







原文:
zh.annas-archive.org/md5/EBCF13D1CBE3CB1395B520B840516EFC译者:飞龙
前言
JavaScript 是一种不拘小节但优雅的语言,它发现自己处于历史上最大的软件转变的中心。它现在是用于在最普遍的平台上提供用户体验的主要编程语言:网络。
这一巨大的责任意味着 JavaScript 语言不得不在不断变化的需求中迅速成熟起来。对于新兴的 JavaScript 程序员或 Web 开发人员来说,这些变化意味着语言及其生态系统变得越来越复杂。如今,可用的框架和库的数量之多令人不知所措,即使对于在这个行业工作多年的人也是如此。
本书的任务是剥开世界放在这种语言上的混乱层和概念,揭示其潜在的本质,并考虑如何利用它来编写可靠和可维护的代码,重点放在可用性上。我们将从放大并以非常基本的方式考虑为什么我们甚至编写代码开始。我们将发现我们编写的代码并不是独立存在的。我们将探讨我们的代码如何在很大和很小的方面极大地影响我们的用户和其他程序员,并讨论我们如何满足他们的各种需求。
除了对清洁编码原则的基本探索,我们还将深入研究 JavaScript 本身,引导您了解语言,从其最基本的语法到更抽象的设计模式和约定。我们还将探讨如何以最清洁的方式记录和测试我们的代码。您应该对 JavaScript 语言有扎实的掌握,并对清洁代码有敏锐的感觉。
这本书适合谁?
这本书适合所有对提高他们的 JavaScript 技能感兴趣的人。无论您是业余爱好者还是专业人士,本书都有一些方面对您有价值。在技术知识方面,本书假定读者有一些先前的编程经验,至少对 JavaScript 本身有一些经验。从这本书中获益最多的读者是那些在 JavaScript 中已经编程了几个月或几年,但一直感到被其复杂性压倒,并不确定如何编写干净且无 bug 的 JavaScript 的人。
本书涵盖的内容
第一章,“设定场景”,要求您考虑我们为什么编写代码,并探讨了我们通过代码传达意图的多种方式。本章为您提供了一个坚实的基础,您可以在此基础上建立和调整对清洁代码的理解。
第二章,“清洁代码的原则”,使用真实的 JavaScript 示例来探讨清洁代码的四个原则:可靠性、效率、可维护性和可用性。这些重要的原则为本书的其余部分奠定了基础。
第三章,“清洁代码的敌人”,揭示了一些臭名昭著的清洁代码的敌人。这些是导致不洁净代码泛滥的力量和动态,例如自我中心的编程、糟糕的度量和货物崇拜。
第四章,“SOLID 和其他原则”,探讨了著名的 SOLID 原则,并通过将它们与函数式编程原则、迪米特法则和抽象原则联系在一起,揭示了它们更深层的含义。
第五章,“命名是困难的”,讨论了编程中最具挑战性的方面之一:命名事物。它提出了一些命名的具体挑战,并将基础命名理论与现实命名问题和解决方案联系在一起。
第六章,“基本类型和内置类型”,开始深入探讨 JavaScript。本章详细介绍了 JavaScript 程序员可用的基本类型和内置类型,警告常见陷阱并分享最佳实践。
第七章,“动态类型”,讨论了 JavaScript 的动态特性,并介绍了与此相关的一些挑战。它解释了我们如何清晰地检测和转换各种类型(通过显式转换或隐式强制转换)。
第八章,“运算符”,详细介绍了 JavaScript 中可用的运算符,讨论了它们的行为和挑战。这包括对每个运算符的详细说明,以及示例、陷阱和最佳实践。
第九章,“语法和作用域的部分”,提供了对语言的更宏观的视角,突出了更广泛的语法和可用的构造,如语句、表达式、块和作用域。
第十章,“控制流”,广泛涵盖了控制流的概念,突出了命令式和声明式编程形式之间的关键区别。然后探讨了如何通过利用控制移动机制(如调用、返回、产出、抛出等)在 JavaScript 中清晰地控制流。
第十一章,“设计模式”,广泛探讨了 JavaScript 中一些更流行的设计模式。它描述了 MVC 和 MVVM 等主要架构设计模式,以及更模块化的设计模式,如构造器模式、类模式、原型模式和揭示模块模式。
第十二章,“现实世界的挑战”,探讨了 JavaScript 生态系统中一些更现实的问题领域,并考虑了如何清晰地处理这些问题。涵盖的主题包括 DOM 和单页面应用程序、依赖管理和安全性(XSS、CSRF 等)。
第十三章,“测试的景观”,描述了测试软件的广泛概念,以及如何将这些概念应用到 JavaScript 中。它特别探讨了单元测试、集成测试、端到端测试和 TDD。
第十四章,“编写清晰的测试”,进一步深入探讨了测试领域,建议您以完全清晰、直观、代表问题领域和概念上分层的方式编写断言和测试套件。
第十五章,“更干净代码的工具”,简要考虑了几种可用的工具和开发流程,可以极大地帮助我们编写和维护清洁的代码。包括诸如代码检查、格式化、源代码控制和持续集成等主题。
第十六章,“记录你的代码”,揭示了文档编写的独特挑战。本章要求您考虑所有可用的文档媒介,并要求您考虑如何理解和满足可能希望使用或维护我们的代码的个人的需求和问题。
第十七章,“其他人的代码”,探讨了在我们的 JavaScript 项目中选择、理解和利用第三方代码的挑战(如第三方库、框架和实用工具)。它还讨论了允许我们以清晰和最小侵入方式与第三方代码进行交互的封装方法。
第十八章,“沟通和倡导”,探讨了在编写和交付干净软件时固有的更广泛的基于项目和人际关系的挑战。这包括对以下内容的详细调查:规划和设置要求、沟通策略以及识别问题和推动变革。
第十九章,“案例研究”,通过对 JavaScript 项目的开发进行逐步讲解,包括客户端和服务器端的部分。本章将本书中的原则汇集起来,并通过让您接触到一个真实的问题领域和可用解决方案的开发来加以证实。
为了充分利用本书
为了更好地利用本书,有必要对 JavaScript 语言有基本的了解,并且至少有一种 JavaScript 使用平台的经验。例如,这可能包括浏览器或 Node.js。
为了执行本书中分享的代码片段,您有几种选择:
-
创建一个包含
<script>的 HTML 文件,您可以在其中放置任何您想要测试的 JavaScript 代码。为了观察可视化输出,您可以使用alert()或console.log()。为了查看通过console.log()输出的值,您可以打开浏览器的开发工具。 -
直接打开任何现代浏览器的开发工具,并直接在 JavaScript 控制台中输入 JavaScript 表达式和语句。在 Chrome 浏览器中执行此操作的指南可以在这里找到:
developers.google.com/web/tools/chrome-devtools/console/javascript。 -
创建一个
test.js文件,并通过 Node.js 运行它,或者使用 Node.js REPL 来交互式地测试不同的 JavaScript 语句和表达式。有关开始使用 Node.js 的全面指南可以在这里找到:nodejs.org/en/docs/guides/getting-started-guide/。
浏览器开发工具可在所有现代浏览器中访问。快捷键如下:
-
在 Chrome 中:Windows 上按 Ctrl + Shift + J,macOS 上按 CMD + Shift + J
-
在 Firefox 中:Windows 和 Linux 上按 Ctrl + Shift + I 或 F12,macOS 上按 CMD + OPTION + I
-
在 IE 中:Windows 上按 F12
建议您按照自己的步调阅读本书,并在发现某个主题难以理解时,在网上进行额外的研究和探索。一些特别有用的资源包括以下内容:
-
Mozilla 开发者网络:
developer.mozilla.org/en-US/docs/Web/JavaScript -
ECMAScript 语言规范:
www.ecma-international.org/publications/standards/Ecma-262.htm
随着您在书中的进展,书中的内容会变得越来越详细,因此在后面的章节中放慢步伐是很自然的。这对于第 6-12 章尤其如此,这些章节非常详细地介绍了 JavaScript 语言本身的特性。
下载示例代码文件
您可以从www.packt.com的帐户中下载本书的示例代码文件。如果您在其他地方购买了本书,您可以访问www.packtpub.com/support并注册,以便文件直接通过电子邮件发送给您。
您可以按照以下步骤下载代码文件:
-
在www.packt.com上登录或注册。
-
选择“支持”选项卡。
-
点击“代码下载”。
-
在搜索框中输入书名,然后按照屏幕上的说明操作。
下载文件后,请确保使用以下最新版本的软件解压或提取文件夹:
-
Windows 系统使用 WinRAR/7-Zip
-
Mac 系统使用 Zipeg/iZip/UnRarX
-
7-Zip/PeaZip for Linux
该书的代码包也托管在 GitHub 上,网址为github.com/PacktPublishing/Clean-Code-in-JavaScript。如果代码有更新,将在现有的 GitHub 存储库上进行更新。
我们还有来自我们丰富书籍和视频目录的其他代码包,可在**github.com/PacktPublishing/**上找到。去看看吧!
下载彩色图像
我们还提供了一个 PDF 文件,其中包含本书中使用的屏幕截图/图表的彩色图像。您可以在这里下载:static.packt-cdn.com/downloads/9781789957648_ColorImages.pdf。
使用的约定
本书中使用了许多文本约定。
CodeInText:表示文本中的代码词,数据库表名,文件夹名,文件名,文件扩展名,路径名,虚拟 URL,用户输入和 Twitter 句柄。这是一个例子:“我们找到一个名为shipping_address_validator的公开可用的包,并决定使用它。”
代码块设置如下:
function validatePostalCode(code) {
return /^[0-9]{5}(?:-[0-9]{4})?$/.test(code);
}
任何命令行输入或输出都以以下方式编写:
npm install --save react react-dom
粗体:表示一个新术语,一个重要的词,或者屏幕上看到的词。例如,菜单或对话框中的单词会以这种方式出现在文本中。这是一个例子:“对于我们的案例研究,植物名称只以它们的拉丁全名存在,其中包括一个科(例如,Acanthaceae)。”
警告或重要提示会以这种方式出现。提示和技巧会以这种方式出现。
第一部分:清洁代码到底是什么?
在这一部分,我们将讨论代码的目的以及其原则,如清晰度和可维护性。我们还将涵盖命名事物的广泛挑战,以及一些有价值的问题和需要注意的危险。
这一部分包括以下章节:
-
第一章,设定场景
-
第二章,清洁代码的原则
-
第三章,清洁代码的敌人
-
第四章,SOLID 和其他原则
-
第五章,命名事物很难
第一章:设定场景
JavaScript 是由 Brendan Eich 于 1995 年创建的,旨在成为一种“粘合语言”。它旨在帮助网页设计师和业余爱好者轻松地操纵和从他们的 HTML 中派生行为。JavaScript 能够通过 DOM API 实现这一点,DOM API 是浏览器提供的一组接口,可以访问 HTML 的解析表示。不久之后,DHTML成为流行术语,指的是 JavaScript 实现的更动态的用户界面:从动画按钮状态到客户端表单验证等各种功能。最终出现了 Ajax,它实现了客户端和服务器之间的通信。这为潜在应用程序开辟了一个巨大的可能性。以前纯粹是文档领域的网络,现在正在成为一个处理器和内存密集型应用程序的强大平台:

1995 年,没有人能预测 JavaScript 有一天会被用来构建复杂的 Web 应用程序,编程机器人,查询数据库,为照片处理软件编写插件,并成为现存最受欢迎的服务器运行时之一,Node.js 的背后。
1997 年,JavaScript 在创立后不久由 Ecma International 标准化,以 ECMAScript 的名字,它仍在 TC39 委员会的频繁变更中。语言的最新版本根据发布年份命名,比如 ECMAScript 2020(ES2020)。
由于其不断增长的功能,JavaScript 吸引了一个充满激情的社区,推动了它的增长和普及。由于它的相当受欢迎,现在有无数种不同的方法可以在 JavaScript 中完成相同的事情。有成千上万的流行框架、库和实用程序。语言本身也在不断变化,以应对其应用程序日益增长的需求。这带来了一个巨大的挑战:在所有这些变化中,当被推拉到不同的方向时,我们如何知道如何编写最佳的代码?我们应该使用哪些框架?我们应该采用什么约定?我们应该如何测试我们的代码?我们应该如何构建明智的抽象?
为了回答这些问题,我们需要简要回顾基础知识。这就是本章的目的。我们将讨论以下内容:
-
代码的真正目的是什么
-
我们的用户是谁,他们有什么问题
-
为人类编写代码意味着什么
我们为什么写代码
简单来说,我们知道编程是关于指导计算机,但我们在指导它们做什么?以及为了什么目的?代码还有什么其他用途?
我们可以广泛地说,代码是解决问题的一种方式。通过编写代码,我们表达了一个复杂的任务或一系列操作,将它们浓缩成一个可以被用户轻松利用的单一过程。因此,我们可以说代码是问题领域的表达。我们甚至可以说它是一种沟通方式,一种传达信息和意图的方式。了解代码是一个具有许多互补目的的复杂事物,比如解决问题和沟通,将使我们能够充分发挥其潜力。让我们深入探讨一下这种复杂性,探索我们所说的代码作为传达意图的方法是什么意思。
代码的意图
我们经常认为代码只是计算机执行的一系列指令。但在很多方面,这忽略了我们写代码时所做的真正魔力。当我们传达指令时,我们在向世界表达我们的意图;我们在说“这些是我想发生的事情”。
人类一直以来都在传达指令。一个简单的烹饪食谱就是一个例子:
切大约 300 克黄油(小方块!)
取 185 克黑巧克力
在平底锅上用黄油融化
打破半打鸡蛋,最好是大个的
将它们与几杯糖混合在一起
像这样的指令对人类来说很容易理解,但您会注意到它们没有严格的规范。计量单位不一致,标点和措辞也不一致。一些指令非常模棱两可,因此对于以前没有做过饭的人来说,容易产生误解:
-
什么构成一个大鸡蛋?
-
何时应该考虑黄油完全融化?
-
深色巧克力应该有多深?
-
小方块黄油有多小?
-
在锅上是什么意思?
人类通常可以通过他们的主动性和经验来应对这种模棱两可,但机器并不那么擅长。机器必须被指示具有足够的具体性来执行每一步。我们希望向机器传达的是我们的意图,也就是请做这件事,但由于机器的性质,我们必须非常具体。值得庆幸的是,我们选择如何编写这些指令取决于我们;有许多编程语言和方法,几乎所有这些方法都是为了让人类以更轻松的方式传达他们的意图而创建的。
人类能力和计算能力之间的距离迅速缩小。机器学习、自然语言处理和高度专业化的程序的出现意味着机器在能够执行的指令类型上更加灵活。然而,代码将继续有用一段时间,因为它使我们能够以一种高度具体和标准化的方式进行沟通。通过这种高度的具体性和一致性,我们可以更有信心地相信我们的指令每次都会按照预期执行。
谁是用户?
在考虑用户时,没有关于编程的有意义的对话。用户,无论他们是其他程序员还是 UI 的最终用户,都是我们所做的核心。
让我们想象一下,我们的任务是验证网站上用户输入的送货地址。这个特定的网站向世界各地的医院销售药物。我们有点匆忙,宁愿使用别人已经实施的东西。我们找到了一个名为shipping_address_validator的公开可用的包,并决定使用它。
如果我们花时间检查包中的代码,在其邮政编码验证文件中,我们会看到这样:
function validatePostalCode(code) {
return /^[0-9]{5}(?:-[0-9]{4})?$/.test(code);
}
这个validatePostalCode函数碰巧使用了正则表达式(也称为RegExp和 regex),用斜杠分隔,以定义要与字符串匹配的字符模式。您可以在第六章中阅读更多关于这些构造的内容,原始和内置类型。
不幸的是,由于我们的匆忙,我们没有质疑shipping_address_validator包的功能。我们假设它做了罐头上说的那样。发布代码到生产环境后一周,我们收到了一个错误报告,说一些用户无法输入他们的地址信息。我们查看代码后,惊恐地意识到它只验证美国的邮政编码,而不是所有国家的邮政编码(例如,它无法在英国邮政编码上运行,比如 GR82 5JY)。
通过这一系列不幸的事件,这段代码现在负责阻止成千上万的全球客户的重要药物发货。幸运的是,修复它并不需要太长时间。
暂且不论谁对这一失误负责,我想提出以下问题:这段代码的用户是谁?
-
我们,程序员,决定使用
shipping_address_validator包? -
那些试图输入他们地址的无意的客户?
-
在医院等待他们药物的患者?
这个问题没有明确的答案。当代码中出现错误时,我们可以看到可能会产生巨大的不幸的下游影响。原始程序包的程序员是否应该关心所有这些下游依赖关系?当聘请一名管子工来修理水槽上的水龙头时,他们只应该考虑水龙头本身的功能,还是倾倒进入其中的水槽?
当我们编写代码时,我们正在定义一个隐含的规范。这个规范通过它的名称、配置选项、输入和输出来传达。使用我们代码的任何人都有权期望它按照规范工作,所以我们越明确越好。如果我们正在编写只验证美国邮政编码的代码,那么我们应该相应地命名它。当人们在我们的代码之上创建软件时,我们无法控制他们如何使用它。但我们可以明确地传达关于它的信息,确保其功能清晰且符合预期。
重要的是要考虑我们代码的所有用例,想象它可能被使用的方式以及人类对它的期望,包括程序员和最终用户。我们对什么负责或负有责任是值得讨论的,这既是一个法律问题,也是一个技术问题。但我们的用户是谁的问题完全取决于我们。根据我的经验,更好的程序员会考虑到所有用户,意识到他们编写的软件并不是在真空中存在的。
问题是什么?
我们已经谈到了用户在编程中的重要性,以及如果我们希望有帮助他们的希望,我们必须首先了解他们希望做什么。
只有通过了解问题,我们才能开始组装我们的代码必须满足的要求。在探索问题时,有必要问自己以下问题:
-
用户遇到了什么问题?
-
他们目前是如何执行这项任务的?
-
有哪些现有解决方案,它们是如何工作的?
当我们完全了解了问题后,我们就可以开始构思、规划和编写代码来解决它。在每一步,我们通常在不知不觉中会以对我们有意义的方式对问题进行建模。我们思考问题的方式将对我们最终创建的解决方案产生重大影响。我们创建的问题模型将决定我们最终编写的代码。
问题的模型是什么? 模型或概念模型是描述事物运作方式的图表或表示。我们在不知不觉中一直在创建和调整模型。随着时间的推移,随着您对问题领域的了解增加,您的模型将得到改进,以更好地符合现实。
让我们想象一下,我们负责为学生设计一个笔记应用,并且被要求为用户表达的以下问题创建一个解决方案:
“我有很多学习笔记,所以发现很难对它们进行组织。具体来说,当试图找到有关某个主题的笔记时,我会尝试使用搜索功能,但很少能找到我要找的内容,因为我并不总是能回忆起我写的具体文字。”
我们已经决定这需要对软件进行更改,因为我们已经从其他用户那里听到了类似的事情。因此,我们坐下来尝试想出各种想法,看看我们如何改进笔记的组织。我们可以探索一些选项:
-
分类:将为分类创建一个分层文件夹结构。有关长颈鹿的笔记可能存在于学习/动物学下。分类可以通过手动或搜索轻松导航。
-
标签:将能够使用一个或多个单词或短语对笔记进行标记。有关长颈鹿的笔记可能会被标记为哺乳动物和长颈。标签可以通过手动或搜索轻松导航。
-
链接:引入一个链接功能,使笔记可以链接到其他相关的笔记。例如,关于长颈鹿的笔记可能会被链接到另一篇笔记,比如长颈动物。
每个解决方案都有其利弊,也有可能实现它们的组合。显而易见的一点是,这些解决方案将极大地影响用户最终使用应用程序的方式。我们可以想象,用户接触到这些解决方案后,会在他们的脑海中形成“记笔记”的模型:
-
类别:我写的笔记在我的分类层次结构中有它们的位置
-
标签:我写的笔记涉及许多不同的事情
-
链接:我写的笔记与我写的其他笔记相关
在这个例子中,我们正在开发一个 UI,因此我们与应用程序的最终用户非常接近。然而,问题建模适用于我们所做的所有工作。如果我们为笔记保存创建一个纯粹的 REST API,那么将需要做出完全相同的考虑。Web 程序员在决定其他人最终采用的模型方面起着关键作用。我们不应该轻视这一责任。
真正理解问题领域
典型的失败点通常是对问题的误解。如果我们不了解用户真正想要实现什么,也没有收到所有的需求,那么我们将不可避免地保留问题的错误模型,从而实施错误的解决方案。
想象一下,在水壶发明之前的某个时刻发生了这种情况:
-
苏珊娜(工程师):马特,我们被要求设计一个用户可以煮水的容器
-
马修(工程师):明白了;我会创建一个完全符合要求的容器
马修没有提出任何问题,立即开始工作,对能够将自己的创造力发挥出来感到兴奋。一天后,他想出了以下装置:
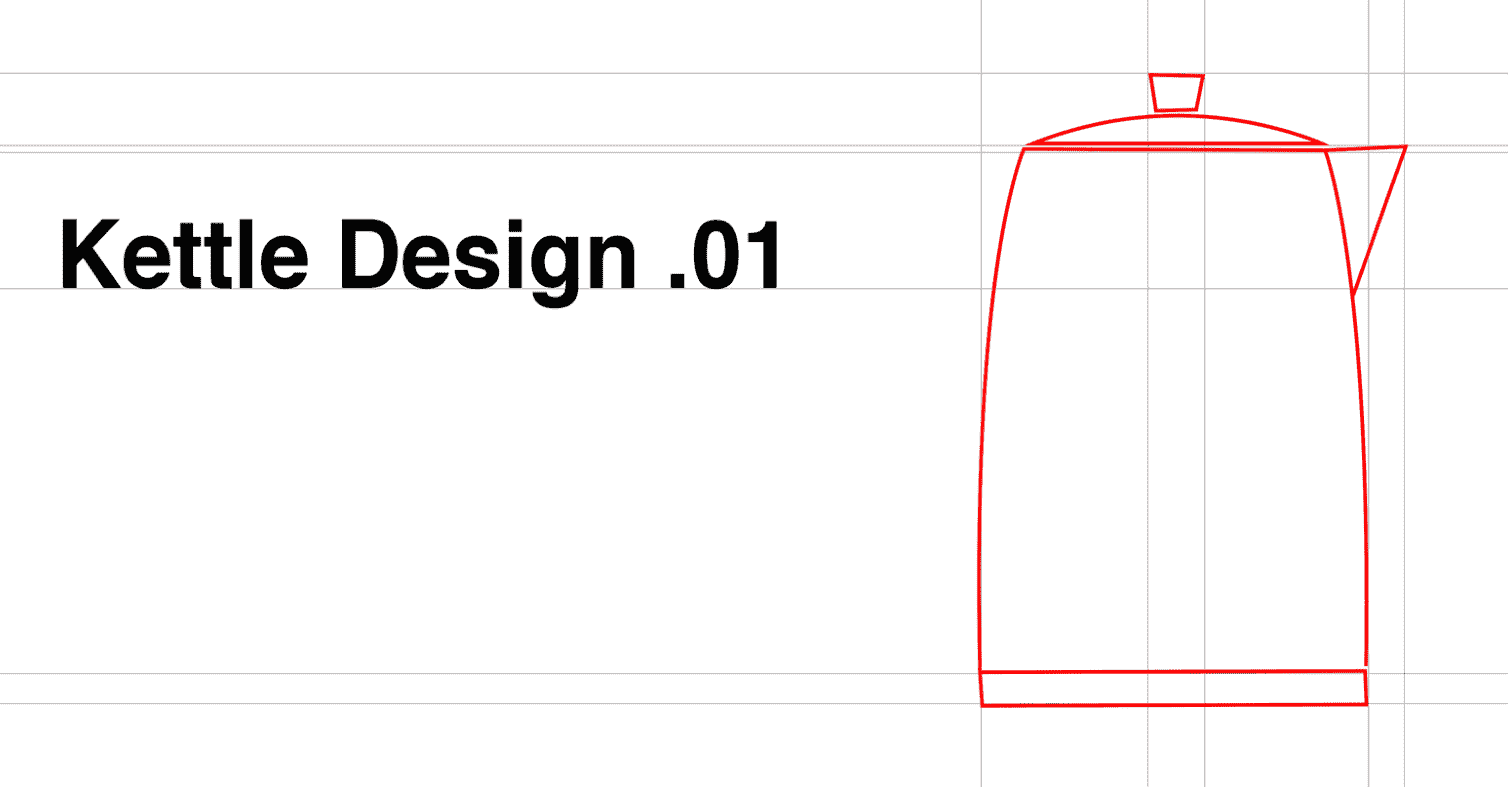
很明显,马修忘记了一个关键组成部分。在匆忙中,他没有停下来向苏珊娜询问有关用户或问题的更多信息,因此没有考虑到用户可能需要以某种方式拿起热气腾腾的容器。在收到反馈后,他自然而然地为水壶设计并引入了一个手柄:
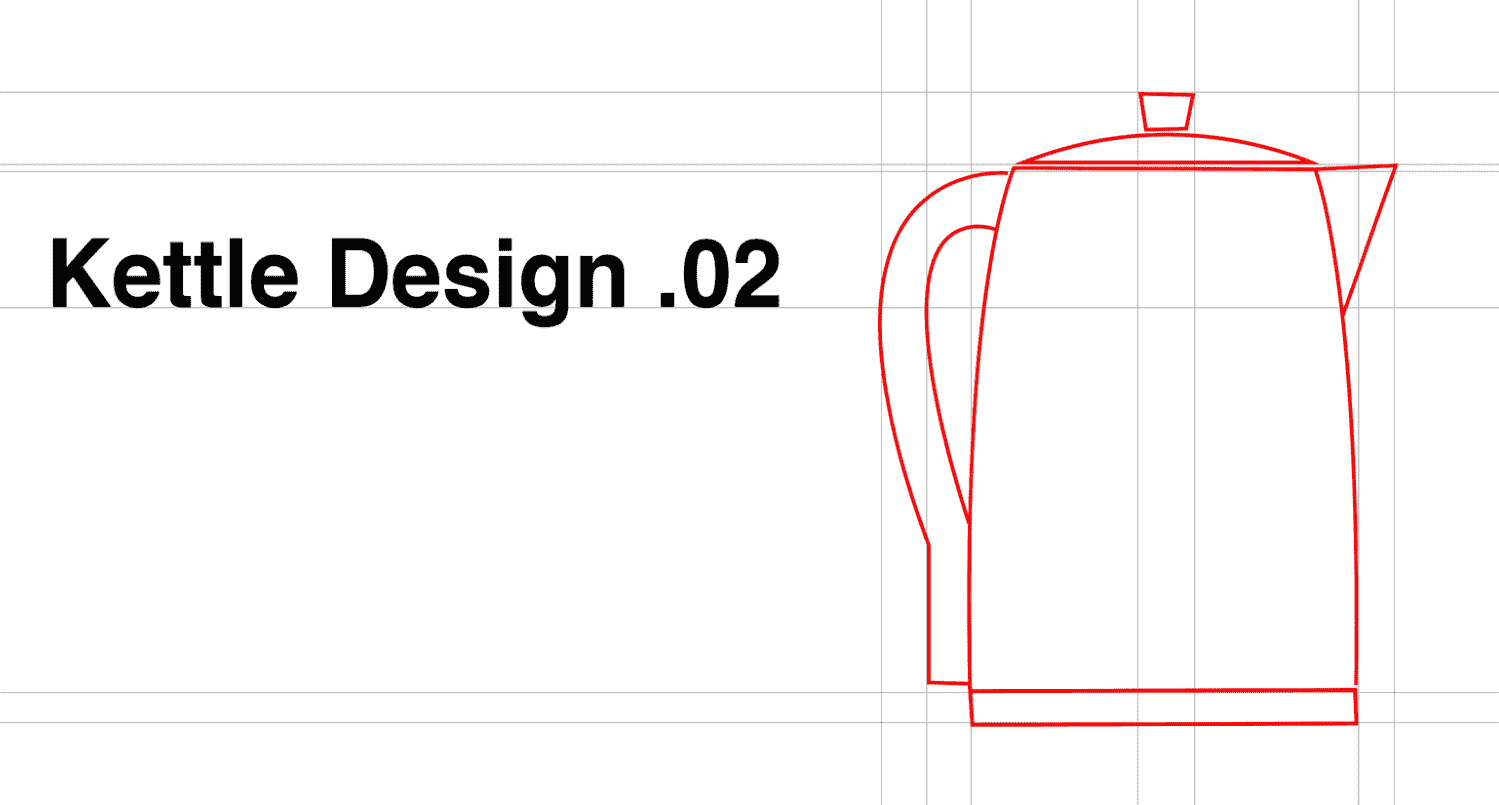
然而,这完全没有必要发生。想象一下,将这种水壶情景推广到跨越多个月的大型软件项目的复杂性和长度。想象一下在这样的误解中涉及的头痛和不必要的痛苦。解决问题的关键在于首先正确和完整地理解问题。如果没有这一点,我们甚至在开始之前就会失败。这在设计大型项目中很重要,但也在实现最小的 JavaScript 实用程序和组件中很重要。事实上,在我们编写的每一行代码中,如果我们不首先了解问题领域,我们都将完全有可能失败。
问题领域不仅包括用户遇到的问题,还包括通过我们可用的技术来满足他们需求的问题。因此,例如,在浏览器中编写 JavaScript 的问题领域包括 HTTP 的复杂性,浏览器对象模型,DOM,CSS 以及其他一系列细节。一个优秀的 JavaScript 程序员不仅必须精通这些技术,还必须理解用户遇到的新问题领域。
为人类编写代码
整本书都致力于教你如何在 JavaScript 中编写干净的代码。在接下来的章节中,我们将详细讨论几乎语言中的每个构造。首先,我们需要确定几个重要的观点,在我们考虑为人类编写干净代码意味着什么时,这些观点将非常重要。
沟通意图
我们可以说,为人类编写代码在广义上是关于意图的清晰度。而为机器编写代码在广义上是关于功能性。当然,这些需求会交叉,但是区分这种差异是至关重要的。如果我们只为机器编写代码,只关注功能,忘记了人类的受众,我们就能看到这种区别。这里有一个例子:
function chb(d,m,y) {
return new Date(y,m-1,d)-new Date / 6e4 * 70;
}
你明白这段代码在做什么吗?你可能能够解释这段代码在做什么,但它的意图——它的真正含义——几乎不可能被理解。
如果我们清楚地表达我们的意图,那么前面的代码看起来会像这样:
const AVG_HEART_RATE_PER_MILLISECOND = 70 / 60000;
function calculateHeartBeatsSinceBirth(birthDay, birthMonth, birthYear) {
const birthMonthIndex = birthMonth - 1;
const birthDate = new Date(birthYear, birthMonthIndex, birthDay);
const currentDate = new Date();
return (currentDate - birthDate) / AVG_HEART_RATE_PER_MILLISECOND;
}
从前面的代码中,我们可以看出这个函数的意图是计算自出生以来心脏跳动的次数。这两段代码之间在功能上没有区别。然而,后一段代码更好地传达了程序员的意图,因此更容易理解和维护。
我们编写的代码主要是为了人类。你可能正在构建一个宣传网站,编写一个 Web 应用程序,或者为框架制作一个复杂的实用函数。所有这些都是为人类而做的:那些作为我们代码驱动的 GUI 的最终用户,或者那些使用我们抽象和接口的程序员。程序员的业务是帮助这些人。
即使你只是为自己编写代码,没有任何可能被其他人以任何方式使用,如果你写出清晰的代码,你未来的自己会感谢你。
可读性
当我们编写代码时,考虑人类大脑如何消化它是至关重要的。其他程序员会扫视你的代码,阅读相关部分,试图对其内部运作有一个运行的理解。可读性是他们必须克服的第一个障碍。如果他们无法阅读和认知地导航你写的代码,那么他们将更难使用它。这将严重限制你的代码的效用和价值。
根据我的经验,程序员不太喜欢以审美设计的方式思考代码,但是最好的程序员会欣赏到这些概念是内在联系的。我们代码的设计在呈现或视觉意义上与其架构设计一样重要。设计最终是关于以最佳方式为用户提供目的的创造。对于我们的同行程序员,这个目的是理解。因此,我们必须设计我们的代码来实现这个目的。
机器纯粹关心规范,并会轻松地将有效的代码解析成其部分。然而,人类更加复杂。我们在机器擅长的领域能力较弱,这也是它们存在的原因,但我们在机器可能失败的领域也很有技巧。我们高度进化的大脑,在其众多才能中,已经变得非常擅长发现模式和不一致之处。我们依赖差异或对比来集中我们的注意力。如果一个模式没有被遵循,那么对我们的大脑来说就会产生更多的工作。举个不一致的例子,看看这段代码:
var TheName='James' ;
var City = 'London'
var hobby = 'Photography',job='Programming'
你可能不喜欢看这段代码。它的混乱让人分心,似乎没有遵循任何特定的模式。命名和间距是不一致的。我们的大脑在这方面很吃力,因此阅读代码,对其有一个完整的理解,变得更加认知昂贵。
我们可以重构前面的代码,使其更加一致,如下所示:
var name = 'James';
var city = 'London';
var hobby = 'Photography';
var job = 'Programming';
在这里,我们使用了单一的命名模式,并在每个语句中采用了一致的语法和间距。
或者,也许我们想在单个var声明中声明所有变量,并对齐赋值(=)运算符,使所有值沿着相同的垂直轴开始:
var name = 'James',
city = 'London',
hobby = 'Photography',
job = 'Programming';
你会注意到这些不同的风格非常主观。有些人喜欢一种方式,其他人喜欢另一种方式。这都没问题。我并没有说哪种方法更优越。相反,我指出,如果我们关心为人类编写代码,那么我们应该首先关心其可读性和表现,而一致性是其中的关键部分。
有意义的抽象
当我们编写代码时,我们不断使用和创建抽象。抽象是当我们将复杂性简化后提供对该复杂性的访问时发生的。通过这样做,我们使人们能够利用这种复杂性,而无需完全理解它。这个想法支撑着大多数现代技术:

JavaScript,像许多其他高级语言一样,提供了一种抽象,使我们不必担心计算机的运行细节。例如,我们可以忽略内存分配的问题。即使我们必须对硬件的限制敏感,特别是在移动设备上,我们很少会考虑它。语言不要求我们这样做。
浏览器也是一个著名的抽象。它提供了一个图形用户界面,抽象掉了 HTTP 通信和 HTML 渲染等许多细节。用户可以轻松地浏览互联网,而无需担心这些机制。
在本书的后续章节中,我们将学习更多关于如何打造良好抽象的知识。目前,可以说:在你写的每一行代码中,你都在使用、创建和传达抽象。
抽象的塔
抽象的塔是一种看待技术复杂性的方式。在基础层,我们有计算中依赖的硬件机制,如 CPU 中的晶体管和 RAM 中的存储单元。在上面,我们有集成电路。再上面,有机器码、汇编语言和操作系统。再上面,有几层,有浏览器和其 JavaScript 运行时。每一层都将复杂性抽象化,以便上面的层可以在不费太多力气的情况下利用这种复杂性:

当我们为浏览器编写 JavaScript 时,我们已经在一个非常高的抽象塔上操作。这座塔越高,操作起来就越不稳定。我们依赖于每个部分都按预期工作。这是一个脆弱的系统。
当我们考虑我们的用户时,抽象的塔是一个有用的比喻。当我们编写代码时,我们正在为这座塔增添东西,一层又一层地建造。我们的用户总是位于这座塔的上方,利用我们精心打造的机制来实现他们自己的目标。这些用户可能是利用我们的代码的其他程序员,为系统增加更多的抽象层。或者,我们的用户可能是软件的最终用户,通常坐在塔顶,通过简化的图形用户界面利用其庞大的复杂性。
干净代码的层次
在本书的下一部分中,我们将以本章讨论的基本概念为基础,并用我们自己的抽象来构建;这些抽象是我们在软件行业中用来谈论编写干净代码意味着什么的抽象。
如果我们说我们的软件是可靠的或可用的,那么我们正在运用抽象概念。这些概念必须被深入挖掘。在后面的章节中,我们还将剖析 JavaScript 的内部,看看处理支撑我们程序的语法的各个部分意味着什么。到本书结束时,我们应该能够说我们对从单独可读的代码行到设计良好且可靠的架构的多个层次的干净代码有完整的了解。
摘要
在这一章中,我们已经为自己打下了良好的基础,探索了支撑我们所有编写的代码的基本原理。我们已经讨论了我们的代码如何表达意图,以及为了构建这种意图,我们必须对用户需求和我们所涉及的问题领域有深刻的理解。我们还探讨了如何编写对人类清晰易读的代码,以及如何创建清晰的抽象,为用户提供利用复杂性的能力。
在下一章中,我们将以清晰代码的具体原则:可靠性、效率、可维护性和可用性,来进一步构建这一基础。这些原则将为我们提供重要的视角,因为我们将继续研究 JavaScript 的许多方面,以及我们如何运用它来服务于清晰的代码。
第二章:清洁代码的原则
在上一章中,我们讨论了代码开头的目的:为用户解决问题。我们讨论了迎合机器和人的困难。我们提醒自己,写代码的核心是传达意图。
在本章中,我们将从这些基础中得出四个核心原则,这些原则在创建软件时是必要考虑的。这些原则是可靠性、效率、可维护性和可用性。一个好的软件可以说具有所有这些品质。一个糟糕的软件可以说没有一个。然而,这些原则并不是规则。相反,将它们视为您可以查看代码的透镜是有用的。对于每个原则,我们将通过类比和 JavaScript 示例的混合来发现它的重要性。您应该能够从本章中学会将这些原则应用到您的代码中。
具体来说,我们将涵盖以下原则:
-
可靠性
-
效率
-
可维护性
-
可用性
可靠性
可靠性是一个良好软件系统的核心支柱。没有可靠性,技术的实用性很快就会消失,使我们陷入一种可能更好不使用它的境地。技术的整个目的可能会被不可靠性所破坏。
然而,可靠性不仅仅是大型和复杂软件系统的特征。每一行代码都可以构建成不可靠或可靠的。但是这是什么意思呢?可靠性这个词指的是可靠的质量。编写可以让人们依赖的代码是什么意思呢?通过定义三个不同的特质来帮助定义可靠性:可靠性是正确、稳定和有弹性的质量。
正确性
正确的代码是符合一组期望和要求的代码。如果我编写一个函数来验证电子邮件地址,那么期望是该函数可以使用各种类型的电子邮件地址进行调用,并正确地确定它们的有效性或无效性,如下所示:
isValidEmail('someone@example.org'); // => true
isValidEmail('foo+bar_baz@example.org'); // => true
isValidEmail('john@thecompany.$$$'); // => false
isValidEmail('this is not an email'); // => false
要编写正确的代码,我们必须首先了解要求是什么。要求是我们对代码行为的正式期望。对于先前的电子邮件验证函数的情况,我们可能有以下要求:
-
当传递有效的电子邮件地址作为第一个参数时,该函数将返回
true -
否则,该函数将返回
false
然而,第一个要求是模棱两可的。我们需要弄清楚电子邮件地址甚至是什么意思才能有效。电子邮件地址看起来是一个简单的格式;然而,实际上有许多边缘情况和奇怪的有效表现。例如,根据 RFC 5322 规范,以下电子邮件地址在技术上是有效的:
-
admin@mailserver1 -
example@s.example -
john..doe@example.org
要知道我们的函数是否应该完全符合 RFC 规范,我们首先需要了解它的真正用例。它是电子邮件客户端软件的实用程序,还是可能在社交媒体网站的用户注册中使用?在后一种情况下,我们可能希望将更奇特的电子邮件地址视为无效,类似于之前列出的那些。我们甚至可能希望 ping 一下域名的邮件服务器来确认其存在。关键是要弄清楚确切的要求将为我们提供正确的含义。
顺便说一句,自己编写电子邮件验证函数是非常不明智的,因为有许多边缘情况需要考虑。这突显了我们追求可靠性时需要考虑的一个重要问题;通常,我们可以通过使用现有的经过验证的开源库和实用程序来实现最高级别的可靠性。在第十七章中,其他人的代码,我们将详细讨论选择第三方代码的过程以及需要注意的事项。
我们编码的要求应该始终直接源自我们的代码将如何使用。从用户及其问题开始非常重要;从那里,我们可以建立一组清晰的要求,可以进行独立测试。测试我们的代码是必要的,这样我们就可以确认,对自己和利益相关者来说,我们的代码是否满足所有不同的要求。
通过以前的电子邮件地址验证示例,一组良好的测试将包括许多电子邮件地址的变化,确保所有边缘情况都得到充分考虑。在第十三章中,测试的景观,我们将更详细地讨论测试。然而,现在,简单地反思正确性的重要性以及我们可以建立和确认的方式就足够了:
-
了解正在解决的问题以及用户的需求
-
将您的要求细化,直到清楚明确需要什么
-
测试您的代码以验证其正确性
稳定性
稳定性是我们在所有技术中都希望具备的特征。没有稳定性,事情就会变得不稳定;我们会不确定事情是否会在任何时刻发生故障。稳定性最好由现实世界技术的一个常见例子来说明。比较这两座桥:

[来自 Unsplash 的照片/由 Zach Lezniewicz/由 Jacalyn Beales]
它们在技术上都是正确的桥梁。然而,其中一座之前曾遭受损坏,并且已经用一块简单的木板修复。你会相信哪座桥安全地运送一百人?可能是右边的那座。它牢固地固定在那里,有护栏,而且关键的是,没有可以掉下去的缝隙。
在代码中,我们可以说稳定性是关于在不同有效输入和情况下持续正确的行为。浏览器中的 JavaScript 特别容易出现这种失败。它必须在多种条件下运行,包括不同的硬件、操作系统、屏幕尺寸,而且通常在具有不同功能的浏览器中。
如果我们编写的代码严重依赖于某些条件,那么当这些条件不存在时,它可能会变得笨拙和不可靠。例如,如果我们设计和实现网络应用程序的布局,可能会忘记考虑并适应小于 1,024 像素宽的屏幕尺寸,导致以下混乱:
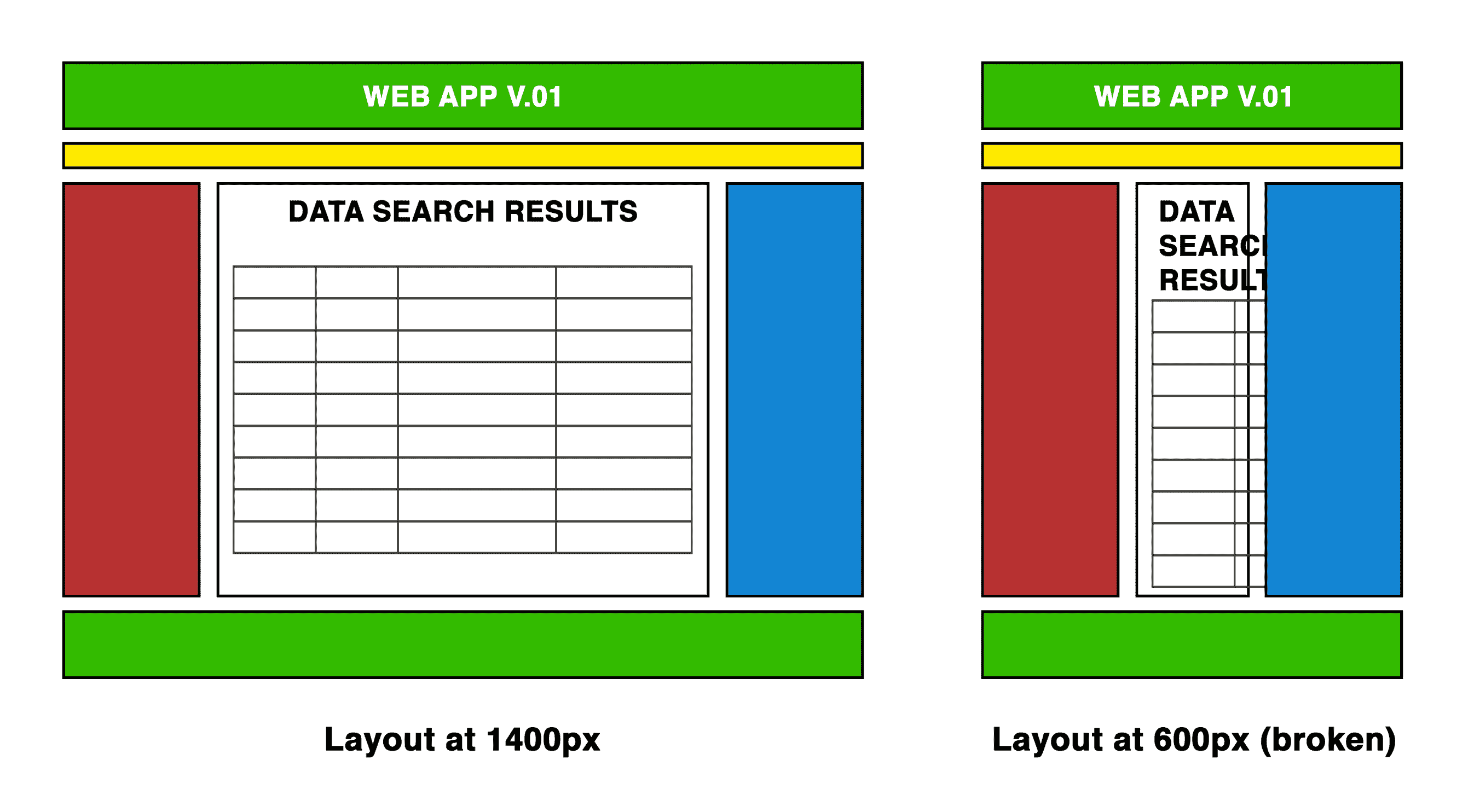
这是一个不稳定的例子。当某个环境因素不同时,无法依赖网络应用程序提供其正确的行为。在移动设备使用不断增加的世界中,屏幕尺寸小于 1,024 像素的情况是完全可能和合理的;这是我们网络应用程序的绝对有效用例,而未能适应它会对用户依赖它的能力产生负面影响。
稳定性是通过充分了解代码可能暴露的所有不同有效输入和情况来获得的。与正确性类似,稳定性最好通过一组测试来确认,这些测试将代码暴露给各种输入和情况。
弹性
弹性是关于避免失败的。稳定性主要关注预期输入,而弹性关注的是当您的代码暴露于意外或非例行输入时会发生什么。软件系统中的弹性也被称为容错,有时会以冗余或应急措施的形式讨论。从根本上讲,所有这些都是为了实现同样的目标——最小化失败的影响。
对于关键系统,生命取决于持续功能的情况,通常会在系统中建立各种应急措施。如果出现故障或故障,系统可以利用其应急措施隔离和容忍该故障。
在为航天飞机建造飞行控制系统时,美国国家航空航天局(NASA)通过使用一组同步冗余的机器来为系统构建了弹性。如果一个机器由于意外情况或错误而失败,那么另一个机器将接管。回到地球上,我们在医院中建立了备用发电机,如果电力网断电,备用发电机将立即启动。同样,一些城市交通网络在火车不运行的情况下会受益于替代公交车服务的应急措施。
这些庞大而复杂的系统似乎与 JavaScript 的世界相去甚远。但通常情况下,我们也在不知不觉中经常考虑并在我们的代码库中实现弹性。我们实现这一点的一种方式是通过优雅降级。当我们为浏览器环境编写 JavaScript 时,我们有一些关键的期望:
-
JavaScript 将通过 HTTP 正确传递
-
JavaScript 的版本得到浏览器支持
-
JavaScript 没有被广告拦截器或其他附加组件阻止
-
浏览器通常没有禁用 JavaScript
如果这些条件中的任何一个不成立,用户可能面临完全无法使用的网站或 Web 应用程序。缓解这些问题的方法是考虑优雅降级。优雅降级涉及应用程序的一些方面降级到仍然可以使用的状态,即使在面对意外故障时仍然对用户有用。
优雅降级通常以一个简单的扶梯来说明:

[照片来自 Unsplash,由 Teemu Laukkarinen 拍摄]
当扶梯正常运行时,它会通过一组由强大的齿轮系统和电动机驱动的移动金属台阶传送人们。如果系统由于任何原因失败,那么扶梯将保持静止,就像一般的楼梯一样。因此,可以说扶梯具有弹性,因为即使发生意外故障,它们仍然可用。用户仍然可以通过扶梯上下移动,尽管可能需要更长的时间。
在编写 JavaScript 时,我们可以通过检测我们依赖的功能并仅在可用时使用它们来为我们的代码构建弹性。例如,我可能希望向用户播放 MP3 音频。为了实现这一点,我将使用 HTML5 音频元素。然而,在这之前,我将检测浏览器是否支持 MP3 音频。如果不支持,我可以通知用户并指引他们阅读音频的转录:
function detectAudioMP3Support() {
const audio = document.createElement('audio');
const canPlayMP3 = audio.canPlayType &&
audio.canPlayType('audio/mpeg; codecs="mp3"')
return canPlayMP3 === 'probably';
}
function playAudio() {
if (detectAudioMP3Support()) {
// Code to play the audio
// ...
} else {
// Code to display link to transcript
// ...
}
}
上述代码使用 HTMLMediaElement 的canPlayType方法来识别支持。我们将这一点抽象成一个detectAudioMP3Support函数,然后调用它来决定我们是否继续播放音频,或者显示音频的转录。显示音频的转录是一种优雅降级,因为它仍然允许用户在无法播放音频的情况下获得一些效用。
重要的是要注意,仅仅进行功能检测本身并不是优雅降级。如果我检测到 MP3 支持,但如果不可用则默默失败,那就不会有太大作用。然而,为我们的用户激活替代路径——在这种情况下,启用音频的转录阅读——是优雅降级和对故障的弹性的完美例子。
将弹性构建到软件中有一些奇怪之处。通过考虑和适应潜在的意外故障状态,我们实际上是在使这些故障状态变得可预期。这使我们的软件更加稳定和更加可用。随着时间的推移,我们曾经需要对其进行弹性处理的问题现在将成为软件稳定性的日常部分。
韧性是编写清晰、可靠代码的重要组成部分。从根本上说,我们编写代码是为了解决用户的问题。如果我们的代码能够容忍和适应边缘情况、意想不到的情况和意外的输入,那么它将更有效地实现这一目的。
效率
我们生活在一个资源有限的世界中。为了编写最佳的代码,我们需要考虑到这种稀缺性。因此,在设计和实现我们的想法时,我们应该着眼于效率。
在本节中,我们将通过示例探讨效率的不同方面,并将它们与 JavaScript 的世界联系起来。希望您能对效率不仅仅是快速的概念有所了解,而是包含许多间接影响,从经济到生态的方方面面。
时间
时间是我们一直关注的一个关键稀缺资源。时间是一种重要的资源,我们应该只在经过考虑后才使用。在编程世界中,我们应该寻求优化在任何给定任务上花费的时间或 CPU 周期的数量。这是为了迎合我们的最终用户,因为他们自己的时间有限,但也是为了谨慎使用有限且昂贵的硬件。
在 JavaScript 中,几乎任何函数都有更高效和更低效的编写方式。例如,这个函数,它删除数组中的重复字符串:
function removeDuplicateStrings(array) {
const outputArray = [];
array.forEach((arrayItem, index) => {
// Check if the same item exists ahead of where we are.
// If it does, then don't add it to the output.
if (array.indexOf(arrayItem, index + 1) === -1) {
outputArray.push(arrayItem);
}
});
return outputArray;
}
这段代码是可靠的,满足要求,并且在大多数情况下都是完全可以的。但它做了不必要的工作。在数组的每次迭代中,它都会重新遍历整个数组,从当前索引开始发现是否存在重复值。这种方法可能看起来有点直观,但是很浪费。
我们可以不再检查整个输入数组,而是只需检查现有的输出数组是否包含特定值。如果输出数组已经包含该值,那么我们就知道不需要再添加它。这是我们稍微优化过的if条件:
// Check if the same item exists already in the output array.
// If it doesn't, then we can add it:
if (outputArray.indexOf(arrayItem) === -1) {
outputArray.push(arrayItem);
}
还有其他优化的方法,取决于有多少个唯一值,以及输入数组的大小。例如,我们可以将找到的值存储为对象中的键(HashMap方法),这在某些情况下可以减少查找时间。
要谨慎对代码进行微观优化。它们可能并不总是值得成本。相反,首先衡量代码的性能,然后解决真正存在的性能瓶颈。
花费太长时间在一个任务上可能会对用户执行任务的能力产生重大影响。在本章的后面,我们将讨论可用性的原则,但现在重要的是要注意,时间效率不仅在原则上很重要;它之所以重要是因为在规模上,这些通常微小的效率努力可能对可用性产生巨大的积极影响。
空间
空间是一种稀缺资源,与事物的大小有关。数据在网络和机器之间穿梭,在 RAM 中临时存储,可能以硬盘或固态驱动器(HDD、SSD)的形式保存到永久存储中。作为效率的倡导者,我们只对完成给定任务所需的空间感兴趣,其中一部分是以最有效的方式使用可用空间,并且只在有必要时移动数据。
由于 JavaScript 语言的高级特性和通常构建的应用程序,我们很少需要考虑临时 RAM 使用或永久存储。然而,JavaScript 在性能敏感的环境中已经取得了显著进展,例如数据库基础设施和 HTTP 中间件,因此这些问题现在更加相关。
此外,客户端应用程序的需求在浏览器和本地环境中都大大增加。这些应用程序的复杂性意味着我们必须时刻保持警惕,考虑如何优化服务器、用户设备和日益复杂的网络上的内存和带宽使用。我们在 Web 应用程序中吸收的带宽将直接影响用户等待应用程序可用的时间。
首次渲染时间是我们在开发 Web 应用程序前端时感兴趣的常见指标。通过谨慎使用大型资源并不阻塞初始加载时间来优化这一点。
时间和空间效率是紧密相连的,两者直接影响彼此。效率的总体主题是只做必要的事情,避免浪费,并节约可用资源。
效率的影响
时间和空间效率在软件本身和更广泛的世界中负责许多其他效应,两者都直接影响另一个。没有优化是孤立存在的。在一个领域节省的资源将总是在其他领域产生连锁效应。同样,任何不必要的成本通常会在后续产生瓶颈和问题。
有太多这些效应可以列举,但在软件世界中一些最明显的效应包括以下内容:
-
电力消耗的生态效应(例如气候变化)
-
使用慢软件所带来的认知负担(例如分散注意力和烦恼)
-
用户设备的电池寿命,因此他们选择优先考虑的任务
我们在做出选择时,始终要考虑我们所做选择的连锁效应,无论是为了效率还是其他要求。我们所创造的一切都不是孤立存在的。
可维护性
可维护性是指可以对您的代码进行适当更改的容易程度。与机动车不同,代码通常不需要例行维护来避免生锈等问题,但它仍然需要不时修复。对其功能的更改也经常是必要的,特别是在积极开发时。我们所工作的大部分代码也正在被其他人积极开发。这种共享所有权在很大程度上依赖于可维护性的原则。
使代码易于维护不应该成为一个次要的优先事项。这与代码满足的任何其他要求一样重要。在第一章中,我们谈到了考虑用户是多么重要。如果我们不考虑维护和更改我们的代码的人也是我们的用户,那就是虚伪的。他们希望使用我们创建的东西来实现某种目的;因此,他们是我们的用户。因此,我们需要考虑如何最好地满足他们的需求。
在接下来的部分中,我们将探讨可维护性的两个方面:适应性和熟悉度。
适应性
可以说,最好的维护是不需要发生的维护。适应性是指您的代码适应和适应不同需求和环境的能力。代码不能无限适应。代码的本质是为特定目的而制定的;解决用户的特定问题。我们可以并且应该在我们的代码中提供一定程度的配置,以满足不同的需求,但我们无法预见所有可能性。最终,可能需要有新需求的人来进行更改底层代码。
如果我们创建一个显示图片轮播(幻灯片放映)的 JavaScript 组件,很明显可以想象用户会想要配置显示的特定图片。例如,我们还可以有一个配置选项来启用或禁用轮播的淡入或淡出行为。我们的完整配置选项可能如下所示:
-
(数组) images:您希望在轮播中显示的图像 URL
-
(布尔值) fadeEffectEnabled:是否在图像之间进行淡入淡出
-
(数字) imageTimeout:单个图像显示的毫秒数
-
(布尔值) cycleEnabled:是否保持幻灯片重复播放
这些配置选项定义了我们的组件的适应程度。通过使用这些选项,可以以多种不同的方式使用它。如果用户希望它以这些选项无法实现的方式行为,那么他们可能希望通过修改底层代码来改变其行为。
当需要对底层代码进行更改时,重要的是能够尽可能轻松地进行更改。可能会导致麻烦的两个有害特征是脆弱性和僵化:
-
脆弱性是在尝试更改时变得脆弱的特征。如果更改代码的某个区域以进行错误修复或添加功能,并且它影响了代码库中另一个部分中的几个看似无关的事物,那么我们可以说代码是脆弱的。
-
僵化是指难以轻松适应变化的特征。如果需要更改某个行为,理想情况下,我们应该只需要在一个地方进行更改。但如果我们不得不到处重写代码才能实现那个变化,那么我们可以说代码是僵化的。
脆弱性和僵化通常是较大代码库的症状,其中模块之间存在许多相互依赖。这就是为什么我们说模块化如此重要。模块化是指将关注点分离到代码的不同区域,以减少交织的代码路径。
有各种原则和设计模式可以用来实现模块化。这些在第四章中讨论,SOLID 和其他原则,并且在第十一章中有更多的代码示例,设计模式。即使在这个早期阶段,问问自己:我可以以什么方式实现模块化?
努力避免脆弱性和僵化是一个很好的目标,将使我们的代码更容易适应变化,但对于维护者来说,代码库最关键的方面是可理解性。也就是说,它可以被理解的程度。如果维护者不理解,甚至无法开始进行更改。事实上,在晦涩和令人困惑的代码库中,有时甚至无法确定是否需要进行更改。这就是为什么我们现在将探讨熟悉度作为可维护性的一个方面。通过使用熟悉的约定和直观的模式,我们可以帮助确保我们的维护者之间有高水平的理解。
熟悉度
熟悉是一种美好的感觉。这是一种让你感到舒适的感觉,因为你知道发生了什么,因为你以前见过。这是我们应该希望在所有可能遇到我们代码的维护者身上产生的感觉。
想象一下,你是一个技术娴熟的技师。你打开一辆旧车的引擎盖。你期望各种组件都能以各自的位置可见。你擅长识别特定的组件,即使不用移动东西,你也能看到组件是如何连接在一起的。
进行了一些小的修改;也许车主之前安装了涡轮增压发动机或修改了齿轮比,但总的来说,你会发现一切都基本在应该的位置上。对于你这个技师来说,进行改变将会非常简单:

[Unsplash image (Public Domain) by Hosea Georgeson]
在这个例子中,所有的东西都在预期的指定位置。即使汽车在许多方面有所不同,它们的基本功能是相同的,因此布局和设计对于技师来说是熟悉的。
当我们考虑软件时,它并不那么不同。我们最终创建的大多数软件在许多方面都类似于其他软件。例如,大多数网络应用程序都会有用户注册、登录和更改名称的方式。大多数软件,无论问题领域如何,都会有创建、读取、更新和删除(CRUD)的概念。这构成了持久存储的著名动词。大多数软件可以被认为是坐落在持久存储之上的花哨中间件。因此,即使我们可能认为所有软件应用都非常不同,它们的基本原理通常是非常相似的。因此,我们应该不难编写满足打开引擎盖的技工的代码。
为了使技工的工作尽可能简单,我们需要首先关注我们的代码的熟悉度。这并不简单,因为不同的东西对不同的人来说是熟悉的,但总的来说,我们可以从以下指南中获得启示:
-
不要偏离常见的设计模式
-
在语法和表现上保持一致
-
为陌生的问题领域提供清晰度
最后一点提到了陌生的问题领域。这是你作为程序员在每个你工作的代码库中都需要考虑的事情。要分辨某物是否可以被视为陌生的,你可以问自己:另一个行业的程序员是否能够在很少的介绍下理解这个?
可用性
尽管可维护性主要是关于迎合其他程序员,但可用性是关于迎合所有用户,无论他们是谁。我们可以说有两大类用户参与我们的服务:
-
希望通过接口(GUI、API 等)运用我们代码的人。
-
希望对我们的代码进行更改以完成新任务或修复错误的人
可用性是关于使我们的代码以及它所启用的函数和交互对于所有用户尽可能有用和易于使用。所有的代码都是至少针对一个用例编写的,因此根据它实现这一目的的程度来评判代码是公平的。然而,可用性不仅仅是关于满足用户需求;它是关于创造能够让用户以最小的麻烦、时间和认知努力实现他们目标的体验。
无论是在网络上创建用户界面还是深度嵌入的服务器基础设施,可用性都是至关重要的,即使它们很少见光。在这两种情况下,我们都在为用户提供服务,因此我们必须关心可用性。
看一下这个函数的签名,试着分辨你会如何使用它:
function checkIsNewYear(
configuration,
filter,
formatter,
MDY,
SMH
) {...}
这个函数是我曾经工作过的一个代码库中的真实函数签名。它没有文档,其中的代码是混乱的。它被用来计算给定时间是否可以被视为新年,并决定何时向用户显示新年快乐的消息。然而,它的使用方式或工作原理非常不清楚。发现这个函数时我可能会有一些开放性问题,如下:
-
配置是什么,这样一个简单的函数中可以配置什么?
-
据推测,SMH 是秒、分钟和小时,但它预期是什么样的值?一个对象吗?
-
据推测,MDY 是月、日和年,但它预期是什么样的值?一个对象吗?
-
这个函数比较传递的日期是哪一年,以判断它是否是新年?
-
假设在表面上的新年中任何日期都可以工作,还是只有比如说 1 月 1 日?
-
为什么有过滤器和格式化程序参数,它们是什么作用?它们是可选的吗?
-
这个函数返回什么?一个布尔值吗?格式化程序参数似乎不是这样。
-
为什么我不能只传递一个日期对象而不是单独的日期组件?
该函数可能会按要求执行,但是,正如你所看到的,它并不是非常易用。要弄清楚它的工作原理需要花费大量时间和认知努力。要完全弄清楚它,我们必须研究其在代码其他部分的用法,并尝试解密其中的混乱。作为这个函数的用户,我个人会觉得整个过程非常痛苦。
如果说有什么,易用性就是要避免这种痛苦和负担。作为程序员,我们参与创建抽象来简化复杂的任务,但前面的所有代码所实现的只是对一个简单问题的进一步复杂化。
用户故事
易用性是指某物在特定目的下易于使用的程度。其目的由对问题的一个清晰的模型和一组明确的要求定义。表达这些目的的一个有用的技术是通过用户故事,这是 Scrum 和敏捷方法论所著名的。用户故事通常采用以下形式:
作为{角色},我想要{愿望},以便{目的}…
以下是一些用户故事的示例,如果我们设计一个联系人应用程序,你会期望看到这些类型的用户故事:
-
作为用户,我想要添加一个新的联系人,以便我以后可以从我的联系人列表中回忆起该联系人。
-
作为用户,我想要删除一个联系人,以便我将不再在我的联系人列表中看到该联系人。
-
作为用户,我想要通过他们的姓氏轻松找到一个联系人,以便我可以联系他们。
用户故事有助于定义你所满足的目的,并有助于集中精力关注用户的视角。无论你是创建一个五行函数还是一个一万行的系统,规划你的用户故事总是值得的。
直观设计
直观地设计某物意味着设计它,使用户不必花费认知努力来弄清楚它的工作原理。直观设计的核心理念是它只是工作。
当我们编写代码时,我们参与了它的设计,它的大体架构,它的功能和逐行语法。所有这些都是设计的重要部分。使用直观的设计模式对于编写可用的代码至关重要。所有用户都熟悉一组在他们的抽象层次上使用的模式。以下是一些例子:
-
在 GUI 中:使用X按钮表示退出程序或进程
-
在代码中:以is开头的函数或方法表示布尔返回值
-
在 GUI 中:使用绿色表示肯定操作,红色表示否定操作
-
在代码中:大写常量,例如,
VARIABLE_NAME -
在 GUI 中:使用软盘图标表示保存的概念
这些是许多用户在使用软件时携带的假设和期望。利用这些假设意味着你的代码和它所促成的交互可以更容易使用。
无障碍
无障碍是易用性中的一个关键原则,它强调满足所有用户的重要性,而不考虑他们的能力和环境。易用性往往关注用户,好像他们是一个单一的实体。我们通常对用户做出具体的假设,赋予他们一组特征和能力,这些特征和能力可能并不反映现实。然而,无障碍是关于真正将要使用你所创建的任何东西的用户。这些真正的用户是一个多样化的个体群体,可能有各种不同。当我们谈论软件的无障碍时,我们通常关注直接影响一个人使用该软件能力的差异。这些可能包括以下内容:
-
学习障碍或不同,如阅读障碍。
-
身体残疾。例如,手部活动能力受限或失明。
-
自闭症和 ADHD 等发育障碍。
-
移动性、经济或基础设施的限制导致技术的获取减少。
除此之外,还有许多其他差异涵盖了人类存在的方方面面,因此我们应该随时准备根据我们的用户遇到的新需求和差异进行学习和适应。
我们致力于在服务器和浏览器上创建 Web 应用程序。作为 JavaScript 程序员,我们与为最终用户提供的界面非常接近。因此,我们必须对 Web 上的可访问性有很好的把握。这包括对 W3C 发布的《Web 内容可访问性指南》(WCAG 2.0)的了解,其中包括以下规定:
-
为任何非文本内容提供文本替代方案(指南 1.1)
-
从键盘上使所有功能可用(指南 2.1)
-
使文本内容可读和可理解(指南 3.1)
可访问性不仅仅是关于非程序员最终用户。正如前面提到的,我们应该将其他程序员也视为我们的用户,就像 GUI 或其他 Web 界面的最终用户一样。重要的是我们要迎合其他程序员。一些程序员是盲人或部分视障。一些程序员有学习或认知困难。并非所有程序员都在最新和最快的硬件上工作。也并非所有程序员都理解你可能认为理所当然的所有事情。在我们编写的代码中考虑所有这些事情是很重要的。
现在完成了这一章,你可能会感到被原则、原则和指南的数量所压倒。事情可能看起来很复杂,但如果我们遵循一个简单的规则——始终关注用户,那么就不会复杂。还要记住,可能会在你的代码上工作的其他程序员也是你的用户。
作为程序员,我们处于一个位置,拥有前所未有的力量,可以帮助定义人们在执行各种任务时的行为。最初在 Twitter、Google 或 Microsoft 工作的程序员可能没有预料到他们的代码会运行多少次。他们可能最初无法想象他们的代码会影响多少人。我们应该始终对这种力量保持谦卑,并努力对我们服务的所有用户和他们试图执行的各种任务负责。如果你从本章中得到一件事,我希望就是:在你写的每一行代码中,都谦卑地考虑用户。
总结
在本章中,我们探讨了可靠性、效率、可维护性和可用性的重要原则。通过这些原则作为我们审视代码库的透镜,可以确保我们更有可能编写更干净的代码。在本章中学到的最重要的一点是,始终考虑代码中的人。用户可能是坐在 GUI 另一侧的人,也可能是使用我们的 API 的其他程序员。无论如何,始终意识到这个人是至关重要的。
在下一章中,我们将继续研究干净代码的基本特征,例如要注意的敌人,如模仿式编程和自我。
第三章:清洁代码的敌人
到目前为止,我们应该已经对我们所说的清洁代码有了一个相当清晰的认识。在上一章中,我们探讨了可靠性、效率、可维护性和可用性的原则。这些原则共同引导我们朝着更清洁的代码方向前进,但是如果我们不小心,仍然可能会遇到问题。在本章中,我们将探讨清洁代码的敌人:可能阻止我们编写可靠、高效、可维护或可用的代码的因素。
这些敌人都不应被视为您的敌人;相反,它们应被视为清洁代码的煽动者。我们需要全面看待这些潜在有害因素,并在我们的代码库、团队和工作场所中留意它们。
具体来说,本章我们将涵盖以下敌人:
-
敌人#1 - JavaScript
-
敌人#2 - 管理
-
敌人#3 - Self
-
敌人#4 - 货物崇拜
敌人#1 - JavaScript
最糟糕的 JavaScript 特性也可以说是它最好的特性。它是一种非常普遍的语言,不得不以非常快的速度增长和适应。语言本身及其在浏览器中的位置促成了这种普及性。
JavaScript 是一种非常富有表现力和多样化的语言,从 Lisp 和 Scheme 中获得了功能上的灵感,从 Self 中获得了原型继承,并且具有类似于 Java 的 C 样式的语法。它是一种具有多种范式的语言。无论您想以经典的面向对象方式、原型方式还是完全功能方式进行编程,JavaScript 都可以胜任。JavaScript 的灵活性以及其在更广泛的 Web 堆栈中的位置也使其非常适合初学者。您可以立即开始使用它,并且这正是 Brendan Eich 最初的意图。它旨在让设计师和程序员都能轻松上手,为他们提供编写曾经是单一用途平台的浏览器脚本的能力。然而,曾经不起眼的浏览器现在已经发展成一个非常广泛和复杂的互补抽象集合。
JavaScript 本身的增长以及其在客户端和服务器端(以及其他领域)的广泛应用意味着该语言已经被推向和拉向了成千上万个不同的方向。大量的框架、库、分支语言(例如 CoffeeScript)、语言扩展(例如 JSX)、编译器、构建工具和其他抽象已经涌现并试图以新的独特方式利用 JavaScript。这些工具共同构成了 JavaScript 的景观,这是一个非常丰富和多样化的景观。有无数种方法来做同样的事情,因此我们几乎无法希望做任何事情都正确。这就是为什么我说 JavaScript 的普及性既是它自己的最大敌人,也是它自己的最大优势。
在本书中,我们将探讨基础概念,这些概念将教会我们对清洁代码的本质进行批判性思考,并允许我们在不总是很好地满足代码清洁度的语言和环境中编写清洁代码。如果使用得当,JavaScript 将以其高效性和表现力让您感到惊讶,并且经过时间和努力,它可以在可靠性和可维护性方面与任何其他语言相媲美。
敌人#2 - 管理
清洁代码与培养它的过程和原则一样重要。无论我们的代码在孤立环境中有多完美和美丽,它通常是作为项目的一部分编写的,与团队一起,并由可犯错误的人和可犯错误的流程管理。只有通过看到和理解这些缺陷,我们才能希望预防或避免它们。
如今,我们都在承担更具挑战性的工作。JavaScript 仅限于普通的宣传手册网站已经成为历史。Web 的创造者们被要求构建更加雄心勃勃的项目。随着技术抽象塔不断增长,这些项目的复杂性只会增加。因此,如果我们真的要写出干净的代码,我们必须广泛考虑这种复杂性。我们必须超越我们的代码库,考虑我们所在团队和组织的背景。
将管理视为敌人可能会暗示经理们本身有过错,但事实并非如此。我们将在本节中发现,是个人文化实践使得发布干净代码变得困难。其中包括发布压力、糟糕的度量标准和缺乏所有权。
发布压力
通常情况下,由于截止日期或其他管理规定的压力,发布代码的压力是软件世界中一个经常存在且不好的力量。对外部利益相关者或经理来说,截止日期是一件好事;它似乎提供了确定性和问责制,但对于项目中工作的人来说,它可能只会被视为强加的不受欢迎的妥协。有时,做出的第一个妥协就是代码质量的妥协。这并不是故意发生的,而是将完成优先于质量的自然结果。
在这种情况下,利益相关者是指依赖于您工作成果的任何个人或组织。通常的利益相关者包括项目经理、同一组织内的其他团队、外部客户和用户。
当有发布压力时,代码质量可能会慢慢下降。其中包括以下几点:
-
文档:当开发人员赶时间时,他们将无法花足够的时间来确保他们的代码及其 API 被正确记录。现有的文档将逐渐荒废。
-
架构:开发人员将开始专注于他们需要进行的最必要的更改,忽视代码的更大架构结构以及它们之间的相互关系。依赖关系将变得混乱,架构将随着时间的推移而分裂,最终形成混乱的代码。
-
一致性:无论是在架构上还是在语法上,一致性都将开始受到影响。多个不同的开发人员,可能被隔离在一起,被迫以最快的方式构建东西。无意中,他们可能忽视了沟通和建立标准,导致一致性减少。
-
测试:编写测试通常需要时间,调整测试以适应新需求也需要时间。现有的测试可能会被禁用或删除。新的测试不会被编写,因为根本没有时间。
-
最佳实践:当时间紧张时,开发人员将开始在他们的代码中采取捷径,而不是花费必要的时间和精力来确保他们的软件适合其目的。他们会绕过最佳实践,而选择快速和拼凑在一起的解决方案。在 Web 上,这往往会导致 UI 的可访问性和可用性降低。
当截止日期开始逼近时,上述项目通常会首先被搁置。如果我们不小心,我们可能会遇到以下二阶效应:
-
Bugginess:在缺乏测试和文档的情况下,代码的架构基础受到威胁,不稳定和有缺陷的代码将开始成为常态。许多这些错误可能会在质量保证过程中被捕捉到,但还有许多其他错误会出现在用户面前。代码及其 API 和 UI 的脆弱性将增加,给用户带来更大的负担。
-
不满意的用户:由于出现在用户面前的错误数量增加,软件的可用性降低,他们的生产力和幸福感也会降低。他们可能会开始避开或放弃该平台,寻找更高质量的替代品。
-
疲惫的开发者:疲惫的开发者,不得不不断放弃他们最好的原则,会开始感到疲惫。他们可能会对继续在团队中工作感到沮丧。面临心理健康和一般满足感受到威胁,他们会开始离开。
所有这些影响如果持续时间足够长,就会汇聚在一起,导致项目失败。因此,解决这种鲁莽高速的根本压力是至关重要的。迅速交付代码的压力通常是由那些对软件项目长期退化缺乏深刻了解的力量所发起的。这种缺乏了解可能部分是因为他们与自己决策的长期影响隔离开来。他们可能会认为,一旦交付并得到利益相关者的批准,问题就解决了。但正如我们所知,快速交付的代码满足了即时需求,并不意味着它符合良好的质量水平。低质量的代码可能会产生许多负面的连锁效应,这些效应只有在实施后的几周或几个月后才会完全意识到。几个月后,利益相关者可能会发现自己对减速和质量下降感到恼火,却没有意识到最初施加压力的是他们导致了这一切。
解决这一混乱局面的关键妥协在于交付时间和技术债务之间。技术债务会随着时间的推移而积累。它描述了需要解决以保持代码库健康和良好运行状态的赤字。这可能包括修复 bug、编写测试、重构旧模块,或者集成工具以提高代码质量。从根本上说,技术债务是所有工作,理想情况下应该是自然开发周期的一部分,但由于时间限制,被推迟到以后。还有其他因素决定了技术债务的增加,但时间是最重要的因素。不偿还我们的技术债务是确保代码衰退和项目最终失败的一种方法。
在项目管理方面,有无数的建议和流程可以利用。我不会在这里详细介绍它们,但我会分享一些启发式方法,以确保代码库的健康:
-
不要在没有测试的情况下发布功能或修复 bug。没有测试,可能随时会发生回归。测试是一种防御技术,可以确保我们的代码持续正确。
-
经常偿还技术债务。可能每周一次,或者每两周一次,尝试让每个人都处理技术债务,即任何被认为能增加代码健康的工作。
-
定期与利益相关者沟通,表达与代码和项目健康相关的限制和成本。不要过度承诺交付,也不要低估问题。
作为开发者,我们并不总是能控制项目管理的方式。尽管如此,我们应该始终感到自如地提出关注并倡导促进代码整洁的流程。第十八章,沟通和倡导,详细介绍了我们如何做到这一点。
糟糕的指标
世界上似乎没有哪个行业能逃脱指标的束缚。对于衡量事物的狂热迷恋既是一种像邪教一样的迷恋,也是一种产生必要的反省和改变的真正需求。在软件工程领域,我们对这种需求并不陌生。作为程序员,我们对能够为我们提供对代码洞察的指标非常感兴趣:
-
有多少 bug?
-
这段代码运行需要多长时间?
-
我的测试覆盖率有多高?
然而,经理和其他利益相关者通常会怀有自己的利益和指标。其中最臭名昭著的是试图衡量开发者产出或生产力的指标:
-
有多少行代码或提交?
-
我们发布了多少功能?
-
我们写了多少行文档?
如果出于正确的原因提出这些问题,那么这些都是很好的问题。例如,代码行数可以作为一个有用的度量,如果我们将其用作讨论是否重构特定类/实用程序的复杂性的代理。但许多度量完全脱离了它们试图衡量的事物。
非技术经理或利益相关者可能会认为编写一定数量的代码应该总是需要相同的时间。当曾经一天写 200 行代码的开发人员最近花了 10 天才提交了 10 行代码时,他们可能会感到困惑。当然,他们的困惑表明他们对编程过程及其混乱复杂性的理解存在严重误解。但这些误解很普遍,所以我们需要对它们保持警惕。
解决糟糕度量的明确方法是推动并创建更好的度量。要创建好的度量,了解我们试图回答的基本问题是至关重要的,然后集思广益地想出回答这个问题的方法。让我们看一个例子:
| 问题 | 糟糕的度量 | 为什么糟糕 | 更好的度量或方法 |
|---|---|---|---|
| 我们是否在高效工作? | 代码行数/提交 | 一个程序员可能需要很多天来解决一个只需要一行更改的关键错误。 | 询问开发人员并探索是什么拖慢了他们的工作效率;进行团队回顾,发现改进的领域。 |
| 我们是否为用户提供了价值? | 已发布功能数量 | 用户可能会从更少但质量更高的功能中获得更多好处。 | 建立度量或 A/B 实验来判断哪些功能被使用和受欢迎。专注于每个功能的质量。 |
| 我们是否在编写有用的文档? | 文档行数 | 开发人员可能最终只会记录他们熟悉的事物,而不是最需要记录的代码区域。 | 创建一个跟踪文档使用情况的指标。通过询问开发人员来确定哪些代码区域的文档不足。 |
| 我们是否有一个经过良好测试的代码库? | 测试覆盖率 | 如果它只衡量某些代码行是否被调用,那么它可能会被一些非常广泛的集成测试所欺骗。 | 结合传统的测试覆盖率和其他度量。跟踪经常出现 bug 的回归区域。 |
| 我们的代码库是否有 bug? | bug 数量 | 一个代码库可能在一个几乎没有使用的应用程序区域中有很多 bug。某些区域的 bug 可能没有被报告。 | 不要计算 bug 数量;而是专注于并衡量用户和开发人员的满意度。根据 bug 对用户的影响来优先处理 bug。 |
组织或团队内对糟糕的度量的执着可能导致优化了错误的事物。更关心写更多代码行数的开发人员可能对其代码的基本质量不太感兴趣。被迫发布更多功能的开发人员可能会妥协最佳实践和清晰的代码,优化速度和交付。
确保我们跟踪的任何度量都受到现实的制约,并且我们不仅仅根据这些度量来判断成功是非常重要的。特别是当你看到度量与我们的清晰代码原则相对立时要特别小心。随着时间的推移,如果一个度量被过于雄心勃勃地追求,它最终可能会破坏它试图衡量的事物。这是通过一种被称为古德哈特定律的效应来实现的:
“当一个度量成为目标时,它就不再是一个好的度量。”
- Marilyn Strathern
缺乏所有权
所有权是健康代码库的关键原则,它依赖于个人对其代码健康状况的利益。这里的所有权并不意味着一段代码属于一个人,其他人不能在其上工作。相反,它意味着一段代码是由一个人或一组人培育的,其持续的健康和可靠性是一个关键的优先事项。
缺乏所有权可能会导致以下方式中的清洁代码的关键原则受损:
-
可靠性:随着不知不觉地引入脆弱性的新变化,代码的正确性和稳定性可能会随着时间的推移而衰退。代码的持续稳定性没有得到监控或关注。
-
效率:没有人直接测量或观察代码,基本假设是它只是有效的。随着时间的推移,其效率可能会下降。
-
可维护性:许多非所有者进行迅速和轻率的更改可能导致非连贯的架构,从而使长期维护变得更加困难。
-
可用性:没有人会考虑或监控代码的文档和一般可用性,导致其衰退,最终导致软件变得复杂和使用起来繁琐。
正确应用的所有权可以从根本上改变前述原则的衰退:
-
可靠性:代码的正确性和持续稳定性将得到关注和监控
-
效率:代码将被持续地测量和评估效率
-
可维护性:代码将保持其架构和语法的独特视角
-
可用性:文档将不断更新,代码的可用性将是一个持续关注的问题
从根本上讲,所有权是关于个人或团队对代码的持续关注。为了实现这一点,需要一定程度的自我或自豪感。个人或团队必须对代码的持续健康有一定的利益。通常是组织或管理文化导致了健康或不健康的所有权水平,因此,再次,正确沟通和倡导过程和动态对我们程序员来说是至关重要的,这将使我们能够确保我们的代码的整洁和健康。
缺乏所有权也会导致更严重和意想不到的后果。由于对工作缺乏自豪感和监护责任感,程序员更容易出现疲劳,因为他们无法实现对工作的自豪感和自我价值感。由于没有所有权,团队成员可能无法在任何一个领域培养高水平的理解,这意味着团队或组织的整体知识会受到影响,每个人只能以一种非常肤浅或粗略的方式理解代码库。
小心所有权中的自我过多!自我是一种脆弱的特质。总是存在“过度所有权”的风险,这可能导致顽固和防御性文化,使“内部人”不允许“外部人”进行更改,并且强烈的以自我为中心的观点泛滥。要小心。记住可用性和可维护性的关键原则。这将引导您对那些希望使用您的代码或对其进行更改的人表现出善良和开放的态度。
敌人#3 - 自我
程序员作为创作者,永远在向世界展示他们对事物应该是什么样的版本,因此几乎不可能不时地对我们的工作感到自豪。如果不加以控制,这很容易演变成我们编写代码来给人留下深刻印象,提升自己的优越感,而不考虑我们正在编写的代码是否可维护或可用。但是,如果我们的自然自我不能得到发展,那么我们就不会对自己的工作感到自豪,也不会倾向于在我们所做的事情上培养卓越。因此,在编程中,就像生活的其他领域一样,关键是保持自我平衡,保留其好的部分,而不让其坏的部分影响太多。
在这种情况下,“自我”是指我们的自我;我们如何认同自己以及我们如何在世界上表达自己。所有程序员都有自我,它对他们编写的代码产生了许多影响。
炫耀语法
作为一个年轻的程序员,我经常发现我的自我占了上风。我不敢说这是一个普遍的真理。这只是我的经验。每当我发现一个新的 JavaScript 特异功能时,我会尝试在我的下一段代码中加以利用。
其中一个例子是使用位运算符来实现向下取整的效果。传统上,要对数字进行向下取整,即将数字四舍五入到最接近的整数,你会使用语言提供的原生方法:
Math.floor(65.7); // => 65
然而,当时,我更喜欢使用位运算符来实现相同的结果:
~~65.7; // => 65
0|65.7; // => 65
这里发生了什么?位运算符(包括~、&、|等)用于改变操作数的位,但作为副作用,它们首先会将它们的操作数转换为 32 位整数。这意味着它们会丢弃小数部分。为了利用这种隐式转换为整数而不改变整数值,我们可以执行双重位反转,例如使用双波浪号(~~)。这实质上是反转操作数的所有位,然后再次反转。我们也可以执行与零的位或运算(0|...),这将始终返回非零操作数的位,从而通过利用副作用(整数转换)而不改变基础值来产生相同的效果。
至关重要的是要注意,这种副作用在负数的情况下并不与Math.floor的向下取整行为功能匹配。请注意以下两个表达式的区别:
Math.floor(-25.6); // => 26
~~(-25.6); // => 25
这些神秘技术的吸引力很容易理解。它们的使用似乎表明了对语言的高水平理解,这非常吸引人的自我。这类似于使用不必要的长或复杂的词来表达简单的想法:说起来很有趣,但对听众来说很难理解。
这样的技术通常会导致代码的可维护性降低。我们的代码的维护者不应该被期望理解很少使用的运算符的内部工作原理,并且应该能够相信我们不会轻率地利用语言内部的副作用来实现可以通过更熟悉和明显的方法清晰地实现的结果。
复杂或罕见的语法通常是自我代码的载体。另一个例子是错误使用逻辑运算符来指定控制流:
function showNotification(message) {
hasUserEnabledNotifications() && (
new Notification(message).show() &&
logNotificationShown(message)
);
}
前面的代码可以更常规、更清晰地表达为一个IF语句:
function showNotification(message) {
if (hasUserEnabledNotifications()) {
new Notification(message).show();
logNotificationShown(message);
}
}
这样更清晰,更熟悉,更易读,适合更多的人群。
有人认为我们应该能够自由地利用整个语言的全部功能,利用其所有的特异功能和副作用来编写更简洁、更高效的代码。如果我们的唯一目标是编写能够工作的代码,这是一个很好的态度。但编写干净的代码是关于采取审慎的方法,使用能够提供更多可读性的技术,并避免那些相反的技术。
还要记住,从根本上说,代码是关于传达意图的。沟通既关乎听众也关乎说话者。自我代码往往在这方面表现不佳;它将你的代码熟悉度限制在少数精通相同知识的精英之中。这并非理想。我们应该始终考虑到将不得不阅读、使用和维护我们代码的人们的多样知识和能力。这种关注应该优先于我们的自我。
固执的观点
代码很少是孤立编写的;我们经常与他人合作将项目变为现实。因此,清晰的代码取决于你的方法和整个团队的方法。持续拥有代码库的团队不断决定他们将用来实现目标的工具、约定和抽象。因此,团队成员必须能够良好沟通并分享观点,将这些观点塑造成明确的结果。有时,妥协是必要的。而妥协往往会伤及自尊。
JavaScript 及其工具容易受到强烈意见的影响。随着时间的推移,我们每个人都会在不同的方法中获得经验,并且通常通过辛勤劳动和痛苦,最终形成一套我们认为最好的方法的信念。然而,这些信念可能并不总是与我们的同事相匹配。当存在分歧时,解决的路径是不清晰的。没有解决,团队和代码库可能会分裂,造成更多的损害。
想象一下亚当和苏珊之间的以下情景:
亚当:我们应该使用 Foo 测试框架;它更可靠,而且更好。
苏珊:不,我们一定要使用 Baz;它更优秀,而且有着成熟的记录。
这种分歧可能有很多不同的解决方法。例如,我们可以建议两个人都提出自己的观点,并继续辩论各种测试框架的优点。这可能会解决问题。但同样,也可能不会。争论可能会持续下去,造成两个人之间的裂痕,并使代码库处于一种没有明确选择测试框架的状态。在这种情况下,解决的路径并不总是清晰的,但清楚的是,如果牵涉到不妥协的自尊心,解决的可能性就会降低。如果亚当和苏珊都能开始看到彼此的观点,拓宽自己的视野,摆脱自己的观点,那么解决的路径就会变得更清晰。
冒名顶替综合症
自尊心作为一种脆弱的特质,也影响着我们对自己能力和观点的信仰。毫无疑问,对自己的信仰是编程中创造和解决问题的关键。尤其在技术行业,冒名顶替综合症似乎是一种普遍现象。冒名顶替综合症的特征是一种感觉,即自己是一个冒名顶替者——你在某种程度上不适合或不够胜任你所担任的角色,而你觉得周围的其他人要能力更强。
可以说,软件行业中冒名顶替综合症的普遍存在是由于固有的复杂性和专业知识的丰富性。我们最多只能希望在相对狭窄的领域拥有高水平的熟练程度,但永远不会在所有领域都有专业知识。在日常工作中,我们时刻意识到自己不知道的所有事情,这可以理解地造成一种焦虑和对自己谦卑能力的不信任。这种感觉有时会导致压力、疏远和对自己能力的不信任。
这可能会产生以下负面结果:
-
缺乏果断: 对自己能力的信念不足可能导致在决定代码架构时信心水平较低;不知道该选择哪条路线往往意味着采取默认路线,这特别容易形成迷信。
-
缺乏大胆: 缺乏果断可能导致更少的冒险和更少的大胆决策,但有时需要做出这样的决定来推动项目或代码库的进展。例如,选择更可靠的 UI 或测试框架可能是一个巨大而大胆的风险,考虑到重构的成本,但可以导致代码健康的整体改善。
-
缺乏沟通:对自己的观点和技能缺乏信心可能导致较少重要的沟通发生,例如程序员与项目利益相关者之间的沟通。这里的沟通并不意味着外向或健谈,而是识别关键问题并对其有足够的信心以提倡变革。
编程是一种传达意图的行为,也就是说,以某种方式向世界表达我们认为事物应该运作的方式。这本身就是一种大胆的行动和一种我们不应该视为理所当然的技能。如果你正在阅读这篇文章,并担心自己可能缺乏特定的特质或能力,我提供以下建议:地球上没有人是完全有能力的。每个人都有自己的优点和缺点。正是每个人的多样性和他们不同的能力将决定项目和代码库的成功。即使你感到自己是个骗子,也要承认这种感觉是自然的,而且尽管如此,你所能提供的远远超出你的想象。
敌人#4 - 模仿行为
在 20 世纪初,人们观察到一些美拉尼西亚文化会进行模仿西方技术和行为的仪式,比如用木头和黏土建造跑道和控制塔。他们这样做是希望物质财富,比如食物,会被送到他们那里。这些奇怪的仪式出现是因为他们之前观察到货物是通过西方飞机送来的,错误地得出结论认为是跑道本身召唤了货物。
现在,在编程中,我们使用术语“模仿行为”或“模仿”来广泛描述复制模式和行为,而不完全理解它们真正的目的和功能。当程序员在网上搜索解决方案,并复制并粘贴他们找到的第一段代码,而不考虑其可靠性或安全性时,他们正在进行模仿行为,试图通过使用在其他上下文中似乎负责这个任务的代码来完成某个任务。
模仿行为通常包括以下过程:
-
人处于一个略微陌生的技术环境中
-
- 人看到他们希望模仿的效果
-
- 人复制似乎产生所需效果的代码
这种行为在组织和技术上都可能发生。程序员有时被要求将他们很少了解的不同技术依赖关系联系在一起,通常会别无选择,只能进行模仿。而组织通常没有时间考虑所有的基本原则,往往最终会从其他组织中模仿流行的行为和流程。
- 模仿代码
为了说明模仿行为,让我们想象一个程序员的任务是向他们的 Node.js 服务器添加一个新的 HTTP GET 路由。他们需要添加/about_us路由。他们打开routes.js文件,在其中的众多行中找到以下代码:
app.use('/admin', (req, res, next) => {
const admin = await attemptLoadAdminSection(req, res);
if (admin) {
next();
} else {
res.status(403).end('You are not authorized');
}
});
这段代码碰巧使用了一个 Node.js 框架:Express。不幸的是,程序员对 Express API 并不很熟悉。他们看到前面的代码,并试图为自己的目的模仿它:
app.use('/about_us', (req, res, next) => {
attemptLoadAboutSection(req, res);
next();
});
不幸的是,正如你可能已经注意到的,这位程序员已经犯了模仿的行为。他们复制了用于将流量引导到管理员部分的代码,并假设他们应该使用类似的代码来将流量引导到关于页面。
他们在这样做时错过了一些事情:
-
管理员路由实际上是中间件,用于阻止未经授权的用户访问
/admin。 -
app.use()方法应该只用于中间件,而不是用于直接的 GET 路由。 -
调用
next()只有中间件才会感兴趣
如果程序员花时间阅读 Express 文档,他们会发现正确的方法更接近以下内容:
app.get('/about_us', (req, res) => {
loadAboutSection(res);
});
这只是一个非常简短的例子。货物崇拜的行为通常更加复杂。它可能不涉及直接复制代码,而可能只涉及模式或语法的微妙复制。我们可能会对前面的例子摇头,确信自己永远不会做这样的事情,但我们很可能已经以不那么明显的方式做了。
参与项目的程序员通常会合理地继承现有代码库的命名、语法和空白符约定。他们可能会在不经意间这样做,自然地反映和符合现有范例,而不是在每一步都应用他们的批判性技能。这并不一定是负面的:这是对约定和表现一致性的明智维护。这些都是重要的品质。但同样地,盲目地复制这些东西往往会导致冗余代码的无谓增加,或者更糟糕的是,由于对代码的误解而产生负面影响。
想象一下,你是一名初学者程序员,你想要在以下略微奇怪的对象中添加一个hobby字段:
const person = {
"name": ("James"),
"location": ("London")
};
很容易想象,当您添加新字段时,您可能倾向于复制现有的语法:
const person = {
"name": ("James"),
"location": ("London"),
"hobby": ("kayaking")
};
这对于第一次尝试者来说是完全合理的事情。他们处于一个陌生的环境中,看到了他们希望模仿的效果,于是采用了产生这种效果的模式。即使是有经验的人也可以理解这种行为,他们希望对代码进行最小必要的改动,而不影响其周围环境。
这段代码并没有明显的错误。它是可用的。然而,如果我们要编写最大程度上可维护和高效的代码,那么我们应该采用更广泛接受和常规的约定和语法。因此,在这种情况下,前述代码存在两个具体问题:
-
将每个键名都用双引号括起来(不必要!)
-
将每个值都用括号括起来(不必要!)
没有进行货物崇拜的文件版本可能如下所示:
const person = {
name: "James",
location: "London",
hobby: "kayaking"
};
然而,这个文件和对象可能会继续存在数月甚至数年。没有人会质疑或挑战它的语法,因为他们会认为它一定有它的原因。遵循已建立的做事方式会带来舒适和便利。挑战它通常更容易。这种形式的货物崇拜是更隐匿的类型,它给项目和团队引入了很多惯性。我们盲目地采用做法,而不质疑它们的持续有效性和适用性。
模仿工具和库
就像代码可以被盲目地复制一样,工具也可以。作为 JavaScript 程序员,我们接触到一个快速变化的工具和库的景观。每个月都会发布一个新的实用程序或工具。围绕一些工具产生的兴奋和夸大其词为货物崇拜的爆发创造了肥沃的土壤。程序员可能开始使用这些新工具,相信它们的价值,而没有充分了解它们或正确考虑它们是否适合手头的项目。工具可能被公司或经理指定,非程序员和程序员可能会根据工具的流行度或新颖性发表意见,而不考虑它实际上是如何工作的,或者它与当前方法有何不同。
货物崇拜中的“崇拜”往往是一种非常有说服力的力量,告诉我们,如果我们只是使用这种方法或工具,所有问题都将得到解决。自然地,这很少发生。我们可能最终只是用新问题交换了我们当前的问题。因此,在决定使用工具时,无论是框架、库还是任何第三方抽象或服务,我们都应该始终采用深思熟虑的方法,问自己以下关键问题:
-
适用性:它是否是解决手头问题的最合适的工具?
-
可靠性:它是否可靠地工作,而且将继续如此?
-
可用性:它是否简单易用并且有良好的文档?
-
兼容性:它是否与现有的代码库很好地集成?
-
适应性:它是否适应我们不断变化的需求?
为了避免装运崇拜,我们应该尽量避免轶事和道听途说,而更倾向于详细的比较分析,通过比较和对比各种可能性来找到最合适的方案。
总结
在本章中,我们对一些最普遍的对清晰代码的“敌人”有了一定的了解。我们讨论了 JavaScript 本身是一种语言,当被错误使用时,会导致不清晰的代码。我们还探讨了团队和个人的陷阱。我们了解到,清晰的代码不仅仅是代码的特征,而是一种必须在整个组织和我们自己的思想中培养的文化。
在下一章中,我们将探讨一些众所周知和一些不太为人知的清晰代码原则,并将我们迄今所学的内容整合到一些具体的 JavaScript 抽象中。
第四章:SOLID 和其他原则
软件世界充斥着原则和首字母缩略词。关于我们应该如何编写代码有许多坚定和根深蒂固的想法。所有这些原则的数量之多可能令人不知所措,特别难以知道在设计抽象时应该选择哪条道路。JavaScript 能够适应许多不同的范式是它作为一种编程语言的优势之一,但这也可能使我们的工作更加困难。JavaScript 程序员需要实现自己的范式。
在希望使事情变得不那么复杂的这一章中,我们将介绍各种众所周知的原则,并将它们分解,以便我们可以看到它们的基本意图。我们将探讨这些原则如何与我们已经讨论过的清晰代码的原则相关联,使我们能够做出自己的明智决定,以便在追求清晰代码时使用什么方法。
我们将涵盖面向对象和函数式编程原则。通过探索这些原则范围,我们将能够为自己制定一张指导思想的地图,这将使我们能够批判性地思考如何在我们所从事的任何范式中编写清晰的代码。
在本章中,我们将涵盖以下主题:
-
迪米特法则(LoD)
-
SOLID
-
抽象原则
-
函数式编程原则
迪米特法则
在我们深入探讨 SOLID 领域之前,探索一个不太知名的原则是很有用的,即所谓的迪米特法则,或者最少知识原则。这个所谓的法则有三个核心思想:
-
一个单元应该只对其他单元有有限的了解
-
一个单元只应该和它的直接朋友交谈
-
一个单元不应该和陌生人交谈
你可能会想知道一个单元与陌生人交谈是什么意思。在这种情况下,一个单元是一个特定的编码抽象:可能是一个函数、一个模块或一个类。这里的交谈意味着接口,比如调用另一个模块的代码或让另一个模块调用你的代码。
这是一个非常有用且简单的法则,可以应用于我们所有的编程,无论是编写一行代码还是设计整个架构。然而,它经常被遗忘或忽视。
让我们以在商店购物的简单行为为例。我们可以用顾客和店主的抽象来表达这种互动:
class Customer {}
class Shopkeeper {}
我们还可以说顾客类有一个钱包,他们在里面存放他们的钱:
class Customer {
constructor() {
this.wallet = new CustomerWallet();
}
}
class CustomerWallet {
constructor() {
this.amount = 0;
}
addMoney(deposit) {
this.amount += deposit;
}
takeMoney(debit) {
this.amount -= debit;
}
}
店主和顾客之间的简化交互版本可能是这样的:
class Shopkeeper {
processPurchase(product, customer) {
const price = product.price();
customer.wallet.takeMoney(price);
// ...
}
}
这看起来可能没问题,但让我们考虑一下这种互动的现实生活类比。店主从顾客口袋里拿走钱包,然后打开钱包,拿走所需的金额,而不以任何方式直接与顾客互动。
很明显,这在现实生活中永远不会是一种社交上合适的互动,但至关重要的是,店主正在做出超出他们权限范围之外的假设。顾客可能希望使用不同的支付方式,或者甚至可能没有钱包。顾客的支付方式是他们自己的事情。这就是我们所说的只和朋友交谈:你只应该与你应该了解的抽象进行接口。这里的店主不应该(也不会)了解顾客的钱包,因此不应该与之交谈。
接受这些教训,我们可以按照以下方式编写一个更清晰的抽象:
class Shopkeeper {
processPurchase(product, customer) {
const price = product.price();
customer.requestPayment(price);
// ...
}
}
现在看起来更合理了。店主直接与顾客交谈。顾客反过来将与他们的顾客钱包实例交谈,取回所需的金额,然后交给店主。
我们很可能都写过一些违反了迪米特法则的代码。当然,我们编写的代码并不总是像商店老板和顾客之间的互动那样刻意或整洁,但迪米特法则仍然适用。我们可以通过一个典型的 JavaScript 代码来进一步说明这一点,该代码负责通过文档对象模型(DOM)向用户显示消息:
function displayHappyBirthday(name) {
const container = document.createElement('div');
container.className = 'message birthday-message';
container.appendChild(
document.createTextNode(`Happy Birthday ${name}!`)
);
document.body.appendChild(container);
}
这是典型和惯用的前端 JavaScript。要在文档中显示生日消息,我们首先自己构建字符串,并将其放入文本节点,然后将其附加到具有message和birthday-message类的<div>元素中。然后,我们将这个 DOM 树附加到文档中,以便用户查看。
DOM 是一组 API,使我们能够与解析的 HTML 文档进行交互,通常在浏览器中。DOM 作为一个术语,也用来描述由此解析过程生成的节点树。因此,DOM 树可以从给定的 HTML 文档中派生,但我们也可以构建自己的 DOM 树并自由地操纵它们。
前面的代码是否遵守了迪米特法则?我们的抽象,displayHappyBirthday函数,关注的是生日快乐消息的概念,并且直接与 DOM 进行交互。然而,DOM 并不是它的朋友。DOM 是一个实现细节——一个陌生人——在生日快乐消息的概念中。生日快乐消息的机制不应该需要了解 DOM。因此,适当的做法是构建另一个抽象来连接这两个陌生人:
function displayMessage(message, className) {
const container = document.createElement('div');
container.className = `message ${className}`;
container.appendChild(
document.createTextNode(message)
);
document.body.appendChild(container);
}
在这里,我们有一个更通用的displayMessage函数,直接与 DOM 进行交互。我们的displayHappyBirthday函数可以被改变,使其纯粹与这个displayMessage抽象进行交互:
function displayHappyBirthday(name) {
return displayMessage(
`Happy Birthday ${name}!`,
'birthday-message'
);
}
现在可以说这段代码与displayMessage的实现更松散地耦合在一起。我们以后可以决定改变我们用来显示消息的确切机制,而不需要改变displayHappyBirthday函数。因此,我们增强了代码的可维护性。通过概括一个常见的功能——显示消息,我们还可以使未来的功能更加无缝——例如,显示新年快乐的消息:
function displayHappyNewYear(name) {
return displayMessage(
`Happy New Year! ${name}`,
'happy-new-year-message'
);
}
迪米特法则,本质上关注的是我们认为应该与其他抽象进行接口的抽象。它并不提供关于朋友或陌生人是什么,或者一个单元只能有有限的其他单元知识的指导。这个法则挑战我们为自己定义这些术语,以及我们正在构建的抽象。我们有责任停下来考虑我们的抽象是如何进行接口的,也许我们应该以不同的方式设计它们。
我选择首先写关于这个原则,因为我觉得它是最值得记住和最普遍有用的编写干净代码和干净抽象的工具。
接下来,我们将讨论 SOLID 和其他原则,它们各自以不同的方式补充了迪米特法则。
SOLID
SOLID 是一组常用的原则,用于构建单个模块或更大的架构。具体来说,它是一个缩写,代表五个特定的面向对象编程设计原则:
-
单一职责原则(SRP)
-
开闭原则
-
里氏替换原则
-
接口隔离原则
-
依赖倒置原则
不必记住这些名字甚至是缩写本身,但这些原则背后的思想是有用的。在本节中,我们将探讨每个原则以及 JavaScript 示例。需要注意的是,虽然 SOLID 主要与面向对象编程有关,但其背后有更深层次的真理,无论你的编程范式如何,都是有用的。
单一职责原则
当我们编写代码时,我们不断地构建抽象;在这样做时,我们对构建正确的抽象、以正确的方式划分感兴趣。SRP 通过查看它们的责任来帮助我们弄清楚如何划分这些抽象。
在这种情况下,责任指的是您的抽象所涵盖的目的和关注领域。验证电话号码的函数可以说具有单一责任。然而,同时验证和规范这些带有国家代码的号码的函数可以说具有两个责任。SRP 会告诉我们需要将该抽象拆分为两个独立的抽象。
SRP 的目标是得到高度内聚的代码。内聚性是指抽象的各个部分在某种方式上都功能统一,它们可以说都共同工作以实现抽象的目的。关于识别单一责任的一个有用问题是:您的抽象设计有多少个原因需要更改?
我们可以通过一个例子来探讨这个问题。假设我们的任务是构建一个小型日历应用程序。最初,我们可能想象这里有两个不同的抽象:
class Calendar {}
class Event {}
“事件”类可以说包含有关事件的时间和元信息,“日历”类可以说包含事件。基本的起始前提是您可以向“日历”实例添加和删除一个或多个“事件”实例。在这里,我们表达了用于向“日历”添加和删除事件的方法:
class Calendar {
addEvent(event) {...}
removeEvent(event) {...}
}
随着时间的推移,我们必须向我们的“日历”添加各种其他功能,例如检索特定日期内的事件的方法,以及以各种格式导出事件的方法:
class Calendar {
addEvent(event) {...}
removeEvent(event) {...}
getEventsBetween(stateDate, endDate) {...}
setTimeOfEvent(event, startTime, endTime) {...}
setTitleOfEvent(event, title) {...}
exportFilteredEventsToXML(filter) {...}
exportFilteredEventsToJSON(filter) {...}
}
即使没有实现,您也可以看到所有这些方法的添加已经创建了一个更加复杂的类。从技术上讲,所有这些方法都与日历的功能相关,因此有理由让它们保留在一个抽象中,但是如果我们回到我们提出的问题——*我们的抽象设计有多少个原因需要更改?*我们可以看到“日历”类现在有很多可能的原因:
-
事件上定义的时间可能需要更改
-
事件上定义的标题的方式可能需要更改
-
搜索事件的方式可能需要更改
-
XML 模式可能需要更改
-
JSON 模式可能需要更改
鉴于潜在变更的不同原因的数量,将变更分割为更合适的抽象是有意义的。例如,特定事件的时间和标题设置方法(setTimeOfEvent,setTitleOfEvent)绝对应该在“事件”类本身内部,因为它们与“事件”类的目的高度相关:包含有关特定事件的详细信息。导出到 JSON 和 XML 的方法也应该移动,可能移到一个专门负责导出逻辑的类中。以下代码显示了我们所做的更改:
class Event {
setTime(startTime, endTime) {...}
setTitle(title) {...}
}
class Calendar {
addEvent(event) {...}
removeEvent(event) {...}
getEventsBetween(stateDate, endDate) {...}
}
class CalendarExporter {
exportFilteredEventsToXML(filter) {...}
exportFilteredEventsToJSON(filter) {...}
}
希望你能看到,我们每个抽象都内部紧凑,并且每个抽象都比如果所有功能都仅驻留在“日历”类中要更紧凑地封装其责任。
SRP 不仅仅是关于创建易于使用和维护的抽象,它还允许我们编写更专注于其主要目的的代码。以这种方式更加专注使我们更清晰地优化和测试我们的代码单元,这有利于我们代码库的可靠性和效率。由 SRP 指导的内聚抽象的正确划分可能是您改进代码清晰度的最重要方式之一。
开闭原则
开闭原则(OCP)陈述如下:
*软件实体(类、模块、函数等)应该对扩展开放,但对修改关闭
-梅耶,伯特兰(1988 年)
在构建抽象时,我们应该使它们能够开放以便其他开发人员可以构建其行为,使抽象适应他们的需求。 在这种情况下,扩展最好被认为是一个广义术语,包括所有类型的适应。 如果一个模块或函数的行为不符合我们的要求,最好能够使其适应我们的需求,而无需修改它或创建我们自己的替代品。
考虑我们的日历应用程序中的Event类和renderNotification方法:
class Event {
renderNotification() {
return `
You have an event occurring in
${this.calcMinutesUntil()} minutes!
`;
}
// ...
}
我们可能希望有一种单独的事件类型,它会渲染一个以“紧急!”开头的通知,以确保用户更加关注它。 实现这种适应的最简单方法是通过继承Event类:
class ImportantEvent extends Event {
renderNotification() {
return `Urgent! ${super.renderNotification()}`;
}
}
我们通过覆盖renderNotification方法来给我们紧急消息加上前缀,并调用超类的renderNotification来填充通知字符串的其余部分。 在这里,通过继承,我们已经实现了扩展,使Event类适应我们的需求。
继承只是实现扩展的一种方式。 我们可以采取各种其他方法。 一种可能性是,在最初实现Event时,我们预见到需要自定义通知字符串,并实现了一种配置renderCustomNotifcation函数的方法:
class Event {
renderNotification() {
const defaultNotification = `
You have an event occurring in
${this.calcMinutesUntil()} minutes!
`;
return (
this.config.renderCustomNotification
? this.config.renderCustomNotification(defaultNotification)
: defaultNotification
);
}
// ...
}
这段代码假设有一个config对象可用。 我们可以选择调用renderCustomNotification并传递默认通知字符串。 如果没有配置,则仍然使用默认通知字符串。 这与继承方法有根本的不同,因为Event类本身规定了可能的扩展。
通过配置提供适应性意味着用户无需担心在扩展类时所需的内部实现知识。 适应的路径变得简化:
new Event({
title: 'Doctor Appointment',
config: {
renderCustomNotification: defaultNotification => {
return `Urgent! ${defaultNotifcation}`;
}
}
});
这种方法要求您的实现能够预见其最可能的适应性,并且这些适应性可预测地内部化到抽象本身。 但是,不可能预见所有需求,即使我们试图这样做,我们可能最终会创建一个如此复杂和庞大的配置,以至于用户和维护人员会受到影响。 因此,在这里需要取得平衡:适应性是一件好事,但我们也必须平衡它与一个有限目的的专注和连贯的抽象。
里斯科夫替换原则
里斯科夫替换原则规定类型应能够被其子类型替换,而不会改变程序的可靠性。 这在表面上是一个晦涩的原则,因此值得用现实世界的类比来解释它。
许多现实世界的技术创新都具有替代的特点。 沃尔沃 XC90 是一种汽车,福特福克斯也是。 两者都提供了我们期望的汽车的常见接口。 对于我们作为这些车辆的人类用户,我们可以假设它们各自的操作方式都继承自一种常见的车辆操作模式,比如有方向盘,门,刹车踏板等。
人类的假设是,这两种车型是超类型 car的子类型,因此作为人类,我可以依赖于它们各自从超类型(汽车)继承的方面。 另一种表达里斯科夫替换原则的方式是:类型的使用者只应关注操作它所需的最不具体的类型。 举个例子,如果我们要在代码中编写一个Driver抽象,我们希望它通常与所有Car抽象进行接口,而不是编写依赖于特定车型(如沃尔沃 XC90)的特定代码。
为了使里氏替换原则更具体一些,让我们回到我们的Calendar应用程序示例中。在前一节关于开闭原则的部分,我们探讨了如何通过继承将Event类扩展为新的ImportantEvent类:
class ImportantEvent extends Event {
renderNotification() {
return `Urgent! ${super.renderNotification()}`;
}
}
我们这样做的假设是,我们的Calendar类及其实现不会关心事件是Events还是Events的子类。我们期望它会对待它们一样。例如,Calendar类可能有一个notifyUpcomingEvents方法,它会遍历所有即将发生的事件,并在每个事件上调用renderNotification:
class Calendar {
getEventsWithinMinutes(minutes) {
return this.events.filter(event => {
return event.startsWithinMinutes(minutes);
});
}
notifiyUpcomingEvents() {
this.getEventsWithinMinutes(10).forEach(event => {
this.sendNotification(
event.renderNotification()
);
});
}
// ...
}
关键的是,Calendar的实现并不考虑它正在处理的Event实例的类型。事实上,前面的代码(并未涵盖整个实现)只规定了事件对象必须具有startsWithinMinutes方法和renderNotification方法。
与里氏替换原则相关的是我们已经讨论过的一个概念:最少知识原则(LoD),它驱使我们问:这个抽象需要多少信息才能实现其目的?对于Calendar来说,它只需要规定事件具有它将使用的方法和属性。没有理由让它做出更多的考虑。Calendar的实现现在不仅可以处理事件的子类,还可以处理任何提供所需属性和方法的对象。
接口隔离原则
接口隔离原则关注的是保持接口高度内聚,只从事一个任务或一组高度相关的任务。它规定不应该强迫客户端依赖它们不使用的方法。
这个原则在精神上类似于单一责任原则:它的目标是确保您创建专注且高度内聚的抽象,只关注一个责任领域。但它不是让您考虑责任本身的概念,而是让您看待您正在创建的接口,并考虑它们是否适当地隔离。
考虑一个地方政府办公室。他们有一张纸质表格(让我们称之为 1A 表),用于更改个人信息。这是一张存在了 50 多年的表格。通过这张表格,当地公民可以更改他们的一些信息,包括但不限于以下内容:
-
姓名变更
-
婚姻状况变更
-
地址变更
-
地方税折扣状态变更(学生/老年人)
-
残疾状态变更
正如你可以想象的那样,这是一张非常复杂和密集的表格,有许多独立的部分,公民必须确保填写正确。我们都可能接触过政府文书工作的官僚复杂性,如下所示:

1A 表提供了一组接口,用于地方政府办公室提供的各种更改功能。接口隔离原则要求我们考虑这张表格是否强迫其客户端依赖他们不使用的方法。在这个上下文中,客户端是表格的用户,也就是公民,而方法是表格提供的所有可用功能:注册姓名更改、地址更改等等。
显而易见,1A 表单并没有很好地遵循接口隔离原则。如果我们重新设计它,我们可能会将其服务的各个功能分离成独立的表单。我们可以通过使用我们在本章开头学到的东西来做到这一点:最少信息原则(LoD),它向我们提出一个非常简单的问题:每个抽象(例如,更改地址)需要的最少信息是什么?然后我们可以选择只在每个表单中包含完成其功能所需的内容:
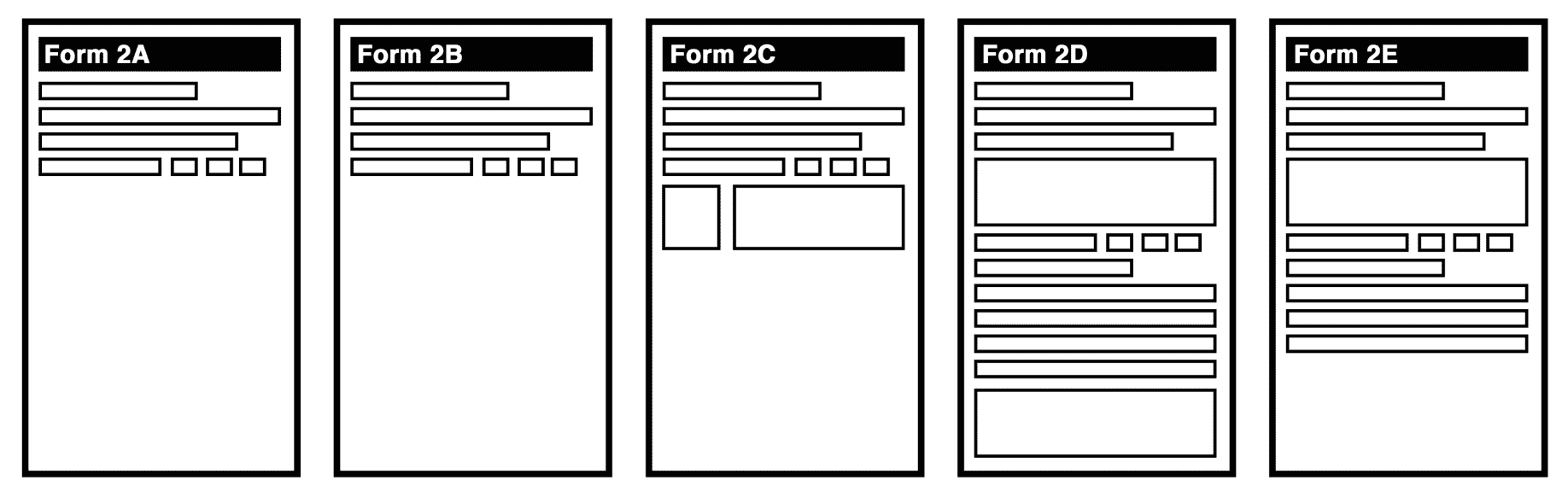
将纸质表单中必要的字段分离出来,可能看起来很明显,但程序员在其编码抽象中经常忽视有效地执行这一点。接口隔离原则提醒我们正确地将抽象分离成独立和内部一致的接口的重要性。这样做有以下好处:
-
增强可靠性:拥有真正解耦的正确隔离接口使得代码更易于测试和验证,从而有助于其长期的可靠性和稳定性。
-
增强可维护性:拥有分离的接口意味着对一个接口的更改不需要影响其他接口。正如我们在 1A 表单的布局中所看到的,位置和可用空间严重依赖于表单的每个部分。然而,一旦我们解耦了这些依赖关系,我们就可以自由地维护和更改每一个部分,而不用担心其他部分。
-
增强可用性:拥有根据目的和功能分离的接口意味着用户能够以更少的时间和认知努力理解和浏览接口。用户是我们接口的消费者,因此最依赖接口清晰地划分。
依赖倒置原则
依赖倒置原则陈述如下:
-
高层模块不应该依赖于低层模块。两者都应该依赖于抽象(即接口)
-
抽象不应该依赖于细节。细节(如具体实现)应该依赖于抽象
第一点可能会让你想起 LoD。它在很大程度上谈论了相同的概念:高级与低级的分离。
我们的抽象应该被分离(解耦),以便我们可以在以后轻松更改低级实现细节,而无需重构所有代码。依赖倒置原则在其第二点中建议我们通过中间抽象来实现这一点,通过这些中间抽象,高级模块可以与低级细节进行接口。这些中间抽象有时被称为适配器,因为它们适应了低级抽象,以便高级抽象可以使用。
为什么叫做依赖倒置?高级模块最初可能依赖于低级模块。在提供面向对象编程概念(如抽象类和接口)的语言中,比如 Java,可以说低级模块最终可能依赖于接口,因为接口提供了低级模块实现的脚手架。高级模块也依赖于这个接口,以便可以利用低级模块。我们可以看到这里依赖关系是倒置的,以便高级和低级模块都依赖于同一个接口。
再次考虑我们的“日历”应用程序,假设我们想要实现一种方法来检索固定位置周围发生的事件。我们可以选择实现一个类似这样的方法:
class Calendar {
getEventsAtLocation(targetLocation, kilometerRadius) {
const geocoder = new GeoCoder();
const distanceCalc = new DistanceCalculator();
return this.events.filter(event => {
const eventLocation = event.location.address
? geocoder.geocode(event.location.address)
: event.location.coords;
return distanceCalc.haversineFormulaDistance(
eventLocation,
targetLocation
) <= kilometerRadius / 1000;
});
}
// ...
}
getEventsAtLocation方法负责检索距离给定位置一定半径(以公里为单位)内的事件。如您所见,它使用GeoCoder类和DistanceCalculator类来实现其目的。
Calendar类是一个高级抽象,涉及日历及其事件的广泛概念。然而,getEventsAtLocation方法包含了许多与位置相关的细节,更多地是低级关注。这里的Calendar类关注于在DistanceCalculator上使用哪个公式以及计算中使用的测量单位。例如,您可以看到kilometerRadius参数必须除以1000才能得到以米为单位的距离,然后与haversineFormulaDistance方法返回的距离进行比较。
所有这些细节都不应该是高级抽象,如Calendar类的业务。依赖倒置原则要求我们考虑如何将这些关注点抽象到一个中间抽象中,作为高级和低级之间的桥梁。我们可以通过一个新类EventLocationCalculator来实现这一点:
const distanceCalculator = new DistanceCalculator();
const geocoder = new GeoCoder();
const METRES_IN_KM = 1000;
class EventLocationCalculator {
constructor(event) {
this.event = event;
}
getCoords() {
return this.event.location.address
? geocoder.geocode(this.event.location.address)
: this.event.location.coords
}
calculateDistanceInKilometers(targetLocation) {
return distanceCalculator.haversineFormulaDistance(
this.getCoords(),
targetLocation
) / METRES_IN_KM;
}
}
然后,Event类可以在其自己的isEventWithinRadiusOf方法中利用这个类。以下代码展示了这一示例:
class Event {
constructor() {
// ...
this.locationCalculator = new EventLocationCalculator();
}
isEventWithinRadiusOf(targetLocation, kilometerRadius) {
return locationCalculator.calculateDistanceInKilometers(
targetLocation
) <= kilometerRadius;
}
// ...
}
因此,Calendar类只需要关注Event实例具有isEventWithinRadiusOf方法这一事实。它不需要任何信息,也不对确定距离的具体实现做出规定;这些细节留给我们的低级EventLocationCalculator类:
class Calendar {
getEventsAtLocation(targetLocation, kilometerRadius) {
return this.events.filter(event => {
return event.isEventWithinRadiusOf(
targetLocation,
kilometerRadius
);
});
}
// ...
}
依赖倒置原则类似于与抽象界面分离原则相关的其他原则,但它特别关注依赖关系以及这些依赖关系的指向。当我们设计和构建抽象时,我们隐含地建立了一个依赖图。例如,如果我们要绘制出我们得到的实现的依赖关系,那么它看起来会像这样:

绘制此类依赖图非常有用。它们是探索代码真正复杂性的有用方式,通常可以突出可能改进的领域。最重要的是,它们让我们观察到我们的低级实现(细节)在何处,如果有的话,影响了我们的高级抽象。只有当我们看到这种情况时,我们才能加以纠正。因此,在阅读本书及以后的过程中,始终要在脑海中有一个依赖关系图;这将有助于引导您编写更脱耦、更可靠的代码。
依赖倒置原则是 SOLID 首字母缩写中的最后一个,而 SOLID,正如我们所见,主要关注于我们构建抽象的方式。我们将要介绍的下一个原则将绑定我们迄今为止所涵盖的大部分内容,因为它就是抽象本身的原则。如果我们从本章中记住的唯一一件事是什么,那么我们至少应该记住抽象原则。
抽象原则
在第一章中,我们介绍了抽象塔的概念,以及每个抽象都是隐藏复杂性的简化杠杆的想法。编程中的抽象原则陈述如下:
实现应该与接口分离。
实现是抽象的复杂底层:它所隐藏的部分。接口是简化的顶层。这就是为什么我们说抽象是隐藏复杂性的简化杠杆。创建将实现与接口分离到恰到好处的抽象的技艺并不像看起来那么简单。因此,编程世界为我们提供了两个警告:
-
不要重复自己(DRY):这是一个警告,告诉我们要避免编写重复我们已经编写的代码。如果你发现自己不得不重复自己,那么这表明你未能抽象出某些东西,或者抽象得不够。
-
你不会需要它(YAGNI):也被称为保持简单,愚蠢!(KISS),这个警告告诉我们要警惕过度抽象不需要被抽象的代码。这与 DRY 截然相反,并提醒我们除非有必要(如果我们开始重复自己,也许),我们不应尝试抽象。
在这两个警告之间,中间某处,就是完美的抽象。设计抽象,使其尽可能简单和有用,是一种平衡。一方面,我们可以说我们有过度抽象(DRY 警告我们要注意这一点),另一方面,我们有过度抽象(YAGNI 警告我们要注意这一点)。
过度抽象
过度抽象是指已经移除或替换了太多复杂性,以至于底层复杂性变得难以利用。过度抽象的风险在于,我们要么过度简化以求简单,要么添加新的不必要的复杂性,使抽象的用户感到困惑。
例如,假设我们需要一个画廊抽象,我们希望在网站和各种移动应用程序上都能使用它来显示画廊。根据平台的不同,画廊将使用可用的接口来生成布局。在网页上,它将生成 HTML 和 DOM,但在移动应用程序上,它将使用各种可用的本机 UI SDK。抽象为我们提供了所有这些跨平台复杂性的控制杆。
我们对画廊的最初要求非常简单:
-
能够显示一个或多个图像
-
能够在图像旁显示标题
-
能够控制单个图像的尺寸
外部团队为我们创建了一个画廊组件。我们打开文档,看到它有以下示例代码,向我们展示如何创建一个包含两张图片的画廊:
const gallery = new GalleryComponent(
[
new GalleryComponentImage(
new GalleryComponentImage.PathOfImage('JPEG', '/foo/images/Picture1.jpg'),
new GalleryComponentImage.Options({
imageDimensionWidth: { unit: 'px', amount: 200 },
imageDimensionHeight: { unit: 'px', amount: 150 },
customStyleStrings: ['border::yellow::1px']
}),
[
new GalleryComponentImage.SubBorderCaptionElementWithText({
content: { e: 'paragraph', t: 'The caption for this employee' }
})
]
}),
new GalleryComponentImage(
new GalleryComponentImage.PathOfImage('JPEG', '/foo/images/Picture2.jpg'),
new GalleryComponentImage.Options({
imageDimensionWidth: { unit: 'px', amount: 200 },
imageDimensionHeight: { unit: 'px', amount: 150 },
customStyleStrings: ['border::yellow::1px']
}),
[
new GalleryComponentImage.SubBorderCaptionElementWithText({
content: { e: 'paragraph', t: 'The caption for this employee' }
})
]
})
]
);
这个接口对于只显示几张图片的基本目的来说似乎非常复杂。考虑到我们简单的需求,我们可以说前面的接口是过度抽象的证据:它没有简化底层复杂性,而是引入了一整套我们甚至不需要的新的复杂性和各种功能。它在技术上满足了我们的要求,但我们必须在其复杂的领域中导航才能实现我们想要的东西。
这样的抽象,编码了新的复杂性并规定了自己的特性和命名约定,有可能不仅无法减少复杂性,还可能增加复杂性!抽象不应增加复杂性;这与抽象的整个目的背道而驰。
请记住,适当的抽象级别取决于上下文。对于您的用例来说可能是过度抽象的,对于另一个用例来说可能是不足抽象的。F1 赛车手对引擎的抽象级别与福特福克斯车手不同。抽象,像许多清洁代码概念一样,取决于受众和用户。
过度抽象还可以奇怪地采用过度简化的形式,其中对底层复杂性的控制杆并不向我们开放。我们的GalleryComponent接口的过度简化版本可能如下所示:
const gallery = new GalleryComponent(
'/foo/images/PictureOne.jpg',
'/foo/images/PictureTwo.jpg'
);
这种最小接口可能看起来与以前的代码完全相反,在某些方面是这样,但奇怪的是,它也是过度抽象的一个例子。记住,抽象是指通过接口提供对底层复杂性的杠杆。在这种情况下,这个杠杆太简单了,只提供了非常有限的复杂性,我们希望利用这种复杂性。它不允许我们添加标题或控制图像尺寸;它只允许我们列出一组图像,什么都不能做。
通过前面两个例子,你已经看到过度抽象可以有两种不同的风格:一种是过于复杂,一种是过于简化。这两种都是不受欢迎的。
低抽象
如果过度抽象是指过多的复杂性已被移除或替换,那么低抽象是指过少的复杂性已被移除或替换。这导致用户需要关注底层复杂性。想象一下,你有一辆汽车,你必须在没有方向盘或仪表盘的情况下驾驶它。你必须直接通过引擎来控制它,用你的双手拉动杠杆和转动油腻的齿轮,同时注意路况。我们可以说这辆车有一种低抽象的控制方法。
我们探讨了我们的画廊组件的过度抽象版本,那么让我们看看低抽象版本可能是什么样子:
const gallery = new GalleryComponent({
web: [
() => {
const el = document.createElement('div');
el.className = 'gallery-container';
return el;
},
{
data: [
`<img src="/foo/images/PictureOne.jpg" width=200 height=150 />
<span>The caption</span>`,
`<img src="/foo/images/PictureTwo.jpg" width=200 height=150 />
<span>The caption</span>`
]
}
],
android: [
(view, galleryPrepData) => {
view.setHasFixedSize(true);
view.setLayoutManager(new GridLayoutManager(getApplicationContext(),2));
return new MyAdapter(getApplicationContext(), galleryPrepData());
},
{
data: [
['/foo/images/PictureOne.jpg', 200, 150, 'The Caption']
['/foo/images/PictureTwo.jpg', 200, 150, 'The Caption']
]
}
]
});
这个GalleryComponent的版本似乎在强迫我们定义特定于 Web 的 HTML 和特定于 Android 的代码。理想情况下,我们依赖于抽象来隐藏这种复杂性,给我们一个简化的接口来利用它,但它没有做到。在这里,编写特定于平台的代码的复杂性在这里没有得到足够的抽象,因此我们可以说这是一个低抽象的例子。
从前面的代码中,你也可以看到我们被迫重复我们图像的源 URL 和标题文本。这应该提醒我们之前探讨过的一个警告:DRY,它表明我们没有充分抽象出某些东西。
如果我们留意那些被迫重复自己的领域,那么我们可以希望构建更好的抽象。但要注意,低抽象并不总是显而易见。
可以说各种抽象都是泄漏的抽象,因为它们通过它们的接口向上泄漏它们的一部分复杂性。前面的代码就是一个例子:我们可以说它正在向上泄漏其跨平台复杂性的实现细节。
平衡的抽象
根据我们对低抽象和过度抽象的了解,我们可以说平衡的抽象是坐落在这两种不受欢迎的对立面之间的抽象。创建平衡的抽象的技巧既是一门艺术,也是一门科学,需要我们对问题领域和用户的能力和意图有很好的理解。通过运用本章中的许多原则和警告,我们可以希望在我们的代码构建中保持平衡。对于GalleryComponent的上一个例子,我们应该再次探索抽象的要求:
-
显示一个或多个图像的能力
-
显示图像旁边的标题的能力
-
控制各个图像的尺寸的能力
这些,我们可以说,是我们必须提供给底层跨平台复杂性的杠杆。我们的抽象应该只旨在暴露这些杠杆,而不是其他不必要的复杂性。以下是这种抽象的一个例子:
const gallery = new GalleryComponent([
{
src: '/foo/images/PictureOne.jpg',
caption: 'The Caption',
width: 200,
height: 150
},
{
src: '/foo/images/PictureTwo.jpg',
caption: 'The Caption',
width: 200,
height: 150
},
]);
通过这个接口,我们可以定义一个或多个图像,设置它们的尺寸,并为每个图像定义标题。它满足了所有的要求,而不会引入新的复杂性或从底层实现中泄漏复杂性。因此,这是一个平衡的抽象。
功能性编程原则
JavaScript 允许我们以多种不同的方式进行编程。到目前为止,在本书中分享的许多示例更倾向于面向对象编程,它主要使用对象来表达问题领域。函数式编程不同之处在于,它主要使用纯函数和不可变数据来表达问题领域。
所有编程范式都广泛关注同一件事:使表达问题领域更容易,作为程序员传达我们的意图,并容纳有用和可用的抽象的创建。我们从一种范式中采纳的最佳原则可能仍然适用于另一种范式,因此要采取开放的态度!
通过探索一个示例,最容易观察和讨论面向对象编程和函数式编程之间的差异。假设我们希望构建一个机制,以便我们可以从服务器获取分页数据。为了以面向对象的方式实现这一点,我们可能会创建一个PaginatedDataFetcher类:
// An OOP approach
class PaginatedDataFetcher {
constructor(endpoint, startingPage) {
this.endpoint = endpoint;
this.nextPage = startingPage || 1;
}
getNextPage() {
const response = fetch(
`/api/${this.endpoint}/${this.nextPage}`
);
this.nextPage++;
return fetched;
}
}
下面是一个使用PaginatedDataFetcher类的示例:
const pageFetcher = new PaginatedDataFetcher('account_data', 30);
await pageFetcher.getNextPage(); // => Fetches /api/account_data/30
await pageFetcher.getNextPage(); // => Fetches /api/account_data/31
await pageFetcher.getNextPage(); // => Fetches /api/account_data/32
如您所见,每次调用getNextPage时,我们都会检索下一页的数据。getNextPage方法依赖于其对象的记忆状态,endpoint和nextPage,以了解下一个要请求的 URL。
状态可以被视为任何程序或代码片段的基础记忆数据,其结果或效果是由此派生的。汽车的状态可能意味着它的当前保养情况,燃油和机油水平等。同样,运行程序的状态是它从中派生功能的基础数据。
函数式编程与面向对象编程有所不同,它纯粹关注函数的使用和不可变状态来实现其目标。人们在探索函数式编程时通常遇到的第一个心理障碍与状态有关,引发了诸如“我应该把状态存储在哪里?”和“如何使事物改变而无法改变状态?”等问题。我们可以通过查看分页数据获取器的函数式编程等价物来探讨这个问题。
我们创建了一个函数getPage,我们将传递一个endpoint和一个pageNumber,如下所示:
// A more functional approach
const getPage = async (endpoint, pageNumber = 1) => ({
endpoint,
pageNumber,
response: await fetch(`/api/${endpoint}/${pageNumber}`)
next: () => getPage(endpoint, pageNumber + 1)
});
调用getPage函数时,将返回一个包含来自服务器的响应以及使用的endpoint和pageNumber的对象。除了这些属性之外,该对象还将包含一个名为next的函数,如果调用,将通过随后调用getPage来触发另一个请求。可以按以下方式使用它:
const page1 = await getPage('account_data');
const page2 = await page1.next();
const page3 = await page2.next();
const page4 = await page3.next();
// Etc.
您会注意到,使用这种模式时,我们只需要引用最后检索到的页面,即可进行下一次请求。通过页面 2 返回的next()函数检索页面 3。通过页面 3 返回的next()函数检索页面 4。
我们的getPage函数不会改变任何数据:它只使用传递的数据来派生新数据,因此可以说它采用了不可变性。还可以说它也是一个纯函数,因为对于给定的输入参数(endpoint和pageNumber),它将始终返回相同的结果。getPage返回的next函数也是纯的,因为它将始终返回相同的结果:如果我调用page2.next()一百万次,它将始终获取page 3。
函数纯度和不可变性是最重要的函数式概念之一,而且,值得注意的是,这些原则适用于所有编程范式。我们并不打算在这里深入探讨函数式编程,而只是涵盖其最适用的原则,以增强我们的抽象构建能力。
函数纯度
当函数的返回值仅从其输入值派生时(也称为幂等性),并且没有副作用时,可以说函数是纯的。这些特征给我们带来了以下好处:
-
可预测性:不会对程序的其他部分产生副作用的函数是可以轻松推理的函数。如果一个函数改变了它不拥有的状态,可能会在代码的其他部分创建级联的变化,这可能会非常复杂,从而产生维护和可靠性问题。
-
可测试性:纯函数总是在给定相同的输入时返回相同的结果,因此非常容易验证。纯函数可能变得复杂,但如果保持纯净,它们将始终易于测试。
幂等性是指在提供特定输入时总是得出相同结果的特性。因此,幂等函数是高度确定性的。幂等函数可能仍然具有副作用,因此它可能并不总是一个纯函数,但从抽象用户的角度来看,幂等性是非常可取的,因为这意味着我们总是知道可以期望什么。
在面向对象编程中,对象上的方法通常不能说是纯的,因为它们会改变状态(在对象上)或在相同的输入参数下返回不同的结果。例如,考虑以下Adder类:
class Adder {
constructor() {
this.total = 0;
}
add(n) {
return this.total += n;
}
}
const adder = new Adder();
adder.add(10); // => 10
adder.add(10); // => 20
adder.add(5); // => 25
add方法在这里不是纯的。即使给定相同的参数,它返回不同的结果,并且具有副作用:改变它不拥有的状态(即对象的 total 属性)。我们可以很简单地创建一个功能纯粹的加法抽象:
const add = (a, b) => a + b;
add(10, 10); // => 20
add(10, 20); // => 30
这可能看起来有些牵强,但功能纯度背后的概念是,从复杂的需求中得出真正纯粹的基本原语和函数,以构造它所需的。功能纯度在这里教给我们一个一般性的教训:将功能分解为其最原始的部分,直到你拥有一个真正可测试的独立单元。然后我们可以将这些较小的单元组合成更复杂的单元,以执行更复杂的工作。
不可变性
这一章主要讨论了我们如何构建和分离抽象,但同样重要的是考虑数据在这些抽象之间传递的期望。
不可变性是指数据不应该发生变化的简单想法。这意味着,当我们初始化一个对象时,例如,我们不应该向其添加新属性或随时间更改现有属性。相反,我们应该派生一个全新的对象,只对我们自己的副本进行更改。不可变性是数据的特征,也是函数式编程的一般原则。语言也可以通过不允许已声明的变量或对象的变异来强制不可变性。JavaScript 的const就是这种强制的一个例子:
const name = 'James';
name = 'Samuel L. Jackson';
// => Uncaught TypeError: Assignment to constant variable.
知道某物是不可变的意味着我们可以放心地知道它不会改变;我们可以依赖它的特性,而不必担心程序的其他部分可能在我们不知情的情况下改变它。这在 JavaScript 的异步世界中尤为重要,数据以复杂的方式在作用域和接口之间穿梭。
与本章涵盖的许多原则一样,不可变性并不一定要严格遵循才能从中获得好处。在某些领域保持不可变性,在其他领域保持可变性,可能是一种可行的方法。想象一份官方文件在政府大楼中穿梭。每个部门都默认文件没有被意外的人任意修改;特定部门可能选择复制文件,然后对其自己的副本进行各种变更,以满足自己独特的目的。代码库与此并无二致。通过构建抽象并让它们相互依赖,我们有意地使它们能够操纵彼此的数据和功能。
总结
在本章中,我们涵盖了大量的理论和实践技能。我们涵盖了 LoD(或最少信息原则)、所有 SOLID 原则、抽象原则,以及函数式编程范式中的一些关键原则。即使你不记得所有的名字,希望你能记住每个原则所包含的基础知识和关键教训。
编程既是一门艺术,也是一门科学。它涉及在追求真正平衡的抽象时平衡所有这些原则。这些原则都不应被视为硬性规则。它们只是指导方针,将在我们的旅程中帮助我们。
在下一章中,我们将继续探讨编程中最具挑战性的一个方面,无论是在 JavaScript 中还是在其他地方:命名事物的问题。
第五章:命名事物很难
名字无处不在。它们是我们大脑抽象宇宙复杂性的方式。在软件世界中,我们总是在努力创造新的抽象来描述我们的日常现实。编程世界中的一个常见警句是命名事物很难。想出一个名字并不总是很难,但想出一个好名字通常是很难的。
在之前的章节中,我们已经探讨了抽象背后的原则和理论。在本章中,我们将提供这个谜题的最后一把钥匙。一个抽象如果没有好的命名,就不能成为一个好的抽象。在我们使用的名字中,我们在提炼一个概念,而这种提炼将定义人们最终理解这个概念的方式。因此,命名事物不仅仅是提供任意标签;它是提供理解。只有通过一个好的名字,用户或其他程序员才能完全内化我们的抽象,并以全面的理解来使用它。
在本章中,我们将使用一些例子来探讨一个好名字的关键特征。我们还将讨论在 JavaScript 这样的动态类型语言中命名事物的挑战。通过本章,我们应该清楚地了解如何提出干净和描述性的名字。
具体来说,我们将涵盖以下主题:
-
名字中有什么?
-
命名反模式
-
一致性和层次结构
-
技术和考虑事项
名字中有什么?
分解一个好名字的关键元素是困难的。它似乎更像是一门艺术而不是一门科学。一个相当好的名字和一个非常好的名字之间的界限模糊不清,容易受主观意见的影响。
考虑一个负责将多个 CSS 样式应用于按钮的函数。想象一种情况,这是一个独立的函数。以下哪个名字你认为最合适?
-
styleButton -
setStyleOfButton -
setButtonCSS -
stylizeButton -
setButtonStyles -
applyButtonCSS
你可能已经选择了你喜欢的。在阅读本书的人中,肯定会有分歧。这些分歧中的许多将根植于我们自己的偏见。我们的许多偏见将受到诸如我们说什么语言、我们之前接触过哪些编程语言以及我们花时间创建哪种类型的程序等因素的影响。我们之间存在许多差异,但是,不知何故,我们必须提出一个关于好名字或干净名字的非模糊概念。至少可以说,一个好的名字可能具有以下特征:
-
目的:某物的用途和行为方式
-
概念:它的核心思想以及如何思考它
-
合同:关于它如何工作的期望
这并不能完全涵盖命名的复杂性,但是有了这三个特征,我们有了一个起点。在本节的其余部分,我们将学习这些特征如何对命名事物的过程至关重要。
目的
一个好的名字表明了目的。目的是某物做什么,或者某物是什么。在函数的情况下,它的目的就是它的行为。这就是为什么函数通常以动词形式命名,比如getUser或createAccount,而存储值的东西通常是名词,比如account或button。
一个概括清晰目的的名字永远不需要进一步解释。它应该是不言自明的。如果一个名字需要注释来解释它的目的,那通常意味着它没有完成作为名字的工作。
某物的目的是高度上下文化的,因此将受到周围代码和该名字所在代码库区域的影响。这就是为什么通常可以使用通用名字,只要它周围有助于说明其目的的上下文。例如,比较TenancyAgreement类中的这三个方法签名:
class TenancyAgreement {
// Option #1:
saveSignedDocument(
id,
timestamp
) {}
// Option #2:
saveSignedDocument(
documentId,
documentTimestamp
) {}
// Option #3:
saveSignedDocument(
tenancyAgreementSignedDocumentID,
tenancyAgreementSignedDocumentTimestamp
) {}
}
当然,这是有主观性的,但大多数人会同意,当我们有一个能够很好地传达其目的的周围上下文时,我们不需要详细命名该上下文中的每个变量。考虑到这一点,我们可以说前面代码中的Option #1过于局限,可能会引起歧义,而Option #3过于冗长,因为其参数名称的一部分已经由其上下文提供。然而,Option #2,使用documentId和documentTimestamp,是恰到好处的:它充分传达了参数的目的。这就是我们需要的。
目的对于任何名称来说绝对是至关重要的。没有描述或目的的指示,名称只是装饰而已,通常意味着我们的代码使用者只能在文档和其他代码片段之间翻找,才能弄清楚某些事情。因此,我们必须记住始终考虑我们的名称是否能很好地传达目的。
概念
一个好的名称表明概念。名称的概念指的是其背后的想法,其创建的意图,以及我们应该如何思考它。例如,一个名为relocateDeviceAccurately的函数不仅告诉我们它将做什么(它的目的),还告诉我们关于其行为周围概念的概念。从这个名称中,我们可以看到设备是可以被定位的东西,并且可以以不同的精度定位这些设备。一个相对简单的名称可以在阅读它的人的头脑中唤起丰富的概念。这是命名事物的重要力量的一部分:名称是理解的途径。
一个名称的概念,就像它的目的一样,与它存在的上下文紧密相关。上下文是我们的名称存在的共享空间。围绕我们感兴趣的名称的其他名称绝对有助于帮助我们理解它的概念。想象一下以下名称一起出现:
-
rejectedDeal -
acceptedDeal -
pendingDeal -
stalledDeal
通过这些名称,我们立即理解到deal是一种至少可以有四种不同状态的东西。这暗示着这些状态是相互排斥的,不能同时适用于一项交易,尽管目前还不清楚。我们可能会假设是否有特定条件与交易是否待定或停滞有关,尽管我们不确定这些条件是什么。因此,即使存在歧义,我们已经开始建立对问题领域的丰富理解。这仅仅是通过查看名称,甚至没有阅读实现。
我们已经谈到上下文作为名称的一种共享空间。在编程术语中,我们通常说在一个区域中命名的事物占据一个单一的命名空间。命名空间可以被认为是一个地方,其中事物彼此共享一个概念区域。一些语言已经将命名空间的概念正式化为自己的语言构造(通常称为包,或者简单地称为命名空间)。即使没有这样的正式语言构造,JavaScript 仍然可以通过对象等分层构造来构建命名空间,如下所示:
const app = {};
app.transactions = {};
app.transactions.dealMaking = {};
app.transactions.dealMaking.states = [
'REJECTED_DEAL',
'ACCEPTED_DEAL',
'PENDING_DEAL',
'STALLED_DEAL'
];
大多数程序员倾向于将命名空间视为一个非常正式的构造,但这并不经常是这种情况。通常,我们在编写函数时会在其中使用函数来组成暗示的命名空间,而不自知。在这种情况下,命名空间不是由对象层次结构的级别界定的,而是由我们函数的作用域界定的,如下所示:
function makeFilteredRequest(endpoint, filterFn) {
return fetch(`/${endpoint}/`)
.then(response => response.json())
.then(data => data.filter(filterFn);
}
在这里,我们通过fetch向一个端点发出请求,在返回之前,我们通过利用fetch返回的 promise 来收集所需的数据。为了做到这一点,我们使用了两个then(...)处理程序。
Promise是一个原生提供的类,为处理异步操作提供了有用的抽象。通常可以通过其 then 方法来识别 promise,就像我们在前面的代码中使用的那样。在利用异步操作时,通常会使用 promise 或回调。您可以在异步控制流部分的第十章中了解更多信息。
我们的第一个then(...)处理程序将其参数命名为response,而第二个处理程序将其参数命名为data。在makeFilteredRequest的上下文之外,这些术语将非常模糊。然而,因为我们在与制作过滤请求相关的函数的暗示命名空间内,术语response和data足以传达它们的概念。
我们的名称传达的概念,就像它们的目的一样,与它们指定的上下文密切相关,因此重要的是不仅要考虑名称本身,还要考虑其周围的一切:它所在的复杂逻辑和行为的错综复杂。所有代码都涉及一定程度的复杂性,对这种复杂性的概念理解对于能够掌握它至关重要。因此,在命名某物时,有助于问自己:*我希望他们如何理解这种复杂性?*如果您正在为其他程序员创建一个简单的接口,编写一个深度嵌入的硬件驱动程序,或者为非程序员创建一个 GUI,这是相关的。
合同
一个好的名称表示与周围抽象的其他部分的合同。通过其名称,变量可能指示它将如何使用或包含什么类型的值以及我们对其行为应有的一般期望。通常不会考虑,但是当我们命名某物时,实际上正在建立一系列隐含的期望或合同,这些期望或合同将定义人们如何理解和使用该物。以下是 JavaScript 中存在的隐含合同的一些示例:
-
以is开头的变量,例如
isUser,预期是布尔类型(true或false)。 -
全大写的变量预期是一个常量(只设置一次且不可变),例如
DEFAULT_USER_EXPIRY。 -
以复数命名的变量(例如 elements)预期包含一个或多个项目的集合对象(例如数组),而以单数命名的变量(例如 element)只预期包含一个项目(不在集合中)。
-
以
get、find或select开头的函数通常预期会向您返回一些东西。以process、build或run开头的函数更加模糊,可能不会这样做。 -
属性或方法名称以下划线开头,例如
_processConfig,通常意味着是内部实现或伪私有的。它们不打算公开调用。
不管我们喜欢与否,所有名称都携带着关于其值和行为的不可避免的期望。重要的是要意识到这些约定,以免意外违反其他程序员依赖的合同。当然,每个约定都会有例外,但尽管如此,我们应该尽量遵守它们。
不幸的是,并没有一个可以定义所有这些合同的规范列表。它们通常相当主观,并且将取决于代码库。尽管如此,在我们遇到这种约定的地方,我们应该遵循它们。正如我们在第二章中提到的,《清洁代码的原则》,确保熟悉性是增加代码可维护性的好方法。而确保熟悉性的最佳方法莫过于采用其他程序员已经采用的约定。
许多这些暗示的合同与类型有关,而 JavaScript,正如你可能知道的,是动态类型的。这意味着值的类型将在运行时确定,并且任何变量包含的类型可能会有所改变:
var something;
something = 1; // a number
something = true; // a boolean
something = []; // an array
something = {}; // an object
变量可以引用许多不同的类型这一事实意味着我们采用的名称所暗示的合同和约定更加重要。没有静态类型检查器来帮助我们。我们只能在自己和其他程序员的混乱心情中独自面对。
在本章的后面,我们将讨论匈牙利命名法,这是一种在动态类型语言中有用的命名方式。另外,值得知道的是,对于 JavaScript,有各种静态类型检查和类型注释工具可用,如果你发现处理其动态性很痛苦。这将在第十五章中进行介绍,更干净代码的工具。
合同不仅因为 JavaScript 的动态类型而重要。它们在给予我们对某些值的行为以及在程序运行时可以从中期望什么方面上是基本有用的。想象一下,如果有一个名为getCurrentValue()的方法的 API 并不总是返回当前值。那将违反其暗示的合同。通过合同的视角看名字是一种很有意思的方式。很快,你将开始在各处看到合同 - 变量之间的合同,接口之间的合同,以及整个架构和系统之间的集成级别的合同。
现在我们已经讨论了一个好名称的三个特征(目的、概念、合同),我们可以开始探讨一些反模式,也就是我们应该尽量避免的命名方式。
命名反模式
与 DRY 和 YAGNI 的抽象构建警告类似,命名也有自己的警告和反模式。有许多组成糟糕名称的方式,几乎所有这些方式都可以分为三种广泛的命名反模式:不必要的短名称,不必要的奇异名称和不必要的长名称。
名称是我们和其他人将查看我们构建的抽象的初始镜头。因此,了解如何避免创建最终只会模糊理解并为其他程序员复杂化事情的镜头是至关重要的。让我们从探讨不必要的短名称开始,以及它们如何最终极大地限制我们理解某些事物的能力。
不必要的短名称
名称太短通常使用程序特定知识或领域特定知识,这些知识可能不适用于代码的受众。一个孤独的程序员可能认为写下以下代码是合理的:
function incId(id, f) {
for (let x = 0; x < ids.length; ++x) {
if (ids[x].id === id && f(ids[x])) {
ids[x].n++;
}
}
}
我们能够辨别出它与 ID 相关,并且其目的是有条件地增加ids数组中特定对象的n属性。因此,在功能层面上,我们可以辨别出它在做什么,但其含义和意图很难理解。程序员使用了单个字母的名称(f,x,n),并且还使用了缩写的函数名称(incId)。这些名称大多未能满足我们从名称中期望的基本特征:指示目的、概念和合同。我们只能通过它们的使用方式来猜测这些名称的目的和概念。用更有意义的名称重构将大大有助于这一点。
function incrementJobInstancesByIdIfFilter(id, filter) {
for (let i = 0; i < jobs.length; i++) {
let job = jobs[i];
if (job.id === id && filter(job)) {
job.nInstances++;
}
}
}
现在我们对情况有了更清晰的了解。被迭代的数组包含作业。函数的目的是找到具有指定 ID 的作业,并且在该作业满足指定过滤器的条件下递增作业的nInstances属性。通过这些新名称,我们已经对这个抽象有了更丰富的概念理解。我们现在明白作业是可以有任意数量实例的项目,并且当前实例的数量通过nInstances属性进行跟踪。通过名称提供的视角,我们能够更清晰地理解底层问题领域。现在,我们可以看到名称不仅仅是装饰或不必要的冗长;名称是你抽象的本质。
不必要的短名称在很多方面只是一个意义不足的名称。然而,名称的短并不一定表示问题。我们在前面的代码中使用的迭代变量i是完全可以的,因为这是一个几十年来已经确立的惯例。世界各地的程序员都理解它的概念和约定义:它只用于遍历数组,并在每个迭代阶段访问数组元素。
总的来说,除了我们的迭代变量等极少数例外情况外,避免使用短名称带来的意义不足非常重要。它们通常是匆忙或懒惰地组成的,甚至可能会让程序员感到有所成就。毕竟,能够运用晦涩的逻辑是一种自我陶醉的礼物。但正如我们所讨论的,自我陶醉并不是清晰代码的朋友。每当你感到想要使用短名称的冲动时,抵制这种冲动,花时间选择一个更有意义的名称。
不必要的异国情调的名称
自我陶醉的另一个方面是异国情调的名称的泛滥。异国情调的名称是那些不必要地吸引注意力的名称,通常在意义上是模糊或难以理解的,比如:
function deStylizeParameters(params) {
disEntangleParams(params, p => !!p.style).obliterate();
}
这是一个表面上简单的行为,却因不必要的异国情调的名称而变得模糊。我们只需稍加努力,就可以大大提高这些抽象的可理解性:
function removeStylingFromParams(params) {
filterParams(params, param => !!param.style).remove();
}
总的来说,名称应该是无聊的。它们不应该吸引注意力。它们应该只展示它们的简单含义,而不会让其他程序员感到*哦,原来是这个意思!或哈哈,好聪明!*我们的自我可能对命名有自己的想法,但我们应该记住限制自我,纯粹考虑那些必须忍受尝试理解我们的代码和我们创建的接口的人。总的来说,以下建议将使我们走上正确的道路:
-
避免使用普通词的花哨或更长的同义词:例如,使用
kill或obliterate而不是delete -
避免不存在的词:例如,
deletify,elementize或dedupify -
避免双关语或巧妙的暗示:例如,使用化学元素名称来指代 DOM 元素
过度异国情调会冒险疏远我们的受众。你可能很容易理解你采用的名称,但这并不意味着其他人也能轻松理解。程序员社区非常多样化,有许多不同的文化和语言背景。最好坚持使用描述性和无聊的名称,以便你的代码能够被尽可能多的人理解。
不必要的冗长的名称
正如我们已经发现的,不必要的短名称实际上是没有足够意义的名称。因此,不必要的长名称是一个意义过多的名称。你可能会想一个名称怎么会有太多的意义。意义是好事,但是过多的意义压缩到一个名称中只会导致混淆;例如:
documentManager.refreshAndSaveSignedAndNonPendingDocuments();
这个名称很难理解:它是在刷新和保存已签署和非挂起的文档,还是在刷新和保存既已签署又非挂起的文档?不清楚。
这个长名称给了我们一个线索,表明底层抽象是不必要地复杂。我们可以将名称分解为其组成部分,以充分了解其接口:
-
refresh (verb):文档上发生的刷新动作
-
save (verb):文档上发生的保存动作
-
signed (adjective):文档的已签署状态
-
non-pending (adjective):文档的非挂起状态
-
document (noun):文档本身
在这里我们有一些不同的事情发生。对于这么长的名称,一个很好的指导原则是重构底层抽象,以便我们只需要一个最多包含一个动词,一个形容词和一个名词的名称。例如,我们可以将我们的长名称拆分为四个不同的函数:
documentManager.refreshSignedDocuments();
documentManager.refreshNonPendingDocuments();
documentManager.saveSignedDocuments();
documentManager.saveNonPendingDocuments();
或者,如果意图是对携带多种状态(SIGNED和NON_PENDING)的文档执行操作,那么我们可以为刷新实现这样的方法(保存动作也可以类似):
documentManager.refreshDocumentsWithStates([
documentManager.STATE_SIGNED,
documentManager.STATE_NON_PENDING
]);
关键是,长名称是一个破碎或混乱抽象的线索。使名称更易理解通常与使抽象更易理解相辅相成。
与短名称一样,问题不在于名称本身的长度:而是长度通常所指的含义。长名称所指的是将太多的含义压缩到一个名称中,表明了混乱的抽象。
一致性和层次结构
到目前为止,我们已经谈到了名称的三个最重要的特征:目的,概念和合同。赋予名称这些特征的最简单的方法之一是利用一致性和层次结构。这里的一致性是指在代码的给定区域内使用相同的命名模式。另一方面,层次结构是指我们构建和组合不同代码区域以形成整体架构的方式。它们共同使我们能够为名称提供丰富的上下文,可以用来对其目的,概念和合同进行强有力的推断。
这最好通过查看虚构应用程序的 JavaScript 目录来解释。我们有一个满是文件的目录,如下所示:
app/
|-- deepClone.js
|-- deepEquality.js
|-- getParamsFromURL.js
|-- getURL.js
|-- openModal.js
|-- openModalWithTemplate.js
|-- setupAppWithCustomConfig.js
|-- setupAppWithDefaultConfig.js
|-- setURL.js
|-- ...
没有层次结构,因此我们只能从名称本身和它们似乎相关的内容中推断上下文。例如,有一个getURL和一个setURL文件,它们都可能与 URL 相关,并且可以被视为实用程序。因此,将这些占据相同层次结构的部分或共享命名空间,例如app/utils/url,将是有帮助的。我们还可以将目录结构的其他部分重构为更具上下文丰富的层次结构:
app/
|-- setup/
| |-- defaultConfig.js
| |-- setup.js
|-- modal/
| |-- open.js
| |-- openWithTemplate.js
|-- utils/
|-- url/
| |-- getParams.js
| |-- get.js
| |-- set.js
|-- obj/
|-- deepEquality.js
|-- deepClone.js
立即,事情变得更清晰。理解所有这些文件及其功能的认知负担现在因每个文件都有其丰富的上下文而减轻了。您还会注意到,我们已经能够简化层次结构的各个部分的名称;例如,我们已将openModal.js重命名为modal/open.js。这是使用名称层次结构的额外好处:在每个命名级别,我们可以简化和缩短名称,减少理解时间。
层次结构内的名称自然地从其所在的上下文中获得一部分含义。这意味着名称本身不需要包含所有含义。始终寻找机会为类似的抽象提供共同的上下文,以减轻理解的负担。
就像我们通过目录结构的层次结构提供了含义一样,我们也可以在代码本身中提供含义。例如,在一个函数内部,名称自然会从函数的名称本身和它在更大模块中的情境中获得很多上下文。想象一下,如果写出这样的代码会很不寻常:
function displayModalWithMessage(
modalDisplayer_Message,
modalDisplayer_Options
) {
const modalDisplayer_ModalInstance = new Modal();
modalDisplayer_ModalInstance.setMessage(modalDisplayerMessage);
modalDisplayer_ModalInstance.setOptions(modalDisplayerOptions);
modalDisplayer_ModalInstance.show();
return modalDisplayer_ModalInstance;
}
函数内部的名称不必要地加上了上下文信息(比如modalDisplayer_...),而代码的读者已经可以从函数本身获取这些信息。通常,我们编写的代码会利用变量所处的位置以及从上下文中获得的含义。前面的代码更正常的写法应该是这样的:
function showModalWithMessage(message, options) {
const modalInstance = new Modal();
modalInstance.setMessage(message);
modalInstance.setOptions(options);
modalInstance.show();
return modalInstance;
}
在之前的一章中,我们讨论了抽象原则以及模块的实现应该独立于其接口。我们可以看到这个原则在这个函数中得到了体现。函数的范围(其实现)应该完全独立(甚至无知!)于其接口。因此,可以说,modalInstance变量不需要知道它位于哪个函数中,因此前缀为modalDisplayer_...的命名技术将违反抽象原则。
考虑到抽象的层次结构是关键。层次结构不仅仅在组织上有用。它们应该理想地反映出我们代码中存在的抽象层次。更高级的抽象位于层次结构的顶部,我们进入层次结构的深处,就会变得更低级。这是一个很好的一般规则:让你的层次结构反映你的抽象。
命名事物时要保持一致性,这符合这个规则。在我们的抽象的一个层次内,也就是在层次结构的一个层级内,我们应该采用常见的命名模式,这样我们代码的读者就可以轻松地浏览和理解其中的概念。例如,如果我们正在创建一个用于向数据结构添加和删除项目的接口,那么我们应该避免以不一致的方式命名类似的操作。考虑以下类的示意图:
class MyDataStructure {
addItem() {}
pushItems() {}
setItemIfNotExists() {}
// ...
}
非常令人困惑的是,这个抽象提供了三种不同的添加概念的变体:添加、推送和设置。实际上,这些名称都指的是同一个概念,所以我们应该采用一个常见的命名模式,比如以下方式:
class MyDataStructure {
addItem() {}
addItems() {}
addItemIfNotExists() {}
// ...
}
这个接口现在更容易理解了。使用起来更加清晰,认知负担更小。作为这个抽象的用户,我不再需要记住我应该使用add、set还是push。一致性是通过避免不必要的差异而产生的特征。不一致会让人感到不适,因此它们只应该用于标示真正的功能或概念差异。
技术和考虑因素
由于 JavaScript 的不断变化,它积累了大量相互冲突的约定。其中许多约定在支持或反对方面都引起了强烈的意见。然而,我们已经就一些基本的命名约定达成了一致,这些约定或多或少地得到了全球范围内的接受:
-
常量应该用下划线分隔的大写字母命名;例如,
DEFAULT_COMPONENT_COLOR -
构造函数或类应该采用驼峰命名法,首字母大写;例如,
MyComponent -
其他所有内容都应该采用驼峰命名法,首字母小写;例如,
myComponentInstance
除了这些基本约定之外,命名的决定很大程度上取决于程序员的创造力和技能。你最终使用的名称将在很大程度上由你解决的问题所定义。大多数代码将继承与其接口的 API 的命名约定。例如,使用 DOM API 通常意味着你采用诸如element、attribute和node之类的名称。许多流行的可用框架也会倾向于规定我们采用的名称。从你所在的生态系统中采用这样的常规范式是非常有用和必要的,但同时拥有一些基本的技术和概念也是很有用的,这样你就可以在新的和陌生的问题领域中构建出命名得体的抽象。
匈牙利命名法
JavaScript 是一种动态类型语言,这意味着值的类型将在运行时确定,并且任何变量包含的类型可能在运行时发生变化。这与静态类型语言相反,后者在编译时会警告你关于类型的使用。这意味着,作为 JavaScript 程序员,我们需要在使用类型和命名变量的方式上更加小心。
众所周知,当我们命名事物时,我们是在暗示一个约定。这个约定将定义其他程序员如何使用该事物。这就是为什么在各种语言中,匈牙利命名法非常流行的部分原因。它涉及在名称本身中包含类型注释,就像这样:
-
我们可以使用
elButton或buttonElement,而不是button -
我们可以使用
nAge或ageNumber,而不是age -
我们可以使用
objDetails或detailsObject,而不是details
匈牙利命名法有以下几个原因:
-
确定性:它为您的代码读者提供了更多关于名称目的和约定的确定性
-
一致性:它会导致更一致的命名方式
-
强制执行:它可能导致代码内更好地执行类型约定
然而,它也有以下缺点:
-
运行时更改:如果底层类型在运行时被糟糕的代码更改(例如,如果函数将
nAge变成字符串),那么该名称将不再有用,甚至可能误导我们。 -
代码库的僵化:它可能导致代码库变得僵化,难以对类型进行适当的更改。重构旧代码可能变得更加繁重。
-
缺乏含义:仅知道变量的类型并不能告诉我们它的目的、概念或约定,就像一个真正描述性的非类型变量名那样。
在 JavaScript 的领域中,我们看到匈牙利命名法在一些地方被使用:最常见的是在命名可能指向 DOM 元素的变量时。这些名称的标注通常以elHeader、headerEl、headingElement或者$header的形式出现。以美元符号为前缀的后者最著名地用在 jQuery 库中。它在那里的名声导致它成为各种其他地方的标准。例如,Chromium DevTools在元素引用和与查询 DOM 相关的方法中使用了美元前缀(例如,$$(...)被别名为document.querySelectorAll(...))。
匈牙利命名法是一种可以部分利用的东西,当你担心可能存在歧义时。例如,你可以在一个作用域内同时引用复杂类型和原始类型来使用它:
function renderArticle(name) {
const article = Article.getByName(name);
const title = article.getTitle();
const strArticle = article.toString();
// ...
}
在这里,我们有一个指向Article类实例的article变量。除此之外,我们还想使用我们文章的字符串表示。为了避免潜在的命名冲突,我们使用了一个str前缀来表示该变量是指向一个字符串值。在这样的孤立情况下,匈牙利命名法是有用的。你不需要完全使用它,但它是一个有用的工具。
命名和抽象函数
在 JavaScript 中,大多数抽象最终都会体现在函数中。即使在大型架构中,也是单个函数和方法在工作,而且在它们的构思中,一个好的抽象开始显现出来。因此,值得深入思考我们应该如何命名我们的函数以及在这样做时应该考虑哪些因素。
函数的名称通常应该使用语法中所谓的命令形式。当我们给出指示时,就是我们使用的命令形式,比如走到商店,买面包,停在那里。
尽管我们通常在命名函数时使用命令形式,但也有例外。例如,惯例上也会在返回布尔值的函数前加上is或has;例如,isValid(...)。在创建构造函数(它们也是函数)时,我们会根据它们将生成的实例来命名;例如,Route或SpecialComponent。
在编程环境中,命令形式的直接性是最容易理解和阅读的。要找到特定问题的正确命令形式,最好想象一下发布军事命令的过程,也就是说,不要拐弯抹角,准确地说明你想要发生的事情:
-
如果你想显示提示,使用
displayPrompt() -
如果你想要移除元素,使用
removeElements() -
如果你想要一个在
x和y之间的随机数,使用generateRandomNumber(x, y)
通常,我们希望对我们的指示进行限定。如果你要给一个人下达指示,比如找到我的自行车,你可能会进一步限定这个指示,比如它是蓝色的和它的前轮丢了。然而,重要的是不要让函数的名称被这些限定所拖累。以下函数就是一个例子:
findBlueBicycleWithAMissingFrontWheel();
正如我们之前提到的,一个不必要地长的名称是一个糟糕抽象的标志。当我们看到这种过度限定的情况时,我们应该退一步重新考虑。在这里,重要的是要在口语和编程语言中划清界限。在编程中,函数是抽象常见行为的方式,可以通过参数根据需要进行调整或配置。
因此,我们应该通过参数来表达蓝色和丢失前轮的限定。例如,我们可以将它们表达为一个单一的对象参数,如下所示:
findBicycle({
color: 'blue',
frontWheel: 'missing'
});
通过将函数名称的限定部分移到其参数中,我们正在产生一个更清晰和更易理解的抽象。这不仅增加了抽象的可配置性,还为用户提供了更多的可能性。
在我们的情况下,我们可能希望让用户能够找到除自行车以外的其他对象。为了满足这一点,我们会使函数的名称更加通用(例如,findObject),并通过添加一个新的选项属性(例如,type)将限定部分移到参数中,如下所示:
findObject({
type: 'bicycle',
color: 'blue',
frontWheel: 'missing'
});
在这个过程的阶段,发生了一些奇怪的事情。我们已经正确地将各种限定词移到函数的参数中,扩展了我们抽象的有用性和配置。但现在我们得到的是一个做很多事情的抽象,因此在某个时候,退一步构建更高级别的抽象来封装这些不同的行为可能是明智的。在我们的情况下,我们可以通过函数组合来实现这一点,如下所示:
const findBicycle = config => findObject({ ...config, type: 'bicycle' });
const findSkateboard = config => findObject({ ...config, type: 'skateboard' });
const findScooter = config => findObject({ ...config, type: 'scooter' });
首先,函数是行为的一个单元。正如 SRP 告诉我们的那样,确保它们只做一件可辨认的事情非常重要。在考虑这些事情或行为单元时,重要的是要从将使用它的人的角度考虑函数的作用。从技术上讲,我们组合的findScooter函数很可能在表面之下做了各种事情。它可能非常复杂。但在它将被使用的抽象层面上,可以说它只做了一件事,这才是重要的。
三个糟糕的名字
如果你对名字感到困惑,有一个聪明的方法可以帮助你摆脱困境。当你有一个需要命名的抽象或变量时,仔细看看它的功能或包含的内容,然后想出至少三个描述它的糟糕名字。现在不要担心你希望提供的抽象或接口;只是想象你在向一个对代码库一无所知的人描述功能。直接而描述性。
例如,假设我们嵌入在处理设置新用户名的代码库的部分。我们需要检查用户名是否与一组特定的禁止单词匹配,比如admin、root或user。我们想写一个函数来做这个,但我们不确定该选什么名字。因此,我们决定尝试三个糟糕的名字的方法。这是我们想出的名字:
-
matchUsernameAgainstForbiddenWords -
checkForForbiddenWordConflicts -
isUsernameReservedWord
想出三个不太完美的名字要比花很多时间试图找到完美的名字容易得多。这三个名字有多糟糕并不重要。重要的是我们至少能想出三个。现在,我们已经有了一系列可能性,我们可以自由地比较和对比我们找到的名字,并混合它们以找到最具描述性和直接表达我们函数目的的方式。在这种情况下,我们可能最终决定采用从这三个可能性中改编的名字:isUsernameForbiddenWord。如果不是因为采用了三个糟糕的名字的方法,我们就不会得到这个名字。
总结
在本章中,我们已经探讨了命名的艰难艺术。我们讨论了一个好名字的特征,即目的、概念和约定。我们通过示例讲解了如何将这些特征编织到我们的名字中,以及要避免的反模式。我们还讨论了在追求清晰抽象时层次结构和一致性的重要性。最后,我们介绍了一些有用的技术和惯例,当我们在命名事物时遇到困难时可以利用。
在下一章中,我们将终于开始深入了解 JavaScript 语言本身,并学习如何以一种能产生真正清晰代码的方式运用它的构造和语法。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









