







原文:
zh.annas-archive.org/md5/EBCF13D1CBE3CB1395B520B840516EFC译者:飞龙
第四部分:测试和工具
在本节中,我们将学习如何通过测试和工具来促进和捍卫更清洁的 JavaScript 代码库。具体来说,我们将学习如何编写良好的测试,以保护我们免受代码退化和不干净代码的影响。通过这样做,我们将了解各种工具和自动化流程,可以在团队环境中交付更高质量的代码。
本节包括以下章节:
-
第十三章,测试的领域
-
第十四章,编写清晰的测试
-
第十五章,更清洁代码的工具
第十三章:测试的景观
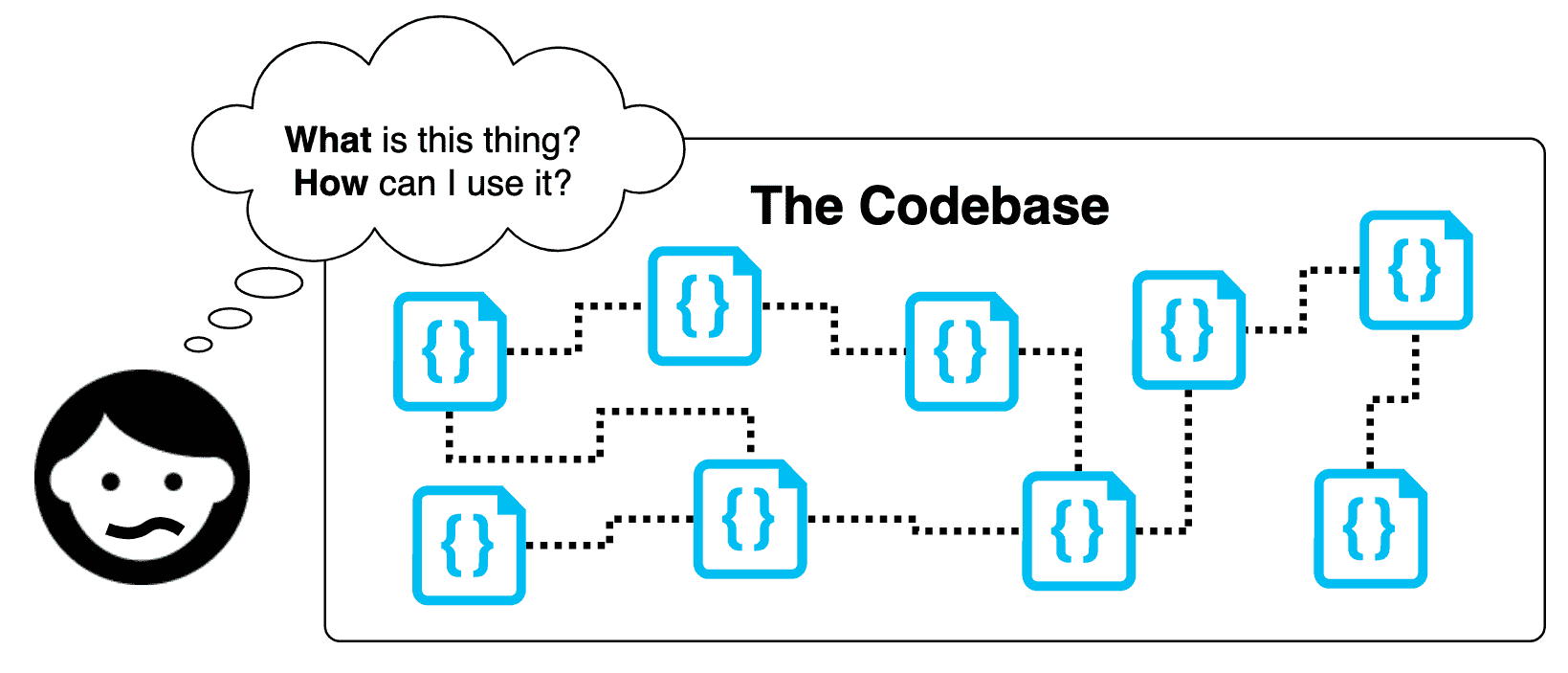
在本书的开头,我们阐明了清晰代码的主要原则。其中之一是可靠性。确认可靠性的最佳方法莫过于让您的代码库持续和多样化地接受使用。这意味着真正的用户坐在您的软件前并使用它。只有通过这种类型的暴露,我们才能了解我们的代码是否真正实现了它的目的。然而,经常进行这种现实生活测试通常是不合理的,甚至可能是危险的。如果代码发生变化,用户依赖的某个功能可能出现故障或退化。为了防止这种情况,并且通常确认我们的期望是否得到满足,我们编写测试。如果没有一套好的测试,我们就 passively and arrogantly closing our eyes and hoping that nothing goes wrong。
在本章中,我们将涵盖以下主题:
-
什么是测试?
-
测试类型
-
测试驱动开发(TDD)
什么是测试?
软件测试是一个自动化的程序,它对一段代码进行断言,然后将这些断言的成功报告给您。测试可以对任何东西进行断言,从一个单独的函数到整个功能的行为。
测试,就像我们的其他代码一样,涉及抽象和细节的层次。如果我们要抽象地测试一辆汽车,我们可能只是寻求断言以下属性:
-
它有四个轮子
-
它有一个方向盘
-
它能开车
-
它有一个工作的喇叭
显然,这对汽车工程师来说并不是一个非常有用的断言集,因为这些属性要么非常明显,要么描述不足。断言“它能开车”很重要,但如果没有额外的细节,它所表达的只是一个通用的业务目标。这类似于项目经理要求软件工程师确保用户登录门户,例如,可以让用户成功登录。工程师的工作不仅是实现用户登录门户,还要得出成功调查断言用户可以成功登录的工作测试。从通用陈述中得出好的测试并不总是容易的。
要正确地设计一个测试,我们必须将通用和抽象的要求提炼到它们的细节和非抽象的细节。例如,当我们断言我们的汽车“有一个工作的喇叭”时,我们可以这样提炼:
当驾驶员至少举起一只手并指示手按下方向盘中心 1 秒钟,汽车将发出大约 107 分贝的固定频率为 400 赫兹的响亮声音 1 秒钟。
当我们开始为我们的断言添加关键细节时,它们对我们变得有用。我们可以将它们用作实施的指南和功能的确认。即使有了这些额外的细节,我们的陈述仍然只是一个断言或要求。这些要求是软件设计中的一个有用步骤。事实上,我们应该非常不愿意在具体性达到这种程度之前开始实施软件。
例如,如果客户要求您实施一个付款表单,收集确切的要求是明智的:它应接受哪些类型的付款?还需要收集哪些其他客户信息?我们在存储这些数据时受到什么法规或约束?这些扩展的要求随后成为我们和客户将衡量完整性的标准。因此,我们可以将这些要求作为单独的测试来实施,以确认它们在软件中的存在。
一个良好的测试方法将涉及对代码库所有不同部分的测试,并将提供以下好处:
-
证明实现:测试使我们能够向自己和利益相关者证明期望和要求得到满足。
-
拥有 信心:测试使我们和我们的同事对我们的代码库有信心,既能正确运行,又能容纳变化而不会出现我们不知道的故障。
-
分享 知识:测试允许我们分享关于代码部分如何运作的重要知识。在某种意义上,它们是一种文档形式。
良好的测试方法还有许多二阶效应。同事对代码库的增加信心将意味着您可以更快地进行更大的变更,从而在长远来看削减成本和痛苦。知识的共享可以使您的同事和用户更快地执行操作,更加理解,减少时间和费用的开销。证明实现目标的能力使团队和个人能够更好地向利益相关者、管理者和用户传达他们工作的价值。
现在我们已经讨论了测试的明显好处,我们可以讨论如何编写测试。每个测试的核心都是一组断言,所以我们现在将探讨我们所说的断言以及如何使用断言来编码我们的期望。
简单的断言
测试有许多工具、术语和测试范式。这么多复杂性的存在可能看起来令人生畏,但重要的是要记住,从本质上讲,测试实际上只是关于对某些东西的工作方式进行断言。
可以通过表达特定结果来以编程方式进行断言,如下例所示,要么是SUCCESS,要么是FAILURE:
if (sum(100, 200) !== 300) {
console.log('SUCCESS! :) sum() is not behaving correctly');
} else {
console.log('FAILURE! :( sum() is behaving correctly');
}
在这里,如果我们的sum函数没有给出预期的输出,我们将收到FAILURE!的日志。我们可以通过实现一个assert函数来抽象这种成功和失败的模式,如下所示:
function assert(assertion, description) {
if (assertion) {
console.log('SUCCESS! ', description);
} else {
console.log('FAILURE! ', description);
}
}
然后可以使用这个日志进行一系列的断言并添加描述:
assert(sum(1, 2) === 3, 'sum of 1 and 2 should be 3');
assert(sum(5, 60) === 65, 'sum of 60 and 5 should be 65');
assert(isNaN(sum(0, null)), 'sum of null and any number should be NaN');
这是任何测试框架或库的基本核心。它们都有一种机制来进行断言,并报告这些断言的成功和失败。测试库通常也提供一种机制来包装或包含相关的断言,并一起称之为测试或测试用例。我们可以通过提供一个测试函数来做类似的事情,允许您传递描述和函数(包含断言):
function test(description, assertionsFn) {
console.log(`Test: ${description}`);
assertionsFn();
}
然后我们可以这样使用它:
test('sum() small numbers', () => {
assert(sum(1, 2) === 3, 'sum of 1 and 2 should be 3');
assert(sum(0, 0) === 0, 'sum of 0 and 0 should be 0');
assert(sum(1, 8) === 9, 'sum of 1 and 8 should be 9');
});
test('sum() large numbers', () => {
assert(
sum(1e6, 1e10) === 10001000000,
'sum of 1e6 and 1e10 should be 10001e6'
);
});
运行后生成的测试日志如下:
> Test: sum() small numbers
> SUCCESS! sum of 1 and 2 should be 3
> SUCCESS! sum of 0 and 0 should be 0
> SUCCESS! sum of 1 and 8 should be 9
> Test: sum() large numbers
> SUCCESS! sum of 1e6 and 1e10 should be 10001e6
从技术角度来看,编写断言和简单测试并不太具有挑战性。为单个函数编写测试很少会很困难。然而,要编写完整的测试套件并彻底测试代码库的所有部分,我们必须利用更复杂的测试机制和方法来帮助我们。
许多移动部件
回想汽车类比,让我们想象我们面前有一辆汽车,我们希望测试它的喇叭。喇叭不是一个独立的机械部件。它嵌入在汽车内部,并且依赖于一个与其本身分离的电源。事实上,我们可能会发现,在喇叭工作之前,我们必须先通过点火启动汽车。而点火的成功本身取决于其他几个组件,包括工作的点火开关、油箱中的燃料、工作的燃油过滤器和未耗尽的电池。因此,喇叭的功能取决于许多移动部件。因此,我们对喇叭的测试不仅仅是对喇叭本身的测试,而实际上是对几乎整个汽车的测试!这并不理想。
为了解决这个问题,我们可以将喇叭连接到一个单独的电源供应上,只用于测试目的。通过这样做,我们隔离了喇叭,使测试只反映喇叭本身的功能。在测试世界中,我们使用的这个替身电源供应可能被称为存根或模拟。
在软件世界中,存根和模拟都是一种代替真实抽象的类型,它提供适当的输出,而不执行被替换抽象的真实工作。一个例子是makeCreditCardPayment存根,它返回SUCCESS,而不创建真实的支付。这可能在测试电子商务功能的上下文中使用。
我们隔离喇叭电源的方法不幸地存在缺陷。即使我们的测试成功了,喇叭能够工作,我们也没有保证喇叭连接到汽车真正的电源时仍然能够工作。对喇叭的隔离测试仍然有用,因为它告诉我们喇叭特定电路和机制内的任何故障,但它本身是不够的。我们需要测试喇叭在实际情况下的工作情况,即依赖其他组件。在软件中,我们称这样的实际测试为集成测试或端到端测试,而隔离测试通常称为单元测试。有效的测试方法将始终包括这两种类型:
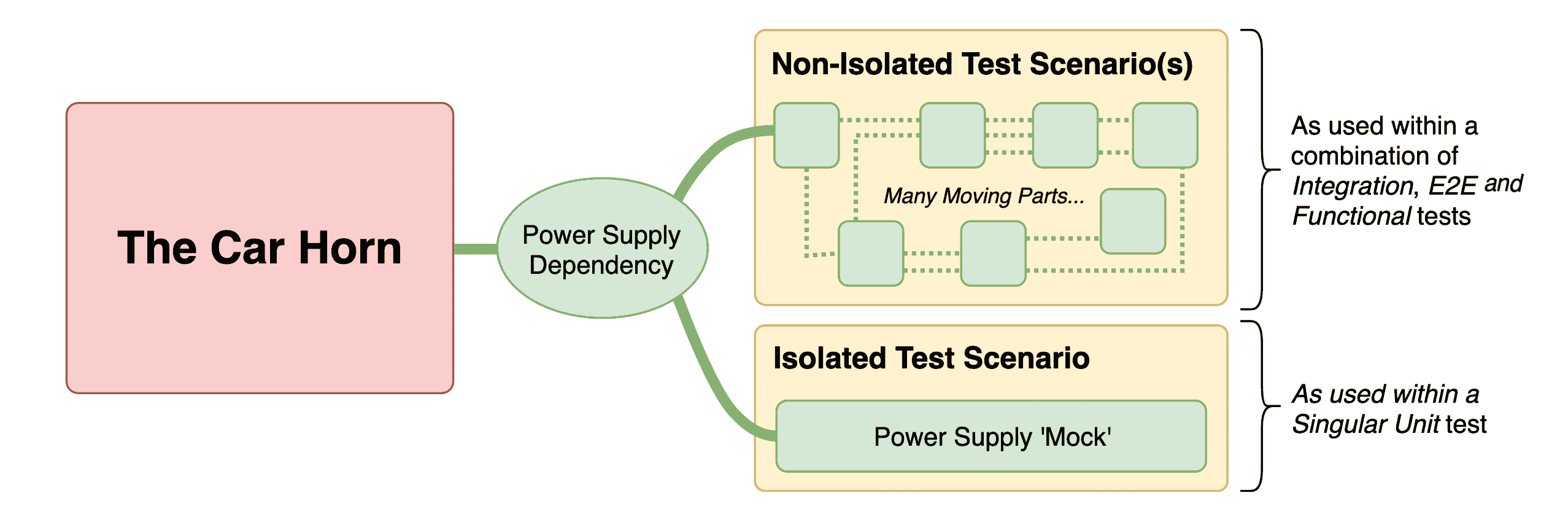
在测试时隔离各个部分存在风险,可能会创建一个不真实的场景,最终你实际上并没有测试代码库的真实功能,而是测试了你的模拟的有效性。在这里,以我们的汽车类比为例,通过提供一个模拟电源来隔离喇叭,使我们能够纯粹地测试喇叭的电路和发声机制,并为我们提供了一条明确的调试路径,如果测试失败的话。但我们需要通过几个集成测试来补充这个测试,以便我们可以确信整个系统正常工作。即使我们对系统的所有部分进行了一千次单元测试,也不能保证没有测试所有这些部分的集成的工作系统。
测试类型
为了确保代码库经过了彻底的测试,我们必须进行不同类型的测试。正如前面提到的,单元测试使我们能够测试隔离的部分,而各种部分的组合可以通过集成、功能或端到端测试进行测试。首先了解我们谈论部分或单元时的含义是很有用的。
当我们谈论代码的一个单元时,概念上有一些模糊。通常,它将是系统内具有单一职责的代码片段。当用户希望通过我们的软件执行操作时,实际上他们将激活我们代码的一系列部分,所有这些部分一起工作以给用户提供他们所需的输出。考虑一个用户可以创建和分享图像的应用程序。典型的用户体验(流程或旅程)可能涉及几个不同的步骤,所有这些步骤都涉及代码库的不同部分。用户执行的每个操作,通常在他们不知情的情况下,都将包含一系列代码操作:
-
(用户)通过上传存储在桌面上的照片创建新图像:
-
(代码)通过
<form>上传照片 -
(代码)将照片保存到 CDN
-
(代码)在
<canvas>中显示位图,以便应用滤镜 -
(用户)对图像应用滤镜:
-
(代码)通过
<canvas>像素操作应用滤镜 -
(代码)更新存储在 CDN 上的图像
-
(代码)重新下载保存的图像
-
(用户)与朋友分享图像:
-
(代码)在数据库中查找用户的朋友
-
(代码)将图像添加到每个朋友的动态中
-
(代码)向所有朋友发送推送通知
所有这些步骤,再加上用户可能采取的所有其他步骤,可以被视为一个系统。一个经过充分测试的系统可能涉及对每个单独步骤进行单元测试,对每对步骤进行集成测试,以及对形成用户流或用户旅程的每个步骤组合进行功能或端到端(E2E)测试。我们可以将可能需要作为系统一部分存在的测试类型可视化如下:
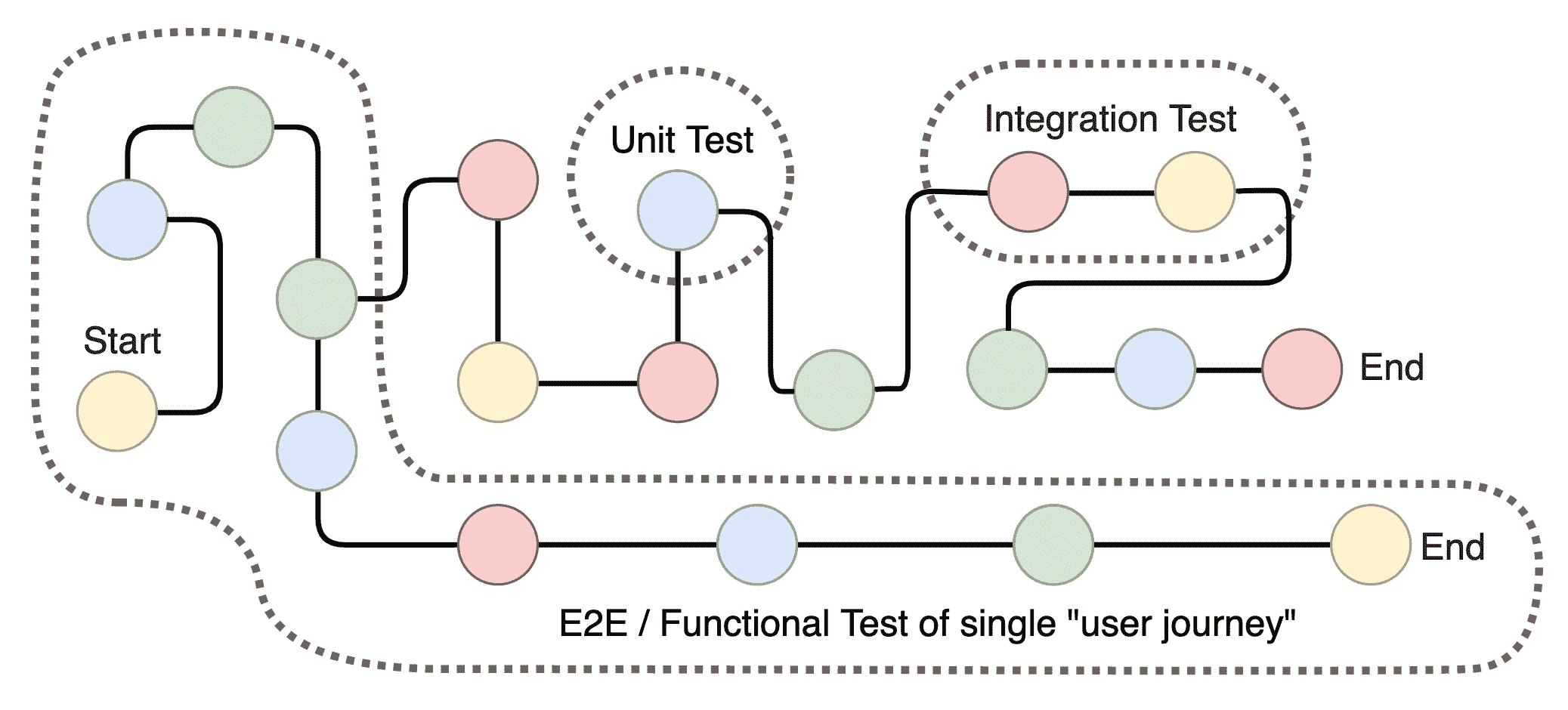
在这里,我们可以看到一个开始点和两个结束点,表示两个不同的用户旅程。每个点可以被视为一个单独的责任区域或单元,作为这些旅程的一部分被激活。正如您所看到的,单元测试只关注一个单一的责任区域。集成测试关注两个(或更多)相邻的整合区域。而 E2E 或功能测试关注涉及单一用户旅程的所有区域。在我们图像分享应用的前面例子中,我们可以想象我们可能有特定的单元测试,例如将照片上传到 CDN 或发送推送通知的操作,一个测试朋友数据库整合的集成测试,以及一个测试从创建到分享新图像的整个流程的 E2E 测试。这些测试方法对确保一个真正经过充分测试的系统至关重要,每种方法都有其独特的好处以及需要克服的缺点和挑战。
单元测试
正如我们在汽车类比中所描述的,单元测试是处理孤立的代码单元的测试。这通常是一个单一的函数或模块,将对代码的操作进行一个或多个简单的断言。
以下是一些单一单元测试场景的示例:
-
您有一个
Button组件,应该包含值Submit My Data,并且应该有一个btn_success类。您可以通过简单的单元测试来断言这些特征,检查生成的 DOM 元素的属性。 -
您有一个任务调度实用程序,它将在请求的时间执行给定的操作。您可以通过给它一个在特定时间执行的任务,然后检查该任务的成功执行来断言它是否这样做。
-
您有一个 REST API 端点
/todo/list/item/{ID},它从数据库中检索特定的项目。您可以通过模拟数据库抽象(提供虚假数据),然后断言请求 URL 是否正确返回您的数据来断言该路由是否正常工作。
逐个测试代码单元的几个好处:
-
完整性: 给定的单元通常会有一小部分明确定义的要求。因此,很容易确保您正在测试单元功能的全部范围。所有输入变化都可以很容易地进行测试。还可以测试每个单元的极限,包括通常复杂的操作细节。
-
可报告性: 当给定的单元测试失败时,您可以很容易地辨别失败的确切性质和情况,这意味着更快地调试和修复潜在问题。这与我们将发现的集成测试形成对比,后者可能具有更通用的报告,无法指示代码中失败的确切点。
-
理解: 单元测试是给定模块或函数的有用且独立的文档形式。单元测试的狭窄性和特定性帮助我们充分理解某些东西的工作原理,从而便于维护。当其他地方没有最新的文档时,这是特别有用的。
完整性在这里类似于流行的测试覆盖率概念。关键的区别在于,虽然覆盖率是关于最大化测试代码库中的代码量,完整性是关于最大化每个单元的覆盖率,以便表达单元的整个输入空间。作为一个度量标准,测试覆盖率只告诉我们是否进行了测试,而不告诉我们是否测试得很好。
然而,单元测试也存在挑战:
-
正确模拟:创建正确隔离的单元测试有时意味着我们必须构建其他单元的模拟或存根,就像我们之前讨论的汽车类比一样。创建逼真的模拟并确保你没有引入新的复杂性和潜在故障有时是具有挑战性的。
-
测试真实输入:编写提供各种真实输入的单元测试是关键,尽管这可能是具有挑战性的。很容易陷入编写看似给予信心但实际上不测试代码在生产中可能出现的情况的测试的陷阱。
-
测试真正的单元而不是组合:如果不小心构建,单元测试可能会变得臃肿并变成集成测试。有时,一个测试在表面上看起来非常简单,但实际上取决于表面下一系列的集成。举个例子,如果我们试图在隔离其电路之前进行简单的单元测试来断言汽车喇叭的声音,那么我们将不知不觉地创建一个端到端测试。
作为最细粒度的测试类型,单元测试对于任何代码库都是至关重要的。最容易将其视为一种复式记账系统。当你进行更改时,你必须通过断言来反映这种变化。这种实现-测试循环最好是在接近的时间内进行——一个接一个地进行——可能通过 TDD,这将在后面讨论。单元测试是你确认自己真正写了你打算写的代码的方式。它提供了一定程度的确定性和可靠性,你的团队和利益相关者会非常感激。
集成测试
集成测试,顾名思义,涉及到代码的不同单元的集成。与简单的单元测试相比,集成测试将为您提供有关您的软件在生产中的运行方式的更有用的信号。在我们的汽车类比中,集成测试可能会根据它与汽车自己的电源供应的操作方式来断言喇叭的功能,而不是提供模拟电源供应。然而,它可能仍然是一个部分隔离的测试,确保它不涉及汽车内的所有组件。
以下是可能的集成测试的一些例子:
-
你有一个
Button组件,当点击时应该向列表中添加一个项目。一个可能的集成测试是在真实 DOM 中渲染组件,并检查模拟的click事件是否正确地将项目添加到列表中。这测试了Button组件、DOM 和确定何时向列表中添加项目的逻辑之间的集成。 -
你有一个 REST API 路由
/users/get/{ID},它应该从数据库中返回用户配置文件数据。一个可能的集成测试是创建一个 ID 为456的真实数据库条目,然后通过/users/get/456请求数据。这测试了 HTTP 路由抽象和数据库层之间的集成。
集成模块和测试它们的行为一起有很多优势:
-
获得更好的覆盖率:集成测试将一个或多个集成模块作为测试对象,因此通过这样的测试,我们可以增加代码库中的“测试覆盖率”,这意味着我们正在增加代码的测试覆盖范围,从而增加我们捕捉故障的可能性。
-
清晰地看到故障:在一定程度上模拟我们在生产中可能看到的模块集成,使我们能够看到实际发生的集成故障和失败。对这些故障的清晰视图使我们能够快速进行修复并保持可靠的系统。
-
暴露错误的期望:集成测试使我们能够挑战在构建单个代码单元时可能做出的假设。
因此,虽然单元测试给我们提供了对特定模块和函数的输入和输出的狭窄和详细的视图,但集成测试使我们能够看到所有这些模块如何一起工作,并通过这样做,为我们提供了对集成潜在问题的视图。这是非常有用的,但编写集成测试也存在陷阱和挑战:
-
隔离集成(避免大爆炸测试):在实施集成测试时,有时更容易避免隔离单个集成,而是只测试系统的一个大部分,所有集成都完整。这更类似于端到端测试,当然很有用,但同样重要的是也要有隔离的集成,以便您可以更精确地了解潜在的失败。
-
真实的集成(例如,数据库服务器和客户端):在选择和隔离要测试的集成时,有时很难创建真实的情况。例如,测试您的 REST API 如何与数据库服务器集成,但是在测试目的上没有单独的数据库服务器,只有一个本地数据库服务器。这仍然是一个有见地的测试,但因为它没有模拟数据库服务器的远程性(在生产中存在),您可能会产生错误的信心。可能会有潜在的失败潜伏,未被发现。
集成测试在决定代码库的所有单独部分如何作为一个系统一起工作的关键接口和 I/O 的关键点提供了重要的洞察。集成测试通常提供了关于系统潜在故障的最明显的信号,因为它们通常运行速度快,并且在失败时非常透明(不像潜在笨重的端到端测试)。当然,集成测试只能告诉您它们封装的集成点的信息。为了更完全地对系统功能的信心,始终使用端到端测试是一个好主意。
端到端和功能测试
端到端测试是集成测试的一种更极端的形式,它不是测试模块之间的单个集成,而是测试整个系统,通常通过执行一系列在现实中会发生的操作来产生给定的结果。这些测试有时也被称为功能测试,因为它们致力于从用户的角度测试功能区域。构建良好的端到端测试使我们确信整个系统正常工作,但当与更粒度的单元和集成测试结合使用时,可以更快速和准确地识别故障。
以下是编写端到端测试的好处的简要概述:
-
正确性和健康:端到端测试为您提供了对系统整体健康状况的清晰洞察。由于许多单独的部分将通过典型的端到端测试进行有效测试,其成功可以给您一个良好的指示,表明在生产中一切都正常。粒度单元或集成测试虽然在其自身的方式上非常有用,但无法给您这种系统洞察力。
-
真实的效果:通过端到端测试,我们可以尝试更真实的情况,模拟我们的代码在野外运行的方式。通过模拟典型用户的流程,端到端测试可以突出显示更粒度的单元或集成测试可能无法揭示的潜在问题。例如,当存在竞争条件或其他时间问题时,只有当代码库作为一个整体系统运行时才能揭示这些问题。
-
更全面的视角:E2E 测试为开发人员提供了系统的视角,使他们能够更准确地推断出不同模块如何共同产生工作的用户流程。当试图建立对系统操作方式的全面理解时,这是非常有价值的。与单元测试和集成测试一样,E2E 测试也可以作为一种文档形式。
然而,制作 E2E 测试也存在挑战:
-
性能和时间成本:E2E 测试涉及激活许多个别代码片段并置身于真实环境中,因此在时间和硬件资源方面可能会非常昂贵。E2E 测试运行所需的时间可能会妨碍开发,因此团队为了避免开发周期变慢,避免 E2E 测试并不罕见。
-
真实的步骤:在 E2E 测试中准确模拟真实生活中的情况可能是一种挑战。使用虚假或捏造的情况和数据仍然可以提供足够真实的测试,但也可能给你一种虚假的信心。由于 E2E 测试是脚本化的,不仅依赖于虚假数据是相当常见的,而且还可能以一种不真实的快速或直接的方式进行操作,错过了通过创建更人性化情况获得的可能的见解(重复:永远考虑用户)。
-
复杂的工具:E2E 测试的目的是真实地模拟用户在实际环境中的流程。为了实现这一点,我们需要良好的工具,使我们能够建立真实的环境(例如,无头浏览器和可编写脚本的浏览器实例)。这样的工具可能存在 bug 或者使用起来很复杂,并且可能会引入另一个变量到测试过程中,导致不真实的失败(工具可能会给出关于事物是否真正工作的错误信号)。
尽管 E2E 测试很难做到完美,但它可以提供一种洞察和信心,这是仅仅通过单元测试和集成测试很难获得的。在自动化测试程序方面,E2E 测试是我们可以合理获得软件真实用户反馈的最接近方式。这是最不精细、最系统化的方式来判断我们的软件是否按照用户的期望工作,这毕竟是我们最感兴趣的。
测试驱动开发
TDD 是一种在实现之前编写测试的范式。通过这样做,我们的测试最终会影响我们实现的设计和接口。通过这样做,我们开始将测试视为不仅是一种文档形式,而且是一种规范形式。通过我们的测试,我们可以指定我们希望某些功能的工作方式,编写断言,就好像功能已经存在一样,然后我们可以逐步构建实现,使我们所有的测试最终都通过。
为了说明 TDD,让我们想象一下我们希望实现一个单词计数功能。在实现之前,我们可以开始写一些关于它如何工作的断言:
assert(
wordCount('Lemonade and chocolate') === 3,
'"Lemonade and chocolate" contains 3 words'
);
assert(
wordCount('Never-ending long-term') === 2,
'Hyphenated words count as singular words'
);
assert(
wordCount('This,is...a(story)') === 4,
'Punctuation is treated as word boundaries'
);
这是一个非常简单的函数,所以我们只用了三个断言来表达它的大部分功能。当然还有其他边缘情况,但我们已经拼凑出了足够的期望,可以开始实现这个函数了。这是我们的第一次尝试:
function wordCount(string) {
return string.match(/[\w]+/g).length;
}
立即通过我们的小测试套件运行这个实现,我们收到了以下结果:
SUCCESS! "Lemonade and chocolate" contains 3 words
FAILURE! Hyphenated words count as singular words
SUCCESS! Punctuation is treated as word boundaries
连字符单词测试失败了。TDD 的本质是期望通过迭代的失败和重构来使实现与测试套件保持一致。鉴于这个特定的失败,我们可以简单地在正则表达式的字符类中添加一个连字符(在[...]分隔符之间):
function wordCount(string) {
return string.match(/[\w-]+/g).length;
}
这产生了以下的测试日志:
SUCCESS! "Lemonade and chocolate" contains 3 words
SUCCESS! Hyphenated words count as singular words
SUCCESS! Punctuation is treated as word boundaries
成功!通过逐步迭代,尽管为了说明简化,我们已经通过 TDD 实现了一些东西。
正如你可能已经观察到的,TDD 并不是一种特定类型或风格的测试,而是一种关于何时、如何和为什么进行测试的范式。传统观点认为测试是事后的想法,这种观点是有限的,通常会迫使我们处于这样一种境地:我们根本没有时间编写一个好的测试套件。然而,TDD 迫使我们以一个完整的测试套件为先导,给我们带来了一些显著的好处:
-
它指导实施
-
它优先考虑用户
-
它强制进行完整的测试覆盖
-
它强制单一责任
-
它能够快速发现问题领域
-
它给予你即时反馈
TDD 在开始测试时是一种特别有用的范式,因为它会迫使你在实施之前退后一步,真正考虑你想要做什么。这个规划阶段对于确保我们的代码与用户期望完全一致非常有帮助。
总结
在本章中,我们介绍了测试的概念以及它与软件的关系。虽然简短和入门级,但这些基础概念对于我们以可靠性和可维护性为目标进行测试是至关重要的。测试,就像软件世界中的许多其他问题一样,可能会容易地变成一种迷信,因此保持对我们编写的测试背后的基本原理和理论的视角至关重要。测试,本质上是关于证明期望和防范故障的。我们已经讨论了单元测试、集成测试和端到端测试之间的区别,讨论了每种测试中固有的优势和挑战。
在下一章中,我们将探讨如何将这些知识应用于制定干净的测试和实际示例。具体来说,我们将介绍我们可以使用哪些措施和指导原则来确保我们的测试和其中的断言是可靠的、直观的和最大程度有用的。
第十四章:写清晰的测试
在上一章中,我们讨论了软件测试的理论和原则。我们深入探讨了单元测试、集成测试和端到端测试中固有的好处和挑战。在本章中,我们将把这些知识应用到一些现实世界的例子中。
仅仅理解测试是什么,并从商业角度看到它的优点是不够的。我们编写的测试构成了我们代码库的重要部分,因此应该以与我们编写的所有其他代码一样小心的方式来制作。我们希望编写的测试不仅能让我们对代码的预期工作方式有信心,而且它们本身也是可靠的、高效的、可维护的和可用的。我们还必须警惕编写过于复杂的测试。这样做会让我们陷入一种情况,使我们的测试增加了理解的负担,并导致代码库的整体复杂性和脆弱性增加,降低了整体生产力和满意度。
如果小心谨慎地使用,测试可以使代码库变得清晰和干净,从而使用户和同事能够以更快的速度和更高的质量进行工作。在接下来的章节中,我们将探讨编写测试时应遵循的最佳实践以及要避免的潜在陷阱。
在本章中,我们将涵盖以下主题:
-
测试正确的事情
-
编写直观的断言
-
创建清晰的层次结构
-
提供最终的清晰度
-
创建清晰的目录结构
测试正确的事情
在编写任何测试时,无论是细粒度的单元测试还是广泛的端到端测试,最重要的考虑之一是要测试什么。完全有可能测试错误的东西;这样做会让我们对我们的代码产生错误的信心。我们可能编写了一个庞大的测试套件,然后面带微笑离开,认为我们的代码现在满足了所有期望,并且完全容错。但我们的测试套件可能并没有测试我们认为它测试的东西。也许它只测试了一些狭窄的用例,让我们暴露在许多破坏的可能性中。或者它可能以一种在现实中从未模拟的方式进行测试,导致我们的测试无法保护我们免受生产中的故障。为了防范这些可能性,我们必须了解我们真正希望测试什么。
考虑一个我们编写的函数,从任意字符串中提取指定格式的电话号码。电话号码可以是各种形式,但始终有 9 到 12 位数字:
-
0800-144-144 -
07792316877 -
01263 109388 -
111-222-333 -
0822 888 111
这是我们当前的实现:
function extractPhoneNumbers(string) {
return string.match(/(?:[0-9][- ]?)+/g);
}
我们决定编写一个测试来断言我们代码的正确性:
expect(
extractPhoneNumbers('my number is 0899192032')
).toEqual([
'0899192032'
]);
使用的断言至关重要。测试正确的事情很重要。在我们的例子中,这应该包括包含完整输入的示例字符串:包含电话号码的字符串,不包含数字的字符串,以及包含电话号码和非电话号码的字符串。仅测试正例太容易了,但实际上检查负例同样重要。在我们的场景中,负例包括没有电话号码可提取的情况,因此可能包含以下字符串:
-
"this string is just text..." -
"this string has some numbers (012), but no phone numbers!" -
"1 2 3 4 5 6 7 8 9" -
"01-239-34-32-1" -
"0800 144 323 492 348" -
"123"
当编写这样的示例案例时,我们很快就会看到我们的实现将不得不迎合的复杂性范围。顺便说一句,这突显了采用测试驱动开发(TDD)来明确定义期望的巨大优势。现在我们有了一些包含我们不希望*提取的数字的字符串的案例,我们可以将这些表达为断言,就像这样:
expect(
extractPhoneNumbers('123')
).toEqual([/* empty */]);
目前这个测试失败了。extractPhoneNumbers('123')调用错误地返回["123"]。这是因为我们的正则表达式尚未对长度做出任何规定。我们可以很容易地进行修复:
function extractPhoneNumbers(string) {
return string.match(/([0-9][- ]?){9,12}/g);
}
添加{9,12}部分将确保前面的组(([0-9][- ]?))只匹配 9 到 12 次,这意味着我们对extractPhoneNumbers('123')的测试现在将正确返回[](一个空数组)。如果我们对每个示例字符串重复进行这个测试和迭代过程,最终我们将得到一个正确的实现。
从这种情况中得出的关键是,我们应该寻求测试我们可能期望的所有输入。根据我们正在测试的内容,通常可以说我们编写的任何代码都将适用于有限的一组可能场景。我们希望确保我们有一组测试来分析这一系列场景。这一系列场景通常被称为给定函数或模块的输入空间或输入域。如果我们将其暴露给其输入空间中的代表性各种输入,我们可以认为它经过了充分测试,这种情况下,包括具有有效电话号码和不具有有效电话号码的字符串:
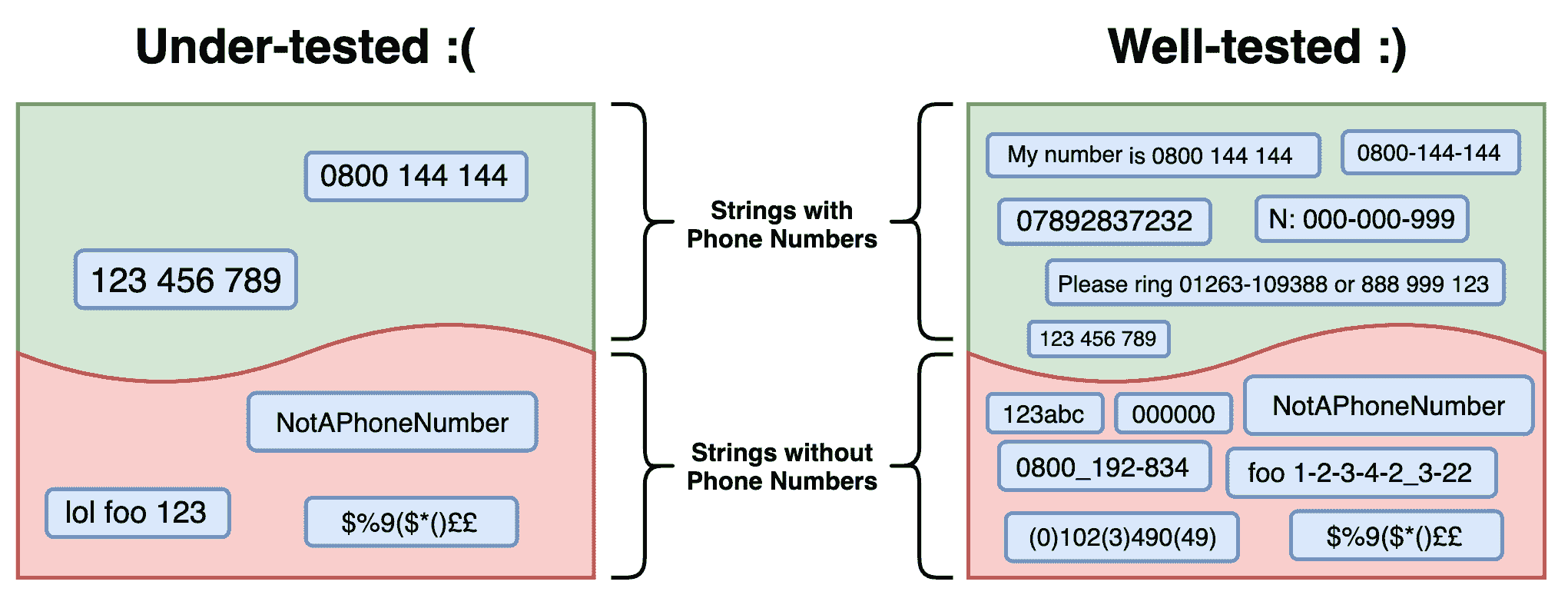
不需要测试每种可能性。更重要的是测试它们的代表性样本。为此,首先要确定我们的输入空间,然后将其分成单个代表性输入,然后逐个进行测试。例如,我们需要测试电话号码"012 345 678"是否被正确识别和提取,但对同一格式的变化进行详尽测试(如"111 222 333","098 876 543"等)是没有意义的。这样做不太可能揭示代码中的任何其他错误或漏洞。但我们确实应该测试具有不同标点符号或空格的其他格式(如"111-222-333"或"111222333")。另外,建立可能超出预期输入空间的输入也很重要,例如无效类型和不受支持的值。
对软件需求的充分理解将使您能够产生一个经过正确实现并经过充分测试的实现。因此,在我们开始编写代码之前,我们应该始终确保我们清楚地知道我们的任务是什么。如果我们发现自己不确定完整的输入空间可能是什么,那就是一个强烈的指示,表明我们应该退一步,与利益相关者和用户交谈,并建立一套详尽的需求。再次强调,这是测试驱动的实施(TDD)的一个强大优势,因为这些需求的不足会在成本投入到无意义的实施之前被及早发现和解决。
当我们心中有了需求,并对整个输入空间有了很好的理解后,就可以开始编写我们的测试了。测试的最基本部分是其断言,因此我们要确保能够有效地制定直观的断言,以清晰地传达我们的期望。这将是接下来要讨论的内容。
编写直观的断言
任何测试的核心都是其断言。断言准确地规定了我们期望发生的事情,因此不仅要准确地制定它,而且要以一种清晰地表达我们期望的方式来制定它。
通常,单个测试会涉及多个断言。测试通常遵循以下形式:给定输入 X,我是否收到输出 Y?有时,建立Y是复杂的,可能不限于单个断言。我们可能希望内省Y,以确认它确实是期望的输出。
考虑一个名为getActiveUsers(users)的函数,它将从所有用户中仅返回活跃用户。我们可能希望对其输出进行多个断言:
const activeUsers = getActiveUsers([
{ name: 'Bob', active: false },
{ name: 'Sue', active: true },
{ name: 'Yin', active: true }
]);
assert(activeUsers.length === 2);
assert(activeUsers[0].name === 'Sue');
assert(activeUsers[1].name === 'Yin');
在这里,我们清楚地表达了对 getActiveUsers(...) 输出的期望,作为一系列断言。鉴于更全面的断言库或更复杂的代码,我们可以轻松地将其限制为一个单一的断言,但将它们分开可能更清晰。
许多测试库和实用程序提供了抽象来帮助我们进行断言。例如,流行的测试库 Jasmine 和 Jest 都提供了一个名为 expect 的函数,它提供了许多 匹配器 的接口,每个匹配器都允许我们声明值应该具有的特征,如以下示例所示:
-
expect(x).toBe(y)断言x与y相同 -
expect(x).toEqual(y)断言x等于y(类似于抽象相等) -
expect(x).toBeTruthy()断言x为真(或Boolean(x) === true) -
expect(x).toThrow()断言当作为函数调用x时,会抛出错误
这些匹配器的确切实现可能因库而异,提供的抽象和命名也可能不同。例如,Chai.js 提供了 expect 抽象和简化的 assert 抽象,允许您以以下方式进行断言:
assert('foo' !== 'bar', 'foo is not bar');
assert(Array.isArray([]), 'empty arrays are arrays');
制作断言时最重要的是要非常清晰。就像其他代码一样,很不幸,写一个难以理解或难以解析的断言是相当容易的。考虑以下断言:
chai.expect( someValue ).to.not.be.an('array').that.is.not.empty;
由于 Chai.js 提供的抽象,这个语句看起来像是一个可读性强、易于理解的断言。但实际上,确切地理解正在发生什么是相当困难的。让我们考虑这个语句可能正在检查以下哪一个:
-
该项不是数组?
-
该项不是空数组?
-
该项的长度大于零且不是数组?
实际上,它正在检查该项既不是数组,又不为空——这意味着,如果该项是对象,它将检查它至少有一个自己的属性,如果是字符串,它将检查它的长度是否大于零。这些断言的真正基本机制被掩盖了,因此当程序员接触到这些东西时,可能会陷入一种幸福的无知状态(认为断言按照他们希望的方式工作)或痛苦的困惑状态(想知道它到底是如何工作的)。
也许我们一直想要断言的是 someValue 不仅不是数组,而且是“类似数组”,因此具有大于零的长度。因此,我们可以使用 Chai.js 的 lengthOf 方法来创建一个新的断言,以增加清晰度:
chai.expect( someValue ).to.not.be.an('array');
chai.expect( someValue ).to.have.a.lengthOf.above(0);
为了避免任何疑惑和混淆,我们可以更直接地进行断言,而不依赖于 Chai.js 的类似句子的抽象:
assert(!Array.isArray(someValue), "someValue is not an array");
assert(someValue.length > 0, "someValue has a length greater than zero");
这可能更清晰,因为它向程序员解释了正在进行的确切检查,消除了更抽象的断言风格可能引起的疑虑。
一个好的断言的关键在于它的清晰度。许多库提供了复杂和抽象的断言机制(例如通过 expect() 接口)。这些可以增加清晰度,但如果过度使用,可能会变得不太清晰。有时,我们只需要“保持简单,愚蠢”(KISS)。测试代码是最不适合使用自负或过度抽象的代码的地方。简单直接的代码每次都胜出。
现在我们已经探讨了制作直观断言的挑战,我们可以稍微“放大”一下,看看我们应该如何制作和组织包含它们的测试。下一节将介绍 层次结构 作为一个有助于通过我们的测试套件传达含义的机制。
创建清晰的层次结构
要测试任何代码库,我们可能需要编写大量的断言。从理论上讲,我们可以有一个很长的断言列表,除此之外什么也没有。然而,这样做可能会使阅读、编写和分析测试报告变得非常困难。为了避免这种混乱,测试库通常会在断言周围提供一些支撑抽象。例如,Jasmine 和 Jest 等 BDD 风格的库提供了两个支撑部分:it块和describe块。这些只是我们传递描述和回调的函数,但它们一起可以创建一个测试的分层树,使我们更容易理解发生了什么。使用这种模式来测试sum函数可能会这样做:
// A singular test or "spec":
describe('sum()', () => {
it('adds two numbers together', () => {
expect( sum(8, 9) ).toEqual( 17 );
});
});
行为驱动开发(BDD)是一种测试风格和方法,类似于 TDD,它强制我们先编写测试,然后再实现。然而,它更注重行为而不是实现的重要性,因为行为更容易沟通,从用户(或利益相关者)的角度来看更重要。BDD 风格的测试通常会使用诸如*描述 X»当 Z 发生时,它会执行 Y…*的语言。
非 BDD 库往往用更简单的无限嵌套的test块来包围断言组,如下所示:
test('sum()', () => {
test('addition works correctly', () => {
assert(sum(8, 9) == 17, '8 + 9 is equal to 17');
});
});
正如你所看到的,BDD 风格的it和describe术语的命名可以帮助我们为测试套件编写描述,这些描述读起来像完整的英语句子(例如描述一个苹果»它又圆又甜)。这并不是强制的,但可以帮助我们更好地描述。我们还可以无限嵌套describe块,以便我们的描述可以反映我们正在测试的事物的分层结构。因此,例如,如果我们正在测试一个名为myMathLib的数学工具,我们可以想象以下测试套件及其各种子套件和规范:
-
描述
myMathLib: -
描述
add(): -
它可以添加两个整数
-
它可以添加两个分数
-
对于非数字输入,它返回
NaN -
描述
subtract(): -
它可以减去两个整数
-
它可以减去两个分数
-
对于非数字输入,它返回
NaN -
描述
PI: -
它在十五位小数处等于
PI
这种层次结构自然地反映了我们正在测试的抽象的概念层次结构。测试库提供的报告将有用地反映这种层次结构。以下是Mocha测试库的一个示例输出,其中myMathLib的每个测试都成功通过:
myMathLib
add()
✓ can add two integers
✓ can add two fractions
✓ returns NaN for non-numeric inputs
subtract()
✓ can subtract two integers
✓ can subtract two fractions
✓ returns NaN for non-numeric inputs
PI
✓ is equal to PI at fifteen decimal places
单个断言汇聚在一起形成测试。单个测试汇聚在一起形成测试套件。每个测试套件都为我们提供了关于特定单元、集成或流程(在 E2E 测试中)的清晰和信心。这些测试套件的组成对于确保我们的测试简单和可理解至关重要。我们必须花时间考虑如何表达我们正在测试的概念层次结构。我们创建的测试套件还需要直观地放置在代码库的目录结构中。这是我们接下来要探讨的内容。
提供最终的清晰度
可以说,测试的目标只是描述你所做的事情。通过描述,你被迫断言关于某事操作方式的假设真相。当这些断言被执行时,我们可以辨别出我们的描述,我们的假设的真相是否正确地反映了现实。
在描述的过程中,我们必须谨慎选择措辞,以便清晰和易于理解地表达我们的意思。测试是我们对模糊和复杂性的最后一道防线。有些代码是不可避免地复杂的,我们理想情况下应该以减少其模糊性的方式来构建它,但如果我们无法完全做到这一点,那么测试的作用就是消除任何剩余的困惑,并提供最终的清晰度。
在测试时保持清晰的关键是纯粹专注于必须阅读测试(或其记录输出)的人的视角。以下是一些特定的清晰度要点需要注意:
-
使用测试的名称准确描述测试的内容,必要时过度描述。例如,不要说测试
Navigation组件是否渲染,而是说测试Navigation组件是否正确渲染所有导航项。我们的名称也可以传达我们问题域的概念层次结构。回想一下我们在第五章的一致性和层次结构部分中所说的内容,命名是困难的。 -
使用变量作为意义的载体。在编写测试时,使用变量名过于明确或者甚至在可能不需要的地方使用变量,以充分传达你的意图是一个好主意。例如,考虑
expect(value).toEqual(eulersNumber)比expect(value).toEqual(2.7182818)更容易理解。 -
使用注释来解释奇怪的行为。如果你正在测试的代码以一种意外或不直观的方式执行某些操作,那么你的测试本身可能会显得不直观。作为最后的手段,提供额外的上下文和解释是很重要的。但是要注意,不要让注释变得陈旧,而不随着代码的更新而更新。
考虑AnalogClockComponent的以下测试:
describe('AnalogClockComponent', () => {
it('works', () => {
const r = render(AnalogClockComponent, { time: "02:50:30" });
expect(rendered.querySelector('.mm-h').style.transform)
.toBe('rotate(210deg)');
expect(rendered.querySelector('.hh-h').style.transform)
.toBe('rotate(-30deg)');
expect(rendered.querySelector('.ss-h').style.transform)
.toBe('rotate(90deg)');
expect(/\btheme-default\b/).test(rendered.className)).toBe(true);
});
});
正如你所看到的,这个测试对特定元素的transform CSS 属性做出了几个断言。我们可能可以对这些做出一个知情的猜测,但是清晰度肯定可以得到改善。为了使其更清晰,我们可以使用更好的名称来反映我们正在测试的内容,将测试分开以代表不同的被测试概念,使用变量名来清楚地说明我们正在做断言的值,使用注释来解释任何可能不直观的事情:
describe('AnalogClockComponent', () => {
const analogClockDOM = render(AnalogClockComponent, {
time: "02:50:30"
});
const [
hourHandTransform,
minuteHandTransform,
secondHandTransform
] = [
analogClockDOM.querySelector('.hh-h').style.transform,
analogClockDOM.querySelector('.mm-h').style.transform,
analogClockDOM.querySelector('.ss-h').style.transform
];
describe('Hands', () => {
// Note: the nature of rotate/deg in CSS means that a
// time of 03:00:00 would render its hour-hand at 0deg.
describe('Hour', () => {
it('Renders at -30 deg reflecting 2/12 hours', () => {
expect(hourHandTransform).toBe('rotate(-30deg)');
});
});
describe('Minute', () => {
it('Renders at 210 deg reflecting 50/60 minutes', () => {
expect(minuteHandTransform).toBe('rotate(210deg)');
});
});
describe('Second', () => {
it('Renders at 90deg reflecting 30/60 seconds', () => {
expect(secondHandTransform).toBe('rotate(90deg)');
});
});
});
describe('Theme', () => {
it('Has the default theme set', () => {
expect(
/\btheme-default\b/).test(analogClockDOM.className)
).toBe(true);
});
});
});
你可能会观察到更清晰的方式要长得多,但是在测试时,最好偏向于这种冗长的描述。过度描述要比不足描述好,因为在后一种情况下,你的同事们会缺乏信息,他们会摸不着头脑,可能会对功能性做出错误的猜测。当我们提供大量的清晰度和解释时,我们正在帮助更广泛的同事和用户。然而,如果我们模糊和简洁,我们特别是限制了能理解我们代码的人群,从而限制了其可维护性和可用性。
现在我们已经探讨了通过良好结构的测试套件来展示最终的清晰度,我们可以再次放大,讨论我们如何通过目录结构和文件命名约定来传达我们正在编写的测试的目的和类型。
创建清晰的目录结构
我们的测试套件通常应该限制在单个文件中,以划分出我们的程序员同事关注的领域。尽管将这些测试文件组织成更大代码库的一部分可能是一个挑战。
想象一个具有以下目录结构的小型 JavaScript 代码库:
app/
components/
ClockComponent.js
GalleryComponent.js
utilities/
timer.js
urlParser.js
将与特定代码相关的测试放置在靠近该代码所在位置的子目录中是相当典型的。在我们的示例代码库中,我们可以创建以下tests子目录来包含我们components和utilities的单元测试:
app/
components/
ClockComponent.js
GalleryComponent.js
tests/
ClockComponent.test.js
GalleryComponent.test.js
utilities/
timer.js
urlParser.js
tests/
timer.test.js
urlParser.test.js
以下是一些关于约定的额外说明,正如我们现在应该知道的那样,这些约定对于增加代码库的熟悉度和直观性至关重要,因此也对整体清晰度至关重要:
-
有时测试被称为规范(specifications)。规范通常与测试没有什么不同,尽管作为名称,在 BDD 范式中稍微更受青睐。使用你感到舒适的那个。
-
通常会看到测试文件的后缀是
.test.js或.spec.js。这样你的测试运行器可以轻松识别要执行的文件,对我们的同事也是一个有用的提醒。 -
看到测试目录的命名模式涉及下划线或其他非典型字符并不罕见,例如
__tests__。这些命名模式通常用于确保这些测试不会作为主要源代码的一部分被编译或捆绑,并且可以很容易地被我们的同事辨别。 -
端到端或集成测试更常放置在更高的层次,这暗示了它们对多个部分的依赖。很常见看到一个高级别的
e2e目录(或一些改编)。有时,集成测试被单独命名并存储在高层;其他时候,它们与单元测试交错存放在代码库中。
一次又一次,层次结构在这里是关键。我们必须确保我们目录的层次结构有助于反映我们代码和问题域的概念层次结构。作为代码库中平等且重要的一部分,测试应该被小心地和适当地放置在代码库中,而不是作为事后的想法。
总结
在本章中,我们将我们对测试的理论知识应用到了构建真实、有效和清晰的测试套件的实际技艺中。我们看了一些在这样做时存在的陷阱,并且我们强调了要努力追求的重要品质,比如清晰、直观的命名和遵循惯例。
在下一章中,我们将探讨各种工具,从代码检查器到编译器,以及更多,来帮助我们编写更干净的代码!
第十五章:更干净代码的工具
我们使用的工具对我们编写代码时养成的习惯有很大影响。在编码时,就像生活中一样,我们希望养成良好的习惯,避免坏习惯。良好习惯的一个例子是编写符合语法的 JavaScript。为了帮助我们强制执行这个良好习惯,我们可以使用代码检查工具在我们的代码无效时通知我们。我们应该以这种方式考虑每个工具。它激发了什么良好习惯?它又抑制了什么坏习惯?
如果我们回顾一下我们原始的清晰代码原则(R.E.M.U),我们可以看到各种工具如何帮助我们遵守这些原则。以下是一小部分对这四个原则有帮助的工具:
-
可靠性:测试工具、用户反馈、错误记录器、分析数据、代码检查工具、静态类型工具和语言
-
效率:性能测量、分析数据、用户反馈、用户体验评估、生态成本(例如碳足迹)
-
可维护性:格式化程序、代码检查工具、文档生成器、自动化构建和持续集成
-
可用性:分析数据、用户反馈、文档生成器、可访问性检查器、用户体验评估和走廊测试
激发良好习惯的工具通过增强我们的反馈循环。反馈循环是最终让您意识到需要做出改变的任何事物。也许您引入了一个导致错误日志的错误。也许您的实现不清晰,同事抱怨了。如果工具能及早捕捉到这些情况,那么它可以加快我们的反馈循环,使我们能够更快地工作并达到更高的质量水平。在下图中,我们说明了我们的反馈循环,以及它是如何在开发的每个阶段接收来自工具的信息的:
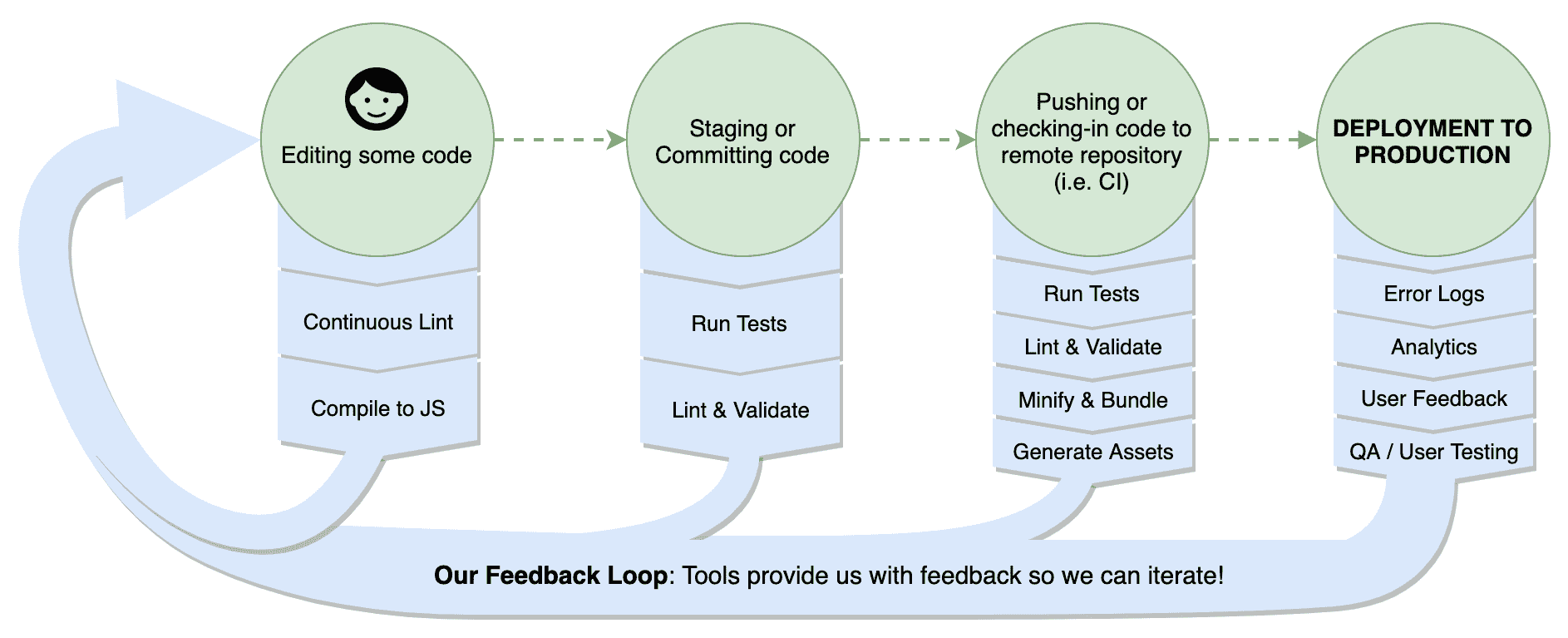
在我们的开发阶段,有许多反馈渠道。有代码检查工具告诉我们语法有问题,静态类型检查器确认我们正确使用类型,测试确认我们的期望。即使在部署后,这种反馈仍在继续。我们有错误日志指示失败,分析数据告诉我们用户行为,以及来自最终用户和其他个人的反馈,告诉我们有关故障或改进的领域。
不同的项目将以不同的方式运作。您可能是一个独立的程序员,或者是专门从事特定项目的 100 名程序员之一。无论如何,可能会有各种开发阶段,并且在每个阶段都存在反馈的可能性。工具和沟通对于有效的反馈循环至关重要。
在本章中,我们将介绍一小部分可以帮助我们养成良好习惯和积极反馈循环的工具。具体来说,我们将介绍以下内容:
-
代码检查和格式化工具
-
静态类型
-
端到端测试工具
-
自动化构建和持续集成
代码检查和格式化工具
代码检查工具是一种用于分析代码并发现错误、语法错误、风格不一致和可疑结构的工具。JavaScript 的流行代码检查工具包括 ESLint、JSLint 和 JSHint。
大多数代码检查工具允许我们指定我们想要查找的错误或不一致的类型。例如,ESLint 将允许我们为给定代码库指定全局配置在根级别的 .eslintrc(或 .eslintrc.json)文件中。在其中,我们可以指定我们正在使用的语言版本,我们正在使用的功能,以及我们想要强制执行的代码检查规则。以下是一个示例 .eslintrc.json 文件:
{
"parserOptions": {
"ecmaVersion": 6,
"sourceType": "module",
"ecmaFeatures": {
"jsx": true
}
},
"extends": "eslint:recommended",
"rules": {
"semi": "error",
"quotes": "single"
}
}
以下是我们配置的解释:
-
ecmaVersion:在这里,我们指定我们的代码基于 ECMAScript 6(2016)版本的 JavaScript 编写。这意味着如果 linter 发现您正在使用 ES6 特性,它不会抱怨。但是,如果您使用 ES7/8 特性,它会抱怨,这是您所期望的。 -
sourceType:这指定了我们正在使用 ES 模块(导入和导出)。 -
ecmaFeatures: 这告诉 ESLint 我们希望使用 JSX,这是一种允许我们指定类似 XML 的层次结构的语法扩展(这在像 React 这样的组件框架中被广泛使用)。 -
extends: 在这里,我们指定了一个默认的规则集"eslint:recommended",这意味着我们愿意让 ESLint 强制执行一组推荐的规则。如果没有这个,ESLint 只会执行我们指定的规则。 -
rules: 最后,我们正在配置我们希望在推荐配置之上设置的具体规则: -
semi: 这个规则涉及到分号;在我们的覆盖中,我们指定如果缺少分号则产生错误而不是仅仅警告。 -
quotes: 这个规则涉及到引号,并指定我们希望强制使用单引号,这意味着 linter 会在我们的代码中看到双引号时发出警告。
我们可以通过编写一个故意违反规则的代码片段来尝试我们的配置:
const message = "hello"
const another = `what`
if (true) {}
如果我们在这段代码上安装并运行 ESLint(在 bash 中:> eslint example.js),那么我们将收到以下内容:
/Users/me/code/example.js
1:7 error 'message' is assigned a value but never used
1:17 error Strings must use singlequote
1:24 error Missing semicolon
2:7 error 'another' is assigned a value but never used
2:17 error Strings must use singlequote
2:23 error Missing semicolon
4:5 error Unexpected constant condition
4:11 error Empty block statement
8 problems (8 errors, 0 warnings)
4 errors and 0 warnings potentially fixable with the `--fix` option.
这详细说明了根据我们配置的规则的所有语法错误。正如你所看到的,它详细说明了被违反的规则以及发现问题的行。ESLint 和其他 linting 工具在发现难以发现的语法错误方面非常有帮助,其中一些如果不加以处理,可能会导致将来难以调试的功能性错误。Linting 还使代码更加一致,使程序员感到熟悉,并减少认知负担,就像在一个具有许多不同语法约定的代码库中一样。
ESLint 还包括一个通过其--fix选项修复这些语法错误子集的功能,尽管您可能已经注意到只有一部分错误可以通过这种方式修复。其他错误需要手动修复。不过,值得庆幸的是,有许多更高级的工具可用来帮助我们。格式化工具,如 Prettier 和 Standard JS,将采用我们的语法偏好并对我们的代码进行积极的更改,以确保它保持一致。这意味着程序员不必为特定的语法规则负担,也不必无休止地更改代码以响应 linters。他们可以按照自己的意愿编写代码,完成后,格式化程序将更改代码以符合约定的语法约定,或者在出现严重或无效的语法错误时警告程序员。
为了说明,让我们用默认配置在一个简单的代码片段上运行 Prettier:
function reverse( str ) {
return ( String( str ).split( '' ).reverse().join( '' ) );
}
当在 Prettier 上运行上述代码时,我们会收到以下内容:
function reverse(str) {
return String(str)
.split("")
.reverse()
.join("");
}
正如我们所看到的,Prettier 已经删除并更改了我们的语法习惯以符合其配置的约定。换句话说,它已经将单引号换成双引号,删除了多余的括号,并对空格进行了重大更改。格式化工具的魔力在于它们帮助程序员摆脱痛苦。它们会纠正一些微小的语法习惯,让程序员可以自由地进行更重要的工作。行业的一般趋势是远离简单的 linters,转向更全面的工具,将 linting 和格式化结合在一起。
遵守哪种语法约定的决定是可配置的,完全取决于你。关于这个问题有很多坚定的观点,但最重要的原则是一致性。例如,我个人更喜欢单引号而不是双引号,但如果我在一个已经建立了双引号约定的代码库中工作,那么我会毫不犹豫地改变我的习惯。大多数时候,语法偏好只是主观的和传统的规范,所以重要的不是我们使用哪种规范,而是我们是否都遵守它。
我们已经习惯了 JavaScript 语言中的许多规范,这些规范是由其动态类型的特性引导的。例如,我们已经习惯了必须手动检查特定类型,以便在接口中提供有意义的警告或错误。对许多人来说,这些规范很难适应,他们渴望对他们使用的类型有更高的信心。因此,人们将各种静态类型工具和语言扩展引入了 JavaScript。接下来我们将探讨这些内容,同时注意这些静态类型工具如何改变或改进您的个人开发反馈循环。
静态类型
正如我们长时间探讨的那样,JavaScript 是一种动态类型语言。如果小心使用,这可能是一个巨大的好处,可以让您快速工作,并允许您的代码具有一定的灵活性,使同事能够更轻松地使用它。然而,动态类型可能会在某些情况下导致程序员的认知负担和不必要的 bug 可能性。静态类型编译语言,如 Java 或 Scala,强制程序员在声明的时候指定他们期望的类型(或者根据使用方式推断类型,以便在执行之前)。
静态类型具有以下潜在的好处:
-
程序员可以对他们将要处理的类型有信心,因此可以对他们的值的能力和特性做出一些安全的假设,从而简化开发。
-
代码可以在执行之前进行静态类型检查,这意味着潜在的 bug 可以轻松地被捕捉到,并且不会受到特定(和意外的)类型排列的影响。
-
代码的维护者和用户(或其 API)有一个更清晰的期望集,并且不会猜测可能会或可能不会起作用。类型的规范本身可以作为一种文档。
尽管 JavaScript 是动态类型的,但已经有努力为 JavaScript 程序员提供静态类型系统的好处。其中两个相关的例子是 Flow 和 TypeScript:
-
Flow (
flow.org/) 是 JavaScript 的静态类型检查器和语言扩展。它允许您使用自己特定的语法注释类型,尽管它不被认为是一种独立的语言。 -
TypeScript (
www.typescriptlang.org/) 是由微软开发的 JavaScript 的超集语言(这意味着有效的 JavaScript 始终是有效的 TypeScript)。它是一种独立的语言,具有自己的类型注释语法。
Flow 和 TypeScript 都允许您声明正在声明的类型,可以是变量声明或函数内的参数声明。以下是一个接受productName(string)和rating(number)的函数声明的示例:
function addRating(productName: string, rating: number) {
console.log(
`Adding rating for product ${productName} of ${rating}`
);
}
Flow 和 TypeScript 通常允许在声明标识符后注释类型,形式为IDENTIFIER: TYPE,其中TYPE可以是number、string、boolean等。但它们在许多方面有所不同,因此重要的是要对两者进行调查。当然,Flow 和 TypeScript 以及 JavaScript 的大多数其他静态类型检查技术都需要构建或编译步骤才能工作,因为它们包括语法扩展。
请注意,静态类型并不是一种灵丹妙药。我们代码的整洁程度不仅仅限于其避免与类型相关的错误和困难的能力。我们必须放大我们的视角,记得考虑用户以及他们通过我们的软件试图实现的目标。很常见看到热情的程序员迷失在他们的语法细节中,但忽略了更大的画面。因此,为了稍微改变方向,我们现在将探讨端到端测试工具,因为端到端测试对代码质量的影响可能与我们使用的类型系统或语法一样重要,甚至更重要!
端到端测试工具
在过去的几章中,我们探讨了测试的好处和类型,包括端到端测试的概述。我们通常用于构建测试套件和进行断言的测试库很少包括端到端测试功能,因此我们需要为此找到自己的工具。
端到端测试的目的是模拟用户在我们的应用程序上的行为,并在用户交互的各个阶段对应用程序的状态进行断言。通常,端到端测试将测试特定的用户流程,例如用户可以注册新帐户或用户可以登录并购买产品。无论我们是在服务器端还是客户端使用 JavaScript,如果我们正在构建一个网络应用程序,进行这样的测试将是非常有益的。为此,我们需要使用一个可以人为创建用户环境的工具。在网络应用程序的情况下,用户环境是浏览器。幸运的是,有大量的工具可以模拟或运行真实(或无头**s)浏览器,我们可以通过 JavaScript 访问和控制。
无头浏览器是一个没有图形用户界面的网络浏览器。想象一下 Chrome 或 Firefox 浏览器,但没有任何可见的 UI,完全可以通过 CLI 或 JavaScript 库进行控制。无头浏览器允许我们加载我们的网络应用程序并对其进行断言,而无需无谓地消耗硬件能力来渲染 GUI(这意味着我们可以在我们自己的计算机上或在云端作为我们持续集成/部署过程的一部分来运行这些测试)。
这样一个工具的例子是Puppeteer,这是一个 Node.js 库,提供了一个控制 Chrome(或 Chromium)的 API。它可以在无头或非无头模式下运行。以下是一个示例,我们在其中打开一个页面并记录其<title>:
import puppeteer from 'puppeteer';
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
const titleElement = await page.$('title');
const title = await page.evaluate(el => el.textContent, titleElement);
console.log('Title of example.com is ', title);
await browser.close();
})();
Puppeteer 提供了一个高级 API,允许创建和导航浏览器页面。在这个上下文中,使用page实例,我们可以通过evaluate()方法评估特定的客户端 JavaScript。传递给此方法的任何代码将在文档的上下文中运行,并且因此可以访问 DOM 和其他浏览器 API。
这就是我们如何能够检索<title>元素的textContent属性。您可能已经注意到,Puppeteer 的 API 大部分是异步的,这意味着我们必须使用Promise#then或await来等待每个指令的完成。这可能有些麻烦,但考虑到代码正在运行和控制整个网络浏览器,一些任务是异步的是有道理的。
端到端测试很少被接受,因为它被认为很难。虽然这种看法曾经是准确的,但现在不再是这样。有了像 Puppeteer 这样的 API,我们可以轻松地启动我们的网络应用程序,触发特定的操作,并对结果进行断言。以下是使用 Jest(一个测试库)与 Puppeteer 对https://google.com的<title>元素中的文本进行断言的示例:
import puppeteer from 'puppeteer';
describe('Google.com', () => {
let page;
beforeAll(async () => {
const browser = await puppeteer.launch();
page = await browser.newPage();
await page.goto('https://google.com');
});
afterAll(async () => await browser.close());
it('has a <title> of "Google"', async () => {
const titleElement = await page.$('title');
const title = await page.evaluate(el => el.textContent, titleElement);
expect(title).toBe('Google');
});
});
获取页面、解析其 HTML,并生成我们可以进行断言的 DOM 是一个非常复杂的过程。浏览器在这方面非常有效,因此在我们的测试过程中利用它们是有意义的。毕竟,决定最终用户看到的是浏览器看到的内容。端到端测试为我们提供了对潜在故障的真实见解,现在编写或运行它们也不再困难。对于干净的代码编写者来说,它们尤其强大,因为它们让我们从更加用户导向的角度看到我们代码的可靠性。
与我们探索过的许多工具一样,端到端测试可能最好通过自动化集成到我们的开发体验中。我们现在简要探讨一下这一点。
自动化构建和持续集成
正如我们所强调的,有大量的工具可用于帮助我们编写干净的代码。这些工具通常可以通过命令行界面(CLI)手动激活,有时也可以在我们的集成开发环境中激活。然而,通常情况下,将它们作为我们开发的各个阶段的一部分运行是明智的。如果使用源代码控制,那么这个过程将包括提交或暂存过程,然后是推送或检入过程。这些事件,与简单地对文件进行更改相结合,代表了我们的工具可以用来生成它们的输出的三个重要开发阶段。
-
在对文件进行更改时:通常在这个阶段会发生 JavaScript(或 CSS)的转译或编译。例如,如果你正在编写包含 JSX 语言扩展(React)的 JS,那么你可能会依赖Babel来不断地将你的 JS 混合编译为有效的 ECMAScript(参见 Babel 的
--watch命令标志)。当文件发生变化时,进行代码检查或其他代码格式化也很常见。 -
在提交时:通常在提交前或提交后阶段会进行代码检查、测试或其他代码验证。这很有用,因为任何无效或损坏的代码都可以在推送之前被标记出来。在这个阶段进行资源生成或编译也并不罕见(例如,从 SASS 生成有效的 CSS,一种替代样式表语言)。
-
在推送时:当新代码被推送到特性分支或主分支时,通常会在远程机器上发生所有过程(代码检查、测试、编译、资源生成等)。这被称为持续集成,它允许程序员在部署到生产环境之前看到他们的代码与同事的代码结合后会如何运行。用于持续集成的工具和服务的例子包括TravisCI、Jenkins和CircleCI。
自动激活工具可以极大地简化开发,但这并不是必需的。你可以通过命令行进行代码检查、运行测试、转译 CSS,或生成压缩的资源,而无需费心自动化。然而,这样做可能会更慢,如果没有将工具标准化为一组自动化工具,那么你的团队中可能会出现工具使用不一致的情况。例如,你的同事可能总是在将 SCSS 转译为 CSS 之前运行测试,而你可能倾向于相反的方式。这可能导致不一致的 bug 和“在我的机器上可以运行”的情况。
总结
在本章中,我们已经发现了工具的用处,突出了它改进我们的反馈循环的能力,以及它如何赋予我们编写更干净代码的能力。我们还探索了一些具体的库和实用工具,让我们对存在的工具类型和以编程者的能力和习惯可以被增强的各种方式有了一些了解。我们尝试了代码检查器、格式化程序、静态类型检查器和端到端测试工具,并且我们已经看到了工具在开发的每个阶段的优点。
下一章开始我们的合作艺术和科学之旅;这对于想要编写清晰代码的人来说是至关重要的要素。我们将从探讨如何编写清晰易懂的文档开始。
第五部分:合作和变革
在这一部分,我们将涵盖与他人合作和沟通所涉及的重要技能,以及如何应对需要重构代码的情况。在这样做的过程中,我们将讨论文档编制、合作策略,以及如何识别和倡导团队、组织或社区的变革。
本节包括以下章节:
-
第十六章,编写代码文档
-
第十七章,其他人的代码
-
第十八章,沟通和倡导
-
第十九章,案例研究
第十六章:记录您的代码
文档有一个不好的名声。很难找到动力来写它,维护它是一种麻烦,多年来我们对它的接触使我们相信它是最枯燥的知识传递方法之一。然而,它不必这样!
如果我们选择完全关注用户,那么我们的文档可以简单而愉快。为此,我们必须首先考虑我们文档的用户是谁。他们想要什么?每个用户,无论是 GUI 最终用户还是其他程序员,都以某项任务为目标开始使用我们的软件。在软件和文档中,我们的责任是使他们能够尽可能少地感到痛苦和困惑地完成任务。考虑到这一点,在本章中,我们将探讨为我们构建无痛文档可能意味着什么。我们将具体涵盖以下内容:
-
清晰文档的方面
-
文档无处不在
-
为非技术受众编写
清晰文档的方面
文档的目的是传达软件的功能和如何使用它。我们可以将清晰文档的特点分为四个方面:清晰的文档传达了软件的概念,提供了其行为的规范,并包含了执行特定操作的说明。而且它所有这些都是以可用性为重点。通过本节的学习,我们希望能够理解在构建清晰文档时用户的重要性。
文档是大多数人不太关心的东西。它通常是一个事后想法。我在本章的任务是说服您,它可以是,也应该是,远不止如此。当我们进入这些方面时,忘记您对文档的了解-从一张白纸开始,看看您是否能得出自己的启示。
概念
清晰的文档将传达软件的基本概念。它将通过解释软件的目的的方式来做到这一点,以便潜在用户可以看到他们如何使用它。这可以被认为是文档的教育部分:阐明术语和范例,使读者能够轻松理解文档的其他部分和所描述的软件。
为了正确表达软件的概念,有必要站在用户的角度,从他们的角度看事情,并用他们的术语与他们交流:
-
确定您的受众:他们是谁,他们的技术熟练程度如何?
-
确定他们对问题领域的理解:他们对这个特定软件项目、API 或代码库已经了解多少?
-
确定正确的抽象级别和最佳类比:如何以一种对他们有意义并与他们当前的知识融合良好的方式进行交流?
良好的文档编写是一个考虑用户然后为他们精心打造适当抽象的过程。您会希望注意到这与编写清晰代码的过程非常相似。实际上,两者之间几乎没有什么区别。在构建文档时,我们正在打造一个用户可以用来完成一组特定任务的工具。我们有责任以一种用户可以轻松完成最终目标而不会被软件的庞大和复杂所压倒的方式来打造它:
考虑一个花了几周时间完成的项目。这是一个名为SuperCoolTypeAnimator的JavaScript(JS)库,其他程序员可以使用它来创建字体转换。它允许他们向用户显示一块从一种字体动画到另一种字体(例如从 Helvetica 到 Times New Roman)的文本。这是一个相当复杂的代码库,可以手动计算这些转换。其复杂性的深度意味着您作为程序员已经发现了远远超出您所能想象的关于连字、衬线和路径插值的知识。在数月的沉浸在这个日益深入的问题领域之后,您很可能难以理解没有您这种程度接触的用户的观点。因此,您的文档的第一稿可能会以以下方式开始:
SuperCoolTypeAnimator 是一种 SVG 字形动画实用程序,允许创建和逐帧操纵源字形和其相应目标字形之间的过渡,并在飞行中计算适当的过渡锚点。
让我们将其与以下替代介绍进行比较:
SuperCoolTypeAnimator 是一个 JS 库,可以让您轻松地将文本的小部分从一种字体动画到另一种字体。
作为介绍,后者更广泛地可理解,并且即使是非专家用户也能立即理解库的功能。前者的介绍虽然信息丰富,但可能会导致当前和潜在用户感到困惑或疏远。我们构建的软件的整个目的是为了将复杂性抽象化,以简洁和简化的方式呈现出来。给用户带来复杂性应该是一种令人遗憾和考虑的行为:这通常是最后的选择。
我们在文档中试图传达的概念,首先是关于我们的软件如何帮助用户。为了让他们理解它如何帮助他们,我们需要以符合他们当前理解的方式来描述它。
两种介绍突出的另一个因素是它们对特殊术语的使用(如字形和锚点)。使用这种领域特定的术语是一种平衡行为。如果您的用户对字体问题领域有很好的理解,那么字形和字体等术语可能是合适的。可以说,对您的库感兴趣的用户很可能也了解这些概念。但是,使用过渡锚点等更微妙的术语可能有点过头。这可能是您在抽象中使用的术语,用来描述高度复杂的实现领域。这对您来说是一个有用的术语,也许对于希望对库进行更改的任何人来说也是有用的,但对库的用户来说可能不那么有用。因此,在我们的文档介绍中最好避免使用它。
规范
好的文档除了为软件提供概念外,还将提供规范,详细说明软件提供的接口的特定特征和行为。文档的这一部分详细说明了用户或程序员在使用软件时可以期望的合同。
规范理想情况下应该是撰写文档中最简单的部分,原因如下:
-
它就在代码中:行为规范包含在代码及其测试中,通常很容易手动将此信息编写为文档。但是,如果编写起来很困难,那就表明您的代码及其接口中存在基本复杂性,可能应该作为优先事项进行修复。
-
它可以自动生成:存在许多文档生成器,它们要么依赖于静态类型注释,要么依赖于注释注释(例如JSDoc)。这些允许您通过 CLI 或构建工具为整个接口生成文档。
-
它遵循固定格式:规范将遵循一个简单易写的直接格式。它通常包含各个端点或方法签名的标题,以及解释每个参数的句子。
提供规范的最主要目的是回答用户可能对您的代码操作有的具体问题。
以下是一个名为removeWords的函数规范示例。
removeWords( subjectString, wordsToRemove );
此函数将从指定的主题字符串中删除指定的单词,并将一个新字符串返回给您。这里的单词被定义为由单词边界(\b)限定的字符串。例如,对于"I like apple juice"主题字符串和["app", "juice"]的wordsToRemove,只会删除"juice",因为"app"存在于主题中,但没有被单词边界限定。以下是参数:
-
subjectString(String): 这是指定单词将从中移除的字符串。如果您没有传递String类型,那么您传递的值将被转换为String。 -
wordsToRemove(Array): 这是一个包含您希望移除的单词的数组。空数组或 null 将导致没有单词被移除。
希望您能看出,这个规范纯粹是对函数行为的技术解释。它准确告诉用户他们必须提供什么参数以及他们将收到什么输出。在撰写文档规范部分时,最重要的品质是清晰和正确。要注意以下陷阱:
-
没有足够的信息允许使用:提供关于您的实现的足够信息非常重要,这样另一个程序员,即使对您的软件一无所知,也可以开始使用它。仅仅指定参数类型是不够的。如果知识领域特别晦涩,还需要提供额外的信息。
-
不正确或过时的信息:文档很容易过时或不正确。这就是为什么从带注释的代码自动生成文档非常常见的原因。这样,信息不正确或过时的几率会大大降低。
-
缺乏示例:通常只列出模块、方法和参数签名,而没有提供任何示例。如果这样做,混乱和困难的几率会更高,因此提供合理的示例或将读者链接到更像教程的文档总是值得的。
规范可以说是文档中最重要的部分,因为它清晰地解释了软件相关 API 的每个部分的行为。确保在撰写文档时像编写代码一样仔细和勤奋。
指令
除了概念和规范,一份干净的文档还将指导用户如何完成常见任务。这些通常被称为步骤、教程、操作指南或食谱。
主要是用户,无论是程序员还是最终用户,都关心如何从现在所在的位置到达他们想要的位置。他们想知道应该采取哪些步骤。如果没有常见用例的说明,他们将绝望地从直觉或其他文档片段中拼凑出对您的软件的了解。想象一本只详细说明了食材及其烹饪方式的烹饪书,但没有包含任何将食材按特定顺序组合的具体食谱。这将是一本难以使用的烹饪书。虽然它可能提供了高度详细的烹饪信息,但它并没有帮助用户回答他们实际的问题:

在撰写说明时,无论是视频教程还是书面步骤说明,都要考虑对用户来说最常见或最具挑战性的使用情况。与生活中的许多事情一样,您只能合理地满足大多数用户的需求,而不是所有用户。为每种可能的使用情况创建教程是不合理的。同样,从用户的角度来看,仅为最常见的使用情况提供单一教程也是不合理的。明智的做法是取得折衷,拥有一小部分教程,每个教程都表达:
-
提前期望和先决条件:一组说明应该指明作者对读者的硬件、软件环境和能力有什么期望。它还应该说明读者在开始以下步骤之前是否需要做好任何准备。
-
读者可以模仿的具体步骤:说明应该包括一些具体步骤,用户可以按照这些步骤达到他们期望的目标。用户在遵循这些步骤时不应该需要太多(或任何)主动性;这些步骤应该清楚而详尽地概述用户需要做什么,如果可能的话,附上代码示例。用户应该明显地知道他们已成功完成每个步骤(例如,“您现在应该收到 X 输出”)。
-
可实现和可观察的目标:说明应该朝着用户可以观察到的目标努力。如果教程的最后一步说“由于 X 或 Y 的原因,目前无法正常工作,但通常您会期望看到 Z”,这将令人沮丧。确保您的软件以这样的方式运行,以便教程可以完成到最后,用户可以更接近他们的总体目标。
不要只告诉用户该做什么。告诉他们在每个阶段都完成了什么,以及为什么重要。也就是说,不要只告诉我在菜里放盐,告诉我为什么需要盐!
文档的教学部分可能是最具挑战性的。它要求我们扮演老师的角色,从另一个人的相对无知的位置看问题。保持专注于我们正在教授的人,也就是用户,是绝对至关重要的。这非常好地契合了我们清晰文档的最后一个方面:可用性。
可用性
可用性是清晰文档的最后一个组成部分。就像我们的软件一样,我们的文档必须关注用户及其特定需求。前面三个方面(概念、规范、说明)都关注内容,而可用性纯粹关乎我们表达内容的方式。当用户了解您的软件时,不要使其感到不知所措或困惑是非常重要的:
有许多方式可以使人困惑和不知所措。其中包括以下几种:
-
内容过多:这可能会使只想执行某个具体而狭窄任务的用户感到不知所措。他们可能不明白为了实现简单任务而必须翻阅大量文档的意义。
-
内容过少:如果用户希望做的事情没有得到充分的记录,那么他们的选择就很少。他们要么希望有社区驱动的文档,要么希望界面足够易懂,可以在没有帮助的情况下解释清楚。
-
内部不一致:当文档的不同部分在不同时间更新时,这种情况很常见。用户会疑惑哪个文档或示例是正确的和最新的。
-
缺乏结构:没有结构,用户无法轻松地浏览或获得对整个软件的概念理解。他们只能在细节中摸索,无法获得清晰的整体图景。在软件中,层次结构很重要,因此在我们的文档中反映这一点很重要。
-
内容难以导航:没有良好的 UX/UI 考虑,文档可能非常难以导航。如果它不是集中的、可搜索的和可访问的,那么导航就会受到影响,用户会陷入困惑和痛苦之中。
-
呈现不足:除了导航之外,文档中另一个至关重要的 UX 组件是其美学和排版布局。一个布局良好的文档易于阅读和学习。设计文档是完全合理的。它不应该是无尽散文的枯燥倾倒场所,而是一个美丽的教育体验!
在第二章《清洁代码的原则》中,我们详细讨论了可用性的含义。我们讨论了它不仅仅是直观设计和可访问性,还涉及对用户故事的考虑——用户希望执行的具体任务以及如何满足这些任务。文档与我们提供的任何其他界面并无二致;它必须解决用户的问题。考虑如何设计文档以满足这些示例用户故事:
-
作为用户,我希望了解这个框架的功能以及如何将其应用到我的项目中
-
作为用户,我希望找出如何将这个框架安装到我的 Node.js 项目中
-
作为用户,我希望了解在使用这个框架时的最佳实践
-
作为用户,我希望了解如何使用这个框架构建一个简单的示例应用程序
每个用户都是不同的。一些用户更喜欢阅读长篇技术文档,而另一些用户更喜欢简短的独立教程。考虑人们的不同学习风格(视觉、听觉、社交、独立等)。有些人通过长时间学习来学习;其他人通过实践来学习。
我们可以考虑为用户寻求的不同类型信息构建不同风格的文档。更加具体的信息(例如,这个特定框架的功能如何工作?)可能更适合传统的长篇文档格式,而更加指导性的信息(例如,如何使用这个框架构建一个应用程序?)可能更适合丰富的媒体(例如,视频教程)。
由于用户可能寻求的信息类型众多,以及我们正在为不同的个体用户提供服务,因此值得花费大量时间来规划、设计和执行清晰的文档。它不应该是事后的想法。
现在我们已经探讨了清晰文档的四个方面,让我们探索一下我们可以使用的各种媒介来表达我们的文档。我们不必只使用单一的沉闷、可滚动的文档:我们还有数十种其他方式可以向用户和同事提供信息和教育。
文档无处不在
如果我们慷慨地将文档定义为了解软件的一种方式,我们可以观察到存在数十种不同的文档媒介。其中许多是隐性或偶然的;其他更多是有意识地制作的,无论是软件的创建者还是围绕它聚集的专家社区:
-
书面文档(API 规范、概念解释)
-
解释性图片和图表(例如流程图)
-
书面教程(步骤、食谱、如何做 X)
-
丰富的媒体介绍和教程(视频、播客、屏幕录像)
-
公共问答或问题(例如解释如何修复某些问题的 GitHub 问题)
-
社区驱动的问答(例如 StackOverflow)
-
程序员之间的独立沟通(线上或线下)
-
聚会、会议和研讨会(所有者或社区驱动)
-
官方支持(付费支持电话、邮件、线下会议)
-
教育课程(例如线下或在线的 Coursera)
-
测试(解释概念、流程和期望)
-
良好的抽象(有助于解释概念)
-
可读且熟悉的代码(易于理解)
-
结构和界定(目录结构,项目名称等)
-
直观设计的界面(通过良好设计教育使用方式)
-
错误流和消息(例如* X 不起作用?尝试 Z 代替*)。
考虑所有这些媒介是如何被照顾的是值得的。当官方文档无法帮助解决用户的问题时,他们在放弃你的软件之前会探索哪些其他途径?我们如何能够尽快和流畅地将用户的困难或问题引导到解决方案?如果用户不太可能阅读整个规范文档,那么我们可以为他们创建哪些其他媒介?
为非技术受众撰写
正如我们所见,撰写文档时,有必要将所用语言适应于受众。为此,我们必须清楚地了解受众是谁,他们目前的知识水平是什么,以及他们试图实现什么。对程序员来说,与不太技术化或非技术人员沟通是一个臭名昭著的挑战。这是作为软件创作者的一个非常常见且至关重要的部分。无论是在 UX 的特定点与最终用户沟通,还是与非技术利益相关者合作,都需要根据受众调整我们的沟通方式。为此,我们应该做到以下几点:
-
选择正确的抽象层次:找到受众完全理解的抽象层次至关重要。使用他们的角色和能力来指导你用来解释事物的类比。例如,如果你在向患者谈论一款医疗软件,你可能更愿意说请添加您的医疗信息,而不是请填写医疗档案字段。
-
避免过于技术化的术语:避免对听众毫无意义的词语。使用普通语言解释详细概念。例如,你可以谈论视觉增强,而不是CSS 修改。
-
不断获得反馈:确保通过与听众核对来确保自己被理解。不要假设人们理解你,只是因为他们没有明确表示不理解。在你的文档或软件中考虑面向用户的提示(例如,“这条消息有帮助吗?[是] [否]”)
与非技术人员沟通可能看起来是一个独特的挑战,但与任何其他人沟通并无二致。正如我们应该一直做的那样,我们只需要以他们的理解水平为准,并根据他们对问题领域的当前理解进行沟通。
总结
在本章中,我们探讨了撰写清晰文档的艰难之处,将其分解为清晰文档的四个关键方面:概念,规范,指导和可用性。我们讨论了正确识别受众的挑战以及如何制定我们的沟通以适应他们。这种知识不仅在撰写正式文档时有用,也在我们与利益相关者以及软件与用户进行沟通时有用。
在下一章中,我们将迅速转向处理他人代码的独特挑战。当我们作为接收端需要高效工作时,如果文档可能不佳或代码不直观,会发生什么?我们将找出答案。
第十七章:其他人的代码
人类是复杂而善变的,创造出复杂而善变的东西。然而,处理其他人和他们的代码是作为程序员不可避免的一部分。无论是处理他人构建的库和框架,还是继承整个遗留代码库,挑战都是相似的。第一步应该始终是寻求对代码及其范例的理解。当我们完全理解代码时,我们可以开始以清晰的方式与之交互,使我们能够在现有工作的基础上创建新功能或进行改进。在本章中,我们将更详细地探讨这个主题,并通过清晰的代码视角考虑我们可以采取的行动,使其他人的代码处理起来不那么痛苦。
在本章中,我们将涵盖以下主题:
-
继承代码
-
处理第三方代码
继承代码
当我们加入一个新团队或接手一个新项目时,通常会继承大量代码。我们在这些继承的代码库中的生产力取决于我们对它们的理解。因此,在我们寻求进行第一次更改之前,我们需要在脑海中建立一个关于事物如何运作的概念模型。它不需要是详尽和完整的,但它必须使我们至少能够进行更改并准确理解这些更改可能对代码库的所有组成部分产生的影响。
探索和理解
完全理解代码基础并不是必须的,也不是必须的,但如果我们对所有相互关联部分的复杂性没有足够的理解,那么我们就会陷入陷阱。当我们相信自己已经很好地理解时,开始进行更改时,陷阱就会出现。如果不理解我们行为的全部影响,我们最终会浪费时间,实现不完善的东西,并产生意外的错误。因此,我们必须充分了解情况。为了做到这一点,我们必须首先评估我们对系统或代码基础复杂性的视图是完整还是不完整。
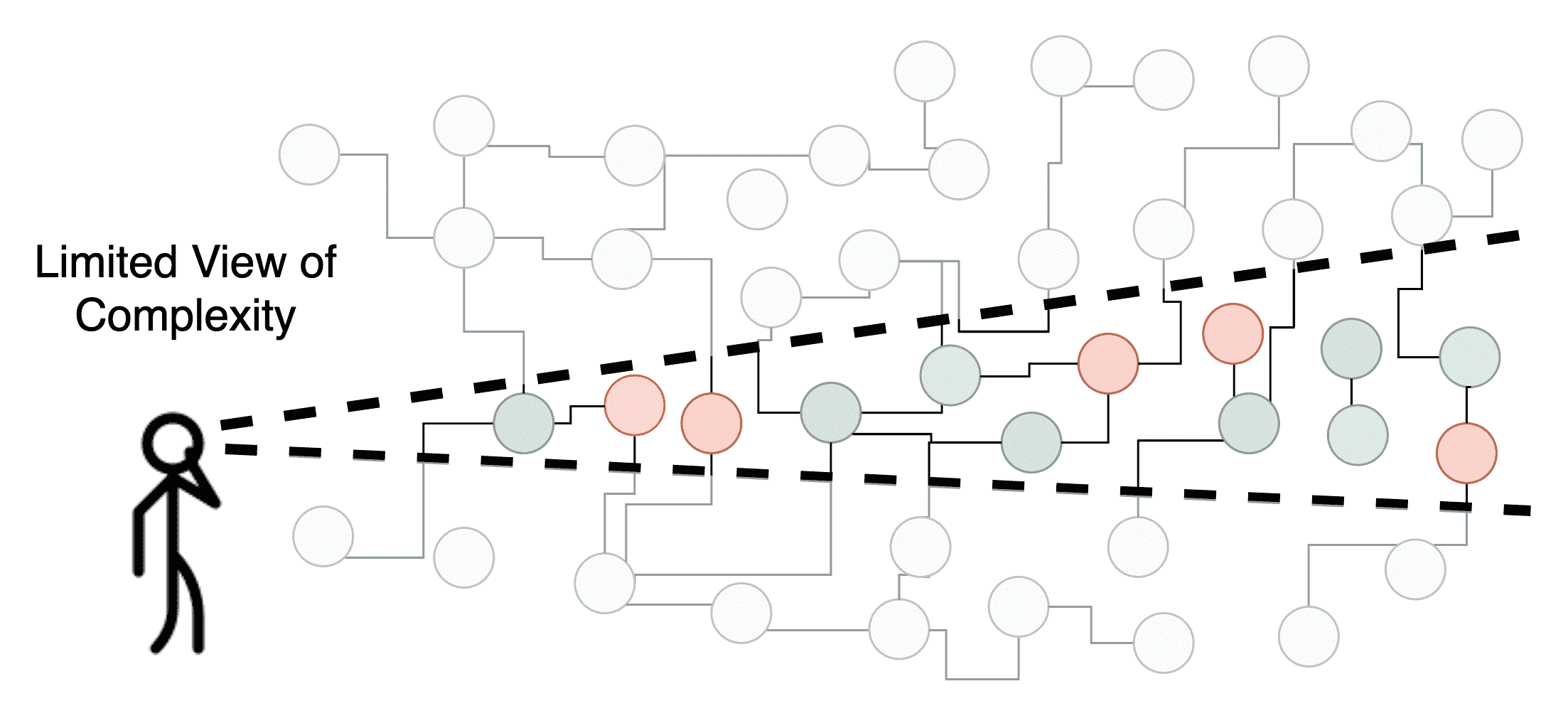
通常,我们看不见的事情对我们来说是完全未知的,因此我们不知道自己根本没有任何理解。这就是常见表达式我们不知道自己不知道什么所概括的。因此,在探索新的代码库时,积极主动地努力去发现和突出我们的无知领域是有帮助的。我们可以通过以下三个步骤来做到这一点:
-
收集可用信息:与知情的同事交谈,阅读文档,使用软件,内化概念结构和层次结构,阅读源代码。
-
做出知情的假设:用知情的假设填补你不确定的地方。如果有人告诉你应用程序有注册页面,你可以直观地假设这意味着用户注册涉及典型的个人数据字段,如姓名、电子邮件、密码等。
-
证明或否定假设:寻求通过直接查询系统(例如编写和执行测试)或询问有经验的人(例如对代码库有经验的同事)来证明或否定你的假设。
在创建和扩展对新代码库的理解时,有一些特定的方法值得采用。这些方法包括制作流程图,内化变更的时间线,使用调试器逐步执行代码,并通过测试确认你的假设。我们将逐个探讨这些方法。
制作流程图
当我们遇到一个新的代码库时,我们几乎可以立即采用的一个有用的方法是填充一个心智图或流程图,突出显示我们知道的事情以及我们尚不确定的事情。以下是我曾经在一款医疗软件上使用的这种图表的简化示例:
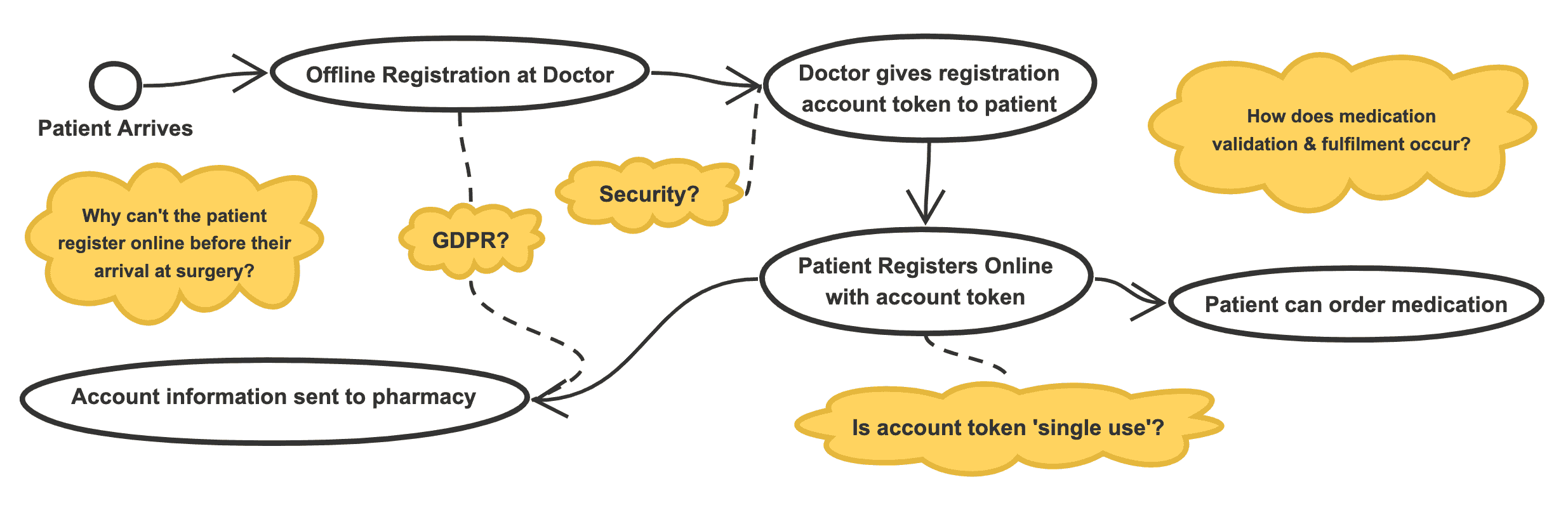
正如你所看到的,我已经尝试概述了我对用户流程的当前理解,并在云注释中添加了我个人在其中遇到的困惑或问题。随着我的理解的增长,我可以补充这个流程图。
人们以各种方式学习。这种视觉辅助可能对某些人更有用,但对其他人可能不那么有用。还有无数种组成这样的流程图的方式。为了达到个人理解的目的,最好使用任何对你有效的方法。
寻找结构和观察历史
想象一下,你面对一个包含几种专门类型的视图或组件的大型 JavaScript 应用程序代码库。我们的任务是在应用程序中的一个付款表单中添加一个新的下拉菜单。我们快速搜索代码库,并确定了许多不同的下拉菜单相关组件:
-
GenericDropdownComponent -
DropdownDataWidget -
EnhancedDropdownDataWidget -
TextDropdown -
ImageDropdown
它们的命名令人困惑,因此在进行更改或使用它们之前,我们希望更好地了解它们。为了做到这一点,我们可以打开每个组件的源代码,以确定它可能与其他组件有何关联(或者没有关联)。
最终我们发现,例如TextDropdown和ImageDropdown都似乎继承自GenericDropdownComponent:
// TextDropdown.js
class TextDropdown extends GenericDropdownComponent {
//...
}
// ImageDropdown.js
class ImageDropdown extends GenericDropdownComponent {
}
我们还观察到DropdownDataWidget和EnhancedDropdownDataWidget都是TextDropdown的子类。增强下拉小部件的命名可能会让我们困惑,这可能是我们在不久的将来想要更改的内容,但是,目前,我们需要屏住呼吸,只需专注于完成我们被分配的工作。
在完成遗留或不熟悉的代码库中的任务时,避免走神。许多事情可能看起来奇怪或错误,但你的任务必须始终是最重要的事情。在早期,你可能没有足够的接触代码库的经验来做出明智的更改。
通过逐个查看每个与下拉菜单相关的源文件,我们可以在不进行任何更改的情况下建立对它们的深入理解。如果代码库使用源代码控制,那么我们还可以责备每个文件,以发现最初是谁编写的以及何时编写的。这可以告诉我们事物是如何随时间变化的。在我们的情况下,我们发现了以下变更时间线:
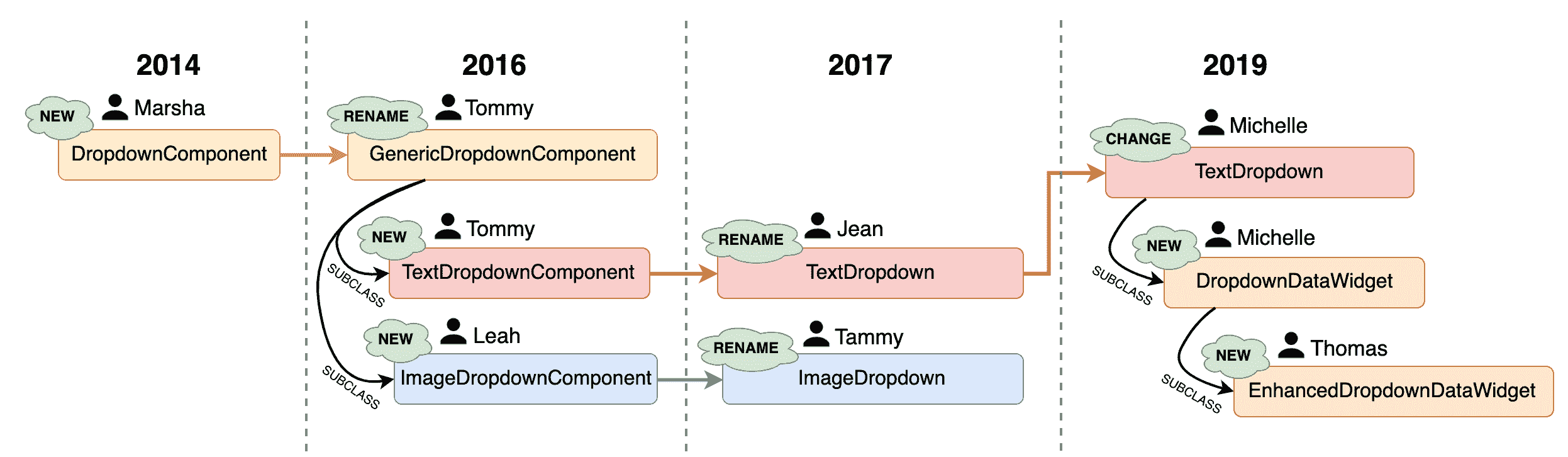
这对我们非常有帮助。最初只有一个类(名为DropdownComponent),后来改为GenericDropdownComponent,有两个子类TextDropdownComponent和ImageDropdownComponent。每个都改名为TextDropdown和ImageDropdown。随着时间的推移,这些各种变化阐明了现在事物的原因。
当查看代码库时,我们经常会假设它是一次性创建的,并且有完整的远见;然而,正如我们的时间线所示,事实要复杂得多。代码库随着时间的推移而变化,以应对新的需求。参与代码库工作的人员也在变化,每个人都不可避免地有自己解决问题的方式。我们接受每个代码库缓慢演变的本质,将有助于我们接受它的不完美之处。
逐步查看代码
在大型应用程序中建立对单个代码片段的理解时,我们可以使用工具来调试和研究其功能。在 JavaScript 中,我们可以简单地放置一个debugger;语句,然后执行我们知道会激活特定代码的应用程序部分。然后,我们可以逐行查看代码,以回答以下问题:
-
**这段代码被调用在哪里?**对于一个抽象如何被激活的明确期望可以帮助我们在脑海中建立应用程序的流或顺序的模型,使我们能够更准确地判断如何修复或更改某些东西。
-
**这段代码接收了什么?**抽象接收的输入示例可以帮助我们建立一个清晰的概念,了解它的功能,以及它期望如何被接口化。这可以直接指导我们使用这个抽象。
-
**这段代码输出了什么?**观察一个抽象的输出,以及它的输入,可以让我们对它的计算方式有一个非常明确的概念,并且可以帮助我们判断我们可能希望如何使用它。
-
**这里存在什么级别的误导或复杂性?**观察复杂和高的堆栈跟踪(意味着被函数调用的函数被函数调用,无限循环…)可以表明我们在某个区域内导航和理解控制和信息流的困难。这将告诉我们,我们可能需要通过额外的文档或与知情的同事沟通来增加我们的理解。
以下是在浏览器环境中这样做的一个例子(使用 Chrome Inspector):
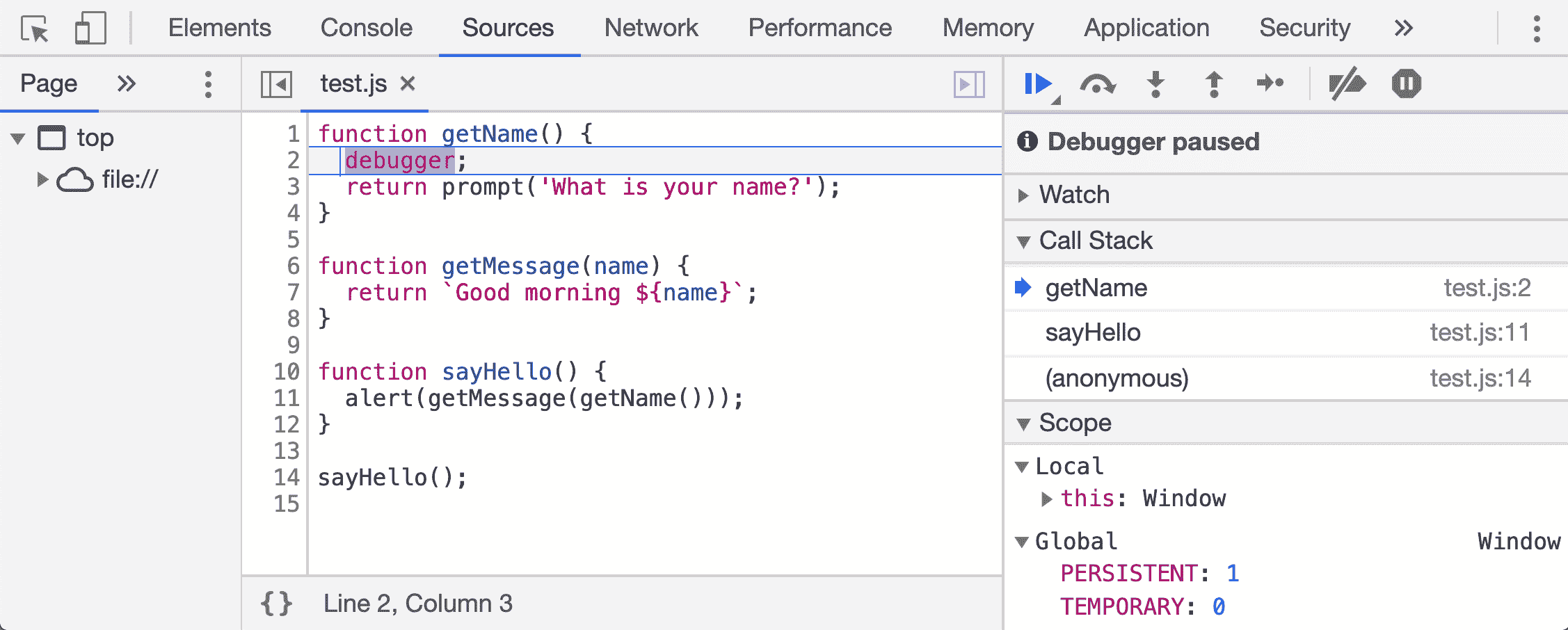
即使在 Node.js 中实现服务器端 JavaScript,您也可以使用 Chrome 的调试器。要做到这一点,在执行 JavaScript 时使用--inspect标志,例如,node --inspect index.js。
像这样使用调试器可以为我们呈现调用堆栈或堆栈跟踪,告诉我们通过代码库采取了哪条路径到达我们的debugger;语句。如果我们试图了解陌生类或模块如何适应代码库的整体情况,这将非常有帮助。
验证您的假设
扩展我们对陌生代码的了解的最佳方法之一是编写测试来确认代码的行为方式。想象一下,我们被要求维护这段晦涩的代码:
class IssuerOOIDExtractor {
static makeExtractor(issuerInfoInterface) {
return raw => {
const infos = [];
const cleansed = raw
.replace(/[_\-%*]/g, '')
.replace(/\bo(\d+?)\b/g, ($0, id) => {
if (issuerInfoInterface) {
infos.push(issuerInfoInterface.get(id));
}
return `[[ ${id} ]]`;
})
.replace(/^[\s\S]*?(\[\[.+\]\])[\s\S]*$/, '$1');
return { raw, cleansed, data: infos };
};
}
}
这段代码只在几个地方使用,但各种输入是在应用程序的难以调试的区域动态生成的。此外,没有文档,绝对没有测试。这段代码到底做了什么还不太清楚,但是,当我们逐行研究代码时,我们可以开始做一些基本的假设,并将这些假设编码为断言。例如,我们可以清楚地看到makeExtractor静态函数本身返回一个函数。我们可以将这个事实规定为一个测试:
describe('IssuerOOIDExtractor.makeExtractor', () => {
it('Creates a function (the extractor)', () => {
expect(typeof IssuerOOIDExtractor.makeExtractor()).toBe('function');
});
});
我们还可以看到某种正则表达式替换发生;它似乎在寻找字母o后面跟着一串数字的模式(\bo(\d+?)\b)。我们可以通过编写一个简单的断言来开始探索这个提取功能,其中我们给提取器一个匹配该模式的字符串:
const extractor = IssuerOOIDExtractor.makeExtractor();
it('Extracts a single OOID of the form oNNNN', () => {
expect(extractor('o1234')).toEqual({
raw: 'o1234',
cleansed: '[[ 1234 ]]',
data: []
});
});
随着我们慢慢发现代码的功能,我们可以添加额外的断言。我们可能永远无法达到 100%的理解,但这没关系。在这里,我们断言提取器能够正确提取单个字符串中存在的多个 OOID:
it('Extracts multiple OOIDs of the form oNNNN', () => {
expect(extractor('o0012 o0034 o0056 o0078')).toEqual({
raw: 'o0012 o0034 o0056 o0078',
cleansed: '[[ 0012 ]] [[ 0034 ]] [[ 0056 ]] [[ 0078 ]]',
data: []
});
});
运行这些测试时,我们观察到以下成功的结果:
PASS ./IssuerOOIDExtractor.test.js
IssuerOOIDExtractor.makeExtracator
✓ Creates a function (the extractor) (3ms)
The extractor
✓ Extracts a single OOID of the form oNNNN (1ms)
✓ Extracts multiple OOIDs of the form oNNNN (1ms)
请注意,我们仍然不完全确定原始代码的作用。我们只是触及了表面,但这样做,我们正在建立一个有价值的理解基础,这将使我们将来更容易地与这段代码进行交互或更改。随着每个新的成功断言,我们离完整和准确地理解代码的目标更近。如果我们将这些断言作为新的测试提交,那么我们也正在提高代码库的测试覆盖率,并为将来可能同样被这段代码困惑的同事提供帮助。
现在我们已经牢固掌握了如何探索和理解继承的代码,我们现在可以研究如何对该代码进行更改。
进行更改
一旦我们对代码库的某个区域有了很好的理解水平,我们就可以开始进行更改。然而,即使在这个阶段,我们也应该谨慎。我们对代码库和相关系统仍然相对较新,所以我们可能仍然不了解其中许多部分。任何更改都可能造成意想不到的影响。因此,为了继续前进,我们必须慢慢和谨慎地进行,确保我们的代码设计良好并经过充分测试。在这里,我们应该注意两种具体的方法:
-
在陌生环境中进行孤立更改的精细手术过程
-
通过测试确认更改
让我们逐一探讨这些。
最小侵入手术
当需要在旧的或陌生的代码库中进行更改时,可以想象自己在进行一种最小侵入手术。这样做的目的是最大化更改的积极影响,同时最小化更改本身的影响范围,确保不会对代码库的其他部分造成损害或影响过大。这样做的希望是,我们将能够产生必要的更改(优势),而不会过多地暴露自己于破坏或错误的可能性(劣势)。当我们不确定更改是否完全必要时,这也是有用的,因此我们最初只想在其上花费最少的精力。
假设我们继承了一个负责呈现单个图像的GalleryImage组件。在我们的 Web 应用程序中有许多地方使用它。任务是在资产的 URL 指示其为视频时,添加呈现视频的能力。两种 CDN URL 的类型如下:
-
https://cdn.example.org/VIDEO/{ID} -
https://cdn.example.org/IMAGE/{ID}
正如您所看到的,图像和视频 URL 之间存在明显的区别。这为我们提供了一种在页面上呈现这些媒体的简单方法。理想情况下,我们应该实现一个名为GalleryVideo的新组件来处理这种新类型的媒体。这样的新组件将能够独特地满足视频的问题域,这显然与图像的问题域不同。至少,视频必须通过<VIDEO>元素呈现,而图像必须通过<IMG>呈现。
我们发现GalleryImage的许多用法都没有经过充分测试,有些依赖于隐晦的内部实现细节,这些细节如果要大规模辨别将会很困难(例如,如果我们想要更改所有GalleryImage的用法,进行查找和替换将会很困难)。
我们的可用选项如下:
- 创建一个容器
GalleryAsset组件,它本身根据 CDN URL 决定是否呈现GalleryImage或GalleryVideo。这将涉及替换每个当前使用GalleryImage的情况:
-
时间估计:1-2 周
-
代码库中的影响:显著
-
可能出现意想不到的破坏:显著
-
架构清洁度:高
- 在
GalleryImage中添加一个条件,根据 CDN URL 可选择呈现<video>而不是<img>标签:
-
时间估计:1-2 天
-
代码库中的影响:最小
-
可能出现意想不到的破坏:最小
-
架构清洁度:中等
在理想情况下,如果考虑代码库的长期架构,很明显创建一个新的GalleryAsset组件是最好的选择。它为我们提供了一个清晰定义的抽象,直观地满足了图片和视频的两种情况,并为我们提供了在将来添加不同资产类型(例如音频)的可能性。然而,它需要更长的时间来实现,并且带有相当大的风险。
第二个选项要简单得多。实际上,它可能只涉及以下四行更改集:
@@ -17,6 +17,10 @@ class GalleryImage {
render() {
+ if (/\/VIDEO\//.test(this.props.url)) {
+ return <video src={this.props.url} />;
+ }
+
return <img src={this.props.url} />
}
这不一定是一个好的长期选择,但它给了我们一些可以立即交付给用户的东西,满足他们的需求和我们利益相关者的需求。一旦交付,我们可以计划未来的时间来完成更大的必要更改。
重申一下,最小侵入性更改的价值在于它减少了代码库在实施时间和潜在破坏方面的立即不利因素(风险)。显然,确保我们在短期利益和长期利益之间取得平衡是至关重要的。利益相关者通常会向程序员施加压力,要求他们快速实施更改,但如果没有技术 债务或协调过程,那么所有这些最小侵入性的更改可能会积聚成一个相当可怕的怪物。
为了确保我们更改的代码不太脆弱或容易出现未来的回归,最好是在更改的同时编写测试,编码我们的期望。
将更改编码为测试
我们已经探讨了如何编写测试来发现和指定当前功能,而且在之前的章节中,我们讨论了遵循测试驱动开发(TDD)方法的明显好处。因此,当在一个陌生的代码库中操作时,我们应该始终通过清晰编写的测试来确认我们的更改。
在没有现有测试的情况下,与您的更改一起编写测试绝对是必要的。在代码区域编写第一个测试可能会很繁重,因为需要设置库和必要的模拟,但这绝对是值得的。
在我们之前介绍的向GalleryImage引入渲染视频功能的示例中,明智的做法是添加一个简单的测试来确认当 URL 包含"/VIDEO/"子字符串时,<VIDEO>被正确渲染。这可以防止未来的回归,并给我们带来了强大的信心,表明它按预期工作:
import { mount } from 'enzyme';
import GalleryImage from './GalleryImage';
describe('GalleryImage', () => {
it('Renders a <VIDEO> when URL contains "/VIDEO/"', () => {
const rendered = mount(
<GalleryImage url="https://cdn.example.org/VIDEO/1234" />
);
expect(rendered.find('video')).to.have.lengthOf(1);
});
it('Renders a <IMG> when URL contains "/IMAGE/"', () => {
const rendered = mount(
<GalleryImage url="https://cdn.example.org/IMAGE/1234" />
);
expect(rendered.find('img')).to.have.lengthOf(1);
});
});
这是一个相当简单的测试;然而,它完全编码了我们在进行更改后的期望。在进行小型和自包含的更改或更大的系统性更改时,通过这样的测试验证和传达我们的意图是非常有价值的。除了防止回归,它们还在立即的代码审查方面帮助我们的同事,以及在文档和整体可靠性方面帮助整个团队。因此,拥有一个团队强制执行或政策,即如果没有测试,就不能提交更改是相当正常和可取的。长期执行这一政策将使代码库产生更可靠的功能,对用户更加友好,对其他程序员更加愉快。
我们现在已经完成了关于继承代码的部分,所以你应该对如何处理这种情况有了良好的基础知识。在处理其他人的代码时,另一个挑战是选择和集成第三方代码,即库和框架。我们现在将探讨这个问题。
处理第三方代码
JavaScript 的领域充斥着各种框架和库,可以减轻实现各种功能的负担。在第十二章中,真实挑战,我们看到了在 JavaScript 项目中包含外部依赖项所涉及的困难。现代 JavaScript 生态系统在这里提供了丰富的解决方案,因此处理第三方代码的负担要比以前少得多。尽管如此,与这些代码进行接口的本质并没有真正改变。我们仍然必须希望我们选择的第三方库或框架提供直观和良好文档的接口,以及满足我们需求的功能。
在处理第三方代码时,有两个关键的过程将决定我们所获得的持续风险或收益。第一个是选择过程,我们在这个过程中选择要使用的库,第二个是我们将库集成和适应到我们的代码库中。现在我们将详细讨论这两点。
选择和理解
选择一个库或框架可能是一个冒险的决定。选择错误的库可能最终会驱动系统的大部分架构。框架尤其以此闻名,因为它们的本质决定了架构的结构和概念基础。选择错误的库然后试图更改它可能是一个相当大的工作量;这需要对应用程序中几乎每一行代码的更改。因此,认真考虑和选择第三方代码的技能至关重要:

在选择过程中,我们可以考虑一些有用的考虑因素:
-
功能性:库或框架必须满足一组固定的功能期望。重要的是以足够详细的方式指定这些功能,以便可以量化比较不同的选项。
-
兼容性:库或框架必须与当前代码库的工作方式大部分兼容,并且必须能够以技术简单易懂的方式集成,以便同事们能够理解。
-
可用性:库或框架必须易于使用和理解。它应该有良好的文档和一定程度的直观性,可以在没有痛苦或困惑的情况下立即提高生产力。对于使用相关问题或疑问的考虑也属于可用性范畴。
-
维护和安全性:库或框架应该得到维护,并且有一个清晰可信的流程来报告和解决错误,特别是那些可能具有安全影响的错误。变更日志应该是详尽的。
这里的四个标准也可以通过启发式来指导,比如项目由谁支持?,有多少人在使用该项目?,或者我是否熟悉构建它的团队?。但请注意,这些只是启发式,因此并不是衡量第三方代码适用性的完美方式。
然而,即使使用这四个标准,我们可能会陷入陷阱。如果你还记得,在第三章中,清洁代码的敌人,我们讨论了最显著的自我(或自负)和物质崇拜。在选择第三方代码时,这些也是相关的。请特别注意以下内容:
-
强烈的观点: 尽可能地与决策过程分开,并非常谨慎地对待我们的无知和偏见。程序员以他们的固执著称。在这些时刻,重要的是要从自己身上退后一步,用纯粹的逻辑来推理出我们认为最好的是什么。给每个人一个发言的机会同样很重要,根据他们自身的价值观和轶事来权衡人们的意见,而不是根据他们的资历(或其他个人特征)。
-
流行文化: 不要被流行所左右。由于其社区的规模和狂热,很容易被流行的抽象所吸引,但再次,重要的是要退一步,考虑框架本身的优点。当然,流行可能表明易于集成和更丰富的学习资源,所以在这方面,谈论它是合理的,但要小心使用流行作为优越性的唯一指标。
-
分析瘫痪: 有很多选择,所以有可能陷入一种似乎无法做出选择的情况,因为害怕做出错误选择。大多数情况下,这些决定是可逆的,所以做出不太理想的选择并不是世界末日。很容易陷入这样一种情况,花费大量时间来决定选择哪个框架或库,而更有效的方法是只是选择任何东西,然后根据以后的需求进行迭代或转变。
在做关于第三方库的决定时,关键是要充分意识到它们对代码库的最终影响。我们花在做决定上的时间应该与它们的潜在影响成比例。决定客户端框架用于组件渲染可能是一个相当重要的选择,因为它可能规定了代码库的一个重要部分,而例如一个小的 URL 解析实用程序并没有很大的影响,并且可以在将来轻松替换。
接下来,我们可以讨论如何集成和封装第三方代码,遵循一个知情的选择过程。
封装和适应第三方代码
选择第三方抽象,特别是框架的缺点是,你最终可能会改变你的代码库以适应抽象的作者的任意约定和设计决策。通常情况下,我们被迫说同样的语言,而不是让它们说我们的语言。确实,在许多情况下,可能是抽象的约定和设计吸引了我们,所以我们更愿意让它驱动我们的代码库的设计和性质。但在其他情况下,我们可能希望更多地受到我们选择的抽象的保护。我们可能希望在将来轻松地将它们替换为其他抽象,或者我们可能已经有一套我们更愿意使用的约定。
在这种情况下,封装这些第三方抽象并纯粹通过我们自己的抽象层来处理它们可能是有用的。这样的层通常被称为适配器:
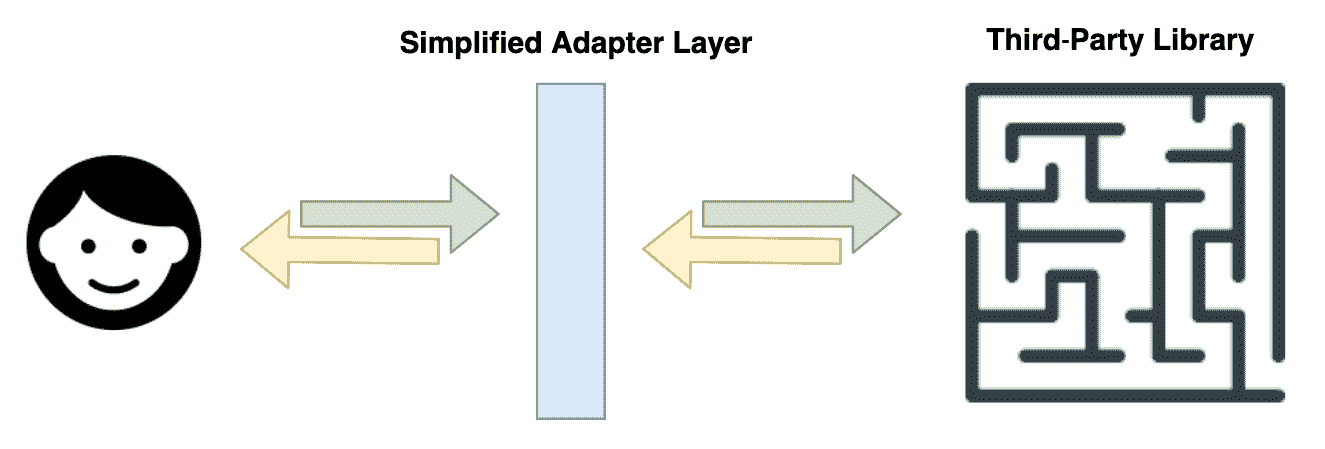
非常简单地说,适配器将提供一个我们设计的接口,然后委托给第三方抽象来完成其任务。想象一下,如果我们希望使用一个名为YOORL的 URL 解析实用程序。我们已经决定它完全符合我们的需求,并且完全符合 RFC 3986(URI 标准)。唯一的问题是它的 API 相当繁琐和冗长。
import YOORL from 'yoorl';
YOORL.parse(
new YOORL.URL.String('http://foo.com/abc/?x=123'),
{ parseSearch: true }
).parts();
这将返回以下对象:
{
protocol: 'http',
hostname: 'foo.com',
pathname: '/abc',
search: { x: 123 }
}
我们希望 API 更简单。我们认为当前 API 的长度和复杂性会使我们的代码库面临不必要的复杂性和风险(例如错误调用)。使用适配器可以让我们将这个不理想的接口封装成我们自己设计的接口。
// URLUtils.js
import YOORL from 'yoorl';
export default {
parse(url) {
return YOORL.parse(
new YOORL.URL.String(url)
).parts();
}
};
这意味着我们代码库中的任何模块现在都可以与这个简化的适配器进行接口,使它们与 YOORL 的不理想 API 隔离开来。
import URLUtils from './URLUtils';
URLUtils.parse('http://foo.com/abc/?x=123'); // Easy!
适配器可以被视为翻译媒介,使我们的代码库能够使用其选择的语言,而不必受到第三方库的任意和不一致的设计决策的拖累。这不仅有助于代码库的可用性和直观性,还使我们能够非常轻松地对基础第三方库进行更改,而无需改变太多代码。
总结
在本章中,我们探讨了其他人的代码这个棘手的话题。我们考虑了如何处理我们继承的遗留代码;我们如何建立对它的理解,如何进行调试和进行改变而不困难,以及如何通过良好的测试方法确认我们的改变。我们还涵盖了处理第三方代码的困难,包括如何选择它以及如何通过适配器模式以风险规避的方式与其进行接口。在本章中我们还可以谈论许多其他事情,但希望我们能够探讨的主题和原则已经让您充分了解如何以干净的代码库为目标来处理其他人的代码。
在下一章中,我们将涵盖沟通的主题。这可能看起来不相关,但对于程序员来说,沟通在我们的工作场所内部和向用户之间都是一项绝对重要的技能,没有它,干净的代码几乎不可能存在。我们将具体探讨如何规划和设定要求,如何与同事合作和沟通,以及如何在我们的项目和工作场所内推动变革。
第十八章:沟通和倡导
我们不是孤立地编写代码。我们生活在一个高度混乱的社会世界中,必须不断与其他人沟通。我们的软件本身将通过其接口成为这种沟通的一部分。此外,如果我们在团队、工作场所或社区中工作,我们将面临有效沟通的挑战。
沟通对我们的代码库产生最重要影响的方式是设定要求、提出问题和反馈。软件开发本质上是一个非常长期的反馈过程,每一次变更都是由一次沟通引发的:
在这一章中,我们将学习如何有效地与他人合作和沟通,如何规划和设定要求,一些常见的合作陷阱及其解决方案。我们还将学习如何识别和提出阻碍我们编写清晰 JavaScript 的更大问题。在整个本章中,我们希望开始意识到我们在软件开发反馈周期中的重要角色。
在本章中,我们将看到以下主题:
-
规划和设定要求
-
沟通策略
-
识别问题并推动变革
规划和设定要求
最常见的沟通困难之一在于决定到底要构建什么。程序员通常会花费大量时间与经理、设计师和其他利益相关者会面,将真正的用户需求转化为可行的解决方案。理想情况下,这个过程应该很简单:*用户有[问题];我们创建[解决方案]。故事结束!*不幸的是,实际情况可能要复杂得多。
即使在看似简单的项目中,也会有许多技术约束和沟通偏见,使得项目变得异常艰难。这对 JavaScript 程序员和其他程序员同样重要,因为我们现在操作的系统复杂性水平以前只有企业程序员才能使用 Java、C#或 C++。形势已经改变,因此谦卑的 JavaScript 程序员现在必须准备学习新技能,并就他们构建的系统提出新问题。
理解用户需求
确立用户需求至关重要,但往往被视为理所当然。程序员和其他项目成员通常会假设他们了解某个用户需求,而实际上并没有深入了解细节,因此有一个备用的流程是很有用的。对于每一个表面上的需求或问题,我们应该确保理解以下方面:
-
我们的用户是谁?:他们有什么特点?他们使用什么设备?
-
他们试图做什么?:他们试图执行什么行动?他们的最终目标是什么?
-
他们目前是如何做的?:他们目前采取了哪些步骤来实现他们的目标?目前的方法是否存在明显问题?
-
他们以这种方式遇到了什么问题?:需要很长时间吗?认知成本高吗?使用起来困难吗?
在书的开头,我们问自己为什么要编写代码,并探讨了真正理解问题领域本质的含义。理想情况下,我们应该能够站在用户的角度,亲身体验问题领域,然后从第一手经验中制定可行的解决方案。
不幸的是,我们并不总能直接与用户交谈或亲身体验。相反,我们可能依赖项目经理和设计师等中间人。因此,我们依赖他们的沟通效果,以便将用户需求传达给我们,从而使我们能够构建正确的解决方案。
在这里,我们看到了我们用户的需求,结合技术和业务约束,流入一个构建成解决方案并进行迭代的想法。将用户需求转化为想法至关重要,反馈过程使我们能够对解决方案进行迭代和改进:
由于用户需求对开发过程至关重要,我们必须仔细考虑如何平衡这些需求和其他约束。通常不可能构建出完美的解决方案,能够很好地满足每个用户的需求。几乎每个软件,无论是作为 GUI 还是 API 呈现,都是一种折衷,平均用户得到很好的满足,不可避免地意味着边缘情况的用户只能得到部分满足。重要的是要考虑如何尽可能充分地满足尽可能多的用户需求,巧妙地平衡时间、金钱和技术能力等约束。
在了解用户需求之后,我们可以开始设计和实现系统可能运行的原型和模型。接下来我们将简要讨论这个过程。
快速原型和 PoC
软件,尤其是 Web 平台,为我们提供了快速的构建周期的好处。我们可以在很短的时间内从概念到 UI。这意味着在头脑风暴的过程中,想法可以几乎实时地变为现实。然后我们可以将这些原型放在真实用户面前,获得真实反馈,然后快速迭代,朝着最佳解决方案迈进。事实上,Web 平台的优势——HTML、CSS 和 JavaScript 的三位一体——在于它允许快速而粗糙的解决方案,并且可以轻松进行迭代,并且可以在多个平台和设备上运行:
很容易被 JavaScript 框架和库的多样性和复杂性所压倒;它们的沉重负担会迫使我们进展缓慢。这就是为什么在原型设计时,最好坚持使用你已经很了解的更简单的技术栈。如果你习惯于某个框架,或者你准备花时间学习,那么值得利用现有的骨架模板作为起点。以下是一些例子:
-
React boilerplate (github.com/react-boilerplate/react-boilerplate)
-
Angular bootstrap boilerplate (github.com/mdbootstrap/Angular-Bootstrap-Boilerplate)
-
Ember boilerplate (github.com/mirego/ember-boilerplate)
-
Svelte template (github.com/sveltejs/template)
每个模板都提供了一个相对简单的项目模板,可以让你非常快速地设置一个新的原型。尽管每个模板中使用了多个构建工具和框架选项,但设置成本很低,因此开始解决项目的真正问题领域所需的时间非常短。当然,你也可以找到类似的骨架模板和示例应用程序,适用于服务器端 Node.js 项目、同构 Web 应用程序,甚至是机器人或硬件项目。
现在我们已经探讨了规划和需求设置的技术过程,我们可以继续探讨一些重要的沟通策略,这些策略将帮助我们在我们的代码库上与他人合作。
沟通策略
我们直觉地知道沟通对于一个有效的项目和清晰的代码库是至关重要的,然而,很常见的情况是我们发现自己处于以下情况:
-
我们觉得自己没有被倾听到
-
我们觉得自己没有表达清楚
-
我们对某个主题或计划感到困惑
-
我们感到不在圈内或被忽视
这些困难是由于文化和不良沟通习惯造成的。这不仅影响了我们工作中的士气和整体满足感,还可能对我们构建的代码库的整洁性和技术的可靠性造成巨大问题。为了培养一个干净的代码库,我们必须专注于我们采用的基础沟通实践。一套良好的沟通策略和实践对确保一个干净的代码库非常有用,特别是帮助我们做到以下几点:
-
确保与同事良好的反馈
-
接收正确的错误报告
-
执行改进和修复
-
接收用户需求和愿望
-
宣布变化或问题
-
就约定和标准达成一致
-
对库和框架做出决策
但我们如何实际实现良好的沟通呢?我们在本质上偏向于我们自己社会化的沟通实践,所以改变或甚至看到我们的沟通存在问题可能是困难的。因此,识别一套沟通策略和陷阱,可以让我们重新偏向更好和更高信号的沟通,这是非常有用的。
高信号沟通是指在最小噪音的情况下压缩大量高价值或富有洞察力的信息的任何沟通。用简洁和高度客观的段落表达错误报告可能是高信号的一个例子,而用三部分的散文和夹杂着观点的表达则是低信号的一个例子。
倾听并回应
无论是在线还是线下对话,很容易陷入一个陷阱,我们最终是在互相交谈而不是互相交流。一个良好而有用的对话是参与者真正倾听彼此,而不仅仅是等待自己说话的轮到。
考虑以下人员#1和人员#2之间的对话:
-
人员#1:我们应该使用 React 框架,它有着良好的记录。
-
人员#2:我同意它的记录。我们是否应该探讨其他选项,权衡它们的利弊呢?
-
人员#1:React 非常快速,文档完善,API 非常易用。我喜欢它。
这里人员#1没有注意人员#2在说什么。相反,他们只是继续他们现有的思路,重申他们对 React 框架的偏好。如果人员#1努力倾听人员#2的观点,然后具体回应他们,这将更有利于团队合作和项目的健康。将上述对话与以下对话进行比较:
-
人员#1:我们应该使用 React 框架,它有着良好的记录。
-
人员#2:我同意它的记录。我们是否应该探讨其他选项,权衡它们的利弊呢?
-
人员#1:那是个好主意,你认为我们应该考虑哪些其他框架呢?
在这里,人员#1是接受的,而不仅仅是在人员#2上面说话。这显示了一种非常需要的敏感性和对话关注。这可能看起来很明显,甚至无聊,但你可能会惊讶地发现我们经常互相打断对方,这给我们带来了什么代价。考虑在下次会议中扮演一个观察者的角色,观察人们未能正确地关注、倾听或回应的情况。你可能会对它的普遍性感到惊讶。
从用户的角度解释
在关于代码库的几乎每一次在线或离线沟通中,用户应该是最重要的事情。我们的工作目的是满足用户的期望,并为他们提供直观和功能性的用户体验。这一点很重要,无论我们的最终产品是消费者软件还是开发者 API。用户始终是我们的首要任务。然而,我们经常发现自己处于需要做出决定而不知道如何做出决定的情况;我们最终依赖直觉或自己的偏见。请考虑以下内容:
-
当然用户应该满足我们的密码强度要求
-
当然我们的 API 应该严格检查类型
-
当然,我们应该为国家选择使用下拉组件
这些可能看起来是相当无可非议的声明,但我们应该始终从用户的角度来限定它们。如果我们做不到这一点,那么决定很可能站不住脚,应该受到质疑。
对于上述每一条声明,我们可以如下辩护我们的推理:
-
当然用户应该满足我们的密码强度要求:拥有更强密码的用户将更安全地抵御暴力破解密码攻击。虽然我们作为服务方需要确保密码的安全存储,但确保密码强度是用户的责任,也符合他们的利益。
-
当然我们的 API 应该严格检查类型:严格检查类型的 API 将确保用户获得更多关于不正确使用的警告,从而更快地达到他们的目标。
-
当然我们应该为国家选择使用下拉组件:下拉是用户已经习惯的传统。我们也可以随时增加自动完成功能。
注意我们如何通过与用户相关的推理来扩展我们的“当然”的声明。我们很容易在周围断言事物应该如何,而实际上并没有用强有力的推理支持我们的主张。这样做可能导致毫无意义且论据不足的反对。最好始终从用户的角度推理我们的决定,这样,如果有争论,我们就是基于对用户最有利的事情进行争论,而不仅仅是最受欢迎或最坚定的观点。始终从用户的角度解释也有助于灌输一种文化,即我们和同事们始终在思考用户,无论我们是在编写深度专业的 API 还是开发通用的 GUI。
进行简短而专注的沟通
与我们编码时使用的“单一责任原则”类似,我们的沟通理想上应该一次只涉及一件事。这将极大地提高参与者之间的理解,并确保所做出的任何决定都与手头的问题有关。此外,保持会议或沟通的简短确保人们能够在整个持续时间内保持注意力。长时间的会议,就像长篇的电子邮件一样,最终会引起厌倦和烦躁。随着每个话题或话题的增加,每个问题被单独解决的机会也会大大减少。在提出问题和错误时记住这一点很重要。保持简单。
提出愚蠢的问题,提出大胆的想法
在专业环境中,有一种倾向,即假装有很高的信心和理解。这可能对知识传递有害。如果每个人都假装自己是熟练的,那么没有人会采取学习所需的谦卑立场。在我们的质疑中诚实(甚至愚蠢)是非常有价值的。如果我们是团队的新成员或者对代码库的某个区域感到困惑,重要的是提出我们真正有的问题,这样我们才能建立必要的理解,以便在我们的任务中成为高效和可靠的人。没有这种理解,我们将挣扎不已,可能会引起错误和其他问题。如果团队中的每个人都采取了假装自信的立场,团队很快就会变得无效,没有人能够解决他们的问题或困惑:

我们想要朝着的这种质疑可以称为开放性质疑;*一个过程,在这个过程中,我们尽可能地揭示我们的无知,以便在给定领域获得尽可能多的理解。类似于这样的开放性质疑,我们也可以说还有开放性构思,在这种构思中,我们尽可能地探索和揭示我们所拥有的任何想法,希望其中的一些子集是有用的。
有时,未说出口的想法是最有效的。通常,如果你觉得一个想法或问题太愚蠢或太疯狂,不值得说出来,通常最好说出来。最坏的情况(下行)是它是一个不适用或显而易见的问题或想法。但最好的情况(上行)是你要么获得了理解,要么问了很多人心中的问题(从而帮助了他们的理解),要么提出了一个极大地改变了团队效率或代码质量的想法。开放性的好处绝对值得坏处。
配对编程和 1:1s
程序员的大部分时间都被孤立地写代码所占据。对许多程序员来说,这是他们理想的情况;他们能够屏蔽掉世界的其他部分,找到流畅的生产力,以速度和流畅度编写逻辑。然而,这种孤立的风险是,代码库或系统的重要知识可能会积累在少数人的头脑中。如果不进行分发,代码库将变得越来越专业化和复杂,限制新人和同事轻松地导航。因此,有效地在程序员之间传递知识是至关重要的。
正如在书中之前讨论的,我们已经有了许多正式的方法来传递关于一段代码的知识:
-
通过文档,以各种形式
-
通过代码本身,包括注释
-
通过测试,包括单元测试和端到端测试
即使这些媒介,如果构建正确,可以有效地传递知识,似乎总是需要其他东西。临时沟通的基本人类约定是一种经受时间考验的方法,仍然是最有效的方法之一。
了解新代码库的最佳方法之一是通过配对编程,这是一种活动,在这种活动中,你坐在一个经验更丰富的程序员旁边,一起合作修复错误或实现功能。对于不熟悉的程序员来说,这是特别有用的,因为他们能够从他们的编程伙伴的现有知识和经验中受益。当需要解决一个特别复杂的问题时,配对编程也是有用的。有两个或更多的大脑来解决问题可以极大地增加解决问题的能力,并限制错误的可能性。
即使不是在配对编程的情况下,通常进行问答或师生动态可能非常有用。抽出时间与拥有你所需知识的个人交谈,并向他们提出有针对性但探索性的问题通常会产生很多理解。不要低估与拥有你所需知识的人进行专注对话的力量。
识别问题和推动变革
作为程序员的重要部分是识别问题并解决它们。作为我们工作的一部分,我们使用许多不同的移动部件,其中许多将由其他团队或个人维护,因此,我们需要有效地识别和提出对我们没有完全理解的代码和系统的问题。就像我们作为程序员所做的任何事情一样,我们表达这些问题的方式必须考虑到目标受众(用户)。当我们开始将这些沟通片段视为用户体验时,我们将开始成为真正有效的沟通者。
提出错误报告
提出错误是一种技能。它可以做得很差或有效。为了说明这一点,让我们考虑 GitHub 上的两个问题。它们中的每一个都提出了相同的问题,但方式大不相同。这是第一个变体:

这是第二种变体:
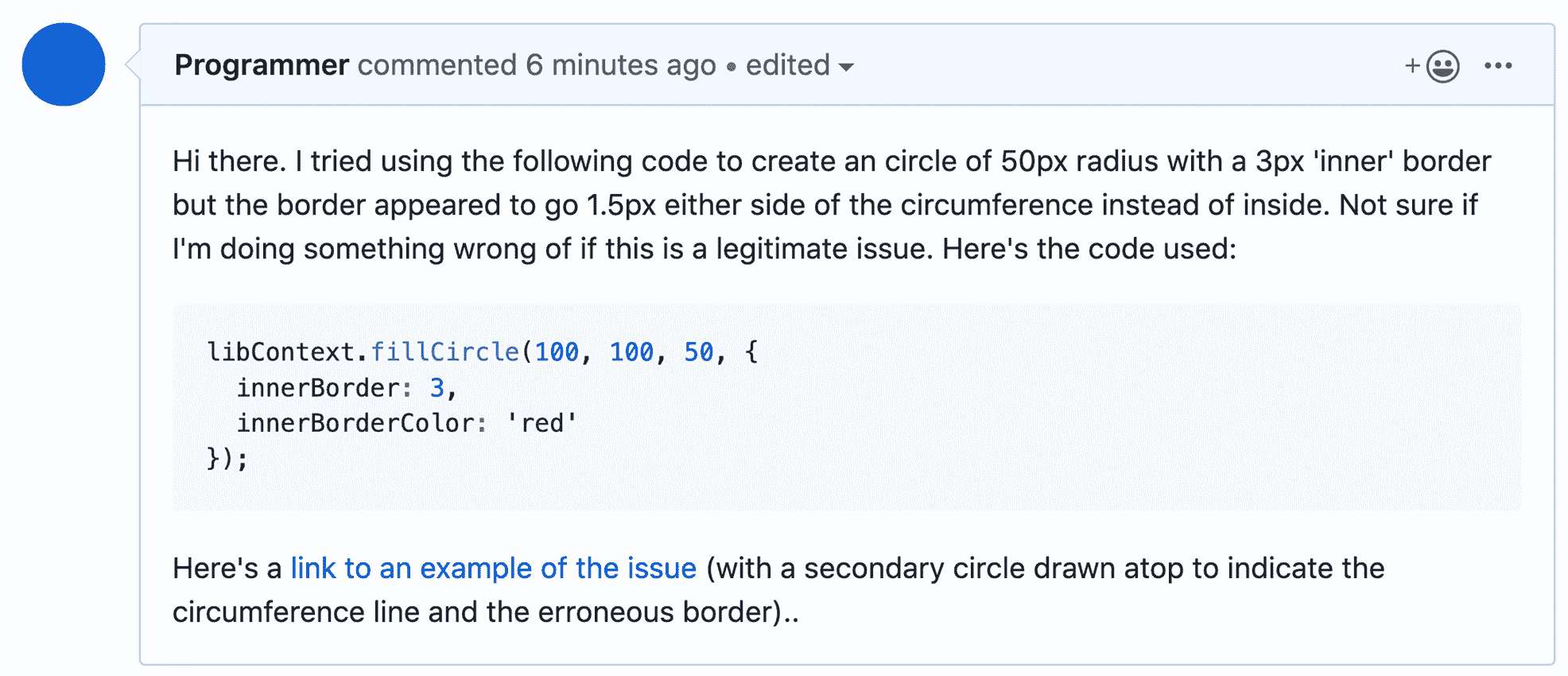
作为这个代码库的维护者,你更希望收到哪个错误报告?显然是第二个。然而我们看到,一次又一次,成千上万的错误报告和对开源项目提出的问题不仅未能准确传达问题,而且用词急躁,不尊重项目所有者的时间和努力。
通常,在提出错误时,最好至少包括以下信息:
-
问题总结:你应该简要总结正常散文中遇到的问题,以便可以快速理解和分级(可能是由不擅长诊断或修复确切问题的人)。
-
已采取的步骤:您应该展示可以用来重现您收到的实际行为的确切代码。您的错误的读者应该能够使用您共享的代码或输入参数来重现行为。
-
预期行为:您应该演示在给定输入的情况下您期望的行为或输出。
-
实际行为:您应该演示您观察到的不正确的输出或行为。
以下是一个虚构的sum()函数的错误报告的示例:
-
问题总结:
sum()在给定空输入时表现不直观 -
已采取的步骤:调用
sum(null, null) -
预期行为:
sum(null, null)应返回NaN -
实际行为:
sum(null, null)返回0
还可以包括有关代码运行环境的信息,包括硬件和软件(例如,MacBook 2013 Retina,Chrome 版本 43.01)。提出错误的整个目的是以准确和详细的方式传达意外或不正确的行为,以便能够迅速解决。如果我们限制提供的信息量,或者直接无礼,我们大大降低了问题被解决的可能性。
除了提出问题时应采取的具体步骤外,还有一个更广泛的问题,即我们应该如何在软件或文化中推动和激发系统性变革。我们将在接下来探讨这个问题。
推动系统性变革
通常情况下,bug 被认为是一个与硬件或软件的特定技术问题。然而,我们每天面临的更大或更系统性的问题可以用文化的术语或我们在整个系统中采用的日常惯例和模式来表达。以下是一些典型 IT 咨询公司内部问题的虚构例子:
-
我们在设计中经常使用不可访问的字体
-
我们有一百种不同的标准来编写良好的 JavaScript
-
我们似乎总是忘记更新第三方依赖
-
我们没有回馈到开源社区
这些问题稍微过于宽泛或主观,无法表达为明确的bug,因此我们需要探索其他方法来展现它们并解决它们。将这样的系统性问题视为成长的机会而不是bug可能会对人们对你提出的变化有多大影响。
总的来说,创建系统性变革涉及的步骤如下:
-
资格:用具体例子阐明问题:找到能够展示你试图描述的问题的例子。确保这些例子清楚地显示问题,不要太复杂。以一种即使对于完全沉浸在问题领域之外的人也能理解的方式描述问题。
-
反馈:从他人那里收集反馈:从他人那里收集想法和建议。向他们提出开放式问题,比如你对[…]有什么看法?。接受可能不存在问题,或者你遇到的问题最好以其他方式看待。
-
构思:共同探讨可能的解决方案:从多个人那里收集关于可能解决方案的想法。不要试图重复造轮子。有时候最简单的解决方案也是最好的。很可能系统性问题不能仅通过技术手段解决。你可能需要考虑社会和沟通方面的解决方案。
-
提出:提出问题以及可能的解决方案:根据问题的性质,将其提出给适当的人。这可以通过团队会议、一对一交流或在线沟通来进行。确保以一种非对抗的方式提出问题,并专注于改进和成长。
-
实施:共同选择解决方案并开始工作:假设你仍然认为这个问题值得追求,你可以开始实施最优选的解决方案,可能是以一种孤立的概念验证的方式。例如,如果正在解决的问题是我们有一百种不同的标准来编写良好的 JavaScript,那么你可以开始协作实施一套标准,使用一个代码检查工具或格式化工具,一路上寻求反馈,然后慢慢更新旧代码以符合这些标准。
-
衡量:经常检查解决方案的成功:从他人那里获得反馈,并寻求可量化的数据来判断所选解决方案是否按预期运行。如果不是,那么考虑重新审视并探索其他解决方案。
创建系统性变革的一个陷阱是等待太久或者在解决问题时过于谨慎。从他人那里获得反馈是非常有价值的,但不必完全依赖他们的验证。有时候,人们很难超越自己的视角看到某些问题,特别是如果他们非常习惯目前的做法。与其等待他们接受你的观点,也许最好的办法是继续推进你提出的解决方案的孤立版本,并后来向他们证明其有效性。
当人们对当前的做法做出反应性的辩护时,他们通常表达的是现状偏见,这是一种情感偏见,偏好当前的事态。面对这样的反应,人们对变化往往会不太欢迎。因此,要谨慎对待他人对你提出的变化的负面反馈。
我们每天希望在我们使用的技术和系统中改变的许多事情并不容易解决。它们可能是复杂的、难以控制的,通常是多学科的问题。这些类型的问题的例子很容易在讨论论坛和围绕标准迭代的社区反馈中找到,比如 ECMAScript 语言规范。很少有一种语言的添加或更改是简单完成的。耐心、考虑和沟通都是解决这些问题并推动我们自己和我们的技术前进所需要的。
总结
在本章中,我们试图探讨技术背景下有效沟通的挑战,并广泛讨论了将问题从构思阶段转化为原型阶段所涉及的沟通过程。我们还涵盖了沟通和倡导技术变革的任务,无论是以错误报告的形式还是提出关于系统性问题的更广泛问题。程序员不仅仅是代码的作者;他们作为正在构建的系统的一部分,是迭代反馈周期中至关重要的代理人,这些反馈周期最终会产生干净的软件。了解我们在这些系统和反馈周期中扮演的重要角色是非常有力量的,并开始触及成为一名干净的 JavaScript 程序员意味着什么的核心。
在下一章中,我们将汇集迄今为止在本书中学到的一切,通过一个案例研究探索一个新的问题领域。这将结束我们对 JavaScript 中干净代码的探索。
第十九章:案例研究
在这本书中,我们已经讨论了一系列原则,几乎涵盖了 JavaScript 语言的方方面面,并且长篇大论地讨论了什么是干净的代码。这一切都是为了最终能够撰写美丽而干净的 JavaScript 代码,解决真实而具有挑战性的问题领域。然而,追求干净的代码永远不会完成;新的挑战总会出现,让我们以新的、颠覆性的方式思考我们所写的代码。
在本章中,我们将走过 JavaScript 中创建新功能的过程。这将涉及客户端和服务器端的部分,并且将迫使我们应用我们在整本书中积累的许多原则和知识。我们将要解决的具体问题是从我负责的一个真实项目中改编的,虽然我们不会涉及其实施的每一个细节,但我们将涵盖最重要的部分。完成的项目可以在以下链接的 GitHub 上查看:github.com/PacktPublishing/Clean-Code-in-JavaScript。
在本章中,我们将涵盖以下主题:
-
问题:我们将定义并探讨问题
-
设计:我们将设计一个解决问题的用户体验和架构
-
实施:我们将实施我们的设计
问题
我们将要解决的问题涉及到我们网页应用程序用户体验的核心部分。我们将要处理的网页应用程序是一个大型植物数据库的前端,其中有成千上万种不同的植物。除了其他功能外,它允许用户找到特定的植物并将它们添加到集合中,以便他们可以跟踪他们的异国温室和植物研究清单。如下图所示:
目前,当用户希望找到一种植物时,他们必须使用一个涉及将植物名称(全拉丁名称)输入到文本字段中,点击搜索,并收到一组结果的搜索设施,如下截图所示:

对于我们的案例研究,植物名称只存在于它们的全拉丁名称中,其中包括一个科(例如,Acanthaceae)、一个属(例如,Acanthus)和一个种(例如,Carduaceus)。这突显了满足复杂问题领域所涉及的挑战。
这样做已经足够好了,但在一些用户焦点小组和在线反馈之后,我们决定需要为用户提供更好的用户体验,让他们更快地找到他们感兴趣的植物。提出的具体问题如下:
-
有时候我觉得查找物种很麻烦而且慢。我希望它更即时和灵活,这样我就不必一直回去修改我的查询,特别是如果我拼错了的话。
-
通常,当我知道植物的种或属的名称时,我仍然会稍微出错,没有得到结果。然后我就不得不回去调整我的拼写或在其他地方进行搜索。
-
我希望我在输入时能看到种和属的出现。这样我就可以更快地找到适当的植物,不浪费时间。
这里提出了一些可用性问题。我们可以将它们归纳为以下三个主题:
-
性能:当前的搜索功能使用起来很慢且笨拙
-
错误 更正:不得不纠正打字错误的过程令人讨厌和繁琐
-
反馈:在输入时获得有关现有属/种的反馈将是有用的
任务现在变得更加清晰。我们需要改进用户体验,使用户能够以更快的方式查询植物数据库,提供更即时的反馈,并让他们在途中防止或纠正输入错误。
设计
经过一些头脑风暴,我们决定可以以相当传统的方式解决我们的问题;我们可以简单地将输入字段转换为提供自动建议下拉框的字段。这是一个模拟:
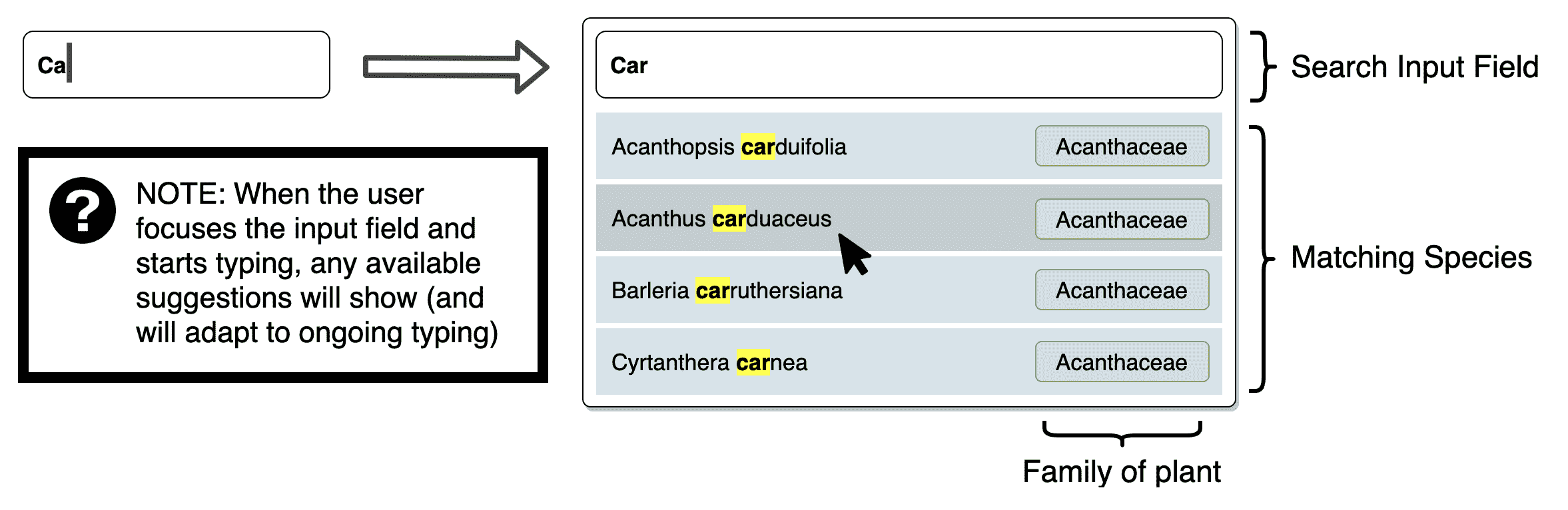
这个自动建议下拉框将具有以下特点:
-
当输入一个术语时,它将显示一个按优先级排序的植物名称列表,这些名称包含该术语作为前缀,例如,搜索
car将产生结果carnea,但不会产生encarea -
当通过点击、箭头(上/下)或Enter键选择一个术语时,它将运行指定的函数(以后可能用于将选定的项目添加到用户的集合中)
-
当找不到匹配的植物名称时,用户将收到通知,例如“没有该名称的植物存在”
这些是我们组件的核心行为,为了实现它们,我们需要考虑客户端和服务器端的部分。我们的客户端将不得不向用户呈现<input>,并且当他们输入时,它将不得不动态调整建议列表。服务器将不得不为每个潜在的查询提供给客户端一个建议列表,同时考虑到结果需要快速交付。任何显著的延迟都将严重降低我们试图创建的用户体验的好处。
实施
恰好这个新的植物选择组件将是我们网页应用中第一个重要的客户端代码片段,因此,重要的是要注意我们的设计决策不仅会影响到这个特定的组件,还会影响到我们将来考虑构建的任何其他组件。
为了帮助我们实施,并考虑到将来可能的其他潜在添加,我们决定采用 JavaScript 库来辅助 DOM 的操作,并采用支持工具集,使我们能够迅速高质量地工作。在这种情况下,我们决定在客户端使用 React,使用 webpack 和 Babel 进行编译和打包,并在服务器端使用 Express 进行 HTTP 路由。
植物选择应用
正如讨论的那样,我们决定将植物选择功能构建为一个独立的应用,包括客户端(React 组件)和服务器(植物数据 API)。这种隔离程度使我们能够纯粹地专注于选择植物的问题,但这并不意味着这不能在以后集成到更大的代码库中。
我们的目录结构大致如下:
EveryPlantSelectionApp/
├── server/
│ ├── package.json
| ├── babel.config.js
│ ├── index.js
| └── plantData/
│ ├── plantData.js
│ ├── plantData.test.js
| └── data.json
└── client/
├── package.json
├── webpack.config.js
├── babel.config.js
├── app/
| ├── index.jsx
| └── components/
| └── PlantSelectionInput/
└── dist/
├── main.js (bundling target)
└── index.html
除了为我们(程序员)减少复杂性之外,服务器和客户端的分离意味着服务器端应用(即植物选择 API)可以在必要时在自己独立的服务器上运行,而客户端可以从 CDN 静态提供,只需要服务器端的地址即可访问其 REST API。
创建 REST API
EveryPlantSelectionApp的服务器负责检索植物名称(植物科、属和种),并通过简单的 REST API 使它们可用于我们的客户端代码。为此,我们可以使用express Node.js 库,它使我们能够将 HTTP 请求路由到特定的函数,轻松地向客户端提供 JSON。
这是我们服务器实现的基本框架:
import express from 'express';
const app = express();
const port = process.env.PORT || 3000;
app.get('/plants/:query', (req, res) => {
req.params.query; // => The query
res.json({
fakeData: 'We can later place some real data here...'
});
});
app.listen(
port,
() => console.log(`App listening on port ${port}!`)
);
正如您所看到的,我们只实现了一个路由(/plants/:query)。每当用户在<input/>中输入部分植物名称时,客户端将请求这个路由,因此用户输入Carduaceus可能会产生以下一系列请求到服务器:
GET /plants/c
GET /plants/ca
GET /plants/car
GET /plants/card
GET /plants/cardu
GET /plants/cardua
...
你可以想象这可能导致更多昂贵且可能冗余的请求,特别是如果用户输入速度很快。有可能用户在任何之前的请求完成之前就输入了cardua。因此,当我们开始实现客户端时,我们需要使用某种请求节流(或请求防抖)来确保我们只发出合理数量的请求。
请求节流是通过只允许在指定时间间隔内执行新请求来减少总请求量的行为,这意味着在五秒内跨度为 100 个请求,节流到一个间隔为一秒,将只产生五个请求。请求防抖类似,不过它不是在每个间隔上执行单个请求,而是在实际请求之前等待一定的时间,以便停止产生请求。因此,在五秒内进行 100 个请求,通过五秒的防抖,将在五秒标记处只产生一个最终请求。
为了实现/plants/端点,我们需要考虑通过超过300,000不同植物物种的名称进行匹配的最佳搜索方式。为了实现这一点,我们将使用一种特殊的内存数据结构,称为trie。这也被称为前缀树,在需要自动建议或自动完成的情况下非常常见。
Trie 是一种类似树状结构的数据结构,它将相邻的字母块存储为一系列通过分支连接的节点。它比描述起来更容易可视化,所以让我们想象一下,我们需要基于以下数据创建一个 trie:
['APPLE', 'ACORN', 'APP', 'APPLICATION']
利用这些数据,生成的 trie 可能看起来像这样:
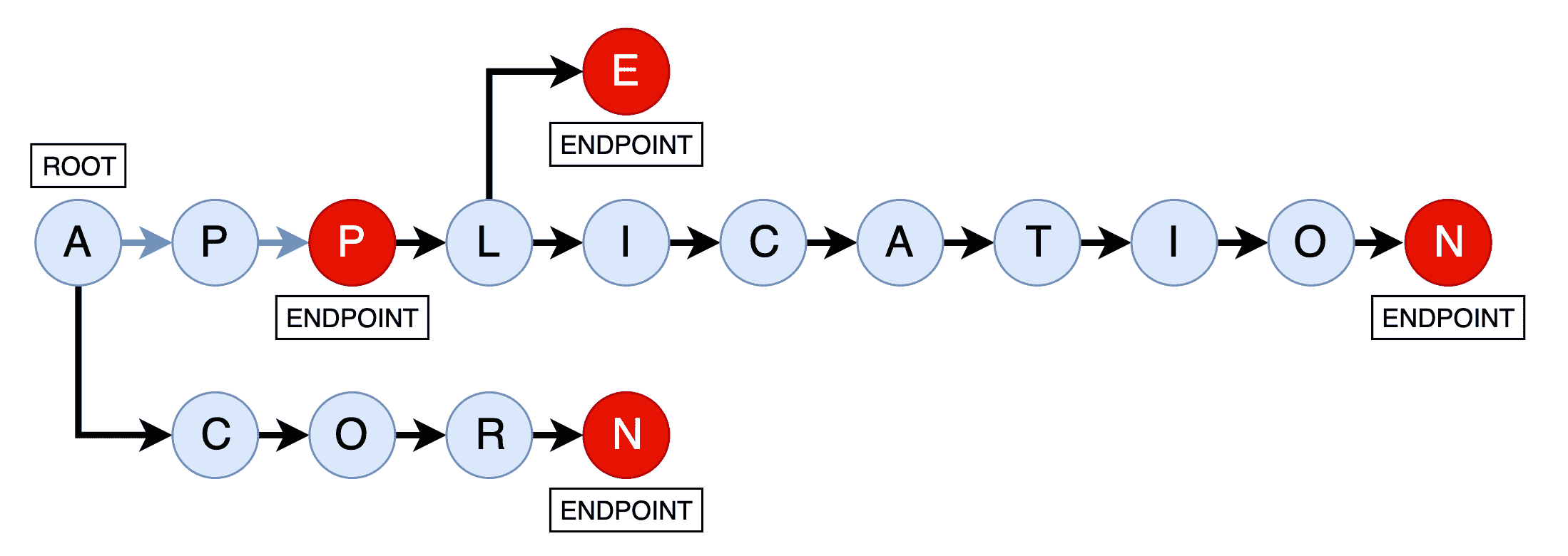
如您所见,我们的四个单词的数据集已被表示为类似树状结构的结构,其中第一个共同的字母"A"作为根。 "CORN"后缀从这里分支出来。此外, "PP"分支(形成"APP")分支出来,然后最后的"P"分支到"L",然后分支到"E"(形成"APPLE")和"ICATION"(形成"APPLICATION")。
这可能看起来很复杂,但是鉴于这种 trie 结构,我们可以根据用户输入的初始前缀(如"APPL")轻松地通过树的节点找到所有匹配的单词("APPLE"和"APPLICATION")。这比任何线性搜索算法都要高效得多。对于我们的目的,给定植物名称的前缀,我们希望能够高效地显示前缀可能导致的每个植物名称。
我们的特定数据集将包括超过 300,000 种不同的植物物种,但在本案例研究中,我们将只使用Acanthaceae科的物种,大约有 8,000 种。这些可以以 JSON 的形式使用,如下所示:
[
{ id: 105,
family: 'Acanthaceae',
genus: 'Andrographis',
species: 'alata' },
{ id: 106,
family: 'Acanthaceae',
genus: 'Justicia',
species: 'alata' },
{ id: 107,
family: 'Acanthaceae',
genus: 'Pararuellia',
species: 'alata' },
{ id: 108,
family: 'Acanthaceae',
genus: 'Thunbergia',
species: 'alata' },
// ...
]
我们将把这些数据输入到一个名为trie-search的第三方 trie 实现中。选择这个包是因为它满足我们的要求,并且似乎是一个经过充分测试和维护良好的库。
为了使 trie 按我们的期望运行,我们需要将每种植物的科、属和种连接成一个字符串。这使得 trie 可以包括完全合格的植物名称(例如"Acanthaceae Pararuellia alata")和分割名称(["Acanthaceae", "Pararuellia", "alata"])。分割名称是由我们使用的 trie 实现自动生成的(意思是它通过正则表达式/\s/g在空格上分割字符串):
const trie = new TrieSearch(['name'], {
ignoreCase: true // Make it case-insensitive
});
trie.addAll(
data.map(({ family, genus, species, id }) => {
return { name: family + ' ' + genus + ' ' + species, id };
})
);
前面的代码将我们的数据集输入到 trie 中。之后,可以通过简单地将前缀字符串传递给其get(...)方法来查询它:
trie.get('laxi');
这样的查询(例如前缀laxi)将从我们的数据集中返回以下内容:
[
{ id: 203,
name: 'Acanthaceae Acanthopale laxiflora' },
{ id: 809,
name: 'Acanthaceae Andrographis laxiflora' },
{ id: 390,
name: 'Acanthaceae Isoglossa laxiflora' },
//... (many more)
]
关于我们的 REST 端点/photos/:query,它所需要做的就是返回一个 JSON 有效负载,其中包含我们从trie.get(query)获取的内容:
app.get('/plants/:query', (req, res) => {
const queryString = req.params.query;
if (queryString.length < 3) {
return res.json([]);
}
res.json(
trie.get(queryString)
);
});
为了更好地分离我们的关注点,并确保我们没有混合太多不同的抽象层(可能违反了迪米特法则),我们可以将我们的 trie 数据结构和植物数据抽象到自己的模块中。我们可以称之为plantData,以传达它封装和提供对植物数据的访问的事实。它的工作方式,恰好是通过内存 trie 数据结构,不需要为其使用者所知:
// server/plantData.js
import TrieSearch from 'trie-search';
import plantData from './data.json';
const MIN_QUERY_LENGTH = 3;
const trie = new TrieSearch(['fullyQualifiedName'], {
ignoreCase: true
});
trie.addAll(
plantData.map(plant => {
return {
...plant,
fullyQualifiedName:
`${plant.family} ${plant.genus} ${plant.species}`
};
})
);
export default {
query(partialString) {
if (partialString.length < MIN_QUERY_LENGTH) {
return [];
}
return trie.get(partialString);
}
};
如您所见,此模块返回一个接口,提供一个query()方法,我们的主 HTTP 路由代码可以利用它来为/plants/:query提供 JSON 结果:
//...
import plantData from './plantData';
//...
app.get('/plants/:query', (req, res) => {
const query = req.params.query;
res.json( plantData.query(partial) );
});
因为我们已经隔离和包含了植物查询功能,现在更容易对其进行断言。编写一些针对plantData抽象的测试将使我们对我们的 HTTP 层使用可靠的抽象具有高度的信心,最大程度地减少了 HTTP 层内部可能出现的潜在错误。
此时,由于这是我们为项目编写的第一组测试,我们将安装 Jest(npm install jest --save-dev)。有许多可用的测试框架,风格各异,但对于我们的目的来说,Jest 是合适的。
我们可以在与之直观地位于一起并命名为plantData.test.js的文件中为我们的plantData模块编写测试。
import plantData from './plantData';
describe('plantData', () => {
describe('Family+Genus name search (Acanthaceae Thunbergia)', () => {
it('Returns plants with family and genus of "Acanthaceae Thunbergia"', () =>{
const results = plantData.query('Acanthaceae Thunbergia');
expect(results.length).toBeGreaterThan(0);
expect(
results.filter(plant =>
plant.family === 'Acanthaceae' &&
plant.genus === 'Thunbergia'
)
).toHaveLength(results.length);
});
});
});
plantData.test.js中有许多测试未在此处包含,以保持简洁;但是,您可以在 GitHub 存储库中查看它们:github.com/PacktPublishing/Clean-Code-in-JavaScript。
如您所见,此测试断言Acanthaceae Thunbergia查询是否直观地返回包含这些术语的完全限定名称的植物。在我们的数据集中,这将仅包括具有Acanthaceae家族和Thunbergia属的植物,因此我们可以简单地确认结果是否符合预期。我们还可以检查部分搜索,例如Acantu Thun,是否也直观地返回任何以Acantu或Thun开头的家族、属或种名称的植物:
describe('Partial family & genus name search (Acantu Thun)', () => {
it('Returns plants that have a fully-qualified name containing both "Acantu" and "Thunbe"', () => {
const results = plantData.query('Acant Thun');
expect(results.length).toBeGreaterThan(0);
expect(
results.filter(plant =>
/\bAcant/i.test(plant.fullyQualifiedName) &&
/\bThun/i.test(plant.fullyQualifiedName)
)
).toHaveLength(results.length);
});
});
我们通过断言每个返回结果的fullyQualifiedName是否与正则表达式/\bAcant/i和/\bThun/i匹配来确认我们的期望。/i表达式表示区分大小写。这里的\b表达式表示单词边界,以便我们可以确保Acant和Thun子字符串出现在单词的开头,并且不嵌入在单词中。例如,想象一个名为Luathunder的植物。我们不希望我们的自动建议机制匹配这样的实例。我们只希望它匹配前缀,因为用户将输入植物家族、属或种到<input />中(从每个单词的开头)。
现在我们有了经过充分测试和隔离的服务器端架构,我们可以开始转向客户端,我们将在用户输入时呈现由/plants/:query提供的植物名称。
创建客户端构建过程
我们在客户端的第一步是引入React和一个支持开发的工具集。在以前的网页开发时代,可以在没有复杂工具和构建步骤的情况下构建东西,这在某种程度上仍然是可能的。在过去,我们可以简单地创建一个 HTML 页面,内联包含任何第三方依赖项,然后开始编写我们的 JavaScript,而不必担心其他任何事情:
<body>
... Content
<script src="//example.org/libraryFoo.js"></script>
<script src="//example.org/libraryBaz.js"></script>
<script>
// Our JavaScript code...
</script>
</body>
从技术上讲,我们仍然可以这样做。即使使用现代前端框架如 React,我们也可以选择将其作为<script>依赖项包含在内,然后内联编写原始 JavaScript。然而,通过这样做,我们将无法获得以下优势:
-
更新的 JavaScript 语法(ES 2019 及更高版本):能够使用现代 JavaScript 语法,并将其编译为在所有环境/浏览器中安全使用的 JavaScript。
-
自定义语法和语言扩展:能够使用语言扩展(如 JSX 或 FlowJS)或编译为 JavaScript 的其他语言(如 TypeScript 或 CoffeeScript)。
-
依赖树管理:能够轻松指定您的依赖关系(例如使用
import语句),并将这些自动协调和合并成一个捆绑,而无需手动操作<script>标签和版本化噩梦。 -
性能改进:智能编译和打包可以通过减少 JavaScript 和 CSS 的整体占用空间,从而提供有意义的 HTTP 和运行时性能增益。
-
检查器和分析器:能够在您的 JavaScript(以及您的 CSS 和 HTML)上使用检查器和其他形式的分析,让我们深入了解代码质量和潜在的错误。
从根本上说,现在 Web 应用的性质更加复杂,特别是在前端。为了创建一个自动建议组件,我们需要确保我们有一套良好的工具和构建步骤基础,以便持续开发可以无缝和简单。在设置这些东西时可能会带来一些麻烦,但从长远来看是值得的。
为了编译我们的 JavaScript(包括 React 的 JSX),我们将使用Babel,它可以将我们的 JavaScript 转换为广泛支持的常规 JavaScript 语法。要在EveryPlantSelectionApp/client中添加 Babel 作为依赖项,我们可以使用npm来安装它及其各种预设配置:
# Install babel's core dependencies:
npm install --save-dev @babel/core @babel/cli
# Install some smart presets for Babel, allowing us to not have
# to worry about which specific JS syntax we're using:
npm install --save-dev @babel/preset-env
# Install a smart preset for React (i.e. JSX) usage:
npm install --save-dev @babel/preset-react
Babel 将管理我们的 JavaScript 的编译,使其成为广泛支持的语法。但是,为了使这些文件准备好交付给浏览器,我们需要将它们捆绑成一个单一的文件,可以像这样在我们的 HTML 中单独交付:
<script src="./ourBundledJavaScript.js"></script>
为了实现这一点,我们需要使用一个打包工具,比如 webpack。Webpack 可以为我们执行以下任务:
-
它可以通过 Babel 编译 JavaScript
-
然后它可以协调每个模块,包括任何依赖项
-
它可以生成一个包含所有依赖关系的单一捆绑的 JavaScript 文件
为了使用 webpack,我们需要安装几个相关的依赖项:
# Install Webpack and its CLI:
npm install --save-dev webpack webpack-cli
# Install Webpack's development server, which enables us to more easily
# develop without having to keep re-running the build process:
npm install --save-dev webpack-dev-server
# Install a couple of helpful packages that make it easier for
# Webpack to make use of Babel:
npm install --save-dev babel-loader babel-preset-react
Webpack 还需要自己的配置文件,名为webpack.config.js。在这个文件中,我们必须告诉它如何打包我们的代码,以及我们希望打包的代码输出到项目中的哪个位置:
const path = require('path');
module.exports = {
entry: './app/index.jsx',
module: {
rules: [
{
test: /\.(js|jsx)$/,
exclude: /node_modules/,
use: {
loader: 'babel-loader',
options: {
presets: ['@babel/react']
}
}
}
]
},
devServer: {
contentBase: path.join(__dirname, 'dist'),
compress: true,
port: 9000
},
output: {
filename: 'main.js',
path: path.resolve(__dirname, 'dist'),
}
};
这个配置基本上告诉 webpack 以下内容:
-
请从
EveryPlantSelectionApp/client/app/index.jsx开始 -
请使用 Babel 来编译此模块及其以
.jsx或.js结尾的所有依赖项 -
请将编译和捆绑文件输出到
EveryPlantSelectionApp/client/dist/
最后,我们需要安装 React,这样我们就可以准备创建我们的植物选择组件:
npm install --save react react-dom
看起来好像这样做很多工作只是为了渲染一个基本的 UI 组件,但实际上我们已经创建了一个基础,可以容纳许多新功能,并且我们已经创建了一个构建流水线,可以更容易地将我们的开发代码库交付到生产环境。
创建组件
我们组件的工作是显示一个增强的<input>元素,当聚焦时,会根据用户输入的内容呈现一个下拉式的可用选项列表,用户可以从中选择。
作为一个原始的大纲,我们可以想象组件包含<div>,用户可以在其中输入的<input>,以及显示建议的<ol>:
const PlantSelectionInput = () => {
return (
<div className="PlantSelectionInput">
<input
autoComplete="off"
aria-autocomplete="inline"
role="combobox" />
<ol>
<li>A plant name...</li>
<li>A plant name...</li>
<li>A plant name...</li>
</ol>
</div>
);
};
<input>上的role和aria-autocomplete属性用于指示浏览器(以及任何屏幕阅读器),用户在键入时将提供一组预定义的选择。这对于可访问性至关重要。autoComplete属性用于简单地启用或禁用浏览器的默认自动完成行为。在我们的情况下,我们希望禁用它,因为我们提供了自己的自定义自动完成/建议功能。
我们只希望在<input>聚焦时显示<ol>。为了实现这一点,我们需要绑定到<input>的焦点和失焦事件,然后创建一个可以跟踪我们是否应该考虑组件打开或关闭的独立状态。我们可以称这个状态为isOpen,并根据它的布尔值有条件地渲染或不渲染<ol>:
const PlantSelectionInput = () => {
const [isOpen, setIsOpen] = useState(false);
return (
<div className="PlantSelectionInput">
<input
onFocus={() => setIsOpen(true)}
onBlur={() => setIsOpen(false)}
autoComplete="off"
aria-autocomplete="inline"
role="combobox" />
{
isOpen &&
<ol>
<li>A plant name...</li>
<li>A plant name...</li>
<li>A plant name...</li>
</ol>
}
</div>
);
};
React 有自己关于状态管理的约定,如果你之前没有接触过,可能看起来很奇怪。const [foo, setFoo] = useState(null)代码创建了一个状态(称为foo),我们可以根据某些事件来改变它。每当这个状态改变时,React 就会知道触发相关组件的重新渲染。回到第十二章*,真实世界的挑战*,看看DOM 绑定和协调部分,以便重新了解这个主题。
接下来,我们需要绑定到<input>的change事件,以便获取用户输入的内容,并触发对我们的/plants/:query端点的请求,以便确定向用户显示什么建议。然而,首先,我们希望创建一个机制,通过它可以发出请求。在 React 世界中,它建议将这种功能建模为自己的Hook。记住,按照约定,Hook 通常以use动词为前缀,我们可以将其称为usePlantLike。作为它的唯一参数,它可以接受一个query字段(用户键入的字符串),它可以返回一个带有loading字段(指示当前加载状态)和plants字段(包含建议)的对象:
// Example of calling usePlantsLike:
const {loading, plants} = usePlantsLike('Acantha');
我们的usePlantsLike的实现非常简单:
// usePlantLike.js
import {useState, useEffect} from 'react';
export default (query) => {
const [loading, setLoading] = useState(false);
const [plants, setPlants] = useState([]);
useEffect(() => {
setLoading(true);
fetch(`/plants/${query}`)
.then(response => response.json())
.then(data => {
setLoading(false);
setPlants(data);
});
}, [query]);
return { loading, plants };
};
在这里,我们使用另一种React状态管理模式useEffect(),以便在query参数发生变化时运行特定的函数。因此,如果usePlantLike接收到一个新的query参数,例如Acantha,那么加载状态将被设置为true,并且将启动一个新的fetch(),其结果将填充plants状态。这可能很难理解,但就案例研究而言,我们真正需要理解的是usePlantsLike这种抽象封装了向服务器发出/plants/:query请求的复杂性。
将渲染逻辑与数据逻辑分开是明智的。这样做可以确保良好的抽象层次和关注点分离,并将每个模块作为单一责任的领域。传统的 MVC 和 MVVM 框架有助于强制进行这种分离,而更现代的渲染库(如 React)则给了你更多的选择。因此,在这里,我们选择将数据和服务器通信逻辑隔离在一个 React Hook 中,然后由我们的组件使用。
现在,每当用户在<input>中键入内容时,我们可以使用我们的新 React Hook。为了做到这一点,我们可以绑定到它的change事件,每次触发时,获取它的value,然后将其作为query参数传递给usePlantsLike,以便为用户派生一组新的建议。然后可以在我们的<ol>容器中呈现这些建议:
const PlantSelectionInput = ({ isInitiallyOpen, value }) => {
const inputRef = useRef();
const [isOpen, setIsOpen] = useState(isInitiallyOpen || false);
const [query, setQuery] = useState(value);
const {loading, plants} = usePlantsLike(query);
return (
<div className="PlantSelectionInput">
<input
ref={inputRef}
onFocus={() => setIsOpen(true)}
onBlur={() => setIsOpen(false)}
onChange={() => setQuery(inputRef.current.value)}
autoComplete="off"
aria-autocomplete="inline"
role="combobox"
value={value} />
{
isOpen &&
<ol>{
plants.map(plant =>
<li key={plant.id}>{plant.fullyQualifiedName}</li>
)
}</ol>
}
</div>
);
};
在这里,我们添加了一个新的状态query,通过<input>的onChange处理程序设置它。然后,这个query变化将导致usePlantsLike从服务器发出一个新的请求,并用多个<li>元素填充<ol>,每个元素代表一个单独的植物名称建议。
有了这一点,我们已经完成了组件的基本实现。为了使用它,我们可以在我们的client/index.jsx入口点中呈现它:
import ReactDOM from 'react-dom';
import React from 'react';
import PlantSelectionInput from './components/PlantSelectionInput';
ReactDOM.render(
<PlantSelectionInput />,
document.getElementById('root')
);
此代码尝试将<PlantSelectionInput/>呈现到具有"root"ID 的元素上。如前所述,我们的捆绑工具 webpack 将自动将编译后的 JavaScript 捆绑成一个名为main.js的文件,并将其放置在dist/(即分发)目录中。这将与我们的index.html文件并排,后者将作为用户界面的入口到我们的应用程序。对于我们的目的,这只需要是一个简单的页面,用于演示PlantSelectionInput:
<!DOCTYPE html>
<html>
<head>
<title>EveryPlant Selection App</title>
<style>
/* our styles... */
</style>
</head>
<body>
<div id="root"></div>
<script src="./main.js"></script>
</body>
</html>
我们可以在index.html中的<style>标签中放置任何相关的 CSS:
<style>
.PlantSelectionInput {
width: 100%;
display: flex;
position: relative;
}
.PlantSelectionInput input {
background: #fff;
font-size: 1em;
flex: 1 1;
padding: .5em;
outline: none;
}
/* ... more styles here ... */
</style>
在较大的项目中,最好提出一个可以很好地与许多不同组件配合使用的缩放 CSS 解决方案。在React中运行良好的示例包括CSS 模块或styled components,两者都允许您定义仅针对单个组件的 CSS,避免了全局 CSS 的麻烦。
我们组件的样式并不特别具有挑战性,因为它只是一个文本项的列表。主要挑战在于确保当组件处于完全打开状态时,建议列表出现在页面上的任何其他内容之上。这可以通过相对定位<input>容器,然后绝对定位<ol>来实现,如下所示:
这结束了我们组件的实现,但我们还应该实现基本级别的测试(至少)。为了实现这一点,我们将使用 Jest,一个测试库,以及它的快照匹配功能。这将使我们能够确认我们的 React 组件生成了预期的 DOM 元素层次结构,并将保护我们免受未来的回归:
// PlantSelectionInput.test.jsx
import React from 'react';
import renderer from 'react-test-renderer';
import PlantSelectionInput from './';
describe('PlantSelectionInput', () => {
it('Should render deterministically to its snapshot', () => {
expect(
renderer
.create(<PlantSelectionInput />)
.toJSON()
).toMatchSnapshot();
});
describe('With configured isInitiallyOpen & value properties', () => {
it('Should render deterministically to its snapshot', () => {
expect(
renderer
.create(
<PlantSelectionInput
isInitiallyOpen={true}
value="Example..."
/>
)
.toJSON()
).toMatchSnapshot();
});
});
});
Jest 会将生成的快照保存到__snapshots__目录中,然后将任何将来执行的测试与这些保存的快照进行比较。除了这些测试,我们还可以实现常规的功能性测试,甚至是 E2E 测试,可以编码期望,比如当用户输入时,建议列表相应更新。
这结束了我们对组件和案例研究的构建。如果您查看我们的 GitHub 存储库,您可以看到已完成的项目,与组件一起玩耍,自己运行测试,并且您还可以分叉存储库以进行自己的更改。
这是 GitHub 存储库的链接:github.com/PacktPublishing/Clean-Code-in-JavaScript。
总结
在这最后一章中,我们通过书中积累的原则和经验,探讨了一个真实世界的问题。我们提出了用户遇到的问题,然后设计和实现了一个干净的用户体验来解决他们的问题。这包括了服务器端和客户端的部分,使我们能够从头到尾看到一个独立的 JavaScript 项目可能是什么样子。虽然我们无法涵盖每一个细节,但我希望这一章对于巩固干净代码背后的核心思想有所帮助,现在您应该更有信心编写干净的 JavaScript 代码来解决各种问题领域。我希望您能带走的一个核心原则就是:专注于用户。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









