







原文:
zh.annas-archive.org/md5/125f0c03ca93490db2ba97b08bc69e99译者:飞龙
第六章:使用 CMake 进行链接
你可能会认为,在我们成功将源代码编译成二进制文件之后,作为构建工程师我们的工作就完成了。事实几乎如此——二进制文件包含了 CPU 执行的所有代码,但代码分散在多个文件中,方式非常复杂。链接是一个简化事物并使机器代码整洁、易于消费的过程。
快速查看命令列表会让你知道 CMake 并没有提供很多与链接相关的命令。承认,target_link_libraries()是唯一一个实际配置这一步骤的命令。那么为什么要用一整章来讲述一个命令呢?不幸的是,在计算机科学中,几乎没有什么事情是容易的,链接也不例外。
为了获得正确的结果,我们需要跟随整个故事——了解链接器究竟如何工作,并正确掌握基础知识。我们将讨论对象文件的内部结构,如何进行重定位和引用解析,以及它们的用途。我们将讨论最终可执行文件与其组件的区别以及系统如何构建进程映像。
然后,我们将向您介绍各种库——静态库、共享库和共享模块。它们都被称为库,但实际上它们几乎没有任何共同之处。构建正确链接的可执行文件严重依赖于有效的配置(以及关注如位置无关代码(PIC)这样的微小细节。
我们将学习链接过程中的另一个麻烦——一定义规则(ODR)。我们需要正好得到定义的数量。处理重复的符号有时可能非常棘手,特别是当共享库涉及其中时。然后,我们将了解为什么有时链接器找不到外部符号,即使可执行文件与适当的库链接在一起。
最后,我们将了解到如何节省时间并使用链接器为我们的解决方案准备测试,专用框架。
在本章中,我们将涵盖以下主要主题:
-
正确掌握链接的基础知识
-
构建不同类型的库
-
解决一定义规则的问题
-
链接的顺序和未解析的符号
-
为测试分离
main()
技术要求
你可以在 GitHub 上找到本章中存在的代码文件,地址为github.com/PacktPublishing/Modern-CMake-for-Cpp/tree/main/examples/chapter06。
要构建本书中提供的示例,请始终使用建议的命令:
cmake -B <build tree> -S <source tree>
cmake --build <build tree>
请确保将占位符<build tree>和<source tree>替换为适当的路径。作为提醒:build tree是指向目标/输出目录的路径,source tree是指你的源代码所在的路径。
正确掌握链接的基础知识
我们在第五章中讨论了 C++ 程序的生命周期,使用 CMake 编译 C++ 源代码。它包括五个主要阶段——编写、编译、链接、加载和执行。在正确编译所有源代码后,我们需要将它们组合成一个可执行文件。编译过程中产生的 对象文件 不能直接被处理器执行。但为什么不能呢?
为了回答这个问题,让我们来看看编译器是如何构建流行 ELF 格式的(Unix-like 系统和许多其他系统使用)对象文件的:
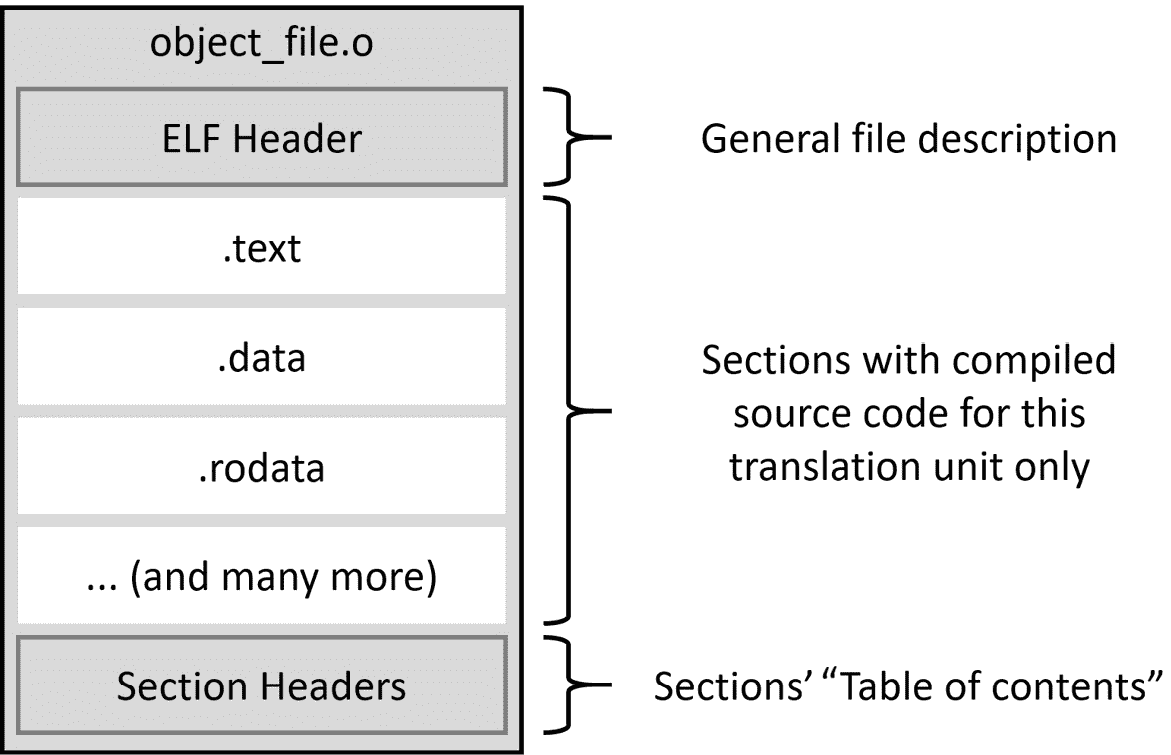
图 6.1 – 对象文件的结构
编译器将为每个翻译单元(每个 .cpp 文件)准备一个 对象文件。这些文件将用于构建我们程序的内存映像。对象文件包含以下元素:
-
一个 ELF 头,用于标识目标操作系统、ELF 文件类型、目标指令集架构以及 ELF 文件中找到的两个头表的位置和大小信息——程序头表(不在对象文件中)和段头表。
-
按类型分组的信息段。
-
一个段头表,包含关于名称、类型、标志、内存中的目标地址、文件中的偏移量以及其他杂项信息。它用于理解这个文件中有哪些段以及它们的位置,就像目录一样。
编译器在处理你的源代码时,会将收集的信息分组到几个不同的容器中,这些容器将被放在它们自己的独立部分。其中一些如下:
-
.text段:机器代码,包含处理器要执行的所有指令 -
.data段:所有初始化全局和静态对象(变量)的值 -
.bss段:所有未初始化全局和静态对象(变量)的值,将在程序启动时初始化为零 -
.rodata段:所有常量(只读数据)的值 -
.strtab段:包含所有常量字符串的字符串表,如我们在基本hello.cpp示例中放入的 Hello World -
.shstrtab段:包含所有段名称的字符串表
这些组非常类似于最终的可执行版本,它们将被放入 RAM 中以运行我们的应用程序。然而,我们并不能像这样直接将这个文件加载到内存中。这是因为每个 对象文件 都有自己的段集合。如果我们只是将它们连接在一起,我们就会遇到各种问题。我们将浪费大量的空间和时间,因为我们需要更多的内存页面。指令和数据将更难复制到 CPU 缓存中。整个系统将不得不更加复杂,并且会在运行时浪费宝贵的周期在许多(可能达到数万).text、.data 和其他段之间跳转。
所以,我们将要做的 instead is take each section of the object file and put it together with the same type of section from all other object files. 这个过程称为Relocatable对于对象文件). 除了只是将相应的段放在一起,它还必须更新文件内的内部关联——即,变量的地址、函数的地址、符号表索引或字符串表索引。所有这些值都是针对对象文件的局部值,它们的编号从零开始。当我们捆绑文件在一起时,我们需要偏移这些值,以便它们指向捆绑文件中的正确地址。
图 6.2 显示了移动 in action – .text 段被移动,.data 正在从所有链接的文件中构建,.rodata 和 .strtab 将紧随其后(为了简化,图不包括头):
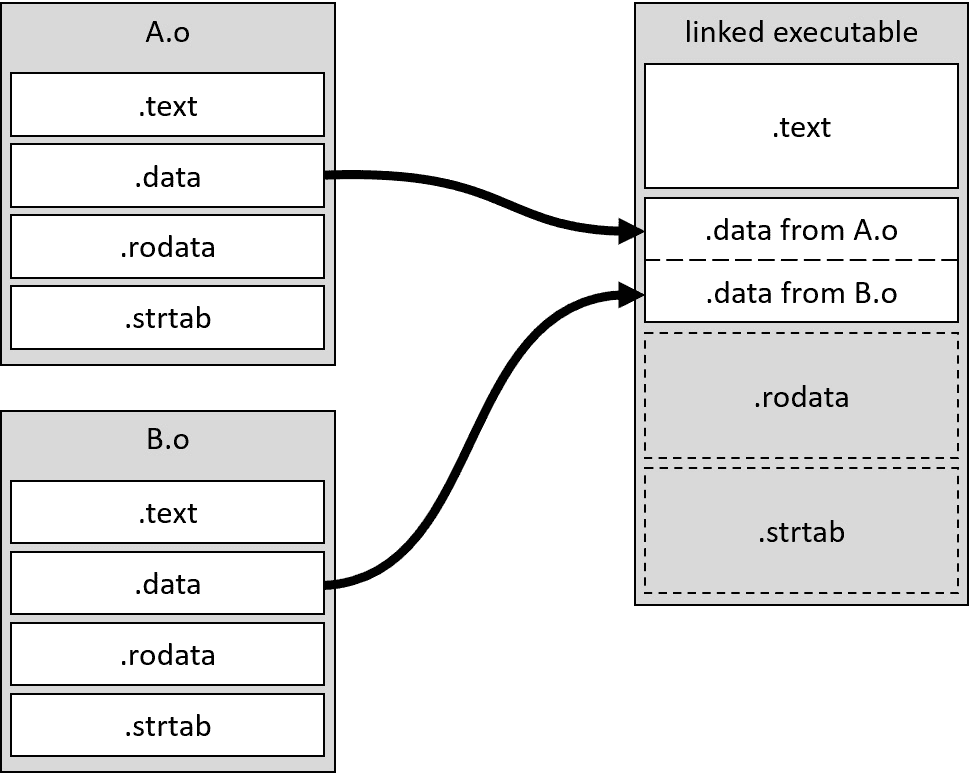
图 6.2 – .data 段的移动
第二,链接器需要extern关键字),编译器读取声明并信任定义在外面某个地方,稍后再提供。链接器负责收集此类未解决的外部符号引用,在合并到可执行文件后找到并填充它们所在的地址。图 6.3 显示了一个简单的引用解析示例:
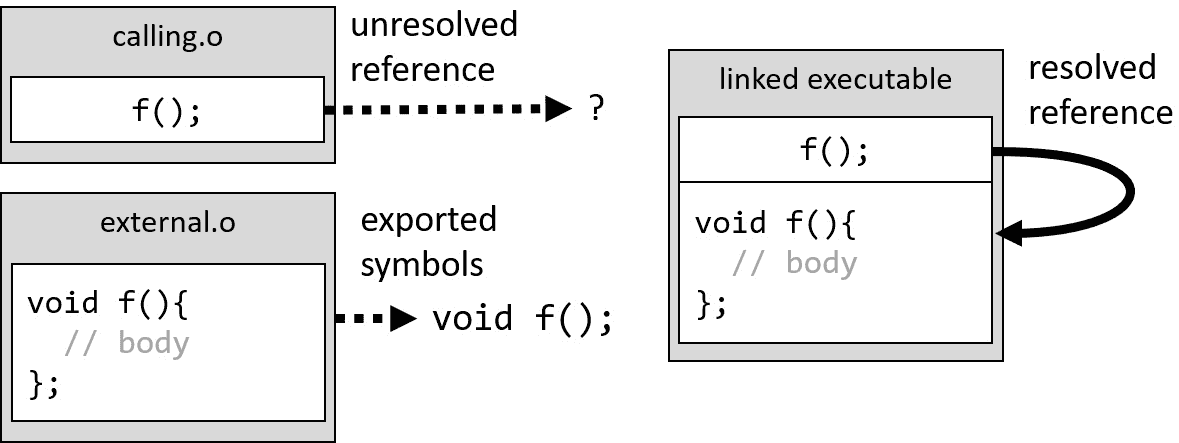
图 6.3 – 引用解析
如果程序员不知道它是如何工作的,链接的这部分可能会成为问题之源。我们可能会最终得到未解决的引用,它们找不到它们的外部符号,或者相反——我们提供了太多的定义,链接器不知道选择哪一个。
最终的可执行文件与对象文件非常相似;它包含已移动的段和已解决的引用、段头表,当然还有描述整个文件的 ELF 头。主要区别在于存在程序头(如图6.4所示)。
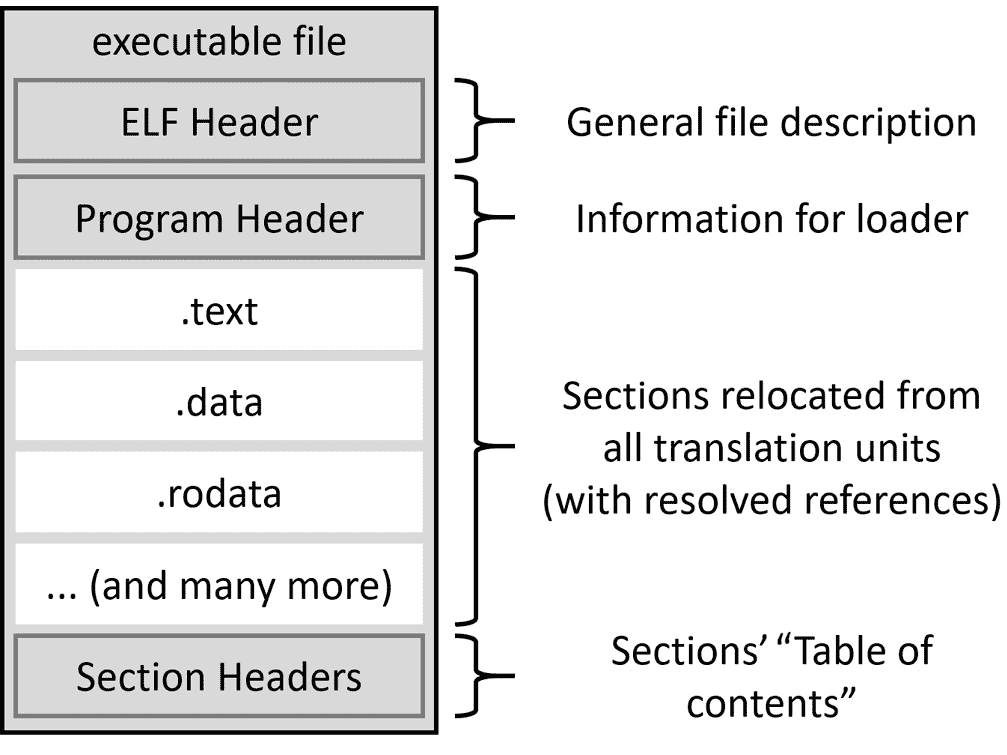
图 6.4 – ELF 中可执行文件的结构
程序头位于 ELF 头之后。系统加载器将读取此头以创建进程映像。该头包含一些通用信息和内存布局的描述。布局中的每个条目代表一个称为段的内存片段。条目指定要读取哪些段,以什么顺序,以及虚拟内存中的哪些地址,它们的标志是什么(读、写或执行),还有一些其他有用的细节。
对象文件*也可能被打包进库中,这是一种中间产品,可以被用于最终的执行文件或其他库中。在下一节中,我们将讨论三种库的类型。
构建不同类型的库
在源代码编译后,我们可能希望避免在同一平台上一再编译,甚至尽可能与外部项目共享。当然,你也可以简单地提供所有的目标文件,就像它们最初被创建的那样,但这有几个缺点。分发多个文件并分别添加到构建系统中更加困难。如果它们很多,这可能会很麻烦。相反,我们可以简单地将所有的目标文件合并到一个单一的目标中并共享它。CMake 在这个过程中极大地帮助我们。我们可以使用简单的add_library()命令(与target_link_libraries()命令一起使用)创建这些库。按惯例,所有库都有一个公共前缀lib,并使用特定于系统的扩展名表示它们是哪种类型的库:
-
在类 Unix 系统上,静态库有一个
.a扩展名,在 Windows 上则是.lib。 -
共享库在类 Unix 系统上有
.so扩展名,在 Windows 上有.dll。
当构建库(静态、共享或共享模块)时,你经常会遇到这个名字链接来表示这个过程。即使 CMake 在chapter06/01-libraries项目的构建输出中也这样称呼它:
[ 33%] Linking CXX static library libmy_static.a
[ 66%] Linking CXX shared library libmy_shared.so
[100%] Linking CXX shared module libmy_module.so
[100%] Built target module_gui
与可能看起来相反,链接器并不用于创建所有上述库。执行重定位和引用解析有例外。让我们来看看每种库类型,了解它们是如何工作的。
静态库
要构建一个静态库,我们可以简单地使用我们在前面章节中已经看到的命令:
add_library(<name> [<source>...])
如果BUILD_SHARED_LIBS变量没有设置为ON,上述代码将生成一个静态库。如果我们想无论如何都构建一个静态库,我们可以提供一个显式的关键字:
add_library(<name> STATIC [<source>...])
静态库是什么?它们本质上是一组存储在归档中的原始目标文件。在类 Unix 系统上,这样的归档可以通过ar工具创建。静态库是最古老、最基本的提供编译代码的方法。如果你想避免将你的依赖项与可执行文件分离,那么你可以使用它们,但代价是可执行文件的大小和占用内存会增加。
归档可能包含一些额外的索引,以加快最终的链接过程。每个平台都使用自己的方法来生成这些索引。类 Unix 系统使用一个名为ranlib的工具来完成这项工作。
共享库
了解到我们可以使用SHARED关键字来构建共享库,这并不令人惊讶:
add_library(<name> SHARED [<source>...])
我们也可以通过将BUILD_SHARED_LIBS变量设置为ON并使用简短版本来实现:
add_library(<name> SHARED [<source>...])
与静态库相比,这种差异是显著的。共享库使用链接器构建,并将执行链接的两个阶段。这意味着我们将收到带有正确段头、段和段头表的文件(图 6.1)。
共享库(也称为共享对象)可以在多个不同的应用程序之间共享。操作系统将在第一个使用它的程序中将这样的库加载到内存中的一个实例,并且所有随后启动的程序都将提供相同的地址(感谢复杂的虚拟内存机制)。只有.data和.bss段将为每个消耗库的进程创建单独的实例(这样每个进程就可以修改自己的变量,而不会影响其他消费者)。
得益于这种方法,系统中的整体内存使用情况得到了改善。如果我们使用一个非常受欢迎的库,我们可能不需要将其与我们的程序一起分发。很可能目标机器上已经提供了这个库。然而,如果情况不是这样,用户在运行应用程序之前需要明确地安装它。这可能会导致一些问题,当安装的库版本与预期不符时(这类问题被称为依赖地狱;更多信息可以在进阶阅读部分找到)。
共享模块
要构建共享模块,我们需要使用MODULE关键字:
add_library(<name> MODULE [<source>...])
这是一个旨在作为插件在运行时加载的共享库版本,而不是在编译时与可执行文件链接的东西。共享模块不会随着程序的启动自动加载(像常规共享库那样)。只有在程序通过进行系统调用(如 Windows 上的LoadLibrary或 Linux/macOS 上的dlopen()/dlsym())明确请求时,才会发生这种情况。
你不应该尝试将你的可执行文件与模块链接,因为这在所有平台上都不能保证有效。如果你需要这样做,请使用常规共享库。
位置无关代码
所有共享库和模块的源代码都应该使用位置无关代码标志编译。CMake 检查目标的POSITION_INDEPENDENT_CODE属性,并适当地添加编译器特定的编译标志,如gcc或clang的-fPIC。
PIC 这个词有点让人困惑。现在,程序已经在某种意义上位置无关,因为它们使用虚拟内存来抽象实际的物理地址。在调用函数时,CPU 使用对每个进程来说都是0的物理地址,该物理地址在分配时可用。这些映射不必指向连续的物理地址或遵循任何特定的顺序。
PIC 是关于将符号(对函数和全局变量的引用)映射到它们的运行时地址。在库的编译过程中,不知道哪些进程可能会使用它。无法预先确定库将在虚拟内存中的哪个位置加载,或者将以什么顺序加载。这反过来意味着符号的地址是未知的,以及它们相对于库机器代码的位置也是未知的。
为了解决这个问题,我们需要增加一个间接层。PIC 将为我们添加一个新节到输出中——.text节在链接时是已知的;因此,所有符号引用可以在那时指向占位符 GOT。指向内存中符号的实际值将在首次执行访问引用符号的指令时填充。那时,加载器将设置 GOT 中特定条目的值(这就是懒加载这个术语的由来)。
共享库和模块将自动将POSITION_INDEPENDENT_CODE属性设置为ON。然而,重要的是要记住,如果你的共享库被链接到另一个目标,比如静态库或对象库,你也需要在这个目标上设置这个属性。这是如何做到的:
set_target_properties(dependency_target
PROPERTIES POSITION_INDEPENDENT_CODE
ON)
不这样做会在 CMake 上遇到麻烦,因为默认情况下,此属性会以描述处理传播属性冲突一节中的方式进行检查第四章,与目标一起工作。
说到符号,还有一个问题需要讨论。下一节将讨论名称冲突导致定义不明确和不一致的问题。
使用单一定义规则解决问题的方法
菲尔·卡尔顿说得一点也没错,他说如下的话:
“计算机科学中有两件困难的事情:缓存失效和命名事物。”
名称之所以难以处理,有几个原因——它们必须精确、简单、短小且富有表现力。这使得它们具有意义,并允许程序员理解背后的概念。C++和许多其他语言提出了一个额外的要求——许多名称必须是唯一的。
这以几种不同的方式表现出来。程序员需要遵循 ODR。这表明,在单个翻译单元(单个.cpp文件)的作用域内,您需要精确一次地定义它,即使您多次声明相同的名称(变量、函数、类类型、枚举、概念或模板)。
此规则将扩展到整个程序的作用域,适用于您在代码中实际使用的所有变量和非内联函数。考虑以下示例:
第六章/02-odr-fail/shared.h
int i;
第六章/02-odr-fail/one.cpp
#include <iostream>
#include "shared.h"
int main() {
std::cout << i << std::endl;
}
第六章/02-odr-fail/two.cpp
#include "shared.h"
第六章/02-odr-fail/two.cpp
cmake_minimum_required(VERSION 3.20.0)
project(ODR CXX)
set(CMAKE_CXX_STANDARD 20)
add_executable(odr one.cpp two.cpp)
正如你所看到的,这是非常直接的——我们创建了一个shared.h头文件,它在两个单独的翻译单元中使用:
-
one.cpp文件,它简单地将i打印到屏幕上 -
two.cpp文件,它除了包含头文件外什么也不做
然后我们将这两个文件链接成一个可执行文件,并收到以下错误:
[100%] Linking CXX executable odr
/usr/bin/ld: CMakeFiles/odr.dir/two.cpp.o:(.bss+0x0): multiple definition of 'i'
; CMakeFiles/odr.dir/one.cpp.o:(.bss+0x0): first defined here
collect2: error: ld returned 1 exit status
你不能定义这些事情两次。然而,有一个值得注意的例外——类型、模板和外部内联函数可以在多个翻译单元中重复定义,如果它们完全相同(即,它们的标记序列相同)。我们可以通过将简单的定义int i;替换为类定义来证明这一点:
chapter06/03-odr-success/shared.h
struct shared {
static inline int i = 1;
};
然后,我们像这样使用它:
chapter06/03-odr-success/one.cpp
#include <iostream>
#include "shared.h"
int main() {
std::cout << shared::i << std::endl;
}
剩下的两个文件two.cpp和CMakeLists.txt保持不变,与02odrfail示例中的一样。这样的更改将允许链接成功:
-- Build files have been written to: /root/examples/chapter06/03-odr-success/b
[ 33%] Building CXX object CMakeFiles/odr.dir/one.cpp.o
[ 66%] Building CXX object CMakeFiles/odr.dir/two.cpp.o
[100%] Linking CXX executable odr
[100%] Built target odr
或者,我们可以将变量标记为翻译单元局部(它不会被导出到对象文件之外)。为此,我们将使用static关键字,如下所示:
chapter06/04-odr-success/shared.h
static int i;
所有其他文件都将保持不变,与原始示例一样,链接仍然成功。这当然意味着前面的代码中的变量为每个翻译单元存储在单独的内存中,一个翻译单元的更改不会影响另一个。
动态链接的重复符号
名称解析规则(ODR)对静态库和对象文件的作用完全一样,但当我们使用SHARED库构建代码时,情况就不那么明确了。链接器将允许在此处重复符号。在以下示例中,我们将创建两个共享库A和B,其中一个duplicated()函数和两个独特的a()和b()函数:
chapter06/05-dynamic/a.cpp
#include <iostream>
void a() {
std::cout << "A" << std::endl;
}
void duplicated() {
std::cout << "duplicated A" << std::endl;
}
第二个实现文件几乎是第一个的完全副本:
chapter06/05-dynamic/b.cpp
#include <iostream>
void b() {
std::cout << "B" << std::endl;
}
void duplicated() {
std::cout << "duplicated B" << std::endl;
}
现在,让我们使用每个函数来看看会发生什么(为了简单起见,我们将用extern局部声明它们):
chapter06/05-dynamic/main.cpp
extern void a();
extern void b();
extern void duplicated();
int main() {
a();
b();
duplicated();
}
上述代码将运行每个库的独特函数,然后调用在两个动态库中都定义有相同签名的函数。你认为会发生什么?在这种情况下链接顺序重要吗?让我们为两种情况测试一下:
-
main_1首先与a库链接。 -
main_2首先与b库链接。
以下是一个此类项目的代码:
chapter06/05-dynamic/CMakeLists.txt
cmake_minimum_required(VERSION 3.20.0)
project(Dynamic CXX)
add_library(a SHARED a.cpp)
add_library(b SHARED b.cpp)
add_executable(main_1 main.cpp)
target_link_libraries(main_1 a b)
add_executable(main_2 main.cpp)
target_link_libraries(main_2 b a)
构建并运行两个可执行文件后,我们将看到以下输出:
root@ce492a7cd64b:/root/examples/chapter06/05-dynamic# b/main_1
A
B
duplicated A
root@ce492a7cd64b:/root/examples/chapter06/05-dynamic# b/main_2
A
B
duplicated B
啊哈!所以,链接器确实关心链接库的顺序。如果我们不小心,这可能会造成一些混淆。实际上,名称冲突并不像看起来那么罕见。
这种行为有一些例外;如果我们定义本地可见符号,它们将优先于从动态链接库中可用的那些。在main.cpp中添加以下函数将使两个二进制的输出最后一行都变为重复的 MAIN,如下所示:
#include <iostream>
void duplicated() {
std::cout << "duplicated MAIN" << std::endl;
}
当导出库中的名称时,总是要非常小心,因为迟早会遇到名称冲突。
使用命名空间——不要依赖链接器
命名空间的概念是为了避免这种奇怪的问题,并以一种可管理的方式处理 ODR(唯一公共引用规则)。难怪建议用与库同名的命名空间包裹你的库代码。这样,我们可以摆脱所有重复符号的问题。
在我们的项目中,我们可能会遇到一种情况,其中一个共享库会链接另一个,然后又链接另一个,形成一个漫长的链。这并不罕见,尤其是在更复杂的设置中。重要的是要记住,简单地将一个库链接到另一个库并不意味着有任何命名空间继承。这个链中的每个符号都保持未保护状态,保存在它们最初编译的命名空间中。
链接器的怪癖在某些场合很有趣且有用,但让我们谈谈一个并不那么罕见的问题——当正确定义的符号无缘无故失踪时该怎么办。
链接顺序和未解决符号
链接器往往看起来有些古怪,经常会无缘无故地抱怨一些事情。这对刚开始接触的程序员来说是一个尤其艰难的考验,因为他们还不太熟悉这个工具。难怪他们会尽可能长时间地避免接触构建配置。最终,他们不得不修改一些东西(也许是在可执行文件中添加一个他们工作的库),然后一切就乱套了。
让我们考虑一个相当简单的依赖链——主可执行文件依赖于outer库,而outer库又依赖于nested库(包含必要的int b变量)。突然间,程序员的屏幕上出现了一个不起眼的提示信息:
outer.cpp:(.text+0x1f): undefined reference to 'b'
这并不是一个罕见的诊断——通常,这意味着我们忘记向链接器添加一个必要的库。但在这种情况下,库实际上已经被正确地添加到了target_link_libraries()命令中:
第六章/06-order/CMakeLists.txt
cmake_minimum_required(VERSION 3.20.0)
project(Order CXX)
add_library(outer outer.cpp)
add_library(nested nested.cpp)
add_executable(main main.cpp)
target_link_libraries(main nested outer)
那接下来怎么办!?很少有错误会让人如此抓狂地去调试和理解。我们在这里看到的是链接顺序的不正确。让我们深入源代码找出原因:
第六章/06-order/main.cpp
#include <iostream>
extern int a;
int main() {
std::cout << a << std::endl;
}
前面的代码看起来简单 enough —— 我们将打印一个名为a的外部变量,可以在outer库中找到。我们提前用extern关键词声明它。以下是该库的源代码:
第六章/06-order/outer.cpp
extern int b;
int a = b;
这也相当简单——outer依赖于nested库来提供b外部变量,该变量被分配给a导出变量。让我们查看nested的源代码,以确认我们没有错过定义:
第六章/06-order/nested.cpp
int b = 123;
的确,我们已经为b提供了定义,而且因为没用static关键词标记为局部,所以它正确地从nested目标导出。正如我们之前看到的,这个目标在CMakeLists.txt中与main可执行文件链接:
target_link_libraries(main nested outer)
那么undefined reference to 'b'错误是从哪里来的呢?
解决未定义符号的方式是这样的——链接器从左到右处理二进制文件。当链接器遍历二进制文件时,它将执行以下操作:
-
收集此二进制文件导出的所有未定义符号并将它们存储以供以后使用
-
尝试使用此二进制文件中定义的符号解决未定义符号(从迄今为止处理的所有二进制文件中收集)
-
对下一个二进制文件重复此过程
如果在整个操作完成后还有任何符号未定义,链接失败。
这是我们示例中的情况(CMake 将在可执行目标的对象文件之前放置库):
-
我们处理了
main.o,发现了一个对a的未定义引用,并将其收集以供以后解决。 -
我们处理了
libnested.a,没有发现未定义的引用,所以没有什么需要解决的。 -
我们处理了
libouter.a,发现了一个对b的未定义引用,并解决了a的引用。
我们正确地解决了a变量的引用,但不是b。我们只需要将链接顺序颠倒,以便nested在outer之后:
target_link_libraries(main outer nested)
另一个不太优雅的选项是重复库(这对于循环引用很有用):
target_link_libraries(main nested outer nested)
最后,我们可以尝试使用链接器特定的标志,如--start-group或--end-group。查看您链接器的文档,因为这些具体内容超出了本书的范围。
既然我们已经知道如何解决常见问题,那么让我们谈谈如何利用链接器的好处。
为测试分离 main()
正如我们迄今为止所建立的,链接器强制执行 ODR,并确保在链接过程中所有外部符号提供它们的定义。我们可能会遇到的一个有趣的问题是正确地进行构建测试。
理想情况下,我们应该测试与生产中运行的完全相同的源代码。一个彻底的测试管道应该构建源代码,在生成的二进制文件上运行其测试,然后才打包和分发可执行文件(不包括测试本身)。
但我们实际上是如何实现这一点的呢?可执行文件有非常具体的执行流程,这通常需要阅读命令行参数。C++的编译性质实际上并不支持可以仅用于测试目的而临时注入到二进制文件中的可插拔单元。这似乎需要一个相当复杂的解决方案。
幸运的是,我们可以使用链接器以优雅的方式帮助我们处理这个问题。考虑将您程序的main()中的所有逻辑提取到一个外部函数start_program()中,如下所示:
chapter06/07-testing/main.cpp
extern int start_program(int, const char**);
int main(int argc, const char** argv) {
return start_program(argc, argv);
}
现在跳过测试这个新的main()函数是合理的;它只是将参数传递给定义在其他地方(在另一个文件中)的函数。然后我们可以创建一个库,其中包含从main()原始源代码包装在一个新函数中的内容——start_program()。在这个示例中,我将使用一个简单的程序来检查命令行参数的数量是否大于1:
chapter06/07-testing/program.cpp
#include <iostream>
int start_program(int argc, const char** argv) {
if (argc <= 1) {
std::cout << "Not enough arguments" << std::endl;
return 1;
}
return 0;
}
现在我们可以准备一个项目,用于构建这个应用程序并将这两个翻译单元链接在一起:
chapter06/07-testing/CMakeLists.cpp
cmake_minimum_required(VERSION 3.20.0)
project(Testing CXX)
add_library(program program.cpp)
add_executable(main main.cpp)
target_link_libraries(main program)
main目标只是提供了所需的main()函数。program目标包含了所有的逻辑。现在我们可以通过创建另一个包含其自己的main()和测试逻辑的可执行文件来测试它。
在现实场景中,像main()方法这样的框架可以用来替换程序的入口点并运行所有定义的测试。我们将在第八章深入研究实际的测试主题,测试框架。现在,让我们关注通用原则,并在另一个main()函数中编写我们自己的测试:
chapter06/07-testing/test.cpp
#include <iostream>
extern int start_program(int, const char**);
using namespace std;
int main() {
auto exit_code = start_program(0, nullptr);
if (exit_code == 0)
cout << "Non-zero exit code expected" << endl;
const char* arguments[2] = {"hello", "world"};
exit_code = start_program(2, arguments);
if (exit_code != 0)
cout << "Zero exit code expected" << endl;
}
前面的代码将两次调用start_program,带参数和不带参数,并检查返回的退出码是否正确。这个单元测试在代码整洁和优雅的测试实践方面还有很多不足,但至少它是一个开始。重要的是,我们现在定义了两次main():
-
用于生产环境的
main.cpp -
用于测试目的的
test.cpp
我们现在将在CMakeLists.txt的底部添加第二个可执行文件:
add_executable(test test.cpp)
target_link_libraries(test program)
这创建了另一个目标,它与生产中的完全相同的二进制代码链接,但它允许我们以任何喜欢的方式调用所有导出的函数。得益于这一点,我们可以自动运行所有代码路径,并检查它们是否如预期般工作。太好了!
总结
CMake 中的链接似乎很简单,微不足道,但实际上,它的内容远比表面上看到的要多。毕竟,链接可执行文件并不是像拼图一样简单地组合在一起。正如我们学习了关于对象文件和库的结构,我们发现程序在运行前需要移动一些东西。这些被称为节,它们在程序的生命周期中扮演着不同的角色——存储不同类型的数据、指令、符号名等。链接器需要根据最终二进制文件的要求将它们组合在一起。这个过程被称为重定位。
我们还需要注意符号的处理——在所有翻译单元之间解决引用,确保不遗漏任何内容。然后,链接器可以创建程序头部并将其添加到最终的可执行文件中。它将包含系统加载器的指令,描述如何将合并的段转换为组成进程运行时内存映像的段。
我们还讨论了三种不同类型的库(静态库、共享库和共享模块),并解释了它们之间的区别以及哪些场景适合某些库。我们还涉及了 PIC 的概念——一个允许延迟绑定符号的强大概念。
ODR 是一个 C++概念,但我们已经知道,链接器对其进行了严格的实施。在介绍了这个主题之后,我们简要探讨了如何在静态和动态库中处理最基本的符号重复。这之后是一些建议,尽可能使用命名空间,并不要过分依赖链接器来防止符号冲突。
这样一个看似简单的步骤(CMake 只提供了一些与链接器相关的命令),确实有很多古怪之处!其中一个难以掌握的是链接顺序,尤其是在库有嵌套依赖时。我们现在知道如何处理一些基本情况,以及我们可以研究哪些其他方法来处理更复杂的情况。
最后,我们研究了如何利用链接器为我们的程序准备测试——将main()函数分离到另一个翻译单元中。这使我们能够引入另一个可执行文件,它运行的测试针对的是将在生产中运行的完全相同的机器代码。
现在我们已经知道了如何链接,我们可以检索外部库并将其用于我们的 CMake 项目中。在下一章中,我们将学习如何在 CMake 中管理依赖关系。
进一步阅读
关于本章涵盖的主题,你可以参考以下内容:
- ELF 文件的结构:
- 关于
add_library()的 CMake 手册:
- 依赖地狱:
- 模块与共享库的区别:
第七章:使用 CMake 管理依赖
你的解决方案是大型还是小型,并不重要;随着它的成熟,你最终会决定引入外部依赖。避免根据普遍的商业逻辑创建和维护代码的成本是很重要的。这样,你就可以将时间投入到对你和你的客户有意义的事情上。
外部依赖不仅用于提供框架和功能以及解决古怪的问题。它们在构建和控制代码质量的过程中也起着重要的作用——无论是特殊编译器如Protobuf,还是测试框架如GTest。
无论你是在处理开源项目,还是在使用你公司其他开发者编写的项目,你仍然需要一个良好、干净的流程来管理外部依赖。自己解决这个问题将花费无数的设置时间和大量的额外支持工作。幸运的是,CMake 在适应不同风格和依赖管理的历史方法的同时,还能跟上行业批准标准的不断演变。
为了提供一个外部依赖,我们首先应该检查宿主系统是否已经有了这个依赖,因为最好避免不必要的下载和漫长的编译。我们将探讨如何找到并把这样的依赖转换成 CMake 目标,在我们的项目中使用。这可以通过很多方式完成,特别是当包支持 CMake 开箱即用,或者至少提供给一个稍微老一点的 PkgConfig 工具的文件时。如果情况不是这样,我们仍然可以编写自己的文件来检测并包含这样的依赖。
我们将讨论当一个依赖在系统上不存在时应该做什么。正如你可以想象,我们可以采取替代步骤来自动提供必要的文件。我们将考虑使用不同的 Git 方法来解决这个问题,并将整个 CMake 项目作为我们构建的一部分引入。
在本章中,我们将涵盖以下主要内容:
-
如何找到已安装的包
-
使用
FindPkgConfig0发现遗留包 -
编写自己的 find-modules
-
与 Git 仓库协作
-
使用
ExternalProject和FetchContent模块
技术要求
你可以在这个章节中找到的代码文件在 GitHub 上,地址为github.com/PacktPublishing/Modern-CMake-for-Cpp/tree/main/examples/chapter07。
为了构建本书中提供的示例,总是使用推荐的命令:
cmake -B <build tree> -S <source tree>
cmake --build <build tree>
请确保将占位符<build tree>和<source tree>替换为适当的路径。作为提醒:build tree 是目标/输出目录的路径,source tree 是源代码所在的位置的路径。
如何找到已安装的包
好的,假设你已经决定通过网络通信或静态存储数据来提高你的技能。纯文本文件、JSON,甚至是老旧的 XML 都不行。你希望将你的数据直接序列化为二进制格式,最好使用业界知名的库——比如谷歌的 protocol buffers(Protobuf)。你找到了文档,在系统中安装了依赖项,现在怎么办?我们实际上如何告诉 CMake 找到并使用你引入的这项外部依赖?幸运的是,有一个find_package()命令。在大多数情况下,它都像魔法一样起作用。
让我们倒带并从头开始设置场景——我们必须安装我们想要使用的依赖项,因为find_package(),正如其名,只是关于在系统中发现包。我们假设依赖项已经安装,或者我们解决方案的用户知道如何在提示时安装特定的、必要的依赖项。为了覆盖其他场景,你需要提供一个备份计划(关于这方面的更多信息可以在与 Git 仓库一起工作部分中找到)。
在 Protobuf 的情况下,情况相当直接:你可以从官方存储库(github.com/protocolbuffers/protobuf)下载、编译并自行安装库,也可以使用你操作系统的包管理器。如果你正在使用第章 1《CMake 初步》中提到的 Docker 镜像,你将使用 Debian Linux。安装 Protobuf 库和编译器的命令如下:
$ apt update
$ apt install protobuf-compiler libprotobuf-dev
每个系统都有它自己的安装和管理包的方式。找到一个包所在的路径可能会很棘手且耗时,特别是当你想要支持今天大多数操作系统时。幸运的是,如果涉及的包提供了一个合适的配置文件,允许 CMake 确定支持该包所需的变量,find_package()通常可以为你完成这个任务。
如今,许多项目都符合这一要求,在安装过程中提供了这个文件给 CMake。如果你计划使用某个流行的库而它没有提供此文件,暂时不必担心。很可能 CMake 的作者已经将文件与 CMake 本身捆绑在一起(这些被称为find-modules,以便与配置文件区分开来)。如果情况不是这样,我们仍然还有一些选择:
-
为特定包提供我们自己的 find-modules,并将其与我们的项目捆绑在一起。
-
编写一个配置文件,并请包维护者将该包与文件一起分发。
你可能会说你还没有完全准备好自己创建这样的合并请求,这没关系,因为很可能你不需要这么做。CMake 附带了超过 150 个查找模块,可以找到如 Boost、bzip2、curl、curses、GIF、GTK、iconv、ImageMagick、JPEG、Lua、OpenGL、OpenSSL、PNG、PostgreSQL、Qt、SDL、Threads、XML-RPC、X11 和 zlib 等库,幸运的是,还包括我们在这个例子中将要使用的 Protobuf 文件。完整的列表在 CMake 文档中可以找到:cmake.org/cmake/help/latest/manual/cmake-modules.7.html#find modules。
查找模块和配置文件都可以在 CMake 项目中用一个find_package()命令。CMake 寻找匹配的查找模块,如果找不到任何模块,它会转向配置文件。搜索将从存储在CMAKE_MODULE_PATH变量中的路径开始(默认情况下这个变量是空的)。当项目想要添加和使用外部查找模块时,这个变量可以被项目配置。接下来,CMake 将扫描安装的 CMake 版本的内置查找模块列表。
如果没有找到适用的模块,该寻找相应的包配置文件了。CMake 有一长串适合宿主操作系统的路径,可以扫描与以下模式匹配的文件名:
-
<CamelCasePackageName>Config.cmake -
<kebab-case-package-name>-config.cmake
让我们稍微谈谈项目文件;在这个例子中,我其实并不打算设计一个带有远程过程调用和所有附件的网络解决方案。相反,我只是想证明我能构建并运行一个依赖于 Protobuf 的项目。为了实现这一点,我将创建一个尽可能小的合同的.proto文件。如果你对 Protobuf 不是特别熟悉,只需知道这个库提供了一种机制,可以将结构化数据序列化为二进制形式。为此,我们需要提供一个此类结构的模式,它将用于将二进制形式写入和读取 C++对象。
我想出的是这样的:
chapter07/01-find-package-variables/message.proto
syntax = "proto3";
message Message {
int32 id = 1;
}
如果你不熟悉 Protobuf 语法(这其实不是这个例子真正关注的),不必担心。这是一个只包含一个 32 位整数的简单message。Protobuf 有一个特殊的编译器,它会读取这些文件,并生成可以被我们的应用程序使用的 C++源文件和头文件。这意味着我们需要将这个编译步骤以某种方式添加到我们的过程中。我们稍后再回到这个问题。现在,让我们看看我们的main.cpp文件长什么样:
chapter07/01-find-package-variables/main.cpp
#include "message.pb.h"
#include <fstream>
using namespace std;
int main()
{
Message m;
m.set_id(123);
m.PrintDebugString();
fstream fo("./hello.data", ios::binary | ios::out);
m.SerializeToOstream(&fo);
fo.close();
return 0;
}
如我所说,Message包含一个唯一的id字段。在main.cpp文件中,我创建了一个代表这个消息的对象,将字段设置为123,并将其调试信息打印到标准输出。接下来,我创建了一个文件流,将这个对象的二进制版本写入其中,并关闭流——这是序列化库最简单的可能用途。
请注意,我已经包含了一个message.pb.h头文件。这个文件还不存在;它需要在message.proto编译期间由 Protobuf 编译器protoc创建。这种情况听起来相当复杂,暗示这样一个项目的列表文件必须非常长。根本不是!这就是 CMake 魔法发生的地方:
chapter07/01-find-package-variables/CMakeLists.txt
cmake_minimum_required(VERSION 3.20.0)
project(FindPackageProtobufVariables CXX)
find_package(Protobuf REQUIRED)
protobuf_generate_cpp(GENERATED_SRC GENERATED_HEADER
message.proto)
add_executable(main main.cpp
${GENERATED_SRC} ${GENERATED_HEADER})
target_link_libraries(main PRIVATE ${Protobuf_LIBRARIES})
target_include_directories(main PRIVATE
${Protobuf_INCLUDE_DIRS}
${CMAKE_CURRENT_BINARY_DIR})
让我们来分解一下:
-
前两行我们已经知道了;它们创建了一个项目和声明了它的语言。
-
find_package(Protobuf REQUIRED)要求 CMake 运行捆绑的FindProtobuf.cmake查找模块,并为我们设置 Protobuf 库。那个查找模块将扫描常用路径(因为我们提供了REQUIRED关键字)并在找不到库时终止。它还将指定有用的变量和函数(如下面的行所示)。 -
protobuf_generate_cpp是 Protobuf 查找模块中定义的自定义函数。在其内部,它调用add_custom_command(),该命令使用适当的参数调用protoc编译器。我们通过提供两个变量来使用这个函数,这些变量将被填充生成的源文件(GENERATED_SRC)和头文件(GENERATED_HEADER)的路径,以及要编译的文件列表(message.proto)。 -
如我们所知,
add_executable将使用main.cpp和前面命令中配置的 Protobuf 文件创建我们的可执行文件。 -
target_link_libraries将由find_package()找到的(静态或共享)库添加到我们的main目标链接命令中。 -
target_include_directories()将必要的INCLUDE_DIRS(由包提供)添加到包含路径中,以及CMAKE_CURRENT_BINARY_DIR。后者是必需的,以便编译器可以找到生成的message.pb.h头文件。
换句话说,它实现了以下功能:
-
查找库和编译器的所在位置
-
提供辅助函数,教会 CMake 如何调用
.proto文件的定制编译器 -
添加包含包含和链接所需路径的变量
在大多数情况下,当你调用find_package()时,你可以期待一些变量会被设置,不管你是使用内置的查找模块还是随包附带的配置文件(假设已经找到了包):
-
<PKG_NAME>_FOUND -
<PKG_NAME>_INCLUDE_DIRS或<PKG_NAME>_INCLUDES -
<PKG_NAME>_LIBRARIES或<PKG_NAME>_LIBRARIES或<PKG_NAME>_LIBS -
<PKG_NAME>_DEFINITIONS -
由查找模块或配置文件指定的
IMPORTED目标
最后一个观点非常有趣——如果一个包支持所谓的“现代 CMake”(以目标为中心),它将提供这些IMPORTED目标而不是这些变量,这使得代码更简洁、更简单。建议优先使用目标而不是变量。
Protobuf 是一个很好的例子,因为它提供了变量和IMPORTED目标(自从 CMake 3.10 以来):protobuf::libprotobuf,protobuf::libprotobuf-lite,protobuf::libprotoc和protobuf::protoc。这允许我们编写更加简洁的代码:
chapter07/02-find-package-targets/CMakeLists.txt
cmake_minimum_required(VERSION 3.20.0)
project(FindPackageProtobufTargets CXX)
find_package(Protobuf REQUIRED)
protobuf_generate_cpp(GENERATED_SRC GENERATED_HEADER
message.proto)
add_executable(main main.cpp
${GENERATED_SRC} ${GENERATED_HEADER})
target_link_libraries(main PRIVATE protobuf::libprotobuf)
target_include_directories(main PRIVATE
${CMAKE_CURRENT_BINARY_DIR})
protobuf::libprotobuf导入的目标隐式地指定了包含目录,并且多亏了传递依赖(或者我叫它们传播属性),它们与我们的main目标共享。链接器和编译器标志也是同样的过程。
如果你需要确切知道特定 find-module 提供了什么,最好是访问其在线文档。Protobuf 的一个可以在以下位置找到:cmake.org/cmake/help/latest/module/FindProtobuf.html。
重要提示
为了保持简单,本节中的示例如果用户系统中没有找到 protobuf 库(或其编译器)将简单地失败。但一个真正健壮的解决方案应该通过检查Protobuf_FOUND变量并相应地行事,要么打印给用户的清晰诊断消息(这样他们可以安装它)要么自动执行安装。
关于find_package()命令的最后一点是它的选项。完整的列表有点长,所以我们只关注基本的签名。它看起来像这样:
find_package(<Name> [version] [EXACT] [QUIET] [REQUIRED])
最重要的选项如下:
-
[version],它允许我们选择性地请求一个特定的版本。使用major.minor.patch.tweak格式(如1.22)或提供一个范围——1.22...1.40.1(使用三个点作为分隔符)。 -
EXACT关键字意味着我们想要一个确切的版本(这里不支持版本范围)。 -
QUIET关键字可以静默所有关于找到/未找到包的消息。 -
REQUIRED关键字如果找不到包将停止执行,并打印一个诊断消息(即使启用了QUIET也是如此)。
有关命令的更多信息可以在文档页面找到:cmake.org/cmake/help/latest/command/find_package.html。
为包提供配置文件的概念并不新鲜。而且它肯定不是 CMake 发明的。还有其他工具和格式为此目的而设计。PkgConfig 就是其中之一。CMake 还提供了一个有用的包装模块来支持它。
使用 FindPkgConfig 发现遗留的包
管理依赖项和发现它们所需的所有编译标志的问题与 C++库本身一样古老。有许多工具可以处理这个问题,从非常小和简单的机制到作为构建系统和 IDE 的一部分提供的非常灵活的解决方案。其中一个(曾经非常流行)的工具被称为 PkgConfig(freedesktop.org/wiki/Software/pkg-config/)。它通常在类 Unix 系统中可用(尽管它也适用于 macOS 和 Windows)。
pkg-config正逐渐被其他更现代的解决方案所取代。这里出现了一个问题——你应该投入时间支持它吗?答案一如既往——视情况而定:
-
如果一个库真的很受欢迎,它可能已经有了自己的 CMake find-module;在这种情况下,你可能不需要它。
-
如果没有 find-module(或者它不适用于您的库)并且库只提供 PkgConfig
.pc文件,只需使用现成的即可。
许多(如果不是大多数)库已经采用了 CMake,并在当前版本中提供了包配置文件。如果您不发布您的解决方案并且您控制环境,请使用find_package(),不要担心遗留版本。
遗憾的是,并非所有环境都可以快速更新到库的最新版本。许多公司仍在使用生产中的遗留系统,这些系统不再获得最新包。在这种情况下,用户可能只能使用较旧的(但希望兼容)版本。而且经常情况下,它会提供一个.pc文件。
此外,如果这意味着您的项目可以为大多数用户无障碍地工作,那么支持旧的 PkgConfig 格式的努力可能是值得的。
在任何情况下,首先使用find_package(),如前一部分所述,如果<PKG_NAME>_FOUND为假,则退回到 PkgConfig。这样,我们覆盖了一种场景,即环境升级后我们只需使用主方法而无需更改代码。
这个助手工具的概念相当简单——库的作者提供一个小型的.pc文件,其中包含编译和链接所需的信息,例如这个:
prefix=/usr/local
exec_prefix=${prefix}
includedir=${prefix}/include
libdir=${exec_prefix}/lib
Name: foobar
Description: A foobar library
Version: 1.0.0
Cflags: -I${includedir}/foobar
Libs: -L${libdir} -lfoobar
这个格式相当直接,轻量级,甚至支持基本变量扩展。这就是为什么许多开发者更喜欢它而不是像 CMake 这样的复杂、健壮的解决方案。尽管 PkgConfig 极其易于使用,但其功能却相当有限:
-
检查系统中是否存在库,并且是否提供了与之一起的
.pc文件 -
检查是否有一个库的足够新版本可用
-
通过运行
pkg-config --libs libfoo获取库的链接器标志 -
获取库的包含目录(此字段技术上可以包含其他编译器标志)——
pkg-config --cflags libfoo
为了在构建场景中正确使用 PkgConfig,您的构建系统需要在操作系统中找到pkg-config可执行文件,运行它几次,并提供适当的参数,然后将响应存储在变量中,以便稍后传递给编译器。在 CMake 中我们已经知道如何做到这一点——扫描已知存储辅助工具的路径以检查是否安装了 PkgConfig,然后使用几个exec_program()命令来发现如何链接依赖项。尽管步骤有限,但似乎每次使用 PkgConfig 时都这样做是过于繁琐的。
幸运的是,CMake 提供了一个方便的内置查找模块,正是为了这个目的——FindPkgConfig。它遵循大多数常规查找模块的规则,但不是提供PKG_CONFIG_INCLUDE_DIRS或PKG_CONFIG_LIBS变量,而是设置一个变量,直接指向二进制文件的路径——PKG_CONFIG_EXECUTABLE。不出所料,PKG_CONFIG_FOUND变量也被设置了——我们将使用它来确认系统中是否有这个工具,然后使用模块中定义的pkg_check_modules()帮助命令扫描一个pkg_check_modules()包。
我们来实际看看这个过程。一个提供.pc文件的相对受欢迎的库的一个例子是一个 PostgreSQL 数据库的客户端——libpqxx。
为了在 Debian 上安装它,您可以使用libpqxx-dev包(您的操作系统可能需要不同的包):
apt-get install libpqxx-dev
我们将创建一个尽可能短的main.cpp文件,其中包含一个虚拟连接类:
chapter07/02-find-pkg-config/main.cpp
#include <pqxx/pqxx>
int main()
{
// We're not actually connecting, but
// just proving that pqxx is available.
pqxx::nullconnection connection;
}
现在我们可以通过使用 PkgConfig 查找模块为之前的代码提供必要的依赖项:
chapter07/03-find-pkg-config/CMakeLists.txt
cmake_minimum_required(VERSION 3.20.0)
project(FindPkgConfig CXX)
find_package(PkgConfig REQUIRED)
pkg_check_modules(PQXX REQUIRED IMPORTED_TARGET libpqxx)
message("PQXX_FOUND: ${PQXX_FOUND}")
add_executable(main main.cpp)
target_link_libraries(main PRIVATE PkgConfig::PQXX)
让我们分解一下发生了什么:
-
我们要求 CMake 使用
find_package()命令查找 PkgConfig 可执行文件。如果因为REQUIRED关键字而没有pkg-config,它将会失败。 -
在
FindPkgConfig查找模块中定义的pkg_check_modules()自定义宏被调用,以创建一个名为PQXX的新IMPORTED目标。查找模块将搜索一个名为libpxx的依赖项,同样,因为REQUIRED关键字,如果库不可用,它将会失败。注意IMPORTED_TARGET关键字——没有它,就不会自动创建目标,我们必须手动定义由宏创建的变量。 -
我们通过打印
PQXX_FOUND来确认一切是否正确,并显示诊断信息。如果我们之前没有指定REQUIRED,我们在这里可以检查这个变量是否被设置(也许是为了允许其他备选机制介入)。 -
我们创建了
main可执行文件。 -
我们链接了由
pkg_check_modules()创建的PkgConfig::PQXXIMPORTED目标。注意PkgConfig::是一个常量前缀,PQXX来自传递给该命令的第一个参数。
这是一种相当方便的方法,可以引入尚不支持 CMake 的依赖项。这个查找模块还有其他一些方法和选项;如果你对了解更多感兴趣,我建议你参考官方文档:cmake.org/cmake/help/latest/module/FindPkgConfig.html。
查找模块旨在为 CMake 提供一个非常方便的方式来提供有关已安装依赖项的信息。大多数流行的库在所有主要平台上都广泛支持 CMake。那么,当我们想要使用一个还没有专用的查找模块的第三方库时,我们能做些什么呢?
编写你自己的查找模块
在少数情况下,你真正想在项目中使用的库没有提供配置文件或 PkgConfig 文件,而且 CMake 中没有现成的查找模块可供使用。在这种情况下,你可以为该库编写一个自定义的查找模块,并将其与你的项目一起分发。这种情况并不理想,但为了照顾到你的项目的用户,这是必须的。
既然我们已经在上一节中熟悉了libpqxx,那么现在就让我们为它编写一个好的查找模块吧。我们首先在项目中源代码树的cmake/module目录下创建一个新文件FindPQXX.cmake,并开始编写。我们需要确保当调用find_package()时,CMake 能够发现这个查找模块,因此我们将这个路径添加到CMakeLists.txt中的CMAKE_MODULE_PATH变量里,用list(APPEND)。整个列表文件应该看起来像这样:
chapter07/04-find-package-custom/CMakeLists.txt
cmake_minimum_required(VERSION 3.20.0)
project(FindPackageCustom CXX)
list(APPEND CMAKE_MODULE_PATH
"${CMAKE_SOURCE_DIR}/cmake/module/")
find_package(PQXX REQUIRED)
add_executable(main main.cpp)
target_link_libraries(main PRIVATE PQXX::PQXX)
现在我们已经完成了这个步骤,接下来我们需要编写实际的查找模块。从技术上讲,如果FindPQXX.cmake文件为空,将不会有任何事情发生:即使用户调用find_package()时使用了REQUIRED,CMake 也不会抱怨一些特定的变量没有被设置(包括PQXX_FOUND),这是查找模块的作者需要尊重 CMake 文档中概述的约定:
-
当调用
find_package(<PKG_NAME> REQUIRED)时,CMake 将提供一个<PKG_NAME>_FIND_REQUIRED变量,设置为1。如果找不到库,查找模块应该调用message(FATAL_ERROR)。 -
当调用
find_package(<PKG_NAME> QUIET)时,CMake 将提供一个<PKG_NAME>_FIND_QUIETLY变量,设置为1。查找模块应避免打印诊断信息(除了前面提到的一次)。 -
当调用列表文件时,CMake 将提供一个
<PKG_NAME>_FIND_VERSION变量,设置为所需版本。查找模块应该找到适当的版本,或者发出FATAL_ERROR。
当然,为了与其他查找模块保持一致性,最好遵循前面的规则。让我们讨论创建一个优雅的PQXX查找模块所需的步骤:
-
如果已知库和头文件的路径(要么由用户提供,要么来自之前运行的缓存),使用这些路径并创建一个
IMPORTED目标。在此结束。 -
否则,请找到嵌套依赖项——PostgreSQL 的库和头文件。
-
在已知的路径中搜索 PostgreSQL 客户端库的二进制版本。
-
在已知的路径中搜索 PostgreSQL 客户端包含头文件。
-
检查是否找到了库和包含头文件;如果是,创建一个
IMPORTED目标。
创建IMPORTED目标发生了两次——如果用户从命令行提供了库的路径,或者如果它们是自动找到的。我们将从编写一个函数来处理我们搜索过程的结果开始,并保持我们的代码 DRY。
要创建一个IMPORTED目标,我们只需要一个带有IMPORTED关键字的库(以便在CMakeLists.txt中的target_link_libraries()命令中使用它)。该库必须提供一个类型——我们将其标记为UNKNOWN,以表示我们不希望检测找到的库是静态的还是动态的;我们只想为链接器提供一个参数。
接下来,我们将IMPORTED_LOCATION和INTERFACE_INCLUDE_DIRECTORIES``IMPORTED目标的必需属性设置为函数被调用时传递的参数。我们还可以指定其他属性(如COMPILE_DEFINITIONS);它们对于PQXX来说只是不必要的。
在那之后,我们将路径存储在缓存变量中,这样我们就无需再次执行搜索。值得一提的是,PQXX_FOUND在缓存中被显式设置,因此它在全局变量作用域中可见(所以它可以被用户的CMakeLists.txt访问)。
最后,我们将缓存变量标记为高级,这意味着除非启用“高级”选项,否则它们不会在 CMake GUI 中显示。对于这些变量,这是一种常见的做法,我们也应该遵循约定:
chapter07/04-find-package-custom/cmake/module/FindPQXX.cmake
function(add_imported_library library headers)
add_library(PQXX::PQXX UNKNOWN IMPORTED)
set_target_properties(PQXX::PQXX PROPERTIES
IMPORTED_LOCATION ${library}
INTERFACE_INCLUDE_DIRECTORIES ${headers}
)
set(PQXX_FOUND 1 CACHE INTERNAL "PQXX found" FORCE)
set(PQXX_LIBRARIES ${library}
CACHE STRING "Path to pqxx library" FORCE)
set(PQXX_INCLUDES ${headers}
CACHE STRING "Path to pqxx headers" FORCE)
mark_as_advanced(FORCE PQXX_LIBRARIES)
mark_as_advanced(FORCE PQXX_INCLUDES)
endfunction()
接下来,我们覆盖第一种情况——一个用户如果将他们的PQXX安装在非标准位置,可以通过命令行(使用-D参数)提供必要的路径。如果是这种情况,我们只需调用我们刚刚定义的函数并使用return()放弃搜索。我们相信用户最清楚,能提供库及其依赖项(PostgreSQL)的正确路径给我们。
如果配置阶段在过去已经执行过,这个条件也将为真,因为PQXX_LIBRARIES和PQXX_INCLUDES变量是被缓存的。
if (PQXX_LIBRARIES AND PQXX_INCLUDES)
add_imported_library(${PQXX_LIBRARIES} ${PQXX_INCLUDES})
return()
endif()
是时候找到一些嵌套依赖项了。为了使用PQXX,宿主机器还需要 PostgreSQL。在我们的查找模块中使用另一个查找模块是完全合法的,但我们应该将REQUIRED和QUIET标志传递给它(以便嵌套搜索与外层搜索行为一致)。这不是复杂的逻辑,但我们应该尽量避免不必要的代码。
CMake 有一个内置的帮助宏,正是为此而设计——find_dependency()。有趣的是,文档中指出它不适合用于 find-modules,因为它如果在找不到依赖项时调用return()命令。因为这是一个宏(而不是一个函数),return()将退出调用者的作用域,即FindPQXX.cmake文件,停止外层 find-module 的执行。可能有些情况下这是不希望的,但在这个情况下,这正是我们想要做的——阻止 CMake 深入寻找PQXX的组件,因为我们已经知道 PostgreSQL 不可用:
# deliberately used in mind-module against the
documentation
include(CMakeFindDependencyMacro)
find_dependency(PostgreSQL)
为了找到PQXX库,我们将设置一个_PQXX_DIR帮助变量(转换为 CMake 风格的路径)并使用find_library()命令扫描我们在PATHS关键字之后提供的路径列表。该命令将检查是否有与NAMES关键字之后提供的名称匹配的库二进制文件。如果找到了匹配的文件,其路径将被存储在PQXX_LIBRARY_PATH变量中。否则,该变量将被设置为<VAR>-NOTFOUND,在这种情况下是PQXX_HEADER_PATH-NOTFOUND。
NO_DEFAULT_PATH关键字禁用了默认行为,这将扫描 CMake 为该主机环境提供的默认路径列表:
file(TO_CMAKE_PATH "$ENV{PQXX_DIR}" _PQXX_DIR)
find_library(PQXX_LIBRARY_PATH NAMES libpqxx pqxx
PATHS
${_PQXX_DIR}/lib/${CMAKE_LIBRARY_ARCHITECTURE}
# (...) many other paths - removed for brevity
/usr/lib
NO_DEFAULT_PATH
)
接下来,我们将使用find_path()命令搜索所有已知的头文件,这个命令的工作方式与find_library()非常相似。主要区别在于find_library()知道库的系统特定扩展,并将这些扩展作为需要自动添加,而对于find_path(),我们需要提供确切的名称。
在这里也不要混淆pqxx/pqxx。这是一个实际的头文件,但库作者故意省略了扩展名,以符合 C++风格#include指令(而不是遵循 C 风格.h扩展名):#include <pqxx/pqxx>:
find_path(PQXX_HEADER_PATH NAMES pqxx/pqxx
PATHS
${_PQXX_DIR}/include
# (...) many other paths - removed for brevity
/usr/include
NO_DEFAULT_PATH
)
现在是检查PQXX_LIBRARY_PATH和PQXX_HEADER_PATH变量是否包含任何-NOTFOUND值的时候。同样,我们可以手动进行这项工作,然后根据约定打印诊断信息或终止构建执行,或者我们可以使用 CMake 提供的FindPackageHandleStandardArgs列表文件中的find_package_handle_standard_args()帮助函数。这是一个帮助命令,如果路径变量被填充,则将<PKG_NAME>_FOUND变量设置为1,并提供关于成功和失败的正确诊断信息(它将尊重QUIET关键字)。如果传递了REQUIRED关键字给 find-module,而其中一个提供的路径变量为空,它还将以FATAL_ERROR终止执行。
如果找到了库,我们将调用函数定义IMPORTED目标并将路径存储在缓存中:
include(FindPackageHandleStandardArgs)
find_package_handle_standard_args(
PQXX DEFAULT_MSG PQXX_LIBRARY_PATH PQXX_HEADER_PATH
)
if (PQXX_FOUND)
add_imported_library(
"${PQXX_LIBRARY_PATH};${POSTGRES_LIBRARIES}"
"${PQXX_HEADER_PATH};${POSTGRES_INCLUDE_DIRECTORIES}"
)
endif()
就这些。这个 find-module 将找到PQXX并创建相应的PQXX::PQXX目标。你可以在整个文件中找到这个模块,文件位于书籍示例仓库中:chapter07/04-find-package-custom/cmake/module/FindPQXX.cmake。
如果一个库很受欢迎,并且很可能会在系统中已经安装,这种方法非常有效。然而,并非所有的库随时都能获得。我们能否让这个步骤变得简单,让我们的用户使用 CMake 获取和构建这些依赖项?
使用 Git 仓库工作
许多项目依赖于 Git 作为版本控制系统。假设我们的项目和外部库都在使用它,有没有某种 Git 魔法能让我们把这些仓库链接在一起?我们能否构建库的特定(或最新)版本,作为构建我们项目的一个步骤?如果是,怎么做?
通过 Git 子模块提供外部库
一个可能的解决方案是使用 Git 内置的机制,称为Git 子模块。子模块允许项目仓库使用其他 Git 仓库,而实际上不将引用的文件添加到项目仓库中。它们的工作方式与软链接类似——它们指向外部仓库中的特定分支或提交(但你需要显式地更新它们)。要向你的仓库中添加一个子模块(并克隆其仓库),执行以下命令:
git submodule add <repository-url>
如果你拉取了一个已经包含子模块的仓库,你需要初始化它们:
git submodule update --init -- <local-path-to-submodule>
正如你所看到的,这是一个多功能的机制,可以利用第三方代码在我们的解决方案中。一个小缺点是,当用户克隆带有根项目的仓库时,子模块不会自动拉取。需要一个显式的init/pull命令。暂时保留这个想法——我们也会用 CMake 解决它。首先,让我们看看我们如何在代码中使用一个新创建的子模块。
为了这个例子,我决定写一个小程序,从 YAML 文件中读取一个名字,并在欢迎消息中打印出来。YAML 是一种很好的简单格式,用于存储可读的配置,但机器解析起来相当复杂。我找到了一个由 Jesse Beder(及当时 92 名其他贡献者)解决这个问题的整洁小型项目,称为 yaml-cpp(github.com/jbeder/yaml-cpp)。
这个例子相当直接。它是一个问候程序,打印出欢迎<名字>的消息。name的默认值将是Guest,但我们可以在 YAML 配置文件中指定一个不同的名字。以下是代码:
第七章/05-git-submodule-manual/main.cpp
#include <string>
#include <iostream>
#include "yaml-cpp/yaml.h"
using namespace std;
int main() {
string name = "Guest";
YAML::Node config = YAML::LoadFile("config.yaml");
if (config["name"])
name = config["name"].as<string>();
cout << "Welcome " << name << endl;
return 0;
}
这个示例的配置文件只有一行:
第七章/05-git-submodule-manual/config.yaml
name: Rafal
让我们回到main.cpp一会儿——它包含了"yaml-cpp/yaml.h"头文件。为了使其可用,我们需要克隆yaml-cpp项目并构建它。让我们创建一个extern目录来存储所有第三方依赖项(如第三章、设置你的第一个 CMake 项目部分中所述)并添加一个 Git 子模块,引用库的仓库:
$ mkdir extern
$ cd extern
$ git submodule add https://github.com/jbeder/yaml-cpp.git
Cloning into 'chapter07/01-git-submodule-manual/extern/yaml-cpp'...
remote: Enumerating objects: 8134, done.
remote: Total 8134 (delta 0), reused 0 (delta 0), pack-reused 8134
Receiving objects: 100% (8134/8134), 3.86 MiB | 3.24 MiB/s, done.
Resolving deltas: 100% (5307/5307), done.
Git 已经克隆了仓库;现在我们可以将其作为项目的依赖项,并让 CMake 负责构建:
chapter07/05-git-submodule-manual/CMakeLists.txt
cmake_minimum_required(VERSION 3.20.0)
project(GitSubmoduleManual CXX)
add_executable(welcome main.cpp)
configure_file(config.yaml config.yaml COPYONLY)
add_subdirectory(extern/yaml-cpp)
target_link_libraries(welcome PRIVATE yaml-cpp)
让我们分解一下我们在这里给予 CMake 的指令:
-
设置项目并添加我们的
welcome可执行文件。 -
接下来,调用
configure_file,但实际上不配置任何内容。通过提供COPYONLY关键字,我们只是将我们的config.yaml复制到构建树中,这样可执行文件在运行时能够找到它。 -
添加 yaml-cpp 仓库的子目录。CMake 会将其视为项目的一部分,并递归执行任何嵌套的
CMakeLists.txt文件。 -
将库提供的
yaml-cpp目标与welcome目标链接。
yaml-cpp 的作者遵循在第三章《设置你的第一个 CMake 项目》中概述的实践,并将公共头文件存储在单独的目录中——<项目名称>/include/<项目名称>。这允许库的客户(如main.cpp)通过包含"yaml-cpp/yaml.h"库名称的路径来访问这些文件。这种命名实践非常适合发现——我们立即知道是哪个库提供了这个头文件。
正如你所看到的,这并不是一个非常复杂的过程,但它并不理想——用户在克隆仓库后必须手动初始化我们添加的子模块。更糟糕的是,它没有考虑到用户可能已经在他们的系统上安装了这个库。这意味着浪费了下载并构建这个依赖项的过程。一定有更好的方法。
自动初始化 Git 子模块
为用户提供整洁的体验并不总是对开发者来说是痛苦的。如果一个库提供了一个包配置文件,我们只需让find_package()在安装的库中搜索它。正如承诺的那样,CMake 首先检查是否有合适的 find 模块,如果没有,它将寻找配置文件。
我们已经知道,如果<LIB_NAME>_FOUND变量被设置为1,则库被找到,我们可以直接使用它。我们也可以在库未找到时采取行动,并提供方便的解决方法来默默改善用户的体验:退回到获取子模块并从源代码构建库。突然之间,一个新克隆的仓库不自动下载和初始化嵌套子模块的事实看起来并没有那么糟糕,不是吗?
让我们将上一个示例中的代码进行扩展:
chapter07/06-git-submodule-auto/CMakeLists.txt
cmake_minimum_required(VERSION 3.20.0)
project(GitSubmoduleAuto CXX)
add_executable(welcome main.cpp)
configure_file(config.yaml config.yaml COPYONLY)
find_package(yaml-cpp QUIET)
if (NOT yaml-cpp_FOUND)
message("yaml-cpp not found, initializing git submodule")
execute_process(
COMMAND git submodule update --init -- extern/yaml-cpp
WORKING_DIRECTORY ${CMAKE_CURRENT_SOURCE_DIR}
)
add_subdirectory(extern/yaml-cpp)
endif()
target_link_libraries(welcome PRIVATE yaml-cpp)
我们添加了高亮显示的行:
-
我们将尝试悄悄地查找 yaml-cpp 并使用它。
-
如果它不存在,我们将打印一个简短的诊断信息,并使用
execute_process()命令来初始化子模块。这实际上是从引用仓库中克隆文件。 -
最后,我们将
add_subdirectory()用于从源代码构建依赖项。
简短而精炼。这也适用于未使用 CMake 构建的库——我们可以遵循 git submodule 的示例,再次调用 execute_process() 以同样的方式启动任何外部构建工具。
可悲的是,如果您的公司使用 Concurrent Versions System (CVS)、Subversion (SVN)、Mercurial 或任何其他方法向用户提供代码,这种方法就会崩溃。如果您不能依赖 Git submodules,替代方案是什么?
为不使用 Git 的项目克隆依赖项
如果您使用另一个 VCS 或者提供源代码的存档,您可能会在依赖 Git submodules 将外部依赖项引入您的仓库时遇到困难。很有可能是构建您代码的环境安装了 Git 并能执行 git clone 命令。
让我们看看我们应该如何进行:
chapter07/07-git-clone/CMakeLists.txt
cmake_minimum_required(VERSION 3.20.0)
project(GitClone CXX)
add_executable(welcome main.cpp)
configure_file(config.yaml config.yaml COPYONLY)
find_package(yaml-cpp QUIET)
if (NOT yaml-cpp_FOUND)
message("yaml-cpp not found, cloning git repository")
find_package(Git)
if (NOT Git_FOUND)
message(FATAL_ERROR "Git not found, can't initialize!")
endif ()
execute_process(
COMMAND ${GIT_EXECUTABLE} clone
https://github.com/jbeder/yaml-cpp.git
WORKING_DIRECTORY ${CMAKE_CURRENT_SOURCE_DIR}/extern
)
add_subdirectory(extern/yaml-cpp)
endif()
target_link_libraries(welcome PRIVATE yaml-cpp)
再次,加粗的行是我们 YAML 项目中的新部分。发生了以下情况:
-
首先,我们通过
FindGit查找模块检查 Git 是否可用。 -
如果不可以使用,我们就束手无策了。我们将发出
FATAL_ERROR,并希望用户知道接下来该做什么。 -
否则,我们将使用
FindGit查找模块设置的GIT_EXECUTABLE变量调用execute_process()并克隆我们感兴趣的仓库。
Git 对于有一定经验的开发者来说尤其有吸引力。它可能适合一个不包含对相同仓库的嵌套引用的小项目。然而,如果确实如此,您可能会发现您可能需要多次克隆和构建同一个项目。如果依赖项目根本不使用 Git,您将需要另一个解决方案。
使用 ExternalProject 和 FetchContent 模块
在线 CMake 参考书籍将建议使用 ExternalProject 和 FetchContent 模块来处理更复杂项目中依赖项的管理。这实际上是个好建议,但它通常在没有适当上下文的情况下给出。突然之间,我们面临了许多问题。这些模块是做什么的?何时选择一个而不是另一个?它们究竟是如何工作的,以及它们是如何相互作用的?一些答案比其他的更难找到,令人惊讶的是,CMake 的文档没有为该主题提供一个平滑的介绍。不用担心——我们在这里会处理。
外部项目
CMake 3.0.0 引入了一个名为 ExternalProject 的模块。正如您所猜测的,它的目的是为了添加对在线仓库中可用的外部项目的支持。多年来,该模块逐渐扩展以满足不同的需求,最终变得相当复杂的命令——ExternalProject_Add()。我是说复杂——它接受超过 85 个不同的选项。不足为奇,因为它提供了一组令人印象深刻的特性:
-
为外部项目管理目录结构
-
从 URL 下载源代码(如有需要,从归档中提取)
-
支持 Git、Subversion、Mercurial 和 CVS 仓库
-
如有需要,获取更新
-
使用 CMake、Make 配置和构建项目,或使用用户指定的工具
-
执行安装和运行测试
-
记录到文件
-
从终端请求用户输入
-
依赖于其他目标
-
向构建过程中添加自定义命令/步骤
ExternalProject 模块在构建阶段填充依赖项。对于通过 ExternalProject_Add() 添加的每个外部项目,CMake 将执行以下步骤:
-
mkdir– 为外部项目创建子目录 -
download– 从仓库或 URL 获取项目文件 -
update– 在支持差量更新的下载方法中重新运行时更新文件 -
patch– 可选执行一个补丁命令,用于修改下载文件以满足项目需求 -
configure– 为 CMake 项目执行配置阶段,或为非 CMake 依赖手动指定命令 -
build– 为 CMake 项目执行构建阶段,对于其他依赖项,执行make命令 -
install– 安装 CMake 项目,对于其他依赖项,执行make install命令 -
test– 如果定义了任何TEST_...选项,则执行依赖项的测试
步骤按照前面的确切顺序进行,除了 test 步骤,该步骤可以通过 TEST_BEFORE_INSTALL <bool> 或 TEST_AFTER_INSTALL <bool> 选项在 install 步骤之前或之后可选地启用。
下载步骤选项
我们主要关注控制 download 步骤或 CMake 如何获取依赖项的选项。首先,我们可能选择不使用 CMake 内置的此方法,而是提供一个自定义命令(在此处支持生成器表达式):
DOWNLOAD_COMMAND <cmd>...
这样做后,我们告诉 CMake 忽略此步骤的所有其他选项,只需执行一个特定于系统的命令。空字符串也被接受,用于禁用此步骤。
从 URL 下载依赖项
我们可以提供一系列 URL,按顺序扫描直到下载成功。CMake 将识别下载文件是否为归档文件,并默认进行解压:
URL <url1> [<url2>...]
其他选项允许我们进一步自定义此方法的行为:
-
URL_HASH <algo>=<hashValue>– 检查通过<algo>生成的下载文件的校验和是否与提供的<hashValue>匹配。建议确保下载的完整性。支持的算法包括MD5、SHA1、SHA224、SHA256、SHA384、SHA512、SHA3_224、SHA3_256、SHA3_384和SHA3_512,这些算法由string(<HASH>)命令定义。对于MD5,我们可以使用简写选项URL_MD5 <md5>。 -
DOWNLOAD_NO_EXTRACT <bool>– 显式禁用下载后的提取。我们可以通过访问<DOWNLOADED_FILE>变量,在后续步骤中使用下载文件的文件名。 -
DOWNLOAD_NO_PROGRESS <bool>– 不记录下载进度。 -
TIMEOUT <seconds>和INACTIVITY_TIMEOUT <seconds>– 在固定总时间或无活动期后终止下载的超时时间。 -
HTTP_USERNAME <username>和HTTP_PASSWORD <password>– 提供 HTTP 认证值的选项。确保在项目中避免硬编码任何凭据。 -
HTTP_HEADER <header1> [<header2>…]– 发送额外的 HTTP 头。用这个来访问 AWS 中的内容或传递一些自定义令牌。 -
TLS_VERIFY <bool>– 验证 SSL 证书。如果没有设置,CMake 将从CMAKE_TLS_VERIFY变量中读取这个设置,默认为false。跳过 TLS 验证是一种不安全、糟糕的做法,应该避免,尤其是在生产环境中。 -
TLS_CAINFO <file>– 如果你的公司发行自签名 SSL 证书,这个选项很有用。这个选项提供了一个权威文件的路径;如果没有指定,CMake 将从CMAKE_TLS_CAINFO变量中读取这个设置。
从 Git 下载依赖项
要从 Git 下载依赖项,你需要确保主机安装了 Git 1.6.5 或更高版本。以下选项是克隆 Git 的必要条件:
GIT_REPOSITORY <url>
GIT_TAG <tag>
<url>和<tag>都应该符合git命令能理解的格式。此外,建议使用特定的 git 哈希,以确保生成的二进制文件可以追溯到特定的提交,并且不会执行不必要的git fetch。如果你坚持使用分支,使用如origin/main的远程名称。这保证了本地克隆的正确同步。
其他选项如下:
-
GIT_REMOTE_NAME <name>– 远程名称,默认为origin。 -
GIT_SUBMODULES <module>...– 指定应该更新的子模块。从 3.16 起,这个值默认为无(之前,所有子模块都被更新)。 -
GIT_SUBMODULES_RECURSE 1– 启用子模块的递归更新。 -
GIT_SHALLOW 1– 执行浅克隆(不下载历史提交)。这个选项推荐用于性能。 -
TLS_VERIFY <bool>– 这个选项在从 URL 下载依赖项部分解释过。它也适用于 Git,并且为了安全起见应该启用。
从 Subversion 下载依赖项
要从 Subversion 下载,我们应该指定以下选项:
SVN_REPOSITORY <url>
SVN_REVISION -r<rev>
此外,我们还可以提供以下内容:
-
SVN_USERNAME <user>和SVN_PASSWORD <password>– 用于检出和更新的凭据。像往常一样,避免在项目中硬编码它们。 -
SVN_TRUST_CERT <bool>– 跳过对 Subversion 服务器证书的验证。只有在你信任网络路径到服务器及其完整性时才使用这个选项。默认是禁用的。
从 Mercurial 下载依赖项
这种模式非常直接。我们需要提供两个选项,就完成了:
HG_REPOSITORY <url>
HG_TAG <tag>
从 CVS 下载依赖项
要从 CVS 检出模块,我们需要提供这三个选项:
CVS_REPOSITORY <cvsroot>
CVS_MODULE <module>
CVS_TAG <tag>
更新步骤选项
默认情况下,update步骤如果支持更新,将会重新下载外部项目的文件。我们可以用两种方式覆盖这个行为:
-
提供一个自定义命令,在更新期间执行
UPDATE_COMMAND <cmd>。 -
完全禁用
update步骤(允许在断开网络的情况下构建)–UPDATE_DISCONNECTED <bool>。请注意,第一次构建期间的download步骤仍然会发生。
修补步骤选项
Patch是一个可选步骤,在源代码获取后执行。要启用它,我们需要指定我们要执行的确切命令:
PATCH_COMMAND <cmd>...
CMake 文档警告说,一些修补程序可能比其他修补程序“更粘”。例如,在 Git 中,更改的文件在更新期间不会恢复到原始状态,我们需要小心避免错误地再次修补文件。理想情况下,patch命令应该是真正健壮且幂等的。
重要提示
前面提到的选项列表只包含最常用的条目。确保参考官方文档以获取更多详细信息和描述其他步骤的选项:cmake.org/cmake/help/latest/module/ExternalProject.html。
在实际中使用 ExternalProject
依赖项在构建阶段被填充非常重要,它有两个效果——项目的命名空间完全分离,任何外部项目定义的目标在主项目中不可见。后者尤其痛苦,因为我们在使用find_package()命令后不能以同样的方式使用target_link_libraries()。这是因为两个配置阶段的分离。主项目必须完成配置阶段并开始构建阶段,然后依赖项才能下载并配置。这是一个问题,但我们将学习如何处理第二个。现在,让我们看看ExternalProject_Add()如何与我们在 previous examples 中使用的 yaml-cpp 库工作:
chapter07/08-external-project-git/CMakeLists.txt
cmake_minimum_required(VERSION 3.20.0)
project(ExternalProjectGit CXX)
add_executable(welcome main.cpp)
configure_file(config.yaml config.yaml COPYONLY)
include(ExternalProject)
ExternalProject_Add(external-yaml-cpp
GIT_REPOSITORY https://github.com/jbeder/yaml-cpp.git
GIT_TAG yaml-cpp-0.6.3
)
target_link_libraries(welcome PRIVATE yaml-cpp)
构建该项目采取以下步骤:
-
我们包含了
ExternalProject模块以访问其功能。 -
我们调用了
FindExternalProject_Add()命令,该命令将构建阶段任务为下载必要文件,并在我们的系统中配置、构建和安装依赖项。
我们需要小心这里,并理解这个例子之所以能工作,是因为 yaml-cpp 库在其CMakeLists.txt中定义了一个安装阶段。这个阶段将库文件复制到系统中的标准位置。target_link_libraries()命令中的yaml-cpp参数被 CMake 解释为直接传递给链接器的参数——-lyaml-cpp。这个行为与之前的例子不同,在那里我们明确定义了yaml-cpp目标。如果库不提供安装阶段(或者二进制版本的名字不匹配),链接器将抛出错误。
在此之际,我们应该更深入地探讨每个阶段的配置,并解释如何使用不同的下载方法。我们将在FetchContent部分讨论这些问题,但首先,让我们回到讨论ExternalProject导致的依赖项晚获取问题。我们不能在外部项目被获取的时候使用它们的目标,因为编译阶段已经结束了。CMake 将通过将其标记为特殊的UTILITY类型来显式保护使用FindExternalProject_Add()创建的目标。当你错误地尝试在主项目中使用这样一个目标(也许是为了链接它)时,CMake 将抛出一个错误:
Target "external-yaml-cpp-build" of type UTILITY may not be linked into another target.
为了绕过这个限制,技术上我们可以创建另一个目标,一个IMPORTED库,然后使用它(就像我们在这个章节前面用FindPQXX.cmake做的那样)。但这实在太麻烦了。更糟糕的是,CMake 实际上理解外部 CMake 项目创建的目标(因为它在构建它们)。在主项目中重复这些声明不会是一个非常 DRY 的做法。
另一个可能的解决方案是将整个依赖项的获取和构建提取到一个独立的子项目中,并在配置阶段构建该子项目。要实现这一点,我们需要用execute_process()启动 CMake 的另一个实例。通过一些技巧和add_subdirectory()命令,我们随后可以将这个子项目的列表文件和二进制文件合并到主项目中。这种方法(有时被称为超级构建)过时且不必要的复杂。在这里我不详细说明,因为对初学者来说没有太大用处。如果你好奇,可以阅读 Craig Scott 这篇很好的文章:crascit.com/2015/07/25/cmake-gtest/。
总之,当项目间存在命名空间冲突时,ExternalProject可以帮我们摆脱困境,但在其他所有情况下,FetchContent都远远优于它。让我们来找出为什么。
FetchContent
现在,建议使用FetchContent模块来导入外部项目。这个模块自 CMake 3.11 版本以来一直可用,但我们建议至少使用 3.14 版本才能有效地与之工作。
本质上,它是一个高级别的ExternalProject包装器,提供类似的功能和更多功能。关键区别在于执行阶段——与ExternalProject不同,FetchContent在配置阶段填充依赖项,将外部项目声明的所有目标带到主项目的范围内。这样,我们可以像定义自己的目标一样精确地使用它们。
使用FetchContent模块需要三个步骤:
-
将模块包含在你的项目中,使用
include(FetchModule)。 -
使用
FetchContent_Declare()命令配置依赖项。 -
使用
FetchContent_MakeAvailable()命令填充依赖项——下载、构建、安装,并将其列表文件添加到主项目中并解析。
你可能会问自己为什么Declare和MakeAvailable命令被分开。这是为了在层次化项目中启用配置覆盖。这是一个场景——一个父项目依赖于A和B外部库。A库也依赖于B,但A库的作者仍在使用与父项目不同的旧版本(图 7.1):
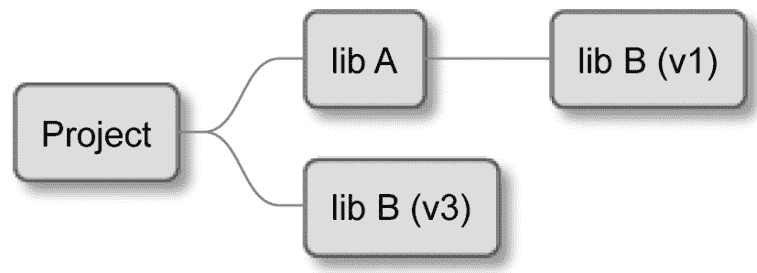
图 7.1 —— 层次化项目
而且,对MakeAvailable的依赖既不能配置也不能填充依赖,因为要覆盖A库中的版本,父项目将被迫无论在A库中最终是否需要,都要填充依赖。
由于有了单独的配置步骤,我们能够为父项目指定一个版本,并在所有子项目和依赖项中使用它:
FetchContent_Declare(
googletest
GIT_REPOSITORY https://github.com/google/googletest.git
# release-1.11.0
GIT_TAG e2239ee6043f73722e7aa812a459f54a28552929
)
任何后续调用FetchContent_Declare(),以googletest作为第一个参数,都将被忽略,以允许层次结构最高的项目决定如何处理这个依赖。
FetchContent_Declare()命令的签名与ExternalProject_Add()完全相同:
FetchContent_Declare(<depName> <contentOptions>...)
这并非巧合——这些参数会被 CMake 存储,直到调用FetchContent_MakeAvailable()并且需要填充时才会传递。然后,内部会将这些参数传递给ExternalProject_Add()命令。然而,并非所有的选项都是允许的。我们可以指定download、update或patch步骤的任何选项,但不能是configure、build、install或test步骤。
当配置就绪后,我们会像这样填充依赖项:
FetchContent_MakeAvailable(<depName>)
这将下载文件并读取目标到项目中,但在这次调用中实际发生了什么?FetchContent_MakeAvailable()是在 CMake 3.14 中添加的,以将最常用的场景封装在一个命令中。在图 7.2中,你可以看到这个过程的详细信息:
-
调用
FetchContent_GetProperties(),从全局变量将FetchContent_Declare()设置的配置从全局变量传递到局部变量。 -
检查(不区分大小写)是否已经为具有此名称的依赖项进行了填充,以避免重复下载。如果是,就在这里停止。
-
调用
FetchContent_Populate()。它会配置包装的ExternalProject模块,通过传递我们设置的(但跳过禁用的)选项并下载依赖项。它还会设置一些变量,以防止后续调用重新下载,并将必要的路径传递给下一个命令。 -
最后,
add_subdirectory()带着源和构建树作为参数调用,告诉父项目列表文件在哪里以及构建工件应放在哪里。
通过调用add_subdirectory(),CMake 实际上执行了获取项目的配置阶段,并在当前作用域中检索那里定义的任何目标。多么方便!
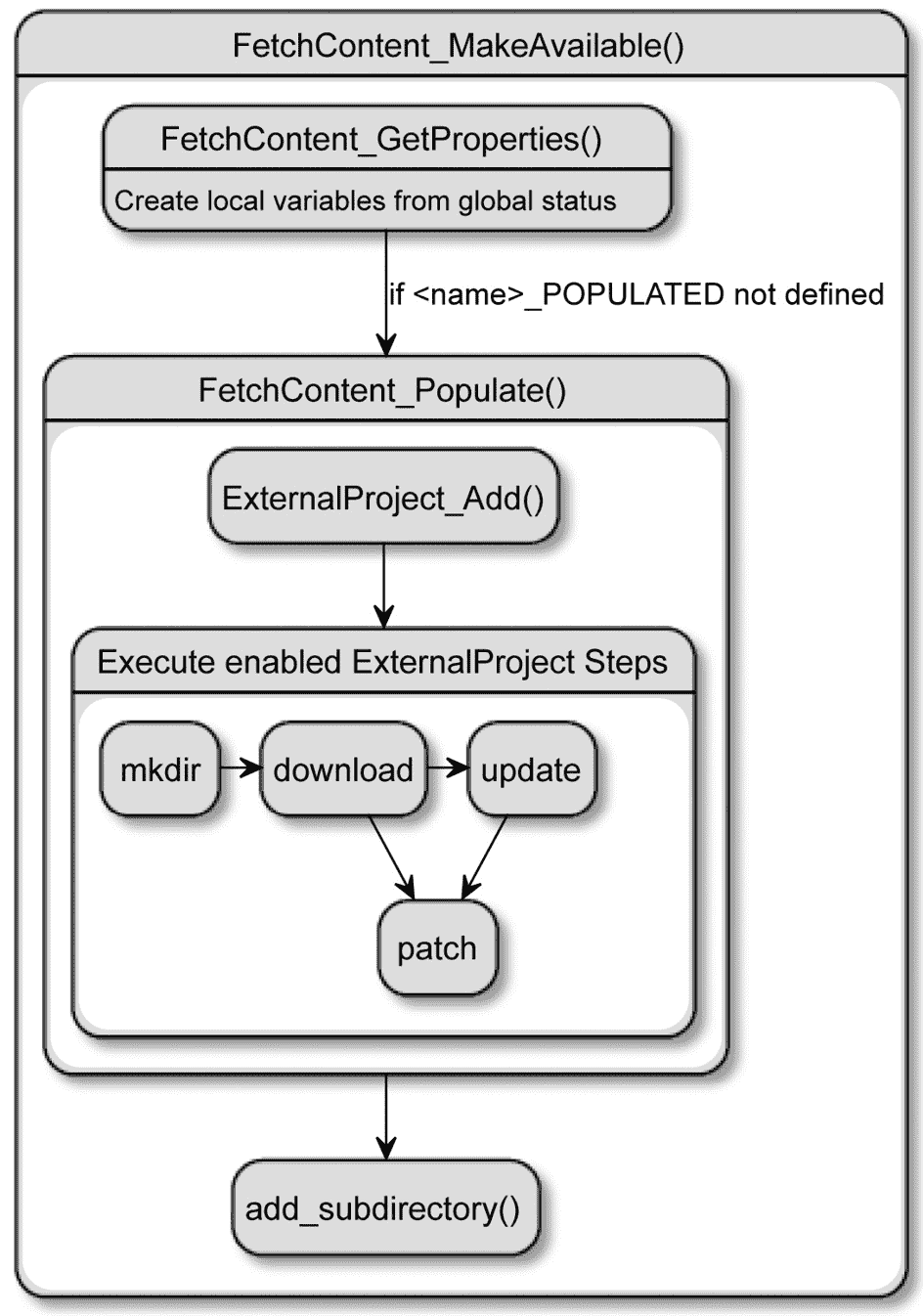
](https://gitee.com/OpenDocCN/freelearn-c-cpp-pt2-zh/raw/master/docs/mdn-cmk-cpp/img/Figure_7.2_B17205.jpg)
图 7.2 – FetchContent_MakeAvailable()如何包装对 ExternalProject 的调用
显然,我们可能遇到两个无关项目声明具有相同名称的目标的情况。这是一个只能通过回退到ExternalProject或其他方法来解决的问题。幸运的是,这种情况并不经常发生。
为了使这个解释完整,它必须与一个实际例子相补充。让我们看看当我们将FetchContent更改为FetchContent时,前一部分的列表文件是如何变化的:
chapter07/09-fetch-content/CMakeLists.txt
cmake_minimum_required(VERSION 3.20.0)
project(ExternalProjectGit CXX)
add_executable(welcome main.cpp)
configure_file(config.yaml config.yaml COPYONLY)
include(FetchContent)
FetchContent_Declare(external-yaml-cpp
GIT_REPOSITORY https://github.com/jbeder/yaml-cpp.git
GIT_TAG yaml-cpp-0.6.3
)
FetchContent_MakeAvailable(external-yaml-cpp)
target_link_libraries(welcome PRIVATE yaml-cpp)
ExternalProject_Add直接被FetchContent_Declare替换,我们还添加了另一个命令——FetchContent_MakeAvailable。代码的变化微乎其微,但实际的区别却很大!我们可以明确地访问由 yaml-cpp 库创建的目标。为了证明这一点,我们将使用CMakePrintHelpers帮助模块,并向之前的文件添加这些行:
include(CMakePrintHelpers)
cmake_print_properties(TARGETS yaml-cpp
PROPERTIES TYPE SOURCE_DIR)
现在,配置阶段将打印以下输出:
Properties for TARGET yaml-cpp:
yaml-cpp.TYPE = "STATIC_LIBRARY"
yaml-cpp.SOURCE_DIR = "/tmp/b/_deps/external-yaml-cpp-src"
目标存在;它是一个静态库,其源代码目录位于构建树内部。使用相同的助手在ExternalProject示例中调试目标简单地返回:
No such TARGET "yaml-cpp" !
在配置阶段目标没有被识别。这就是为什么FetchContent要好得多,并且应该尽可能地在任何地方使用。
总结
当我们使用现代的、得到良好支持的项目时,管理依赖关系并不复杂。在大多数情况下,我们只需依赖系统中有可用的库,如果没有就回退到FetchContent。如果依赖项相对较小且易于构建,这种方法是合适的。
对于一些非常大的库(如 Qt),从源代码构建会花费大量时间。为了在这些情况下提供自动依赖解析,我们不得不求助于提供与用户环境匹配的库编译版本的包管理器。像 Apt 或 Conan 这样的外部工具超出了本书的范围,因为它们要么太依赖于系统,要么太复杂。
好消息是,大多数用户知道如何安装您的项目可能需要的依赖项,只要您为他们提供清晰的指示即可。从这一章,您已经知道如何使用 CMake 的 find-modules 检测系统中的包,以及库捆绑的配置文件。
我们还了解到,如果一个库有点旧,不支持 CMake,但 distribution 中包含.pc文件,我们可以依靠 PkgConfig 工具和随 CMake 捆绑的FindPkgConfig查找模块。我们可以期待,当使用上述任一方法找到库时,CMake 会自动创建构建目标,这是方便且优雅的。我们还讨论了依赖 Git 及其子模块和克隆整个仓库的方法。当其他方法不适用或实施起来不切实际时,这种方法非常有用。
最后,我们探讨了ExternalProject模块及其功能和限制。我们研究了FetchContent如何扩展ExternalProject模块,它与模块有哪些共同之处,与模块有何不同,以及为什么FetchContent更优越。
现在你已准备好在你的项目中使用常规库;然而,我们还应该覆盖另一种类型的依赖——测试框架。每个认真的项目都需要 Correctness testing,而 CMake 是一个很好的工具来自动化这一过程。我们将在下一章学习如何操作。
深入阅读
关于本章涵盖的主题的更多信息,你可以参考以下内容:
-
CMake 文档 - 使用依赖关系指南:
cmake.org/cmake/help/latest/guide/using-dependencies/index.html -
教程:使用 CMake 和 Git 进行 C++的简易依赖管理:
www.foonathan.net/2016/07/cmake-dependency-handling/ -
CMake 和用于依赖项目的 git-submodule 使用:
stackoverflow.com/questions/43761594/ -
利用 PkgConfig 进行依赖共享:
gitlab.kitware.com/cmake/community/-/wikis/doc/tutorials/How-To-Find-Libraries#piggybacking-on-pkg-config -
关于在 findmodules 中导入库的
UNKNOWN类型的讨论:gitlab.kitware.com/cmake/cmake/-/issues/19564 -
什么是 Git 子模块:
git-scm.com/book/en/v2/Git-Tools-Submodules -
如何使用 ExternalProject:
www.jwlawson.co.uk/interest/2020/02/23/cmake-external-project.html -
CMake FetchContent 与 ExternalProject 的比较:
www.scivision.dev/cmake-fetchcontent-vs-external-project/ -
使用 CMake 与外部项目:
www.saoe.net/blog/using-cmake-with-external-projects/
第三部分:使用 CMake 自动化
完成前面的章节后,你已经变成了一个能够使用 CMake 构建各种项目的自给自足的构建工程师。成为 CMake 专家的最后一个步骤是学习如何引入和自动化各种质量检查,并为协作工作和发布做好准备。在大型公司内部开发的高质量项目往往共享同样的理念:自动化耗竭心灵能量的重复性任务,以便重要决策得以实施。
为了实现这一点,我们利用 CMake 生态系统的力量,添加构建过程中进行的所有测试:代码风格检查、单元测试以及我们解决方案的静态和动态分析。我们还将通过使用工具来简化文档过程,生成漂亮的网页,并且我们将打包和安装我们的项目,使其消费变得轻而易举,无论是对于其他开发者还是最终用户。
作为总结,我们将把我们所学的所有内容整合成一个连贯的单元:一个能够经受住时间考验的专业项目。
本节包括以下章节:
-
第八章,测试框架
-
第九章,程序分析工具
-
第十章,生成文档
-
第十一章,安装和打包
-
第十二章,创建你的专业项目
第八章:测试框架
有经验的专家知道测试必须自动化。有人向他们解释了这一点,或者他们通过艰苦的方式学到了。这种做法对于没有经验的程序员来说并不那么明显:它似乎是不必要的,额外的工作,并不会带来太多价值。难怪:当某人刚开始编写代码时,他们会避免编写复杂的解决方案和为庞大的代码库做出贡献。他们很可能是他们宠物项目的唯一开发者。这些早期的项目通常需要不到几个月就能完成,所以几乎没有任何机会看到代码在更长时间内是如何变质的。
所有这些因素共同构成了编写测试是浪费时间和精力的观念。编程实习生可能会对自己说,每次执行“构建-运行”流程时,他们实际上确实测试了他们的代码。毕竟,他们已经手动确认了他们的代码可以工作,并且做到了预期。现在是时候转向下一个任务了,对吧?
自动化测试确保新的更改不会意外地破坏我们的程序。在本章中,我们将学习测试的重要性以及如何使用与 CMake 捆绑的 CTest 工具来协调测试执行。CTest 能够查询可用的测试、过滤执行、洗牌、重复和限制时间。我们将探讨如何使用这些特性、控制 CTest 的输出以及处理测试失败。
接下来,我们将调整我们项目的结构以支持测试,并创建我们自己的测试运行器。在讨论基本原理之后,我们将继续添加流行的测试框架:Catch2 和 GoogleTest 及其模拟库。最后,我们将介绍使用 LCOV 进行详细测试覆盖率报告。
在本章中,我们将涵盖以下主要主题:
-
自动化测试为什么值得麻烦?
-
使用 CTest 在 CMake 中标准化测试
-
为 CTest 创建最基本的单元测试
-
单元测试框架
-
生成测试覆盖率报告
技术要求
您可以在 GitHub 上的以下链接找到本章中存在的代码文件:
github.com/PacktPublishing/Modern-CMake-for-Cpp/tree/main/examples/chapter08
为了构建本书中提供的示例,请始终使用推荐的命令:
cmake -B <build tree> -S <source tree>
cmake --build <build tree>
请确保将占位符<build tree>和<source tree>替换为适当的路径。作为提醒:build tree是目标/输出目录的路径,source tree是您的源代码所在的路径。
自动化测试为什么值得麻烦?
想象一个工厂生产线,有一个机器在钢板上打孔。这些孔必须具有特定的尺寸和形状,以便它们可以容纳将最终产品固定的螺栓。这样一个工厂线的设计者会设置机器,测试孔是否正确,然后继续。迟早,一些东西会改变:工厂会使用不同、更厚的钢材;工人可能会意外地改变孔的大小;或者,简单地说,需要打更多的孔,机器必须升级。一个聪明的设计师会在生产线的某些点上设置质量控制检查,以确保产品遵循规格并保持其关键特性。孔必须符合特定的要求,但它们是如何产生的并不重要:钻孔、冲孔还是激光切割。
同样的方法在软件开发中也得到了应用:很难预测哪些代码将保持多年不变,哪些代码将经历多次修订。随着软件功能的扩展,我们需要确保我们不会意外地破坏东西。但是,我们还是会犯错。即使是最优秀的程序员也会犯错,因为他们无法预见他们所做的每一处改动的全部影响。更不用说,开发者经常在别人编写的代码上工作,他们不知道之前做出了哪些微妙的假设。他们会阅读代码,建立一个粗略的心理模型,添加必要的改动,并希望他们做对了。大多数时候,这是真的——直到它不再是。在这种情况下,引入的错误可能需要花费数小时甚至数天来修复,更不用说它可能对产品和客户造成的损害。
偶尔,你可能会遇到一些非常难以理解和跟进去的代码。你不仅会质疑这段代码是如何产生的以及它做了什么,你还会开始追查谁应该为创造这样的混乱负责。如果你发现自己是作者,也别太惊讶。这曾经发生在我身上,也会发生在你身上。有时候,代码是在匆忙中编写的,没有完全理解问题。作为开发者,我们不仅受到截止日期或预算的压力。半夜被叫醒修复一个关键故障,你会对某些错误如何逃过代码审查感到震惊。
大多数这些问题都可以通过自动化测试来避免。这些测试代码用于检查另一段代码(即生产中使用的代码)是否正确运行。正如其名,自动化测试应该在每次有人做出改动时无需提示地执行。这通常作为构建过程的一部分发生,并且经常作为控制代码质量的一个步骤,在将其合并到仓库之前执行。
你可能会有避免自动化测试以节省时间的冲动。这将是一个非常昂贵的教训。史蒂文·赖特(Steven Wright)说得对:“经验是你需要的经验之后才得到的。”相信我:除非你正在为个人目的编写一次性脚本,或者为非生产性原型编写脚本,否则不要跳过编写测试。最初,你可能会因为自己精心编写的代码不断在测试中失败而感到烦恼。但如果你真的思考一下,那个失败的测试刚刚阻止了你将一个破坏性更改推送到生产环境中。现在投入的努力将在节省修复 bug(和完整的夜晚睡眠)方面得到回报。测试并不像看起来那么难以添加和维护。
使用 CTest 在 CMake 中标准化测试
最终,自动化测试涉及到的不过是运行一个可执行文件,设置你的 test_my_app,另一个将使用 unit_tests,第三个将使用一些不明显或者根本不提供测试的文件。找出需要运行哪个文件,使用哪个框架,向运行器传递哪些参数,以及如何收集结果是用户希望避免的问题。
CMake 通过引入一个独立的 ctest 命令行工具来解决这个问题。它由项目作者通过列表文件进行配置,并为执行测试提供了一个统一的方式:对于使用 CMake 构建的每个项目,都有一个相同的、标准化的接口。如果你遵循这个约定,你将享受其他好处:将项目添加到(CI/CD)流水线将更容易,在诸如 Visual Studio 或 CLion 等(IDE)中突出显示它们——所有这些事情都将得到简化,更加方便。更重要的是,你将用非常少的投入获得一个更强大的测试运行工具。
如何在一个已经配置的项目上使用 CTest 执行测试?我们需要选择以下三种操作模式之一:
-
测试
-
构建与测试
-
仪表板客户端
最后一种模式允许您将测试结果发送到一个名为 CDash 的单独工具(也来自 Kitware)。CDash 通过一个易于导航的仪表板收集和汇总软件质量测试结果,如下面的屏幕截图所示:
图 8.1 ‒ CDash 仪表板时间轴视图的屏幕截图
CDash 不在本书的范围内,因为它是作为共享服务器的高级解决方案,可供公司中的所有开发者访问。
注意
如果你有兴趣在线学习,请参考 CMake 的官方文档并访问 CDash 网站:
cmake.org/cmake/help/latest/manual/ctest.1.html#dashboard-client
让我们回到前两种模式。测试模式的命令行如下所示:
ctest [<options>]
在这种模式下,应在构建树中执行 CTest,在用cmake构建项目之后。在开发周期中,这有点繁琐,因为您需要执行多个命令并来回更改工作目录。为了简化这个过程,CTest 增加了一个第二种模式:build-and-test模式。
构建和测试模式
要使用此模式,我们需要以--build-and-test开始执行ctest,如下所示:
ctest --build-and-test <path-to-source> <path-to-build>
--build-generator <generator> [<options>...]
[--build-options <opts>...]
[--test-command <command> [<args>...]]
本质上,这是一个简单的包装器,它围绕常规测试模式接受一些构建配置选项,并允许我们添加第一个模式下的命令——换句话说,所有可以传递给ctest <options>的选项,在传递给ctest --build-and-test时也会生效。这里唯一的要求是在--test-command参数之后传递完整的命令。与您可能认为的相反,除非在--test-command后面提供ctest关键字,否则构建和测试模式实际上不会运行任何测试,如下所示:
ctest --build-and-test project/source-tree /tmp/build-tree --build-generator "Unix Makefiles" --test-command ctest
在这个命令中,我们需要指定源和构建路径,并选择一个构建生成器。这三个都是必需的,并且遵循cmake命令的规则,在第一章、CMake 的初步步骤中有详细描述。
您可以传递额外的参数给这个模式。它们分为三组,分别控制配置、构建过程或测试。
以下是控制配置阶段的参数:
-
--build-options—任何额外的cmake配置(不是构建工具)选项应紧接在--test-command之前,这是最后一个参数。 -
--build-two-config—为 CMake 运行两次配置阶段。 -
--build-nocmake—跳过配置阶段。 -
--build-generator-platform,--build-generator-toolset—提供生成器特定的平台和工具集。 -
--build-makeprogram—在使用 Make 或 Ninja 生成器时指定make可执行文件。
以下是控制构建阶段的参数:
-
--build-target—构建指定的目标(而不是all目标)。 -
--build-noclean—在不首先构建clean目标的情况下进行构建。 -
--build-project—提供构建项目的名称。
这是用于控制测试阶段的参数:
--test-timeout—限制测试的执行时间(以秒为单位)。
剩下的就是在--test-command cmake参数之后配置常规测试模式。
测试模式
假设我们已经构建了我们的项目,并且我们在构建树中执行ctest(或者我们使用build-and-test包装器),我们最终可以执行我们的测试。
在没有任何参数的情况下,一个简单的ctest命令通常足以在大多数场景中获得满意的结果。如果所有测试都通过,ctest将返回一个0的退出码。您可以在 CI/CD 管道中使用此命令,以防止有错误的提交合并到您仓库的生产分支。
编写好的测试可能和编写生产代码本身一样具有挑战性。我们将 SUT 设置为特定的状态,运行一个测试,然后拆除 SUT 实例。这个过程相当复杂,可能会产生各种问题:跨测试污染、时间和并发干扰、资源争用、由于死锁而导致的执行冻结,以及其他许多问题。
我们可以采用一些策略来帮助检测和解决这些问题。CTest 允许你影响测试选择、它们的顺序、产生的输出、时间限制、重复等等。以下部分将提供必要的上下文和对最有用选项的简要概述。像往常一样,请参阅 CMake 文档以获取详尽的列表。
查询测试
我们可能需要做的第一件事就是理解哪些测试实际上是为本项目编写的。CTest 提供了一个-N选项,它禁用执行,只打印列表,如下所示:
# ctest -N
Test project /tmp/b
Test #1: SumAddsTwoInts
Test #2: MultiplyMultipliesTwoInts
Total Tests: 2
你可能想用下一节中描述的筛选器与-N一起使用,以检查当应用筛选器时会执行哪些测试。
如果你需要一个可以被自动化工具消费的 JSON 格式,请用--show-only=json-v1执行ctest。
CTest 还提供了一个用LABELS关键字来分组测试的机制。要列出所有可用的标签(而不实际执行任何测试),请使用--print-labels。这个选项在测试用手动定义时很有帮助,例如在你的列表文件中使用add_test(<name> <test-command>)命令,因为你可以通过测试属性指定个别标签,像这样:
set_tests_properties(<name> PROPERTIES LABELS "<label>")
另一方面,我们稍后讨论的框架提供了自动测试发现,不幸的是,它还不支持如此细粒度的标签。
过滤测试
有很多理由只运行所有测试的一部分——最常见的原因可能是需要调试一个失败的测试或你正在工作的模块。在这种情况下,等待所有其他测试是没有意义的。其他高级测试场景甚至可能将测试用例分区并在测试运行器集群上分布负载。
这些标志将根据提供的<r> 正则表达式(regex)过滤测试,如下所示:
-
-R <r>,--tests-regex <r>—只运行名称匹配<r>的测试 -
-E <r>,--exclude-regex <r>—跳过名称匹配<r>的测试 -
-L <r>,--label-regex <r>—只运行标签匹配<r>的测试 -
-LE <r>,--label-exclude <正则表达式>—跳过标签匹配<r>的测试
使用--tests-information选项(或更短的形式,-I)可以实现高级场景。用这个筛选器提供一个逗号分隔的范围内的值:<开始>, <结束>, <步长>。任意字段都可以为空,再有一个逗号之后,你可以附加个别<测试 ID>值来运行它们。以下是几个例子:
-
-I 3,,将跳过 1 和 2 个测试(执行从第三个测试开始) -
-I ,2,只运行第一和第二个测试 -
-I 2,,3将从第二行开始运行每个第三测试 -
-I ,0,,3,9,7将只运行第三、第九和第七个测试
选择性地,CTest 将接受包含规格的文件名,格式与上面相同。正如您所想象的,用户更喜欢按名称过滤测试。此选项可用于将测试分布到多台机器上,适用于非常大的测试套件。
默认情况下,与-R一起使用的-I选项将缩小执行范围(仅运行同时满足两个要求的测试)。如果您需要两个要求的并集来执行(任一要求即可),请添加-U选项。
如前所述,您可以使用-N选项来检查过滤结果。
洗牌测试
编写单元测试可能很棘手。遇到的一个更令人惊讶的问题就是测试耦合,这是一种情况,其中一个测试通过不完全设置或清除 SUT 的状态来影响另一个测试。换句话说,首先执行的测试可能会“泄漏”其状态,污染第二个测试。这种耦合之所以糟糕,是因为它引入了测试之间的未知、隐性关系。
更糟糕的是,这种错误在测试场景的复杂性中隐藏得非常好。我们可能会在它导致测试失败时检测到它,但反之亦然:错误的状态导致测试通过,而它本不该通过。这种虚假通过的测试给开发者带来了安全感,这比没有测试还要糟糕。代码正确测试的假设可能会鼓励更大胆的行动,导致意外的结果。
发现此类问题的一种方法是单独运行每个测试。通常,当我们直接从测试框架中执行测试运行器而不使用 CTest 时,并非如此。要运行单个测试,您需要向测试可执行文件传递框架特定的参数。这允许您检测在测试套件中通过但在单独执行时失败的测试。
另一方面,CTest 有效地消除了所有基于内存的测试交叉污染,通过隐式执行子 CTest 实例中的每个测试用例。您甚至可以更进一步,添加--force-new-ctest-process选项以强制使用单独的进程。
不幸的是,仅凭这一点还不足以应对测试使用的外部、争用资源,如 GPU、数据库或文件。我们可以采取的额外预防措施之一是简单地随机化测试执行顺序。这种干扰通常足以最终检测到这种虚假通过的测试。CTest 支持这种策略,通过--schedule-random选项。
处理失败
这里有一句约翰·C· Maxwell 著名的名言:“Fail early, fail often, but always fail forward.” 这正是我们在执行单元测试时(也许在生活的其他领域)想要做的事情。除非你在运行测试时附带了调试器,否则很难了解到你在哪里出了错,因为 CTest 会保持简洁,只列出失败的测试,而不实际打印它们的输出。
测试案例或 SUT 打印到stdout的信息可能对确定具体出了什么问题非常有价值。为了看到这些信息,我们可以使用--output-on-failure运行ctest。另外,设置CTEST_OUTPUT_ON_FAILURE环境变量也会有相同的效果。
根据解决方案的大小,在任何一个测试失败后停止执行可能是有意义的。这可以通过向ctest提供--stop-on-failure参数来实现。
CTest 存储了失败测试的名称。为了在漫长的测试套件中节省时间,我们可以关注这些失败的测试,并在解决问题前跳过运行通过的测试。这个特性可以通过使用--rerun-failed选项来实现(忽略其他任何过滤器)。记得在解决问题后运行所有测试,以确保在此期间没有引入回归。
当 CTest 没有检测到任何测试时,这可能意味着两件事:要么是测试不存在,要么是项目有问题。默认情况下,ctest会打印一条警告信息并返回一个0退出码,以避免混淆。大多数用户会有足够的上下文来理解他们遇到了哪种情况以及接下来应该做什么。然而,在某些环境中,ctest总是会执行,作为自动化流水线的一部分。那么,我们可能需要明确表示,测试的缺失应该被解释为错误(并返回非零退出码)。我们可以通过提供--no-tests=error参数来配置这种行为。要实现相反的行为(不警告),请使用--no-tests=ignore选项。
重复执行测试
迟早在你的职业生涯中,你将会遇到那些大部分时间都能正确工作的测试。我想强调一下most这个词。偶尔,这些测试会因为环境原因而失败:由于错误地模拟了时间、事件循环问题、异步执行处理不当、并发性、散列冲突,以及其他在每次运行时都不会发生的非常复杂的情况。这些不可靠的测试被称为“flaky tests”。
这种不一致性看起来并不是一个很重要的问题。我们可能会说测试并不等同于真正的生产环境,这也是它们有时候会失败的根本原因。这种说法有一定的道理:测试不可能模拟每一个细节,因为这并不可行。测试是一种模拟,是对可能发生的事情的一种近似,这通常已经足够好了。如果测试在下次执行时会通过,重新运行测试有什么害处呢?
实际上,这是有关系的。主要有三个担忧,如下所述:
-
如果你在你的代码库中收集了足够的不稳定测试,它们将成为代码变更顺利交付的一个严重障碍。尤其是当你急于回家(比如周五下午)或交付一个严重影响客户问题的紧急修复时,这种情况尤其令人沮丧。
-
你无法真正确信你的不稳定测试之所以失败是因为测试环境的不足。可能正好相反:它们失败是因为它们复现了一个在生产环境中已经发生的罕见场景。只是还没有足够明显地发出警报… 而已。
-
不是测试本身具有不稳定性——是你的代码有问题!环境有时确实会出问题——作为程序员,我们以确定性的方式处理这些问题。如果 SUT 以这种方式运行,这是一个严重错误的迹象——例如,代码可能正在读取未初始化的内存。
没有一种完美的方式来解决所有上述情况——可能的原因太多。然而,我们可以通过使用–repeat <mode>:<#>选项来重复运行测试,从而增加我们识别不稳定测试的机会。以下是三种可供选择的模式:
-
until-fail—运行测试<#>次;所有运行都必须通过。 -
until-pass—运行测试至<#>次;至少要通过一次。当处理已知具有不稳定性的测试时,这个方法很有用,但这些测试太难且重要,无法进行调试或禁用。 -
after-timeout—运行测试至<#>次,但只有在测试超时的情况下才重试。在繁忙的测试环境中使用它。
一般建议尽快调试不稳定测试或如果它们不能被信任以产生一致的结果,就摆脱它们。
控制输出
每次都将所有信息打印到屏幕上会立即变得非常繁忙。Ctest 减少了噪音,并将它执行的测试的输出收集到日志文件中,在常规运行中只提供最有用的信息。当事情变坏,测试失败时,如果你启用了--output-on-failure(如前面所述),你可以期待一个摘要,可能还有一些日志。
我从经验中知道,“足够的信息”是足够的,直到它不再足够。有时,我们可能希望查看通过测试的输出,也许是为了检查它们是否真的在正常工作(而不是默默地停止,没有错误)。为了获取更详细的输出,可以添加-V选项(或者如果你想在自动化管道中明确表示,可以使用--verbose)。如果这还不够,你可能想要-VV或--extra-verbose。对于非常深入的调试,可以使用--debug(但要做好准备,因为会有很多文本细节)。
如果你在寻找相反的,CTest 还提供了通过-Q启用的“禅模式”,或--quiet。那时将不会打印任何输出(你可以停止担心,学会平静)。似乎这个选项除了让人困惑之外没有其他用途,但请注意,输出仍然会存储在测试文件中(默认在./Testing/Temporary中)。自动化管道可以通过检查退出代码是否非零值,并在不向开发者输出可能混淆的详细信息的情况下,收集日志文件进行进一步处理。
要将在特定路径存储日志,请使用-O <文件>、--output-log <文件>选项。如果您苦于输出过长,有两个限制选项可以将它们限制为每个测试给定的字节数:--test-output-size-passed <大小>和--test-output-size-failed <大小>。
杂项
还有一些其他的有用选项,可以满足你日常测试需求,如下所述:
-
-C <配置>, --build-config <配置>(仅限多配置生成器)—使用此选项指定要测试的配置。Debug配置通常包含调试符号,使事情更容易理解,但Release也应该测试,因为强烈的优化选项可能会潜在地影响 SUT 的行为。 -
-j <作业数>, --parallel <作业数>—这设置了并行执行的测试数量。在开发过程中,它非常有用,可以加快长测试的执行。请注意,在一个繁忙的环境中(在共享的测试运行器上),它可能会因调度而产生不利影响。这可以通过下一个选项稍微缓解。 -
--test-load <级别>—使用此选项以一种方式安排并行测试,使 CPU 负载不超过<级别>值(尽最大努力)。 -
--timeout <秒>—使用此选项指定单个测试的默认时间限制。
既然我们已经了解了如何在许多不同场景下执行ctest,那么让我们学习如何添加一个简单的测试。
为 CTest 创建最基本的单元测试
技术上讲,编写单元测试可以在没有任何框架的情况下进行。我们只需要做的是创建一个我们想要测试的类的实例,执行其一种方法,并检查返回的新状态或值是否符合我们的期望。然后,我们报告结果并删除被测试对象。让我们试一试。
我们将使用以下结构:
- CMakeLists.txt
- src
|- CMakeLists.txt
|- calc.cpp
|- calc.h
|- main.cpp
- test
|- CMakeLists.txt
|- calc_test.cpp
从main.cpp开始,我们可以看到它将使用一个Calc类,如下面的代码片段所示:
chapter08/01-no-framework/src/main.cpp
#include <iostream>
#include "calc.h"
using namespace std;
int main() {
Calc c;
cout << "2 + 2 = " << c.Sum(2, 2) << endl;
cout << "3 * 3 = " << c.Multiply(3, 3) << endl;
}
并不太复杂—main.cpp简单地包含了calc.h头文件,并调用了Calc对象的两种方法。让我们快速看一下Calc的接口,我们的 SUT 如下:
chapter08/01-no-framework/src/calc.h
#pragma once
class Calc {
public:
int Sum(int a, int b);
int Multiply(int a, int b);
};
界面尽可能简单。我们在这里使用了#pragma once——它的工作方式与常见的预处理器包含保护符完全一样,尽管它不是官方标准的一部分,但几乎所有现代编译器都能理解。让我们看看类的实现,如下所示:
chapter08/01-no-framework/src/calc.cpp
#include "calc.h"
int Calc::Sum(int a, int b) {
return a + b;
}
int Calc::Multiply(int a, int b) {
return a * a; // a mistake!
}
哎呀!我们引入了一个错误!Multiply忽略了b参数,而是返回a的平方。这应该被正确编写的单元测试检测到。所以,让我们写一些!开始吧:
chapter08/01-no-framework/test/calc_test.cpp
#include "calc.h"
#include <cstdlib>
void SumAddsTwoIntegers() {
Calc sut;
if (4 != sut.Sum(2, 2))
std::exit(1);
}
void MultiplyMultipliesTwoIntegers() {
Calc sut;
if(3 != sut.Multiply(1, 3))
std::exit(1);
}
我们开始编写calc_test.cpp文件,其中包含两个测试方法,分别针对 SUT 的每个测试方法。如果从调用方法返回的值与期望不符,每个函数都将调用std::exit(1)。我们本可以使用assert()、abort()或terminate(),但那样的话,在ctest的输出中,我们将得到一个更难读的Subprocess aborted消息,而不是更易读的Failed消息。
是时候创建一个测试运行器了。我们的将会尽可能简单,因为正确地做这将需要大量的工作。 just look at the main() function we had to write in order to run just two tests:
chapter08/01-no-framework/test/unit_tests.cpp
#include <string>
void SumAddsTwoIntegers();
void MultiplyMultipliesTwoIntegers();
int main(int argc, char *argv[]) {
if (argc < 2 || argv[1] == std::string("1"))
SumAddsTwoIntegers();
if (argc < 2 || argv[1] == std::string("2"))
MultiplyMultipliesTwoIntegers();
}
下面是这里发生的事情的分解:
-
我们声明了两个外部函数,它们将从另一个翻译单元链接过来。
-
如果没有提供任何参数,执行两个测试(
argv[]中的零元素总是程序名)。 -
如果第一个参数是测试的标识符,执行它。
-
如果有任何测试失败,它内部调用
exit()并返回1退出码。 -
如果没有执行任何测试或所有测试都通过,它隐式地返回
0退出码。
要运行第一个测试,我们将执行./unit_tests 1;要运行第二个,我们将执行./unit_tests 2。我们尽可能简化代码,但它仍然变得相当难以阅读。任何可能需要维护这一部分的人在添加更多测试后都不会有很好的时光,更不用说这个功能相当原始——调试这样一个测试套件将是一项艰巨的工作。尽管如此,让我们看看我们如何使用它与 CTest,如下所示:
chapter08/01-no-framework/CMakeLists.txt
cmake_minimum_required(VERSION 3.20.0)
project(NoFrameworkTests CXX)
enable_testing()
add_subdirectory(src bin)
add_subdirectory(test)
我们从常用的标题和enable_testing()开始。这是为了告诉 CTest 我们想在当前目录及其子目录中启用测试。接下来,我们在每个子目录中包含两个嵌套的列表文件:src和test。高亮的bin值表示我们希望src子目录的二进制输出放在<build_tree>/bin中。否则,二进制文件将出现在<build_tree>/src中,这可能会引起混淆。毕竟,构建工件不再是源文件。
src目录的列表文件非常直接,包含一个简单的main目标定义,如下所示:
chapter08/01-no-framework/src/CMakeLists.txt
add_executable(main main.cpp calc.cpp)
我们还需要为test目录编写一个列表文件,如下所示:
chapter08/01-no-framework/test/CMakeLists.txt
add_executable(unit_tests
unit_tests.cpp
calc_test.cpp
../src/calc.cpp)
target_include_directories(unit_tests PRIVATE ../src)
add_test(NAME SumAddsTwoInts COMMAND unit_tests 1)
add_test(NAME MultiplyMultipliesTwoInts COMMAND unit_tests 2)
我们现在定义了第二个unit_tests目标,它也使用src/calc.cpp实现文件和相应的头文件。最后,我们明确添加了两个测试:SumAddsTwoInts和MultiplyMultipliesTwoInts。每个都将其 ID 作为add_test()命令的参数。CTest将简单地取COMMAND关键字之后提供的一切,并在子壳中执行它,收集输出和退出代码。不要对add_test()过于依赖——在单元测试框架部分,我们将发现处理测试用例的更好方法,所以我们在这里不详细描述它。
这是在构建树中执行时ctest实际的工作方式:
# ctest
Test project /tmp/b
Start 1: SumAddsTwoInts
1/2 Test #1: SumAddsTwoInts ................... Passed 0.00 sec
Start 2: MultiplyMultipliesTwoInts
2/2 Test #2: MultiplyMultipliesTwoInts ........***Failed 0.00 sec
50% tests passed, 1 tests failed out of 2
Total Test time (real) = 0.00 sec
The following tests FAILED:
2 - MultiplyMultipliesTwoInts (Failed)
Errors while running CTest
Output from these tests are in: /tmp/b/Testing/Temporary/LastTest.log
Use "--rerun-failed --output-on-failure" to re-run the failed cases verbosely.
ctest执行了这两个测试,并报告说其中一个失败——Calc::Multiply返回的值没有达到预期。非常好。我们现在知道我们的代码有一个错误,有人应该修复它。
注意
你可能注意到,在迄今为止的大多数例子中,我们并没有一定使用在第第三章,设置你的第一个 CMake 项目中描述的项目结构。这是为了保持事情的简洁。本章讨论更多高级概念,因此使用完整的结构是合适的。在你的项目中(无论多么小),最好从一开始就遵循这个结构。正如一个智者曾经说过:“你踏上道路,如果你不保持你的脚步,你不知道会被冲到哪里.”
众所周知,你应避免在项目中构建测试框架。即使是最基础的例子也会让人眼睛疲劳,开销很大,并且没有增加任何价值。然而,在我们采用单元测试框架之前,我们需要重新思考项目的结构。
为测试搭建项目结构
C++具有一些有限的内省能力,但无法提供像 Java 那样的强大回顾功能。这可能正是编写 C++代码的测试和单元测试框架比在其他更丰富的环境中困难的原因。这种经济方法的含义之一是程序员必须更参与构造可测试代码。我们不仅要更仔细地设计我们的接口,还要回答关于实践问题,例如:我们如何避免编译双重,并在测试和生产之间重用工件?
编译时间对于小型项目可能不是一个问题,但随着时间推移,项目会增长。对于短编译循环的需求并不会消失。在之前的例子中,我们将所有sut源文件附加到单元测试可执行文件中,除了main.cpp文件。如果你仔细阅读,你会发现我们在这个文件中有些代码是没有被测试的(main()本身的内容)。通过编译代码两次,产生的工件可能不会完全相同。这些事物可能会随着时间的推移而逐渐偏离(由于添加了编译标志和预处理器指令)。当工程师匆忙、缺乏经验或不熟悉项目时,这可能尤其危险。
处理这个问题有多种方法,但最优雅的方法是将整个解决方案构建为一个库,并与单元测试链接。你可能会问:“我们怎么运行它呢?”我们需要一个引导可执行文件,它将链接库并运行其代码。
首先,将您当前的main()函数重命名为run()、start_program()或类似名称。然后,创建另一个实现文件(bootstrap.cpp),其中包含一个新的main()函数,仅此而已。这将成为我们的适配器(或者说是包装器):它的唯一作用是提供一个入口点并调用run()转发命令行参数(如果有)。剩下的就是将所有内容链接在一起,这样我们就有了一个可测试的项目。
通过重命名main(),我们现在可以链接被测试的系统(SUT)和测试,并且还能测试它的主要功能。否则,我们就违反了main()函数。正如第六章“为测试分离 main()”部分所承诺的,我们将详细解释这个主题。
测试框架可能提供自己的main()函数实现,所以我们不需要编写。通常,它会检测我们链接的所有测试,并根据所需配置执行它们。
这种方法产生的工件可以分为以下目标:
-
带有生产代码的
sut库 -
bootstrap带有main()包装器,调用sut中的run() -
带有
main()包装器,运行所有sut测试的单元测试
以下图表展示了目标之间的符号关系:
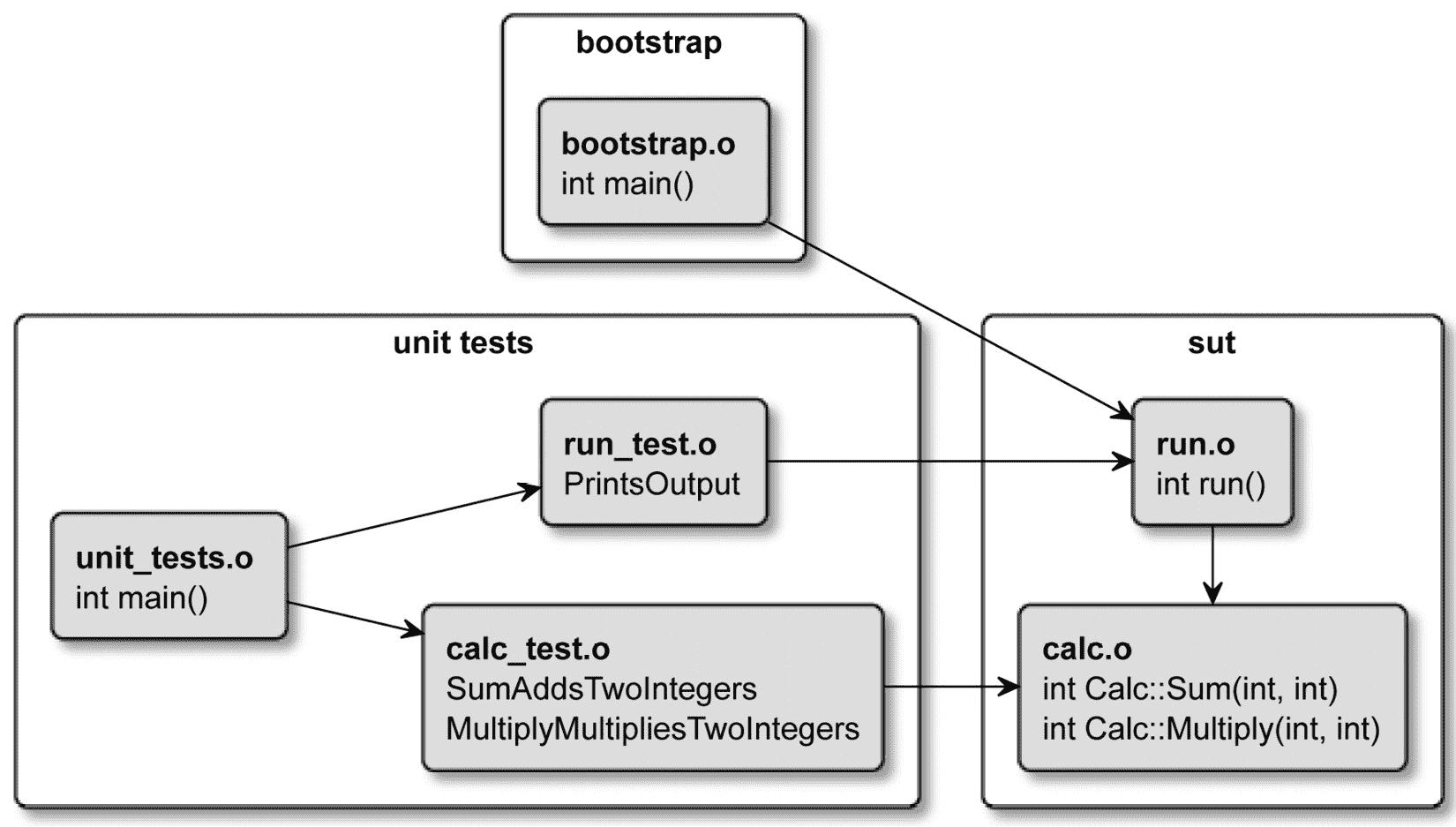
图 8.2 ‒ 在测试和生产可执行文件之间共享工件
我们最终会得到六个实现文件,它们将生成各自的(.o)目标文件,如下所示:
-
calc.cpp—要进行单元测试的Calc类。这被称为被测试单元(UUT),因为 UUT 是 SUT 的一个特化。 -
run.cpp—原始入口点重命名为run(),现在可以进行测试。 -
bootstrap.cpp—新的main()入口点调用run()。 -
calc_test.cpp—测试Calc类。 -
run_test.cpp—新增run()的测试可以放在这里。 -
unit_tests.o—单元测试的入口点,扩展为调用run()的测试。
我们即将构建的库实际上并不需要是一个实际的库:静态的或共享的。通过创建一个对象库,我们可以避免不必要的归档或链接。从技术上讲,通过为 SUT 依赖动态链接来节省几秒钟是可能的,但往往我们同时在两个目标上进行更改:tests和sut,抵消了任何潜在的收益。
让我们看看我们的文件有哪些变化,首先是从先前命名为main.cpp的文件开始,如下所示:
chapter08/02-structured/src/run.cpp
#include <iostream>
#include "calc.h"
using namespace std;
int run() {
Calc c;
cout << "2 + 2 = " << c.Sum(2, 2) << endl;
cout << "3 * 3 = " << c.Multiply(3, 3) << endl;
return 0;
}
变化并不大:重命名文件和函数。我们还添加了一个return语句,因为编译器不会隐式地为非main()函数这样做。
新的main()函数看起来像这样:
chapter08/02-structured/src/bootstrap.cpp
int run(); // declaration
int main() {
run();
}
尽可能简单——我们声明链接器将从另一个翻译单元提供run()函数,并且我们调用它。接下来需要更改的是src列表文件,您可以看到这里:
chapter08/02-structured/src/CMakeLists.txt
add_library(sut STATIC calc.cpp run.cpp)
target_include_directories(sut PUBLIC .)
add_executable(bootstrap bootstrap.cpp)
target_link_libraries(bootstrap PRIVATE sut)
首先,我们创建了一个sut库,并将.标记为PUBLIC 包含目录,以便将其传播到所有将链接sut的目标(即bootstrap和unit_tests)。请注意,包含目录是相对于列表文件的,因此我们可以使用点(.)来引用当前的<source_tree>/src目录。
是时候更新我们的unit_tests目标了。在这里,我们将移除对../src/calc.cpp文件的直接引用,改为sut的链接引用作为unit_tests目标。我们还将为run_test.cpp文件中的主函数添加一个新测试。为了简洁起见,我们将跳过讨论那个部分,但如果您感兴趣,可以查看在线示例。同时,这是整个test列表文件:
chapter08/02-structured/test/CMakeLists.txt
add_executable(unit_tests
unit_tests.cpp
calc_test.cpp
run_test.cpp)
target_link_libraries(unit_tests PRIVATE sut)
我们还应该注册新的测试,如下所示:
add_test(NAME SumAddsTwoInts COMMAND unit_tests 1)
add_test(NAME MultiplyMultipliesTwoInts COMMAND unit_tests 2)
add_test(NAME RunOutputsCorrectEquations COMMAND unit_tests 3)
完成!通过遵循这种做法,您可以确信您的测试是在将用于生产的实际机器代码上执行的。
注意
我们在这里使用的目标名称sut和bootstrap,是为了让从测试的角度来看它们非常清晰。在实际项目中,您应该选择与生产代码上下文相匹配的名称(而不是测试)。例如,对于一个 FooApp,将您的目标命名为foo,而不是bootstrap,将lib_foo命名为sut。
既然我们已经知道如何在一个适当的目标中结构一个可测试的项目,那么让我们将重点转移到测试框架本身。我们不想手动将每个测试用例添加到我们的列表文件中,对吧?
单元测试框架
上一节证明了编写一个微小的单元测试驱动并不非常复杂。它可能不够美观,但信不信由你,专业开发者实际上确实喜欢重新发明轮子(他们的轮子会更漂亮、更圆、更快)。不要陷入这个陷阱:你会创建出如此多的模板代码,它可能成为一个独立的项目。将一个流行的单元测试框架引入你的解决方案中,可以使它符合超越项目和公司的标准,并为你带来免费的更新和扩展。你没有损失。
我们如何将单元测试框架添加到我们的项目中呢?嗯,根据所选框架的规则在实现文件中编写测试,并将这些测试与框架提供的测试运行器链接起来。测试运行器是您的入口点,将启动所选测试的执行。与我们在本章早些时候看到的基本的unit_tests.cpp文件不同,许多它们将自动检测所有测试。太美了。
本章我决定介绍两个单元测试框架。我选择它们的原因如下:
-
Catch2 是一个相对容易学习、得到良好支持和文档的项目。它提供了简单的测试用例,但同时也提供了用于行为驱动开发(BDD)的优雅宏。它缺少一些功能,但在需要时可以与外部工具配合使用。您可以在这里访问其主页:
github.com/catchorg/Catch2。 -
GTest 也非常方便,但功能更加强大。它的关键特性是一组丰富的断言、用户定义的断言、死亡测试、致命和非致命失败、值和类型参数化测试、XML 测试报告生成以及模拟。最后一个是通过从同一存储库中可用的 GMock 模块提供的:
github.com/google/googletest。
您应该选择哪个框架取决于您的学习方法和项目大小。如果您喜欢缓慢、逐步的过程,并且不需要所有的花哨功能,那么选择 Catch2。那些喜欢从深层次开始并需要大量火力支持的开发人员将受益于选择 GTest。
Catch2
这个由 Martin Hořeňovský维护的框架,对于初学者和小型项目来说非常棒。这并不是说它不能处理更大的应用程序,只要你记住,只要记得在需要额外工具的区域会有所需要。如果我详细介绍这个框架,我就会偏离本书的主题太远,但我仍然想给你一个概述。首先,让我们简要地看看我们可以为我们的Calc类编写单元测试的实现,如下所示:
chapter08/03-catch2/test/calc_test.cpp
#include <catch2/catch_test_macros.hpp>
#include "calc.h"
TEST_CASE("SumAddsTwoInts", "[calc]") {
Calc sut;
CHECK(4 == sut.Sum(2, 2));
}
TEST_CASE("MultiplyMultipliesTwoInts", "[calc]") {
Calc sut;
CHECK(12 == sut.Multiply(3, 4));
}
就这样。这几行比我们之前写的例子要强大得多。CHECK()宏不仅验证期望是否满足——它们还会收集所有失败的断言,并在单个输出中呈现它们,这样你就可以进行一次修复,避免重复编译。
现在,最好的一部分:我们不需要在任何地方添加这些测试,甚至不需要通知 CMake 它们存在;你可以忘记add_test(),因为你再也用不到了。如果允许的话,Catch2 会自动将你的测试注册到 CTest。在上一节中描述的配置项目后,添加框架非常简单。我们需要使用FetchContent()将其引入项目。
有两个主要版本可供选择:v2和v3。版本 2 作为一个单头库(只需#include <catch2/catch.hpp>)提供给 C++11,最终将被版本 3 所取代。这个版本由多个头文件组成,被编译为静态库,并要求 C++14。当然,如果你能使用现代 C++(是的,C++11 不再被认为是“现代”的),那么推荐使用更新的版本。在与 Catch2 合作时,你应该选择一个 Git 标签并在你的列表文件中固定它。换句话说,不能保证升级不会破坏你的代码(升级很可能不会破坏代码,但如果你不需要,不要使用devel分支)。要获取 Catch2,我们需要提供一个仓库的 URL,如下所示:
chapter08/03-catch2/test/CMakeLists.txt
include(FetchContent)
FetchContent_Declare(
Catch2
GIT_REPOSITORY https://github.com/catchorg/Catch2.git
GIT_TAG v3.0.0
)
FetchContent_MakeAvailable(Catch2)
然后,我们需要定义我们的unit_tests目标,并将其与sut以及一个框架提供的入口点和Catch2::Catch2WithMain库链接。由于 Catch2 提供了自己的main()函数,我们不再使用unit_tests.cpp文件(这个文件可以删除)。代码如下所示:
chapter08/03-catch2/test/CMakeLists.txt(续)
add_executable(unit_tests
calc_test.cpp
run_test.cpp)
target_link_libraries(unit_tests PRIVATE
sut Catch2::Catch2WithMain)
最后,我们使用由 Catch2 提供的模块中定义的catch_discover_tests()命令,该命令将检测unit_tests中的所有测试用例并将它们注册到 CTest,如下所示:
chapter08/03-catch2/test/CMakeLists.txt(续)
list(APPEND CMAKE_MODULE_PATH ${catch2_SOURCE_DIR}/extras)
include(Catch)
catch_discover_tests(unit_tests)
完成了。我们刚刚为我们的解决方案添加了一个单元测试框架。现在让我们看看它的实际应用。测试运行器的输出如下所示:
# ./test/unit_tests
unit_tests is a Catch v3.0.0 host application.
Run with -? for options
--------------------------------------------------------------
MultiplyMultipliesTwoInts
--------------------------------------------------------------
examples/chapter08/03-catch2/test/calc_test.cpp:9
..............................................................
examples/chapter08/03-catch2/test/calc_test.cpp:11: FAILED:
CHECK( 12 == sut.Multiply(3, 4) )
with expansion:
12 == 9
==============================================================
test cases: 3 | 2 passed | 1 failed
assertions: 3 | 2 passed | 1 failed
直接执行运行器(编译的unit_test可执行文件)稍微快一点,但通常,你希望使用ctest --output-on-failure命令,而不是直接执行测试运行器,以获得前面提到的所有 CTest 好处。注意 Catch2 能够方便地将sut.Multiply(3, 4)表达式扩展为9,为我们提供更多上下文。
这就结束了 Catch2 的设置。如果你还需要添加更多测试,只需创建实现文件并将它们的路径添加到unit_tests目标的源列表中。
这个框架包含了一些有趣的小技巧:事件监听器、数据生成器和微基准测试,但它并不提供模拟功能。如果你不知道什么是模拟,继续阅读——我们马上就会涉及到这一点。然而,如果你发现自己需要模拟,你总是可以在这里列出的一些模拟框架旁边添加 Catch2:
-
FakeIt (
github.com/eranpeer/FakeIt) -
Hippomocks (
github.com/dascandy/hippomocks) -
Trompeloeil (
github.com/rollbear/trompeloeil)
话说回来,对于一个更简洁、更先进的体验,还有另一个框架值得一看。
GTest
使用 GTest 有几个重要的优点:它已经存在很长时间,并且在 C++社区中高度认可(因此,多个 IDE 支持它)。背后最大的搜索引擎公司的维护和广泛使用,所以它很可能在不久的将来变得过时或被遗弃。它可以测试 C++11 及以上版本,所以如果你被困在一个稍微老一点的环境中,你很幸运。
GTest 仓库包括两个项目:GTest(主测试框架)和 GMock(一个添加模拟功能的库)。这意味着你可以用一个FetchContent()调用来下载它们。
使用 GTest
要使用 GTest,我们的项目需要遵循为测试结构化项目部分的方向。这就是我们在这个框架中编写单元测试的方法:
chapter08/04-gtest/test/calc_test.cpp
#include <gtest/gtest.h>
#include "calc.h"
class CalcTestSuite : public ::testing::Test {
protected:
Calc sut_;
};
TEST_F(CalcTestSuite, SumAddsTwoInts) {
EXPECT_EQ(4, sut_.Sum(2, 2));
}
TEST_F(CalcTestSuite, MultiplyMultipliesTwoInts) {
EXPECT_EQ(12, sut_.Multiply(3, 4));
}
由于这个例子也将用于 GMock,我决定将测试放在一个CalcTestSuite类中。测试套件是相关测试的组,因此它们可以重用相同的字段、方法和设置(初始化)以及清理步骤。要创建一个测试套件,我们需要声明一个新的类,从::testing::Test继承,并将重用元素(字段、方法)放在其protected部分。
测试套件中的每个测试用例都是用TEST_F()预处理器宏声明的,该宏将测试套件和测试用例提供的名称字符串化(还有一个简单的TEST()宏,定义不相关的测试)。因为我们已经在类中定义了Calc sut_,每个测试用例可以像CalcTestSuite的一个方法一样访问它。实际上,每个测试用例在其自己的类中隐式继承自CalcTestSuite运行(这就是我们需要protected关键字的原因)。请注意,重用字段不是为了在连续测试之间共享任何数据——它们的目的是保持代码DRY。
GTest 没有提供像 Catch2 那样的自然断言语法。相反,我们需要使用一个显式的比较,比如EXPECT_EQ()。按照惯例,我们将期望值作为第一个参数,实际值作为第二个参数。还有许多其他断言、助手和宏值得学习。
注意
关于 GTest 的详细信息,请参阅官方参考资料(google.github.io/googletest/).
要将此依赖项添加到我们的项目中,我们需要决定使用哪个版本。与 Catch2 不同,GTest 倾向于采用“现场开发”的理念(起源于 GTest 所依赖的 Abseil 项目)。它指出:“如果你从源代码构建我们的依赖项并遵循我们的 API,你不会遇到任何问题。”(更多详情请参阅进阶阅读部分。)
如果你习惯于遵循这个规则(并且从源代码构建没有问题),将你的 Git 标签设置为master分支。否则,从 GTest 仓库中选择一个版本。我们还可以选择首先在宿主机器上搜索已安装的副本,因为 CMake 提供了一个捆绑的FindGTest模块来查找本地安装。自 v3.20 起,CMake 将使用上游的GTestConfig.cmake配置文件(如果存在),而不是依赖于可能过时的查找模块。
无论如何,添加对 GTest 的依赖项看起来是这样的:
chapter08/04-gtest/test/CMakeLists.txt
include(FetchContent)
FetchContent_Declare(
googletest
GIT_REPOSITORY https://github.com/google/googletest.git
GIT_TAG master
)
set(gtest_force_shared_crt ON CACHE BOOL "" FORCE)
FetchContent_MakeAvailable(googletest)
我们遵循与 Catch2 相同的方法——执行FetchContent()并从源代码构建框架。唯一的区别是在 GTest 作者建议的set(gtest...)命令,以防止在 Windows 上覆盖父项目的编译器和链接器设置。
最后,我们可以声明我们的测试运行器可执行文件,链接gtest_main,并借助内置的 CMake GoogleTest模块自动发现我们的测试用例,如下所示:
chapter08/04-gtest/test/CMakeLists.txt(续)
add_executable(unit_tests
calc_test.cpp
run_test.cpp)
target_link_libraries(unit_tests PRIVATE sut gtest_main)
include(GoogleTest)
gtest_discover_tests(unit_tests)
这完成了 GTest 的设置。测试运行器的输出比 Catch2 更详细,但我们可以传递--gtest_brief=1来限制它仅显示失败,如下所示:
# ./test/unit_tests --gtest_brief=1
~/examples/chapter08/04-gtest/test/calc_test.cpp:15: Failure
Expected equality of these values:
12
sut_.Multiply(3, 4)
Which is: 9
[ FAILED ] CalcTestSuite.MultiplyMultipliesTwoInts (0 ms)
[==========] 3 tests from 2 test suites ran. (0 ms total)
[ PASSED ] 2 tests.
幸运的是,即使从 CTest 运行时,噪音输出也会被抑制(除非我们显式地在ctest --output-on-failure命令行上启用它)。
现在我们已经有了框架,让我们讨论一下模拟。毕竟,当它与其他元素耦合时,没有任何测试可以真正称为“单元”。
GMock
编写真正的单元测试是关于从其他代码中隔离执行一段代码。这样的单元被理解为一个自包含的元素,要么是一个类,要么是一个组件。当然,用 C++编写的几乎没有任何程序将它们的所有单元与其他单元清晰地隔离。很可能,你的代码将严重依赖于类之间某种形式的关联关系。这种关系有一个问题:此类对象将需要另一个类的对象,而这些将需要另一个。在不知不觉中,你的整个解决方案就参与了一个“单元测试”。更糟糕的是,你的代码可能与外部系统耦合,并依赖于其状态——例如,数据库中的特定记录,网络数据包的传入,或磁盘上存储的特定文件。
为了测试目的而解耦单元,开发人员使用测试替身或类的特殊版本,这些类被测试类使用。一些例子包括伪造品、存根和模拟。以下是这些的一些大致定义:
-
伪造品是某些更复杂类的有限实现。一个例子可能是在实际数据库客户端之内的内存映射。
-
存根为方法调用提供特定的、预先录制的回答,限于测试中使用的回答。它还可以记录调用了哪些方法以及发生了多少次。
-
模拟是存根的一个更扩展版本。它还将验证测试期间方法是否如预期地被调用。
这样一个测试替身是在测试开始时创建的,作为测试类构造函数的参数提供,以代替真实对象使用。这种机制称为依赖注入。
简单测试替身的问题是它们太简单。为了为不同的测试场景模拟行为,我们可能需要提供许多不同的替身,每一个都是耦合对象可能处于的不同状态。这并不实用,并且会将测试代码分散到太多的文件中。这就是 GMock 出现的地方:它允许开发人员为特定类创建一个通用的测试替身,并在每一行中定义其行为。GMock 将这些替身称为“模拟”,但实际上,它们是上述所有类型的混合,具体取决于场合。
考虑以下示例:让我们为我们的Calc类添加一个功能,它将提供一个随机数添加到提供的参数。它将通过一个AddRandomNumber()方法表示,该方法返回这个和作为一个int。我们如何确认返回的值确实是随机数和提供给类的值的准确和?正如我们所知,依赖随机性是许多重要过程的关键,如果我们使用不当,我们可能会遭受各种后果。检查所有随机数直到我们耗尽所有可能性并不太实用。
为了测试它,我们需要将一个随机数生成器封装在一个可以被模拟(或者说,用一个模拟对象替换)的类中。模拟对象将允许我们强制一个特定的响应,即“伪造”一个随机数的生成。Calc将在AddRandomNumber()中使用这个值,并允许我们检查该方法返回的值是否符合预期。将随机数生成分离到另一个单元中是一个额外的价值(因为我们将能够交换一种生成器类型为另一种)。
让我们从抽象生成器的公共接口开始。这将允许我们在实际生成器和模拟中实现它,使其可以相互替换。我们将执行以下代码:
chapter08/05-gmock/src/rng.h
#pragma once
class RandomNumberGenerator {
public:
virtual int Get() = 0;
virtual ~RandomNumberGenerator() = default;
};
实现此接口的类将从Get()方法提供随机数。注意virtual关键字——除非我们希望涉及更复杂的基于模板的模拟,否则所有要模拟的方法都必须有它,除非我们希望涉及更复杂的基于模板的模拟。我们还需要记得添加一个虚拟析构函数。接下来,我们需要扩展我们的Calc类以接受和存储生成器,如下所示:
第八章/05-gmock/源码/calc.h
#pragma once
#include "rng.h"
class Calc {
RandomNumberGenerator* rng_;
public:
Calc(RandomNumberGenerator* rng);
int Sum(int a, int b);
int Multiply(int a, int b);
int AddRandomNumber(int a);
};
我们包含了头文件并添加了一个提供随机增加的方法。此外,创建了一个存储生成器指针的字段以及一个参数化构造函数。这就是依赖注入在实际工作中的运作方式。现在,我们实现这些方法,如下所示:
第八章/05-gmock/源码/calc.cpp
#include "calc.h"
Calc::Calc(RandomNumberGenerator* rng) {
rng_ = rng;
}
int Calc::Sum(int a, int b) {
return a + b;
}
int Calc::Multiply(int a, int b) {
return a * b; // now corrected
}
int Calc::AddRandomNumber(int a) {
return a + rng_->Get();
}
在构造函数中,我们将提供的指针赋值给一个类字段。然后我们在AddRandomNumber()中使用这个字段来获取生成的值。生产代码将使用一个真正的数字生成器;测试将使用模拟。记住我们需要对指针进行解引用以启用多态。作为奖励,我们可能为不同的实现创建不同的生成器类。我只需要一个:一个梅森旋转伪随机生成器,具有均匀分布,如下面的代码片段所示:
第八章/05-gmock/源码/rng_mt19937.cpp
#include <random>
#include "rng_mt19937.h"
int RandomNumberGeneratorMt19937::Get() {
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<> distrib(1, 6);
return distrib(gen);
}
这段代码不是非常高效,但它将适用于这个简单的例子。目的是生成1到6之间的数字并将它们返回给调用者。这个类的头文件尽可能简单,正如我们所见:
第八章/05-gmock/源码/rng_mt19937.h
#include "rng.h"
class RandomNumberGeneratorMt19937
: public RandomNumberGenerator {
public:
int Get() override;
};
这是我们如何在生产代码中使用它:
第八章/05-gmock/源码/运行.cpp
#include <iostream>
#include "calc.h"
#include "rng_mt19937.h"
using namespace std;
int run() {
auto rng = new RandomNumberGeneratorMt19937();
Calc c(rng);
cout << "Random dice throw + 1 = "
<< c.AddRandomNumber(1) << endl;
delete rng;
return 0;
}
我们创建了一个生成器,并将它的指针传递给Calc的构造函数。一切准备就绪,我们可以开始编写我们的模拟。为了保持组织性,开发人员通常将模拟放在一个单独的test/mocks目录中。为了防止模糊性,头文件名有一个_mock后缀。我们将执行以下代码:
第八章/05-gmock/测试/模拟/rng_mock.h
#pragma once
#include "gmock/gmock.h"
class RandomNumberGeneratorMock : public
RandomNumberGenerator {
public:
MOCK_METHOD(int, Get, (), (override));
};
在添加gmock.h头文件后,我们可以声明我们的模拟。如计划,它是一个实现RandomNumberGenerator接口的类。我们不需要自己编写方法,需要使用 GMock 提供的MOCK_METHOD宏。这些通知框架应该模拟接口中的哪些方法。使用以下格式(注意括号):
MOCK_METHOD(<return type>, <method name>,
(<argument list>), (<keywords>))
我们准备好在我们的测试套件中使用模拟(为了简洁,省略了之前的测试案例),如下所示:
第八章/05-gmock/测试/calc_test.cpp
#include <gtest/gtest.h>
#include "calc.h"
#include "mocks/rng_mock.h"
using namespace ::testing;
class CalcTestSuite : public Test {
protected:
RandomNumberGeneratorMock rng_mock_;
Calc sut_{&rng_mock_};
};
TEST_F(CalcTestSuite, AddRandomNumberAddsThree) {
EXPECT_CALL(rng_mock_,
Get()).Times(1).WillOnce(Return(3));
EXPECT_EQ(4, sut_.AddRandomNumber(1));
}
让我们分解一下更改:我们在测试套件中添加了新的头文件并为rng_mock_创建了一个新字段。接下来,将模拟的地址传递给sut_的构造函数。我们可以这样做,因为字段是按声明顺序初始化的(rng_mock_先于sut_)。
在我们的测试用例中,我们对rng_mock_的Get()方法调用 GMock 的EXPECT_CALL宏。这告诉框架,如果在执行过程中没有调用Get()方法,则测试失败。Times链式调用明确指出,为了测试通过,必须发生多少次调用。WillOnce确定在方法调用后,模拟框架做什么(它返回3)。
借助 GMock,我们能够一边表达期望的结果,一边表达被模拟的行为。这极大地提高了可读性,并使得测试的维护变得更加容易。最重要的是,它在每个测试用例中提供了弹性,因为我们可以通过一个单一的表达式来区分发生了什么。
最后,我们需要确保gmock库与一个测试运行器链接。为了实现这一点,我们需要将其添加到target_link_libraries()列表中,如下所示:
第八章/05-gmock/test/CMakeLists.txt
include(FetchContent)
FetchContent_Declare(
googletest
GIT_REPOSITORY https://github.com/google/googletest.git
GIT_TAG release-1.11.0
)
# For Windows: Prevent overriding the parent project's
compiler/linker settings
set(gtest_force_shared_crt ON CACHE BOOL "" FORCE)
FetchContent_MakeAvailable(googletest)
add_executable(unit_tests
calc_test.cpp
run_test.cpp)
target_link_libraries(unit_tests PRIVATE sut gtest_main
gmock)
include(GoogleTest)
gtest_discover_tests(unit_tests)
现在,我们可以享受 GTest 框架的所有好处。GTest 和 GMock 都是非常先进的工具,拥有大量的概念、实用程序和帮助器,适用于不同的场合。这个例子(尽管有点长)只是触及了可能实现的功能的表面。我鼓励你将它们纳入你的项目中,因为它们将极大地提高你的代码质量。开始使用 GMock 的一个好地方是官方文档中的Mocking for Dummies页面(你可以在进阶阅读部分找到这个链接)。
有了测试之后,我们应该以某种方式衡量哪些部分被测试了,哪些没有,并努力改善这种情况。最好使用自动化工具来收集和报告这些信息。
生成测试覆盖报告
向如此小的解决方案中添加测试并不是非常具有挑战性。真正的困难来自于稍微高级一些和更长的程序。多年来,我发现当我接近 1,000 行代码时,逐渐变得难以跟踪测试中执行了哪些行和分支,哪些没有。超过 3,000 行后,几乎是不可能的。大多数专业应用程序将拥有比这更多的代码。为了解决这个问题,我们可以使用一个工具来了解哪些代码行被“测试用例覆盖”。这样的代码覆盖工具连接到 SUT,并在测试中收集每行的执行信息,以方便的报告形式呈现,就像这里显示的这样:

图 8.3 ‒ 由 LCOV 生成的代码覆盖报告
这些报告将显示哪些文件被测试覆盖了,哪些没有。更重要的是,你还可以查看每个文件的具体细节,确切地看到哪些代码行被执行了,以及这种情况发生了多少次。在下面的屏幕截图中,Calc 构造函数被执行了 4 次,每次都是针对不同的测试:

图 8.4 ‒ 代码覆盖报告的详细视图
生成类似报告有多种方法,它们在平台和编译器之间有所不同,但它们通常遵循相同的程序:准备要测量的 SUT,获取基线,测量和报告。
执行这项工作的最简单工具名叫gcov,它是gcov的一个覆盖率工具,用于测量覆盖率。如果你在使用 Clang,不用担心——Clang 支持生成这种格式的指标。你可以从由Linux 测试项目维护的官方仓库获取 LCOV(github.com/linux-test-project/lcov),或者简单地使用包管理器。正如其名,它是一个面向 Linux 的工具。虽然可以在 macOS 上运行它,但不支持 Windows 平台。最终用户通常不关心测试覆盖率,所以通常可以手动在自建的构建环境中安装 LCOV,而不是将其绑定到项目中。
为了测量覆盖率,我们需要做以下工作:
-
以
Debug配置编译,使用编译器标志启用代码覆盖。这将生成覆盖注释(.gcno)文件。 -
将测试可执行文件与
gcov库链接。 -
在不运行任何测试的情况下收集基线覆盖率指标。
-
运行测试。这将创建覆盖数据(
.gcda)文件。 -
将指标收集到聚合信息文件中。
-
生成一个(
.html)报告。
我们应该首先解释为什么代码必须以Debug配置编译。最重要的原因是,通常Debug配置使用-O0标志禁用了任何优化。CMake 通过默认在CMAKE_CXX_FLAGS_DEBUG变量中实现这一点(尽管在文档中没有提到这一点)。除非你决定覆盖这个变量,否则你的调试构建应该是未优化的。这是为了防止任何内联和其他类型的隐式代码简化。否则,将很难追踪哪一行机器指令来自哪一行源代码。
在第一步中,我们需要指示编译器为我们的 SUT 添加必要的 instrumentation。需要添加的确切标志是编译器特定的;然而,两个主要的编译器—GCC 和 Clang—提供相同的--coverage标志,以启用覆盖率,生成 GCC 兼容的gcov格式的数据。
这就是我们如何将覆盖率 instrumentation 添加到前面章节中的示例 SUT:
chapter08/06-coverage/src/CMakeLists.txt
add_library(sut STATIC calc.cpp run.cpp rng_mt19937.cpp)
target_include_directories(sut PUBLIC .)
if (CMAKE_BUILD_TYPE STREQUAL Debug)
target_compile_options(sut PRIVATE --coverage)
target_link_options(sut PUBLIC --coverage)
add_custom_command(TARGET sut PRE_BUILD COMMAND
find ${CMAKE_BINARY_DIR} -type f
-name '*.gcda' -exec rm {} +)
endif()
add_executable(bootstrap bootstrap.cpp)
target_link_libraries(bootstrap PRIVATE sut)
让我们逐步分解,如下所述:
-
确保我们正在使用
if(STREQUAL)命令以Debug配置运行。记住,除非你使用-DCMAKE_BUILD_TYPE=Debug选项运行cmake,否则你无法获得任何覆盖率。 -
为
sut库的所有object files的PRIVATE编译选项添加--coverage。 -
为
PUBLIC链接器选项添加--coverage: both GCC 和 Clang 将此解释为请求与所有依赖于sut的目标链接gcov(或兼容)库(由于传播属性)。 -
add_custom_command()命令被引入以清除任何陈旧的.gcda文件。讨论添加此命令的原因在避免 SEGFAULT 陷阱部分中有详细说明。
这足以生成代码覆盖率。如果你使用的是 Clion 之类的 IDE,你将能够运行带有覆盖率的单元测试,并在内置的报告视图中获取结果。然而,这不会在 CI/CD 中运行的任何自动化管道中工作。要获取报告,我们需要自己使用 LCOV 生成它们。
为此目的,最好定义一个名为coverage的新目标。为了保持整洁,我们将在另一个文件中定义一个单独的函数AddCoverage,用于在test列表文件中使用,如下所示:
chapter08/06-coverage/cmake/Coverage.cmake
function(AddCoverage target)
find_program(LCOV_PATH lcov REQUIRED)
find_program(GENHTML_PATH genhtml REQUIRED)
add_custom_target(coverage
COMMENT "Running coverage for ${target}..."
COMMAND ${LCOV_PATH} -d . --zerocounters
COMMAND $<TARGET_FILE:${target}>
COMMAND ${LCOV_PATH} -d . --capture -o coverage.info
COMMAND ${LCOV_PATH} -r coverage.info '/usr/include/*'
-o filtered.info
COMMAND ${GENHTML_PATH} -o coverage filtered.info
--legend
COMMAND rm -rf coverage.info filtered.info
WORKING_DIRECTORY ${CMAKE_BINARY_DIR}
)
endfunction()
在前面的片段中,我们首先检测lcov和genhtml(来自 LCOV 包的两个命令行工具)的路径。REQUIRED关键字指示 CMake 在找不到它们时抛出错误。接下来,我们按照以下步骤添加一个自定义的coverage目标:
-
清除之前运行的任何计数器。
-
运行
target可执行文件(使用生成器表达式获取其路径)。$<TARGET_FILE:target>是一个特殊的生成器表达式,在此情况下它会隐式地添加对target的依赖,使其在执行所有命令之前构建。我们将target作为此函数的参数提供。 -
从当前目录(
-d .)收集解决方案的度量,并输出到文件(-o coverage.info)中。 -
删除(
-r)不需要的覆盖数据('/usr/include/*')并输出到另一个文件(-o filtered.info)。 -
在
coverage目录中生成 HTML 报告,并添加一个--legend颜色。 -
删除临时
.info文件。 -
指定
WORKING_DIRECTORY关键字可以将二叉树作为所有命令的工作目录。
这些是 GCC 和 Clang 通用的步骤,但重要的是要知道gcov工具的版本必须与编译器的版本匹配。换句话说,不能用 GCC 的gcov工具来编译 Clang 代码。要使lcov指向 Clang 的gcov工具,我们可以使用--gcov-tool参数。这里唯一的问题是它必须是一个单一的可执行文件。为了解决这个问题,我们可以提供一个简单的包装脚本(别忘了用chmod +x将其标记为可执行文件),如下所示:
cmake/gcov-llvm-wrapper.sh
#!/bin/bash
exec llvm-cov gcov "$@"
我们之前函数中所有对${LCOV_PATH}的调用应接受以下额外标志:
--gcov-tool ${CMAKE_SOURCE_DIR}/cmake/gcov-llvm-wrapper.sh
确保此函数可用于包含在test列表文件中。我们可以通过在主列表文件中扩展包含搜索路径来实现:
chapter08/06-coverage/CMakeLists.txt
cmake_minimum_required(VERSION 3.20.0)
project(Coverage CXX)
enable_testing()
list(APPEND CMAKE_MODULE_PATH "${CMAKE_SOURCE_DIR}/cmake")
add_subdirectory(src bin)
add_subdirectory(test)
这行小代码允许我们将cmake目录中的所有.cmake文件包括在我们的项目中。现在我们可以在test列表文件中使用Coverage.cmake,如下所示:
chapter08/06-coverage/test/CMakeLists.txt(片段)
# ... skipped unit_tests target declaration for brevity
include(Coverage)
AddCoverage(unit_tests)
include(GoogleTest)
gtest_discover_tests(unit_tests)
为了构建这个目标,请使用以下命令(注意第一个命令以DCMAKE_BUILD_TYPE=Debug构建类型选择结束):
# cmake -B <binary_tree> -S <source_tree>
-DCMAKE_BUILD_TYPE=Debug
# cmake --build <binary_tree> -t coverage
完成所有提到的步骤后,你将看到一个简短的摘要,就像这样:
Writing directory view page.
Overall coverage rate:
lines......: 95.2% (20 of 21 lines)
functions..: 75.0% (6 of 8 functions)
[100%] Built target coverage
接下来,在你的浏览器中打开coverage/index.html文件,享受这些报告吧!不过有一个小问题……
避免 SEGFAULT 陷阱
当我们开始在如此解决方案中编辑源代码时,我们可能会陷入困境。这是因为覆盖信息被分成两部分,如下所示:
-
gcno文件,或GNU 覆盖笔记,在 SUT 编译期间生成 -
gcda文件,或GNU 覆盖数据,在测试运行期间生成和更新
“更新”功能是段错误的一个潜在来源。在我们最初运行测试后,我们留下了许多gcda文件,在任何时候都没有被移除。如果我们对源代码做一些更改并重新编译对象文件,将创建新的gcno文件。然而,没有擦除步骤——旧的gcda文件仍然跟随过时的源代码。当我们执行unit_tests二进制文件(它在gtest_discover_tests宏中发生)时,覆盖信息文件将不匹配,我们将收到一个SEGFAULT(段错误)错误。
为了避免这个问题,我们应该删除任何过时的gcda文件。由于我们的sut实例是一个静态库,我们可以将add_custom_command(TARGET)命令挂钩到构建事件上。在重建开始之前,将执行清理。
在进一步阅读部分找到更多信息链接。
摘要
在表面上看,似乎与适当测试相关的复杂性如此之大,以至于不值得付出努力。令人惊讶的是,运行没有任何测试的代码量有多少,主要论点是测试软件是一个令人畏惧的任务。我要补充的是:如果手动完成,更是如此。不幸的是,如果没有严格的自动化测试,代码中任何问题的可见性是不完整或根本不存在的。未测试的代码通常写起来更快(并非总是如此),但肯定更慢阅读、重构和修复。
在本章中,我们概述了从一开始就进行测试的一些关键原因。其中最引人入胜的是心理健康和一个良好的夜晚睡眠。没有开发人员会躺在床上想:“我迫不及待地想在几小时后醒来灭火和修复 bug。”但认真地说:在部署到生产之前捕获错误,可能对你(和公司)来说是个救命稻草。
谈到测试工具,CMake 确实显示了其真正的实力。CTest 可以在检测错误测试方面做到 wonders:隔离、洗牌、重复、超时。所有这些技术都非常方便,并且可以通过简单的命令行标志直接使用。我们还学会了如何使用 CTest 列出测试、过滤测试以及控制测试用例的输出,但最重要的是,我们现在知道了采用标准解决方案的真正力量。任何使用 CMake 构建的项目都可以以完全相同的方式进行测试,而无需调查其内部细节。
接下来,我们优化了项目结构,以简化测试过程并在生产代码和测试运行器之间复用相同的对象文件。编写自己的测试运行器很有趣,但也许让我们专注于程序应该解决的实际问题,并投入时间去拥抱一个流行的第三方测试框架。
说到这个,我们学习了 Catch2 和 GTest 的基础知识。我们进一步深入研究了 GMock 库的细节,并理解了测试替身是如何工作以使真正的单元测试成为可能的。最后,我们使用 LCOV 设置了报告。毕竟,没有什么比硬数据更能证明我们的解决方案实际上是完全测试过的了。
在下一章中,我们将讨论更多有用的工具来提高源代码的质量并发现我们甚至不知道存在的 issue。
进一步阅读
您可以通过以下链接获取更多信息:
-
CMake 关于 CTest 的文档:
cmake.org/cmake/help/latest/manual/ctest.1.html -
Catch2 文档:
github.com/catchorg/Catch2/blob/devel/docs/cmake-integration.md
github.com/catchorg/Catch2/blob/devel/docs/tutorial.md
-
Abseil:
abseil.io/ -
与 Abseil 一起生活在头部:
abseil.io/about/philosophy#we-recommend-that-you-choose-to-live-at-head -
GTest 为何依赖 Abseil:
github.com/google/googletest/issues/2883 -
GCC 中的覆盖率:
gcc.gnu.org/onlinedocs/gcc/Instrumentation-Options.html
gcc.gnu.org/onlinedocs/gcc/Invoking-Gcov.html
gcc.gnu.org/onlinedocs/gcc/Gcov-Data-Files.html
-
Clang 中的覆盖率:
clang.llvm.org/docs/SourceBasedCodeCoverage.html -
命令行工具的 LCOV 文档:
ltp.sourceforge.net/coverage/lcov/lcov.1.php
ltp.sourceforge.net/coverage/lcov/genhtml.1.php
- GCOV 更新功能:
gcc.gnu.org/onlinedocs/gcc/Invoking-Gcov.html#Invoking-Gcov
的sut实例是一个静态库,我们可以将add_custom_command(TARGET)命令挂钩到构建事件上。在重建开始之前,将执行清理。
在进一步阅读部分找到更多信息链接。
摘要
在表面上看,似乎与适当测试相关的复杂性如此之大,以至于不值得付出努力。令人惊讶的是,运行没有任何测试的代码量有多少,主要论点是测试软件是一个令人畏惧的任务。我要补充的是:如果手动完成,更是如此。不幸的是,如果没有严格的自动化测试,代码中任何问题的可见性是不完整或根本不存在的。未测试的代码通常写起来更快(并非总是如此),但肯定更慢阅读、重构和修复。
在本章中,我们概述了从一开始就进行测试的一些关键原因。其中最引人入胜的是心理健康和一个良好的夜晚睡眠。没有开发人员会躺在床上想:“我迫不及待地想在几小时后醒来灭火和修复 bug。”但认真地说:在部署到生产之前捕获错误,可能对你(和公司)来说是个救命稻草。
谈到测试工具,CMake 确实显示了其真正的实力。CTest 可以在检测错误测试方面做到 wonders:隔离、洗牌、重复、超时。所有这些技术都非常方便,并且可以通过简单的命令行标志直接使用。我们还学会了如何使用 CTest 列出测试、过滤测试以及控制测试用例的输出,但最重要的是,我们现在知道了采用标准解决方案的真正力量。任何使用 CMake 构建的项目都可以以完全相同的方式进行测试,而无需调查其内部细节。
接下来,我们优化了项目结构,以简化测试过程并在生产代码和测试运行器之间复用相同的对象文件。编写自己的测试运行器很有趣,但也许让我们专注于程序应该解决的实际问题,并投入时间去拥抱一个流行的第三方测试框架。
说到这个,我们学习了 Catch2 和 GTest 的基础知识。我们进一步深入研究了 GMock 库的细节,并理解了测试替身是如何工作以使真正的单元测试成为可能的。最后,我们使用 LCOV 设置了报告。毕竟,没有什么比硬数据更能证明我们的解决方案实际上是完全测试过的了。
在下一章中,我们将讨论更多有用的工具来提高源代码的质量并发现我们甚至不知道存在的 issue。
进一步阅读
您可以通过以下链接获取更多信息:
-
CMake 关于 CTest 的文档:
cmake.org/cmake/help/latest/manual/ctest.1.html -
Catch2 文档:
github.com/catchorg/Catch2/blob/devel/docs/cmake-integration.md
github.com/catchorg/Catch2/blob/devel/docs/tutorial.md
-
Abseil:
abseil.io/ -
与 Abseil 一起生活在头部:
abseil.io/about/philosophy#we-recommend-that-you-choose-to-live-at-head -
GTest 为何依赖 Abseil:
github.com/google/googletest/issues/2883 -
GCC 中的覆盖率:
gcc.gnu.org/onlinedocs/gcc/Instrumentation-Options.html
gcc.gnu.org/onlinedocs/gcc/Invoking-Gcov.html
gcc.gnu.org/onlinedocs/gcc/Gcov-Data-Files.html
-
Clang 中的覆盖率:
clang.llvm.org/docs/SourceBasedCodeCoverage.html -
命令行工具的 LCOV 文档:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









