓扑结构,如 JSON 文件中所编码的。其次,正如信息框中所述,量化需要存储两个额外的浮点数值(w[Min]和w[Scale]),以及一个新的整数值(量化的位数)。然而,与用于表示权重参数的位数的减少相比,这些通常是次要的。
量化是一种有损转换。由于精度降低,原始权重值中的一些信息会丢失。这类似于将 24 位颜色图像的位深度减少为 8 位(你可能在任天堂的游戏机上见过的类型),这种效果对人眼来说很容易看到。图 12.2 提供了 16 位和 8 位量化导致的离散程度的直观比较。正如你所预期的,8 位量化会导致对原始权重的粗糙表示。在 8 位量化下,对于权重参数的整个范围,只有 256 个可能的值,而在 16 位量化下有 65536 个可能的值。与 32 位浮点表示相比,这两者都是精度的显著降低。
图 12.2。16 位和 8 位权重量化的示例。原始的恒等函数(y = x,面板 A)通过 16 位和 8 位量化减小了尺寸;结果分别显示在面板 B 和面板 C 中。为了使页面上的量化效果可见,我们放大了恒等函数在x = 0 附近的一小部分。

在实践中,由于权重参数的精度损失真的重要吗?在神经网络的部署中,重要的是它在测试数据上的准确性。为了回答这个问题,我们在 tfjs-examples 的量化示例中编译了许多涵盖不同类型任务的模型。你可以在那里运行量化实验,并亲眼看到效果。要查看示例,请使用以下命令:
git clone https://github.com/tensorflow/tfjs-examples.git
cd tfjs-examples/quantization
yarn
示例包含四个场景,每个场景展示了一个数据集和应用于数据集的模型的独特组合。第一个场景涉及使用数值特征(例如物业的中位数年龄、房间总数等)来预测加利福尼亚州地理区域的平均房价。该模型是一个包含了防止过拟合的 dropout 层的五层网络。要训练和保存原始(非量化)模型,请使用以下命令:
yarn train-housing
下面的命令对保存的模型进行 16 位和 8 位量化,并评估这两种量化水平对测试数据集(模型训练期间未见的数据的子集)的模型准确性产生了什么影响:
yarn quantize-and-evaluate-housing
这个命令将许多操作封装在内,以便使用。然而,实际量化模型的关键步骤可以在 quantization/quantize_evaluate.sh 的 shell 脚本中看到。在该脚本中,你可以看到以下 shell 命令,它对路径为MODEL_JSON_PATH的模型进行 16 位量化。你可以按照这个命令的示例来量化自己的 TensorFlow.js 保存的模型。如果选项标志--quantization_bytes设置为1,则将执行 8 位量化:
tensorflowjs_converter \
--input_format tfjs_layers_model \
--output_format tfjs_layers_model \
--quantization_bytes 2 \
"${MODEL_JSON_PATH}" "${MODEL_PATH_16BIT}"
前述命令展示了如何在 JavaScript 中对训练模型执行权重量化。当将模型从 Python 转换为 JavaScript 时,tensorflowjs_converter还支持权重量化,其详细信息显示在信息框 12.2 中。
权重量化和来自 Python 的模型
在第五章中,我们展示了如何将来自 Keras(Python)的模型转换为可以加载和使用 TensorFlow.js 的格式。在此类 Python 到 JavaScript 的转换期间,您可以应用权重量化。要执行此操作,请使用与主文中描述的相同的--quantization_bytes标志。例如,要将由 Keras 保存的 HDF5(.h5)格式的模型转换为具有 16 位量化的模型,请使用以下命令:
tensorflowjs_converter \
--input_format keras \
--output_format tfjs_layers_model \
--quantization_bytes 2 \
"${KERAS_MODEL_H5_PATH}" "${TFJS_MODEL_PATH}"
在此命令中,KERAS_MODEL_H5_PATH是由 Keras 导出的模型的路径,而TFJS_MODEL_PATH是转换并进行权重量化的模型将生成的路径。
由于权重的随机初始化和训练过程中数据批次的随机洗牌,您获得的详细准确性值可能会有轻微变化。然而,总体结论应始终保持不变:正如 table 12.1 的第一行所示,对权重进行 16 位量化会导致住房价格预测的 MAE 发生微小变化,而对权重进行 8 位量化会导致 MAE 相对较大(但在绝对值上仍然微小)的增加。
表 12.1。四个不同模型的评估准确性,经过训练后进行权重量化
| 数据集和模型 | 在无量化和不同量化级别下的评估损失和准确性 |
|---|---|
| 32 位全精度(无量化) | 16 位量化 |
| — | — |
| 加利福尼亚房屋:MLP 回归器 | MAE^([a]) = 0.311984 |
| MNIST:卷积神经网络 | 准确率 = 0.9952 |
| Fashion-MNIST:卷积神经网络 | 准确率 = 0.922 |
| ImageNet 1000 子集:MobileNetV2 | Top-1 准确率 = 0.618 Top-5 准确率 = 0.788 |
^a
加利福尼亚房屋模型使用 MAE 损失函数。对于 MAE 而言,较低的值更好,与准确率不同。
量化示例中的第二个场景基于熟悉的 MNIST 数据集和深度卷积网络架构。与住房实验类似,您可以使用以下命令训练原始模型并对其进行量化版本的评估:
yarn train-mnistyarn quantize-and-evaluate-mnist
正如 table 12.1 的第二行所示,16 位和 8 位量化都不会导致模型的测试准确性发生可观的变化。这反映了卷积神经网络是一个多类分类器的事实,因此其层输出值的微小偏差可能不会改变最终的分类结果,该结果是通过argMax()操作获得的。
这一发现是否代表了面向图像的多类分类器?请记住,MNIST 是一个相对容易的分类问题。即使是像本例中使用的简单卷积网络也能达到几乎完美的准确率。当我们面对更难的图像分类问题时,量化如何影响准确率?要回答这个问题,请看量化示例中的另外两个场景。
Fashion-MNIST,你在 第十章 中的变分自动编码器部分遇到的问题,是一个比 MNIST 更难的问题。通过使用以下命令,你可以在 Fashion-MNIST 数据集上训练一个模型,并检查 16 位和 8 位量化如何影响其测试准确率:
yarn train-fashion-mnist
yarn quantize-and-evaluate-fashion-mnist
结果显示在 表 12.1 的第三行,表明由于权重的 8 位量化而导致测试准确率略微下降(从 92.2% 下降到 92.1%),尽管 16 位量化仍然没有观察到变化。
更难的图像分类问题是 ImageNet 分类问题,涉及 1,000 个输出类别。在这种情况下,我们下载了一个预先训练的 MobileNetV2,而不是像在本例的其他三个场景中那样从头开始训练一个模型。预训练模型在 ImageNet 数据集的 1,000 张图像样本上以其非量化和量化形式进行评估。我们选择不评估整个 ImageNet 数据集,因为数据集本身非常庞大(有数百万张图像),并且我们从中得出的结论不会有太大不同。
要更全面地评估模型在 ImageNet 问题上的准确性,我们计算了 top-1 和 top-5 的准确率。Top-1 准确率是仅考虑模型最高单个逻辑输出时的正确预测比率,而 top-5 准确率则是在最高的五个逻辑中有任何一个包含正确标签时将预测视为正确。这是评估 ImageNet 模型准确性的标准方法,因为由于大量类标签,其中一些非常接近,模型通常不会在 top 逻辑中显示正确标签,而是在 top-5 逻辑中之一。要查看 MobileNetV2 + ImageNet 实验的结果,请使用
yarn quantize-and-evaluate-MobileNetV2
不同于前面的三种情况,这个实验显示了 8 位对测试准确率的重大影响(见表 12.1 的第四行)。8 位量化的 MobileNet 的 top-1 和 top-5 准确率都远低于原始模型,使得 8 位量化成为 MobileNet 不可接受的尺寸优化选项。然而,16 位量化的 MobileNet 仍然显示出与非量化模型相当的准确率[⁹]。我们可以看到量化对准确率的影响取决于模型和数据。对于某些模型和任务(如我们的 MNIST convnet),16 位和 8 位量化都不会导致测试准确率的任何可观察降低。在这些情况下,我们应该尽可能在部署时使用 8 位量化模型以减少下载时间。对于一些模型,如我们的 Fashion-MNIST convnet 和我们的房价回归模型,16 位量化不会导致准确率的任何观察到的恶化,但 8 位量化确实会导致准确率略微下降。在这种情况下,您应根据判断是否额外的 25% 模型大小减小超过准确率减少。最后,对于某些类型的模型和任务(如我们的 MobileNetV2 对 ImageNet 图像的分类),8 位量化会导致准确率大幅下降,这在大多数情况下可能是不可接受的。对于这样的问题,您需要坚持使用原始模型或其 16 位量化版本。
⁹
实际上,我们可以看到准确率略微增加,这归因于由仅包含 1,000 个示例的相对较小的测试集上的随机波动。
量化示例中的案例是可能有些简化的典型问题。您手头的问题可能更加复杂,与这些案例大不相同。重要的是,是否在部署之前对模型进行量化以及应该对其进行多少位深度的量化都是经验性问题,只能根据具体情况来回答。在做出决定之前,您需要尝试量化并在真实的测试数据上测试生成的模型。本章末尾的练习 1 让您尝试使用我们在 第十章 中训练的 MNIST ACGAN 模型,并决定对于这样的生成模型是选择 16 位还是 8 位量化是正确的决定。
权重量化和 gzip 压缩
要考虑到的 8 位量化的另一个好处是,在诸如 gzip 等数据压缩技术下提供的附加压缩模型大小的额外减少。gzip 被广泛用于通过网络传输大文件。在通过网络提供 TensorFlow.js 模型文件时,应始终启用 gzip。神经网络的非量化 float32 权重通常不太适合这种压缩,因为参数值中存在类似噪声的变化,其中包含很少的重复模式。我们观察到,对于模型的非量化权重,gzip 通常不能获得超过 10-20%的大小减小。对于具有 16 位权重量化的模型也是如此。然而,一旦模型的权重经过 8 位量化,通常压缩比例会有相当大的增加(对于小型模型可高达 30-40%,对于较大的模型约为 20-30%;见 table 12.2)。
表 12.2。不同量化级别下模型构件的 gzip 压缩比例
| 数据集和模型 | gzip 压缩比例^([a]) |
|---|---|
| 32 位全精度(无量化) | 16 位量化 |
| — | — |
| California 房屋:MLP 回归器 | 1.121 |
| MNIST:卷积网络 | 1.082 |
| Fashion-MNIST:卷积网络 | 1.078 |
| ImageNet 1000 个子集:MobileNetV2 | 1.085 |
^a
(模型.json 和权重文件的总大小)/(gzipped tar ball 的大小)
这是由于极大降低的精度(仅 256)下可用的小箱数,导致许多值(例如 0 周围的值)落入相同的箱中,因此导致权重的二进制表示中出现更多的重复模式。这是在不会导致测试准确度不可接受的情况下更喜欢 8 位量化的另一个原因。
总之,通过训练后的权重量化,我们可以大大减少通过网络传输和存储在磁盘上的 TensorFlow.js 模型的大小,尤其是在使用 gzip 等数据压缩技术的帮助下。这种改进的压缩比的好处不需要开发者进行代码更改,因为浏览器在下载模型文件时会自动进行解压缩。但是,这并不会改变执行模型推断调用所涉及的计算量。也不会改变这些调用的 CPU 或 GPU 内存消耗量。这是因为在加载权重后对它们进行去量化(参见方程 12.2 中的信息框 12.1)。就运行的操作、张量的数据类型和形状以及操作输出的张量而言,非量化模型和量化模型之间没有区别。然而,对于模型部署,同样重要的问题是如何使模型在部署时以尽可能快的速度运行,并且使其在运行时消耗尽可能少的内存,因为这可以提高用户体验并减少功耗。在不丢失预测准确性和在模型大小优化之上,有没有办法使现有的 TensorFlow.js 模型运行得更快?幸运的是,答案是肯定的。在下一节中,我们将重点介绍 TensorFlow.js 提供的推断速度优化技术。
12.2.2. 使用 GraphModel 转换进行推断速度优化
这一节的结构如下。我们将首先介绍使用GraphModel转换来优化 TensorFlow.js 模型的推断速度所涉及的步骤。然后,我们将列出详细的性能测量结果,量化了该方法所提供的速度增益。最后,我们将解释GraphModel转换方法在底层的工作原理。
假设您有一个路径为 my/layers-model 的 TensorFlow.js 模型;您可以使用以下命令将其转换为tf.GraphModel:
tensorflowjs_converter \
--input_format tfjs_layers_model \
--output_format tfjs_graph_model \
my/layers-model my/graph-model
此命令将在输出目录 my/graph-model 下创建一个 model.json 文件(如果该目录不存在),以及若干二进制权重文件。表面上看,这一组文件在格式上可能与包含序列化tf.LayersModel的输入目录中的文件相同。然而,输出的文件编码了一种称为tf.GraphModel的不同类型的模型(这个优化方法的同名)。为了在浏览器或 Node.js 中加载转换后的模型,请使用 TensorFlow.js 的tf.loadGraphModel()方法,而不是熟悉的tf.loadLayersModel()方法。加载tf.GraphModel对象后,您可以通过调用对象的predict()方法以完全相同的方式执行推断,就像对待tf.LayersModel一样。例如,
const model = await tf.loadGraphModel('file://./my/graph-model/model.json');***1***
const ys = model.predict(xs); ***2***
-
1 如果在浏览器中加载模型,则可以使用 http:// 或 https:// URL。
-
2 使用输入数据’xs’进行推断。
提高的推理速度带来了两个限制:
-
在撰写本文时,最新版本的 TensorFlow.js(1.1.2)不支持循环层,如
tf.layers.simpleRNN()、tf.layers.gru()和tf.layers.lstm()(见第九章)用于GraphModel转换。 -
载入的
tf.GraphModel对象没有fit()方法,因此不支持进一步的训练(例如,迁移学习)。
表 12.3 比较了两种模型类型在有和没有GraphModel转换时的推理速度。由于GraphModel转换尚不支持循环层,因此仅呈现了 MLP 和卷积神经网络(MobileNetV2)的结果。为了覆盖不同的部署环境,该表呈现了来自 Web 浏览器和后端环境中运行的 tfjs-node 的结果。从这个表中,我们可以看到GraphModel转换始终加快了推理速度。但是,加速比取决于模型类型和部署环境。对于浏览器(WebGL)部署环境,GraphModel转换会带来 20-30%的加速,而如果部署环境是 Node.js,则加速效果更加显著(70-90%)。接下来,我们将讨论为什么GraphModel转换加快了推理速度,以及它为什么在 Node.js 环境中比在浏览器环境中加速更多的原因。
表 12.3 比较了两种模型类型(MLP 和 MobileNetV2)在不同部署环境下进行GraphModel转换优化和不进行优化时的推理速度^([a])
^a
获得这些结果的代码可在
github.com/tensorflow/tfjs/tree/master/tfjs/integration_tests/找到。
| 模型名称和拓扑结构 | 预测时间(毫秒;值越低越好)(在 20 次热身调用之后的 30 次预测调用的平均值) |
|---|---|
| 浏览器 WebGL | tfjs-node(仅 CPU) |
| — | — |
| LayersModel | GraphModel |
| — | — |
| MLP^([b]) | 13 |
| MobileNetV2(宽度=1.0) | 68 |
^b
MLP 由单元数为 4,000、1,000、5,000 和 1 的密集层组成。前三层使用 relu 激活函数;最后一层使用线性激活函数。
GraphModel 转换如何加速模型推理
GraphModel 转换是如何提高 TensorFlow.js 模型推断速度的?这是通过利用 TensorFlow(Python)对模型计算图进行细粒度的提前分析来实现的。计算图分析后,会对图进行修改,减少计算量同时保持图的输出结果的数值正确性。不要被提前分析和细粒度等术语吓到。稍后我们会对它们进行解释。
为了给出我们所说的图修改的具体例子,让我们考虑一下在 tf.LayersModel 和 tf.GraphModel 中 BatchNormalization 层的工作原理。回想一下,BatchNormalization 是一种在训练过程中改善收敛性和减少过拟合的类型的层。它在 TensorFlow.js API 中可用作 tf.layers.batchNormalization(),并且被诸如 MobileNetV2 这样的常用预训练模型使用。当 BatchNormalization 层作为 tf.LayersModel 的一部分运行时,计算会严格遵循批量归一化的数学定义:
方程式 12.3。
为了从输入 (x) 生成输出,需要六个操作(或 ops),大致顺序如下:
-
sqrt,将var作为输入 -
add,将epsilon和步骤 1 的结果作为输入 -
sub,将x和平均值作为输入 -
div,将步骤 2 和 3 的结果作为输入 -
mul,将gamma和步骤 4 的结果作为输入 -
add,将beta和步骤 5 的结果作为输入
基于简单的算术规则,可以看出方程式 12.3 可以被显著简化,只要 mean、var、epsilon、gamma 和 beta 的值是常量(不随输入或层被调用的次数而变化)。在训练包含 BatchNormalization 层的模型后,所有这些变量确实都变成了常量。这正是 GraphModel 转换所做的:它“折叠”常量并简化算术,从而导致以下在数学上等效的方程式:
方程式 12.4。
k 和 b 的值是在 GraphModel 转换期间计算的,而不是在推断期间:
方程式 12.5。
方程式 12.6。
因此,方程式 12.5 和 12.6 在推断过程中不计入计算量;只有方程式 12.4 计入。将方程式 12.3 和 12.4 进行对比,您会发现常数折叠和算术简化将操作数量从六个减少到了两个(x和k之间的mul操作,以及b和该mul操作结果之间的add操作),从而极大加速了该层的执行速度。但为什么tf.LayersModel不执行此优化?因为它需要支持 BatchNormalization 层的训练,在训练的每一步都会更新mean、var、gamma和beta的值。GraphModel转换利用了这一事实,即这些更新的值在模型训练完成后不再需要。
在 BatchNormalization 示例中看到的优化类型仅在满足两个要求时才可能实现。首先,计算必须以足够细粒度的方式表示——即在基本数学操作(如add和mul)的层面上,而不是 TensorFlow.js 的 Layers API 所在的更粗粒度的层面。其次,所有的计算在执行模型的predict()方法之前都是已知的。GraphModel转换经过了 TensorFlow(Python),可以得到满足这两个条件的模型的图表示。
除了之前讨论的常数折叠和算术优化外,GraphModel的转换还能执行另一种称为op fusion的优化类型。以经常使用的密集层类型(tf.layers.dense())为例。密集层涉及三种操作:输入x和内核W的矩阵乘法(matMul),matMul结果和偏置(b)之间的广播加法,以及逐元素的 relu 激活函数(图 12.3,面板 A)。op fusion 优化使用一种单一操作替换了这三个分开的操作,该单一操作执行了所有等效步骤(图 12.3,面板 B)。这种替换可能看起来微不足道,但由于 1)启动 op 的开销减少(是的,启动 op 总是涉及一定的开销,无论计算后端如何),以及 2)在融合的 op 实现中执行速度优化的更多机会,这导致了更快的计算。
图 12.3. 密集层内部操作的示意图,带有(面板 A)和不带有(面板 B)op fusion。
操作融合优化与我们刚刚看到的常量折叠和算术简化有何不同?操作融合要求特殊融合操作(在本例中为 Fused matMul+relu)在所使用的计算后端中定义并可用,而常量折叠则不需要。这些特殊融合操作可能仅对某些计算后端和部署环境可用。这就是为什么我们在 Node.js 环境中看到了比在浏览器中更大量的推理加速的原因(参见 table 12.3)。Node.js 计算后端使用的是用 C++ 和 CUDA 编写的 libtensorflow,它配备了比浏览器中的 TensorFlow.js WebGL 后端更丰富的操作集。
除了常量折叠、算术简化和操作融合之外,TensorFlow(Python)的图优化系统 Grappler 还能够进行其他许多种类的优化,其中一些可能与如何通过 GraphModel 转换优化 TensorFlow.js 模型相关。然而,由于空间限制,我们不会涵盖这些内容。如果你对此主题想要了解更多,你可以阅读本章末尾列出的 Rasmus Larsen 和 Tatiana Shpeisman 的信息性幻灯片。
总之,GraphModel 转换是由 tensorflowjs_ converter 提供的一种技术。它利用 TensorFlow(Python)的提前图优化能力简化计算图,并减少模型推理所需的计算量。尽管推理加速的详细量取决于模型类型和计算后端,但通常它提供了 20% 或更多的加速比,因此在部署 TensorFlow.js 模型之前执行此步骤是明智的。
如何正确测量 TensorFlow.js 模型的推理时间
tf.LayersModel 和 tf.GraphModel 都提供了统一的 predict() 方法来支持推理。该方法接受一个或多个张量作为输入,并返回一个或多个张量作为推理结果。然而,在基于 WebGL 的浏览器推理环境中,重要的是要注意,predict() 方法仅安排在 GPU 上执行的操作;它不等待它们执行完成。因此,如果你天真地按照以下方式计时 predict() 调用,计时测量结果将是错误的:
console.time('TFjs inference');
const outputTensor = model.predict(inputTensor);
console.timeEnd('TFjs inference'); ***1***
- 1 测量推理时间的不正确方式!
当predict()返回时,预定的操作可能尚未执行完毕。因此,前面的示例将导致比完成推理所需实际时间更短的时间测量。为了确保在调用console.timeEnd()之前操作已完成,需要调用返回的张量对象的以下方法之一:array()或data()。这两种方法都会将保存输出张量元素的纹理值从 GPU 下载到 CPU。为了实现这一点,它们必须等待输出张量的计算完成。因此,正确的计时方法如下所示:
console.time('TFjs inference');
const outputTensor = model.predict(inputTensor);
await outputTensor.array(); ***1***
console.timeEnd('TFjs inference');
- 1
array()调用直到输出张量的计算完成才会返回,从而确保推理时间测量的正确性。
另一个需要记住的重要事情是,与所有其他 JavaScript 程序一样,TensorFlow.js 模型推理的执行时间是变化的。为了获得推理时间的可靠估计,应该将上面代码段放在一个for循环中,以便可以多次执行(例如,50 次),并且可以根据累积的单个测量计算出平均时间。最初的几次执行通常比随后的执行慢,因为需要编译新的 WebGL 着色程序并设置初始状态。因此,性能测量代码通常会忽略前几次运行(例如,前五次),这些被称为热身或预热运行。
如果你对这些性能基准技术有更深入的了解感兴趣,可以通过本章末尾的练习 3 来进行实践。
12.3. 在各种平台和环境上部署 TensorFlow.js 模型
你已经优化了你的模型,它又快又轻,而且所有的测试都通过了。你准备好了! 好消息! 但在你开香槟庆祝之前,还有更多的工作要做。
是时候将你的模型部署到应用程序中,并让它出现在用户基础之前了。在本节中,我们将涵盖一些部署平台。部署到网络和部署到 Node.js 服务是众所周知的途径,但我们还将涵盖一些更奇特的部署情景,比如部署到浏览器扩展程序或单板嵌入式硬件应用。我们将指向简单的例子,并讨论平台重要的特殊注意事项。
12.3.1. 部署到网络时的额外考虑事项
让我们首先重新审视 TensorFlow.js 模型最常见的部署场景:将其部署到网页中。在这种场景下,我们经过训练且可能经过优化的模型通过 JavaScript 从某个托管位置加载,然后模型利用用户浏览器内的 JavaScript 引擎进行预测。一个很好的例子是 第五章 中的 MobileNet 图像分类示例。该示例也可从 tfjs-examples/ mobilenet 进行下载。作为提醒,以下是加载模型并进行预测的相关代码概述:
const MOBILENET_MODEL_PATH =
'https://storage.googleapis.com/tfjs-models/tfjs/mobilenet_v1_0.25_224/model.json';
const mobilenet = await tf.loadLayersModel(MOBILENET_MODEL_PATH);
const response = mobilenet.predict(userQueryAsTensor);
该模型是从 Google 云平台(GCP)存储桶中托管的。对于像这样的低流量、静态应用程序,很容易将模型静态托管在站点内容的其他部分旁边。对于更大、更高流量的应用程序,可以选择通过内容交付网络(CDN)将模型与其他重型资产一起托管。一个常见的开发错误是在设置 GCP、Amazon S3 或其他云服务中的存储桶时忘记考虑跨域资源共享(CORS)。如果 CORS 设置不正确,模型加载将失败,并且您应该会在控制台上收到与 CORS 相关的错误消息。如果您的 Web 应用在本地正常工作,但在发布到分发平台后失败,请注意这一点。
在用户的浏览器加载 HTML 和 JavaScript 后,JavaScript 解释器将发出加载模型的调用。在具备良好的网络连接的现代浏览器中,加载一个小型模型的过程大约需要几百毫秒,但在初始加载后,可以从浏览器缓存中更快地加载模型。序列化格式确保将模型切分为足够小的部分以支持标准浏览器缓存限制。
Web 部署的一个好处是预测直接在浏览器中进行。传递给模型的任何数据都不会通过网络传输,这对于延迟很有好处,且对于隐私保护也非常重要。想象一下,如果模型正在预测辅助输入法的下一个单词,这在我们常见的场景中经常出现,比如 Gmail。如果需要将输入的文本发送到云端服务器,并等待远程服务器的响应,那么预测将会被延迟,输入的预测结果将会变得不太有用。此外,一些用户可能会认为将其不完整的按键输入发送到远程计算机中侵犯了他们的隐私。在用户自己的浏览器中进行本地预测更加安全和注重隐私。
在浏览器中进行预测的缺点是模型安全性。将模型发送给用户使其容易保留该模型并将其用于其他目的。TensorFlow.js 目前(截至 2019 年)在浏览器中没有模型安全的解决方案。其他一些部署场景使用户更难以将模型用于开发者未预期的目的。最大模型安全性的分发路径是将模型保留在你控制的服务器上,并从那里提供预测请求。当然,这需要牺牲延迟和数据隐私。平衡这些问题是产品决策。
12.3.2. 云服务部署
许多现有的生产系统提供机器学习训练预测服务,例如 Google Cloud Vision AI(cloud.google.com/vision)或 Microsoft Cognitive Services(azure.microsoft.com/en-us/services/cognitive-services)。这样的服务的最终用户会进行包含预测输入值的 HTTP 请求,例如用于对象检测任务的图像,响应会对预测的输出进行编码,例如图像中对象的标签和位置。
截至 2019 年,有两种方法可以从服务器上服务于 TensorFlow.js 模型。第一种方法是运行 Node.js 的服务器,使用原生 JavaScript 运行时进行预测。由于 TensorFlow.js 很新,我们不知道有哪些生产用例选择了这种方法,但概念证明很容易构建。
第二条路线是将模型从 TensorFlow.js 转换为可以从已知的现有服务器技术(例如标准的 TensorFlow Serving 系统)服务的格式。从www.tensorflow.org/tfx/guide/serving的文档中可知:
TensorFlow Serving 是一个为生产环境设计的灵活高效的机器学习模型服务系统。TensorFlow Serving 使得部署新的算法和实验变得容易,同时保持相同的服务器体系结构和 API。TensorFlow Serving 提供了与 TensorFlow 模型的开箱即用的集成,但也可以轻松扩展以用于其他类型的模型和数据。
到目前为止,我们已经将 TensorFlow.js 模型序列化为 JavaScript 特定的格式。TensorFlow Serving 期望模型使用 TensorFlow 标准的 SavedModel 格式打包。幸运的是,tfjs-converter 项目使转换为所需格式变得容易。
在第五章(迁移学习)中,我们展示了如何在 TensorFlow.js 中使用 Python 实现的 TensorFlow 构建 SavedModels。要做相反的操作,首先安装 tensorflowjs pip 包:
pip install tensorflowjs
接下来,您必须运行转换器二进制文件,并指定输入:
tensorflowjs_converter \
--input_format=tfjs_layers_model \
--output_format=keras_saved_model \
/path/to/your/js/model.json \
/path/to/your/new/saved-model
这将创建一个新的 saved-model 目录,其中包含 TensorFlow Serving 可理解的所需拓扑和权重格式。然后,您应该能够按照构建 TensorFlow Serving 服务器的说明,并对运行中的模型进行 gRPC 预测请求。也存在托管解决方案。例如,Google Cloud 机器学习引擎提供了一条路径,您可以将保存的模型上传到 Cloud Storage,然后设置为服务,而无需维护服务器或机器。您可以从文档中了解更多信息:cloud.google.com/ml-engine/docs/tensorflow/deploying-models。
从云端提供模型的优点是您完全控制模型。可以很容易地对执行的查询类型进行遥测,并快速检测出问题。如果发现模型存在一些意外问题,可以快速删除或升级,并且不太可能出现在您控制之外的机器上的其他副本。缺点是额外的延迟和数据隐私问题,如前所述。还有额外的成本——无论是货币支出还是维护成本——在操作云服务时,您控制着系统配置。
12.3.3. 部署到浏览器扩展,如 Chrome 扩展
一些客户端应用程序可能需要您的应用程序能够跨多个不同的网站工作。所有主要桌面浏览器都提供了浏览器扩展框架,包括 Chrome、Safari 和 FireFox 等。这些框架使开发人员能够创建通过添加新的 JavaScript 和操作网站的 DOM 来修改或增强浏览体验的体验。
由于扩展是在浏览器执行引擎内部的 JavaScript 和 HTML 之上运行的,您可以在浏览器扩展中使用 TensorFlow.js 的功能与在标准网页部署中相似。模型安全性和数据隐私性与网页部署相同。通过在浏览器内直接执行预测,用户的数据相对安全。模型安全性与网页部署的情况也类似。
作为使用浏览器扩展的可能性的示例,请参阅 tfjs-examples 中的 chrome-extension 示例。此扩展加载一个 MobileNetV2 模型,并将其应用于用户在网络上选择的图像。安装和使用该扩展与我们看到的其他示例有点不同,因为它是一个扩展,而不是托管网站。这个示例需要 Chrome 浏览器。^([10])
¹⁰
较新版本的 Microsoft Edge 也为跨浏览器扩展加载提供了一些支持。
首先,您必须下载并构建扩展,类似于您可能构建其他示例的方式:
git clone https://github.com/tensorflow/tfjs-examples.git
cd tfjs-examples/chrome-extension
yarn
yarn build
扩展构建完成后,可以在 Chrome 中加载未打包的扩展。要这样做,您必须导航至 chrome://extensions,启用开发者模式,然后单击“加载未打包”,如图 12.4 所示。这将弹出一个文件选择对话框,在这里您必须选择在 chrome-extension 目录下创建的 dist 目录。那个包含 manifest.json 文件的目录。
图 12.4。在开发者模式下加载 TensorFlow.js MobileNet Chrome 扩展
安装扩展后,您应该能够在浏览器中对图像进行分类。要这样做,请导航至一些包含图像的网站,例如在此处使用的 Google 图像搜索页面上的“tiger”关键词。然后右键单击要分类的图像。您应该会看到一个名为“使用 TensorFlow.js 对图像进行分类”的菜单选项。单击该菜单选项将使扩展执行 MobileNet 模型的操作,并在图像上添加一些文本,表示预测结果(参见图 12.5)。
图 12.5。TensorFlow.js MobileNet Chrome 扩展可帮助分类网页中的图像。
要删除扩展名,请在“扩展”页面上单击“删除”(参见图 12.4),或右键单击右上角的扩展图标时使用“从 Chrome 菜单中删除”选项。
请注意,运行在浏览器扩展中的模型可以访问与运行在网页中的模型相同的硬件加速,并且确实使用了大部分相同的代码。该模型使用适当的 URL 来调用tf.loadGraphModel(...)进行加载,并使用相同的model.predict(...) API 进行预测。从网页部署迁移技术或概念验证到浏览器扩展相对较容易。
12.3.4。在基于 JavaScript 的移动应用中部署 TensorFlow.js 模型
对于许多产品来说,桌面浏览器提供的覆盖范围不够,移动浏览器也无法提供顾客所期望的平稳动画化的定制产品体验。在这些项目上工作的团队通常面临着如何管理他们的 Web 应用程序代码库以及(通常)Android(Java 或 Kotlin)和 iOS(Objective C 或 Swift)本机应用程序中的存储库的困境。虽然非常庞大的团队可以支持这样的支出,但许多开发人员越来越倾向于通过利用混合跨平台开发框架在这些部署之间重复使用大部分代码。
跨平台应用程序框架,如 React Native、Ionic、Flutter 和渐进式 Web 应用程序,使您能够使用通用语言编写应用程序的大部分功能,然后编译这些核心功能,以创建具有用户期望的外观、感觉和性能的本机体验。跨平台语言/运行时处理大部分业务逻辑和布局,并连接到本机平台绑定以获得标准的外观和感觉。如何选择合适的混合应用程序开发框架是网络上无数博客和视频的主题,因此我们不会在这里重新讨论这个问题,而是将重点放在一个流行的框架上,即 React Native。图 12.6 示例了一个运行 MobileNet 模型的简单 React Native 应用程序。请注意任何浏览器顶部栏的缺失。虽然这个简单的应用程序没有 UI 元素,但如果有的话,你会发现它们与本机 Android 的外观和感觉匹配。为 iOS 构建的相同应用程序也会匹配那些元素。
图 12.6. React Native 构建的样本本机 Android 应用程序的屏幕截图。在这里,我们在本机应用程序中运行了一个 TensorFlow.js MobileNet 模型。

令人高兴的是,React Native 中的 JavaScript 运行时原生支持 TensorFlow.js,无需做任何特殊工作。tfjs-react-native 包目前仍处于 alpha 发布阶段(截至 2019 年 12 月),但通过 expo-gl 提供了基于 WebGL 的 GPU 支持。用户代码如下所示:
import * as tf from '@tensorflow/tfjs';
import '@tensorflow/tfjs-react-native';
该软件包还提供了特殊 API,用于帮助在移动应用程序中加载和保存模型资源。
列表 12.2. 在使用 React-Native 构建的移动应用程序中加载和保存模型
import * as tf from '@tensorflow/tfjs';
import {asyncStorageIO} from '@tensorflow/tfjs-react-native';
async trainSaveAndLoad() {
const model = await train();
await model.save(asyncStorageIO( ***1***
'custom-model-test')) ***1***
model.predict(tf.tensor2d([5], [1, 1])).print();
const loadedModel =
await tf.loadLayersModel(asyncStorageIO( ***2***
'custom-model-test')); ***2***
loadedModel.predict(tf.tensor2d([5], [1, 1])).print();
}
-
1 将模型保存到 AsyncStorage——一种对应用程序全局可见的简单键-值存储系统
-
2 从 AsyncStorage 加载模型
虽然通过 React Native 进行本机应用程序开发仍需要学习一些新的工具,比如 Android Studio 用于 Android 和 XCode 用于 iOS,但学习曲线比直接进行本机开发要平缓。这些混合应用程序开发框架支持 TensorFlow.js 意味着机器学习逻辑可以存在于一个代码库中,而不需要我们为每个硬件平台表面开发、维护和测试一个单独的版本,这对于希望支持本机应用体验的开发人员来说是一个明显的胜利!但是,本机桌面体验呢?
12.3.5. 在基于 JavaScript 的跨平台桌面应用程序中部署 TensorFlow.js 模型
诸如 Electron.js 等 JavaScript 框架允许以类似于使用 React Native 编写跨平台移动应用程序的方式编写桌面应用程序。 使用这样的框架,您只需编写一次代码,就可以在主流桌面操作系统(包括 macOS、Windows 和主要的 Linux 发行版)上部署和运行。 这大大简化了传统开发流程,即为大部分不兼容的桌面操作系统维护单独的代码库。 以此类别中的主要框架 Electron.js 为例。 它使用 Node.js 作为支撑应用程序主要进程的虚拟机; 对于应用程序的 GUI 部分,它使用了 Chromium,一个完整但轻量级的网络浏览器,它与 Google Chrome 共享大部分代码。
TensorFlow.js 兼容 Electron.js,如 tfjs-examples 仓库中简单示例所示。 这个示例位于 electron 目录中,演示了如何在基于 Electron.js 的桌面应用中部署 TensorFlow.js 模型以进行推理。 该应用允许用户搜索文件系统中与一个或多个关键词视觉匹配的图像文件(请参阅 图 12.7 中的截图)。 这个搜索过程涉及在一组图像目录上应用 TensorFlow.js MobileNet 模型进行推理。
图 12.7. 一个使用 TensorFlow.js 模型的示例 Electron.js 桌面应用程序的屏幕截图,来自 tfjs-examples/electron
尽管这个示例应用程序很简单,但它展示了在将 TensorFlow.js 模型部署到 Electron.js 时一个重要的考虑因素:计算后端的选择。 Electron.js 应用程序在基于 Node.js 的后端进程和基于 Chromium 的前端进程上运行。 TensorFlow.js 可以在这两种环境中运行。 因此,同一个模型可以在应用程序的类似 node 的后端进程或类似浏览器的前端进程中运行。 在后端部署的情况下,使用 @tensorflow/tfjs-node 包,而在前端情况下使用 @tensorflow/tfjs 包(图 12.8)。 示例应用程序的 GUI 中的复选框允许您在后端和前端推理模式之间切换(图 12.7),尽管在由 Electron.js 和 TensorFlow.js 驱动的实际应用程序中,您通常会事先决定模型的运行环境。 接下来我们将简要讨论各个选项的优缺点。
图 12.8. 基于 Electron.js 的桌面应用程序架构,利用 TensorFlow.js 进行加速深度学习。TensorFlow.js 的不同计算后端可以从主后端进程或浏览器渲染器进程中调用。不同的计算后端导致模型在不同的底层硬件上运行。无论计算后端的选择如何,在 TensorFlow.js 中加载、定义和运行深度学习模型的代码基本相同。此图中的箭头表示库函数和其他可调用程序的调用。
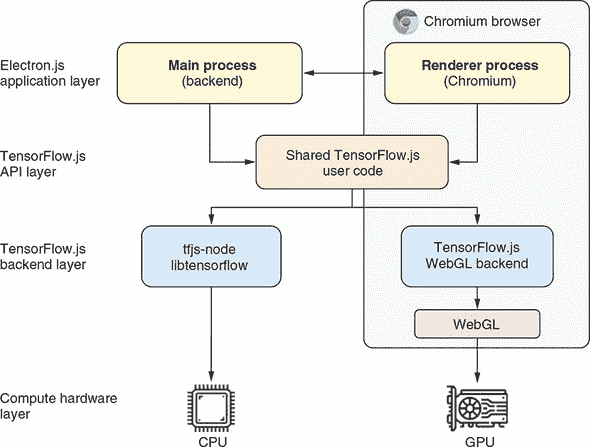
如图 12.8 所示,不同的计算后端选择会导致深度学习计算在不同的计算硬件上进行。基于 @tensorflow/tfjs-node 的后端部署将工作负载分配到 CPU 上,利用多线程和 SIMD(单指令多数据)功能的 libtensorflow 库。这种基于 Node.js 的模型部署选项通常比前端选项更快,并且由于后端环境没有资源限制,可以容纳更大的模型。然而,它们的主要缺点是包大小较大,这是由于 libtensorflow 的体积较大(对于 tfjs-node,约为 50 MB 带有压缩)。
前端部署将深度学习工作负载分派给 WebGL。对于中小型模型以及推理延迟不是主要关注点的情况,这是一个可接受的选项。此选项导致包大小较小,并且由于对 WebGL 的广泛支持,可在广泛范围的 GPU 上直接运行。
如图 12.8 所示,计算后端的选择在很大程度上是与加载和运行模型的 JavaScript 代码分开的。相同的 API 对所有三个选项都适用。这在示例应用中得到了清楚的展示,其中相同的模块(ImageClassifier 在 electron/image_classifier.js 中)在后端和前端环境下均用于执行推理任务。我们还应指出,尽管 tfjs-examples/electron 示例仅显示推理,但您确实可以将 TensorFlow.js 用于 Electron.js 应用程序中的其他深度学习工作流程,例如模型创建和训练(例如,迁移学习)同样有效。
12.3.6. 在微信和其他基于 JavaScript 的移动应用插件系统上部署 TensorFlow.js 模型
有些地方的主要移动应用分发平台既不是 Android 的 Play Store 也不是 Apple 的 App Store,而是一小部分“超级移动应用程序”,它们允许在其自己的第一方精选体验中使用第三方扩展。
这些超级移动应用程序中有一些来自中国科技巨头,特别是腾讯的微信、阿里巴巴的支付宝和百度。它们使用 JavaScript 作为主要技术,以实现第三方扩展的创建,使得 TensorFlow.js 成为在其平台上部署机器学习的自然选择。然而,这些移动应用程序插件系统中可用的 API 集与本机 JavaScript 中可用的集合不同,因此在那里部署需要一些额外的知识和工作。
让我们以微信为例。微信是中国最广泛使用的社交媒体应用程序,每月活跃用户数超过 10 亿。2017 年,微信推出了小程序,这是一个让应用开发者在微信系统内部创建 JavaScript 小程序的平台。用户可以在微信应用程序内分享和安装这些小程序,这是一个巨大的成功。截至 2018 年第二季度,微信拥有 100 多万个小程序和 6 亿多日活跃用户。还有超过 150 万的开发者在这个平台上开发应用程序,部分原因是 JavaScript 的流行。
WeChat 小程序 API 旨在为开发者提供便捷访问移动设备传感器(摄像头、麦克风、加速计、陀螺仪、GPS 等)的功能。然而,原生 API 在平台上提供的机器学习功能非常有限。TensorFlow.js 作为小程序的机器学习解决方案带来了几个优势。以前,如果开发者想要在他们的应用程序中嵌入机器学习,他们需要在小程序开发环境之外使用服务器端或基于云的机器学习堆栈。这使得大量小程序开发者想要构建和使用机器学习变得更难。搭建外部服务基础设施对于大多数小程序开发者来说是不可能的。有了 TensorFlow.js,机器学习开发就在本地环境中进行。此外,由于它是一个客户端解决方案,它有助于减少网络流量和改善延迟,并利用了 WebGL 的 GPU 加速。
TensorFlow.js 团队创建了一个微信小程序,你可以使用它来为你的小程序启用 TensorFlow.js(见github.com/tensorflow/tfjs-wechat)。该存储库还包含一个使用 PoseNet 来注释移动设备摄像头感知到的人的位置和姿势的示例小程序。它使用了微信新增加的 WebGL API 加速的 TensorFlow.js。如果没有 GPU 加速,模型的运行速度对大多数应用程序来说太慢了。有了这个插件,微信小程序可以拥有与在移动浏览器内运行的 JavaScript 应用程序相同的模型执行性能。事实上,我们已经观察到微信传感器 API 通常优于浏览器中的对应 API。
到 2019 年底,为超级应用插件开发机器学习体验仍然是非常新的领域。获得高性能可能需要一些来自平台维护者的帮助。但是,这仍是将您的应用部署到数以亿计的将超级移动应用作为互联网的人民面前的最佳方式。
12.3.7. 在单板计算机上部署 TensorFlow.js 模型
对许多网页开发者来说,部署到无头单板计算机听起来非常技术化和陌生。然而,多亏了树莓派的成功,开发和构建简单的硬件设备变得前所未有的容易。单板计算机提供了一个平台,可以廉价部署智能,而不依赖于云服务器的网络连接或笨重昂贵的计算机。单板计算机可用于支持安全应用、调节互联网流量、控制灌溉,无所不能。
许多这些单板计算机提供通用输入输出(GPIO)引脚,以便轻松连接物理控制系统,并包含完整的 Linux 安装,允许教育工作者、开发人员和黑客开发各种互动设备。JavaScript 迅速成为构建这些类型设备的一种流行语言。开发人员可以使用像 rpi-gpio 这样的 Node 库在 JavaScript 中以最低层次进行电子交互。
为了帮助支持这些用户,TensorFlow.js 当前在这些嵌入式 ARM 设备上有两个运行时:tfjs-node (CPU^([11]))和tfjs-headless-nodegl (GPU)。整个 TensorFlow.js 库通过这两个后端在这些设备上运行。开发人员可以在设备硬件上运行推断,使用现有模型或自己训练模型!
¹¹
如果您希望在这些设备上利用 ARM NEON 加速 CPU,则应该使用 tfjs-node 软件包。该软件包支持 ARM32 和 ARM64 架构。
近期推出的设备(如 NVIDIA Jetson Nano 和 Raspberry Pi 4)带来了现代图形堆栈的 SoC(系统级芯片)。这些设备上的 GPU 可以被 TensorFlow.js 核心中使用的基础 WebGL 代码利用。无头 WebGL 包(tfjs-backend-nodegl)`允许用户纯粹通过这些设备上的 GPU 加速在 Node.js 上运行 TensorFlow.js(见图 12.9)。通过将 TensorFlow.js 的执行委托给 GPU,开发人员可以继续利用 CPU 来控制设备的其他部分。
图 12.9. 使用无头 WebGL 在树莓派 4 上执行 MobileNet 的 TensorFLow.js
单板计算机部署的模型安全性和数据安全性非常强。计算和执行直接在设备上处理,这意味着数据不需要传输到所有者无法控制的设备上。即使物理设备遭到破坏,也可以使用加密保护模型。
对于 JavaScript 来说,将部署到单板计算机仍然是一个非常新颖的领域,尤其是 TensorFlow.js,但它为其他部署领域不适用的广泛应用提供了可能。
12.3.8. 部署摘要
在本节中,我们介绍了几种不同的方法,可以使您的 TensorFlow.js 机器学习系统走在用户基础的前面(表 12.4 总结了它们)。我们希望我们能激发您的想象力,并帮助您梦想着技术的激进应用!JavaScript 生态系统广阔而广阔,在未来,具有机器学习功能的系统将在我们今天甚至无法想象的领域运行。
表 12.4. TensorFlow.js 模型可以部署到的目标环境以及每个环境可以使用的硬件加速器
| 部署 | 硬件加速器支持 |
|---|---|
| 浏览器 | WebGL |
| Node.js 服务器 | 具有多线程和 SIMD 支持的 CPU;具有 CUDA 支持的 GPU |
| 浏览器插件 | WebGL |
| 跨平台桌面应用程序(如 Electron) | WebGL,支持多线程和 SIMD 的 CPU,或者具有 CUDA 支持的 GPU |
| 跨平台移动应用程序(如 React Native) | WebGL |
| 移动应用程序插件(如微信) | 移动 WebGL |
| 单板计算机(如 Raspberry Pi) | GPU 或 ARM NEON |
进一步阅读材料
-
Denis Baylor 等,“TFX:基于 TensorFlow 的生产规模机器学习平台”,KDD 2017,www.kdd.org/kdd2017/papers/view/tfx-a-tensorflow-based-production-scale-machine-learning-platform。
-
Raghuraman Krishnamoorthi,“为高效推理量化深度卷积网络:一份白皮书”,2018 年 6 月,
arxiv.org/pdf/1806.08342.pdf。 -
Rasmus Munk Larsen 和 Tatiana Shpeisman,“TensorFlow 图优化”,
ai.google/research/pubs/pub48051。
练习
-
在第十章中,我们训练了一个辅助类生成对抗网络(ACGAN)来生成 MNIST 数据集的假冒图像,以类别为单位。具体来说,我们使用的示例位于 tfjs-examples 存储库的 mnist-acgan 目录中。训练模型的生成器部分总共约占用了大约 10 MB 的空间,其中大部分是以 32 位浮点数存储的权重。诱人的是对该模型进行训练后的权重量化以加快页面加载速度。但是,在执行此操作之前,我们需要确保这种量化不会导致生成的图像质量显着下降。测试 16 位和 8 位量化,并确定它们中的任何一个或两者都是可接受的选项。使用 section 12.2.1 中描述的
tensorflowjs_converter工作流程。在这种情况下,您将使用什么标准来评估生成的 MNIST 图像的质量? -
作为 Chrome 扩展运行的 Tensorflow 模型具有控制 Chrome 本身的优势。在第四章中的语音命令示例中,我们展示了如何使用卷积模型识别口语。Chrome 扩展 API 允许您查询和更改标签页。尝试将语音命令模型嵌入到扩展中,并调整它以识别“下一个标签页”和“上一个标签页”短语。使用分类器的结果来控制浏览器标签焦点。
-
信息框 12.3 描述了正确测量 TensorFlow.js 模型的
predict()调用(推断调用)所需时间以及涉及的注意事项。在这个练习中,加载一个 TensorFlow.js 中的 MobileNetV2 模型(如果需要提醒如何做到这一点,请参见 5.2 节 中的简单对象检测示例),并计时其predict()调用:-
作为第一步,生成一个形状为
[1, 224, 224, 3]的随机值图像张量,并按照信息框 12.3 中的步骤对其进行模型推断。将结果与输出张量上的array()或data()调用进行比较。哪一个更短?哪一个是正确的时间测量? -
当正确的测量在循环中执行 50 次时,使用 tfjs-vis 折线图(第七章)绘制单独的时间数字,并直观地了解可变性。你能清楚地看到前几次测量与其余部分明显不同吗?鉴于这一观察结果,讨论在性能基准测试期间执行 burn-in 或预热运行的重要性。
-
与任务 a 和 b 不同,将随机生成的输入张量替换为真实的图像张量(例如,使用
tf.browser.fromPixels()从img元素获取的图像张量),然后重复步骤 b 中的测量。输入张量的内容是否对时间测量产生任何重大影响? -
不要在单个示例(批量大小 = 1)上运行推断,尝试将批量大小增加到 2、3、4 等,直到达到相对较大的数字,例如 32。平均推断时间与批量大小之间的关系是单调递增的吗?是线性的吗?
-
概要
-
对于机器学习代码,良好的工程纪律围绕测试同样重要,就像对非机器学习代码一样重要。然而,避免过分关注“特殊”示例或对“黄金”模型预测进行断言的诱惑。相反,依靠测试模型的基本属性,如其输入和输出规范。此外,请记住,机器学习系统之前的所有数据预处理代码都只是“普通”代码,应该相应地进行测试。
-
优化下载速度和推断速度是 TensorFlow.js 模型客户端部署成功的重要因素。 使用
tensorflowjs_converter二进制文件的后训练权重量化功能,您可以减小模型的总大小,在某些情况下,无需观察到推断精度的损失。tensorflowjs_converter的图模型转换功能可通过操作融合等图转换来加速模型推断。 在部署 TensorFlow.js 模型到生产环境时,强烈建议您测试和采用这两种模型优化技术。 -
经过训练和优化的模型并不是您机器学习应用程序的终点。 您必须找到一种方法将其与实际产品集成。 TensorFlow.js 应用程序最常见的部署方式是在网页中,但这只是各种部署方案中的一个,每种部署方案都有其自身的优势。 TensorFlow.js 模型可以作为浏览器扩展程序运行,在原生移动应用程序中运行,作为原生桌面应用程序运行,甚至在树莓派等单板硬件上运行。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









