







原文:
zh.annas-archive.org/md5/60442E9F3DEB860EA5C31D69FB8A3E2C译者:飞龙
前言
Django 是当今最受欢迎的 Web 框架之一。它为大型网站提供动力,例如 Pinterest、Instagram、Disqus 和 NASA。只需几行代码,您就可以快速构建一个功能齐全且安全的网站,可以扩展到数百万用户。
本书试图分享解决 Django 开发人员面临的几个常见设计问题的解决方案。有时,有几种解决方案,但我们经常想知道是否有推荐的方法。经验丰富的开发人员经常使用某些习惯用法,同时故意避免其他一些习惯用法。
本书是这些模式和见解的集合。它分为几章,每章涵盖框架的一个关键领域,例如模型,或 Web 开发的一个方面,例如调试。重点是构建清洁、模块化和更易维护的代码。
我们已经尽力提供最新信息并使用最新版本。Django 1.7 充满了令人兴奋的新功能,例如内置模式迁移和应用程序重新加载。Python 3.4 是该语言的最前沿,具有几个新模块,例如 asyncio。这两者都在这里使用了。
超级英雄是本书中的一个不断出现的主题。大多数代码示例都是关于构建 SuperBook——一个超级英雄的社交网络。作为呈现 Web 开发项目挑战的一种新颖方式,每章都以故事框的形式编织了一个令人兴奋的虚构叙述。
本书涵盖的内容
第一章,“Django 和模式”,通过告诉我们为什么创建 Django 以及它如何随着时间的推移而发展,帮助我们更好地理解 Django。然后,介绍设计模式、其重要性和几种流行的模式集合。
第二章,“应用程序设计”,指导我们通过应用程序生命周期的早期阶段,例如收集要求和创建模型。我们还将看到如何通过我们的运行项目 SuperBook 将项目分解为模块化应用程序。
第三章,“模型”,让我们了解模型如何以图形方式表示,使用几种模式进行结构化,并使用迁移(内置于 Django 1.7)进行后续更改。
第四章,“视图和 URL”,向我们展示了如何将基于函数的视图演变为具有强大混合概念的基于类的视图,使我们熟悉有用的视图模式,并教会我们如何设计简短而有意义的 URL。
第五章,“模板”,通过 Django 模板语言构造,解释其设计选择,建议如何组织模板文件,介绍方便的模板模式,并指出几种集成和自定义 Bootstrap 的方法。
第六章,“管理界面”,向我们展示了如何更有效地使用 Django 出色的开箱即用的管理界面,以及多种自定义方式,从增强模型到改进其默认外观和感觉。
第七章,“表单”,说明了常常令人困惑的表单工作流程,以及渲染表单的不同方式,如何使用 crispy forms 改善表单的外观以及各种应用表单模式。
第八章,“处理遗留代码”,解决了遗留 Django 项目的常见问题,例如确定正确的版本、定位文件、从何处开始阅读大型代码库,以及如何通过添加新功能来增强遗留代码。
第九章,“测试和调试”,概述了各种测试和调试工具和技术,介绍了测试驱动开发、模拟、日志记录和调试器。
第十章,安全性,使您熟悉各种 Web 安全威胁及其对策,特别是 Django 如何保护您。最后,一个方便的安全性检查表提醒您常常被忽视的领域。
第十一章,准备投产,介绍了部署面向公众的应用程序的速成课程,从选择 Web 堆栈开始,了解托管选项,并走过典型的部署过程。我们在这个阶段深入了解监控和性能的细节。
附录,Python 2 与 Python 3,向 Python 2 开发人员介绍了 Python 3。首先展示了最相关的差异,然后在 Django 中工作时,我们转向 Python 3 中提供的新模块和工具。
本书需要什么
您只需要一台计算机(PC 或 Mac)和互联网连接即可开始。然后,请确保已安装以下内容:
-
Python 3.4(或 Python 2.7,在阅读附录之后,Python 2 与 Python 3)或更高版本
-
Django 1.7 或更高版本
-
文本编辑器(或 Python IDE)
-
Web 浏览器(请使用最新版本)
我建议使用基于 Linux 的系统,如 Ubuntu 或 Arch Linux。如果您使用 Windows,可以使用 Vagrant 或 VirtualBox 在 Linux 虚拟机上工作。这里有一个充分的披露:我更喜欢命令行界面、Emacs 和荷包蛋。
某些章节可能需要安装特定的 Python 库或 Django 包。它们将被提及,比如说factory_boy包。在大多数情况下,它们可以使用pip进行安装,如下所示:
$ pip install factory_boy
因此,强烈建议您首先创建一个单独的虚拟环境,如第二章中所述,应用程序设计。
这本书是为谁准备的
本书旨在帮助开发人员洞察使用 Django 构建高度可维护的网站。它将帮助您更深入地了解框架,但也会使您熟悉几个 Web 开发概念。
它对于初学者和有经验的 Django 开发人员都很有用。它假设您熟悉 Python,并已完成了 Django 的基本教程(尝试官方的投票教程或来自arunrocks.com的视频教程)。
您不必是 Django 或 Python 的专家。阅读本书不需要对模式有先验知识。更具体地说,本书不是关于经典的四人帮模式,尽管它们可能会被提及。
这里的许多实用信息可能不仅仅适用于 Django,而是适用于 Web 开发。在本书结束时,您应该是一个更高效和务实的 Web 开发人员。
惯例
在本书中,您会发现许多文本样式,用于区分不同类型的信息。以下是一些这些样式的示例,以及它们的含义解释。
文本中的代码词、文件夹名称、文件名、包名称和用户输入显示如下:“HttpResponse对象被呈现为字符串。”
代码块设置如下:
from django.db import models
class SuperHero(models.Model):
name = models.CharField(max_length=100)
任何命令行(通常是 Unix)的输入或输出都写成如下形式:
$ django-admin.py --version
1.6.1
以美元提示符($符号)开头的行是要在 shell 中输入的(但跳过提示本身)。其余行是系统输出,如果输出非常长,可能会使用省略号(…)进行修剪。
每个章节(除了第一章)都将有一个故事框,样式如下:
注意
超级书籍章节标题
那是一个漆黑而风雨交加的夜晚;披着斗篷的超级英雄的剪影在烧焦的里克森数字图书馆的废墟中移动。捡起一块看起来像是半融化的硬盘盒;显而易见队长咬紧牙关喊道:“我们需要备份!”
故事框最好按顺序阅读,以遵循线性叙事。
本书中描述的模式以《本书中的模式》一节中提到的格式编写,位于第一章 Django 和模式 中。
提示和最佳实践的风格如下:
提示
最佳实践
每 5 年更换你的超级服装。
新术语和重要单词以粗体显示。
第一章:Django 和模式
在本章中,我们将讨论以下主题:
-
为什么选择 Django?
-
Django 的故事
-
Django 的工作原理
-
什么是模式?
-
知名的模式集合
-
Django 中的模式
根据盖博伟的“世界初创企业报告”,2013 年全球有超过 136,000 家互联网公司,仅美国就有超过 60,000 家。其中,87 家美国公司的估值超过 10 亿美元。另一项研究表明,在 27 个国家的 12,000 名 18 至 30 岁的人中,超过三分之二看到了成为企业家的机会。
这种数字初创企业的繁荣主要归功于初创企业的工具和技术变得廉价和普遍。现在,创建一个完整的网络应用所需的时间比以前少得多,这要归功于强大的框架。
即使是第一次编程的人也可以轻松学习创建网络应用,因为它的学习曲线很平缓。然而,很快他们会一遍又一遍地解决其他人一直在面对的相同问题。这就是理解模式可以真正帮助节省时间的地方。
为什么选择 Django?
每个网络应用都是不同的,就像手工制作的家具一样。你很少会找到一个完全符合你需求的大规模生产的产品。即使你从一个基本需求开始,比如一个博客或一个社交网络,你的需求会慢慢增长,你很容易最终得到很多临时解决方案粗制滥造地贴在一个曾经简单的模板解决方案上。
这就是为什么像 Django 或 Rails 这样的网络框架变得极其受欢迎。框架可以加快开发速度,并且内置了所有最佳实践。然而,它们也足够灵活,可以让你获得足够的工具来完成工作。如今,网络框架是无处不在的,大多数编程语言都至少有一个类似 Django 的端到端框架。
Python 可能比大多数编程语言都有更多的网络框架。快速浏览 Python 包索引(PyPi)会发现有惊人的 13021 个与框架相关的包。对于 Django 来说,总共有 5467 个包。
Python 维基列出了超过 54 个活跃的网络框架,其中最受欢迎的是 Django、Flask、Pyramid 和 Zope。Python 的框架也具有广泛的多样性。紧凑的Bottle微型网络框架只有一个 Python 文件,没有依赖性,但却能够出人意料地创建一个简单的网络应用。
尽管有这么多的选择,Django 已经成为了绝大多数人的首选。Djangosites.org列出了超过 4700 个使用 Django 编写的网站,包括著名的成功案例,如 Instagram、Pinterest 和 Disqus。
正如官方描述所说,Django(djangoproject.com)是一个高级的 Python 网络框架,鼓励快速开发和清晰的实用设计。换句话说,它是一个完整的网络框架,就像 Python 一样,内置了所有必要的功能。
开箱即用的管理界面是 Django 的独特功能之一,对于早期数据输入和测试非常有帮助。Django 的文档因为非常适合开源项目而受到赞扬。
最后,Django 在几个高流量网站上经过了实战测试。它在安全方面有着异常的关注,可以防范常见攻击,如跨站脚本(XSS)和跨站请求伪造(CSRF)。
尽管理论上你可以使用 Django 构建任何类型的网络应用,但它可能并不适合每种情况。例如,要构建基于实时聊天的网络界面,你可能会想使用 Tornado,而你的网络应用的其余部分仍然可以使用 Django 完成。选择合适的工具来完成工作。
一些内置功能,比如管理界面,如果你习惯于其他网络框架,可能会听起来有些奇怪。为了理解 Django 的设计,让我们找出它是如何诞生的。
Django 的故事
当你看着埃及金字塔时,你可能会认为这样简单而简约的设计一定是相当明显的。事实上,它们是 4000 年建筑演变的产物。阶梯金字塔,最初(而且笨重)的设计,有六个尺寸递减的矩形块。经过几次建筑和工程改进,直到现代、玻璃化和持久的石灰石结构被发明出来。
看着 Django,你可能会有类似的感觉。如此优雅地构建,一定是毫无瑕疵地构想出来的。相反,它是在一个想象得到的最高压力环境中的重写和快速迭代的结果 - 一个新闻编辑室!
2003 年秋天,两名程序员 Adrian Holovaty 和 Simon Willison 在劳伦斯报纸 Journal-World 工作,致力于在堪萨斯州创建几个当地新闻网站。这些网站,包括LJWorld.com,Lawrence.com和KUsports.com - 像大多数新闻网站一样,不仅是充满文本、照片和视频的内容驱动门户,而且还不断试图满足劳伦斯社区的需求,例如当地商业目录、活动日历、分类广告等。
一个框架诞生了
当然,这意味着对 Simon、Adrian 和后来加入他们团队的 Jacob Kaplan Moss 来说,有很多工作;有很短的截止日期,有时只有几个小时的通知。由于当时 Python 的网络开发还处于早期阶段,他们不得不大部分从头开始编写网络应用程序。因此,为了节省宝贵的时间,他们逐渐将常见的模块和工具重构为名为“The CMS”的东西。
最终,内容管理部分被分拆成一个名为 Ellington CMS 的独立项目,后来成为一个成功的商业 CMS 产品。剩下的“CMS”是一个干净的基础框架,通用到足以用来构建任何类型的网络应用程序。
2005 年 7 月,这个网页开发框架以 Django(发音为 Jang-Oh)的形式发布,采用了开源的伯克利软件分发(BSD)许可证。它以传奇爵士吉他手 Django Reinhardt 的名字命名。剩下的,就像他们说的那样,就成了历史。
去除魔法
由于它作为内部工具的起源谦逊,Django 有很多劳伦斯 Journal-World 特有的怪癖。为了使 Django 真正通用,一个名为“去除劳伦斯”的努力已经在进行中。
然而,Django 开发人员必须进行的最重要的重构工作被称为“去除魔法”。这个雄心勃勃的项目涉及清理 Django 多年来积累的所有瑕疵,包括很多魔法(隐含功能的非正式术语),并用更自然和明确的 Python 代码替换它们。例如,模型类曾经是从一个名为django.models.*的魔法模块导入的,而不是直接从它们定义的models.py模块导入。
当时,Django 有大约十万行代码,这是 API 的重大重写。2006 年 5 月 1 日,这些变化,几乎相当于一本小书的大小,被整合到 Django 的开发版本主干中,并作为 Django 0.95 版本发布。这是迈向 Django 1.0 里程碑的重要一步。
Django 不断变得更好
每年,全球各地都会举行名为DjangoCons的会议,供 Django 开发人员相互交流。他们有一个可爱的传统,即在“为什么 Django 糟糕”上发表半幽默的主题演讲。这可能是 Django 社区的成员,或者是在竞争的网络框架上工作的人,或者只是任何知名人士。
多年来,令人惊讶的是 Django 开发人员如何积极地接受这些批评,并在随后的版本中加以缓解。以下是对应于 Django 曾经的缺点的改进的简要总结以及它们所解决的版本:
-
新的表单处理库(Django 0.96)
-
将管理界面与模型解耦(Django 1.0)
-
多数据库支持(Django 1.2)
-
更好地管理静态文件(Django 1.3)
-
更好的时区支持(Django 1.4)
-
可定制的用户模型(Django 1.5)
-
更好的事务处理(Django 1.6)
-
内置数据库迁移(Django 1.7)
随着时间的推移,Django 已成为公共领域中最符合 Python 习惯的代码库之一。Django 源代码也是学习 Python web 框架架构的好地方。
Django 是如何工作的?
要真正欣赏 Django,您需要窥探一下内部,看看其中的各种组成部分。这既可以启发,也可能令人不知所措。如果您已经熟悉这一点,您可能想跳过本节。

典型 Django 应用程序中的 Web 请求是如何处理的
上述图显示了来自访问者浏览器的 Web 请求到达您的 Django 应用程序并返回的简化旅程。编号路径如下:
-
浏览器将请求(基本上是一串字节)发送到您的 Web 服务器。
-
您的 Web 服务器(比如 Nginx)将请求交给 WSGI 服务器(比如 uWSGI),或者直接从文件系统中提供文件(比如 CSS 文件)。
-
与 web 服务器不同,WSGI 服务器可以运行 Python 应用程序。请求填充了一个名为
environ的 Python 字典,并且可以通过多层中间件,最终到达您的 Django 应用程序。 -
应用程序的
urls.py中包含的 URLconf 根据请求的 URL 选择一个视图来处理请求。请求已经转换为HttpRequest——一个 Python 对象。 -
所选视图通常会执行以下一项或多项操作:
5a. 通过模型与数据库进行交谈
5b. 使用模板呈现 HTML 或任何其他格式化响应
5c. 返回纯文本响应(未显示)
5d. 引发异常
-
HttpResponse对象在离开 Django 应用程序时被渲染为一个字符串。 -
用户浏览器中看到了一个精美的网页。
尽管省略了某些细节,但这种表示应该有助于您欣赏 Django 的高级架构。它还展示了关键组件(如模型、视图和模板)所扮演的角色。Django 的许多组件都基于几种众所周知的设计模式。
什么是模式?
“蓝图”、“脚手架”和“维护”之间有什么共同之处?这些软件开发术语都是从建筑施工和建筑领域借来的。然而,最有影响力的术语之一来自于 1977 年奥地利著名建筑师克里斯托弗·亚历山大及其团队(包括 Murray Silverstein、Sara Ishikawa 等人)撰写的一部关于建筑和城市规划的专著。
“模式”这个术语在他们的开创性作品《模式语言:城镇、建筑、建筑》(五卷系列中的第二卷)之后开始流行,该作品基于一个惊人的洞察力,即用户对他们的建筑了解比任何建筑师都要多。模式指的是日常问题及其提议但经过时间考验的解决方案。
在书中,克里斯托弗·亚历山大(Christopher Alexander)指出:“每个模式描述了一个在我们的环境中反复出现的问题,然后以这样一种方式描述了这个问题的核心解决方案,以至于您可以一百万次使用这个解决方案,而不必重复两次。”
例如,光之翼模式描述了人们更喜欢有更多自然光线的建筑,并建议安排建筑物以由翼组成。这些翼应该是长而窄的,绝不超过 25 英尺宽。下次你在一所古老大学的长长明亮的走廊上散步时,要感谢这种模式。
他们的书包含了 253 种这样的实用模式,从房间设计到整个城市的设计。最重要的是,这些模式中的每一个都给了一个抽象问题一个名称,并共同形成了一个“模式语言”。
还记得当你第一次遇到“ déjà vu”这个词吗?你可能会想“哇,我从来不知道有一个词来描述那种经历。”同样,建筑师不仅能够在他们的环境中识别模式,而且最终还能以一种同行能够理解的方式来命名它们。
在软件世界中,术语“设计模式”指的是软件设计中常见问题的一般可重复解决方案。它是开发人员可以使用的最佳实践的正式化。就像在建筑世界一样,模式语言已被证明对于向其他程序员传达解决设计问题的某种方式非常有帮助。
有几种设计模式的集合,但有些比其他的影响力更大。
四人帮模式
早期研究和记录设计模式的努力之一是一本名为《设计模式:可复用面向对象软件的元素》的书,作者是 Erich Gamma、Richard Helm、Ralph Johnson 和 John Vlissides,后来被称为四人帮(GoF)。这本书影响深远,以至于许多人认为书中的 23 种设计模式对软件工程本身是基本的。
实际上,这些模式主要是针对面向对象编程语言编写的,并且它在 C++和 Smalltalk 中有代码示例。正如我们将很快看到的,许多这些模式在其他具有更好高阶抽象的编程语言中甚至可能不需要。
这 23 种模式已经被广泛分类为以下类型:
-
创建模式:这些包括抽象工厂、生成器模式、工厂方法、原型模式和单例模式
-
结构模式:这些包括适配器模式、桥接模式、组合模式、装饰器模式、外观模式、享元模式和代理模式
-
行为模式:这些包括责任链模式、命令模式、解释器模式、迭代器模式、中介者模式、备忘录模式、观察者模式、状态模式、策略模式、模板模式和访问者模式
虽然详细解释每种模式超出了本书的范围,但在 Django 本身中识别一些这些模式是很有趣的:
| GoF 模式 | Django 组件 | 解释 |
|---|---|---|
| 命令模式 | HttpRequest | 这将请求封装在一个对象中 |
| 观察者模式 | 信号 | 当一个对象改变状态时,所有监听器都会被通知并自动更新 |
| 模板方法 | 基于类的通用视图 | 可以通过子类化重新定义算法的步骤而不改变算法的结构 |
虽然这些模式大多是对研究 Django 内部感兴趣的人来说,Django 本身可以归类的模式是一个常见的问题。
Django 是 MVC 吗?
模型-视图-控制器(MVC)是 70 年代由施乐 PARC 发明的一种架构模式。作为构建 Smalltalk 用户界面的框架,它在《Gang of Four》一书中早早地被提及。
今天,MVC 是 Web 应用程序框架中非常流行的模式。初学者经常问这样的问题:Django 是一个 MVC 框架吗?
答案既是肯定的,也是否定的。MVC 模式倡导将表示层与应用程序逻辑解耦。例如,在设计在线游戏网站 API 时,您可能会将游戏的高分榜呈现为 HTML、XML 或逗号分隔(CSV)文件。但是,其底层模型类将独立设计,不受数据最终呈现方式的影响。
MVC 对模型、视图和控制器的功能非常严格。然而,Django 对 Web 应用程序采取了更加实用的观点。由于 HTTP 协议的性质,对 Web 页面的每个请求都是独立的。Django 的框架被设计成一个处理每个请求并准备响应的管道。
Django 将其称为模型-模板-视图(MTV)架构。数据库接口类(模型)、请求处理类(视图)和最终呈现的模板语言(模板)之间存在关注点的分离。
如果将此与经典的 MVC 进行比较——“模型”可与 Django 的模型相媲美,“视图”通常是 Django 的模板,“控制器”是处理传入的 HTTP 请求并将其路由到正确视图函数的框架本身。
如果这还没有让您困惑,Django 更倾向于将处理每个 URL 的回调函数命名为“视图”函数。不幸的是,这与 MVC 模式中“视图”的概念无关。
Fowler 的模式
2002 年,Martin Fowler 写了《企业应用架构模式》,描述了他在构建企业应用程序时经常遇到的 40 多种模式。
与 GoF 书不同,Fowler 的书是关于架构模式的。因此,它们以更高的抽象级别描述模式,并且在很大程度上与编程语言无关。
Fowler 的模式组织如下:
-
领域逻辑模式:包括领域模型、事务脚本、服务层和表模块
-
数据源架构模式:包括行数据网关、表数据网关、数据映射器和活动记录
-
对象关系行为模式:包括身份映射、工作单元和延迟加载
-
对象关系结构模式:包括外键映射、映射、依赖映射、关联表映射、标识字段、序列化 LOB、嵌入值、继承映射器、单表继承、具体表继承和类表继承
-
对象关系元数据映射模式:包括查询对象、元数据映射和存储库
-
Web 演示模式:包括页面控制器、前端控制器、模型视图控制器、转换视图、模板视图、应用程序控制器和两步视图
-
分发模式:包括数据传输对象和远程外观
-
离线并发模式:包括粗粒度锁、隐式锁、乐观离线锁和悲观离线锁
-
会话状态模式:包括数据库会话状态、客户端会话状态和服务器会话状态
-
基本模式:包括映射器、网关、层超类型、注册表、值对象、分离接口、货币、插件、特殊情况、服务存根和记录集
几乎所有这些模式在设计 Django 应用程序时都会很有用。事实上,Fowler 的网站martinfowler.com/eaaCatalog/上有这些模式的优秀目录。我强烈建议您查看一下。
Django 还实现了许多这些模式。以下表格列出了其中的一些:
| Fowler 模式 | Django 组件 | 解释 |
|---|---|---|
| 活动记录 | Django 模型 | 封装数据库访问,并在该数据上添加领域逻辑 |
| 类表继承 | 模型继承 | 层次结构中的每个实体都映射到一个单独的表中 |
| 身份字段 | ID 字段 | 在对象中保存数据库 ID 字段以维护身份 |
| 模板视图 | Django 模板 | 通过在 HTML 中嵌入标记呈现为 HTML |
还有更多的模式吗?
是的,当然。模式一直在不断被发现。就像生物一样,有些会变异并形成新的模式:例如,MVC 的变体,如模型-视图-呈现者(MVP)、分层模型-视图-控制器(HMVC)或模型视图视图模型(MVVM)。
模式也随着时间的推移而发展,因为对已知问题的更好解决方案被识别出来。例如,单例模式曾经被认为是一种设计模式,但现在被认为是一种反模式,因为它引入了共享状态,类似于使用全局变量。反模式可以被定义为常常被重新发明的,但是一个糟糕的解决方案。
一些其他众所周知的模式目录书籍包括 Buschmann、Meunier、Rohnert、Sommerlad 和 Sta 的面向模式的软件架构(称为POSA);Hohpe 和 Woolf 的企业集成模式;以及 Duyne、Landay 和 Hong 的网站设计:为打造以客户为中心的网页体验而编织的模式、原则和流程。
本书中的模式
本书将涵盖 Django 特定的设计和架构模式,这对 Django 开发人员很有用。接下来的章节将描述每个模式将如何呈现。
模式名称
标题是模式名称。如果是一个众所周知的模式,就使用常用的名称;否则,选择一个简洁的、自我描述的名称。名称很重要,因为它有助于建立模式词汇。所有模式都将包括以下部分:
问题:这简要提到了问题。
解决方案:这总结了提出的解决方案。
问题详情:这详细阐述了问题的背景,并可能给出一个例子。
解决方案详情:这以一般术语解释了解决方案,并提供了一个 Django 实现的示例。
对模式的批评
尽管它们几乎被普遍使用,但模式也有它们的批评。最常见的反对意见如下:
-
模式弥补了缺失的语言特性:Peter Norvig 发现《设计模式》中的 23 个模式中有 16 个在 Lisp 中是“不可见或更简单的”。考虑到 Python 的内省能力和一级函数,这对 Python 来说也可能是这样。
-
模式重复最佳实践:许多模式本质上是对最佳实践的形式化,比如关注点分离,可能看起来是多余的。
-
模式可能导致过度工程化:实现模式可能比更简单的解决方案效率低且过度。
如何使用模式
虽然之前的一些批评是相当合理的,但它们是基于模式被误用的情况。以下是一些建议,可以帮助你了解如何最好地使用设计模式:
-
如果你的语言支持直接解决方案,就不要实现模式
-
不要试图用模式的术语来适配一切
-
只有在你的上下文中它是最优雅的解决方案时才使用模式
-
不要害怕创建新的模式
最佳实践
除了设计模式,可能还有一种推荐的解决问题的方法。在 Django 中,与 Python 一样,可能有几种解决问题的方法,但其中一种是惯用的方法。
Python 之禅和 Django 的设计哲学
一般来说,Python 社区使用术语“Pythonic”来描述一段惯用的代码。它通常指的是《Python 之禅》中阐述的原则。这本书像一首诗一样写成,对于描述这样一个模糊的概念非常有用。
提示
尝试在 Python 提示符中输入import this来查看《Python 之禅》。
此外,Django 开发人员在设计框架时已经清晰地记录了他们的设计理念,网址为docs.djangoproject.com/en/dev/misc/design-philosophies/。
虽然该文档描述了 Django 设计背后的思维过程,但对于使用 Django 构建应用程序的开发人员也是有用的。某些原则,如“不要重复自己”(DRY)、“松耦合”和“紧凑性”可以帮助您编写更易维护和成熟的 Django 应用程序。
本书建议的 Django 或 Python 最佳实践将以以下方式格式化:
提示
最佳实践:
在 settings.py 中使用 BASE_DIR,并避免硬编码目录名称。
摘要
在本章中,我们探讨了人们为什么选择 Django 而不是其他 Web 框架,它有趣的历史以及它的工作原理。我们还研究了设计模式、流行的模式集合和最佳实践。
在下一章中,我们将看一下 Django 项目开始阶段的前几个步骤,比如收集需求、创建模型和设置项目。
第二章:应用程序设计
在本章中,我们将涵盖以下主题:
-
收集需求
-
创建概念文件
-
HTML 模拟
-
如何将项目分成应用程序
-
是写一个新应用程序还是重用现有的应用程序
-
项目开始前的最佳实践
-
为什么选择 Python 3?
-
开始 SuperBook 项目
许多新手开发人员在开始新项目时会立即开始编写代码。往往会导致错误的假设、未使用的功能和浪费时间。即使在时间紧迫的项目中,花一些时间与客户一起了解核心需求,都能产生令人难以置信的结果。管理需求是值得学习的关键技能。
如何收集需求
| 创新不是说 YES,而是说 NO,除了最关键的功能之外。 | ||
|---|---|---|
| –史蒂夫·乔布斯 |
通过花几天时间与客户仔细倾听他们的需求并设定正确的期望,我挽救了几个注定失败的项目。只带着一支铅笔和纸(或它们的数字化等价物),这个过程非常简单但有效。在收集需求时要记住以下一些关键点:
-
直接与应用程序所有者交谈,即使他们不懂技术。
-
确保你充分倾听他们的需求并记录下来。
-
不要使用“模型”等技术术语。保持简单,使用终端用户友好的术语,如“用户资料”。
-
设定正确的期望。如果某事在技术上不可行或困难,确保立即告诉他们。
-
尽可能多地进行素描。人类天生是视觉动物。网站更是如此。使用粗线和简笔画。不需要完美。
-
分解流程,如用户注册。任何多步功能都需要用箭头连接的框来绘制。
-
最后,以用户故事的形式或任何易于理解的形式逐个处理功能列表。
-
在将功能优先级划分为高、中、低桶时要积极参与。
-
在接受新功能时要非常保守。
-
会后,与所有人分享你的笔记,以避免误解。
第一次会议会很长(可能是一整天的研讨会或几个小时的会议)。后来,当这些会议变得频繁时,你可以将它们缩短到 30 分钟或一个小时。
所有这一切的产出将是一个一页的写作和几张粗糙的素描。
在这本书中,我们自愿承担了一个崇高的项目,为超级英雄建立一个名为 SuperBook 的社交网络。根据我们与一群随机选择的超级英雄讨论的简单草图如下所示:

SuperBook 网站的响应式设计草图。显示了桌面(左)和智能手机(右)布局。
你是一个讲故事的人吗?
那么这个一页的写作是什么?这是一个简单的文件,解释了使用该网站的感受。在我参与的几乎所有项目中,当有新成员加入团队时,他们通常不会浏览每一份文件。如果他们找到一个简短的单页文件,快速告诉他们网站的意图,他们会感到高兴。
你可以随意称呼这个文件——概念文件、市场需求文件、客户体验文档,甚至是史诗脆弱故事日志™(专利申请中)。这真的无关紧要。
文件应该侧重于用户体验,而不是技术或实施细节。要简短有趣。事实上,Joel Spolsky 在记录需求方面的第一条规则是“要幽默”。
如果可能的话,写一篇关于典型用户(在营销术语中称为“角色”)的文章,他们面临的问题以及 Web 应用程序如何解决它。想象他们如何向朋友解释这种体验。试着捕捉这一点。
这是 SuperBook 项目的概念文件:
注
SuperBook 概念
以下采访是在我们的网站 SuperBook 在未来推出后进行的。在采访之前进行了 30 分钟的用户测试。
请介绍一下自己。
我的名字是阿克塞尔。我是一只灰松鼠,住在纽约市中心。不过,每个人都叫我橡子。我爸爸,著名的嘻哈明星 T.贝瑞,过去常常叫我那个。我想我从来没有唱歌好到可以接手家族生意。
事实上,在我早期,我有点偷窃癖。你知道,我对坚果过敏。其他兄弟们很容易就能在公园里生活。我不得不 improvisation——咖啡馆、电影院、游乐园等等。我也非常仔细地阅读标签。
好的,橡子。你为什么认为你被选中进行用户测试?
可能是因为我曾在纽约星报上被介绍为一个不太知名的超级英雄。我猜人们觉得一个松鼠能用 MacBook 很有趣(采访者:这次采访是通过聊天进行的)。另外,我有一个松鼠一样的注意力。
根据你看到的,你对 SuperBook 有什么看法?
我认为这是一个很棒的主意。我的意思是,人们经常看到超级英雄。然而,没有人关心他们。大多数都是孤独和反社会的。SuperBook 可以改变这一点。
你认为 Superbook 有什么不同?
它是为像我们这样的人从零开始构建的。我的意思是,当你想要使用你的秘密身份时,没有“工作和教育”的废话。虽然我没有,但我能理解为什么有人会有一个。
你能简要告诉我们你注意到的一些特点吗?
当然,我认为这是一个相当不错的社交网络,你可以:
-
用任何用户名注册(不再需要“输入你的真实姓名”了,愚蠢的要求)
-
粉丝可以关注别人,而不必把他们添加为“朋友”
-
发布帖子,对其进行评论,并重新分享
-
给另一个用户发送私人帖子
一切都很容易。弄清楚它并不需要超人的努力。
谢谢你的时间,橡子。
HTML 模型
在构建 Web 应用程序的早期,工具如 Photoshop 和 Flash 被广泛使用来获得像素完美的模型。它们几乎不再被推荐或使用。
在智能手机、平板电脑、笔记本电脑和其他平台上提供本地和一致的体验现在被认为比获得像素完美的外观更重要。事实上,大多数网页设计师直接在 HTML 上创建布局。
创建 HTML 模型比以前快得多,也更容易。如果你的网页设计师不可用,开发人员可以使用 CSS 框架,如 Bootstrap 或 ZURB Foundation 框架来创建相当不错的模型。
创建模型的目标是创建网站的真实预览。它不应该只关注细节和修饰,使其看起来比草图更接近最终产品,而且还应该增加交互性。用一些简单的 JavaScript 驱动的交互性,让你的静态 HTML 变得生动起来。
一个好的模型可以用不到总体开发工作量的 20%来提供 80%的客户体验。
设计应用程序
当你对需要构建的东西有一个相当好的想法时,你可以开始考虑在 Django 中的实现。再一次,开始编码是很诱人的。然而,当你花几分钟思考设计时,你会发现解决设计问题的许多不同方法。
你也可以首先开始设计测试,这是测试驱动设计(TDD)方法论所倡导的。我们将在测试章节中看到更多 TDD 方法的应用。
无论你采取哪种方法,最好停下来思考一下——“我可以用哪些不同的方式来实现这个?有什么权衡?在我们的情境中哪些因素更重要?最后,哪种方法是最好的?”
有经验的 Django 开发人员以不同的方式看待整个项目。遵循 DRY 原则(有时是因为他们变懒了),他们会想——“我以前见过这个功能吗?例如,可以使用django-all-auth这样的第三方包来实现社交登录功能吗?”
如果他们必须自己编写应用程序,他们会开始考虑各种设计模式,希望能够设计出优雅的设计。然而,他们首先需要将项目在顶层分解为应用程序。
将项目分成应用
Django 应用程序称为项目。一个项目由多个应用程序或应用组成。应用是提供一组功能的 Python 包。
理想情况下,每个应用都必须是可重用的。您可以创建尽可能多的应用。永远不要害怕添加更多的应用或将现有的应用重构为多个应用。一个典型的 Django 项目包含 15-20 个应用。
在这个阶段做出的一个重要决定是是否使用第三方 Django 应用程序还是从头开始构建一个。第三方应用程序是现成的应用程序,不是由您构建的。大多数包都可以快速安装和设置。您可以在几分钟内开始使用它们。
另一方面,编写自己的应用通常意味着自己设计和实现模型、视图、测试用例等。Django 不会区分这两种类型的应用。
重用还是自己编写?
Django 最大的优势之一是庞大的第三方应用生态系统。在撰写本文时,djangopackages.com列出了 2600 多个包。您可能会发现您的公司或个人库甚至更多。一旦您的项目被分成应用程序,并且您知道需要哪种类型的应用程序,您将需要为每个应用程序做出决定——是编写还是重用现有的应用程序。
安装和使用现成的应用可能听起来更容易。然而,事实并不像听起来那么简单。让我们来看看我们项目中一些第三方身份验证应用,并列出我们在撰写本文时为 SuperBook 未使用它们的原因:
-
为我们的需求过度设计: 我们觉得支持任何社交登录的
python-social-auth是不必要的 -
太具体: 使用
django-facebook将意味着将我们的身份验证与特定网站提供的身份验证绑定在一起 -
Python 依赖:
django-allauth的要求之一是python-openid,这个包目前没有得到积极维护或批准。 -
非 Python 依赖: 一些包可能具有非 Python 依赖项,例如 Redis 或 Node.js,这会增加部署的开销
-
不可重用: 我们自己的许多应用程序之所以没有被使用,是因为它们不太容易重用,或者没有被编写成可重用的
这些包都不是坏的。它们只是暂时不符合我们的需求。它们可能对不同的项目有用。在我们的情况下,内置的 Django auth应用程序已经足够好了。
另一方面,您可能会因以下一些原因而更喜欢使用第三方应用程序:
-
太难做到正确: 您的模型实例需要形成一个树吗?使用
django-mptt进行数据库高效实现 -
最佳或推荐的应用程序: 这会随时间而改变,但像
django-redis这样的包是最推荐的用例 -
缺少功能: 许多人认为
django-model-utils和django-extensions等包应该是框架的一部分 -
最小依赖: 这在我的书中总是很好的。
那么,您是应该重用应用程序并节省时间,还是编写一个新的自定义应用程序?我建议您在沙盒中尝试第三方应用程序。如果您是一名中级 Django 开发人员,那么下一节将告诉您如何在沙盒中尝试包。
我的应用沙盒
不时地,您会看到一些博客文章列出了“必备的 Django 包”。然而,决定一个包是否适合您的项目的最佳方法是原型设计。
即使您已经为开发创建了 Python 虚拟环境,尝试所有这些软件包然后将它们丢弃可能会污染您的环境。因此,我通常会创建一个名为“sandbox”的单独虚拟环境,纯粹用于尝试这些应用程序。然后,我构建一个小项目来了解使用起来有多容易。
稍后,如果我对应用程序的试用感到满意,我会使用 Git 等版本控制工具在我的项目中创建一个分支来集成该应用程序。然后,我会在分支中继续编码和运行测试,直到必要的功能被添加。最后,这个分支将被审查并合并回主线(有时称为master)分支。
哪些软件包成功了?
为了说明这个过程,我们的 SuperBook 项目可以大致分为以下应用程序(不是完整的列表):
-
身份验证(内置
django.auth):这个应用程序处理用户注册、登录和注销 -
账户(自定义):这个应用程序提供额外的用户个人资料信息
-
帖子(自定义):这个应用程序提供帖子和评论功能
-
Pows(自定义):这个应用程序跟踪任何项目获得多少“pows”(点赞或喜欢)
-
Bootstrap forms(crispy-forms):这个应用程序处理表单布局和样式
在这里,一个应用程序被标记为从头开始构建(标记为“自定义”)或我们将使用的第三方 Django 应用程序。随着项目的进展,这些选择可能会改变。但是,这已经足够好了。
在开始项目之前
在准备开发环境时,请确保以下内容已经就位:
-
一个新的 Python 虚拟环境:Python 3 包括
venv模块,或者您可以安装virtualenv。它们都可以防止污染全局 Python 库。 -
版本控制:始终使用 Git 或 Mercurial 等版本控制工具。它们是救命稻草。您还可以更加自信和无畏地进行更改。
-
选择一个项目模板:Django 的默认项目模板不是唯一的选择。根据您的需求,尝试其他模板,如
twoscoops(github.com/twoscoops/django-twoscoops-project)或edge(github.com/arocks/edge)。 -
部署流水线:我通常会稍后再担心这个问题,但是拥有一个简单的部署流程有助于早期展示进展。我更喜欢 Fabric 或 Ansible。
SuperBook-您的任务,如果您选择接受
本书认为通过示例演示 Django 设计模式和最佳实践的实际和务实的方法。为了保持一致,我们所有的例子都将围绕构建一个名为 SuperBook 的社交网络项目。
SuperBook 专注于被忽视的超能力人群的利基市场。您是一个开发团队中的开发人员,团队中还有其他开发人员、网页设计师、市场经理和项目经理。
该项目将在撰写时的最新版本的 Python(版本 3.4)和 Django(版本 1.7)中构建。由于选择 Python 3 可能是一个有争议的话题,它值得更详细的解释。
为什么选择 Python 3?
尽管 Python 3 的开发始于 2006 年,但它的第一个版本 Python 3.0 是在 2008 年 12 月 3 日发布的。不向后兼容版本的主要原因是——将所有字符串切换为 Unicode,增加迭代器的使用,清理弃用的特性,如旧式类,以及一些新的语法添加,如nonlocal语句。
Django 社区对 Python 3 的反应相当复杂。尽管 2 和 3 版本之间的语言变化很小(并且随着时间的推移减少),但迁移整个 Django 代码库是一项重大的工作。
2 月 13 日,Django 1.5 成为第一个支持 Python 3 的版本。开发人员已经明确表示,未来 Django 将使用 Python 3 编写,并旨在向后兼容 Python 2。
对于本书来说,Python 3 是理想的,原因如下:
-
更好的语法:这修复了很多丑陋的语法,比如
izip,xrange和__unicode__,用更清晰、更直接的zip,range和__str__。 -
充分的第三方支持:在前 200 个第三方库中,超过 80%支持 Python 3。
-
没有遗留代码:我们正在创建一个新项目,而不是处理需要支持旧版本的遗留代码。
-
现代平台的默认设置:这已经是 Arch Linux 中的默认 Python 解释器。Ubuntu 和 Fedora 计划在将来的版本中完成切换。
-
它很容易:从 Django 开发的角度来看,几乎没有什么变化,而且可以在几分钟内学会所有变化。
最后一点很重要。即使你使用 Python 2,这本书也会对你有所帮助。阅读附录 A 以了解这些变化。你只需要做最小的调整来回溯示例代码。
启动项目
本节包含了 SuperBook 项目的安装说明,其中包含了本书中使用的所有示例代码。请查看项目的 README 文件以获取最新的安装说明。建议您首先创建一个名为superbook的新目录,其中包含虚拟环境和项目源代码。
理想情况下,每个 Django 项目都应该在自己单独的虚拟环境中。这样可以轻松安装、更新和删除软件包,而不会影响其他应用程序。在 Python 3.4 中,建议使用内置的venv模块,因为它默认还会安装pip:
$ python3 -m venv sbenv
$ source sbenv/bin/activate
$ export PATH="`pwd`/sbenv/local/bin:$PATH"
这些命令应该在大多数基于 Unix 的操作系统中都能工作。有关其他操作系统的安装说明或详细步骤,请参阅 Github 存储库中的 README 文件:github.com/DjangoPatternsBook/superbook。在第一行中,我们将 Python 3.4 可执行文件称为python3;请确认这对于您的操作系统和发行版是否正确。
在某些情况下,最后一个导出命令可能不是必需的。如果运行pip freeze列出的是系统包而不是空的,那么你需要输入这行。
提示
在开始 Django 项目之前,请创建一个新的虚拟环境。
接下来,从 GitHub 克隆示例项目并安装依赖项:
$ git clone https://github.com/DjangoPatternsBook/superbook.git
$ cd superbook
$ pip install -r requirements.txt
如果你想看一下完成的 SuperBook 网站,只需运行migrate并启动测试服务器:
$ cd final
$ python manage.py migrate
$ python manage.py createsuperuser
$ python manage.py runserver
在 Django 1.7 中,migrate命令已经取代了syncdb命令。我们还需要显式调用createsuperuser命令来创建一个超级用户,以便我们可以访问管理员。
你可以访问http://127.0.0.1:8000或终端中指示的 URL,并随意在网站上玩耍。
总结
初学者经常低估了良好的需求收集过程的重要性。与此同时,重要的是不要被细节所困扰,因为编程本质上是一个探索过程。最成功的项目在开发之前花费适当的时间进行准备和规划,以获得最大的收益。
我们讨论了设计应用程序的许多方面,比如创建交互式模型或将其分成可重用的组件,称为应用程序。我们还讨论了设置我们的示例项目 SuperBook 的步骤。
在下一章中,我们将详细了解 Django 的每个组件,并学习围绕它们的设计模式和最佳实践。
第三章:模型
在本章中,我们将讨论以下主题:
-
模型的重要性
-
类图
-
模型结构模式
-
模型行为模式
-
迁移
M 比 V 和 C 更大
在 Django 中,模型是提供与数据库打交道的面向对象方式的类。通常,每个类都指的是一个数据库表,每个属性都指的是一个数据库列。你可以使用自动生成的 API 对这些表进行查询。
模型可以成为许多其他组件的基础。一旦你有了一个模型,你就可以快速地派生模型管理员、模型表单和各种通用视图。在每种情况下,你都需要写一两行代码,这样它就不会显得太神奇。
此外,模型的使用范围比你想象的要广。这是因为 Django 可以以多种方式运行。Django 的一些入口点如下:
-
熟悉的 Web 请求-响应流程
-
Django 交互式 shell
-
管理命令
-
测试脚本
-
诸如 Celery 之类的异步任务队列
在几乎所有这些情况下,模型模块都会被导入(作为django.setup()的一部分)。因此,最好让你的模型摆脱任何不必要的依赖,或者导入其他 Django 组件,如视图。
简而言之,正确设计你的模型非常重要。现在让我们开始 SuperBook 模型设计。
注意
午餐袋
*作者注:SuperBook 项目的进展将出现在这样的一个框中。你可以跳过这个框,但你会错过在 Web 应用项目中工作的见解、经验和戏剧。
史蒂夫与他的客户超级英雄情报和监控或S.H.I.M。简称,度过了一个波澜起伏的第一周。办公室非常 futurist,但要做任何事情都需要一百个批准和签字。
作为首席 Django 开发人员,史蒂夫在两天内完成了设置一个中型开发服务器,托管了四台虚拟机。第二天早上,机器本身已经消失了。附近一个洗衣机大小的机器人说,它被带到了法证部门,因为未经批准的软件安装。
然而,CTO 哈特非常乐意帮忙。他要求机器在一个小时内归还,并保持所有安装完好。他还发送了对 SuperBook 项目的预批准,以避免将来出现任何类似的障碍。
那天下午,史蒂夫和他一起吃了午餐。哈特穿着米色西装外套和浅蓝色牛仔裤,准时到达。尽管比大多数人高,头发光秃秃的,他看起来很酷,很平易近人。他问史蒂夫是否看过上世纪六十年代尝试建立超级英雄数据库的尝试。
"哦,是哨兵项目,对吧?"史蒂夫说。 "我看过。数据库似乎被设计为实体-属性-值模型,我认为这是一种反模式。也许他们当时对超级英雄的属性知之甚少。"哈特几乎在最后一句话上略显不悦。他声音稍微低了一些,说:“你说得对,我没看过。而且,他们只给了我两天的时间来设计整个东西。我相信当时确实有一个核弹在某个地方滴答作响。”
史蒂夫张大了嘴,他的三明治在嘴里僵住了。哈特微笑着说:“当然不是我的最佳作品。一旦超过了大约十亿条目,我们花了几天时间才能对那该死的数据库进行任何分析。SuperBook 会在短短几秒钟内完成,对吧?”
史蒂夫微弱地点了点头。他从未想象过第一次会有大约十亿个超级英雄。
模型搜索
这是对 SuperBook 中模型的第一次识别。典型的早期尝试,我们只表示了基本模型及其关系,以类图的形式:
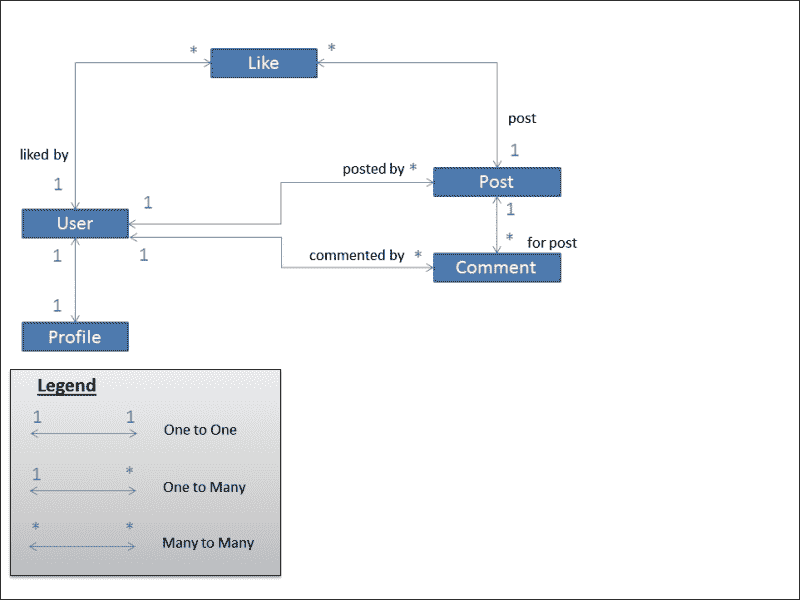
让我们暂时忘记模型,用我们建模的对象来谈论。每个用户都有一个个人资料。用户可以发表多条评论或多篇文章。喜欢可以与单个用户/帖子组合相关联。
建议绘制类图来描述您的模型。在这个阶段可能会缺少一些属性,但您可以稍后详细说明。一旦整个项目在图表中表示出来,就会更容易分离应用程序。
以下是创建此表示形式的一些提示:
-
方框表示实体,这些实体将成为模型。
-
您的写作中的名词通常最终成为实体。
-
箭头是双向的,代表 Django 中三种关系类型之一:一对一,一对多(使用外键实现),和多对多。
-
在实体-关系模型(ER 模型)的模型中定义了表示一对多关系的字段。换句话说,星号是声明外键的地方。
类图可以映射到以下 Django 代码(将分布在几个应用程序中):
class Profile(models.Model):
user = models.OneToOneField(User)
class Post(models.Model):
posted_by = models.ForeignKey(User)
class Comment(models.Model):
commented_by = models.ForeignKey(User)
for_post = models.ForeignKey(Post)
class Like(models.Model):
liked_by = models.ForeignKey(User)
post = models.ForeignKey(Post)
稍后,我们将不直接引用User,而是使用更一般的settings.AUTH_USER_MODEL。
将 models.py 拆分为多个文件
与 Django 的大多数组件一样,可以将大型的models.py文件拆分为包内的多个文件。包被实现为一个目录,其中可以包含多个文件,其中一个必须是一个名为__init__.py的特殊命名文件。
可以在包级别公开的所有定义都必须在__init__.py中以全局范围定义。例如,如果我们将models.py拆分为单独的类,放在models子目录内的相应文件中,如postable.py,post.py和comment.py,那么__init__.py包将如下所示:
from postable import Postable
from post import Post
from comment import Comment
现在您可以像以前一样导入models.Post。
__init__.py包中的任何其他代码在导入包时都会运行。因此,这是任何包级别初始化代码的理想位置。
结构模式
本节包含几种设计模式,可以帮助您设计和构造模型。
模式 - 规范化模型
问题:按设计,模型实例具有导致数据不一致的重复数据。
解决方案:通过规范化将模型分解为较小的模型。使用这些模型之间的逻辑关系连接这些模型。
问题细节
想象一下,如果有人以以下方式设计我们的 Post 表(省略某些列):
| 超级英雄名称 | 消息 | 发布于 |
|---|---|---|
| 阿尔法队长 | 是否已发布? | 2012/07/07 07:15 |
| 英语教授 | 应该是’Is’而不是’Has’。 | 2012/07/07 07:17 |
| 阿尔法队长 | 是否已发布? | 2012/07/07 07:18 |
| 阿尔法队长 | 是否已发布? | 2012/07/07 07:19 |
我希望您注意到了最后一行中不一致的超级英雄命名(以及队长一贯的缺乏耐心)。
如果我们看第一列,我们不确定哪种拼写是正确的—Captain Temper还是Capt. Temper。这是我们希望通过规范化消除的数据冗余。
解决方案细节
在我们查看完全规范化的解决方案之前,让我们简要介绍一下 Django 模型的数据库规范化的概念。
规范化的三个步骤
规范化有助于您高效地存储数据。一旦您的模型完全规范化,它们将不会有冗余数据,每个模型应该只包含与其逻辑相关的数据。
举个快速的例子,如果我们要规范化 Post 表,以便我们可以明确地引用发布该消息的超级英雄,那么我们需要将用户详细信息隔离在一个单独的表中。Django 已经默认创建了用户表。因此,您只需要在第一列中引用发布消息的用户的 ID,如下表所示:
| 用户 ID | 消息 | 发布于 |
|---|---|---|
| 12 | 是否已发布? | 2012/07/07 07:15 |
| 8 | 应该是’Is’而不是’Has’。 | 2012/07/07 07:17 |
| 12 | 这个帖子发出来了吗? | 2012/07/07 07:18 |
| 12 | 这个帖子发出来了吗? | 2012/07/07 07:19 |
现在,不仅清楚地知道有三条消息是由同一用户(具有任意用户 ID)发布的,而且我们还可以通过查找用户表找到该用户的正确姓名。
通常,您将设计您的模型以达到其完全规范化的形式,然后出于性能原因选择性地对其进行去规范化。在数据库中,正常形式是一组可应用于表以确保其规范化的准则。通常的正常形式有第一、第二和第三正常形式,尽管它们可以达到第五正常形式。
在下一个示例中,我们将规范化一个表并创建相应的 Django 模型。想象一个名为*‘Sightings’*的电子表格,列出了第一次有人发现超级英雄使用力量或超人能力的时间。每个条目都提到已知的起源、超能力和第一次目击的位置,包括纬度和经度。
| 名字 | 起源 | 力量 | 第一次使用地点(纬度、经度、国家、时间) |
|---|---|---|---|
| 突袭 | 外星人 | 冻结飞行 | +40.75, -73.99; 美国; 2014/07/03 23:12+34.05, -118.24; 美国; 2013/03/12 11:30 |
| 十六进制 | 科学家 | 念力飞行 | +35.68, +139.73; 日本; 2010/02/17 20:15+31.23, +121.45; 中国; 2010/02/19 20:30 |
| 旅行者 | 亿万富翁 | 时空旅行 | +43.62, +1.45, 法国; 2010/11/10 08:20 |
前面的地理数据已从www.golombek.com/locations.html中提取。
第一正常形式(1NF)
要符合第一正常形式,表必须具有:
-
没有具有多个值的属性(单元格)
-
定义为单列或一组列(复合键)的主键
让我们尝试将我们的电子表格转换为数据库表。显然,我们的*‘Power’*列违反了第一条规则。
这里更新的表满足了第一正常形式。主键(用标记)是’Name’和’Power’*的组合,对于每一行来说应该是唯一的。
| 名字* | 起源 | 力量* | 纬度 | 经度 | 国家 | 时间 |
|---|---|---|---|---|---|---|
| 突袭 | 外星人 | 冻结 | +40.75170 | -73.99420 | 美国 | 2014/07/03 23:12 |
| 突袭 | 外星人 | 飞行 | +40.75170 | -73.99420 | 美国 | 2013/03/12 11:30 |
| 十六进制 | 科学家 | 念力 | +35.68330 | +139.73330 | 日本 | 2010/02/17 20:15 |
| 十六进制 | 科学家 | 飞行 | +35.68330 | +139.73330 | 日本 | 2010/02/19 20:30 |
| 旅行者 | 亿万富翁 | 时空旅行 | +43.61670 | +1.45000 | 法国 | 2010/11/10 08:20 |
第二正常形式或 2NF
第二正常形式必须满足第一正常形式的所有条件。此外,它必须满足所有非主键列都必须依赖于整个主键的条件。
在前面的表中,注意*‘Origin’只取决于超级英雄,即’Name’。我们谈论的Power无关紧要。因此,Origin并不完全依赖于复合主键—Name和Power*。
让我们将起源信息提取到一个名为*‘Origins’*的单独表中,如下所示:
| 名字* | 起源 |
|---|---|
| 突袭 | 外星人 |
| 十六进制 | 科学家 |
| 旅行者 | 亿万富翁 |
现在,我们更新为符合第二正常形式的Sightings表如下:
| 名字* | 力量* | 纬度 | 经度 | 国家 | 时间 |
|---|---|---|---|---|---|
| 突袭 | 冻结 | +40.75170 | -73.99420 | 美国 | 2014/07/03 23:12 |
| 突袭 | 飞行 | +40.75170 | -73.99420 | 美国 | 2013/03/12 11:30 |
| 十六进制 | 念力 | +35.68330 | +139.73330 | 日本 | 2010/02/17 20:15 |
| 十六进制 | 飞行 | +35.68330 | +139.73330 | 日本 | 2010/02/19 20:30 |
| 旅行者 | 时空旅行 | +43.61670 | +1.45000 | 法国 | 2010/11/10 08:20 |
第三正常形式或 3NF
在第三范式中,表必须满足第二范式,并且还必须满足所有非主键列必须直接依赖于整个主键并且彼此独立的条件。
想一下国家列。根据纬度和经度,您可以很容易地推导出国家列。尽管超级能力出现的国家取决于名称-能力复合主键,但它只间接依赖于它们。
因此,让我们将位置细节分离到一个单独的国家表中,如下所示:
| 位置 ID | 纬度* | 经度* | 国家 |
|---|---|---|---|
| 1 | +40.75170 | -73.99420 | 美国 |
| 2 | +35.68330 | +139.73330 | 日本 |
| 3 | +43.61670 | +1.45000 | 法国 |
现在我们的Sightings表在第三范式中看起来像这样:
| 用户 ID* | 能力* | 位置 ID | 时间 |
|---|---|---|---|
| 2 | 冰冻 | 1 | 2014/07/03 23:12 |
| 2 | 飞行 | 1 | 2013/03/12 11:30 |
| 4 | 念力 | 2 | 2010/02/17 20:15 |
| 4 | 飞行 | 2 | 2010/02/19 20:30 |
| 7 | 时间旅行 | 3 | 2010/11/10 08:20 |
与以前一样,我们已经用对应的用户 ID替换了超级英雄的名字,这可以用来引用用户表。
Django 模型
现在我们可以看一下这些规范化表如何表示为 Django 模型。Django 不直接支持复合键。这里使用的解决方案是应用代理键,并在Meta类中指定unique_together属性:
class Origin(models.Model):
superhero = models.ForeignKey(settings.AUTH_USER_MODEL)
origin = models.CharField(max_length=100)
class Location(models.Model):
latitude = models.FloatField()
longitude = models.FloatField()
country = models.CharField(max_length=100)
class Meta:
unique_together = ("latitude", "longitude")
class Sighting(models.Model):
superhero = models.ForeignKey(settings.AUTH_USER_MODEL)
power = models.CharField(max_length=100)
location = models.ForeignKey(Location)
sighted_on = models.DateTimeField()
class Meta:
unique_together = ("superhero", "power")
性能和去规范化
规范化可能会对性能产生不利影响。随着模型数量的增加,回答查询所需的连接数量也会增加。例如,要找到在美国具有冰冻能力的超级英雄数量,您将需要连接四个表。在规范化之前,可以通过查询单个表找到任何信息。
您应该设计您的模型以保持数据规范化。这将保持数据完整性。但是,如果您的网站面临可扩展性问题,那么您可以有选择地从这些模型中派生数据,以创建去规范化的数据。
提示
最佳实践
设计时规范化,优化时去规范化。
例如,如果在某个特定国家中计算目击事件是非常常见的,那么将其作为Location模型的一个附加字段。现在,您可以使用 Django 的 ORM 包括其他查询,而不是使用缓存值。
但是,您需要在每次添加或删除一个目击事件时更新这个计数。您需要将这个计算添加到Sighting的save方法中,添加一个信号处理程序,或者甚至使用异步作业进行计算。
如果您有一个跨多个表的复杂查询,比如按国家统计超能力的数量,那么您需要创建一个单独的去规范化表。与以前一样,每当规范化模型中的数据发生更改时,我们都需要更新这个去规范化表。
去规范化在大型网站中非常常见,因为它是速度和空间之间的权衡。如今,空间是廉价的,但速度对用户体验至关重要。因此,如果您的查询响应时间过长,那么您可能需要考虑去规范化。
我们是否总是要规范化?
过度规范化并不一定是件好事。有时,它可能会引入一个不必要的表,从而使更新和查找变得复杂。
例如,您的用户模型可能有几个字段用于他们的家庭地址。严格来说,您可以将这些字段规范化为一个地址模型。但是,在许多情况下,引入一个额外的表到数据库中可能是不必要的。
与其追求最规范化的设计,不如在重构之前仔细权衡每个规范化的机会并考虑权衡。
模式-模型混合
问题:不同的模型具有相同的字段和/或重复的方法,违反了 DRY 原则。
解决方案:将常见字段和方法提取到各种可重用的模型混合中。
问题细节
在设计模型时,您可能会发现某些共享模型类之间共享的常见属性或行为。例如,“帖子”和“评论”模型需要跟踪其“创建”日期和“修改”日期。手动复制字段及其关联方法并不是一种非常 DRY 的方法。
由于 Django 模型是类,因此可以使用面向对象的方法,如组合和继承。但是,组合(通过具有包含共享类实例的属性)将需要额外的间接级别来访问字段。
继承可能会变得棘手。我们可以为“帖子”和“评论”使用一个共同的基类。但是,在 Django 中有三种继承方式:具体,抽象和代理。
具体继承通过从基类派生,就像在 Python 类中通常做的那样。但是,在 Django 中,这个基类将被映射到一个单独的表中。每次访问基本字段时,都需要隐式连接。这会导致性能恶化。
代理继承只能向父类添加新行为。您不能添加新字段。因此,对于这种情况,它并不是非常有用。
最后,我们剩下了抽象继承。
解决方案细节
抽象基类是用于在模型之间共享数据和行为的优雅解决方案。当您定义一个抽象类时,它不会在数据库中创建任何相应的表。相反,这些字段将在派生的非抽象类中创建。
访问抽象基类字段不需要JOIN语句。由于这些优势,大多数 Django 项目使用抽象基类来实现常见字段或方法。
抽象模型的局限性如下:
-
它们不能有来自另一个模型的外键或多对多字段
-
它们不能被实例化或保存
-
它们不能直接在查询中使用,因为它没有一个管理器
以下是如何最初设计帖子和评论类的抽象基类:
class Postable(models.Model):
created = models.DateTimeField(auto_now_add=True)
modified = models.DateTimeField(auto_now=True)
message = models.TextField(max_length=500)
class Meta:
abstract = True
class Post(Postable):
...
class Comment(Postable):
...
要将模型转换为抽象基类,您需要在其内部Meta类中提到abstract = True。在这里,Postable是一个抽象基类。但是,它并不是非常可重用的。
实际上,如果有一个只有“创建”和“修改”字段的类,那么我们可以在几乎任何需要时间戳的模型中重用该时间戳功能。在这种情况下,我们通常定义一个模型混合。
模型混合
模型混合是可以添加为模型的父类的抽象类。Python 支持多重继承,不像其他语言如 Java。因此,您可以为模型列出任意数量的父类。
混合类应该是正交的并且易于组合。将混合类放入基类列表中,它们应该可以工作。在这方面,它们更类似于组合而不是继承的行为。
较小的混合类更好。每当混合类变得庞大并违反单一责任原则时,考虑将其重构为较小的类。让混合类只做一件事,并且做得很好。
在我们之前的示例中,用于更新“创建”和“修改”时间的模型混合可以很容易地被分解,如下面的代码所示:
class TimeStampedModel(models.Model):
created = models.DateTimeField(auto_now_add=True)
modified = models.DateTimeField(auto_now =True)
class Meta:
abstract = True
class Postable(TimeStampedModel):
message = models.TextField(max_length=500)
...
class Meta:
abstract = True
class Post(Postable):
...
class Comment(Postable):
...
现在我们有两个基类。但是,功能明显分开。混合类可以分离到自己的模块中,并在其他上下文中重用。
模式 - 用户配置文件
问题:每个网站存储不同的用户配置文件详细信息。但是,Django 内置的User模型是用于身份验证详细信息的。
解决方案:创建一个用户配置文件类,与用户模型有一对一的关系。
问题细节
Django 提供了一个相当不错的User模型。您可以在创建超级用户或登录到管理界面时使用它。它有一些基本字段,如全名,用户名和电子邮件。
然而,大多数现实世界的项目都会保存更多关于用户的信息,比如他们的地址、喜欢的电影,或者他们的超能力。从 Django 1.5 开始,默认的User模型可以被扩展或替换。然而,官方文档强烈建议即使在自定义用户模型中也只存储认证数据(毕竟它属于auth应用)。
某些项目需要多种类型的用户。例如,SuperBook 可以被超级英雄和非超级英雄使用。根据用户类型,可能会有共同的字段和一些特殊的字段。
解决方案细节
官方推荐的解决方案是创建一个用户配置模型。它应该与用户模型有一对一的关系。所有额外的用户信息都存储在这个模型中:
class Profile(models.Model):
user = models.OneToOneField(settings.AUTH_USER_MODEL,
primary_key=True)
建议您将primary_key显式设置为True,以防止一些数据库后端(如 PostgreSQL)中的并发问题。模型的其余部分可以包含任何其他用户详细信息,例如出生日期、喜欢的颜色等。
在设计配置模型时,建议所有配置详细字段都必须是可空的或包含默认值。直观地,我们可以理解用户在注册时无法填写所有配置详细信息。此外,我们还将确保信号处理程序在创建配置实例时也不传递任何初始参数。
信号
理想情况下,每次创建用户模型实例时,都必须创建一个相应的用户配置实例。这通常是使用信号来完成的。
例如,我们可以监听用户模型的post_save信号,使用以下信号处理程序:
# signals.py
from django.db.models.signals import post_save
from django.dispatch import receiver
from django.conf import settings
from . import models
@receiver(post_save, sender=settings.AUTH_USER_MODEL)
def create_profile_handler(sender, instance, created, **kwargs):
if not created:
return
# Create the profile object, only if it is newly created
profile = models.Profile(user=instance)
profile.save()
请注意,配置模型除了用户实例之外,没有传递任何额外的初始参数。
以前,没有特定的位置来初始化信号代码。通常它们被导入或实现在models.py中(这是不可靠的)。然而,随着 Django 1.7 中的应用加载重构,应用初始化代码的位置得到了明确定义。
首先,为您的应用创建一个__init__.py包,以提及您的应用的ProfileConfig:
default_app_config = "profiles.apps.ProfileConfig"
接下来,在app.py中对ProfileConfig方法进行子类化,并在ready方法中设置信号:
# app.py
from django.apps import AppConfig
class ProfileConfig(AppConfig):
name = "profiles"
verbose_name = 'User Profiles'
def ready(self):
from . import signals
设置好信号后,访问user.profile应该会返回一个Profile对象给所有用户,甚至是新创建的用户。
管理员
现在,用户的详细信息将在管理员中的两个不同位置:通常用户管理员页面中的认证详细信息和同一用户的额外配置详细信息在单独的配置管理员页面中。这变得非常繁琐。
为了方便起见,可以通过定义自定义的UserAdmin将配置管理员内联到默认的用户管理员中:
# admin.py
from django.contrib import admin
from .models import Profile
from django.contrib.auth.models import User
class UserProfileInline(admin.StackedInline):
model = Profile
class UserAdmin(admin.UserAdmin):
inlines = [UserProfileInline]
admin.site.unregister(User)
admin.site.register(User, UserAdmin)
多种配置类型
假设您的应用程序需要几种不同类型的用户配置。需要有一个字段来跟踪用户拥有的配置类型。配置数据本身需要存储在单独的模型或统一的模型中。
建议使用聚合配置方法,因为它可以灵活地更改配置类型而不会丢失配置详细信息,并且可以最小化复杂性。在这种方法中,配置模型包含来自所有配置类型的所有配置字段的超集。
例如,SuperBook 将需要一个SuperHero类型的配置和一个Ordinary(非超级英雄)配置。可以使用单一统一的配置模型来实现如下:
class BaseProfile(models.Model):
USER_TYPES = (
(0, 'Ordinary'),
(1, 'SuperHero'),
)
user = models.OneToOneField(settings.AUTH_USER_MODEL,
primary_key=True)
user_type = models.IntegerField(max_length=1, null=True,
choices=USER_TYPES)
bio = models.CharField(max_length=200, blank=True, null=True)
def __str__(self):
return "{}: {:.20}". format(self.user, self.bio or "")
class Meta:
abstract = True
class SuperHeroProfile(models.Model):
origin = models.CharField(max_length=100, blank=True, null=True)
class Meta:
abstract = True
class OrdinaryProfile(models.Model):
address = models.CharField(max_length=200, blank=True, null=True)
class Meta:
abstract = True
class Profile(SuperHeroProfile, OrdinaryProfile, BaseProfile):
pass
我们将配置详细信息分组到几个抽象基类中以分离关注点。BaseProfile类包含所有用户类型无关的公共配置详细信息。它还有一个user_type字段,用于跟踪用户的活动配置。
SuperHeroProfile类和OrdinaryProfile类包含特定于超级英雄和非英雄用户的配置详细信息。最后,profile类从所有这些基类派生,以创建配置详细信息的超集。
在使用这种方法时需要注意的一些细节如下:
-
属于类或其抽象基类的所有配置文件字段必须是可空的或具有默认值。
-
这种方法可能会消耗更多的数据库空间,但提供了巨大的灵活性。
-
配置文件类型的活动和非活动字段需要在模型之外进行管理。比如,编辑配置文件的表单必须根据当前活动用户类型显示适当的字段。
模式 - 服务对象
问题:模型可能会变得庞大且难以管理。随着模型的功能变得多样化,测试和维护变得更加困难。
解决方案:将一组相关方法重构为专门的Service对象。
问题细节
对于 Django 初学者来说,经常听到的一句话是“模型臃肿,视图薄”。理想情况下,您的视图除了呈现逻辑之外不应包含任何其他内容。
然而,随着时间的推移,无法放置在其他位置的代码片段往往会进入模型。很快,模型就成了代码的垃圾场。
一些表明您的模型可以使用Service对象的迹象如下:
-
与外部服务的交互,例如使用 Web 服务检查用户是否有资格获得
SuperHero配置文件。 -
不涉及数据库的辅助任务,例如为用户生成短网址或随机验证码。
-
涉及没有数据库状态的短暂对象,例如为 AJAX 调用创建 JSON 响应。
-
涉及多个实例的长时间运行任务,例如 Celery 任务。
Django 中的模型遵循 Active Record 模式。理想情况下,它们封装了应用程序逻辑和数据库访问。但是,要保持应用程序逻辑最小化。
在测试过程中,如果我们发现自己在不使用数据库的情况下不必要地模拟数据库,那么我们需要考虑拆分模型类。在这种情况下,建议使用Service对象。
解决方案细节
服务对象是封装“服务”或与系统交互的普通 Python 对象(POPOs)。它们通常保存在名为services.py或utils.py的单独文件中。
例如,有时将检查 Web 服务转储到模型方法中,如下所示:
class Profile(models.Model):
...
def is_superhero(self):
url = "http://api.herocheck.com/?q={0}".format(
self.user.username)
return webclient.get(url)
可以将此方法重构为使用服务对象,如下所示:
from .services import SuperHeroWebAPI
def is_superhero(self):
return SuperHeroWebAPI.is_hero(self.user.username)
现在可以在services.py中定义服务对象,如下所示:
API_URL = "http://api.herocheck.com/?q={0}"
class SuperHeroWebAPI:
...
@staticmethod
def is_hero(username):
url =API_URL.format(username)
return webclient.get(url)
在大多数情况下,Service对象的方法是无状态的,即它们仅基于函数参数执行操作,而不使用任何类属性。因此,最好明确将它们标记为静态方法(就像我们为is_hero所做的那样)。
考虑将业务逻辑或领域逻辑从模型中重构到服务对象中。这样,您也可以在 Django 应用程序之外使用它们。
假设有一个业务原因,根据用户名将某些用户列入黑名单,以防止他们成为超级英雄类型。我们的服务对象可以很容易地修改以支持这一点:
class SuperHeroWebAPI:
...
@staticmethod
def is_hero(username):
blacklist = set(["syndrome", "kcka$$", "superfake"])
url =API_URL.format(username)
return username not in blacklist and webclient.get(url)
理想情况下,服务对象是自包含的。这使它们易于在没有模拟的情况下进行测试,比如数据库。它们也可以很容易地被重用。
在 Django 中,使用诸如 Celery 之类的任务队列异步执行耗时服务。通常,Service对象操作作为 Celery 任务运行。此类任务可以定期运行或延迟运行。
检索模式
本节包含处理访问模型属性或对其执行查询的设计模式。
模式 - 属性字段
问题:模型具有实现为方法的属性。但是,这些属性不应持久存储到数据库中。
解决方案:对这些方法使用 property 装饰器。
问题细节
模型字段存储每个实例的属性,例如名字、姓氏、生日等。它们也存储在数据库中。但是,我们还需要访问一些派生属性,例如全名或年龄。
它们可以很容易地从数据库字段中计算出来,因此不需要单独存储。在某些情况下,它们只是一个条件检查,比如基于年龄、会员积分和活跃状态的优惠资格。
实现这一点的一个直接方法是定义函数,比如get_age,类似于以下内容:
class BaseProfile(models.Model):
birthdate = models.DateField()
#...
def get_age(self):
today = datetime.date.today()
return (today.year - self.birthdate.year) - int(
(today.month, today.day) <
(self.birthdate.month, self.birthdate.day))
调用profile.get_age()将返回用户的年龄,通过计算根据月份和日期调整的年份差。
然而,调用profile.age更可读(和 Pythonic)。
解决方案细节
Python 类可以使用property装饰器将函数视为属性。Django 模型也可以使用它。在前面的例子中,用以下内容替换函数定义行:
@property
def age(self):
现在,我们可以通过profile.age访问用户的年龄。注意函数的名称也被缩短了。
属性的一个重要缺点是它对 ORM 是不可见的,就像模型方法一样。你不能在QuerySet对象中使用它。例如,这样是行不通的,Profile.objects.exclude(age__lt=18)。
也许定义一个属性来隐藏内部类的细节是一个好主意。这在正式上被称为迪米特法则。简单来说,这个法则规定你只能访问自己的直接成员或者“只使用一个点”。
例如,与其访问profile.birthdate.year,最好定义一个profile.birthyear属性。这样可以帮助隐藏birthdate字段的底层结构。
提示
最佳实践
遵循迪米特法则,在访问属性时只使用一个点。
这个法则的一个不良副作用是它会导致模型中创建几个包装属性。这可能会使模型变得臃肿并且难以维护。在合适的地方使用这个法则来改进你的模型 API 并减少耦合是更可读(和 Pythonic)的。
缓存属性
每次调用属性时,我们都在重新计算一个函数。如果这是一个昂贵的计算,我们可能希望缓存结果。这样,下次访问属性时,将返回缓存的值。
from django.utils.functional import cached_property
#...
@cached_property
def full_name(self):
# Expensive operation e.g. external service call
return "{0} {1}".format(self.firstname, self.lastname)
缓存的值将作为 Python 实例的一部分保存。只要实例存在,就会返回相同的值。
作为一种保险机制,你可能希望强制执行昂贵操作以确保不返回陈旧的值。在这种情况下,设置一个关键字参数,比如cached=False来防止返回缓存的值。
模式 - 自定义模型管理器
问题:模型上的某些查询在整个代码中被定义和访问,违反了 DRY 原则。
解决方案:定义自定义管理器来为常见查询提供有意义的名称。
问题细节
每个 Django 模型都有一个名为objects的默认管理器。调用objects.all(),将返回数据库中该模型的所有条目。通常,我们只对所有条目的一个子集感兴趣。
我们应用各种过滤器来找到我们需要的条目集。选择它们的标准通常是我们的核心业务逻辑。例如,我们可以通过以下代码找到对公众可访问的帖子:
public = Posts.objects.filter(privacy="public")
这个标准可能会在未来发生变化。比如,我们可能还想检查帖子是否被标记为编辑。这个变化可能看起来像这样:
public = Posts.objects.filter(privacy=POST_PRIVACY.Public,
draft=False)
然而,这个变化需要在需要公共帖子的每个地方进行。这可能会变得非常令人沮丧。需要有一个地方来定义这样的常用查询,而不是“重复自己”。
解决方案细节
QuerySets是一个非常强大的抽象。它们只在需要时进行延迟评估。因此,通过方法链接(一种流畅接口的形式)构建更长的QuerySets不会影响性能。
事实上,随着应用更多的过滤,结果数据集会变小。这通常会减少结果的内存消耗。
模型管理器是模型获取其QuerySet对象的便捷接口。换句话说,它们帮助你使用 Django 的 ORM 来访问底层数据库。事实上,管理器实际上是围绕QuerySet对象实现的非常薄的包装器。注意相同的接口:
>>> Post.objects.filter(posted_by__username="a")
[<Post: a: Hello World>, <Post: a: This is Private!>]
>>> Post.objects.get_queryset().filter(posted_by__username="a")
[<Post: a: Hello World>, <Post: a: This is Private!>]
Django 创建的默认管理器objects有几个方法,比如all、filter或exclude,它们返回QuerySets。然而,它们只是对数据库的低级 API。
自定义管理器用于创建特定领域的高级 API。这不仅更易读,而且不受实现细节的影响。因此,你能够在更高层次上工作,与你的领域紧密建模。
我们之前的公共帖子示例可以很容易地转换为自定义管理器,如下所示:
# managers.py
from django.db.models.query import QuerySet
class PostQuerySet(QuerySet):
def public_posts(self):
return self.filter(privacy="public")
PostManager = PostQuerySet.as_manager
这个方便的快捷方式用于从QuerySet对象创建自定义管理器,出现在 Django 1.7 中。与以往的方法不同,这个PostManager对象可以像默认的objects管理器一样进行链式操作。
有时候,用我们的自定义管理器替换默认的objects管理器是有意义的,就像下面的代码所示:
from .managers import PostManager
class Post(Postable):
...
objects = PostManager()
通过这样做,我们的代码可以更简化地访问public_posts如下:
public = Post.objects.public_posts()
由于返回的值是一个QuerySet,它们可以进一步过滤:
public_apology = Post.objects.public_posts().filter(
message_startswith="Sorry")
QuerySets有几个有趣的属性。在接下来的几节中,我们可以看一下涉及组合QuerySets的一些常见模式。
对 QuerySets 进行集合操作
忠于它们的名字(或名字的后半部分),QuerySets支持许多(数学)集合操作。为了举例说明,考虑包含用户对象的两个QuerySets:
>>> q1 = User.objects.filter(username__in=["a", "b", "c"])
[<User: a>, <User: b>, <User: c>]
>>> q2 = User.objects.filter(username__in=["c", "d"])
[<User: c>, <User: d>]
你可以对它们执行的一些集合操作如下:
-
并集:这将组合并移除重复项。使用
q1|q2得到[<User: a>,<User: b>,<User: c>,<User: d>] -
交集:这找到共同的项目。使用
q1和q2得到[<User: c>] -
差集:这将从第一个集合中移除第二个集合中的元素。没有逻辑运算符。而是使用
q1.exclude(pk__in=q2)得到[<User: a>,<User: b>]
使用Q对象也可以执行相同的操作:
from django.db.models import Q
# Union
>>> User.objects.filter(Q(username__in=["a", "b", "c"]) | Q(username__in=["c", "d"]))
[<User: a>, <User: b>, <User: c>, <User: d>]
# Intersection
>>> User.objects.filter(Q(username__in=["a", "b", "c"]) & Q(username__in=["c", "d"]))
[<User: c>]
# Difference
>>> User.objects.filter(Q(username__in=["a", "b", "c"]) & ~Q(username__in=["c", "d"]))
[<User: a>, <User: b>]
请注意,差异是使用&(AND)和~(Negation)实现的。Q对象非常强大,可以用来构建非常复杂的查询。
然而,Set的类比并不完美。QuerySets与数学集合不同,是有序的。因此,在这方面它们更接近于 Python 的列表数据结构。
链式多个 QuerySets
到目前为止,我们已经组合了属于同一基类的相同类型的QuerySets。然而,我们可能需要组合来自不同模型的QuerySets并对它们执行操作。
例如,用户的活动时间线包含了他们所有的帖子和评论,按照时间顺序排列。以前的组合QuerySets的方法不起作用。一个天真的解决方案是将它们转换为列表,连接并对它们进行排序,就像这样:
>>>recent = list(posts)+list(comments)
>>>sorted(recent, key=lambda e: e.modified, reverse=True)[:3]
[<Post: user: Post1>, <Comment: user: Comment1>, <Post: user: Post0>]
不幸的是,这个操作已经评估了惰性的QuerySets对象。两个列表的组合内存使用可能会很大。此外,将大型的QuerySets转换为列表可能会相当慢。
一个更好的解决方案使用迭代器来减少内存消耗。使用itertools.chain方法来组合多个QuerySets如下:
>>> from itertools import chain
>>> recent = chain(posts, comments)
>>> sorted(recent, key=lambda e: e.modified, reverse=True)[:3]
一旦评估了QuerySet,命中数据库的成本可能会相当高。因此,通过只执行将返回未评估的QuerySets的操作,尽可能地延迟它是很重要的。
提示
尽可能保持QuerySets未评估。
迁移
迁移帮助你自信地对模型进行更改。在 Django 1.7 中引入的迁移是开发工作流程中必不可少且易于使用的部分。
新的工作流程基本上如下:
- 第一次定义模型类时,你需要运行:
python manage.py makemigrations <app_label>
-
这将在
app/migrations文件夹中创建迁移脚本。 -
在相同(开发)环境中运行以下命令:
python manage.py migrate <app_label>
这将把模型更改应用到数据库中。有时会有关于处理默认值、重命名等问题的提问。
-
将迁移脚本传播到其他环境。通常情况下,您的版本控制工具,例如 Git,会处理这个问题。当最新的源代码被检出时,新的迁移脚本也会出现。
-
在这些环境中运行以下命令以应用模型更改:
python manage.py migrate <app_label>
- 无论何时您对模型类进行更改,都要重复步骤 1-5。
如果在命令中省略了应用标签,Django 将会在每个应用中找到未应用的更改并进行迁移。
总结
模型设计很难做到完美。然而,对于 Django 开发来说,这是基础性的。在本章中,我们看了几种处理模型时常见的模式。在每种情况下,我们都看了提议解决方案的影响以及各种权衡。
在下一章中,我们将研究在处理视图和 URL 配置时遇到的常见设计模式。
第四章:视图和 URL
在本章中,我们将讨论以下主题:
-
基于类和基于函数的视图
-
混合
-
装饰器
-
常见的视图模式
-
设计 URL
从顶部看视图
在 Django 中,视图被定义为一个可调用的函数,它接受一个请求并返回一个响应。它通常是一个带有特殊类方法(如as_view())的函数或类。
在这两种情况下,我们创建一个普通的 Python 函数,它以HTTPRequest作为第一个参数,并返回一个HTTPResponse。URLConf也可以向该函数传递其他参数。这些参数可以从 URL 的部分捕获或设置为默认值。
一个简单的视图如下所示:
# In views.py
from django.http import HttpResponse
def hello_fn(request, name="World"):
return HttpResponse("Hello {}!".format(name))
我们的两行视图函数非常简单易懂。我们目前没有对request参数执行任何操作。我们可以检查请求以更好地理解调用视图的上下文,例如通过查看GET/POST参数、URI 路径或 HTTP 头部(如REMOTE_ADDR)。
它在URLConf中对应的行如下:
# In urls.py
url(r'^hello-fn/(?P<name>\w+)/$', views.hello_fn),
url(r'^hello-fn/$', views.hello_fn),
我们正在重用相同的视图函数来支持两个 URL 模式。第一个模式需要一个名称参数。第二个模式不从 URL 中获取任何参数,视图函数将在这种情况下使用World的默认名称。
视图变得更加优雅
基于类的视图是在 Django 1.4 中引入的。以下是将先前的视图重写为功能等效的基于类的视图的样子:
from django.views.generic import View
class HelloView(View):
def get(self, request, name="World"):
return HttpResponse("Hello {}!".format(name))
同样,相应的URLConf将有两行,如下命令所示:
# In urls.py
url(r'^hello-cl/(?P<name>\w+)/$', views.HelloView.as_view()),
url(r'^hello-cl/$', views.HelloView.as_view()),
这个view类与我们之前的视图函数之间有一些有趣的区别。最明显的区别是我们需要定义一个类。接下来,我们明确地定义我们只处理GET请求。之前的视图函数对于GET、POST或任何其他 HTTP 动词都会给出相同的响应,如下所示,使用 Django shell 中的测试客户端的命令:
>>> from django.test import Client
>>> c = Client()
>>> c.get("http://0.0.0.0:8000/hello-fn/").content
b'Hello World!'
>>> c.post("http://0.0.0.0:8000/hello-fn/").content
b'Hello World!'
>>> c.get("http://0.0.0.0:8000/hello-cl/").content
b'Hello World!'
>>> c.post("http://0.0.0.0:8000/hello-cl/").content
b''
从安全性和可维护性的角度来看,明确是好的。
使用类的优势在于需要自定义视图时会变得很明显。比如,您需要更改问候语和默认名称。然后,您可以编写一个通用视图类来适应任何类型的问候,并派生您的特定问候类如下:
class GreetView(View):
greeting = "Hello {}!"
default_name = "World"
def get(self, request, **kwargs):
name = kwargs.pop("name", self.default_name)
return HttpResponse(self.greeting.format(name))
class SuperVillainView(GreetView):
greeting = "We are the future, {}. Not them. "
default_name = "my friend"
现在,URLConf将引用派生类:
# In urls.py
url(r'^hello-su/(?P<name>\w+)/$', views.SuperVillainView.as_view()),
url(r'^hello-su/$', views.SuperVillainView.as_view()),
虽然以类似的方式自定义视图函数并非不可能,但您需要添加几个带有默认值的关键字参数。这可能很快变得难以管理。这正是通用视图从视图函数迁移到基于类的视图的原因。
注意
Django Unchained
在寻找优秀的 Django 开发人员花了 2 周后,史蒂夫开始打破常规。注意到最近黑客马拉松的巨大成功,他和哈特在 S.H.I.M 组织了一个 Django Unchained 比赛。规则很简单——每天构建一个 Web 应用程序。它可以很简单,但你不能跳过一天或打破链条。谁创建了最长的链条,谁就赢了。
获胜者——布拉德·扎尼真是个惊喜。作为一个传统的设计师,几乎没有任何编程背景,他曾经参加了为期一周的 Django 培训,只是为了好玩。他设法创建了一个由 21 个 Django 站点组成的不间断链条,大部分是从零开始。
第二天,史蒂夫在他的办公室安排了一个 10 点的会议。虽然布拉德不知道,但这将是他的招聘面试。在预定的时间,有轻轻的敲门声,一个二十多岁的瘦削有胡须的男人走了进来。
当他们交谈时,布拉德毫不掩饰他不是程序员这一事实。事实上,他根本不需要假装。透过他那副厚框眼镜,透过他那宁静的蓝色眼睛,他解释说他的秘诀非常简单——获得灵感,然后专注。
他过去每天都以一个简单的线框开始。然后,他会使用 Twitter bootstrap 模板创建一个空的 Django 项目。他发现 Django 的基于类的通用视图是以几乎没有代码创建视图的绝佳方式。有时,他会从 Django-braces 中使用一个或两个 mixin。他还喜欢通过管理界面在移动中添加数据。
他最喜欢的项目是 Labyrinth——一个伪装成棒球论坛的蜜罐。他甚至设法诱捕了一些搜寻易受攻击站点的监视机器人。当史蒂夫解释了 SuperBook 项目时,他非常乐意接受这个提议。创建一个星际社交网络的想法真的让他着迷。
通过更多的挖掘,史蒂夫能够在 S.H.I.M 中找到半打像布拉德这样有趣的个人资料。他得知,他应该首先在组织内部搜索,而不是寻找外部。
基于类的通用视图
基于类的通用视图通常以面向对象的方式实现(模板方法模式)以实现更好的重用。我讨厌术语通用视图。我宁愿称它们为库存视图。就像库存照片一样,您可以在稍微调整的情况下用于许多常见需求。
通用视图是因为 Django 开发人员觉得他们在每个项目中都在重新创建相同类型的视图。几乎每个项目都需要显示对象列表(ListView),对象的详细信息(DetailView)或用于创建对象的表单(CreateView)的页面。为了遵循 DRY 原则,这些可重用的视图与 Django 捆绑在一起。
Django 1.7 中通用视图的方便表格如下:
| 类型 | 类名 | 描述 |
|---|---|---|
| 基类 | View | 这是所有视图的父类。它执行分发和健全性检查。 |
| 基类 | TemplateView | 这呈现模板。它将URLConf关键字暴露到上下文中。 |
| 基类 | RedirectView | 这在任何GET请求上重定向。 |
| 列表 | ListView | 这呈现任何可迭代的项目,例如queryset。 |
| 详细 | DetailView | 这根据URLConf中的pk或slug呈现项目。 |
| 编辑 | FormView | 这呈现并处理表单。 |
| 编辑 | CreateView | 这呈现并处理用于创建新对象的表单。 |
| 编辑 | UpdateView | 这呈现并处理用于更新对象的表单。 |
| 编辑 | DeleteView | 这呈现并处理用于删除对象的表单。 |
| 日期 | ArchiveIndexView | 这呈现具有日期字段的对象列表,最新的对象排在第一位。 |
| 日期 | YearArchiveView | 这在URLConf中给出的year上呈现对象列表。 |
| 日期 | MonthArchiveView | 这在year和month上呈现对象列表。 |
| 日期 | WeekArchiveView | 这在year和week号上呈现对象列表。 |
| 日期 | DayArchiveView | 这在year,month和day上呈现对象列表。 |
| 日期 | TodayArchiveView | 这在今天的日期上呈现对象列表。 |
| 日期 | DateDetailView | 这根据其pk或slug在year,month和day上呈现对象。 |
我们没有提到诸如BaseDetailView之类的基类或SingleObjectMixin之类的混合类。它们被设计为父类。在大多数情况下,您不会直接使用它们。
大多数人混淆了基于类的视图和基于类的通用视图。它们的名称相似,但它们并不是相同的东西。这导致了一些有趣的误解,如下所示:
- Django 捆绑的唯一通用视图:幸运的是,这是错误的。提供的基于类的通用视图中没有特殊的魔法。
您可以自由地编写自己的通用基于类的视图集。您还可以使用第三方库,比如django-vanilla-views(django-vanilla-views.org/),它具有标准通用视图的更简单的实现。请记住,使用自定义通用视图可能会使您的代码对他人来说变得陌生。
- 基于类的视图必须始终派生自通用视图:同样,通用视图类并没有什么神奇之处。虽然 90%的时间,您会发现像
View这样的通用类非常适合用作基类,但您可以自由地自己实现类似的功能。
视图混入
混入是类基视图中 DRY 代码的本质。与模型混入一样,视图混入利用 Python 的多重继承来轻松重用功能块。它们通常是 Python 3 中没有父类的类(或者在 Python 2 中从object派生,因为它们是新式类)。
混入在明确定义的位置拦截视图的处理。例如,大多数通用视图使用get_context_data来设置上下文字典。这是插入额外上下文的好地方,比如一个feed变量,指向用户可以查看的所有帖子,如下命令所示:
class FeedMixin(object):
def get_context_data(self, **kwargs):
context = super().get_context_data(**kwargs)
context["feed"] = models.Post.objects.viewable_posts(self.request.user)
return context
get_context_data方法首先通过调用所有基类中的同名方法来填充上下文。接下来,它使用feed变量更新上下文字典。
现在,可以很容易地使用这个混入来通过将其包含在基类列表中来添加用户的 feed。比如,如果 SuperBook 需要一个典型的社交网络主页,其中包括一个创建新帖子的表单,然后是您的 feed,那么可以使用这个混入如下:
class MyFeed(FeedMixin, generic.CreateView):
model = models.Post
template_name = "myfeed.html"
success_url = reverse_lazy("my_feed")
一个写得很好的混入几乎没有要求。它应该灵活,以便在大多数情况下都能派上用场。在前面的例子中,FeedMixin将覆盖派生类中的feed上下文变量。如果父类使用feed作为上下文变量,那么它可能会受到包含此混入的影响。因此,使上下文变量可定制会更有用(这留给您作为练习)。
混入能够与其他类结合是它们最大的优势和劣势。使用错误的组合可能导致奇怪的结果。因此,在使用混入之前,您需要检查混入和其他类的源代码,以确保没有方法或上下文变量冲突。
混入的顺序
您可能已经遇到了包含几个混入的代码,如下所示:
class ComplexView(MyMixin, YourMixin, AccessMixin, DetailView):
确定列出基类的顺序可能会变得非常棘手。就像 Django 中的大多数事情一样,通常适用 Python 的正常规则。Python 的方法解析顺序(MRO)决定了它们应该如何排列。
简而言之,混入首先出现,基类最后出现。父类越专业,它就越向左移动。在实践中,这是您需要记住的唯一规则。
要理解为什么这样做,请考虑以下简单的例子:
class A:
def do(self):
print("A")
class B:
def do(self):
print("B")
class BA(B, A):
pass
class AB(A, B):
pass
BA().do() # Prints B
AB().do() # Prints A
正如您所期望的,如果在基类列表中提到B在A之前,那么将调用B的方法,反之亦然。
现在想象A是一个基类,比如CreateView,B是一个混入,比如FeedMixin。混入是对基类基本功能的增强。因此,混入代码应该首先执行,然后根据需要调用基本方法。因此,正确的顺序是BA(混入在前,基类在后)。
调用基类的顺序可以通过检查类的__mro__属性来确定:
>>> AB.__mro__
(__main__.AB, __main__.A, __main__.B, object)
因此,如果AB调用super(),首先会调用A;然后,A的super()将调用B,依此类推。
提示
Python 的 MRO 通常遵循深度优先,从左到右的顺序来选择类层次结构中的方法。更多细节可以在www.python.org/download/releases/2.3/mro/找到。
装饰器
在类视图之前,装饰器是改变基于函数的视图行为的唯一方法。作为函数的包装器,它们不能改变视图的内部工作,因此有效地将它们视为黑匣子。
装饰器是一个接受函数并返回装饰函数的函数。感到困惑?有一些语法糖可以帮助你。使用注解符号@,如下面的login_required装饰器示例所示:
@login_required
def simple_view(request):
return HttpResponse()
以下代码与上面完全相同:
def simple_view(request):
return HttpResponse()
simple_view = login_required(simple_view)
由于login_required包装了视图,所以包装函数首先获得控制权。如果用户未登录,则重定向到settings.LOGIN_URL。否则,它执行simple_view,就好像它不存在一样。
装饰器不如 mixin 灵活。但它们更简单。在 Django 中,您可以同时使用装饰器和 mixin。实际上,许多 mixin 都是用装饰器实现的。
视图模式
让我们看一些在设计视图中看到的常见设计模式。
模式 - 受控访问视图
问题:页面需要根据用户是否已登录、是否为工作人员或任何其他条件有条件地访问。
解决方案:使用 mixin 或装饰器来控制对视图的访问。
问题详情
大多数网站有一些只有在登录后才能访问的页面。其他一些页面对匿名或公共访问者开放。如果匿名访问者尝试访问需要登录用户的页面,则可能会被路由到登录页面。理想情况下,登录后,他们应该被路由回到他们最初希望看到的页面。
同样,有些页面只能由某些用户组看到。例如,Django 的管理界面只对工作人员可访问。如果非工作人员用户尝试访问管理页面,他们将被路由到登录页面。
最后,有些页面只有在满足某些条件时才能访问。例如,只有帖子的创建者才能编辑帖子。其他任何人访问此页面都应该看到权限被拒绝的错误。
解决方案详情
有两种方法可以控制对视图的访问:
- 通过在基于函数的视图或基于类的视图上使用装饰器:
@login_required(MyView.as_view())
- 通过 mixin 重写类视图的
dispatch方法:
from django.utils.decorators import method_decorator
class LoginRequiredMixin:
@method_decorator(login_required)
def dispatch(self, request, *args, **kwargs):
return super().dispatch(request, *args, **kwargs)
我们这里真的不需要装饰器。推荐更明确的形式如下:
class LoginRequiredMixin:
def dispatch(self, request, *args, **kwargs):
if not request.user.is_authenticated():
raise PermissionDenied
return super().dispatch(request, *args, **kwargs)
当引发PermissionDenied异常时,Django 会在您的根目录中显示403.html模板,或者在其缺失时显示标准的“403 Forbidden”页面。
当然,对于真实项目,您需要一个更健壮和可定制的 mixin 集。django-braces包(github.com/brack3t/django-braces)有一套出色的 mixin,特别是用于控制对视图的访问。
以下是使用它们来控制登录和匿名视图的示例:
from braces.views import LoginRequiredMixin, AnonymousRequiredMixin
class UserProfileView(LoginRequiredMixin, DetailView):
# This view will be seen only if you are logged-in
pass
class LoginFormView(AnonymousRequiredMixin, FormView):
# This view will NOT be seen if you are loggedin
authenticated_redirect_url = "/feed"
Django 中的工作人员是在用户模型中设置了is_staff标志的用户。同样,您可以使用一个名为UserPassesTestMixin的 django-braces mixin,如下所示:
from braces.views import UserPassesTestMixin
class SomeStaffView(UserPassesTestMixin, TemplateView):
def test_func(self, user):
return user.is_staff
您还可以创建 mixin 来执行特定的检查,比如对象是否正在被其作者编辑(通过与登录用户进行比较):
class CheckOwnerMixin:
# To be used with classes derived from SingleObjectMixin
def get_object(self, queryset=None):
obj = super().get_object(queryset)
if not obj.owner == self.request.user:
raise PermissionDenied
return obj
模式 - 上下文增强器
问题:基于通用视图的几个视图需要相同的上下文变量。
解决方案:创建一个设置共享上下文变量的 mixin。
问题详情
Django 模板只能显示存在于其上下文字典中的变量。然而,站点需要在多个页面中具有相同的信息。例如,侧边栏显示您的动态中最近的帖子可能需要在多个视图中使用。
然而,如果我们使用通用的基于类的视图,通常会有一组与特定模型相关的有限上下文变量。在每个视图中设置相同的上下文变量并不符合 DRY 原则。
解决方案详情
大多数通用的基于类的视图都是从ContextMixin派生的。它提供了get_context_data方法,大多数类都会重写这个方法,以添加他们自己的上下文变量。在重写这个方法时,作为最佳实践,您需要首先调用超类的get_context_data,然后添加或覆盖您的上下文变量。
我们可以将这个抽象成一个 mixin 的形式,就像我们之前看到的那样:
class FeedMixin(object):
def get_context_data(self, **kwargs):
context = super().get_context_data(**kwargs)
context["feed"] = models.Post.objects.viewable_posts(self.request.user)
return context
我们可以将这个 mixin 添加到我们的视图中,并在我们的模板中使用添加的上下文变量。请注意,我们正在使用第三章中定义的模型管理器,模型,来过滤帖子。
一个更一般的解决方案是使用django-braces中的StaticContextMixin来处理静态上下文变量。例如,我们可以添加一个额外的上下文变量latest_profile,其中包含最新加入站点的用户:
class CtxView(StaticContextMixin, generic.TemplateView):
template_name = "ctx.html"
static_context = {"latest_profile": Profile.objects.latest('pk')}
在这里,静态上下文意味着任何从一个请求到另一个请求都没有改变的东西。在这种意义上,您也可以提到QuerySets。然而,我们的feed上下文变量需要self.request.user来检索用户可查看的帖子。因此,在这里不能将其包括为静态上下文。
模式 - 服务
问题:您网站的信息经常被其他应用程序抓取和处理。
解决方案:创建轻量级服务,以机器友好的格式返回数据,如 JSON 或 XML。
问题细节
我们经常忘记网站不仅仅是人类使用的。网站流量的很大一部分来自其他程序,如爬虫、机器人或抓取器。有时,您需要自己编写这样的程序来从另一个网站提取信息。
通常,为人类消费而设计的页面对机械提取来说很麻烦。HTML 页面中的信息被标记包围,需要进行大量的清理。有时,信息会分散,需要进行大量的数据整理和转换。
在这种情况下,机器接口将是理想的。您不仅可以减少提取信息的麻烦,还可以实现混搭。如果应用程序的功能以机器友好的方式暴露,其功能的持久性将大大增加。
解决方案细节
面向服务的架构(SOA)已经推广了服务的概念。服务是向其他应用程序公开的一个独特的功能块。例如,Twitter 提供了一个返回最新公共状态的服务。
一个服务必须遵循一定的基本原则:
-
无状态性:这避免了通过外部化状态信息来避免内部状态
-
松耦合:这样可以减少依赖和假设的最小数量
-
可组合的:这应该很容易重用并与其他服务组合
在 Django 中,您可以创建一个基本的服务,而无需任何第三方包。您可以返回 JSON 格式的序列化数据,而不是返回 HTML。这种形式的服务通常被称为 Web 应用程序编程接口(API)。
例如,我们可以创建一个简单的服务,返回 SuperBook 中最近的五篇公共帖子:
class PublicPostJSONView(generic.View):
def get(self, request, *args, **kwargs):
msgs = models.Post.objects.public_posts().values(
"posted_by_id", "message")[:5]
return HttpResponse(list(msgs), content_type="application/json")
为了更可重用的实现,您可以使用django-braces中的JSONResponseMixin类,使用其render_json_response方法返回 JSON:
from braces.views import JSONResponseMixin
class PublicPostJSONView(JSONResponseMixin, generic.View):
def get(self, request, *args, **kwargs):
msgs = models.Post.objects.public_posts().values(
"posted_by_id", "message")[:5]
return self.render_json_response(list(msgs))
如果我们尝试检索这个视图,我们将得到一个 JSON 字符串,而不是 HTML 响应:
>>> from django.test import Client
>>> Client().get("http://0.0.0.0:8000/public/").content
b'{"posted_by_id": 23, "message": "Hello!"},
{"posted_by_id": 13, "message": "Feeling happy"},
...
请注意,我们不能直接将QuerySet方法传递给 JSON 响应。它必须是一个列表、字典或任何其他基本的 Python 内置数据类型,被 JSON 序列化器识别。
当然,如果您需要构建比这个简单 API 更复杂的东西,您将需要使用诸如 Django REST 框架之类的包。 Django REST 框架负责序列化(和反序列化)QuerySets,身份验证,生成可在 Web 上浏览的 API,以及许多其他必要功能,以创建一个强大而完整的 API。
设计 URL
Django 拥有最灵活的 Web 框架之一。基本上,没有暗示的 URL 方案。您可以使用适当的正则表达式明确定义任何 URL 方案。
然而,正如超级英雄们喜欢说的那样——“伴随着伟大的力量而来的是巨大的责任。”您不能再随意设计 URL。
URL 曾经很丑陋,因为人们认为用户会忽略它们。在 90 年代,门户网站流行时,普遍的假设是您的用户将通过前门,也就是主页进入。他们将通过点击链接导航到网站的其他页面。
搜索引擎已经改变了这一切。根据 2013 年的一份研究报告,近一半(47%)的访问来源于搜索引擎。这意味着您网站中的任何页面,根据搜索相关性和受欢迎程度,都可能成为用户看到的第一个页面。任何 URL 都可能是前门。
更重要的是,浏览 101 教会了我们安全。我们警告初学者不要在网上点击蓝色链接。先读 URL。这真的是您银行的 URL 还是一个试图钓取您登录详细信息的网站?
如今,URL 已经成为用户界面的一部分。它们被看到,复制,分享,甚至编辑。让它们看起来好看且一目了然。不再有眼睛的疼痛,比如:
http://example.com/gallery/default.asp?sid=9DF4BC0280DF12D3ACB60090271E26A8&command=commntform
短而有意义的 URL 不仅受到用户的欣赏,也受到搜索引擎的欢迎。长且与内容相关性较低的 URL 会对您的网站搜索引擎排名产生不利影响。
最后,正如“酷炫的 URI 不会改变”所暗示的,您应该尽量保持 URL 结构随时间的稳定。即使您的网站完全重新设计,您的旧链接仍应该有效。Django 可以轻松确保如此。
在我们深入了解设计 URL 的细节之前,我们需要了解 URL 的结构。
URL 解剖
从技术上讲,URL 属于更一般的标识符家族,称为统一资源标识符(URI)。因此,URL 的结构与 URI 相同。
URI 由几个部分组成:
URI = 方案 + 网络位置 + 路径 + 查询 + 片段
例如,可以使用urlparse函数在 Python 中解构 URI(http://dev.example.com:80/gallery/videos?id=217#comments):
>>> from urllib.parse import urlparse
>>> urlparse("http://dev.example.com:80/gallery/videos?id=217#comments")
ParseResult(scheme='http', netloc='dev.example.com:80', path='/gallery/videos', params='', query='id=217', fragment='comments')
URI 的各个部分可以以图形方式表示如下:
![URL 解剖
尽管 Django 文档更喜欢使用术语 URLs,但更准确地说,您大部分时间都在使用 URI。在本书中,我们将这些术语互换使用。
Django URL 模式主要涉及 URI 的“路径”部分。所有其他部分都被隐藏起来。
urls.py 中发生了什么?
通常有助于将urls.py视为项目的入口点。当我研究 Django 项目时,这通常是我打开的第一个文件。基本上,urls.py包含整个项目的根 URL 配置或URLConf。
它将是从patterns返回的 Python 列表,分配给名为urlpatterns的全局变量。每个传入的 URL 都会与顺序中的每个模式进行匹配。在第一次匹配时,搜索停止,并且请求被发送到相应的视图。
这里,是从Python.org的urls.py中的一个摘录,最近在 Django 中重新编写:
urlpatterns = patterns(
'',
# Homepage
url(r'^$', views.IndexView.as_view(), name='home'),
# About
url(r'^about/$',
TemplateView.as_view(template_name="python/about.html"),
name='about'),
# Blog URLs
url(r'^blogs/', include('blogs.urls', namespace='blog')),
# Job archive
url(r'^jobs/(?P<pk>\d+)/$',
views.JobArchive.as_view(),
name='job_archive'),
# Admin
url(r'^admin/', include(admin.site.urls)),
)
这里需要注意的一些有趣的事情如下:
-
patterns函数的第一个参数是前缀。对于根URLConf,通常为空。其余参数都是 URL 模式。 -
每个 URL 模式都是使用
url函数创建的,该函数需要五个参数。大多数模式有三个参数:正则表达式模式,视图可调用和视图的名称。 -
about模式通过直接实例化TemplateView来定义视图。有些人讨厌这种风格,因为它提到了实现,从而违反了关注点的分离。 -
博客 URL 在其他地方提到,特别是在 blogs 应用程序的
urls.py中。一般来说,将应用程序的 URL 模式分离成自己的文件是一个很好的做法。 -
jobs模式是这里唯一的一个命名正则表达式的例子。
在未来的 Django 版本中,urlpatterns应该是一个 URL 模式对象的普通列表,而不是patterns函数的参数。这对于有很多模式的站点来说很棒,因为urlpatterns作为一个函数只能接受最多 255 个参数。
如果你是 Python 正则表达式的新手,你可能会觉得模式语法有点神秘。让我们试着揭开它的神秘面纱。
URL 模式语法
URL 正则表达式模式有时看起来像一团令人困惑的标点符号。然而,像 Django 中的大多数东西一样,它只是普通的 Python。
通过了解 URL 模式的两个功能,可以很容易地理解它:匹配以某种形式出现的 URL,并从 URL 中提取有趣的部分。
第一部分很容易。如果你需要匹配一个路径,比如/jobs/1234,那么只需使用"^jobs/\d+"模式(这里\d代表从 0 到 9 的单个数字)。忽略前导斜杠,因为它会被吞掉。
第二部分很有趣,因为在我们的例子中,有两种提取作业 ID(即1234)的方法,这是视图所需的。
最简单的方法是在要捕获的每组值周围放括号。每个值将作为位置参数传递给视图。例如,"^jobs/(\d+)"模式将把值"1234"作为第二个参数(第一个是请求)发送给视图。
位置参数的问题在于很容易混淆顺序。因此,我们有基于名称的参数,其中每个捕获的值都可以被命名。我们的例子现在看起来像"^jobs/(?P<pk>\d+)/“。这意味着视图将被调用,关键字参数pk等于"1234”。
如果你有一个基于类的视图,你可以在self.args中访问你的位置参数,在self.kwargs中访问基于名称的参数。许多通用视图期望它们的参数仅作为基于名称的参数,例如self.kwargs["slug"]。
记忆法-父母质疑粉色动作人物
我承认基于名称的参数的语法很难记住。我经常使用一个简单的记忆法作为记忆助手。短语“Parents Question Pink Action-figures”代表括号、问号、(字母)P 和尖括号的首字母。
把它们放在一起,你会得到(?P<。你可以输入模式的名称,然后自己找出剩下的部分。
这是一个很方便的技巧,而且很容易记住。想象一下一个愤怒的父母拿着一个粉色的浩克动作人物。
另一个提示是使用在线正则表达式生成器,比如pythex.org/或www.debuggex.com/来制作和测试你的正则表达式。
名称和命名空间
总是给你的模式命名。这有助于将你的代码与确切的 URL 路径解耦。例如,在以前的URLConf中,如果你想重定向到about页面,可能会诱人地使用redirect("/about")。相反,使用redirect("about"),因为它使用名称而不是路径。
以下是一些反向查找的更多示例:
>>> from django.core.urlresolvers import reverse
>>> print(reverse("home"))
"/"
>>> print(reverse("job_archive", kwargs={"pk":"1234"}))
"jobs/1234/"
名称必须是唯一的。如果两个模式有相同的名称,它们将无法工作。因此,一些 Django 包用于向模式名称添加前缀。例如,一个名为 blog 的应用程序可能必须将其编辑视图称为’blog-edit’,因为’edit’是一个常见的名称,可能会与另一个应用程序发生冲突。
命名空间是为了解决这类问题而创建的。在命名空间中使用的模式名称必须在该命名空间内是唯一的,而不是整个项目。建议您为每个应用程序都分配一个命名空间。例如,我们可以通过在根URLconf中包含此行来创建一个“blog”命名空间,其中只包括博客的 URL:
url(r'^blog/', include('blog.urls', namespace='blog')),
现在博客应用程序可以使用模式名称,比如“edit”或其他任何名称,只要它们在该应用程序内是唯一的。在引用命名空间内的名称时,您需要在名称之前提到命名空间,然后是“:”。在我们的例子中,它将是“blog:edit”。
正如 Python 之禅所说 - “命名空间是一个非常棒的想法 - 让我们做更多这样的事情。”如果这样做可以使您的模式名称更清晰,您可以创建嵌套的命名空间,比如“blog:comment:edit”。我强烈建议您在项目中使用命名空间。
模式顺序
按照 Django 处理它们的方式,即自上而下,对您的模式进行排序以利用它们。一个很好的经验法则是将所有特殊情况放在顶部。更广泛的模式可以在更下面提到。最广泛的 - 如果存在的话,可以放在最后。
例如,您的博客文章的路径可以是任何有效的字符集,但您可能希望单独处理关于页面。正确的模式顺序应该如下:
urlpatterns = patterns(
'',
url(r'^about/$', AboutView.as_view(), name='about'),
url(r'^(?P<slug>\w+)/$', ArticleView.as_view(), name='article'),
)
如果我们颠倒顺序,那么特殊情况AboutView将永远不会被调用。
URL 模式样式
一致地设计网站的 URL 很容易被忽视。设计良好的 URL 不仅可以合理地组织您的网站,还可以让用户猜测路径变得容易。设计不良的 URL 甚至可能构成安全风险:比如,在 URL 模式中使用数据库 ID(它以单调递增的整数序列出现)可能会增加信息窃取或网站剥离的风险。
让我们来看一些在设计 URL 时遵循的常见样式。
百货商店 URL
有些网站的布局就像百货商店。有一个食品区,里面有一个水果通道,通道里有不同种类的苹果摆在一起。
在 URL 的情况下,这意味着您将按以下层次结构找到这些页面:
http://site.com/ <section> / <sub-section> / <item>
这种布局的美妙之处在于很容易向上爬到父级部分。一旦删除斜杠后面的部分,您就会上升一个级别。
例如,您可以为文章部分创建一个类似的结构,如下所示:
# project's main urls.py
urlpatterns = patterns(
'',
url(r'^articles/$', include(articles.urls), namespace="articles"),
)
# articles/urls.py
urlpatterns = patterns(
'',
url(r'^$', ArticlesIndex.as_view(), name='index'),
url(r'^(?P<slug>\w+)/$', ArticleView.as_view(), name='article'),
)
注意“index”模式,它将在用户从特定文章上升时显示文章索引。
RESTful URL
2000 年,Roy Fielding 在他的博士论文中引入了表现状态转移(REST)这个术语。强烈建议阅读他的论文(www.ics.uci.edu/~fielding/pubs/dissertation/top.htm)以更好地理解 Web 本身的架构。它可以帮助你编写更好的 Web 应用程序,不违反架构的核心约束。
其中一个关键的见解是 URI 是资源的标识符。资源可以是任何东西,比如一篇文章,一个用户,或者一组资源,比如事件。一般来说,资源是名词。
Web 为您提供了一些基本的 HTTP 动词来操作资源:GET,POST,PUT,PATCH和DELETE。请注意,这些不是 URL 本身的一部分。因此,如果您在 URL 中使用动词来操作资源,这是一个不好的做法。
例如,以下 URL 被认为是不好的:
http://site.com/articles/submit/
相反,你应该删除动词,并使用 POST 操作到这个 URL:
http://site.com/articles/
提示
最佳实践
如果 HTTP 动词可以使用,就不要在 URL 中使用动词。
请注意,在 URL 中使用动词并不是错误的。您网站的搜索 URL 可以使用动词“search”,因为它不符合 REST 的一个资源:
http://site.com/search/?q=needle
RESTful URL 对于设计 CRUD 接口非常有用。创建、读取、更新和删除数据库操作与 HTTP 动词之间几乎是一对一的映射。
请注意,RESTful URL 风格是部门商店 URL 风格的补充。大多数网站混合使用这两种风格。它们被分开以便更清晰地理解。
提示
下载示例代码
您可以从www.packtpub.com的帐户中下载您购买的所有 Packt 图书的示例代码文件。如果您在其他地方购买了这本书,您可以访问www.packtpub.com/support并注册,将文件直接发送到您的电子邮件。拉取请求和错误报告可以发送到github.com/DjangoPatternsBook/superbook的 SuperBook 项目。
总结
在 Django 中,视图是 MVC 架构中非常强大的部分。随着时间的推移,基于类的视图已被证明比传统的基于函数的视图更灵活和可重用。混合是这种可重用性的最好例子。
Django 拥有非常灵活的 URL 分发系统。设计良好的 URL 需要考虑几个方面。设计良好的 URL 也受到用户的赞赏。
在下一章中,我们将看一下 Django 的模板语言以及如何最好地利用它。

















 158
158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









