







原文:
zh.annas-archive.org/md5/BCB2906673DC89271C447ACAA17D3E00译者:飞龙
第三部分:扩展您的 C++编程技能
本节的目标是扩展您的 C++编程技能,超越面向对象编程技能,涵盖 C++的其他关键特性。
本节的初始章节通过理解 try、throw 和 catch 的机制,并通过检查许多示例来探索异常机制,深入研究各种异常处理场景来探索 C++中的异常处理。此外,本章通过引入新的异常类来扩展异常类层次结构。
下一章深入探讨了友元函数和友元类的正确使用方式,以及运算符重载(有时可能需要友元)以使内置类型和用户定义类型之间的操作多态化。
下一章探讨了使用 C++模板来帮助使代码通用化,并对各种数据类型使用模板函数和模板类。此外,本章解释了运算符重载如何帮助使模板代码对几乎任何数据类型都可扩展。
在下一章中,将介绍 C++中的标准模板库,并检查核心 STL 容器,如列表、迭代器、双端队列、栈、队列、优先队列和映射。此外,还将介绍 STL 算法和函数对象。
本节的最后一章通过探索规范类形式、为组件测试创建驱动程序、测试通过继承、关联和聚合相关的类以及测试异常处理机制,对测试 OO 程序和组件进行了调查。
本节包括以下章节:
-
[第十一章],处理异常
-
[第十二章],友元和运算符重载
-
[第十三章],使用模板
-
[第十四章],理解 STL 基础
-
[第十五章],测试类和组件
第十一章:处理异常
本章将开始我们的探索,扩展你的 C++编程技能,超越面向对象编程的概念,目标是让你能够编写更健壮、更可扩展的代码。我们将通过探索 C++中的异常处理来开始这个努力。在我们的代码中添加语言规定的方法来处理错误,将使我们能够实现更少的错误和更可靠的程序。通过使用语言内置的正式异常处理机制,我们可以实现对错误的统一处理,从而实现更易于维护的代码。
在本章中,我们将涵盖以下主要主题:
-
理解异常处理的基础知识——
try、throw和catch -
探索异常处理机制——尝试可能引发异常的代码,引发(抛出)、捕获和处理异常,使用多种变体
-
利用标准异常对象或创建自定义异常类的异常层次结构
通过本章结束时,你将了解如何在 C++中利用异常处理。你将看到如何识别错误以引发异常,通过抛出异常将程序控制转移到指定区域,然后通过捕获异常来处理错误,并希望修复手头的问题。
你还将学习如何利用 C++标准库中的标准异常,以及如何创建自定义异常对象。可以设计一组异常类的层次结构,以增加健壮的错误检测和处理能力。
通过探索内置的语言异常处理机制,扩展我们对 C++的理解。
技术要求
完整程序示例的在线代码可以在以下 GitHub URL 找到:github.com/PacktPublishing/Demystified-Object-Oriented-Programming-with-CPP/blob/master/Chapter11。每个完整程序示例都可以在 GitHub 存储库中找到,位于相应章节标题(子目录)下的文件中,文件名与所在章节编号相对应,后跟该章节中的示例编号。例如,本章的第一个完整程序可以在名为Chp11-Ex1.cpp的文件中的子目录Chapter11中找到,位于上述 GitHub 目录下。
本章的 CiA 视频可在以下链接观看:bit.ly/3r8LHd5。
理解异常处理
应用程序中可能会出现错误条件,这些错误条件可能会阻止程序正确地继续运行。这些错误条件可能包括超出应用程序限制的数据值、必要的输入文件或数据库不可用、堆内存耗尽,或者任何其他可能的问题。C++异常提供了一种统一的、语言支持的方式来处理程序异常。
在引入语言支持的异常处理机制之前,每个程序员都会以自己的方式处理错误,有时甚至根本不处理。程序错误和未处理的异常意味着在应用程序的其他地方,将会发生意外的结果,应用程序往往会异常终止。这些潜在的结果肯定是不可取的!
C++异常处理提供了一种语言支持的机制,用于检测和纠正程序异常,使应用程序能够继续运行,而不是突然结束。
让我们从语言支持的关键字try、throw和catch开始,来看一下这些机制,它们构成了 C++中的异常处理。
利用 try、throw 和 catch 进行异常处理
异常处理检测到程序异常,由程序员或类库定义,并将控制传递到应用程序的另一个部分,该部分可能处理特定的问题。只有作为最后的手段,才需要退出应用程序。
让我们首先看一下支持异常处理的关键字。这些关键字是:
-
try:允许程序员尝试可能引发异常的代码部分。 -
throw:一旦发现错误,throw会引发异常。这将导致跳转到与关联 try 块下面的 catch 块。Throw 将允许将参数返回到关联的 catch 块。抛出的参数可以是任何标准或用户定义的类型。 -
catch:指定一个代码块,旨在寻找已抛出的异常,以尝试纠正情况。同一作用域中的每个 catch 块将处理不同类型的异常。
在使用异常处理时,回溯的概念是有用的。当调用一系列函数时,我们在堆栈上建立起与每个连续函数调用相关的状态信息(参数、局部变量和返回值空间),以及每个函数的返回地址。当抛出异常时,我们可能需要解开堆栈,直到这个函数调用序列(或 try 块)开始的原点,同时重置堆栈指针。这个过程被称为回溯,它允许程序返回到代码中的较早序列。回溯不仅适用于函数调用,还适用于包括嵌套 try 块在内的嵌套块。
这里有一个简单的例子,用来说明基本的异常处理语法和用法。尽管代码的部分没有显示出来以节省空间,但完整的示例可以在我们的 GitHub 上找到,如下所示:
// Assume Student class is as we've seen before, but with one
// additional virtual member function. Assume usual headers.
void Student::Validate() // defined as virtual in class def
{ // so derived classes may override
// check constructed Student to see if standards are met
// if not, throw an exception
throw "Does not meet prerequisites";
}
int main()
{
Student s1("Sara", "Lin", 'B', "Dr.", 3.9,"C++", "23PSU");
try // Let's 'try' this block of code --
{ // Validate() may raise an exception
s1.Validate(); // does s1 meet admission standards?
}
catch (const char *err)
{
cout << err << endl;
// try to fix problem here…
exit(1); // only if you can't fix, exit gracefully
}
cout << "Moving onward with remainder of code." << endl;
return 0;
}
在上面的代码片段中,我们可以看到关键字try、throw和catch的作用。首先,让我们注意Student::Validate()成员函数。想象一下,在这个虚方法中,我们验证一个Student是否符合入学标准。如果是,函数会正常结束。如果不是,就会抛出异常。在这个例子中,抛出一个简单的const char *,其中包含消息"Does not meet prerequisites"。
在我们的main()函数中,我们首先实例化一个Student,即s1。然后,我们将对s1.Validate()的调用嵌套在一个 try 块中。我们实际上是在说,我们想尝试这个代码块。如果Student::Validate()按预期工作,没有错误,我们的程序将完成 try 块,跳过 try 块下面的 catch 块,并继续执行 catch 块下面的代码。
然而,如果Student::Validate()抛出异常,我们将跳过 try 块中的任何剩余代码,并在随后定义的 catch 块中寻找与const char *类型匹配的异常。在匹配的 catch 块中,我们的目标是尽可能地纠正错误。如果成功,我们的程序将继续执行 catch 块下面的代码。如果不成功,我们的工作就是优雅地结束程序。
让我们看一下上述程序的输出:
Student does not meet prerequisites
接下来,让我们总结一下异常处理的整体流程,具体如下:
-
当程序完成 try 块而没有遇到任何抛出的异常时,代码序列将继续执行 catch 块后面的语句。多个 catch 块(带有不同的参数类型)可以跟在 try 块后面。
-
当抛出异常时,程序必须回溯并返回到包含原始函数调用的 try 块。程序可能需要回溯多个函数。当回溯发生时,遇到的对象将从堆栈中弹出,因此被销毁。
-
一旦程序(引发异常)回溯到执行 try 块的函数,程序将继续执行与抛出的异常类型匹配的 catch 块(在 try 块之后)。
-
类型转换(除了通过公共继承相关的向上转型对象)不会被执行以匹配潜在的 catch 块。然而,带有省略号(
…)的 catch 块可以作为最一般类型的 catch 块使用,并且可以捕获任何类型的异常。 -
如果不存在匹配的
catch块,程序将调用 C++标准库中的terminate()。请注意,terminate()将调用abort(),但程序员可以通过set_terminate()函数注册另一个函数供terminate()调用。
现在,让我们看看如何使用set_terminate()注册一个函数。虽然我们这里只展示了代码的关键部分,完整的程序可以在我们的 GitHub 上找到:
void AppSpecificTerminate()
{ // first, do what is necessary to end program gracefully
cout << "Uncaught exception. Program terminating" << endl;
exit(1);
}
int main()
{
set_terminate(AppSpecificTerminate); // register fn.
return 0;
}
在前面的代码片段中,我们定义了自己的AppSpecificTerminate()函数。这是我们希望terminate()函数调用的函数,而不是调用abort()的默认行为。也许我们使用AppSpecificTerminate()来更优雅地结束我们的应用程序,保存关键数据结构或数据库值。当然,我们也会自己exit()(或abort())。
在main()中,我们只需调用set_terminate(AppSpecificTerminate)来注册我们的terminate函数到set_terminate()。现在,当否则会调用abort()时,我们的函数将被调用。
有趣的是,set_terminate()返回一个指向先前安装的terminate_handler的函数指针(在第一次调用时将是指向abort()的指针)。如果我们选择保存这个值,我们可以使用它来恢复先前注册的终止处理程序。请注意,在这个示例中,我们选择不保存这个函数指针。
以下是使用上述代码未捕获异常的输出:
Uncaught exception. Program terminating
请记住,诸如terminate()、abort()和set_terminate()之类的函数来自标准库。虽然我们可以使用作用域解析运算符在它们的名称前加上库名称,比如std::terminate(),但这并非必需。
注意
异常处理并不意味着取代简单的程序员错误检查;异常处理的开销更大。异常处理应该保留用于以统一方式和在一个公共位置处理更严重的程序错误。
现在我们已经了解了异常处理的基本机制,让我们来看一些稍微复杂的异常处理示例。
探索异常处理机制及典型变化
异常处理可以比之前所示的基本机制更加复杂和灵活。让我们来看看异常处理基础的各种组合和变化,因为每种情况可能适用于不同的编程情况。
将异常传递给外部处理程序
捕获的异常可以传递给外部处理程序进行处理。或者,异常可以部分处理,然后抛出到外部范围进行进一步处理。
让我们在之前的示例基础上演示这个原则。完整的程序可以在以下 GitHub 位置看到:
// Assume Student class is as we've seen it before, but with
// two additional member functions. Assume usual header files.
void Student::Validate() // defined as virtual in class def
{ // so derived classes may override
// check constructed student to see if standards are met
// if not, throw an exception
throw "Does not meet prerequisites";
}
bool Student::TakePrerequisites()
{
// Assume this function can correct the issue at hand
// if not, it returns false
return false;
}
int main()
{
Student s1("Alex", "Ren", 'Z', "Dr.", 3.9, "C++", "89CU");
try // illustrates a nested try block
{
// Assume another important task occurred in this
// scope, which may have also raised an exception
try
{
s1.Validate(); // may raise an exception
}
catch (const char *err)
{
cout << err << endl;
// try to correct (or partially handle) error.
// If you cannot, pass exception to outer scope
if (!s1.TakePrerequisites())
throw; // re-throw the exception
}
}
catch (const char *err) // outer scope catcher (handler)
{
cout << err << endl;
// try to fix problem here…
exit(1); // only if you can't fix, exit gracefully
}
cout << "Moving onward with remainder of code. " << endl;
return 0;
}
在上述代码中,假设我们已经包含了我们通常的头文件,并且已经定义了Student的通常类定义。现在我们将通过添加Student::Validate()方法(虚拟的,以便可以被覆盖)和Student::TakePrerequisites()方法(非虚拟的,后代应该按原样使用)来增强Student类。
请注意,我们的Student::Validate()方法抛出一个异常,这只是一个包含指示问题的消息的字符串字面量。我们可以想象Student::TakePrerequisites()方法的完整实现验证了Student是否满足适当的先决条件,并根据情况返回true或false的布尔值。
在我们的main()函数中,我们现在注意到一组嵌套的 try 块。这里的目的是说明一个内部 try 块可能调用一个方法,比如s1.Validate(),这可能会引发异常。注意到与内部 try 块相同级别的处理程序捕获了这个异常。理想情况下,异常应该在与其来源的 try 块相等的级别上处理,所以让我们假设这个范围内的捕获器试图这样做。例如,我们最内层的 catch 块可能试图纠正错误,并通过调用s1.TakePrerequisites()来测试是否已经进行了纠正。
但也许这个捕获器只能部分处理异常。也许有一个外层处理程序知道如何进行剩余的修正。在这种情况下,将这个异常重新抛出到外层(嵌套)级别是可以接受的。我们在最内层的 catch 块中的简单的throw;语句就是这样做的。注意外层有一个捕获器。如果抛出的异常与外层的类型匹配,现在外层就有机会进一步处理异常,并希望纠正问题,以便应用程序可以继续。只有当这个外部 catch 块无法纠正错误时,应用程序才应该退出。在我们的例子中,每个捕获器都打印表示错误消息的字符串;因此这条消息在输出中出现了两次。
让我们看看上述程序的输出:
Student does not meet prerequisites
Student does not meet prerequisites
现在我们已经看到了如何使用嵌套的 try 和 catch 块,让我们继续看看如何一起使用各种抛出类型和各种 catch 块。
添加各种处理程序
有时,内部范围可能会引发各种异常,从而需要为各种数据类型制定处理程序。异常处理程序(即 catch 块)可以接收任何数据类型的异常。我们可以通过使用基类类型的 catch 块来最小化引入的捕获器数量;我们知道派生类对象(通过公共继承相关)总是可以向上转换为它们的基类类型。我们还可以在 catch 块中使用省略号(…)来允许我们捕获以前未指定的任何东西。
让我们在我们的初始示例上建立,以说明各种处理程序的操作。虽然缩写,但我们完整的程序示例可以在我们的 GitHub 上找到:
// Assume Student class is as we've seen before, but with one
// additional virtual member function, Graduate(). Assume
// a simple Course class exists. All headers are as usual.
void Student::Graduate()
{ // Assume the below if statements are fully implemented
if (gpa < 2.0) // if gpa doesn't meet requirements
throw gpa;
// if Student is short credits, throw how many are missing
throw numCreditsMissing; // assume this is an int
// or if Student is missing a Course, construct and
// then throw the missing Course as a referenceable object
// Assume appropriate Course constructor exists
throw *(new Course("Intro. To Programming", 1234));
// or if another issue, throw a diagnostic message
throw ("Does not meet requirements");
}
int main()
{
Student s1("Ling", "Mau", 'I', "Ms.", 3.1, "C++", "55UD");
try
{
s1.Graduate();
}
catch (float err)
{
cout << "Too low gpa: " << err << endl;
exit(1); // only if you can't fix, exit gracefully
}
catch (int err)
{
cout << "Missing " << err << " credits" << endl;
exit(2);
}
catch (const Course &err)
{
cout << "Needs to take: " << err.GetTitle() << endl;
cout << "Course #: " << err.GetCourseNum() << endl;
// If you correct the error, and continue the program,
// be sure to deallocate heap mem using: delete &err;
exit(3); // Otherwise, heap memory for err will be
} // reclaimed upon exit()
catch (const char *err)
{
cout << err << endl;
exit(4);
}
catch (...)
{
cout << "Exiting" << endl;
exit(5);
}
cout << "Moving onward with remainder of code." << endl;
return 0;
}
在上述代码段中,我们首先检查了Student::Graduate()成员函数。在这里,我们可以想象这个方法通过许多毕业要求,并且因此可能引发各种不同类型的异常。例如,如果Student实例的gpa太低,就会抛出一个浮点数作为异常,指示学生的gpa太低。如果Student的学分太少,就会抛出一个整数,指示学生还需要多少学分才能获得学位。
也许Student::Graduate()可能引发的最有趣的潜在错误是,如果学生的毕业要求中缺少了一个必需的Course。在这种情况下,Student::Graduate()将分配一个新的Course对象,通过构造函数填充Course的名称和编号。接下来,Course的指针被解引用,并且对象被引用抛出。处理程序随后可以通过引用捕获这个对象。
在main()函数中,我们只是在 try 块中包装了对Student::Graduate()的调用,因为这个语句可能会引发异常。接着 try 块后面是一系列的 catch 块 - 每种可能被抛出的对象类型对应一个catch语句。在这个序列中的最后一个 catch 块使用省略号(…),表示这个 catch 块将处理Student::Graduate()抛出的任何其他类型的异常,这些异常没有被其他 catch 块捕获到。
实际上被激活的 catch 块是使用const Course &err捕获Course的那个。有了const限定符,我们不能在处理程序中修改Course,所以我们只能对这个对象应用const成员函数。
请注意,尽管上面显示的每个 catch 块只是简单地打印出错误然后退出,但理想情况下,catch 块应该尝试纠正错误,这样应用程序就不需要终止,允许在 catch 块下面的代码继续执行。
让我们看看上述程序的输出:
Needs to take: Intro. to Programming
Course #: 1234
现在我们已经看到了各种抛出的类型和各种 catch 块,让我们继续向前了解在单个 try 块中应该将什么内容分组在一起。
在 try 块中分组相关的项目
重要的是要记住,当 try 块中的一行代码遇到异常时,try 块的其余部分将被忽略。相反,程序将继续执行匹配的 catch 块(或者如果没有合适的 catch 块存在,则调用terminate())。然后,如果错误被修复,catch 块之后的代码将开始执行。请注意,我们永远不会返回来完成初始 try 块的其余部分。这种行为的含义是,你应该只在 try 块中将一起的元素分组在一起。也就是说,如果一个项目引发异常,完成该分组中的其他项目就不再重要了。
请记住,catch 块的目标是尽可能纠正错误。这意味着在适用的 catch 块之后,程序可能会继续向前。你可能会问:现在跳过了与 try 块相关的项目是否可以接受?如果答案是否定的,那么请重写你的代码。例如,你可能想在try-catch分组周围添加一个循环,这样如果 catch 块纠正了错误,整个企业就会重新开始,从初始的 try 块开始重试。
或者,将较小的、连续的try-catch分组。也就是说,try只在自己的 try 块中尝试一个重要的任务(后面跟着适用的 catch 块)。然后在自己的 try 块中尝试下一个任务,后面跟着适用的 catch 块,依此类推。
接下来,让我们看一种在函数原型中包含它可能抛出的异常类型的方法。
检查函数原型中的异常规范
我们可以通过扩展函数的签名来可选地指定 C++函数可能抛出的异常类型,包括可能被抛出的对象类型。然而,因为一个函数可能抛出多种类型的异常(或者根本不抛出异常),所以必须在运行时检查实际抛出的类型。因此,函数原型中的这些增强规范也被称为动态异常规范。
让我们看一个在函数的扩展签名中使用异常类型的例子:
void Student::Graduate() throw(float, int, Course &, char *)
{
// this method might throw any of the above mentioned types
}
void Student::Enroll() throw()
{
// this method might throw any type of exception
}
在上述代码片段中,我们看到了Student的两个成员函数。Student::Graduate()在其参数列表后包含throw关键字,然后作为该方法的扩展签名的一部分,包含了可能从该函数中抛出的对象类型。请注意,Student::Enroll()方法在其扩展签名中仅在throw()后面有一个空列表。这意味着Student::Enroll()可能抛出任何类型的异常。
在这两种情况下,通过在签名中添加throw()关键字和可选的数据类型,我们提供了一种向该函数的用户宣布可能被抛出的对象类型的方法。然后我们要求程序员在 try 块中包含对该方法的任何调用,然后跟上适当的 catcher。
我们将看到,尽管扩展签名的想法似乎非常有帮助,但在实践中存在不利问题。因此,动态异常规范已被弃用。因为您可能仍然会在现有代码中看到这些规范的使用,包括标准库原型(如异常),编译器仍然支持这个已弃用的特性,您需要了解它们的用法。
尽管动态异常(如前所述的扩展函数签名)已被弃用,但语言中已添加了具有类似目的的指定符号noexcept关键字。此指定符号可以在扩展签名之后添加如下:
void Student::Graduate() noexcept // will not throw()
{ // same as noexcept(true) in extended signature
} // same as deprecated throw() in ext. signature
void Student::Enroll() noexcept(false) // may throw()
{ // an exception
}
尽管如此,让我们调查一下为什么与动态异常相关的不利问题存在,看看当我们的应用程序抛出不属于函数扩展签名的异常时会发生什么。
处理意外类型的动态异常
如果在扩展函数原型中指定的类型之外抛出了异常,C++标准库中的unexpected()将被调用。您可以像我们在本章前面注册set_terminate()时那样,注册自己的函数到unexpected()。
您可以允许您的AppSpecificUnexpected()函数重新抛出应该由原始函数抛出的异常类型,但是如果没有发生这种情况,将会调用terminate()。此外,如果没有可能匹配的 catcher 存在来处理从原始函数正确抛出的内容(或者由您的AppSpecificUnexpected()重新抛出),那么将调用terminate()。
让我们看看如何使用我们自己的函数set_unexpected():
void AppSpecificUnexpected()
{
cout << "An unexpected type was thrown" << endl;
// optionally re-throw the correct type, or
// terminate() will be called.
}
int main()
{
set_unexpected(AppSpecificUnexpected)
}
注册我们自己的函数到set_unexpected()非常简单,就像前面章节中所示的代码片段一样。
历史上,在函数的扩展签名中使用异常规范的一个激励原因是提供文档效果。也就是说,您可以通过检查其签名来看到函数可能抛出的异常,然后计划在 try 块中封装该函数调用,并提供适当的 catcher 来处理任何潜在情况。
然而,关于动态异常,值得注意的是编译器不会检查函数体中实际抛出的异常类型是否与函数扩展签名中指定的类型匹配。这取决于程序员来确保它们同步。因此,这个已弃用的特性可能容易出错,总体上比其原始意图更少用。
尽管初衷良好,动态异常目前未被使用,除了在大量的库代码中,比如 C++标准库。由于您将不可避免地使用这些库,了解这些过时的特性非常重要。
注意
在 C++中,动态异常规范(即在方法的扩展签名中指定异常类型的能力)已经被弃用。这是因为编译器无法验证它们的使用,必须延迟到运行时。尽管它们仍然受支持(许多库具有这种规范),但现在已经被弃用。
现在我们已经看到了一系列异常处理检测、引发、捕获和(希望)纠正方案,让我们看看如何创建一系列异常类的层次结构,以增强我们的错误处理能力。
利用异常层次结构
创建一个类来封装与程序错误相关的细节似乎是一个有用的努力。事实上,C++标准库已经创建了一个这样的通用类,exception,为构建整个有用的异常类层次结构提供了基础。
让我们看看带有其标准库后代的exception类,然后看看我们如何用自己的类扩展exception。
使用标准异常对象
<exception>头文件。exception类包括一个带有以下签名的虚函数:virtual const char *what() const throw()。这个签名表明派生类应该重新定义what(),返回一个描述手头错误的const char *。what()后面的const关键字表示这是一个const成员函数;它不会改变派生类的任何成员。扩展签名中的throw()表示这个函数可能抛出任何类型。在签名中使用throw()是一个已弃用的陈词滥调。
std::exception类是各种预定义的 C++异常类的基类,包括bad_alloc、bad_cast、bad_exception、bad_function_call、bad_typeid、bad_weak_ptr、logic_error、runtime_error和嵌套类ios_base::failure。这些派生类中的许多都有自己的后代,为预定义的异常层次结构添加了额外的标准异常。
如果函数抛出了上述任何异常,这些异常可以通过捕获基类类型exception或捕获单个派生类类型来捕获。根据处理程序将采取的行动,您可以决定是否希望将这样的异常作为其广义基类类型或特定类型捕获。
就像标准库基于exception类建立了一系列类的层次结构一样,你也可以。接下来让我们看看我们可能如何做到这一点!
创建自定义异常类
作为程序员,您可能会认为建立自己的专门异常类型是有利的。每种类型可以将有用的信息打包到一个对象中,详细说明应用程序出了什么问题。此外,您可能还可以将线索打包到(将被抛出的)对象中,以指导如何纠正手头的错误。只需从标准exception类派生您的类。
让我们通过检查我们下一个示例的关键部分来看看这是如何轻松实现的,完整的程序可以在我们的 GitHub 上找到:
#include <iostream>
#include <exception>
using namespace std;
class StudentException: public exception
{
private:
int errCode;
char *details;
public:
StudentException(const char *det, int num): errCode(num)
{
details = new char[strlen(det) + 1];
strcpy(details, det);
}
virtual ~StudentException() { delete details; }
virtual const char *what() const throw()
{ // overridden function from exception class
return "Student Exception";
}
int GetCode() const { return errCode; }
const char *GetDetails() const { return details; }
};
// Assume Student class is as we've seen before, but with one
// additional virtual member function Graduate()
void Student::Graduate() // fn. may throw (StudentException)
{
// if something goes wrong, instantiate a StudentException,
// pack it with relevant data during construction, and then
// throw the dereferenced pointer as a referenceable object
throw *(new StudentException("Missing Credits", 4));
}
int main()
{
Student s1("Alexandra", "Doone", 'G', "Miss", 3.95,
"C++", "231GWU");
try
{
s1.Graduate();
}
catch (const StudentException &e) // catch exc. by ref
{
cout << e.what() << endl;
cout << e.GetCode() << " " << e.GetDetails() << endl;
// Grab useful info from e and try to fix the problem
// so that the program can continue.
// If we fix the problem, deallocate heap memory for
// thrown exception (take addr. of a ref): delete &e;
// Otherwise, memory will be reclaimed upon exit()
exit(1); // only exit if necessary!
}
return 0;
}
让我们花几分钟来检查前面的代码段。首先,注意我们定义了自己的异常类,StudentException。它是从 C++标准库exception类派生的类。
StudentException类包含数据成员来保存错误代码以及使用数据成员errCode和details描述错误条件的字母数字细节。我们有两个简单的访问函数,StudentException::GetCode()和StudentException::GetDetails(),可以轻松地检索这些值。由于这些方法不修改对象,它们是const成员函数。
我们注意到StudentException构造函数通过成员初始化列表初始化了两个数据成员,一个在构造函数的主体中初始化。我们还重写了exception类引入的virtual const char *what() const throw()方法。请注意,exception::what()方法在其扩展签名中使用了不推荐的throw()规范,这也是你必须在你的重写方法中做的事情。
接下来,让我们检查一下我们的Student::Graduate()方法。这个方法可能会抛出一个StudentException。如果必须抛出异常,我们使用new()分配一个异常,用诊断数据构造它,然后从这个函数中throw解引用指针(这样我们抛出的是一个可引用的对象,而不是一个对象的指针)。请注意,在这个方法中抛出的对象没有本地标识符 - 没有必要,因为任何这样的本地变量名很快就会在throw发生后从堆栈中弹出。
在我们的main()函数中,我们将对s1.Graduate()的调用包装在一个 try 块中,后面是一个接受StudentException的引用(&)的 catch 块,我们将其视为const。在这里,我们首先调用我们重写的what()方法,然后从异常e中打印出诊断细节。理想情况下,我们将使用这些信息来尝试纠正手头的错误,只有在真正必要时才退出应用程序。
让我们看一下上述程序的输出:
Student Exception
4 Missing Credits
尽管创建自定义异常类的最常见方式是从标准的exception类派生一个类,但也可以利用不同的技术,即嵌套异常类。
创建嵌套异常类
作为另一种实现,异常处理可以通过在特定外部类的公共访问区域添加嵌套类定义来嵌入到一个类中。内部类将代表自定义异常类。
嵌套的、用户定义的类型的对象可以被创建并抛出给预期这种类型的 catcher。这些嵌套类内置在外部类的公共访问区域,使它们很容易为派生类的使用和特化而使用。一般来说,内置到外部类中的异常类必须是公共的,以便可以在外部类的范围之外(即在主要的外部实例存在的范围内)捕获和处理抛出的嵌套类型的实例。
让我们通过检查代码的关键部分来看一下异常类的另一种实现,完整的程序可以在我们的 GitHub 上找到:
// Assume Student class is as before, but with the addition
// of a nested exception class. All headers are as usual.
class Student: public Person
{
private: // assume usual data members
public: // usual constructors, destructor, and methods
virtual void Graduate();
class StudentException // nested exception class
{
private:
int number;
public:
StudentException(int num): number(num) { }
~StudentException() { }
int GetNum() const { return number; }
};
};
void Student::Graduate()
{ // assume we determine an error and wish to throw
// the nested exception type
throw *(new StudentException(5));
}
int main()
{
Student s1("Ling", "Mau", 'I', "Ms.", 3.1, "C++", "55UD");
try
{
s1.Graduate();
}
catch (const Student::StudentException &err)
{
cout << "Error: " << err.GetNum() << endl;
// If you correct err and continue with program, be
// sure to delete heap mem for err: delete &err;
exit(1); // Otherwise, heap memory for err will be
} // reclaimed upon exit()
cout << "Moving onward with remainder of code." << endl;
return 0;
}
在前面的代码片段中,我们扩展了Student类,包括一个名为StudentException的私有嵌套类。尽管所示的类过于简化,但嵌套类理想上应该定义一种方法来记录相关错误以及收集任何有用的诊断信息。
在我们的main()函数中,我们实例化了一个Student,名为s1。然后在 try 块中调用s1.Graduate()。我们的Student::Graduate()方法可能会检查Student是否符合毕业要求,如果不符合,则抛出一个嵌套类类型Student::StudentException的异常(根据需要实例化)。
请注意,我们相应的catch块利用作用域解析来指定err的内部类类型(即const Student::StudentException &err)。虽然我们理想情况下希望在处理程序内部纠正程序错误,但如果我们无法这样做,我们只需打印一条消息并exit()。
让我们看看上述程序的输出:
Error: 5
了解如何创建我们自己的异常类(作为嵌套类或派生自std::exception)是有用的。我们可能还希望创建一个特定于应用程序的异常的层次结构。让我们继续看看如何做到这一点。
创建用户定义异常类型的层次结构
一个应用程序可能希望定义一系列支持异常处理的类,以引发特定错误,并希望提供一种收集错误诊断信息的方法,以便在代码的适当部分处理错误。
您可能希望创建一个从标准库exception派生的子层次结构,属于您自己的异常类。确保使用公共继承。在使用这些类时,您将实例化所需异常类型的对象(填充有有价值的诊断信息),然后抛出该对象。请记住,您希望新分配的对象存在于堆上,以便在函数返回时不会从堆栈中弹出(因此使用new进行分配)。在抛出之前简单地对这个对象进行解引用,以便它可以被捕获为对该对象的引用,这是标准做法。
此外,如果您创建异常类型的层次结构,您的 catcher 可以捕获特定的派生类类型或更一般的基类类型。选择权在您手中,取决于您计划如何处理异常。但请记住,如果您对基类和派生类类型都有 catcher,请将派生类类型放在前面 - 否则,您抛出的对象将首先匹配到基类类型的 catcher,而不会意识到更合适的派生类匹配是可用的。
我们现在已经看到了 C++标准库异常类的层次结构,以及如何创建和利用自己的异常类。让我们在继续前进到下一章之前,简要回顾一下本章中我们学到的异常特性。
总结
在本章中,我们已经开始将我们的 C++编程技能扩展到 OOP 语言特性之外,以包括能够编写更健壮程序的特性。用户代码不可避免地具有错误倾向;使用语言支持的异常处理可以帮助我们实现更少错误和更可靠的代码。
我们已经看到如何使用try、throw和catch来利用核心异常处理特性。我们已经看到了这些关键字的各种用法 - 将异常抛出到外部处理程序,使用各种类型的处理程序,以及在单个 try 块内有选择地将程序元素分组在一起,例如。我们已经看到如何使用set_terminate()和set_unexpected()注册我们自己的函数。我们已经看到了如何利用现有的 C++标准库exception层次结构。我们还探讨了定义我们自己的异常类以扩展此层次结构。
通过探索异常处理机制,我们已经为我们的 C++技能增加了关键特性。现在我们准备继续前进到第十二章,友元和运算符重载,以便我们可以继续扩展我们的 C++编程技能,使用有用的语言特性,使我们成为更好的程序员。让我们继续前进!
问题
- 将异常处理添加到您之前的
Student/University练习中第十章,实现关联、聚合和组合:
a. 如果一个学生尝试注册超过每个学生允许的最大定义课程数量,抛出TooFullSchedule异常。这个类可以从标准库exception类派生。
b. 如果一个学生尝试注册一个已经满员的课程,让Course::AddStudent(Student *)方法抛出一个CourseFull异常。这个类可以从标准库exception类派生。
c. 学生/大学申请中还有许多其他领域可以利用异常处理。决定哪些领域应该采用简单的错误检查,哪些值得异常处理。
第十二章:友元和运算符重载
本章将继续扩展你的 C++编程技能,超越 OOP 概念,目标是编写更具可扩展性的代码。接下来,我们将探索友元函数、友元类和运算符重载在 C++中的应用。我们将了解运算符重载如何将运算符扩展到与用户定义类型一致的行为,以及为什么这是一个强大的 OOP 工具。我们将学习如何安全地使用友元函数和类来实现这一目标。
在本章中,我们将涵盖以下主要主题:
-
理解友元函数和友元类,适当使用它们的原因,以及增加安全性的措施
-
学习运算符重载的基本要点——如何以及为何重载运算符,并确保运算符在标准类型和用户定义类型之间是多态的
-
实现运算符函数;了解何时需要友元
在本章结束时,您将掌握友元的正确使用,并了解它们在利用 C++重载运算符的能力方面的实用性。尽管可以利用友元函数和类的使用,但您将只学习它们在两个紧密耦合的类中的受限使用。您将了解如何正确使用友元可以增强运算符重载,使运算符能够扩展以支持用户定义类型,以便它们可以与其操作数关联工作。
让我们通过探索友元函数、友元类和运算符重载来扩展你的 C++编程技能,增进对 C++的理解。
技术要求
完整程序示例的在线代码可以在以下 GitHub 网址找到:github.com/PacktPublishing/Demystified-Object-Oriented-Programming-with-CPP/blob/master/Chapter12。每个完整程序示例都可以在 GitHub 存储库中的适当章节标题(子目录)下找到,文件名与所在章节编号相对应,后跟破折号,再跟所在章节中的示例编号。例如,本章的第一个完整程序可以在名为Chp12-Ex1.cpp的文件中的Chapter12子目录下找到。
本章的 CiA 视频可在以下网址观看:bit.ly/3f3tIm4。
理解友元类和友元函数
封装是 C++通过类和访问区域的正确使用提供的宝贵的 OOP 特性。封装提供了数据和行为被操作的统一方式。总的来说,放弃类提供的封装保护是不明智的。
然而,在某些编程情况下,略微破坏封装性被认为比提供一个过度公开的类接口更可接受,也就是说,当一个类需要为两个类提供合作的方法时,但总的来说,这些方法不适合公开访问时。
让我们考虑一个可能导致我们稍微放弃(即破坏)封装的情景:
-
可能存在两个紧密耦合的类,它们在其他方面没有关联。一个类可能与另一个类有一个或多个关联,并且需要操作另一个类的成员。然而,为了允许访问这些成员的公共接口会使这些内部过度公开,并且容易受到远远超出这对紧密耦合类的需求的操纵。
-
在这种情况下,允许紧密耦合的一对类中的一个类访问另一个类的成员比在另一个类中提供一个公共接口更好,这个公共接口允许对这些成员进行更多操作,而这通常是不安全的。我们将看到,如何最小化这种潜在的封装损失。
-
我们很快将看到,选定的运算符重载情况可能需要一个实例在其类作用域之外的函数中访问其成员。再次强调,一个完全可访问的公共接口可能被认为是危险的。
友元函数和友元类允许这种有选择性地打破封装。打破封装是严肃的,不应该简单地用来覆盖访问区域。相反,当在两个紧密耦合的类之间轻微打破封装或提供一个过度公开的接口时,可以使用友元函数和友元类,同时加入安全措施,这样做可能会从应用程序的各个作用域中获得更大且可能不受欢迎的对另一个类成员的访问。
让我们看一下如何使用每个,然后我们将添加我们应该坚持使用的相关安全措施。让我们从友元函数和友元类开始。
使用友元函数和友元类
友元函数是被单独授予扩展作用域的函数,以包括它们所关联的类。让我们来看一下其含义和具体情况:
-
在友元函数的作用域中,关联类型的实例可以访问自己的成员,就好像它在自己的类作用域中一样。
-
友元函数需要在放弃访问权限的类的类定义中作为友元进行原型声明(即扩展其作用域)。
-
关键字
friend用于提供访问权限的原型前面。 -
重载友元函数的函数不被视为友元。
友元类是指该类的每个成员函数都是关联类的友元函数。让我们来看一下具体情况:
-
友元类应该在提供访问权限的类的类定义中进行前向声明(即作用域)。
-
关键字
friend应该在获得访问权限的类的前向声明之前。
注意
友元类和友元函数应该谨慎使用,只有在有选择地和轻微地打破封装比提供一个过度公开的接口更好的选择时才使用(即一个普遍提供对应用程序中任何作用域中的选定成员的不受欢迎访问的公共接口)。
让我们首先来看一下友元类和友元函数声明的语法。以下类并不代表完整的类定义;然而,完整的程序可以在我们的在线 GitHub 存储库中找到,链接如下:
class Student; // forward declaration of Student class
class Id
{
private:
char *idNumber;
Student *student;
public: // Assume constructors, destructor, etc. exist
void SetStudent(Student *);
// all member functions of Student are friend fns to/of Id
friend class Student;
};
class Student
{
private:
char *name;
float gpa;
Id *studentId;
public: // Assume constructors, destructor, etc. exist
// only the following mbr function of Id is a friend fn.
friend void Id::SetStudent(Student *); // to/of Student
};
在前面的代码片段中,我们首先注意到了Id类中的友元类定义。语句friend class Student;表明Student中的所有成员函数都是Id的友元函数。这个包容性的语句用来代替将Student类的每个函数都命名为Id的友元函数。
另外,在Student类中,注意friend void Id::SetStudent(Student *);的声明。这个友元函数声明表明只有Id的这个特定成员函数是Student的友元函数。
友元函数原型friend void Id::SetStudent(Student *);的含义是,如果一个Student发现自己在Id::SetStudent()方法的范围内,那么这个Student可以操纵自己的成员,就好像它在自己的范围内一样,也就是Student的范围。你可能会问:哪个Student可能会发现自己在Id::SetStudent(Student *)的范围内?很简单。就是作为输入参数传递给方法的那个。结果是,在Id::SetStudent()方法中的Student *类型的输入参数可以访问自己的私有和受保护成员,就好像Student实例在自己的类范围内一样——它在友元函数的范围内。
同样,Id类中的友元类前向声明friend class Student;的含义是,如果任何Id实例发现自己在Student方法中,那么这个Id实例可以访问自己的私有或受保护方法,就好像它在自己的类中一样。Id实例可以在其友元类Student的任何成员函数中,就好像这些方法也扩展到了Id类的范围一样。
请注意,放弃访问的类——也就是扩大其范围的类——是宣布友谊的类。也就是说,在Id中的friend class Student;语句表示:如果任何Id恰好在Student的任何成员函数中,允许该Id完全访问其成员,就好像它在自己的范围内一样。同样,在Student中的友元函数语句表示:如果Student实例(通过输入参数)在Id的特定方法中被找到,它可以完全访问其元素,就好像它在自己类的成员函数中一样。以友谊作为扩大范围的手段来思考。
现在我们已经了解了友元函数和友元类的基本机制,让我们使用一个简单的约定来使其更具吸引力,以有选择地打破封装。
在使用友元时使访问更安全
我们已经看到,通过关联相关的两个紧密耦合的类可能需要通过使用友元函数或友元类来有选择地扩展它们的范围。另一种选择是为每个类提供公共接口。然而,请考虑您可能不希望这些元素的公共接口在应用程序的任何范围内都是统一可访问的。您确实面临着一个艰难的选择:使用友元或提供一个过度公共的接口。
虽然最初使用友元可能会让您感到不安,但这可能比提供不需要的公共接口给类元素更安全。
为了减少对友元允许的选择性打破封装的恐慌,考虑在使用友元时添加以下约定:
-
在使用友元时,为了减少封装的损失,一个类可以为另一个类的数据成员提供私有访问方法。尽可能将这些方法设置为内联,以提高效率。
-
问题实例应同意只使用创建的私有访问方法来适当地访问其所需的成员,而在友元函数的范围内(即使它实际上可以在友元函数的范围内无限制地访问自己类型的任何数据或方法)。
这里有一个简单的例子来说明两个紧密耦合的类如何适当地使用main()函数,为了节省空间,省略了几个方法,完整的例子可以在我们的 GitHub 存储库中找到:
typedef int Item;
class LinkList; // forward declaration
class LinkListElement
{
private:
void *data;
LinkListElement *next;
// private access methods to be used in scope of friend
void *GetData() { return data; }
LinkListElement *GetNext() { return next; }
void SetNext(LinkListElement *e) { next = e; }
public:
// All mbr fns of LinkList are friend fns of LinkListElement
friend class LinkList;
LinkListElement() { data = 0; next = 0; }
LinkListElement(Item *i) { data = i; next = 0; }
~LinkListElement(){ delete (Item *)data; next = 0;}
};
// LinkList should only be extended as a protected or private
// base class; it does not contain a virtual destructor. It
// can be used as-is, or as implementation for another ADT.
class LinkList
{
private:
LinkListElement *head, *tail, *current;
public:
LinkList() { head = tail = current = 0; }
LinkList(LinkListElement *e) { head = tail = current = e; }
void InsertAtFront(Item *);
LinkListElement *RemoveAtFront();
void DeleteAtFront() { delete RemoveAtFront(); }
int IsEmpty() { return head == 0; }
void Print(); // see online definition
~LinkList() { while (!IsEmpty()) DeleteAtFront(); }
};
让我们来看看LinkListElement和LinkList的前面的类定义。请注意,在LinkListElement类中,我们有三个私有成员函数,即void *GetData();,LinkListElement *GetNext();和void SetNext(LinkListElement *);。这三个成员函数不应该是公共类接口的一部分。这些方法只适合在LinkList的范围内使用,这是与LinkListElement紧密耦合的类。
接下来,请注意LinkListElement类中的friend class LinkList;前向声明。这个声明意味着LinkList的所有成员函数都是LinkListElement的友元函数。因此,任何发现自己在LinkList方法中的LinkListElement实例都可以访问自己前面提到的私有GetData(),GetNext()和SetNext()方法,因为它们将在友元类的范围内。
接下来,让我们看看前面代码中的LinkList类。类定义本身没有与友好相关的唯一声明。毕竟,是LinkListElement类扩大了其范围以包括LinkedList类的方法,而不是相反。
现在,让我们来看一下LinkList类的两个选定的成员函数。这些方法的完整组合可以在网上找到,就像之前提到的 URL 中一样。
void LinkList::InsertAtFront(Item *theItem)
{
LinkListElement *temp = new LinkListElement(theItem);
// Note: temp can access private SetNext() as if it were
// in its own scope – it is in the scope of a friend fn.
temp->SetNext(head); // same as: temp->next = head;
head = temp;
}
LinkListElement *LinkList::RemoveAtFront()
{
LinkListElement *remove = head;
head = head->GetNext(); // head = head->next;
current = head; // reset current for usage elsewhere
return remove;
}
当我们检查前面的代码时,我们可以看到在LinkList方法的抽样中,LinkListElement可以调用自己的私有方法,因为它在友元函数的范围内(本质上是自己的范围,扩大了)。例如,在LinkList::InsertAtFront()中,LinkListElement *temp使用temp->SetNext(head)将其next成员设置为head。当然,我们也可以直接在这里访问私有数据成员,使用temp->next = head;。但是,通过LinkListElement提供私有访问函数,如SetNext(),并要求LinkList方法(友元函数)让temp利用私有方法SetNext(),而不是直接操作数据成员本身,我们保持了封装的程度。
因为LinkListElement中的GetData(),GetNext()和SetNext()是内联函数,所以我们不会因为提供对成员data和next的封装访问而损失性能。
我们还可以看到LinkList的其他成员函数,比如RemoveAtFront()(以及在线代码中出现的Print()),都有LinkListElement实例利用其私有访问方法,而不是允许LinkListElement实例直接获取其私有的data和next成员。
LinkListElement和LinkList是两个紧密耦合的类的标志性示例,也许最好是扩展一个类以包含另一个类的范围,以便访问,而不是提供一个过度公开的接口。毕竟,我们不希望main()中的用户接触到LinkListElement并应用SetNext(),例如,这可能会在不知道LinkList类的情况下改变整个LinkedList。
现在我们已经看到了友元函数和类的机制以及建议的用法,让我们探索另一个可能需要利用友元的语言特性 - 运算符重载。
解密运算符重载要点
C++语言中有各种运算符。C++允许大多数运算符重新定义以包括与用户定义类型的使用;这被称为运算符重载。通过这种方式,用户定义的类型可以利用与标准类型相同的符号来执行这些众所周知的操作。我们可以将重载的运算符视为多态的,因为它的相同形式可以与各种类型 - 标准和用户定义的类型一起使用。
并非所有运算符都可以在 C++中重载。以下运算符无法重载:成员访问(。),三元条件运算符(?:),作用域解析运算符(::),成员指针运算符(.*),sizeof()运算符和typeid()运算符。其余的都可以重载,只要至少有一个操作数是用户定义的类型。
在重载运算符时,重要的是要促进与标准类型相同的含义。例如,当与cout一起使用时,提取运算符(<<)被定义为打印到标准输出。这个运算符可以应用于各种标准类型,如整数,浮点数和字符串。如果提取运算符(<<)被重载为用户定义的类型,如Student,它也应该意味着打印到标准输出。这样,运算符<<在输出缓冲区的上下文中是多态的;也就是说,对于所有类型,它具有相同的含义,但不同的实现。
重载 C++中的运算符时,重要的是要注意,我们不能改变语言中运算符的预定义优先级。这是有道理的 - 我们不是在重写编译器以解析和解释表达式。我们只是将运算符的含义从其与标准类型的使用扩展到包括与用户定义类型的使用。运算符优先级将保持不变。
运算符,后跟表示您希望重载的运算符的符号。
让我们来看看运算符函数原型的简单语法:
Student &operator+(float gpa, const Student &s);
在这里,我们打算提供一种方法,使用 C++加法运算符(+)来添加一个浮点数和一个Student实例。这种加法的含义可能是将新的浮点数与学生现有的平均成绩进行平均。在这里,运算符函数的名称是operator+()。
在上述原型中,运算符函数不是任何类的成员函数。左操作数将是float,右操作数将是Student。函数的返回类型(Student&)允许我们将+与多个操作数级联使用,或者与多个运算符配对使用,例如s1 = 3.45 + s2;。总体概念是我们可以定义如何使用+与多种类型,只要至少有一个操作数是用户定义的类型。
实际上,比上面显示的简单语法涉及的内容要多得多。在我们完全检查详细示例之前,让我们首先看一下与实现运算符函数相关的更多后勤事项。
实现运算符函数并知道何时可能需要友元
运算符函数,重载运算符的机制,可以作为成员函数或常规外部函数实现。让我们总结实现运算符函数的机制,以下是关键点:
-
作为成员函数实现的运算符函数将接收一个隐式参数(
this指针),最多一个显式参数。如果重载操作中的左操作数是可以轻松修改类的用户定义类型,则将运算符函数实现为成员函数是合理且首选的。 -
作为外部函数实现的运算符函数将接收一个或两个显式参数。如果重载操作中的左操作数是不可修改的标准类型或类类型,则必须使用外部(非成员)函数来重载此运算符。这个外部函数可能需要是用作右操作数的任何对象类型的“友元”。
-
运算符函数通常应该被互相实现。也就是说,当重载二元运算符时,确保它已经被定义为可以工作,无论数据类型(如果它们不同)以何种顺序出现在运算符中。
让我们看一个完整的程序示例,以说明运算符重载的机制,包括成员和非成员函数,以及需要使用友元的情况。尽管为了节省空间,程序的一些众所周知的部分已被排除在外,但完整的程序示例可以在我们的 GitHub 存储库中找到:
// Assume usual header files and std namespace
class Person
{
private:
char *firstName, *lastname, *title;
char middleInitial;
protected:
void ModifyTitle(const char *);
public:
Person(); // default constructor
Person(const char *, const char *, char, const char *);
Person(const Person &); // copy constructor
virtual ~Person(); // destructor
const char *GetFirstName() const { return firstName; }
const char *GetLastName() const { return lastName; }
const char *GetTitle() const { return title; }
char GetMiddleInitial() const { return middleInitial; }
virtual void Print() const;
// overloaded operator functions
Person &operator=(const Person &); // overloaded assign
bool operator==(const Person &); // overloaded comparison
Person &operator+(const char *); // overloaded plus
// non-mbr friend fn. for operator+ (to make associative)
friend Person &operator+(const char *, Person &);
};
让我们从代码审查开始,首先查看前面的Person类定义。除了我们习惯看到的类元素之外,我们还有四个运算符函数的原型:operator=()、operator==()和operator+(),它被实现了两次 - 以便可以颠倒+的操作数。
operator=()、operator==()和operator+()的一个版本将作为此类的成员函数实现,而另一个operator+(),带有const char *和Person参数,将作为非成员函数实现,并且还需要使用友元函数。
重载赋值运算符
让我们继续检查此类的适用运算符函数定义,首先是重载赋值运算符:
// Assume the required constructors, destructor and basic
// member functions prototyped in the class definition exist.
// overloaded assignment operator
Person &Person::operator=(const Person &p)
{
if (this != &p) // make sure we're not assigning an
{ // object to itself
delete firstName; // or call ~Person() to release
delete lastName; // this memory (unconventional)
delete title;
firstName = new char [strlen(p.firstName) + 1];
strcpy(firstName, p.firstName);
lastName = new char [strlen(p.lastName) + 1];
strcpy(lastName, p.lastName);
middleInitial = p.middleInitial;
title = new char [strlen(p.title) + 1];
strcpy(title, p.title);
}
return *this; // allow for cascaded assignments
}
现在让我们回顾一下前面代码中重载的赋值运算符。它由成员函数Person &Person::operator=(const Person &p);指定。在这里,我们将从源对象(输入参数p)分配内存到目标对象(由this指向)。
我们的首要任务是确保我们没有将对象分配给自身。如果是这种情况,就没有工作要做!我们通过测试if (this != &p)来检查这一点,看看两个地址是否指向同一个对象。如果我们没有将对象分配给自身,我们继续。
接下来,在条件语句(if)中,我们首先释放由this指向的动态分配的数据成员的现有内存。毕竟,赋值语句左侧的对象已经存在,并且无疑为这些数据成员分配了内存。
现在,我们注意到条件语句中的核心代码看起来与复制构造函数非常相似。也就是说,我们仔细为指针数据成员分配空间,以匹配输入参数p的相应数据成员所需的大小。然后,我们将适用的数据成员从输入参数p复制到由this指向的数据成员。对于char数据成员middleInitial,不需要内存分配;我们仅使用赋值。在这段代码中,我们确保已执行了深度赋值。浅赋值,其中源对象和目标对象否则会共享数据成员的内存部分的指针,将是一场等待发生的灾难。
最后,在我们对operator=()的实现结束时,我们返回*this。请注意,此函数的返回类型是Person的引用。由于this是一个指针,我们只需对其进行解引用,以便返回一个可引用的对象。这样做是为了使Person实例之间的赋值可以级联;也就是说,p1 = p2 = p3;其中p1、p2和p3分别是Person的实例。
注意
重载的赋值运算符不会被派生类继承,因此必须由层次结构中的每个类定义。如果忽略为类重载operator=,编译器将为该类提供默认的浅赋值运算符;这对于包含指针数据成员的任何类都是危险的。
如果程序员希望禁止两个对象之间的赋值,可以在重载的赋值操作符的原型中使用关键字delete。
// disallow assignment
Person &operator=(const Person &) = delete;
有必要记住,重载的赋值操作符与复制构造函数有许多相似之处;对这两种语言特性都需要同样的小心和谨慎。然而,赋值操作符将在两个已存在对象之间进行赋值时被调用,而复制构造函数在创建新实例后隐式被调用进行初始化。对于复制构造函数,新实例使用现有实例作为其初始化的基础;同样,赋值操作符的左操作数使用右操作数作为其赋值的基础。
重载比较操作符
接下来,让我们看看我们对重载比较操作符的实现:
// overloaded comparison operator
bool Person::operator==(const Person &p)
{
// if the objects are the same object, or if the
// contents are equal, return true. Otherwise, false.
if (this == &p)
return 1;
else if ( (!strcmp(firstName, p.firstName)) &&
(!strcmp(lastName, p.lastName)) &&
(!strcmp(title, p.title)) &&
(middleInitial == p.middleInitial) )
return 1;
else
return 0;
}
继续我们之前程序的一部分,我们重载比较操作符。它由成员函数int Person::operator==(const Person &p);指定。在这里,我们将比较右操作数上的Person对象,它将由输入参数p引用,与左操作数上的Person对象进行比较,它将由this指向。
同样,我们的首要任务是测试if (this != &p),看看两个地址是否指向同一个对象。如果两个地址指向同一个对象,我们返回true的布尔值。
接下来,我们检查两个Person对象是否包含相同的值。它们可能是内存中的不同对象,但如果它们包含相同的值,我们同样可以选择返回true的bool值。如果没有匹配,我们返回false的bool值。
作为成员函数重载加法操作符
现在,让我们看看如何为Person和const char *重载operator+:
// overloaded operator + (member function)
Person &Person::operator+(const char *t)
{
ModifyTitle(t);
return *this;
}
继续前面的程序,我们重载加法操作符(+),用于Person和const char *。操作符函数由成员函数原型Person& Person::operator+(const char *t);指定。参数t代表operator+的右操作数,即一个字符串。左操作数将由this指向。一个例子是p1 + "Miss",我们希望使用operator+给Person p1添加一个称号。
在这个成员函数的主体中,我们仅仅将输入参数t作为ModifyTitle()的参数使用,即ModifyTitle(t);。然后我们返回*this,以便我们可以级联使用这个操作符(注意返回类型是Person &)。
作为非成员函数重载加法操作符(使用友元)
现在,让我们颠倒operator+的操作数顺序,允许const char *和Person:
// overloaded + operator (not a mbr function)
Person &operator+(const char *t, Person &p)
{
p.ModifyTitle(t);
return p;
}
继续前面的程序,我们理想地希望operator+不仅适用于Person和const char *,还适用于操作数的顺序颠倒;也就是说,const char *和Person。没有理由这个操作符只能单向工作。
为了完全实现operator+,接下来我们将重载operator+(),用于const char *和Person。操作符函数由非成员函数Person& operator+(const char *t, Person &p);指定,有两个显式输入参数。第一个参数t代表operator+的左操作数,即一个字符串。第二个参数p是用于operator+的右操作数的引用。一个例子是"Miss" + p1,我们希望使用operator+给Person p1添加一个称号。
在这个非成员函数的主体中,我们只是取输入参数p,并使用参数t指定的字符串应用受保护的方法ModifyTitle()。也就是说,p.ModifyTitle(t)。然而,因为Person::ModifyTitle()是受保护的,Person &p不能在Person的成员函数之外调用这个方法。我们在一个外部函数中;我们不在Person的范围内。因此,除非这个成员函数是Person的friend,否则p不能调用ModifyTitle()。幸运的是,在Person类中已经将Person &operator+(const char *, Person &);原型化为friend函数,为p提供了必要的范围,使其能够调用它的受保护方法。就好像p在Person的范围内一样;它在Person的friend函数的范围内!
最后,让我们继续前进到我们的main()函数,将我们之前提到的许多代码段联系在一起,这样我们就可以看到如何调用我们的操作函数,利用我们重载的运算符:
int main()
{
Person p1; // default constructed Person
Person p2("Gabby", "Doone", 'A', "Miss");
Person p3("Renee", "Alexander", 'Z', "Dr.");
p1.Print();
p2.Print();
p3.Print();
p1 = p2; // invoke overloaded assignment operator
p1.Print();
p2 = "Ms." + p2; // invoke overloaded + operator
p2.Print(); // then invoke overloaded = operator
p1 = p2 = p3; // overloaded = can handle cascaded =
p2.Print();
p1.Print();
if (p2 == p2) // overloaded comparison operator
cout << "Same people" << endl;
if (p1 == p3)
cout << "Same people" << endl;
return 0;
}
最后,让我们来检查一下前面程序的main()函数。我们首先实例化了三个Person的实例,即p1、p2和p3;然后我们使用成员函数Print()打印它们的值。
现在,我们用语句p1 = p2;调用了我们重载的赋值运算符。在底层,这转换成了以下的操作函数调用:p1.operator=(p2);。从这里,我们可以清楚地看到,我们正在调用之前定义的Person的operator=()方法,它从源对象p2深度复制到目标对象p1。我们应用p1.Print();来查看我们的复制结果。
接下来,我们使用重载的operator+来处理"Ms." + p2。这行代码的一部分转换成以下的操作函数调用:operator+("Ms.", p2);。在这里,我们简单地调用了之前描述的operator+()函数,这是一个Person类的非成员函数和friend。因为这个函数返回一个Person &,我们可以将这个函数调用级联,看起来更像是通常的加法上下文,并且额外地写成p2 = "Ms." + p2;。在这行完整的代码中,首先对"Ms." + p2调用了operator+()。这个调用的返回值是p2,然后被用作级联调用operator=的右操作数。注意到operator=的左操作数也恰好是p2。幸运的是,重载的赋值运算符会检查自我赋值。
现在,我们看到了p1 = p2 = p3;的级联赋值。在这里,我们两次调用了重载的赋值运算符。首先,我们用p2和p3调用了operator=。翻译后的调用将是p2.operator=(p3);。然后,使用第一个函数调用的返回值,我们将第二次调用operator=。p1 = p2 = p3;的嵌套、翻译后的调用看起来像p1.operator=(p2.operator=(p3));。
最后,在这个程序中,我们两次调用了重载的比较运算符。例如,每次比较if (p2 == p2)或if (p1 == p3)只是调用了我们上面定义的operator==成员函数。回想一下,我们已经编写了这个函数,如果对象在内存中相同或者只是包含相同的值,就报告true,否则返回false。
让我们来看一下这个程序的输出:
No first name No last name
Miss Gabby A. Doone
Dr. Renee Z. Alexander
Miss Gabby A. Doone
Ms. Gabby A. Doone
Dr. Renee Z. Alexander
Dr. Renee Z. Alexander
Same people
Same people
我们现在已经看到了如何指定和使用友元类和友元函数,如何在 C++中重载运算符,以及这两个概念如何互补。在继续前往下一章之前,让我们简要回顾一下我们在本章学到的特性。
总结
在本章中,我们将我们的 C++编程努力进一步推进,超越了面向对象编程语言特性,包括了能够编写更具扩展性的程序的特性。我们已经学会了如何利用友元函数和友元类,以及如何在 C++中重载运算符。
我们已经看到友元函数和类应该谨慎使用。它们并不是为了提供一个明显的方法来绕过访问区域。相反,它们的目的是处理编程情况,允许两个紧密耦合的类之间进行访问,而不在这些类中的任何一个提供过度公开的接口,这可能会被广泛滥用。
我们已经看到如何在 C++中使用运算符函数重载运算符,既作为成员函数又作为非成员函数。我们已经了解到,重载运算符将允许我们扩展 C++运算符的含义,以包括用户定义类型,就像它们包含标准类型一样。我们还看到,在某些情况下,友元函数或类可能会派上用场,以帮助实现运算符函数,使其可以进行关联行为。
通过探索友元和运算符重载,我们已经为我们的 C++技能库添加了重要的功能,后者将帮助我们确保我们即将使用模板编写的代码可以用于几乎任何数据类型,从而为高度可扩展和可重用的代码做出贡献。我们现在准备继续前进到[第十三章],使用模板,以便我们可以继续扩展我们的 C++编程技能,使用将使我们成为更好的程序员的基本语言特性。让我们继续前进!
问题
- 在[第八章](B15702_08_Final_NM_ePub.xhtml#_idTextAnchor335)的
Shape练习中重载operator=,掌握抽象类,或者在你正在进行的LifeForm/Person/Student类中重载operator=如下:
a. 在Shape(或LifeForm)中定义operator=,并在其所有派生类中重写这个方法。提示:operator=()的派生实现将比其祖先做更多的工作,但可以调用其祖先的实现来执行基类部分的工作。
- 在你的
Shape类(或LifeForm类)中重载operator<<,以打印关于每个Shape(或LifeForm)的信息。这个函数的参数应该是ostream &和Shape &(或LifeForm &)。注意,ostream来自 C++标准库(using namespace std;)。
a. 你可以提供一个函数ostream &operator<<(ostream &, Shape &);,并从中调用多态的Print(),它在Shape中定义,并在每个派生类中重新定义),或者提供多个operator<<方法来实现这个功能(每个派生类一个)。如果使用Lifeform层次结构,将Shape替换为LifeForm。
- 创建一个
ArrayInt类,提供带边界检查的安全整数数组。重载operator[],如果数组中存在元素,则返回该元素,否则抛出异常OutOfBounds。在你的ArrayInt中添加其他方法,比如Resize()和RemoveElement()。使用动态分配数组(即使用int *contents)来模拟数组的数据,这样你就可以轻松处理调整大小。代码将以以下方式开始:
class ArrayInt
{
private:
int numElements;
int *contents; // dynamically allocated array
public:
ArrayInt(int size);// set numElements, alloc contents
int &operator[](int index) // returns a referenceable
{ // memory location
if (index < numElements) return contents[index];
else cout << "error"; // or throw OutOfBounds
} // exception
};
int main()
{
ArrayInt a1(5); // Create an ArrayInt of 5 elements
A1[4] = 7; // a1.operator[](4) = 7;
}
第十三章:使用模板
本章将继续追求扩展您的 C++编程技能,超越面向对象编程概念,继续编写更具可扩展性的代码。我们将探索使用 C++模板创建通用代码 - 包括模板函数和模板类。我们将学习如何编写正确的模板代码,以实现代码重用的最高境界。我们将探讨如何创建模板函数和模板类,以及理解适当使用运算符重载如何使模板函数可重用于几乎任何类型的数据。
在本章中,我们将涵盖以下主要主题:
-
探索模板基础知识以通用化代码
-
理解如何创建和使用模板函数和模板类
-
理解运算符重载如何使模板更具可扩展性
通过本章结束时,您将能够通过构建模板函数和模板类来设计更通用的代码。您将了解运算符重载如何确保模板函数对任何数据类型都具有高度可扩展性。通过将精心设计的模板成员函数与运算符重载配对使用,您将能够在 C++中创建高度可重用和可扩展的模板类。
让我们通过探索模板来扩展您的编程技能,从而增进对 C++的理解。
技术要求
完整程序示例的在线代码可在以下 GitHub URL 找到:github.com/PacktPublishing/Demystified-Object-Oriented-Programming-with-CPP/blob/master/Chapter13。每个完整程序示例都可以在 GitHub 存储库中找到,位于相应章节标题(子目录)下,文件名与所在章节编号对应,后跟破折号,再跟上所在章节中示例编号。例如,本章的第一个完整程序可以在Chapter13子目录中的名为Chp13-Ex1.cpp的文件中找到,位于上述 GitHub 目录下。
本章的 CiA 视频可在以下链接观看:bit.ly/2OUaLrb。
探索模板基础知识以通用化代码
模板允许以一种抽象的方式对代码进行通用指定,这种方式与主要用于相关函数或类中的数据类型无关。创建模板的动机是为了通用指定我们反复想要使用的函数和类的定义,但使用不同的数据类型。这些组件的个性化版本在核心数据类型上会有所不同;这些关键数据类型可以被提取并以通用方式编写。
当我们选择使用特定类型的类或函数时,而不是复制和粘贴现有代码(带有预设数据类型)并稍作修改,预处理器会取代模板代码并为我们请求的类型进行扩展。这种模板扩展能力使程序员只需编写和维护通用化代码的一个版本,而不是需要编写许多特定类型版本的代码。另一个好处是,预处理器将更准确地将模板代码扩展为请求的类型,而不是我们可能使用复制、粘贴和轻微修改方法所做的扩展。
让我们花点时间进一步探讨在我们的代码中使用模板的动机。
审视使用模板的动机
假设我们希望创建一个类来安全地处理动态分配的int数据类型的数组,就像我们在第十二章的问题 3解决方案中创建的那样,运算符重载和友元。我们的动机可能是要有一个数组类型,可以增长或缩小到任何大小(不像本地的固定大小数组),但对于安全使用有边界检查(不像使用int *实现的动态数组的原始操作,它会肆意地允许我们访问远远超出我们动态数组分配长度的元素)。
我们可能决定创建一个以下开始框架的ArrayInt类:
class ArrayInt
{
private:
int numElements;
int *contents; // dynamically allocated array
public:
ArrayInt(int size) : numElements(size)
{
contents = new int [size];
}
~ArrayInt() { delete contents; }
int &operator[](int index) // returns a referenceable
{ // memory location
if (index < numElements) return contents[index];
else cout << "Out of Bounds"; // or better – throw an
} // OutOfBounds exception
};
int main()
{
ArrayInt a1(5); // Create an ArrayInt of 5 elements
a1[4] = 7; // a1.operator[](4) = 7;
}
在前面的代码段中,请注意我们的ArrayInt类使用int *contents;来模拟数组的数据,它在构造函数中动态分配到所需的大小。我们已经重载了operator[],以安全地返回数组中范围内的索引值。我们可以添加Resize()和ArrayInt等方法。总的来说,我们喜欢这个类的安全性和灵活性。
现在,我们可能想要有一个ArrayFloat类(或者以后是ArrayStudent类)。例如,我们可能会问是否有一种更自动化的方法来进行这种替换,而不是复制我们的基线ArrayInt类并稍微修改它以创建一个ArrayFloat类。毕竟,如果我们使用ArrayInt类作为起点创建ArrayFloat类,我们会改变什么呢?我们会改变数据成员contents的类型 - 从int *到float *。我们会在构造函数中改变内存分配中的类型,从contents = new int [size];到使用float而不是int(以及在任何重新分配中也是如此,比如在Resize()方法中)。
与其复制、粘贴和稍微修改ArrayInt类以创建ArrayFloat类,我们可以简单地使用模板类来泛型化与该类中操作的数据相关联的类型。同样,依赖于特定数据类型的任何函数将成为模板函数。我们将很快研究创建和使用模板的语法。
使用模板,我们可以创建一个名为Array的模板类,其中类型是泛型化的。在编译时,如果预处理器检测到我们在代码中使用了这个类来处理int或float类型,那么预处理器将为我们提供必要的模板扩展。也就是说,通过复制和粘贴(在幕后)每个模板类(及其方法)并替换预处理器识别出我们正在使用的数据类型。
扩展后的代码在幕后并不比我们自己为每个单独的类编写代码要小。但关键是,我们不必费力地创建、修改、测试和后续维护每个略有不同的类。这是 C++代表我们完成的。这就是模板类和模板函数的值得注意的目的。
模板不仅限于与原始数据类型一起使用。例如,我们可能希望创建一个用户定义类型的Array,比如Student。我们需要确保我们的模板成员函数对我们实际扩展模板类以利用的数据类型是有意义的。我们可能需要重载选定的运算符,以便我们的模板成员函数可以与用户定义的类型无缝地工作,就像它们与原始类型一样。
在本章的后面部分,我们将看到一个例子,说明如果我们选择扩展模板类以适用于用户定义的类型,我们可能需要重载选定的运算符,以便类的成员函数可以与任何数据类型流畅地工作。幸运的是,我们知道如何重载运算符!
让我们继续探索指定和利用模板函数和模板类的机制。
理解模板函数和类
模板通过抽象与这些函数和类相关的数据类型,提供了创建通用函数和类的能力。模板函数和类都可以被精心编写,以使这些函数和类的相关数据类型通用化。
让我们首先来看看如何创建和利用模板函数。
创建和使用模板函数
模板函数将函数中的参数类型参数化,除了参数本身。模板函数要求函数体适用于大多数任何数据类型。模板函数可以是成员函数或非成员函数。运算符重载可以帮助确保模板函数的函数体适用于用户定义的类型 - 我们很快会看到更多。
关键字template,以及尖括号< >和类型名称的占位符,用于指定模板函数及其原型。
让我们来看一个不是类成员的模板函数(我们将很快看到模板成员函数的例子)。这个例子可以在我们的 GitHub 仓库中找到,作为一个完整的工作程序,如下所示:
// template function prototype
template <class Type1, class Type2> // template preamble
Type2 ChooseFirst(Type1, Type2);
// template function definition
template <class Type1, class Type2> // template preamble
Type2 ChooseFirst(Type1 x, Type2 y)
{
if (x < y) return (Type2) x;
else return y;
}
int main()
{
int value1 = 4, value2 = 7;
float value3 = 5.67f;
cout << "First: " << ChooseFirst(value1, value3) << endl;
cout << "First: " << ChooseFirst(value2, value1) << endl;
}
看一下前面的函数示例,我们首先看到一个模板函数原型。前言template <class Type1, class Type 2>表示原型将是一个模板原型,并且占位符Type1和Type2将被用来代替实际数据类型。占位符Type1和Type2可以是(几乎)任何名称,遵循创建标识符的规则。
然后,为了完成原型,我们看到Type2 ChooseFirst(Type1, Type2);,这表明这个函数的返回类型将是Type2,ChooseFirst()函数的参数将是Type1和Type2(它们肯定可以扩展为相同的类型)。
接下来,我们看到函数定义。它也以template <class Type1, class Type 2>开头。与原型类似,函数头Type2 ChooseFirst(Type1 x, Type2 y)表示形式参数x和y分别是类型Type1和Type2。这个函数的主体非常简单。我们只需使用<运算符进行简单比较,确定这两个参数中哪一个应该在这两个值的排序中排在第一位。
现在,在main()中,当编译器的预处理部分看到对ChooseFirst()的调用,实际参数为int value1和float value3时,预处理器注意到ChooseFirst()是一个模板函数。如果还没有这样的ChooseFirst()版本来处理int和float,预处理器将复制这个模板函数,并用int替换Type1,用float替换Type2 - 为我们创建适合我们需求的函数的适当版本。请注意,当调用ChooseFirst(value2, value1)并且类型都是整数时,当预处理器再次扩展(在代码底层)模板函数时,占位符类型Type1和Type2将都被int替换。
虽然ChooseFirst()是一个简单的函数,但通过它,我们可以看到创建通用关键数据类型的模板函数的简单机制。我们还可以看到预处理器注意到模板函数的使用方式,并代表我们扩展这个函数,根据我们特定的类型使用需求。
让我们来看一下这个程序的输出:
First: 4
First: 4
现在我们已经看到了模板函数的基本机制,让我们继续了解如何将这个过程扩展到包括模板类。
创建和使用模板类
模板类参数化类定义的最终类型,并且还需要模板成员函数来处理需要知道被操作的核心数据类型的任何方法。
关键字template和class,以及尖括号<``>和type名称的占位符,用于指定模板类定义。
让我们来看一个模板类定义及其支持的模板成员函数。这个例子可以在我们的 GitHub 存储库中找到,作为一个完整的程序。
template <class Type> // template class preamble
class Array
{
private:
int numElements;
Type *contents; // dynamically allocated array
public:
Array(int size) : numElements(size)
{
contents = new Type [size];
}
~Array() { delete contents; }
void Print() const;
Type &operator[](int index) // returns a referenceable
{ // memory location
if (index < numElements) return contents[index];
else cout << "Out of Bounds"; // or better – throw an
} // OutOfBounds exception
void operator+(Type); // prototype only
};
template <class Type>
void Array<Type>::operator+(Type item)
{
// resize array as necessary, add new data element and
// increment numElements
}
template <class Type>
void Array<Type>::Print() const
{
for (int i = 0; i < numElements; i++)
cout << contents[i] << " ";
cout << endl;
}
int main()
{
// Creation of int array will trigger template expansion
Array<int> a1(3); // Create an int Array of 3 int elements
a1[2] = 12;
a1[1] = 70; // a1.operator[](1) = 70;
a1[0] = 2;
a1.Print();
}
在前面的类定义中,让我们首先注意template <class Type>的模板类前言。这个前言指定了即将到来的类定义将是一个模板类,占位符Type将用于泛型化主要在这个类中使用的数据类型。
然后我们看到了Array的类定义。数据成员contents将是占位符类型Type。当然,并不是所有的数据类型都需要泛型化。数据成员int numElements作为整数是完全合理的。接下来,我们看到了一系列成员函数的原型,以及一些内联定义的成员函数,包括重载的operator[]。对于内联定义的成员函数,在函数定义前不需要模板前言。我们唯一需要做的是使用我们的占位符Type泛型化数据类型。
现在让我们来看一下选定的成员函数。在构造函数中,我们现在注意到contents = new Type [size];的内存分配仅仅使用了占位符Type而不是实际的数据类型。同样,对于重载的operator[],这个方法的返回类型是Type。
然而,看一个不是内联的成员函数,我们注意到模板前言template <class Type>必须在成员函数定义之前。例如,让我们考虑void Array<Type>::operator+(Type item);的成员函数定义。除了前言之外,在函数定义中类名(在成员函数名和作用域解析运算符::之前)必须增加占位符类型<Type>在尖括号中。此外,任何通用函数参数必须使用占位符类型Type。
现在,在我们的main()函数中,我们仅使用Array<int>的数据类型来实例化一个安全、易于调整大小的整数数组。如果我们想要实例化一个浮点数数组,我们可以选择使用Array<float>。在幕后,当我们创建特定数组类型的实例时,预处理器会注意到我们是否先前为该type扩展了这个类。如果没有,类定义和适用的模板成员函数将被复制,占位符类型将被替换为我们需要的类型。这并不比我们自己复制、粘贴和稍微修改代码少一行;然而,重点是我们只需要指定和维护一个版本。这样做更不容易出错,更容易进行长期维护。
让我们来看一下这个程序的输出:
2 70 12
接下来让我们看一个不同的完整程序例子,来整合模板函数和模板类。
检查一个完整的程序例子
有必要看一个额外的例子,说明模板函数和模板类。让我们扩展我们最近在第十二章中审查的LinkList程序,运算符重载和友元;我们将升级这个程序以利用模板。
这个完整的程序可以在我们的 GitHub 存储库中找到。
#include <iostream>
using namespace std;
template <class Type> class LinkList; // forward declaration
// with template preamble
template <class Type> // template preamble for class def
class LinkListElement
{
private:
Type *data;
LinkListElement *next;
// private access methods to be used in scope of friend
Type *GetData() { return data; }
LinkListElement *GetNext() { return next; }
void SetNext(LinkListElement *e) { next = e; }
public:
friend class LinkList<Type>;
LinkListElement() { data = 0; next = 0; }
LinkListElement(Type *i) { data = i; next = 0; }
~LinkListElement(){ delete data; next = 0;}
};
// LinkList should only be extended as a protected or private
// base class; it does not contain a virtual destructor. It
// can be used as-is, or as implementation for another ADT.
template <class Type>
class LinkList
{
private:
LinkListElement<Type> *head, *tail, *current;
public:
LinkList() { head = tail = current = 0; }
LinkList(LinkListElement<Type> *e)
{ head = tail = current = e; }
void InsertAtFront(Type *);
LinkListElement<Type> *RemoveAtFront();
void DeleteAtFront() { delete RemoveAtFront(); }
int IsEmpty() { return head == 0; }
void Print();
~LinkList(){ while (!IsEmpty()) DeleteAtFront(); }
};
让我们来检查LinkListElement和LinkList的前面的模板类定义。最初,我们注意到LinkList类的前向声明包含了必要的template class <Type>的模板前言。我们还应该注意到每个类定义本身都包含相同的模板前言,以双重指定该类将是一个模板类,并且数据类型的占位符将是标识符Type。
在LinkListElement类中,注意到数据类型将是Type(占位符类型)。另外,注意到类型的占位符在LinkList的友元类规范中是必要的,即friend class LinkList<Type>;。
在LinkList类中,注意到任何与LinkListElement的关联类的引用都将包括<Type>的类型占位符。例如,在LinkListElement<Type> *head;的数据成员声明中或者RemoveAtFront()的返回类型中,都使用了占位符。此外,注意到内联函数定义不需要在每个方法之前加上模板前言;我们仍然受到类定义本身之前的前言的覆盖。
现在,让我们继续来看看LinkList类的三个非内联成员函数:
template <class Type> // template preamble
void LinkList<Type>::InsertAtFront(Type *theItem)
{
LinkListElement<Type> *temp;
temp = new LinkListElement<Type>(theItem);
temp->SetNext(head); // temp->next = head;
head = temp;
}
template <class Type> // template preamble
LinkListElement<Type> *LinkList<Type>::RemoveAtFront()
{
LinkListElement<Type> *remove = head;
head = head->GetNext(); // head = head->next;
current = head; // reset current for usage elsewhere
return remove;
}
template <class Type> // template preamble
void LinkList<Type>::Print()
{
Type output;
if (!head)
cout << "<EMPTY>" << endl;
current = head;
while (current)
{
output = *(current->GetData());
cout << output << " ";
current = current->GetNext();
}
cout << endl;
}
当我们检查前面的代码时,我们可以看到在LinkList的非内联方法中,template <class Type>的模板前言出现在每个成员函数定义之前。我们还看到与作用域解析运算符相关联的类名被增加了<Type>;例如,void LinkList<Type>::Print()。
我们注意到前面提到的模板成员函数需要利用占位符类型Type的一部分来实现它们的方法。例如,InsertAtFront(Type *theItem)方法将占位符Type用作形式参数theItem的数据类型,并在声明一个本地指针变量temp时指定关联类LinkListElement<Type>。RemoveAtFront()方法类似地利用了类型为LinkListElement<Type>的本地变量,因此需要将其用作模板函数。同样,Print()引入了一个类型为Type的本地变量来辅助输出。
现在让我们来看看我们的main()函数,看看我们如何利用我们的模板类:
int main()
{
LinkList<int> list1; // create a LinkList of integers
list1.InsertAtFront(new int (3000));
list1.InsertAtFront(new int (600));
list1.InsertAtFront(new int (475));
cout << "List 1: ";
list1.Print();
// delete elements from list, one by one
while (!(list1.IsEmpty()))
{
list1.DeleteAtFront();
cout << "List 1 after removing an item: ";
list1.Print();
}
LinkList<float> list2; // now make a LinkList of floats
list2.InsertAtFront(new float(30.50));
list2.InsertAtFront(new float (60.89));
list2.InsertAtFront(new float (45.93));
cout << "List 2: ";
list2.Print();
}
在我们前面的main()函数中,我们利用我们的模板类创建了两种类型的链表,即整数的LinkList声明为LinkList<int> list1;和浮点数的LinkList声明为LinkList<float> list2;。
在每种情况下,我们实例化各种链表,然后添加元素并打印相应的列表。在第一个LinkList实例的情况下,我们还演示了如何连续从列表中删除元素。
让我们来看看这个程序的输出:
List 1: 475 600 3000
List 1 after removing an item: 600 3000
List 1 after removing an item: 3000
List 1 after removing an item: <EMPTY>
List 2: 45.93 60.89 30.5
总的来说,我们看到创建LinkList<int>和LinkList<float>非常容易。模板代码在幕后被简单地扩展,以适应我们所需的每种数据类型。然后我们可能会问自己,创建Student实例的链表有多容易?非常容易!我们可以简单地实例化LinkList<Student> list3;并调用适当的LinkList方法,比如list3.InsertAtFront(new Student("George", "Katz", 'C', "Mr.", 3.2, "C++", "123GWU"));。
也许我们想在模板LinkList类中包含一种方法来对我们的元素进行排序,比如添加一个OrderedInsert()方法(通常依赖于operator<或operator>来比较元素)。这对所有数据类型都适用吗?这是一个很好的问题。只要方法中的代码是通用的,可以适用于所有数据类型,它就可以,运算符重载可以帮助实现这个目标。是的!
现在我们已经看到了模板类和函数的工作原理,让我们考虑如何确保我们的模板类和函数能够完全扩展以适用于任何数据类型。为了做到这一点,让我们考虑运算符重载如何有价值。
使模板更灵活和可扩展
在 C++中添加模板使我们能够让程序员一次性地指定某些类型的类和函数,而在幕后,预处理器会代表我们生成许多版本的代码。然而,为了使一个类真正可扩展以适用于许多不同的用户定义类型,成员函数中编写的代码必须普遍适用于任何类型的数据。为了帮助实现这个目标,可以使用运算符重载来扩展可能轻松存在于标准类型的操作,以包括对用户定义类型的定义。
总结一下,我们知道运算符重载可以使简单的运算符不仅适用于标准类型,还适用于用户定义的类型。通过在模板代码中重载运算符,我们可以确保模板代码具有高度的可重用性和可扩展性。
让我们考虑如何通过运算符重载来加强模板。
通过添加运算符重载来进一步泛化模板代码。
回想一下,当重载运算符时,重要的是要促进与标准类型相同的含义。想象一下,我们想要在我们的LinkList类中添加一个OrderedInsert()方法。这个成员函数的主体可能依赖于比较两个元素,以确定哪个应该排在另一个之前。最简单的方法是使用operator<。这个运算符很容易定义为与标准类型一起使用,但它是否适用于用户定义的类型?只要我们重载运算符以适用于所需的类型,它就可以适用。
让我们看一个例子,我们需要重载一个运算符,使成员函数代码普遍适用:
template <class Type>
void LinkList<Type>::OrderedInsert(Type *theItem)
{
current = head;
if (theItem < head->GetData())
InsertAtFront(theItem); // add theItem before head
else
// Traverse list, add theItem in the proper location
}
在前面的模板成员函数中,我们依赖于operator<能够与我们想要使用这个模板类的任何数据类型一起工作。也就是说,当预处理器为特定的用户定义类型扩展这段代码时,<运算符必须适用于此方法特定扩展的任何数据类型。
如果我们希望创建一个LinkList的Student实例,并对一个Student与另一个Student进行OrderedInsert(),那么我们需要确保为两个Student实例定义了operator<的比较。当然,默认情况下,operator<仅适用于标准类型。但是,如果我们简单地为Student重载operator<,我们就可以确保LinkList<Type>::OrderedInsert()方法也适用于Student数据类型。
让我们看看如何为Student实例重载operator<,无论是作为成员函数还是非成员函数:
// overload operator < As a member function of Student
bool Student::operator<(const Student &s)
{
if (this->gpa < s.gpa)
return true;
else
return false;
}
// OR, overload operator < as a non-member function
bool operator<(const Student &s1, const Student &s2)
{
if (s1.gpa < s2.gpa)
return true;
else
return false;
}
在前面的代码中,我们可以识别operator<被实现为Student的成员函数,或者作为非成员函数。如果你可以访问Student类的定义,首选的方法是利用成员函数定义来实现这个运算符函数。然而,有时我们无法访问修改一个类。在这种情况下,我们必须使用非成员函数的方法。无论如何,在任何一种实现中,我们只是比较两个Student实例的gpa,如果第一个实例的gpa低于第二个Student实例,则返回true,否则返回false。
现在operator<已经为两个Student实例定义了,我们可以回到我们之前的LinkList<Type>::OrderedInsert(Type *)模板函数,它利用LinkList中类型为Type的两个对象进行比较。当我们的代码中某处创建了LinkList<Student>时,LinkList和LinkListElement的模板代码将被预处理器为Student进行扩展;Type将被替换为Student。然后编译扩展后的代码时,扩展的LinkList<Student>::OrderedInsert()中的代码将会无错误地编译,因为operator<已经为两个Student对象定义了。
然而,如果我们忽略为给定类型重载operator<会发生什么,然而,OrderedInsert()(或者另一个依赖于operator<的方法)在我们的代码中对该扩展模板类型的对象从未被调用?信不信由你,代码将会编译并且正常工作。在这种情况下,我们实际上并没有调用一个需要为该类型实现operator<的函数(即OrderedInsert())。因为这个函数从未被调用,该成员函数的模板扩展被跳过。编译器没有理由去发现operator<应该为该类型重载(为了使方法成功编译)。未被调用的方法只是没有被扩展,以供编译器验证。
通过运算符重载来补充模板类和函数,我们可以通过确保在方法体中使用的典型运算符可以应用于模板扩展中我们想要使用的任何类型,使模板代码变得更具可扩展性。我们的代码变得更加普适。
我们现在已经看到了如何使用模板函数和类,以及如何运算符重载可以增强模板,创建更具可扩展性的代码。在继续前进到下一章之前,让我们简要回顾一下这些概念。
总结
在这一章中,我们进一步加强了我们的 C++编程知识,超越了面向对象编程语言特性,包括了额外的语言特性,使我们能够编写更具可扩展性的代码。我们学会了如何利用模板函数和模板类,以及运算符重载如何很好地支持这些努力。
我们已经看到,模板可以让我们以泛型方式指定一个类或函数,与该类或函数中主要使用的数据类型相关。我们已经看到,模板类不可避免地利用模板函数,因为这些方法通常需要泛型地使用构建类的数据。我们已经看到,通过利用用户定义类型的运算符重载,我们可以利用使用简单运算符编写的方法体来适应更复杂的数据类型的使用,使模板代码变得更加有用和可扩展。
我们现在明白,使用模板可以让我们更抽象地指定一个类或函数,让预处理器为我们生成许多该类或函数的版本,基于应用程序中可能需要的特定数据类型。
通过允许预处理器根据应用程序中需要的类型来扩展模板类或一组模板函数的许多版本,创建许多类似的类或函数(并维护这些版本)的工作被传递给了 C++,而不是程序员。除了减少用户需要维护的代码外,模板类或函数中所做的更改只需要在一个地方进行 – 预处理器在需要时将重新扩展代码而不会出错。
我们通过研究模板为我们的 C++技能库增加了额外的有用功能,结合运算符重载,这将确保我们可以为几乎任何数据类型编写高度可扩展和可重用的代码。我们现在准备继续进行第十四章,理解 STL 基础,以便我们可以继续扩展我们的 C++编程技能,使用有用的 C++库功能,这将使我们成为更好的程序员。让我们继续前进!
问题
- 将您的
ArrayInt类从第十二章,运算符重载和友元,转换为一个模板Array类,以支持可以轻松调整大小并具有内置边界检查的任何数据类型的动态分配数组。
a. 考虑一下,如果需要的话,您将需要重载哪些运算符,以支持模板的Array类型中存储的任何用户定义类型的通用代码。
b. 使用您的模板的Array类,创建Student实例的数组。利用各种成员函数来演示各种模板函数是否正确运行。
- 使用模板的
LinkList类,完成LinkList<Type>::OrderedInsert()的实现。在main()中创建Student实例的LinkList。在列表中使用OrderedInsert()插入了几个Student实例后,通过显示每个Student及其gpa来验证该方法是否正确工作。Student实例应按gpa从低到高排序。您可能希望使用在线代码作为起点。
第十四章:理解 STL 基础知识
本章将继续我们对增加您的 C++编程技能库的追求,超越面向对象编程概念,深入研究已经完全融入到语言通用使用中的核心 C++库。我们将通过检查该库的一个子集来探索 C++中的标准模板库(STL),这个子集代表了可以简化我们的编程并使我们的代码更容易被熟悉 STL 的其他人理解的常用工具。
在本章中,我们将涵盖以下主要主题:
-
调查 C++中 STL 的内容和目的
-
了解如何使用基本的 STL 容器:
list、iterator、vector、deque、stack、queue、priority_queue、map和使用函数器的map -
自定义 STL 容器
到本章结束时,您将能够利用核心 STL 类来增强您的编程技能。因为您已经了解了基本的 C++语言和面向对象编程特性,您将会发现您现在有能力浏览和理解几乎任何 C++类库,包括 STL。通过熟悉 STL,您将能够显著增强您的编程技能,并成为一个更精明和有价值的程序员。
让我们通过研究一个非常广泛使用的类库 STL 来增加我们的 C++工具包。
技术要求
完整程序示例的在线代码可以在以下 GitHub URL 找到:github.com/PacktPublishing/Demystified-Object-Oriented-Programming-with-CPP/blob/master/Chapter14。每个完整程序示例都可以在 GitHub 存储库中的适当章节标题(子目录)下找到,文件名与当前章节编号相对应,后跟当前章节中的示例编号。例如,本章的第一个完整程序可以在子目录Chapter14中的名为Chp14-Ex1.cpp的文件中找到,位于上述 GitHub 目录下。
本章的 CiA 视频可在以下链接观看:bit.ly/3ch15A5。
调查 STL 的内容和目的
C++中的标准模板库是一个扩展 C++语言的标准类和工具库。STL 的使用是如此普遍,以至于它就像是语言本身的一部分;它是 C++的一个基本和不可或缺的部分。C++中的 STL 有四个组成部分组成库:容器、迭代器、函数和算法。
STL 还影响了 C++标准库,提供了一套编程标准;这两个库实际上共享常见特性和组件,尤其是容器和迭代器。我们已经使用了标准库的组件,即<iostream>用于 iostreams,<exception>用于异常处理,以及<new>用于new()和delete()操作符。在本章中,我们将探索 STL 和 C++标准库之间的许多重叠组件。
STL 有一整套容器类。这些类封装了传统的数据结构,允许相似的项目被收集在一起并统一处理。有几类容器类 - 顺序、关联和无序。让我们总结这些类别并提供每个类别的一些示例:
-
list、queue或stack。有趣的是,queue和stack可以被看作是更基本容器的定制或自适应接口,比如list。尽管如此,queue和stack仍然提供对它们的元素的顺序访问。 -
set或map。 -
unordered_set或unordered_map。
为了使这些容器类能够潜在地用于任何数据类型(并保持强类型检查),模板被用来抽象和泛型化收集项目的数据类型。事实上,在第十三章中,我们使用模板构建了自己的容器类,包括LinkList和Array,因此我们已经对模板化的容器类有了基本的了解!
此外,STL 提供了一整套迭代器,允许我们遍历容器。迭代器跟踪我们当前的位置,而不会破坏相应对象集合的内容或顺序。我们将看到迭代器如何让我们更安全地处理 STL 中的容器类。
STL 还包含大量有用的算法。例如排序、计算集合中满足条件的元素数量、搜索特定元素或子序列、以及以各种方式复制元素。算法的其他示例包括修改对象序列(替换、交换和删除值)、将集合分成范围,或将集合合并在一起。此外,STL 还包含许多其他有用的算法和实用程序。
最后,STL 包括函数。实际上,更正确的说法是 STL 包括operator()(函数调用运算符),通过这样做,允许我们通过函数指针实现参数化灵活性。虽然这不是 STL 的基本特性,我们将在本章中立即(或经常)使用,我们将在本章中看到一个小而简单的仿函数示例,与即将到来的章节使用仿函数检查 STL map中的 STL 容器类配对。
在本章中,我们将专注于 STL 的容器类部分。虽然我们不会检查 STL 中的每个容器类,但我们将回顾一系列这些类。我们会注意到,一些这些容器类与我们在本书的前几章中一起构建的类相似。顺便说一句,在本书的渐进章节进展中,我们也建立了我们的 C++语言和面向对象编程技能,这些技能对于解码 STL 这样的 C++类库是必要的。
让我们继续前进,看看选择性的 STL 类,并在解释每个类时测试我们的 C++知识。
理解如何使用基本的 STL 容器
在本节中,我们将运用我们的 C++技能,解码各种 STL 容器类。我们将看到,从核心 C++语法到面向对象编程技能,我们掌握的语言特性使我们能够轻松解释我们现在将要检查的 STL 的各个组件。特别是,我们将运用我们对模板的了解!例如,我们对封装和继承的了解将指导我们理解如何使用 STL 类中的各种方法。然而,我们会注意到虚函数和抽象类在 STL 中非常罕见。熟练掌握 STL 中的新类的最佳方法是接受详细说明每个类的文档。有了 C++的知识,我们可以轻松地浏览给定类,解码如何成功使用它。
C++ STL 中的容器类实现了各种list、iterator、vector、deque、stack、queue、priority_queue和map。
让我们开始检查如何利用一个非常基本的 STL 容器,list。
使用 STL list
STL list 类封装了实现链表所需的数据结构。我们可以说 list 实现了链表的抽象数据类型。回想一下,在第六章中,我们通过创建 LinkedListElement 和 LinkedList 类来制作自己的链表。STL list 允许轻松插入、删除和排序元素。不支持直接访问单个元素(称为随机访问)。相反,必须迭代地遍历链表中的先前项,直到达到所需的项。list 是顺序容器的一个很好的例子。
STL list 类有各种成员函数;我们将从这个例子中开始看一些流行的方法,以熟悉基本的 STL 容器类的用法。
现在,让我们看看如何使用 STL list 类。这个例子可以在我们的 GitHub 上找到,作为一个完整的工作程序,其中包括必要的类定义:
#include <list>
int main()
{
list<Student> studentBody; // create a list
Student s1("Jul", "Li", 'M', "Ms.", 3.8, "C++", "117PSU");
Student *s2 = new Student("Deb", "King", 'H', "Dr.", 3.8,
"C++", "544UD");
// Add Students to the studentBody list.
studentBody.push_back(s1);
studentBody.push_back(*s2);
// The next 3 instances are anonymous objects in main()
studentBody.push_back(Student("Hana", "Sato", 'U', "Dr.",
3.8, "C++", "178PSU"));
studentBody.push_back(Student("Sara", "Kato", 'B', "Dr.",
3.9, "C++", "272PSU"));
studentBody.push_back(Student("Giselle", "LeBrun", 'R',
"Ms.", 3.4, "C++", "299TU"));
while (!studentBody.empty())
{
studentBody.front().Print();
studentBody.pop_front();
}
delete s2; // delete any heap instances
return 0;
}
让我们检查上述程序段,其中我们创建和使用了一个 STL list。首先,我们#include <list> 包含适当的 STL 头文件。现在,在 main() 中,我们可以使用 list<Student> studentBody; 实例化一个列表。我们的列表将包含 Student 实例。然后我们在堆栈上创建 Student s1 和使用 new() 进行分配在堆上创建 Student *s2。
接下来,我们使用 list::push_back() 将 s1 和 *s2 添加到列表中。请注意,我们正在向 push_back() 传递对象。当我们向 studentBody 列表添加 Student 实例时,列表将在内部制作对象的副本,并在这些对象不再是列表成员时正确清理这些对象。我们需要记住,如果我们的实例中有任何分配在堆上的实例,比如 *s2,我们必须在 main() 结束时删除我们的实例的副本。展望到 main() 的末尾,我们可以看到我们适当地 delete s2;。
接下来,我们向列表中添加三个学生。这些 Student 实例没有本地标识符。这些学生是在调用 push_back() 中实例化的,例如,studentBody.push_back(Student("Hana", "Sato", 'U', "Dr.", 3.8, "C++", "178PSU"));。在这里,我们实例化了一个匿名(堆栈)对象,一旦 push_back() 调用结束,它将被正确地从堆栈中弹出并销毁。请记住,push_back() 也会为这些实例创建它们自己的本地副本,以在 list 中存在期间使用。
现在,在一个 while 循环中,我们反复检查列表是否为空,如果不是,则检查 front() 项并调用我们的 Student::Print() 方法。然后我们使用 pop_front() 从列表中移除该项。
让我们看一下这个程序的输出:
Ms. Jul M. Li with id: 117PSU GPA: 3.8 Course: C++
Dr. Deb H. King with id: 544UD GPA: 3.8 Course: C++
Dr. Hana U. Sato with id: 178PSU GPA: 3.8 Course: C++
Dr. Sara B. Kato with id: 272PSU GPA: 3.9 Course: C++
Ms. Giselle R. LeBrun with id: 299TU GPA: 3.4 Course: C++
现在我们已经解析了一个简单的 STL list 类,让我们继续了解 iterator 的概念,以补充容器,比如我们的 list。
使用 STL 迭代器
我们经常需要一种非破坏性的方式来遍历对象集合。例如,重要的是要维护给定容器中的第一个、最后一个和当前位置,特别是如果该集合可能被多个方法、类或线程访问。使用迭代器,STL 提供了一种通用的方法来遍历任何容器类。
使用迭代器有明显的好处。一个类可以创建一个指向集合中第一个成员的 iterator。然后可以将迭代器移动到集合的连续下一个成员。迭代器可以提供对 iterator 指向的元素的访问。
总的来说,容器的状态信息可以通过iterator来维护。迭代器通过将状态信息从容器中抽象出来,而是放入迭代器类,为交错访问提供了安全的手段。
我们可以想象一个iterator,您可能会在不知情的情况下修改容器。
让我们看看如何使用 STLiterator。这个例子可以在我们的 GitHub 上找到,作为一个完整的程序:
#include <list>
#include <iterator>
bool operator<(const Student &s1, const Student &s2)
{ // overloaded operator< -- required to use list::sort()
return (s1.GetGpa() < s2.GetGpa());
}
int main()
{
list<Student> studentBody;
Student s1("Jul", "Li", 'M', "Ms.", 3.8, "C++", "117PSU");
// Add Students to the studentBody list.
studentBody.push_back(s1);
// The next Student instances are anonymous objects
studentBody.push_back(Student("Hana", "Sato", 'U', "Dr.",
3.8, "C++", "178PSU"));
studentBody.push_back(Student("Sara", "Kato", 'B', "Dr.",
3.9, "C++", "272PSU"));
studentBody.push_back(Student("Giselle", "LeBrun", 'R',
"Ms.", 3.4, "C++", "299TU"));
studentBody.sort(); // sort() will rely on operator<
// Create a list iterator; set to first item in the list
list <Student>::iterator listIter = studentBody.begin();
while (listIter != studentBody.end())
{
Student &temp = *listIter;
temp.Print();
listIter++;
}
return 0;
}
让我们看一下我们之前定义的代码段。在这里,我们从 STL 中包括了<list>和<iterator>头文件。与之前的main()函数一样,我们实例化了一个list,它可以包含Student实例,使用list<Student> studentbody;。然后,我们实例化了几个Student实例,并使用push_back()将它们添加到列表中。再次注意,几个Student实例都是匿名对象,在main()中没有本地标识符。这些实例将在push_back()完成时从堆栈中弹出。这没有问题,因为push_back()将为列表创建本地副本。
现在,我们可以使用studentBody.sort();对列表进行排序。重要的是要注意,这个list方法要求我们重载operator<,以提供两个Student实例之间的比较手段。幸运的是,我们已经做到了!我们选择通过比较gpa来实现operator<,但也可以使用studentId进行比较。
现在我们有了一个list,我们可以创建一个iterator,并将其建立为指向list的第一个项目。我们通过声明list <Student>::iterator listIter = studentBody.begin();来实现这一点。有了iterator,我们可以使用它来安全地循环遍历list,从开始(初始化时)到end()。我们将一个本地引用变量temp赋给列表中当前第一个元素的循环迭代,使用Student &temp = *listIter;。然后我们使用temp.Print();打印这个实例,然后我们通过listIter++;增加一个元素来增加我们的迭代器。
让我们看一下此程序的排序输出(按gpa排序):
MS. Giselle R. LeBrun with id: 299TU GPA: 3.4 Course: C++
Ms. Jul M. Li with id: 117PSU GPA: 3.8 Course: C++
Dr. Hana U. Sato with id: 178PSU GPA: 3.8 Course: C++
Dr. Sara B. Kato with id: 272PSU GPA: 3.9 Course: C++
现在我们已经看到了iterator类的实际应用,让我们来研究一系列其他 STL 容器类,从vector开始。
使用 STLvector
STLvector类实现了动态数组的抽象数据类型。回想一下,我们通过在第十三章中创建一个Array类来创建了自己的动态数组,使用模板工作。然而,STL 版本将更加广泛。
vector(动态或可调整大小的数组)将根据需要扩展以容纳超出其初始大小的额外元素。vector类允许通过重载operator[]直接(即随机访问)访问元素。vector允许通过直接访问在常量时间内访问元素。不需要遍历所有先前的元素来访问特定索引处的元素。
然而,在vector中间添加元素是耗时的。也就是说,在除vector末尾之外的任何位置添加元素都需要内部重新排列所有插入点后的元素;它还可能需要内部调整vector的大小。
显然,通过比较,list和vector具有不同的优势和劣势。每个都适用于数据集的不同要求。我们可以选择最适合我们需求的那个。
让我们看一下一些常见的vector成员函数。这远非完整列表:
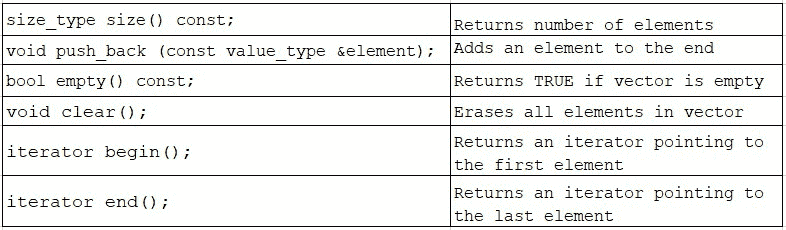
STL vector还有一个重载的operator=(用源向目标vector进行赋值替换),operator==(逐个元素比较向量),和operator[](返回所请求位置的引用,即可写内存)。
让我们来看看如何使用 STL vector类及其基本操作。这个例子可以在我们的 GitHub 上找到,作为一个完整的工作程序,如下所示:
#include <vector>
int main()
{
vector<Student> studentBody1, studentBody2; // two vectors
// add 3 Students, which are anonymous objects, to vect 1
studentBody1.push_back(Student("Hana", "Sato", 'U', "Dr.",
3.8, "C++", "178PSU"));
studentBody1.push_back(Student("Sara", "Kato", 'B', "Dr.",
3.9, "C++", "272PSU"));
studentBody1.push_back(Student("Giselle", "LeBrun", 'R',
"Ms.", 3.4, "C++", "299TU"));
for (int i = 0; i < studentBody1.size(); i++)
studentBody1[i].Print(); // print vector1's contents
studentBody2 = studentBody1; // assign one to another
if (studentBody1 == studentBody2)
cout << "Vectors are the same" << endl;
for (auto iter = studentBody2.begin(); // print vector2
iter != studentBody2.end(); iter++)
(*iter).Print();
if (!studentBody1.empty()) // clear first vector
studentBody1.clear();
return 0;
}
在前面列出的代码段中,我们#include <vector>来包含适当的 STL 头文件。现在,在main()中,我们可以使用vector<Student> studentBody1, studentBody2;来实例化两个向量。然后,我们可以使用vector::push_back()方法将几个Student实例连续添加到我们的第一个vector中。再次注意,在main()中,Student实例是匿名对象。也就是说,没有本地标识符引用它们 - 它们只是被创建用于放入我们的vector中,每次插入时都会创建每个实例的本地副本。一旦我们的vector中有元素,我们就可以遍历我们的第一个vector,使用studentBody1[i].Print();打印每个Student。
接下来,我们通过studentBody1 = studentBody2;来演示vector的重载赋值运算符。在这里,我们在赋值中从右到左进行深度复制。然后,我们可以使用重载的比较运算符在条件语句中测试这两个向量是否相等。也就是说,if (studentBody1 == studentBody2)。然后,我们使用指定为auto iter = studentBody2.begin();的迭代器在for循环中打印出第二个向量的内容。auto关键字允许迭代器的类型由其初始使用确定。最后,我们遍历我们的第一个vector,测试它是否empty(),然后使用studentBody1.clear();逐个清除一个元素。我们现在已经看到了vector方法及其功能的一部分。
让我们来看看这个程序的输出:
Dr. Hana U. Sato with id: 178PSU GPA: 3.8 Course: C++
Dr. Sara B. Kato with id: 272PSU GPA: 3.9 Course: C++
Ms. Giselle R. LeBrun with id: 299TU GPA: 3.4 Course: C++
Vectors are the same
Dr. Hana U. Sato with id: 178PSU GPA: 3.8 Course: C++
Dr. Sara B. Kato with id: 272PSU GPA: 3.9 Course: C++
Ms. Giselle R. LeBrun with id: 299TU GPA: 3.4 Course: C++
接下来,让我们研究 STL deque类,以进一步了解 STL 容器。
使用 STL deque
STL deque类(发音为deck)实现了双端队列的抽象数据类型。这个 ADT 扩展了队列先进先出的概念。相反,deque允许更大的灵活性。在deque的两端快速添加元素。在deque的中间添加元素是耗时的。deque是一个顺序容器,尽管比我们的list更灵活。
你可能会想象deque是queue的一个特例;它不是。相反,灵活的deque类将作为实现其他容器类的基础,我们很快就会看到。在这些情况下,私有继承将允许我们将deque隐藏为更严格的专门类的底层实现(具有广泛的功能)。
让我们来看看一些常见的deque成员函数。这远非完整列表:
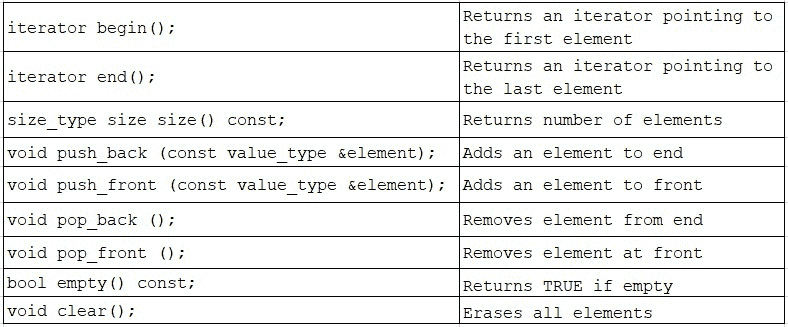
STL deque还有一个重载的operator=(将源分配给目标 deque)和operator[](返回所请求位置的引用 - 可写内存)。
让我们来看看如何使用 STL deque类。这个例子可以在我们的 GitHub 上找到,作为一个完整的工作程序,如下所示:
include <deque>
int main()
{
deque<Student> studentBody; // create a deque
Student s1("Tim", "Lim", 'O', "Mr.", 3.2, "C++", "111UD");
// the remainder of the Students are anonymous objects
studentBody.push_back(Student("Hana", "Sato", 'U', "Dr.",
3.8, "C++", "178PSU"));
studentBody.push_back(Student("Sara", "Kato", 'B', "Dr.",
3.9, "C++", "272PSU"));
studentBody.push_front(Student("Giselle", "LeBrun", 'R',
"Ms.", 3.4, "C++", "299TU"));
// insert one past the beginning
studentBody.insert(studentBody.begin() + 1, Student
("Anne", "Brennan", 'B', "Ms.", 3.9, "C++", "299CU"));
studentBody[0] = s1; // replace element;
// no bounds checking!
while (studentBody.empty() == false)
{
studentBody.front().Print();
studentBody.pop_front();
}
return 0;
}
在前面列出的代码段中,我们#include <deque>来包含适当的 STL 头文件。现在,在main()中,我们可以实例化一个deque来包含Student实例,使用deque<Student> studentBody;。然后,我们调用deque::push_back()或deque::push_front()来向我们的deque中添加几个Student实例(一些匿名对象)。我们已经掌握了这个!现在,我们使用studentBody.insert(studentBody.begin() + 1, Student("Anne", "Brennan", 'B', "Ms.", 3.9, "C++", "299CU"));在我们的甲板前面插入一个Student。
接下来,我们利用重载的operator[]将一个Student插入我们的deque,使用studentBody[0] = s1;。请注意,operator[]不会对我们的deque进行任何边界检查!在这个语句中,我们将Student s1插入到deque的 位置,而不是曾经占据该位置的
位置,而不是曾经占据该位置的Student。更安全的方法是使用deque::at()方法,它将包含边界检查。关于前述的赋值,我们还要确保operator=已经被重载为Person和Student,因为每个类都有动态分配的数据成员。
现在,我们循环直到我们的deque为空,使用studentBody.front().Print();提取并打印 deque 的前一个元素。每次迭代,我们还使用studentBody.pop_front();从我们的deque中弹出前一个项目。
让我们来看看这个程序的输出:
Mr. Tim O. Lim with id: 111UD GPA: 3.2 Course: C++
Ms. Anne B. Brennan with id: 299CU GPA: 3.9 Course: C++
Dr. Hana U. Sato with id: 178PSU GPA: 3.8 Course: C++
Dr. Sara B. Kato with id: 272PSU GPA: 3.9 Course: C++
现在我们对deque有了一些了解,接下来让我们调查 STL stack类。
使用 STL stack
STL stack类实现了堆栈的抽象数据类型。堆栈 ADT 支持stack包括一个不公开其底层实现的公共接口。毕竟,stack可能会改变其实现;ADT 的使用不应以任何方式依赖其底层实现。STL stack被认为是基本顺序容器的自适应接口。
回想一下,我们在第六章中制作了我们自己的Stack类,使用继承实现层次结构,使用了LinkedList作为私有基类。STL 版本将更加广泛;有趣的是,它是使用deque作为其底层私有基类来实现的。deque作为 STL stack的私有基类,隐藏了deque更多的通用功能;只有适用的方法被用来实现堆栈的公共接口。此外,因为实现的方式被隐藏了,一个stack可以在以后使用另一个容器类来实现,而不会影响其使用。
让我们来看看一系列常见的stack成员函数。这远非完整列表。重要的是要注意,stack的公共接口远比其私有基类deque要小:
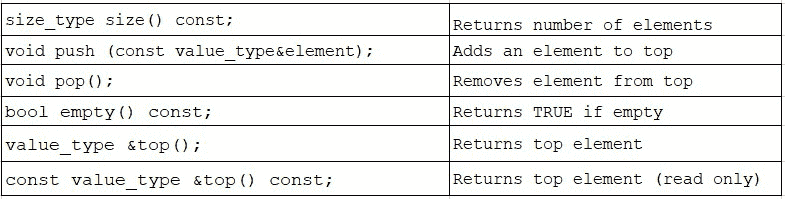
STL stack还有一个重载的operator=(将源分配给目标堆栈),operator==和operator!=(两个堆栈的相等/不相等),以及operator<,operator>,operator<=和operator >=(堆栈的比较)。
让我们看看如何使用 STL stack类。这个例子可以在我们的 GitHub 上找到,作为一个完整的工作程序,如下所示:
include <stack> // template class preamble
int main()
{
stack<Student> studentBody; // create a stack
// add Students to the stack (anonymous objects)
studentBody.push(Student("Hana", "Sato", 'U', "Dr.", 3.8,
"C++", "178PSU"));
studentBody.push(Student("Sara", "Kato", 'B', "Dr.", 3.9,
"C++", "272PSU"));
studentBody.push(Student("Giselle", "LeBrun", 'R', "Ms.",
3.4, "C++", "299TU"));
while (!studentBody.empty())
{
studentBody.top().Print();
studentBody.pop();
}
return 0;
}
在前面列出的代码段中,我们#include <stack>来包含适当的 STL 头文件。现在,在main()中,我们可以实例化一个stack来包含Student实例,使用stack<Student> studentBody;。然后,我们调用stack::push()来向我们的stack中添加几个Student实例。请注意,我们使用传统的push()方法,这有助于堆栈的 ADT。
然后我们循环遍历我们的stack,直到它不是empty()为止。我们的目标是使用studentBody.top().Print();来访问并打印顶部的元素。然后我们使用studentBody.pop();来整洁地从栈中弹出我们的顶部元素。
让我们来看看这个程序的输出:
Ms. Giselle R. LeBrun with id: 299TU GPA: 3.4 Course: C++
Dr. Sara B. Kato with id: 272PSU GPA: 3.9 Course: C++
Dr. Hana U. Sato with id: 178PSU GPA: 3.8 Course: C++
接下来,让我们研究 STL queue类,以进一步增加我们的 STL 容器知识。
使用 STL queue
STL queue类实现了队列的 ADT。作为典型的队列类,STL 的queue支持FIFO(先进先出)的插入和删除成员的顺序。
回想一下,在第六章**,使用继承实现层次结构中,我们制作了自己的Queue类;我们使用私有继承从我们的LinkedList类派生了我们的Queue。STL 版本将更加广泛;STL queue是使用deque作为其底层实现的(同样使用私有继承)。请记住,因为使用私有继承隐藏了实现手段,所以queue可以在以后使用另一种数据类型来实现,而不会影响其公共接口。STL queue是基本顺序容器的另一个自适应接口的例子。
让我们来看看一系列常见的queue成员函数。这远非完整列表。重要的是要注意,queue的公共接口远比其私有基类deque的接口小得多:
[外链图片转存中…(img-q5pHH0kq-1720491561402)]
STL queue还有一个重载的operator=(将源队列分配给目标队列),operator==和operator!=(两个队列的相等/不相等),以及operator<,operator>,operator<=和operator >=(队列的比较)。
让我们看看如何使用 STL queue类。这个例子可以在我们的 GitHub 上找到,作为一个完整的工作程序:
#include <queue>
int main()
{
queue<Student> studentBody; // create a queue
// add Students to the queue (anonymous objects)
studentBody.push(Student("Hana", "Sato", 'U', "Dr.", 3.8,
"C++", "178PSU"));
studentBody.push(Student("Sara", "Kato", 'B', "Dr.", 3.9,
"C++", "272PSU"));
studentBody.push(Student("Giselle", "LeBrun", 'R', "Ms.",
3.4, "C++", "299TU"));
while (!studentBody.empty())
{
studentBody.front().Print();
studentBody.pop();
}
return 0;
}
在上一个代码段中,我们首先#include <queue>来包含适当的 STL 头文件。现在,在main()中,我们可以实例化一个queue来包含Student实例,使用queue<Student> studentBody;。然后我们调用queue::push()来向我们的queue中添加几个Student实例。回想一下,使用队列 ADT,push()意味着我们在队列的末尾添加一个元素;一些程序员更喜欢使用术语enqueue来描述这个操作;然而,STL 选择了将这个操作命名为push()。使用队列 ADT,pop()将从队列的前面移除一个项目。一个更好的术语是dequeue;然而,这不是 STL 选择的。我们可以适应。
然后我们循环遍历我们的queue,直到它不是empty()为止。我们的目标是使用studentBody.front().Print();来访问并打印前面的元素。然后我们使用studentBody.pop();来整洁地从queue中弹出我们的前面的元素。我们的工作完成了。
让我们来看看这个程序的输出:
Dr. Hana U. Sato with id: 178PSU GPA: 3.8 Course: C++
Dr. Sara B. Kato with id: 272PSU GPA: 3.9 Course: C++
Ms. Giselle R. LeBrun with id: 299TU GPA: 3.4 Course: C++
现在我们已经尝试了queue,让我们来研究一下 STL priority_queue类。
使用 STL 优先队列
STL priority_queue类实现了优先队列的抽象数据类型。优先队列 ADT 支持修改后的 FIFO 插入和删除成员的顺序,使得元素被加权。前面的元素具有最大值(由重载的operator<确定),其余元素按顺序从次大到最小。STL priority_queue被认为是顺序容器的自适应接口。
请记住,我们在第六章中实现了我们自己的PriorityQueue类,使用继承实现层次结构。我们使用公共继承来允许我们的PriorityQueue专门化我们的Queue类,添加额外的方法来支持优先级(加权)入队方案。Queue的底层实现(使用私有基类LinkedList)是隐藏的。通过使用公共继承,我们允许我们的PriorityQueue能够通过向上转型被泛化为Queue(这是我们在第七章中学习多态性和虚函数后理解的)。我们做出了一个可以接受的设计选择:PriorityQueue Is-A(专门化为)Queue,有时可以以更一般的形式对待。我们还记得,Queue和PriorityQueue都不能向上转型为它们的底层实现LinkedList,因为Queue是从LinkedList私有继承的;我们不能越过非公共继承边界向上转型。
与此相反,STL 版本的priority_queue是使用 STL vector作为其底层实现。请记住,由于实现方式是隐藏的,priority_queue可能会在以后使用另一种数据类型进行实现,而不会影响其公共接口。
STL priority_queue允许检查,但不允许修改顶部元素。STL priority_queue不允许通过其元素进行插入。也就是说,元素只能按从大到小的顺序添加。因此,可以检查顶部元素,并且可以删除顶部元素。
让我们来看一下一系列常见的priority_queue成员函数。这不是一个完整的列表。重要的是要注意,priority_queue的公共接口要比其私有基类vector要小得多:

与之前检查过的容器类不同,STL priority_queue不重载运算符,包括operator=, operator==, 和 operator<。
priority_queue最有趣的方法是void emplace(args);。这是允许优先级入队机制向该 ADT 添加项目的成员函数。我们还注意到top()必须用于返回顶部元素(与queue使用的front()相反)。但再说一遍,STL priority_queue并不是使用queue实现的)。要使用priority_queue,我们需要#include <queue>,就像我们为queue一样。
由于priority_queue的使用方式与queue非常相似,因此我们将在本章末尾的问题集中进一步探讨它的编程方式。
现在我们已经看到了 STL 中许多顺序容器类型的示例(包括自适应接口),让我们接下来研究 STL map类,这是一个关联容器。
检查 STL map
STL map类实现了哈希表的抽象数据类型。map类允许快速存储和检索哈希表或映射中的元素,如果需要将多个数据与单个键关联起来,则可以使用multimap。
哈希表(映射)对于数据的存储和查找非常快。性能保证为O(log(n))。STL map被认为是一个关联容器,因为它将一个键与一个值关联起来,以快速检索值。
让我们来看一下一系列常见的map成员函数。这不是一个完整的列表:

STL map还有重载的运算符operator==(逐个元素比较映射),实现为全局函数。STL map还有重载的operator[](返回与用作索引的键关联的映射元素的引用;这是可写内存)。
让我们看看如何使用 STL map类。这个例子可以在我们的 GitHub 上找到,作为一个完整的工作程序:
#include <map>
bool operator<(const Student &s1, const Student &s2)
{ // We need to overload operator< to compare Students
return (s1.GetGpa() < s2.GetGpa());
}
int main()
{
Student s1("Hana", "Lo", 'U', "Dr.", 3.8, "C++", "178UD");
Student s2("Ali", "Li", 'B', "Dr.", 3.9, "C++", "272UD");
Student s3("Rui", "Qi", 'R', "Ms.", 3.4, "C++", "299TU");
Student s4("Jiang", "Wu", 'C', "Ms.", 3.8, "C++","887TU");
// Create map and map iterator, of Students w char * keys
map<const char *, Student> studentBody;
map<const char *, Student>::iterator mapIter;
// create three pairings of ids to Students
pair<const char *, Student> studentPair1
(s1.GetStudentId(), s1);
pair<const char *, Student> studentPair2
(s2.GetStudentId(), s2);
pair<const char *, Student> studentPair3
(s3.GetStudentId(), s3);
studentBody.insert(studentPair1); // insert 3 pairs
studentBody.insert(studentPair2);
studentBody.insert(studentPair3);
// insert using virtual indices per map
studentBody[s4.GetStudentId()] = s4;
mapIter = studentBody.begin();
while (mapIter != studentBody.end())
{
// set temp to current item in map iterator
pair<const char *, Student> temp = *mapIter;
Student &tempS = temp.second; // get 2nd item in pair
// access using mapIter
cout << temp.first << " "<<temp.second.GetFirstName();
// or access using temporary Student, tempS
cout << " " << tempS.GetLastName() << endl;
mapIter++;
}
return 0;
}
让我们检查前面的代码段。同样,我们使用#include <map>包含适用的头文件。接下来,我们实例化四个Student实例。我们将制作一个哈希表(map),其中Student实例将由键(即它们的studentId)索引。接下来,我们声明一个map来保存Student实例的集合,使用map<const char*,Student> studentBody;。在这里,我们指示键和元素之间的关联将在const char*和Student之间进行。然后,我们使用map<const char*,Student>::iterator mapIter;声明映射迭代器,使用相同的数据类型。
现在,我们创建三个pair实例,将每个Student与其键(即其相应的studentId)关联起来,使用声明pair<const char*,Student> studentPair1(s1.GetStudentId(), s1);。这可能看起来令人困惑,但让我们将这个声明分解成其组成部分。在这里,实例的数据类型是pair<const char*,Student>,变量名是studentPair1,(s1.GetStudentId(), s1)是传递给特定pair实例构造函数的参数。
现在,我们只需将三个pair实例插入map中。一个示例是studentBody.insert(studentPair1);。然后,我们使用以下语句将第四个Student,s4,插入map中:studentBody[s4.GetStudentId()] = s4;。请注意,在operator[]中使用studentId作为索引值;这个值将成为哈希表中Student的键值。
最后,我们将映射迭代器建立到map的开头,然后在end()之前处理map。在循环中,我们将一个变量temp设置为映射迭代器指示的pair的前端。我们还将tempS设置为map中的Student的临时引用,由temp.second(映射迭代器管理的当前pair中的第二个值)指示。现在,我们可以使用temp.first(当前pair中的第一个项目)打印出每个Student实例的studentId(键)。在同一语句中,我们可以使用temp.second.GetFirstName()打印出每个Student实例的firstName(因为与键对应的Student是当前pair中的第二个项目)。类似地,我们还可以使用tempS.GetLastName()打印出学生的lastName,因为tempS在每次循环迭代开始时被初始化为当前pair中的第二个元素。
让我们来看看这个程序的输出:
299TU Rui Qi
178UD Hana Lo
272UD Ali Li
887TU Jiang Wu
接下来,让我们看看使用 STL map的另一种方法,这将向我们介绍 STL functor的概念。
使用函数对象检查 STL 映射
STL map类具有很大的灵活性,就像许多 STL 类一样。在我们过去的map示例中,我们假设我们的Student类中存在比较的方法。毕竟,我们为两个Student实例重载了operator<。然而,如果我们无法修改未提供此重载运算符的类,并且我们选择不重载operator<作为外部函数,会发生什么呢?
幸运的是,当实例化map或映射迭代器时,我们可以为模板类型扩展指定第三种数据类型。这个额外的数据类型将是一种特定类型的类,称为函数对象。一个operator()。在重载的operator()中,我们将为问题中的对象提供比较的方法。函数对象本质上是通过重载operator()来模拟封装函数指针。
让我们看看如何修改我们的map示例以利用一个简单的函数对象。这个例子可以在我们的 GitHub 上找到,作为一个完整的工作程序:
#include <map>
struct comparison // This struct represents a 'functor'
{ // that is, a 'function object'
bool operator() (const char *key1, const char *key2) const
{
int ans = strcmp(key1, key2);
if (ans >= 0) return true; // return a boolean
else return false;
}
comparison() {} // empty constructor and destructor
~comparison() {}
};
int main()
{
Student s1("Hana", "Sato", 'U', "Dr.", 3.8, "C++",
"178PSU");
Student s2("Sara", "Kato", 'B', "Dr.", 3.9, "C++",
"272PSU");
Student s3("Jill", "Long", 'R', "Dr.", 3.7, "C++",
"234PSU");
// Now, map is maintained in sorted order per 'comparison'
// functor using operator()
map<const char *, Student, comparison> studentBody;
map<const char *, Student, comparison>::iterator mapIter;
// The remainder of the program is similar to prior
} // map program. See online code for complete example.
在前面提到的代码片段中,我们首先介绍了一个名为comparison的用户定义类型。这可以是一个class或一个struct。在这个结构的定义中,我们重载了函数调用运算符(operator()),并提供了两个const char *键的Student实例之间的比较方法。这个比较将允许Student实例按照比较函数对象确定的顺序插入。
现在,当我们实例化我们的map和 map 迭代器时,我们在模板类型扩展的第三个参数中指定了我们的comparison类型(函数对象)。并且在这个类型中嵌入了重载的函数调用运算符operator(),它将提供我们所需的比较。其余的代码将类似于我们原来的 map 程序。
当然,函数对象可能会以额外的、更高级的方式被使用,超出了我们在这里使用map容器类所见到的。尽管如此,你现在已经对函数对象如何应用于 STL 有了一定的了解。
现在我们已经看到了如何利用各种 STL 容器类,让我们考虑为什么我们可能想要定制一个 STL 类,以及如何做到这一点。
定制 STL 容器
C++中的大多数类都可以以某种方式进行定制,包括 STL 中的类。然而,我们必须注意 STL 中的设计决策将限制我们如何定制这些组件。因为 STL 容器类故意不包括虚析构函数或其他虚函数,我们不应该使用公共继承来扩展这些类。请注意,C++不会阻止我们,但我们知道从第七章,通过多态使用动态绑定,我们永远不应该覆盖非虚函数。STL 选择不包括虚析构函数和其他虚函数,以允许进一步专门化这些类,这是在 STL 容器被创建时做出的一个坚实的设计选择。
然而,我们可以使用私有或受保护的继承,或者包含或关联的概念,将 STL 容器类用作构建块,也就是说,隐藏新类的底层实现,STL 为新类提供了一个坚实但隐藏的实现。我们只需为新类提供我们自己的公共接口,在幕后,将工作委托给我们的底层实现(无论是私有或受保护的基类,还是包含或关联的对象)。
在扩展任何模板类时,包括使用私有或受保护基类的 STL 中的模板类,必须非常小心谨慎。这种小心谨慎也适用于包含或关联其他模板类。模板类通常不会被编译(或语法检查)直到创建具有特定类型的模板类的实例。这意味着只有当创建特定类型的实例时,任何派生或包装类才能被充分测试。
新类需要适当的重载运算符,以便这些运算符能够自动地与定制类型一起工作。请记住,一些运算符函数,比如operator=,并不是从基类继承到派生类的,需要在每个新类中编写。这是合适的,因为派生类可能需要完成的工作比operator=的通用版本中找到的更多。请记住,如果您无法修改需要选定重载运算符的类的类定义,您必须将该运算符函数实现为外部函数。
除了定制容器,我们还可以选择根据 STL 中现有的算法来增强算法。在这种情况下,我们将使用 STL 的许多函数之一作为新算法的基础实现的一部分。
在编程中经常需要定制来自现有库的类。例如,考虑我们如何扩展标准库exception类以创建自定义异常第十一章中的情况,处理异常(尽管该场景使用了公共继承,这不适用于定制 STL 类)。请记住,STL 提供了非常丰富的容器类。您很少会发现需要增强 STL 类的情况 - 或许只有在非常特定领域的类需求中。尽管如此,您现在知道了定制 STL 类所涉及的注意事项。请记住,在增强类时必须始终谨慎小心。我们现在看到了需要为我们创建的任何类使用适当的 OO 组件测试的必要性。
我们现在考虑如何在我们的程序中可能定制 STL 容器类和算法。我们也看到了一些 STL 容器类的实际示例。在继续下一章之前,让我们简要回顾一下这些概念。
总结
在本章中,我们进一步扩展了我们的 C++知识,超越了面向对象的语言特性,以熟悉 C++标准模板库。由于这个库在 C++中被如此普遍地使用,我们必须理解它包含的类的范围和广度。我们现在准备在我们的代码中利用这些有用的、经过充分测试的类。
通过检查选择的 STL 类,我们已经看了很多 STL 的例子,应该有能力自己理解 STL 的其余部分(或任何 C++库)。
我们已经看到了如何使用常见和基本的 STL 类,比如list、iterator、vector、deque、stack、queue、priority_queue和map。我们还看到了如何将一个函数对象与容器类结合使用。我们被提醒,我们现在有可能定制任何类的工具,甚至是来自类库如 STL 的类(通过私有或受保护的继承)或者包含或关联。
通过检查选定的 STL 类,我们还看到了我们有能力理解 STL 剩余的深度和广度,以及解码许多可用于我们的额外类库。当我们浏览每个成员函数的原型时,我们注意到关键的语言概念,比如const的使用,或者一个方法返回一个表示可写内存的对象的引用。每个原型都揭示了新类的使用机制。能够在编程努力中走到这一步真是令人兴奋!
通过在 C++中浏览 STL,我们现在已经为我们的 C++技能库增加了额外的有用特性。使用 STL(封装传统的数据结构)将确保我们的代码可以轻松地被其他程序员理解,他们无疑也在使用 STL。依靠经过充分测试的 STL 来使用这些常见的容器和实用程序,可以确保我们的代码更少出现错误。
我们现在准备继续进行[第十五章],测试类和组件。我们希望用有用的 OO 组件测试技能来补充我们的 C++编程技能。测试技能将帮助我们了解我们是否以稳健的方式创建、扩展或增强了类。这些技能将使我们成为更好的程序员。让我们继续前进!
问题
- 用 STL
vector替换您在[第十三章](B15702_13_Final_NM_ePub.xhtml#_idTextAnchor486)的练习中的模板Array类,使用模板。创建Student实例的vector。使用vector操作来插入、检索、打印、比较和从向量中删除对象。或者,利用 STLlist。利用这个机会利用 STL 文档来浏览这些类的全部操作。
a. 考虑您是否需要重载哪些运算符。考虑是否需要一个iterator来提供对集合的安全交错访问。
b. 创建第二个vector的Students。将一个分配给另一个。打印两个vectors。
-
修改本章的
map,以根据它们的lastName而不是studentId来索引Student实例的哈希表(map)。 -
修改本章的
queue示例,以改用priority_queue。确保利用优先级入队机制priority_queue::emplace()将元素添加到priority_queue中。您还需要利用top()而不是front()。请注意,priority_queue可以在<queue>头文件中找到。 -
尝试使用
sort()的 STL 算法。确保#include <algorithm>。对整数数组进行排序。请记住,许多容器都内置了排序机制,但本地集合类型,如语言提供的数组,没有(这就是为什么您应该使用基本整数数组)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









