







原文:
zh.annas-archive.org/md5/051c92f3ddab22ee9b33739e7a959dd3译者:飞龙
第四章:微服务
只要我们一直在谈论一个过程的设计、实施和调优,我们就能够用生动的形象(尽管只存在于我们的想象中)来说明它,比如金字塔建筑。基于平等原则的多线程管理,也具有集中规划和监督的意义。不同的优先级是根据程序员经过深思熟虑后根据预期负载进行编程分配的,并在监控后进行调整。可用资源的上限是固定的,尽管在一个相对较大的集中决策后可以增加。
这些系统取得了巨大的成功,仍然构成当前部署到生产环境的大多数 Web 应用程序。其中许多是单体应用,封装在一个.ear或.war文件中。对于相对较小的应用程序和相应的团队规模来说,这样做效果很好。它们易于(如果代码结构良好)维护、构建,并且如果生产负载不是很高,它们可以很容易地部署。如果业务不增长或对公司的互联网存在影响不大,它们将继续发挥作用,可能在可预见的未来也是如此。许多服务提供商急于通过收取少量费用来托管这样的网站,并解除网站所有者与业务无直接关系的生产维护的技术烦恼。但并非所有情况都是如此。
负载越高,扩展就会变得越困难和昂贵,除非代码和整体架构进行重构,以使其更灵活和能够承受不断增长的负载。本课程描述了许多行业领袖在解决这个问题时采取的解决方案以及背后的动机。
我们将在本课程中讨论微服务的特定方面,包括以下内容:
-
微服务兴起的动机
-
最近开发的支持微服务的框架
-
微服务开发过程,包括实际示例,以及在微服务构建过程中的考虑和决策过程
-
无容器、自包含和容器内三种主要部署方法的优缺点
为什么要使用微服务?
一些企业由于需要跟上更大量的流量,对部署计划有更高的需求。对这一挑战的自然回答是并且已经是将具有相同.ear或.war文件部署的服务器加入到集群中。因此,一个失败的服务器可以自动被集群中的另一个服务器替换,用户不会感受到服务中断。支持所有集群服务器的数据库也可以进行集群化。连接到每个集群的连接都通过负载均衡器,确保没有一个集群成员比其他成员工作更多。
Web 服务器和数据库集群有所帮助,但只能在一定程度上,因为随着代码库的增长,其结构可能会产生一个或多个瓶颈,除非采用可扩展的设计来解决这些问题。其中一种方法是将代码分成层:前端(或 Web 层)、中间层(或应用层)和后端(或后端层)。然后,每个层都可以独立部署(如果层之间的协议没有改变),并在自己的服务器集群中,因为每个层都可以根据需要独立地水平扩展。这样的解决方案提供了更多的扩展灵活性,但使部署计划更加复杂,特别是如果新代码引入了破坏性变化。其中一种方法是创建一个将托管新代码的第二个集群,然后逐个从旧集群中取出服务器,部署新代码,并将它们放入新集群。只要每个层中至少有一个服务器具有新代码,新集群就会启动。这种方法对 Web 和应用层效果很好,但对后端来说更复杂,因为偶尔需要数据迁移和类似的愉快练习。加上部署过程中由人为错误、代码缺陷、纯粹的意外或所有前述因素的组合引起的意外中断,很容易理解为什么很少有人喜欢将主要版本发布到生产环境。
程序员天生是问题解决者,他们尽力防止早期的情景,通过编写防御性代码、弃用而不是更改、测试等。其中一种方法是将应用程序分解为更独立部署的部分,希望避免同时部署所有内容。他们称这些独立单元为服务,面向服务的架构(SOA)应运而生。
很不幸,在许多公司中,代码库的自然增长没有及时调整到新的挑战。就像那只最终在慢慢加热的水壶里被煮熟的青蛙一样,他们从来没有时间通过改变设计来跳出热点。向现有功能的一团泥中添加另一个功能总是比重新设计整个应用程序更便宜。时间到市场和保持盈利始终是决策的主要标准,直到结构不良的源代码最终停止工作,将所有业务交易一并拖垮,或者,如果公司幸运的话,让他们度过风暴并显示重新设计的重要性。
由此产生的结果是,一些幸运的公司仍然在经营中,他们的单片应用程序仍然如预期般运行(也许不久,但谁知道),一些公司倒闭,一些从错误中吸取教训,进入新挑战的勇敢世界,另一些则从错误中吸取教训,并从一开始就设计他们的系统为 SOA。
有趣的是观察社会领域中类似的趋势。社会从强大的中央集权政府转向更松散耦合的半独立国家联盟,通过相互有利的经济和文化交流联系在一起。
不幸的是,维护这样一种松散的结构是有代价的。每个参与者都必须在维护合同(社会上的社会合同,在软件上的 API)方面更加负责,不仅在形式上,而且在精神上。否则,例如,来自一个组件新版本的数据流,虽然类型正确,但在值上可能对另一个组件是不可接受的(太大或太小)。保持跨团队的理解和责任重叠需要不断保持文化的活力和启发。鼓励创新和冒险,这可能导致业务突破,与来自同一业务人员的稳定和风险规避的保护倾向相矛盾。
从单一团队开发的整体式系统转变为多个团队和基于独立组件的系统需要企业各个层面的努力。你所说的“不再有质量保证部门”是什么意思?那么谁来关心测试人员的专业成长呢?IT 团队又怎么办?你所说的“开发人员将支持生产”是什么意思?这些变化影响人的生活,并不容易实施。这就是为什么 SOA 架构不仅仅是一个软件原则。它影响公司中的每个人。
与此同时,行业领袖们已经成功地超越了我们十年前所能想象的任何事情,他们被迫解决更加艰巨的问题,并带着他们的解决方案回到软件社区。这就是我们与金字塔建筑的类比不再适用的地方。因为新的挑战不仅仅是建造以前从未建造过的如此庞大的东西,而且要快速完成,不是几年的时间,而是几周甚至几天。而且结果不仅要持续千年,而且必须能够不断演变,并且足够灵活,以适应实时的新、意想不到的需求。如果功能的某个方面发生了变化,我们应该能够重新部署只有这一个服务。如果任何服务的需求增长,我们应该能够只扩展这一个服务,并在需求下降时释放资源。
为了避免全体人员参与的大规模部署,并接近持续部署(缩短上市时间,因此得到业务支持),功能继续分割成更小的服务块。为了满足需求,更复杂和健壮的云环境、部署工具(包括容器和容器编排)以及监控系统支持了这一举措。在前一课中描述的反应流开始发展之前,甚至在反应宣言出台之前,它们就已经开始发展,并在现代框架堆栈中插入了一个障碍。
将应用程序拆分为独立的部署单元带来了一些意想不到的好处,增加了前进的动力。服务的物理隔离允许更灵活地选择编程语言和实施平台。这不仅有助于选择最适合工作的技术,还有助于雇佣能够实施它的人,而不受公司特定技术堆栈的约束。它还帮助招聘人员扩大网络,利用更小的单元引入新的人才,这对于可用专家数量有限、快速增长的数据处理行业的无限需求来说是一个不小的优势。
此外,这样的架构强化了复杂系统各个部分之间的接口讨论和明确定义,从而为进一步的增长和调整提供了坚实的基础。
这就是微服务如何出现并被 Netflix、Google、Twitter、eBay、亚马逊和 Uber 等交通巨头所采用的情况。现在,让我们谈谈这一努力的结果和所学到的教训。
构建微服务
在着手构建过程之前,让我们重新审视一下代码块必须具备的特征,以便被视为微服务。我们将无序地进行这项工作:
-
一个微服务的源代码大小应该比 SOA 的源代码小,一个开发团队应该能够支持其中的几个。
-
它必须能够独立部署,而不依赖于其他服务。
-
每个微服务都必须有自己的数据库(或模式或一组表),尽管这种说法仍在争论中,特别是在几个服务修改相同数据集或相互依赖的数据集的情况下;如果同一个团队拥有所有相关服务,那么更容易实现。否则,我们将在后面讨论几种可能的策略。
-
它必须是无状态的和幂等的。如果服务的一个实例失败了,另一个实例应该能够完成服务所期望的工作。
-
它应该提供一种检查其健康的方式,意味着服务正在运行并且准备好做工作。
在设计、开发和部署后,必须考虑共享资源,并对假设进行监控验证。在上一课中,我们谈到了线程同步。您可以看到这个问题并不容易解决,我们提出了几种可能的解决方法。类似的方法可以应用于微服务。尽管它们在不同的进程中运行,但如果需要,它们可以相互通信,以便协调和同步它们的操作。
在修改相同的持久数据时,无论是跨数据库、模式还是同一模式内的表,都必须特别小心。如果可以接受最终一致性(这在用于统计目的的较大数据集中经常发生),则不需要采取特殊措施。然而,对事务完整性的需求提出了一个更为困难的问题。
支持跨多个微服务的事务的一种方法是创建一个扮演分布式事务管理器(DTM)角色的服务。需要协调的其他服务将新修改的值传递给它。DTM 服务可以将并发修改的数据暂时保存在数据库表中,并在所有数据准备好(并且一致)后一次性将其移入主表中。
如果访问数据的时间成为问题,或者您需要保护数据库免受过多的并发连接,将数据库专门用于某些服务可能是一个答案。或者,如果您想尝试另一种选择,内存缓存可能是一个好方法。添加一个提供对缓存的访问(并根据需要更新它)的服务可以增加对使用它的服务的隔离,但也需要(有时很困难的)对管理相同缓存的对等体之间进行同步。
在考虑了数据共享的所有选项和可能的解决方案之后,重新考虑为每个微服务创建自己的数据库(或模式)的想法通常是有帮助的。如果与动态同步数据相比,数据隔离(以及随后在数据库级别上的同步)的工作并不像以前那样艰巨,人们可能会发现。
说到这里,让我们来看看微服务实现的框架领域。一个人肯定可以从头开始编写微服务,但在这之前,值得看看已有的东西,即使最终发现没有什么符合你的特定需求。
目前有十多种框架用于构建微服务。最流行的两种是 Spring Boot(projects.spring.io/spring-boot/)和原始的 J2EE。J2EE 社区成立了 MicroProfile 倡议(microprofile.io/),旨在优化企业 Java以适应微服务架构。KumuluzEE(ee.kumuluz.com/)是一个轻量级的开源微服务框架,符合 MicroProfile。
其他一些框架的列表包括以下内容(按字母顺序排列):
-
Akka:这是一个用于构建高度并发、分布式和具有韧性的消息驱动应用程序的工具包,适用于 Java 和 Scala(akka.io)
-
Bootique:这是一个对可运行的 Java 应用程序没有太多主观看法的框架(bootique.io)
-
Dropwizard:这是一个用于开发友好的、高性能的、RESTful Web 服务的 Java 框架(www.dropwizard.io)
-
Jodd:这是一组 Java 微框架、工具和实用程序,大小不到 1.7MB(jodd.org)
-
Lightbend Lagom:这是一个基于 Akka 和 Play 构建的主观微服务框架(www.lightbend.com)
-
Ninja:这是一个用于 Java 的全栈 Web 框架(www.ninjaframework.org)
-
Spotify Apollo:这是 Spotify 用于编写微服务的一组 Java 库(spotify.github.io/apollo)
-
Vert.x:这是一个在 JVM 上构建反应式应用程序的工具包(vertx.io)
所有框架都支持微服务之间的 HTTP/JSON 通信;其中一些还有其他发送消息的方式。如果没有后者,可以使用任何轻量级的消息系统。我们在这里提到它是因为,正如您可能记得的那样,基于消息驱动的异步处理是由微服务组成的反应式系统的弹性、响应能力和韧性的基础。
为了演示微服务构建的过程,我们将使用 Vert.x,这是一个事件驱动、非阻塞、轻量级和多语言工具包(组件可以用 Java、JavaScript、Groovy、Ruby、Scala、Kotlin 和 Ceylon 编写)。它支持异步编程模型和分布式事件总线,甚至可以延伸到浏览器中的 JavaScript(从而允许创建实时 Web 应用程序)。
通过创建实现io.vertx.core.Verticle接口的Verticle类来开始使用 Vert.x:
package io.vertx.core;
public interface Verticle {
Vertx getVertx();
void init(Vertx vertx, Context context);
void start(Future<Void> future) throws Exception;
void stop(Future<Void> future) throws Exception;
}
先前提到的方法名不言自明。方法getVertex()提供对Vertx对象的访问,这是进入 Vert.x Core API 的入口点。它提供了构建微服务所需的以下功能:
-
创建 TCP 和 HTTP 客户端和服务器
-
创建 DNS 客户端
-
创建数据报套接字
-
创建周期性服务
-
提供对事件总线和文件系统 API 的访问
-
提供对共享数据 API 的访问
-
部署和取消部署 verticles
使用这个 Vertx 对象,可以部署各种 verticles,它们彼此通信,接收外部请求,并像其他任何 Java 应用程序一样处理和存储数据,从而形成一个微服务系统。使用io.vertx.rxjava包中的 RxJava 实现,我们将展示如何创建一个反应式的微服务系统。
Vert.x 世界中的一个构建块是 verticle。它可以通过扩展io.vertx.rxjava.core.AbstractVerticle类轻松创建:
package io.vertx.rxjava.core;
import io.vertx.core.Context;
import io.vertx.core.Vertx;
public class AbstractVerticle
extends io.vertx.core.AbstractVerticle {
protected io.vertx.rxjava.core.Vertx vertx;
public void init(Vertx vertx, Context context) {
super.init(vertx, context);
this.vertx = new io.vertx.rxjava.core.Vertx(vertx);
}
}
前面提到的类,反过来又扩展了io.vertx.core.AbstractVerticle:
package io.vertx.core;
import io.vertx.core.json.JsonObject;
import java.util.List;
public abstract class AbstractVerticle
implements Verticle {
protected Vertx vertx;
protected Context context;
public Vertx getVertx() { return vertx; }
public void init(Vertx vertx, Context context) {
this.vertx = vertx;
this.context = context;
}
public String deploymentID() {
return context.deploymentID();
}
public JsonObject config() {
return context.config();
}
public List<String> processArgs() {
return context.processArgs();
}
public void start(Future<Void> startFuture)
throws Exception {
start();
startFuture.complete();
}
public void stop(Future<Void> stopFuture)
throws Exception {
stop();
stopFuture.complete();
}
public void start() throws Exception {}
public void stop() throws Exception {}
}
也可以通过扩展io.vertx.core.AbstractVerticle类来创建 verticle。但是,我们将编写反应式微服务,因此我们将扩展其 rx-fied 版本,io.vertx.rxjava.core.AbstractVerticle。
要使用 Vert.x 并运行提供的示例,您只需要添加以下依赖项:
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-web</artifactId>
<version>${vertx.version}</version>
</dependency>
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-rx-java</artifactId>
<version>${vertx.version}</version>
</dependency>
其他 Vert.x 功能可以根据需要添加其他 Maven 依赖项。
使Vert.x Verticle具有反应性的是事件循环(线程)的底层实现,它接收事件并将其传递给Handler(我们将展示如何为其编写代码)。当Handler获得结果时,事件循环将调用回调函数。
注意
如您所见,重要的是不要编写阻塞事件循环的代码,因此 Vert.x 的黄金规则是:不要阻塞事件循环。
如果没有阻塞,事件循环将非常快速地工作,并在短时间内传递大量事件。这称为反应器模式(en.wikipedia.org/wiki/Reactor_pattern)。这种事件驱动的非阻塞编程模型非常适合响应式微服务。对于某些本质上是阻塞的代码类型(JDBC 调用和长时间计算是很好的例子),可以异步执行工作 verticle(不是由事件循环,而是使用vertx.executeBlocking()方法由单独的线程执行),这保持了黄金规则的完整性。
让我们看几个例子。这是一个作为 HTTP 服务器工作的Verticle类:
import io.vertx.rxjava.core.http.HttpServer;
import io.vertx.rxjava.core.AbstractVerticle;
public class Server extends AbstractVerticle{
private int port;
public Server(int port) {
this.port = port;
}
public void start() throws Exception {
HttpServer server = vertx.createHttpServer();
server.requestStream().toObservable()
.subscribe(request -> request.response()
.end("Hello from " +
Thread.currentThread().getName() +
" on port " + port + "!\n\n")
);
server.rxListen(port).subscribe();
System.out.println(Thread.currentThread().getName()
+ " is waiting on port " + port + "...");
}
}
在上面的代码中,创建了服务器,并将可能的请求的数据流包装成Observable。然后,我们订阅了来自Observable的数据,并传入一个函数(请求处理程序),该函数将处理请求并生成必要的响应。我们还告诉服务器要监听哪个端口。使用这个Verticle,我们可以部署几个实例,监听不同的端口的 HTTP 服务器。这是一个例子:
import io.vertx.rxjava.core.RxHelper;
import static io.vertx.rxjava.core.Vertx.vertx;
public class Demo01Microservices {
public static void main(String... args) {
RxHelper.deployVerticle(vertx(), new Server(8082));
RxHelper.deployVerticle(vertx(), new Server(8083));
}
}
如果我们运行此应用程序,输出将如下所示:

如您所见,同一个线程同时监听两个端口。如果我们现在向每个正在运行的服务器发送请求,我们将得到我们已经硬编码的响应:

我们从main()方法运行示例。插件maven-shade-plugin允许您指定要作为应用程序起点的 verticle。以下是来自vertx.io/blog/my-first-vert-x-3-application的示例:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<manifestEntries>
<Main-Class>io.vertx.core.Starter</Main-Class>
<Main-Verticle>io.vertx.blog.first.MyFirstVerticle</Main-Verticle>
</manifestEntries>
</transformer>
</transformers>
<artifactSet/>
<outputFile>${project.build.directory}/${project.artifactId}-${project.version}-fat.jar</outputFile>
</configuration>
</execution>
</executions>
</plugin>
现在,运行以下命令:
mvn package
它将生成一个指定的 JAR 文件(在本例中称为target/my-first-app-1.0-SNAPSHOT-fat.jar)。它被称为fat,因为它包含所有必要的依赖项。此文件还将包含MANIFEST.MF,其中包含以下条目:
Main-Class: io.vertx.core.Starter
Main-Verticle: io.vertx.blog.first.MyFirstVerticle
您可以使用任何 verticle 来代替此示例中使用的io.vertx.blog.first.MyFirstVerticle,但必须有io.vertx.core.Starter,因为那是知道如何读取清单并执行指定 verticle 的Vert.x类的名称。现在,您可以运行以下命令:
java -jar target/my-first-app-1.0-SNAPSHOT-fat.jar
此命令将执行MyFirstVerticle类的start()方法,就像我们的示例中执行main()方法一样,我们将继续使用它来简化演示。
为了补充 HTTP 服务器,我们也可以创建一个 HTTP 客户端。但是,首先,我们将修改server verticle 中的start()方法,以接受参数name:
public void start() throws Exception {
HttpServer server = vertx.createHttpServer();
server.requestStream().toObservable()
.subscribe(request -> request.response()
.end("Hi, " + request.getParam("name") +
"! Hello from " +
Thread.currentThread().getName() +
" on port " + port + "!\n\n")
);
server.rxListen(port).subscribe();
System.out.println(Thread.currentThread().getName()
+ " is waiting on port " + port + "...");
}
现在,我们可以创建一个 HTTP“客户端”verticle,每秒发送一个请求并打印出响应,持续 3 秒,然后停止:
import io.vertx.rxjava.core.AbstractVerticle;
import io.vertx.rxjava.core.http.HttpClient;
import java.time.LocalTime;
import java.time.temporal.ChronoUnit;
public class Client extends AbstractVerticle {
private int port;
public Client(int port) {
this.port = port;
}
public void start() throws Exception {
HttpClient client = vertx.createHttpClient();
LocalTime start = LocalTime.now();
vertx.setPeriodic(1000, v -> {
client.getNow(port, "localhost", "?name=Nick",
r -> r.bodyHandler(System.out::println));
if(ChronoUnit.SECONDS.between(start,
LocalTime.now()) > 3 ){
vertx.undeploy(deploymentID());
}
});
}
}
假设我们部署两个 verticle 如下:
RxHelper.deployVerticle(vertx(), new Server2(8082));
RxHelper.deployVerticle(vertx(), new Client(8082));
输出将如下所示:

在最后一个示例中,我们演示了如何创建 HTTP 客户端和周期性服务。现在,让我们为我们的系统添加更多功能。例如,让我们添加另一个 verticle,它将与数据库交互,并通过我们已经创建的 HTTP 服务器使用它。
首先,我们需要添加此依赖项:
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-jdbc-client</artifactId>
<version>${vertx.version}</version>
</dependency>
新添加的 JAR 文件允许我们创建一个内存数据库和一个访问它的处理程序:
public class DbHandler {
private JDBCClient dbClient;
private static String SQL_CREATE_WHO_CALLED =
"CREATE TABLE IF NOT EXISTS " +
"who_called ( name VARCHAR(10), " +
"create_ts TIMESTAMP(6) DEFAULT now() )";
private static String SQL_CREATE_PROCESSED =
"CREATE TABLE IF NOT EXISTS " +
"processed ( name VARCHAR(10), " +
"length INTEGER, " +
"create_ts TIMESTAMP(6) DEFAULT now() )";
public DbHandler(Vertx vertx){
JsonObject config = new JsonObject()
.put("driver_class", "org.hsqldb.jdbcDriver")
.put("url", "jdbc:hsqldb:mem:test?shutdown=true");
dbClient = JDBCClient.createShared(vertx, config);
dbClient.rxGetConnection()
.flatMap(conn ->
conn.rxUpdate(SQL_CREATE_WHO_CALLED)
.doAfterTerminate(conn::close) )
.subscribe(r ->
System.out.println("Table who_called created"),
Throwable::printStackTrace);
dbClient.rxGetConnection()
.flatMap(conn ->
conn.rxUpdate(SQL_CREATE_PROCESSED)
.doAfterTerminate(conn::close) )
.subscribe(r ->
System.out.println("Table processed created"),
Throwable::printStackTrace);
}
}
熟悉 RxJava 的人可以看到,Vert.x 代码紧密遵循 RxJava 的风格和命名约定。尽管如此,我们鼓励您阅读 Vert.x 文档,因为它具有非常丰富的 API,涵盖了比我们演示的更多情况。在前面的代码中,flatMap()操作接收运行脚本然后关闭连接的函数。在这种情况下,doAfterTerminate()操作的作用就像是在传统代码中放置在 finally 块中并在成功或生成异常时关闭连接。subscribe()方法有几个重载版本。对于我们的代码,我们选择了一个在成功时执行一个函数(我们打印有关创建表的消息),在异常时执行另一个函数(我们只打印堆栈跟踪)。
要使用创建的数据库,我们可以向DbHandler添加insert()、process()和readProcessed()方法,这将允许我们演示如何构建一个响应式系统。insert()方法的代码可能如下所示:
private static String SQL_INSERT_WHO_CALLED =
"INSERT INTO who_called(name) VALUES (?)";
public void insert(String name, Action1<UpdateResult>
onSuccess, Action1<Throwable> onError){
printAction("inserts " + name);
dbClient.rxGetConnection()
.flatMap(conn ->
conn.rxUpdateWithParams(SQL_INSERT_WHO_CALLED,
new JsonArray().add(name))
.doAfterTerminate(conn::close) )
.subscribe(onSuccess, onError);
}
insert()方法以及我们将要编写的其他方法充分利用了 Java 函数接口。它在表who_called中创建一条记录(使用传入的参数name)。然后,subscribe()操作执行调用此方法的代码传递的两个函数中的一个。我们仅使用printAction()方法以获得更好的可追踪性。
private void printAction(String action) {
System.out.println(this.getClass().getSimpleName()
+ " " + action);
}
process()方法还接受两个函数,但不需要其他参数。它处理表who_called中尚未处理的所有记录(未在processed表中列出):
private static String SQL_SELECT_TO_PROCESS =
"SELECT name FROM who_called w where name not in " +
"(select name from processed) order by w.create_ts " +
"for update";
private static String SQL_INSERT_PROCESSED =
"INSERT INTO processed(name, length) values(?, ?)";
public void process(Func1<JsonArray, Observable<JsonArray>>
process, Action1<Throwable> onError) {
printAction("process all records not processed yet");
dbClient.rxGetConnection()
.flatMapObservable(conn ->
conn.rxQueryStream(SQL_SELECT_TO_PROCESS)
.flatMapObservable(SQLRowStream::toObservable)
.flatMap(process)
.flatMap(js ->
conn.rxUpdateWithParams(SQL_INSERT_PROCESSED, js)
.flatMapObservable(ur->Observable.just(js)))
.doAfterTerminate(conn::close))
.subscribe(js -> printAction("processed " + js), onError);
}
如果两个线程正在读取表who_called以选择尚未处理的记录,SQL 查询中的for update子句确保只有一个线程获取每条记录,因此它们不会被处理两次。process()方法代码的显着优势在于其使用rxQueryStream()操作,该操作逐个发出找到的记录,以便它们独立地进行处理。在大量未处理记录的情况下,这样的解决方案保证了结果的平稳交付,而不会消耗资源。以下的flatMap()操作使用传递的函数进行处理。该函数的唯一要求是它必须返回一个整数值(在JsonArray中),该值将用作SQL_INSERT_PROCESSED语句的参数。因此,调用此方法的代码决定处理的性质。代码的其余部分类似于insert()方法。代码缩进有助于跟踪操作的嵌套。
readProcessed()方法的代码看起来与insert()方法的代码非常相似:
private static String SQL_READ_PROCESSED =
"SELECT name, length, create_ts FROM processed
order by create_ts desc limit ?";
public void readProcessed(String count, Action1<ResultSet>
onSuccess, Action1<Throwable> onError) {
printAction("reads " + count +
" last processed records");
dbClient.rxGetConnection()
.flatMap(conn ->
conn.rxQueryWithParams(SQL_READ_PROCESSED,
new JsonArray().add(count))
.doAfterTerminate(conn::close) )
.subscribe(onSuccess, onError);
}
前面的代码读取了指定数量的最新处理记录。与process()方法的不同之处在于,readProcessed()方法返回一个结果集中的所有读取记录,因此由使用此方法的用户决定如何批量处理结果或逐个处理。我们展示所有这些可能性只是为了展示可能的选择的多样性。有了DbHandler类,我们准备好使用它并创建DbServiceHttp微服务,它允许通过包装一个 HTTP 服务器来远程访问DbHandler的功能。这是新微服务的构造函数:
public class DbServiceHttp extends AbstractVerticle {
private int port;
private DbHandler dbHandler;
public DbServiceHttp(int port) {
this.port = port;
}
public void start() throws Exception {
System.out.println(this.getClass().getSimpleName() +
"(" + port + ") starts...");
dbHandler = new DbHandler(vertx);
Router router = Router.router(vertx);
router.put("/insert/:name").handler(this::insert);
router.get("/process").handler(this::process);
router.get("/readProcessed")
.handler(this::readProcessed);
vertx.createHttpServer()
.requestHandler(router::accept).listen(port);
}
}
在前面提到的代码中,您可以看到 Vert.x 中的 URL 映射是如何完成的。对于每个可能的路由,都分配了相应的Verticle方法,每个方法都接受包含所有 HTTP 上下文数据的RoutingContext对象,包括HttpServerRequest和HttpServerResponse对象。各种便利方法使我们能够轻松访问 URL 参数和其他处理请求所需的数据。这是start()方法中引用的insert()方法:
private void insert(RoutingContext routingContext) {
HttpServerResponse response = routingContext.response();
String name = routingContext.request().getParam("name");
printAction("insert " + name);
Action1<UpdateResult> onSuccess =
ur -> response.setStatusCode(200).end(ur.getUpdated() +
" record for " + name + " is inserted");
Action1<Throwable> onError = ex -> {
printStackTrace("process", ex);
response.setStatusCode(400)
.end("No record inserted due to backend error");
};
dbHandler.insert(name, onSuccess, onError);
}
它只是从请求中提取参数name并构造调用我们先前讨论过的DbHandler的insert()方法所需的两个函数。process()方法看起来与先前的insert()方法类似:
private void process(RoutingContext routingContext) {
HttpServerResponse response = routingContext.response();
printAction("process all");
response.setStatusCode(200).end("Processing...");
Func1<JsonArray, Observable<JsonArray>> process =
jsonArray -> {
String name = jsonArray.getString(0);
JsonArray js =
new JsonArray().add(name).add(name.length());
return Observable.just(js);
};
Action1<Throwable> onError = ex -> {
printStackTrace("process", ex);
response.setStatusCode(400).end("Backend error");
};
dbHandler.process(process, onError);
}
先前提到的process函数定义了从DbHandler方法process()中的SQL_SELECT_TO_PROCESS语句获取的记录应该做什么。在我们的情况下,它计算了呼叫者姓名的长度,并将其作为参数与姓名本身一起(作为返回值)传递给下一个 SQL 语句,将结果插入到processed表中。
这是readProcessed()方法:
private void readProcessed(RoutingContext routingContext) {
HttpServerResponse response = routingContext.response();
String count = routingContext.request().getParam("count");
printAction("readProcessed " + count + " entries");
Action1<ResultSet> onSuccess = rs -> {
Observable.just(rs.getResults().size() > 0 ?
rs.getResults().stream().map(Object::toString)
.collect(Collectors.joining("\n")) : "")
.subscribe(s -> response.setStatusCode(200).end(s) );
};
Action1<Throwable> onError = ex -> {
printStackTrace("readProcessed", ex);
response.setStatusCode(400).end("Backend error");
};
dbHandler.readProcessed(count, onSuccess, onError);
}
这就是(在前面的onSuccess()函数中的先前代码中)从查询SQL_READ_PROCESSED中读取并用于构造响应的结果集。请注意,我们首先通过创建Observable,然后订阅它并将订阅的结果作为响应传递给end()方法来执行此操作。否则,可以在构造响应之前返回响应而不必等待响应。
现在,我们可以通过部署DbServiceHttp verticle 来启动我们的反应式系统。
RxHelper.deployVerticle(vertx(), new DbServiceHttp(8082));
如果我们这样做,输出中将会看到以下代码行:
DbServiceHttp(8082) starts...
Table processed created
Table who_called created
在另一个窗口中,我们可以发出生成 HTTP 请求的命令:

如果现在读取处理过的记录,应该没有:

日志消息显示如下:

现在,我们可以请求处理现有记录,然后再次读取结果:

原则上,已经足够构建一个反应式系统。我们可以在不同端口部署许多DbServiceHttp微服务,或者将它们集群化以增加处理能力、韧性和响应能力。我们可以将其他服务包装在 HTTP 客户端或 HTTP 服务器中,让它们相互通信,处理输入并将结果传递到处理管道中。
然而,Vert.x 还具有一个更适合消息驱动架构(而不使用 HTTP)的功能。它被称为事件总线。任何 verticle 都可以访问事件总线,并可以使用send()方法(在响应式编程的情况下使用rxSend())或publish()方法向任何地址(只是一个字符串)发送任何消息。一个或多个 verticle 可以注册自己作为某个地址的消费者。
如果许多 verticle 是相同地址的消费者,那么send()(rxSend())方法只将消息传递给其中一个(使用循环轮询算法选择下一个消费者)。publish()方法如您所期望的那样,将消息传递给具有相同地址的所有消费者。让我们看一个例子,使用已经熟悉的DbHandler作为主要工作马。
基于事件总线的微服务看起来与我们已经讨论过的基于 HTTP 协议的微服务非常相似:
public class DbServiceBus extends AbstractVerticle {
private int id;
private String instanceId;
private DbHandler dbHandler;
public static final String INSERT = "INSERT";
public static final String PROCESS = "PROCESS";
public static final String READ_PROCESSED
= "READ_PROCESSED";
public DbServiceBus(int id) { this.id = id; }
public void start() throws Exception {
this.instanceId = this.getClass().getSimpleName()
+ "(" + id + ")";
System.out.println(instanceId + " starts...");
this.dbHandler = new DbHandler(vertx);
vertx.eventBus().consumer(INSERT).toObservable()
.subscribe(msg -> {
printRequest(INSERT, msg.body().toString());
Action1<UpdateResult> onSuccess
= ur -> msg.reply(...);
Action1<Throwable> onError
= ex -> msg.reply("Backend error");
dbHandler.insert(msg.body().toString(),
onSuccess, onError);
});
vertx.eventBus().consumer(PROCESS).toObservable()
.subscribe(msg -> {
.....
dbHandler.process(process, onError);
});
vertx.eventBus().consumer(READ_PROCESSED).toObservable()
.subscribe(msg -> {
...
dbHandler.readProcessed(msg.body().toString(),
onSuccess, onError);
});
}
我们通过跳过一些部分(与DbServiceHttp类非常相似)简化了前面的代码,并试图突出代码结构。为了演示目的,我们将部署两个此类的实例,并向每个地址INSERT、PROCESS和READ_PROCESSED发送三条消息:
void demo_DbServiceBusSend() {
Vertx vertx = vertx();
RxHelper.deployVerticle(vertx, new DbServiceBus(1));
RxHelper.deployVerticle(vertx, new DbServiceBus(2));
delayMs(200);
String[] msg1 = {"Mayur", "Rohit", "Nick" };
RxHelper.deployVerticle(vertx,
new PeriodicServiceBusSend(DbServiceBus.INSERT, msg1, 1));
String[] msg2 = {"all", "all", "all" };
RxHelper.deployVerticle(vertx,
new PeriodicServiceBusSend(DbServiceBus.PROCESS, msg2, 1));
String[] msg3 = {"1", "1", "2", "3" };
RxHelper.deployVerticle(vertx,
new PeriodicServiceBusSend(DbServiceBus.READ_PROCESSED,
msg3, 1));
}
请注意,我们使用delayMs()方法插入了 200 毫秒的延迟:
void delayMs(int ms){
try {
TimeUnit.MILLISECONDS.sleep(ms);
} catch (InterruptedException e) {}
}
延迟是必要的,以便让DbServiceBus顶点被部署和启动(并且消费者注册到地址)。否则,发送消息的尝试可能会失败,因为消费者尚未注册到地址。PeriodicServiceBusSend()顶点的代码如下:
public class PeriodicServiceBusSend
extends AbstractVerticle {
private EventBus eb;
private LocalTime start;
private String address;
private String[] caller;
private int delaySec;
public PeriodicServiceBusSend(String address,
String[] caller, int delaySec) {
this.address = address;
this.caller = caller;
this.delaySec = delaySec;
}
public void start() throws Exception {
System.out.println(this.getClass().getSimpleName()
+ "(" + address + ", " + delaySec + ") starts...");
this.eb = vertx.eventBus();
this.start = LocalTime.now();
vertx.setPeriodic(delaySec * 1000, v -> {
int i = (int)ChronoUnit.SECONDS.between(start,
LocalTime.now()) - 1;
System.out.println(this.getClass().getSimpleName()
+ " to address " + address + ": " + caller[i]);
eb.rxSend(address, caller[i]).subscribe(reply -> {
System.out.println(this.getClass().getSimpleName()
+ " got reply from address " + address
+ ":\n " + reply.body());
if(i + 1 >= caller.length ){
vertx.undeploy(deploymentID());
}
}, Throwable::printStackTrace);
});
}
}
之前的代码每delaySec秒向一个地址发送一条消息,次数等于数组caller[]的长度,然后取消部署该顶点(自身)。如果我们运行演示,输出的开头将如下所示:
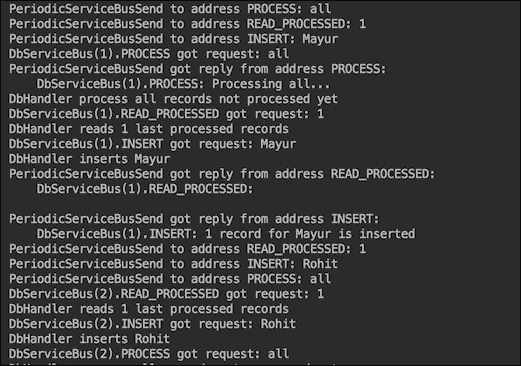
正如您所看到的,对于每个地址,只有DbServiceBus(1)是第一条消息的接收者。第二条消息到达相同地址时,被DbServiceBus(2)接收。这就是轮询算法(我们之前提到过的)的运行方式。输出的最后部分看起来像这样:
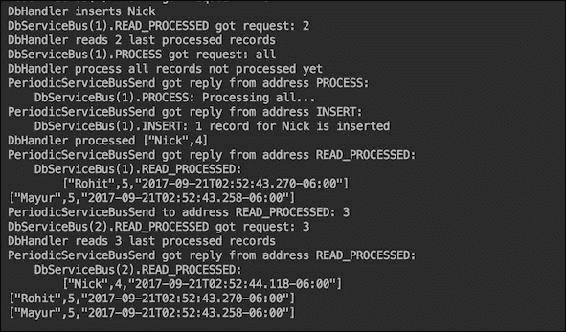
我们可以部署所需数量的相同类型的顶点。例如,让我们部署四个发送消息到地址INSERT的顶点:
String[] msg1 = {"Mayur", "Rohit", "Nick" };
RxHelper.deployVerticle(vertx,
new PeriodicServiceBusSend(DbServiceBus.INSERT, msg1, 1));
RxHelper.deployVerticle(vertx,
new PeriodicServiceBusSend(DbServiceBus.INSERT, msg1, 1));
RxHelper.deployVerticle(vertx,
new PeriodicServiceBusSend(DbServiceBus.INSERT, msg1, 1));
RxHelper.deployVerticle(vertx,
new PeriodicServiceBusSend(DbServiceBus.INSERT, msg1, 1));
为了查看结果,我们还将要求读取顶点读取最后八条记录:
String[] msg3 = {"1", "1", "2", "8" };
RxHelper.deployVerticle(vertx,
new PeriodicServiceBusSend(DbServiceBus.READ_PROCESSED,
msg3, 1));
结果(输出的最后部分)将如预期的那样:
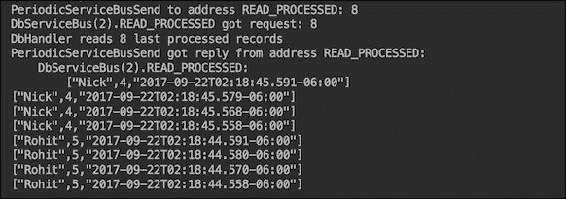
四个顶点发送了相同的消息,所以每个名称被发送了四次并被处理,这就是我们在之前输出中看到的。
现在,我们将返回到一个插入周期性顶点,但将其从使用rxSend()方法更改为使用publish()方法:
PeriodicServiceBusPublish(String address, String[] caller, int delaySec) {
...
vertx.setPeriodic(delaySec * 1000, v -> {
int i = (int)ChronoUnit.SECONDS.between(start,
LocalTime.now()) - 1;
System.out.println(this.getClass().getSimpleName()
+ " to address " + address + ": " + caller[i]);
eb.publish(address, caller[i]);
if(i + 1 == caller.length ){
vertx.undeploy(deploymentID());
}
});
}
这个改变意味着消息必须发送到所有在该地址注册为消费者的顶点。现在,让我们运行以下代码:
Vertx vertx = vertx();
RxHelper.deployVerticle(vertx, new DbServiceBus(1));
RxHelper.deployVerticle(vertx, new DbServiceBus(2));
delayMs(200);
String[] msg1 = {"Mayur", "Rohit", "Nick" };
RxHelper.deployVerticle(vertx,
new PeriodicServiceBusPublish(DbServiceBus.INSERT,
msg1, 1));
delayMs(200);
String[] msg2 = {"all", "all", "all" };
RxHelper.deployVerticle(vertx,
new PeriodicServiceBusSend(DbServiceBus.PROCESS,
msg2, 1));
String[] msg3 = {"1", "1", "2", "8" };
RxHelper.deployVerticle(vertx,
new PeriodicServiceBusSend(DbServiceBus.READ_PROCESSED,
msg3, 1));
我们已经增加了另一个延迟为 200 毫秒,以便发布顶点有时间发送消息。输出(在最后部分)现在显示每条消息被处理了两次:
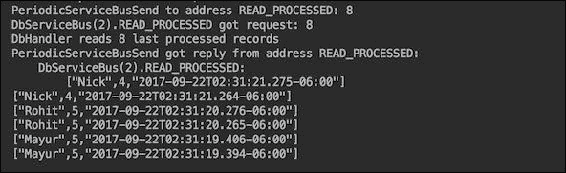
这是因为部署了两个消费者DbServiceBus(1)和DbServiceBus(2),每个都收到了发送到地址INSERT的消息,并将其插入到表who_called中。
我们之前的所有示例都在一个 JVM 进程中运行。如果需要,Vert.x 实例可以部署在不同的 JVM 进程中,并通过在运行命令中添加-cluster选项进行集群化。因此,它们共享事件总线,地址对所有 Vert.x 实例可见。这样,资源可以根据需要添加到每个地址。例如,我们只能增加处理微服务的数量,并补偿负载的增加。
我们之前提到的其他框架也具有类似的功能。它们使得微服务的创建变得容易,并可能鼓励将应用程序分解为微小的单方法操作,期望组装一个非常具有弹性和响应性的系统。
然而,这些并不是唯一的优质标准。系统分解会增加其部署的复杂性。此外,如果一个开发团队负责许多微服务,那么在不同阶段(开发、测试、集成测试、认证、暂存、生产)中对这么多部分进行版本控制的复杂性可能会导致混乱和非常具有挑战性的部署过程,反过来可能会减缓保持系统与市场需求同步所需的变更速度。
除了开发微服务,还必须解决许多其他方面来支持反应式系统:
-
必须设计一个监控系统,以便深入了解应用程序的状态,但不应该太复杂,以至于将开发资源从主要应用程序中抽离出来。
-
必须安装警报以及及时警告团队可能和实际问题,以便在影响业务之前解决这些问题。
-
如果可能的话,必须实施自我纠正的自动化流程。例如,系统应该能够根据当前负载添加和释放资源;必须实施重试逻辑,并设置合理的尝试上限,以避免宣布失败。
-
必须有一层断路器来保护系统,防止一个组件的故障导致其他组件缺乏必要的资源。
-
嵌入式测试系统应该能够引入中断并模拟处理负载,以确保应用程序的弹性和响应能力不会随时间而降低。例如,Netflix 团队引入了一个名为“混沌猴”的系统,它能够关闭生产系统的各个部分,以测试其恢复能力。他们甚至在生产环境中使用它,因为生产环境具有特定的配置,其他环境中的测试无法保证找到所有可能的问题。
响应式系统设计的主要考虑因素之一是选择部署方法论,可以是无容器、自包含或容器内部。我们将在本课程的后续部分中探讨每种方法的利弊。
无容器部署
人们使用术语“容器”来指代非常不同的东西。在最初的用法中,容器是指将其内容从一个位置运送到另一个位置而不改变内部任何内容的东西。然而,当服务器被引入时,只强调了一个方面,即容纳应用程序的能力。此外,还添加了另一层含义,即提供生命支持基础设施,以便容器的内容(应用程序)不仅能够存活,而且能够活跃并响应外部请求。这种重新定义的容器概念被应用到了 Web 服务器(Servlet 容器)、应用服务器(带有或不带有 EJB 容器的应用程序容器)以及其他为应用程序提供支持环境的软件设施。有时,甚至将 JVM 本身称为容器,但这种关联可能没有持续下去,可能是因为能够积极参与(执行)内容的能力与容器的原始含义不太吻合。
这就是为什么后来,当人们开始谈论无容器部署时,他们通常指的是能够直接将应用程序部署到 JVM 中,而无需先安装 WebSphere、WebLogic、JBoss 或任何其他提供应用程序运行环境的中介软件。
在前面的部分中,我们描述了许多框架,这些框架使我们能够构建和部署应用程序(或者说是微服务的响应式系统),而无需 JVM 本身以外的任何其他容器。你所需要做的就是构建一个包含所有依赖项(除了来自 JVM 本身的依赖项)的大型 JAR 文件,然后将其作为独立的 Java 进程运行。
$ java -jar myfatjar.jar
此外,您还需要确保 JAR 文件中的MANIFEST.MF包含一个指向完全限定类名的main类的条目,该类具有main()方法,并将在启动时运行。我们已经在前一节“构建微服务”中描述了如何做到这一点。
这就是 Java 的一次编译,到处运行的承诺,到处意味着安装了某个版本或更高版本的 JVM 的任何地方。这种方法有几个优点和缺点。我们将讨论它们,而不是相对于传统的服务器容器部署。不使用传统容器进行部署的优势是非常明显的,从许多(如果有的话)许可成本更少开始,以及更轻量级的部署和可扩展性过程,甚至没有提到更少的资源消耗。相反,我们将不是将无容器部署与传统部署进行比较,而是与自包含和新一代容器中的容器进行比较,这些容器是几年前开发的。
它们不仅允许包含和执行包含的代码,传统容器也可以做到,而且还可以将其移动到不需要对包含的代码进行任何更改的不同位置。从现在开始,通过容器,我们只指的是新的容器。
无容器部署的优势如下:
-
很容易在同一台物理(或虚拟或云)机器上或在新硬件上添加更多的 Java 进程
-
进程之间的隔离级别很高,在共享环境中尤其重要,当您无法控制其他共同部署的应用程序时,可能会有恶意应用程序试图渗透到相邻的执行环境中
-
它的占用空间很小,因为除了应用程序本身或一组微服务之外,它不包括任何其他内容
无容器部署的缺点如下:
-
每个 JAR 文件都需要某个版本或更高版本的 JVM,这可能会迫使您因此而启动一个新的物理或虚拟机器,以部署一个特定的 JAR 文件
-
在您无法控制的环境中,您的代码可能会使用错误版本的 JVM 部署,这可能会导致不可预测的结果。
-
在同一 JVM 中的进程竞争资源,这在由不同团队或不同公司共享的环境中尤其难以管理
-
当几个微服务捆绑到同一个 JAR 文件中时,它们可能需要不同版本的第三方库,甚至是不兼容的库
微服务可以每个 JAR 部署一个,也可以由团队捆绑在一起,由相关服务,按比例单位,或使用其他标准。最不重要的考虑是这些 JAR 文件的总数。随着这个数字的增长(今天谷歌一次处理数十万个部署单元),可能无法通过简单的 bash 脚本处理部署,并需要一个复杂的过程,以便考虑可能的不兼容性。如果是这种情况,那么考虑使用虚拟机或容器(在它们的新版本中,见下一节)以获得更好的隔离和管理是合理的。
自包含的微服务
自包含的微服务看起来与无容器非常相似。唯一的区别是 JVM(或实际上是 JRE)或应用程序运行所需的任何其他外部框架和服务器也包含在 fat JAR 文件中。有许多构建这样一个全包 JAR 文件的方法。
例如,Spring Boot 提供了一个方便的 GUI,其中包含复选框列表,允许您选择要打包的 Spring Boot 应用程序及外部工具的哪些部分。同样,WildFly Swarm 允许您选择要与应用程序捆绑在一起的 Java EE 组件的哪些部分。或者,您可以使用javapackager工具自己来完成。它将应用程序和 JRE 编译打包到同一个 JAR 文件中(也可以是.exe或.dmg)以进行分发。您可以在 Oracle 网站上阅读有关该工具的信息docs.oracle.com/javase/9/tools/javapackager.htm,或者您可以在安装了 JDK 的计算机上运行javapackager命令(它也随 Java 8 一起提供),您将获得工具选项列表及其简要描述。
基本上,要使用javapackager工具,您只需要准备一个项目,其中包括您想要一起打包的所有内容,包括所有依赖项(打包在 JAR 文件中),然后使用必要的选项运行javapackager命令,这些选项允许您指定您想要的输出类型(例如.exe或.dmg),您想要捆绑在一起的 JRE 位置,要使用的图标,MANIFEST.MF的main类入口等。还有 Maven 插件可以使打包命令更简单,因为pom.xml中的大部分设置都必须进行配置。
自包含部署的优点如下:
-
这是一个文件(包含组成反应系统或其中某部分的所有微服务)需要处理,这对用户和分发者来说更简单
-
无需预先安装 JRE,也无需担心版本不匹配。
-
隔离级别很高,因为您的应用程序有专用的 JRE,因此来自共同部署应用程序的入侵风险很小
-
您可以完全控制捆绑包中包含的依赖关系
缺点如下:
-
文件大小更大,如果必须下载,可能会成为障碍
-
与无容器的 JAR 文件相比,配置更复杂
-
该捆绑包必须在与目标平台匹配的平台上生成,如果您无法控制安装过程,可能会导致不匹配。
-
部署在同一硬件或虚拟机上的其他进程可能会占用您的应用程序所需的关键资源,如果您的应用程序不是由开发团队下载和运行,这将特别难以管理
容器内部部署
熟悉虚拟机(VM)而不熟悉现代容器(如 Docker、CoreOS 的 Rocket、VMware Photon 或类似产品)的人可能会认为我们在说容器不仅可以包含和执行包含的代码,还可以将其移动到不同位置而不对包含的代码进行任何更改。如果是这样,那将是一个相当恰当的假设。虚拟机确实允许所有这些,而现代容器可以被认为是轻量级虚拟机,因为它也允许分配资源并提供独立机器的感觉。然而,容器并不是一个完全隔离的虚拟计算机。
关键区别在于作为 VM 传递的捆绑包包含了整个操作系统(部署的应用程序)。因此,运行两个 VM 的物理服务器可能在其上运行两个不同的操作系统。相比之下,运行三个容器化应用程序的物理服务器(或 VM)只运行一个操作系统,并且两个容器共享(只读)操作系统内核,每个容器都有自己的访问(挂载)以写入它们不共享的资源。这意味着,例如,启动时间更短,因为启动容器不需要我们引导操作系统(与 VM 的情况相反)。
举个例子,让我们更仔细地看看 Docker,这是容器领域的社区领袖。2015 年,一个名为Open Container Project的倡议被宣布,后来更名为Open Container Initiative(OCI),得到了 Google、IBM、亚马逊、微软、红帽、甲骨文、VMware、惠普、Twitter 等许多公司的支持。它的目的是为所有平台开发容器格式和容器运行时软件的行业标准。Docker 捐赠了大约 5%的代码库给该项目,因为其解决方案被选为起点。
Docker 有广泛的文档,网址为:docs.docker.com。使用 Docker,可以将所有的 Java EE 容器和应用程序作为 Docker 镜像打包,实现与自包含部署基本相同的结果。然后,你可以通过在 Docker 引擎中启动 Docker 镜像来启动你的应用程序,使用以下命令:
$ docker run mygreatapplication
它启动一个看起来像在物理计算机上运行操作系统的进程,尽管它也可以在云中的一个运行在物理 Linux 服务器上的 VM 中发生,该服务器由许多不同的公司和个人共享。这就是为什么在不同的部署模型之间选择时,隔离级别(在容器的情况下几乎与 VM 一样高)可能是至关重要的。
典型的建议是将一个微服务放入一个容器中,但没有什么阻止你将多个微服务放入一个 Docker 镜像(或者任何其他容器)。然而,在容器管理系统(在容器世界中称为编排)中已经有成熟的系统可以帮助你进行部署,因此拥有许多容器的复杂性,虽然是一个有效的考虑因素,但如果韧性和响应性受到威胁,这并不应该是一个大障碍。一个名为Kubernetes的流行编排支持微服务注册表、发现和负载均衡。Kubernetes 可以在任何云或私有基础设施中使用。
容器允许在几乎任何当前的部署环境中进行快速、可靠和一致的部署,无论是你自己的基础设施还是亚马逊、谷歌或微软的云。它们还允许应用程序在开发、测试和生产阶段之间轻松移动。这种基础设施的独立性允许你在必要时在开发和测试中使用公共云,而在生产中使用自己的计算机。
一旦创建了基本的操作镜像,每个开发团队都可以在其上构建他们的应用程序,从而避免环境配置的复杂性。容器的版本也可以在版本控制系统中进行跟踪。
使用容器的优势如下:
-
与无容器和自包含部署相比,隔离级别最高。此外,最近还投入了更多的精力来为容器增加安全性。
-
每个容器都由相同的一组命令进行管理、分发、部署、启动和停止。
-
无需预先安装 JRE,也不会出现所需版本不匹配的风险。
-
你可以完全控制容器中包含的依赖关系。
-
通过添加/删除容器实例,很容易扩展/缩小每个微服务。
使用容器的缺点如下:
- 你和你的团队必须学习一整套新的工具,并更深入地参与到生产阶段中。另一方面,这似乎是近年来的一般趋势。
总结
微服务是一个新的架构和设计解决方案,用于高负载处理系统,在被亚马逊、谷歌、Twitter、微软、IBM 等巨头成功用于生产后变得流行起来。不过这并不意味着你必须也采用它,但你可以考虑这种新方法,看看它是否能帮助你的应用程序更具韧性和响应性。
使用微服务可以提供实质性的价值,但并非免费。它会带来更多单元的管理复杂性,从需求和开发到测试再到生产的整个生命周期。在承诺全面采用微服务架构之前,通过实施一些微服务并将它们全部移至生产环境来尝试一下。然后,让它运行一段时间并评估经验。这将非常具体化您的组织。任何成功的解决方案都不应盲目复制,而应根据您特定的需求和能力进行采用。
通过逐步改进已经存在的内容,通常可以实现更好的性能和整体效率,而不是通过彻底的重新设计和重构。
在下一课中,我们将讨论并演示新的 API,可以通过使代码更易读和更快速执行来改进您的代码。
评估
-
使用 _________ 对象,可以部署各种垂直,它们彼此交流,接收外部请求,并像任何其他 Java 应用程序一样处理和存储数据,从而形成微服务系统。
-
容器化部署的以下哪一项是优势?
-
每个 JAR 文件都需要特定版本或更高版本的 JVM,这可能会迫使您出于这个原因启动一个新的物理或虚拟机,以部署一个特定的 JAR 文件
-
在您无法控制的环境中,您的代码可能会使用正确版本的 JVM 部署,这可能会导致不可预测的结果
-
在同一 JVM 中的进程竞争资源,这在由不同团队或不同公司共享的环境中尤其难以管理
-
它的占地面积很小,因为除了应用程序本身或一组微服务之外,它不包括任何其他东西
-
判断是 True 还是 False:支持跨多个微服务的事务的一种方法是创建一个扮演并行事务管理器角色的服务。
-
以下哪些是包含在 Java 9 中的 Java 框架?
-
Akka
-
忍者
-
橙色
-
Selenium
-
判断是 True 还是 False:与无容器和自包含部署相比,容器中的隔离级别最高。
第五章:利用新的 API 来改进您的代码
在之前的课程中,我们谈到了改进 Java 应用程序性能的可能方法–从使用新的命令和监控工具到添加多线程和引入响应式编程,甚至到将当前解决方案彻底重新架构为一组不规则且灵活的小独立部署单元和微服务。在不了解您特定情况的情况下,我们无法猜测提供的建议中哪些对您有帮助。这就是为什么在本课程中,我们还将描述 JDK 的一些最新添加,这对您也可能有帮助。正如我们在上一课中提到的,性能和整体代码改进并不总是需要我们彻底重新设计它。小的增量变化有时会带来比我们预期的更显著的改进。
回到我们建造金字塔的类比,与其试图改变石块交付到最终目的地的物流以缩短建造时间,通常更明智的是首先仔细查看建筑工人正在使用的工具。如果每个操作都可以在一半的时间内完成,那么项目交付的整体时间可以相应缩短,即使每个石块的旅行距离相同,甚至更大。
这些是我们将在本课程中讨论的编程工具的改进:
-
使用流上的过滤器作为查找所需内容和减少工作量的方法
-
一种新的堆栈遍历 API,作为分析堆栈跟踪的方式,以便自动应用更正
-
创建紧凑的、不可修改的集合实例的新便利的静态工厂方法
-
新的
CompletableFuture类作为访问异步处理结果的方法 -
JDK 9 流 API 的改进,可以加快处理速度,同时使您的代码更易读
过滤流
java.util.streams.Stream接口是在 Java 8 中引入的。它发出元素并支持执行基于这些元素的各种操作的计算。流可以是有限的或无限的,发射速度快或慢。自然地,总是担心新发出的元素的速率可能高于处理的速率。此外,跟上输入的能力反映了应用程序的性能。Stream实现通过使用缓冲区和其他各种技术来调整发射和处理速率来解决反压(当元素处理速率低于它们的发射速率时)。此外,如果应用程序开发人员确保尽早做出有关处理或跳过每个特定元素的决定,以便不浪费处理资源,这总是有帮助的。根据情况,可以使用不同的操作来过滤数据。
基本过滤
进行过滤的第一种最直接的方法是使用filter()操作。为了演示所有以下的功能,我们将使用Senator类:
public class Senator {
private int[] voteYes, voteNo;
private String name, party;
public Senator(String name, String party,
int[] voteYes, int[] voteNo) {
this.voteYes = voteYes;
this.voteNo = voteNo;
this.name = name;
this.party = party;
}
public int[] getVoteYes() { return voteYes; }
public int[] getVoteNo() { return voteNo; }
public String getName() { return name; }
public String getParty() { return party; }
public String toString() {
return getName() + ", P" +
getParty().substring(getParty().length() - 1);
}
}
如您所见,这个类捕获了参议员的姓名、政党以及他们对每个问题的投票情况(0表示否,1表示是)。对于特定问题i,如果voteYes[i]=0,而voteNo[i]=0,这意味着参议员不在场。对于同一个问题,不可能同时有voteYes[i]=1和voteNo[i]=1。
假设有 100 名参议员,每个人属于两个政党中的一个:Party1或Party2。我们可以使用这些对象来收集参议员对最近 10 个问题的投票统计,使用Senate类:
public class Senate {
public static List<Senator> getSenateVotingStats(){
List<Senator> results = new ArrayList<>();
results.add(new Senator("Senator1", "Party1",
new int[]{1,0,0,0,0,0,1,0,0,1},
new int[]{0,1,0,1,0,0,0,0,1,0}));
results.add(new Senator("Senator2", "Party2",
new int[]{0,1,0,1,0,1,0,1,0,0},
new int[]{1,0,1,0,1,0,0,0,0,1}));
results.add(new Senator("Senator3", "Party1",
new int[]{1,0,0,0,0,0,1,0,0,1},
new int[]{0,1,0,1,0,0,0,0,1,0}));
results.add(new Senator("Senator4", "Party2",
new int[]{1,0,1,0,1,0,1,0,0,1},
new int[]{0,1,0,1,0,0,0,0,1,0}));
results.add(new Senator("Senator5", "Party1",
new int[]{1,0,0,1,0,0,0,0,0,1},
new int[]{0,1,0,0,0,0,1,0,1,0}));
IntStream.rangeClosed(6, 98).forEach(i -> {
double r1 = Math.random();
String name = "Senator" + i;
String party = r1 > 0.5 ? "Party1" : "Party2";
int[] voteNo = new int[10];
int[] voteYes = new int[10];
IntStream.rangeClosed(0, 9).forEach(j -> {
double r2 = Math.random();
voteNo[j] = r2 > 0.4 ? 0 : 1;
voteYes[j] = r2 < 0.6 ? 0 : 1;
});
results.add(new Senator(name,party,voteYes,voteNo));
});
results.add(new Senator("Senator99", "Party1",
new int[]{0,0,0,0,0,0,0,0,0,0},
new int[]{1,1,1,1,1,1,1,1,1,1}));
results.add(new Senator("Senator100", "Party2",
new int[]{1,1,1,1,1,1,1,1,1,1},
new int[]{0,0,0,0,0,0,0,0,0,0}));
return results;
}
public static int timesVotedYes(Senator senator){
return Arrays.stream(senator.getVoteYes()).sum();
}
}
我们为前五位参议员硬编码了统计数据,这样我们在测试我们的过滤器时可以获得可预测的结果,并验证过滤器的工作。我们还为最后两位参议员硬编码了投票统计数据,这样我们在寻找只对每个问题投了“是”或只投了“否”的参议员时可以获得可预测的计数。我们还添加了timesVotedYes()方法,它提供了给定senator投了多少次“是”的计数。
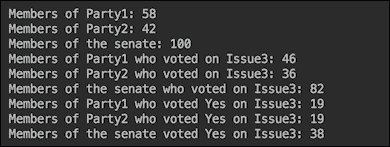
现在我们可以从Senate类中收集一些数据。例如,让我们看看每个党派在Senate类中有多少成员:
List<Senator> senators = Senate.getSenateVotingStats();
long c1 = senators.stream()
.filter(s -> s.getParty() == "Party1").count();
System.out.println("Members of Party1: " + c1);
long c2 = senators.stream()
.filter(s -> s.getParty() == "Party2").count();
System.out.println("Members of Party2: " + c2);
System.out.println("Members of the senate: " + (c1 + c2));
由于我们在Senate类中使用了随机值生成器,因此前面代码的结果会因运行不同而不同,因此如果您尝试运行示例,不要期望看到完全相同的数字。重要的是两个党派成员的总数应该等于 100——Senate类中参议员的总数:

表达式s -> s.getParty()=="Party1"是过滤器,只过滤出那些属于Party1的参议员。因此,Party2的元素(Senator对象)不会通过,也不会包括在计数中。这很直接了当。
现在让我们看一个更复杂的过滤示例。让我们计算每个党派有多少名参议员在issue 3上投票:
int issue = 3;
c1 = senators.stream()
.filter(s -> s.getParty() == "Party1")
.filter(s -> s.getVoteNo()[issue] != s.getVoteYes()[issue])
.count();
System.out.println("Members of Party1 who voted on Issue" +
issue + ": " + c1);
c2 = senators.stream()
.filter(s -> s.getParty() == "Party2" &&
s.getVoteNo()[issue] != s.getVoteYes()[issue])
.count();
System.out.println("Members of Party2 who voted on Issue" +
issue + ": " + c2);
System.out.println("Members of the senate who voted on Issue"
+ issue + ": " + (c1 + c2));
对于Party1,我们使用了两个过滤器。对于Party2,我们将它们合并只是为了展示另一个可能的解决方案。这里的重点是首先使用按党派过滤(s -> s.getParty() == "Party1")的过滤器,然后再使用选择只投票的过滤器。这样,第二个过滤器只用于大约一半的元素。否则,如果首先放置选择只投票的过滤器,它将应用于Senate的全部 100 名成员。
结果如下:

同样,我们可以计算每个党派有多少成员在issue 3上投了“是”:
c1 = senators.stream()
.filter(s -> s.getParty() == "Party1" &&
s.getVoteYes()[issue] == 1)
.count();
System.out.println("Members of Party1 who voted Yes on Issue"
+ issue + ": " + c1);
c2 = senators.stream()
.filter(s -> s.getParty() == "Party2" &&
s.getVoteYes()[issue] == 1)
.count();
System.out.println("Members of Party2 who voted Yes on Issue"
+ issue + ": " + c2);
System.out.println("Members of the senate voted Yes on Issue"
+ issue + ": " + (c1 + c2));
前面代码的结果如下:

我们可以通过利用 Java 的函数式编程能力(使用 lambda 表达式)并创建countAndPrint()方法来重构前面的示例:
long countAndPrint(List<Senator> senators,
Predicate<Senator> pred1, Predicate<Senator> pred2,
String prefix) {
long c = senators.stream().filter(pred1::test)
.filter(pred2::test).count();
System.out.println(prefix + c);
return c;
}
现在所有之前的代码可以以更紧凑的方式表达:
int issue = 3;
Predicate<Senator> party1 = s -> s.getParty() == "Party1";
Predicate<Senator> party2 = s -> s.getParty() == "Party2";
Predicate<Senator> voted3 =
s -> s.getVoteNo()[issue] != s.getVoteYes()[issue];
Predicate<Senator> yes3 = s -> s.getVoteYes()[issue] == 1;
long c1 = countAndPrint(senators, party1, s -> true,
"Members of Party1: ");
long c2 = countAndPrint(senators, party2, s -> true,
"Members of Party2: ");
System.out.println("Members of the senate: " + (c1 + c2));
c1 = countAndPrint(senators, party1, voted3,
"Members of Party1 who voted on Issue" + issue + ": ");
c2 = countAndPrint(senators, party2, voted3,
"Members of Party2 who voted on Issue" + issue + ": ");
System.out.println("Members of the senate who voted on Issue"
+ issue + ": " + (c1 + c2));
c1 = countAndPrint(senators, party1, yes3,
"Members of Party1 who voted Yes on Issue" + issue + ": ");
c2 = countAndPrint(senators, party2, yes3,
"Members of Party2 who voted Yes on Issue" + issue + ": ");
System.out.println("Members of the senate voted Yes on Issue"
+ issue + ": " + (c1 + c2));
我们创建了四个谓词,party1,party2,voted3和yes3,并且我们多次将它们用作countAndPrint()方法的参数。这段代码的输出与之前的示例相同:
使用Stream接口的filter()方法是过滤的最流行方式。但是也可以使用其他Stream方法来实现相同的效果。
使用其他 Stream 操作进行过滤
或者,或者除了前一节中描述的基本过滤之外,其他操作(Stream接口的方法)也可以用于选择和过滤发出的流元素。
例如,让我们使用flatMap()方法按其党派成员身份过滤出参议院成员:
long c1 = senators.stream()
.flatMap(s -> s.getParty() == "Party1" ?
Stream.of(s) : Stream.empty())
.count();
System.out.println("Members of Party1: " + c1);
这种方法利用了Stream.of()(生成一个元素的流)和Stream.empty()工厂方法(它生成一个没有元素的流,因此不会向下游发出任何内容)。或者,可以使用一个新的工厂方法(在 Java 9 中引入)Stream.ofNullable()来实现相同的效果:
c1 = senators.stream().flatMap(s ->
Stream.ofNullable(s.getParty() == "Party1" ? s : null))
.count();
System.out.println("Members of Party1: " + c1);
Stream.ofNullable()方法如果不是null则创建一个元素的流;否则,创建一个空流,就像前面的示例一样。如果我们对相同的参议院组成运行它们,那么前面的两个代码片段会产生相同的输出:
然而,使用java.uti.Optional类也可以实现相同的结果,该类可能包含或不包含值。如果值存在(且不为null),则其isPresent()方法返回true,get()方法返回该值。以下是我们如何使用它来过滤一个党派的成员:
long c2 = senators.stream()
.map(s -> s.getParty() == "Party2" ?
Optional.of(s) : Optional.empty())
.flatMap(o -> o.map(Stream::of).orElseGet(Stream::empty))
.count();
System.out.println("Members of Party2: " + c2);
首先,我们将一个元素(Senator对象)映射(转换)为一个带有或不带有值的Optional对象。接下来,我们使用flatMap()方法来生成一个单个元素的流,或者是一个空流,然后计算通过的元素数量。在 Java 9 中,Optional类获得了一个新的工厂stream()方法,如果Optional对象携带非空值,则生成一个元素的流;否则,生成一个空流。使用这个新方法,我们可以将前面的代码重写如下:
long c2 = senators.stream()
.map(s -> s.getParty() == "Party2" ?
Optional.of(s) : Optional.empty())
.flatMap(Optional::stream)
.count();
System.out.println("Members of Party2: " + c2);
如果我们对相同的参议院组成运行这两个示例,前面两个示例的输出结果是相同的:
当我们需要捕获流发出的第一个元素时,我们可以应用另一种过滤。这意味着在发出第一个元素后终止流。例如,让我们找到Party1中投了issue 3上的第一位参议员:
senators.stream()
.filter(s -> s.getParty() == "Party1" &&
s.getVoteYes()[3] == 1)
.findFirst()
.ifPresent(s -> System.out.println("First senator "
"of Party1 found who voted Yes on issue 3: "
+ s.getName()));
findFirst() method, which does the described job. It returns the Optional object, so we have added another ifPresent() operator that is invoked only if the Optionalobject contains a non-null value. The resulting output is as follows:

这正是我们在Senate类中设置数据时所期望的。
同样,我们可以使用findAny()方法来找到在issue 3上投了Yes的任何senator:
senators.stream().filter(s -> s.getVoteYes()[3] == 1)
.findAny()
.ifPresent(s -> System.out.println("A senator " +
"found who voted Yes on issue 3: " + s));
结果也和我们预期的一样:

这通常(但不一定)是流的第一个元素。但是,人们不应该依赖这一假设,特别是在并行处理的情况下。
Stream接口还有三种match方法,虽然它们返回一个布尔值,但如果不需要特定对象,只需要确定这样的对象是否存在,也可以用于过滤。这些方法的名称分别是anyMatch()、allMatch()和noneMatch()。它们每个都接受一个谓词并返回一个布尔值。让我们从演示anyMatch()方法开始。我们将使用它来查找Party1中至少有一个投了issue 3上的Yes的senator:
boolean found = senators.stream()
.anyMatch(s -> (s.getParty() == "Party1" &&
s.getVoteYes()[3] == 1));
String res = found ?
"At least one senator of Party1 voted Yes on issue 3"
: "Nobody of Party1 voted Yes on issue 3";
System.out.println(res);
运行前面代码的结果应该如下所示:

为了演示allMatch()方法,我们将使用它来查找Senate类中Party1的所有成员是否在issue 3上投了Yes:
boolean yes = senators.stream()
.allMatch(s -> (s.getParty() == "Party1" &&
s.getVoteYes()[3] == 1));
String res = yes ?
"All senators of Party1 voted Yes on issue 3"
: "Not all senators of Party1 voted Yes on issue 3";
System.out.println(res);
前面代码的结果可能如下所示:

三种match方法中的最后一种–noneMatch()方法–将用于确定Party1的一些参议员是否在issue 3上投了Yes:
boolean yes = senators.stream()
.noneMatch(s -> (s.getParty() == "Party1" &&
s.getVoteYes()[3] == 1));
String res = yes ?
"None of the senators of Party1 voted Yes on issue 3"
: "Some of senators of Party1 voted Yes on issue 3";
System.out.println(res);
前面示例的结果如下:

然而,在现实生活中,情况可能会截然不同,因为Senate类中有相当多的问题是按党派线投票的。
当我们需要跳过流中的所有重复元素并仅选择唯一元素时,我们需要另一种类型的过滤。distinct()方法就是为此设计的。我们将使用它来找到在Senate类中有成员的党派的名称:
senators.stream().map(s -> s.getParty())
.distinct().forEach(System.out::println);
结果如预期的那样:

嗯,这一点并不奇怪吧?
我们还可以使用limit()方法来过滤掉stream中除了前几个元素之外的所有元素:
System.out.println("These are the first 3 senators "
+ "of Party1 in the list:");
senators.stream()
.filter(s -> s.getParty() == "Party1")
.limit(3)
.forEach(System.out::println);
System.out.println("These are the first 2 senators "
+ "of Party2 in the list:");
senators.stream().filter(s -> s.getParty() == "Party2")
.limit(2)
.forEach(System.out::println);
如果你记得我们如何设置列表中的前五位参议员,你可以预测结果会是这样的:

现在让我们只在流中找到一个元素–最大的一个。为此,我们可以使用Stream接口的max()方法和Senate.timeVotedYes()方法(我们将对每个参议员应用它):
senators.stream()
.max(Comparator.comparing(Senate::timesVotedYes))
.ifPresent(s -> System.out.println("A senator voted "
+ "Yes most of times (" + Senate.timesVotedYes(s)
+ "): " + s));
timesVotedYes() method to select the senator who voted Yes most often. You might remember, we have assigned all instances of Yes to Senator100. Let's see if that would be the result:
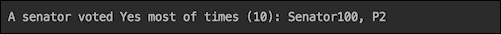
是的,我们过滤出了Senator100,他是在所有 10 个问题上都投了赞成票的人。
同样,我们可以找到在所有 10 个问题上都投了反对票的参议员:
senators.stream()
.min(Comparator.comparing(Senate::timesVotedYes))
.ifPresent(s -> System.out.println("A senator voted "
+ "Yes least of times (" + Senate.timesVotedYes(s)
+ "): " + s));
我们期望它是Senator99,结果如下:

这就是为什么我们在Senate类中硬编码了几个统计数据,这样我们就可以验证我们的查询是否正确。
由于最后两种方法可以帮助我们进行过滤,我们将演示 JDK 9 中引入的takeWhile()和dropWhile()方法。我们将首先打印出前五位参议员的数据,然后使用takeWhile()方法打印出第一位参议员,直到我们遇到投票超过四次的参议员,然后停止打印:
System.out.println("Here is count of times the first "
+ "5 senators voted Yes:");
senators.stream().limit(5)
.forEach(s -> System.out.println(s + ": "
+ Senate.timesVotedYes(s)));
System.out.println("Stop printing at a senator who "
+ "voted Yes more than 4 times:");
senators.stream().limit(5)
.takeWhile(s -> Senate.timesVotedYes(s) < 5)
.forEach(s -> System.out.println(s + ": "
+ Senate.timesVotedYes(s)));
前面代码的结果如下:
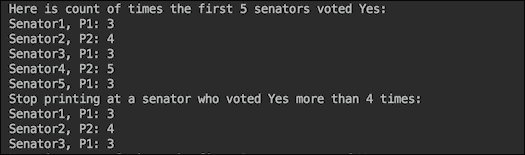
dropWhile()方法可以用于相反的效果,即过滤掉,跳过前几位参议员,直到我们遇到投票超过四次的参议员,然后继续打印剩下的所有参议员:
System.out.println("Here is count of times the first "
+ "5 senators voted Yes:");
senators.stream().limit(5)
.forEach(s -> System.out.println(s + ": "
+ Senate.timesVotedYes(s)));
System.out.println("Start printing at a senator who "
+ "voted Yes more than 4 times:");
senators.stream().limit(5)
.dropWhile(s -> Senate.timesVotedYes(s) < 5)
.forEach(s -> System.out.println(s + ": "
+ Senate.timesVotedYes(s)));
System.out.println("...");
结果将如下:

这结束了我们对元素流可以被过滤的方式的演示。我们希望您已经学会了足够的知识,能够为您的任何过滤需求找到解决方案。然而,我们鼓励您自己学习和尝试 Stream API,这样您就可以保留到目前为止学到的知识,并对 Java 9 丰富的 API 有自己的看法。
堆栈遍历 API
异常确实会发生,特别是在开发过程中或软件稳定期间。但在一个大型复杂系统中,即使在生产环境中,也有可能出现异常,特别是当多个第三方系统被整合在一起,并且需要以编程方式分析堆栈跟踪以应用自动修正时。在本节中,我们将讨论如何做到这一点。
Java 9 之前的堆栈分析
使用java.lang.Thread和java.lang.Throwable类的对象来传统地读取堆栈跟踪是通过从标准输出中捕获它来完成的。例如,我们可以在代码的任何部分包含这行:
Thread.currentThread().dumpStack();
前一行将产生以下输出:

同样,我们可以在代码中包含这行:
new Throwable().printStackTrace();
然后输出看起来像这样:

这个输出可以被程序捕获、读取和分析,但需要相当多的自定义代码编写。
JDK 8 通过使用流使这变得更容易。以下是允许从流中读取堆栈跟踪的代码:
Arrays.stream(Thread.currentThread().getStackTrace())
.forEach(System.out::println);
前一行产生以下输出:

或者,我们可以使用这段代码:
Arrays.stream(new Throwable().getStackTrace())
.forEach(System.out::println);
前面代码的输出以类似的方式显示堆栈跟踪:

例如,如果您想要找到调用者类的完全限定名,可以使用以下方法之一:
new Throwable().getStackTrace()[1].getClassName();
Thread.currentThread().getStackTrace()[2].getClassName();
这种编码是可能的,因为getStackTrace()方法返回java.lang.StackTraceElement类的对象数组,每个对象代表堆栈跟踪中的一个堆栈帧。每个对象都携带着可以通过getFileName()、getClassName()、getMethodName()和getLineNumber()方法访问的堆栈跟踪信息。
为了演示它是如何工作的,我们创建了三个类,Clazz01、Clazz02和Clazz03,它们相互调用:
public class Clazz01 {
public void method(){ new Clazz02().method(); }
}
public class Clazz02 {
public void method(){ new Clazz03().method(); }
}
public class Clazz03 {
public void method(){
Arrays.stream(Thread.currentThread()
.getStackTrace()).forEach(ste -> {
System.out.println();
System.out.println("ste=" + ste);
System.out.println("ste.getFileName()=" +
ste.getFileName());
System.out.println("ste.getClassName()=" +
ste.getClassName());
System.out.println("ste.getMethodName()=" +
ste.getMethodName());
System.out.println("ste.getLineNumber()=" +
ste.getLineNumber());
});
}
}
现在,让我们调用Clazz01的method()方法:
public class Demo02StackWalking {
public static void main(String... args) {
demo_walking();
}
private static void demo_walking(){
new Clazz01().method();
}
}
以下是前面代码打印出的六个堆栈跟踪帧中的两个(第二个和第三个):
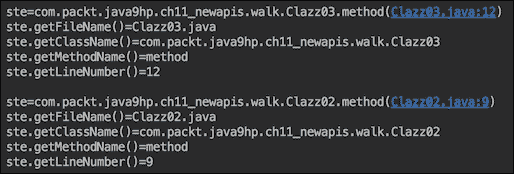
原则上,每个被调用的类都可以访问这些信息。但是要找出哪个类调用了当前类可能并不容易,因为你需要找出哪个帧代表了调用者。此外,为了提供这些信息,JVM 会捕获整个堆栈(除了隐藏的堆栈帧),这可能会影响性能。
这就是引入 JDK 9 中的java.lang.StackWalker类、其嵌套的Option类和StackWalker.StackFrame接口的动机。
更好的堆栈遍历方式
StackWalker类有四个getInstance()静态工厂方法:
-
getInstance(): 这返回一个配置为跳过所有隐藏帧和调用者类引用的StackWalker类实例 -
getInstance(StackWalker.Option option): 这创建一个具有给定选项的StackWalker类实例,指定它可以访问的堆栈帧信息 -
getInstance(Set<StackWalker.Option> options): 这创建一个具有给定选项集的StackWalker类实例 -
getInstance(Set<StackWalker.Option> options, int estimatedDepth): 这允许您传入指定估计堆栈帧数量的estimatedDepth参数,以便 Java 虚拟机可以分配可能需要的适当缓冲区大小。
作为选项传递的值可以是以下之一:
-
StackWalker.Option.RETAIN_CLASS_REFERENCE -
StackWalker.Option.SHOW_HIDDEN_FRAMES -
StackWalker.Option.SHOW_REFLECT_FRAMES
StackWalker类的另外三种方法如下:
-
T walk(Function<Stream<StackWalker.StackFrame>, T> function): 这将传入的函数应用于堆栈帧流,第一个帧代表调用walk()方法的方法 -
void forEach(Consumer<StackWalker.StackFrame> action): 这对当前线程的流中的每个元素(StalkWalker.StackFrame接口类型)执行传入的操作 -
Class<?> getCallerClass(): 这获取调用者类的Class类对象
正如你所看到的,它允许更加直接的堆栈跟踪分析。让我们使用以下代码修改我们的演示类,并在一行中访问调用者名称:
public class Clazz01 {
public void method(){
System.out.println("Clazz01 was called by " +
StackWalker.getInstance(StackWalker
.Option.RETAIN_CLASS_REFERENCE)
.getCallerClass().getSimpleName());
new Clazz02().method();
}
}
public class Clazz02 {
public void method(){
System.out.println("Clazz02 was called by " +
StackWalker.getInstance(StackWalker
.Option.RETAIN_CLASS_REFERENCE)
.getCallerClass().getSimpleName());
new Clazz03().method();
}
}
public class Clazz03 {
public void method(){
System.out.println("Clazz01 was called by " +
StackWalker.getInstance(StackWalker
.Option.RETAIN_CLASS_REFERENCE)
.getCallerClass().getSimpleName());
}
}
前面的代码将产生以下输出:

你可以欣赏到这种解决方案的简单性。如果我们需要查看整个堆栈跟踪,我们可以在Clazz03的代码中添加以下行:
StackWalker.getInstance().forEach(System.out::println);
产生的输出将如下所示:
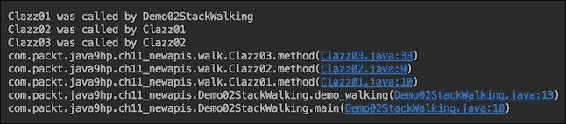
再次,只需一行代码,我们就实现了更加可读的输出。我们也可以使用walk()方法来实现相同的结果:
StackWalker.getInstance().walk(sf -> {
sf.forEach(System.out::println); return null;
});
我们不仅可以打印StackWalker.StackFrame,如果需要的话,还可以对其进行更深入的分析,因为它的 API 比java.lang.StackTraceElement的 API 更加广泛。让我们运行打印每个堆栈帧及其信息的代码示例:
StackWalker stackWalker =
StackWalker.getInstance(Set.of(StackWalker
.Option.RETAIN_CLASS_REFERENCE), 10);
stackWalker.forEach(sf -> {
System.out.println();
System.out.println("sf="+sf);
System.out.println("sf.getFileName()=" +
sf.getFileName());
System.out.println("sf.getClass()=" + sf.getClass());
System.out.println("sf.getMethodName()=" +
sf.getMethodName());
System.out.println("sf.getLineNumber()=" +
sf.getLineNumber());
System.out.println("sf.getByteCodeIndex()=" +
sf.getByteCodeIndex());
System.out.println("sf.getClassName()=" +
sf.getClassName());
System.out.println("sf.getDeclaringClass()=" +
sf.getDeclaringClass());
System.out.println("sf.toStackTraceElement()=" +
sf.toStackTraceElement());
});
前面代码的输出如下:

注意StackFrameInfo类实现了StackWalker.StackFrame接口并实际执行了任务。该 API 还允许将其转换回熟悉的StackTraceElement对象,以实现向后兼容性,并让那些习惯于它并且不想改变他们的代码和习惯的人享受它。
相比之下,与在内存中生成并存储完整堆栈跟踪(就像传统堆栈跟踪实现的情况)不同,StackWalker类只提供了请求的元素。这是它引入的另一个动机,除了演示的使用简单性。有关StackWalker类 API 及其用法的更多详细信息,请参阅docs.oracle.com/javase/9/docs/api/java/lang/StackWalker.html。
集合的便利工厂方法
随着 Java 中函数式编程的引入,对不可变对象的兴趣和需求增加了。传递到方法中的函数可能在与创建它们的上下文大不相同的情况下执行,因此减少意外副作用的可能性使得不可变性的案例更加有力。此外,Java 创建不可修改集合的方式本来就相当冗长,所以这个问题在 Java 9 中得到了解决。以下是在 Java 8 中创建Set接口的不可变集合的代码示例:
Set<String> set = new HashSet<>();
set.add("Life");
set.add("is");
set.add("good!");
set = Collections.unmodifiableSet(set);
做了几次之后,作为任何软件专业人员思考的基本重构考虑的一部分,自然而然地会出现对方便方法的需求。在 Java 8 中,前面的代码可以改为以下形式:
Set<String> immutableSet =
Collections.unmodifiableSet(new HashSet<>(Arrays
.asList("Life", "is", "good!")));
或者,如果流是你的朋友,你可以写如下代码:
Set<String> immutableSet = Stream.of("Life","is","good!")
.collect(Collectors.collectingAndThen(Collectors.toSet(),
Collections::unmodifiableSet));
前面代码的另一个版本如下:
Set<String> immutableSet =
Collections.unmodifiableSet(Stream.of("Life","is","good!")
.collect(Collectors.toSet()));
然而,它比你试图封装的值有更多的样板代码。因此,在 Java 9 中,前面的代码的更短版本成为可能:
Set<String> immutableSet = Set.of("Life","is","good!");
类似的工厂被引入来生成List接口和Map接口的不可变集合:
List<String> immutableList = List.of("Life","is","good!");
Map<Integer,String> immutableMap1 =
Map.of(1, "Life", 2, "is", 3, "good!");
Map<Integer,String> immutableMap2 =
Map.ofEntries(entry(1, "Life "), entry(2, "is"),
entry(3, "good!");
Map.Entry<Integer,String> entry1 = Map.entry(1,"Life");
Map.Entry<Integer,String> entry2 = Map.entry(2,"is");
Map.Entry<Integer,String> entry3 = Map.entry(3,"good!");
Map<Integer,String> immutableMap3 =
Map.ofEntries(entry1, entry2, entry3);
为什么要使用新的工厂方法?
能够以更紧凑的方式表达相同的功能是非常有帮助的,但这可能不足以成为引入这些新工厂的动机。更重要的是要解决现有的Collections.unmodifiableList()、Collections.unmodifiableSet()和Collections.unmodifiableMap()实现的弱点。虽然使用这些方法创建的集合在尝试修改或添加/删除元素时会抛出UnsupportedOperationException类,但它们只是传统可修改集合的包装器,因此可能会受到修改的影响,取决于构造它们的方式。让我们通过示例来说明这一点。另外,现有的不可修改实现的另一个弱点是它不会改变源集合的构造方式,因此List、Set和Map之间的差异–它们可以被构造的方式–仍然存在,这可能是程序员在使用它们时的错误或甚至是挫折的来源。新的工厂方法也解决了这个问题,只使用of()工厂方法(以及Map的附加ofEntries()方法)。话虽如此,让我们回到示例。看一下以下代码片段:
List<String> list = new ArrayList<>();
list.add("unmodifiableList1: Life");
list.add(" is");
list.add(" good! ");
list.add(null);
list.add("\n\n");
List<String> unmodifiableList1 =
Collections.unmodifiableList(list);
//unmodifiableList1.add(" Well..."); //throws exception
//unmodifiableList1.set(2, " sad."); //throws exception
unmodifiableList1.stream().forEach(System.out::print);
list.set(2, " sad. ");
list.set(4, " ");
list.add("Well...\n\n");
unmodifiableList1.stream().forEach(System.out::print);
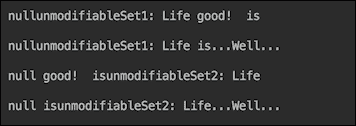
直接修改unmodifiableList1的元素会导致UnsupportedOperationException。然而,我们可以通过底层的list对象来修改它们。如果我们运行前面的示例,输出将如下所示:

即使我们使用Arrays.asList()来创建源列表,它也只能保护创建的集合免受添加新元素的影响,而不能防止修改现有元素。以下是一个代码示例:
List<String> list2 =
Arrays.asList("unmodifiableList2: Life",
" is", " good! ", null, "\n\n");
List<String> unmodifiableList2 =
Collections.unmodifiableList(list2);
//unmodifiableList2.add(" Well..."); //throws exception
//unmodifiableList2.set(2, " sad."); //throws exception
unmodifiableList2.stream().forEach(System.out::print);
list2.set(2, " sad. ");
//list2.add("Well...\n\n"); //throws exception
unmodifiableList2.stream().forEach(System.out::print);
如果我们运行前面的代码,输出将如下所示:

我们还包括了一个null元素来演示现有实现如何处理它们,因为相比之下,不可变集合的新工厂不允许包含null。另外,它们也不允许在Set中包含重复元素(而现有的实现只是忽略它们),但我们将在后面的代码示例中使用新的工厂方法来演示这一方面。
公平地说,使用现有的实现也可以创建List接口的真正不可变集合。看一下以下代码:
List<String> immutableList1 =
Collections.unmodifiableList(new ArrayList<>() {{
add("immutableList1: Life");
add(" is");
add(" good! ");
add(null);
add("\n\n");
}});
//immutableList1.set(2, " sad."); //throws exception
//immutableList1.add("Well...\n\n"); //throws exception
immutableList1.stream().forEach(System.out::print);
创建不可变列表的另一种方法如下:
List<String> immutableList2 =
Collections.unmodifiableList(Stream
.of("immutableList2: Life"," is"," good! ",null,"\n\n")
.collect(Collectors.toList()));
//immutableList2.set(2, " sad."); //throws exception
//immutableList2.add("Well...\n\n"); //throws exception
immutableList2.stream().forEach(System.out::print);
以下是前面代码的变体:
List<String> immutableList3 =
Stream.of("immutableList3: Life",
" is"," good! ",null,"\n\n")
.collect(Collectors.collectingAndThen(Collectors.toList(),
Collections::unmodifiableList));
//immutableList3.set(2, " sad."); //throws exception
//immutableList3.add("Well...\n\n"); //throws exception
immutableList3.stream().forEach(System.out::print);
如果我们运行前面的三个示例,将看到以下输出:
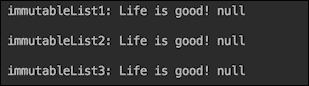
请注意,尽管我们不能修改这些列表的内容,但我们可以在其中放入null。
与先前看到的列表情况相似,Set的情况也是如此。以下是显示如何修改不可修改的Set接口集合的代码:
Set<String> set = new HashSet<>();
set.add("unmodifiableSet1: Life");
set.add(" is");
set.add(" good! ");
set.add(null);
Set<String> unmodifiableSet1 =
Collections.unmodifiableSet(set);
//unmodifiableSet1.remove(" good! "); //throws exception
//unmodifiableSet1.add("...Well..."); //throws exception
unmodifiableSet1.stream().forEach(System.out::print);
System.out.println("\n");
set.remove(" good! ");
set.add("...Well...");
unmodifiableSet1.stream().forEach(System.out::print);
System.out.println("\n");
即使我们将原始集合从数组转换为列表,然后再转换为集合,也可以修改Set接口的结果集合,如下所示:
Set<String> set2 =
new HashSet<>(Arrays.asList("unmodifiableSet2: Life",
" is", " good! ", null));
Set<String> unmodifiableSet2 =
Collections.unmodifiableSet(set2);
//unmodifiableSet2.remove(" good! "); //throws exception
//unmodifiableSet2.add("...Well..."); //throws exception
unmodifiableSet2.stream().forEach(System.out::print);
System.out.println("\n");
set2.remove(" good! ");
set2.add("...Well...");
unmodifiableSet2.stream().forEach(System.out::print);
System.out.println("\n");
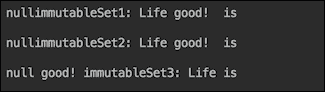
运行前两个示例的输出如下:
如果您在 Java 9 中没有使用集合,可能会对输出中集合元素的异常顺序感到惊讶。实际上,这是 JDK 9 中引入的集合和映射的另一个新特性。过去,Set和Map的实现不能保证保留元素的顺序。但很多时候,顺序是被保留的,一些程序员编写了依赖于此的代码,从而在应用程序中引入了一个令人讨厌的不一致且不易重现的缺陷。新的Set和Map实现更经常地改变顺序,如果不是在每次运行代码时都改变。这样,它可以在开发的早期暴露潜在的缺陷,并减少其传播到生产环境的机会。
与列表类似,即使不使用 Java 9 的新不可变集合工厂,我们也可以创建不可变集合。其中一种方法如下:
Set<String> immutableSet1 =
Collections.unmodifiableSet(new HashSet<>() {{
add("immutableSet1: Life");
add(" is");
add(" good! ");
add(null);
}});
//immutableSet1.remove(" good! "); //throws exception
//immutableSet1.add("...Well..."); //throws exception
immutableSet1.stream().forEach(System.out::print);
System.out.println("\n");
与列表的情况一样,这里还有另一种方法:
Set<String> immutableSet2 =
Collections.unmodifiableSet(Stream
.of("immutableSet2: Life"," is"," good! ", null)
.collect(Collectors.toSet()));
//immutableSet2.remove(" good!"); //throws exception
//immutableSet2.add("...Well..."); //throws exception
immutableSet2.stream().forEach(System.out::print);
System.out.println("\n");
前面代码的另一种变体如下:
Set<String> immutableSet3 =
Stream.of("immutableSet3: Life"," is"," good! ", null)
.collect(Collectors.collectingAndThen(Collectors.toSet(),
Collections::unmodifiableSet));
//immutableList5.set(2, "sad."); //throws exception
//immutableList5.add("Well..."); //throws exception
immutableSet3.stream().forEach(System.out::print);
System.out.println("\n");
如果我们运行刚刚介绍的创建iSet接口的不可变集合的三个示例,结果将如下:
对于Map接口,我们只能想出一种修改unmodifiableMap对象的方法:
Map<Integer, String> map = new HashMap<>();
map.put(1, "unmodifiableleMap: Life");
map.put(2, " is");
map.put(3, " good! ");
map.put(4, null);
map.put(5, "\n\n");
Map<Integer, String> unmodifiableleMap =
Collections.unmodifiableMap(map);
//unmodifiableleMap.put(3, " sad."); //throws exception
//unmodifiableleMap.put(6, "Well..."); //throws exception
unmodifiableleMap.values().stream()
.forEach(System.out::print);
map.put(3, " sad. ");
map.put(4, "");
map.put(5, "");
map.put(6, "Well...\n\n");
unmodifiableleMap.values().stream()
.forEach(System.out::print);
前面代码的输出如下:

我们找到了四种在不使用 Java 9 增强功能的情况下创建Map接口的不可变集合的方法。以下是第一个示例:
Map<Integer, String> immutableMap1 =
Collections.unmodifiableMap(new HashMap<>() {{
put(1, "immutableMap1: Life");
put(2, " is");
put(3, " good! ");
put(4, null);
put(5, "\n\n");
}});
//immutableMap1.put(3, " sad. "); //throws exception
//immutableMap1.put(6, "Well..."); //throws exception
immutableMap1.values().stream().forEach(System.out::print);
第二个示例有点复杂:
String[][] mapping =
new String[][] {{"1", "immutableMap2: Life"},
{"2", " is"}, {"3", " good! "},
{"4", null}, {"5", "\n\n"}};
Map<Integer, String> immutableMap2 =
Collections.unmodifiableMap(Arrays.stream(mapping)
.collect(Collectors.toMap(a -> Integer.valueOf(a[0]),
a -> a[1] == null? "" : a[1])));
immutableMap2.values().stream().forEach(System.out::print);
null value in the source array:
String[][] mapping =
new String[][]{{"1", "immutableMap3: Life"},
{"2", " is"}, {"3", " good! "}, {"4", "\n\n"}};
Map<Integer, String> immutableMap3 =
Collections.unmodifiableMap(Arrays.stream(mapping)
.collect(Collectors.toMap(a -> Integer.valueOf(a[0]),
a -> a[1])));
//immutableMap3.put(3, " sad."); //throws Exception
//immutableMap3.put(6, "Well..."); //throws exception
immutableMap3.values().stream().forEach(System.out::print);
前面代码的另一种变体如下:
mapping[0][1] = "immutableMap4: Life";
Map<Integer, String> immutableMap4 = Arrays.stream(mapping)
.collect(Collectors.collectingAndThen(Collectors
.toMap(a -> Integer.valueOf(a[0]), a -> a[1]),
Collections::unmodifiableMap));
//immutableMap4.put(3, " sad."); //throws exception
//immutableMap4.put(6, "Well..."); //throws exception
immutableMap4.values().stream().forEach(System.out::print);
在运行了所有四个最后的示例之后,输出如下:
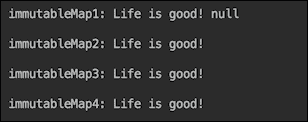
通过对现有集合实现的修订,我们现在可以讨论并欣赏 Java 9 中集合的新工厂方法。
在实践中使用新的工厂方法
在重新审视集合创建的现有方法之后,我们现在可以回顾并享受 Java 9 中引入的相关 API。就像在前一节中一样,我们从List接口开始。使用新的List.of()工厂方法创建不可变列表是多么简单和一致:
List<String> immutableList =
List.of("immutableList: Life",
" is", " is", " good!\n\n"); //, null);
//immutableList.set(2, "sad."); //throws exception
//immutableList.add("Well..."); //throws exception
immutableList.stream().forEach(System.out::print);
从前面的代码注释中可以看出,新的工厂方法不允许将null包括在列表值中。
immutableSet的创建看起来类似于这样:
Set<String> immutableSet =
Set.of("immutableSet: Life", " is", " good!");
//, " is" , null);
//immutableSet.remove(" good!\n\n"); //throws exception
//immutableSet.add("...Well...\n\n"); //throws exception
immutableSet.stream().forEach(System.out::print);
System.out.println("\n");
从前面的代码注释中可以看出,Set.of()工厂方法在创建Set接口的不可变集合时不允许添加null或重复元素。
不可变的Map接口集合格式也类似:
Map<Integer, String> immutableMap =
Map.of(1</span>, "immutableMap: Life", 2, " is", 3, " good!");
//, 4, null);
//immutableMap.put(3, " sad."); //throws exception
//immutableMap.put(4, "Well..."); //throws exception
immutableMap.values().stream().forEach(System.out::print);
System.out.println("\n");
Map.of()方法也不允许值为null。Map.of()方法的另一个特性是它允许在编译时检查元素类型,这减少了运行时问题的可能性。
对于那些更喜欢更紧凑代码的人,这是另一种表达相同功能的方法:
Map<Integer, String> immutableMap3 =
Map.ofEntries(entry(1, "immutableMap3: Life"),
entry(2, " is"), entry(3, " good!"));
immutableMap3.values().stream().forEach(System.out::print);
System.out.println("\n");
如果我们运行所有先前使用新工厂方法的示例,输出如下:

正如我们已经提到的,具有不可变集合的能力,包括空集合,对于函数式编程非常有帮助,因为这个特性确保这样的集合不能作为副作用被修改,也不能引入意外和难以追踪的缺陷。新工厂方法的完整种类包括多达 10 个显式条目,再加上一个具有任意数量元素的条目。对于List接口,它看起来是这样的:
static <E> List<E> of()
static <E> List<E> of(E e1)
static <E> List<E> of(E e1, E e2)
static <E> List<E> of(E e1, E e2, E e3)
static <E> List<E> of(E e1, E e2, E e3, E e4)
static <E> List<E> of(E e1, E e2, E e3, E e4, E e5)
static <E> List<E> of(E e1, E e2, E e3, E e4, E e5, E e6)
static <E> List<E> of(E e1, E e2, E e3, E e4, E e5, E e6, E e7)
static <E> List<E> of(E e1, E e2, E e3, E e4, E e5, E e6, E e7, E e8)
static <E> List<E> of(E e1, E e2, E e3, E e4, E e5, E e6, E e7, E e8, E e9)
static <E> List<E> of(E e1, E e2, E e3, E e4, E e5, E e6, E e7, E e8, E e9, E e10)
static <E> List<E> of(E... elements)
Set工厂方法看起来类似:
static <E> Set<E> of()
static <E> Set<E> of(E e1)
static <E> Set<E> of(E e1, E e2)
static <E> Set<E> of(E e1, E e2, E e3)
static <E> Set<E> of(E e1, E e2, E e3, E e4)
static <E> Set<E> of(E e1, E e2, E e3, E e4, E e5)
static <E> Set<E> of(E e1, E e2, E e3, E e4, E e5, E e6)
static <E> Set<E> of(E e1, E e2, E e3, E e4, E e5, E e6, E e7)
static <E> Set<E> of(E e1, E e2, E e3, E e4, E e5, E e6, E e7, E e8)
static <E> Set<E> of(E e1, E e2, E e3, E e4, E e5, E e6, E e7, E e8, E e9)
static <E> Set<E> of(E e1, E e2, E e3, E e4, E e5, E e6, E e7, E e8, E e9, E e10)
static <E> Set<E> of(E... elements)
此外,Map工厂方法也遵循相同的规则:
static <K,V> Map<K,V> of()
static <K,V> Map<K,V> of(K k1, V v1)
static <K,V> Map<K,V> of(K k1, V v1, K k2, V v2)
static <K,V> Map<K,V> of(K k1, V v1, K k2, V v2, K k3, V v3)
static <K,V> Map<K,V> of(K k1, V v1, K k2, V v2, K k3, V v3, K k4, V v4)
static <K,V> Map<K,V> of(K k1, V v1, K k2, V v2, K k3, V v3, K k4, V v4, K k5, V v5
static <K,V> Map<K,V> of(K k1, V v1, K k2, V v2, K k3, V v3, K k4, V v4, K k5, V v5, K k6, V v6)
static <K,V> Map<K,V> of(K k1, V v1, K k2, V v2, K k3, V v3, K k4, V v4, K k5, V v5, K k6, V v6, K k7, V v7
static <K,V> Map<K,V> of(K k1, V v1, K k2, V v2, K k3, V v3, K k4, V v4, K k5, V v5, K k6, V v6, K k7, V v7,
K k8, V v8)
static <K,V> Map<K,V> of(K k1, V v1, K k2, V v2, K k3, V v3, K k4, V v4, K k5, V v5, K k6, V v6, K k7, V v7,
K k8, V v8, K k9, V v9)
static <K,V> Map<K,V> of(K k1, V v1, K k2, V v2, K k3, V v3, K k4, V v4, K k5, V v5, K k6, V v6, K k7, V v7,
K k8, V v8, K k9, V v9, K k10, V v10)
static <K,V> Map<K,V> ofEntries(Map.Entry<? extends K,? extends V>... entries
决定不为不可变集合添加新接口使它们容易引起偶尔的混淆,当程序员假设可以在它们上调用add()或put()时。如果没有经过测试,这样的假设会导致抛出UnsupportedOperationException的运行时错误。尽管存在这种潜在的陷阱,不可变集合创建的新工厂方法是 Java 中非常有用的补充。
支持异步处理的 CompletableFuture
java.util.concurrent.CompletableFuture<T>类首次在 Java 8 中引入。它是对java.util.concurrent.Future<T>接口的异步调用控制的下一级。它实际上实现了Future,以及java.util.concurrent.CompletionStage<T>。在 Java 9 中,通过添加新的工厂方法、支持延迟和超时以及改进的子类化,增强了CompletableFuture——我们将在接下来的章节中更详细地讨论这些特性。但首先,让我们概述一下CompletableFuture的 API。
CompletableFuture API 概述
CompletableFuture的 API 包括 70 多个方法,其中 38 个是CompletionStage接口的实现,5 个是Future的实现。因为CompletableFuture类实现了Future接口,它可以被视为Future,并且不会破坏基于FutureAPI 的现有功能。
因此,API 的大部分来自CompletionStage。大多数方法返回CompletableFuture(在CompletionStage接口中,它们返回CompletionStage,但在CompletableFuture类中实现时会转换为CompletableFuture),这意味着它们允许链接操作,类似于Stream方法在管道中只有一个元素通过时的操作。每个方法都有一个接受函数的签名。一些方法接受Function<T,U>,它将被应用于传入的值T并返回结果U。其他方法接受Consumer<T>,它接受传入的值并返回void。还有其他方法接受Runnable,它不接受任何输入并返回void。以下是其中一组这些方法:
thenRun(Runnable action)
thenApply(Function<T,U> fn)
thenAccept(Consumer<T> action)
它们都返回CompletableFuture,它携带函数或 void 的结果(在Runnable和Consumer的情况下)。它们每个都有两个执行相同功能的异步伴侣方法。例如,让我们看一下thenRun(Runnable action)方法。以下是它的伴侣们:
-
thenRunAsync(Runnable action)方法会在另一个线程中运行操作,使用默认的ForkJoinPool.commonPool()线程池。 -
thenRun(Runnable action, Executor executor)方法会在传入的参数 executor 作为线程池的另一个线程中运行操作。
因此,我们已经介绍了CompletionStage接口的九种方法。
另一组方法包括以下内容:
thenCompose(Function<T,CompletionStage<U>> fn)
applyToEither(CompletionStage other, Function fn)
acceptEither(CompletionStage other, Consumer action)
runAfterBoth(CompletionStage other, Runnable action)
runAfterEither(CompletionStage other, Runnable action)
thenCombine(CompletionStage<U> other, BiFunction<T,U,V> fn)
thenAcceptBoth(CompletionStage other, BiConsumer<T,U> action)
这些方法在一个或两个CompletableFuture(或CompletionStage)对象产生作为输入传递给操作的结果后执行传入的操作。这里的“两个”指的是提供方法的CompletableFuture和作为方法参数传入的CompletableFuture。从这些方法的名称中,你可以相当可靠地猜测它们的意图。我们将在接下来的示例中演示其中一些。每个这七个方法都有两个用于异步处理的伴侣。这意味着我们已经描述了CompletionStage接口的 30 种(共 38 种)方法。
还有一组通常用作终端操作的两种方法,因为它们可以处理前一个方法的结果(作为T传入)或异常(作为Throwable传入):
handle(BiFunction<T,Throwable,U> fn)
whenComplete(BiConsumer<T,Throwable> action)
我们稍后将看到这些方法的使用示例。当链中的方法抛出异常时,所有其余的链接方法都会被跳过,直到遇到第一个handle()方法或whenComplete()方法。如果链中没有这两个方法中的任何一个,那么异常将像其他 Java 异常一样冒泡。这两个方法也有异步伴侣,这意味着我们已经讨论了CompletionStage接口的 36 种(共 38 种)方法。
还有一个仅处理异常的方法(类似于传统编程中的 catch 块):
exceptionally(Function<Throwable,T> fn)
这个方法没有异步伴侣,就像最后剩下的方法一样。
toCompletableFuture()
它只返回一个具有与此阶段相同属性的CompletableFuture对象。有了这个,我们已经描述了CompletionStage接口的所有 38 种方法。
CompletableFuture类中还有大约 30 种不属于任何实现接口的方法。其中一些在异步执行提供的函数后返回CompletableFuture对象:
runAsync(Runnable runnable)
runAsync(Runnable runnable, Executor executor)
supplyAsync(Supplier<U> supplier)
supplyAsync(Supplier<U> supplier, Executor executor)
其他人并行执行几个CompletableFuture对象:
allOf(CompletableFuture<?>... cfs)
anyOf(CompletableFuture<?>... cfs)
还有一组生成已完成 future 的方法,因此返回的CompletableFuture对象上的get()方法将不再阻塞:
complete(T value)
completedStage(U value)
completedFuture(U value)
failedStage(Throwable ex)
failedFuture(Throwable ex)
completeAsync(Supplier<T> supplier)
completeExceptionally(Throwable ex)
completeAsync(Supplier<T> supplier, Executor executor)
completeOnTimeout(T value, long timeout, TimeUnit unit)
其余的方法执行各种其他有用的功能:
join()
defaultExecutor()
newIncompleteFuture()
getNow(T valueIfAbsent)
getNumberOfDependents()
minimalCompletionStage()
isCompletedExceptionally()
obtrudeValue(T value)
obtrudeException(Throwable ex)
orTimeout(long timeout, TimeUnit unit)
delayedExecutor(long delay, TimeUnit unit)
请参考官方 Oracle 文档,其中描述了CompletableFuture API 的这些和其他方法,网址为download.java.net/java/jdk9/docs/api/index.html?java/util/concurrent/CompletableFuture.html。
Java 9 中的CompletableFuture API 增强
Java 9 为CompletableFuture引入了几项增强功能:
-
CompletionStage<U> failedStage(Throwable ex)工厂方法返回使用给定异常完成的CompletionStage对象 -
CompletableFuture<U> failedFuture(Throwable ex)工厂方法返回使用给定异常完成的CompletableFuture对象 -
新的
CompletionStage<U> completedStage(U value)工厂方法返回使用给定U值完成的CompletionStage对象 -
CompletableFuture<T> completeOnTimeout(T value, long timeout, TimeUnit unit)如果在给定的超时之前未完成,则使用给定的T值完成CompletableFuture任务 -
CompletableFuture<T> orTimeout(long timeout, TimeUnit unit)如果在给定的超时之前未完成,则使用java.util.concurrent.TimeoutException完成CompletableFuture -
现在可以重写
defaultExecutor()方法以支持另一个默认执行程序 -
一个新方法
newIncompleteFuture()使得子类化CompletableFuture类更容易
问题和解决方案使用 Future
为了演示和欣赏CompletableFuture的强大功能,让我们从使用Future解决的问题开始,然后看看使用CompletableFuture可以更有效地解决多少。假设我们的任务是对由四个阶段组成的建筑进行建模:
-
收集地基、墙壁和屋顶的材料
-
安装地基
-
竖起墙壁
-
搭建和完成屋顶
在传统的单线程顺序编程中,模型如下:
StopWatch stopWatch = new StopWatch();
Stage failedStage;
String SUCCESS = "Success";
stopWatch.start();
String result11 = doStage(Stage.FoundationMaterials);
String result12 = doStage(Stage.Foundation, result11);
String result21 = doStage(Stage.WallsMaterials);
String result22 = doStage(Stage.Walls,
getResult(result21, result12));
String result31 = doStage(Stage.RoofMaterials);
String result32 = doStage(Stage.Roof,
getResult(result31, result22));
System.out.println("House was" +
(isSuccess(result32)?"":" not") + " built in "
+ stopWatch.getTime()/1000\. + " sec");
这里,Stage是一个枚举:
enum Stage {
FoundationMaterials,
WallsMaterials,
RoofMaterials,
Foundation,
Walls,
Roof
}
doStage()方法有两个重载版本。这是第一个版本:
String doStage(Stage stage) {
String result = SUCCESS;
boolean failed = stage.equals(failedStage);
if (failed) {
sleepSec(2);
result = stage + " were not collected";
System.out.println(result);
} else {
sleepSec(1);
System.out.println(stage + " are ready");
}
return result;
}
第二个版本如下:
String doStage(Stage stage, String previousStageResult) {
String result = SUCCESS;
boolean failed = stage.equals(failedStage);
if (isSuccess(previousStageResult)) {
if (failed) {
sleepSec(2);
result = stage + " stage was not completed";
System.out.println(result);
} else {
sleepSec(1);
System.out.println(stage + " stage is completed");
}
} else {
result = stage + " stage was not started because: "
+ previousStageResult;
System.out.println(result);
}
return result;
}
sleepSec()、isSuccess()和getResult()方法如下:
private static void sleepSec(int sec) {
try {
TimeUnit.SECONDS.sleep(sec);
} catch (InterruptedException e) {
}
}
boolean isSuccess(String result) {
return SUCCESS.equals(result);
}
String getResult(String result1, String result2) {
if (isSuccess(result1)) {
if (isSuccess(result2)) {
return SUCCESS;
} else {
return result2;
}
} else {
return result1;
}
}
成功的房屋建造(如果我们运行之前的代码而没有为failedStage变量分配任何值)如下所示:

如果我们设置failedStage=Stage.Walls,结果将如下:
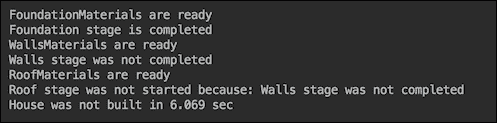
使用Future,我们可以缩短建造房屋所需的时间:
ExecutorService execService = Executors.newCachedThreadPool();
Callable<String> t11 =
() -> doStage(Stage.FoundationMaterials);
Future<String> f11 = execService.submit(t11);
List<Future<String>> futures = new ArrayList<>();
futures.add(f11);
Callable<String> t21 = () -> doStage(Stage.WallsMaterials);
Future<String> f21 = execService.submit(t21);
futures.add(f21);
Callable<String> t31 = () -> doStage(Stage.RoofMaterials);
Future<String> f31 = execService.submit(t31);
futures.add(f31);
String result1 = getSuccessOrFirstFailure(futures);
String result2 = doStage(Stage.Foundation, result1);
String result3 =
doStage(Stage.Walls, getResult(result1, result2));
String result4 =
doStage(Stage.Roof, getResult(result1, result3));
这里,getSuccessOrFirstFailure()方法如下:
String getSuccessOrFirstFailure(
List<Future<String>> futures) {
String result = "";
int count = 0;
try {
while (count < futures.size()) {
for (Future<String> future : futures) {
if (future.isDone()) {
result = getResult(future);
if (!isSuccess(result)) {
break;
}
count++;
} else {
sleepSec(1);
}
}
if (!isSuccess(result)) {
break;
}
}
} catch (Exception ex) {
ex.printStackTrace();
}
return result;
}
现在成功建造房屋的速度更快,因为材料收集是并行进行的:

通过利用 Java 函数式编程,我们可以将实现的后半部分改为以下内容:
Supplier<String> supplier1 =
() -> doStage(Stage.Foundation, result1);
Supplier<String> supplier2 =
() -> getResult(result1, supplier1.get());
Supplier<String> supplier3 =
() -> doStage(Stage.Walls, supplier2.get());
Supplier<String> supplier4 =
() -> getResult(result1, supplier3.get());
Supplier<String> supplier5 =
() -> doStage(Stage.Roof, supplier4.get());
System.out.println("House was" +
(isSuccess(supplier5.get()) ? "" : " not") +
" built in " + stopWatch.getTime() / 1000\. + " sec");
前面嵌套函数的链由最后一行的supplier5.get()触发。它会阻塞,直到所有函数按顺序完成,因此没有性能改进:

这就是我们可以使用Future的地方。现在让我们看看是否可以使用CompletableFuture改进之前的代码。
使用 CompletableFuture 的解决方案
以下是我们如何使用CompletableFuture API 链接相同操作的方式:
stopWatch.start();
ExecutorService pool = Executors.newCachedThreadPool();
CompletableFuture<String> cf1 =
CompletableFuture.supplyAsync(() ->
doStageEx(Stage.FoundationMaterials), pool);
CompletableFuture<String> cf2 =
CompletableFuture.supplyAsync(() ->
doStageEx(Stage.WallsMaterials), pool);
CompletableFuture<String> cf3 =
CompletableFuture.supplyAsync(() ->
doStageEx(Stage.RoofMaterials), pool);
CompletableFuture.allOf(cf1, cf2, cf3)
.thenComposeAsync(result ->
CompletableFuture.supplyAsync(() -> SUCCESS), pool)
.thenApplyAsync(result ->
doStage(Stage.Foundation, result), pool)
.thenApplyAsync(result ->
doStage(Stage.Walls, result), pool)
.thenApplyAsync(result ->
doStage(Stage.Roof, result), pool)
.handleAsync((result, ex) -> {
System.out.println("House was" +
(isSuccess(result) ? "" : " not") + " built in "
+ stopWatch.getTime() / 1000\. + " sec");
if (result == null) {
System.out.println("Because: " + ex.getMessage());
return ex.getMessage();
} else {
return result;
}
}, pool);
System.out.println("Out!!!!!");
为了使其工作,我们不得不将doStage()中的一个实现更改为doStageEx()方法:
String doStageEx(Stage stage) {
boolean failed = stage.equals(failedStage);
if (failed) {
sleepSec(2);
throw new RuntimeException(stage +
" stage was not completed");
} else {
sleepSec(1);
System.out.println(stage + " stage is completed");
}
return SUCCESS;
}
Out!!!!!) came out first, which means that all the chains of the operations related to building the house were executed asynchronously
现在,让我们看看系统在收集材料的第一个阶段失败时的行为(failedStage = Stage.WallsMaterials):

异常由WallsMaterials阶段抛出,并被handleAsync()方法捕获,正如预期的那样。而且,在打印Out!!!!!消息后,处理是异步进行的。
CompletableFuture 的其他有用功能
CompletableFuture的一个巨大优势是它可以作为对象传递并多次使用,以启动不同的操作链。为了演示这种能力,让我们创建几个新操作:
String getData() {
System.out.println("Getting data from some source...");
sleepSec(1);
return "Some input";
}
SomeClass doSomething(String input) {
System.out.println(
"Doing something and returning SomeClass object...");
sleepSec(1);
return new SomeClass();
}
AnotherClass doMore(SomeClass input) {
System.out.println("Doing more of something and " +
"returning AnotherClass object...");
sleepSec(1);
return new AnotherClass();
}
YetAnotherClass doSomethingElse(AnotherClass input) {
System.out.println("Doing something else and " +
"returning YetAnotherClass object...");
sleepSec(1);
return new YetAnotherClass();
}
int doFinalProcessing(YetAnotherClass input) {
System.out.println("Processing and finally " +
"returning result...");
sleepSec(1);
return 42;
}
AnotherType doSomethingAlternative(SomeClass input) {
System.out.println("Doing something alternative " +
"and returning AnotherType object...");
sleepSec(1);
return new AnotherType();
}
YetAnotherType doMoreAltProcessing(AnotherType input) {
System.out.println("Doing more alternative and " +
"returning YetAnotherType object...");
sleepSec(1);
return new YetAnotherType();
}
int doFinalAltProcessing(YetAnotherType input) {
System.out.println("Alternative processing and " +
"finally returning result...");
sleepSec(1);
return 43;
}
这些操作的结果将由myHandler()方法处理:
int myHandler(Integer result, Throwable ex) {
System.out.println("And the answer is " + result);
if (result == null) {
System.out.println("Because: " + ex.getMessage());
return -1;
} else {
return result;
}
}
注意所有操作返回的不同类型。现在我们可以构建一个在某个点分叉的链:
ExecutorService pool = Executors.newCachedThreadPool();
CompletableFuture<SomeClass> completableFuture =
CompletableFuture.supplyAsync(() -> getData(), pool)
.thenApplyAsync(result -> doSomething(result), pool);
completableFuture
.thenApplyAsync(result -> doMore(result), pool)
.thenApplyAsync(result -> doSomethingElse(result), pool)
.thenApplyAsync(result -> doFinalProcessing(result), pool)
.handleAsync((result, ex) -> myHandler(result, ex), pool);
completableFuture
.thenApplyAsync(result -> doSomethingAlternative(result), pool)
.thenApplyAsync(result -> doMoreAltProcessing(result), pool)
.thenApplyAsync(result -> doFinalAltProcessing(result), pool)
.handleAsync((result, ex) -> myHandler(result, ex), pool);
System.out.println("Out!!!!!");
这个例子的结果如下:
CompletableFuture API 提供了一个非常丰富和经过深思熟虑的 API,支持最新的反应式微服务趋势,因为它允许完全异步地处理数据,根据需要拆分流,并扩展以适应输入的增加。我们鼓励您学习示例(本书附带的代码提供了更多示例),并查看 API:download.java.net/java/jdk9/docs/api/index.html?java/util/concurrent/CompletableFuture.html。
Stream API 改进
Java 9 中大多数新的Stream API 功能已经在描述Stream过滤的部分中进行了演示。为了提醒您,以下是我们基于 JDK 9 中Stream API 改进所演示的示例:
long c1 = senators.stream()
.flatMap(s -> Stream.ofNullable(s.getParty()
== "Party1" ? s : null))
.count();
System.out.println("OfNullable: Members of Party1: " + c1);
long c2 = senators.stream()
.map(s -> s.getParty() == "Party2" ? Optional.of(s)
: Optional.empty())
.flatMap(Optional::stream)
.count();
System.out.println("Optional.stream(): Members of Party2: "
+ c2);
senators.stream().limit(5)
.takeWhile(s -> Senate.timesVotedYes(s) < 5)
.forEach(s -> System.out.println("takeWhile(<5): "
+ s + ": " + Senate.timesVotedYes(s)));
senators.stream().limit(5)
.dropWhile(s -> Senate.timesVotedYes(s) < 5)
.forEach(s -> System.out.println("dropWhile(<5): "
+ s + ": " + Senate.timesVotedYes(s)));
我们还没有提到的是新的重载iterate()方法:
static <T> Stream<T> iterate(T seed, UnaryOperator<T> f)
其用法示例如下:
String result =
IntStream.iterate(1, i -> i + 2)
.limit(5)
.mapToObj(i -> String.valueOf(i))
.collect(Collectors.joining(", "));
System.out.println("Iterate: " + result);
我们不得不添加limit(5),因为iterate()方法的这个版本创建了一个无限的整数流。前面代码的结果如下:

在 Java 9 中,新增了一个重载的iterate()方法:
static <T> Stream<T> iterate(T seed,
Predicate<? super T> hasNext, UnaryOperator<T> next)
正如您所看到的,现在它作为参数具有Predicate函数接口,允许根据需要限制流。例如,以下代码产生的结果与先前的limit(5)示例完全相同:
String result =
IntStream.iterate(1, i -> i < 11, i -> i + 2)
.mapToObj(i -> String.valueOf(i))
.collect(Collectors.joining(", "));
System.out.println("Iterate: " + result);
请注意,流元素的类型不需要是整数。它可以是源产生的任何类型。因此,新的iterate()方法可以用于提供任何类型数据流终止的条件。
总结
在这节课中,我们涵盖了 Java 9 引入的新功能领域。首先,我们从基本的filter()方法开始,介绍了许多流过滤的方法,并最终使用了 JDK 9 的Stream API 新增功能。然后,您学会了使用新的StackWalker类来分析堆栈跟踪的更好方法。讨论通过具体示例进行了说明,帮助您看到真正的工作代码。
我们在为创建不可变集合的新便利工厂方法和与CompletableFuture类及其 JDK 9 中的增强一起提供的新异步处理功能时使用了相同的方法。
我们通过列举Stream API 的改进来结束了这节课–这些改进我们在过滤代码示例和新的iterate()方法中已经演示过。
通过这些内容,我们结束了这本书。现在你可以尝试将你学到的技巧和技术应用到你的项目中,或者如果不适合,可以为高性能构建自己的 Java 项目。在这个过程中,尝试解决真实的问题。这将迫使你学习新的技能和框架,而不仅仅是应用你已经掌握的知识,尽管后者也很有帮助–它可以保持你的知识更新和实用。
学习的最佳方式是自己动手。随着 Java 的不断改进和扩展,敬请期待 Packt 出版的本书及类似书籍的新版本。
评估
-
在 Java 8 中引入了 _______ 接口,用于发出元素并支持执行基于流元素的各种操作的计算。
-
StackWalker类的以下哪个工厂方法创建具有指定堆栈帧信息访问权限的StackWalker类实例? -
getInstance() -
getInstance(StackWalker.Option option) -
getInstance(Set<StackWalker.Option> options) -
getInstance(Set<StackWalker.Option> options, int estimatedDepth) -
判断是 True 还是 False:
CompletableFutureAPI 由许多方法组成,这些方法是CompletionStage接口的实现,并且是Future的实现。 -
以下哪种方法用于在流中需要进行过滤类型以跳过所有重复元素并仅选择唯一元素。
-
distinct() -
unique() -
selectall() -
filtertype() -
判断是 True 还是 False:
CompletableFuture的一个巨大优势是它可以作为对象传递并多次使用,以启动不同的操作链。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









