







原文:
annas-archive.org/md5/024671a6ef06ea57693023eca62b8eea译者:飞龙
第三章:探索 C++类型
在过去的两章中,您已经学会了如何组合 C++程序,了解了您使用的文件以及控制执行流程的方法。本章是关于您将在程序中使用的数据:数据类型和将保存该数据的变量。
变量可以处理特定格式和特定行为的数据,这由变量的类型确定。变量的类型确定您可以对数据执行的操作以及用户输入或查看数据的格式。
基本上,您可以查看三种一般类型:内置类型、自定义类型和指针。指针通常将在下一章中介绍,自定义类型或类以及指向它们的指针将在第六章《类》中介绍。本章将介绍作为 C++语言一部分提供的类型。
探索内置类型
C++提供整数、浮点和布尔类型。char类型是整数,但它可以用于保存单个字符,因此其数据可以被视为数字或字符。C++标准库提供了string类,允许您使用和操作字符串。字符串将在第九章《使用字符串》中深入介绍。
顾名思义,整数类型包含没有小数部分的整数值。如果使用整数进行计算,您应该期望任何小数部分都将被丢弃,除非您采取措施保留它们(例如,通过取余运算符%)。浮点类型保存可能具有小数部分的数字;因为浮点类型可以以尾数指数格式保存数字,所以它们可以保存异常大或异常小的数字。
变量是类型的实例;它是分配的内存,用于保存类型可以保存的数据。整数和浮点变量声明可以修改以告诉编译器分配多少内存,从而限制变量可以保存的数据和对变量执行的计算的精度。此外,您还可以指示变量是否将保存重要的符号数字。如果数字用于保存位图(其中位不组成数字,而具有自己的独立含义),则通常没有意义使用有符号类型。
在某些情况下,您将使用 C++从文件或网络流中解压数据,以便对其进行操作。在这种情况下,您需要知道数据是浮点还是整数,有符号还是无符号,使用了多少字节以及这些字节的顺序。字节的顺序(多字节数字中的第一个字节是数字的低位还是高位)由您正在编译的处理器确定,在大多数情况下,您不需要担心它。
同样,有时您可能需要了解变量的大小以及它在内存中的对齐方式;特别是当您使用 C++中称为structs的数据记录时。C++提供了sizeof运算符来给出用于保存变量的字节数,以及alignof运算符来确定内存中类型的对齐方式。对于基本类型,sizeof和alignof运算符返回相同的值;只有在自定义类型上调用alignof运算符时,它才会返回类型中最大数据成员的对齐方式。
整数
顾名思义,整数保存整数数据,即没有小数部分的数字。因此,在需要重视小数部分的情况下,使用整数进行任何算术运算几乎没有意义;在这种情况下,应该使用浮点数。上一章中展示了一个例子:
int height = 480;
int width = 640;
int aspect_ratio = width / height;
这给出了一个明显不正确且毫无意义的宽高比。即使将结果分配给浮点数,您也会得到相同的结果:
float aspect_ratio = width / height;
原因是表达式width / height中的算术是在整数上执行的,这将使用整数的除法运算符丢弃结果的任何小数部分。要使用浮点除法运算符,您将需要将操作数之一强制转换为浮点数,以便使用浮点运算符:
float aspect_ratio = width / (float)height;
这将为aspect_ratio变量分配一个值为 1.3333(或 4:3)。这里使用的强制转换运算符是 C 强制转换运算符,它强制将一个类型的数据用作另一个类型的数据。(这是因为我们还没有介绍 C++强制转换运算符,并且 C 强制转换运算符的语法是清晰的。)这种转换没有类型安全性。C++提供了强制转换运算符,下文将讨论其中一些将以类型安全的方式进行转换,当您使用自定义类型的对象指针时,这将变得很重要。
C++提供了各种大小的整数类型,如下表所总结。这些是五种标准整数类型。标准规定int是处理器的自然大小,并且其值在(包括)INT_MIN和INT_MAX之间(在<climits>头文件中定义)。整数类型的大小至少与列表中前面的整数类型一样大,因此int至少与short int和long long int类型一样大,至少与long int类型一样大。短语“至少与”如果这些类型都是相同大小,那么就没有多大用处,因此<climits>头文件还为其他基本整数类型定义了范围。存储这些整数范围需要多少字节是依赖于实现的。这个表给出了基本类型的范围和 x86,32 位处理器上的大小:
| 类型 | 范围 | 字节大小 |
|---|---|---|
signed char | -128 到 127 | 1 |
short int | -32768 到 32767 | 2 |
int | -2147483648 到 2147483647 | 4 |
long int | -2147483648 到 2147483647 | 4 |
long long int | -9223372036854775808 到 9223372036854775807 | 8 |
在实践中,您将使用short而不是short int类型;对于long int,您将使用long;对于long long int,通常会使用long long。从这个表中可以看出,int和long int类型的大小相同,但它们仍然是两种不同的类型。
除了char类型,缺省情况下整数类型都是有符号的,也就是说,它们可以保存负数和正数(例如,short类型的变量的值可以在-32,768 和 32,767 之间)。您可以使用signed关键字显式指示类型为有符号。您还可以使用unsigned关键字来获得无符号的等价类型,这将给您一个额外的位,但也意味着按位运算符和移位运算符将按您的预期工作。您可能会发现unsigned在没有类型的情况下使用,这种情况下它指的是unsigned int。类似地,没有类型的signed指的是signed int。
char类型是unsigned char和signed char的独立类型。标准规定char中的每一位都用于保存字符信息,因此根据实现的不同,char是否可以被视为能够保存负数是依赖于实现的。如果您希望char保存有符号数,您应该明确使用signed char。
标准对于标准整数类型的大小并不精确,如果您正在编写代码(例如,访问文件中的数据或网络流),这可能是一个问题。<cstdlib>头文件定义了将保存特定数据范围的命名类型。这些类型具有包含在范围内使用的位数的名称(尽管实际类型可能需要更多位)。因此,有诸如int16_t和uint16_t之类的类型,其中第一个类型是将保存 16 位值范围的有符号整数,第二个类型是无符号整数。还声明了 8 位、32 位和 64 位值的类型。
以下显示了在 x86 机器上使用sizeof运算符确定的这些类型的实际大小:
// #include <cstdint>
using namespace std; // Values for x86
cout << sizeof(int8_t) << endl; // 1
cout << sizeof(int16_t) << endl; // 2
cout << sizeof(int32_t) << endl; // 4
cout << sizeof(int64_t) << endl; // 8
此外,<cstdlib>头文件还定义了诸如int_least16_t和uint_least16_t之类的类型,使用与之前相同的命名方案,并且有 8 位、16 位、32 位和 64 位的版本。名称中的least部分表示该类型将保存至少指定数量的位的值,但可能会更多。还有诸如int_fast16_t和uint_fast16_t之类的类型,具有 8 位、16 位、32 位和 64 位的版本,被视为可以保存该位数的最快类型。
指定整数文字
要为整数变量赋值,您提供一个没有小数部分的数字。编译器将确定数字表示的最接近精度的类型,并尝试分配整数,必要时执行转换。
要明确指定文字是long值,您可以使用l或L后缀。同样,对于unsigned long,您可以使用后缀ul或UL。对于long long值,您使用ll或LL后缀,并对于unsigned long long使用ull或ULL。u(或U)后缀用于unsigned(即unsigned int),对于int不需要后缀。以下是使用大写后缀的示例:
int i = 3;
signed s = 3;
unsigned int ui = 3U;
long l = 3L;
unsigned long ul = 3UL;
long long ll = 3LL;
unsigned long long ull = 3ULL;
使用 10 进制数字系统来指定位图的数字是令人困惑和繁琐的。位图中的位是 2 的幂,因此更合理的是使用 2 的幂的数字系统。C++允许您以八进制(基数 8)或十六进制(基数 16)提供数字。要在八进制中提供文字,您需要使用零字符(0)作为前缀。要在十六进制中提供文字,您需要使用0x字符序列作为前缀。八进制数字使用数字 0 到 7,但十六进制数字需要 16 个数字,即 0 到 9 和 a 到 f(或 A 到 F),其中 A 在十进制中是 10,F 在十进制中是 15:
unsigned long long every_other = 0xAAAAAAAAAAAAAAAA;
unsigned long long each_other = 0x5555555555555555;
cout << hex << showbase << uppercase;
cout << every_other << endl;
cout << each_other << endl;
在此代码中,两个 64 位(在 Visual C++中)整数被分配了位图值,其中每隔一位设置为 1。第一个变量从底位设置,第二个变量从底位取消设置,并设置次低位。在插入数字之前,流被修改了三个操纵器。第一个hex表示整数应以十六进制形式打印在控制台上,showbase表示将打印前导的0x。默认情况下,字母数字(A 到 F)将以小写形式给出,要指定必须使用大写形式,您可以使用uppercase。一旦流被修改,设置将保持直到被更改。要随后更改流以使用小写字母十六进制数字,您可以在流中插入nouppercase,要打印没有基数的数字,插入noshowbase操纵器。要使用八进制数字,您可以插入oct操纵器,要使用十进制,插入dec操纵器。
当您指定这样的大数字时,很难看出您是否已经指定了正确数量的数字。您可以使用单引号(')将数字分组在一起:
unsigned long long every_other = 0xAAAA'AAAA'AAAA'AAAA;
int billion = 1'000'000'000;
编译器忽略引号;它只是用作视觉辅助。在第一个示例中,引号将数字分组为两个字节组;在第二种情况下,引号将小数分组为千位和百万位。
使用位集来显示位模式
没有操纵器告诉cout对象将整数打印为位图,但是可以使用bitset对象模拟该行为:
// #include <bitset>
unsigned long long every_other = 0xAAAAAAAAAAAAAAAA;
unsigned long long each_other = 0x5555555555555555;
bitset<64> bs_every(every_other);
bitset<64> bs_each(each_other);
cout << bs_every << endl;
cout << bs_each << endl;
结果是:
1010101010101010101010101010101010101010101010101010101010101010
0101010101010101010101010101010101010101010101010101010101010101
在这里,bitset类是参数化的,这意味着您通过尖括号(<>)提供一个参数,在这种情况下使用 64,表示bitset对象将容纳 64 位。在这两种情况下,bitset对象的初始化使用看起来像函数调用的语法(实际上,它确实调用了一个称为构造函数的函数),这是初始化对象的首选方式。将bitset对象插入流中,打印出从最高位开始的每个位。(原因是定义了一个operator <<函数,它接受一个bitset对象,这是大多数标准库类的情况)。
bitset类对于访问和设置单个位而不使用位运算符是有用的:
bs_every.set(0);
every_other = bs_every.to_ullong();
cout << bs_every << endl;
cout << every_other << endl;
set函数将在指定位置设置位为 1。to_ullong函数将返回bitset表示的long long数字。
对set函数的调用和赋值具有与以下相同的结果:
every_other |= 0x0000000000000001;
确定整数字节顺序
整数中字节的顺序取决于实现;它取决于处理器如何处理整数。在大多数情况下,您不需要知道。但是,如果您以二进制模式从文件中读取字节,或者从网络流中读取字节,并且需要将两个或更多字节解释为整数的一部分,则需要知道它们的顺序,并且必要时将它们转换为处理器识别的顺序。
C 网络库(在 Windows 上称为Winsock库)包含一组函数,用于将unsigned short和unsigned long类型从网络顺序转换为主机顺序(即当前机器上处理器使用的顺序),反之亦然。网络顺序是大端序。大端序意味着第一个字节将是整数中的最高字节,而小端序意味着第一个字节是最小字节。当您将整数传输到另一台机器时,您首先将其从源机器的处理器使用的顺序(主机顺序)转换为网络顺序,接收机在使用数据之前将整数从网络顺序转换为接收机的主机顺序。
更改字节顺序的函数是ntohs和ntohl;用于将unsigned short和unsigned long从网络顺序转换为主机顺序的函数,以及htons和htonl,用于将主机顺序转换为网络顺序。在调试代码时,了解字节顺序将是重要的(例如,如第十章中所述,诊断和调试)。
编写代码以反转字节顺序很容易:
unsigned short reverse(unsigned short us)
{
return ((us & 0xff) << 8) | ((us & 0xff00) >> 8);
}
这使用位运算符将假定组成unsigned short的两个字节分开为较低字节,将其左移八位,并将右移八位的上字节,然后使用按位或运算符|将这两个数字重新组合为unsigned short。编写此函数的 4 字节和 8 字节整数版本很简单。
浮点类型
有三种基本的浮点类型:
-
float(单精度) -
double(双精度) -
long double(扩展精度)
所有这些都是有符号的。内存中数字的实际格式和使用的字节数是特定于 C++实现的,但<cfloat>头文件给出了范围。以下表格给出了 x86、32 位处理器上使用的正数范围和字节数:
| 类型 | 范围 | 字节大小 |
|---|---|---|
| 浮点 | 1.175494351e-38 到 3.402823466e+38 | 4 |
| 双精度 | 2.2250738585072014e-308 到 1.7976931348623158e+308 | 8 |
| 长双精度 | 2.2250738585072014e-308 到 1.7976931348623158e+308 | 8 |
正如您所看到的,在 Visual C++中,double和long double具有相同的范围,但它们仍然是两种不同的类型。
指定浮点文字
用于初始化double的文字是通过使用科学格式或简单地提供小数点来指定的浮点数:
double one = 1.0;
double two = 2.;
double one_million = 1e6;
第一个例子表明变量one被赋予了浮点值 1.0。结尾的零并不重要,如第二个变量two所示;然而,结尾的零确实使代码更易读,因为很容易忽略句号。第三个例子使用了科学计数法。第一部分是尾数,可以是有符号的,e后面的部分是指数。指数是数字的 10 的幂大小(可以是负数)。变量被赋予尾数乘以 10 并提升到指数的值。虽然不建议这样做,但您可以写以下内容:
double one = 0.0001e4;
double one_billion = 1000e6;
编译器将适当地解释这些数字。第一个例子是反常的,但第二个有些意义;它在您的代码中显示了十亿是一千万的意思。
这些示例将双精度浮点值分配给double变量。要为单精度变量指定值,以便可以分配float变量,使用f(或F)后缀。类似地,对于long double文字,使用l(或L)后缀:
float one = 1.f;
float two = 2f; // error
long double one_million = 1e6L;
如果您使用这些后缀,仍然必须以正确的格式提供数字。2f的文字是不正确的;您必须提供一个小数点,2.f。当您指定具有大量数字的浮点数时,可以使用单引号(')来分组数字。如前所述,这只是对程序员的一种视觉辅助:
double one_billion = 1'000'000'000.;
字符和字符串
string类和 C 字符串函数将在第九章中介绍,使用字符串;本节介绍了代码中字符变量的基本用法。
字符类型
char类型是一个整数,所以也存在signed char和unsigned char。这是三种不同的类型;signed char和unsigned char类型应该被视为数值类型。char类型用于在实现的字符集中保存单个字符。在 Visual C++中,这是一个可以容纳 ISO-8859 或 UTF-8 字符集中的字符的 8 位整数。这些字符集能够表示英语和大多数欧洲语言中使用的字符。其他语言的字符占用多个字节,C++提供了char16_t类型来保存 16 位字符和char32_t来保存 32 位字符。
还有一种称为wchar_t(宽字符)的类型,它将能够容纳来自最大扩展字符集的字符。通常,当您看到带有w前缀的 C 运行时库或 C++标准库函数时,它将使用宽字符字符串而不是char字符串。因此,cout对象将允许您插入char字符串,而wcout对象将允许您插入宽字符字符串。
C++标准规定char中的每个位都用于保存字符信息,因此根据实现,char是否可以被视为能够保存负数是依赖于实现的。以下是说明:
char c = '~';
cout << c << " " << (signed short)c << endl;
c += 2;
cout << c << " " << (signed short)c << endl;
signed char的范围是-128 到 127,但此代码使用了单独的类型char并尝试以相同的方式使用它。变量c首先被赋值为 ASCII 字符~(126)。当您将字符插入输出流时,它将尝试打印一个字符而不是一个数字,因此下一行将此字符打印到控制台,为了获得数值,代码将变量转换为signed short整数。(再次,为了清晰起见,使用了 C 转换。)接下来,变量增加了两个,也就是说,字符在字符集中向后移动了两个字符,这意味着扩展 ASCII 字符集中的第一个字符;结果是这样的:
~ 126
C -128
扩展字符集中的第一个字符是 C-锐音。
值为 126 增加两个的结果是-128,这相当反直觉,并且这是由于带符号类型的溢出计算导致的。即使这是有意的,最好还是避免这样做。
在 Visual C++中,C-锐音字符被视为-128,因此您可以编写以下内容以达到相同的效果:
char c = -128;
这是特定于实现的,因此对于可移植代码,您不应该依赖它。
使用字符宏
<cctype>头文件包含了各种宏,您可以使用这些宏来检查char包含的字符类型。这些是在<ctype.h>中声明的 C 运行时宏。以下表格中解释了一些更有用的测试字符值的宏。请记住,由于这些是 C 例程,它们不会返回bool值;而是返回一个具有非零值的int表示true,零表示false。
| 宏 | 测试字符是否为: |
|---|---|
isalnum | 字母数字字符,A 到 Z,a 到 z,0 到 9 |
isalpha | 一个字母字符,A 到 Z,a 到 z |
isascii | 一个 ASCII 字符,0x00 到 0x7f |
isblank | 一个空格或水平制表符 |
iscntrl | 一个控制字符,0x00 到 0x1f 或 0x7f |
isdigit | 十进制数字 0 到 9 |
isgraph | 可打印字符,不包括空格,0x21 到 0x7e |
islower | 一个小写字符,a 到 z |
isprint | 可打印字符,0x20 到 0x7e |
ispunct | 一个标点字符,! " # $ % & ' ( ) * + , - . / : ; < = > ? @ [ ] ^ _ { | } ~ ` |
isspace | 一个空格 |
isupper | 一个大写字符,A 到 Z |
isxdigit | 一个十六进制数字,0 到 9,a 到 f,A 到 F |
例如,以下代码循环读取输入流中的单个字符(在每个字符后,您需要按Enter键)。当提供非数字值时,循环结束:
char c;
do
{
cin >> c
} while(isdigit(c));
还有用于更改字符的宏。同样,这些将返回一个int值,您应该将其转换为char。
| 宏 | 返回 |
|---|---|
toupper | 字符的大写版本 |
tolower | 字符的小写版本 |
在以下代码中,从控制台键入的字符被回显,直到用户键入q或Q为止。如果键入的字符是小写字符,则回显的字符会转换为大写:
char c;
do
{
cin >> c;
if (islower(c)) c = toupper(c);
cout << c << endl;
} while (c != 'Q');
指定字符文字
您可以使用文字字符初始化char变量。这将是受支持的字符集中的一个字符。ASCII 字符集包括一些不可打印的字符,因此您可以使用这些,C++提供了两个使用反斜杠字符(\)的字符序列。
| 名称 | ASCII 名称 | C++序列 |
|---|---|---|
| 换行符 | LF | \n |
| 水平制表符 | HT | \t |
| 垂直制表符 | VT | \v |
| 退格 | BS | \b |
| 回车 | CR | \r |
| 换页符 | FF | \f |
| 警报 | BEL | \a |
| 反斜杠 | \ | \\ |
| 问号 | ? | \? |
| 单引号 | ’ | \' |
| 双引号 | " | \" |
此外,您还可以将该字符的数值作为八进制或十六进制数给出。要提供八进制数,您需要使用三个字符(必要时前缀为一个或两个0字符)前缀为反斜杠。对于十六进制数,您需要使用\x前缀。字符M在十进制中是字符编号 77,在八进制中是 115,在十六进制中是 4d,因此您可以用三种方式初始化一个字符变量为M字符。
char m1 = 'M';
char m2 = '\115';
char m3 = '\x4d';
为了完整起见,值得指出您可以将 char 初始化为整数,因此以下内容也将初始化每个变量为M字符:
char m4 = 0115; // octal
char m5 = 0x4d; // hexadecimal
所有这些方法都是有效的。
指定字符串文字
字符串由一个或多个字符组成,您也可以在字符串文字中使用转义字符。
cout << "This is \x43\x2b\05\3n";
这个相当难读的字符串将被打印在控制台上,后面跟着一个换行符,显示为This is C++。大写字母 C 的十六进制是 43,加号的十六进制是 2b,八进制是 53。\n字符是一个换行符。转义字符对于打印不在 C++编译器使用的字符集中的字符以及一些不可打印的字符(例如,\t插入水平制表符)非常有用。cout对象在将字符写入输出流之前会对其进行缓冲。如果您使用\n作为换行符,它将被视为缓冲区中的任何其他字符。endl操作符将\n插入缓冲区,然后刷新缓冲区,使字符立即写入控制台。
空或NULL字符是\0。这是一个重要的字符,因为它是不可打印的,并且除了标记字符串中字符序列的结束之外没有其他用途。空字符串是"",但由于字符串由NULL字符界定,因此使用空字符串初始化的字符串变量占用的内存将有一个字符,即\0。
换行符允许您在字符串中插入换行符。如果您只对段落进行格式化,并且要打印短段落,这将非常有用。
cout << "Mary had a little lamb,n its fleece was white as snow."
<< endl;
这在控制台上打印了两行:
Mary had a little lamb,
its fleece was white as snow.
但是,您可能希望使用长序列的字符初始化字符串,而您使用的编辑器的限制可能意味着您希望将字符串分割成几行。您可以通过将字符串的每个片段放在双引号内来实现这一点。
cout << "And everywhere that Mary went, "
"the lamb was sure to go."
<< endl;
您将在控制台上看到以下内容:
And everywhere that Mary went, the lamb was sure to go.
除了在最后使用endl明确请求的换行符外,不会打印其他换行符。这种语法允许您在代码中使长字符串更易读;当然,您也可以在这样的字符串中使用换行字符\n。
Unicode 文字
wchar_t变量也可以用字符初始化,编译器将通过使用字符的字节并将剩余(更高的)字节分配为零来将字符提升为宽字符。但是,将这样的变量分配为宽字符更有意义,您可以使用L前缀来实现这一点。
wchar_t dollar = L'$';
wchar_t euro = L'\u20a0';
wcout << dollar;
请注意,这段代码使用的是wcout,而不是cout对象,使用引号内的\u前缀的语法表示后面的字符是 Unicode 字符。
请注意,要显示 Unicode 字符,您需要使用一个可以显示 Unicode 字符的控制台,默认情况下,Windows 控制台设置为Code Page 850,不会显示 Unicode 字符。您可以通过在标准输出流stdout上调用_setmode(在<io.h>中定义)来更改输出控制台的模式,指定 UTF-16 文件模式(使用<fcntl.h>中定义的_O_U16TEXT):
_setmode(_fileno(stdout), _O_U16TEXT);
您可以在unicode.org/charts/找到 Unicode 支持的所有字符的列表。
UTF-16 字符也可以分配给char16_t变量,UTF-32 字符也可以分配给char32_t变量。
原始字符串
当您使用原始字符串文字时,实质上是关闭了转义字符的含义。无论您输入什么内容到原始字符串中,甚至包括换行符在内,原始字符串都会将其作为内容。原始字符串用R"(和)"来界定。也就是说,字符串位于内部括号之间。
cout << R"(newline is \n in C++ and "quoted text" use quotes)";
请注意,()是语法的一部分,不是字符串的一部分。前面的代码将以下内容打印到控制台:
newline is \n in C++ and "quoted text" use quotes
通常在字符串中,\n是一个转义字符,将被翻译为换行符,但在原始字符串中,它不会被翻译,而是打印为两个字符。
在普通的 C++字符串中,您将不得不转义一些字符;例如,双引号必须转义为\",反斜杠必须转义为\\。不使用原始字符串,以下将给出相同的结果:
cout << "newline is \\n in C++ and \"quoted text\" use quotes";
您还可以在原始字符串中使用换行符:
cout << R"(Mary had a little lamb,
its fleece was white as snow)"
cout << endl;
在这段代码中,逗号后面的换行符将被打印到控制台。不幸的是,所有空白字符都将被打印到控制台上,因此假设在前面的代码中缩进为三个空格,cout缩进一次,您将在控制台上看到以下内容:
Mary had a little lamb,
its fleece was white as snow
在its前面有 14 个空格,因为在源代码中its前面有 14 个空格。因此,您应该谨慎使用原始字符串。
也许,原始字符串的最佳用途是在 Windows 上初始化文件路径的变量。在 Windows 中,文件夹分隔符是反斜杠,这意味着对于表示文件路径的文字字符串,您将不得不转义每个这些分隔符;因此,字符串将有很多双反斜杠,有可能漏掉一个。使用原始字符串,这种转义是不必要的。以下的两个字符串变量代表相同的字符串:
string path1 = "C:\\Beginning_C++\\Chapter_03\\readme.txt";
string path2 = R"(C:\Beginning_C++\Chapter_03\readme.txt)";
这两个字符串具有相同的内容,但第二个更易读,因为 C++文字字符串没有转义反斜杠。
转义反斜杠的要求仅适用于在代码中声明的文字字符串;这是对编译器如何解释字符的指示。如果您从函数(或通过argv[0])获取文件路径,分隔符将是反斜杠。
字符串字节顺序
扩展字符集使用每个字符超过一个字节。如果这些字符存储在文件中,字节的顺序就变得重要起来。在这种情况下,字符的编写者必须使用与潜在读者将要使用的相同顺序。
一种方法是使用字节顺序标记(BOM)。这是已知字节数和已知模式的一组字节,通常作为流的第一项放置,以便流的读取者可以使用它来确定流中剩余字符的字节顺序。Unicode 定义了 16 位字符\uFEFF和非字符\uFFFE作为字节顺序标记。对于\uFEFF,除了第 8 位(如果最低位标记为第 0 位)之外,所有位都被设置。这个 BOM 可以作为前缀添加到在机器之间传递的数据中。目标机器可以将 BOM 读入一个 16 位变量并测试位。如果第 8 位为零,这意味着两台机器具有相同的字节顺序,因此字符可以按照流中的顺序读取为两个字节值。如果第 0 位为零,则意味着目标机器以与源机器相反的顺序读取 16 位变量,因此必须采取措施确保以正确的顺序读取字节。
Unicode 字节顺序标记(BOM)序列化如下(十六进制):
| 字符集 | 字节顺序标记 |
|---|---|
| UTF-8 | EF BB BF |
| UTF-16 大尾 | FE FF |
| UTF-16 小尾 | FF FE |
| UTF-32 大尾 | 00 00 FE FF |
| UTF-32 小尾 | FF FE 00 00 |
请记住,当您从文件中读取数据时。字符序列 FE FF 在非 Unicode 文件中非常罕见,因此如果您将它们读取为文件中的前两个字节,这意味着该文件是 Unicode。由于\uFEFF和\uFFFE不是可打印的 Unicode 字符,这意味着以这两者之一开头的文件具有字节顺序标记,然后您可以使用 BOM 来确定如何解释文件中剩余的字节。
布尔
bool类型保存布尔值,即两个值中的一个:true或false。C++允许您将 0(零)视为false,将任何非零值视为true,但这可能会导致错误,因此最好养成明确检查值的习惯:
int use_pointer(int *p)
{
if (p) { /* not a null pointer */ }
if (p != nullptr) { /* not a null pointer */ }
return 0;
}
这两种方式中的第二种更可取,因为您正在比较的内容更清晰。
请注意,即使指针不是nullptr,它仍然可能不是有效的指针,但通常的做法是将指针分配给nullptr以传达其他含义,也许是说指针操作不合适。
可以将布尔值插入输出流。但是,默认行为是将布尔值视为整数。如果要使cout输出带有字符串名称的bool值,则在流中插入操作符boolalpha;这将使流打印true或false到控制台。可以使用noboolalpha操作符来实现默认行为。
void
在某些情况下,您需要指示函数没有参数或不会返回值;在这两种情况下,您可以使用关键字void:
void print_message(void)
{
cout << "no inputs, no return value" << endl;
}
在参数列表中使用void是可选的;接受空括号对并且更可取。这是唯一的一种方式来指示函数返回除返回void之外的值。
请注意,void实际上不是一种类型,因为您无法创建void变量;它是没有类型。正如您将在下一章中了解到的那样,您可以创建void类型的指针,但是您将无法使用这些指针指向的内存而不进行类型转换:要使用内存,您必须决定内存保存的数据的类型。
初始化器
初始化器在上一章中已经提到过,但我们将在这里更深入地讨论。对于内置类型,您必须在使用变量之前初始化变量。对于自定义类型,类型可能定义默认值,但在这样做时会出现一些问题,这将在第六章中进行介绍,类。
在 C++的所有版本中,有三种初始化内置类型的方式:赋值、函数语法或调用构造函数。在 C++11 中引入了另一种初始化变量的方式:通过列表初始化进行构造。这四种方式如下所示:
int i = 1;
int j = int(2);
int k(3);
int m{4};
这三种方式中的第一种是最清晰的;它使用易于理解的语法显示变量正在初始化为一个值。第二个示例通过调用类型来初始化变量,就好像它是一个函数一样。第三个示例调用int类型的构造函数。这是初始化自定义类型的典型方式,因此最好将此语法保留给自定义类型。
第四种语法是 C++11 中的新语法,并使用花括号({})之间的初始化列表初始化变量。稍微令人困惑的是,您还可以使用与分配给单个项目列表相同的语法来初始化内置类型:
int n = { 5 };
这真的让事情变得混乱,类型n是一个整数,而不是数组。回想一下,在上一章中,我们创建了一个包含 The Beatles 的出生日期的数组:
int birth_years[] = { 1940, 1942, 1943, 1940 };
这将创建一个包含四个整数的数组;每个项目的类型为int,但数组变量的类型为int*。该变量指向保存四个整数的内存。同样,您还可以将变量初始化为一个项目的数组:
int john[] = { 1940 };
这正是 C++11 允许初始化单个整数的初始化代码。此外,相同的语法用于初始化记录类型(structs)的实例,增加了关于语法意义的另一层潜在混淆。
最好避免使用花括号语法进行变量初始化,而将其专门用于初始化列表。然而,这种语法在类型转换方面有一些优势,稍后会解释。
花括号语法可以用于为 C++标准库中的任何集合类提供初始值,以及用于 C++数组。即使用于初始化集合对象,也存在混淆的可能。例如,考虑vector集合类。它可以保存通过一对尖括号(<>)提供的类型的集合。这个类的对象的容量可以随着向对象添加更多项目而增长,但你可以通过指定初始容量来优化其使用:
vector<int> a1 (42);
cout << " size " << a1.size() << endl;
for (int i : a1) cout << i << endl;
这段代码的第一行表示:创建一个可以保存整数的vector对象,并开始为 42 个整数保留空间,每个整数初始化为零值。第二行将向控制台打印出向量的大小(42),第三行将向控制台打印出数组中的所有项目,它将打印出 42 个零值。
现在考虑以下情况:
vector<int> a2 {42};
cout << " size " << a2.size() << endl;
for (int i : a2) cout << i << endl;
这里只有一个变化:括号已经改为花括号,但这意味着初始化已经完全改变。第一行现在表示:创建一个可以保存整数的vector,并用单个整数 42 进行初始化。a2的大小为 1,最后一行将只打印一个值,42。
C++的强大之处在于应该很容易编写正确的代码,并且说服编译器帮助你避免错误。使用花括号进行单个项目初始化会增加难以发现错误的可能性。
默认值
内置类型的变量在首次使用前应该被初始化,但有一些情况下编译器会提供一个默认值。
如果你在文件范围或项目中全局声明一个变量,并且没有给它一个初始值,编译器会给它一个默认值。例如:
int outside;
int main()
{
outside++;
cout << outside << endl;
}
这段代码将编译并运行,打印出一个值为 1;编译器已经将outside初始化为 0,然后递增为 1。以下代码将无法编译:
int main()
{
int inside;
inside++;
cout << inside << endl;
}
编译器会抱怨增量运算符被用在一个未初始化的变量上。
在上一章中,我们看到编译器提供了默认值的另一个例子:static。
int counter()
{
static int count;
return ++count;
}
这是一个简单的函数,用于维护一个计数。变量count被标记为static存储类修饰符,意味着该变量与应用程序具有相同的生命周期(在代码启动时分配,在程序结束时释放);然而,它具有内部链接,意味着该变量只能在声明它的范围内使用,即counter函数。编译器将使用默认值 0 初始化count变量,因此第一次调用counter函数时将返回值 1。
C++11 的新初始化列表语法提供了一种声明变量并指定你希望它由编译器初始化为该类型的默认值的方法:
int a {};
当阅读这段代码时,你必须知道int的默认值是什么(是零)。再次强调,将变量简单地初始化为一个值要容易得多,也更明确:
int a = 0;
默认值的规则很简单:零值。整数和浮点数的默认值为 0,字符的默认值为\0,bool的默认值为false,指针的默认值为常量nullptr。
没有类型的声明
C++11 引入了一种机制,声明变量的类型应该根据初始化的数据来确定,即auto。
这里有一个小混淆,因为在 C++11 之前,auto关键字用于声明自动变量,即在函数中自动分配在堆栈上的变量。除了在文件范围内声明的变量或static变量之外,到目前为止本书中的所有其他变量都是自动变量,自动变量是最广泛使用的存储类(稍后解释)。由于它是可选的并且适用于大多数变量,auto关键字在 C++中很少被使用,因此 C++11 利用了这一点,删除了旧的含义,并赋予了auto新的含义。
如果你正在使用 C++11 编译器编译旧的 C++代码,并且那个旧代码使用了auto,你会得到错误,因为新的编译器会假定auto将用于没有指定类型的变量。如果发生这种情况,只需搜索并删除每个auto实例;在 C++11 之前的 C++中,它是多余的,开发人员几乎没有理由使用它。
auto关键字意味着编译器应该创建一个与分配给它的数据类型相同的变量。变量只能有一个类型,编译器决定的类型是它需要的数据分配的类型,你不能在其他地方使用变量来保存不同类型的数据。因为编译器需要从初始化程序确定类型,这意味着所有auto变量必须被初始化:
auto i = 42; // int
auto l = 42l; // long
auto ll = 42ll; // long long
auto f = 1.0f; // float
auto d = 1.0; // double
auto c = 'q'; // char
auto b = true; // bool
请注意,没有语法来指定整数值是单字节还是双字节,因此你不能以这种方式创建unsigned char变量或short变量。
这是auto关键字的一个微不足道的用法,你不应该这样使用。auto的威力在于你使用可能导致一些看起来相当复杂的类型的容器时:
// #include <string>
// #include <vector>
// #include <tuple>
vector<tuple<string, int> > beatles;
beatles.push_back(make_tuple("John", 1940));
beatles.push_back(make_tuple("Paul", 1942));
beatles.push_back(make_tuple("George", 1943));
beatles.push_back(make_tuple("Ringo", 1940));
for (tuple<string, int> musician : beatles)
{
cout << get<0>(musician) << " " << get<1>(musician) << endl;
}
这段代码使用了我们之前使用过的vector容器,但是使用tuple存储了两个值。tuple类很简单;在尖括号之间的声明中声明了tuple对象中项目类型的列表。因此,tuple<string, int>声明表示对象将按顺序保存一个字符串和一个整数。make_tuple函数由 C++标准库提供,将创建一个包含两个值的tuple对象。push_back函数将项目放入向量容器中。在四次调用push_back函数之后,beatles变量将包含四个项目,每个项目都是一个带有姓名和出生年份的tuple。
范围for循环遍历容器,并在每次循环中将musician变量分配给容器中的下一个项目。tuple中的值在for循环中的语句中打印到控制台。使用get参数化函数(来自<tuple>)访问tuple中的项目,尖括号中的参数指示从作为参数传递的tuple对象中获取的项目的索引(从零开始索引)。在这个例子中,对get<0>的调用获取了名字,然后是一个空格,然后get<1>获取了tuple中的年份项目。这段代码的结果是:
John 1940
Paul 1942
George 1943
Ringo 1940
这段文字格式不佳,因为它没有考虑名称的长度。这可以通过第九章中解释的操作符来解决,使用字符串。
再看一下for循环:
for (tuple<string, int> musician : beatles)
{
cout << get<0>(musician) << " " << get<1>(musician) << endl;
}
音乐家的类型是tuple<string, int>;,这是一个相当简单的类型,随着你使用标准模板更多,你可能会得到一些复杂的类型(特别是当你使用迭代器时)。这就是auto变得有用的地方。下面的代码是相同的,但更容易阅读:
for (auto musician : beatles)
{
cout << get<0>(musician) << " " << get<1>(musician) << endl;
}
音乐家变量仍然是有类型的,它是一个tuple<string, int>,但auto意味着你不必明确编写这个。
存储类
在声明变量时,你可以指定它的存储类,这表示变量的生存期、链接(其他代码可以访问它的内容)和内存位置。
您已经看到了一个存储类static,当应用于函数中的变量时,意味着该变量只能在该函数内访问,但其生存期与程序相同。然而,static可以用于在文件范围内声明的变量,这种情况下表明该变量只能在当前文件中使用,这被称为内部链接。如果在文件范围内声明的变量上省略static关键字,则具有外部链接,这意味着变量的名称对其他文件中的代码可见。static关键字可以用于类的数据成员和类中定义的方法,这两者都有有趣的影响,将在第六章 类中进行描述。
static关键字表示该变量只能在当前文件中使用。extern关键字表示相反;变量(或函数)具有外部链接,并且可以在项目的其他文件中访问。在大多数情况下,您将在一个源文件中定义一个变量,然后在头文件中声明它为extern,以便在其他源文件中使用相同的变量。
最后一个存储类说明符是thread_local。这是 C++11 中的新功能,它只适用于多线程代码。本书不涉及线程,因此这里只会给出一个简要描述。
线程是执行和并发的单位。程序中可以有多个线程运行,可能有两个或更多个线程同时运行相同的代码。这意味着两个不同的执行线程可以访问和更改同一个变量。由于并发访问可能会产生不良影响,多线程代码通常涉及采取措施确保只有一个线程可以在任何时候访问数据。如果这样的代码没有小心编写,就有死锁的危险,其中线程的执行被暂停(在最坏的情况下,是无限期地)以独占访问变量,从而抵消了使用线程的好处。
thread_local存储类表示每个线程将有自己的变量副本。因此,如果两个线程访问同一个函数,并且该函数中的变量标记为thread_local,这意味着每个线程只看到它所做的更改。
您有时会在旧的 C++代码中看到存储类register的使用。这现在已经不推荐使用了。它被用作向编译器提示变量对程序性能有重要影响,并建议编译器尽可能使用 CPU 寄存器来保存变量。编译器可以忽略这个建议。事实上,在 C++11 中,编译器确实忽略了这个关键字;带有register变量的代码将编译而不会出现错误或警告,并且编译器将根据需要优化代码。
虽然它不是存储类说明符,但volatile关键字对编译器代码优化有影响。volatile关键字表示变量(可能通过直接内存访问(DMA)到某些硬件)可以被外部操作改变,因此对编译器来说很重要不要应用任何优化。
还有一个存储类修饰符叫做mutable。这只能用于类成员,因此将在第六章 类中进行介绍。
使用类型别名
有时类型的名称可能变得相当繁琐。如果您使用嵌套命名空间,类型的名称包括所有使用的命名空间。如果您定义参数化类型(本章迄今为止使用的示例是vector和tuple),参数会增加类型的名称。例如,我们之前看到了一个用于音乐家姓名和出生年份的容器:
// #include <string>
// #include <vector>
// #include <tuple>
vector<tuple<string, int> > beatles;
在这里,容器是vector,它包含tuple项,每个项将包含一个字符串和一个整数。为了使类型更易于使用,您可以定义一个预处理器符号:
#define name_year tuple<string, int>
现在您可以在代码中使用name_year而不是tuple,预处理器将在编译代码之前用该类型替换符号:
vector<name_year> beatles;
但是,由于#define是一个简单的搜索和替换,正如本书前面解释的那样,可能会出现问题。C++提供了typedef语句来为类型创建别名:
typedef tuple<string, int> name_year_t;
vector<name_year_t> beatles;
在这里,为tuple<string, int>创建了一个名为name_year_t的别名。
使用typedef时,别名通常位于行末,前面是它的别名。这与#define相反,其中您要定义的符号在#define之后,后面是其定义。还要注意,typedef以分号结束。对于函数指针,情况变得更加复杂,您将在第五章 使用函数中看到。
现在,无论何时您想使用tuple,都可以使用别名:
for (name_year_t musician : beatles)
{
cout << get<0>(musician) << " " << get<1>(musician) << endl;
}
您可以typedef别名:
typedef tuple<string, int> name_year_t;
typedef vector<name_year_t> musician_collection_t;
musician_collection_t beatles2;
beatles2变量的类型是vector<tuple<string, int>>。重要的是要注意,typedef创建一个别名;它不会创建新类型,因此您可以在原始类型和其别名之间切换。
typedef关键字是在 C++中创建别名的一种成熟方式。
C++11 引入了另一种创建类型别名的方法,即using语句:
using name_year = tuple<string, int>;
同样,这不会创建新类型,而是为相同类型创建新名称,从语义上讲,这与typedef相同。using语法可能比使用typedef更易读,它还允许您使用模板。
使用using方法创建别名比typedef更易读,因为赋值的使用遵循用于变量的约定,也就是说,左边的新名称用于=右边的类型。
在记录类型中聚合数据
通常,您将具有相关联且必须一起使用的数据:聚合类型。这样的记录类型允许您将数据封装到单个变量中。C++继承自 Cstruct和union,作为提供记录的方式。
结构
在大多数应用程序中,您将希望将多个数据项关联在一起。例如,您可能希望定义一个时间记录,其中每个时间都有一个整数:指定时间的小时、分钟和秒。您可以这样声明它们:
// start work
int start_sec = 0;
int start_min = 30;
int start_hour = 8;
// end work
int end_sec = 0
int end_min = 0;
int end_hour = 17;
这种方法变得相当繁琐且容易出错。没有封装,也就是说,_min变量可以独立于其他变量使用。当没有它所指的小时时,“小时过去的分钟”是否有意义?您可以定义一个结构,将这些项关联起来:
struct time_of_day
{
int sec;
int min;
int hour;
};
现在,您已经将三个值作为一个记录的一部分,这意味着您可以声明此类型的变量;尽管您可以访问单个项目,但很明显数据与其他成员相关联:
time_of_day start_work;
start_work.sec = 0;
start_work.min = 30;
start_work.hour = 8;
time_of_day end_work;
end_work.sec = 0;
end_work.min = 0;
end_work.hour = 17;
print_time(start_work);
print_time(end_work);
现在我们有两个变量:一个表示开始时间,另一个表示结束时间。struct的成员封装在struct内部,也就是说,您通过struct的实例访问成员。为此,您使用点运算符。在此代码中,start_work.sec表示您正在访问名为start_work的time_of_day结构的实例的sec成员。结构的成员默认为public,也就是说,struct外部的代码可以访问成员。
类和结构可以指示成员访问级别,第六章 类将展示如何做到这一点。例如,可以将struct的某些成员标记为private,这意味着只有类型的成员才能访问成员。
调用名为print_time的辅助函数以将数据打印到控制台:
void print_time(time_of_day time)
{
cout << setw(2) << setfill('0') << time.hour << ":";
cout << setw(2) << setfill('0') << time.min << ":";
cout << setw(2) << setfill('0') << time.sec << endl;
}
在这种情况下,使用setw和setfill操作器将下一个插入的项目的宽度设置为两个字符,并用零填充任何未填充的位置(更多细节将在第九章,“使用字符串”中给出;实际上,setw给出了下一个插入数据所占列的大小,setfill指定了所使用的填充字符)。
第五章,“使用函数”,将更详细地介绍将结构传递给函数的机制以及最有效的方法,但是为了本节的目的,我们将在这里使用最简单的语法。重要的是,调用者使用struct关联了三个数据项,并且所有数据项可以作为一个单元传递给函数。
初始化
有几种初始化结构实例的方法。前面的代码显示了一种方法:使用点运算符访问成员,并为其赋值。您还可以通过一个特别提供的名为构造函数的函数为struct的实例分配值。由于有关如何命名构造函数以及您可以在其中执行的特殊规则,这将留到第六章,“类”。
您还可以使用列表初始化程序语法使用大括号({})初始化结构。大括号中的项目应与struct的成员按照声明的成员顺序匹配。如果提供的值少于成员数量,则其余成员将初始化为零。实际上,如果在大括号之间不提供任何项目,则所有成员都将设置为零。如果提供的初始化程序多于成员数量,则会出错。因此,使用先前定义的time_of_day记录类型:
time_of_day lunch {0, 0, 13};
time_of_day midnight {};
time_of_day midnight_30 {0, 30};
在第一个示例中,lunch变量被初始化为下午 1 点。请注意,因为hour成员被声明为类型中的第三个成员,所以它是使用初始化列表中的第三个项目进行初始化的。在第二个示例中,所有成员都设置为零,当然,零小时是午夜。第三个示例提供了两个值,因此这些值用于初始化sec和min。
您可以有一个struct的成员本身是一个struct,并且可以使用嵌套的大括号进行初始化:
struct working_hours
{
time_of_day start_work;
time_of_day end_work;
};
working_hours weekday{ {0, 30, 8}, {0, 0, 17} };
cout << "weekday:" << endl;
print_time(weekday.start_work);
print_time(weekday.end_work);
结构字段
结构可以有最小为单个位的成员,称为位字段。在这种情况下,您声明一个整数成员,该成员将占用成员的位数。您可以声明未命名的成员。例如,您可能有一个结构,其中包含有关项目长度以及项目是否已更改(脏)的信息。此引用的项目的最大大小为 1,023,因此您需要一个宽度至少为 10 位的整数来保存这个信息。您可以使用unsigned short来保存长度和脏信息:
void print_item_data(unsigned short item)
{
unsigned short size = (item & 0x3ff);
char *dirty = (item > 0x7fff) ? "yes" : "no";
cout << "length " << size << ", ";
cout << "is dirty: " << dirty << endl;
}
此代码将信息分开,然后将其打印出来。这样的位图对代码来说非常不友好。您可以使用struct来保存这些信息,使用unsigned short来保存 10 位长度信息,使用bool来保存脏信息。使用位字段,您可以定义结构如下:
struct item_length
{
unsigned short len : 10;
unsigned short : 5;
bool dirty : 1;
};
len成员标记为unsigned short,但只需要 10 位,因此使用冒号语法进行了说明。同样,一个布尔值可以仅用一个位来保存。结构指示两个值之间有五位未使用,因此没有名称。
字段只是一种便利。尽管看起来item_length结构应该只占用 16 位(unsigned short),但不能保证编译器会这样做。如果您从文件或网络流接收到unsigned short,则必须自己提取位:
unsigned short us = get_length();
item_length slen;
slen.len = us & 0x3ff;
slen.dirty = us > 0x7fff;
使用结构名
在某些情况下,你可能需要在实际定义之前使用类型。只要你不使用成员,你可以在定义之前声明类型:
struct time_of_day;
void print_day(time_of_day time);
这可以在头文件中声明,在那里它说有一个在其他地方定义的函数,它接受一个time_of_day记录并将其打印出来。要能够声明print_day函数,你必须已经声明了time_of_day名称。time_of_day结构必须在代码的其他地方定义,然后才能定义函数,否则你将会得到一个未定义类型的错误。
然而,有一个例外:在类型完全声明之前,类型可以保存指向相同类型实例的指针。这是因为编译器知道指针的大小,所以它可以为成员分配足够的内存。只有在整个类型定义之后,你才能创建类型的实例。这个经典的例子是链表,但由于这需要使用指针和动态分配,这将留到下一章节。
确定对齐
结构的一个用途是,如果你知道数据在内存中的存储方式,你可以将结构作为内存块处理。如果你有一个映射到内存中的硬件设备,不同的内存位置指向控制或返回设备值的值。访问设备的一种方式是定义一个与设备的直接内存访问到 C++类型的内存布局匹配的结构。此外,结构对于文件或需要通过网络传输的数据包也是有用的:你操作结构,然后将结构占用的内存复制到文件或网络流中。
结构的成员在内存中按照它们在类型中声明的顺序排列。项将占用至少每个类型所需的内存。成员可能占用的内存比类型所需的内存更多,这是一种叫做对齐的机制。
编译器将以最有效的方式将变量放置在内存中,无论是在内存使用还是访问速度方面。各种类型将对齐到对齐边界。例如,32 位整数将对齐到四字节边界,如果下一个可用的内存位置不在这个边界上,编译器将跳过几个字节,并将整数放在下一个对齐边界上。你可以使用alignof运算符传递类型名称来测试特定类型的对齐方式:
cout << "alignment boundary for int is " 0
<< alignof(int) << endl; // 4
cout << "alignment boundary for double is "
<< alignof(double) << endl; // 8
int的对齐方式是 4,这意味着int变量将被放置在内存中的下一个四字节边界上。double的对齐方式是 8,这是有道理的,因为在 Visual C++中,double占用八个字节。到目前为止,alignof的结果看起来与sizeof是一样的;然而,事实并非如此。
cout << "alignment boundary for time_of_day is "
<< alignof(time_of_day) << endl; // 4
这个例子打印了time_of_day结构的对齐方式,我们之前定义为三个整数。这个struct的对齐方式是 4,也就是说,struct中最大项的对齐方式。这意味着time_of_day的实例将被放置在 4 字节边界上;它并没有说明time_of_day变量内的项将如何对齐。
例如,考虑以下struct,它有四个成员,分别占用一、二、四和八个字节:
struct test
{
uint8_t uc;
uint16_t us;
uint32_t ui;
uint64_t ull;
}
编译器会告诉你对齐是 8(最大项ull的对齐),但大小是 16,这可能看起来有点奇怪。如果每个项都对齐在 8 字节边界上,那么大小将是 32(四倍八)。如果项被存储在内存中并尽可能有效地打包,那么大小将是 15。相反,实际发生的是第二个项在两字节边界上对齐,这意味着在uc和us之间有一个字节的未使用空间。
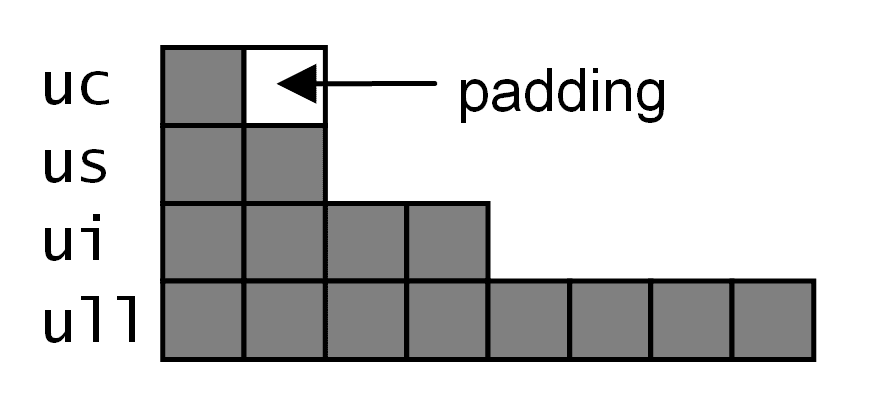
如果要将内部项对齐到与uint32_t变量使用的相同边界上,可以使用alignas标记一个项,并给出所需的对齐方式。请注意,因为 8 大于 4,因此在 8 字节边界上对齐的任何项也将在 4 字节边界上对齐:
struct test
{
uint8_t uc;
alignas(uint32_t) uint16_t us;
uint32_t ui;
uint64_t ull;
}
uc项已经对齐在 4 字节边界上(alignof(test)将为 8),它将占用一个字节。us成员是一个uint16_t,但标有alignas(uint32_t),表示它应该与uint32_t以相同的方式对齐,即在 4 字节边界上。这意味着uc和us都将在提供填充的 4 字节边界上。当然,ui成员也将对齐在 4 字节边界上,因为它是一个uint32_t。
如果struct只有这三个成员,那么大小将是 12。然而,struct还有另一个成员,即 8 字节的ull成员。这必须对齐在 8 字节边界上,这意味着从struct的开始到 16 字节,因此在ui和ull之间需要有 4 字节的填充。因此,test的大小现在报告为 24:uc和us各占 4 字节(因为接下来的项ui必须对齐在下一个 4 字节边界上),ull占 8 字节(因为它是一个 8 字节整数),ui占 8 字节,因为接下来的项(ull)必须在下一个 8 字节边界上。
以下图表显示了test类型的各个成员在内存中的位置:

您不能使用alignas来放宽对齐要求,因此您不能将uint64_t变量标记为在不是 8 字节边界的情况下对齐在两字节边界上。
在大多数情况下,您不需要担心对齐;但是,如果您正在访问内存映射设备或来自文件的二进制数据,如果您可以直接将这些数据映射到一个struct,那将非常方便,在这种情况下,您将发现必须非常注意对齐。这被称为纯旧数据,您经常会看到struct被称为POD 类型。
POD 是一个非正式的描述,有时用来描述具有简单构造并且没有虚拟成员的类型(参见第六章,类和第七章,面向对象编程简介)。标准库提供了<type_traits>中的一个名为is_pod的函数,用于测试这些成员的类型。
在同一内存中存储数据的联合
联合是一个结构,其中所有成员占用相同的内存。这种类型的大小是最大成员的大小。由于联合只能容纳一个数据项,它是一种以多种方式解释数据的机制。
联合的一个示例是用于在 Microsoft 的组件对象模型(COM)中的对象链接和嵌入(OLE)对象之间传递数据的VARIANT类型。VARIANT类型可以容纳 COM 能够在 OLE 对象之间传输的任何数据类型的数据。有时,OLE 对象将在同一个进程中,但它们也可能在同一台机器上的不同进程中,或者在不同的机器上。COM 保证可以在不需要开发人员提供任何额外的网络代码的情况下传输VARIANT。结构很复杂,但这里显示了一个编辑过的版本:
// edited version
struct VARIANT
{
unsigned short vt;
union
{
unsigned char bVal;
short iVal;
long lVal;
long long llVal;
float fltVal;
double dblVal;
};
};
注意,您可以使用没有名称的联合:这是一个匿名的union,从成员访问的角度来看,您访问联合的成员就像访问包含它的VARIANT的成员一样。union包含可以在 OLE 对象之间传输的每种类型的成员,并且vt成员指示使用哪种类型。当您创建VARIANT实例时,必须将vt设置为适当的值,然后初始化相关的成员:
enum VARENUM
{
VT_EMPTY = 0,
VT_NULL = 1,
VT_UI1 = 17,
VT_I2 = 2,
VT_I4 = 3,
VT_I8 = 20,
VT_R4 = 4,
VT_R8 = 5
};
这条记录确保只使用所需的内存,并且从一个进程传输数据到另一个进程的代码将能够读取vt成员,以确定数据需要如何被处理以便传输:
// pseudo code, real VARIANT should not be handled like this
VARIANT var {}; // clear all items
var.vt = VT_I4; // specify the type
var.lVal = 42; // set the appropriate member
pass_to_object(var);
请注意,你必须自律,只初始化适当的成员。当你的代码接收到一个VARIANT时,你必须读取vt来查看应该使用哪个成员来访问数据。
一般来说,当使用联合时,你应该只访问你初始化的项目:
union d_or_i {double d; long long i};
d_or_i test;
test.i = 42;
cout << test.i << endl; // correct use
cout << test.d << endl; // nonsense printed
访问运行时类型信息
C++提供了一个名为typeid的运算符,它将在运行时返回关于变量(或类型)的类型信息。运行时类型信息(RTTI)在你使用可以以多态方式使用的自定义类型时很重要;具体细节将留到后面的章节。RTTI 允许你在运行时检查变量的类型并相应地处理变量。RTTI 通过一个type_info对象返回(在<typeinfo>头文件中):
cout << "int type name: " << typeid(int).name() << endl;
int i = 42;
cout << "i type name: " << typeid(i).name() << endl;
在这两种情况下,你会看到int作为类型被打印出来。type_info类定义了比较运算符(==和!=),所以你可以比较类型:
auto a = i;
if (typeid(a) == typeid(int))
{
cout << "we can treat a as an int" << endl;
}
确定类型限制
<limits>头文件包含一个名为numeric_limits的模板类,通过为每种内置类型提供的特化来使用。使用这些类的方法是在尖括号中提供你想要获取信息的类型,然后使用作用域解析运算符(::)在类上调用static成员。(有关类上的static函数的完整详情将在第六章中给出,类)。以下将int类型的限制打印到控制台:
cout << "The int type can have values between ";
cout << numeric_limits<int>::min() << " and ";
cout << numeric_limits<int>::max() << endl;
在类型之间进行转换
即使你非常努力地在你的代码中使用正确的类型,最终你会发现你必须在不同类型之间进行转换。例如,你可能正在使用返回特定类型值的库函数,或者你可能正在从外部来源读取与你的例程不同类型的数据。
对于内置类型,有关不同类型之间的转换有标准规则,其中一些将是自动的。例如,如果你有一个表达式a + b,并且a和b是不同的类型,那么,如果可能的话,编译器将自动将一个变量的值转换为另一个变量的类型,并调用该类型的+运算符。
在其他情况下,你可能需要强制一种类型转换为另一种类型,以便调用正确的运算符,这将需要某种类型的转换。C++允许你使用类似 C 的转换,但这些转换没有运行时测试,因此最好使用 C++转换,它具有各种级别的运行时检查和类型安全性。
类型转换
内置转换可能有两种结果:提升或缩小。提升是指将较小的类型提升为较大的类型,不会丢失数据。缩小转换发生在将较大类型的值转换为较小类型的值时,可能会丢失数据。
提升转换
在混合类型表达式中,编译器将尝试将较小的类型提升为较大的类型。因此,char或short可以在需要int的表达式中使用,因为它可以被提升为较大的类型而不会丢失数据。
考虑一个声明为接受int参数的函数:
void f(int i);
我们可以写:
short s = 42;
f(s); // s is promoted to int
这里变量s被悄悄地转换为int。有些情况可能看起来很奇怪:
bool b = true;
f(b); // b is promoted to int
再次强调,转换是悄悄进行的。编译器假设你知道自己在做什么,你的意图是希望false被视为 0,true被视为 1。
缩小转换
在某些情况下,缩小会发生。一定要非常小心,因为这会丢失数据。在下面的示例中,尝试将double转换为int。
int i = 0.0;
这是允许的,但编译器会发出警告:
C4244: 'initializing': conversion from 'double' to 'int', possible loss of data
这段代码显然是错误的,但这个错误并不是一个错误,因为它可能是有意的。例如,在下面的代码中,我们有一个函数,它有一个浮点参数,并且在例程中,参数用来初始化一个int:
void calculation(double d)
{
// code
int i = d;
// use i
// other code
}
这可能是有意的,但因为会丢失精度,你应该记录为什么这样做。至少使用一个转换操作符,这样很明显你理解了这个行为的后果。
缩小到 bool
如前所述,指针、整数和浮点值可以在非零值转换为true,零值转换为false的地方隐式转换为bool。这可能导致一个难以注意到的严重错误:
int x = 0;
if (x = 1) cout << "not zero" << endl;
else cout << "is zero" << endl;
在这里,编译器看到赋值表达式x = 1,这是一个 bug;它应该是比较x == 1。然而,这是有效的 C++,因为表达式的值是 1,编译器会将其转换为true的bool值。这段代码将编译而不会有警告,不仅会产生一个与你期望相反的结果(你会在控制台上看到not zero打印出来),而且赋值会改变变量的值,从而在整个程序中传播错误。
通过养成一个习惯,总是构造一个比较,使得潜在赋值的 rvalue 在左边,很容易避免这个 bug。在比较中,将没有 rvalue 或 lvalue 的概念,因此这使用编译器来捕捉一个意外的赋值:
if (1 = x) // error
cout << "not zero" << endl;
转换有符号类型
有符号到无符号的转换可能会发生,导致意外的结果。例如:
int s = -3;
unsigned int u = s;
unsigned short变量将被赋值为0xfffffffd,即 3 的二进制补码。这可能是你想要的结果,但这是一个奇怪的方式来得到它。
有趣的是,如果你尝试比较这两个变量,编译器会发出一个警告:
if (u < s) // C4018
cout << "u is smaller than s" << endl;
这里给出的 Visual C++警告 C4018 是'<': signed/unsigned mismatch,它表示你不能比较有符号和无符号类型,这样做需要一个转换。
转换
在某些情况下,你需要在不同类型之间进行转换。例如,这可能是因为数据以不同的类型提供给你用来处理它的例程。你可能有一个库,它将浮点数作为float处理,但你的数据是以double输入的。你知道转换会丢失精度,但知道这对最终结果几乎没有影响,所以你不希望编译器警告你。你想告诉编译器,将一种类型强制转换为另一种类型是可以接受的。
下表总结了 C++11 中可以使用的各种转换操作:
| 名称 | 语法 |
|---|---|
| 构造 | {} |
移除const要求 | const_cast |
| 没有运行时检查的转换 | static_cast |
| 类型的位转换 | reinterpret_cast |
| 在类指针之间进行转换,带有运行时检查 | dynamic_cast |
| C 风格 | () |
| 函数风格 | () |
放弃 const-ness
如上一章所述,const修饰符用于指示编译器一个项目不会改变,并且你的代码尝试改变项目是一个错误。还有另一种使用这个修饰符的方法,将在下一章中探讨。当const应用于指针时,它表示指针指向的内存不能被改变:
char *ptr = "0123456";
// possibly lots of code
ptr[3] = '\0'; // RUNTIME ERROR!
这段糟糕的代码告诉编译器创建一个值为0123456的字符串常量,然后将这个内存的地址放入字符串指针ptr。最后一行尝试写入字符串。这将编译,但会在运行时导致访问冲突。将const应用于指针声明将确保编译器检查这种情况:
const char *ptr = "0123456";
更典型的情况是将const应用于函数参数的指针,意图是相同的:它向编译器指示指针指向的数据应该是只读的。然而,可能存在你想要删除这样一个指针的const属性的情况,这可以使用const_cast操作符来实现:
char * pWriteable = const_cast<char *>(ptr);
pWriteable[3] = '\0';
语法很简单。要转换为的类型在尖括号(<>)中给出,变量(一个const指针)在括号中提供。
您还可以将指针转换为const指针。这意味着您可以有一个指针用于访问内存,以便您可以对其进行写入,然后在进行更改后,您可以创建一个指向内存的const指针,从而通过指针使内存只读。
显然,一旦你取消指针的 const 属性,你就要对写入内存造成的损害负责,所以你的代码中的const_cast操作符是你在代码审查期间检查代码的一个良好标记。
不带运行时检查的转换
大多数转换都是使用static_cast操作符执行的,它可以用于将指针转换为相关的指针类型,以及在不同数值类型之间进行转换。不执行运行时检查,因此您应该确信转换是可接受的:
double pi = 3.1415;
int pi_whole = static_cast<int>(pi);
在这里,double 被转换为 int,这意味着小数部分被丢弃。通常编译器会发出警告,表示数据丢失,但static_cast操作符表明这是你的意图,因此不会发出警告。
该操作符通常用于将void*指针转换为类型化指针。在下面的代码中,unsafe_d函数假设参数是指向内存中 double 值的指针,因此它可以将void*指针转换为double*指针。与pd指针一起使用的*操作符解引用指针以提供它指向的数据。因此,*pd表达式将返回一个double。
void unsafe_d(void* pData)
{
double* pd = static_cast<double*>(pData);
cout << *pd << endl;
}
这是不安全的,因为您依赖调用者确保指针实际上指向double。可以这样调用它:
void main()
{
double pi = 3.1415;
unsafe_d(&pi); // works as expected
int pi_whole = static_cast<int>(pi);
unsafe_d(&pi_whole); // oops!
}
&操作符将操作数的内存地址作为类型化指针返回。在第一种情况下,获得一个double*指针并传递给unsafe_d函数。编译器将自动将此指针转换为void*参数。编译器会自动执行此操作,而不检查指针在函数中是否被正确使用。这可以通过对unsafe_d的第二次调用来说明,在这次调用中,int*指针被转换为void*参数,然后在unsafe_d函数中,它被static_cast转换为double*,即使指针指向int。因此,解引用将返回不可预测的数据,cout将打印无意义的内容。
不带运行时检查的转换
reinterpret_cast操作符允许将一个类型的指针转换为另一个类型的指针,并且可以从指针转换为整数,从整数转换为指针:
double pi = 3.1415;
int i = reinterpret_cast<int>(&pi);
cout << hex << i << endl;
与static_cast不同,此操作符始终涉及指针:在指针之间进行转换,从指针转换为整数类型,或者从整数类型转换为指针。在这个例子中,将指向double变量的指针转换为int,并将值打印到控制台。实际上,这打印出了变量的内存地址。
带有运行时检查的转换
dynamic_cast操作符用于在相关类之间转换指针,因此将在第六章 类中进行解释。此操作符涉及运行时检查,因此只有在操作数可以转换为指定类型时才执行转换。如果转换不可能,则操作符返回nullptr,使您有机会仅使用指向该类型的实际对象的转换指针。
使用列表初始化符进行转换
C++编译器将允许一些隐式转换;在某些情况下,它们可能是有意的,在某些情况下可能不是。例如,以下代码类似于之前显示的代码:变量初始化为double值,然后稍后在代码中用于初始化int。编译器将执行转换,并发出警告:
double pi = 3.1415;
// possibly loss of code
int i = pi;
如果忽略警告,则可能不会注意到这种精度损失,这可能会导致问题。解决此问题的一种方法是使用花括号进行初始化:
int i = {pi};
在这种情况下,如果pi可以在不损失的情况下转换为int(例如,如果pi是short),则代码将甚至不会发出警告而编译。但是,如果pi是不兼容的类型(在这种情况下是double),编译器将发出错误:
C2397: conversion from 'double' to 'int' requires a narrowing conversion
这是一个有趣的例子。char类型是一个整数,但来自osteam类的char的<<运算符将char变量解释为字符,而不是数字,如下所示:
char c = 35;
cout << c << endl;
这将在控制台上打印#,而不是 35,因为 35 是#的 ASCII 码。要使变量被视为数字,可以使用以下之一:
cout << static_cast<short>(c) << endl;
cout << short{ c } << endl;
正如您所看到的,第二个版本(构造)与第一个版本一样可读,但比第一个版本更短。
使用 C 转换
最后,您可以使用 C 样式转换,但这些仅提供以便您可以编译旧代码。您应该改用 C++转换之一。为了完整起见,这里显示了 C 样式转换:
double pi = 3.1415;
float f1 = (float)pi;
float f2 = float(pi);
有两个版本:第一个转换运算符将括号放在要转换的类型周围,而在第二个版本中,转换看起来像函数调用。在这两种情况下,最好使用static_cast,以便进行编译时检查。
使用 C++类型
在本章的最后部分,我们将开发一个命令行应用程序,允许您以混合字母数字和十六进制格式打印文件的内容。
应用程序必须以文件名运行,但是您可以选择指定要打印多少行。该应用程序将在控制台上打印文件的内容,每行 16 个字节。左侧显示十六进制表示,右侧显示可打印表示(如果字符不在可打印的非扩展 ASCII 范围内,则显示一个点)。

在C:\Beginning_C++下创建一个名为Chapter_03的新文件夹。启动 Visual C++并创建一个 C++源文件,并将其保存到刚创建的文件夹中,命名为hexdump.cpp。添加一个简单的main函数,允许应用程序接受参数,并使用 C++流提供输入和输出支持:
#include <iostream>
using namespace std;
int main(int argc, char* argv[])
{
}
该应用程序最多有两个参数:第一个是文件名,第二个是要在命令行上打印的 16 字节块的数量。这意味着您需要检查参数是否有效。首先添加一个usage函数,以提供应用程序参数,并且如果使用非空参数调用,则打印出错误消息:
void usage(const char* msg)
{
cout << "filedump filename blocks" << endl;
cout << "filename (mandatory) is the name of the file to dump"
<< endl;
cout << "blocks (option) is the number of 16 byte blocks "
<< endl;
if (nullptr == msg) return;
cout << endl << "Error! ";
cout << msg << endl;
}
在main函数之前添加此函数,以便您可以从那里调用它。该函数可以使用指向 C 字符串的指针或nullptr来调用。参数是const,指示编译器在函数中不会更改字符串,因此如果有任何尝试更改字符串,编译器将生成错误。
将以下行添加到main函数中:
int main(int argc, char* argv[])
{
if (argc < 2) { usage("not enough parameters"); return 1; } if (argc > 3) { usage("too many parameters"); return 1; } // the second parameter is file name string filename = argv[1];
}
编译文件并确认没有拼写错误。由于此应用程序使用 C++标准库,因此必须使用/EHsc开关提供对 C++异常的支持:
cl /EHsc hexdump.cpp
您可以通过从命令行调用该应用程序并使用零、一个、两个,然后三个参数来测试它。确认该应用程序只允许在命令行上使用一个或两个参数进行调用(实际上意味着使用两个或三个参数,因为argc和argv包括应用程序名称)。
下一个任务是确定用户是否提供了一个数字来指示要将多少个 16 字节块转储到控制台,如果是的话,将命令行提供的字符串转换为整数。这段代码将使用istringstream类将字符串转换为数字,所以你需要包含定义这个类的头文件。在文件的顶部添加以下内容:
#include <iostream>
#include <sstream>
在filename变量声明之后添加以下突出显示的代码:
string filename = argv[1];
int blocks = 1; // default value if (3 == argc) { // we have been passed the number of blocks istringstream ss(argv[2]); ss >> blocks; if (ss.fail() || 0 >= blocks) { // cannot convert to a number usage("second parameter: must be a number," "and greater than zero"); return 1; } }
默认情况下,应用程序将从文件中转储一行数据(最多 16 字节)。如果用户提供了不同数量的行,字符串格式的数字将通过istringstream对象转换为整数。这个对象被初始化为参数,然后从流对象中提取数字。如果用户输入了零值,或者输入的值无法解释为字符串,代码将打印错误消息。错误字符串被分成两行,但仍然是一个字符串。
注意,if语句使用了短路运算;也就是说,如果表达式的第一部分(ss.fail(),表示转换失败)为true,那么第二个表达式(0 >= blocks,也就是blocks必须大于零)将不会被评估。
编译这段代码并尝试几次。例如:
hexdump readme.txt
hexdump readme.txt 10
hexdump readme.txt 0
hexdump readme.txt -1
前两个应该可以正常运行;后两个应该会生成错误。
不用担心readme.txt不存在,因为它只是作为一个测试参数存在。
接下来,你将添加打开文件并处理它的代码。由于你将使用ifstream类从文件中输入数据,所以在文件的顶部添加以下头文件:
#include <iostream>
#include <sstream>
#include <fstream>
然后在main函数的底部添加打开文件的代码:
ifstream file(filename, ios::binary);
if (!file.good())
{
usage("first parameter: file does not exist");
return;
}
while (blocks-- && read16(file) != -1);
file.close();
第一行创建了一个名为file的流对象,并将其附加到filename中给定路径的文件。如果找不到文件,good函数将返回false。这段代码使用!运算符否定值,所以如果文件不存在,则执行if后面大括号中的语句。如果文件存在并且ifstream对象可以打开它,数据将以 16 字节的方式一次读取一次在while循环中。请注意,在这段代码的末尾,file对象上调用了close函数。当你完成资源的使用时,显式关闭资源是一个好的做法。
read16函数将按字节访问文件,包括不可打印的字节,因此像\r或\n这样的控制字符没有特殊含义,并且仍然会被读取。然而,流类以特殊方式处理\r字符:这被视为一行的结束,通常流会默默地消耗这个字符。为了防止这种情况,我们使用ios::binary以二进制模式打开文件。
再次审查while语句:
while (blocks-- && read16(file) != -1);
这里有两个表达式。第一个表达式递减blocks变量,该变量保存将要打印的 16 字节块的数量。后缀递减意味着表达式的值是递减之前的变量值,所以如果在blocks为零时调用表达式,整个表达式会被短路,while循环结束。如果第一个表达式非零,则调用read16函数,如果返回值为-1(到达文件结尾),则循环结束。循环的实际工作发生在read16函数内部,所以while循环语句是空语句。
现在你必须在main函数的上面实现read16函数。这个函数将使用一个常量来定义每个块的长度,所以在文件的顶部附近添加以下声明:
using namespace std;
const int block_length = 16;
在main函数之前,添加以下代码:
int read16(ifstream& stm)
{
if (stm.eof()) return -1;
int flags = cout.flags();
cout << hex;
string line;
// print bytes
cout.setf(flags);
return line.length();
}
这只是函数的框架代码。你将在一会儿添加更多的代码。
这个函数每次最多读取 16 个字节,并将这些字节的内容打印到控制台。返回值是读取的字节数,如果到达文件末尾则返回-1。注意用于将流对象传递给函数的语法。这是一个引用,一种指向实际对象的指针类型。之所以使用引用是因为如果不这样做,函数将得到流的副本。引用将在下一章中介绍,使用对象引用作为函数参数将在第五章中介绍,使用函数。
这个函数测试的第一行是验证是否已经到达文件末尾,如果是,就不能再进行处理,返回-1 的值。代码将操作cout对象(例如插入hex操纵器);所以你总是知道函数外部的cout对象的状态,函数确保在返回时cout对象的状态与调用函数时相同。通过调用flags函数获取cout对象的初始格式状态,并在函数返回之前通过调用setf函数重置cout对象。
这个函数什么也不做,所以可以安全地编译文件并确认没有拼写错误。
read16函数有三个作用:
-
它按字节读取,最多 16 个字节。
-
它打印出每个字节的十六进制值。
-
它打印出字节的可打印值。
这意味着每行有两部分:左边是十六进制部分,右边是可打印部分。用突出显示的代码替换函数中的注释:
string line;
for (int i = 0; i < block_length; ++i) { // read a single character from the stream unsigned char c = stm.get(); if (stm.eof())
break; // need to make sure that all hex are printed
// two character padded with zeros cout << setw(2) << setfill('0'); cout << static_cast<short>(c) << " "; if (isprint(c) == 0) line += '.'; else line += c; }
for循环将最多循环block_length次。第一条语句从流中读取一个字符。这个字节被作为原始数据读取。如果get发现流中没有更多的字符,它将在流对象中设置一个标志,并通过调用eof函数进行测试。如果eof函数返回true,意味着已经到达文件末尾,所以for循环结束,但函数不会立即返回。原因是可能已经读取了一些字节,所以必须进行更多的处理。
循环中的其余语句有两个作用:
-
有语句在控制台打印字符的十六进制值
-
有一条语句将字符以可打印形式存储在
line变量中。
我们已经将cout对象设置为输出十六进制值,但如果字节小于 0x10,则值不会以零为前缀打印。为了获得这种格式,我们插入setw操纵器,表示插入的数据将占用两个字符位置,并且setfill表示使用0字符填充字符串。这两个操纵器在<iomanip>头文件中可用,所以将它们添加到文件的顶部:
#include <fstream>
#include <iomanip>
通常,当你将一个char插入流中时,字符值会显示出来,所以char变量被转换为short,以便流打印十六进制数值。最后,每个项目之间打印一个空格。
for循环中的最后几行在这里显示:
if (isprint(c) == 0) line += '.';
else line += c;
这段代码检查字节是否是可打印字符(" “到”~")使用isprint宏,如果字符是可打印的,它就被追加到line变量的末尾。如果字节不可打印,则在line变量的末尾追加一个点作为占位符。
到目前为止的代码将按顺序将字节的十六进制表示打印到控制台,唯一的格式是字节之间的空格。如果要测试代码,可以编译并在源文件上运行它:
hexdump hexdump.cpp 5
你会看到一些难以理解的东西,比如下面的内容:
C:\Beginning_C++\Chapter_03>hexdump hexdump.cpp 5
23 69 6e 63 6c 75 64 65 20 3c 69 6f 73 74 72 65 61 6d 3e 0d 0a
23 69 6e 63 6c 75 64 65 20 3c 73 73 74 72 65 61 6d 3e 0d 0a 23
69 6e 63 6c 75 64 65 20 3c 66 73 74 72 65 61 6d 3e 0d 0a 23 69
6e 63 6c 75 64 65 20 3c 69 6f 6d 61 6e 69 70 3e 0d
23的值是#,20是空格,0d和0a是回车和换行。
现在我们需要打印line变量中的字符表示,并进行一些格式化,并添加换行符。在for循环之后,添加以下内容:
string padding = " ";
if (line.length() < block_length)
{
padding += string(
3 * (block_length - line.length()), ' ');
}
cout << padding;
cout << line << endl;
十六进制显示和字符显示之间至少会有两个空格。一个空格来自for循环中打印的最后一个字符,第二个空格在padding变量的初始化中提供。
每行的最大字节数应为 16 字节(block_length),因此控制台上打印 16 个十六进制值。如果读取的字节数少于 16 个,则需要额外的填充,以便在连续的行上字符表示对齐。实际读取的字节数将是通过调用length函数获得的line变量的长度,因此缺少的字节数是表达式block_length - line.length()。由于每个十六进制表示占用三个字符(两个用于数字,一个用于空格),所需的填充是缺少字节数的三倍。为了创建适当数量的空格,将使用字符串构造函数调用两个参数:复制的数量和要复制的字符。
最后,这个填充字符串被打印到控制台,后面是字节的字符表示。
此时,您应该能够编译代码而不会出现错误或警告。当您在源文件上运行代码时,您应该会看到类似以下的内容:
C:\Beginning_C++\Chapter_03>hexdump hexdump.cpp 5
23 69 6e 63 6c 75 64 65 20 3c 69 6f 73 74 72 65 #include <iostre
61 6d 3e 0d 0a 23 69 6e 63 6c 75 64 65 20 3c 73 am>..#include <s
73 74 72 65 61 6d 3e 0d 0a 23 69 6e 63 6c 75 64 stream>..#includ
65 20 3c 66 73 74 72 65 61 6d 3e 0d 0a 23 69 6e e <fstream>..#in
63 6c 75 64 65 20 3c 69 6f 6d 61 6e 69 70 3e 0d clude <iomanip>.
现在这些字节更有意义了。由于应用程序不会更改转储的文件,因此可以放心地在二进制文件上使用此工具,包括本身:
C:\Beginning_C++\Chapter_03>hexdump hexdump.exe 17
4d 5a 90 00 03 00 00 00 04 00 00 00 ff ff 00 00 MZ..............
b8 00 00 00 00 00 00 00 40 00 00 00 00 00 00 00 ........@.......
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
00 00 00 00 00 00 00 00 00 00 00 00 00 01 00 00 ................
0e 1f ba 0e 00 b4 09 cd 21 b8 01 4c cd 21 54 68 ........!..L.!Th
69 73 20 70 72 6f 67 72 61 6d 20 63 61 6e 6e 6f is program canno
74 20 62 65 20 72 75 6e 20 69 6e 20 44 4f 53 20 t be run in DOS
6d 6f 64 65 2e 0d 0d 0a 24 00 00 00 00 00 00 00 mode....$.......
2b c4 3f 01 6f a5 51 52 6f a5 51 52 6f a5 51 52 +.?.o.QRo.QRo.QR
db 39 a0 52 62 a5 51 52 db 39 a2 52 fa a5 51 52 .9.Rb.QR.9.R..QR
db 39 a3 52 73 a5 51 52 b2 5a 9a 52 6a a5 51 52 .9.Rs.QR.Z.Rj.QR
6f a5 50 52 30 a5 51 52 8a fc 52 53 79 a5 51 52 o.PR0.QR..RSy.QR
8a fc 54 53 54 a5 51 52 8a fc 55 53 2f a5 51 52 ..TST.QR..US/.QR
9d fc 54 53 6e a5 51 52 9d fc 53 53 6e a5 51 52 ..TSn.QR..SSn.QR
52 69 63 68 6f a5 51 52 00 00 00 00 00 00 00 00 Richo.QR........
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
50 45 00 00 4c 01 05 00 6b e7 07 58 00 00 00 00 PE..L...k..X....
MZ 表示这是 Microsoft 的可移植可执行文件(PE)文件格式的 DOS 头部部分。实际的 PE 头部从底部一行的字符 PE 开始。
总结
在本章中,您已经了解了 C++中各种内置类型的初始化和使用方法。您还学会了如何使用转换运算符将变量转换为不同的类型。本章还向您介绍了记录类型,这是一个将在第六章 类中进一步扩展的主题。最后,您已经看到了各种指针的示例,这是下一章将更详细地探讨的主题。
第四章:处理内存、数组和指针
C++允许您通过指针直接访问内存。这为您提供了很大的灵活性,潜在地可以通过消除一些不必要的数据复制来提高代码的性能。然而,它也提供了额外的错误来源;一些错误对您的应用程序可能是致命的,甚至更糟(是的,比致命更糟!),因为对内存缓冲区的不良使用可能会在您的代码中打开安全漏洞,从而允许恶意软件接管机器。显然,指针是 C++的一个重要方面。
在本章中,您将学习如何声明指针并将其初始化为内存位置,如何在堆栈上分配内存和 C++自由存储器,并如何使用 C++数组。
在 C++中使用内存
C++使用与 C 相同的语法来声明指针变量并将它们分配给内存地址,并且具有类似 C 的指针算术。与 C 一样,C++还允许您在堆栈上分配内存,因此在堆栈帧被销毁时会自动清理内存,并且动态分配(在 C++自由存储器上),程序员有责任释放内存。本节将涵盖这些概念。
使用 C++指针语法
C++中访问内存的语法很简单。&运算符返回一个对象的地址。这个对象可以是一个变量,一个内置类型或自定义类型的实例,甚至是一个函数(函数指针将在下一章中介绍)。地址被分配给一个类型化的指针变量或一个void*指针。void*指针应该被视为内存地址的存储,因为你不能访问数据,也不能对void*指针进行指针算术(即使用算术运算符操作指针值)。指针变量通常使用类型和*符号声明。例如:
int i = 42;
int *pi = &i;
在这段代码中,变量i是一个整数,编译器和链接器将确定分配这个变量的位置。通常,函数中的变量将在堆栈帧上,如后面的部分所述。在运行时,堆栈将被创建(基本上将分配一块内存),并且在堆栈内存中为变量i保留空间。然后,程序将一个值(42)放入该内存中。接下来,为变量i分配的内存的地址放入变量pi中。上述代码的内存使用情况如下图所示:
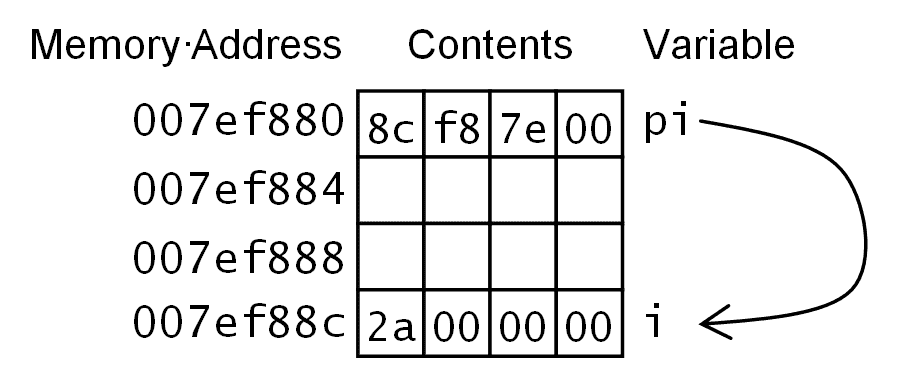
指针保存了一个值为0x007ef8c(注意最低字节存储在内存中的最低字节;这是针对 x86 机器的)。内存位置0x007ef8c的值为0x0000002a,即 42 的值,即变量i的值。由于pi也是一个变量,它也占用内存空间,在这种情况下,编译器将指针放在内存中的较低位置,在这种情况下,这两个变量不是连续的。
像这样在堆栈上分配的变量,您不应该假设变量分配在内存中的位置,也不应该假设它们与其他变量的位置有关。
这段代码假设是 32 位操作系统,因此指针pi占用 32 位并包含 32 位地址。如果操作系统是 64 位,则指针将是 64 位宽(但整数可能仍然是 32 位)。在本书中,我们将使用 32 位指针,因为 32 位地址比 64 位地址少打字。
类型化指针使用*符号声明,我们将其称为int*指针,因为指针指向保存int的内存。在声明指针时,约定是将*放在变量名旁边,而不是放在类型旁边。这种语法强调了指向的类型是int。但是,如果您在单个语句中声明多个变量,则重要使用此语法:
int *pi, i;
很明显,第一个变量是int*指针,第二个是int。以下则不太清楚:
int* pi, i;
你可能会理解这意味着两个变量的类型都是int*,但事实并非如此,因为这声明了一个指针和一个int。如果你想声明两个指针,那么对每个变量应用*:
int *p1, *p2;
最好是将这两个指针分开声明。
当你对指针应用sizeof运算符时,你将得到指针的大小,而不是它指向的内容。因此,在 x86 机器上,sizeof(int*)将返回 4;在 x64 机器上,它将返回 8。这是一个重要的观察,特别是当我们在后面的部分讨论 C++内置数组时。
要访问指针指向的数据,你必须使用*运算符对其进行解引用:
int i = 42;
int *pi = &i;
int j = *pi;
在赋值的右侧使用解引用指针可以访问指针指向的值,所以j被初始化为 42。与指针的声明相比,*符号也被使用,但意义不同。
解引用运算符不仅可以读取内存位置的数据。只要指针没有限制(使用const关键字;见后文),你也可以解引用指针来写入内存位置:
int i = 42;
cout << i << endl;
int *pi { &i };
*pi = 99;
cout << i << endl;
在这段代码中,指针pi指向变量i在内存中的位置(在这种情况下,使用大括号语法)。对解引用指针进行赋值将值分配给指针指向的位置。结果是在最后一行,变量i的值将是 99 而不是 42。
使用空指针
指针可以指向计算机中安装的内存的任何位置,通过解引用指针进行赋值意味着你可能会覆盖操作系统使用的敏感内存,或者(通过直接内存访问)写入计算机硬件使用的内存。然而,操作系统通常会给可执行文件分配一个特定的内存范围,它可以访问,尝试访问超出此范围的内存将导致操作系统内存访问违规。
因此,你几乎总是应该使用&运算符或从操作系统函数调用中获取指针值。你不应该给指针一个绝对地址。唯一的例外是 C++对于无效内存地址的常量nullptr:
int *pi = nullptr;
// code
int i = 42;
pi = &i;
// code
if (nullptr != pi) cout << *pi << endl;
这段代码将指针pi初始化为nullptr。稍后在代码中,指针被初始化为整数变量的地址。代码中稍后使用了指针,但是不是立即调用它,而是首先检查指针以确保它已经被初始化为非空值。编译器将检查你是否即将使用一个未初始化的变量,但如果你正在编写库代码,编译器将不知道你的代码的调用者是否正确使用指针。
常量nullptr的类型不是整数,而是std::nullptr_t。所有指针类型都可以隐式转换为此类型,因此nullptr可以用于初始化所有指针类型的变量。
内存类型
一般来说,你可以将内存视为四种类型之一:
-
静态或全局
-
字符串池
-
自动或堆栈
-
自由存储
当你在全局级别声明一个变量,或者在函数中将变量声明为static时,编译器将确保变量分配的内存具有与应用程序相同的生命周期–变量在应用程序启动时创建,在应用程序结束时删除。
当您使用字符串常量时,数据实际上也是全局变量,但存储在可执行文件的不同部分。对于 Windows 可执行文件,字符串常量存储在可执行文件的.rdata PE/COFF 部分中。文件的.rdata部分用于只读初始化数据,因此您无法更改数据。Visual C++允许您更进一步,并为您提供了字符串池的选项。考虑这个:
char *p1 { "hello" };
char *p2 { "hello" };
cout << hex;
cout << reinterpret_cast<int>(p1) << endl;
cout << reinterpret_cast<int>(p2) << endl;
在这段代码中,两个指针被初始化为字符串常量hello的地址。在接下来的两行中,每个指针的地址都打印在控制台上。由于<<运算符对于char*将变量视为指向字符串的指针,它将打印字符串而不是指针的地址。为了解决这个问题,我们调用reinterpret_cast运算符将指针转换为整数并打印整数的值。
如果您在命令行使用 Visual C++编译器编译代码,您将看到打印出两个不同的地址。这两个地址都在.rdata部分,并且都是只读的。如果您使用/GF开关编译此代码以启用字符串池(这是 Visual C++项目的默认设置),编译器将看到两个字符串常量是相同的,并且只会在.rdata部分存储一个副本,因此此代码的结果将是在控制台上打印两次相同的地址。
在这段代码中,两个变量p1和p2是自动变量,也就是说,它们是在当前函数的堆栈上创建的。当调用函数时,为函数分配一块内存,其中包含为函数传递的参数和调用函数的代码的返回地址,以及在函数中声明的自动变量的空间。当函数结束时,堆栈帧被销毁。
函数的调用约定决定了是调用函数还是被调用函数负责这样做。在 Visual C++中,默认的是__cdecl调用约定,这意味着调用函数清理堆栈。__stdcall调用约定被 Windows 操作系统函数使用,并且堆栈清理由被调用函数执行。更多细节将在下一章中给出。
自动变量只在函数执行期间存在,这样变量的地址只在函数内部有意义。在本章的后面,您将看到如何创建数据数组。作为自动变量分配的数组是在编译时确定的固定大小的堆栈上分配的。对于大数组,可能会超出堆栈的大小,特别是在递归调用的函数中。在 Windows 上,默认堆栈大小为 1 MB,在 x86 Linux 上为 2 MB。Visual C++允许您使用/F编译器开关(或/STACK链接器开关)指定更大的堆栈。gcc 编译器允许您使用--stack开关更改默认堆栈大小。
最后一种类型的内存是在自由存储器或有时称为堆上创建的动态内存。这是使用内存的最灵活的方式。顾名思义,您在运行时分配大小确定的内存。自由存储器的实现取决于 C++的实现,但您应该将自由存储器视为具有与应用程序相同的生命周期,因此从自由存储器分配的内存应该至少持续与应用程序一样长的时间。
然而,这里存在潜在的危险,特别是对于长期运行的应用程序。从自由存储器分配的所有内存都应在使用完毕后返回到自由存储器,以便自由存储器管理器可以重用内存。如果不适当地返回内存,那么自由存储管理器可能会耗尽内存,这将促使它向操作系统请求更多内存,因此,应用程序的内存使用量将随时间增长,导致由于内存分页而引起性能问题。
指针算术
指针指向内存,指针的类型决定了可以通过指针访问的数据的类型。因此,int*指针将指向内存中的整数,并且您可以通过解引用指针(*)来获取整数。如果指针允许(未标记为const),则可以通过指针算术更改其值。例如,您可以增加或减少指针。内存地址的值取决于指针的类型。由于类型化指针指向类型,任何指针算术都将以该类型的size为单位更改指针。
如果您增加一个int*指针,它将指向内存中的下一个整数,内存地址的变化取决于整数的大小。这相当于数组索引,其中诸如v[1]的表达式意味着您应该从v中的第一项的内存位置开始,然后在内存中移动一个项,并返回那里的项:
int v[] { 1, 2, 3, 4, 5 };
int *pv = v;
*pv = 11;
v[1] = 12;
pv[2] = 13;
*(pv + 3) = 14;
第一行在堆栈上分配了一个包含五个整数的数组,并将值初始化为 1 到 5。在这个例子中,因为使用了初始化列表,编译器将为所需数量的项创建空间,因此数组的大小没有给出。如果在括号之间给出数组的大小,那么初始化列表中的项数不能超过数组大小。如果列表中的项数较少,则数组中的其余项将被初始化为默认值(通常为零)。
此代码中的下一行获取数组中第一项的指针。这一行很重要:数组名称被视为指向数组中第一项的指针。接下来的几行以各种方式更改数组项。其中第一行(*pv)通过解引用指针并赋值来更改数组中的第一项。第二行(v[1])使用数组索引为数组中的第二项赋值。第三行(pv[2])使用索引,但这次使用指针,并为数组中的第三个值赋值。最后一个例子(*(pv + 3))使用指针算术来确定数组中第四项的地址(请记住,第一项的索引为 0),然后解引用指针来为该项赋值。在这些操作之后,数组包含值{ 11, 12, 13, 14, 5 },内存布局如下所示:

如果您有一个包含值的内存缓冲区(在本例中,通过数组分配),并且想要将每个值乘以 3,可以使用指针算术来实现:
int v[] { 1, 2, 3, 4, 5 };
int *pv = v;
for (int i = 0; i < 5; ++i)
{
*pv++ *= 3;
}
循环语句很复杂,您需要参考第二章中给出的运算符优先级,理解语言特性。后缀递增运算符具有最高的优先级,其次是解引用运算符(*),最后是*=运算符的优先级最低,因此这些运算符按照这个顺序运行:++,*,*=。后缀运算符返回递增之前的值,因此尽管指针被递增到内存中的下一个项目,表达式使用的是递增之前的地址。然后对这个地址进行解引用,由赋值运算符赋予值乘以 3 的值。这说明了指针和数组名称之间的一个重要区别;您可以递增指针,但不能递增数组:
pv += 1; // can do this
v += 1; // error
当然,您可以在数组名称和指针上都使用索引(使用[])。
使用数组
顾名思义,C++内置数组是零个或多个相同类型的数据项。在 C++中,使用方括号声明数组和访问数组元素:
int squares[4];
for (int i = 0; i < 4; ++i)
{
squares[i] = i * i;
}
squares变量是一个整数数组。第一行为四个整数分配了足够的内存,然后for循环初始化了前四个平方的内存。编译器从堆栈中分配的内存是连续的,数组中的项目是顺序的,因此squares[3]的内存位置是从squares[2]的sizeof(int)开始的。由于数组是在堆栈上创建的,数组的大小是对编译器的一条指令;这不是动态分配,因此大小必须是一个常量。
这里存在潜在的问题:数组的大小被提到两次,一次在声明中,然后在for循环中再次提到。如果使用两个不同的值,那么您可能会初始化太少的项目,或者可能会访问数组之外的内存。范围for语法允许您访问数组中的每个项目;编译器可以确定数组的大小,并将在范围for循环中使用它。在下面的代码中,有一个故意的错误,显示了数组大小的问题:
int squares[5];
for (int i = 0; i < 4; ++i)
{
squares[i] = i * i;
}
for(int i : squares)
{
cout << i << endl;
}
数组的大小和第一个for循环的范围不一致,因此最后一个项目将不会被初始化。然而,范围for循环将循环遍历所有五个项目,因此将打印出最后一个值的一些随机值。如果使用相同的代码,但将squares数组声明为三个项目呢?这取决于您使用的编译器以及您是否正在编译调试版本,但显然您将写入数组分配之外的内存。
有一些方法可以缓解这些问题。第一个方法在早期的章节中已经提到过:声明一个数组大小的常量,并在代码需要知道数组大小时使用它:
constexpr int sq_size = 4;
int squares[sq_size];
for (int i = 0; i < sq_size; ++i)
{
squares[i] = i * i;
}
数组声明必须有一个常量作为大小,并且通过使用sq_size常量变量来管理。
您可能还想计算已分配数组的大小。sizeof运算符,当应用于数组时,返回整个数组的字节大小,因此您可以通过将这个值除以单个项目的大小来确定数组的大小:
int squares[4];
for (int i = 0; i < sizeof(squares)/sizeof(squares[0]); ++i)
{
squares[i] = i * i;
}
这是更安全的代码,但显然很冗长。C 运行时库包含一个名为_countof的宏,用于执行这个计算。
函数参数
正如所示,数组会自动转换为适当的指针类型,如果你将数组传递给一个函数,或者从一个函数返回它。这种衰变为愚蠢的指针意味着其他代码不能假设数组的大小。指针可能指向在函数确定内存生命周期的堆栈上分配的内存,或者指向程序的内存生命周期的全局变量,或者可能指向由程序员确定内存的动态分配的内存。在指针声明中没有任何信息表明内存的类型或谁负责释放内存。在愚蠢的指针中也没有任何关于指针指向多少内存的信息。当你使用指针编写代码时,你必须严格遵守它们的使用方式。
函数可以有一个数组参数,但这意味着的远不及它表面所示的那么多:
// there are four tires on each car
bool safe_car(double tire_pressures[4]);
这个函数将检查数组的每个成员是否具有在允许的最小和最大值之间的值。汽车上一次使用四个轮胎,所以这个函数应该被调用以传递一个包含四个值的数组。问题在于,尽管看起来编译器应该检查传递给函数的数组是否是适当的大小,但它并没有。你可以这样调用这个函数:
double car[4] = get_car_tire_pressures();
if (!safe_car(car)) cout << "take off the road!" << endl;
double truck[8] = get_truck_tire_pressures();
if (!safe_car(truck)) cout << "take off the road!" << endl;
当然,开发人员应该明显地意识到卡车不是汽车,因此这个开发人员不应该编写这段代码,但编译语言的通常优势是编译器会为你执行一些合理性检查。在数组参数的情况下,它不会。
原因是数组被传递为指针,因此尽管参数看起来是一个内置数组,但你不能使用你习惯使用的数组功能,比如范围for。事实上,如果safe_car函数调用sizeof(tire_pressures),它将得到一个双指针的大小,而不是 16,即四个int数组的字节大小。
数组参数的衰变为指针特性意味着函数只有在你明确告诉它大小时才会知道数组参数的大小。你可以使用一对空的方括号来表示应该传递一个数组,但实际上它只是一个指针:
bool safe_car(double tire_pressures[], int size);
这里的函数有一个指示数组大小的参数。前面的函数与声明第一个参数为指针完全相同。以下不是函数的重载;它是相同的函数:
bool safe_car(double *tire_pressures, int size);
重要的一点是,当你把一个数组传递给一个函数时,数组的第一个维度会被视为一个指针。到目前为止,数组一直是单维的,但它们可能有多个维度。
多维数组
数组可以是多维的,要添加另一个维度,需要添加另一组方括号:
int two[2];
int four_by_three[4][3];
第一个例子创建了一个包含两个整数的数组,第二个例子创建了一个包含 12 个整数的二维数组,排列成四行三列。当然,行和列是任意的,并且将二维数组视为传统的电子表格表格,但这有助于可视化数据在内存中的排列方式。
注意每个维度周围都有方括号。在这方面,C++与其他语言不同,所以int x[10,10]的声明将被 C++编译器报告为错误。
初始化多维数组涉及一对大括号和按照将用于初始化维度的顺序排列的数据:
int four_by_three[4][3] { 11,12,13,21,22,23,31,32,33,41,42,43 };
在这个例子中,具有最高数字的值反映了最左边的索引,较低的数字反映了右边的索引(在这两种情况下,比实际索引多一个)。显然,你可以将这个分成几行,并使用空格来将值分组在一起,以使其更易读。你也可以使用嵌套的大括号。例如:
int four_by_three[4][3] = { {11,12,13}, {21,22,23},
{31,32,33}, {41,42,43} };
如果你从左到右读取维度,你可以读取初始化值进入更深层次的嵌套。有四行,所以在外部大括号内有四组嵌套的大括号。有三列,所以在嵌套的大括号内有三个初始化值。
嵌套的大括号不仅仅是为了格式化你的 C++代码的方便,因为如果你提供了一对空的大括号,编译器将使用默认值:
int four_by_three[4][3] = { {11,12,13}, {}, {31,32,33}, {41,42,43} };
这里,第二行的项目被初始化为 0。
当你增加维度时,原则仍然适用:增加最右边维度的嵌套:
int four_by_three_by_two[4][3][2]
= { { {111,112}, {121,122}, {131,132} },
{ {211,212}, {221,222}, {231,232} },
{ {311,312}, {321,322}, {331,332} },
{ {411,412}, {421,422}, {431,432} }
};
这是四行三列的成对数组(当维度增加时,可以看出术语行和列在很大程度上是任意的)。
你可以使用相同的语法访问项目:
cout << four_by_three_by_two[3][2][0] << endl; // prints 431
就内存布局而言,编译器以以下方式解释语法。第一个索引确定了从数组开始处的偏移量,每次偏移六个整数(3 * 2),第二个索引指示了在这六个整数“块”内的偏移量,每次偏移两个整数,第三个索引是以单个整数为单位的偏移量。因此[3][2][0]是从开始处*(3 * 6) + (2 * 2) + 0 = 22*个整数的偏移量,将第一个整数视为索引零。
多维数组被视为数组的数组,因此每个“行”的类型是int[3][2],我们从声明中知道有四个这样的行。
将多维数组传递给函数
你可以将多维数组传递给一个函数:
// pass the torque of the wheel nuts of all wheels
bool safe_torques(double nut_torques[4][5]);
这样编译后,你可以将参数作为一个 4x5 的数组访问,假设这辆车有四个轮子,每个轮子上有五个螺母。
如前所述,当你传递一个数组时,第一个维度将被视为指针,所以虽然你可以将一个 4x5 的数组传递给这个函数,你也可以传递一个 2x5 的数组,编译器不会抱怨。然而,如果你传递一个 4x3 的数组(也就是说,第二个维度与函数中声明的不同),编译器将发出一个数组不兼容的错误。参数可能更准确地描述为double row[][5]。由于第一个维度的大小不可用,函数应该声明该维度的大小:
bool safe_torques(double nut_torques[][5], int num_wheels);
这说明nut_torques是一个或多个“行”,每个行有五个项目。由于数组没有提供有关它有多少行的信息,你应该提供它。另一种声明方式是:
bool safe_torques(double (*nut_torques)[5], int num_wheels);
这里括号很重要,如果你省略它们并使用double *nut_torques[5],那么*将指的是数组中的类型,也就是说,编译器将把nut_torques视为一个double*指针的五个元素数组。我们之前已经看到了这样一个数组的例子:
void main(int argc, char *argv[]);
argv参数是一个char*指针数组。你也可以将argv参数声明为char**,它具有相同的含义。
一般来说,如果你打算将数组传递给一个函数,最好使用自定义类型,或者使用 C++数组类型。
使用多维数组的范围for循环比第一眼看上去更复杂,并且需要在本章后面的部分中解释的引用的使用。
使用字符数组
字符串将在第九章 使用字符串中更详细地介绍,但值得指出的是,C 字符串是字符数组,并且通过指针变量访问。这意味着如果你想操作字符串,你必须操作指针指向的内存,而不是操作指针本身。
比较字符串
以下分配了两个字符串缓冲区,并调用strcpy_s函数来用相同的字符串初始化每个缓冲区:
char p1[6];
strcpy_s(p1, 6, "hello");
char p2[6];
strcpy_s(p2, 6, p1);
bool b = (p1 == p2);
strcpy_c函数将从最后一个参数中给定的指针(直到终止的NUL)复制字符,到第一个参数中给定的缓冲区中,该缓冲区的最大大小在第二个参数中给出。这两个指针在最后一行进行比较,这将返回一个false值。问题在于比较函数比较的是指针的值,而不是指针指向的内容。这两个缓冲区具有相同的字符串,但指针不同,因此b将是false。
比较字符串的正确方法是逐个字符比较数据以查看它们是否相等。C 运行时提供了strcmp,它逐个字符比较两个字符串缓冲区,并且std::string类定义了一个名为compare的函数,也将执行这样的比较;但是,要注意这些函数返回的值:
string s1("string");
string s2("string");
int result = s1.compare(s2);
返回值不是bool类型,表示两个字符串是否相同;它是一个int。这些比较函数进行词典比较,如果参数(在这个代码中是s2)在词典上大于操作数(s1),则返回一个负值,如果操作数大于参数,则返回一个正数。如果两个字符串相同,函数返回 0。记住,bool对于值为 0 是false,对于非零值是true。标准库为std::string提供了==运算符的重载,因此可以安全地编写这样的代码:
if (s1 == s2)
{
cout << "strings are the same" << endl;
}
操作员将比较两个变量中包含的字符串。
防止缓冲区溢出
用于操作字符串的 C 运行时库以允许缓冲区溢出而臭名昭著。例如,strcpy函数将一个字符串复制到另一个字符串,并且您可以通过<cstring>头文件访问它,该头文件由<iostream>头文件包含。您可能会尝试编写类似这样的代码:
char pHello[5]; // enough space for 5 characters
strcpy(pHello, "hello");
问题在于strcpy将复制所有字符直到包括终止的NULL字符,因此您将把六个字符复制到只有五个空间的数组中。您可能会从用户输入中获取一个字符串(比如,从网页上的文本框),并认为您分配的数组足够大,但是恶意用户可能会提供一个故意大于缓冲区的过长字符串,以便覆盖程序的其他部分。这种缓冲区溢出导致许多程序遭受黑客控制服务器的攻击,以至于 C 字符串函数都已被更安全的版本所取代。实际上,如果您尝试键入上述代码,您会发现strcpy是可用的,但是 Visual C++编译器会发出错误:
error C4996: 'strcpy': This function or variable may be unsafe.
Consider using strcpy_s instead. To disable deprecation, use _CRT_SECURE_NO_WARNINGS. See online help for details.
如果您有使用strcpy的现有代码,并且需要使该代码编译,可以在<cstring>之前定义该符号:
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
防止这个问题的一个初始尝试是调用strncpy,它将复制特定数量的字符:
char pHello[5]; // enough space for 5 characters
strncpy(pHello, "hello", 5);
该函数将复制最多五个字符,然后停止。问题在于要复制的字符串有五个字符,因此结果将没有NULL终止。此函数的更安全版本具有一个参数,您可以使用该参数指定目标缓冲区的大小:
size_t size = sizeof(pHello)/sizeof(pHello[0]);
strncpy_s(pHello, size, "hello", 5);
在运行时,这仍然会导致问题。您告诉函数缓冲区大小为五个字符,它将确定这不足以容纳您要求它复制的六个字符。与其允许程序悄悄继续并且缓冲区溢出导致问题,更安全的字符串函数将调用一个名为约束处理程序的函数,其默认版本将关闭程序,理由是缓冲区溢出意味着程序已受到威胁。
C 运行时库字符串函数最初是为了返回函数的结果,现在更安全的版本返回一个错误值。strncpy_s函数也可以被告知截断复制而不是调用约束处理程序:
strncpy_s(pHello, size, "hello", _TRUNCATE);
C++的string类可以保护你免受这些问题的困扰。
在 C++中使用指针
在 C++中,指针显然非常重要,但与任何强大的功能一样,都存在问题和危险,因此值得指出一些主要问题。指针指向内存中的单个位置,指针的类型表示应该如何解释内存位置。你最多可以假设的是在内存中该位置的字节数是指针类型的大小。就是这样。这意味着指针本质上是不安全的。然而,在 C++中,它们是使你的进程内的代码快速访问大量数据的最快方式。
访问超出边界
当你分配一个缓冲区,无论是在堆栈上还是在自由存储器上,并且你得到一个指针时,很少有东西能阻止你访问你没有分配的内存–无论是在缓冲区的位置之前还是之后。这意味着当你使用指针算术或数组的索引访问时,你要仔细检查你是否将要访问超出边界的数据。有时错误可能并不立即显而易见:
int arr[] { 1, 2, 3, 4 };
for (int i = 0; i < 4; ++i)
{
arr[i] += arr[i + 1]; // oops, what happens when i == 3?
}
当你使用索引时,你必须不断提醒自己数组是从零开始索引的,所以最高的索引是数组大小减 1。
指向释放内存的指针
这适用于在堆栈上分配的内存和动态分配的内存。以下是一个糟糕编写的函数,它在函数中返回了一个在堆栈上分配的字符串:
char *get()
{
char c[] { "hello" };
return c;
}
前面的代码分配了一个六个字符的缓冲区,然后用字符串字面量hello的五个字符和NULL终止字符对其进行初始化。问题在于一旦函数完成,堆栈帧就会被拆除,以便内存可以被重新使用,指针将指向可能被其他东西使用的内存。这个错误是由糟糕的编程引起的,但在这个例子中可能并不像这么明显。如果函数使用了几个指针并执行了指针赋值,你可能不会立即注意到你已经返回了一个指向堆栈分配对象的指针。最好的做法就是简单地不要从函数中返回原始指针,但如果你确实想使用这种编程风格,确保内存缓冲区是通过参数传递的(所以函数不拥有缓冲区),或者是动态分配的,并且你正在将所有权传递给调用者。
这引出了另一个问题。如果你在指针上调用delete,然后在你的代码中稍后尝试访问指针,你将访问可能被其他变量使用的内存。为了缓解这个问题,你可以养成在删除指针时将指针赋值为null_ptr并在使用指针之前检查null_ptr的习惯。或者,你可以使用智能指针对象来代替。智能指针将在第六章中介绍,类。
转换指针
你可以使用类型化指针,也可以使用void*指针。类型化指针将访问内存,就好像它是指定的类型(当你在类中使用继承时,这会产生有趣的后果,但这将留到第六章,类和第七章,面向对象编程简介)。因此,如果你将指针转换为不同的类型并对其进行解引用,内存将被视为包含转换类型。这很少有意义。void*指针不能被解引用,因此你永远无法通过void*指针访问数据,要访问数据,你必须转换指针。void*指针类型的整个原因是它可以指向任何东西。通常情况下,只有当类型对该函数无关紧要时,才应该使用void*指针。例如,C 中的malloc函数返回一个void*指针,因为该函数仅分配内存;它不关心该内存将用于什么目的。
常量指针
指针可以声明为const,这取决于你在哪里应用它,这意味着指针指向的内存是只读的,或者指针的值是只读的:
char c[] { "hello" }; // c can be used as a pointer
*c = 'H'; // OK, can write thru the pointer
const char *ptc {c}; // pointer to constant
cout << ptc << endl; // OK, can read the memory pointed to
*ptc = 'Y'; // cannot write to the memory
char *const cp {c}; // constant pointer
*cp = 'y'; // can write thru the pointer
cp++; // cannot point to anything else
在这里,ptc是一个指向常量char的指针,也就是说,尽管你可以更改ptc指向的内容,并且可以读取它指向的内容,但你不能使用它来更改内存。另一方面,cp是一个常量指针,这意味着你既可以读取也可以写入指针指向的内存,但你不能更改它指向的位置。通常将const char*指针传递给函数,因为函数不知道字符串在哪里分配,或者缓冲区的大小(调用者可能传递一个无法更改的文字)。请注意,没有const*运算符,因此char const*被视为const char*,即指向常量缓冲区的指针。
你可以使用转换使指针变为常量,更改它,或者移除它。以下是对const关键字进行了一些相当无意义的更改,以证明这一点:
char c[] { "hello" };
char *const cp1 { c }; // cannot point to any other memory
*cp1 = 'H'; // can change the memory
const char *ptc = const_cast<const char*>(cp1);
ptc++; // change where the pointer points to
char *const cp2 = const_cast<char *const>(ptc);
*cp2 = 'a'; // now points to Hallo
指针cp1和cp2可以用于更改它们指向的内存,但一旦分配,它们都不能指向其他内存。第一个const_cast去除了指向其他内存的const属性,但不能用于更改内存,ptc。第二个const_cast去除了ptc的const属性,以便可以通过指针更改内存,cp2。
更改指向的类型
static_cast运算符用于进行编译时检查的转换,而不是运行时检查,这意味着指针必须是相关的。void*指针可以转换为任何指针,因此以下内容可以编译并且是有意义的:
int *pi = static_cast<int*>(malloc(sizeof(int)));
*pi = 42;
cout << *pi << endl;
free(pi);
C 中的malloc函数返回一个void*指针,因此你必须转换它才能使用内存。(当然,C++的new运算符消除了这种转换的需要。)内置类型不足够“相关”,无法使用static_cast在指针类型之间进行转换,因此你不能使用static_cast将int*指针转换为char*指针,即使int和char都是整数类型。对于通过继承相关的自定义类型,你可以使用static_cast进行指针转换,但没有运行时检查来验证转换是否正确。要进行带有运行时检查的转换,应该使用dynamic_cast,更多细节将在第六章,类和第七章,面向对象编程简介中给出。
reinterpret_cast运算符是转换运算符中最灵活、最危险的,因为它将在没有任何类型检查的情况下在任何指针类型之间进行转换。这是不安全的。例如,以下代码使用文字初始化宽字符数组。数组wc将有六个字符,hello后跟NULL。wcout对象将wchar_t*指针解释为wchar_t字符串中第一个字符的指针,因此插入wc将打印字符串(直到NUL为止)。要获取实际的内存位置,您必须将指针转换为整数:
wchar_t wc[] { L"hello" };
wcout << wc << " is stored in memory at ";
wcout << hex;
wcout << reinterpret_cast<int>(wc) << endl;
同样,如果将wchar_t插入wcout对象中,它将打印字符,而不是数值。因此,要打印出各个字符的代码,我们需要将指针转换为合适的整数指针。此代码假定short与wchar_t大小相同:
wcout << "The characters are:" << endl;
short* ps = reinterpret_cast<short*>(wc);
do
{
wcout << *ps << endl;
} while (*ps++);
在代码中分配内存
C++定义了两个运算符new和delete,它们从自由存储区分配内存并将内存释放回自由存储区。
分配单个对象
new运算符与类型一起用于分配内存,并将返回指向该内存的类型化指针:
int *p = new int; // allocate memory for one int
new运算符将为创建的每个对象调用自定义类型的默认构造函数(如第六章中所述,类)。内置类型没有构造函数,因此将发生类型初始化,这通常会将对象初始化为零(在此示例中为零整数)。
一般来说,您不应该在没有明确初始化的情况下使用为内置类型分配的内存。实际上,在 Visual C++中,new运算符的调试版本将将内存初始化为每个字节的值0xcd,作为调试器中的视觉提醒,表明您尚未初始化内存。对于自定义类型,将分配的内存初始化留给类型的作者。
重要的是,当您使用完内存后,将其返回到自由存储区,以便分配器可以重用它。您可以通过调用delete运算符来执行此操作:
delete p;
当您删除指针时,将调用对象的析构函数。对于内置类型,这不会有任何作用。在删除指针后,将指针初始化为nullptr是一个良好的做法,如果您使用在使用指针之前检查指针的值的约定,这将保护您免受使用已删除指针的伤害。C++标准规定,如果删除具有nullptr值的指针,delete运算符将不起作用。
C++允许您以两种方式在调用new运算符时初始化值:
int *p1 = new int (42);
int *p2 = new int {42};
对于自定义类型,new运算符将调用类型的构造函数;对于内置类型,最终结果是相同的,并且通过将项目初始化为提供的值来执行。您还可以使用初始化列表语法,如前面代码中的第二行所示。重要的是要注意,初始化是指向的内存,而不是指针变量。
分配对象数组
您还可以使用new运算符在动态内存中创建对象数组。您可以通过提供要创建的项目数的一对方括号来执行此操作。以下代码为两个整数分配内存:
int *p = new int[2];
p[0] = 1;
*(p + 1) = 2;
for (int i = 0; i < 2; ++i) cout << p[i] << endl;
delete [] p;
该运算符返回分配的类型的指针,您可以使用指针算术或数组索引来访问内存。您不能在new语句中初始化内存;您必须在创建缓冲区后执行此操作。当您使用new为多个对象创建缓冲区时,必须使用适当版本的delete运算符:[]用于指示删除多个项目,并将调用每个对象的析构函数。重要的是,您始终要使用与用于创建指针的new版本相适应的正确版本的delete。
自定义类型可以为单个对象定义自己的运算符new和运算符delete,以及为对象数组定义运算符new[]和运算符delete[]。自定义类型的作者可以使用这些来为其对象使用自定义内存分配方案。
处理失败的分配
如果new运算符无法为对象分配内存,它将引发std::bad_alloc异常,并且返回的指针将为nullptr。异常在第十章中有所涵盖,诊断和调试,因此此处仅给出语法的简要概述。在生产代码中,重要的是检查内存分配失败。以下代码显示了如何保护分配,以便捕获std::bad_alloc异常并处理它:
// VERY_BIG_NUMER is a constant defined elsewhere
int *pi;
try
{
pi = new int[VERY_BIG_NUMBER];
// other code
}
catch(const std::bad_alloc& e)
{
cout << "cannot allocate" << endl;
return;
}
// use pointer
delete [] pi;
如果try块中的任何代码引发异常控制,则将其传递到catch子句,忽略尚未执行的任何其他代码。catch子句检查异常对象的类型,如果是正确的类型(在本例中是分配故障),则创建对该对象的引用,并将控制传递到catch块,异常引用的范围是此块。在此示例中,代码仅打印错误,但您将使用它来采取措施以确保内存分配失败不会影响后续代码。
使用其他版本的 new 运算符
此外,自定义类型可以定义放置运算符new,允许您为自定义new函数提供一个或多个参数。放置new的语法是通过括号提供放置字段。
C++标准库版本的new运算符提供了一个可以将常量std::nothrow作为放置字段的版本。如果分配失败,此版本不会抛出异常,而是只能从返回指针的值来评估失败:
int *pi = new (std::nothrow) int [VERY_BIG_NUMBER];
if (nullptr == pi)
{
cout << "cannot allocate" << endl;
}
else
{
// use pointer
delete [] pi;
}
在类型之前使用括号用于传递放置字段。如果在类型之后使用括号,这些将为成功分配内存的对象初始化一个值。
内存寿命
由new分配的内存将保持有效,直到调用delete。这意味着您可能拥有寿命很长的内存,并且代码可能在代码中的各种函数之间传递。考虑以下代码:
int *p1 = new int(42);
int *p2 = do_something(p1);
delete p1;
p1 = nullptr;
// what about p2?
此代码创建一个指针并初始化其指向的内存,然后将指针传递给一个函数,该函数本身返回一个指针。由于不再需要p1指针,因此将其删除并分配为nullptr,以便不能再次使用。这段代码看起来不错,但问题是您如何处理函数返回的指针?想象一下,该函数只是操作指针指向的数据:
int *do_something(int *p)
{
*p *= 10;
return p;
}
实际上,调用do_something会创建指针的副本,但不会创建指向的内容的副本。这意味着当删除p1指针时,它指向的内存将不再可用,因此指针p2指向无效内存。
可以使用一种称为资源获取即初始化(RAII)的机制来解决这个问题,这意味着使用 C++对象的特性来管理资源。C++中的 RAII 需要类,特别是复制构造函数和析构函数。智能指针类可用于管理指针,以便在复制时也复制其指向的内存。析构函数是在对象超出范围时自动调用的函数,因此智能指针可以使用它来释放内存。智能指针和析构函数将在第六章中进行介绍,类。
Windows SDK 和指针
从函数返回指针具有其固有的危险:内存的责任被传递给调用者,调用者必须确保内存得到适当释放,否则可能导致内存泄漏和相应的性能损失。在本节中,我们将探讨 Windows 软件开发工具包(SDK)提供对内存缓冲区的访问以及学习 C++中使用的一些技术。
首先,值得指出的是,Windows SDK 中返回字符串或具有字符串参数的任何函数都将有两个版本。带有A后缀的版本表示该函数使用 ANSI 字符串,而W版本将使用宽字符字符串。对于本讨论,使用 ANSI 函数更容易。
GetCommandLineA函数具有以下原型(考虑 Windows SDK 的typedef):
char * __stdcall GetCommandLine();
所有 Windows 函数都被定义为使用__stdcall调用约定。通常,您会看到WINAPI的typedef用于__stdcall调用约定。
该函数可以这样调用:
//#include <windows.h>
cout << GetCommandLineA() << endl;
请注意,我们没有努力释放返回的缓冲区。原因是指针指向的内存存在于进程的生命周期中,因此您不应释放它。实际上,如果您释放它,您该如何做呢?您无法保证该函数是使用相同的编译器或您正在使用的相同库编写的,因此您无法使用 C++的delete运算符或 C 的free函数。
当函数返回缓冲区时,重要的是查阅文档以查看是谁分配了缓冲区,以及谁应该释放它。
另一个例子是GetEnvironmentStringsA:
char * __stdcall GetEnvironmentStrings();
这也返回一个指向缓冲区的指针,但这次文档清楚地指出在使用缓冲区后应释放它。SDK 提供了一个名为FreeEnvironmentStrings的函数来执行此操作。缓冲区中包含形式为name=value的每个环境变量的一个字符串,并且每个字符串都以NUL字符终止。缓冲区中的最后一个字符串只是一个NUL字符,也就是说,缓冲区的末尾有两个NUL字符。这些函数可以这样使用:
char *pBuf = GetEnvironmentStringsA();
if (nullptr != pBuf)
{
char *pVar = pBuf;
while (*pVar)
{
cout << pVar << endl;
pVar += strlen(pVar) + 1;
}
FreeEnvironmentStringsA(pBuf);
}
strlen函数是 C 运行时库的一部分,它返回字符串的长度。您不需要知道GetEnvironmentStrings函数如何分配缓冲区,因为FreeEnvironmentStrings将调用正确的释放代码。
有些情况下,开发人员有责任分配缓冲区。Windows SDK 提供了一个名为GetEnvironmentVariable的函数,用于返回命名环境变量的值。当您调用此函数时,您不知道环境变量是否设置,或者如果设置了,其值有多大,因此这意味着您很可能需要分配一些内存。该函数的原型是:
unsigned long __stdcall GetEnvironmentVariableA(const char *lpName,
char *lpBuffer, unsigned long nSize);
有两个参数是指向 C 字符串的指针。这里有一个问题,char*指针可以用于将字符串传递给函数,也可以用于传递字符串返回的缓冲区。您如何知道char*指针的预期用途是什么?
完整的参数声明给了你一个线索。lpName指针被标记为const,所以函数不会改变它指向的字符串;这意味着它是一个输入参数。这个参数用于传递你想要获取的环境变量的名称。另一个参数只是一个char*指针,所以它可以用来向函数传递一个字符串输入,或者输出,或者两者兼而有之。知道如何使用这个参数的唯一方法是阅读文档。在这种情况下,它是一个输出参数;如果变量存在,函数将返回lpBuffer中的环境变量的值,如果变量不存在,函数将保持缓冲区不变,并返回值 0。你有责任以任何你认为合适的方式分配这个缓冲区,并且你要在最后一个参数nSize中传递这个缓冲区的大小。
函数的返回值有两个目的。它用于指示发生了错误(只有一个值,0,这意味着你必须调用GetLastError函数来获取错误),它还用于提供有关缓冲区lpBuffer的信息。如果函数成功,则返回值是复制到缓冲区中的字符数,不包括NULL终止字符。然而,如果函数确定缓冲区太小(它从nSize参数知道缓冲区的大小)无法容纳环境变量值,将不会发生复制,并且函数将返回缓冲区所需的大小,即环境变量中的字符数,包括NULL终止符。
调用这个函数的常见方法是先用一个大小为零的缓冲区调用它,然后再使用返回值来分配一个缓冲区,然后再次调用它:
unsigned long size = GetEnvironmentVariableA("PATH", nullptr, 0);
if (0 == size)
{
cout << "variable does not exist " << endl;
}
else
{
char *val = new char[size];
if (GetEnvironmentVariableA("PATH", val, size) != 0)
{
cout << "PATH = ";
cout << val << endl;
}
delete [] val;
}
一般来说,和所有的库一样,你必须阅读文档来确定参数的使用方式。Windows 文档会告诉你指针参数是输入、输出还是输入/输出。它还会告诉你谁拥有内存,以及你是否有责任分配和/或释放内存。
每当你看到一个函数的指针参数时,一定要特别注意检查文档,了解指针的用途以及内存是如何管理的。
内存和 C++标准库
C++标准库提供了各种类来允许你操作对象的集合。这些类被称为标准模板库(STL),它们提供了一种标准的方式来向集合对象插入项目,并且访问项目并遍历整个集合(称为迭代器)。STL 定义了作为队列、堆栈或具有随机访问的向量的集合类。这些类将在第八章中深入讨论,使用标准库容器,所以在本节中我们将仅限于讨论两个行为类似于 C++内置数组的类。
标准库数组
C++标准库提供了两个容器,通过索引器可以随机访问数据。这两个容器还允许你访问底层内存,并且由于它们保证将项目顺序存储并且在内存中是连续的,所以当你需要提供一个指向缓冲区的指针时,它们可以被使用。这两种类型都是模板,这意味着你可以用它们来保存内置类型和自定义类型。这两个集合类分别是array和vector。
使用基于堆栈的数组类
array类在<array>头文件中定义。该类允许您在堆栈上创建固定大小的数组,并且与内置数组一样,它们不能在运行时收缩或扩展。由于它们是在堆栈上分配的,因此它们不需要在运行时调用内存分配器,但显然,它们应该比堆栈帧大小小。这意味着array是小型项目的良好选择。array的大小必须在编译时知道,并作为模板参数传递:
array<int, 4> arr { 1, 2, 3, 4 };
在这段代码中,尖括号(<>)中的第一个模板参数是数组中每个项目的类型,第二个参数是项目的数量。这段代码使用初始化列表初始化数组,但请注意,您仍然必须在模板中提供数组的大小。这个对象将像内置数组(或者确实,任何标准库容器)一样使用范围for:
for (int i : arr) cout << i << endl;
原因是array实现了所需的begin和end函数,这是这种语法所必需的。您还可以使用索引来访问项目:
for (int i = 0; i < arr.size(); ++i) cout << arr[i] << endl;
size函数将返回数组的大小,方括号索引器将随机访问数组的成员。您可以访问数组范围之外的内存,因此对于先前定义的具有四个成员的数组,您可以访问arr[10]。这可能会导致运行时出现意外行为,甚至某种内存故障。为了防范这种情况,该类提供了一个at函数,它将执行范围检查,如果索引超出范围,该类将抛出 C++异常out_of_range。
使用array对象的主要优势在于,您可以在编译时检查是否无意中将对象作为愚蠢的指针传递给函数。考虑这个函数:
void use_ten_ints(int*);
在运行时,函数不知道传递给它的缓冲区的大小,在这种情况下,文档说您必须传递一个具有 10 个int类型变量的缓冲区,但是,正如我们所见,C++允许使用内置数组作为指针:
int arr1[] { 1, 2, 3, 4 };
use_ten_ints(arr1); // oops will read past the end of the buffer
没有编译器检查,也没有运行时检查来捕捉此错误。array类不会允许发生这样的错误,因为没有自动转换为愚蠢的指针:
array<int, 4> arr2 { 1, 2, 3, 4 };
use_ten_ints(arr2); // will not compile
如果您坚持要获得一个愚蠢的指针,您可以这样做,并保证以顺序存储的方式访问数据作为一个连续的内存块:
use_ten_ints(&arr2[0]); // compiles, but on your head be it
use_ten_ints(arr2.data()); // ditto
该类不仅是内置数组的包装器,还提供了一些额外的功能。例如:
array<int, 4> arr3;
arr3.fill(42); // put 42 in each item
arr2.swap(arr3); // swap items in arr2 with items in arr3
使用动态分配的向量类
标准库还在<vector>头文件中提供了vector类。同样,这个类是一个模板,所以你可以用它来处理内置和自定义类型。然而,与array不同,内存是动态分配的,这意味着vector可以在运行时扩展或收缩。项目是连续存储的,因此您可以通过调用data函数或访问第一个项目的地址来访问底层缓冲区(为了支持调整集合的大小,缓冲区可能会改变,因此这样的指针应该只是暂时使用)。当然,与array一样,没有自动转换为愚蠢的指针。vector类提供了带方括号语法的索引随机访问和at函数的范围检查。该类还实现了允许容器与标准库函数和范围for一起使用的方法。
vector类比array类更灵活,因为您可以插入项目,并移动项目,但这会带来一些开销。因为类的实例在运行时动态分配内存,使用分配器的成本,以及在初始化和销毁时的一些额外开销(当vector对象超出范围时)。vector类的对象也比它所持有的数据占用更多的内存。因此,它不适用于少量项目(当array是更好的选择时)。
引用
引用是对象的别名。也就是说,它是对象的另一个名称,因此通过引用访问对象与通过对象的变量名访问对象是相同的。引用使用&符号在引用名称上声明,并且它的初始化和访问方式与变量完全相同:
int i = 42;
int *pi = &i; // pointer to an integer
int& ri1 = i; // reference to a variable
i = 99; // change the integer thru the variable
*pi = 101; // change the integer thru the pointer
ri1 = -1; // change the integer thru the reference
int& ri2 {i}; // another reference to the variable
int j = 1000;
pi = &j; // point to another integer
在这段代码中,声明并初始化了一个变量,然后初始化了一个指针以指向这个数据,并且初始化了一个引用作为变量的别名。引用ri1是使用赋值运算符初始化的,而引用ri2是使用初始化器列表语法初始化的。
指针和引用有两个不同的含义。引用不是初始化为变量的值,变量的数据;它是变量名的别名。
无论变量在哪里被使用,都可以使用引用;对引用所做的任何操作实际上都等同于对变量执行相同的操作。指针指向数据,因此您可以通过取消引用指针来更改数据,同样,您也可以使指针指向任何数据,并通过取消引用指针来更改该数据(这在前面代码的最后两行中有所说明)。您可以为一个变量有几个别名,并且每个别名在声明时必须初始化为该变量。一旦声明,就不能使引用引用不同的对象。
以下代码将无法编译:
int& r1; // error, must refer to a variable
int& r2 = nullptr; // error, must refer to a variable
由于引用是另一个变量的别名,因此它不能存在而不被初始化为一个变量。同样,您不能将其初始化为除变量名以外的任何东西,因此没有空引用的概念。
一旦初始化,引用只是一个变量的别名。实际上,当您将引用用作任何运算符的操作数时,操作是在变量上执行的。
int x = 1, y = 2;
int& rx = x; // declaration, means rx is an alias for x
rx = y; // assignment, changes value of x to the value of y
在这段代码中,rx是变量x的别名,因此最后一行的赋值只是将x赋值为y的值:赋值是在别名变量上执行的。此外,如果您取引用的地址,将返回引用的变量的地址。虽然您可以有一个数组的引用,但不能有一个引用的数组。
常量引用
到目前为止使用的引用允许您更改它是别名的变量,因此它具有左值语义。还有const左值引用,也就是说,引用一个对象,您可以读取,但不能写入。
与const指针一样,您可以使用const关键字在左值引用上声明const引用。这基本上使引用只读:您可以访问变量的数据以读取它,但不能更改它。
int i = 42;
const int& ri = i;
ri = 99; // error!
返回引用
有时,一个对象将被传递给一个函数,函数的语义是应该返回该对象。一个例子是与流对象一起使用的<<运算符。对此运算符的调用是链接的:
cout << "The value is " << 42;
这实际上是一系列对名为operator<<的函数的调用,其中一个接受const char*指针,另一个接受int参数。这些函数还有一个ostream参数,用于指定将要使用的流对象。然而,如果这只是一个ostream参数,那么意味着会创建参数的副本,并且插入操作将在副本上执行。流对象通常使用缓冲,因此对流对象的副本进行更改可能不会产生预期的效果。此外,为了启用插入操作符的链接,插入函数将返回作为参数传递的流对象。意图是通过多个函数调用传递相同的流对象。如果这样的函数返回一个对象,那么它将是一个副本,这不仅意味着一系列插入将涉及大量的副本,这些副本也将是临时的,因此对流的任何更改(例如,std::hex等操作符)将不会持久存在。为了解决这些问题,使用引用。这样的函数的典型原型是:
ostream& operator<<(ostream& _Ostr, int _val);
显然,你必须小心返回引用,因为你必须确保对象的生命周期与引用一样长。这个operator<<函数将返回第一个参数传递的引用,但在下面的代码中,引用将返回给一个自动变量:
string& hello()
{
string str ("hello");
return str; // don't do this!
} // str no longer exists at this point
在前面的代码中,string对象的生存期只有函数的生存期那么长,因此这个函数返回的引用将指向一个不存在的对象。当然,你可以返回一个指向函数中声明的static变量的引用。
从函数返回引用是一种常见的习惯用法,但每当你考虑这样做时,一定要确保别名变量的生命周期不是函数的作用域。
临时对象和引用
左值引用必须引用一个变量,但是当涉及到堆栈上声明的const引用时,C++有一些奇怪的规则。如果引用是const,编译器将延长临时对象的生命周期,使其与引用的生命周期相同。例如,如果你使用初始化列表语法,编译器将创建一个临时对象:
const int& cri { 42 };
在这段代码中,编译器将创建一个临时的int并将其初始化为一个值,然后将其别名到cri引用(这个引用是const很重要)。只要引用在作用域内,临时对象就可以通过引用使用。这可能看起来有点奇怪,但考虑在这个函数中使用一个const引用:
void use_string(const string& csr);
你可以用一个string变量、一个明确转换为string的变量或一个string字面量来调用这个函数:
string str { "hello" };
use_string(str); // a std::string object
const char *cstr = "hello";
use_string(cstr); // a C string can be converted to a std::string
use_string("hello"); // a literal can be converted to a std::string
在大多数情况下,你不会想要一个内置类型的const引用,但对于自定义类型,其中复制会有开销,这是一个优势,正如你在这里看到的,编译器将退回到创建临时对象的方式。
右值引用
C++11 定义了一种新类型的引用,即右值引用。在 C++11 之前,代码(比如赋值操作符)无法知道传递给它的右值是临时对象还是其他。如果这样的函数被传递一个对象的引用,那么函数必须小心不要改变引用,因为这会影响它所引用的对象。如果引用是指向临时对象的,那么函数可以对临时对象做任何喜欢的事情,因为对象在函数完成后不会存在。C++11 允许你专门为临时对象编写代码,因此在赋值的情况下,临时对象的操作符可以将数据从临时对象移动到被赋值的对象中。相比之下,如果引用不是指向临时对象,那么数据将被复制。如果数据很大,那么这将阻止潜在的昂贵的分配和复制。这实现了所谓的移动语义。
考虑这个相当牵强的代码:
string global{ "global" };
string& get_global()
{
return global;
}
string& get_static()
{
static string str { "static" };
return str;
}
string get_temp()
{
return "temp";
}
这三个函数返回一个string对象。在前两种情况下,string的生命周期为整个程序,因此可以返回一个引用。在最后一个函数中,函数返回一个字符串字面值,因此会构造一个临时的string对象。这三个函数都可以用来提供一个string值。例如:
cout << get_global() << endl;
cout << get_static() << endl;
cout << get_temp() << endl;
所有三个函数都可以提供一个可以用来赋值给string对象的字符串。重要的是,前两个函数返回一个已经存在的对象,而第三个函数返回一个临时对象,但这些对象可以被同样使用。
如果这些函数返回对一个大对象的访问,你可能不希望将对象传递给另一个函数,因此,在大多数情况下,你会希望将这些函数返回的对象作为引用传递。例如:
void use_string(string& rs);
引用参数可以避免对字符串进行另一个复制。然而,这只是故事的一半。use_string函数可以操作字符串。例如,下面的函数从参数创建一个新的string,但用下划线替换了字母 a、b 和 o(表示没有这些字母的单词中的空格,模拟没有 A、B 和 O 血型捐赠的生活)。一个简单的实现看起来像这样:
void use_string(string& rs)
{
string s { rs };
for (size_t i = 0; i < s.length(); ++i)
{
if ('a' == s[i] || 'b' == s[i] || 'o' == s[i])
s[i] = '_';
}
cout << s << endl;
}
string对象有一个索引运算符([]),因此可以将其视为一个字符数组,既可以读取字符的值,也可以为字符位置分配值。string的大小通过length函数获得,该函数返回一个unsigned int(typedef为size_t)。由于参数是一个引用,这意味着对string的任何更改都将反映在传递给函数的string中。这段代码的意图是保持其他变量不变,因此首先对参数进行复制。然后在副本上,代码遍历所有字符,将a、b和o字符更改为下划线,然后打印出结果。
这段代码显然有一个复制开销–从引用rs创建string s;但如果我们想要将get_global或get_static返回的字符串传递给这个函数,这是必要的,否则更改将会影响实际的全局和static变量。
然而,从get_temp返回的临时string是另一种情况。这个临时对象只存在到调用get_temp的语句结束。因此,可以对变量进行更改,知道这不会影响其他东西。这意味着可以使用移动语义:
void use_string(string&& s)
{
for (size_t i = 0; i < s.length(); ++i)
{
if ('a' == s[i] || 'b' == s[i] || 'o' == s[i]) s[i] = '_';
}
cout << s << endl;
}
这里只有两个变化。第一个是参数被标识为一个右值引用,使用&&后缀来表示类型。另一个变化是对引用所指向的对象进行更改,因为我们知道它是一个临时对象,这些更改将被丢弃,因此不会影响其他变量。请注意,现在有两个函数,重载了相同的名称:一个带有左值引用,一个带有右值引用。当调用这个函数时,编译器将根据传递给它的参数调用正确的函数:
use_string(get_global()); // string& version
use_string(get_static()); // string& version
use_string(get_temp()); // string&& version
use_string("C string"); // string&& version
string str{"C++ string"};
use_string(str); // string& version
请记住,get_global和get_static返回将在程序的生命周期内存在的对象的引用,因此编译器选择了接受左值引用的use_string版本。更改是在函数内的临时变量上进行的,这会产生复制开销。get_temp返回一个临时对象,因此编译器调用接受右值引用的use_string的重载。这个函数改变了引用所指的对象,但这并不重要,因为该对象不会持续到行末的分号之后。对于使用类似 C 的字符串文字调用use_string也是一样的:编译器会创建一个临时的string对象,并调用带有右值引用参数的重载。在这段代码的最后一个例子中,一个 C++ string对象在堆栈上创建,并传递给use_string。编译器看到这个对象是一个左值,并且可能会被改变,因此调用了接受左值引用的重载,这种重载的实现方式只会改变函数中的临时局部变量。
这个例子表明,C++编译器会检测参数是否是临时对象,并调用带有右值引用的重载。通常,这种功能用于编写复制构造函数(用于从现有实例创建新自定义类型的特殊函数)和赋值运算符,以便这些函数可以实现左值引用重载以从参数复制数据,并实现右值引用重载以将数据从临时对象移动到新对象。其他用途是编写仅移动的自定义类型,它们使用无法复制的资源,例如文件句柄。
范围for和引用
作为引用的一个例子,值得看看 C++11 中的范围for功能。下面的代码非常简单;数组squares用 0 到 4 的平方初始化:
constexpr int size = 4;
int squares[size];
for (int i = 0; i < size; ++i)
{
squares[i] = i * i;
}
编译器知道数组的大小,因此可以使用范围for来打印数组中的值。在下面的例子中,每次迭代,局部变量j都是数组中项目的副本。作为副本,这意味着你可以读取该值,但对变量所做的任何更改都不会反映到数组中。因此,下面的代码按预期工作;它打印出数组的内容。
for (int j : squares)
{
cout << J << endl;
}
如果要更改数组中的值,那么必须访问实际的值,而不是副本。在范围for中实现这一点的方法是使用引用作为循环变量:
for (int& k : squares)
{
k *= 2;
}
现在,在每次迭代中,k变量都是数组中实际成员的别名,因此对k变量所做的任何操作实际上都是在数组成员上执行的。在这个例子中,squares数组的每个成员都乘以 2。你不能使用int*作为k的类型,因为编译器会看到数组中的项目类型是int,并将其作为范围for中的循环变量。由于引用是变量的别名,编译器将允许引用作为循环变量,并且由于引用是别名,你可以使用它来更改实际的数组成员。
对于多维数组,范围for变得很有趣。例如,在下面的例子中,声明了一个二维数组,并尝试使用auto变量来使用嵌套循环:
int arr[2][3] { { 2, 3, 4 }, { 5, 6, 7} };
for (auto row : arr)
{
for (auto col : row) // will not compile
{
cout << col << " " << endl;
}
}
由于二维数组是数组的数组(每一行都是一个一维数组),意图是在外部循环中获取每一行,然后在内部循环中访问每一行中的每个项目。这种方法存在一些问题,但是最直接的问题是这段代码无法编译。
编译器将抱怨内部循环,说它找不到类型int*的begin或end函数。原因是范围for使用迭代器对象,对于数组,它使用 C++标准库函数begin和end来创建这些对象。编译器将从外部范围for中的arr数组中看到每个项目都是一个int[3]数组,因此在外部for循环中,循环变量将是每个元素的副本,在这种情况下是一个int[3]数组。你不能像这样复制数组,所以编译器将提供指向第一个元素的指针,一个int*,并且这在内部for循环中使用。
编译器将尝试为int*获取迭代器,但这是不可能的,因为int*不包含有关它指向多少项的信息。对于int[3](以及所有大小的数组)定义了begin和end的版本,但对于int*没有定义。
简单的更改使得这段代码可以编译。只需将row变量转换为引用即可:
for (auto& row : arr)
{
for (auto col : row)
{
cout << col << " " << endl;
}
}
引用参数表示int[3]数组使用别名,当然,别名与元素相同。使用auto隐藏了实际发生的丑陋。内部循环变量当然是int,因为这是数组中项目的类型。外部循环变量实际上是int (&)[3]。也就是说,它是一个int[3]的引用(括号用于指示它引用一个int[3],而不是一个int&数组)。
在实践中使用指针
一个常见的要求是拥有一个可以在运行时是任意大小并且可以增长和缩小的集合。C++标准库提供了各种类来允许你做到这一点,将在第八章中描述,使用标准库容器。以下示例说明了这些标准集合是如何实现的一些原则。一般来说,你应该使用 C++标准库类而不是实现你自己的。此外,标准库类将代码封装在一个类中,因为我们还没有涵盖类,所以下面的代码将使用潜在可能被错误调用的函数。因此,你应该把这个例子只是一个例子代码。链表是一种常见的数据结构。这些通常用于队列,其中项目的顺序很重要。例如,先进先出队列,其中任务按照它们插入队列的顺序执行。在这个例子中,每个任务都表示为一个包含任务描述和指向要执行的下一个任务的指针的结构。
如果下一个任务的指针是nullptr,那么这意味着当前任务是列表中的最后一个任务:
struct task
{
task* pNext;
string description;
};
回想一下上一章,你可以通过实例使用点运算符访问结构的成员:
task item;
item.descrription = "do something";
在这种情况下,编译器将创建一个用字符串字面量do something初始化的string对象,并将其分配给名为item的实例的description成员。你也可以使用new运算符在自由存储区创建一个task:
task* pTask = new task;
// use the object
delete pTask;
在这种情况下,必须通过指针访问对象的成员,C++提供了->运算符来给你这种访问:
task* pTask = new task;
pTask->descrription = "do something";
// use the object
delete pTask;
这里description成员被赋予了字符串。请注意,由于task是一个结构,没有访问限制,这在类中是很重要的,并在第六章中描述,类。
创建项目
在C:\Beginning_C++下创建一个名为Chapter_04的新文件夹。启动 Visual C++,创建一个 C++源文件并将其保存到刚创建的文件夹中,命名为tasks.cpp。添加一个简单的没有参数的main函数,并使用 C++流提供输入和输出支持:
#include <iostream>
#include <string>
using namespace std;
int main()
{
}
在main函数上面,添加一个代表列表中任务的结构的定义:
using namespace std;
struct task { task* pNext; string description; };
这有两个成员。对象的核心是description项。在我们的例子中,执行任务将涉及将description项打印到控制台。在实际项目中,您很可能会有许多与任务相关的数据项,甚至可能有成员函数来执行任务,但我们还没有涵盖成员函数;这是第六章 类的主题。
链表的连接是另一个成员,pNext。请注意,在声明pNext成员时,task结构尚未完全定义。这不是问题,因为pNext是一个指针。您不能有一个未定义或部分定义类型的数据成员,因为编译器不知道为其分配多少内存。您可以有一个指向部分定义类型的指针成员,因为指针成员的大小不受其指向的内容的影响。
如果我们知道列表中的第一个链接,那么我们可以访问整个列表,在我们的例子中,这将是一个全局变量。在构造列表时,构造函数需要知道列表的末尾,以便它们可以将新的链接附加到列表上。同样,为了方便起见,我们将使其成为一个全局变量。在task结构的定义之后添加以下指针:
task* pHead = nullptr; task* pCurrent = nullptr;
int main()
{
}
就目前而言,代码什么也没做,但这是一个很好的机会来编译文件,以测试是否有拼写错误:
cl /EHsc tasks.cpp
向列表中添加任务对象
为了提供代码,下一步是向任务列表添加一个新任务。这需要创建一个新的task对象并适当地初始化它,然后通过改变列表中的最后一个链接来将其添加到列表中,使其指向新的链接。
在main函数之前,添加以下函数:
void queue_task(const string& name)
{
...
}
参数是const引用,因为我们不会改变参数,也不希望产生额外的复制开销。这个函数必须做的第一件事是创建一个新的链接,所以添加以下行:
void queue_task(const string& name)
{
task* pTask = new task; pTask->description = name; pTask->pNext = nullptr;
}
第一行在自由存储器上创建一个新的链接,接下来的行初始化它。这不一定是初始化这样一个对象的最佳方式,更好的机制,构造函数,将在第六章 类中介绍。请注意,pNext项被初始化为nullptr;这表示该链接将位于列表的末尾。
该函数的最后部分将链接添加到列表中,即使链接成为列表中的最后一个。但是,如果列表为空,这意味着该链接也是列表中的第一个链接。代码必须执行这两个操作。在函数的末尾添加以下代码:
if (nullptr == pHead)
{
pHead = pTask;
pCurrent = pTask;
}
else
{
pCurrent->pNext = pTask;
pCurrent = pTask;
}
第一行检查列表是否为空。如果pHead是nullptr,这意味着没有其他链接,因此当前链接是第一个链接,因此pHead和pCurrent都初始化为新链接指针。如果列表中存在现有链接,则必须将链接添加到最后一个链接,因此在else子句中,第一行使最后一个链接指向新链接,第二行使用新链接指针初始化pCurrent,使新链接成为列表中任何新插入的最后一个链接。
通过在main函数中调用此函数将项目添加到列表中。在这个例子中,我们将排队进行粘贴壁纸的任务。这涉及到去除旧壁纸,填补墙壁上的任何孔洞,调整墙壁大小(用稀释的糊状物涂抹墙壁,使墙壁变得粘性),然后将粘贴的壁纸贴到墙上。您必须按照这个顺序完成这些任务,不能改变顺序,因此这些任务非常适合使用链表。在main函数中添加以下行:
queue_task("remove old wallpaper");
queue_task("fill holes");
queue_task("size walls");
queue_task("hang new wallpaper");
在最后一行之后,列表已创建。pHead变量指向列表中的第一项,您可以通过简单地从一个链接到下一个链接来访问列表中的任何其他项。
您可以编译代码,但没有输出。更糟糕的是,代码的当前状态存在内存泄漏。程序没有代码来delete由new运算符在自由存储器上创建的task对象所占用的内存。
删除任务列表
遍历列表很简单,只需按照pNext指针从一个链接到下一个链接。在执行此操作之前,让我们先修复上一节中引入的内存泄漏。在main函数上面,添加以下函数:
bool remove_head()
{
if (nullptr == pHead) return false;
task* pTask = pHead;
pHead = pHead->pNext;
delete pTask;
return (pHead != nullptr);
}
此函数将删除列表开头的链接,并确保pHead指针指向下一个链接,这将成为列表的新开头。该函数返回一个bool值,指示列表中是否还有其他链接。如果此函数返回false,则表示整个列表已被删除。
第一行检查此函数是否已使用空列表调用。一旦我们确信列表至少有一个链接,我们就会创建此指针的临时副本。原因是打算删除第一项并使pHead指向下一项,为此我们必须反向执行这些步骤:使pHead指向下一项,然后删除pHead先前指向的项。
要删除整个列表,需要通过链接进行迭代,可以使用while循环进行。在remove_head函数下面,添加以下内容:
void destroy_list()
{
while (remove_head());
}
要删除整个列表,并解决内存泄漏问题,将以下行添加到主函数的底部
destroy_list();
}
现在可以编译代码并运行它。但是,您将看不到任何输出,因为所有代码只是创建一个列表,然后删除它。
遍历任务列表
下一步是从第一个链接开始迭代列表,直到通过每个pNext指针到达列表的末尾。对于访问的每个链接,应执行任务。首先编写一个执行任务的函数,该函数通过打印任务的描述然后返回指向下一个任务的指针来执行任务。在main函数上面,添加以下代码:
task *execute_task(const task* pTask)
{
if (nullptr == pTask) return nullptr;
cout << "executing " << pTask->description << endl;
return pTask->pNext;
}
这里的参数标记为const,因为我们不会改变指向的task对象。这告诉编译器,如果代码尝试更改对象,则会出现问题。第一行检查确保函数不是用空指针调用的。如果是,那么接下来的行将取消引用无效的指针并导致内存访问故障。最后一行返回指向下一个链接的指针(对于列表中的最后一个链接可能是nullptr),以便可以在循环中调用该函数。在此函数之后,添加以下内容以迭代整个列表:
void execute_all()
{
task* pTask = pHead;
while (pTask != nullptr)
{
pTask = execute_task(pTask);
}
}
此代码从开头pHead开始,并在列表中的每个链接上调用execute_task,直到函数返回nullptr。在main函数的末尾添加对此函数的调用:
execute_all();
destroy_list();
}
现在可以编译并运行代码。结果将是:
executing remove old wallpaper
executing fill holes
executing size walls executing hang new wallpaper
插入项目
链表的一个优点是,您可以通过仅分配一个新项目并更改适当的指针来将项目插入列表,并使其指向列表中的下一个项目。与分配task对象的数组相比,这与在中间插入新项目要简单得多;如果要在中间插入新项目,您必须为旧项目和新项目分配足够大的新数组,然后将旧项目复制到新数组中,在正确的位置复制新项目。
壁纸任务列表的问题在于房间有一些涂过油漆的木制品,正如任何装饰者所知,最好在贴壁纸之前先涂油漆,通常是在涂墙之前。我们需要在填补任何孔之后和调整墙壁之前插入一个新任务。此外,在进行任何装饰之前,您应该先覆盖房间中的任何家具,因此需要在开头添加一个新任务。
第一步是找到我们想要放置新任务的位置来粉刷木制品。我们将寻找我们要插入的任务之前的任务。在main之前添加以下内容:
task *find_task(const string& name)
{
task* pTask = pHead;
while (nullptr != pTask)
{
if (name == pTask->description) return pTask;
pTask = pTask->pNext;
}
return nullptr;
}
这段代码搜索整个列表,查找与参数匹配的description链接。这是通过循环执行的,循环使用string比较运算符,如果找到所需的链接,则返回指向该链接的指针。如果比较失败,循环将循环变量初始化为下一个链接的地址,如果此地址为nullptr,则意味着列表中没有所需的任务。
在主函数中创建列表后,添加以下代码来搜索fill holes任务:
queue_task("hang new wallpaper");
// oops, forgot to paint
woodworktask* pTask = find_task("fill holes"); if (nullptr != pTask) { // insert new item after pTask }
execute_all();
如果find_task函数返回有效指针,那么我们可以在此处添加一个项目。
此函数允许您在传递给它的列表中的任何项目后添加新项目,如果传递nullptr,它将在开头添加新项目。它被称为insert_after,但显然,如果你传递nullptr,它也意味着在开头之前插入。在main函数上面添加以下内容:
void insert_after(task* pTask, const string& name)
{
task* pNewTask = new task;
pNewTask->description = name;
if (nullptr != pTask)
{
pNewTask->pNext = pTask->pNext;
pTask->pNext = pNewTask;
}
}
第二个参数是const引用,因为我们不会改变string,但第一个参数不是const指针,因为我们将改变它指向的对象。此函数创建一个新的task对象,并将description成员初始化为新的任务名称。然后检查传递给函数的task指针是否为空。如果不是,则可以在列表中指定链接之后插入新项目。为此,新链接pNext成员被初始化为列表中的下一个项目,并且前一个链接的pNext成员被初始化为新链接的地址。
当函数传递nullptr作为要插入的项目时,如何在开头插入一个项目?添加以下else子句。
void insert_after(task* pTask, const string& name)
{
task* pNewTask = new task;
pNewTask->description = name;
if (nullptr != pTask)
{
pNewTask->pNext = pTask->pNext;
pTask->pNext = pNewTask;
}
else { pNewTask->pNext = pHead; pHead = pNewTask; }
}
在这里,我们使新项目的pNext成员指向旧列表的开头,然后将pHead更改为指向新项目。
现在,在main函数中,您可以添加一个调用来插入一个新任务来粉刷木制品,因为我们还忘记指出最好在用防尘布覆盖所有家具后装饰房间,所以在列表中首先添加一个任务来做到这一点:
task* pTask = find_task("fill holes");
if (nullptr != pTask)
{
insert_after(pTask, "paint woodwork");
}
insert_after(nullptr, "cover furniture");
现在可以编译代码了。运行代码时,您应该按照所需的顺序执行任务:
executing cover furniture executing remove old wallpaper
executing fill holes
executing paint woodwork
executing size walls
executing hang new wallpaper
总结
可以说使用 C++的主要原因之一是你可以使用指针直接访问内存。这是大多数其他语言的程序员无法做到的特性。这意味着作为 C++程序员,你是一种特殊类型的程序员:一个被信任处理内存的人。在本章中,你已经看到如何获取和使用指针,以及指针的不当使用如何使你的代码出现严重错误的一些示例。
在下一章中,我们将介绍包括另一种指针类型的描述:函数指针。如果你被信任使用数据指针和函数指针,那么你真的是一种特殊类型的程序员。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









