







LiLT
原文:
huggingface.co/docs/transformers/v4.37.2/en/model_doc/lilt
概述
LiLT 模型在Jiapeng Wang, Lianwen Jin, Kai Ding 撰写的《LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding》中提出。LiLT 允许将任何预训练的 RoBERTa 文本编码器与轻量级的 Layout Transformer 结合起来,以实现多种语言的 LayoutLM 类似文档理解。
从论文摘要中得出的结论是:
结构化文档理解近年来引起了广泛关注并取得了显著进展,这归功于其在智能文档处理中的关键作用。然而,大多数现有的相关模型只能处理特定语言(通常是英语)的文档数据,这些文档数据包含在预训练集合中,这是极其有限的。为了解决这个问题,我们提出了一个简单而有效的 Language-independent Layout Transformer(LiLT)用于结构化文档理解。LiLT 可以在单一语言的结构化文档上进行预训练,然后直接在其他语言上进行对应的现成的单语/多语预训练文本模型的微调。在八种语言上的实验结果表明,LiLT 可以在各种广泛使用的下游基准测试中取得竞争性甚至优越的性能,这使得可以从文档布局结构的预训练中获益而不受语言限制。
 LiLT 架构。摘自原始论文。
LiLT 架构。摘自原始论文。
使用提示
- 将 Language-Independent Layout Transformer 与来自hub的新 RoBERTa 检查点结合起来,请参考此指南。脚本将导致
config.json和pytorch_model.bin文件被存储在本地。完成此操作后,可以执行以下操作(假设您已登录您的 HuggingFace 帐户):
from transformers import LiltModel
model = LiltModel.from_pretrained("path_to_your_files")
model.push_to_hub("name_of_repo_on_the_hub")
-
在为模型准备数据时,请确保使用与您与 Layout Transformer 结合的 RoBERTa 检查点相对应的标记词汇表。
-
由于lilt-roberta-en-base使用与 LayoutLMv3 相同的词汇表,因此可以使用 LayoutLMv3TokenizerFast 来为模型准备数据。对于lilt-roberta-en-base也是如此:可以使用 LayoutXLMTokenizerFast 来为该模型准备数据。
资源
官方 Hugging Face 和社区(由🌎表示)资源列表,可帮助您开始使用 LiLT。
- 可以在此处找到 LiLT 的演示笔记本。
文档资源
-
文本分类任务指南
-
标记分类任务指南
-
问答任务指南
如果您有兴趣提交资源以包含在此处,请随时打开 Pull Request,我们将对其进行审查!资源应该展示一些新内容,而不是重复现有资源。
LiltConfig
class transformers.LiltConfig
( vocab_size = 30522 hidden_size = 768 num_hidden_layers = 12 num_attention_heads = 12 intermediate_size = 3072 hidden_act = 'gelu' hidden_dropout_prob = 0.1 attention_probs_dropout_prob = 0.1 max_position_embeddings = 512 type_vocab_size = 2 initializer_range = 0.02 layer_norm_eps = 1e-12 pad_token_id = 0 position_embedding_type = 'absolute' classifier_dropout = None channel_shrink_ratio = 4 max_2d_position_embeddings = 1024 **kwargs )
参数
-
vocab_size(int, optional, 默认为 30522) — LiLT 模型的词汇量。定义了在调用 LiltModel 时可以表示的不同标记数量。 -
hidden_size(int, optional, 默认为 768) — 编码器层和池化器层的维度。应为 24 的倍数。 -
num_hidden_layers(int, optional, 默认为 12) — Transformer 编码器中的隐藏层数量。 -
num_attention_heads(int, optional, 默认为 12) — Transformer 编码器中每个注意力层的注意力头数量。 -
intermediate_size(int, optional, 默认为 3072) — Transformer 编码器中“中间”(通常称为前馈)层的维度。 -
hidden_act(str或Callable, optional, 默认为"gelu") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu","relu","silu"和"gelu_new"。 -
hidden_dropout_prob(float, optional, 默认为 0.1) — 嵌入层、编码器和池化器中所有全连接层的 dropout 概率。 -
attention_probs_dropout_prob(float, optional, 默认为 0.1) — 注意力概率的 dropout 比率。 -
max_position_embeddings(int, optional, 默认为 512) — 该模型可能使用的最大序列长度。通常设置为较大的值以防万一(例如 512、1024 或 2048)。 -
type_vocab_size(int, optional, 默认为 2) — 在调用 LiltModel 时传递的token_type_ids的词汇量。 -
initializer_range(float, optional, 默认为 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 -
layer_norm_eps(float, optional, 默认为 1e-12) — 层归一化层使用的 epsilon。 -
position_embedding_type(str, optional, 默认为"absolute") — 位置嵌入的类型。选择"absolute","relative_key","relative_key_query"之一。对于位置嵌入,请使用"absolute"。有关"relative_key"的更多信息,请参阅Self-Attention with Relative Position Representations (Shaw et al.)。有关"relative_key_query"的更多信息,请参阅Improve Transformer Models with Better Relative Position Embeddings (Huang et al.)中的Method 4。 -
classifier_dropout(float, optional) — 分类头的 dropout 比率。 -
channel_shrink_ratio(int, optional, 默认为 4) — 与布局嵌入的hidden_size相比,通道维度的收缩比率。 -
max_2d_position_embeddings(int, optional, 默认为 1024) — 2D 位置嵌入可能使用的最大值。通常设置为较大的值以防万一(例如 1024)。
这是一个配置类,用于存储 LiltModel 的配置。根据指定的参数实例化一个 LiLT 模型,定义模型架构。使用默认值实例化配置将产生与 LiLT SCUT-DLVCLab/lilt-roberta-en-base架构类似的配置。配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import LiltConfig, LiltModel
>>> # Initializing a LiLT SCUT-DLVCLab/lilt-roberta-en-base style configuration
>>> configuration = LiltConfig()
>>> # Randomly initializing a model from the SCUT-DLVCLab/lilt-roberta-en-base style configuration
>>> model = LiltModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
LiltModel
class transformers.LiltModel
( config add_pooling_layer = True )
参数
config(LiltConfig) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
裸 LiLT 模型变压器输出原始隐藏状态,没有特定的头部。这个模型继承自 PreTrainedModel。检查超类文档,了解库为所有模型实现的通用方法(例如下载或保存、调整输入嵌入、修剪头等)。
这个模型也是一个 PyTorch torch.nn.Module子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
forward
( input_ids: Optional = None bbox: Optional = None attention_mask: Optional = None token_type_ids: Optional = None position_ids: Optional = None head_mask: Optional = None inputs_embeds: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.BaseModelOutputWithPooling or tuple(torch.FloatTensor)
参数
-
input_ids(torch.LongTensorof shape(batch_size, sequence_length)) — 词汇表中输入序列标记的索引。可以使用 AutoTokenizer 获取索引。有关详细信息,请参见 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.
call()。什么是 input IDs?
-
bbox(torch.LongTensorof shape(batch_size, sequence_length, 4), optional) — 每个输入序列标记的边界框。选择范围为[0, config.max_2d_position_embeddings-1]。每个边界框应该是一个规范化版本,格式为(x0, y0, x1, y1),其中(x0, y0)对应于边界框左上角的位置,(x1, y1)表示右下角的位置。有关规范化,请参见概述。 -
attention_mask(torch.FloatTensorof shape(batch_size, sequence_length), optional) — 用于避免在填充标记索引上执行注意力的掩码。掩码值选择在[0, 1]之间:-
1 表示未被
masked的标记, -
0 表示被
masked的标记。
什么是 attention masks?
-
-
token_type_ids(torch.LongTensorof shape(batch_size, sequence_length), optional) — 段标记索引,指示输入的第一部分和第二部分。索引选择在[0, 1]之间:-
0 对应于句子 A标记,
-
1 对应于句子 B标记。
什么是 token type IDs?
-
-
position_ids(torch.LongTensorof shape(batch_size, sequence_length), optional) — 每个输入序列标记在位置嵌入中的位置索引。选择范围为[0, config.max_position_embeddings - 1]。什么是 position IDs?
-
head_mask(torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — 用于使自注意力模块中的选定头部失效的掩码。掩码值选择在[0, 1]之间:-
1 表示头部未被
masked, -
0 表示头部被
masked。
-
-
inputs_embeds(torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您想要更多控制权,以便将input_ids索引转换为相关向量,而不是使用模型的内部嵌入查找矩阵,则这很有用。 -
output_attentions(bool,可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool,可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool,可选) — 是否返回 ModelOutput 而不是普通元组。
返回
transformers.modeling_outputs.BaseModelOutputWithPooling 或tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.BaseModelOutputWithPooling 或一个torch.FloatTensor元组(如果传递return_dict=False或config.return_dict=False,或者return_dict=False时)包含根据配置(LiltConfig)和输入的各种元素。
-
last_hidden_state(torch.FloatTensor,形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层的隐藏状态序列。 -
pooler_output(torch.FloatTensor,形状为(batch_size, hidden_size)) — 序列第一个标记(分类标记)的最后一层隐藏状态,在通过用于辅助预训练任务的层进一步处理后。例如,对于 BERT 系列模型,这返回经过线性层和 tanh 激活函数处理后的分类标记。线性层的权重在预训练期间从下一个句子预测(分类)目标中训练。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于嵌入的输出,如果模型有嵌入层,+ 一个用于每个层的输出)。模型在每一层输出的隐藏状态以及可选的初始嵌入输出。
-
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每个层一个)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
LiltModel 的前向方法,覆盖__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是这个函数,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, AutoModel
>>> from datasets import load_dataset
>>> tokenizer = AutoTokenizer.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
>>> model = AutoModel.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
>>> dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train")
>>> example = dataset[0]
>>> words = example["tokens"]
>>> boxes = example["bboxes"]
>>> encoding = tokenizer(words, boxes=boxes, return_tensors="pt")
>>> outputs = model(**encoding)
>>> last_hidden_states = outputs.last_hidden_state
LiltForSequenceClassification
class transformers.LiltForSequenceClassification
( config )
参数
config(LiltConfig) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
LiLT 模型变压器,顶部带有一个序列分类/回归头(池化输出之上的线性层),例如用于 GLUE 任务。
此模型继承自 PreTrainedModel。检查超类文档以获取库为所有模型实现的通用方法(例如下载或保存、调整输入嵌入、修剪头等)。
此模型还是 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有事项。
forward
( input_ids: Optional = None bbox: Optional = None attention_mask: Optional = None token_type_ids: Optional = None position_ids: Optional = None head_mask: Optional = None inputs_embeds: Optional = None labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.SequenceClassifierOutput or tuple(torch.FloatTensor)
参数
-
input_ids(torch.LongTensorof shape(batch_size, sequence_length)) — 词汇表中输入序列标记的索引。可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.
call()。什么是输入 ID?
-
bbox(torch.LongTensorof shape(batch_size, sequence_length, 4), optional) — 每个输入序列标记的边界框。选择范围为[0, config.max_2d_position_embeddings-1]。每个边界框应该是(x0, y0, x1, y1)格式的归一化版本,其中(x0, y0)对应于边界框左上角的位置,(x1, y1)表示右下角的位置。有关归一化,请参阅概述。 -
attention_mask(torch.FloatTensorof shape(batch_size, sequence_length), optional) — 用于避免在填充标记索引上执行注意力的掩码。掩码值选择在[0, 1]之间:-
对于未被
masked的标记为 1, -
对于被
masked的标记为 0。
什么是注意力掩码?
-
-
token_type_ids(torch.LongTensorof shape(batch_size, sequence_length), optional) — 段标记索引,指示输入的第一部分和第二部分。索引选择在[0, 1]之间:-
0 对应于句子 A标记,
-
1 对应于句子 B标记。
什么是标记类型 ID?
-
-
position_ids(torch.LongTensorof shape(batch_size, sequence_length), optional) — 每个输入序列标记在位置嵌入中的位置索引。选择范围为[0, config.max_position_embeddings - 1]。什么是位置 ID?
-
head_mask(torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — 用于使自注意力模块中选择的头部失效的掩码。掩码值选择在[0, 1]之间:-
1 表示头部未被
masked, -
0 表示头部被
masked。
-
-
inputs_embeds(torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示而不是传递input_ids。如果您想要更多控制如何将input_ids索引转换为相关向量,这将非常有用,而不是使用模型的内部嵌入查找矩阵。 -
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool, optional) — 是否返回 ModelOutput 而不是普通元组。 -
labels(torch.LongTensor,形状为(batch_size,), 可选的) — 用于计算序列分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.modeling_outputs.SequenceClassifierOutput 或tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.SequenceClassifierOutput 或一个torch.FloatTensor元组(如果传递return_dict=False或config.return_dict=False)包含各种元素,具体取决于配置(LiltConfig)和输入。
-
loss(torch.FloatTensor,形状为(1,), 可选的, 当提供labels时返回) — 分类(如果 config.num_labels==1 则为回归)损失。 -
logits(torch.FloatTensor,形状为(batch_size, config.num_labels)) — 分类(如果 config.num_labels==1 则为回归)得分(SoftMax 之前)。 -
hidden_states(tuple(torch.FloatTensor), 可选的, 当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于嵌入的输出,如果模型有一个嵌入层,+ 一个用于每一层的输出)。模型在每一层输出的隐藏状态以及可选的初始嵌入输出。
-
attentions(tuple(torch.FloatTensor), 可选的, 当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。在自注意力头中用于计算加权平均值的注意力 softmax 之后的注意力权重。
LiltForSequenceClassification 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的步骤需要在这个函数内定义,但应该在此之后调用Module实例,而不是这个函数,因为前者负责运行前后处理步骤,而后者则默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
>>> from datasets import load_dataset
>>> tokenizer = AutoTokenizer.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
>>> model = AutoModelForSequenceClassification.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
>>> dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train")
>>> example = dataset[0]
>>> words = example["tokens"]
>>> boxes = example["bboxes"]
>>> encoding = tokenizer(words, boxes=boxes, return_tensors="pt")
>>> outputs = model(**encoding)
>>> predicted_class_idx = outputs.logits.argmax(-1).item()
>>> predicted_class = model.config.id2label[predicted_class_idx]
LiltForTokenClassification
class transformers.LiltForTokenClassification
( config )
参数
config(LiltConfig) — 包含模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
在模型的每一层输出之上有一个标记分类头的 Lilt 模型(在隐藏状态输出之上有一个线性层),例如用于命名实体识别(NER)任务。
这个模型继承自 PreTrainedModel。查看超类文档以获取库为所有模型实现的通用方法(如下载或保存、调整输入嵌入、修剪头等)。
这个模型也是一个 PyTorch torch.nn.Module子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
forward
( input_ids: Optional = None bbox: Optional = None attention_mask: Optional = None token_type_ids: Optional = None position_ids: Optional = None head_mask: Optional = None inputs_embeds: Optional = None labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.TokenClassifierOutput or tuple(torch.FloatTensor)
参数
-
input_ids(torch.LongTensor,形状为(batch_size, sequence_length)) — 词汇表中输入序列标记的索引。可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.
call()。什么是输入 ID?
-
bbox(torch.LongTensor,形状为(batch_size, sequence_length, 4),可选) — 每个输入序列标记的边界框。在范围[0, config.max_2d_position_embeddings-1]中选择。每个边界框应该是(x0, y0, x1, y1)格式的归一化版本,其中(x0, y0)对应于边界框左上角的位置,(x1, y1)表示右下角的位置。有关归一化,请参阅概览。 -
attention_mask(torch.FloatTensor,形状为(batch_size, sequence_length),可选) — 避免在填充标记索引上执行注意力的掩码。掩码值在[0, 1]中选择:-
对于
未屏蔽的标记, -
对于
被屏蔽的标记,为 0。
什么是注意力掩码?
-
-
token_type_ids(torch.LongTensor,形状为(batch_size, sequence_length),可选) — 指示输入的第一部分和第二部分的段标记索引。索引在[0, 1]中选择:-
0 对应于 句子 A 标记,
-
1 对应于 句子 B 标记。
什么是标记类型 ID?
-
-
position_ids(torch.LongTensor,形状为(batch_size, sequence_length),可选) — 每个输入序列标记在位置嵌入中的位置索引。在范围[0, config.max_position_embeddings - 1]中选择。什么是位置 ID?
-
head_mask(torch.FloatTensor,形状为(num_heads,)或(num_layers, num_heads),可选) — 用于使自注意力模块的选定头部失效的掩码。掩码值在[0, 1]中选择:-
1 表示头部
未屏蔽, -
0 表示头部
被屏蔽。
-
-
inputs_embeds(torch.FloatTensor,形状为(batch_size, sequence_length, hidden_size),可选) — 可选地,您可以选择直接传递嵌入表示而不是传递input_ids。如果您想要更多控制如何将input_ids索引转换为相关向量,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 -
output_attentions(bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool, 可选) — 是否返回 ModelOutput 而不是普通元组。 -
labels(torch.LongTensor,形状为(batch_size, sequence_length),可选) — 用于计算标记分类损失的标签。索引应在[0, ..., config.num_labels - 1]中。
返回
transformers.modeling_outputs.TokenClassifierOutput 或tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.TokenClassifierOutput 或一个torch.FloatTensor元组(如果传递了return_dict=False或config.return_dict=False时)包括根据配置(LiltConfig)和输入的不同元素。
-
loss(形状为(1,)的torch.FloatTensor,可选,当提供labels时返回)— 分类损失。 -
logits(形状为(batch_size, sequence_length, config.num_labels)的torch.FloatTensor)— 分类分数(SoftMax 之前)。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回)— 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型有嵌入层,则为嵌入的输出和每一层的输出)。模型在每一层输出处的隐藏状态以及可选的初始嵌入输出。
-
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)— 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。注意力权重在注意力 softmax 之后,用于计算自注意力头中的加权平均值。
LiltForTokenClassification 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的配方需要在此函数内定义,但应该在此之后调用Module实例,而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, AutoModelForTokenClassification
>>> from datasets import load_dataset
>>> tokenizer = AutoTokenizer.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
>>> model = AutoModelForTokenClassification.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
>>> dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train")
>>> example = dataset[0]
>>> words = example["tokens"]
>>> boxes = example["bboxes"]
>>> encoding = tokenizer(words, boxes=boxes, return_tensors="pt")
>>> outputs = model(**encoding)
>>> predicted_class_indices = outputs.logits.argmax(-1)
LiltForQuestionAnswering
class transformers.LiltForQuestionAnswering
( config )
参数
config(LiltConfig)— 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
Lilt 模型在顶部具有一个跨度分类头,用于提取式问答任务,如 SQuAD(在隐藏状态输出的顶部有线性层,用于计算span start logits和span end logits)。
这个模型继承自 PreTrainedModel。检查超类文档以获取库为所有模型实现的通用方法(如下载或保存、调整输入嵌入、修剪头等)。
这个模型也是一个 PyTorch torch.nn.Module子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有内容。
forward
( input_ids: Optional = None bbox: Optional = None attention_mask: Optional = None token_type_ids: Optional = None position_ids: Optional = None head_mask: Optional = None inputs_embeds: Optional = None start_positions: Optional = None end_positions: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.QuestionAnsweringModelOutput or tuple(torch.FloatTensor)
参数
-
input_ids(形状为(batch_size, sequence_length)的torch.LongTensor)— 词汇表中输入序列标记的索引。可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.
call()。什么是输入 ID?
-
bbox(torch.LongTensor,形状为(batch_size, sequence_length, 4),optional) — 每个输入序列标记的边界框。选择范围为[0, config.max_2d_position_embeddings-1]。每个边界框应该是(x0, y0, x1, y1)格式的归一化版本,其中(x0, y0)对应于边界框左上角的位置,(x1, y1)表示右下角的位置。有关归一化,请参阅概述。 -
attention_mask(torch.FloatTensor,形状为(batch_size, sequence_length),optional) — 用于避免在填充标记索引上执行注意力的掩码。掩码值选择在[0, 1]之间:-
1 表示未被
masked的标记, -
0 表示被
masked的标记。
什么是注意力掩码?
-
-
token_type_ids(torch.LongTensor,形状为(batch_size, sequence_length),optional) — 段标记索引,指示输入的第一部分和第二部分。索引选择在[0, 1]之间:-
0 对应于句子 A标记,
-
1 对应于句子 B标记。
什么是标记类型 ID?
-
-
position_ids(torch.LongTensor,形状为(batch_size, sequence_length),optional) — 每个输入序列标记在位置嵌入中的位置索引。选择范围为[0, config.max_position_embeddings - 1]。什么是位置 ID?
-
head_mask(torch.FloatTensor,形状为(num_heads,)或(num_layers, num_heads),optional) — 用于使自注意力模块的选定头部失效的掩码。掩码值选择在[0, 1]之间:-
1 表示头部未被
masked, -
0 表示头部被
masked。
-
-
inputs_embeds(torch.FloatTensor,形状为(batch_size, sequence_length, hidden_size),optional) — 可选地,可以直接传递嵌入表示,而不是传递input_ids。如果您想要更多控制如何将input_ids索引转换为相关向量,而不是使用模型的内部嵌入查找矩阵,则这很有用。 -
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量中的attentions。 -
output_hidden_states(bool,optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量中的hidden_states。 -
return_dict(bool,optional) — 是否返回 ModelOutput 而不是普通元组。 -
start_positions(torch.LongTensor,形状为(batch_size,),optional) — 用于计算标记分类损失的标记跨度开始位置(索引)的标签。位置被夹紧到序列的长度(sequence_length)。序列外的位置不会用于计算损失。 -
end_positions(torch.LongTensor,形状为(batch_size,),optional) — 用于计算标记分类损失的标记跨度结束位置(索引)的标签。位置被夹紧到序列的长度(sequence_length)。序列外的位置不会用于计算损失。
返回
transformers.modeling_outputs.QuestionAnsweringModelOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.QuestionAnsweringModelOutput 或一个torch.FloatTensor元组(如果传递return_dict=False或config.return_dict=False时)包括根据配置(LiltConfig)和输入的不同元素。
-
loss(形状为(1,)的torch.FloatTensor,可选,当提供labels时返回)- 总跨度提取损失是起始和结束位置的交叉熵之和。 -
start_logits(形状为(batch_size, sequence_length)的torch.FloatTensor)- 跨度起始得分(SoftMax 之前)。 -
end_logits(形状为(batch_size, sequence_length)的torch.FloatTensor)- 跨度结束得分(SoftMax 之前)。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回)- 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每个层的输出)。模型在每一层输出的隐藏状态加上可选的初始嵌入输出。
-
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)- 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每个层一个)。在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。
LiltForQuestionAnswering 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的方法需要在此函数内定义,但应该在之后调用Module实例,而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, AutoModelForQuestionAnswering
>>> from datasets import load_dataset
>>> tokenizer = AutoTokenizer.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
>>> model = AutoModelForQuestionAnswering.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
>>> dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train")
>>> example = dataset[0]
>>> words = example["tokens"]
>>> boxes = example["bboxes"]
>>> encoding = tokenizer(words, boxes=boxes, return_tensors="pt")
>>> outputs = model(**encoding)
>>> answer_start_index = outputs.start_logits.argmax()
>>> answer_end_index = outputs.end_logits.argmax()
>>> predict_answer_tokens = encoding.input_ids[0, answer_start_index : answer_end_index + 1]
>>> predicted_answer = tokenizer.decode(predict_answer_tokens)
LLaVa
原始文本:
huggingface.co/docs/transformers/v4.37.2/en/model_doc/llava
概述
LLaVa 是通过在 GPT 生成的多模态指令遵循数据上进行 LlamA/Vicuna 微调而训练的开源聊天机器人。它是一种基于变压器架构的自回归语言模型。换句话说,它是为聊天/指令微调的 LLMs 的多模态版本。
LLaVa 模型最初在视觉指导调整中提出,并在通过视觉指导调整改进基线中由 Haotian Liu、Chunyuan Li、Yuheng Li 和 Yong Jae Lee 改进。
论文摘要如下:
最近,大型多模态模型(LMM)在视觉指导调整方面取得了令人鼓舞的进展。在这篇文章中,我们展示了 LLaVA 中的全连接视觉-语言跨模态连接器出人意料地强大且高效。通过对 LLaVA 进行简单修改,即使用 CLIP-ViT-L-336px 与 MLP 投影,并添加学术任务导向的 VQA 数据以及简单的响应格式提示,我们建立了更强的基线,实现了 11 个基准测试中的最新技术。我们的最终 13B 检查点仅使用了 120 万个公开可用的数据,并在单个 8-A100 节点上的约 1 天内完成了完整训练。我们希望这可以使最先进的 LMM 研究更易于访问。代码和模型将会公开发布
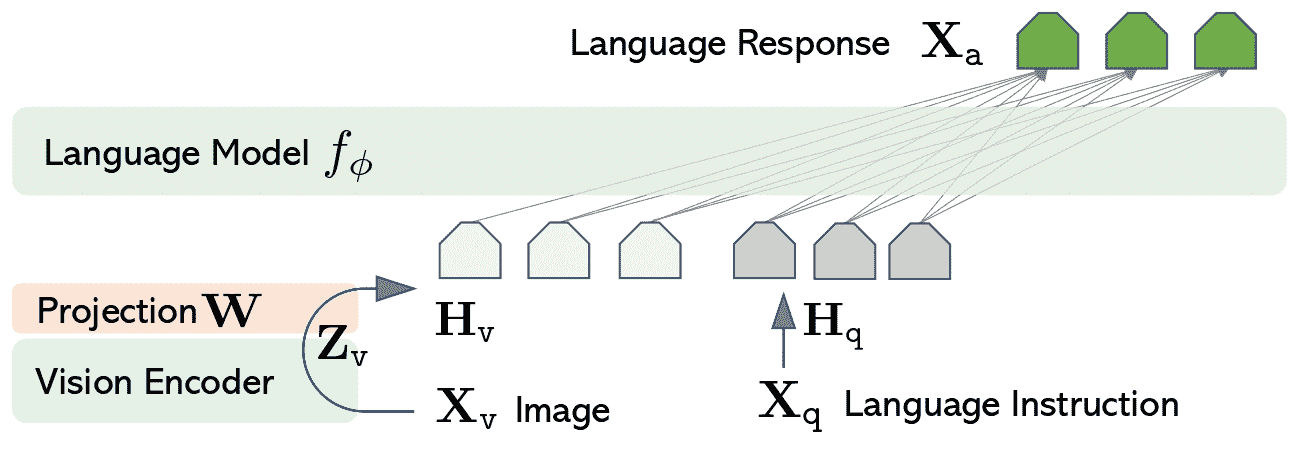 LLaVa 架构。摘自原始论文。
LLaVa 架构。摘自原始论文。
该模型由ArthurZ和ybelkada贡献。原始代码可以在这里找到。
使用提示
-
我们建议用户在计算批量生成时使用
padding_side="left",因为这会导致更准确的结果。只需确保在生成之前调用processor.tokenizer.padding_side = "left"。 -
请注意,该模型尚未明确训练以处理同一提示中的多个图像,尽管从技术上讲这是可能的,但您可能会遇到不准确的结果。
-
为了获得更好的结果,我们建议用户使用正确的提示格式提示模型:
"USER: <image>\n<prompt>ASSISTANT:"
对于多轮对话:
"USER: <image>\n<prompt1>ASSISTANT: <answer1>USER: <prompt2>ASSISTANT: <answer2>USER: <prompt3>ASSISTANT:"
使用 Flash Attention 2
Flash Attention 2 是先前优化的更快、更优化的版本,请参阅性能文档中的 Flash Attention 2 部分。
资源
一份官方 Hugging Face 和社区(由🌎表示)资源列表,可帮助您开始使用 BEiT。
图像到文本
-
关于如何在免费的 Google Colab 实例上运行 Llava 的Google Colab 演示,利用 4 位推理。
-
展示批量推理的类似笔记本。🌎
LlavaConfig
class transformers.LlavaConfig
( vision_config = None text_config = None ignore_index = -100 image_token_index = 32000 projector_hidden_act = 'gelu' vision_feature_select_strategy = 'default' vision_feature_layer = -2 vocab_size = 32000 **kwargs )
参数
-
vision_config(LlavaVisionConfig,可选)— 自定义视觉配置或字典 -
text_config(Union[AutoConfig, dict],可选)— 文本主干的配置对象。可以是LlamaConfig或MistralConfig之一。 -
ignore_index(int,可选,默认为-100)— 损失函数的忽略索引。 -
image_token_index(int,可选,默认为 32000)— 用于编码图像提示的图像标记索引。 -
projector_hidden_act(str,可选,默认为"gelu")— 多模态投影器使用的激活函数。 -
vision_feature_select_strategy(str, optional, 默认为"default") — 用于从 CLIP 骨干中选择视觉特征的特征选择策略。 -
vision_feature_layer(int, optional, 默认为-2) — 选择视觉特征的层的索引。 -
vocab_size(int, optional, 默认为 32000) — Llava 模型的词汇表大小。定义了在调用~LlavaForConditionalGeneration 时可以由inputs_ids表示的不同标记数量。
这是用于存储 LlavaForConditionalGeneration 配置的配置类。它用于根据指定的参数实例化一个 Llava 模型,定义模型架构。使用默认值实例化配置将产生类似于 Llava-9B 的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import LlavaForConditionalGeneration, LlavaConfig, CLIPVisionConfig, LlamaConfig
>>> # Initializing a CLIP-vision config
>>> vision_config = CLIPVisionConfig()
>>> # Initializing a Llama config
>>> text_config = LlamaConfig()
>>> # Initializing a Llava llava-1.5-7b style configuration
>>> configuration = LlavaConfig(vision_config, text_config)
>>> # Initializing a model from the llava-1.5-7b style configuration
>>> model = LlavaForConditionalGeneration(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
LlavaProcessor
class transformers.LlavaProcessor
( image_processor = None tokenizer = None )
参数
-
image_processor(CLIPImageProcessor, optional) — 图像处理器是必需的输入。 -
tokenizer(LlamaTokenizerFast, optional) — Tokenizer 是必需的输入。
构建一个 Llava 处理器,将 Llava 图像处理器和 Llava 分词器封装成一个单一处理器。
LlavaProcessor 提供了 CLIPImageProcessor 和 LlamaTokenizerFast 的所有功能。查看__call__()和 decode()以获取更多信息。
batch_decode
( *args **kwargs )
此方法将所有参数转发给 LlamaTokenizerFast 的 batch_decode()。请参考此方法的文档字符串以获取更多信息。
decode
( *args **kwargs )
此方法将所有参数转发给 LlamaTokenizerFast 的 decode()。请参考此方法的文档字符串以获取更多信息。
LlavaForConditionalGeneration
class transformers.LlavaForConditionalGeneration
( config: LlavaConfig )
参数
config(LlavaConfig 或LlavaVisionConfig)—模型配置类,包含模型的所有参数。使用配置文件初始化不会加载与模型相关的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
LLAVA 模型由视觉主干和语言模型组成。此模型继承自 PreTrainedModel。查看超类文档以获取库为所有模型实现的通用方法(例如下载或保存、调整输入嵌入、修剪头等)。
这个模型也是一个 PyTorch torch.nn.Module子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
forward
( input_ids: LongTensor = None pixel_values: FloatTensor = None attention_mask: Optional = None position_ids: Optional = None past_key_values: Optional = None inputs_embeds: Optional = None vision_feature_layer: Optional = None vision_feature_select_strategy: Optional = None labels: Optional = None use_cache: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.models.llava.modeling_llava.LlavaCausalLMOutputWithPast or tuple(torch.FloatTensor)
参数
-
input_ids(形状为(batch_size, sequence_length)的torch.LongTensor)—词汇表中输入序列标记的索引。默认情况下,如果提供填充,则将忽略填充。索引可以使用 AutoTokenizer 获得。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.
call()。什么是输入 ID?
-
pixel_values(torch.FloatTensorof shape(batch_size, num_channels, image_size, image_size)) -- 输入图像对应的张量。像素值可以使用 AutoImageProcessor 获得。有关详细信息,请参阅 CLIPImageProcessor.__call__()([]LlavaProcessor`]使用 CLIPImageProcessor 来处理图像)。 -
attention_mask(形状为(batch_size, sequence_length)的torch.Tensor,可选)—用于避免在填充标记索引上执行注意力的掩码。掩码值选择在[0, 1]之间:-
1 表示
未被掩码的标记, -
0 表示
被掩码的标记。
什么是注意力掩码?
索引可以使用 AutoTokenizer 获得。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.
call()。如果使用
past_key_values,则只需输入最后的decoder_input_ids(请参阅past_key_values)。如果要更改填充行为,应阅读
modeling_opt._prepare_decoder_attention_mask并根据需要进行修改。有关默认策略的更多信息,请参阅论文中的图表 1。-
1 表示头部
未被掩码, -
0 表示头部
被掩码。
-
-
position_ids(形状为(batch_size, sequence_length)的torch.LongTensor,可选)—每个输入序列标记在位置嵌入中的位置索引。选择范围为[0, config.n_positions - 1]。什么是位置 ID? -
past_key_values(tuple(tuple(torch.FloatTensor)),可选,当传递use_cache=True或config.use_cache=True时返回) — 长度为config.n_layers的tuple(torch.FloatTensor)元组,每个元组有 2 个形状为(batch_size, num_heads, sequence_length, embed_size_per_head)的张量,以及 2 个额外的形状为(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)的张量。包含预先计算的隐藏状态(自注意力块和交叉注意力块中的键和值),可用于加速顺序解码(请参见
past_key_values输入)。如果使用了
past_key_values,用户可以选择仅输入最后的decoder_input_ids(这些没有将其过去的键值状态提供给此模型)的形状为(batch_size, 1),而不是形状为(batch_size, sequence_length)的所有decoder_input_ids。 -
inputs_embeds(torch.FloatTensor,形状为(batch_size, sequence_length, hidden_size),可选) — 可选地,可以直接传递嵌入表示,而不是传递input_ids。如果您希望更多地控制如何将input_ids索引转换为相关向量,而不是使用模型的内部嵌入查找矩阵,则这很有用。 -
use_cache(bool, optional) — 如果设置为True,则返回past_key_values键值状态,并可用于加速解码(请参见past_key_values)。 -
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量中的hidden_states。 -
return_dict(bool,可选) — 是否返回一个 ModelOutput 而不是一个普通元组。参数 — labels (
torch.LongTensor,形状为(batch_size, sequence_length),可选):用于计算掩码语言建模损失的标签。索引应该在[0, ..., config.vocab_size]范围内,或者为-100(请参见input_ids文档字符串)。索引设置为-100的标记将被忽略(掩码),损失仅计算具有标签在[0, ..., config.vocab_size]范围内的标记。
返回
transformers.models.llava.modeling_llava.LlavaCausalLMOutputWithPast 或 tuple(torch.FloatTensor)
一个transformers.models.llava.modeling_llava.LlavaCausalLMOutputWithPast或一个torch.FloatTensor元组(如果传递return_dict=False或config.return_dict=False)包含根据配置(LlavaConfig)和输入的不同元素。
-
loss(torch.FloatTensor,形状为(1,),可选,当提供labels时返回) — 语言建模损失(用于下一个标记预测)。 -
logits(torch.FloatTensor,形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。 -
past_key_values(tuple(tuple(torch.FloatTensor)),可选,当传递use_cache=True或config.use_cache=True时返回) — 长度为config.n_layers的tuple(torch.FloatTensor)元组,每个元组有 2 个形状为(batch_size, num_heads, sequence_length, embed_size_per_head)的张量。包含预先计算的隐藏状态(自注意力块中的键和值),可用于加速顺序解码(请参见
past_key_values输入)。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型具有嵌入层,则为嵌入的输出 + 每层的输出)。模型在每一层输出的隐藏状态以及可选的初始嵌入输出。
-
attentions(tuple(torch.FloatTensor), 可选的, 当传递output_attentions=True或者config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
-
image_hidden_states(tuple(torch.FloatTensor), 可选的) — 图像嵌入输出的元组torch.FloatTensor(形状为(batch_size, num_images, sequence_length, hidden_size))。由视觉编码器产生的模型的图像隐藏状态,以及可选的由感知器产生的隐藏状态。
LlavaForConditionalGeneration 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的步骤需要在这个函数内定义,但应该在此之后调用Module实例,而不是在此之后调用,因为前者会处理运行前后的处理步骤,而后者会默默地忽略它们。
例如:
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, LlavaForConditionalGeneration
>>> model = LlavaForConditionalGeneration.from_pretrained("llava-hf/llava-1.5-7b-hf")
>>> processor = AutoProcessor.from_pretrained("llava-hf/llava-1.5-7b-hf")
>>> prompt = "<image>\nUSER: What's the content of the image?\nASSISTANT:"
>>> url = "https://www.ilankelman.org/stopsigns/australia.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(text=prompt, images=image, return_tensors="pt")
>>> # Generate
>>> generate_ids = model.generate(**inputs, max_length=30)
>>> processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
"\nUSER: What's the content of the image?\nASSISTANT: The image features a stop sign on a street corner"
LXMERT
原始文本:
huggingface.co/docs/transformers/v4.37.2/en/model_doc/lxmert
概述
LXMERT 模型是由 Hao Tan 和 Mohit Bansal 在LXMERT: Learning Cross-Modality Encoder Representations from Transformers中提出的。它是一系列双向 Transformer 编码器(一个用于视觉模态,一个用于语言模态,然后一个用于融合两种模态),使用一种组合的方法进行预训练,包括遮蔽语言建模、视觉-语言文本对齐、ROI 特征回归、遮蔽视觉属性建模、遮蔽视觉对象建模和视觉问题回答目标。预训练包括多个多模态数据集:MSCOCO、Visual-Genome + Visual-Genome Question Answering、VQA 2.0 和 GQA。
摘要如下:
视觉与语言推理需要理解视觉概念、语言语义,最重要的是理解这两种模态之间的对齐和关系。因此,我们提出了 LXMERT(Learning Cross-Modality Encoder Representations from Transformers)框架来学习这些视觉与语言的连接。在 LXMERT 中,我们构建了一个大规模的 Transformer 模型,包括三个编码器:对象关系编码器、语言编码器和跨模态编码器。接下来,为了赋予我们的模型连接视觉和语言语义的能力,我们使用大量的图像和句子对进行预训练,通过五种不同的代表性预训练任务:遮蔽语言建模、遮蔽对象预测(特征回归和标签分类)、跨模态匹配和图像问题回答。这些任务有助于学习模态内部和模态间的关系。在从我们的预训练参数微调后,我们的模型在两个视觉问题回答数据集(即 VQA 和 GQA)上取得了最先进的结果。我们还展示了我们预训练的跨模态模型的泛化能力,通过将其适应具有挑战性的视觉推理任务 NLVR,将先前的最佳结果提高了 22%绝对值(从 54%到 76%)。最后,我们进行了详细的消融研究,证明了我们的新颖模型组件和预训练策略对我们强大结果的显著贡献;并展示了不同编码器的几个注意力可视化
此模型由eltoto1219贡献。原始代码可在此处找到。
使用提示
-
在视觉特征嵌入中不必使用边界框,任何类型的视觉空间特征都可以使用。
-
LXMERT 输出的语言隐藏状态和视觉隐藏状态都经过了跨模态层,因此它们包含来自两种模态的信息。要访问仅关注自身的模态,请从元组中的第一个输入中选择视觉/语言隐藏状态。
-
双向跨模态编码器注意力仅在语言模态用作输入且视觉模态用作上下文向量时返回注意力值。此外,虽然跨模态编码器包含每个相应模态的自注意力和交叉注意力,但只返回交叉注意力,两个自注意力输出都被忽略。
资源
- 问答任务指南
LxmertConfig
class transformers.LxmertConfig
( vocab_size = 30522 hidden_size = 768 num_attention_heads = 12 num_qa_labels = 9500 num_object_labels = 1600 num_attr_labels = 400 intermediate_size = 3072 hidden_act = 'gelu' hidden_dropout_prob = 0.1 attention_probs_dropout_prob = 0.1 max_position_embeddings = 512 type_vocab_size = 2 initializer_range = 0.02 layer_norm_eps = 1e-12 l_layers = 9 x_layers = 5 r_layers = 5 visual_feat_dim = 2048 visual_pos_dim = 4 visual_loss_normalizer = 6.67 task_matched = True task_mask_lm = True task_obj_predict = True task_qa = True visual_obj_loss = True visual_attr_loss = True visual_feat_loss = True **kwargs )
参数
-
vocab_size(int, optional, defaults to 30522) — LXMERT 模型的词汇表大小。定义了在调用 LxmertModel 或 TFLxmertModel 时可以由inputs_ids表示的不同标记数量。 -
hidden_size(int, optional, defaults to 768) — 编码器层和池化器层的维度。 -
num_attention_heads(int, optional, defaults to 12) — Transformer 编码器中每个注意力层的注意力头数量。 -
num_qa_labels(int, optional, defaults to 9500) — 这表示不同的问题回答(QA)标签的总数。如果使用多个具有 QA 的数据集,用户需要考虑所有数据集总共拥有的标签数量。 -
num_object_labels(int, optional, defaults to 1600) — 这表示 LXMERT 将能够将池化对象特征分类为所属的语义唯一对象的总数。 -
num_attr_labels(int, optional, defaults to 400) — 这表示 LXMERT 将能够将池化对象特征分类为具有的语义唯一属性的总数。 -
intermediate_size(int, optional, defaults to 3072) — Transformer 编码器中“中间”(通常称为前馈)层的维度。 -
hidden_act(strorCallable, optional, defaults to"gelu") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu","relu","silu"和"gelu_new"。 -
hidden_dropout_prob(float, optional, defaults to 0.1) — 嵌入层、编码器和池化器中所有全连接层的丢失概率。 -
attention_probs_dropout_prob(float, optional, defaults to 0.1) — 注意力概率的丢失比率。 -
max_position_embeddings(int, optional, defaults to 512) — 该模型可能会与的最大序列长度。通常将其设置为较大的值以防万一(例如,512、1024 或 2048)。 -
type_vocab_size(int, optional, defaults to 2) — 传递给 BertModel 的 token_type_ids 的词汇表大小。 -
initializer_range(float, optional, defaults to 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 -
layer_norm_eps(float, optional, defaults to 1e-12) — 层归一化层使用的 epsilon。 -
l_layers(int, optional, defaults to 9) — Transformer 语言编码器中的隐藏层数量。 -
x_layers(int, optional, defaults to 5) — Transformer 跨模态编码器中的隐藏层数量。 -
r_layers(int, optional, defaults to 5) — Transformer 视觉编码器中的隐藏层数量。 -
visual_feat_dim(int, optional, defaults to 2048) — 这表示用作模型输入的池化对象特征的最后维度,表示每个对象特征本身的大小。 -
visual_pos_dim(int, optional, defaults to 4) — 这表示混合到视觉特征中的空间特征的数量。默认设置为 4,因为通常这将表示边界框的位置。即 (x, y, 宽度, 高度) -
visual_loss_normalizer(float, optional, defaults to 6.67) — 这表示如果在预训练期间决定使用多个基于视觉的损失目标进行训练,则每个视觉损失将乘以的缩放因子。 -
task_matched(bool, optional, defaults toTrue) — 该任务用于句子-图像匹配。如果句子正确描述图像,则标签为 1。如果句子未正确描述图像,则标签为 0。 -
task_mask_lm(bool, optional, defaults toTrue) — 是否添加掩码语言建模(如 BERT 中使用的)到损失目标中。 -
task_obj_predict(bool, optional, defaults toTrue) — 是否添加对象预测、属性预测和特征回归到损失目标中。 -
task_qa(bool, optional, defaults toTrue) — 是否将问答损失添加到目标中。 -
visual_obj_loss(bool, optional, defaults toTrue) — 是否计算对象预测损失目标 -
visual_attr_loss(bool, optional, defaults toTrue) — 是否计算属性预测损失目标 -
visual_feat_loss(bool, optional, defaults toTrue) — 是否计算特征回归损失目标
这是用于存储 LxmertModel 或 TFLxmertModel 配置的配置类。它用于根据指定的参数实例化一个 LXMERT 模型,定义模型架构。使用默认值实例化配置将产生与 Lxmert unc-nlp/lxmert-base-uncased架构类似的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
LxmertTokenizer
class transformers.LxmertTokenizer
( vocab_file do_lower_case = True do_basic_tokenize = True never_split = None unk_token = '[UNK]' sep_token = '[SEP]' pad_token = '[PAD]' cls_token = '[CLS]' mask_token = '[MASK]' tokenize_chinese_chars = True strip_accents = None **kwargs )
参数
-
vocab_file(str) — 包含词汇表的文件。 -
do_lower_case(bool, optional, defaults toTrue) — 在标记化时是否将输入转换为小写。 -
do_basic_tokenize(bool, optional, defaults toTrue) — 在 WordPiece 之前是否进行基本标记化。 -
never_split(Iterable, optional) — 在标记化期间永远不会拆分的标记集合。仅在do_basic_tokenize=True时有效。 -
unk_token(str, optional, defaults to"[UNK]") — 未知标记。词汇表中不存在的标记无法转换为 ID,而是设置为此标记。 -
sep_token(str, optional, defaults to"[SEP]") — 分隔符标记,用于从多个序列构建序列,例如用于序列分类的两个序列或用于文本和问题的问题回答。它还用作使用特殊标记构建的序列的最后一个标记。 -
pad_token(str, optional, defaults to"[PAD]") — 用于填充的标记,例如在批处理不同长度的序列时使用。 -
cls_token(str, optional, defaults to"[CLS]") — 用于进行序列分类(对整个序列进行分类而不是对每个标记进行分类)时使用的分类器标记。它是使用特殊标记构建的序列的第一个标记。 -
mask_token(str, optional, defaults to"[MASK]") — 用于屏蔽值的标记。这是在使用掩码语言建模训练此模型时使用的标记。这是模型将尝试预测的标记。 -
tokenize_chinese_chars(bool, optional, defaults toTrue) — 是否对中文字符进行标记化。这可能应该在日语中停用(请参阅此问题)。
-
strip_accents(bool, optional) — 是否去除所有重音符号。如果未指定此选项,则将由lowercase的值确定(与原始 Lxmert 中相同)。
构建一个 Lxmert 标记器。基于 WordPiece。
此标记器继承自 PreTrainedTokenizer,其中包含大多数主要方法。用户应参考此超类以获取有关这些方法的更多信息。
build_inputs_with_special_tokens
( token_ids_0: List token_ids_1: Optional = None ) → export const metadata = 'undefined';List[int]
参数
-
token_ids_0(List[int]) — 将添加特殊标记的 ID 列表。 -
token_ids_1(List[int], 可选) — 第二个序列对的可选 ID 列表。
返回值
List[int]
带有适当特殊标记的输入 ID 列表。
通过连接和添加特殊标记构建用于序列分类任务的序列或序列对的模型输入。Lxmert 序列的格式如下:
-
单个序列:
[CLS] X [SEP] -
序列对:
[CLS] A [SEP] B [SEP]
convert_tokens_to_string
( tokens )
将一系列标记(字符串)转换为单个字符串。
create_token_type_ids_from_sequences
( token_ids_0: List token_ids_1: Optional = None ) → export const metadata = 'undefined';List[int]
参数
-
token_ids_0(List[int]) — ID 列表。 -
token_ids_1(List[int], 可选) — 第二个序列对的可选 ID 列表。
返回值
List[int]
根据给定序列的标记类型 ID 列表。
从传递的两个序列创建用于序列对分类任务的掩码。一个 Lxmert 序列
序列对掩码的格式如下:
0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
| first sequence | second sequence |
如果token_ids_1为None,则此方法仅返回掩码的第一部分(0)。
get_special_tokens_mask
( token_ids_0: List token_ids_1: Optional = None already_has_special_tokens: bool = False ) → export const metadata = 'undefined';List[int]
参数
-
token_ids_0(List[int]) — ID 列表。 -
token_ids_1(List[int], 可选) — 第二个序列对的可选 ID 列表。 -
already_has_special_tokens(bool, 可选, 默认为False) — 标记列表是否已经使用特殊标记格式化。
返回值
List[int]
一个整数列表,范围为[0, 1]:1 表示特殊标记,0 表示序列标记。
从没有添加特殊标记的标记列表中检索序列 ID。在使用标记器的prepare_for_model方法添加特殊标记时调用此方法。
LxmertTokenizerFast
class transformers.LxmertTokenizerFast
( vocab_file = None tokenizer_file = None do_lower_case = True unk_token = '[UNK]' sep_token = '[SEP]' pad_token = '[PAD]' cls_token = '[CLS]' mask_token = '[MASK]' tokenize_chinese_chars = True strip_accents = None **kwargs )
参数
-
vocab_file(str) — 包含词汇表的文件。 -
do_lower_case(bool, 可选, 默认为True) — 在标记化时是否将输入转换为小写。 -
unk_token(str, 可选, 默认为"[UNK]") — 未知标记。词汇表中没有的标记无法转换为 ID,而是设置为此标记。 -
sep_token(str, 可选, 默认为"[SEP]") — 分隔符标记,在构建多个序列的序列时使用,例如用于序列分类的两个序列或用于文本和问题的问题回答。它也用作使用特殊标记构建的序列的最后一个标记。 -
pad_token(str, 可选, 默认为"[PAD]") — 用于填充的标记,例如在批处理不同长度的序列时使用。 -
cls_token(str, 可选, 默认为"[CLS]") — 用于进行序列分类(对整个序列进行分类而不是每个标记的分类)时使用的分类器标记。当使用特殊标记构建序列时,它是序列的第一个标记。 -
mask_token(str, 可选, 默认为"[MASK]") — 用于屏蔽值的标记。这是在使用掩码语言建模训练此模型时使用的标记。这是模型将尝试预测的标记。 -
clean_text(bool, 可选, 默认为True) — 是否在分词之前清理文本,通过删除所有控制字符并将所有空格替换为经典空格。 -
tokenize_chinese_chars(bool, 可选, 默认为True) — 是否对中文字符进行分词。这可能应该在日语中停用(参见此问题)。 -
strip_accents(bool, 可选) — 是否去除所有重音符号。如果未指定此选项,则将由lowercase的值确定(与原始 Lxmert 中一样)。 -
wordpieces_prefix(str, 可选, 默认为"##") — 用于子词的前缀。
构建一个“快速”Lxmert 分词器(由 HuggingFace 的 tokenizers 库支持)。基于 WordPiece。
这个分词器继承自 PreTrainedTokenizerFast,其中包含大部分主要方法。用户应该参考这个超类以获取有关这些方法的更多信息。
build_inputs_with_special_tokens
( token_ids_0 token_ids_1 = None ) → export const metadata = 'undefined';List[int]
参数
-
token_ids_0(List[int]) — 将添加特殊标记的 ID 列表。 -
token_ids_1(List[int],可选) — 序列对的可选第二个 ID 列表。
返回
List[int]
带有适当特殊标记的输入 ID 列表。
通过连接和添加特殊标记,为序列分类任务从序列或序列对构建模型输入。一个 Lxmert 序列的格式如下:
-
单个序列:
[CLS] X [SEP] -
序列对:
[CLS] A [SEP] B [SEP]
create_token_type_ids_from_sequences
( token_ids_0: List token_ids_1: Optional = None ) → export const metadata = 'undefined';List[int]
参数
-
token_ids_0(List[int]) — ID 列表。 -
token_ids_1(List[int],可选) — 序列对的可选第二个 ID 列表。
返回
List[int]
根据给定序列的标记类型 ID 列表。
从传递的两个序列创建一个用于序列对分类任务的掩码。一个 Lxmert 序列
序列掩码的格式如下:
0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
| first sequence | second sequence |
如果token_ids_1为None,则此方法仅返回掩码的第一部分(0)。
Lxmert 特定输出
class transformers.models.lxmert.modeling_lxmert.LxmertModelOutput
( language_output: Optional = None vision_output: Optional = None pooled_output: Optional = None language_hidden_states: Optional = None vision_hidden_states: Optional = None language_attentions: Optional = None vision_attentions: Optional = None cross_encoder_attentions: Optional = None )
参数
-
language_output(torch.FloatTensor,形状为(batch_size, sequence_length, hidden_size)) — 语言编码器最后一层的隐藏状态序列。 -
vision_output(torch.FloatTensor,形状为(batch_size, sequence_length, hidden_size)) — 视觉编码器最后一层的隐藏状态序列。 -
pooled_output(torch.FloatTensor,形状为(batch_size, hidden_size)) — 序列第一个标记(分类,CLS,标记)的最后一层隐藏状态,进一步通过线性层和 Tanh 激活函数处理。线性 -
language_hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于输入特征 + 一个用于每个跨模态层的输出)。 -
vision_hidden_states(tuple(torch.FloatTensor), optional, 当output_hidden_states=True被传递或者config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于输入特征,一个用于每个跨模态层的输出)。 -
language_attentions(tuple(torch.FloatTensor), optional, 当output_attentions=True被传递或者config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每个层一个)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。 -
vision_attentions(tuple(torch.FloatTensor), optional, 当output_attentions=True被传递或者config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每个层一个)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。 -
cross_encoder_attentions(tuple(torch.FloatTensor), optional, 当output_attentions=True被传递或者config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每个层一个)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
Lxmert 的输出包含语言、视觉和跨模态编码器的最后隐藏状态、汇总输出和注意力概率。(注意:在 Lxmert 中,视觉编码器被称为“关系-ship”编码器)
class transformers.models.lxmert.modeling_lxmert.LxmertForPreTrainingOutput
( loss: Optional = None prediction_logits: Optional = None cross_relationship_score: Optional = None question_answering_score: Optional = None language_hidden_states: Optional = None vision_hidden_states: Optional = None language_attentions: Optional = None vision_attentions: Optional = None cross_encoder_attentions: Optional = None )
参数
-
loss(optional, 当提供labels时返回,形状为(1,)的torch.FloatTensor) — 总损失,作为掩码语言建模损失和下一个序列预测(分类)损失的总和。 -
prediction_logits(torch.FloatTensor,形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。 -
cross_relationship_score(torch.FloatTensor,形状为(batch_size, 2)) — 文本匹配目标(分类)头的预测分数(SoftMax 之前的 True/False 继续分数)。 -
question_answering_score(torch.FloatTensor,形状为(batch_size, n_qa_answers)) — 问答目标(分类)的预测分数。 -
language_hidden_states(tuple(torch.FloatTensor), optional, 当output_hidden_states=True被传递或者config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于输入特征,一个用于每个跨模态层的输出)。 -
vision_hidden_states(tuple(torch.FloatTensor), optional, 当output_hidden_states=True被传递或者config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于输入特征,一个用于每个跨模态层的输出)。 -
language_attentions(tuple(torch.FloatTensor), optional, 当output_attentions=True被传递或者config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每个层一个)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。 -
vision_attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)— 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。 -
cross_encoder_attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)— 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
LxmertForPreTraining 的输出类型。
class transformers.models.lxmert.modeling_lxmert.LxmertForQuestionAnsweringOutput
( loss: Optional = None question_answering_score: Optional = None language_hidden_states: Optional = None vision_hidden_states: Optional = None language_attentions: Optional = None vision_attentions: Optional = None cross_encoder_attentions: Optional = None )
参数
-
loss(可选,当提供labels时返回,形状为(1,)的torch.FloatTensor)— 总损失,作为掩码语言建模损失和下一个序列预测(分类)损失的总和。 -
question_answering_score(形状为(batch_size, n_qa_answers)的torch.FloatTensor,可选)— 问题回答目标(分类)的预测分数。 -
language_hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回)— 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组。 -
vision_hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回)— 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组。 -
language_attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)— 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。 -
vision_attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)— 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。 -
cross_encoder_attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)— 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
LxmertForQuestionAnswering 的输出类型。
class transformers.models.lxmert.modeling_tf_lxmert.TFLxmertModelOutput
( language_output: tf.Tensor | None = None vision_output: tf.Tensor | None = None pooled_output: tf.Tensor | None = None language_hidden_states: Tuple[tf.Tensor] | None = None vision_hidden_states: Tuple[tf.Tensor] | None = None language_attentions: Tuple[tf.Tensor] | None = None vision_attentions: Tuple[tf.Tensor] | None = None cross_encoder_attentions: Tuple[tf.Tensor] | None = None )
参数
-
language_output(形状为(batch_size, sequence_length, hidden_size)的tf.Tensor)— 语言编码器最后一层的隐藏状态序列。 -
vision_output(tf.Tensorof shape(batch_size, sequence_length, hidden_size)) — 视觉编码器最后一层的隐藏状态序列。 -
pooled_output(tf.Tensorof shape(batch_size, hidden_size)) — 序列第一个标记的最后一层隐藏状态(分类,CLS,标记),经过线性层和 Tanh 激活函数进一步处理的隐藏状态。 -
language_hidden_states(tuple(tf.Tensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的tf.Tensor元组(一个用于输入特征 + 一个用于每个跨模态层的输出)。 -
vision_hidden_states(tuple(tf.Tensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的tf.Tensor元组(一个用于输入特征 + 一个用于每个跨模态层的输出)。 -
language_attentions(tuple(tf.Tensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的tf.Tensor元组(每个层一个)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。 -
vision_attentions(tuple(tf.Tensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的tf.Tensor元组(每个层一个)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。 -
cross_encoder_attentions(tuple(tf.Tensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的tf.Tensor元组(每个层一个)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
Lxmert 的输出包含语言、视觉和跨模态编码器的最后隐藏状态、汇聚输出和注意力概率。(注意:在 Lxmert 中,视觉编码器被称为“关系-ship”编码器)
class transformers.models.lxmert.modeling_tf_lxmert.TFLxmertForPreTrainingOutput
( loss: tf.Tensor | None = None prediction_logits: tf.Tensor | None = None cross_relationship_score: tf.Tensor | None = None question_answering_score: tf.Tensor | None = None language_hidden_states: Tuple[tf.Tensor] | None = None vision_hidden_states: Tuple[tf.Tensor] | None = None language_attentions: Tuple[tf.Tensor] | None = None vision_attentions: Tuple[tf.Tensor] | None = None cross_encoder_attentions: Tuple[tf.Tensor] | None = None )
参数
-
loss(可选,在提供labels时返回,tf.Tensorof shape(1,)) — 总损失,作为掩码语言建模损失和下一个序列预测(分类)损失的总和。 -
prediction_logits(tf.Tensorof shape(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。 -
cross_relationship_score(tf.Tensorof shape(batch_size, 2)) — 文本匹配目标(分类)头的预测分数(SoftMax 之前的 True/False 连续性分数)。 -
question_answering_score(tf.Tensorof shape(batch_size, n_qa_answers)) — 问答目标(分类)的预测分数。 -
language_hidden_states(tuple(tf.Tensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的tf.Tensor元组(一个用于输入特征 + 一个用于每个跨模态层的输出)。 -
vision_hidden_states(tuple(tf.Tensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的tf.Tensor元组(一个用于输入特征 + 一个用于每个跨模态层的输出)。 -
language_attentions(tuple(tf.Tensor), 可选的, 当传递output_attentions=True或者当config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的tf.Tensor元组(每层一个)。在自注意力头中用于计算加权平均值的注意力权重。 -
vision_attentions(tuple(tf.Tensor), 可选的, 当传递output_attentions=True或者当config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的tf.Tensor元组(每层一个)。在自注意力头中用于计算加权平均值的注意力权重。 -
cross_encoder_attentions(tuple(tf.Tensor), 可选的, 当传递output_attentions=True或者当config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的tf.Tensor元组(每层一个)。在自注意力头中用于计算加权平均值的注意力权重。
LxmertForPreTraining 的输出类型。
PytorchHide Pytorch 内容
LxmertModel
class transformers.LxmertModel
( config )
参数
config(LxmertConfig) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
裸 Lxmert 模型变换器输出原始隐藏状态,没有特定的头部。
LXMERT 模型是由 Hao Tan 和 Mohit Bansal 在LXMERT: Learning Cross-Modality Encoder Representations from Transformers中提出的。这是一个视觉和语言变换器模型,预训练于包括 GQA、VQAv2.0、MSCOCO 标题和 Visual genome 在内的各种多模态数据集,使用掩码语言建模、感兴趣区域特征回归、交叉熵损失用于问题回答属性预测和对象标签预测。
此模型继承自 PreTrainedModel。查看超类文档以获取库为所有模型实现的通用方法(如下载或保存、调整输入嵌入、修剪头等)。
此模型也是 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有信息。
forward
( input_ids: Optional = None visual_feats: Optional = None visual_pos: Optional = None attention_mask: Optional = None visual_attention_mask: Optional = None token_type_ids: Optional = None inputs_embeds: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.models.lxmert.modeling_lxmert.LxmertModelOutput or tuple(torch.FloatTensor)
参数
-
input_ids(torch.LongTensor,形状为(batch_size, sequence_length)) — 词汇表中输入序列标记的索引。可以使用 AutoTokenizer 获取索引。查看 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.
call()获取详细信息。什么是输入 ID?
-
visual_feats(torch.FloatTensorof shape(batch_size, num_visual_features, visual_feat_dim)) — 此输入表示视觉特征。它们是使用 faster-RCNN 模型从边界框中 ROI 池化的对象特征)目前 transformers 库中没有提供这些。
-
visual_pos(torch.FloatTensorof shape(batch_size, num_visual_features, visual_pos_dim)) — 此输入表示与它们的相对(通过索引)视觉特征对应的空间特征。预训练的 LXMERT 模型期望这些空间特征是在 0 到目前 transformers 库中没有提供这些。
-
attention_mask(torch.FloatTensorof shape(batch_size, sequence_length), optional) — 避免在填充标记索引上执行注意力的掩码。掩码值在[0, 1]中选择:-
1 表示未被屏蔽的标记,
-
0 表示被屏蔽的标记。
什么是注意力掩码?
-
-
visual_attention_mask(torch.FloatTensorof shape(batch_size, sequence_length), optional) — 避免在填充标记索引上执行注意力的掩码。掩码值在[0, 1]中选择:-
1 表示未被屏蔽的标记,
-
0 表示被屏蔽的标记。
什么是注意力掩码?
-
-
token_type_ids(torch.LongTensorof shape(batch_size, sequence_length), optional) — 段落标记索引,用于指示输入的第一部分和第二部分。索引在[0, 1]中选择:-
0 对应于 句子 A 标记,
-
1 对应于 句子 B 标记。
什么是标记类型 ID?
-
-
inputs_embeds(torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以直接传递嵌入表示,而不是传递input_ids。如果您想要更多控制如何将input_ids索引转换为相关向量,这将很有用,而不是使用模型的内部嵌入查找矩阵。 -
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool, optional) — 是否返回一个 ModelOutput 而不是一个普通的元组。
返回
transformers.models.lxmert.modeling_lxmert.LxmertModelOutput 或 tuple(torch.FloatTensor)
一个 transformers.models.lxmert.modeling_lxmert.LxmertModelOutput 或一个 torch.FloatTensor 元组(如果传递了 return_dict=False 或当 config.return_dict=False 时)包含根据配置(LxmertConfig)和输入而异的各种元素。
-
language_output(torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — 语言编码器最后一层的隐藏状态序列。 -
vision_output(torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — 视觉编码器最后一层的隐藏状态序列。 -
pooled_output(torch.FloatTensorof shape(batch_size, hidden_size)) — 序列第一个标记(分类,CLS,标记)的最后一层隐藏状态,进一步由线性层和 Tanh 激活函数处理。线性 -
language_hidden_states(tuple(torch.FloatTensor), optional, 当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于输入特征,一个用于每个交叉模态层的输出)。 -
vision_hidden_states(tuple(torch.FloatTensor), optional, 当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于输入特征,一个用于每个交叉模态层的输出)。 -
language_attentions(tuple(torch.FloatTensor), optional, 当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组。在自注意力头中用于计算加权平均值的注意力权重 softmax 后。 -
vision_attentions(tuple(torch.FloatTensor), optional, 当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组。在自注意力头中用于计算加权平均值的注意力权重 softmax 后。 -
cross_encoder_attentions(tuple(torch.FloatTensor), optional, 当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组。在自注意力头中用于计算加权平均值的注意力权重 softmax 后。
LxmertModel 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的方法需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者会处理运行前后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, LxmertModel
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("unc-nlp/lxmert-base-uncased")
>>> model = LxmertModel.from_pretrained("unc-nlp/lxmert-base-uncased")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
LxmertForPreTraining
class transformers.LxmertForPreTraining
( config )
参数
config(LxmertConfig) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
具有指定预训练头的 Lxmert 模型。
LXMERT 模型是由 Hao Tan 和 Mohit Bansal 在LXMERT: Learning Cross-Modality Encoder Representations from Transformers中提出的。它是一个视觉和语言变换器模型,预训练于包括 GQA、VQAv2.0、MSCOCO 标题和 Visual genome 在内的各种多模态数据集,使用掩码语言建模、感兴趣区域特征回归、交叉熵损失用于问题回答属性预测和对象标签预测的组合。
此模型继承自 PreTrainedModel。检查超类文档以获取库为所有模型实现的通用方法(如下载或保存、调整输入嵌入、修剪头等)。
此模型也是 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有内容。
forward
( input_ids: Optional = None visual_feats: Optional = None visual_pos: Optional = None attention_mask: Optional = None visual_attention_mask: Optional = None token_type_ids: Optional = None inputs_embeds: Optional = None labels: Optional = None obj_labels: Optional = None matched_label: Optional = None ans: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None **kwargs ) → export const metadata = 'undefined';transformers.models.lxmert.modeling_lxmert.LxmertForPreTrainingOutput or tuple(torch.FloatTensor)
参数
-
input_ids(torch.LongTensorof shape(batch_size, sequence_length)) — 输入序列标记在词汇表中的索引。可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.
call()。什么是输入 ID?
-
visual_feats(torch.FloatTensorof shape(batch_size, num_visual_features, visual_feat_dim)) — 这个输入表示视觉特征。它们是通过 faster-RCNN 模型从边界框中 ROI 池化的对象特征。目前这些由 transformers 库不提供。
-
visual_pos(torch.FloatTensorof shape(batch_size, num_visual_features, visual_pos_dim)) — 这个输入表示与它们的相对(通过索引)视觉特征对应的空间特征。预训练的 LXMERT 模型期望这些空间特征是在 0 到 1 的范围内归一化的边界框。目前这些由 transformers 库不提供。
-
attention_mask(torch.FloatTensorof shape(batch_size, sequence_length), 可选) — 避免在填充标记索引上执行注意力的掩码。掩码值选择在[0, 1]:-
1 代表未被
masked的标记, -
0 代表被
masked的标记。
什么是注意力掩码?
-
-
visual_attention_mask(torch.FloatTensorof shape(batch_size, sequence_length), 可选) — 避免在填充标记索引上执行注意力的掩码。掩码值选择在[0, 1]:-
1 代表未被
masked的标记, -
0 代表被
masked的标记。
什么是注意力掩码?
-
-
token_type_ids(torch.LongTensorof shape(batch_size, sequence_length), 可选) — 段标记索引,用于指示输入的第一部分和第二部分。索引选择在[0, 1]:-
0 对应于 句子 A 标记,
-
1 对应于 句子 B 标记。
什么是标记类型 ID?
-
-
inputs_embeds(torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), 可选) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您想要更多控制如何将input_ids索引转换为相关向量,而不是使用模型的内部嵌入查找矩阵,这将很有用。 -
output_attentions(bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool, 可选) — 是否返回 ModelOutput 而不是普通的元组。 -
labels(torch.LongTensorof shape(batch_size, sequence_length), 可选) — 用于计算掩码语言建模损失的标签。索引应在[-100, 0, ..., config.vocab_size](参见input_ids文档字符串)。索引设置为-100的标记将被忽略(被masked),损失仅计算具有标签在[0, ..., config.vocab_size]中的标记。 -
obj_labels(Dict[Str -- Tuple[Torch.FloatTensor, Torch.FloatTensor]], 可选): 每个键以视觉损失中的每一个命名,元组的每个元素的形状分别为(batch_size, num_features)和(batch_size, num_features, visual_feature_dim),用于标签 ID 和标签分数 -
matched_label(形状为(batch_size,)的torch.LongTensor,可选) - 用于计算文本输入是否与图像匹配(分类)损失的标签。输入应为一个序列对(参见input_ids文档字符串)。索引应在[0, 1]中:-
0 表示句子与图像不匹配,
-
1 表示句子与图像匹配。
-
-
ans(形状为(batch_size)的Torch.Tensor,可选) - 正确答案的独热表示可选
返回
transformers.models.lxmert.modeling_lxmert.LxmertForPreTrainingOutput 或tuple(torch.FloatTensor)
一个 transformers.models.lxmert.modeling_lxmert.LxmertForPreTrainingOutput 或一个torch.FloatTensor元组(如果传递return_dict=False或config.return_dict=False)包括根据配置(LxmertConfig)和输入的不同元素。
-
loss(可选,当提供labels时返回,形状为(1,)的torch.FloatTensor) - 作为掩码语言建模损失和下一个序列预测(分类)损失之和的总损失。 -
prediction_logits(形状为(batch_size, sequence_length, config.vocab_size)的torch.FloatTensor) - 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。 -
cross_relationship_score(形状为(batch_size, 2)的torch.FloatTensor) - 文本匹配目标(分类)头的预测分数(SoftMax 之前的 True/False 继续分数)。 -
question_answering_score(形状为(batch_size, n_qa_answers)的torch.FloatTensor) - 问题回答目标(分类)的预测分数。 -
language_hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) - 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于输入特征+一个用于每个跨模态层的输出)。 -
vision_hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) - 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于输入特征+一个用于每个跨模态层的输出)。 -
language_attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) - 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。 -
vision_attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) - 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。 -
cross_encoder_attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) - 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
LxmertForPreTraining 的前向方法,覆盖__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者会负责运行预处理和后处理步骤,而后者会默默地忽略它们。
LxmertForQuestionAnswering
class transformers.LxmertForQuestionAnswering
( config )
参数
config(LxmertConfig](/docs/transformers/v4.37.2/en/main_classes/model#transformers.PreTrainedModel.from_pretrained)方法以加载模型权重。
带有视觉回答头的 Lxmert 模型,用于下游 QA 任务
LXMERT 模型是由 Hao Tan 和 Mohit Bansal 在LXMERT: Learning Cross-Modality Encoder Representations from Transformers中提出的。这是一个视觉和语言变换器模型,预训练于各种多模态数据集,包括 GQA、VQAv2.0、MSCOCO 字幕和 Visual genome,使用掩码语言建模、感兴趣区域特征回归、交叉熵损失用于问题回答属性预测和对象标签预测的组合。
这个模型继承自 PreTrainedModel。查看超类文档,了解库为所有模型实现的通用方法(如下载或保存、调整输入嵌入、修剪头等)。
这个模型也是 PyTorch 的torch.nn.Module子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有信息。
forward
( input_ids: Optional = None visual_feats: Optional = None visual_pos: Optional = None attention_mask: Optional = None visual_attention_mask: Optional = None token_type_ids: Optional = None inputs_embeds: Optional = None labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.models.lxmert.modeling_lxmert.LxmertForQuestionAnsweringOutput or tuple(torch.FloatTensor)
参数
-
input_ids(形状为(batch_size, sequence_length)的torch.LongTensor)—输入序列标记在词汇表中的索引。可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.
call()。什么是输入 ID?
-
visual_feats(形状为(batch_size, num_visual_features, visual_feat_dim)的torch.FloatTensor)—这个输入表示视觉特征。它们是使用 faster-RCNN 模型从边界框中 ROI 池化的对象特征)这些目前不是由 transformers 库提供的。
-
visual_pos(形状为(batch_size, num_visual_features, visual_pos_dim)的torch.FloatTensor)—这个输入表示与它们的相对(通过索引)视觉特征对应的空间特征。预训练的 LXMERT 模型期望这些空间特征是在 0 到 1 的范围内的归一化边界框这些目前不是由 transformers 库提供的。
-
attention_mask(形状为(batch_size, sequence_length)的torch.FloatTensor,可选)—避免在填充标记索引上执行注意力的掩码。选择的掩码值在[0, 1]范围内:-
1 表示“未屏蔽”的标记,
-
0 表示“屏蔽”的标记。
什么是注意力掩码?
-
-
visual_attention_mask(形状为(batch_size, sequence_length)的torch.FloatTensor,可选)—避免在填充标记索引上执行注意力的掩码。选择的掩码值在[0, 1]范围内:-
1 表示“未屏蔽”的标记,
-
0 对于被
masked的标记。
什么是注意力掩码?
-
-
token_type_ids(torch.LongTensorof shape(batch_size, sequence_length), optional) — 段落标记索引,用于指示输入的第一部分和第二部分。索引在[0, 1]中选择:-
0 对应 句子 A 标记,
-
1 对应 句子 B 标记。
什么是标记类型 ID?
-
-
inputs_embeds(torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,可以直接传递嵌入表示,而不是传递input_ids。如果您想要更多控制如何将input_ids索引转换为相关向量,这将非常有用。 -
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool, optional) — 是否返回 ModelOutput 而不是普通元组。 -
labels(Torch.Tensorof shape(batch_size), optional) — 正确答案的独热表示
返回
transformers.models.lxmert.modeling_lxmert.LxmertForQuestionAnsweringOutput 或 tuple(torch.FloatTensor)
一个 transformers.models.lxmert.modeling_lxmert.LxmertForQuestionAnsweringOutput 或一个 torch.FloatTensor 元组(如果传递 return_dict=False 或 config.return_dict=False)包含根据配置(LxmertConfig)和输入的不同元素。
-
loss(optional, 当提供labels时返回,形状为(1,)的torch.FloatTensor) — 作为掩码语言建模损失和下一个序列预测(分类)损失之和的总损失。 -
question_answering_score(torch.FloatTensorof shape(batch_size, n_qa_answers), optional) — 问题回答目标(分类)的预测分数。 -
language_hidden_states(tuple(torch.FloatTensor), optional, 当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于输入特征 + 一个用于每个跨模态层的输出)。 -
vision_hidden_states(tuple(torch.FloatTensor), optional, 当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于输入特征 + 一个用于每个跨模态层的输出)。 -
language_attentions(tuple(torch.FloatTensor), optional, 当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每个层一个)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。 -
vision_attentions(tuple(torch.FloatTensor), optional, 当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每个层一个)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。 -
cross_encoder_attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) - 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
LxmertForQuestionAnswering 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在之后调用Module实例,而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
例子:
>>> from transformers import AutoTokenizer, LxmertForQuestionAnswering
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("unc-nlp/lxmert-base-uncased")
>>> model = LxmertForQuestionAnswering.from_pretrained("unc-nlp/lxmert-base-uncased")
>>> question, text = "Who was Jim Henson?", "Jim Henson was a nice puppet"
>>> inputs = tokenizer(question, text, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> answer_start_index = outputs.start_logits.argmax()
>>> answer_end_index = outputs.end_logits.argmax()
>>> predict_answer_tokens = inputs.input_ids[0, answer_start_index : answer_end_index + 1]
>>> # target is "nice puppet"
>>> target_start_index = torch.tensor([14])
>>> target_end_index = torch.tensor([15])
>>> outputs = model(**inputs, start_positions=target_start_index, end_positions=target_end_index)
>>> loss = outputs.loss
隐藏 TensorFlow 内容
TFLxmertModel
class transformers.TFLxmertModel
( config *inputs **kwargs )
参数
config(LxmertConfig) - 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
裸的 Lxmert 模型变换器,输出原始隐藏状态而没有特定的头部。
LXMERT 模型是由 Hao Tan 和 Mohit Bansal 在LXMERT: Learning Cross-Modality Encoder Representations from Transformers中提出的。这是一个视觉和语言变换器模型,预训练于各种多模态数据集,包括 GQA、VQAv2.0、MCSCOCO 字幕和 Visual genome,使用掩码语言建模、感兴趣区域特征回归、交叉熵损失用于问题回答属性预测和对象标签预测。
这个模型也是一个tf.keras.Model子类。将其用作常规的 TF 2.0 Keras 模型,并参考 TF 2.0 文档以获取与一般用法和行为相关的所有信息。
transformers中的 TensorFlow 模型和层接受两种格式的输入:
-
将所有输入作为关键字参数(类似于 PyTorch 模型),或者
-
将所有输入作为列表、元组或字典放在第一个位置参数中。
支持第二种格式的原因是,当将输入传递给模型和层时,Keras 方法更喜欢这种格式。由于有了这种支持,当使用model.fit()等方法时,应该可以正常工作 - 只需以model.fit()支持的任何格式传递输入和标签即可!但是,如果您想在 Keras 方法之外使用第二种格式,比如在使用 KerasFunctionalAPI 创建自己的层或模型时,有三种可能性可以用来收集所有输入张量放在第一个位置参数中:
-
一个只包含
input_ids的单个张量,没有其他内容:model(input_ids) -
一个长度不定的列表,其中包含一个或多个按照文档字符串中给定顺序的输入张量:
model([input_ids, attention_mask])或model([input_ids, attention_mask, token_type_ids]) -
一个与文档字符串中给定的输入名称相关联的包含一个或多个输入张量的字典:
model({"input_ids": input_ids, "token_type_ids": token_type_ids})
请注意,当使用子类化创建模型和层时,您无需担心这些问题,因为您可以像对待任何其他 Python 函数一样传递输入!
call
( input_ids: TFModelInputType | None = None visual_feats: tf.Tensor | None = None visual_pos: tf.Tensor | None = None attention_mask: np.ndarray | tf.Tensor | None = None visual_attention_mask: np.ndarray | tf.Tensor | None = None token_type_ids: np.ndarray | tf.Tensor | None = None inputs_embeds: np.ndarray | tf.Tensor | None = None output_attentions: Optional[bool] = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None training: bool = False ) → export const metadata = 'undefined';transformers.models.lxmert.modeling_tf_lxmert.TFLxmertModelOutput or tuple(tf.Tensor)
参数
-
input_ids(np.ndarray或tf.Tensor,形状为(batch_size, sequence_length)) — 输入序列标记在词汇表中的索引。可以使用 AutoTokenizer 获取索引。有关详细信息,请参见 PreTrainedTokenizer.
call() 和 PreTrainedTokenizer.encode()。什么是输入 ID?
-
visual_feats(tf.Tensor,形状为(batch_size, num_visual_features, visual_feat_dim)) — 此输入表示视觉特征。它们是使用 faster-RCNN 模型从边界框中 ROI 池化的对象特征。这些目前不由 transformers 库提供。
-
visual_pos(tf.Tensor,形状为(batch_size, num_visual_features, visual_feat_dim)) — 此输入表示与它们的相对(通过索引)视觉特征对应的空间特征。预训练的 LXMERT 模型期望这些空间特征是在 0 到 之间的归一化边界框这些目前不由 transformers 库提供。
-
attention_mask(tf.Tensor,形状为(batch_size, sequence_length),可选) — 避免在填充标记索引上执行注意力的掩码。掩码值选在[0, 1]:-
1 用于未被掩码的标记,
-
0 用于被掩码的标记。
什么是注意力掩码?
-
-
visual_attention_mask(tf.Tensor,形状为(batch_size, sequence_length),可选) — 避免在填充标记索引上执行注意力的掩码。掩码值选在[0, 1]:-
1 用于未被掩码的标记,
-
0 用于被掩码的标记。
什么是注意力掩码?
-
-
token_type_ids(tf.Tensor,形状为(batch_size, sequence_length),可选) — 段标记索引,指示输入的第一部分和第二部分。索引选在[0, 1]:-
0 对应于 句子 A 的标记,
-
1 对应于 句子 B 的标记。
什么是标记类型 ID?
-
-
inputs_embeds(tf.Tensor,形状为(batch_size, sequence_length, hidden_size),可选) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您想要更多控制如何将input_ids索引转换为相关向量,而不是模型内部的嵌入查找矩阵,则这很有用。 -
output_attentions(bool,可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。此参数仅在急切模式下使用,在图模式下将使用配置中的值。 -
output_hidden_states(bool,可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。此参数仅在急切模式下使用,在图模式下将使用配置中的值。 -
return_dict(bool,可选) — 是否返回 ModelOutput 而不是普通元组。此参数可以在急切模式下使用,在图模式下该值将始终设置为 True。 -
training(bool,可选,默认为False) — 是否在训练模式下使用模型(一些模块,如 dropout 模块,在训练和评估之间有不同的行为)。
返回
transformers.models.lxmert.modeling_tf_lxmert.TFLxmertModelOutput 或 tuple(tf.Tensor)
一个 transformers.models.lxmert.modeling_tf_lxmert.TFLxmertModelOutput 或一个tf.Tensor元组(如果传递return_dict=False或config.return_dict=False)包含根据配置(LxmertConfig)和输入的不同元素。
-
language_output(tf.Tensor,形状为(batch_size, sequence_length, hidden_size)) — 语言编码器最后一层的隐藏状态序列。 -
vision_output(tf.Tensor,形状为(batch_size, sequence_length, hidden_size)) — 视觉编码器最后一层的隐藏状态序列。 -
pooled_output(tf.Tensor,形状为(batch_size, hidden_size)) — 序列第一个标记的最后一层隐藏状态(分类,CLS,标记),经过线性层和 Tanh 激活函数进一步处理。线性 -
language_hidden_states(tuple(tf.Tensor), optional, 当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的tf.Tensor元组(一个用于输入特征,一个用于每个跨模态层的输出)。 -
vision_hidden_states(tuple(tf.Tensor), optional, 当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的tf.Tensor元组(一个用于输入特征,一个用于每个跨模态层的输出)。 -
language_attentions(tuple(tf.Tensor), optional, 当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的tf.Tensor元组。在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。 -
vision_attentions(tuple(tf.Tensor), optional, 当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的tf.Tensor元组。在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。 -
cross_encoder_attentions(tuple(tf.Tensor), optional, 当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的tf.Tensor元组。在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。
TFLxmertModel 的前向方法覆盖了__call__特殊方法。
尽管前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, TFLxmertModel
>>> import tensorflow as tf
>>> tokenizer = AutoTokenizer.from_pretrained("unc-nlp/lxmert-base-uncased")
>>> model = TFLxmertModel.from_pretrained("unc-nlp/lxmert-base-uncased")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="tf")
>>> outputs = model(inputs)
>>> last_hidden_states = outputs.last_hidden_state
TFLxmertForPreTraining
class transformers.TFLxmertForPreTraining
( config *inputs **kwargs )
参数
config(LxmertConfig) — 包含模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
在顶部带有语言建模头的 Lxmert 模型。
LXMERT 模型是由 Hao Tan 和 Mohit Bansal 在LXMERT: Learning Cross-Modality Encoder Representations from Transformers中提出的。这是一个视觉和语言变换器模型,使用遮蔽语言建模、感兴趣区域特征回归、交叉熵损失用于问题回答属性预测和对象标签预测,预先在各种多模态数据集上进行了预训练,包括 GQA、VQAv2.0、MCSCOCO 标题和 Visual genome。
此模型还是一个tf.keras.Model子类。将其用作常规的 TF 2.0 Keras 模型,并参考 TF 2.0 文档以获取有关一般用法和行为的所有相关信息。
transformers中的 TensorFlow 模型和层接受两种格式的输入:
-
将所有输入作为关键字参数(类似于 PyTorch 模型),或
-
将所有输入作为列表、元组或字典放在第一个位置参数中。
支持第二种格式的原因是,Keras 方法在将输入传递给模型和层时更喜欢这种格式。由于有了这种支持,当使用model.fit()等方法时,应该可以“正常工作” - 只需以model.fit()支持的任何格式传递您的输入和标签!但是,如果您想在 Keras 方法之外使用第二种格式,例如在使用 KerasFunctional API 创建自己的层或模型时,有三种可能性可用于在第一个位置参数中收集所有输入张量:
-
一个仅包含
input_ids的单个张量,没有其他内容:model(input_ids) -
按照文档字符串中给定的顺序,一个长度可变的列表,包含一个或多个输入张量:
model([input_ids, attention_mask])或model([input_ids, attention_mask, token_type_ids]) -
一个包含一个或多个与文档字符串中给定的输入名称相关联的输入张量的字典:
model({"input_ids": input_ids, "token_type_ids": token_type_ids})
请注意,在使用子类化创建模型和层时,您无需担心任何这些,因为您可以像对待任何其他 Python 函数一样传递输入!
call
( input_ids: TFModelInputType | None = None visual_feats: tf.Tensor | None = None visual_pos: tf.Tensor | None = None attention_mask: tf.Tensor | None = None visual_attention_mask: tf.Tensor | None = None token_type_ids: tf.Tensor | None = None inputs_embeds: tf.Tensor | None = None masked_lm_labels: tf.Tensor | None = None obj_labels: Dict[str, Tuple[tf.Tensor, tf.Tensor]] | None = None matched_label: tf.Tensor | None = None ans: tf.Tensor | None = None output_attentions: bool | None = None output_hidden_states: bool | None = None return_dict: bool | None = None training: bool = False ) → export const metadata = 'undefined';transformers.models.lxmert.modeling_tf_lxmert.TFLxmertForPreTrainingOutput or tuple(tf.Tensor)
参数
-
input_ids(形状为(batch_size, sequence_length)的np.ndarray或tf.Tensor)- 词汇表中输入序列标记的索引。可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.
call()和 PreTrainedTokenizer.encode()。什么是 input IDs?
-
visual_feats(形状为(batch_size, num_visual_features, visual_feat_dim)的tf.Tensor)- 此输入表示视觉特征。它们是使用 faster-RCNN 模型从边界框中 ROI 池化的对象特征。目前 transformers 库中没有提供这些。
-
visual_pos(形状为(batch_size, num_visual_features, visual_feat_dim)的tf.Tensor)- 此输入表示与它们的相对(通过索引)视觉特征对应的空间特征。预训练的 LXMERT 模型期望这些空间特征是在 0 到 1 的范围内的归一化边界框。目前 transformers 库中没有提供这些。
-
attention_mask(形状为(batch_size, sequence_length)的tf.Tensor,可选)- 用于避免在填充标记索引上执行注意力的掩码。选择在[0, 1]中的掩码值:-
对于未被“masked”(掩盖)的标记,值为 1,
-
对于被
masked(掩盖)的标记,值为 0。
什么是 attention masks?
-
-
visual_attention_mask(tf.Tensorof shape(batch_size, sequence_length), optional) — 避免在填充令牌索引上执行注意力的 MMask。在[0, 1]中选择的掩码值:-
1 表示未被
masked的令牌, -
0 表示被
masked的令牌。
什么是注意力掩码?
-
-
token_type_ids(tf.Tensorof shape(batch_size, sequence_length), optional) — 段令牌索引,指示输入的第一部分和第二部分。索引在[0, 1]中选择:-
0 对应于句子 A令牌,
-
1 对应于句子 B令牌。
什么是令牌类型 ID?
-
-
inputs_embeds(tf.Tensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示而不是传递input_ids。如果您希望更多地控制如何将input_ids索引转换为相关向量,而不是模型的内部嵌入查找矩阵,则这很有用。 -
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。此参数仅在急切模式下可用,在图模式下将使用配置中的值。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。此参数仅在急切模式下可用,在图模式下将使用配置中的值。 -
return_dict(bool, optional) — 是否返回 ModelOutput 而不是普通元组。此参数可在急切模式下使用,在图模式下该值将始终设置为 True。 -
training(bool, optional, 默认为False) — 是否在训练模式下使用模型(某些模块如丢弃模块在训练和评估之间有不同的行为)。 -
masked_lm_labels(tf.Tensorof shape(batch_size, sequence_length), optional) — 用于计算掩码语言建模损失的标签。索引应在[-100, 0, ..., config.vocab_size]内(请参阅input_ids文档字符串)。索引设置为-100的令牌将被忽略(掩码),仅对具有标签在[0, ..., config.vocab_size]中的令牌计算损失 -
obj_labels(Dict[Str -- Tuple[tf.Tensor, tf.Tensor]], optional, 默认为None): 每个键都以视觉损失中的每个元素命名,元组的每个元素的形状分别为(batch_size, num_features)和(batch_size, num_features, visual_feature_dim),用于标签 id 和标签分数 -
matched_label(tf.Tensorof shape(batch_size,), optional) — 用于计算文本输入是否与图像(分类)损失匹配的标签。输入应为一个序列对(请参阅input_ids文档字符串)索引应在[0, 1]内:-
0 表示句子与图像不匹配,
-
1 表示句子与图像匹配。
-
-
ans(tf.Tensorof shape(batch_size), optional, 默认为None) — 正确答案的独热表示可选
返回
transformers.models.lxmert.modeling_tf_lxmert.TFLxmertForPreTrainingOutput 或tuple(tf.Tensor)
一个 transformers.models.lxmert.modeling_tf_lxmert.TFLxmertForPreTrainingOutput 或一个tf.Tensor元组(如果传递了return_dict=False或config.return_dict=False时)包括根据配置(LxmertConfig)和输入的不同元素。
-
loss(optional, 当提供labels时返回,形状为(1,)) — 总损失,作为掩码语言建模损失和下一个序列预测(分类)损失的总和。 -
prediction_logits(tf.Tensor,形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。 -
cross_relationship_score(tf.Tensor,形状为(batch_size, 2)) — 文本匹配目标(分类)头的预测分数(SoftMax 之前的 True/False 连续性分数)。 -
question_answering_score(tf.Tensor,形状为(batch_size, n_qa_answers)) — 问答目标(分类)的预测分数。 -
language_hidden_states(tuple(tf.Tensor), optional, 当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的tf.Tensor元组(一个用于输入特征,一个用于每个跨模态层的输出)。 -
vision_hidden_states(tuple(tf.Tensor), optional, 当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的tf.Tensor元组(一个用于输入特征,一个用于每个跨模态层的输出)。 -
language_attentions(tuple(tf.Tensor), optional, 当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的tf.Tensor元组。在自注意力头中用于计算加权平均的注意力权重 softmax 之后。 -
vision_attentions(tuple(tf.Tensor), optional, 当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的tf.Tensor元组。在自注意力头中用于计算加权平均的注意力权重 softmax 之后。 -
cross_encoder_attentions(tuple(tf.Tensor), optional, 当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的tf.Tensor元组。在自注意力头中用于计算加权平均的注意力权重 softmax 之后。
TFLxmertForPreTraining 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的步骤需要在这个函数内定义,但应该在此之后调用Module实例,而不是这个函数,因为前者会处理运行前后处理步骤,而后者会默默地忽略它们。
MatCha
原始文本:
huggingface.co/docs/transformers/v4.37.2/en/model_doc/matcha
概述
MatCha 在论文MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering中提出,作者是 Fangyu Liu、Francesco Piccinno、Syrine Krichene、Chenxi Pang、Kenton Lee、Mandar Joshi、Yasemin Altun、Nigel Collier、Julian Martin Eisenschlos。
论文摘要如下:
视觉语言数据,如图表和信息图表,在人类世界中随处可见。然而,最先进的视觉语言模型在这些数据上表现不佳。我们提出 MatCha(数学推理和图表解渲染预训练)来增强视觉语言模型在联合建模图表/图表和语言数据方面的能力。具体来说,我们提出了几个预训练任务,涵盖了图表解构和数值推理,这是视觉语言建模中的关键能力。我们从 Pix2Struct 开始执行 MatCha 预训练,Pix2Struct 是最近提出的图像到文本视觉语言模型。在 PlotQA 和 ChartQA 等标准基准测试中,MatCha 模型的表现优于最先进的方法近 20%。我们还研究了 MatCha 预训练在诸如屏幕截图、教科书图表和文档图表等领域的转移情况,并观察到整体改进,验证了 MatCha 预训练在更广泛的视觉语言任务上的有用性。
模型描述
MatCha 是使用Pix2Struct架构训练的模型。您可以在Pix2Struct 文档中找到有关Pix2Struct的更多信息。MatCha 是Pix2Struct架构的视觉问答子集。它在图像上呈现输入问题并预测答案。
用法
目前有 6 个 MatCha 的检查点可用:
-
google/matcha:基础 MatCha 模型,用于在下游任务上微调 MatCha -
google/matcha-chartqa:在 ChartQA 数据集上微调的 MatCha 模型。可用于回答有关图表的问题。 -
google/matcha-plotqa-v1:在 PlotQA 数据集上微调的 MatCha 模型。可用于回答有关图表的问题。 -
google/matcha-plotqa-v2:在 PlotQA 数据集上微调的 MatCha 模型。可用于回答有关图表的问题。 -
google/matcha-chart2text-statista:在 Statista 数据集上微调的 MatCha 模型。 -
google/matcha-chart2text-pew:在 Pew 数据集上微调的 MatCha 模型。
在chart2text-pew和chart2text-statista上微调的模型更适合摘要,而在plotqa和chartqa上微调的模型更适合回答问题。
您可以按以下方式使用这些模型(在 ChatQA 数据集上的示例):
from transformers import AutoProcessor, Pix2StructForConditionalGeneration
import requests
from PIL import Image
model = Pix2StructForConditionalGeneration.from_pretrained("google/matcha-chartqa").to(0)
processor = AutoProcessor.from_pretrained("google/matcha-chartqa")
url = "https://raw.githubusercontent.com/vis-nlp/ChartQA/main/ChartQA%20Dataset/val/png/20294671002019.png"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, text="Is the sum of all 4 places greater than Laos?", return_tensors="pt").to(0)
predictions = model.generate(**inputs, max_new_tokens=512)
print(processor.decode(predictions[0], skip_special_tokens=True))
微调
要微调 MatCha,请参考 pix2struct 微调笔记本。对于Pix2Struct模型,我们发现使用 Adafactor 和余弦学习率调度器微调模型会导致更快的收敛:
from transformers.optimization import Adafactor, get_cosine_schedule_with_warmup
optimizer = Adafactor(self.parameters(), scale_parameter=False, relative_step=False, lr=0.01, weight_decay=1e-05)
scheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=1000, num_training_steps=40000)
MatCha 是使用Pix2Struct架构训练的模型。您可以在Pix2Struct 文档中找到有关Pix2Struct的更多信息。
del_doc/pix2struct)中找到有关Pix2Struct的更多信息。MatCha 是Pix2Struct架构的视觉问答子集。它在图像上呈现输入问题并预测答案。
用法
目前有 6 个 MatCha 的检查点可用:
-
google/matcha:基础 MatCha 模型,用于在下游任务上微调 MatCha -
google/matcha-chartqa:在 ChartQA 数据集上微调的 MatCha 模型。可用于回答有关图表的问题。 -
google/matcha-plotqa-v1:在 PlotQA 数据集上微调的 MatCha 模型。可用于回答有关图表的问题。 -
google/matcha-plotqa-v2:在 PlotQA 数据集上微调的 MatCha 模型。可用于回答有关图表的问题。 -
google/matcha-chart2text-statista:在 Statista 数据集上微调的 MatCha 模型。 -
google/matcha-chart2text-pew:在 Pew 数据集上微调的 MatCha 模型。
在chart2text-pew和chart2text-statista上微调的模型更适合摘要,而在plotqa和chartqa上微调的模型更适合回答问题。
您可以按以下方式使用这些模型(在 ChatQA 数据集上的示例):
from transformers import AutoProcessor, Pix2StructForConditionalGeneration
import requests
from PIL import Image
model = Pix2StructForConditionalGeneration.from_pretrained("google/matcha-chartqa").to(0)
processor = AutoProcessor.from_pretrained("google/matcha-chartqa")
url = "https://raw.githubusercontent.com/vis-nlp/ChartQA/main/ChartQA%20Dataset/val/png/20294671002019.png"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, text="Is the sum of all 4 places greater than Laos?", return_tensors="pt").to(0)
predictions = model.generate(**inputs, max_new_tokens=512)
print(processor.decode(predictions[0], skip_special_tokens=True))
微调
要微调 MatCha,请参考 pix2struct 微调笔记本。对于Pix2Struct模型,我们发现使用 Adafactor 和余弦学习率调度器微调模型会导致更快的收敛:
from transformers.optimization import Adafactor, get_cosine_schedule_with_warmup
optimizer = Adafactor(self.parameters(), scale_parameter=False, relative_step=False, lr=0.01, weight_decay=1e-05)
scheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=1000, num_training_steps=40000)
MatCha 是使用Pix2Struct架构训练的模型。您可以在Pix2Struct 文档中找到有关Pix2Struct的更多信息。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









