







原文:
annas-archive.org/md5/873bfe33df74385c75906a2f129ca61f译者:飞龙
第五章:部分应用和柯里化
我们已经在探索函数式编程的过程中走得很远!我们学习了纯函数和 lambda,并借助函数组合深入了解了 lambda 演算。我们现在知道如何从其他函数创建函数。
关于 lambda 演算基础的还有一件事要学习。除了函数组合,我们还可以通过两种操作——柯里化和部分应用——从其他函数创建函数。这将完成我们对函数式构建块的讨论,并让你向前迈进,朝着使用函数进行设计。
本章将涵盖以下主题:
-
什么是部分应用?
-
如何在 C++中使用部分应用
-
什么是柯里化?
-
如何在 C++中柯里化函数
-
柯里化和部分应用之间的关系
-
如何将柯里化与函数组合结合
技术要求
你需要一个支持 C++ 17 的编译器。我使用的是 GCC 7.3.0。
代码在 GitHub 上的github.com/PacktPublishing/Hands-On-Functional-Programming-with-Cpp的Chapter05文件夹中。它包括并使用doctest,这是一个单头开源单元测试库。你可以在它的 GitHub 仓库中找到它:github.com/onqtam/doctest。
部分应用和柯里化
如果你考虑 lambda 以及我们可以对它们进行的操作来获得其他 lambda,会想到两件事:
-
关于组合两个 lambda 的事情,我们在函数组合中已经见过
-
关于 lambda 的参数,我们将在下一节讨论
我们可以用 lambda 的参数做什么?有两件事:
-
将具有多个参数的 lambda 分解为具有一个参数的更多 lambda,这个操作称为柯里化
-
通过将具有N个参数的 lambda 的一个参数绑定到一个值来获得具有N-1个参数的 lambda,这个操作称为部分应用
由于很快就会变得明显的原因,这两个操作是相关的,所以我们将一起讨论它们。
部分应用
如果你有一个带有N个参数的 lambda,部分应用意味着通过将一个参数绑定到一个值来获得另一个 lambda,从而获得一个带有N-1个参数的新 lambda。例如,我们可以对add函数进行部分应用,将其中一个参数绑定到值1,从而得到一个increment函数。在伪 C++中,它看起来像这样:
auto add = [](const int first, const int second){return first + second;};
auto increment = partialApplication(add, /*first*/ 1);
/* equivalent with
auto increment = [](const int second){return 1 + second;};
*/
就是这样!部分应用的想法相当简单。让我们看看 C++中的语法。
C++中的部分应用
部分应用的基本实现可以手动完成。我们可以简单地创建一个名为increment的 lambda,调用通用的add函数,将1作为第二个参数传递:
auto add = [](const int first, const int second) { return first + second; };
TEST_CASE("Increments using manual partial application"){
auto increment = [](const int value) { return add(value, 1); };
CHECK_EQ(43, increment(42));
}
这不是我们正在寻找的简洁操作,但在某些情况下可能很有用,你无法使用通用方法时。
幸运的是,STL 在我们友好的头文件functional中提供了一个更好的选择——bind函数。它的参数是函数、你想要绑定的值和占位符参数,它只是转发参数。通过调用bind获得increment函数,我们传入通用的add lambda;第一个参数的参数值1;以及指定未绑定参数的占位符:
using namespace std::placeholders; // to allow _1, _2 etc.
TEST_CASE("Increments using bind"){
// bind the value 1 to the first parameter of add
// _1 is a placeholder for the first parameter of the increment
lambda
auto increment = bind(add, 1, _1);
CHECK_EQ(43, increment(42));
}
虽然方便,但你应该意识到bind具有很高的编译时开销。当这是一个问题时,你总是可以回到之前的选项——从另一个手动编写的 lambda 直接调用更通用的 lambda。
当然,我们可以绑定两个参数。由于程序员喜欢数字42,我将add lambda 的两个参数都绑定到值1和41,以获得另一个 lambda,number42:
TEST_CASE("Constant using bind"){
auto number42 = bind(add, 1, 41);
CHECK_EQ(42, number42());
}
bind语法有时可能有点棘手,所以让我们更详细地看一下。关键是要理解参数占位符指的是结果 lambda 的参数,而不是初始 lambda 的参数。
为了更清楚地说明这一点,让我们看一个添加其三个参数的 lambda 的示例:
auto addThree = [](const int first, const int second, const int third){return first + second + third;};
TEST_CASE("Adds three"){
CHECK_EQ(42, addThree(10, 20, 12));
}
如果我们想通过将其第一个参数绑定到值10,从我们的addThree lambda 中获得另一个 lambda addTwoNumbersTo10,bind的语法是什么?嗯,我们的结果 lambda addTwoNumbersTo10 将接收两个参数。它们的占位符将用 _1 和 _2 表示。因此,我们需要告诉bind我们初始 lambda addThree的第一个参数是10。第二个参数将从addTwoNumbersTo10中转发,所以是_1。第三个参数也将从addNumbersTo10的第二个参数中转发,所以是_2。我们最终得到这段代码:
TEST_CASE("Adds two numbers to 10"){
auto addTwoNumbersTo10 = bind(addThree, 10, _1, _2);
CHECK_EQ(42, addTwoNumbersTo10(20, 12));
}
让我们继续。我们希望通过部分应用从我们最初的addThree lambda 中获得另一个 lambda,addTo10Plus20。结果函数将只有一个参数,_1。要绑定的其他参数将是值10和20。我们最终得到以下代码:
TEST_CASE("Adds one number to 10 + 20"){
auto addTo10Plus20 = bind(addThree, 10, 20, _1);
CHECK_EQ(42, addTo10Plus20(12));
}
如果我们想要绑定第一个和第三个参数呢?现在应该很清楚,参数是完全相同的,但它们在bind调用中的顺序发生了变化:
TEST_CASE("Adds 10 to one number, and then to 20"){
auto addTo10Plus20 = bind(addThree, 10, _1, 20);
CHECK_EQ(42, addTo10Plus20(12));
}
如果我们想要绑定第二和第三个参数呢?嗯,占位符会移动,但它仍然是结果函数的唯一参数,所以 _1。
TEST_CASE("Adds one number to 10, and then to 20"){
auto addTo10Plus20 = bind(addThree, _1, 10, 20);
CHECK_EQ(42, addTo10Plus20(12));
}
如果我们想对类方法进行部分应用呢?
类方法的部分应用
bind函数允许我们对类方法进行部分应用,但有一个问题——第一个参数必须是类的实例。例如,我们将使用一个实现两个数字之间简单相加的AddOperation类来进行示例:
class AddOperation{
private:
int first;
int second;
public:
AddOperation(int first, int second): first(first),
second(second){}
int add(){ return first + second;}
};
我们可以通过将AddOperation类的实例绑定到函数来创建一个新函数add:
TEST_CASE("Bind member method"){
AddOperation operation(41, 1);
auto add41And1 = bind(&AddOperation::add, operation);
CHECK_EQ(42, add41And1());
}
更有趣的是,更接近部分应用的概念,我们可以从调用者那里转发实例参数:
TEST_CASE("Partial bind member method no arguments"){
auto add = bind(&AddOperation::add, _1);
AddOperation operation(41, 1);
CHECK_EQ(42, add(operation));
}
如果方法接收参数,那么绑定也是可能的。例如,假设我们有另一个实现AddToOperation的类:
class AddToOperation{
private:
int first;
public:
AddToOperation(int first): first(first) {}
int addTo(int second){ return first + second;}
};
我们可以使用类的实例对addTo进行部分应用,如下面的代码所示:
TEST_CASE("Partial application member method"){
AddToOperation operation(41);
auto addTo41 = bind(&AddToOperation::addTo, operation, _1);
CHECK_EQ(42, addTo41(1));
}
类方法的部分应用表明,在函数式和面向对象编程之间进行转换是相当容易的。我们将在接下来的章节中看到如何利用这一点。在那之前,让我们为我们现在知道的部分应用和如何在 C++中使用它而感到高兴。现在是时候谈谈它的近亲柯里化了。
柯里化
让我们试着想一想软件开发中的一些著名人物,不要在互联网上搜索。有 Alan Turing,Ada Lovelace(她有一个迷人的故事),Grace Hopper,Donald Knuth,Bjarne Stroustroup,Grady Booch,可能还有其他许多人。他们中有多少人的名字不仅出现在行业中,而且还出现在两个你经常听到的事物中?对于 Alan Turing 来说,这是肯定的,他有图灵机和图灵测试,但对于其他许多人来说并非如此。
因此,令人惊讶的是,Haskell 编程语言的名称和柯里化操作的名称都来自同一个人——Haskell Curry。Haskell Curry 是一位美国数学家和逻辑学家。他研究了一种叫做组合逻辑的东西,这是函数式编程的一部分基础。
但是什么是柯里化?它与部分应用有什么关系?
什么是柯里化?
柯里化是将具有N个参数的函数分解为具有一个参数的N个函数的过程。我们可以通过变量捕获或部分应用来实现这一点。
让我们再次看看我们的add lambda:
auto add = [](const int first, const int second) { return first +
second; };
TEST_CASE("Adds values"){
CHECK_EQ(42, add(25, 17));
}
我们如何分解它?关键在于 lambda 只是一个普通值,这意味着我们可以从函数中返回它。因此,我们可以传入第一个参数并返回一个捕获第一个参数并使用第一个和第二个参数的 lambda。在代码中比在文字中更容易理解,所以这里是:
auto curryAdd = [](const int first){
return first{
return first + second;
};
};
TEST_CASE("Adds values using captured curry"){
CHECK_EQ(42, curryAdd(25)(17));
}
让我们来解开发生了什么:
-
我们的
curryAddlambda 返回一个 lambda。 -
返回的 lambda 捕获第一个参数,接受第二个参数,并返回它们的和。
这就是为什么在调用它时,我们需要使用双括号。
但这看起来很熟悉,好像与偏函数应用有关。
柯里化和偏函数应用
让我们再次看看我们之前是如何进行偏函数应用的。我们通过对add函数进行偏函数应用创建了一个increment函数:
TEST_CASE("Increments using bind"){
auto increment = bind(add, 1, _1);
CHECK_EQ(43, increment(42));
}
然而,让我们对我们的add函数进行柯里化:
auto curryAdd = [](const int first){
return first{
return first + second;
};
};
TEST_CASE("Adds values using captured curry"){
CHECK_EQ(42, curryAdd(25)(17));
}
然后,increment非常容易编写。你能看到吗?
increment lambda 只是curryAdd(1),如下面的代码所示:
TEST_CASE("Increments value"){
auto increment = curryAdd(1);
CHECK_EQ(43, increment(42));
}
这向我们展示了函数式编程语言常用的一个技巧——函数可以默认进行柯里化。在这样的语言中,编写以下内容意味着我们首先将add函数应用于first参数,然后将结果函数应用于second参数:
add first second
看起来好像我们正在使用参数列表调用函数;实际上,这是一个部分应用的柯里化函数。在这样的语言中,increment函数可以通过简单地编写以下内容从add函数派生出来:
increment = add 1
反之亦然。由于 C++默认情况下不进行柯里化,但提供了一种简单的偏函数应用方法,我们可以通过偏函数应用来实现柯里化。不要返回带有值捕获的复杂 lambda,只需绑定到单个值并转发结果函数的单个参数:
auto curryAddPartialApplication = [](const int first){
return bind(add, first, _1);
};
TEST_CASE("Adds values using partial application curry"){
CHECK_EQ(42, curryAddPartialApplication(25)(17));
}
但我们能走多远呢?对带有多个参数的函数进行柯里化容易吗?
对具有多个参数的函数进行柯里化
在前一节中,我们已经看到了如何对带有两个参数的函数进行柯里化。当我们转向三个参数时,柯里化函数也会增长。现在我们需要返回一个返回 lambda 的 lambda。再次,代码比任何解释都更容易理解,所以让我们来看看:
auto curriedAddThree = [](const int first){
return first{
return first, second{
return first + second + third;
};
};
};
TEST_CASE("Add three with curry"){
CHECK_EQ(42, curriedAddThree(15)(10)(17));
}
似乎有一个递归结构在那里。也许通过使用bind我们可以理解它?
原因是它并不那么简单,但是确实是可能的。我想写的是这样的:
bind(bind(bind(addThree, _1),_1), _1)
然而,addThree有三个参数,所以我们需要将它们绑定到某些东西。下一个bind会导致一个具有两个参数的函数,再次,我们需要将它们绑定到某些东西。因此,实际上看起来是这样的:
bind(bind(bind(addThree, ?, ?, _1), ?,_1), _1)
问号应该被之前绑定的值替换,但这在我们当前的语法中不起作用。
然而,有一个变通方法。让我们实现多个使用bind在具有N个参数的函数上的simpleCurryN函数,并将它们减少到N-1。对于一个参数的函数,结果就是以下函数:
auto simpleCurry1 = [](auto f){
return f;
};
对于两个参数,我们绑定第一个参数并转发下一个:
auto simpleCurry2 = [](auto f){
return f{ return bind(f, x, _1); };
};
类似的操作也适用于三个和四个参数:
auto simpleCurry3 = [](auto f){
return f{ return bind(f, x, y, _1); };
};
auto simpleCurry4 = [](auto f){
return f{ return bind(f, x, y, z, _1);
};
};
这组simpleCurryN函数允许我们编写我们的curryN函数,它接受一个具有N个参数的函数并返回其柯里化形式:
auto curry2 = [](auto f){
return simpleCurry2(f);
};
auto curry3 = [](auto f){
return curry2(simpleCurry3(f));
};
auto curry4 = [](auto f){
return curry3(simpleCurry4(f));
};
让我们在具有两个、三个和四个参数的add lambda 上进行测试,如下面的代码所示:
TEST_CASE("Add three with partial application curry"){
auto add = [](int a, int b) { return a+b; };
CHECK_EQ(3, curry2(add)(1)(2));
auto addThreeCurryThree = curry3(addThree);
CHECK_EQ(6, curry3(addThree)(1)(2)(3));
auto addFour = [](int a, int b, int c, int d){return a + b + c +
d;};
CHECK_EQ(10, curry4(addFour)(1)(2)(3)(4));
}
很可能我们可以通过巧妙地使用模板来重写这些函数。我将把这个练习留给读者。
目前,重要的是要看到偏函数应用如何与柯里化相连接。在默认情况下对函数进行柯里化的编程语言中,偏函数应用非常容易——只需使用更少的参数调用函数。对于其他编程语言,我们可以通过偏函数应用来实现柯里化。
这些概念非常有趣,但你可能想知道它们在实践中是否有用。让我们看看如何使用这些技术来消除重复。
使用部分应用和柯里化来消除重复
程序员长期以来一直在寻找写更少的代码做更多事情的解决方案。函数式编程提出了一个解决方案——通过从其他函数派生函数来构建函数。
我们已经在之前的例子中看到了这一点。由于increment是加法的一个特殊情况,我们可以从我们的加法函数中派生它:
auto add = [](const auto first, const auto second) { return first + second; };
auto increment = bind(add, _1, 1);
TEST_CASE("Increments"){
CHECK_EQ(43, increment(42));
}
这对我们有什么帮助?嗯,想象一下,你的客户某天走进来告诉你我们想使用另一种加法类型。想象一下,你不得不在你的代码中到处搜索+和++,并找出实现新行为的方法。
相反,使用我们的add和increment函数,再加上一点模板魔法,我们可以做到这一点:
auto add = [](const auto first, const auto second) { return first +
second; };
template<typename T, T one>
auto increment = bind(add, _1, one);
TEST_CASE("Increments"){
CHECK_EQ(43, increment<int, 1>(42));
}
我们的add方法不关心它得到什么类型,只要它有一个加法运算符。我们的increment函数不关心它使用什么类型和add是如何工作的,只要你为其中一个提供一个值。而我们只用了三行代码就实现了这一点。我很少这样说代码,但这不是很美吗?
当然,你可能会说,但我们的客户并不真的想改变我们添加事物的方式。你会惊讶于用一些简单的运算符可以做多少事情。让我给你举一个简单的例子。实现一个角色在一个循环移动的线上的游戏,如下面的截图所示:
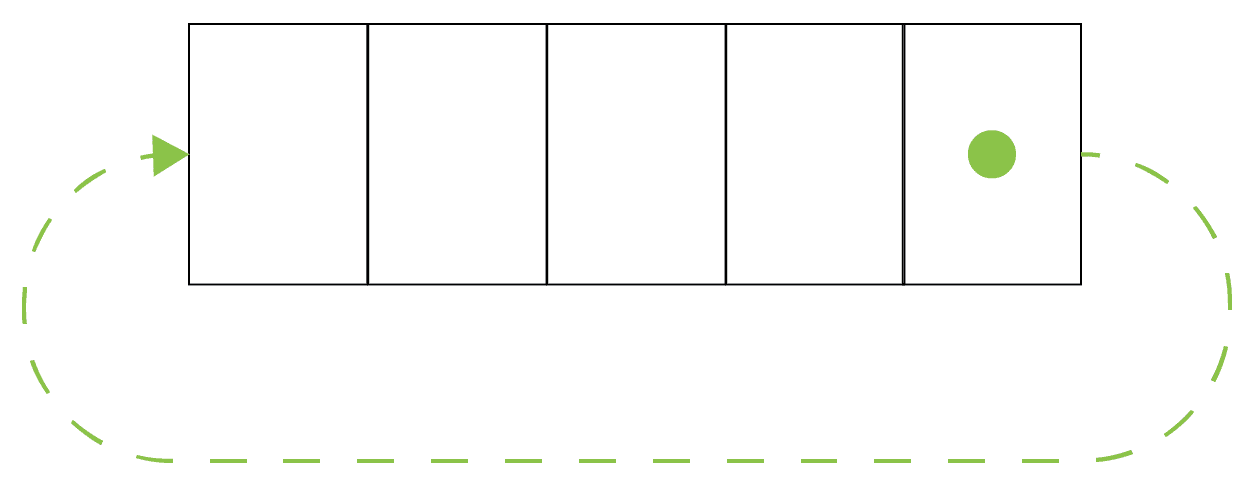
这不就是加法的修改版本吗?让我们来看看:
// Assume wrap at 20 for now
auto addWrapped = [](const auto first, const auto second) { return
(first + second)%20; };
TEST_CASE("Adds values"){
CHECK_EQ(7, addWrapped(10, 17));
}
template<typename T, T one>
auto incrementWrapped = bind<T>(addWrapped, _1, one);
TEST_CASE("Increments"){
CHECK_EQ(1, incrementWrapped<int, 1>(20));
}
嗯,这段代码看起来与add非常相似。也许我们可以使用部分应用?让我们看看:
auto addWrapped = [](const auto first, const auto second, const auto
wrapAt) { return (first + second) % wrapAt; };
auto add = bind(addWrapped, _1, _2, 20);
template<typename T, T one>
auto increment = bind<T>(add, _1, one);
TEST_CASE("Increments"){
CHECK_EQ(1, increment<int, 1>(20));
}
我们的increment函数与以前完全相同,而我们的add函数已经成为了addWrapped的部分应用。值得注意的是,为了使代码更清晰,我仍然会更改函数名称,以便非常清楚地了解函数的功能。然而,主要的观点是,部分应用和柯里化帮助我们从代码中删除某些类型的重复,使我们能够打开代码以实现我们在设计初始解决方案时并不一定知道的实现。虽然我们也可以使用面向对象编程或模板来实现这一点,但函数式解决方案通过消除副作用来限制复杂性,只需要几行代码。这使得在设计程序时成为一个值得选择。
总结
看看我们在理解函数式编程方面取得了多大的进步!我们学习了所有的构建模块——纯函数和 lambda——以及我们可以在它们上面使用的操作——柯里化、部分应用和函数组合。我们还看到了这些操作是如何相互关联的,以及我们如何使用柯里化来实现部分应用,反之亦然。我们还看到了在 C++中实现柯里化的方法。
但我们的探索才刚刚开始。下一站是——开始在更有趣的上下文中使用这些构造。现在是时候解决一个困难的问题了——我们到底如何使用函数进行设计?
问题
-
什么是部分函数应用?
-
什么是柯里化?
-
柯里化如何帮助我们实现部分应用?
-
我们如何在 C++中实现部分应用?
第二部分:使用函数进行设计
到目前为止,我们已经了解了函数式编程的基本构建模块。现在是时候让它们发挥作用,进入以函数为中心的软件设计世界了。
首先,我们将探讨如何从以命令方式编写的面向对象编程(OOP)的思维方式转变为以函数为中心的设计。为此,我们需要了解如何将输入数据转换为期望的输出数据,最好是借助现有的高阶函数。然后,我们将研究“不要重复自己”(DRY)原则以及如何使用函数操作(部分应用、柯里化和函数组合)来从代码中消除某些类型的重复。接着,我们将研究函数和类之间的关系,以及如何将纯函数分组到类中,如果我们想要将设计从以函数为中心转换为面向对象编程,以及如何将类转换为一组纯函数。
掌握了所有这些技术后,我们将学习测试驱动开发以及如何通过使用纯函数简化它。
本节将涵盖以下章节:
-
第六章,从数据输入到数据输出的函数思维
-
第七章,使用函数操作消除重复
-
第八章,使用类改善内聚性
-
第九章,函数式编程的测试驱动开发
第六章:从输入数据到输出数据的函数思维
在我迈向理解函数式编程的旅程中,我遇到了一个困难的障碍——我的思维是在完全不同的编程风格中训练的。我们称之为命令式面向对象编程。那么,我如何将我的思维模式从对象思考转变为函数思考?我如何以一种良好的方式将这两者结合起来?
我首先研究了函数式编程资源。不幸的是,其中大多数都集中在数学和概念的内在美上,这对于那些已经能够以这些术语思考的人来说是很好的。但是,如果你只是想学习它们呢?难道只能通过数学理论来学习吗?虽然我喜欢数学,但我已经生疏了,我宁愿找到更实际的方法。
我已经接触过各种编写代码的方式,比如 Coderetreats、Coding Dojos,或者与来自欧洲各地的程序员进行配对编程。我逐渐意识到,解决这个问题的一个简单方法是专注于输入和输出,而不是专注于它们之间的模型。这是学习以函数思考的一个更具体和实际的方法,接下来我们将探讨这个问题。
本章将涵盖以下主题:
-
函数思维的基础。
-
重新学习如何识别功能的输入和输出数据,并利用类型推断
-
将数据转换定义为纯函数
-
如何使用典型的数据转换,比如 map、reduce、filter 等
-
如何使用函数思维解决问题
-
为围绕函数设计的代码设计错误管理
技术要求
您将需要一个支持 C++ 17 的编译器。我使用的是 GCC 7.3.0。
代码可以在 GitHub 上找到github.com/PacktPublishing/Hands-On-Functional-Programming-with-Cpp,在Chapter06文件夹中。它包括并使用了doctest,这是一个单头开源单元测试库。您可以在其 GitHub 存储库上找到它github.com/onqtam/doctest。
通过函数从输入数据到输出数据
我的计算机编程教育和作为程序员的重点大多是编写代码,而不是深入理解输入和输出数据。当我学习测试驱动开发(TDD)时,这种重点发生了变化,因为这种实践迫使程序员从输入和输出开始。通过应用一种称为“TDD As If You Meant It”的极端形式,我对程序的核心定义有了新的认识——接受输入数据并返回输出数据。
然而,这并不容易。我的训练使我重新思考构成程序的事物。但后来,我意识到这些事物只是纯函数。毕竟,任何程序都可以按照以下方式编写:
-
一组纯函数,如前所定义
-
一组与输入/输出(I/O)交互的函数
如果我们将程序简化到最小,并将所有 I/O 分开,找出其余程序的 I/O,并为我们能够的一切编写纯函数,我们刚刚迈出了以函数思考的第一步。
接下来的问题是——这些函数应该是什么?在本章中,我们将探讨最简单的使用函数进行设计的方法:
-
从输入数据开始。
-
定义输出数据。
-
逐步定义一系列转换(纯函数),将输入数据转换为输出数据。
让我们看一些对比两种编写程序的方法的例子。
命令式与函数式风格的工作示例
为了展示不同的方法之间的差异,我们需要使用一个问题。我喜欢使用从游戏中衍生出的问题来练习新的编程技术。一方面,这是一个我不经常接触的有趣领域。另一方面,游戏提供了许多常见的商业应用所没有的挑战,从而使我们能够探索新的想法。
在接下来的部分中,我们将看一个问题,让人们学会如何开始以函数的方式思考——井字棋结果问题。
井字棋结果
井字棋结果问题有以下要求——给定一个可能为空的井字棋棋盘或已经有了棋子的棋盘,打印出游戏的结果,如果游戏已经结束,或者打印出仍在进行中的游戏。
看起来问题似乎相当简单,但它将向我们展示功能和命令式面向对象(OO)方法之间的根本区别。
如果我们从面向对象的角度来解决问题,我们已经在考虑一些要定义的对象——一个游戏,一个玩家,一个棋盘,也许一些代表X和O的表示(我称之为标记),等等。然后,我们可能会考虑如何连接这些对象——一个游戏有两个玩家和一个棋盘,棋盘上有标记或空格等等。正如你所看到的,这涉及到很多表示。然后,我们需要在某个地方实现一个computeResult方法,返回GameState,要么是XWon,OWon,draw,要么是InProgress。乍一看,computeResult似乎适合于Game类。该方法可能需要在Board内部循环,使用一些条件语句,并返回相应的GameState。
我们将使用一些严格的步骤来帮助我们以不同的方式思考代码结构,而不是使用面向对象的方法:
-
清晰地定义输入;给出例子。
-
清晰地定义输出;给出例子。
-
识别一系列功能转换,你可以将其应用于输入数据,将其转换为输出数据。
在我们继续之前,请注意,这种心态的改变需要一些知识和实践。我们将研究最常见的转换,为您提供一个良好的开始,但您需要尝试这种方法。
输入和输出。
我们作为程序员学到的第一课是任何程序都有输入和输出。然后我们继续把我们的职业生涯的其余部分放在输入和输出之间发生的事情上,即代码本身。
尽管如此,输入和输出值得程序员更多的关注,因为它们定义了我们软件的要求。我们知道,软件中最大的浪费是实现了完美的功能,但却没有完成它应该完成的任务。
我注意到程序员很难重新开始思考输入和输出。对于给定功能的输入和输出应该是什么的看似简单的问题经常让他们感到困惑和困惑。所以,让我们详细看看我们问题的输入和输出数据。
在这一点上,我们将做一些意想不到的事情。我从业务分析师那里学到了一个很棒的技巧——在分析一个功能时最好从输出开始,因为输出往往比输入数据更小更清晰。所以,让我们这样做。
输出数据是什么?
我们期望什么样的输出?鉴于棋盘上可以有任何东西,或者根本没有东西,我们正在考虑以下可能性:
-
游戏未开始
-
游戏正在进行中
-
X赢了 -
O赢了 -
平局
看,输出很简单!现在,我们可以看到输入数据与这些可能性之间的关系。
输入数据是什么?
在这种情况下,输入数据在问题陈述中——我们的输入是一个有棋子的棋盘。但让我们看一些例子。最简单的例子是一个空棋盘:
_ _ _
_ _ _
_ _ _
为了清晰起见,我们使用_来表示棋盘上的空格。
当然,空白的棋盘对应于“游戏未开始”的输出。
这足够简单了。现在,让我们看一个上面有几步的例子:
X _ _
O _ _
_ _ _
X和O都已经走了他们的步子,但游戏仍在进行中。我们可以提供许多进行中的游戏的例子:
X X _
O _ _
_ _ _
这是另一个例子:
X X O
O _ _
_ _ _
有一些例子在井字棋游戏中永远不会发生,比如这个:
X X _
O X _
X _ _
在这种情况下,X已经走了四步,而O只走了一步,这是井字棋规则不允许的。我们现在将忽略这种情况,只返回一个进行中的游戏。不过,一旦我们完成了代码的其余部分,你可以自己实现这个算法。
让我们看一个X赢得的游戏:
X X X
O O _
_ _ _
X赢了,因为第一行被填满了。X还有其他赢的方式吗?是的,在一列上:
X _ _
X O O
X _ _
它也可以在主对角线上获胜:
X O _
O X _
_ _ X
这是X在次对角线上的胜利:
_ O X
O X _
X _ _
同样地,我们有O通过填充一条线获胜的例子:
X X _
O O O
X _ _
这是通过填充一列获胜的情况:
X O _
X O X
_ O _
这是O在主对角线上的胜利:
O X _
_ O X
X _ O
这是通过次对角线获胜的情况:
X X O
_ O X
O _ _
那么,怎么样才能结束成为平局呢?很简单——所有的方格都被填满了,但没有赢家:
X X O
O X X
X O O
我们已经看过了所有可能的输出的例子。现在是时候看看数据转换了。
数据转换
我们如何将输入转换为输出?为了做到这一点,我们将不得不选择一个可能的输出来先解决。现在最容易的是X获胜的情况。那么,X怎么赢?
根据游戏规则,如果棋盘上的一条线、一列或一条对角线被X填满,X就赢了。让我们写下所有可能的情况。如果发生以下任何一种情况,X就赢了:
-
任何一条线都被
X填满了,或者 -
任何一列都被
X填满,或者 -
主对角线被
X填满,或者 -
次对角线被
X填满了。
为了实现这一点,我们需要一些东西:
-
从棋盘上得到所有的线。
-
从棋盘上得到所有的列。
-
从棋盘上得到主对角线和次对角线。
-
如果它们中的任何一个被
X填满了,X就赢了!
我们可以用另一种方式来写这个:
board -> collection(all lines, all columns, all diagonals) -> any(collection, filledWithX) -> X won
filledWithX是什么意思?让我们举个例子;我们正在寻找这样的线:
X X X
我们不是在寻找X O X或X _ X这样的线。
听起来我们正在检查一条线、一列或一条对角线上的所有标记是否都是'X'。让我们将这个检查视为一个转换:
line | column | diagonal -> all tokens equal X -> line | column | diagonal filled with X
因此,我们的转换集合变成了这样:
board -> collection(all lines, all columns, all diagonals) -> if any(collection, filledWithX) -> X won
filledWithX(line|column|diagonal L) = all(token on L equals 'X')
还有一个问题——我们如何得到线、列和对角线?我们可以分别看待这个问题,就像我们看待大问题一样。我们的输入肯定是棋盘。我们的输出是由第一行、第二行和第三行、第一列、第二列和第三列、主对角线和次对角线组成的列表。
下一个问题是,什么定义了一条线?嗯,我们知道如何得到第一条线——我们使用[0, 0],[0, 1]和[0, 2]坐标。第二条线有[1, 0],[1, 1]和[1, 2]坐标。列呢?嗯,第一列有[1, 0],[1, 1]和[2, 1]坐标。而且,正如我们将看到的,对角线也是由特定的坐标集定义的。
那么,我们学到了什么?我们学到了为了得到线、列和对角线,我们需要以下的转换:
board -> collection of coordinates for lines, columns, diagonals -> apply coordinates to the board -> obtain list of elements for lines, columns, and diagonals
这就结束了我们的分析。现在是时候转向实现了。所有之前的转换都可以通过使用函数式构造来用代码表达。事实上,一些转换是如此常见,以至于它们已经在标准库中实现了。让我们看看我们如何可以使用它们!
使用all_of来判断是否被X填满
我们将要看的第一个转换是all_of。给定一个集合和一个返回布尔值的函数(也称为逻辑谓词),all_of将谓词应用于集合的每个元素,并返回结果的逻辑与。让我们看一些例子:
auto trueForAll = [](auto x) { return true; };
auto falseForAll = [](auto x) { return false; };
auto equalsChara = [](auto x){ return x == 'a';};
auto notChard = [](auto x){ return x != 'd';};
TEST_CASE("all_of"){
vector<char> abc{'a', 'b', 'c'};
CHECK(all_of(abc.begin(), abc.end(), trueForAll));
CHECK(!all_of(abc.begin(), abc.end(), falseForAll));
CHECK(!all_of(abc.begin(), abc.end(), equalsChara));
CHECK(all_of(abc.begin(), abc.end(), notChard));
}
all_of函数接受两个定义范围开始和结束的迭代器和一个谓词作为参数。当你想将转换应用于集合的子集时,迭代器是有用的。由于我通常在整个集合上使用它,我发现反复写collection.begin()和collection.end()很烦人。因此,我实现了自己简化的all_of_collection版本,它接受整个集合并处理其余部分:
auto all_of_collection = [](const auto& collection, auto lambda){
return all_of(collection.begin(), collection.end(), lambda);
};
TEST_CASE("all_of_collection"){
vector<char> abc{'a', 'b', 'c'};
CHECK(all_of_collection(abc, trueForAll));
CHECK(!all_of_collection(abc, falseForAll));
CHECK(!all_of_collection(abc, equalsChara));
CHECK(all_of_collection(abc, notChard));
}
知道这个转换后,编写我们的lineFilledWithX函数很容易-我们将标记的集合转换为指定标记是否为X的布尔值的集合:
auto lineFilledWithX = [](const auto& line){
return all_of_collection(line, [](const auto& token){ return token == 'X';});
};
TEST_CASE("Line filled with X"){
vector<char> line{'X', 'X', 'X'};
CHECK(lineFilledWithX(line));
}
就是这样!我们可以确定我们的线是否填满了X。
在我们继续之前,让我们做一些简单的调整。首先,通过为我们的vector<char>类型命名来使代码更清晰:
using Line = vector<char>;
然后,让我们检查代码是否对负面情况也能正常工作。如果Line没有填满X标记,lineFilledWithX应该返回false:
TEST_CASE("Line not filled with X"){
CHECK(!lineFilledWithX(Line{'X', 'O', 'X'}));
CHECK(!lineFilledWithX(Line{'X', ' ', 'X'}));
}
最后,一个敏锐的读者会注意到我们需要相同的函数来满足O获胜的条件。我们现在知道如何做到这一点-记住参数绑定的力量。我们只需要提取一个lineFilledWith函数,并通过将tokenToCheck参数绑定到X和O标记值,分别获得lineFilledWithX和lineFilledWithO函数:
auto lineFilledWith = [](const auto line, const auto tokenToCheck){
return all_of_collection(line, &tokenToCheck{
return token == tokenToCheck;});
};
auto lineFilledWithX = bind(lineFilledWith, _1, 'X');
auto lineFilledWithO = bind(lineFilledWith, _1, 'O');
让我们回顾一下-我们有一个Line数据结构,我们有一个可以检查该行是否填满X或O的函数。我们使用all_of函数来为我们做繁重的工作;我们只需要定义我们的井字棋线的逻辑。
是时候继续前进了。我们需要将我们的棋盘转换为线的集合,由三条线、三列和两条对角线组成。为此,我们需要使用另一个函数式转换map,它在 STL 中实现为transform函数。
使用 map/transform
现在我们需要编写一个将棋盘转换为线、列和对角线列表的函数;因此,我们可以使用一个将集合转换为另一个集合的转换。这种转换通常在函数式编程中称为map,在 STL 中实现为transform。为了理解它,我们将使用一个简单的例子;给定一个字符向量,让我们用'a'替换每个字符:
TEST_CASE("transform"){
vector<char> abc{'a', 'b', 'c'};
// Not the best version, see below
vector<char> aaa(3);
transform(abc.begin(), abc.end(), aaa.begin(), [](auto element){return
'a';});
CHECK_EQ(vector<char>{'a', 'a', 'a'}, aaa);
}
虽然它有效,但前面的代码示例是天真的,因为它用稍后被覆盖的值初始化了aaa向量。我们可以通过首先在aaa向量中保留3个元素,然后使用back_inserter来避免这个问题,这样transform就会自动在aaa向量上调用push_back:
TEST_CASE("transform-fixed") {
const auto abc = vector{'a', 'b', 'c'};
vector<char> aaa;
aaa.reserve(abc.size());
transform(abc.begin(), abc.end(), back_inserter(aaa),
[](const char elem) { return 'a'; }
);
CHECK_EQ(vector{'a', 'a', 'a'}, aaa);
}
如你所见,transform基于迭代器,就像all_of一样。到目前为止,你可能已经注意到我喜欢保持事情简单,专注于我们要完成的任务。没有必要一直写这些;相反,我们可以实现我们自己的简化版本,它可以在整个集合上工作,并处理围绕此函数的所有仪式。
简化转换
让我们尝试以最简单的方式实现transform_all函数:
auto transform_all = [](auto const source, auto lambda){
auto destination; // Compilation error: the type is not defined
...
}
不幸的是,当我们尝试以这种方式实现它时,我们需要一个目标集合的类型。这样做的自然方式是使用 C++模板并传递Destination类型参数:
template<typename Destination>
auto transformAll = [](auto const source, auto lambda){
Destination result;
result.reserve(source.size());
transform(source.begin(), source.end(), back_inserter(result),
lambda);
return result;
};
这对于任何具有push_back函数的集合都有效。一个很好的副作用是,我们可以用它来连接string中的结果字符:
auto turnAllToa = [](auto x) { return 'a';};
TEST_CASE("transform all"){
vector abc{'a', 'b', 'c'};
CHECK_EQ(vector<char>({'a', 'a', 'a'}), transform_all<vector<char>>
(abc, turnAllToa));
CHECK_EQ("aaa", transform_all<string>(abc,turnAllToa));
}
使用transform_all与string允许我们做一些事情,比如将小写字符转换为大写字符:
auto makeCaps = [](auto x) { return toupper(x);};
TEST_CASE("transform all"){
vector<char> abc = {'a', 'b', 'c'};
CHECK_EQ("ABC", transform_all<string>(abc, makeCaps));
}
但这还不是全部-输出类型不一定要与输入相同:
auto toNumber = [](auto x) { return (int)x - 'a' + 1;};
TEST_CASE("transform all"){
vector<char> abc = {'a', 'b', 'c'};
vector<int> expected = {1, 2, 3};
CHECK_EQ(expected, transform_all<vector<int>>(abc, toNumber));
}
因此,transform函数在我们需要将一个集合转换为另一个集合时非常有用,无论是相同类型还是不同类型。在back_inserter的支持下,它还可以用于string输出,从而实现对任何类型集合的字符串表示的实现。
我们现在知道如何使用 transform 了。所以,让我们回到我们的问题。
我们的坐标
我们的转换从计算坐标开始。因此,让我们首先定义它们。STL pair类型是坐标的简单表示:
using Coordinate = pair<int, int>;
从板和坐标获取一条线
假设我们已经为一条线、一列或一条对角线构建了坐标列表,我们需要将令牌的集合转换为Line参数。这很容易通过我们的transformAll函数完成:
auto accessAtCoordinates = [](const auto& board, const Coordinate&
coordinate){
return board[coordinate.first][coordinate.second];
};
auto projectCoordinates = [](const auto& board, const auto&
coordinates){
auto boardElementFromCoordinates = bind(accessAtCoordinates,
board, _1);
return transform_all<Line>(coordinates,
boardElementFromCoordinates);
};
projectCoordinates lambda 接受板和坐标列表,并返回与这些坐标对应的板元素列表。我们在坐标列表上使用transformAll,并使用一个接受两个参数的转换——board参数和coordinate参数。然而,transformAll需要一个带有单个参数的 lambda,即Coordinate值。因此,我们必须要么捕获板的值,要么使用部分应用。
现在我们只需要构建我们的线、列和对角线的坐标列表了!
从板上得到一条线
我们可以通过使用前一个函数projectCoordinates轻松地从板上得到一条线:
auto line = [](auto board, int lineIndex){
return projectCoordinates(board, lineCoordinates(board, lineIndex));
};
line lambda 接受board和lineIndex,构建线坐标列表,并使用projectCoordinates返回线。
那么,我们如何构建线坐标?嗯,由于我们有lineIndex和Coordinate作为一对,我们需要在(lineIndex, 0)、(lineIndex, 1)和(lineIndex, 2)上调用make_pair。这看起来也像是一个transform调用;输入是一个{0, 1, 2}集合,转换是make_pair(lineIndex, index)。让我们写一下:
auto lineCoordinates = [](const auto board, auto lineIndex){
vector<int> range{0, 1, 2};
return transformAll<vector<Coordinate>>(range, lineIndex{return make_pair(lineIndex, index);});
};
范围
但是{0, 1, 2}是什么?在其他编程语言中,我们可以使用范围的概念;例如,在 Groovy 中,我们可以编写以下内容:
def range = [0..board.size()]
范围非常有用,并且已经在 C++ 20 标准中被采用。我们将在第十四章中讨论它们,使用 Ranges 库进行惰性求值。在那之前,我们将编写我们自己的toRange函数:
auto toRange = [](auto const collection){
vector<int> range(collection.size());
iota(begin(range), end(range), 0);
return range;
};
toRange接受一个集合作为输入,并从0到collection.size()创建range。因此,让我们在我们的代码中使用它:
using Board = vector<Line>;
using Line = vector<char>;
auto lineCoordinates = [](const auto board, auto lineIndex){
auto range = toRange(board);
return transform_all<vector<Coordinate>>(range, lineIndex{return make_pair(lineIndex, index);});
};
TEST_CASE("lines"){
Board board {
{'X', 'X', 'X'},
{' ', 'O', ' '},
{' ', ' ', 'O'}
};
Line expectedLine0 = {'X', 'X', 'X'};
CHECK_EQ(expectedLine0, line(board, 0));
Line expectedLine1 = {' ', 'O', ' '};
CHECK_EQ(expectedLine1, line(board, 1));
Line expectedLine2 = {' ', ' ', 'O'};
CHECK_EQ(expectedLine2, line(board, 2));
}
我们已经把所有元素都放在了正确的位置,所以现在是时候看看列了。
获取列
获取列的代码与获取线的代码非常相似,只是我们保留columnIndex而不是lineIndex。我们只需要将其作为参数传递:
auto columnCoordinates = [](const auto& board, const auto columnIndex){
auto range = toRange(board);
return transformAll<vector<Coordinate>>(range, columnIndex{return make_pair(index, columnIndex);});
};
auto column = [](auto board, auto columnIndex){
return projectCoordinates(board, columnCoordinates(board,
columnIndex));
};
TEST_CASE("all columns"){
Board board{
{'X', 'X', 'X'},
{' ', 'O', ' '},
{' ', ' ', 'O'}
};
Line expectedColumn0{'X', ' ', ' '};
CHECK_EQ(expectedColumn0, column(board, 0));
Line expectedColumn1{'X', 'O', ' '};
CHECK_EQ(expectedColumn1, column(board, 1));
Line expectedColumn2{'X', ' ', 'O'};
CHECK_EQ(expectedColumn2, column(board, 2));
}
这不是很酷吗?通过几个函数和标准的函数变换,我们可以在我们的代码中构建复杂的行为。现在对角线变得轻而易举了。
获取对角线
主对角线由相等的行和列坐标定义。使用与之前相同的机制读取它非常容易;我们构建相等索引的对,并将它们传递给projectCoordinates函数:
auto mainDiagonalCoordinates = [](const auto board){
auto range = toRange(board);
return transformAll<vector<Coordinate>>(range, [](auto index)
{return make_pair(index, index);});
};
auto mainDiagonal = [](const auto board){
return projectCoordinates(board, mainDiagonalCoordinates(board));
};
TEST_CASE("main diagonal"){
Board board{
{'X', 'X', 'X'},
{' ', 'O', ' '},
{' ', ' ', 'O'}
};
Line expectedDiagonal = {'X', 'O', 'O'};
CHECK_EQ(expectedDiagonal, mainDiagonal(board));
}
那么对于次对角线呢?嗯,坐标的总和总是等于board参数的大小。在 C++中,我们还需要考虑基于 0 的索引,因此在构建坐标列表时,我们需要通过1进行适当的调整:
auto secondaryDiagonalCoordinates = [](const auto board){
auto range = toRange(board);
return transformAll<vector<Coordinate>>(range, board
{return make_pair(index, board.size() - index - 1);});
};
auto secondaryDiagonal = [](const auto board){
return projectCoordinates(board,
secondaryDiagonalCoordinates(board));
};
TEST_CASE("secondary diagonal"){
Board board{
{'X', 'X', 'X'},
{' ', 'O', ' '},
{' ', ' ', 'O'}
};
Line expectedDiagonal{'X', 'O', ' '};
CHECK_EQ(expectedDiagonal, secondaryDiagonal(board));
}
获取所有线、所有列和所有对角线
说到这一点,我们现在可以构建所有线、列和对角线的集合了。有多种方法可以做到这一点;因为我要写一个以函数式风格编写的通用解决方案,我将再次使用transform。我们需要将(0..board.size())范围转换为相应的线列表和列列表。然后,我们需要返回一个包含主对角线和次对角线的集合:
typedef vector<Line> Lines;
auto allLines = [](auto board) {
auto range = toRange(board);
return transform_all<Lines>(range, board { return
line(board, index);});
};
auto allColumns = [](auto board) {
auto range = toRange(board);
return transform_all<Lines>(range, board { return
column(board, index);});
};
auto allDiagonals = [](auto board) -> Lines {
return {mainDiagonal(board), secondaryDiagonal(board)};
};
我们只需要一件事情——一种连接这三个集合的方法。由于向量没有实现这个功能,推荐的解决方案是使用insert和move_iterator,从而将第二个集合的项目移动到第一个集合的末尾:
auto concatenate = [](auto first, const auto second){
auto result(first);
result.insert(result.end(), make_move_iterator(second.begin()),
make_move_iterator(second.end()));
return result;
};
然后,我们只需将这三个集合合并为两个步骤:
auto concatenate3 = [](auto first, auto const second, auto const third){
return concatenate(concatenate(first, second), third);
};
现在我们可以从棋盘中获取所有行、列和对角线的完整列表,就像你在下面的测试中看到的那样:
auto allLinesColumnsAndDiagonals = [](const auto board) {
return concatenate3(allLines(board), allColumns(board),
allDiagonals(board));
};
TEST_CASE("all lines, columns and diagonals"){
Board board {
{'X', 'X', 'X'},
{' ', 'O', ' '},
{' ', ' ', 'O'}
};
Lines expected {
{'X', 'X', 'X'},
{' ', 'O', ' '},
{' ', ' ', 'O'},
{'X', ' ', ' '},
{'X', 'O', ' '},
{'X', ' ', 'O'},
{'X', 'O', 'O'},
{'X', 'O', ' '}
};
auto all = allLinesColumnsAndDiagonals(board);
CHECK_EQ(expected, all);
}
在找出X是否获胜的最后一步中只剩下一个任务。我们有所有行、列和对角线的列表。我们知道如何检查一行是否被X填满。我们只需要检查列表中的任何一行是否被X填满。
使用 any_of 来检查 X 是否获胜
类似于all_of,另一个函数构造帮助我们在集合上应用的谓词之间表达 OR 条件。在 STL 中,这个构造是在any_of函数中实现的。让我们看看它的作用:
TEST_CASE("any_of"){
vector<char> abc = {'a', 'b', 'c'};
CHECK(any_of(abc.begin(), abc.end(), trueForAll));
CHECK(!any_of(abc.begin(), abc.end(), falseForAll));
CHECK(any_of(abc.begin(), abc.end(), equalsChara));
CHECK(any_of(abc.begin(), abc.end(), notChard));
}
像我们在本章中看到的其他高级函数一样,它使用迭代器作为集合的开始和结束。像往常一样,我喜欢保持简单;因为我通常在完整集合上使用any_of,我喜欢实现我的辅助函数:
auto any_of_collection = [](const auto& collection, const auto& fn){
return any_of(collection.begin(), collection.end(), fn);
};
TEST_CASE("any_of_collection"){
vector<char> abc = {'a', 'b', 'c'};
CHECK(any_of_collection(abc, trueForAll));
CHECK(!any_of_collection(abc, falseForAll));
CHECK(any_of_collection(abc, equalsChara));
CHECK(any_of_collection(abc, notChard));
}
我们只需要在我们的列表上使用它来检查X是否是赢家:
auto xWins = [](const auto& board){
return any_of_collection(allLinesColumnsAndDiagonals(board),
lineFilledWithX);
};
TEST_CASE("X wins"){
Board board{
{'X', 'X', 'X'},
{' ', 'O', ' '},
{' ', ' ', 'O'}
};
CHECK(xWins(board));
}
这就结束了我们对X获胜条件的解决方案。在我们继续之前,能够在控制台上显示棋盘将是很好的。现在是使用map/transform的近亲——reduce的时候了,或者在 STL 中被称为accumulate。
使用 reduce/accumulate 来显示棋盘
我们想在控制台上显示棋盘。通常,我们会使用可变函数,比如cout来做到这一点;然而,记住我们讨论过,虽然我们需要保持程序的某些部分可变,比如调用cout的部分,但我们应该将它们限制在最小范围内。那么,替代方案是什么呢?嗯,我们需要再次考虑输入和输出——我们想要编写一个以board作为输入并返回string表示的函数,我们可以通过使用可变函数,比如cout来显示它。让我们以测试的形式写出我们想要的:
TEST_CASE("board to string"){
Board board{
{'X', 'X', 'X'},
{' ', 'O', ' '},
{' ', ' ', 'O'}
};
string expected = "XXX\n O \n O\n";
CHECK_EQ(expected, boardToString(board));
}
为了获得这个结果,我们首先需要将board中的每一行转换为它的string表示。我们的行是vector<char>,我们需要将它转换为string;虽然有很多方法可以做到这一点,但请允许我使用带有string输出的transformAll函数:
auto lineToString = [](const auto& line){
return transformAll<string>(line, [](const auto token) -> char {
return token;});
};
TEST_CASE("line to string"){
Line line {
' ', 'X', 'O'
};
CHECK_EQ(" XO", lineToString(line));
}
有了这个函数,我们可以轻松地将一个棋盘转换为vector<string>:
auto boardToLinesString = [](const auto board){
return transformAll<vector<string>>(board, lineToString);
};
TEST_CASE("board to lines string"){
Board board{
{'X', 'X', 'X'},
{' ', 'O', ' '},
{' ', ' ', 'O'}
};
vector<string> expected{
"XXX",
" O ",
" O"
};
CHECK_EQ(expected, boardToLinesString(board));
}
最后一步是用\n将这些字符串组合起来。我们经常需要以各种方式组合集合的元素;这就是reduce发挥作用的地方。在函数式编程中,reduce是一个接受集合、初始值(例如,空的strings)和累积函数的操作。该函数接受两个参数,对它们执行操作,并返回一个新值。
让我们看几个例子。首先是添加一个数字向量的经典例子:
TEST_CASE("accumulate"){
vector<int> values = {1, 12, 23, 45};
auto add = [](int first, int second){return first + second;};
int result = accumulate(values.begin(), values.end(), 0, add);
CHECK_EQ(1 + 12 + 23 + 45, result);
}
以下向我们展示了如果需要添加具有初始值的向量应该怎么做:
int resultWithInit100 = accumulate(values.begin(), values.end(),
100, add);
CHECK_EQ(1oo + 1 + 12 + 23 + 45, resultWithInit100);
同样,我们可以连接strings:
vector<string> strings {"Alex", "is", "here"};
auto concatenate = [](const string& first, const string& second) ->
string{
return first + second;
};
string concatenated = accumulate(strings.begin(), strings.end(),
string(), concatenate);
CHECK_EQ("Alexishere", concatenated);
或者,我们可以添加一个前缀:
string concatenatedWithPrefix = accumulate(strings.begin(),
strings.end(), string("Pre_"), concatenate);
CHECK_EQ("Pre_Alexishere", concatenatedWithPrefix);
像我们在整个集合上使用默认值作为初始值的简化实现一样,我更喜欢使用decltype魔术来实现它:
auto accumulateAll = [](auto source, auto lambda){
return accumulate(source.begin(), source.end(), typename
decltype(source)::value_type(), lambda);
};
这只留下了我们的最后一个任务——编写一个连接string行的实现,使用换行符:
auto boardToString = [](const auto board){
auto linesAsString = boardToLinesString(board);
return accumulateAll(linesAsString,
[](string current, string lineAsString) { return current + lineAsString + "\n"; }
);
};
TEST_CASE("board to string"){
Board board{
{'X', 'X', 'X'},
{' ', 'O', ' '},
{' ', ' ', 'O'}
};
string expected = "XXX\n O \n O\n";
CHECK_EQ(expected, boardToString(board));
}
现在我们可以使用cout << boardToString来显示我们的棋盘。再次,我们使用了一些函数变换和非常少的自定义代码来将一切整合在一起。这非常好。
map/reduce组合,或者在 STL 中被称为transform/accumulate,是功能性编程中非常强大且非常常见的。我们经常需要从一个集合开始,多次将其转换为另一个集合,然后再组合集合的元素。这是一个如此强大的概念,以至于它是大数据分析的核心,使用诸如 Apache Hadoop 之类的工具,尽管在机器级别上进行了扩展。这表明,通过掌握这些转换,您可能最终会在意想不到的情况下应用它们,使自己成为一个不可或缺的问题解决者。很酷,不是吗?
使用find_if来显示特定的赢的细节
我们现在很高兴,因为我们已经解决了X的井字游戏结果问题。然而,正如总是一样,需求会发生变化;我们现在不仅需要说X是否赢了,还需要说赢了在哪里——在哪一行、或列、或对角线。
幸运的是,我们已经有了大部分元素。由于它们都是非常小的函数,我们只需要以一种有助于我们的方式重新组合它们。让我们再次从数据的角度思考——我们的输入数据现在是一组行、列和对角线;我们的结果应该是类似于X赢在第一行的信息。我们只需要增强我们的数据结构,以包含有关每行的信息;让我们使用map:
map<string, Line> linesWithDescription{
{"first line", line(board, 0)},
{"second line", line(board, 1)},
{"last line", line(board, 2)},
{"first column", column(board, 0)},
{"second column", column(board, 1)},
{"last column", column(board, 2)},
{"main diagonal", mainDiagonal(board)},
{"secondary diagonal", secondaryDiagonal(board)},
};
我们知道如何找出X是如何赢的——通过我们的lineFilledWithX谓词函数。现在,我们只需要在地图中搜索符合lineFilledWithX谓词的行,并返回相应的消息。
这是功能性编程中的一个常见操作。在 STL 中,它是用find_if函数实现的。让我们看看它的运行情况:
auto equals1 = [](auto value){ return value == 1; };
auto greaterThan11 = [](auto value) { return value > 11; };
auto greaterThan50 = [](auto value) { return value > 50; };
TEST_CASE("find if"){
vector<int> values{1, 12, 23, 45};
auto result1 = find_if(values.begin(), values.end(), equals1);
CHECK_EQ(*result1, 1);
auto result12 = find_if(values.begin(), values.end(),
greaterThan11);
CHECK_EQ(*result12, 12);
auto resultNotFound = find_if(values.begin(), values.end(),
greaterThan50);
CHECK_EQ(resultNotFound, values.end());
}
find_if根据谓词在集合中查找并返回结果的指针,如果找不到任何内容,则返回指向end()迭代器的指针。
像往常一样,让我们实现一个允许在整个集合中搜索的包装器。我们需要以某种方式表示not found的值;幸运的是,我们可以使用 STL 中的可选类型:
auto findInCollection = [](const auto& collection, auto fn){
auto result = find_if(collection.begin(), collection.end(), fn);
return (result == collection.end()) ? nullopt : optional(*result);
};
TEST_CASE("find in collection"){
vector<int> values {1, 12, 23, 45};
auto result1 = findInCollection(values, equals1);
CHECK_EQ(result1, 1);
auto result12 = findInCollection(values, greaterThan11);
CHECK_EQ(result12, 12);
auto resultNotFound = findInCollection(values, greaterThan50);
CHECK(!resultNotFound.has_value());
}
现在,我们可以轻松实现新的要求。我们可以使用我们新实现的findInCollection函数找到被X填满的行,并返回相应的描述。因此,我们可以告诉用户X是如何赢的——是在一行、一列还是对角线上:
auto howDidXWin = [](const auto& board){
map<string, Line> linesWithDescription = {
{"first line", line(board, 0)},
{"second line", line(board, 1)},
{"last line", line(board, 2)},
{"first column", column(board, 0)},
{"second column", column(board, 1)},
{"last column", column(board, 2)},
{"main diagonal", mainDiagonal(board)},
{"secondary diagonal", secondaryDiagonal(board)},
};
auto found = findInCollection(linesWithDescription,[](auto value)
{return lineFilledWithX(value.second);});
return found.has_value() ? found->first : "X did not win";
};
当然,我们应该从棋盘生成地图,而不是硬编码。我将把这个练习留给读者;只需再次使用我们最喜欢的transform函数即可。
完成我们的解决方案
虽然我们已经为X赢实现了解决方案,但现在我们需要研究其他可能的输出。让我们先来看最简单的一个——O赢。
检查O是否赢了
检查O是否赢很容易——我们只需要在我们的函数中做一个小改变。我们需要一个新函数oWins,它检查任何一行、一列或对角线是否被O填满:
auto oWins = [](auto const board){
return any_of_collection(allLinesColumnsAndDiagonals(board),
lineFilledWithO);
};
TEST_CASE("O wins"){
Board board = {
{'X', 'O', 'X'},
{' ', 'O', ' '},
{' ', 'O', 'X'}
};
CHECK(oWins(board));
}
我们使用与xWins相同的实现,只是在作为参数传递的 lambda 中稍作修改。
使用none_of检查平局
那么平局呢?嗯,当board参数已满且既没有X也没有O赢时,就会出现平局:
auto draw = [](const auto& board){
return full(board) && !xWins(board) && !oWins(board);
};
TEST_CASE("draw"){
Board board {
{'X', 'O', 'X'},
{'O', 'O', 'X'},
{'X', 'X', 'O'}
};
CHECK(draw(board));
}
满棋盘意味着每一行都已满:
auto full = [](const auto& board){
return all_of_collection(board, fullLine);
};
那么我们如何知道一行是否已满?嗯,我们知道如果行中的任何一个标记都不是空(' ')标记,那么该行就是满的。正如您现在可能期望的那样,STL 中有一个名为none_of的函数,可以为我们检查这一点:
auto noneOf = [](const auto& collection, auto fn){
return none_of(collection.begin(), collection.end(), fn);
};
auto isEmpty = [](const auto token){return token == ' ';};
auto fullLine = [](const auto& line){
return noneOf(line, isEmpty);
};
检查游戏是否正在进行中
最后一种情况是游戏仍在进行中。最简单的方法就是检查游戏是否没有赢,且棋盘还没有满:
auto inProgress = [](const auto& board){
return !full(board) && !xWins(board) && !oWins(board);
};
TEST_CASE("in progress"){
Board board {
{'X', 'O', 'X'},
{'O', ' ', 'X'},
{'X', 'X', 'O'}
};
CHECK(inProgress(board));
}
恭喜,我们做到了!我们使用了许多功能转换来实现了井字游戏结果问题;还有我们自己的一些 lambda。但更重要的是,我们学会了如何开始像一个功能性程序员一样思考——清晰地定义输入数据,清晰地定义输出数据,并找出可以将输入数据转换为所需输出数据的转换。
使用可选类型进行错误管理
到目前为止,我们已经用函数式风格编写了一个小程序。但是错误情况怎么处理呢?
显然,我们仍然可以使用 C++机制——返回值或异常。但是函数式编程还可以看作另一种方式——将错误视为数据。
我们在实现find_if包装器时已经看到了这种技术的一个例子:
auto findInCollection = [](const auto& collection, auto fn){
auto result = find_if(collection.begin(), collection.end(), fn);
return (result == collection.end()) ? nullopt : optional(*result);
};
我们使用了optional类型,而不是抛出异常或返回collection.end(),这是一个本地值。如其名称所示,optional 类型表示一个可能有值,也可能没有值的变量。可选值可以被初始化,可以使用底层类型支持的值,也可以使用nullopt——一个默认的非值,可以这么说。
当在我们的代码中遇到可选值时,我们需要考虑它,就像我们在检查X赢得函数中所做的那样:
return found.has_value() ? found->first : "X did not win";
因此,“未找到”条件不是错误;相反,它是我们代码和数据的正常部分。事实上,处理这种情况的另一种方法是增强findInCollection,在未找到时返回指定的值:
auto findInCollectionWithDefault = [](auto collection, auto
defaultResult, auto lambda){
auto result = findInCollection(collection, lambda);
return result.has_value() ? (*result) : defaultResult;
};
现在我们可以使用findInCollectionWithDefault来在X没有赢得情况下调用howDidXWin时获得一个X 没有赢的消息:
auto howDidXWin = [](auto const board){
map<string, Line> linesWithDescription = {
{"first line", line(board, 0)},
{"second line", line(board, 1)},
{"last line", line(board, 2)},
{"first column", column(board, 0)},
{"second column", column(board, 1)},
{"last column", column(board, 2)},
{"main diagonal", mainDiagonal(board)},
{"secondary diagonal", secondaryDiagonal(board)},
{"diagonal", secondaryDiagonal(board)},
};
auto xDidNotWin = make_pair("X did not win", Line());
auto xWon = [](auto value){
return lineFilledWithX(value.second);
};
return findInCollectionWithDefault(linesWithDescription, xDidNotWin, xWon).first;
};
TEST_CASE("X did not win"){
Board board {
{'X', 'X', ' '},
{' ', 'O', ' '},
{' ', ' ', 'O'}
};
CHECK_EQ("X did not win", howDidXWin(board));
}
我最好的建议是这样——对所有异常情况使用异常,并将其他所有情况作为数据结构的一部分。使用可选类型,或者带有默认值的转换。你会惊讶于错误管理变得多么容易和自然。
总结
在本章中,我们涵盖了很多内容!我们经历了一次发现之旅——我们首先列出了问题的输出和相应的输入,对它们进行了分解,并找出了如何将输入转换为所需的输出。我们看到了当需要新功能时,小函数和函数操作如何给我们带来灵活性。我们看到了如何使用any、all、none、find_if、map/transform和reduce/accumulate,以及如何使用可选类型或默认值来支持代码中的所有可能情况。
现在我们已经了解了如何以函数式风格编写代码,是时候在下一章中看看这种方法如何与面向对象编程结合了。
第七章:使用函数操作消除重复
软件设计中的一个关键原则是减少代码重复。函数式构造通过柯里化和函数组合提供了额外的机会来减少代码重复。
本章将涵盖以下主题:
-
如何以及为什么避免重复代码
-
如何识别代码相似性
-
使用柯里化来消除某些类型的代码相似性
-
使用组合来消除某些类型的代码相似性
-
使用 lambda 表达式或组合来消除某些类型的代码相似性
技术要求
你需要一个支持 C++ 17 的编译器。我使用的是 GCC 7.3.0。
该代码可以在 GitHub 上找到,网址为github.com/PacktPublishing/Hands-On-Functional-Programming-with-Cpp,在Chapter07文件夹中。它包括并使用了doctest,这是一个单头文件的开源单元测试库。你可以在它的 GitHub 仓库上找到它,网址为github.com/onqtam/doctest。
使用函数操作来消除重复
长时间维护代码时,只需要在一个地方更改代码,以及可以重新组合现有的代码片段,会更加容易。朝着这个理想的最有效方法之一是识别并消除代码中的重复。函数式编程的操作——部分应用、柯里化和函数组合——提供了许多机会,使代码更清晰,重复更少。
但首先,让我们了解重复是什么,以及为什么我们需要减少它。首先,我们将看看不要重复自己(DRY)原则,然后看看重复和代码相似性之间的关系。最后,我们将看看如何消除代码相似性。
DRY 原则
软件开发中核心书籍的数量出乎意料地少。当然,有很多关于细节和帮助人们更好地理解这些想法的书籍,但是关于核心思想的书籍却非常少而且陈旧。能够列入核心书籍名单对作者来说是一种荣誉,也是该主题极其重要的一个暗示。许多程序员会把《程序员修炼之道》(Andrew Hunt 和 David Thomas 合著,1999 年出版)列入这样的书单。这本书详细介绍了一个原则,对于长期从事大型代码库工作的人来说非常有意义——DRY 原则。
在核心,DRY 原则是基于代码是存储知识的理解。每个函数和每个数据成员都代表了对问题的知识。理想情况下,我们希望避免在系统中重复存储知识。换句话说,无论你在找什么,它都应该只存在于一个地方。不幸的是,大多数代码库都是WET(写两遍、我们喜欢打字或浪费每个人的时间的缩写),而不是 DRY。
然而,消除重复的想法是很久以前就有的。肯特·贝克在 1990 年代曾提到过,作为极限编程(XP)实践的一部分。肯特·贝克描述了简单设计的四个要素,这是一种获得或改进软件设计的思维工具。
简单的设计意味着它做了以下事情:
-
通过了测试
-
揭示意图
-
减少重复
-
元素更少
我从 J.B. Rainsberger 那里学到了这些规则,他也致力于简化这些规则。他教会我,在大多数情况下,专注于三件事就足够了——测试代码、改进命名和减少重复。
但这并不是唯一提到消除重复的地方。这个原则以各种方式出现在 Unix 设计哲学中,在领域驱动设计(DDD)技术中,作为测试驱动开发(TDD)实践的帮助,以及许多其他方面。可以说这是一个良好软件设计的普遍原则,每当我们谈论模块内部代码的结构时,使用它是有意义的。
重复和相似
在我迈向学习良好软件设计的旅程中,我意识到术语“重复”对于表达我们试图实现的哲学非常有用,但很难理解如何将其付诸实践。我找到了一个更好的名字,用于描述我在尝试改进设计时寻找的东西——我寻找“代码相似之处”。一旦我找到相似之处,我会问它们是否显示了更深层次的重复,还是它们只是偶然事件。
我也及时注意到,我寻找了一些特定类型的相似之处。以下是一些例子:
-
相似的名称,无论是函数、参数、方法、变量、常量、类、模块、命名空间等的全名或嵌入在更长的名称中
-
相似的参数列表
-
相似的函数调用
-
不同的代码试图实现类似的结果
总的来说,我遵循这两个步骤:
-
首先,注意相似之处。
-
其次,决定是否移除相似之处。
当不确定相似之处是否对设计有更深层次的影响时,最好保留它。一旦你看到它们出现了三次,最好开始消除相似之处;这样,你就知道它违反了 DRY 原则,而不仅仅是一个偶然事件。
接下来,我们将看一下通过函数操作可以消除的几种相似之处。
通过部分应用解决参数相似之处
在我们之前的章节中,你已经看到了在一个参数的值相同时多次调用函数的情况。例如,在我们的井字游戏结果问题中的代码中,我们有一个函数负责检查一行是否被一个标记填满:
auto lineFilledWith = [](const auto& line, const auto tokenToCheck){
return all_of_collection(line, &tokenToCheck{
return token == tokenToCheck;});
};
由于井字游戏使用两个标记,X和O,很明显我们会重复调用这个函数,其中tokenToCheck要么是X要么是O。消除这种相似之处的常见方法是实现两个新函数,lineFilledWithX和lineFilledWithO:
auto lineFilledWithX = [](const auto& line){
return lineFilledWith(line, 'X');
};
这是一个可行的解决方案,但它仍然需要我们编写一个单独的函数和三行代码。正如我们所见,我们在函数式编程中还有另一个选择;我们可以简单地使用部分应用来获得相同的结果:
auto lineFilledWithX = bind(lineFilledWith, _1, 'X');
auto lineFilledWithO = bind(lineFilledWith, _1, 'O');
我更喜欢在可能的情况下使用部分应用,因为这种代码只是管道,我需要编写的管道越少越好。然而,在团队中使用部分应用时需要小心。每个团队成员都应该熟悉部分应用,并且熟练理解这种类型的代码。否则,部分应用的使用只会使开发团队更难理解代码。
用函数组合替换另一个函数输出的调用函数相似之处
你可能已经注意到了过去在下面的代码中显示的模式:
int processA(){
a = f1(....)
b = f2(a, ...)
c = f3(b, ...)
}
通常,如果你足够努力地寻找,你会发现在你的代码库中有另一个做类似事情的函数:
int processB(){
a = f1Prime(....)
b = f2(a, ...)
c = f3(b, ...)
}
由于应用程序随着时间的推移变得越来越复杂,这种相似之处似乎有更深层次的原因。我们经常从实现一个通过多个步骤的简单流程开始。然后,我们实现同一流程的变体,其中一些步骤重复,而其他步骤则发生变化。有时,流程的变体涉及改变步骤的顺序,或者调整一些步骤。
在我们的实现中,这些步骤转化为以各种方式组合在其他函数中的函数。但是,如果我们使用上一步的输出并将其输入到下一步,我们就会发现代码中的相似之处,而不取决于每个步骤的具体操作。
为了消除这种相似之处,传统上我们会提取代码的相似部分并将结果传递,如下所示:
int processA(){
a = f1(....)
return doSomething(a)
}
int processB(){
a = f1Prime(....)
return doSomething(a)
}
int doSomething(auto a){
b = f2(a, ...)
return f3(b, ...)
}
然而,当提取函数时,代码通常变得更难理解和更难更改,如前面的代码所示。提取函数的共同部分并没有考虑到代码实际上是一个链式调用。
为了使这一点显而易见,我倾向于将代码模式重新格式化为单个语句,如下所示:
processA = f3(f2(f1(....), ...), ...)
processB = f3(f2(f1Prime(....), ...), ...)
虽然不是每个人都喜欢这种格式,但两个调用之间的相似性和差异更加清晰。很明显,我们可以使用函数组合来解决问题——我们只需要将f3与f2组合,并将结果与f1或f1Prime组合,就可以得到我们想要的结果:
C = f3 ∘ f2
processA = C ∘ f1
processB = C ∘ f1Prime
这是一个非常强大的机制!我们可以通过函数组合创建无数的链式调用组合,只需几行代码。我们可以用几个组合语句替换隐藏的管道,这些管道伪装成函数中语句的顺序,表达我们代码的真实本质。
然而,正如我们在第四章中所看到的,函数组合的概念,在 C++中这并不一定是一项容易的任务,因为我们需要编写适用于我们特定情况的compose函数。在 C++提供更好的函数组合支持之前,我们被迫将这种机制保持在最低限度,并且只在相似性不仅明显,而且我们预计它会随着时间的推移而增加时才使用它。
使用更高级函数消除结构相似性
到目前为止,我们的讨论中一直存在一个模式——函数式编程帮助我们从代码中消除管道,并表达代码的真实结构。命令式编程使用语句序列作为基本结构;函数式编程减少了序列,并专注于函数的有趣运行。
当我们讨论结构相似性时,这一点最为明显。结构相似性是指代码结构重复的情况,尽管不一定是通过调用相同的函数或使用相同的参数。为了看到它的作用,让我们从我们的井字棋代码中一个非常有趣的相似之处开始。这是我们在第六章中编写的代码,从数据到函数的思考:
auto lineFilledWith = [](const auto& line, const auto& tokenToCheck){
return allOfCollection(line, &tokenToCheck{
return token == tokenToCheck;});
};
auto lineFilledWithX = bind(lineFilledWith, _1, 'X');
auto lineFilledWithO = bind(lineFilledWith, _1, 'O');
auto xWins = [](const auto& board){
return any_of_collection(allLinesColumnsAndDiagonals(board),
lineFilledWithX);
};
auto oWins = [](const auto& board){
return any_of_collection(allLinesColumnsAndDiagonals(board),
lineFilledWithO);
};
xWins和oWins函数看起来非常相似,因为它们都将相同的函数作为第一个参数调用,并且将lineFilledWith函数的变体作为它们的第二个参数。让我们消除它们的相似之处。首先,让我们移除lineFilledWithX和lineFilledWithO,并用它们的lineFilledWith等效替换:
auto xWins = [](const auto& board){
return any_of_collection(allLinesColumnsAndDiagonals(board), []
(const auto& line) { return lineFilledWith(line, 'X');});
};
auto oWins = [](const auto& board){
return any_of_collection(allLinesColumnsAndDiagonals(board), []
(const auto& line) { return lineFilledWith(line, 'O');});
};
现在相似之处显而易见,我们可以轻松提取一个通用函数:
auto tokenWins = [](const auto& board, const auto& token){
return any_of_collection(allLinesColumnsAndDiagonals(board),
token { return lineFilledWith(line, token);});
};
auto xWins = [](auto const board){
return tokenWins(board, 'X');
};
auto oWins = [](auto const board){
return tokenWins(board, 'O');
}
我们还注意到xWins和oWins只是tokenWins的偏函数应用,所以让我们明确这一点:
auto xWins = bind(tokenWins, _1, 'X');
auto oWins = bind(tokenWins, _1, 'O');
现在,让我们专注于tokenWins:
auto tokenWins = [](const auto& board, const auto& token){
return any_of_collection(allLinesColumnsAndDiagonals(board),
token { return lineFilledWith(line, token);});
};
首先,我们注意到我们传递给any_of_collection的 lambda 是一个带有固定令牌参数的偏函数应用,所以让我们替换它:
auto tokenWins = [](const auto& board, const auto& token){
return any_of_collection(
allLinesColumnsAndDiagonals(board),
bind(lineFilledWith, _1, token)
);
};
这是一个非常小的函数,由于我们的偏函数应用,它具有很强的功能。然而,我们已经可以提取一个更高级的函数,它可以让我们创建更相似的函数而不需要编写任何代码。我还不知道该如何命名它,所以我暂时称它为foo:
template <typename F, typename G, typename H>
auto foo(F f, G g, H h){
return ={
return f(g(first),
bind(h, _1, second));
};
}
auto tokenWins = compose(any_of_collection, allLinesColumnsAndDiagonals, lineFilledWith);
我们的foo函数展示了代码的结构,但它相当难以阅读,所以让我们更好地命名事物:
template <typename CollectionBooleanOperation, typename CollectionProvider, typename Predicate>
auto booleanOperationOnProvidedCollection(CollectionBooleanOperation collectionBooleanOperation, CollectionProvider collectionProvider, Predicate predicate){
return ={
return collectionBooleanOperation(collectionProvider(collectionProviderSeed),
bind(predicate, _1, predicateFirstParameter));
};
}
auto tokenWins = booleanOperationOnProvidedCollection(any_of_collection, allLinesColumnsAndDiagonals, lineFilledWith);
我们引入了更高级的抽象层次,这可能会使代码更难理解。另一方面,我们使得能够在一行代码中创建f(g(first), bind(h, _1, second))形式的函数成为可能。
代码变得更好了吗?这取决于上下文、你的判断以及你和同事对高级函数的熟悉程度。然而,请记住——抽象虽然非常强大,但是也是有代价的。抽象更难理解,但如果你能够用抽象进行交流,你可以以非常强大的方式组合它们。使用这些高级函数就像从头开始构建一种语言——它使你能够在不同的层次上进行交流,但也为其他人设置了障碍。谨慎使用抽象!
使用高级函数消除隐藏的循环
结构重复的一个特殊例子经常在代码中遇到,我称之为隐藏的循环。隐藏的循环的概念是我们在一个序列中多次使用相同的代码结构。然而,其中的技巧在于被调用的函数或参数并不一定相同;因为函数式编程的基本思想是函数也是数据,我们可以将这些结构视为对可能也存储我们调用的函数的数据结构的循环。
我通常在一系列if语句中看到这种模式。事实上,我在使用井字棋结果问题进行实践会话时开始看到它们。在面向对象编程(OOP)或命令式语言中,问题的通常解决方案大致如下所示:
enum Result {
XWins,
OWins,
GameNotOverYet,
Draw
};
Result winner(const Board& board){
if(board.anyLineFilledWith(Token::X) ||
board.anyColumnFilledWith(Token::X) ||
board.anyDiagonalFilledWith(Token::X))
return XWins;
if(board.anyLineFilledWith(Token::O) ||
board.anyColumnFilledWith(Token::O) ||
board.anyDiagonalFilledWith(Token::O))
return OWins;
if(board.notFilledYet())
return GameNotOverYet;
return Draw;
}
在前面的示例中,enum标记包含三个值:
enum Token {
X,
O,
Blank
};
Board类大致如下:
using Line = vector<Token>;
class Board{
private:
const vector<Line> _board;
public:
Board() : _board{Line(3, Token::Blank), Line(3, Token::Blank),
Line(3, Token::Blank)}{}
Board(const vector<Line>& initial) : _board{initial}{}
...
}
anyLineFilledWith、anyColumnFilledWith、anyDiagonalFilledWith和notFilledYet的实现非常相似;假设一个 3 x 3 的棋盘,anyLineFilledWith的非常简单的实现如下:
bool anyLineFilledWith(const Token& token) const{
for(int i = 0; i < 3; ++i){
if(_board[i][0] == token && _board[i][1] == token &&
_board[i][2] == token){
return true;
}
}
return false;
};
然而,我们对底层实现不太感兴趣,更感兴趣的是前面的 winner 函数中的相似之处。首先,if语句中的条件重复了,但更有趣的是,有一个重复的结构如下:
if(condition) return value;
如果你看到一个使用数据而不是不同函数的结构,你会立刻注意到这是一个隐藏的循环。当涉及到函数调用时,我们并没有注意到这种重复,因为我们没有接受将函数视为数据的训练。但这确实就是它们的本质。
在我们消除相似之前,让我们简化条件。我将通过部分函数应用使所有条件成为无参数函数:
auto tokenWins = [](const auto board, const auto& token){
return board.anyLineFilledWith(token) ||
board.anyColumnFilledWith(token) || board.anyDiagonalFilledWith(token);
};
auto xWins = bind(tokenWins, _1, Token::X);
auto oWins = bind(tokenWins, _1, Token::O);
auto gameNotOverYet = [](auto board){
return board.notFilledYet();
};
Result winner(const Board& board){
auto gameNotOverYetOnBoard = bind(gameNotOverYet, board);
auto xWinsOnBoard = bind(xWins, board);
auto oWinsOnBoard = bind(oWins, board);
if(xWins())
return XWins;
if(oWins())
return OWins;
if(gameNotOverYetOnBoard())
return GameNotOverYet;
return Draw;
}
我们的下一步是消除四种不同条件之间的差异,并用循环替换相似之处。我们只需要有一对*(lambda, result)*的列表,并使用find_if这样的高级函数来为我们执行循环:
auto True = [](){
return true;
};
Result winner(Board board){
auto gameNotOverYetOnBoard = bind(gameNotOverYet, board);
auto xWinsOnBoard = bind(xWins, board);
auto oWinsOnBoard = bind(oWins, board);
vector<pair<function<bool()>, Result>> rules = {
{xWins, XWins},
{oWins, OWins},
{gameNotOverYetOnBoard, GameNotOverYet},
{True, Draw}
};
auto theRule = find_if(rules.begin(), rules.end(), [](auto pair){
return pair.first();
});
// theRule will always be found, the {True, Draw} by default.
return theRule->second;
}
最后一块拼图是确保我们的代码在没有其他情况适用时返回Draw。由于find_if返回符合规则的第一个元素,我们只需要在最后放上Draw,并与一个总是返回true的函数关联。我将这个函数恰如其分地命名为True。
这段代码对我们有什么作用呢?首先,我们可以轻松地添加新的条件和结果对,例如,如果我们曾经收到要在多个维度或更多玩家的情况下实现井字棋变体的请求。其次,代码更短。第三,通过一些改变,我们得到了一个简单但相当通用的规则引擎:
auto True = [](){
return true;
};
using Rule = pair<function<bool()>, Result>;
auto condition = [](auto rule){
return rule.first();
};
auto result = [](auto rule){
return rule.second;
};
// assumes that a rule is always found
auto findTheRule = [](const auto& rules){
return *find_if(rules.begin(), rules.end(), [](auto rule){
return condition(rule);
});
};
auto resultForFirstRuleThatApplies = [](auto rules){
return result(findTheRule(rules));
};
Result winner(Board board){
auto gameNotOverYetOnBoard = bind(gameNotOverYet, board);
vector<Rule> rules {
{xWins, XWins},
{oWins, OWins},
{gameNotOverYetOnBoard, GameNotOverYet},
{True, Draw}
};
return resultForFirstRuleThatApplies(rules);
}
在前面示例中唯一特殊的代码是规则列表。其他所有内容都是相当通用的,可以在多个问题上重复使用。
和往常一样,提升抽象级别是需要付出代价的。我们花时间尽可能清晰地命名事物,我相信这段代码非常容易阅读。然而,对许多人来说可能并不熟悉。
另一个可能的问题是内存使用。尽管初始版本的代码重复了相同的代码结构,但它不需要为函数和结果对的列表分配内存;然而,重要的是要测量这些东西,因为即使初始代码也需要一些额外指令的处理内存。
这个例子向我们展示了如何通过一个非常简单的代码示例将重复的结构转换为循环。这只是皮毛;这种模式是如此普遍,我相信一旦你开始寻找,你会在你的代码中注意到它。
摘要
在本章中,我们看了不同类型的代码相似之处,以及如何通过各种函数式编程技术来减少它们。从可以用部分应用替换的重复参数,到可以转换为函数组合的链式调用,一直到可以通过更高级别的函数移除的结构相似之处,你现在已经有能力注意并减少任何代码库中的相似之处了。
正如你已经注意到的,我们开始讨论代码结构和软件设计。这将我们引向设计的另一个核心原则——高内聚和低耦合。我们如何使用函数来增加内聚?原来这正是类非常有用的地方,这也是我们将在下一章讨论的内容。















 3446
3446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









